Generative flow induced neural architecture search: Towards discovering optimal architecture in wavelet neural operator
Abstract
We propose a generative flow-induced neural architecture search algorithm. The proposed approach devices simple feed-forward neural networks to learn stochastic policies to generate sequences of architecture hyperparameters such that the generated states are in proportion with the reward from the terminal state. We demonstrate the efficacy of the proposed search algorithm on the wavelet neural operator (WNO), where we learn a policy to generate a sequence of hyperparameters like wavelet basis and activation operators for wavelet integral blocks. While the trajectory of the generated wavelet basis and activation sequence is cast as flow, the policy is learned by minimizing the flow violation between each state in the trajectory and maximizing the reward from the terminal state. In the terminal state, we train WNO simultaneously to guide the search. We propose to use the exponent of the negative of the WNO loss on the validation dataset as the reward function. While the grid search-based neural architecture generation algorithms foresee every combination, the proposed framework generates the most probable sequence based on the positive reward from the terminal state, thereby reducing exploration time. Compared to reinforcement learning schemes, where complete episodic training is required to get the reward, the proposed algorithm generates the hyperparameter trajectory sequentially. Through four fluid mechanics-oriented problems, we illustrate that the learned policies can sample the best-performing architecture of the neural operator, thereby improving the performance of the vanilla wavelet neural operator.
Keywords Architecture search Generative flow Reward Neural operator Scientific machine learning
1 Introduction
Since its first introduction around a couple of centuries ago, partial differential equations (PDEs) have remained an inextricable scientific tool for scientists and engineers in modeling natural phenomena like fluid flows, conduction, diffusion, weather forecasting, electrodynamics, and many more [1, 2]. Traditionally solved using methods such as the finite element and volume methods [3, 4], which are highly mesh and resolution dependent, a recent push is seen towards employing discretization invariant alternatives like neural operators for solving these PDEs. Neural Operators learn the discretization invariant functional mappings between infinite-dimensional function spaces, acting as a generalization of neural networks that have been used to learn extremely complex functions. The diverse literature on neural operators includes the universal approximation theorem [5] based Deep Operator Network (DeepONet) [6] and physics-informed DeepONet [7], graph discretization-based Graph Neural Operator (GNO) [8], spectral convolution-based Fourier Neural Operator (FNO) [9], Wavelet Neural Operator (WNO) [10], and physics-informed WNO (PIWNO) [11]. While DeepONet is developed over the feed-forward neural networks, FNO and WNO use convolution operations to parameterize the neural networks in the feature space. While both FNO and WNO remained discretization invariant, wavelets use both frequency and spatial information to learn the features effectively. Recent works in neural operators also include nonlinear manifold decoder (NOMAD) [12], Laplace neural operator (LNO) [13], and aliasing improved Spectral Neural Operator (SNO) [14]. Nevertheless, all the neural operator frameworks consist of an additional set of hyperparameters on top of the standard neural networks hyperparameters, like the latent dimension of branch and trunk net in DeepONet, Fourier mode number in FNO, and choice of wavelet basis in WNO, which makes tuning more involved and cumbersome. To that end, we propose a generative flow-induced neural architecture search algorithm tailored towards neural operators for automated hyperparameter selection and efficient learning of discretization invariant solution operators of parametric PDEs.
