Gibberish is All You Need for Membership Inference Detection in Contrastive Language-Audio Pretraining
Abstract
Audio can disclose PII, particularly when combined with related text data. Therefore, it is essential to develop tools to detect privacy leakage in Contrastive Language-Audio Pretraining(CLAP). Existing MIAs need audio as input, risking exposure of voiceprint and requiring costly shadow models. We first propose PRMID, a membership inference detector based probability ranking given by CLAP, which does not require training shadow models but still requires both audio and text of the individual as input. To address these limitations, we then propose USMID, a textual unimodal speaker-level membership inference detector, querying the target model using only text data. We randomly generate textual gibberish that are clearly not in training dataset. Then we extract feature vectors from these texts using the CLAP model and train a set of anomaly detectors on them. During inference, the feature vector of each test text is input into the anomaly detector to determine if the speaker is in the training set (anomalous) or not (normal). If available, USMID can further enhance detection by integrating real audio of the tested speaker. Extensive experiments on various CLAP model architectures and datasets demonstrate that USMID outperforms baseline methods using only text data.
Index Terms:
membership inference, CLAP models, privacyI Introduction
Microphones in Internet of Things (IoT) devices [1] like phones can lead to unintended inferences from audio [2, 3, 4, 5]. Vocal features and linguistic content can reveal personally identifiable information (PII) [6] like biometric identity and socioeconomic status. Combining audio with text data increases susceptibility to inference attacks. Thus, developing tools to detect privacy leakage in text-audio models like contrastive language-audio pre-training(CLAP) [7, 8, 9] is essential.
Traditional methods like membership inference attacks (MIAs) [10] focus on determining whether a specific data sample was used for model training. Research on MIAs for multimodal contrastive learning (MCL) [11] like Contrastive Language-Image Pretraining(CLIP) [12] is extensive [13, 14, 15], but little attention is given to CLAP.
Traditional MIAs train shadow models to simulate target model’s behavior [16, 17, 18], which requires high computational costs, particularly for multimodal models like CLAP. We first propose PRMID, which uses the probability ranking provided by CLAP for membership inference detection, thereby avoiding the computational costs of shadow models.
However, current MIAs for MCL as well as PRMID often rely on dual-modal data inputs [19], which may lead to new leakage, as one modal of the pair might not have been exposed to the risky target model. Therefore, a detector that does not query CLAP with explicitly matched audio-text pair of speaker (see an example in Figure 1) is desirable. This concept is known as multimodal data protection [20].

To address these limitations, we propose USMID, a textual unimodal speaker-level membership inference [21] detector for CLAP models, which queries the target model with only text data. Specifically, we introduce a feature extractor that maps text data to feature vectors through CLAP-guided audio optimization. We then generate sufficient text gibberish that clearly does not match any text description in training dataset.

As shown in Figure 2, we observe a distinct separation between the features of gibberish and members in training set.
Based on this observation, we train multiple anomaly detectors using the feature vectors of generated text gibberish, creating an anomaly detection voting system. During testing, USMID inputs the feature vectors of test text into the voting system to determine if the corresponding speaker is in(anomalous) or out(normal) of the training set.
Our contributions are summarized as follows:
-
•
We are the first to study membership inference detection in CLAP, constructing several audio-text pair datasets and trained various architectures of CLAP models.
-
•
We introduce USMID, the first speaker-level membership inference detector for CLAP, which avoids exposing audio data to risky target model and the high cost for training shadow models in traditional MIAs.
-
•
Extensive experiments show that USMID outperforms all baselines even using only text PII for query.
II Related Work
II-A Contrastive Language-Audio Pretraining
II-B Membership Inference in Automatic Speech Recognition
III Threat Model
Consider a CLAP model trained on a dataset . Each sample in contains the PII of a speaker, consisting of a textual description and its corresponding audio . For distinct indices , it is possible for while , indicating that multiple non-identical audio samples may exist for the same speaker.
Detector’s Goal. The detector aims to probe potential leakage of a speaker’s PII through the target CLAP model , seeking to determine whether any PII of the speaker were included in the training set . For a speaker with textual description , the detector aims to determine whether there exists a PII sample such that .
