Global Optimality in Bivariate Gradient-based DAG Learning
Abstract
Recently, a new class of non-convex optimization problems motivated by the statistical problem of learning an acyclic directed graphical model from data has attracted significant interest. While existing work uses standard first-order optimization schemes to solve this problem, proving the global optimality of such approaches has proven elusive. The difficulty lies in the fact that unlike other non-convex problems in the literature, this problem is not “benign”, and possesses multiple spurious solutions that standard approaches can easily get trapped in. In this paper, we prove that a simple path-following optimization scheme globally converges to the global minimum of the population loss in the bivariate setting.
1 Introduction
Over the past decade, non-convex optimization has become a major topic of research within the machine learning community, in part due to the successes of training large-scale models with simple first-order methods such as gradient descent—along with their stochastic and accelerated variants—in spite of the non-convexity of the loss function. A large part of this research has focused on characterizing which problems have benign loss landscapes that are amenable to the use of gradient-based methods, i.e., there are no spurious local minima, or they can be easily avoided. By now, several theoretical results have shown this property for different non-convex problems such as: learning a two hidden unit ReLU network (Wu et al., 2018), learning (deep) over-parameterized quadratic neural networks (Soltanolkotabi et al., 2018; Kazemipour et al., 2019), low-rank matrix recovery (Ge et al., 2017; De Sa et al., 2015; Bhojanapalli et al., 2016), learning a two-layer ReLU network with a single non-overlapping convolutional filter (Brutzkus and Globerson, 2017), semidefinite matrix completion (Boumal et al., 2016; Ge et al., 2016), learning neural networks for binary classification with the addition of a single special neuron (Liang et al., 2018), and learning deep networks with independent ReLU activations (Kawaguchi, 2016; Choromanska et al., 2015), to name a few.
Recently, a new class of non-convex optimization problems due to Zheng et al. (2018) have emerged in the context of learning the underlying structure of a structural equation model (SEM) or Bayesian network. This underlying structure is typically represented by a directed acyclic graph (DAG), which makes the learning task highly complex due to its combinatorial nature. In general, learning DAGs is well-known to be NP-complete (Chickering, 1996; Chickering et al., 2004). The key innovation in Zheng et al. (2018) was the introduction of a differentiable function , whose level set at zero exactly characterizes DAGs. Thus, replacing the challenges of combinatorial optimization by those of non-convex optimization. Mathematically, this class of non-convex problems take the following general form:
| (1) |
where represents the model parameters, is a (possibly non-convex) smooth loss function (sometimes called a score function) that measures the fitness of , and is a smooth non-convex function that takes the value of zero if and only if the induced weighted adjacency matrix of nodes, , corresponds to a DAG.
Given the smoothness of and , problem (1) can be solved using off-the-shelf nonlinear solvers, which has driven a series of remarkable developments in structure learning for DAGs. Multiple empirical studies have demonstrated that global or near-global minimizers for (1) can often be found in a variety of settings, such as linear models with Gaussian and non-Gaussian noises (e.g., Zheng et al., 2018; Ng et al., 2020; Bello et al., 2022), and non-linear models, represented by neural networks, with additive Gaussian noises (e.g., Lachapelle et al., 2020; Zheng et al., 2020; Yu et al., 2019; Bello et al., 2022). The empirical success for learning DAGs via (1), which started with the Notears method of Zheng et al. (2018), bears a resemblance to the success of training deep models, which started with AlexNet for image classification.
Importantly, the reader should note that the majority of applications in ML consist of solving a single unconstrained non-convex problem. In contrast, the class of problems (1) contains a non-convex constraint. Thus, researchers have considered some type of penalty method such as the augmented Lagrangian (Zheng et al., 2018, 2020), quadratic penalty (Ng et al., 2022), and a log-barrier (Bello et al., 2022). In all cases, the penalty approach consists in solving a sequence of unconstrained non-convex problems, where the constraint is enforced progressively (see e.g. Bertsekas, 1997, for background). In this work, we will consider the following form of penalty:
| (2) |
It was shown by Bello et al. (2022) that due to the invexity property of ,111An invex function is any function where all its stationary points are global minima. It is worth noting that the composite objective in (2) is not necessarily invex, even when is convex. solutions to (2) will converge to a DAG as . However, no guarantees on local/global optimality were given.
With the above considerations in hand, one is inevitably led to ask the following questions:
-
(i)
Are the loss landscapes benign for different ?
-
(ii)
Is there a (tractable) solution path {} that converges to a global minimum of (1)?
Due to the NP-completeness of learning DAGs, one would expect the answer to (i) to be negative in its most general form. Moreover, it is known from the classical theory of constrained optimization (e.g. Bertsekas, 1997) that if we can exactly and globally optimize (1) for each , then the answer to (ii) is affirmative. This is not a practical algorithm, however, since the problem (1) is nonconvex. Thus we seek a solution path that can be tractably computed in practice, e.g. by gradient descent.
In this work, we focus on perhaps the simplest setting where interesting phenomena take place. That is, a linear SEM with two nodes (i.e., ), is the population least squared loss (i.e., is convex), and is defined via gradient flow with warm starts. More specifically, we consider the case where is obtained by following the gradient flow of with initial condition .
Under this setting, to answer (i), it is easy to see that for a large enough , the convex function dominates and we can expect a benign landscape, i.e., a (almost) convex landscape. Similarly, when approaches zero, the invexity of kicks in and we could expect that all stationary points are (near) global minimizers.222This transition or path, from an optimizer of a simple function to an optimizer of a function that closely resembles the original constrained formulation, is also known as a homotopy. That is, at the extremes and , the landscapes seem well-behaved, and the reader might wonder if it follows that for any the landscape is well-behaved. We answer the latter in the negative and show that there always exists a where the landscape of is non-benign for any , namely, there exist three stationary points: i) A saddle point, ii) A spurious local minimum, and iii) The global minimum. In addition, each of these stationary points have wide basins of attractions, thus making the initialization of the gradient flow for crucial. Finally, we answer (ii) in the affirmative and provide an explicit scheduling for that guarantees the asymptotic convergence of to the global minimum of (1). Moreover, we show that this scheduling cannot be arbitrary as there exists a sequence of that leads to a spurious local minimum.
Overall, we establish the first set of results that study the optimization landscape and global optimality for the class of problems (1). We believe that this comprehensive analysis in the bivariate case provides a valuable starting point for future research in more complex settings.
Remark 1.
