Gesture Generation from Trimodal Context for Humanoid Robots
Abstract.
Natural co-speech gestures are essential components to improve the experience of Human-robot interaction (HRI). However, current gesture generation approaches have many limitations of not being natural, not aligning with the speech and content, or the lack of diverse speaker styles. Therefore, this work aims to repoduce the work by (Yoon et al., 2020) generating natural gestures in simulation based on tri-modal inputs and apply this to a robot. During evaluation, “motion variance” and “Frechet Gesture Distance (FGD)” is employed to evaluate the performance objectively. Then, human participants were recruited to subjectively evaluate the gestures. Results show that the movements in that paper have been successfully transferred to the robot and the gestures have diverse styles and are correlated with the speech. Moreover, there is a significant likeability and style difference between different gestures.
1. Introduction
Gestures are non-linguistic and can enhance communication when combined with speech (Goldin‐Meadow and McNeill, 1999). However, generating natural and diverse gestures is challenging (Nyatsanga et al., 2023) and issues of lack of style, unnaturalness, and poor alignment with speech context persist.
Yoon et al. introduced an end-to-end gesture generation framework with trimodal input (Yoon et al., 2020). This model outperforms previous end-to-end models and can generate different gesture styles (e.g., introverted or extroverted) for the same sentence due to the speaker identity (Yoon et al., 2020). However, the viability of this approach for conversion of the movements of human to a robot with fewer Degrees of Freedom (DoF) (Fig 1) was not proved, nor did they separately evaluate motion quality and diversity in their user study.
