Geometry of Program Synthesis
Abstract
We re-evaluate universal computation based on the synthesis of Turing machines. This leads to a view of programs as singularities of analytic varieties or, equivalently, as phases of the Bayesian posterior of a synthesis problem. This new point of view reveals unexplored directions of research in program synthesis, of which neural networks are a subset, for example in relation to phase transitions, complexity and generalisation. We also lay the empirical foundations for these new directions by reporting on our implementation in code of some simple experiments.
1 Introduction
The challenge to efficiently learn arbitrary computable functions, that is, synthesise universal computation, seems a prerequisite to build truly intelligent systems. There is strong evidence that neural networks are necessary but not sufficient for this task (Zador, 2019; Akhlaghpour, 2020). Indeed, those functions efficiently learnt by a neural network are those that are continuous on a compact domain and that process memory in a rather primitive manner. This is a rather small subset of the complete set of computable functions, for example, those computable by a Universal Turing Machine. This suggests an opportunity to revisit the basic conceptual framework of modern machine learning by synthesising Turing machines themselves and re-evaluating our concept of programs. We will show that this leads to new unexplored directions for program synthesis.
In the classical model of computation a program is a code for a Universal Turing Machine (UTM). As these codes are discrete, there is no nontrivial “space” of programs. However this may be a limitation in the classical model, and not a fundamental feature of computation. It is worth bearing in mind that, in reality, there is no such thing as a perfect logical state: in any implementation of a UTM in matter a code is realised by an equilibrium state of some physical system (say a magnetic memory). When we say the code on the description tape of the physical UTM “is” what we actually mean is, adopting the thermodynamic language, that the system is in a phase (a local minima of the free energy) including the microstate we associate to . However, when the system is in this phase its microstate is not equal to but rather undergoes rapid spontaneous transitions between many microstates “near” .
So in any possible physical realisation of a UTM, a program is realised by a phase of the physical system. Does this have any computational significance?
One might object that this is physics and not computer science. But this boundary is not so easily drawn: it is unclear, given a particular physical realisation of a UTM, which of the physical characteristics are incidental and which are essentially related to computation, as such. In his original paper Turing highlighted locality in space and time, clearly inspired by the locality of humans operating with eyes, pens and paper, as essential features of his model of computation. Other physical characteristics are left out and hence implicitly regarded as incidental.
In recent years there has been a renewed effort to synthesise programs by gradient descent (Neelakantan et al., 2016; Kaiser & Sutskever, 2016; Bunel et al., 2016; Gaunt et al., 2016; Evans & Grefenstette, 2018; Chen et al., 2018). However, there appear to be serious obstacles to this effort stemming from the singular nature of the loss landscape. When taken seriously at a mathematical level these efforts necessarily come up against this question of programs versus phases. When placed within the correct mathematical setting of singular learning theory (Watanabe, 2009), a clear picture arises of programs as singularities which complements the physical interpretation of phases. The loss function is given as the KL-divergence, an analytic function on the manifold of learnable weights, which corresponds to the microscopic Hamiltonian of the physical system. The Bayesian posterior corresponds to the Boltzmann distribution and we see emerging a dictionary between singular learning theory and statistical mechanics.
The purpose of this article is to (a) explain a formal mathematical setting in which it can be explained why this is the case (b) show how to explore this setting experimentally in code and (c) sketch the new avenues of research in program synthesis that this point of view opens up. The conclusion is that computation should be understood within the framework of singular learning theory with its associated statistical mechanical interpretation which provides a new range of tools to study the learning process, including generalisation and complexity.
1.1 Contributions
Any approach to program synthesis by gradient descent can be formulated mathematically using some kind of manifold containing a discrete subset of codes, and equipped with a smooth function whose set of zeros are such that are precisely the solutions of the synthesis problem. The synthesis process consists of gradient descent with respect to to find a point of , followed perhaps by some secondary process to find a point of . We refer to points of as solutions and points of as classical solutions.
We construct a prototypical example of such a setup, where is a set of codes for a specific UTM with a fixed length, is a space of sequences of probability distributions over code symbols, and is the Kullback-Leibler divergence. The construction of this prototypical example is interesting in its own right, since it puts program synthesis formally in the setting of singular learning theory.
In more detail:
-
•
We define a smooth relaxation of a UTM (Appendix G) based on (Clift & Murfet, 2018) which is well-suited to experiments for confirming theoretical statements in singular learning theory. Propagating uncertainty about the code through this UTM defines a triple in the sense of singular learning theory associated to a synthesis problem. This formally embeds program synthesis within singular learning theory.
-
•
We realise this embedding in code by providing an implementation in PyTorch of this propagation of uncertainty through a UTM. Using the No-U-Turn variant of MCMC (Hoffman & Gelman, 2014) we can approximate the Bayesian posterior of any program synthesis problem (computational constraints permitting).
- •
- •
-
•
We give a simple example (Appendix E) in which contains the set of classical solutions as a proper subset and every point of is a degenerate critical point of , demonstrating the singular nature of the synthesis problem.
-
•
For two simple synthesis problems detectA and parityCheck we demonstrate all of the above, using MCMC to approximate the Bayesian posterior and theorems from (Watanabe, 2013) to estimate the RLCT (Section 7). We discuss how is an extended object and how the RLCT relates to the local dimension of near a classical solution.
2 Preliminaries
We use Turing machines, but mutatis mutandis everything applies to other programming languages. Let be a Turing machine with tape alphabet and set of states and assume that on any input the machine eventually halts with output . Then to the machine we may associate the set . Program synthesis is the study of the inverse problem: given a subset of we would like to determine (if possible) a Turing machine which computes the given outputs on the given inputs.