We emphasize that solving (1) in the bivariate case is not an inherently difficult problem. Indeed, when there are only two nodes, there are only two DAGs to distinguish and one can simply fit under the only two possible DAGs, and select the model with the lowest value for . However, evaluating for each possible DAG structure clearly cannot scale beyond 10 or 20 nodes, and is not a standard algorithm for solving (1). Instead, here our focus is on studying how (1) is actually being solved in practice, namely, by solving unconstrained non-convex problems in the form of (2). Previous work suggests that such gradient-based approaches indeed scale well to hundreds and even thousands of nodes (e.g. Zheng et al., 2018; Ng et al., 2020; Bello et al., 2022).

1.1 Our Contributions
More specifically, we make the following contributions:
- 1.
- 2.
- 3.
-
4.
Experimental results verify our theory, consistently recovering the global minimum of (1), regardless of initialization or initial penalty value. We show that our algorithm converges to the global minimum while naïve approaches can get stuck.
The analysis consists of three main parts: First, we explicitly characterize the trajectory of the stationary points of (2). Second, we classify the number and type of all stationary points (Lemma 1) and use this to isolate the desired global minimum. Finally, we apply Lyapunov analysis to identify the basin of attraction for each stationary point, which suggests a schedule for the penalty coefficient that ensures that the gradient flow is initialized within that basin at the previous solution.
1.2 Related Work
The class of problems (1) falls under the umbrella of score-based methods, where given a score function , the goal is to identify the DAG structure with the lowest score possible (Chickering, 2003; Heckerman et al., 1995). We shall note that learning DAGs is a very popular structure model in a wide range of domains such as biology (Sachs et al., 2005), genetics (Zhang et al., 2013), and causal inference (Spirtes et al., 2000; Pearl, 2009), to name a few.
Score-based methods that consider the combinatorial constraint.
Given the ample set of score-based methods in the literature, we briefly mention some classical works that attempt to optimize by considering the combinatorial DAG constraint. In particular, we have approximate algorithms such as the greedy search method of Chickering et al. (2004), order search methods (Teyssier and Koller, 2005; Scanagatta et al., 2015; Park and Klabjan, 2017), the LP-relaxation method of Jaakkola et al. (2010), and the dynamic programming approach of Loh and Bühlmann (2014). There are also exact methods such as GOBNILP (Cussens, 2012) and Bene (Silander and Myllymaki, 2006), however, these algorithms only scale up to nodes.
Score-based methods that consider the continuous non-convex constraint .
The following works are the closest to ours since they attempt to solve a problem in the form of (1). Most of these developments either consider optimizing different score functions such as ordinary least squares (Zheng et al., 2018, 2020), the log-likelihood (Lachapelle et al., 2020; Ng et al., 2020), the evidence lower bound (Yu et al., 2019), a regret function (Zhu et al., 2020); or consider different differentiable characterizations of acyclicity (Yu et al., 2019; Bello et al., 2022). However, none of the aforementioned works provide any type of optimality guarantee. Few studies have examined the optimization intricacies of problem (1). Wei et al. (2020) investigated the optimality issues and provided local optimality guarantees under the assumption of convexity in the score and linear models. On the other hand, Ng et al. (2022) analyzed the convergence to (local) DAGs of generic methods for solving nonlinear constrained problems, such as the augmented Lagrangian and quadratic penalty methods. In contrast to both, our work is the first to study global optimality and the loss landscapes of actual methods used in practice for solving (1).
Bivariate causal discovery.
Penalty and homotopy methods.
There exist classical global optimality guarantees for the penalty method if and were convex functions, see for instance (Bertsekas, 1997; Boyd et al., 2004; Nocedal and Wright, 1999). However, to our knowledge, there are no global optimality guarantees for general classes of non-convex constrained problems, let alone for the specific type of non-convex functions considered in this work. On the other hand, homotopy methods (also referred to as continuation or embedding methods) are in many cases capable of finding better solutions than standard first-order methods for non-convex problems, albeit they typically do not come with global optimality guarantees either. When homotopy methods come with global optimality guarantees, they are commonly computationally more intensive as it involves discarding solutions, thus, closely resembling simulated annealing methods, see for instance (Dunlavy and O’Leary, 2005). Authors in (Hazan et al., 2016) characterize a family of non-convex functions where a homotopy algorithm provably converges to a global optimum. However, the conditions for such family of non-convex functions are difficult to verify and are very restrictive; moreover, their homotopy algorithm involves Gaussian smoothing, making it also computationally more intensive than the procedure we study here. Other examples of homotopy methods in machine learning include (Chen et al., 2019; Garrigues and Ghaoui, 2008; Wauthier and Donnelly, 2015; Gargiani et al., 2020; Iwakiri et al., 2022), in all these cases, no global optimality guarantees are given.
2 Preliminaries
The objective we consider can be easily written down as follows:
| (3) |
where is a random vector and . Although not strictly necessary for the developments that follow, we begin by introducing the necessary background on linear SEM that leads to this objective and the resulting optimization problem of interest.
The bivariate model.
Let denote the random variables in the model, and let denote a vector of independent errors. Then a linear SEM over is defined as , where is a weighted adjacency matrix encoding the coefficients in the linear model. In order to represent a valid Bayesian network for (see e.g. Pearl, 2009; Spirtes et al., 2000, for details), the matrix must be acyclic: More formally, the weighted graph induced by the adjacency matrix must be a DAG. This (non-convex) acyclicity constraint represents the major computational hurdle that must overcome in practice (cf. Remark 1).
The goal is to recover the matrix from the random vector . Since is acyclic, we can assume the diagonal of is zero (i.e. no self-loops). Thus, under the bivariate linear model, it then suffices to consider two parameters and that define the matrix of parameters333Following the notation in (1), for the bivariate model we simply have and .
| (4) |
For notational simplicity, we will use and interchangeably, similarly for and . Without loss of generality, we write the underlying parameter as
| (5) |
which implies
In general, we only require to have finite mean and variance, hence we do not assume Gaussianity. We assume that , and for simplicity, we consider and , where denotes the identity matrix. Finally, in the sequel we assume w.l.o.g. that .
The population least squares.
In this work, we consider the population squared loss defined by (3). If we equivalently write in terms of and , then we have: In fact, the population loss can be substituted with empirical loss. In such a case, our algorithm can still attain the global minimum, , of problem (6). However, the output will serve as an empirical estimation of . An in-depth discussion on this topic can be found in Appendix B
The non-convex function .