This paper aims to reproduce Yoon et al.’s work (Yoon et al., 2020), apply it to Pepper (pep, 2015), and extend the user study. Results are applied to Pepper using Kinematics with additional angle and velocity adjustments not previously done. Also, likeability and speech-gesture correlation between different gesture styles, and the performance of the originally generated gesture and the robot gesture are compared in detail.
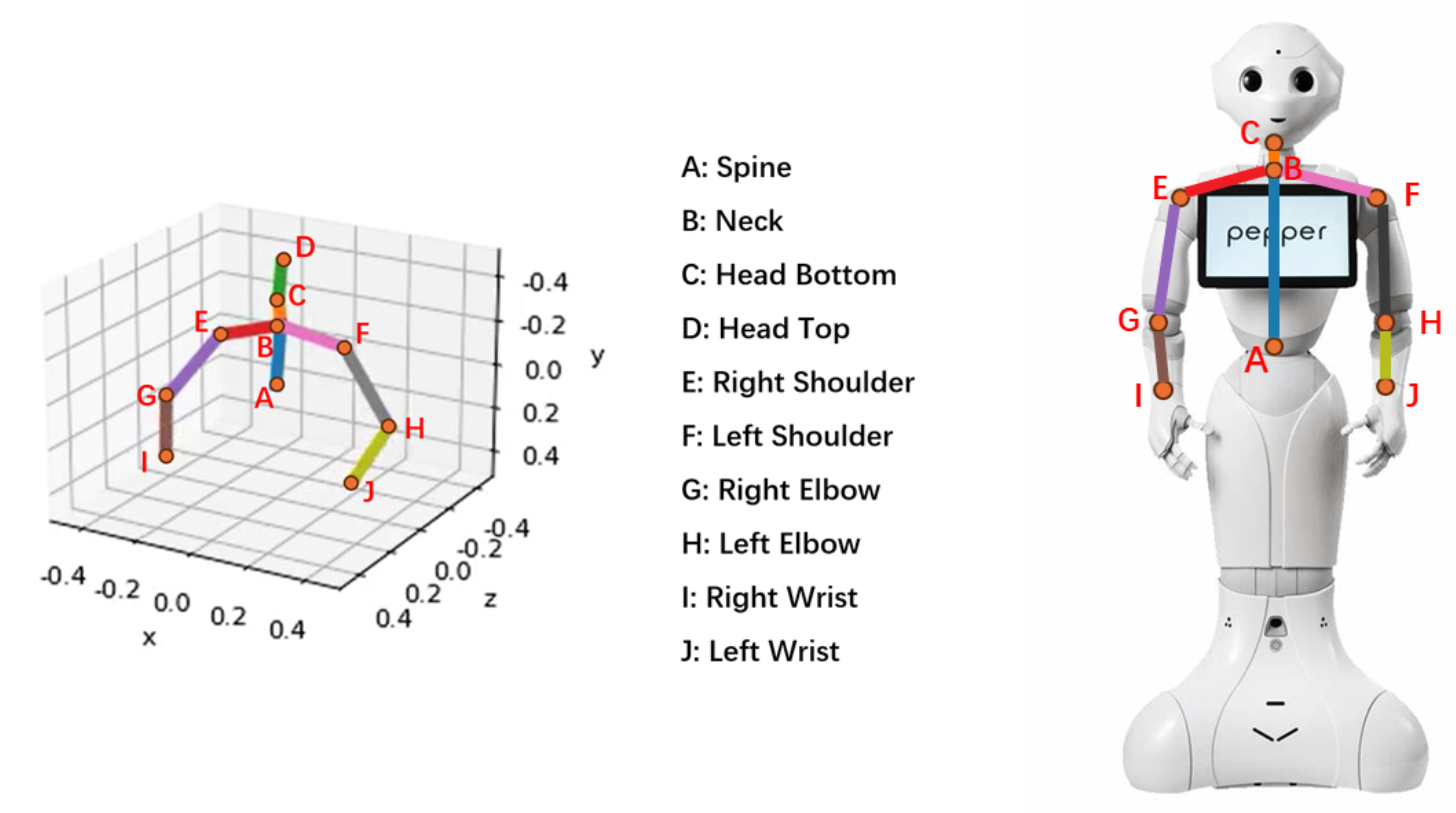
2. Methodology
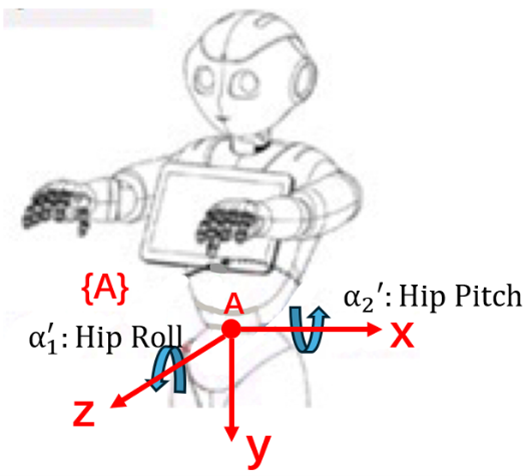
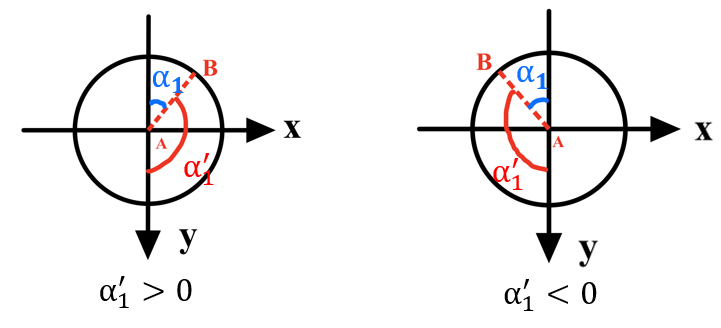
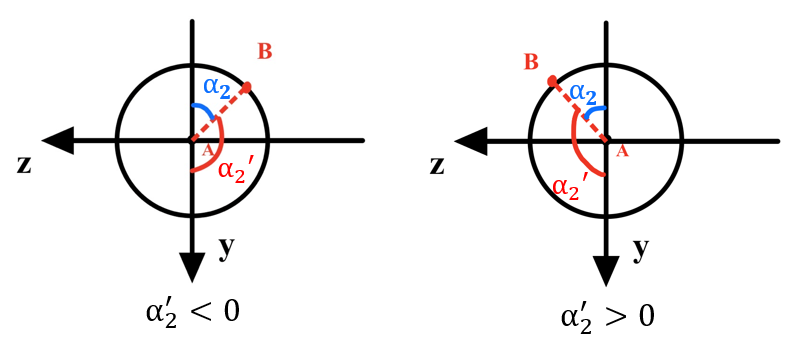
Initially, Google TTS synthesises speech audio from custom input text. Then, the audio, text, and speaker ID are inputs to the Pose Generation module and produce 3D poses frame by frame, with each pose containing 3D coordinates for 10 joints and are visualised as stick figures in Fig. 1 111Images of pepper’s body shown in the following sections are taken from (http://doc.aldebaran.com/2-5/family/pepper_technical/joints_pep.html). Then, the Pose2Angle module calculates rotation angles. For example, and are HipRoll and HipPitch angles. The robot coordinate A is built in Fig 2, where and in range of [, ] are the rotation angles of (Fig 4 and Fig 4). Moreover, 2 constant values and are introduced and allow to manually adjust the performance of the robot. Given 3D coordinates of A and B: and ,
, where .