If we presume given a probability distribution on then we can formulate this as a problem of statistical inference: given a probability distribution on determine the most likely machine producing the observed distribution . If we fix a universal Turing machine then Turing machines can be parametrised by codes with for all . We let denote the probability of (which is either zero or one) so that solutions to the synthesis problem are in bijection with the zeros of the Kullback-Leibler divergence between the true distribution and the model. So far this is just a trivial rephrasing of the combinatorial optimisation problem of finding a Turing machine with for all with .
Smooth relaxation. One approach is to seek a smooth relaxation of the synthesis problem consisting of an analytic manifold and an extension of to an analytic function so that we can search for the zeros of using gradient descent. Perhaps the most natural way to construct such a smooth relaxation is to take to be a space of probability distributions over and prescribe a model for propagating uncertainty about codes to uncertainty about outputs (Gaunt et al., 2016; Evans & Grefenstette, 2018). Supposing that such a smooth relaxation has been chosen together with a prior over , smooth program synthesis becomes the study of the statistical learning theory of the triple .
There are at least two reasons to consider the smooth relaxation. Firstly, one might hope that stochastic gradient descent or techniques like Markov chain Monte Carlo will be effective means of solving the original combinatorial optimisation problem. This is not a new idea (Gulwani et al., 2017, §6) but so far its effectiveness for large programs has not been proven. Independently, one might hope to find powerful new mathematical ideas that apply to the relaxed problem and shed light on the nature of program synthesis.
Singular learning theory. All known approaches to program synthesis can be formulated in terms of a singular learning problem. Singular learning theory is the extension of statistical learning theory to account for the fact that the set of true parameters has in general the structure of an analytic space as opposed to an analytic manifold (Watanabe, 2007, 2009). It is organised around triples consisting of a class of models , a true distribution and a prior on .
Given a triple arising as above from a smooth relaxation (see Section 3 for the key example) the Kullback-Leibler divergence between the true distribution and the model is
We call points of solutions of the synthesis problem and note that
| (1) |
where is the discrete set of solutions to the original synthesis problem. We refer to these as the classical solutions. As the vanishing locus of an analytic function, is an analytic space over (Hironaka, 1964, §0.1), (Griffith & Harris, 1978) and except in trivial cases it is not an analytic manifold.
The set of solutions fails to be a manifold due to singularities. We say is a critical point of if and a singularity of the function if it is a critical point where . Since is a Kullback-Leibler divergence it is non-negative and so it not only vanishes on but also vanishes, hence every point of is a singular point. Thus programs to be synthesised are singularities of analytic functions.
The geometry of depends on the particular model that has been chosen, but some aspects are universal: the nature of program synthesis means that typically is an extended object (i.e. it contains points other than the classical solutions) and the Hessian matrix of second order partial derivatives of at a classical solution is not invertible - that is, the classical solutions are degenerate critical points of . This means that singularity theory is the appropriate branch of mathematics for studying the geometry of near a classical solution. It also means that the Fisher information matrix is degenerate at a classical solution, so that the appropriate branch of statistical learning theory is singular learning theory (Watanabe, 2007, 2009). For an introduction to singular learning theory in the context of deep learning see (Murfet et al., 2020).
This geometry has important consequences for all synthesis tasks. In particular, given a dataset of input-output pairs from and a predictive distribution , the asymptotic form of the Bayes generalization error is given in expectation by where is a rational number called the real log canonical threshold (RLCT) (Watanabe, 2009). Therefore, the RLCT is the key geometric invariant which should be estimated to determine the generalization capacity of program synthesis. We also show how this number measures the model complexity of program synthesis by relating it to the Kolmogorov complexity. One may interpret the RLCT as a refined measure of complexity.
The synthesis process. Synthesis is a problem because we do not assume that the true distribution is known: for example, if is deterministic and the associated function is , we assume that some example pairs are known but no general algorithm for computing is known (if it were, synthesis would have already been performed). In practice synthesis starts with a sample from with associated empirical Kullback-Leibler distance
| (2) |
If the synthesis problem is deterministic and then if and only if explains the data in the sense that for . We now review two natural ways of finding such solutions in the context of machine learning.
Synthesis by stochastic gradient descent (SGD). The first approach is to view the process of program synthesis as stochastic gradient descent for the function . We view as a large training set and further sample subsets with and compute to take gradient descent steps for some learning rate . Stochastic gradient descent has the advantage (in principle) of scaling to high-dimensional parameter spaces , but in practice it is challenging to use gradient descent to find points of (Gaunt et al., 2016).
Synthesis by sampling. The second approach is to consider the Bayesian posterior associated to the synthesis problem, which can be viewed as an update on the prior distribution after seeing
| (3) |
where . If is large the posterior distribution concentrates around solutions and so sampling from the posterior will tend to produce machines that are (nearly) solutions. The gold standard sampling is Markov Chain Monte Carlo (MCMC). Scaling MCMC to where is high-dimensional is a challenging task with many attempts to bridge the gap with SGD (Welling & Teh, 2011; Chen et al., 2014; Ding et al., 2014; Zhang et al., 2020). Nonetheless in simple cases we demonstrate experimentally in Section 7 that machines may be synthesised by using MCMC to sample from the posterior.
3 Program Synthesis as Singular Learning
To demonstrate how program synthesis may be formalised in the context of singular learning theory we construct a very general synthesis model that can in principle synthesise arbitrary computable functions from input-output examples. This is done by propagating uncertaintly through the weights of a smooth relaxation of a universal Turing machine (UTM) (Clift & Murfet, 2018). Related approaches to program synthesis paying particular attention to model complexity have been given in (Schmidhuber, 1997; Hutter, 2004; Gaunt et al., 2016; Freer et al., 2014).
