gLaSDI: Parametric Physics-informed Greedy Latent Space Dynamics Identification
Abstract
A parametric adaptive physics-informed greedy Latent Space Dynamics Identification (gLaSDI) method is proposed for accurate, efficient, and robust data-driven reduced-order modeling of high-dimensional nonlinear dynamical systems. In the proposed gLaSDI framework, an autoencoder discovers intrinsic nonlinear latent representations of high-dimensional data, while dynamics identification (DI) models capture local latent-space dynamics. An interactive training algorithm is adopted for the autoencoder and local DI models, which enables identification of simple latent-space dynamics and enhances accuracy and efficiency of data-driven reduced-order modeling. To maximize and accelerate the exploration of the parameter space for the optimal model performance, an adaptive greedy sampling algorithm integrated with a physics-informed residual-based error indicator and random-subset evaluation is introduced to search for the optimal training samples on the fly. Further, to exploit local latent-space dynamics captured by the local DI models for an improved modeling accuracy with a minimum number of local DI models in the parameter space, a -nearest neighbor convex interpolation scheme is employed. The effectiveness of the proposed framework is demonstrated by modeling various nonlinear dynamical problems, including Burgers equations, nonlinear heat conduction, and radial advection. The proposed adaptive greedy sampling outperforms the conventional predefined uniform sampling in terms of accuracy. Compared with the high-fidelity models, gLaSDI achieves 17 to 2,658 speed-up with 1 to 5 relative errors.
keywords:
Reduced order model, autoencoders, nonlinear dynamical systems, regression-based dynamics identification, physics-informed greedy algorithm, adaptive sampling1 Introduction
Physical simulations have played an increasingly significant role in developments of engineering, science, and technology. The widespread applications of physical simulations in digital twins systems [1, 2] is one recent example. Many physical processes are mathematically modeled by time-dependent nonlinear partial differential equations (PDEs). As it is difficult or even impossible to obtain analytical solutions for many highly complicated problems, various numerical methods have been developed to approximate the analytical solutions. However, due to the complexity and the domain size of problems, high-fidelity forward physical simulations can be computationally intractable even with high performance computing, which prohibits their applications to problems that require a large number of forward simulations, such as design optimization [3, 4], optimal control [5], uncertainty quantification [6, 7], and inverse analysis [7, 8].
To achieve accurate and efficient physical simulations, data can play a key role. For example, various physics-constrained data-driven model reduction techniques have been developed, such as the projection-based reduced-order model (ROM), in which the state fields of the full-order model (FOM) are projected to a linear or nonlinear subspace so that the dimension of the state fields is significantly reduced. Popular linear projection techniques include the proper orthogonal decomposition (POD) [9], the reduced basis method [10], and the balanced truncation method [11], while autoencoders [12, 13] are often applied for nonlinear projection [14, 15, 16]. The linear-subspace ROM (LS-ROM) has been successfully applied to various problems, such as nonlinear heat conduction [17], Lagrangian hydrodynamics [18, 19, 20], nonlinear diffusion equations [17, 21], Burgers equations [20, 22, 23, 24], convection-diffusion equations [25, 26], Navier-Stokes equations [27, 28], Boltzmann transport problems [29, 30], fracture mechanics [31, 32], molecular dynamics [33, 34], fatigue analysis under cycling-induced plastic deformations [35], topology optimization [36, 37], structural design optimization [38, 39], etc. Despite successes of the classical LS-ROM in many applications, it is limited to the assumption that intrinsic solution space falls into a low-dimensional subspace, which means the solution space has a small Kolmogorov -width. This assumption is not satisfied in advection-dominated systems with sharp gradients, moving shock fronts, and turbulence, which prohibits the applications of the LS-ROM approaches for these systems. On the other hand, it has been shown that nonlinear-subspace ROMs based on autoencoders outperforms the LS-ROM on advection-dominated systems [14, 40].
Several strategies have been developed to extend LS-ROM for addressing the challenge posed by advection-dominated systems, which can be mainly categorized into Lagrangian-based approaches and methods based on a transport-invariant coordinate frame. In the first category of approaches, Lagrangian coordinate grids are leveraged to build a ROM that propagates both the wave physics and the coordinate grid in time [41, 42, 43]. Although these methods work well, their applicability is limited by the requirement of full knowledge of the governing equations for obtaining the Lagrangian grid. The second category of strategies is based on transforming the system dynamics to a moving coordinate frame by adding a time-dependent shift to the spatial coordinates such that the system dynamics are absent of advection, such as the shifted POD method [44] and the implicit feature tracking algorithm based on a minimal-residual ROM [45]. Despite the effectiveness of these methods, the high computational costs prohibit their applications in practice.
Most aforementioned physics-constrained data-driven projection-based ROMs are intrusive, which require plugging the reduced-order solution representation into the discretized system of governing equations. Although the intrusive brings many benefits, such as extrapolation robustness, a requirement of less training data, and high accuracy, the implementation of the intrusive ROMs requires not only sufficient understanding of the numerical solver of the high-fidelity simulation but also access to the source code of the numerical solver.
In contrast, non-intrusive ROMs are purely data-driven. It requires neither access to the source code nor the knowledge of the high-fidelity solver. Many non-intrusive ROMs are constructed based on interpolation techniques that provide nonlinear mapping to relate inputs to outputs. Among various interpolation techniques, such as Gaussian processes [46, 47], radial basis functions [48, 49], Kriging [50, 51], neural networks (NNs) have been most popular due to their strong flexibility and capability supported by the universal approximation theorem [52]. NN-based surrogates have been applied to various physical simulations, such as fluid dynamics [53], particle simulations [54], bioinformatics [55], deep Koopman dynamical models [56], porous media flow [57, 58, 59, 60], etc. However, pure black-box NN-based surrogates lack interpretability and suffer from unstable and inaccurate generalization performance. For example, Swischuk, et al. [61] compared various ML models, including NNs, multivariate polynomial regression, -nearest neighbors (k-NNs), and decision trees, used to learn nonlinear mapping between input parameters and low-dimensional representations of solution fields obtained by POD projection. The numerical examples of this study shows that the highly flexible NN-based model performs worst, which highlights the importance of choosing an appropriate ML strategy by considering the bias-variance trade off, especially when the training data coverage of the input space is sparse.
In recent years, several ROM methods have been integrated with latent-space learning algorithms. Kim, et al. [62] proposed a DeepFluids framework in which the autoencoder was applied for nonlinear projection and a latent-space time integrator was used to approximate the evolution of the solutions in the latent space. Xie, et al. [63] applied the POD for linear projection and a multi-step NN to propagate the latent-space dynamical solutions. Hoang, et al. [64] applied the POD to compress space-time solution space to obtain space-time reduced-order basis and examined several surrogate models to map input parameters to space-time basis coefficients, including multivariate polynomial regression, k-NNs, random forest, and NNs. Kadeethum, et al. [59] compared performance of the POD and autoencoder compression along with various latent space interpolation techniques, such as radial basis function and artificial neural networks. However, the latent-space dynamics models of these methods are complex and lack interpretability.
To improve the interpretability and generalization capability, it is critical to identify the underlying equations governing the latent-space dynamics. Many methods have been developed for the identification of interpretable governing laws from data, including symbolic regression that searches both parameters and the governing equations simultaneously [65, 66], parametric models that fit parameters to equations of a given form, such as the sparse identification of nonlinear dynamics (SINDy) [67], and operator inference [68, 69, 70]. Cranmer et al. [71] applied graph neural networks to learn sparse latent representations and symbolic regression with a genetic algorithm to discover explicit analytical relations of the learned latent representations, which enhances efficiency of symbolic regression to high-dimensional data [72]. Instead of genetic algorithms, other techniques have been applied to guide the equation search in symbolic regression, such as gradient descent [73, 74] and Monte Carlo Tree Search with asymptotic constraints in NNs [75].
Champion, et al. [76] applied an autoencoder for nonlinear projection and SINDy to identify simple ordinary differential equations (ODEs) that govern the latent-space dynamics. The autoencoder and the SINDy model were trained interactively to achieve simple latent-space dynamics. However, the proposed SINDy-autoencoder method is not parameterized and generalizable. Bai and Peng [77] proposed parametric non-intrusive ROMs that combine the POD for linear projection and regression surrogates to approximate dynamical systems of latent variables, including support vector machines with kernel functions, tree-based methods, k-NNs, vectorial kernel orthogonal greedy algorithm (VKOGA), and SINDy. The ROMs integrated with VKOGA and SINDy deliver superior cost versus error trade-off. Additionally, various non-intrusive ROMs have been developed based on POD-based linear projection with latent space dynamics captured by polynomials through operator inference [68, 82, 83, 84, 85, 69, 86, 70, 87, 78, 79, 80, 81]. For example, Qian, et al. [69] introduced a lifting map to transform non-polynomial physical dynamics to quadratic polynomial dynamics and then combined POD-based linear projection with operator inference to identify quadratic reduced models for dynamical systems. Due to the limitation of the POD-based linear projection, these non-intrusive ROMs have difficulties with advection-dominated problems.
To address this challenge, Issan and Kramer [88] recently proposed a non-intrusive ROM based on shifted operator inference by transforming the original coordinate frame of dynamical systems to a moving coordinate frame in which the dynamics are absent of translation and rotation. Fries, et al. [40] proposed a parametric latent space dynamics identification (LaSDI) framework in which an autoencoder was applied for nonlinear projection and a set of parametric dynamics identification (DI) models were introduced in the parameter space to identify local latent-space dynamics, as illustrated in Fig. 1. The LaSDI framework can be viewed as a generalization of aforementioned non-intrusive ROMs built upon latent-space dynamics identification, since it allows linear or nonlinear projection and enables latent-space dynamics to be captured by flexible DI models based on general nonlinear functions. However, since a sequential training procedure was adopted for the autoencoder and the DI models, the lack of interaction between the autoencoder and the DI models leads to a strong dependency on the complexity and quality of the latent-space dynamics on the autoencoder architecture, which could pose challenges to the subsequent training of the DI models and thus affect the model performances. Most importantly, all the above-mentioned approaches rely on predefined training samples, such as uniform or Latin hypercube sampling that may not be optimal in terms of the number of samples for achieving the best model performance in the prescribed parameter space. As the generation of the simulation data can be computationally expensive, it is important to minimize the number of samples.
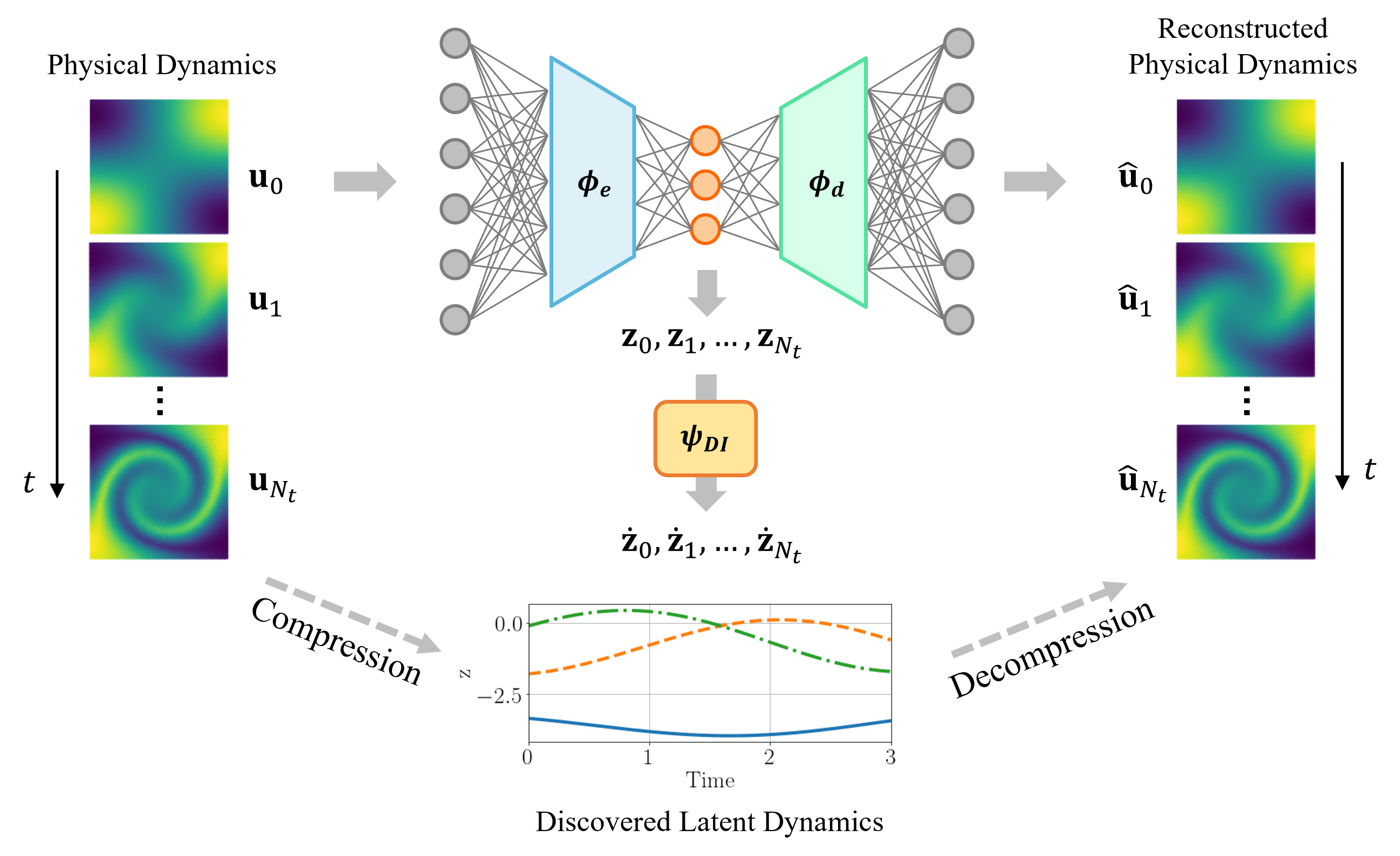
In this study, we propose a parametric adaptive greedy latent space dynamics identification (gLaSDI) framework for accurate, efficient, and robust physics-informed data-driven reduced-order modeling. To maximize and accelerate the exploration of the parameter space for optimal performance, an adaptive greedy sampling algorithm integrated with a physics-informed residual-based error indicator and random-subset evaluation is introduced to search for the optimal and minimal training samples on the fly. The proposed gLaSDI framework contains an autoencoder for nonlinear projection to discover intrinsic latent representations and a set of local DI models to capture local latent-space dynamics in the parameter space, which is further exploited by an efficient k-NN convex interpolation scheme. The concept of gLaSDI is similar to the active learning algorithms that are allowed to choose training data from which it learns [89, 90]. The DI models in gLaSDI can be viewed as the active learners in active learning, which are selected to maximize “diversity” of learners in the parameter space and minimize prediction errors. The autoencoder training and dynamics identification in the gLaSDI take place interactively to achieve an optimal identification of simple latent-space dynamics. The effectiveness and enhanced performance of the proposed gLaSDI framework is demonstrated by modeling various nonlinear dynamical problems with a comparison with the LaSDI framework [40].
The remainder of this paper is organized as follows. The governing equations of dynamical systems is introduced in Section 2. In Section 3, the ingredients of the proposed gLaSDI framework, the mathematical formulations, the training and testing algorithms are introduced. In Section 4, the effectiveness and capability of the proposed gLaSDI framework are examined by modeling various nonlinear dynamical problems, including Burgers equations, nonlinear heat conduction, and radial advection. The effects of various factors on model performance are investigated, including the number of nearest neighbors for convex interpolation, the latent-space dimension, the complexity of the DI models, and the size of the parameter space. A performance comparison between uniform sampling, i.e., LaSDI, and the physics-informed greedy sampling, i.e., gLaSDI, is also presented. Concluding remarks and discussions are summarized in Section 5.
2 Governing equations of dynamical systems
A parameterized dynamical system characterized by a system of ordinary differential equations (ODEs) is considered
| (1a) | |||
| (1b) | |||
where is the final time; is the parameter in a parameter domain . is the parameterized time-dependent solution to the dynamical system; denotes the velocity of ; is the initial state of . Eq. (1) can be considered as a semi-discretized equation of a system of partial differential equations (PDEs) with a spatial domain , and . Spatial discretization can be performed by numerical methods, such as the finite element method.
A uniform time discretization is considered in this study, with a time step size and for where , . Various explicit or implicit time integration schemes can be applied to solve Eq. (1). For example, with the implicit backward Euler time integrator, the approximate solutions to Eq. (1) can be obtained by solving the following nonlinear system of equations
| (2) |
where , and . The residual function of Eq. (2) is expressed as
| (3) |
Solving the dynamical system of equation (Eq. (1)) could be computationally expensive, especially when the solution dimension () is large and the computational domain () is geometrically complex. In this work, an efficient and accurate data-driven reduced-order modeling framework based on physics-informed greedy latent space dynamics identification is proposed, which will be discussed in details in the next section.
3 gLaSDI
The ingredients of the proposed physics-informed parametric adaptive greedy latent space dynamics identification (gLaSDI) framework are introduced in this section, including autoencoders, dynamics identification (DI) models, -nearest neighbors (k-NN) convex interpolation, and an adaptive greedy sampling procedure with a physics-informed error indicator. An autoencoder is trained to discover an intrinsic nonlinear latent representation of high-dimensional data from dynamical PDEs, while training cases are sampled on the fly and associated local DI models are trained simultaneously to capture localized latent-space dynamics. An interactive training procedure is employed for the autoencoder and local DI models, which is referred to as the interactive Autoencoder-DI training, as shown in Fig. 2. The interaction between the autoencoder and local (in the parameter space) DI models enables the identification of simple and smooth latent-space dynamics and therefore accurate and efficient data-driven reduced-order modeling. In the following, Sections 3.1 - 3.3 review the basics of autoencoders, the dynamics identification method, and the convex interpolation scheme, respectively, which are fundamental to the physics-informed adaptive greedy sampling algorithm introduced in Section 3.4. Section 3.5 summarizes the algorithms for gLaSDI training and testing.
The physics-informed adaptive greedy sampling can be performed on either a continuous parameter space () or a discrete parameter space (). In the following demonstration, a discrete parameter space () is considered. denotes a set of selected training sample points.