We use the continuous acyclicity characterization of Yu et al. (2019), i.e., , where denotes the Hadamard product. Then, for the bivariate case, we have We note that the analysis presented in this work is not tailored to this version of , that is, we can use the same techniques used throughout this work for other existing formulations of , such as the trace of the matrix exponential (Zheng et al., 2018), and the log-det formulation (Bello et al., 2022). Nonetheless, here we consider that the polynomial formulation of Yu et al. (2019) is more amenable for the analysis.
Remark 2.
Our restriction to the bivariate case highlights the simplest setting in which this problem exhibits nontrivial behaviour. Extending our analysis to higher dimensions remains a challenging future direction, however, we emphasize that even in two-dimensions this problem is nontrivial. Our approach is similar to that taken in other parts of the literature that started with simple cases (e.g. single-neuron models in deep learning).
Remark 3.
It is worth noting that our choice of the population least squares is not arbitrary. Indeed, for linear models with identity error covariance, such as the model considered in this work, it is known that the global minimizer of the population squared loss is unique and corresponds to the underlying matrix . See Theorem 7 in (Loh and Bühlmann, 2014).
Gluing all the pieces together, we arrive to the following version of (1) for the bivariate case:
| (6) |
Moreover, for any , we have the corresponding version of (2) expressed as:
| (7) |
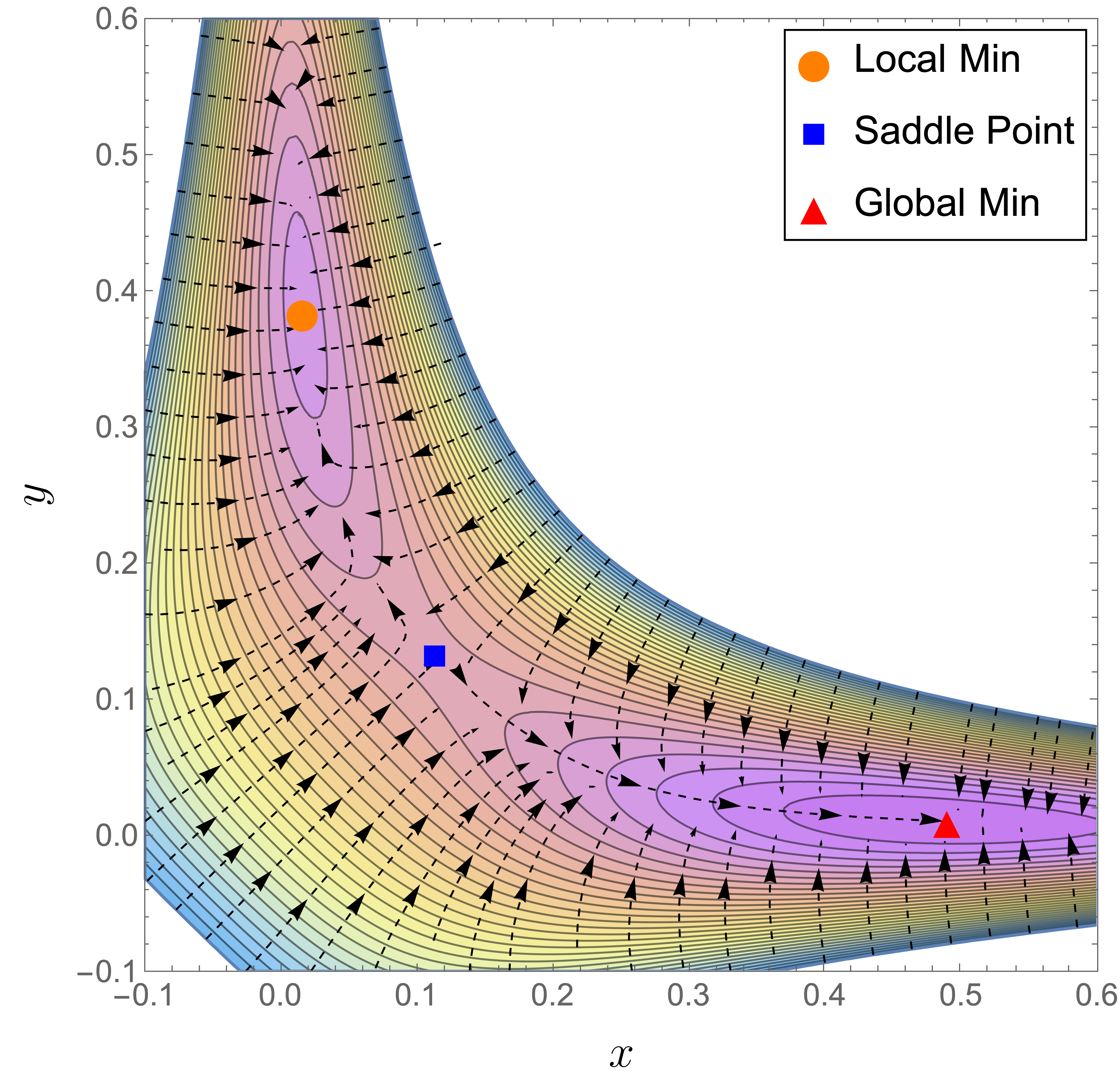
To conclude this section, we present a visualization of the landscape of in Figure 1 (a), for and . We can clearly observe the non-benign landscape of , i.e., there exists a spurious local minimum, a saddle point, and the global minimum. In particular, we can see that the basin of attraction of the spurious local minimum is comparable to that of the global minimum, which is problematic for a local algorithm such as the gradient flow (or gradient descent) as it can easily get trapped in a local minimum if initialized in the wrong basin.
3 A Homotopy-Based Approach and Its Convergence to the Global Optimum
To fix notation, let us write . and let denote the global minimizer of (6). In this section, we present our main result, which provides conditions under which solving a series of unconstrained problems (7) with first-order methods will converge to the global optimum of (6), in spite of facing non-benign landscapes. Recall that from Remark 3, we have that . Since we use gradient flow path to connect and , we specify this path in Procedure 1 for clarity. Although the theory here assumes continuous-time gradient flow with , see Section 5 for an iteration complexity analysis for (discrete-time) gradient descent, which is a straightforward consequence of the continuous-time theory.
In Algorithm 2, we provide an explicit regime of initialization for the homotopy parameter and a specific scheduling for such that the solution path found by Algorithm 2 will converge to the global optimum of (6). This is formally stated in Theorem 1, whose proof is given in Section 5.
Theorem 1.