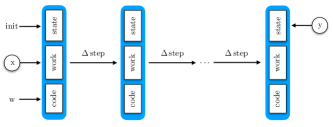
We fix a Universal Turing Machine (UTM), denoted , with a description tape (which specifies the code of the Turing machine to be executed), a work tape (simulating the tape of that Turing machine during its operation) and a state tape (simulating the state of that Turing machine). The general statistical learning problem that can be formulated using is the following: given some initial string on the work tape, predict the state of the simulated machine and the contents of the work tape after some specified number of steps.
For simplicity, in this paper we consider models that only predict the final state; the necessary modifications in the general case are routine. We also assume that parametrises Turing machines whose tape alphabet and set of states have been encoded by individual symbols in the tape alphabet of . Hence is actually what we call a pseudo-UTM (see Appendix G). Again, treating the general case is routine and for the present purposes only introduces uninteresting complexity.
Let denote the tape alphabet of the simulated machine, the set of states and let stand for left, stay and right, the possible motions of the Turing machine head. We assume that since otherwise the synthesis problem is trivial. The set of ordinary codes for a Turing machine sits inside a compact space of probability distributions over codes
| (4) |
where denotes the set of probability distributions over a set , see (H), and the product is over pairs .111The space of parameters is clearly semi-analytic, that is, it is cut out of for some by the vanishing of finitely many analytic functions on open subsets of together with finitely many inequalities where the are analytic. In fact is semi-algebraic, since the and may all be chosen to be polynomial functions. For example the point encodes the machine which when it reads under the head in state writes , transitions into state and moves in direction . Given let denote the contents of the state tape of after timesteps (of the simulated machine) when the work tape is initialised with and the description tape with . There is a principled extension of this operation of to a smooth function
| (5) |
which propagates uncertainty about the symbols on the description tape to uncertainty about the final state and we refer to this extension as the smooth relaxation of . The details are given in Appendix H but at an informal level the idea behind the relaxation is easy to understand: to sample from we run to simulate timesteps in such a way that whenever the UTM needs to “look at” an entry on the description tape we sample from the corresponding distribution specified by .222Noting that this sampling procedure is repeated every time the UTM looks at a given entry.
The class of models that we consider is
| (6) |
where is fixed for simplicity in this paper. More generally we could also view as consisting of a sequence and a timeout, as is done in (Clift & Murfet, 2018, §7.1). The construction of this model is summarised in Figure 1.
Definition 3.1 (Synthesis problem).
A synthesis problem for consists of a probability distribution over . We say that the synthesis problem is deterministic if there is such that for all .
Definition 3.2.
The triple associated to a synthesis problem is the model of (6) together with the true distribution and uniform prior on .
As is a polynomial function, is analytic and so is a semi-analytic space (it is cut out of the semi-analytic space by the vanishing of ). If the synthesis problem is deterministic and is uniform on some finite subset of then is semi-algebraic (it is cut out of by polynomial equations) and all solutions lie at the boundary of the parameter space (Appendix B). However in general is only semi-analytic and intersects the interior of (Example E.2). We assume that is realisable that is, there exists with .
A triple is regular if the model is identifiable, ie. for all inputs , the map sending to the conditional probability distribution is one-to-one, and the Fisher information matrix is non-degenerate. Otherwise, the learning machine is strictly singular (Watanabe, 2009, §1.2.1). Triples arising from synthesis problems are typically singular: in Example 3.5 below we show an explicit example where multiple parameters determine the same model, and in Example E.2 we give an example where the Hessian of is degenerate everywhere on (Watanabe, 2009, §1.1.3).
Remark 3.3.
Non-deterministic synthesis problems arise naturally in various contexts, for example in the fitting of algorithms to the behaviour of deep reinforcement learning agents. Suppose an agent is acting in an environment with starting states encoded by and possible episode end states by . Even if the optimal policy is known to determine a computable function the statistics of the observed behaviour after finite training time will only provide a function and if we wish to fit algorithms to behaviour it makes sense to deal with this uncertainty directly.
Definition 3.4.
Let be the triple associated to a synthesis problem. The Real Log Canonical Threshold (RLCT) of the synthesis problem is defined so that is the largest pole of the meromorphic extension (Atiyah, 1970) of the zeta function .
This important quantity will be estimated in Section 5. Intuitively, the more singular the analytic space of solutions is, the smaller the RLCT. One way to think of the RLCT is as a count of the effective number of parameters near (Murfet et al., 2020, §4). A thermodynamic interpretation is provided in Section 6. In Section 4 we relate the RLCT to Kolmogorov complexity and in Section 7 we estimate the RLCT of the synthesis problem detectA using our estimation method.
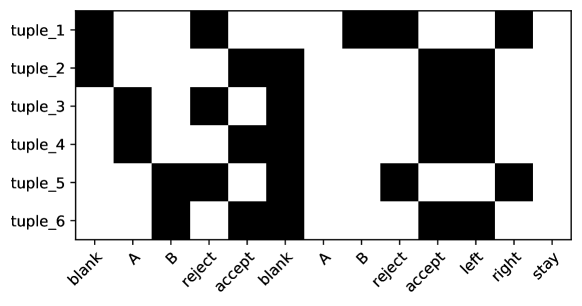
Example 3.5 (detectA).
The deterministic synthesis problem detectA has , and is determined by the function taking in a string of ’s and ’s and returning the state if the string contains an and state otherwise. The conditional true distribution is realisable because this function is computed by a Turing machine.