Let us consider a training sample point , and as the solution at the -th time step of the dynamical system in Eq. (1) with the training sample point . The solutions at all time steps are arranged in a snapshot matrix denoted as . Concatenating snapshot matrices corresponding to all training sample points gives a full snapshot matrix
| (4) |
3.1 Autoencoders for nonlinear dimensionality reduction
An autoencoder [12, 13] is a special architecture of deep neural networks (DNNs) designed for dimensionality reduction or representation learning. As shown in Fig. 1, an autoencoder consists of an encoder function and a decoder function , such that
| (5a) | |||
| (5b) | |||
where denotes the solution of a sampling point , , at the -th time step; is the latent dimension, and are trainable parameters of the encoder and the decoder, respectively; is the output of the autoencoder, a reconstruction of the original input . With the latent dimension much smaller than the input dimension , the encoder is trained to compress the high-dimensional input and learn a low-dimensional representation, denoted as a latent variable , whereas the decoder reconstructs the input data by mapping the latent variable back to the high-dimensional space, as illustrated in Fig. 1.
Let us denote as the matrix of latent variables at all time steps of the sampling point and as the full latent variable matrix of all sampling points in the parameter space. The corresponding reconstructed full snapshot matrix is denoted by , where , , obtained from Eq. (5). The optimal trainable parameters of the autoencoder ( and from Eq. (5)) are obtained by minimizing the loss function:
| (6) |
A standard autoencoder often consists of symmetric architectures for the encoder and the decoder, but it is not required. In this study, a standard autoencoder is adopted and the encoder architecture is used to denote the autoencoder architecture for simplicity. For example, the encoder architecture 6-4-3 denotes that there are 6, 4, and 3 artificial neurons in the input layer, the hidden layer, and the embedding layer that outputs the latent variables, respectively. As such, the decoder architecture in this case is 3-4-6 and the corresponding autoencoder architecture is 6-4-3-4-6. ===================================================================================================
3.2 Latent-space dynamics identification
Instead of learning complex physical dynamics of high-dimensional data, a dynamics identification (DI) model is introduced to capture dynamics of the autoencoder-discovered low-dimensional representation associated with the high-dimensional data. Therefore, the problem of the high-dimensional dynamical system in Eq. (1) is reduced to
| (7) |
where and denotes the encoder function introduced in Section 3.1. The dynamics of can be reconstructed by using the decoder function: .
Given the discrete latent variable matrix of a sampling point , , the governing dynamical function is approximated by a user-defined library of candidate basis functions , expressed as
| (8) |
where has candidate basis functions to capture the latent space dynamics, e.g., polynomial, trigonometric, and exponential functions, with ; denotes the number of columns of the library matrix. Note that is determined by the form of the basis function [67, 40]. For example, if is an exponential function, then
| (9) |
If is a quadratic polynomial, then
| (10) |
is an associated coefficient matrix.
In gLaSDI, the autoencoder and the DI model are trained simultaneously and interactively to identify simple and smooth latent-space dynamics. Note that in Eq. (8) can be obtained by applying the chain rule and automatic differentiation (AD) [91] to the encoder network, i.e.,
| (11) |
Enforcing the consistency on the predicted latent-dynamics, and , allows simple and smooth dynamics to be identified, which are determined by the selection of the basis functions in the DI model. Therefore, the following loss function is constructed, which imposes a constraint on the trainable parameters of the encoder ( via Eq. (11)) and the DI models ( via Eq. (8)),
| (12) |
with
| (13a) | ||||
| (13b) | ||||
The loss function in also enables identification of simple latent-dynamics when simple DI model is prescribed, which will be demonstrated in Section 4.2-4.3. Note that the local DI models are considered to be point-wise (see the detailed description about point-wise and region-based DI models in [40]), which means each local DI model is associated with a distinct sampling point in the parameter space. Hence, each sampling point has an associated DI coefficient matrix.
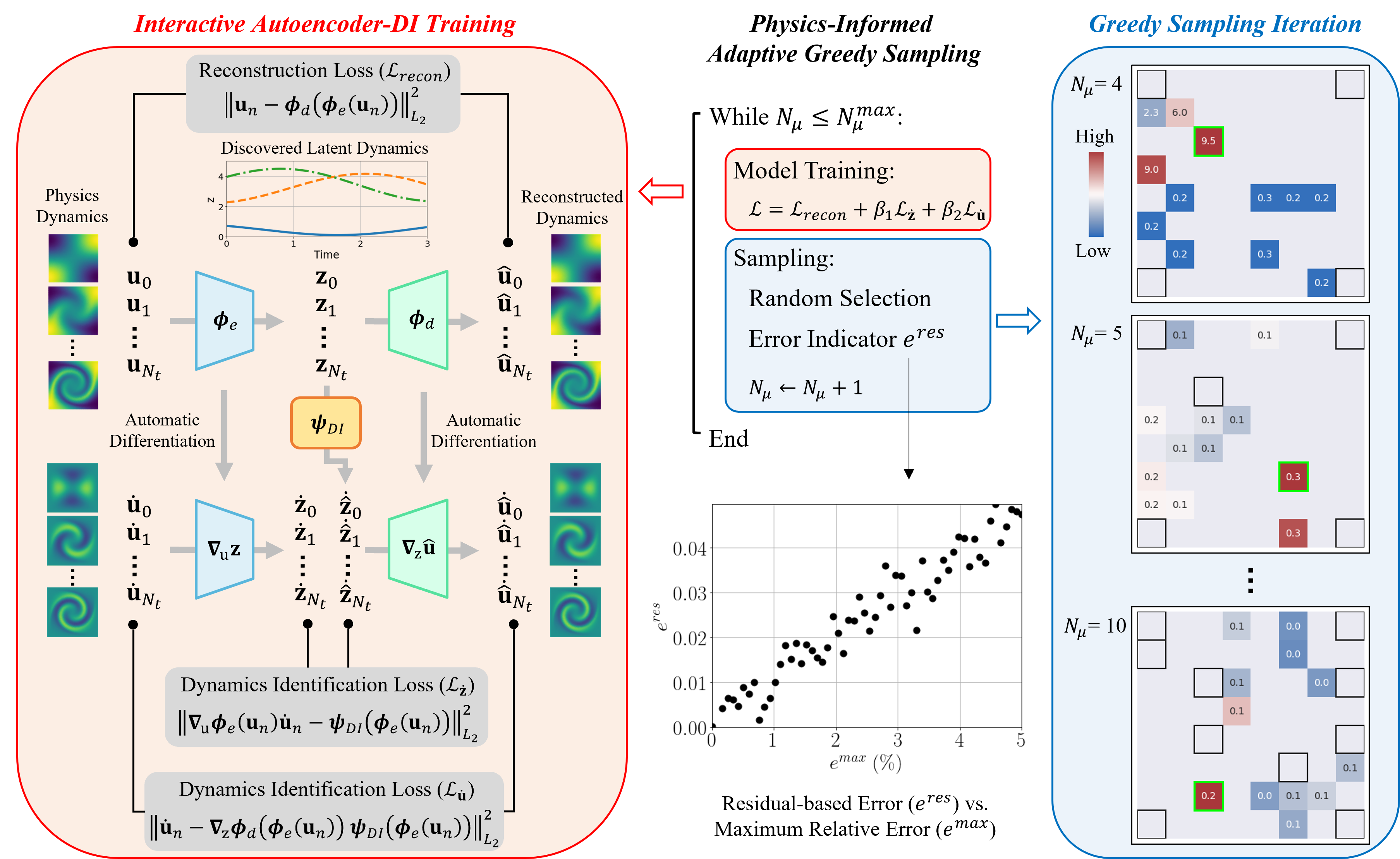
To further enhance the accuracy of the physical dynamics predicted by the decoder, a loss function is constructed to ensure the consistency between the predicted dynamics gradients and the gradients of the solution data, in addition to the reconstruction loss function in Eq. (6). The enhancement is demonstrated in Section 4.1.3. The predicted dynamics gradients, , can be calculated from by following the path: , as illustrated in Fig. 2, and applying the chain rule and AD to the decoder network,
| (14a) | ||||
| (14b) | ||||
| (14c) | ||||
which involves all trainable parameters, including the encoder (), the decoder (), and the DI models (). The loss function in is defined as
| (15) |
with
| (16a) | ||||
| (16b) | ||||
Therefore, the loss function of the interactive autoencoder-DI training consists of three different loss terms, i.e., the reconstruction loss of the autoencoder in Eq. (6), the DI loss in in Eq. (12), and the DI loss in in Eq. (15). They are combined as a linear combination:
| (17) |
where and denote the regularization parameters to balance the scale and contributions from the loss terms. A schematics of the interactive autoencoder-DI training is shown in Fig. 2.
Compared with a global DI model that captures global latent-space dynamics of all sampling points in the parameter space , each local DI model in the proposed framework is associated with one sampling point and thus captures local latent-space dynamics more accurately. Further, an efficient -nearest neighbor (k-NN) convex interpolation scheme, which will be introduced in the next subsection, is employed to exploit the local latent-space dynamics captured by the local DI models for an improved prediction accuracy, which will be demonstrated in Section 4.1.
3.3 k-nearest neighbors convex interpolation
To exploit the local latent-space dynamics captured by the local DI models for enhanced parameterization and efficiency, a k-NN convexity-preserving partition-of-unity interpolation scheme is employed. The interpolation scheme utilizes Shepard function [92] or inverse distance weighting, which has been widely used in data fitting and function approximation with positivity constraint [93, 94, 95, 96]. Compared with other interpolation techniques, such as the locally linear embedding [97, 98] and the radial basis function interpolation [40], which require optimization to obtain interpolation weights and thus more computational cost, the employed Shepard interpolation is more efficient while preserving convexity.
Given a testing parameter , the DI coefficient matrix is obtained by a convex interpolation of coefficient matrices of its -nearest neighbors (existing sampling points), expressed as
| (18) |
where is the interpolated DI coefficient matrix of the testing parameter , is the index set of the -nearest neighbor points of selected from that contains the parameters of the training samples, and is the coefficient matrix of the sampling point . The selection of the -nearest neighbors is based on the Mahalanobis distance between the testing parameter and the training parameters, . The interpolation functions are defined as
| (19) |
where is the number of nearest neighbors. In Eqs. (18) and (19), is a positive kernel function representing the weight on the coefficient set , and denotes the interpolation operator that constructs shape functions with respect to and its neighbors. It should be noted that these functions satisfy a partition of unity, i.e., for transformation objectivity. Furthermore, they are convexity-preserving when the kernel function is a positive function. Here, an inverse distance function is used as the kernel function
| (20) |
where measures the Mahalanobis distance (multivariate distance) between and . The covariance matrix is estimated from the sampled parameters and accounts for the scale and the correlation between the variables along each direction of the parameter space. For uncorrelated variables with a similar scale, the Mahalanobis distance is equivalent to the Euclidean () distance. In the numerical examples of Section 4, the parameter variables along each direction of the parameter space are uncorrelated with a similar scale and therefore the Euclidean distance was applied. If the testing parameter point overlaps with one of the nearest neighbor points, i.e., , , then and , and , resulting in , which is expected.
Note that the interpolation functions are constructed in the parameter space, while the interpolation is performed in the DI coefficient space. For better visualization and demonstration in a two-dimensional coefficient domain, we consider convex interpolation of two components from the DI coefficient matrix, i.e., and , as shown in Fig. 3(b). Fig. 3(a) shows four testing parameter points denoted by asterisks and their 6 nearest neighbor parameter points denoted by solid black dots. The testing parameter points are at different locations relative to the convex hull (depicted by the black dash line) formed by the nearest neighbor points. The interpolation functions are obtained using Eqs. (19-20) based on the distance between the testing points and the nearest neighbor points in the parameter space, which are then used to interpolate the DI coefficients of the testing points from the DI coefficients of the nearest neighbors by using Eq. (18), as shown in Fig. 3(b). It can be seen that the interpolated DI coefficients are all located within the convex hull (depicted by the black dash line) formed by the nearest neighbors’ DI coefficients, showing the desired convexity-preserving capability, which allows existing local DI models to be leveraged for prediction of latent-space dynamics of testing parameters. When the testing parameter point (the green asterisk) overlaps with the nearest neighbor point 5, the DI coefficient of the testing point is identical to that of the nearest neighbor point 5.
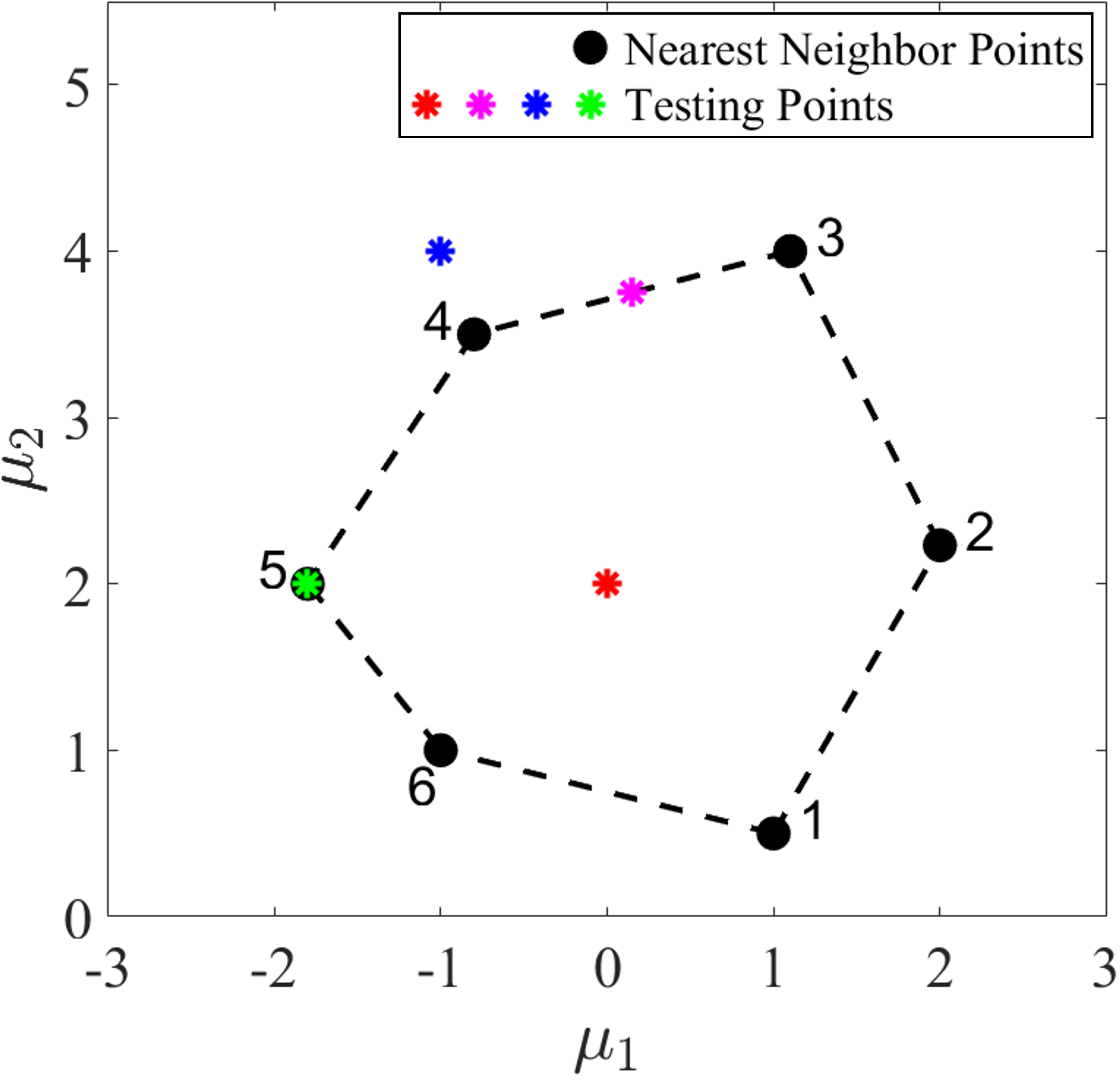
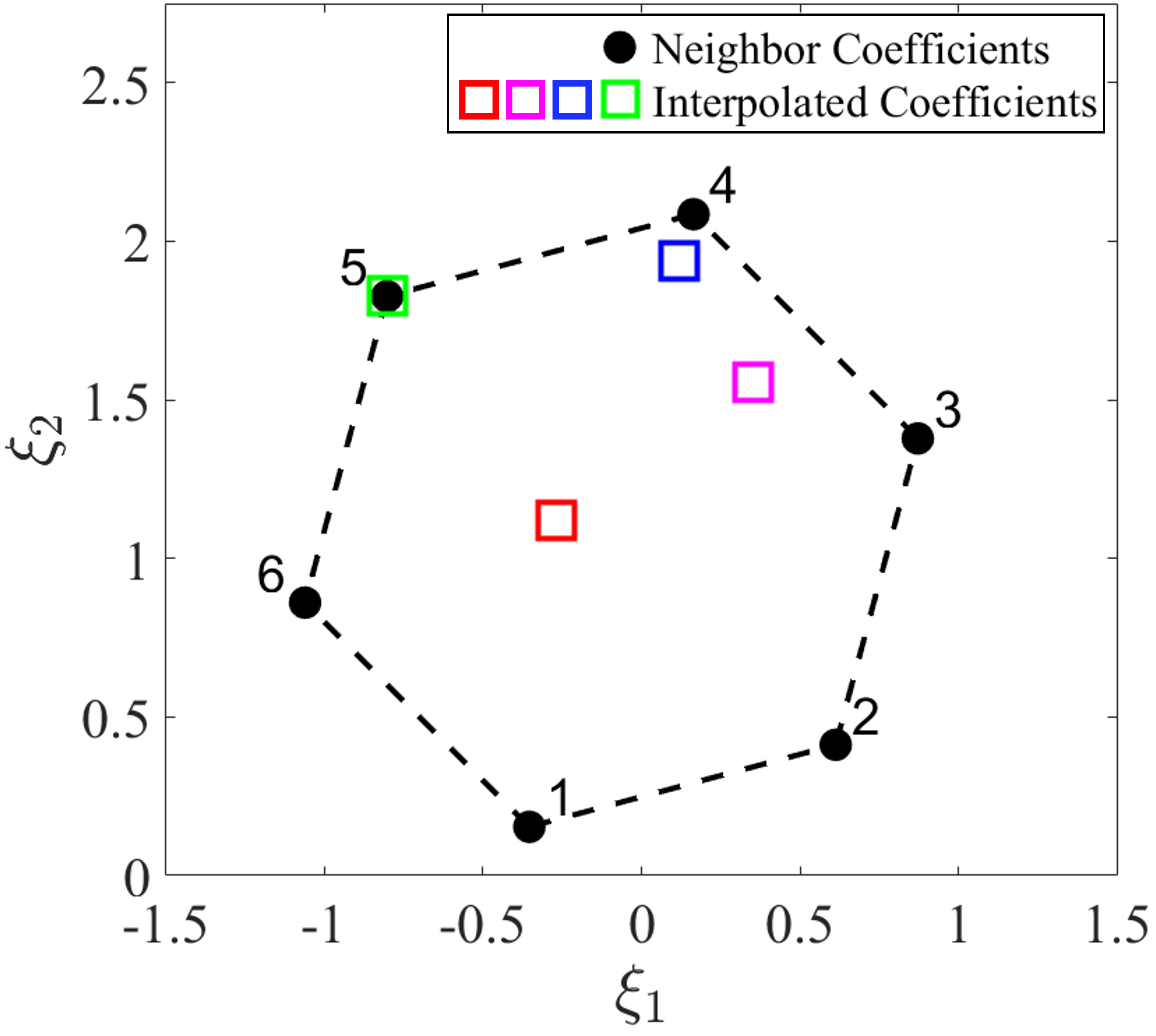
Remark.