A few observations regarding Algorithm 2: Observe that when the underlying model parameter , the regime of initialization for is wider; on the other hand, if is closer to zero then the interval for is much narrower. As a concrete example, if then it suffices to have ; whereas if then the regime is about . This matches the intuition that for a “stronger” value of it should be easier to detect the right direction of the underlying model. Second, although in Line 3 we set in a specific manner, it actually suffices to have
We simply chose a particular expression from this interval for clarity of presentation; see the proof in Section 5 for details.
As presented, Algorithm 2 is of theoretical nature in the sense that the initialization for and the decay rate for in Line 3 depend on the underlying parameter , which in practice is unknown. In Algorithm 3, we present a modification that is independent of and . By assuming instead a lower bound on , which is a standard assumption in the literature, we can prove that Algorithm 3 also converges to the global minimum:
Corollary 1.
For more details on this modification, see Appendix A.
4 A Detailed Analysis of the Evolution of the Stationary Points
The homotopy approach in Algorithm 2 relies heavily on how the stationary points of (7) behave with respect to . In this section, we dive deep into the properties of these critical points.
By analyzing the first-order conditions for , we first narrow our attention to the region By solving the resulting equations, we obtain an equation that only involves the variable :
| (8) |
Likewise, we can find an equation only involving the variable :
| (9) |
To understand the behavior of the stationary points of , we can examine the characteristics of in the range and the properties of in the interval .

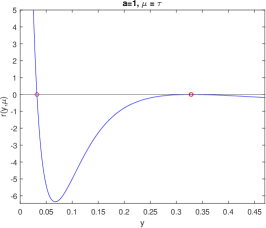




In Figures 2 and 3, we show the behavior of and for . Theorems 5 and 6 in the appendix establish the existence of a with the following useful property:
Corollary 2.
There exists such that the equation has three different solutions, denoted as . Then,
Note that the interesting regime takes place when . Then, we characterize the stationary points as either local minima or saddle points:
Lemma 1.
Let , then has two local minima at , and a saddle point at .
With the above results, it has been established that converges to the global minimum as . In the following section for the proof of Theorem 1, we perform a thorough analysis on how to track and avoid the local minimum at by carefully designing the scheduling for .
5 Convergence Analysis: From continuous to discrete
We now discuss the iteration complexity of our method when gradient descent is used in place of gradient flow. We begin with some preliminaries regarding the continuous-time analysis.
5.1 Continuous case: Gradient flow
The key to ensuring the convergence of gradient flow to is to accurately identify the basin of attraction of . The following lemma provides a region that lies within such basin of attraction.
Lemma 2.
Define . Run Algorithm 1 with input where , then , we have that and .
In Figure 1 (b), the lower-right rectangle corresponds to . Lemma 2 implies that the gradient flow with any initialization inside will converge to at last. Then, by utilizing the previous solution as the initial point, as long as it lies within region , the gradient flow can converge to , thereby achieving the goal of tracking . Following the scheduling for prescribed in Algorithm 2 provides a sufficient condition to ensure that will happen.
The following lemma, with proof in the appendix, is used for the Proof of Theorem 1. It provides a lower bound for and upper bound for
Lemma 3.
If , then , and .
Proof of Theorem 1.
Consider that we are at iteration of Algorithm 2, then . If and , then there is only one stationary point for and , thus, 1 will converge to such stationary point. Hence, let us assume . From Theorem 6 in the appendix, we known that . Then, the following relations hold:
Here (1) and (3) are due to Lemma 3, and (2) follows from for . Then it implies that is in the region . By Lemma 2, the 1 procedure will converge to . Finally, from Theorems 5 and 6, if , then , thus, converging to the global optimum, i.e.,
5.2 Discrete case: Gradient Descent
In Algorithms 2 and 4, gradient flow is employed to locate the next stationary points, which is not practically feasible. A viable alternative is to execute Algorithm 2, replacing the gradient flow with gradient descent. Now, at every iteration , Algorithm 6 uses gradient descent to output , a stationary point of , initialized at , and a step size of . The tolerance parameter can significantly influence the behavior of the algorithm and must be controlled for different iterations. A convergence guarantee is established via a simplified theorem presented here. A more formal version of the theorem and a comprehensive description of the algorithm (i.e., Algorithm 6) can be found in Appendix C.
Theorem 2 (Informal).
For any , set satisfy a mild condition, and use updating rule , , and let . Then, for any initialization , following the updated procedure above for , we have:
that is, is -close in Frobenius norm to global optimum . Moreover, the total number of gradient descent steps is upper bounded by .
6 Experiments
We conducted experiments to verify that Algorithms 2 and 4 both converge to the global minimum of (7). Our purpose is to illustrate two main points: First, we compare our updating scheme as given in Line 3 of Algorithm 2 against a faster-decreasing updating scheme for . In Figure 4 we illustrate how a naive faster decrease of can lead to spurious a local minimum. Second, in Figure 5, we show that regardless of the initialization, Algorithms 2 and 4 always return the global minimum. In the supplementary material, we provide additional experiments where the gradient flow is replaced with gradient descent. For more details, please refer to Appendix F.




References
- (1)
- Bello et al. (2022) Bello, K., Aragam, B. and Ravikumar, P. (2022), DAGMA: Learning dags via M-matrices and a log-determinant acyclicity characterization, in ‘Advances in Neural Information Processing Systems’.
- Bertsekas (1997) Bertsekas, D. P. (1997), ‘Nonlinear programming’, Journal of the Operational Research Society 48(3), 334–334.
- Bhojanapalli et al. (2016) Bhojanapalli, S., Neyshabur, B. and Srebro, N. (2016), ‘Global optimality of local search for low rank matrix recovery’, Advances in Neural Information Processing Systems 29.
- Boumal et al. (2016) Boumal, N., Voroninski, V. and Bandeira, A. (2016), ‘The non-convex burer-monteiro approach works on smooth semidefinite programs’, Advances in Neural Information Processing Systems 29.
- Boyd et al. (2004) Boyd, S., Boyd, S. P. and Vandenberghe, L. (2004), Convex optimization, Cambridge university press.
- Brutzkus and Globerson (2017) Brutzkus, A. and Globerson, A. (2017), Globally optimal gradient descent for a convnet with gaussian inputs, in ‘International conference on machine learning’, PMLR, pp. 605–614.
- Chen et al. (2019) Chen, W., Drton, M. and Wang, Y. S. (2019), ‘On causal discovery with an equal-variance assumption’, Biometrika 106(4), 973–980.
- Chickering (1996) Chickering, D. M. (1996), Learning Bayesian networks is NP-complete, in ‘Learning from data’, Springer, pp. 121–130.