Two solutions are shown in Figure 2. On the left is a parameter and on the right is . Varying the distributions in that have nonzero entropy we obtain a submanifold containing of dimension . This leads by (Watanabe, 2009, Remark 7.3) to a bound on the RLCT of which is consistent with the experimental results in Table 1. This highlights that solutions need not lie at vertices of the probability simplex, and may contain a high-dimensional submanifold around a given classical solution.

4 Kolmogorov Complexity
Every Turing machine is the solution of a deterministic synthesis problem so Section 3 associates to any Turing machine a singularity of a semi-analytic space . To indicate that this connection is not vacuous, we sketch how the length of a program is related to the real log canonical threshold of a singularity.
Let be a deterministic synthesis problem for which only involves input sequences in some restricted alphabet , that is, if . Let be sampled from and let be two explanations for the sample in the sense that . Which explanation for the data should we prefer? The classical answer based on Occam’s razor (Solomonoff, 1964) is that we should prefer the shorter program, that is, the one using the fewest states and symbols.
Set and . Any Turing machine using symbols and states has a code for of length where is a constant. We assume that is included in the tape alphabet of so that and define the Kolmogorov complexity of with respect to to be the infimum of over Turing machines that give classical solutions for .
Let be the RLCT of the triple associated to the synthesis problem (Definition 3.4).
Theorem 4.1.
.
The proof is deferred to Appendix C.
Remark 4.2.
Remark 4.3.
Let and consider the deterministic synthesis problem with where denotes the empty string, and . Here we consider the modification of the statistical model described in Section 3 which predicts the contents of the work tape after steps rather than the state, and condition on the state being . Then a classical solution to this synthesis problem is a Turing machine which halts within steps with on the work tape. If we make sufficiently large then the Kolmogorov complexity of in the above sense is the Kolmogorov complexity of in the usual sense, up to a constant multiplicative factor depending only on . Hence the terminology used above is reasonable.
5 Algorithm for Estimating RLCTs
We have stated that the RLCT is the most important geometric invariant in singular learning theory (Section 2) and shown how it is related to computation by relating it to the Kolmogorov complexity (Section 4). Now we explain how to estimate it in practice.
Given a sample from let
be the negative log likelihood, where is the empirical entropy of the true distribution. We would like to estimate
where for some inverse temperature . If for some constant , then by Theorem 4 of (Watanabe, 2013),
| (7) |
where is a sequence of random variables satisfying and is the RLCT. In practice, the last two terms often vary negligibly with and so approximates a linear function of with slope (Watanabe, 2013, Corollary 3). This is the foundation of the RLCT estimation procedure found in Algorithm 1 which is used in our experiments.
6 Thermodynamics of program synthesis
Now that we have formulated program synthesis in the setting of singular learning theory, we introduce the thermodynamic dictionary that this makes available. Given a triple associated to a synthesis problem, the physical system consists of the space of microstates and the random Hamiltonian
| (8) |
which depends on a sample from the true distribution of size and the inverse temperature . The corresponding Boltzmann distribution is the tempered Bayesian posterior (2) for the synthesis problem
where is called the partition function. In thermodynamics we think of functions of microstates as fundamentally unobservable; what we can observe are averages
possibly restricted to subsets (microstates compatible with some specified macroscopic condition). Taking program synthesis seriously leads us to systematically re-evaluate aspects of the theory of computation with this restriction (that only integrals are observable) in mind.
To give one important example: the energy of the Boltzmann distribution (tempered Bayesian posterior) at a fixed inverse temperature and value of is by definition
which is a random variable. The quantity is the contribution to the energy from interaction with the prior, and by (7) the most important contribution to the first summand is where . We see the fundamental role that the RLCT plays in the thermodynamic picture.
6.1 Programs as phases
In physics a phase is defined to be a local minima of some thermodynamic potential with respect to an extensive thermodynamic coordinate; for example the Gibbs potential as a function of volume . The role of the volume may in principle be played by any analytic function and in the following we assume such a function has been chosen and define the free energy to be
| (9) |
Definition 6.1.
A phase of the synthesis problem is a local minima of the free energy as a function of , at fixed values of .
Any classical solution determines a phase, that is, a local minimum of at . Other solutions may determine phases, and in general there will be phases not associated to any solution.
Different phases have different “physical” properties, such as energy or entropy, calculated in the first case by restricting the integral defining to a range of values near . The methods of asymptotic analysis introduced by Watanabe show that these properties of phases are determined by geometric invariants, such as the RLCT. For example the arguments of Section 4 show that the entropy of the phase associated to a classical solution may be bounded above (up to multiplicative constants depending only on ) by a function of and the Kolmogorov complexity.
6.2 A first-order phase transition
To demonstrate the thermodynamic language in the context of program synthesis we give a qualitative treatment in this section of a simple example of a first-order phase transition.
Let be Turing machines (not necessarily classical solutions) and the associated points of and set . We may approximate the free energy for sufficiently large by (Watanabe, 2009, Section 7.6) as follows:
| (10) |
where is the RLCT of the level set at and the free energies are defined up to an additive constant that is the same for each (and which we may ignore if, as we do, we only want to consider ordinality of the free energies).
By the same argument as Section 4 we have where is a constant depending only on and is the “length” of the code for , taken to be the product of the number of used states and symbols. This demonstrates the following inequalities for
| (11) |
For sufficiently large we may take to be constant, at least for the purposes of comparing free energies. Suppose that but , that is, the Turing machine produces outputs closer to the samples than , but its code is longer. It is possible for small that the free energy is nonetheless lower than (and thus samples from the posterior are more likely to come from than ) since the penalty for longer programs is relatively harsher when is small.