Note that our goal is not to detect a specific text-audio pair , but rather to identify the existence of any pair with textual description . This is because that multiple audio samples of the same speaker may be used for training, any of which could contribute to potential PII leakage.
Detector’s Knowledge and Capability. The detector operates with black-box access to , i.e., it can query and observe the outputs, but does not know the model architecture of , the parameter values, or the training algorithms. For the target textual description , depending on the application scenarios, the detector may or may not have actual audios corresponding to . However, if the detector does have the corresponding audio samples, it cannot include them in its queries to due to privacy concerns. Additionally, the detector is unable to modify or access its internal state.


IV Methodology

IV-A Probability Ranking Membership Inference Detector
CLAP is trained to maximize cosine similarity between audio and text features of members. Thus, if one modality of a member is provided to target model, the corresponding other modality data typically yields a higher probability score in the calculated distribution when input alongside other samples.
Based on this, we propose PRMID (Probability Ranking Membership Inference Detector) as shown in Figure 3.
Probability Distribution Evaluated by CLAP. We first match the tested audio with tested text and a set of textual gibberish . We use CLAP to obtain the probability distribution , where .
Membership Inference through Ranking. We define the rank of the tested text within the probability distribution as . We conduct repeated experiments, generating gibberish samples in each trial. Each experiment yields a probability distribution , which enables us to analyze .
We set thresholds and for top and bottom , where is a specified percentage (for example, 1%).
We consider three scenarios below:
-
•
If count of in top exceeds across experiments, we infer that both and are present in .
-
•
If count of in bottom exceeds across experiments, is outside of , while remains within.
-
•
A sample is classified as random if exhibits a uniform distribution across all options. Specifically, the expected probability for any rank is . If the observed frequencies for each rank fall within the expected range of , we conclude that is outside of , with the status of remaining undetermined.
Membership inference for Audio. In reverse inference, we can swap the roles of audio and text and repeat the inference process above as illustrated in Figure 4, allowing membership inference for both modalities.
IV-B Unimodal Speaker-Level Membership Inference Detector
While PRMID requires both audio and text inputs from the individual as input for the target model, this can introduce new privacy risks, as the target model may not have previously encountered dual-modal PII of that individual.
To address this limitation, we propose USMID (unimodal detector for membership inference detection). This detector is designed to ascertain whether the PII of a speaker is included in the training set of target CLAP model , under the condition that only the speaker’s textual description is provided to .
An overview of USMID is illustrated in Figure 5. Firstly, for a textual description , we develop a feature extractor to map to a feature vector, through audio optimization guided by CLAP. Then, we make the key observation that textual gibberish like “dv3*4l-XT0”—random combinations of numbers and symbols clearly do not match any textual descriptions in training set, and hence the detector can generate large amount of textual gibberish that are known out of . Using feature vectors extracted from these gibberish, detector can train multiple anomaly detectors to form an anomaly detection voting system. Finally, during inference phase, the features of the target textual description are fed into the system, and the inference result is determined through voting. Furthermore, when actual audio samples corresponding to the textual description are available, the detector can leverage them to perform clustering on feature vectors of the test samples to enhance detection performance.
Feature Extraction through CLAP-guided Audio Optimization. The feature extraction for a textual description involves iterative optimization of an audio , to maximize the correlation between the embeddings of and produced by the target CLAP model. The extraction process, described in Algorithm 1, iterates for epochs; and within each epoch, an audio is optimized for iterations, to maximize the cosine similarity between its embedding of CLAP and that of target textual description. The average optimized cosine similarity and standard deviation of optimized audio embeddings are extracted as the features of from model .
Input: Target CLAP model , textual description
Output: Mean optimized cosine similarity , standard deviation of optimized audio embeddings
Generation of Textual Gibberish. USMID starts the detection process with generating a set of gibberish strings , which are random combinations of digits and symbols with certain length. As these gibberish texts are randomly generated at the inference time, with overwhelming probability that they did not appear in the training set. Applying the proposed feature extraction algorithm on , we obtain feature vectors of the gibberish texts.