To prevent the velocity from exceeding the robot’s joint limits, velocities of the next time step are adjusted. and are the rotation angle of a joint at time and . The adjusted angle . Finally, the PlayGesture module uses Naoqi’s python API to enable the Pepper robot to play the audio while performing the gestures.
3. Experimental Design and Results
The research questions are as follows: RQ1: What are the differences in gesture movement performance between the robot and the stick figure? RQ2: How will the gesture styles of the same input sentence differ given different speaker ids? RQ3: What is the difference in likeability between each gesture style? RQ4: Is there a correlation between speech and gesture?
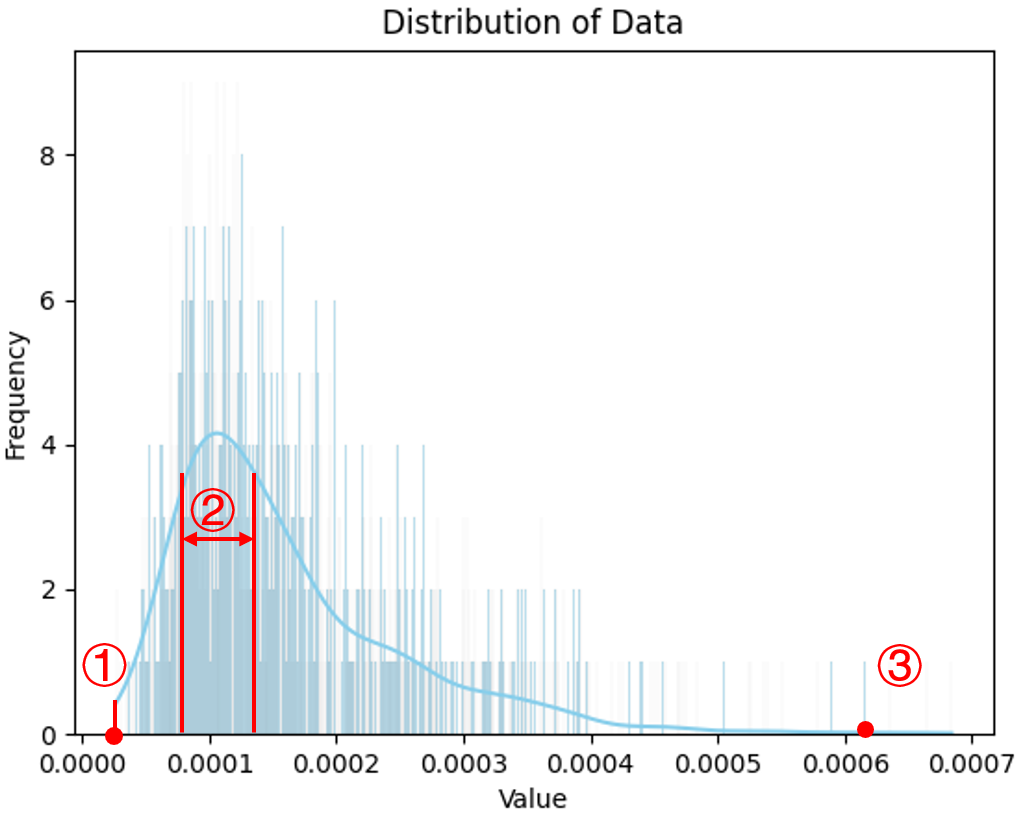
According to Fig 5, 3 speaker IDs were selected from ➀, ➁, and ➂ to represent introverted, normal, and extroverted styles. The (Fréchet distance (Yoon et al., 2020)) between extroverted and introverted styles is the largest (0.6274) compared to other 2 FGDs (0.3093 between extroverted and normal gestures, 0.4338 between introverted and normal gestures).