The likelihood that the DI coefficient matrices () have a perfect negative correlation is very low. Further, the interpolation is weighted by the inverse of the distance between the nearest neighbors and the testing parameter point of interest, and the number of nearest neighbors involved in the interpolation is often greater than two to take the best advantage of the learned DI models. Therefore, a degenerate situation is not likely to happen.
3.4 Physics-informed adaptive greedy sampling
In the proposed algorithm, the training sample points are determined on the fly by a physics-informed adaptive greedy sampling algorithm to maximize parameter space exploration and achieve optimal model performance. To this end, a sampling procedure integrated with an error indicator is needed. The most accurate error indicator would be actual relative error that is computed with high-fidelity solutions. However, requiring high-fidelity solution is computationally expensive, leading to undesirable training cost and time. Therefore, we adopt a physics-informed residual-based error indicator, which does not require high-fidelity solutions. The residual-based error indicator, defined in Eq. (23), has a positive correlation with the maximum relative error and can be efficiently computed based only on predicted gLaSDI solutions. For example, see Figure 2. The physics-informed residual-based error indicator is integrated into an adaptive greedy sampling algorithm with a multi-level random-subset evaluation strategy. Various termination criteria for the adaptive greedy sampling are discussed in the following subsection.
3.4.1 Adaptive greedy sampling procedure
To address the issues of parameter dependency of local latent-space dynamics efficiently and effectively, an adaptive greedy sampling procedure is applied to construct a database on the fly during offline training, which corresponds to a set of sampled parameters from the discrete parameter space , ; is the high-fidelity solution of the parameter .
The database is first initialized with a small set of parameters located, e.g., at the corners of the boundaries or at the center of the parameter space. To enhance sampling reliability and quality, the model training is performed before greedy sampling, as illustrated in Fig. 2. Therefore, the adaptive greedy sampling is performed after every epochs of training, which means a new training sample is added to the training database for every epochs. At the -th sampling iteration, a set of candidate parameters are considered and the parameter that maximizes an error indicator, , is selected. The definition of the error indicator is introduced in the next section. The greedy sampling procedure is summarized as
| (21a) | ||||
| (21b) | ||||
| (21c) | ||||
where denotes a set of candidate parameters and ; contains the parameters associated with ; denotes the selected parameter and is the corresponding high-fidelity solution. The iterations of greedy sampling continue until a certain criterion is reached, which will be discussed in the following subsection.
3.4.2 Physics-informed residual-based error indicator
Given an approximate gLaSDI solution, , of the corresponding high-fidelity true solution, , the maximum relative error, is defined as
| (22) |
The maximum relative error as an error indicator provides the most accurate guidance to the greedy sampling procedure, However, the evaluation of is computationally inefficient because of the requirement of the high-fidelity true solution. To ensure effective and efficient greedy sampling, the error indicator needs to satisfy the following criteria: (i) It must be positively correlated with the maximum relative error measure, as demonstrated in Fig. 2; (ii) The evaluation is computationally efficient, i.e., it must not involve any high-fidelity solution. A computationally feasible error indicator based on the residual of the governing equation is employed in this study, defined as
| (23) |
where the residual function is defined in Eq. (3) and . The residual error indicator satisfies the aforementioned two conditions. For example, note that the evaluation of the error indicator requires only the predicted gLaSDI solutions and the fact that we use further enhances computational efficiency of the error indicator. In this paper, is used. Furthermore, the adopted error indicator is positively correlated with the maximum relative error, which is demonstrated in Figure 2. Note also that it is physics-informed as it is based on the residual of the discretized governing equations, which embeds physics (Eq. (3)).
Finally, the next parameter to be sampled is determined by
| (24) |
3.4.3 Termination criteria
The adaptive greedy sampling procedure is terminated until one of the following criteria is reached: (i) a prescribed maximum number of sampling points (local DI models), (ii) the maximum allowable training iterations, or (iii) a prescribed target tolerance of the maximum relative error.
As the training cost increases with the number of sampling points and the number of training iterations, criteria (i) and (ii) are considered if training efficiency is preferable. On the other hand, if one expects the optimal model performance, criterion (iii) is more suitable as it offers a guidance of the model accuracy in the parameter space.
Since the maximum relative error is estimated by the residual-based error indicator, as described in Section 3.4.2, criterion (iii) only provides an estimated model performance. To alleviate this issue, we exploit the ratio between the maximum relative error and the residual-based error indicator to approximate the correct target relative error. For example, at -th sampling iteration, the model is evaluated to obtain the maximum relative errors and the residual-based errors of all sampled parameters:
| (25a) | ||||
| (25b) | ||||
where and are calculated from Eq. (22) and Eq. (23), respectively. Note that can be obtained because the database contains high-fidelity solutions of all sampled parameters in . Then, linear correlation coefficients between and are obtained by
| (26) |
Finally, the estimated maximum relative error is obtained by
| (27) |
As the correlation between and of all sampled parameters in is used to estimate the maximum relative error , it improves the termination guidance of the greedy sampling procedure in order to achieve the target , leading to more reliable reduced-order models. This provides some level of confidence in the accuracy of the trained gLaSDI.
3.4.4 Multi-level random-subset evaluation
To further accelerate the greedy sampling procedure and guarantee a desirable accuracy, a two-level random-subset evaluation strategy is adopted in this study. At the -th sampling iteration, a subset of parameters, (), is randomly selected from the parameter space. A small subset size is considered in the first-level random-subset selection so that the error evaluation of the parameters in the subset is efficient. When the tolerance of the error indicator is reached the greedy sampling procedure moves to the second-level random-subset evaluation, where the subset size doubles. A bigger subset size is chosen to increase the probability of achieving the desirable accuracy. The greedy sampling procedure continues until the prescribed termination criterion is reached, see Algorithm 2 for more details.
3.5 gLaSDI off-line and on-line stages
The ingredients mentioned in earlier sections are integrated into the proposed greedy latent-space dynamics identification model. The training procedure of the gLaSDI model is summarized in Algorithm 1.
Input: An initial parameter set and the associated database ; an initial random subset size ; a greedy sampling frequency ; the number of nearest neighbors for k-NN convex interpolation; and one of the three terminal criteria:
-
1.
a target tolerance of the maximum relative error
-
2.
the maximum number of sampling points
-
3.
a maximum number of training epochs
Note that is often used together with the error tolerance to avoid excessive training iterations in the case where the prescribed tolerance may not be achieved.