Training Anomaly Detectors. Motivated by the observations in Figure3 that feature vectors of the texts in and out of the training set of are well separated, we propose to train an anomaly detector using , such that texts out of are considered “normal”, and the problem of membership inference on is converted to anomaly detection on its feature vector. More specifically, is classified as part of , if its feature vector is detected “abnormal” by the trained anomaly detector. Specifically in USMID, we train several anomaly detection models on , such as Isolation Forest [24], LocalOutlierFactor [25] and AutoEncoder [26]. These models constitute an anomaly detection voting system that will be used for membership inference on the test textual descriptions.
Textual Membership Inference through Voting. For each textual description in the test set, USMID first extracts its feature vector using Algorithm 1, and then feeds to each of the obtained anomaly detectors to cast a vote on whether is an anomaly. When the total number of votes exceeds a predefined detetion threshold , is determined as an anomaly, i.e., PII with textual description is used to train the CLAP model ; otherwise, is considered normal and no PII with is leaked through training of .
Enhancement with Real audios. At inference time, if real audios of the test texts are available at the detector (e.g., audios of a person), they can be used to extract an additional feature measuring the average distance between the embeddings of real audios and those of optimized audios using the CLAP model, using which the feature vectors of the test texts can be clustered into two partitions with one in and another one out of . This adds an additional vote for each test text to the above described anomaly detection voting system, potentially facilitating the detection accuracy.
Specifically, for each test text , the detector is equipped with a set of real audios . Similar to the feature extraction process in Algorithm 1, over epochs with independent initializations, optimized audios for are obtained under the guidance of the CLAP model. Then, we apply a pretrained feature extraction model (e.g.,DeepFace for face audios) to the real and optimized audios to obtain real embeddings and optimized embeddings . Finally, we compute the average pair-wise distance between the real and optimized embeddings, denoted by , over pairs, and use as an additional feature of the text .
For a batch of test texts , we extract their features first. Feeding the first two features and into a trained anomaly detection system, each text obtains an anomaly score based on the number of detectors that classify it as abnormal. Additionally, the -means algorithm with partitions the feature vectors into “normal” cluster and an “abnormal” clusters, contributing another vote to the anomaly score of each instance. Finally, membership inference is performed by comparing the total votes received to a detection threshold .
V Evaluations
We evaluate the performance of USMID, for speaker-level membership inference using only text PII of the individual.
Dataset Construction. In addition to LibriSpeech [27], we built a speaker recognition dataset based on CommonVoice18.0 [28], which covers various social groups and has richer background information. Specifically, 3,000 speakers (1,500 for training and 1,500 for verification) were selected from CommonVoice, and their audio files were accompanied by unique user PII like ID, age, gender, and region information; then for each user ID, we used GPT-4o to generate detailed background description based on their PII; finally, these expanded background descriptions and audio files corresponding to each user ID constituted the training set of CLAP.
By doing this, we obtained basic facts about who is in the training set and who is not. For each type of content, we created two datasets: one with 1 audio clip per person and another with 50 audio clips per person.
Models. In our CLAP model, audio encoder uses HTSAT[29], which is transformer with 4 groups of swin-transformer blocks. We use the output of its penultimate layer (a 768-dimensional vector) as the output sent to the projection MLP layer. Text encoder uses RoBERTa, which converts input text into a 768-dimensional feature vector. We apply a 2-layer MLP with ReLU activation [30] to map the audio and text outputs to 512 dimensions for final representation.
Evaluation Metrics. USMID’s effectiveness is assessed using Precision, Recall, and Accuracy metrics, measuring anomaly prediction accuracy, correct anomaly identification, and overall prediction correctness, respectively.
Baselines. Current speaker-level membership inference detection methods require detector to query target model with real audio. Most MIAs involve training shadow models, which can be particularly costly for multimodal LLMs. We empirically compare the performance of USMID with PRMID and the following SOTA inference methods. The audio encoders for Audio Auditor and SLMIA-SR are LSTM, for AuditMI they are Transformer, and for PRMID and USMID, they are CLAP.
All experiments are performed using four NVIDIA GeForce RTX 4090 GPUs. Each experiment is repeated for 10 times, and the average values and the standard deviations are reported.