However as it is easy to see using the inequalities (11) that eventually whenever . Hence as the system is exposed to more input-output examples it undergoes a series of first-order phase transitions, where the phases of low entropy but high energy are eventually supplanted as the global minima by phases with low energy.
7 Experiments
We estimate the RLCT for the triples associated to the synthesis problems detectA (Example 3.5) and parityCheck (Appendix F). Hyperparameters of the various machines are contained in Table 2 of Appendix D. The true distribution is defined as follows: we fix a minimum and maximum sequence length and to sample we first sample a length uniformly from and then uniformly sample from .
We perform MCMC on the weight vector for the model class where is represented in our PyTorch implementation by three tensors of shape where is the number of tuples in the description tape of the TM being simulated and are the number of symbols, states and directions respectively. A direct simulation of the UTM is used for all experiments to improve computational efficiency (Appendix I). We generate, for each inverse temperature and dataset , a Markov chain via the No-U-Turn sampler from (Hoffman & Gelman, 2014). We use the standard uniform distribution as our prior .
| Max-length | Temperature | RLCT | Std | R squared |
|---|---|---|---|---|
| 7 | 8.089205 | 3.524719 | 0.965384 | |
| 7 | 6.533362 | 2.094278 | 0.966856 | |
| 8 | 4.601800 | 1.156325 | 0.974569 | |
| 8 | 4.431683 | 1.069020 | 0.967847 | |
| 9 | 5.302598 | 2.415647 | 0.973016 | |
| 9 | 4.027324 | 1.866802 | 0.958805 | |
| 10 | 3.224910 | 1.169699 | 0.963358 | |
| 10 | 3.433624 | 0.999967 | 0.949972 |
For the problem detectA given in Example 3.5 the dimension of parameter space is . We use generalised least squares to fit the RLCT (with goodness-of-fit measured by ), the algorithm of which is given in Section 5. Our results are displayed in Table 1 and Figure 3. Our purpose in these experiments is not to provide high accuracy estimates of the RLCT, as these would require much longer Markov chains. Instead we demonstrate how rough estimates consistent with the theory can be obtained at low computational cost. If this model were regular the RLCT would be .

8 Discussion
We have developed a theoretical framework in which all programs can in principle be synthesised from input-output examples. This is done by propagating uncertainty through a smooth relaxation of a universal Turing machine. In approaches to program synthesis based on gradient descent there is a tendency to think of solutions to the synthesis problem as isolated critical points of the loss function , but this is a false intuition based on regular models.
Since neural networks, Bayesian networks, smooth relaxations of UTMs and all other extant approaches to smooth program synthesis are strictly singular models (the map from parameters to functions is not injective) the set of parameters with is a complex extended object, whose geometry is shown by Watanabe’s singular learning theory to be deeply related to the learning process. We have examined this geometry in several specific examples and shown how to think about programs from a geometric and thermodynamic perspective. It is our hope that this approach can assist in developing the next generation of synthesis machines.
References
- Akhlaghpour (2020) Akhlaghpour, H. A theory of natural universal computation through RNA. arXiv preprint arXiv:2008.08814, 2020.
- Atiyah (1970) Atiyah, M. F. Resolution of singularities and division of distributions. Communications on Pure and Applied Mathematics, 23(2):145–150, 1970.
- Bunel et al. (2016) Bunel, R. R., Desmaison, A., Mudigonda, P. K., Kohli, P., and Torr, P. Adaptive neural compilation. In Advances in Neural Information Processing Systems, pp. 1444–1452, 2016.
- Chen et al. (2014) Chen, T., Fox, E., and Guestrin, C. Stochastic gradient Hamiltonian Monte Carlo. In International Conference on Machine Learning, pp. 1683–1691, 2014.
- Chen et al. (2018) Chen, X., Liu, C., and Song, D. Execution-guided neural program synthesis. In International Conference on Learning Representations, 2018.
- Clift & Murfet (2018) Clift, J. and Murfet, D. Derivatives of Turing machines in linear logic. arXiv preprint arXiv:1805.11813, 2018.
- Ding et al. (2014) Ding, N., Fang, Y., Babbush, R., Chen, C., Skeel, R. D., and Neven, H. Bayesian sampling using stochastic gradient thermostats. In Advances in Neural Information Processing Systems, pp. 3203–3211, 2014.
- Evans & Grefenstette (2018) Evans, R. and Grefenstette, E. Learning explanatory rules from noisy data. Journal of Artificial Intelligence Research, 61:1–64, 2018.
- Freer et al. (2014) Freer, C. E., Roy, D. M., and Tenenbaum, J. B. Towards common-sense reasoning via conditional simulation: legacies of Turing in artificial intelligence. Turing’s Legacy, 42:195–252, 2014.
- Gaunt et al. (2016) Gaunt, A. L., Brockschmidt, M., Singh, R., Kushman, N., Kohli, P., Taylor, J., and Tarlow, D. Terpret: A probabilistic programming language for program induction. arXiv preprint arXiv:1608.04428, 2016.
- Griffith & Harris (1978) Griffith, P. and Harris, J. Principles of Algebraic Geometry. Wiley-Interscience, 1978.
- Gulwani et al. (2017) Gulwani, S., Polozov, O., and Singh, R. Program synthesis. Foundations and Trends in Programming Languages, 4(1-2):1–119, 2017.
- Hironaka (1964) Hironaka, H. Resolution of singularities of an algebraic variety over a field of characteristic zero: I. Annals of Mathematics, 79(1):109–203, 1964.
- Hoffman & Gelman (2014) Hoffman, M. D. and Gelman, A. The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res., 15(1):1593–1623, 2014.