Output: gLaSDI sampled parameter set and the associated database ; autoencoder parameters; and ; DI model coefficients , where contains indices of parameters in
Input: A parameter set and the associated database ; a target tolerance of the maximum relative error ; a random-subset size ; a random-subset level ; the number of nearest neighbors for k-NN convex interpolation
Output: updated parameter set ; database ; estimated maximum relative error ; random-subset size ; random-subset level
After the gLaSDI model is trained by Algorithm 1, the physics-informed greedy sampled parameter set , the autoencoder parameters, and a set of local DI model parameters are obtained. The trained gLaSDI model can then be applied to efficiently predict dynamical solutions given a testing parameter by using Algorithm 3. The prediction accuracy can be evaluated by the maximum relative error with respect to high-fidelity solutions using Eq. (22).
Input: A testing parameter ; the gLaSDI sampled parameter set ; the model coefficients ; ; ; and the number of nearest neighbors for k-NN convex interpolation
Output: gLaSDI prediction
4 Numerical results
The performance of gLaSDI is demonstrated by solving four numerical problems: one-dimensional (1D) Burgers’ equation, two-dimensional (2D) Burgers’ equation, nonlinear time-dependent heat conduction, and radial advection. The effects of the number of nearest neighbors on the model performance are discussed. In each of the numerical examples, the gLaSDI’s performance is compared with that of LaSDI, that is the one without adaptive greedy sampling. Note that the physics-informed adaptive greedy sampling can be performed on either a continuous parameter space () or a discrete parameter space (). In the following examples, a discrete parameter space () is considered. For all numerical experiments, we always start with the initial database and the associated parameter set of four corner points of the parameter space.
The training of gLaSDI are performed on a NVIDIA V100 (Volta) GPU of the Livermore Computing Lassen system at the Lawrence Livermore National Laboratory, with 3,168 NVIDIA CUDA Cores and 64 GB GDDR5 GPU Memory. The open-source TensorFlow library [99] and the Adam optimizer [100] are employed for model training. The testing of gLaSDI and high-fidelity simulations are both performed on an IBM Power9 CPU with 128 cores and 3.5 GHz.
4.1 1D Burgers equation
A 1D parameterized inviscid Burgers equation is considered
| (28a) | ||||
| (28b) | ||||
Eq. (28b) is a periodic boundary condition. The initial condition is parameterized by the amplitude and the width , defined as
| (29) |
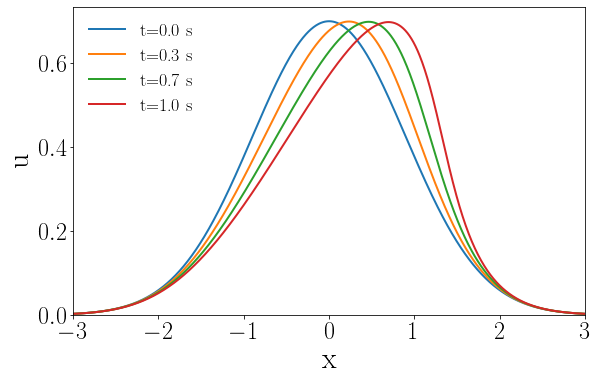
where . A uniform spatial discretization with 1,001 discrete points and nodal spacing as 6/1,000 is applied. The first order spatial derivative is approximated by the backward difference scheme. A semi-discertized system characterized by the ODE described in Eq. (1) is obtained, which is solved by using the implicit backward Euler time integrator with a uniform time step of 1/1,000 to obtain the full-order model solutions. Some solution snapshots are shown in A.
4.1.1 Case 1: Effects of the number of nearest neighbors k
In the first example, the effects of the number of nearest neighbors on model performance are investigated. The parameter space, , considered in this example is constituted by the parameters of the initial condition, including the width, , and the amplitude, , each with 21 evenly distributed discrete points in the respective parameter range, resulting in 441 parameter cases in total. The gLaSDI model is composed of an autoencoder with an architecture of 1,001-100-5 and linear DI models. The greedy sampling is performed until the estimated maximum relative error of sampled parameter points is smaller than the target tolerance, . An initial random subset size is used, around 20 of the size of . A two-level random-subset evaluation scheme is adopted, as described in Section 3.4.4. The maximum number of training epoch is set to be 50,000.
Adaptive greedy sampling with
The greedy sampling frequency is set to be 2,000. The training is performed by using Algorithm 1, where is used for greedy sampling procedure (Algorithm 2), which means the gLaSDI model utilizes the DI coefficient matrix of the existing parameter that is closest to the randomly selected parameter to perform dynamics predictions. Fig. 4 shows the history of the loss function in a red solid line and the maximum residual-based error of the sampled parameter points in a blue solid line, demonstrating the convergence of the training. In Fig. 4, the first blue point indicates the initial state of the model where four corner points of the parameter space are sampled, while the last blue point indicates the final state of the model that satisfies the prescribed termination criterion and no sampling is performed. The blue points in-between indicate the steps where new samples and associated DI models are introduced, corresponding to the spikes in the red curve (training loss history). At the end of the training, 22 parameter points are sampled and stored, including the initial 4 parameter points located at the four corners of the parameter space, which means 22 local DI models are constructed and trained in the gLaSDI model.
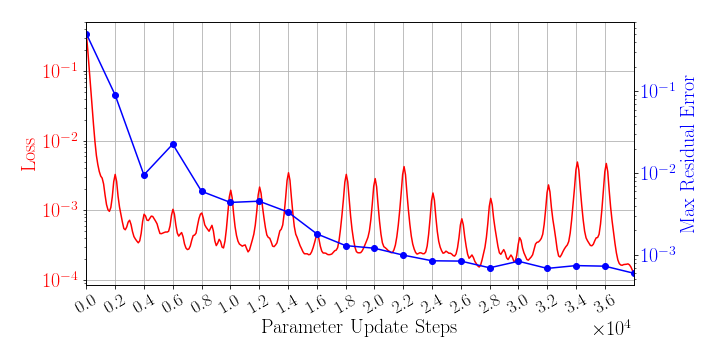
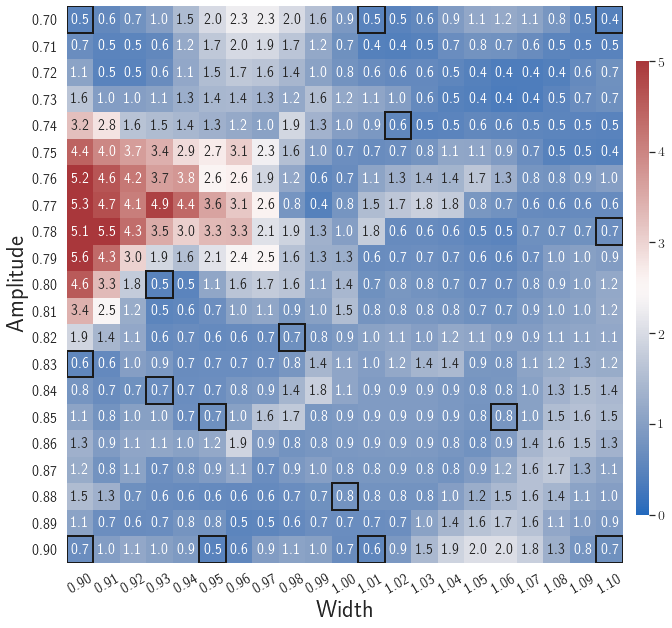
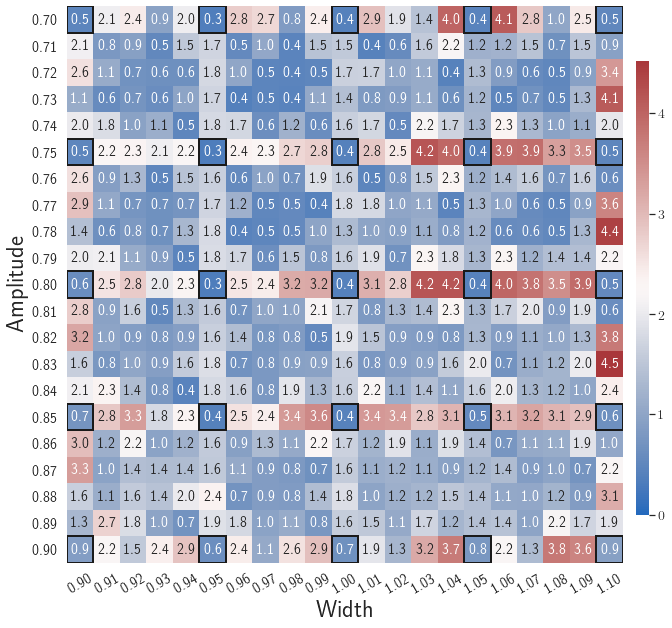
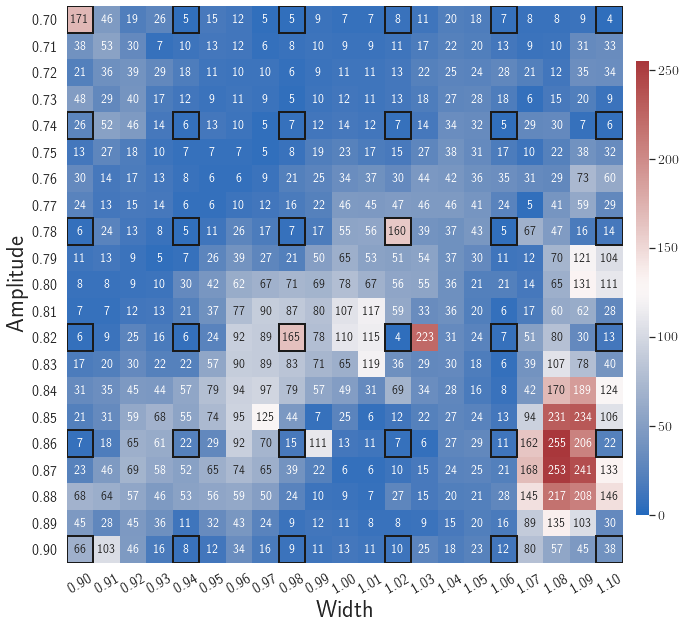
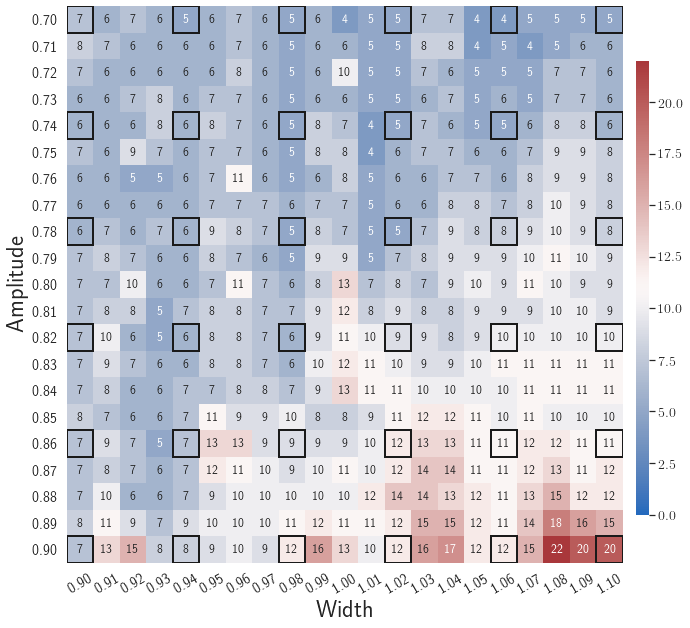
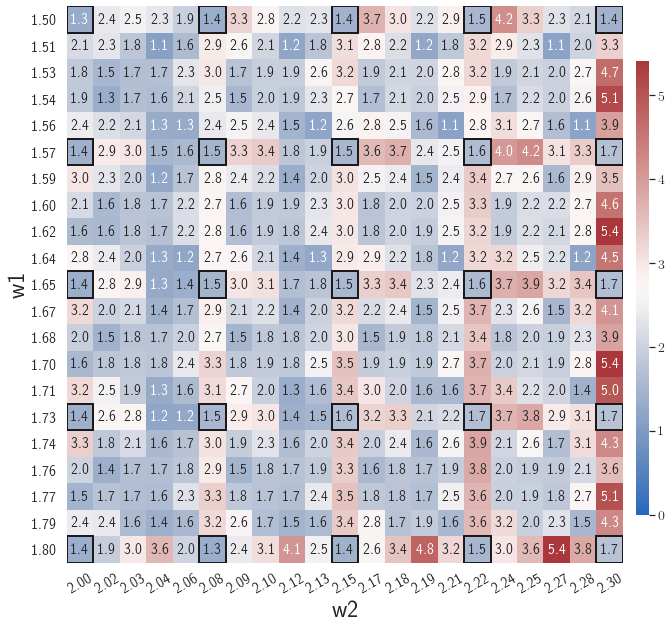
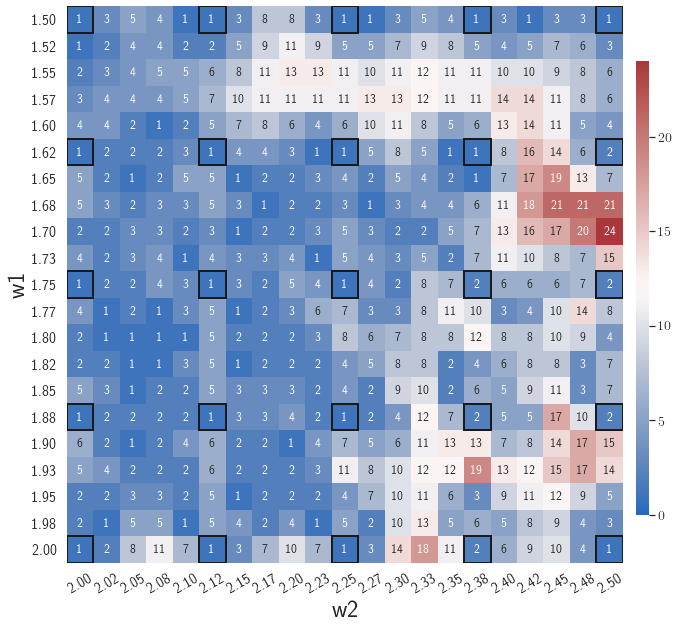
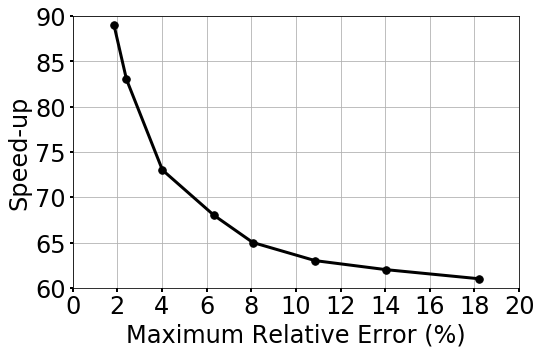
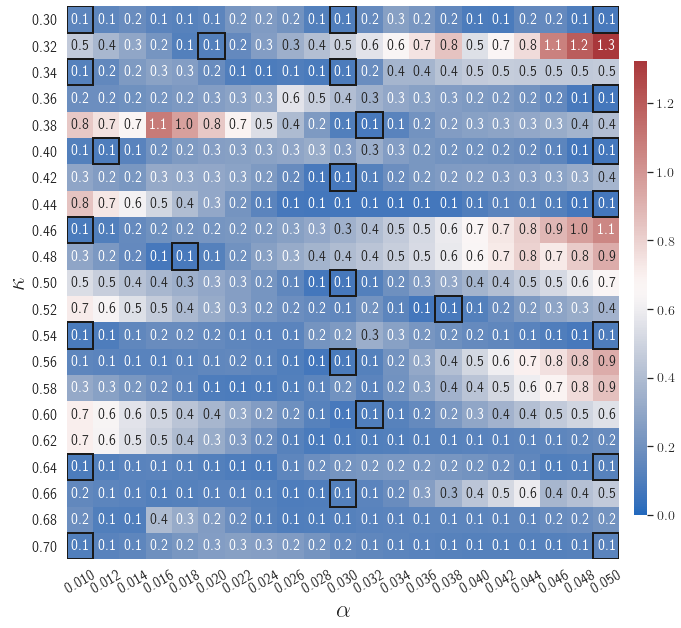
After training, the gLaSDI model is applied for predictions by Algorithm 3, where different values of are used for k-NN convex interpolation of the DI coefficient matrix of the testing parameter. Fig. 5 shows the maximum relative errors in the parameter space evaluated with different values of . The number on each box denotes the maximum relative error of the associated parameter case. The black square boxes indicate the locations of the sampled parameter points. The distance between the sampled parameter points located in the interior domain of is relatively larger than that near the domain corners/boundaries. That means the interior sampled parameter points tend to have a larger trust region within which the model prediction accuracy is high. It can also be observed that model evaluation with produces higher accuracy with around maximum relative error in , smaller than the target tolerance , which is contributed by the k-NN convex interpolation that exploits trust region of local DI models. Compared with the high-fidelity simulation (in-house Python code) that has an around maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 89 speed-up. More information about the speed-up performance of gLaSDI for the 1D Burgers problem can be found in A.
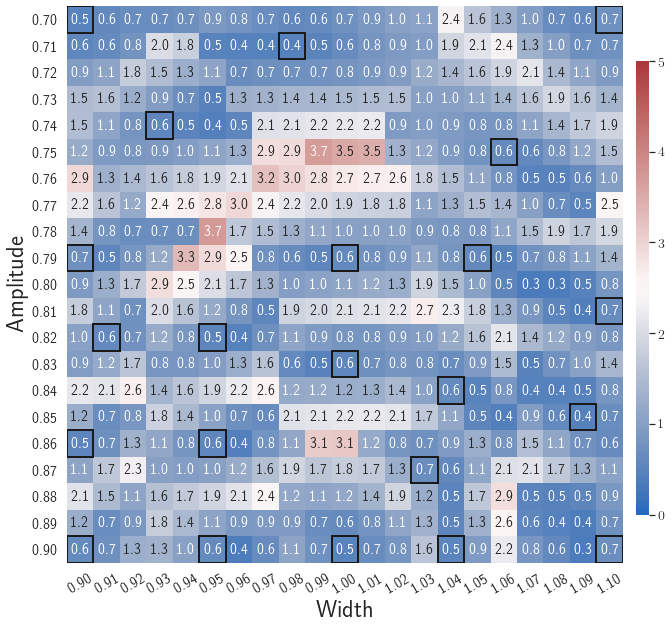
Adaptive greedy sampling with
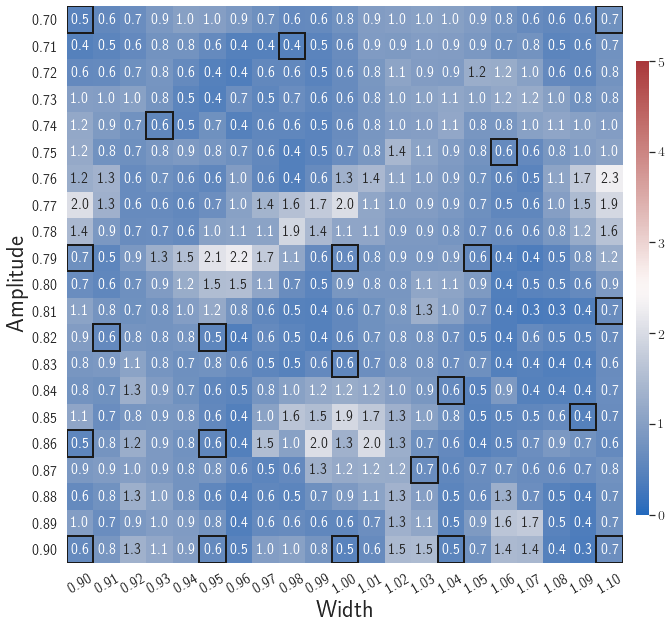
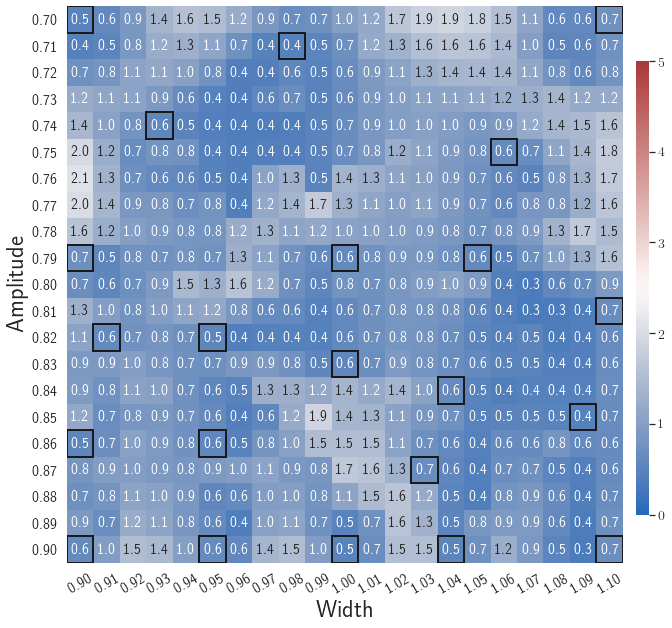
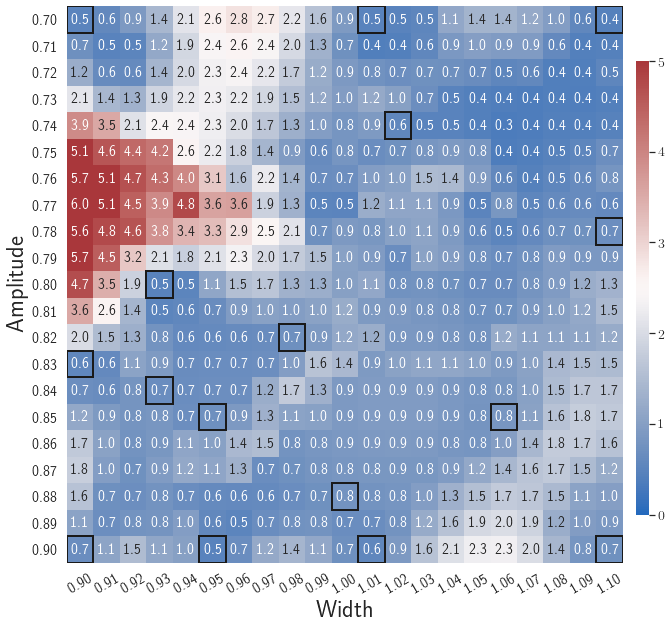
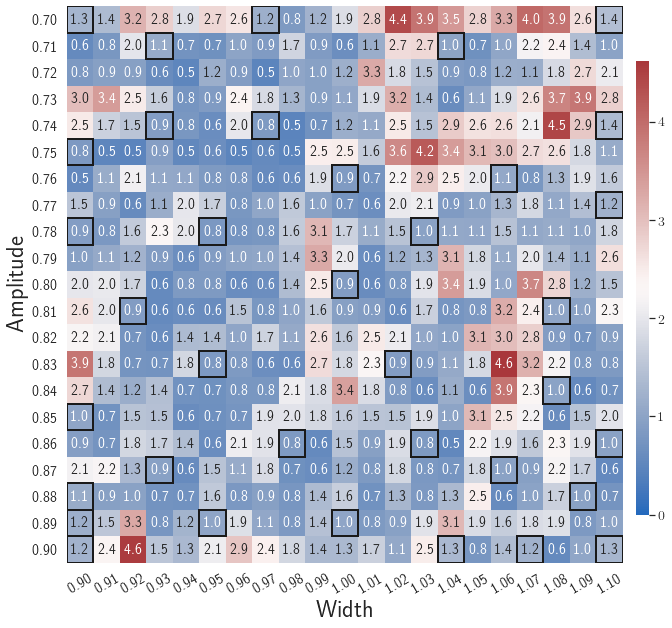
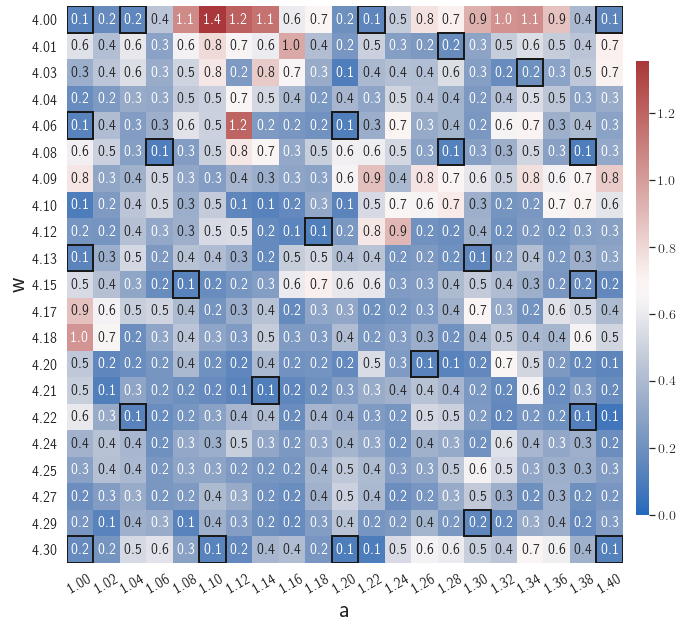
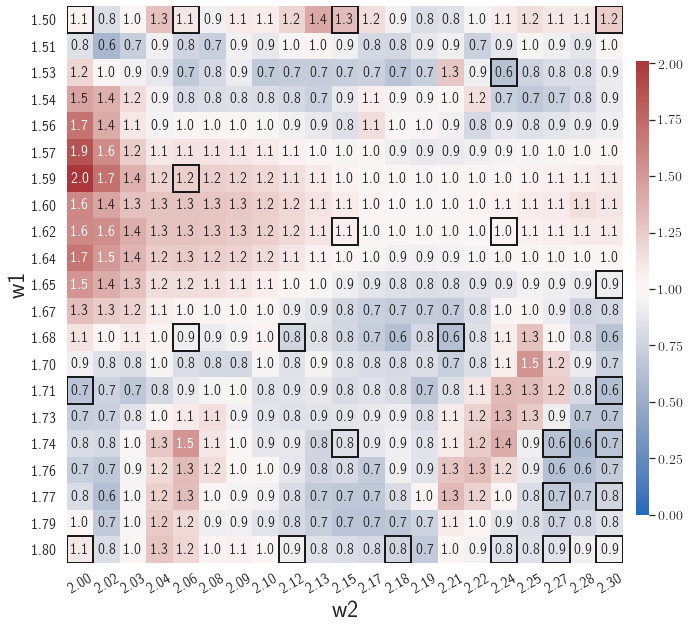
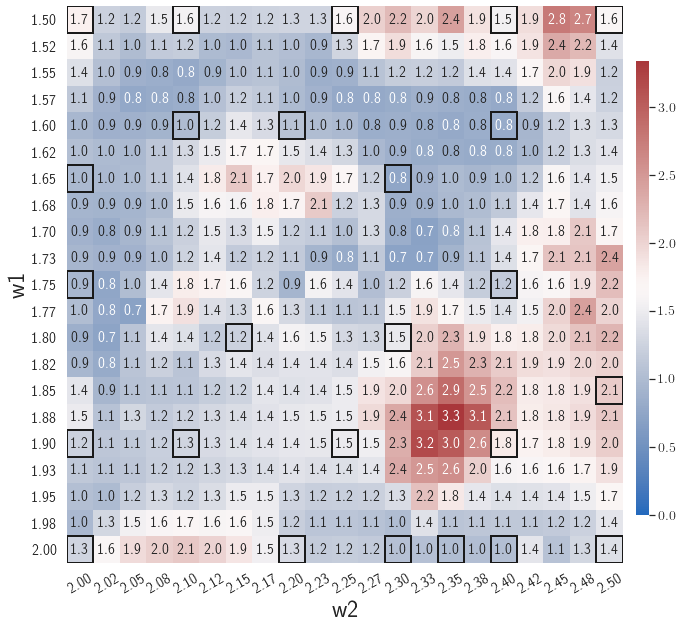
Fig. 6 shows the history of the loss function and the maximum residual-based error of the gLaSDI model trained with for greedy sampling procedure. At the end of the training, 16 parameter points are sampled, including the initial four parameter points located at the 4 corners of the parameter space, which means 16 local DI models are constructed and trained in the gLaSDI model. Compared to the gLaSDI model trained with as in Fig. 4, the training with terminates faster with a sparser sampling to achieve the target tolerance of the maximum relative error, , implying more efficient training. It is because a small for greedy sampling procedure leads to a more conservative gLaSDI model with more local DIs, while a large results in a more aggressive gLaSDI model with fewer local DIs as the trust region of local DI models are exploited by the k-NN convex interpolation during training.