- Chickering (2003) Chickering, D. M. (2003), ‘Optimal structure identification with greedy search’, JMLR 3, 507–554.
- Chickering et al. (2004) Chickering, D. M., Heckerman, D. and Meek, C. (2004), ‘Large-sample learning of Bayesian networks is NP-hard’, Journal of Machine Learning Research 5, 1287–1330.
- Choromanska et al. (2015) Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B. and LeCun, Y. (2015), The loss surfaces of multilayer networks, in ‘Artificial intelligence and statistics’, PMLR, pp. 192–204.
- Cussens (2012) Cussens, J. (2012), ‘Bayesian network learning with cutting planes’, arXiv preprint arXiv:1202.3713 .
- De Sa et al. (2015) De Sa, C., Re, C. and Olukotun, K. (2015), Global convergence of stochastic gradient descent for some non-convex matrix problems, in ‘International conference on machine learning’, PMLR, pp. 2332–2341.
- Dontchev et al. (2009) Dontchev, A. L., Rockafellar, R. T. and Rockafellar, R. T. (2009), Implicit functions and solution mappings: A view from variational analysis, Vol. 11, Springer.
- Dunlavy and O’Leary (2005) Dunlavy, D. M. and O’Leary, D. P. (2005), Homotopy optimization methods for global optimization, Technical report, Sandia National Laboratories (SNL), Albuquerque, NM, and Livermore, CA ….
- Duong and Nguyen (2022) Duong, B. and Nguyen, T. (2022), Bivariate causal discovery via conditional divergence, in ‘Conference on Causal Learning and Reasoning’.
- Gargiani et al. (2020) Gargiani, M., Zanelli, A., Tran-Dinh, Q., Diehl, M. and Hutter, F. (2020), ‘Convergence analysis of homotopy-sgd for non-convex optimization’, arXiv preprint arXiv:2011.10298 .
- Garrigues and Ghaoui (2008) Garrigues, P. and Ghaoui, L. (2008), ‘An homotopy algorithm for the lasso with online observations’, Advances in neural information processing systems 21.
- Ge et al. (2017) Ge, R., Jin, C. and Zheng, Y. (2017), No spurious local minima in nonconvex low rank problems: A unified geometric analysis, in ‘International Conference on Machine Learning’, PMLR, pp. 1233–1242.
- Ge et al. (2016) Ge, R., Lee, J. D. and Ma, T. (2016), ‘Matrix completion has no spurious local minimum’, Advances in neural information processing systems 29.
- Hazan et al. (2016) Hazan, E., Levy, K. Y. and Shalev-Shwartz, S. (2016), On graduated optimization for stochastic non-convex problems, in ‘International conference on machine learning’, PMLR, pp. 1833–1841.
- Heckerman et al. (1995) Heckerman, D., Geiger, D. and Chickering, D. M. (1995), ‘Learning bayesian networks: The combination of knowledge and statistical data’, Machine learning 20(3), 197–243.
- Iwakiri et al. (2022) Iwakiri, H., Wang, Y., Ito, S. and Takeda, A. (2022), ‘Single loop gaussian homotopy method for non-convex optimization’, arXiv preprint arXiv:2203.05717 .
- Jaakkola et al. (2010) Jaakkola, T., Sontag, D., Globerson, A. and Meila, M. (2010), Learning bayesian network structure using lp relaxations, in ‘Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics’, Vol. 9 of Proceedings of Machine Learning Research, pp. 358–365.
- Jiao et al. (2018) Jiao, R., Lin, N., Hu, Z., Bennett, D. A., Jin, L. and Xiong, M. (2018), ‘Bivariate causal discovery and its applications to gene expression and imaging data analysis’, Frontiers Genetics 9, 347.
- Kawaguchi (2016) Kawaguchi, K. (2016), ‘Deep learning without poor local minima’, Advances in neural information processing systems 29.
- Kazemipour et al. (2019) Kazemipour, A., Larsen, B. W. and Druckmann, S. (2019), ‘Avoiding spurious local minima in deep quadratic networks’, arXiv preprint arXiv:2001.00098 .
- Khalil (2002) Khalil, H. K. (2002), ‘Nonlinear systems third edition’, Patience Hall 115.
- Lachapelle et al. (2020) Lachapelle, S., Brouillard, P., Deleu, T. and Lacoste-Julien, S. (2020), Gradient-based neural dag learning, in ‘International Conference on Learning Representations’.
- Liang et al. (2018) Liang, S., Sun, R., Lee, J. D. and Srikant, R. (2018), ‘Adding one neuron can eliminate all bad local minima’, Advances in Neural Information Processing Systems 31.
- Loh and Bühlmann (2014) Loh, P.-L. and Bühlmann, P. (2014), ‘High-dimensional learning of linear causal networks via inverse covariance estimation’, The Journal of Machine Learning Research 15(1), 3065–3105.
- Mooij et al. (2014) Mooij, J. M., Peters, J., Janzing, D., Zscheischler, J. and Schölkopf, B. (2014), ‘Distinguishing cause from effect using observational data: methods and benchmarks’, Arxiv .
- Nesterov et al. (2018) Nesterov, Y. et al. (2018), Lectures on convex optimization, Vol. 137, Springer.
- Ng et al. (2020) Ng, I., Ghassami, A. and Zhang, K. (2020), On the role of sparsity and dag constraints for learning linear DAGs, in ‘Advances in Neural Information Processing Systems’.
- Ng et al. (2022) Ng, I., Lachapelle, S., Ke, N. R., Lacoste-Julien, S. and Zhang, K. (2022), On the convergence of continuous constrained optimization for structure learning, in ‘International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 8176–8198.
- Ni (2022) Ni, Y. (2022), ‘Bivariate causal discovery for categorical data via classification with optimal label permutation’, Arxiv .
- Nocedal and Wright (1999) Nocedal, J. and Wright, S. J. (1999), Numerical optimization, Springer.
- Park and Klabjan (2017) Park, Y. W. and Klabjan, D. (2017), ‘Bayesian network learning via topological order’, The Journal of Machine Learning Research 18(1), 3451–3482.
- Pearl (2009) Pearl, J. (2009), Causality: Models, Reasoning, and Inference, 2nd edn, Cambridge University Press.
- Sachs et al. (2005) Sachs, K., Perez, O., Pe’er, D., Lauffenburger, D. A. and Nolan, G. P. (2005), ‘Causal protein-signaling networks derived from multiparameter single-cell data’, Science 308(5721), 523–529.