- Hutter (2004) Hutter, M. Universal artificial intelligence: Sequential decisions based on algorithmic probability. Springer Science & Business Media, 2004.
- Kaiser & Sutskever (2016) Kaiser, Ł. and Sutskever, I. Neural GPUs learn algorithms. In International Conference on Learning Representations, 2016.
- Murfet et al. (2020) Murfet, D., Wei, S., Gong, M., Li, H., Gell-Redman, J., and Quella, T. Deep learning is singular, and that’s good. arXiv preprint arXiv:2010.11560, 2020.
- Neelakantan et al. (2016) Neelakantan, A., Le, Q. V., and Sutskever, I. Neural programmer: Inducing latent programs with gradient descent. In International Conference on Learning Representations, ICLR 2016, 2016.
- Schmidhuber (1997) Schmidhuber, J. Discovering neural nets with low Kolmogorov complexity and high generalization capability. Neural Networks, 10(5):857–873, 1997.
- Solomonoff (1964) Solomonoff, R. J. A formal theory of inductive inference. Part I. Information and control, 7(1):1–22, 1964.
- Watanabe (2007) Watanabe, S. Almost all learning machines are singular. In 2007 IEEE Symposium on Foundations of Computational Intelligence, pp. 383–388. IEEE, 2007.
- Watanabe (2009) Watanabe, S. Algebraic Geometry and Statistical Learning Theory, volume 25. Cambridge University Press, 2009.
- Watanabe (2013) Watanabe, S. A widely applicable Bayesian information criterion. Journal of Machine Learning Research, 14:867–897, 2013.
- Welling & Teh (2011) Welling, M. and Teh, Y. W. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning, pp. 681–688, 2011.
- Zador (2019) Zador, A. M. A critique of pure learning and what artificial neural networks can learn from animal brains. Nature communications, 10(1):1–7, 2019.
- Zhang et al. (2020) Zhang, R., Li, C., Zhang, J., Chen, C., and Wilson, A. G. Cyclical stochastic gradient MCMC for Bayesian deep learning. In International Conference on Learning Representations, 2020.
Appendix A Practical implications
Using singular learning theory we have explained how programs to be synthesised are singularities of analytic functions, and how the Kolmogorov complexity of a program bounds the RLCT of the associated singularity. We now sketch some practical insights that follow from this point of view.
Why synthesis gets stuck: the kind of local minimum of the free energy that we want the synthesis process to find are solutions where is minimal. By Section 4 one may think of these points as the “lowest complexity” solutions. However it is possible that there are other local minima of the free energy. Indeed, there may be local minima where the free energy is lower than the free energy at any solution since at finite it is possible to tradeoff an increase in against a decrease in the RLCT . In practice, the existence of such “siren minima” of the free energy may manifest itself as regions where the synthesis process gets stuck and fails to converge to a solution. In such a region where is the RLCT of the synthesis problem. In practice it has been observed that program synthesis by gradient descent often fails for complex problems in the sense that it fails to converge to a solution (Gaunt et al., 2016). While synthesis by SGD and sampling are different, it is a reasonable hypothesis that these siren minima are a significant contributing factor in both cases.
Can we avoid siren minima? If we let denote the RLCT of the level set then siren minima of the free energy will be impossible at a given value of and as long as . Recall that the more singular is the lower the RLCT, so this lower bound says that the level sets should not become too singular too quickly as increases. At any given value of there is a “siren free” region in the range since the RLCT is non-negative (Figure 4). Thus the learning process will be more reliable the smaller is. This can be arranged either by increasing (providing more examples) or decreasing .
While the RLCT is determined by the synthesis problem, it is possible to change its value by changing the structure of the UTM . As we have defined it is a “simulation type” UTM, but one could for example add special states such that if a code specifies a transition into that state a series of steps is executed by the UTM (i.e. a subroutine). This amounts to specifying codes in a higher level programming language. Hence one of the practical insights that can be derived from the geometric point of view on program synthesis is that varying this language is a natural way to engineer the singularities of the level sets of , which according to singular learning theory has direct implications for the learning process.

Appendix B Deterministic synthesis problems
In this section we consider the case of a deterministic synthesis problem which is finitely supported in the sense that there exists a finite set such that for all and for all . We first need to discuss the coordinates on the parameter space of (4). To specify a point on is to specify for each pair (that is, for each tuple on the description tape) a triple of probability distributions
The space of distributions is therefore contained in the affine space with coordinate ring
The function is polynomial (Clift & Murfet, 2018, Proposition 4.2) and we denote for by the polynomial computing the associated component of the function . Let denote the boundary of the manifold with corners , that is, the set of all points on where at least one of the coordinate functions given above vanishes
where denotes the vanishing locus of .
Lemma B.1.
.
Proof.
Choose with and let be such that . Let be the code for the Turing machine which ignores the symbol under the head and current state, transitions to some fixed state and stays. Then . ∎
Lemma B.2.
The set is semi-algebraic and .
Proof.
Given with we write for the unique state with . In this notation the Kullback-Leibler divergence is
Hence
is semi-algebraic.
Recall that the function is associated to an encoding of the UTM in linear logic by the Sweedler semantics (Clift & Murfet, 2018) and the particular polynomials involved have a form that is determined by the details of that encoding (Clift & Murfet, 2018, Proposition 4.3). From the design of our UTM we obtain positive integers for and a function where
We represent elements of by tuples where for and and similarly and . The polynomial is
where is a Kronecker delta. With this in hand we may compute
But is a polynomial with non-negative integer coefficients, which takes values in for . Hence it vanishes on if and only if for each triple with one or more of the coordinate functions vanishes on .