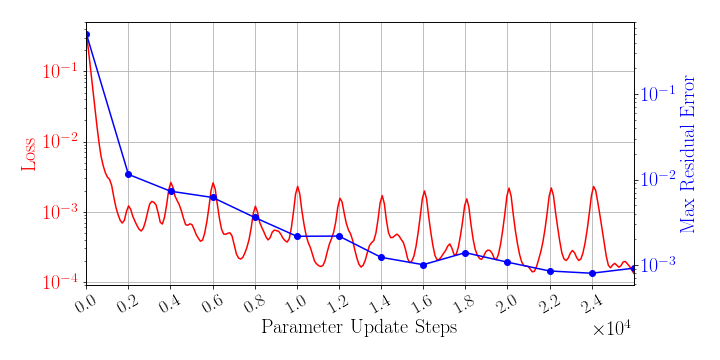
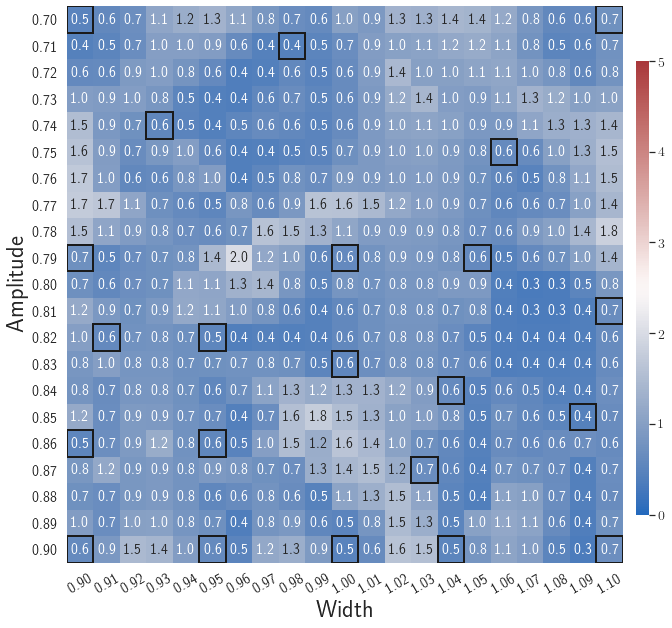
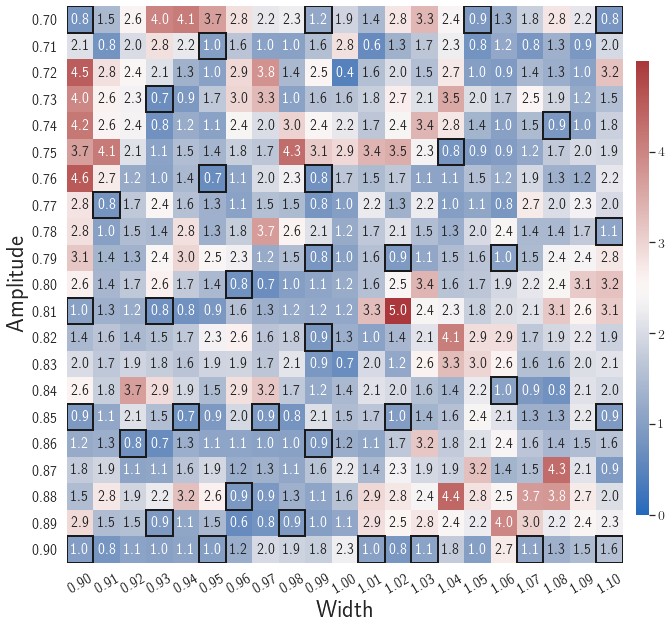
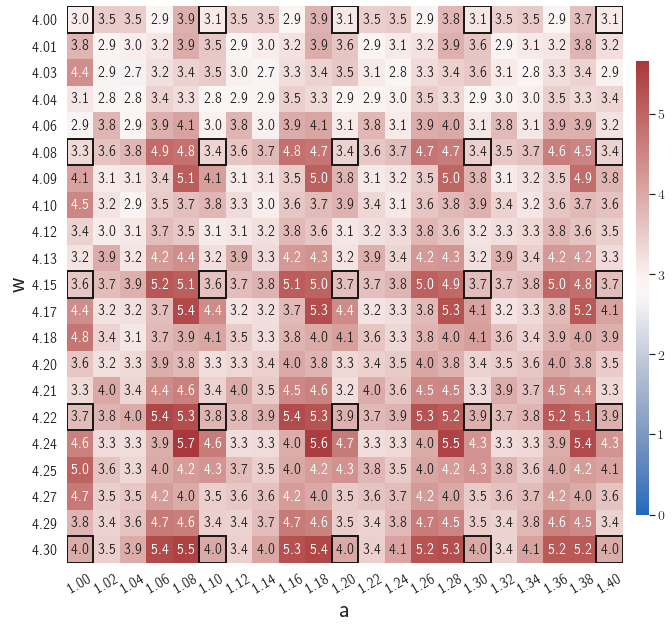
Fig. 7 shows the maximum relative errors in the parameter space evaluated with different values of . Similar to the results shown in Fig. 5, a larger results in higher model accuracy. It is noted that a few violations of the target tolerance exist even when is used for model evaluation. It shows that greedy sampling with results in a more aggressive gLaSDI model with fewer local DIs and higher training efficiency at the cost of model accuracy. We also observed that the trained gLaSDI model achieved the best testing accuracy with , which implies there exists a certain for optimal model performance.
The comparison of these two tests shows that a small for greedy sampling during training results in a more accurate gLaSDI model at the cost of training efficiency, and that using a for model evaluation (testing) improves generalization performance of gLaSDI. In the following numerical examples, is used for greedy sampling procedure during training of gLaSDI. The trained gLaSDI models are evaluated by different and the optimal testing results are presented.
4.1.2 Case 2: gLaSDI vs. LaSDI
In the second test, the autoencoder with an architecture of 1,001-100-5 and linear DI models are considered. The same parameter space with parameter cases in total is considered. The gLaSDI training with adaptive greedy sampling is performed until the total number of sampled parameter points reaches 25. To investigate the effects of adaptive greedy sampling on model performances, a LaSDI model with the same architecture of the autoencoder and DI models is trained using 25 predefined training points uniformly distributed in a grid in the parameter space. The performance of gLaSDI and LaSDI are compared and discussed.
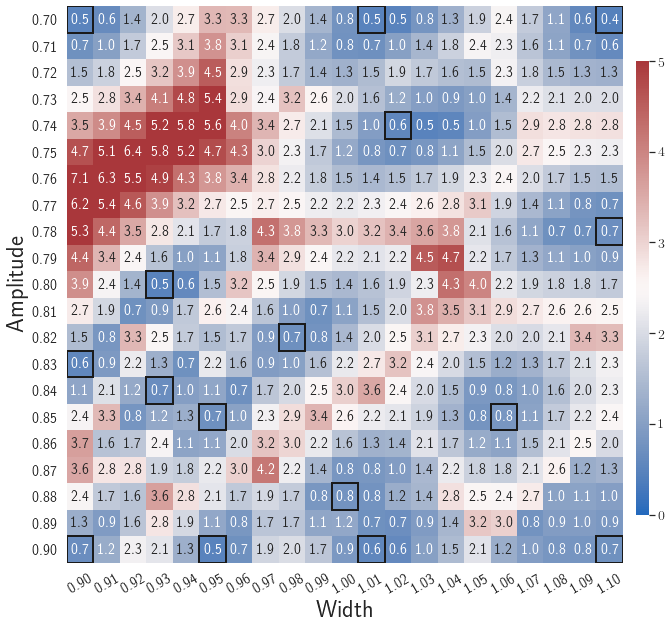
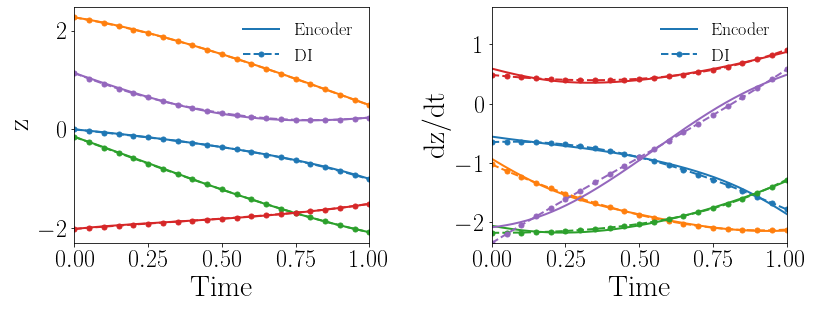
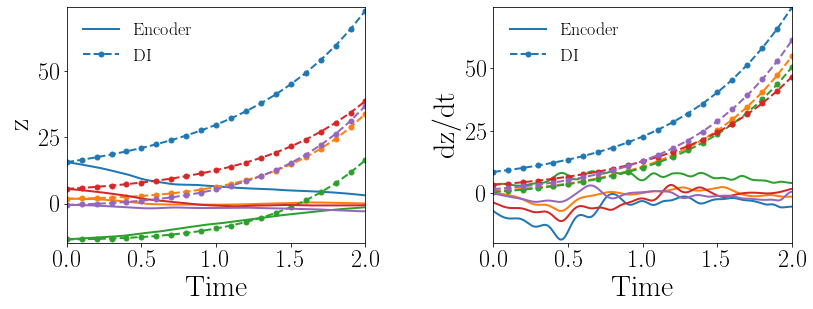
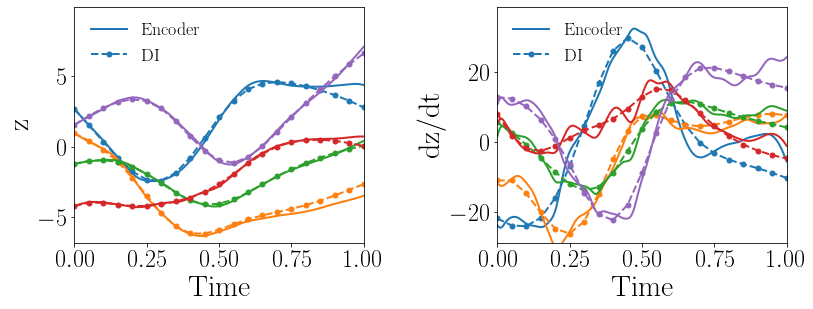
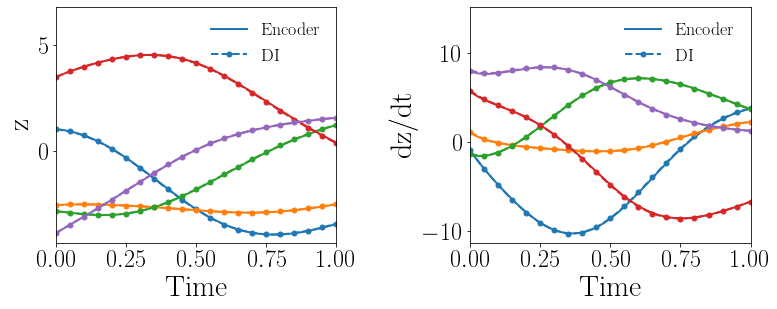
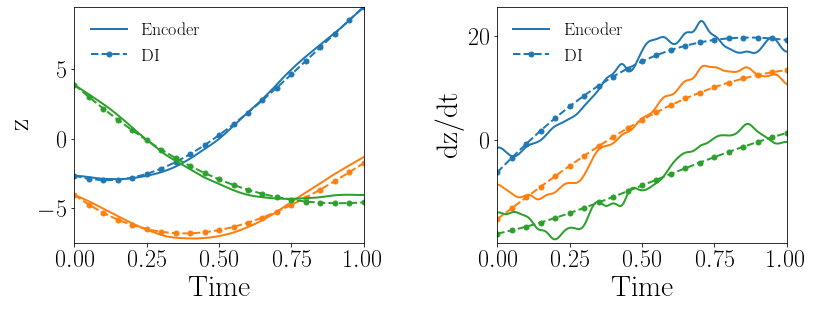
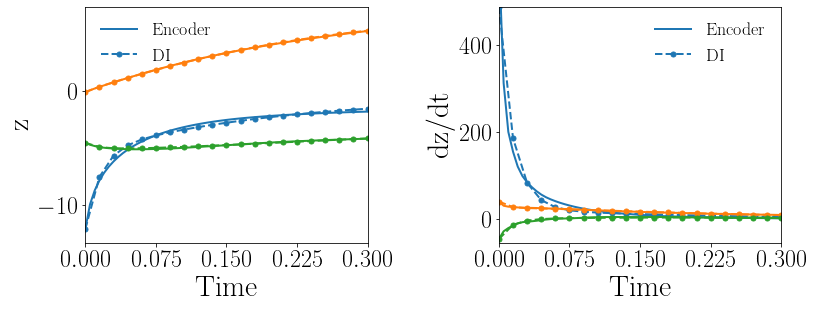
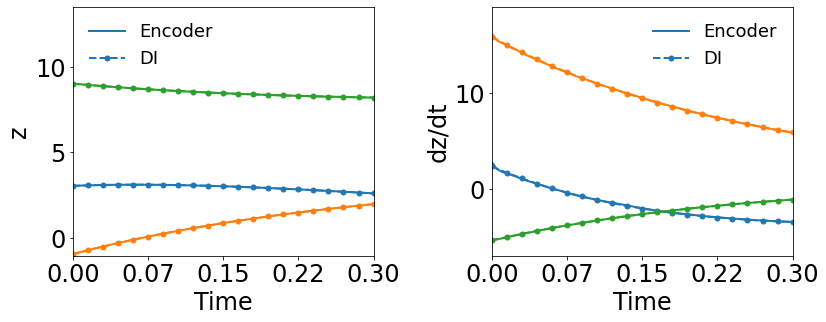
Fig. 8(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. The latent-space dynamics from gLaSDI is more linear and simpler than that from LaSDI. gLaSDI also achieves a better agreement between the encoder and the DI predictions, which is attributed by the interactive learning of gLaSDI. Note that the sequential training of the autoencoder and the DI models of the LaSDI could lead to more complicated and nonlinear latent-space dynamics because of the lack of interaction between the latent-space dynamics learned by the autoencoder and the DI models. As a consequence, it could pose challenges for the subsequent training of DI models to capture the latent-space dynamics learned by the autoencoder and cause higher prediction errors.
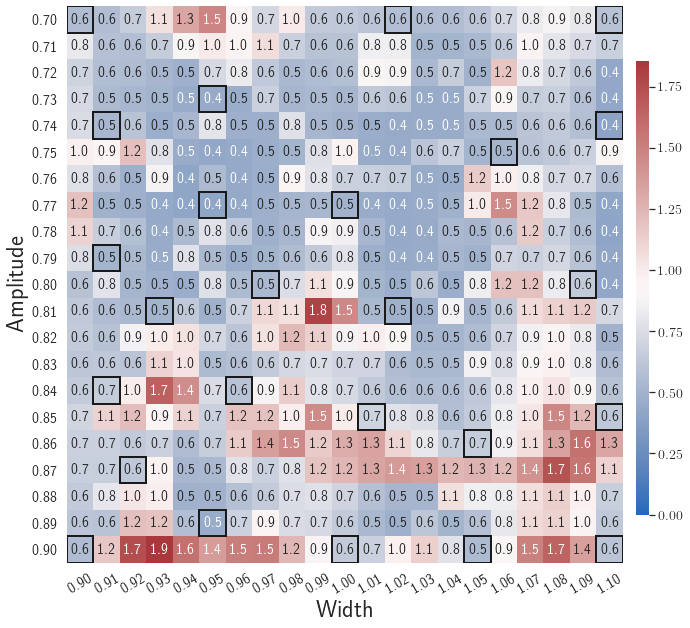
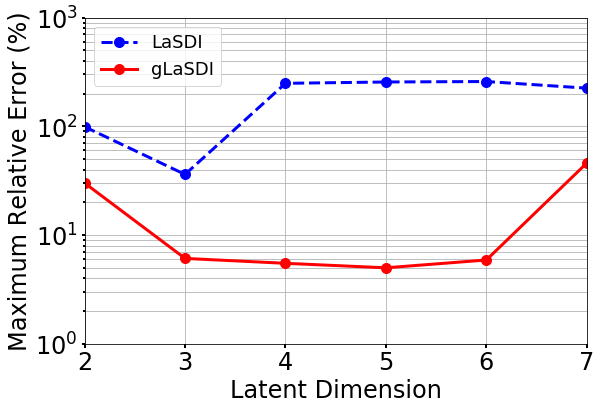
Fig. 8(c-d) show the maximum relative errors of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively, where the black square boxes indicate the locations of the sampled parameter points. For LaSDI, the training parameter points are pre-selected and the associated high-fidelity solutions are obtained before training starts, whereas for gLaSDI, the training parameter points are sampled adaptively on the fly during the training, within which the greedy sampling algorithm is combined with the physics-informed residual-based error indicator, as introduced in Section 3.4, which allows the points with the maximum error to be selected. Thus gLaSDI enhances the accuracy with less number of sampled parameter points than LaSDI. It can be observed that gLaSDI tends to have denser sampling in the lower range of the parameter space. Fig. 8(d) shows that gLaSDI achieves the maximum relative error of 1.9 in the whole parameter space, which is much lower than 4.5 of LaSDI in Fig. 8(c).
4.1.3 Case 3: Effects of the loss terms
As mentioned in Sections 3.1 and 3.2, there are three distinct terms in the loss function of the gLaSDI training. Each term includes a different set of trainable parameters. For example, the reconstruction term includes and ; the latent-space dynamics identification term includes and ; and includes all the trainable parameters, i.e., , , and . Therefore, in this section, we demonstrate the effects of these loss terms.