V-A Results
On training anomaly detectors, we randomly generated textual gibberish (some of them are shown in Table I).
| +̱dhu!fh4Y35x9dew | 453fKer5(s=pnI<S | fewf3_;fw/ |
|---|---|---|
| d3|%5f3et45tfG\_ | 4terbtyh<E{43ter | 5gggtb- =64hgF |
| #43GRGgrt54Hdg | ’2_:gtrg6[45gerg3b | g*|<trgrtthg4t|3/ |
| Architecture | Number of Audios per | Method | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| person in training set | |||||
| LibriSpeech | 1 | Audio Auditor | 63.38 ± 0.24 | 73.24 ± 0.33 | 65.19 ± 0.27 |
| SLMIA-SR | 75.21 ± 0.18 | 88.64 ± 0.14 | 83.42 ± 0.21 | ||
| AuditMI | 82.57 ± 0.21 | 95.26 ± 0.26 | 87.91 ± 0.24 | ||
| PRMID | 85.32 ± 0.18 | 95.58 ± 0.22 | 89.75 ± 0.17 | ||
| USMID | 86.49 ± 0.19 | 96.49 ± 0.23 | 91.27 ± 0.15 | ||
| 50 | Audio Auditor | 65.59 ± 0.23 | 80.13 ± 0.16 | 66.59 ± 0.29 | |
| SLMIA-SR | 76.19 ± 0.31 | 90.07 ± 0.18 | 84.33 ± 0.25 | ||
| AuditMI | 83.41 ± 0.14 | 98.04 ± 0.09 | 88.16 ± 0.13 | ||
| PRMID | 86.15 ± 0.16 | 95.87 ± 0.24 | 90.12 ± 0.19 | ||
| USMID | 88.12 ± 0.26 | 98.76 ± 0.12 | 93.07 ± 0.16 | ||
| CommonVoice | 1 | Audio Auditor | 54.85 ± 0.23 | 68.22 ± 0.19 | 60.52 ± 0.21 |
| SLMIA-SR | 65.39 ± 0.36 | 76.91 ± 0.27 | 70.48 ± 0.24 | ||
| AuditMI | 71.43 ± 0.28 | 81.45 ± 0.41 | 74.36 ± 0.18 | ||
| PRMID | 72.35 ± 0.23 | 84.52 ± 0.20 | 78.43 ± 0.18 | ||
| USMID | 74.96 ± 0.25 | 86.01 ± 0.22 | 81.79 ± 0.15 | ||
| 50 | Audio Auditor | 56.11 ± 0.33 | 73.58 ± 0.27 | 61.35 ± 0.25 | |
| SLMIA-SR | 66.28 ± 0.21 | 79.27 ± 0.34 | 72.18 ± 0.22 | ||
| AuditMI | 73.52 ± 0.17 | 84.81 ± 0.28 | 75.64 ± 0.23 | ||
| PRMID | 75.12 ± 0.19 | 88.26 ± 0.18 | 80.98 ± 0.14 | ||
| USMID | 76.47 ± 0.12 | 89.46 ± 0.32 | 82.33 ± 0.19 |
| Method | Train Time | GPU Memory | Inference Time |
|---|---|---|---|
| Audio Auditor | 7.5h | 11.3GB | 0.359s |
| SLMIA-SR | 9h | 13.7GB | 0.406s |
| AuditMI | 80h | 49.5GB | 2.375s |
| USMID | 3.7h | 24.3GB | 0.628s |
| Architecture | Number of audios per | USMID | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| person in training set | |||||
| LibriSpeech | 1 | Text only | 86.49 ± 0.19 | 96.49 ± 0.23 | 91.27 ± 0.15 |
| With 1 audio | 89.21 ± 0.14 | 98.68 ± 0.18 | 93.54 ± 0.13 | ||
| 50 | Text only | 88.12 ± 0.26 | 98.76 ± 0.12 | 93.07 ± 0.16 | |
| With 1 audio | 91.63 ± 0.21 | 99.57 ± 0.08 | 95.24 ± 0.23 | ||
| CommonVoice | 1 | Text only | 74.96 ± 0.25 | 86.01 ± 0.22 | 81.79 ± 0.15 |
| With 1 audio | 76.02 ± 0.17 | 89.55 ± 0.31 | 83.56 ± 0.21 | ||
| 50 | Text only | 76.47 ± 0.12 | 89.46 ± 0.32 | 82.33 ± 0.19 | |
| With 1 audio | 79.34 ± 0.23 | 91.13 ± 0.16 | 85.69 ± 0.24 |
The audio optimization was performed for epochs; and in each epoch, Gradient Descent (GD) iterations with a learning rate of . Four anomaly detection models, i.e., LocalOutlierFactor [25], IsolationForest [24], OneClassSVM [32, 33], and AutoEncoder [34] were trained, and was chosen as the detection threshold.