The desired conclusion follows unless for every and we have so that for all . But in this case case which contradicts Lemma B.1. ∎
Appendix C Kolmogorov complexity: Proofs
Let be the RLCT of the triple associated to the synthesis problem (Definition 3.4).
Theorem C.1.
.
Proof.
Let be the code of a Turing machine realising the infimum in the definition of the Kolmogorov complexity and suppose that this machine only uses symbols in and states in with and . The time evolution of the staged pseudo-UTM simulating on is independent of the entries on the description tape that belong to tuples of the form with . Let be the submanifold of points which agree with on all tuples with and are otherwise free. Then and and by (Watanabe, 2009, Theorem 7.3) we have . ∎
Appendix D Hyperparameters
The hyperparameters for the various synthesis tasks are contained in Table 2. The number of samples is in Algorithm 1 and the number of datasets is . Samples are taken according to the Dirichlet distribution, a probability distribution over the simplex, which is controlled by the concentration. When the concentration is a constant across all dimensions, as is assumed here, this corresponds to a density which is symmetric about the uniform probability mass function occurring in the centre of the simplex. The value corresponds to the uniform distribution over the simplex. Finally, the chain temperature controls the default value, ie. all inverse temperature values are centered around where is the chain temperature.
| Hyperparameter | detectA | parityCheck |
| Dataset size () | 200 | 100 |
| Minimum sequence length () | 4 | 1 |
| Maximum sequence length () | 7/8/9/10 | 5/6/7 |
| Number of samples () | 20,000 | 2,000 |
| Number of burn-in steps | 1,000 | 500 |
| Number of datasets () | 4 | 3 |
| Target accept probability | 0.8 | 0.8 |
| Concentration () | 1.0 | 1.0 |
| Chain temperature () | / | |
| Number of timesteps () | 10 | 42 |
Appendix E The Shift Machine
The pseudo-UTM is a complicated Turing machine, and the models of Section 3 are therefore not easy to analyse by hand. To illustrate the kind of geometry that appears, we study the simple Turing machine shiftMachine of (Clift & Murfet, 2018) and formulate an associated statistical learning problem. The tape alphabet is and the input to the machine will be a string of the form where is called the counter and . The transition function, given in loc.cit., will move the string of ’s and ’s leftwards by steps and fill the right hand end of the string with ’s, keeping the string length invariant. For example, if is the input to , the output will be .
Set and view as representing a probability distribution for the counter and for . The model is
This model is derived by propagating uncertainty through shiftMachine in the same way that is derived from in Section 3 by propagating uncertainty through . We assume that some distribution over is given.
Example E.1.
Suppose where . It is easy to see that
where is a polynomial in . Hence
is a semi-algebraic variety, that is, it is defined by polynomial equations and inequalities. Here denotes the vanishing locus of a function .
Example E.2.
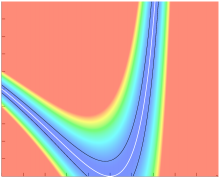
Suppose and . Then the Kullback-Leibler divergence is where . Hence . Note that has no critical points, and so at if and only if . Since is non-negative, any satisfies and so
is semi-algebraic. Note that the curve is regular while the curve is singular and it is the geometry of the singular curve that is related to the behaviour of . This curve is shown in Figure 5. It is straightforward to check that the determinant of the Hessian of is identically zero on , so that every point on is a degenerate critical point of .
Appendix F Parity Check
The deterministic synthesis problem parityCheck has
The distribution is as discussed in Section 7 and is determined by the function taking in a string of ’s and ’s, and terminating in state if the string contains the same number of ’s as ’s, and terminating in state otherwise. The string is assumed to contain no blank symbols. The true distribution is realisable because there is a Turing machine using and which computes this function: the machine works by repeatedly overwriting pairs consisting of a single and with ’s; if there are any ’s without a matching left over (or vice versa), we reject, otherwise we accept.
In more detail, the starting state moves right on the tape until the first or is found, and overwrites it with an . If it’s an (resp. ) we enter state (resp. ). If no or is found, we enter the state . The state (resp. ) moves right until an (resp. ) is found, overwrites it with an and enters state which moves left until a blank symbol is found (resetting the machine to the left end of the tape). If no ’s (resp. ’s) were left on the tape, we enter state . The dimension of the parameter space is . If this model were regular, the RLCT would be . Our RLCT estimates are contained in Table 3 and Figure 6.
| Max-length | Temperature | RLCT | Std | R squared |
|---|---|---|---|---|
| 5 | 4.411732 | 0.252458 | 0.969500 | |
| 6 | 4.005667 | 0.365855 | 0.971619 | |
| 7 | 3.887679 | 0.276337 | 0.973716 |

Appendix G Staged Pseudo-UTM
Simulating a Turing machine with tape alphabet and set of states on a standard UTM requires the specification of an encoding of and in the tape alphabet of the UTM. From the point of view of exploring the geometry of program synthesis, this additional complexity is uninteresting and so here we consider a staged pseudo-UTM whose alphabet is
where the union is disjoint where is the blank symbol (which is distinct from the blank symbol of ). Such a machine is capable of simulating any machine with tape alphabet and set of states but cannot simulate arbitrary machines and is not a UTM in the standard sense. The adjective staged refers to the design of the UTM, which we now explain. The set of states is
| compSymbol, compState, copySymbol, | |||
| copyState, copyDir, compState, copySymbol, | |||
| copyState, copyDir, updateSymbol, | |||
The UTM has four tapes numbered from 0 to 3, which we refer to as the description tape, the staging tape, the state tape and the working tape respectively. Initially the description tape contains a string of the form
corresponding to the tuples which define , with the tape head initially on . The staging tape is initially a string with the tape head over the second . The state tape has a single square containing some distribution in , corresponding to the initial state of the simulated machine , with the tape head over that square. Each square on the the working tape is some distribution in with only finitely many distributions different from . The UTM is initialised in state compSymbol.