- Scanagatta et al. (2015) Scanagatta, M., de Campos, C. P., Corani, G. and Zaffalon, M. (2015), Learning bayesian networks with thousands of variables., in ‘NIPS’, pp. 1864–1872.
- Silander and Myllymaki (2006) Silander, T. and Myllymaki, P. (2006), A simple approach for finding the globally optimal bayesian network structure, in ‘Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence’.
- Soltanolkotabi et al. (2018) Soltanolkotabi, M., Javanmard, A. and Lee, J. D. (2018), ‘Theoretical insights into the optimization landscape of over-parameterized shallow neural networks’, IEEE Transactions on Information Theory 65(2), 742–769.
- Spirtes et al. (2000) Spirtes, P., Glymour, C. N., Scheines, R. and Heckerman, D. (2000), Causation, prediction, and search, MIT press.
- Teyssier and Koller (2005) Teyssier, M. and Koller, D. (2005), Ordering-based search: A simple and effective algorithm for learning bayesian networks, in ‘Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence’.
- Wauthier and Donnelly (2015) Wauthier, F. and Donnelly, P. (2015), A greedy homotopy method for regression with nonconvex constraints, in ‘Artificial Intelligence and Statistics’, PMLR, pp. 1051–1060.
- Wei et al. (2020) Wei, D., Gao, T. and Yu, Y. (2020), DAGs with no fears: A closer look at continuous optimization for learning bayesian networks, in ‘Advances in Neural Information Processing Systems’.
- Wu et al. (2018) Wu, C., Luo, J. and Lee, J. D. (2018), No spurious local minima in a two hidden unit relu network, in ‘International Conference on Learning Representations’.
- Yu et al. (2019) Yu, Y., Chen, J., Gao, T. and Yu, M. (2019), Dag-gnn: Dag structure learning with graph neural networks, in ‘International Conference on Machine Learning’, PMLR, pp. 7154–7163.
- Zhang et al. (2013) Zhang, B., Gaiteri, C., Bodea, L.-G., Wang, Z., McElwee, J., Podtelezhnikov, A. A., Zhang, C., Xie, T., Tran, L., Dobrin, R. et al. (2013), ‘Integrated systems approach identifies genetic nodes and networks in late-onset alzheimer’s disease’, Cell 153(3), 707–720.
- Zheng et al. (2018) Zheng, X., Aragam, B., Ravikumar, P. K. and Xing, E. P. (2018), DAGs with NO TEARS: Continuous optimization for structure learning, in ‘Advances in Neural Information Processing Systems’.
- Zheng et al. (2020) Zheng, X., Dan, C., Aragam, B., Ravikumar, P. and Xing, E. (2020), Learning sparse nonparametric DAGs, in ‘International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 3414–3425.
- Zhu et al. (2020) Zhu, S., Ng, I. and Chen, Z. (2020), Causal discovery with reinforcement learning, in ‘International Conference on Learning Representations’.
Appendix A Practical Implementation of Algorithm 2
We present a practical implementation of our homotopy algorithm in Algorithm 4. The updating scheme for is now independent of the parameter , but as presented, the initialization for still depends on . This is for the following reason: It is possible to make the updating scheme independent of without imposing any additional assumptions on , as evidenced by Lemma 4 below. The initialization for , however, is trickier, and we must consider two separate cases:
-
1.
No assumptions on . In this case, if is too small, then the problem becomes harder and the initial choice of matters.
-
2.
Lower bound on . If we are willing to accept a lower bound on , then there is an initialization for that does not depend on .
In Corollary 1, we illustrate this last point with the additional condition that . This essentially amounts to an assumption on the minimum signal, and is quite standard in the literature on learning SEM.
Appendix B From Population Loss to Empirical Loss
The transformation from population loss to empirical can be thought from two components. First, with a given empirical loss, Algorithms 2 and 3 still attain the global minimum, , of problem 6, but now the output from the Algorithm is an empirical estimator , rather than ground truth , Theorem 1 and Corollary 1 would continue to be valid. Second, the global optimum, , of the empirical loss possesses the same DAG structure as the underlying . The finite-sample findings in Section 5 (specifically, Lemmas 18 and 19) of Loh and Bühlmann (2014) offer sufficient conditions on the sample size to ensure that the DAG structures of and are identical.
Appendix C From Continuous to Discrete: Gradient Descent
Previously, gradient flow was employed to address the intermediate problem (7), a method that poses implementation challenges in a computational setting. In this section, we introduce Algorithm 6 that leverages gradient descent to solve (7) in each iteration. This adjustment serves practical considerations.
We start with the convergence results of Gradient Descent.
Definition 1.
is -smooth, if is differentiable and such that .
Theorem 3 (Nesterov et al. 2018).
If function is -smooth, then Gradient Descent (Algorithm 5) with step size , finds an -first-order stationary point (i.e. ) in iterations.
One of the pivotal factors influencing the convergence of gradient descent is the selection of the step size. Theorem 3 select a step size . Therefore, our initial step is to determine the smoothness of within our region of interest, .
Lemma 5.
Consider the function as defined in Equation 7 within the region . It follows that for all , the function is -smooth.
Since gradient descent is limited to identifying the stationary point of the function. Thus, we study the gradient of , i.e. has the following form
As gradient descent is limited to identifying the stationary point of the function, we, therefore, focus on . This can be expressed in the subsequent manner:
As a result,
Here we denote such region as
| (10) |
Figure 6 and 7 illustrate the region .


Given that the gradient descent can only locate stationary points within the region during each iteration, the boundary of becomes a critical component of our analysis. To facilitate clear presentation, it is essential to establish some pertinent notations.
-
•
(11a) (11b) If the system of equations yields only a single solution, we denote this solution as . If it yields two solutions, these solutions are denoted as , with . In the event that there are three distinct solutions to the system of equations, these solutions are denoted as , where .
-
•
(12a) (12b) If the system of equations yields only a single solution, we denote this solution as . If it yields two solutions, these solutions are denoted as , with . In the event that there are three distinct solutions to the system of equations, these solutions are denoted as , where .
-
•
(13a) (13b) If the system of equations yields only a single solution, we denote this solution as . If it yields two solutions, these solutions are denoted as , with . In the event that there are three distinct solutions to the system of equations, these solutions are denoted as , where .
Remark 4.