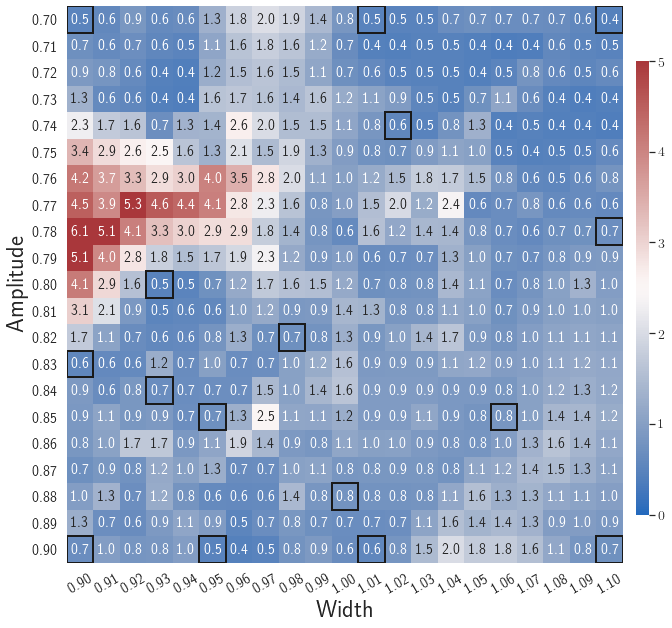
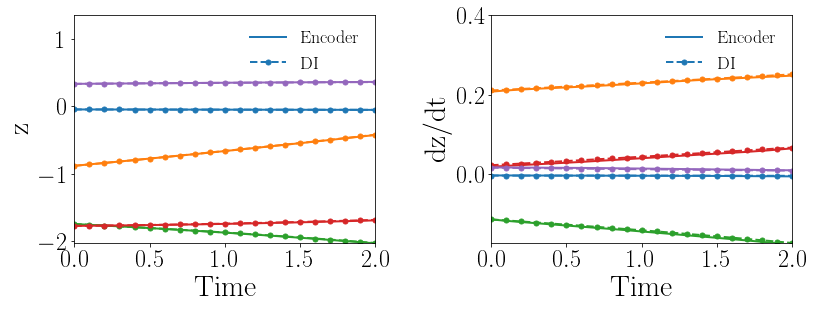
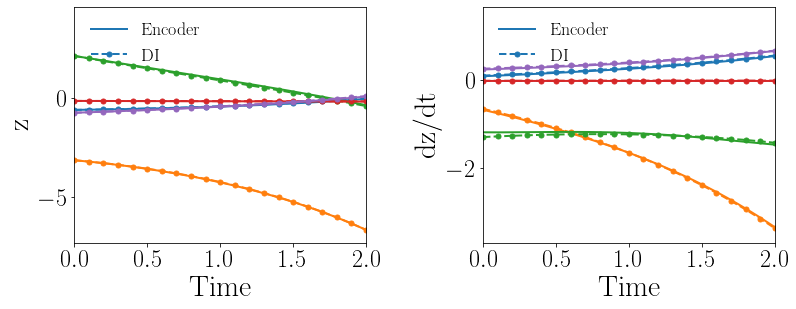
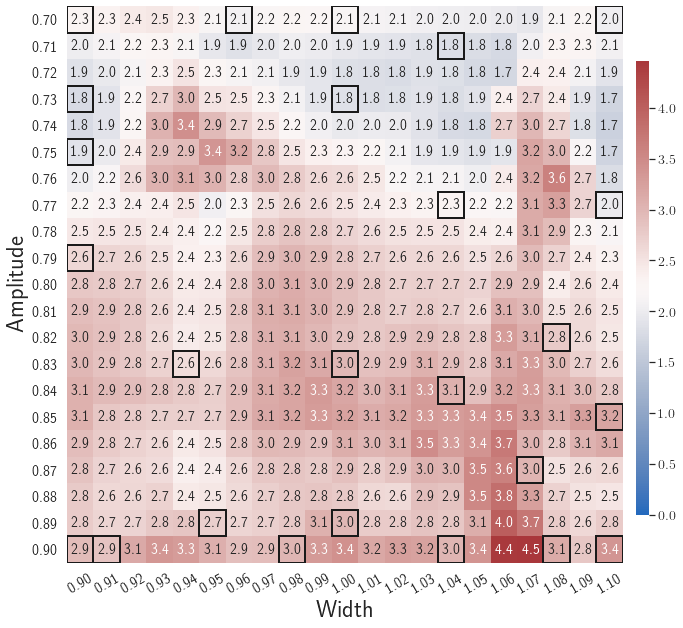
Given the same settings of the gLaSDI model and the parameter space considered in Section 4.1.2, the gLaSDI is trained by only one loss term, (Eq. (15)), that involves all the trainable parameters. The predicted latent-space dynamics and maximum relative errors in the parameter space are shown in Fig. 9(a) and (c), respectively. The large deviation in the predicted latent-space dynamics between the encoder and the DI model leads to large prediction errors in the physical dynamics. It is also observed that the identified latent-space dynamics is more nonlinear, compared with that shown in Fig. 8(b). It implies that cannot impose sufficient constraints on the trainable parameters to identify simple latent-space dynamics although it includes all the trainable parameters.
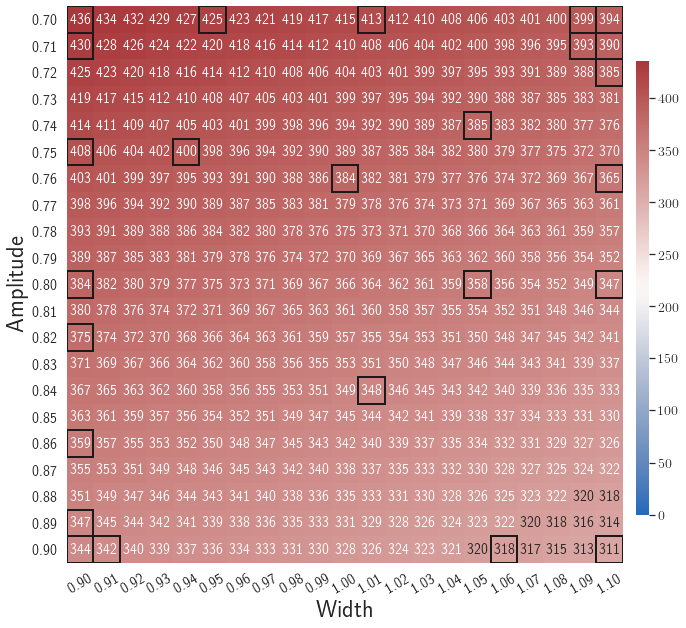
In the second test, the gLaSDI is trained by with different values of the regularization parameter . The motivation is to see if we can achieve as good accuracy with only first two loss terms as the one with all three loss terms. The maximum relative errors in the parameter space corresponding to different values of are summarized in Table 1. Using yields the best model. Compared with the latent-space dynamics of gLaSDI trained with all three loss terms, as shown in Fig. 8(b), the gLaSDI trained without produces relatively more nonlinear latent-space dynamics, as shown in Fig. 9(b). The comparison also shows that the constraint imposed by on model training enhances the generalization performance of gLaSDI, reducing the maximum relative error in the whole parameter space from 4.5 to 1.9, as shown in Fig. 8(d) and 9(d).
| () | 11.5 | 8.5 | 4.5 | 4.7 | 4.6 | 14.5 | 20.9 | 23.8 |
4.2 2D Burgers equation
A 2D parameterized inviscid Burgers equation is considered
| (30a) | ||||
| (30b) | ||||
where is the Reynolds number. Eq. (30b) is an essential boundary condition. The initial condition is parameterized by the amplitude and the width , defined as
| (31) |
where . A uniform spatial discretization with discrete points is applied. The first order spatial derivative is approximated by the backward difference scheme, while the diffusion term is approximated by the central difference scheme. The semi-discertized system is solved by using the implicit backward Euler time integrator with a uniform time step of to obtain the full-order model solutions. Some solution snapshots are shown in B.
4.2.1 Case 1: Comparison between gLaSDI and LaSDI
In the first test, a discrete parameter space is constituted by the parameters of the initial condition, including the width, , and the amplitude, , each with 21 evenly distributed discrete points in the respective parameter range. The autoencoder with an architecture of 7,200-100-5 and quadratic DI models are considered. The gLaSDI training is performed until the total number of sampled parameter points reaches 36. A LaSDI model with the same architecture of the autoencoder and DI models is trained using 36 predefined training points uniformly distributed in a grid in the parameter space. The performance of gLaSDI and LaSDI are compared and discussed.
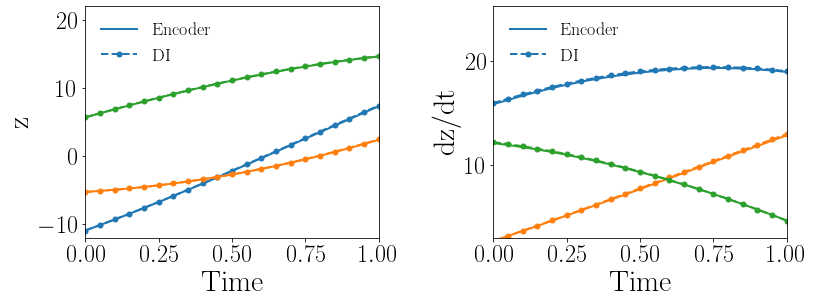
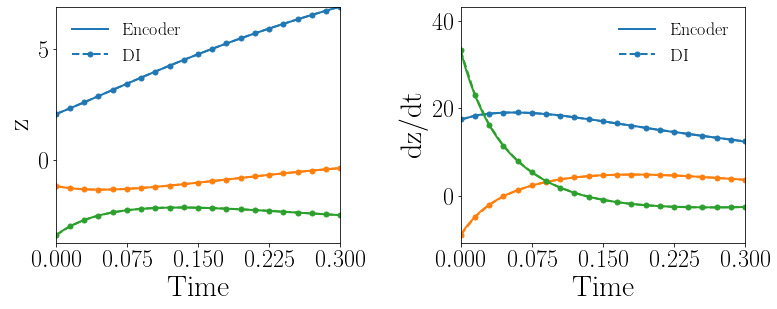
Fig. 10(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. Again, the latent-space dynamics of gLaSDI is simpler than that of LaSDI, with a better agreement between the encoder and the DI predictions, which is attributed by the interactive learning of gLaSDI.
Fig. 10(c-d) show the maximum relative error of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively. The gLaSDI achieves the maximum relative error of 5 in the whole parameter space, much lower than 255 of LaSDI. The poor accuracy of LaSDI could be caused by the deviation between the DI predicted dynamics and the encoder predicted dynamics. It is also observed that gLaSDI tends to have denser sampling in the lower range of the parameter space. This demonstrates the importance of the physics-informed greedy sampling procedure. Compared with the high-fidelity simulation (in-house Python code) that has an around maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 871 speed-up.
4.2.2 Case 2: Effects of the polynomial order in DI models and latent space dimension
In the second test, we want to see if simpler latent-space dynamics can be achieved by gLaSDI and how it affects the reduced-order modeling accuracy. The same parameter space with parameter cases in total is considered. The latent dimension is reduced from 5 to 3 and the polynomial order of the DI models is reduced from quadratic to linear. The autoencoder architecture becomes 7,200-100-3. The gLaSDI training is performed until the total number of sampled parameter points reaches 36. A LaSDI model with the same architecture of the autoencoder and DI models is trained using 36 predefined training parameter points uniformly distributed in a grid in the parameter space.
Fig. 11(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. The latent-space dynamics of gLaSDI is simpler than that of LaSDI, with a better agreement between the encoder and the DI predictions. It also demonstrates that gLaSDI could learn simpler latent-space dynamics, which enhances the reduced-order modeling efficiency. Compared with the high-fidelity simulation (in-house Python code) that has an around maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 2,658 speed-up, which is 3.05 times the speed-up achieved by the gLaSDI model that has a latent dimension of 5 and quadratic DI models, as shown in Section 4.2.1. More information about the speed-up performance of gLaSDI for the 2D Burgers problem can be found in B.
Fig. 11(c-d) show the maximum relative error of LaSDI and gLaSDI predictions on each parameter case in the prescribed parameter space, respectively. Compared with the example with a latent dimension of five and quadratic DI models, as shown in the previous subsection, both gLaSDI and LaSDI achieve lower maximum relative errors, reduced from 5.0 to 4.6 and from 255 to 22, respectively. It indicates that reducing the complexity of the latent-space dynamics allows the DI models of LaSDI to capture the encoder predicted dynamics more accurately although the error level of LaSDI is still larger than that of gLaSDI due to no interactions between the autoencoder and DI models during training. Simplifying latent-space dynamics results in higher reduced-order modeling accuracy of both LaSDI and gLaSDI for this example. We speculate that the intrinsic latent space dimension for the 2D Burgers problem is close to three. More results and discussion about the effects of latent dimension on model performance can be found in B.
4.3 Nonlinear time-dependent heat conduction
A 2D parameterized nonlinear time-dependent heat conduction problem is considered
| (32a) | ||||
| (32b) | ||||
where denotes the unit normal vector. Eq. (32b) is a natural insulating boundary condition. The coefficients and are adopted in the following examples. The initial condition is parameterized as
| (33) |
where denotes the parameters of the initial condition. The spatial domain is discretized by first-order square finite elements constructed on a uniform grid of discrete points. The implicit backward Euler time integrator with a uniform time step of is employed. The conductivity coefficient is computed by linearizing the problem with the temperature field from the previous time step. Some solution snapshots are shown in C. Apart from the parameterization of the initial condition, the effectiveness of gLaSDI on the parameterization of the governing equations (32) is also demonstrated in C.
4.3.1 Case 1: Comparison between gLaSDI and LaSDI
In the first test, a parameter space is constituted by the parameters of the initial condition, including the and , each with 21 evenly distributed discrete points in the respective parameter range. The autoencoder with an architecture of 1,089-100-3 and quadratic DI models are considered. The gLaSDI training is performed until the total number of sampled parameter points reaches 25. A LaSDI model with the same architecture of the autoencoder and DI models is trained using 25 predefined training parameter points uniformly distributed in a grid in the parameter space. The performances of gLaSDI and LaSDI are compared and discussed.
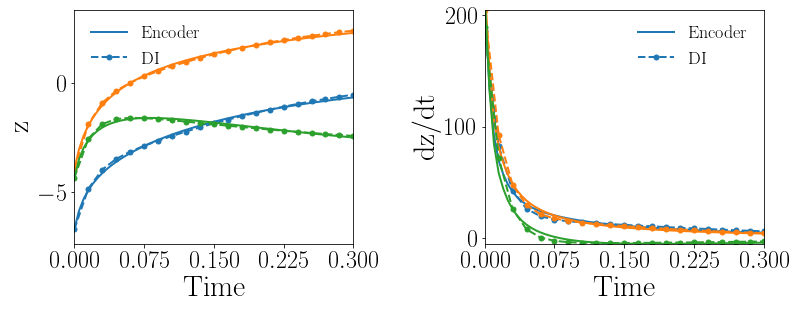
Fig. 12(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. Again, gLaSDI achieves a better agreement between the encoder and the DI prediction than the ones for LaSDI.
Fig. 12(c-d) show the maximum relative error of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively. The gLaSDI achieves higher prediction accuracy than the LaSDI with the maximum relative error of 3.1 in the whole parameter space, compared to 7.1 of LaSDI. Compared with the high-fidelity simulation (MFEM [101]) that has an around maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 17 speed-up.
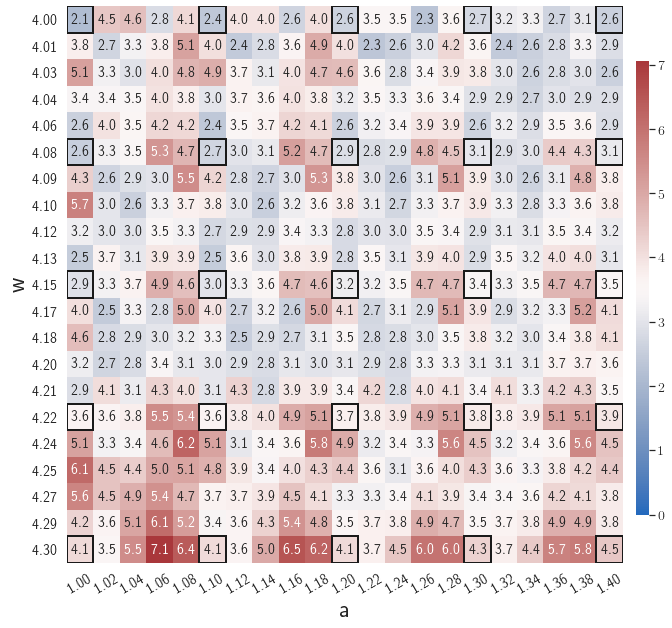
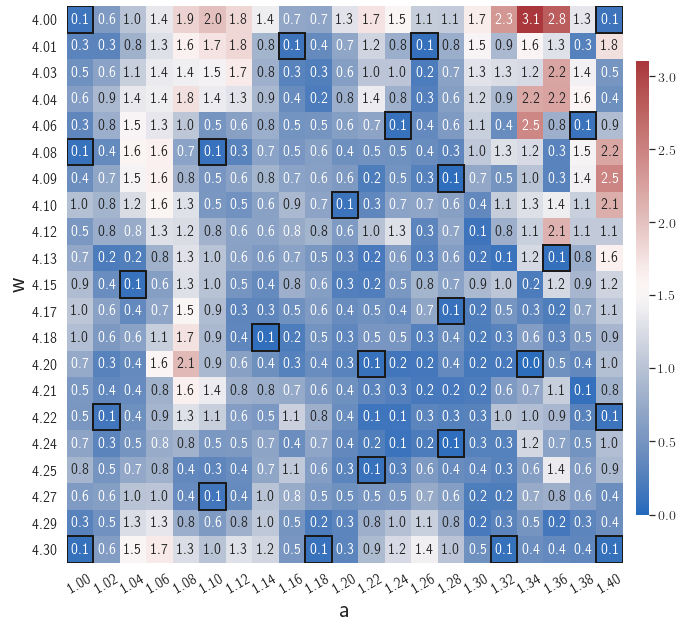
4.3.2 Case 2: Effects of the polynomial order in DI models
In the second test, we want to see if simpler latent-space dynamics can be achieved by gLaSDI and how it affects the reduced-order modeling accuracy. The same settings as the previous example are considered, including the parameter space, the autoencoder architecture (1,089-100-3), the number of training points (25), except that the polynomial order of the DI models is reduced from quadratic to linear.
Fig. 13(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. Compared with the LaSDI’s latent-space dynamics in the previous example, as shown in Fig. 12(a-b), the agreement between the encoder and the DI predictions in this example improves, although not as good as that of gLaSDI. The dynamics learned by gLaSDI is simpler than the previous example with quadratic DI models. Compared with the high-fidelity simulation (MFEM [101]) that has a similar maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 58 speed-up, which is 3.37 times the speed-up achieved by the gLaSDI model that has quadratic DI models, as shown in Section 4.3.1 It further demonstrates that gLaSDI allows learning simpler latent-space dynamics, which could enhance the reduced-order modeling efficiency.
Fig. 13(c-d) show the maximum relative error of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively. Compared with the example with quadratic DI models, as shown in the previous subsection, the maximum relative error achieved by gLaSDI is reduced from 3.1 to 1.4, while that achieved by LaSDI is reduced from 7.1 to 5.7. Simplifying latent-space dynamics contributes to higher reduced-order modeling accuracy of both LaSDI and gLaSDI in this example. This implies that the higher order in DI model does not always help improving the accuracy.
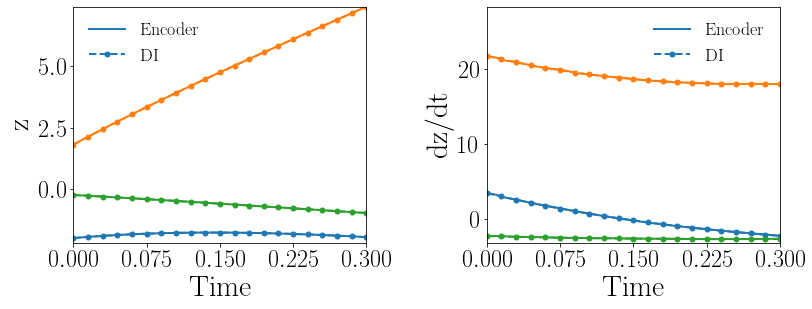
4.4 Time-dependent radial advection
A 2D parameterized time-dependent radial advection problem is considered
| (34a) | ||||
| (34b) | ||||
where Eq. (34b) is a boundary condition and denotes the fluid velocity, defined as
| (35) |
with . The initial condition is defined as
| (36) |
where denotes the paraemeters of the initial condition. The spatial domain is discretized by first-order periodic square finite elements constructed on a uniform grid of discrete points. The fourth-order Runge-Kutta explicit time integrator with a uniform time step of is employed. Some solution snapshots are shown in D.