The main aim of automated hyperparameter optimization in representation learning is to automatically learn the hyperparameters of deep neural networks to infer minimal bias in the trained network. A brief survey on the algorithm proposed for neural architecture search (NAS) in deep learning can be found in [15, 16, 17, 18]. Naive architecture generation algorithms like grid search perform experiments over all possible combinations of hyperparameter space. In the context of neural operators, which are trained over a family of PDEs, performing such a brute-force architecture search requires a humongous amount of computational power and time. Efficient Neural Architecture Search (ENAS) [19], on the other hand, improves the search time by incorporating a strategy for parameter sharing across different neural architectures. Methods like Progressive Neural Architecture Search (PNAS) use sequential model-based optimization (SMBO) to perform hyperparameter search based on the increasing complexity of generated architectures [20]. Despite success, these strategies are limited to convolutional neural networks. Methods involving reinforcement learning for NAS are also proposed, which use expected accuracy over the validation dataset as a reward for automating the generation of novel neural network architectures. The reinforcement learning (RL) based methods for NAS like BlockQNN [21], MetaQNN [22], and NAS-RL [23] have been shown to be particularly successful. In RL-based methods, the objective is generally directed towards actions that maximize the reward. In this work, our objective is to sample the trajectories proportional to the distribution of the reward function relating to the cost and to exploit this capability to produce a diverse set of architectures requiring only partially trained neural operators, a subset of which may then be trained to convergence. To solve this, an elegant architecture search method capable of generating a diverse set of architectures, unlike the deterministic RL-based approaches, is required.
A similar strategy exists in the generative flow networks (GFlowNet) [24, 25], where the neural network agents learn a stochastic policy from a sequence of actions to generate a compositional object such that the objects are generated in proportional to the reward of the object. In GFlownet, each state in the compositional object is built sequentially, with a reward assigned to it, like in RL. However, the reward is estimated only at the terminal state, i.e., when an object is created. The policy converges when the total discrepancy between in- and out-flow from states in the generated sequence vanishes, i.e., when the incoming and outgoing flow into and out of each state match and the reward is maximized. Once training succeeds, the learned policy takes an action with probability proportional to the outgoing flow. A brief study on the successful application of GFlowNets as a generative model can be observed in the generation of new samples of molecules [24] and active learning [26, 27]. In this work, we utilize the concept of turning rewards into a generative policy from GFlowNet to devise a neural architecture search algorithm for the neural operators. The probabilistic policy is learned by using a flow-consistent loss function, which takes into account the discrepancy in the flow between the states of the generated sequence of network hyperparameters and prediction reward from the underlying neural operator. The proposed framework consists of a series of neural networks, each trained to sample a hyperparameter, except the terminal network, which is set as the underlying neural operator. The series of networks learn the probability of taking action given the previous state, which is referred to as the flow associated with that state. The total flow into the network is estimated as the sum of the in- and out-flow from the states. The terminal network uses the generated hyperparameters from previous networks to return a reward. The reward is estimated at the end of the terminal neural operator after having generated the solution of the underlying PDE, like the episodic setting of conventional RL, which, in this case, is a function of the prediction loss.
Since the first introduction, WNO has gone through a significant number of independent developments, including Waveformer [28] for long-term prediction, wavelet elastography for medical imaging [29], multi-fidelity WNO (MFWNO) [30] for learning from multi-fidelity dataset, neural combinatorial WNO (NCWNO) for multi-physics and continual learning of solution operators [31], generative adversarial WNO (GAWNO) for generative modeling [32], and differentiable physics augmented WNO (DPA-WNO) [33] as a deep physics corrector. All these frameworks use wavelet integral blocks, where wavelet decomposition is used to project the features to a space-frequency localized space and subsequently convoluted with neural network kernels to learn the features from data, followed by a non-linear activation operator. In addition to the standard neural network parameters like the number of hidden layers, channel dimension, number of epochs, learning rate, batch size, and regularizer, these integral blocks introduce additional parameters like the choice of wavelet basis, wavelet decomposition level, and activation operators. Choosing the right combination of these wavelet hyperparameters for each wavelet integral block requires prior experience, which further becomes cumbersome as the number of wavelet integral blocks increases. Therefore, the large hyperparameter space makes WNO a natural choice for illustrating the developed neural architecture search algorithm.
The main contribution of the proposed framework can be encapsulated into the following points:
-
•
An automated neural architecture search algorithm rooted in GFlowNet is proposed for neural operators. The efficacy is exemplified in WNO by learning a stochastic policy to generate a sequence of wavelet basis and activation operators.