As shown in Table II, USMID consistently outperforms all baselines even with only text PII, achieving a precision of 88.12% on LibriSpeech with 50 audio clips per person.
Additionally, USMID demonstrates notable advantages in training time and resource efficiency compared to baseline methods as shown in Table III. It requires only 3.7 hours of training, much less than AuditMI’s 80 hours, while maintaining competitive inference times.
We also evaluate the effect of providing USMID with a real audio of the tested person. In this case, the embedding distances between the real and optimized audios of the test samples are used to perform a -means clustering, adding another vote to the inference. We accordingly raise the detection threshold to . As illustrated in Table IV, the given audio helps to improve the performance of USMID across all tested CLAP models, showing an increase of 3.36% on CommonVoice with 1 audio clip per person.
V-B Ablation Study
We further explore the impacts of different system parameters on the detection accuracy.

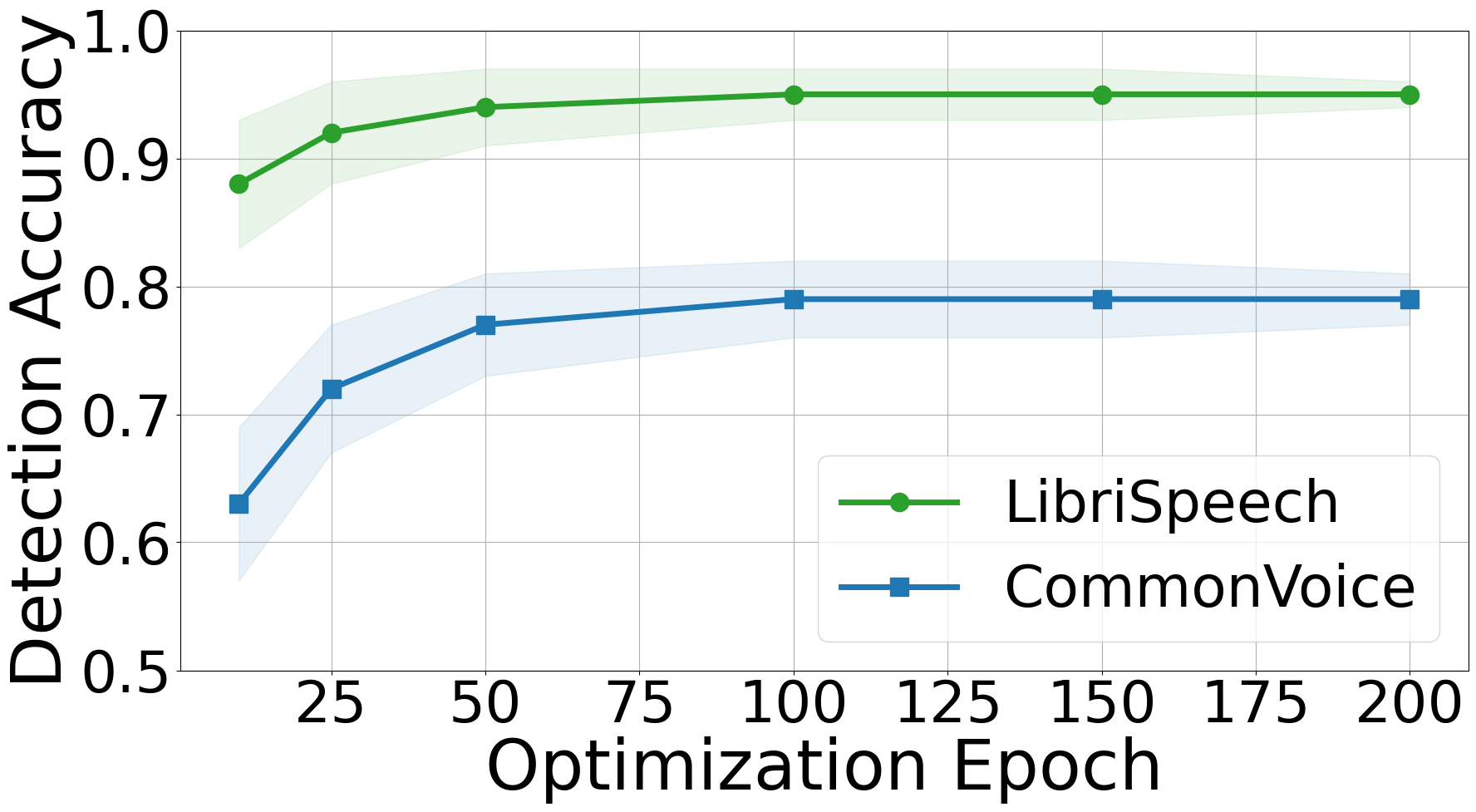




Optimization parameters. Figure 7 and 7 show that during feature extraction, optimizing for epochs, each with iterations, offers the optimal performance. Additional epochs and optimization iterations yield minimal improvements despite increased computational costs.