4.4.1 Case 1: Comparison between gLaSDI and LaSDI
In the first test, a parameter space is constituted by the parameters of the initial condition, including the and , each with 21 evenly distributed discrete points in the respective parameter range. The autoencoder with an architecture of 9,216-100-3 and linear DI models are considered. The gLaSDI training is performed until the total number of sampled parameter points reaches 25. A LaSDI model with the same architecture of the autoencoder and DI models is trained using 25 predefined training points uniformly distributed in a grid in the parameter space. The performances of gLaSDI and LaSDI are compared and discussed.
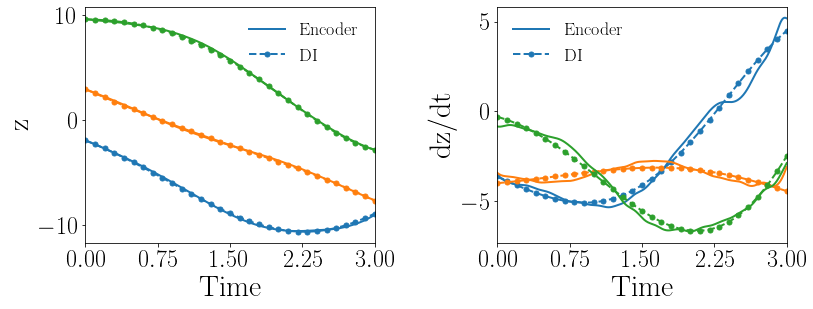
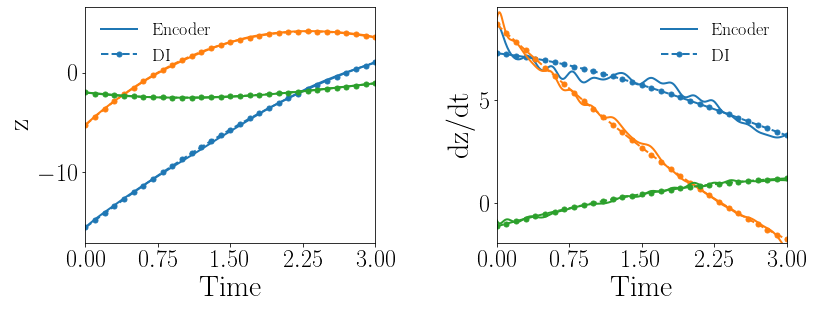
Fig. 14(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. The gLaSDI achieves simpler time derivative latent-space dynamics than LaSDI, with a better agreement between the encoder and the DI prediction.
Fig. 14(c-d) show the maximum relative error of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively. The gLaSDI achieves higher prediction accuracy than the LaSDI with the maximum relative error of 2.0 in the whole parameter space, compared to 5.4 of LaSDI. It is observed that gLaSDI tends to have denser sampling in the regime with higher parameter values, concentrating at the bottom-right corner of the parameter space, which implies that more vibrant change in dynamics is present for higher parameter values, requiring more local DI models there. Compared with the high-fidelity simulation (MFEM [101]) that has an around maximum relative error with respect to the high-fidelity data used for gLaSDI training, the gLaSDI model achieves 121 speed-up.
4.4.2 Case 2: Effects of the size of parameter space
In the second test, we want to see how the size of parameter space affect the model performances of LaSDI and gLaSDI. A larger parameter space is considered and constituted by the parameters of the initial condition, including the and , each with 21 evenly distributed discrete points in the respective parameter range. Other settings remain the same as those used in the previous example, including the number of training points set 25.
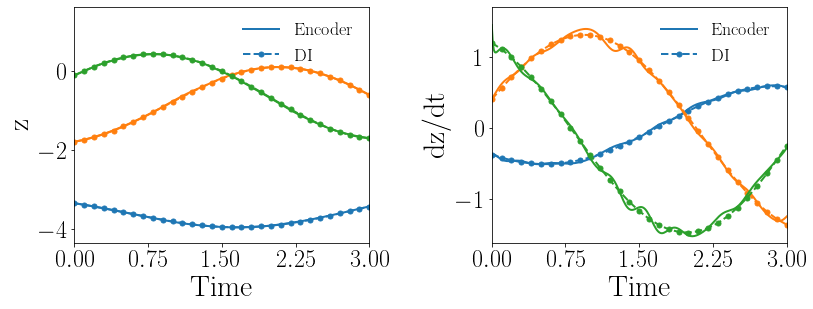
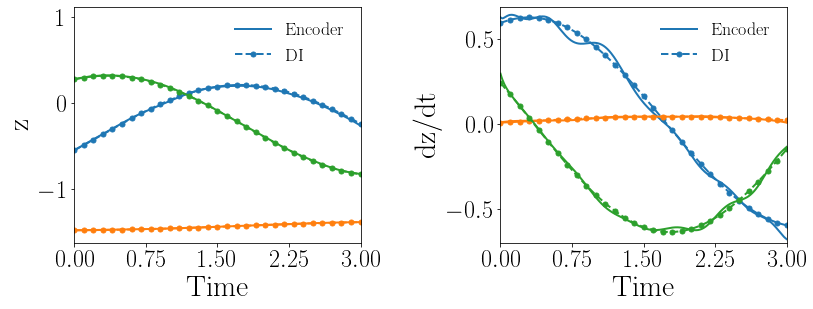
Fig. 15(a-b) show the latent-space dynamics predicted by the trained encoder and the DI model from LaSDI and gLaSDI, respectively. It again shows that gLaSDI learns smoother latent-space dynamics than LaSDI, with a better agreement between the encoder and the DI predictions than LaSDI.
Fig. 15(c-d) show the maximum relative error of LaSDI and gLaSDI predictions in the prescribed parameter space, respectively. Compared with the example with a smaller parameter space, as shown in the previous subsection, the maximum relative error achieved by gLaSDI in the whole parameter space increases from 2.0 to 3.3, while that achieved by LaSDI increases from 5.4 to 24. It shows that gLaSDI maintains high accuracy even when the parameter space is enlarged, while LaSDI’s error increases significantly due to non-optimal sampling and the mismatch between the encoder and DI predictions. It is interesting to note that changing the parameter space affects the distribution of gLaSDI sampling.
5 Conclusions
In this study, we introduced a physics-informed greedy parametric latent-space dynamics identification (gLaSDI) framework for accurate, efficient, and robust data-driven computing of high-dimensional nonlinear dynamical systems. The proposed gLaSDI framework is composed of an autoencoder that performs nonlinear compression of high-dimensional data and discovers intrinsic latent representations as well as dynamics identification (DI) models that capture local latent-space dynamics. The autoencoder and DI models are trained interactively and simultaneously, enabling identification of simple latent-space dynamics for improved accuracy and efficiency of data-driven computing. To maximize and accelerate the exploration of the parameter space, we introduce an adaptive greedy sampling algorithm integrated with a physics-informed residual-based error indicator and random-subset evaluation to search for the optimal training samples on the fly. Moreover, an efficient -nearest neighbor convex interpolation scheme is employed for model evaluation to exploit local latent-space dynamics captured by the local DI models.
To demonstrate the effectiveness of the proposed gLaSDI framework, it has been applied to model various nonlinear dynamical problems, including 1D Burgers’ equations, 2D Burgers’ equations, nonlinear heat conduction, and time-dependent radial advection. It is observed that greedy sampling with a small for model evaluation results in a more conservative gLaSDI model at the cost of training efficiency, and that the model testing with a large enhances generalization performance of gLaSDI. Compared with LaSDI that depends on predefined uniformly distributed training parameters, gLaSDI with adaptive and sparse sampling can intelligently identify the optimal training parameter points to achieve higher accuracy with less number of training points than LaSDI. Owning to interactive and simultaneous training of the autoencoder and DI models, gLaSDI is able to capture simpler and smoother latent-space dynamics than LaSDI that has sequential and decoupled training of the autoencoder and DI models. In the radial advection problem, it is also shown that gLaSDI remains highly accurate as the parameter space increases, whereas LaSDI’s performances could deteriorate tremendously. In the numerical examples, compared with the high-fidelity models, gLaSDI achieves 17 to 2,658 speed-up, with 1 to 5 maximum relative errors in the prescribed parameter space, which reveals the promising potential of applying gLaSDI to large-scale physical simulations.
The proposed gLaSDI framework is general and not restricted to specific use of autoencoders, latent dynamics learning algorithms, or interpolation schemes for exploitation of localized latent-space dynamics learned by DI models. Depending on applications, various linear or nonlinear data compression techniques other than autoencoders could be employed. Further, latent-space dynamics identification could be performed by other system identification techniques or operator learning algorithms.
The autoencoder architecture can be optimized to maximize generalization performance by integrating automatic neural architecture search [102] into the proposed framework. The parameterization in this study considers the parameters from the initial conditions and the governing equations (C) of the problems. The proposed framework can be easily extended to account for other parameterization types, such as material properties, which will be useful for inverse problems. As the training of gLaSDI proceeds, the training efficiency could decrease due to the increase in the training data. A combination of pre-training and re-training could potentially enhance the training efficiency. One could first pre-train the DI model attached to the new sampled training parameter point using only its data rather than the aggregated training data that includes all training parameter points. Then, the gLaSDI model, consisting of an autoencoder and all DI models, is re-trained by the combined training data to fine-tune the trainable parameters. More efficient training strategies will be investigated in future studies.
Acknowledgements
This work was performed at Lawrence Livermore National Laboratory and partially funded by two LDRDs (21-FS-042 and 21-SI-006). Youngsoo was also supported for this work by the CHaRMNET Mathematical Multifaceted Integrated Capability Center (MMICC). Lawrence Livermore National Laboratory is operated by Lawrence Livermore National Security, LLC, for the U.S. Department of Energy, National Nuclear Security Administration under Contract DE-AC52-07NA27344 and LLNL-JRNL-834220.
Appendix A 1D Burgers equation
Solution snapshots
The solution fields at several time steps of the parameter case and the solution fields at the last time step of 4 different parameter cases, i.e., , , , and are shown in Fig. 16.
Speed-up performance
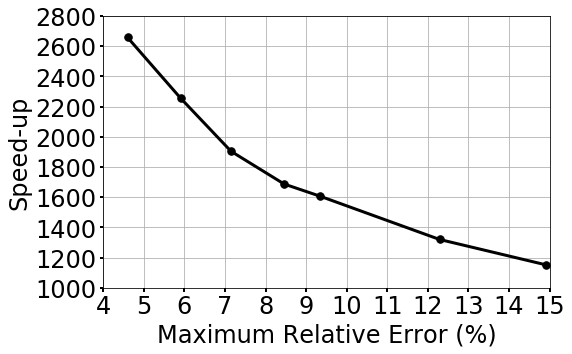
To further quantify the speed-up performance of gLaSDI, we have performed a series of tests using the gLaSDI model and parameter space in case 2 (Section 4.1.2). The gLaSDI model is trained until a prescribed target tolerance is reached by the maximum relative error estimated based on the residual error of the training parameter points (Eq. (27)). The trained gLaSDI model is then evaluated in the parameter space prescribed for training and its maximum relative error is recorded. Meanwhile, the high-fidelity simulations with similar maximum relative errors with respect to the high-fidelity data used for gLaSDI training are selected for speed-up comparison. Fig. 17 shows that the speed-up of gLaSDI increases as the maximum relative error decreases, which is expected as a lower error requires a higher dimension (resolution) of the high-fidelity solution that is much larger than the dimension of the latent space discovered by gLaSDI.
Appendix B 2D Burgers equation
Solution snapshots
The solution fields of the first velocity component at several time steps of the parameter case are shown in Fig. 18.
Effects of the latent dimension
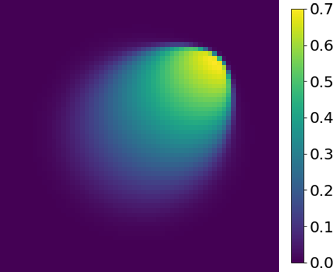
The effects of the latent dimension on the ROM accuracy are further investigated. A series of tests are performed using the parameter space in case 1 (Section 4.2.1). The gLaSDI model has quadratic DI models and an autoencoder architecture of 7,200-100- with the latent dimension ranging from 2 to 7. The gLaSDI is trained until the total number of sampled parameter points reaches 36. For comparison, a LaSDI model with the same architecture of the autoencoder and DI models is trained using 36 predefined training parameter points uniformly distributed in a grid in the parameter space.
Fig. 19 shows that as the latent dimension increases from 2 to 3, the error LaSDI decreases from around 99 to 36 and the error of gLaSDI decreases from around 30 to 6, which indicates that a latent dimension of 2 is insufficient for the autoencoder to capture all intrinsic features of the physical dynamics. As the latent dimension further increases from 3 to 6, gLaSDI maintains a similar level of accuracy, around 5 error, while the error of LaSDI jumps significantly to around 250. Due to strong nonlinearity and flexibility of the autoencoder, the complexity of the latent representation learned by the autoencoder increases with the latent dimension, posing more challenges for the subsequent DI training of LaSDI and therefore leading to large errors. In contrast, the interactive autoencoder-DI training of gLaSDI provides additional constraints on the learned latent representation and contributes to a higher accuracy as well as more stable performance. It is noticed that when the latent dimension is further increased to 7, the error of gLaSDI rises to around 46, which implies the constraints provided by the interactive training is insufficient to counteract the negative effects caused by the overly complex latent representations. It shows that there exists a certain range of the latent dimension for optimal accuracy. Note that a standard fully-connected autoencoder is applied in this study. The accuracy and robustness of gLaSDI could potentially be further improved by more advanced networks, such as convolutional autoencoders, and neural architecture search [102], which will be investigated in future studies.
Speed-up performance
The speed-up performance of gLaSDI is further investigated. A series of tests are performed using the gLaSDI model and parameter space in case 2 (Section 4.2.2). The gLaSDI model is trained until a prescribed target tolerance is reached by the maximum relative error estimated based on the residual error of the training parameter points (Eq. (27)). The trained gLaSDI model is then evaluated in the parameter space prescribed for training and its maximum relative error is recorded. Meanwhile, the high-fidelity simulations with similar maximum relative errors with respect to the high-fidelity data used for gLaSDI training are selected for speed-up comparison. Similar to the observation in the speed-up analysis in A, Fig. 20 shows that the speed-up of gLaSDI increases as the maximum relative error decreases.
Appendix C Nonlinear time-dependent heat conduction
Solution snapshots
The solution fields at several time steps of the parameter case are shown in Fig. 21.



Parameterization of PDE
The effectiveness of the proposed gLaSDI framework on the parameterization of PDEs is investigated, where the coefficients and in Eq. (32) are considered to be the parameters that constitute the parameter space , each with 21 evenly distributed discrete points in the respective parameter range. The parameters and are adopted in the initial condition. The autoencoder with an architecture of 1,089-100-3 and linear DI models are considered. The gLaSDI training is performed until the total number of sampled parameter points reaches 25.
Fig. 22(a) shows that gLaSDI discovers simple latent-space dynamics with a good agreement between the predictions by the trained encoder and the DI model. Fig. 22(b) shows that gLaSDI achieves a maximum relative error of 1.3 in the prescribed parameter space, which demonstrates the effectiveness of the proposed gLaSDI framework for reduced-order modeling with parameterization of PDEs.
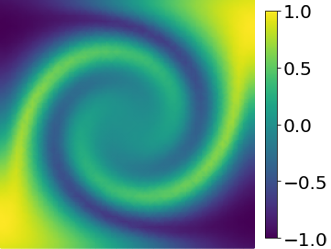
Appendix D Time-dependent radial advection
Solution snapshots
The solution fields at several time steps of the parameter case are shown in Fig. 23.