-
•
By satisfying the in- and out-flow from terminal states, the proposed framework achieves optimality criteria over the neural operator architecture.
-
•
The proposed framework learns to generate the network architecture by learning a probabilistic policy instead of a grid search over the parameter space, thereby reducing tuning time. In the reward-based policy learning setup, the final compositional sequence is generated sequentially based on partially trained WNO, which further reduces the computational costs.
-
•
The proposed framework preserves all the benefits of the parent neural operator architecture; in this case, discretization invariant operator learning of a family of parametric PDEs.
The rest of the paper is arranged as follows. Section 2 gives a brief mathematical introduction to WNO and GFlowNet. Section 3 briefly illustrates the proposed framework on WNO. Section 4 consists of the benchmark examples over which we test our proposed method, including the Burger, Darcy, and Navier Stokes equations. Section 5 concludes this study by reviewing the features of the proposed architecture generative framework.
2 Background on wavelet neural operator and flow networks
A short overview of WNO and GFlowNet is presented in this section, which will be used in the next section to construct the proposed framework of flow-induced wavelet neural operator (FWNO).
2.1 Wavelet Neural Operator (WNO)
Neural operators are a class of deep learning algorithms that learn the functional mapping between two infinite-dimensional function spaces, the input and output spaces, as opposed to the artificial neural networks (ANN) that learn the function map between two finite-dimensional vector spaces. Talking specifically in terms of PDEs, neural operators learn the mapping from the input space, comprised of the initial and boundary conditions, geometry, physical parameters, and source term to the solution space of the PDE. Thus, after training, a neural operator can be used to predict the solution of a family of PDEs, whereas the ANNs need retraining for every input combination. Wavelet Neural Operator (WNO) is one such deep neural operator, which uses the frequency-spatial localization property of wavelet transformation to learn the feature space in wavelet space.
For a mathematical representation, we consider the dimensional fixed domain , bounded by . Over the domain , we consider the Banach spaces and such that and are the input and outputs in the Banach spaces and , respectively. Between the spaces and , we define the nonlinear PDE operator , which maps a given set of input parameters to a unique solution .
Given an number of input-output training pairs are available such that , WNO aims to approximate through a parameter space , i.e., , where denotes the finite-dimensional parameter space for the neural network. The point discretization of the domain yields the set . To increase the channel depth of the parameter space , WNO raises the inputs to a high dimensional space through a local transformation , denoting it as . This can be achieved using either a fully connected neural network (FNN) or a convolution (CNN). The uplifted inputs are passed through a series of recursive wavelet integral blocks . The updates via wavelet integral blocks are defined as,
| (1) |
where is a non-linear activation function, is a linear transformation, represents the convolution operation and is the integral operator over . Since we use a neural network architecture, we can represent the integral operator as a kernel integral operator with parameter . These wavelet integral blocks extract relevant feature maps from the data through convolution in the wavelet domain. In the end, a local transformation such that is used to reduce the channel depth to the desired solution space. Using the concept of element-wise multiplication in spectral space, the convolution in kernel integration is performed in the wavelet space. Parametrizing the kernel in the wavelet domain to learn the kernel leads to the WNO framework. For a brief review, readers are referred to [10, 11].
2.2 Generative Flow Network
GFlowNets are a class of generative models that aim to generate a compositional object , an object that may be represented as a sequence of discrete actions applied iteratively to a base state. At each stage of the iterative updates, we get a partially constructed object which is sequentially updated based on the actions from the remaining iterations. It may be represented as a directed acyclic graph (DAG) of a Markov Decision Process (MDP), where is the set of states possible, or nodes in the graph where , and is the set of all possible actions or the directed edges of DAG. We further define as the set of actions allowed at state , and as the set of sequences of all actions allowed after state . We call state the parent of state if the edge and state a child of if edge . The complete trajectory is defined as where is the state, is the base state and is the terminal state.