Detection threshold. Figure 9 and 9 show that the system achieves higher accuracy with a threshold of three votes for text-only inputs and four votes when real audio is included. A high threshold may miss anomalies, while a low threshold may incorrectly classify normal inputs as anomalies.
Number of textual gibberish. As shown in Figure 11, for different target models, the detection accuracies initially improve as the number of gibberish texts increases, and converge after using more than gibberish strings.
Number of real audios. As shown in Figure 11, integrating real audios can enhance the detection accuracy; however, the improvements of using more than 1 audio are rather marginal.
VI Defense and Covert Gibberish Generation
In real-world scenarios, target models may target models may implement defense mechanisms to detect anomalous inputs, such as gibberish, potentially leading to misleading outputs that cause USMID to misidentify the inclusion of PII. To address this, we prompted GPT-3.5-turbo to generate fictional character backgrounds rather than mere gibberish as shown in Table V.
| Name | Occupation | Hometown |
|---|---|---|
| Jaston Spark | Alien Biologist | Martian Oasis City |
| Carl Thunder | Climate Manipulator | Stormhaven |
| Vega Quasar | Cosmic Navigator | Starfall Galaxy |
VII Conclusion
This paper presents the first focused study on membership inference detection in contrastive language-audio pre-training models. We introduce PRMID and USMID, both of which avoid the need for computationally expensive shadow models required in traditional MIAs. Additionally, USMID is the first approach to conduct membership inference without exposing real audio samples to target CLAP models. Evaluations across various CLAP model architectures and dataset demonstrate the consistent superiority of USMID across baseline methods.
References
- [1] A. S. Abdul-Qawy, P. Pramod, E. Magesh, and T. Srinivasulu, “The internet of things (iot): An overview,” International Journal of Engineering Research and Applications, vol. 5, no. 12, pp. 71–82, 2015.
- [2] M. A. Shah, J. Szurley, M. Mueller, T. Mouchtaris, and J. Droppo, “Evaluating the vulnerability of end-to-end automatic speech recognition models to membership inference attacks,” 2021.
- [3] T. Feng, R. Peri, and S. Narayanan, “User-level differential privacy against attribute inference attack of speech emotion recognition in federated learning,” arXiv preprint arXiv:2204.02500, 2022.
- [4] H. Zhao, H. Chen, Y. Xiao, and Z. Zhang, “Privacy-enhanced federated learning against attribute inference attack for speech emotion recognition,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [5] H. Li and X. Zhao, “Membership information leakage in well-generalized auto speech recognition systems,” in 2023 International Conference on Data Science and Network Security (ICDSNS). IEEE, 2023, pp. 1–7.
- [6] P. M. Schwartz and D. J. Solove, “The pii problem: Privacy and a new concept of personally identifiable information,” NYUL rev., vol. 86, p. 1814, 2011.
- [7] B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “Clap learning audio concepts from natural language supervision,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [8] T. Zhao, M. Kong, T. Liang, Q. Zhu, K. Kuang, and F. Wu, “Clap: Contrastive language-audio pre-training model for multi-modal sentiment analysis,” in Proceedings of the 2023 ACM International Conference on Multimedia Retrieval, 2023, pp. 622–626.