The parameter can substantially influence the behavior of the systems of equations (12a),(12b) and (13a),(13b). A crucial consideration is to ensure that remains adequately small. To facilitate this, we introduce a new parameter, , whose specific value will be determined later. At this stage, we merely require that should lie within the interval . We further impose a constraint on to satisfy the following inequality:
| (14) |
Following the same procedure when we deal with . Let us substitute (12a) into (12b), then we obtain an equation that only involves the variable
| (15) |
Let us substitute (12b) into (12a), then we obtain an equation that only involves the variable
| (16) |
Proceed similarly for equations (13a) and (13b).
| (17) |
| (18) |
Given the substantial role that the system of equations 12a and 12b play in our analysis, the existence of in these equations complicates the analysis, this can be avoided by considering the worst-case scenario, i.e., when . With this particular choice of , we can reformulate (15) and (16) as follows, denoting them as and respectively.
| (19) |
| (20) |
The functions , , and possess similar properties to as defined in Equation (8), with more details available in Theorem 7 and 8. Additionally, the functions , , and share similar characteristics with as defined in Equation (9), with more details provided in Theorem 9.
As illustrated in Figure 6, the -stationary point region can be partitioned into two distinct areas, of which only the lower-right one contains and it is of interest to our analysis. Moreover, and are extremal point of two distinct regions. The upcoming corollary substantiates this intuition.
Corollary 3.
Corollary 3 suggests that can be partitioned into two distinct regions, namely and . Furthermore, for every belonging to , it follows that and . Similarly, for every that lies within , the condition and holds. The region represents the “correct" region that gradient descent should identify. In this context, identifying the region equates to pinpointing the extremal points of the region. As a result, our focus should be on the extremal points of and , specifically at and . Furthermore, the key to ensuring the convergence of the gradient descent to the is to accurately identify the “basin of attraction” of the region . The following lemma provides a region within which, regardless of the initialization point of the gradient descent, it converges inside .
Lemma 6.
Lemma 6 can be considered the gradient descent analogue of Lemma 2. It plays a pivotal role in the proof of Theorem 4. In Figure 6, the lower-right rectangle corresponds to . Lemma 6 implies that the gradient descent with any initialization inside will converge to at last. Then, by utilizing the previous solution as the initial point, as long as it lies within region , the gradient descent can converge to which is stationary points region that contains , thereby achieving the goal of tracking . Following the scheduling for prescribed in Algorithm 6 provides a sufficient condition to ensure that will happen.
We now proceed to present the theorem which guarantees the global convergence of Algorithm 6.
Theorem 4.
If , , , and satisfies
Set the updating rule
Then . Moreover, for any , running Algorithm 6 after outer iteration
| (23) |
where
The total gradient descent steps are
Proof.
Upon substituting gradient flow with gradient descent, it becomes possible to only identify an -stationary point for . This modification necessitates specifying the stepsize for gradient descent, as well as an updating rule for . The adjustment procedure used can substantially influence the result of Algorithm 6. In this proof, we will impose limitations on the update scheme , the stepsize , and the tolerance to ensure their effective operation within Algorithm 6. The approach employed for this proof closely mirrors that of the proof for Theorem 1 albeit with more careful scrutiny. In this proof, we will work out all the requirements for . Subsequently, we will verify that our selection in Theorem 4 conforms to these requirements.
In the proof, we occasionally use or . When we employ , it signifies that the given inequality or equality holds for any . Conversely, when we use , it indicates we are examining how to set these parameters for distinct iterations.
Establish the Bound
Condition 1.
Ensuring the Correct Solution Path via Gradient Descent
Following the argument when we prove Theorem 1, we strive to ensure that the gradient descent, when initiated at , will converge within the "correct" -stationary point region (namely, ) which includes . For this to occur, we necessitate that:
| (24) |
Here (1), (5) are due to Corollary 3; (2) comes from the boundary we established earlier; (3) is based on the constraints we have placed on and , which we will present as Condition 2 subsequently; (4) is from the Theorem 7(ii) and relationship . Also, from the Lemma 9, . Hence, by invoking Lemma 6, we can affirm that our gradient descent consistently traces the correct stationary point. Now we state condition to make it happen,
Condition 2.
In this context, our requirement extends beyond merely ensuring that decreases. We further stipulate that it should decrease by a factor of . Next, we impose another important constraint
Condition 3.
Updating Rules
Now we are ready to check our updating rules satisfy the conditions above
Check for Conditions
First, we check the condition 2. condition 2 requires
Note that
Therefore, once the following inequality is true, Condition 2 is satisfied.
Because from the condition we impose for . Consequently, Condition 2 is satisfied under our choice of .
Now we focus on the Condition 1. Because , if we can ensure holds, then we can show Condition 1 is always satisfied.
We also notice that
Because , the inequality above always holds and this inequality implies that for any
Therefore, Condition 2 holds. Condition 3 also holds because of the choice of .
Bound the Distance
Let , and assume that satisfies the following
| (25) |
Note that when satisfies (25), then , so .
| (26) |
Then
Then we know . Now we can bound the distance , it is important to note that
We use the fact that , and . Next, we can separately establish bounds for these two terms. Due to (24), and
Given that if , then . Therefore, if , we can use the fact that . In this case,
As a result, we have
Just let
| (27) | ||||
| (28) | ||||
| (29) |
We use the fact that . In order to satisfy (25).
| (30) | |||
| (31) |
Consequently, running Algorithm 6 after outer iteration
where
Appendix D Additional Theorems and Lemmas
Theorem 5 (Detailed Property of ).
For in (8), then
-
(i)
For , ,
-
(ii)
For , .
-
(iii)
For
For
(32a) Otherwise (32b) where
Moreover,
-
(iv)
For , let , then and there exist a unique solution to , denoted as . Additionally, .
-
(v)
There exists a such that, , the equation has only one solution. At , the equation has two solutions, and , the equation has three solutions. Moreover, .
-
(vi)
, the equation has three solution, i.e. .
Moreover,
Theorem 6 (Detailed Property of ).
For in (9), then
-
(i)
For , ,
-
(ii)
If or , then .
-
(iii)
For
For
(33a) Otherwise (33b) where
Moreover,
-
(iv)
For and let , then and there exist a unique solution to , denoted as and .
-
(v)
There exists a such that, , the equation has only one solution. At , the equation has two solutions, and , the equation has three solutions. Moreover,
-
(vi)
, has three stationary points, i.e. .
Besides,
It also implies that and
Lemma 8.
For any in (41), and
Theorem 7 (Detailed Property of ).
For in (15), then
-
(i)
For , ,
-
(ii)
For , then . For
(34a) Otherwise (34b) where
Also,
Theorem 8 (Detailed Property of ).
For in (19), then
-
(i)
For ,
-
(ii)
For , then . For
(35a) Otherwise (35b) where
Also,
Theorem 9 (Detailed Property of ).