References
- [1] David Jones et al. “Characterising the Digital Twin: A systematic literature review” In CIRP Journal of Manufacturing Science and Technology 29 Elsevier, 2020, pp. 36–52
- [2] Mengnan Liu, Shuiliang Fang, Huiyue Dong and Cunzhi Xu “Review of digital twin about concepts, technologies, and industrial applications” In Journal of Manufacturing Systems 58 Elsevier, 2021, pp. 346–361
- [3] Shun Wang, Eric de Sturler and Glaucio H Paulino “Large-scale topology optimization using preconditioned Krylov subspace methods with recycling” In International journal for numerical methods in engineering 69.12 Wiley Online Library, 2007, pp. 2441–2468
- [4] Daniel A White, Youngsoo Choi and Jun Kudo “A dual mesh method with adaptivity for stress-constrained topology optimization” In Structural and Multidisciplinary Optimization 61.2 Springer, 2020, pp. 749–762
- [5] Youngsoo Choi, Charbel Farhat, Walter Murray and Michael Saunders “A practical factorization of a Schur complement for PDE-constrained distributed optimal control” In Journal of Scientific Computing 65.2 Springer, 2015, pp. 576–597
- [6] Ralph C Smith “Uncertainty quantification: theory, implementation, and applications” Siam, 2013
- [7] George Biros et al. “Large-scale inverse problems and quantification of uncertainty” John Wiley & Sons, 2011
- [8] David Galbally, Krzysztof Fidkowski, Karen Willcox and Omar Ghattas “Non-linear model reduction for uncertainty quantification in large-scale inverse problems” In International journal for numerical methods in engineering 81.12 Wiley Online Library, 2010, pp. 1581–1608
- [9] Gal Berkooz, Philip Holmes and John L Lumley “The proper orthogonal decomposition in the analysis of turbulent flows” In Annual review of fluid mechanics 25.1 Annual Reviews 4139 El Camino Way, PO Box 10139, Palo Alto, CA 94303-0139, USA, 1993, pp. 539–575
- [10] Anthony T Patera and Gianluigi Rozza “Reduced basis approximation and a posteriori error estimation for parametrized partial differential equations” MIT Cambridge, 2007
- [11] Michael G Safonov and RY1000665 Chiang “A Schur method for balanced-truncation model reduction” In IEEE Transactions on Automatic Control 34.7 IEEE, 1989, pp. 729–733
- [12] David DeMers and Garrison W Cottrell “Non-linear dimensionality reduction” In Advances in neural information processing systems, 1993, pp. 580–587
- [13] Geoffrey E Hinton and Ruslan R Salakhutdinov “Reducing the dimensionality of data with neural networks” In science 313.5786 American Association for the Advancement of Science, 2006, pp. 504–507
- [14] Youngkyu Kim, Youngsoo Choi, David Widemann and Tarek Zohdi “A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder” In Journal of Computational Physics 451 Elsevier, 2022, pp. 110841
- [15] Youngkyu Kim, Youngsoo Choi, David Widemann and Tarek Zohdi “Efficient nonlinear manifold reduced order model” In arXiv preprint arXiv:2011.07727, 2020
- [16] Kookjin Lee and Kevin T Carlberg “Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders” In Journal of Computational Physics 404 Elsevier, 2020, pp. 108973
- [17] Chi Hoang, Youngsoo Choi and Kevin Carlberg “Domain-decomposition least-squares Petrov–Galerkin (DD-LSPG) nonlinear model reduction” In Computer Methods in Applied Mechanics and Engineering 384 Elsevier, 2021, pp. 113997
- [18] Dylan Matthew Copeland, Siu Wun Cheung, Kevin Huynh and Youngsoo Choi “Reduced order models for Lagrangian hydrodynamics” In Computer Methods in Applied Mechanics and Engineering 388 Elsevier, 2022, pp. 114259
- [19] Siu Wun Cheung, Youngsoo Choi, Dylan Matthew Copeland and Kevin Huynh “Local Lagrangian reduced-order modeling for Rayleigh-Taylor instability by solution manifold decomposition” In arXiv preprint arXiv:2201.07335, 2022
- [20] Jessica Lauzon et al. “S-OPT: A points selection algorithm for hyper-reduction in reduced order models” In arXiv preprint arXiv:2203.16494, 2022
- [21] Felix Fritzen, Bernard Haasdonk, David Ryckelynck and Sebastian Schöps “An algorithmic comparison of the hyper-reduction and the discrete empirical interpolation method for a nonlinear thermal problem” In Mathematical and computational applications 23.1 Multidisciplinary Digital Publishing Institute, 2018, pp. 8
- [22] Youngsoo Choi, Deshawn Coombs and Robert Anderson “SNS: A solution-based nonlinear subspace method for time-dependent model order reduction” In SIAM Journal on Scientific Computing 42.2 SIAM, 2020, pp. A1116–A1146
- [23] Youngsoo Choi and Kevin Carlberg “Space–time least-squares Petrov–Galerkin projection for nonlinear model reduction” In SIAM Journal on Scientific Computing 41.1 SIAM, 2019, pp. A26–A58
- [24] Kevin Carlberg, Youngsoo Choi and Syuzanna Sargsyan “Conservative model reduction for finite-volume models” In Journal of Computational Physics 371 Elsevier, 2018, pp. 280–314
- [25] Benjamin McLaughlin, Janet Peterson and Ming Ye “Stabilized reduced order models for the advection–diffusion–reaction equation using operator splitting” In Computers & Mathematics with Applications 71.11 Elsevier, 2016, pp. 2407–2420
- [26] Youngkyu Kim, Karen Wang and Youngsoo Choi “Efficient space–time reduced order model for linear dynamical systems in Python using less than 120 lines of code” In Mathematics 9.14 Multidisciplinary Digital Publishing Institute, 2021, pp. 1690
- [27] Giovanni Stabile and Gianluigi Rozza “Finite volume POD-Galerkin stabilised reduced order methods for the parametrised incompressible Navier–Stokes equations” In Computers & Fluids 173 Elsevier, 2018, pp. 273–284
- [28] Traian Iliescu and Zhu Wang “Variational multiscale proper orthogonal decomposition: Navier-stokes equations” In Numerical Methods for Partial Differential Equations 30.2 Wiley Online Library, 2014, pp. 641–663
- [29] Alexander C Hughes and Andrew G Buchan “A discontinuous and adaptive reduced order model for the angular discretization of the Boltzmann transport equation” In International Journal for Numerical Methods in Engineering 121.24 Wiley Online Library, 2020, pp. 5647–5666
- [30] Youngsoo Choi et al. “Space–time reduced order model for large-scale linear dynamical systems with application to boltzmann transport problems” In Journal of Computational Physics 424 Elsevier, 2021, pp. 109845
- [31] Jiun-Shyan Chen, Camille Marodon and Hsin-Yun Hu “Model order reduction for meshfree solution of Poisson singularity problems” In International Journal for Numerical Methods in Engineering 102.5 Wiley Online Library, 2015, pp. 1211–1237
- [32] Qizhi He, Jiun-Shyan Chen and Camille Marodon “A decomposed subspace reduction for fracture mechanics based on the meshfree integrated singular basis function method” In Computational Mechanics 63.3 Springer, 2019, pp. 593–614
- [33] Chung-Hao Lee and Jiun-Shyan Chen “Proper orthogonal decomposition-based model order reduction via radial basis functions for molecular dynamics systems” In International journal for numerical methods in engineering 96.10 Wiley Online Library, 2013, pp. 599–627
- [34] Chung-Hao Lee and Jiun-Shyan Chen “RBF-POD reduced-order modeling of DNA molecules under stretching and bending” In Interaction and Multiscale Mechanics 6.4, 2013, pp. 395–409
- [35] Shigeki Kaneko et al. “A hyper-reduction computational method for accelerated modeling of thermal cycling-induced plastic deformations” In Journal of the Mechanics and Physics of Solids 151 Elsevier, 2021, pp. 104385
- [36] Christian Gogu “Improving the efficiency of large scale topology optimization through on-the-fly reduced order model construction” In International Journal for Numerical Methods in Engineering 101.4 Wiley Online Library, 2015, pp. 281–304
- [37] Youngsoo Choi, Geoffrey Oxberry, Daniel White and Trenton Kirchdoerfer “Accelerating design optimization using reduced order models” In arXiv preprint arXiv:1909.11320, 2019
- [38] Sean McBane and Youngsoo Choi “Component-wise reduced order model lattice-type structure design” In Computer Methods in Applied Mechanics and Engineering 381 Elsevier, 2021, pp. 113813
- [39] Youngsoo Choi et al. “Gradient-based constrained optimization using a database of linear reduced-order models” In Journal of Computational Physics 423 Elsevier, 2020, pp. 109787
- [40] William D Fries, Xiaolong He and Youngsoo Choi “LaSDI: Parametric latent space dynamics identification” In Computer Methods in Applied Mechanics and Engineering 399 Elsevier, 2022, pp. 115436
- [41] Hannah Lu and Daniel M Tartakovsky “Dynamic mode decomposition for construction of reduced-order models of hyperbolic problems with shocks” In Journal of Machine Learning for Modeling and Computing 2.1 Begel House Inc., 2021
- [42] Hannah Lu and Daniel M Tartakovsky “Lagrangian dynamic mode decomposition for construction of reduced-order models of advection-dominated phenomena” In Journal of Computational Physics 407 Elsevier, 2020, pp. 109229
- [43] Rambod Mojgani and Maciej Balajewicz “Lagrangian basis method for dimensionality reduction of convection dominated nonlinear flows” In arXiv preprint arXiv:1701.04343, 2017
- [44] Julius Reiss, Philipp Schulze, Jörn Sesterhenn and Volker Mehrmann “The shifted proper orthogonal decomposition: A mode decomposition for multiple transport phenomena” In SIAM Journal on Scientific Computing 40.3 SIAM, 2018, pp. A1322–A1344
- [45] Marzieh Alireza Mirhoseini and Matthew J Zahr “Model reduction of convection-dominated partial differential equations via optimization-based implicit feature tracking” In arXiv preprint arXiv:2109.14694, 2021
- [46] Zhiguang Qian et al. “Building surrogate models based on detailed and approximate simulations” In Journal of Mechanical Design 128.4, 2006, pp. 668–677
- [47] Gustavo Tapia et al. “Gaussian process-based surrogate modeling framework for process planning in laser powder-bed fusion additive manufacturing of 316L stainless steel” In The International Journal of Advanced Manufacturing Technology 94.9 Springer, 2018, pp. 3591–3603
- [48] B Daniel Marjavaara et al. “Hydraulic turbine diffuser shape optimization by multiple surrogate model approximations of Pareto fronts” In Journal of Fluids Engineering 129.9, 2007, pp. 1228–1240
- [49] Fuxin Huang, Lijue Wang and Chi Yang “Hull form optimization for reduced drag and improved seakeeping using a surrogate-based method” In The Twenty-fifth International Ocean and Polar Engineering Conference, 2015 OnePetro
- [50] Zhong-Hua Han, Stefan Görtz and Ralf Zimmermann “Improving variable-fidelity surrogate modeling via gradient-enhanced kriging and a generalized hybrid bridge function” In Aerospace Science and technology 25.1 Elsevier, 2013, pp. 177–189
- [51] Zhong-Hua Han and Stefan Görtz “Hierarchical kriging model for variable-fidelity surrogate modeling” In AIAA journal 50.9, 2012, pp. 1885–1896
- [52] Frederic E Bock et al. “A review of the application of machine learning and data mining approaches in continuum materials mechanics” In Frontiers in Materials 6 Frontiers, 2019, pp. 110
- [53] J Nathan Kutz “Deep learning in fluid dynamics” In Journal of Fluid Mechanics 814 Cambridge University Press, 2017, pp. 1–4
- [54] Michela Paganini, Luke Oliveira and Benjamin Nachman “CaloGAN: Simulating 3D high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks” In Physical Review D 97.1 APS, 2018, pp. 014021
- [55] Seonwoo Min, Byunghan Lee and Sungroh Yoon “Deep learning in bioinformatics” In Briefings in bioinformatics 18.5 Oxford University Press, 2017, pp. 851–869
- [56] Jeremy Morton, Antony Jameson, Mykel J Kochenderfer and Freddie Witherden “Deep dynamical modeling and control of unsteady fluid flows” In Advances in Neural Information Processing Systems 31, 2018
- [57] Teeratorn Kadeethum et al. “A framework for data-driven solution and parameter estimation of PDEs using conditional generative adversarial networks” In Nature Computational Science 1.12 Nature Publishing Group, 2021, pp. 819–829
- [58] T Kadeethum et al. “Continuous conditional generative adversarial networks for data-driven solutions of poroelasticity with heterogeneous material properties” In arXiv preprint arXiv:2111.14984, 2021
- [59] Teeratorn Kadeethum et al. “Non-intrusive reduced order modeling of natural convection in porous media using convolutional autoencoders: comparison with linear subspace techniques” In Advances in Water Resources Elsevier, 2022, pp. 104098
- [60] Teeratorn Kadeethum et al. “Reduced order modeling for flow and transport problems with Barlow Twins self-supervised learning” In arXiv preprint arXiv:2202.05460, 2022
- [61] Renee Swischuk, Laura Mainini, Benjamin Peherstorfer and Karen Willcox “Projection-based model reduction: Formulations for physics-based machine learning” In Computers & Fluids 179 Elsevier, 2019, pp. 704–717
- [62] Byungsoo Kim et al. “Deep fluids: A generative network for parameterized fluid simulations” In Computer Graphics Forum 38.2, 2019, pp. 59–70 Wiley Online Library
- [63] Xuping Xie, Guannan Zhang and Clayton G Webster “Non-intrusive inference reduced order model for fluids using deep multistep neural network” In Mathematics 7.8 Multidisciplinary Digital Publishing Institute, 2019, pp. 757
- [64] Chi Hoang, Kenny Chowdhary, Kookjin Lee and Jaideep Ray “Projection-based model reduction of dynamical systems using space–time subspace and machine learning” In Computer Methods in Applied Mechanics and Engineering 389 Elsevier, 2022, pp. 114341
- [65] John R Koza “Genetic programming as a means for programming computers by natural selection” In Statistics and computing 4.2 Springer, 1994, pp. 87–112
- [66] Michael Schmidt and Hod Lipson “Distilling free-form natural laws from experimental data” In science 324.5923 American Association for the Advancement of Science, 2009, pp. 81–85
- [67] Steven L Brunton, Joshua L Proctor and J Nathan Kutz “Discovering governing equations from data by sparse identification of nonlinear dynamical systems” In Proceedings of the national academy of sciences 113.15 National Acad Sciences, 2016, pp. 3932–3937
- [68] Benjamin Peherstorfer and Karen Willcox “Data-driven operator inference for nonintrusive projection-based model reduction” In Computer Methods in Applied Mechanics and Engineering 306 Elsevier, 2016, pp. 196–215
- [69] Elizabeth Qian, Boris Kramer, Benjamin Peherstorfer and Karen Willcox “Lift & learn: Physics-informed machine learning for large-scale nonlinear dynamical systems” In Physica D: Nonlinear Phenomena 406 Elsevier, 2020, pp. 132401
- [70] Peter Benner et al. “Operator inference for non-intrusive model reduction of systems with non-polynomial nonlinear terms” In Computer Methods in Applied Mechanics and Engineering 372 Elsevier, 2020, pp. 113433
- [71] Miles Cranmer et al. “Discovering symbolic models from deep learning with inductive biases” In Advances in Neural Information Processing Systems 33, 2020, pp. 17429–17442
- [72] M Cranmer “PySR: Fast & parallelized symbolic regression in Python/Julia” Sept, 2020
- [73] Subham Sahoo, Christoph Lampert and Georg Martius “Learning equations for extrapolation and control” In International Conference on Machine Learning, 2018, pp. 4442–4450 PMLR
- [74] Matt J Kusner, Brooks Paige and José Miguel Hernández-Lobato “Grammar variational autoencoder” In International conference on machine learning, 2017, pp. 1945–1954 PMLR
- [75] Li Li, Minjie Fan, Rishabh Singh and Patrick Riley “Neural-guided symbolic regression with asymptotic constraints” In arXiv preprint arXiv:1901.07714, 2019
- [76] Kathleen Champion, Bethany Lusch, J Nathan Kutz and Steven L Brunton “Data-driven discovery of coordinates and governing equations” In Proceedings of the National Academy of Sciences 116.45 National Acad Sciences, 2019, pp. 22445–22451
- [77] Zhe Bai and Liqian Peng “Non-intrusive nonlinear model reduction via machine learning approximations to low-dimensional operators” In Advanced Modeling and Simulation in Engineering Sciences 8.1 Springer, 2021, pp. 1–24
- [78] Shane A McQuarrie, Cheng Huang and Karen E Willcox “Data-driven reduced-order models via regularised operator inference for a single-injector combustion process” In Journal of the Royal Society of New Zealand 51.2 Taylor & Francis, 2021, pp. 194–211
- [79] Benjamin Peherstorfer “Sampling low-dimensional Markovian dynamics for preasymptotically recovering reduced models from data with operator inference” In SIAM Journal on Scientific Computing 42.5 SIAM, 2020, pp. A3489–A3515
- [80] Parisa Khodabakhshi and Karen E Willcox “Non-intrusive data-driven model reduction for differential–algebraic equations derived from lifting transformations” In Computer Methods in Applied Mechanics and Engineering 389 Elsevier, 2022, pp. 114296
- [81] Süleyman Yıldız, Pawan Goyal, Peter Benner and Bülent Karasözen “Learning reduced-order dynamics for parametrized shallow water equations from data” In International Journal for Numerical Methods in Fluids 93.8 Wiley Online Library, 2021, pp. 2803–2821
- [82] Rudy Geelen, Stephen Wright and Karen Willcox “Operator inference for non-intrusive model reduction with nonlinear manifolds” In arXiv preprint arXiv:2205.02304, 2022
- [83] Mengwu Guo, Shane McQuarrie and Karen Willcox “Bayesian operator inference for data-driven reduced order modeling” In arXiv preprint arXiv:2204.10829, 2022
- [84] Rudy Geelen and Karen Willcox “Localized non-intrusive reduced-order modeling in the operator inference framework” In Philosophical Transactions of the Royal Society A, to appear, 2022
- [85] Shane A McQuarrie, Parisa Khodabakhshi and Karen E Willcox “Non-intrusive reduced-order models for parametric partial differential equations via data-driven operator inference” In arXiv preprint arXiv:2110.07653, 2021
- [86] Renee Swischuk, Boris Kramer, Cheng Huang and Karen Willcox “Learning physics-based reduced-order models for a single-injector combustion process” In AIAA Journal 58.6 American Institute of AeronauticsAstronautics, 2020, pp. 2658–2672
- [87] Parikshit Jain, Shane McQuarrie and Boris Kramer “Performance comparison of data-driven reduced models for a single-injector combustion process” In AIAA Propulsion and Energy 2021 Forum, 2021, pp. 3633
- [88] Opal Issan and Boris Kramer “Predicting Solar Wind Streams from the Inner-Heliosphere to Earth via Shifted Operator Inference” In arXiv preprint arXiv:2203.13372, 2022
- [89] Burr Settles “Active learning literature survey” University of Wisconsin-Madison Department of Computer Sciences, 2009
- [90] Prem Melville and Raymond J Mooney “Diverse ensembles for active learning” In Proceedings of the twenty-first international conference on Machine learning, 2004, pp. 74
- [91] Adam Paszke et al. “Automatic differentiation in pytorch”, 2017
- [92] Donald Shepard “A two-dimensional interpolation function for irregularly-spaced data” In Proceedings of the 1968 23rd ACM national conference, 1968, pp. 517–524
- [93] Ivo Babuška and Jens M Melenk “The partition of unity method” In International journal for numerical methods in engineering 40.4 Wiley Online Library, 1997, pp. 727–758
- [94] Holger Wendland “Scattered data approximation” Cambridge university press, 2004
- [95] Qizhi He, Zhan Kang and Yiqiang Wang “A topology optimization method for geometrically nonlinear structures with meshless analysis and independent density field interpolation” In Computational Mechanics 54.3 Springer, 2014, pp. 629–644
- [96] Xiaolong He, Qizhi He and Jiun-Shyan Chen “Deep autoencoders for physics-constrained data-driven nonlinear materials modeling” In Computer Methods in Applied Mechanics and Engineering 385 Elsevier, 2021, pp. 114034
- [97] Sam T Roweis and Lawrence K Saul “Nonlinear dimensionality reduction by locally linear embedding” In science 290.5500 American Association for the Advancement of Science, 2000, pp. 2323–2326
- [98] Qizhi He and Jiun-Shyan Chen “A physics-constrained data-driven approach based on locally convex reconstruction for noisy database” In Computer Methods in Applied Mechanics and Engineering 363 Elsevier, 2020, pp. 112791
- [99] Martı́n Abadi et al. “TensorFlow: A System for Large-Scale Machine Learning” In 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016, pp. 265–283
- [100] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [101] Robert Anderson et al. “MFEM: A modular finite element methods library” In Computers & Mathematics with Applications 81 Elsevier, 2021, pp. 42–74
- [102] Thomas Elsken, Jan Hendrik Metzen and Frank Hutter “Neural architecture search: A survey” In The Journal of Machine Learning Research 20.1 JMLR. org, 2019, pp. 1997–2017