The operation of the UTM is outlined in Figure 7. It consists of two phases; the scan phase (middle and right path), and the update phase (left path). During the scan phase, the description tape is scanned from left to right, and the first two squares of each tuple are compared to the contents of the working tape and state tape respectively. If both agree, then the last three symbols of the tuple are written to the staging tape (middle path), otherwise the tuple is ignored (right path). Once the at the end of the description tape is reached, the UTM begins the update phase, wherein the three symbols on the staging tape are then used to print the new symbol on the working tape, to update the simulated state on the state tape, and to move the working tape head in the appropriate direction. The tape head on the description tape is then reset to the initial .
Remark G.1.
One could imagine a variant of the UTM which did not include a staging tape, instead performing the actions on the work and state tape directly upon reading the appropriate tuple on the description tape. However, this is problematic when the contents of the state or working tape are distributions, as the exact time-step of the simulated machine can become unsynchronised, increasing entropy. As a simple example, suppose that the contents of the state tape were , and the symbol under the working tape head was . Upon encountering the tuple , the machine would enter a superposition of states corresponding to the tape head having both moved right and not moved, complicating the future behaviour.
We define the period of the UTM to be the smallest nonzero time interval taken for the tape head on the description tape to return to the initial , and the machine to reenter the state compSymbol. If the number of tuples on the description tape is , then the period of the UTM is . Moreover, other than the working tape, the position of the tape heads are -periodic.
Appendix H Smooth Turing Machines
Let be the staged pseudo-UTM of Appendix G. In defining the model associated to a synthesis problem in Section 3 we use a smooth relaxation of the step function of . In this appendix we define the smooth relaxation of any Turing machine following (Clift & Murfet, 2018).
Let be a Turing machine with a finite set of symbols , a finite set of states and transition function . We write for the th component of for . For , let
We can associate to a discrete dynamical system where
is the step function defined by
| (12) |
with shift map .
Let be a finite set. The standard -simplex is defined as
| (13) |
where is the free vector space on . We often identify with the vertices of under the canonical inclusion given by . For example .
A tape square is said to be at relative position if it is labelled after enumerating all squares in increasing order from left to right such that the square currently under the head is assigned zero. Consider the following random variables at times :
-
•
: the content of the tape square at relative position at time .
-
•
: the internal state at time .
-
•
: the symbol to be written, in the transition from time to .
-
•
: the direction to move, in the transition from time to .
We call a smooth dynamical system a pair consisting of a smooth manifold with corners together with a smooth transformation .
Definition H.1.
Let be a Turing machine. The smooth relaxation of is the smooth dynamical system where
is a smooth transformation sending a state to determined by the equations
-
•
-
•
,
-
•
,
-
•
,
where is an initial state.
We will call the smooth relaxation of a Turing machine a smooth Turing machine. A smooth Turing machine encodes uncertainty in the initial configuration of a Turing machine together with an update rule for how to propagate this uncertainty over time. We interpret the smooth step function as updating the state of belief of a “naive” Bayesian observer. This nomenclature comes from the assumption of conditional independence between random variables in our probability functions.
Remark H.2.
Propagating uncertainty using standard probability leads to a smooth dynamical system which encodes the state evolution of an “ordinary” Bayesian observer of the Turing machine. This requires the calculation of various joint distributions which makes such an extension computationally difficult to work with. Computation aside, the naive probabilistic extension is justified from the point of view of derivatives of algorithms according to the denotational semantics of differential linear logic. See (Clift & Murfet, 2018) for further details.
We call the smooth extension of a universal Turing machine a smooth universal Turing machine. Recall that the staged pseudo-UTM has four tapes: the description tape, the staging tape, the state tape and working tape. The smooth relaxation of is a smooth dynamical system
If we use the staged pseudo-UTM to simulate a Turing machine with tape alphabet and states then with some determined initial state the function restricts to
where the first factor is the configuration of the work tape, is as in (4) and
where the first factor is the configuration of the staging tape. Since is periodic of period (Appendix G) the iterated function takes an input with staging tape in its default state and UTM state compSymbol and returns a configuration with the same staging tape and state, but with the configuration of the work tape, description tape and state tape updated by one complete simulation step. That is,
for some smooth function
| (14) |
Finally we can define the function of (5). We assume all Turing machines are initialised in some common state .
Definition H.3.
Given we define
by
where is the projection onto .
Appendix I Direct Simulation
For computational efficiency in our PyTorch implementation of the staged pseudo-UTM we implement of (14) rather than . We refer to this as direction simulation since it means that we update in one step the state and working tape of the UTM for a full cycle where a cycle consists of steps of the UTM.
Let and be random variables describing the contents of state tape and working tape in relative positions respectively after time steps of the UTM. We define and where and . The task then is to define functions such that
The functional relationship is given as follows: for indexing tuples on the description tape, while processing that tuple, the UTM is in a state distribution where . Given the initial state of the description tape, we assume uncertainty about only. This determines a map
where the description tape at tuple number is given by . We define the conditionally independent joint distribution between by
We then calculate a recursive set of equations for describing distributions and on the staging tape after processing all tuples up to and including tuple . These are given by and
Let . In terms of the above distributions
and
Using these equations, we can state efficient update rules for the staging tape. We have
To enable efficient computation, we can express these equations using tensor calculus. Let . We view
as a tensor and so
Then
If we view as a tensor, then
can be expressed in terms on the vector only. Similarly, with
and with