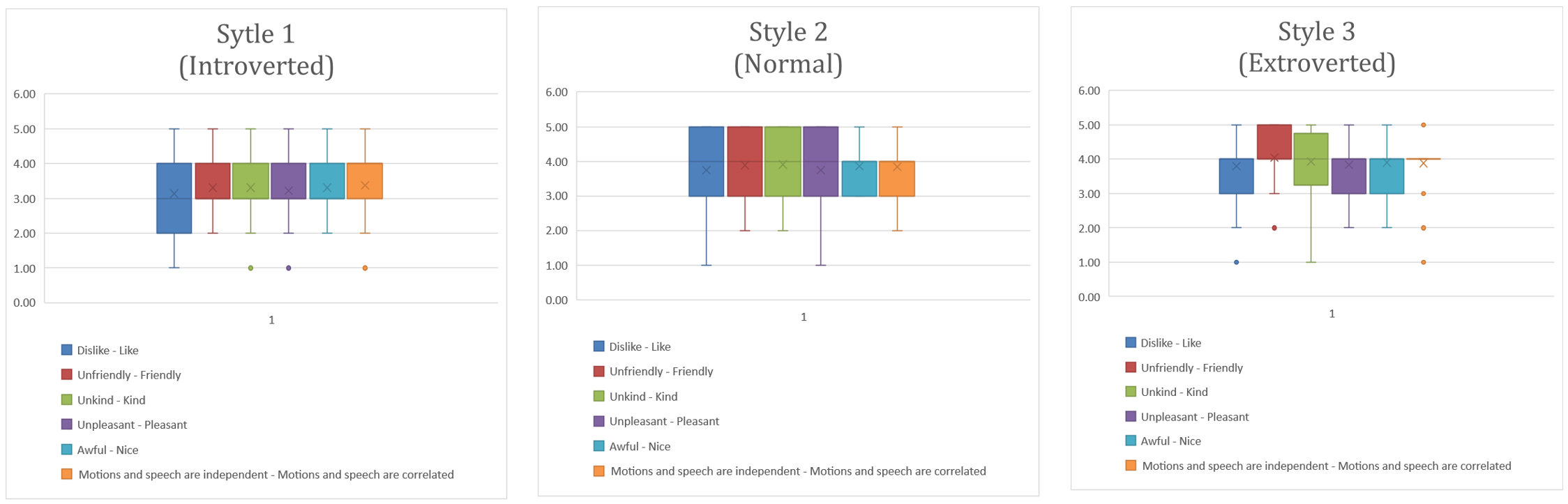
Then in subjective evaluation, after watching a video of the robot, 21 participants completed a questionnaire with the following indexes: Anthropomorphism and Likeability from Godspeed, Speech Gesture Correlation (Yoon et al., 2020), and Style (introverted - extroverted). 3 different sentences were randomly selected and a questionnaire for each of them was created. The number of answers for each sentence is 8, 7 and 6. Participants watched videos of both stick figure and robot with three different gesture styles for the same sentence. To avoid contrast and carryover effects, the videos were played separately in random order and participants evaluated only the movements.
There is no significant difference between the scores of the stick figure and the robot, indicating that the paper’s results apply well to the robot and the velocity adjustment is not noticeable.
| Dependent variable | (I) Style | (J) Style | p |
| Likeability | 1 | 2 | 0.0106 |
| 3 | 0.0028 | ||
| Speech Gesture Correlation | 1 | 2 | 0.038 |
| 3 | 0.017 |
Also, the Likeability and Speech Gesture Correlation of style 1 (introverted) are significantly different from style 2 (normal) and 3 (extroverted) in Table 1 and Fig 6. People prefer normal and extroverted gestures and perceive them as having a higher speech gesture correlation. Therefore, higher speech gesture correlation leads to greater likeability.