For in (20), then
-
(i)
For , ,
-
(ii)
For
For
(36a) Otherwise (36b) where
-
(iii)
If , then there exists a such that, , the equation has only one solution. At , the equation has two solutions, and , the equation has three solutions. Moreover, .
-
(iv)
If , then , has three stationary points, i.e. . Besides,
It implies that
Lemma 9.
Under the same setting as Corollary 3,
Appendix E Technical Proofs
E.1 Proof of Theorem 3
Proof.
For the sake of completeness, we have included the proof here. Please note that this proof can also be found in Nesterov et al. (2018).
Proof.
We use the fact that is -smooth function if and only if for any
Let and , then using the updating rule
Therefore,
∎
∎
E.2 Proof of Theorem 5
Proof.
-
(i)
For any ,
-
(ii)
-
(iii)
For , .
For , . For , or .Note that
The intersection between line and function are exactly and , and .
-
(iv)
Note that for ,
then . Let , because , then
Also note that when , , , and also if , then
Thus,
Because , it is easy to see when , . We know as because of the monotonicity of in Theorem 5(iii). Combining all of these, i.e.
There exists a such that
- (v)
-
(vi)
By Theorem 5(v), , there exists three stationary points such that . Because , then
By implicit function theorem (Dontchev et al., 2009), for solution to equation , there exists a unique continuously differentiable function such that and satisfies . Therefore,
Therefore by Theorem 5(iii),
Because , then . Let us consider where and
∎
E.3 Proof of Theorem 6
Proof.
-
(i)
For ,
-
(ii)
If , then
so when or , then
-
(iii)
For , then . For , and , then , For , or , .
We use the same argument as before to show that
- (iv)
-
(v)
We follow the same proof from the proof of Theorem 5(v).
-
(vi)
By Theorem 6(v), , there exists three stationary points such that . Because , then
By implicit function theorem (Dontchev et al., 2009), for solutions to equation , there exists a unique continuously differentiable function such that and satisfies . Therefore,
Therefore, by Theorem 6(iii)
Because and .
Let us consider where and
By Theorem 6(iii). It implies
taking on both side,
Hence, .
When , because and , is increasing function between then . Moreover, , and are continuous function w.r.t , which is really small, such that and , (by Theorem 6(iv)) and , hence . It implies when decreases, then increases. This relation holds until
and . Note that when , , it implies that and , thus decreasing leads to decreasing . We can conclude
Note that , , so
Note that when , i.e. then
It implies that when decreases, also decreases. It holds true until . The same analysis can be applied to like above, we can conclude that
Hence
∎
E.4 Proof of Theorem 7,8 and 9
E.5 Proof of Lemma 1
E.6 Proof of Lemma 2

Proof.
Let us define the functions as below
| (37a) | |||||
| (37b) |
| (38a) | |||||
| (38b) |
with simple calculations,
and
Here we divide into three parts,
| (39) | ||||
| (40) | ||||
| (41) |
Also note that
The gradient flow follows
then
| (42) | |||
| (43) |
Note that is not diminishing and bounded away from 0. Let us consider the , since , in (42) and boundness of , it implies there exists a finite such that
where is defined as
For the same reason, if , there exists a finite time ,
where is defined as
then by lemma 7, . ∎
E.7 Proof of Lemma 3
Proof.
This is just a result of the Theorem 5. ∎
E.8 Proof of Lemma 5
Proof.
Note that
Let is the spectral norm, and it satisfies triangle inequality
The spectral norm of the second term in area A is bounded by
We use in the inequality. Therefore,
Also, according to Boyd et al. (2004); Nesterov et al. (2018), for any , if exists, then is smooth if and only if . With this, we conclude the proof. ∎
E.9 Proof of Lemma 7
Proof.
First we prove , because if , then there exists a finite such that
where is the boundary of , defined as
W.L.O.G, let us assume and . Here are four different cases,
This indicates that are pointing to the interior of , then can not escape . Here we can focus our attention in , because . For Algorithm 1,
In our setting,
so
Plus, is the unique stationary point of in . By lemma 8
By Lyapunov asymptotic stability theorem (Khalil, 2002), and applying it to gradient flow for in , we can conclude . ∎
E.10 Proof of Lemma 8
Proof.
For any in 41, and , in Algorithm 7. W.L.O.G, we can assume , the analysis details can also be applied to . It is obvious that and . Also, . Otherwise either or hold, Algorithm 7 continues until , i.e. converges to .
Moreover, note that for any
Because
Note that
By the same reason,
By Lemma 1, is local minima, and there exists a and any Since , there exists a such that , , combining them all
∎
E.11 Proof of Lemma 4
E.12 Proof of Lemma 6
E.13 Proof of Lemma 9
E.14 Proof of Corollary 1
Proof.
E.15 Proof of Corollary 2
E.16 Proof of Corollary 3
Proof.
It is easy to know that
and
and when , there are three solutions to by Theorem 5. Also, we know from Theorem 7, 8
Note that when
Therefore,
Also, we know that for defined in Theorem 5(iii), we know from Theorem 5(iv). Therefore,
Besides, . By monotonicity of and from the Theorem 7(ii) and Theorem 8(ii), it implies that there are at least two solutions to and . From the geometry of and , it is trivial to know that , , , .
Finally, for every point , there exists a pair , each satisfying and , such that is the solution to
We can repeat the same analysis above to show that , . Applying the same logic to , we find , . Thus, is the extreme point of and is the extreme point of , we get the results. ∎
Appendix F Experiments Details
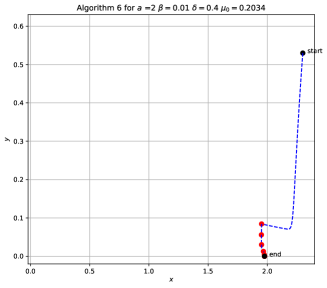
In this section, we present experiments to validate the global convergence of Algorithm 6. Our goal is twofold: First, we aim to demonstrate that irrespective of the starting point, Algorithm 6 using gradient descent consistently returns the global minimum. Second, we contrast our updating scheme for as prescribed in Algorithm 6 with an arbitrary updating scheme for . This comparison illustrates how inappropriate setting of parameters in gradient descent could lead to incorrect solutions.
F.1 Random Initialization Converges to Global Optimum







F.2 Wrong Specification of Leads to Spurious Local Optimial


F.3 Wrong Specification of Leads to Incorrect Solution


F.4 Faster decrease of Leads to Incorrect Solution