- [9] Y. Wu, K. Chen, T. Zhang, Y. Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [10] R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 3–18.
- [11] X. Yuan, Z. Lin, J. Kuen, J. Zhang, Y. Wang, M. Maire, A. Kale, and B. Faieta, “Multimodal contrastive training for visual representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6995–7004.
- [12] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [13] M. Ko, M. Jin, C. Wang et al., “Practical membership inference attacks against large-scale multi-modal models: A pilot study,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4871–4881.
- [14] S. Li, R. Cheng, and X. Jia, “Identity inference from clip models using only textual data,” arXiv preprint arXiv:2405.14517, 2024.
- [15] D. Hintersdorf, L. Struppek, M. Brack, F. Friedrich, P. Schramowski, and K. Kersting, “Does clip know my face?” Journal of Artificial Intelligence Research, vol. 80, pp. 1033–1062, 2024.
- [16] H. Abdullah, M. S. Rahman, W. Garcia, K. Warren, A. S. Yadav, T. Shrimpton, and P. Traynor, “Hear" no evil", see" kenansville": Efficient and transferable black-box attacks on speech recognition and voice identification systems,” in 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 712–729.
- [17] G. Chen, Y. Zhang, and F. Song, “Slmia-sr: Speaker-level membership inference attacks against speaker recognition systems,” arXiv preprint arXiv:2309.07983, 2023.
- [18] W.-C. Tseng, W.-T. Kao, and H.-y. Lee, “Membership inference attacks against self-supervised speech models,” arXiv preprint arXiv:2111.05113, 2021.
- [19] P. Hu, Z. Wang, R. Sun, H. Wang, and M. Xue, “M4i: Multi-modal models membership inference,” Advances in Neural Information Processing Systems, vol. 35, pp. 1867–1882, 2022.
- [20] X. Liu, X. Jia, Y. Xun, S. Liang, and X. Cao, “Multimodal unlearnable examples: Protecting data against multimodal contrastive learning,” arXiv preprint arXiv:2407.16307, 2024.
- [21] Y. Miao, C. Chen, L. Pan, S. Liu, S. Camtepe, J. Zhang, and Y. Xiang, “No-label user-level membership inference for asr model auditing,” in European Symposium on Research in Computer Security. Springer, 2022, pp. 610–628.
- [22] Y. Wu, K. Chen, T. Zhang, Y. Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [23] Y. Li, Z. Guo, X. Wang, and H. Liu, “Advancing multi-grained alignment for contrastive language-audio pre-training,” arXiv preprint arXiv:2408.07919, 2024.
- [24] F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” in 2008 eighth ieee international conference on data mining. IEEE, 2008, pp. 413–422.
- [25] Z. Cheng, C. Zou, and J. Dong, “Outlier detection using isolation forest and local outlier factor,” in Proceedings of the conference on research in adaptive and convergent systems, 2019, pp. 161–168.
- [26] V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A survey,” ACM computing surveys (CSUR), vol. 41, no. 3, pp. 1–58, 2009.
- [27] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An asr corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.
- [28] R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” CoRR, vol. abs/1912.06670, 2019. [Online]. Available: http://arxiv.org/abs/1912.06670
- [29] K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650.
- [30] A. Agarap, “Deep learning using rectified linear units (relu),” arXiv preprint arXiv:1803.08375, 2018.
- [31] F. Teixeira et al., “Exploring features for membership inference in asr model auditing,” Available at SSRN 4937232, 2024.
- [32] K.-L. Li, H.-K. Huang, S.-F. Tian, and W. Xu, “Improving one-class svm for anomaly detection,” in Proceedings of the 2003 international conference on machine learning and cybernetics (IEEE Cat. No. 03EX693), vol. 5. IEEE, 2003, pp. 3077–3081.
- [33] S. S. Khan and M. G. Madden, “One-class classification: taxonomy of study and review of techniques,” The Knowledge Engineering Review, vol. 29, no. 3, pp. 345–374, 2014.
- [34] Z. Chen, C. K. Yeo, B. S. Lee, and C. T. Lau, “Autoencoder-based network anomaly detection,” in 2018 Wireless telecommunications symposium (WTS). IEEE, 2018, pp. 1–5.