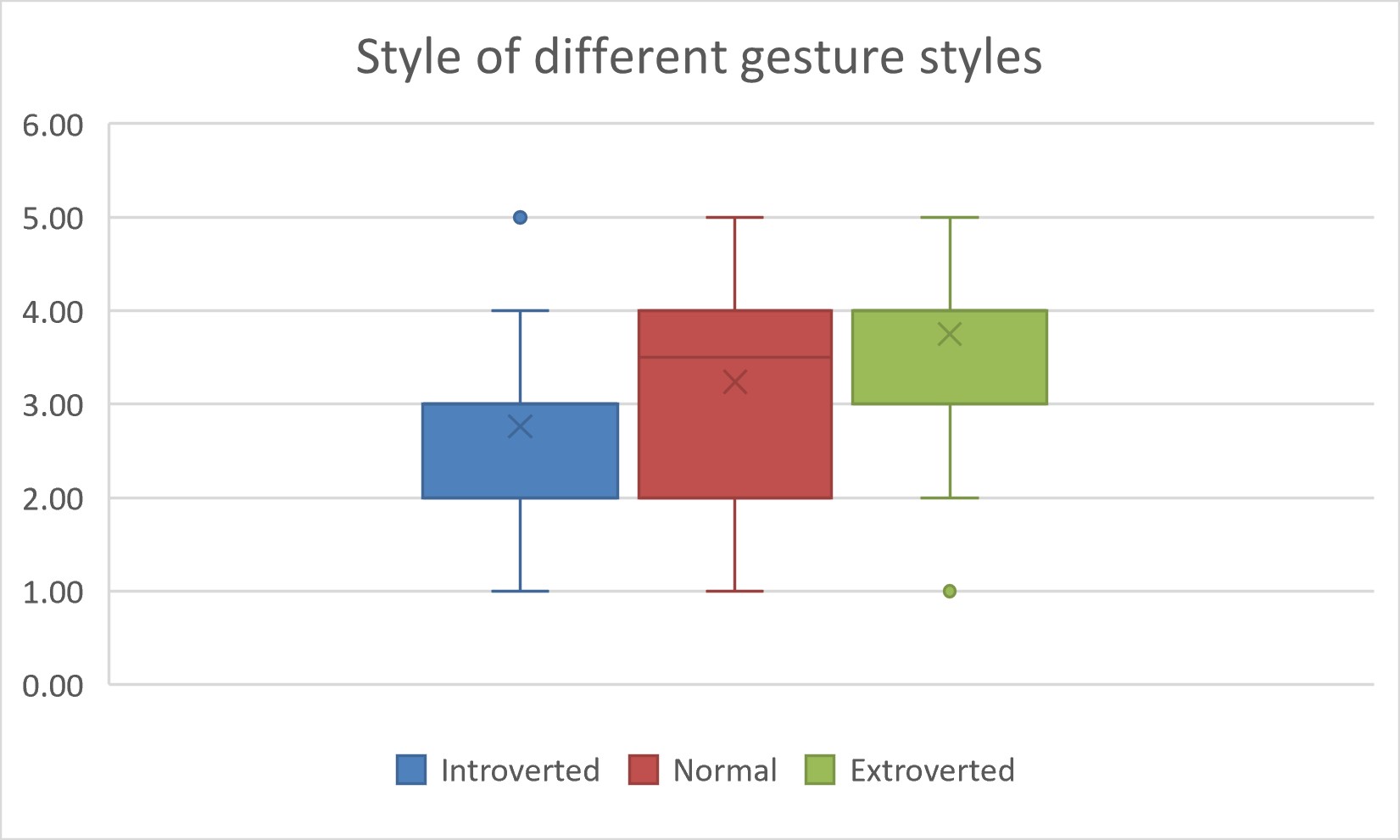
There is also a significant difference (p = 0.000) between the style of different gesture styles. Style 3 significantly differs from styles 1 (p = 0.000) and 2 (p = 0.032) as shown in Fig 7.
4. Discussion
Results showed no significant difference between the robot and the stick figure [RQ1], confirming successful movements transfer from the stick figure to the robot. Moreover, there is a clear sytle difference [RQ2] and people prefer extroverted and normal gestures over introverted ones [RQ3] and perceive extroverted ones has higher speech-gesture correlation [RQ4], which provides a direction to generate more likeable gestures. Future work will focus on an end-to-end model that directly outputs rotation angles within the robot’s maximum velocity, which can eliminate the need for angle calculation and velocity adjustments. Future user studies will include between-subject experiments and recruit more participants. New research questions such as how different voice genders affect perception and likeability of gestures will also be explored.
References
- (1)
- pep (2015) 2015. https://www.aldebaran.com/en/pepper.
- pic (2015) 2015. https://www.gizlogic.com/wp-content/uploads/2015/06/Robot-Pepper.jpg.
- Goldin‐Meadow and McNeill (1999) Susan Goldin‐Meadow and David McNeill. 1999. The role of gesture and mimetic representation in making language the province of speech. https://api.semanticscholar.org/CorpusID:151686384
- Nyatsanga et al. (2023) Simbarashe Nyatsanga, Taras Kucherenko, Chaitanya Ahuja, Gustav Eje Henter, and Michael Neff. 2023. A Comprehensive Review of Data‐Driven Co‐Speech Gesture Generation. Computer Graphics Forum 42 (2023). https://api.semanticscholar.org/CorpusID:255825797
- Yoon et al. (2020) Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. 2020. Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity. ACM Trans. Graph. 39, 6, Article 222 (nov 2020), 16 pages. https://doi.org/10.1145/3414685.3417838
{kind=link}