The reward for any state is denoted as , where the reward is zero for all non-terminal (intermediate) states. The reward is independent of intermediate states for all terminal states . To that end, the flow network is resented as an MDP with the root node as the source , the in-flow as , and the out-flow as that flows out of each terminal state . Any state , when subjected to action , leads to a new state , represented as . is the flow from state to and is the total flow out of state . A policy decides the flow through the sequence . The policy sequentially builds the compositional object with probability . This is defined as,
| (2) |
where and . From the definition, it is understood that is proportional to , i.e., the policy generates with a probability proportional to the associated reward. Learning the policy , therefore, requires minimizing the imbalance between the incoming flow and outgoing flow at a node and maximizing the reward . The flow conditions in a flow network as well as the reward function, can incorporated into the following flow consistency equation,
| (3) |
Note that in this equation for intermediate states while for terminal state , the outflow is zero, i.e., , since is an empty set. The minimization between the left and right-hand sides of the Eq. (3) becomes the loss function of GFlowNet. Since the flow values at the root nodes are exponentially larger than the nodes at the later stages of the flow network, the gradient weights for smaller predictions pose numerical issues to the learning of the neural network, due to which the logarithm of inflow and outflow from a node is matched. Finally to approximate the policy , GFlowNet minimizes the following log-scale objective function,
| (4) |
where . The loss function minimizes the imbalance between inflow and outflow over a trajectory . In a similar manner to the MDP, where the temporal difference between successive states is used to update the value function of states using the Bellman equation, by minimizing , we learn the policy to take best-performing actions.

3 Flow induced wavelet neural operator
This section instantiates the flow-induced wavelet neural operator (FWNO) by incorporating the reward-based policy learning mechanism inside the vanilla WNO. The concept of flow is used to construct a compositional object containing binary sets of an activation operator and a wavelet basis. Each binary set is used for wavelet decomposition and nonlinear activation during the kernel parametrization in each wavelet integral block of the WNO architecture. By learning to generate the sequences of binary sets in proportion to the reward based on the prediction error, an optimal operator learning architecture with improved accuracy is achieved over the vanilla WNO.
For generating the best-performing sequence of wavelet basis functions and activation operators, we propose the reward function as the validation loss for the WNO architecture, i.e., such that , where is the unseen input parametric field, and are the true and predicted solution of the true PDE operator , and is the WNO. The trajectory contains the set of wavelet basis and activation operators. In a physics-informed neural operator framework, this reward function can be tuned depending on the requirement, like giving more weight to the boundary conditions, the physics-informed constraints, smoother curves, and other such criteria. In our data-driven framework, we will consider the relative norm of the prediction error.
Starting at empty state , we generate the WNO model . The model is then trained on the paired dataset to learn the operator . The operator returns a validation loss over the paired validation dataset . The reward for the model is then computed as the exponent of the inverse of this loss to ensure a non-negative reward. Let and denote the sets of wavelet basis functions and activation functions in our operator framework, where each pair is associated with wavelet integral block. Two neural networks and are used to learn distributions of the flow across the state . Here is used to construct the trajectory of wavelet bases, and is used to construct the trajectory of activation operators in the wavelet integral blocks. At each state , the difference between the total inflow to and the total outflow from , which is for the terminal state, are then minimized over the trajectory to train models and . The selection of a binary set of wavelet basis and activation function from the current state using the neural networks and can be represented using the sequential graph as follows,
| (5) |
where and are sequentially selected based on outputs of the two networks ad . This partial set is further constructed by minimizing the discrepancy between the in-and-out flow over the other wavelet integral layers, which is represented as,
| (6) |
Combining such wavelet layers gives us the final compositional object comprising of the incremental sets of wavelet basis and activation function for each of the layers, represented as the trajectory,
| (7) |
Using the compositional set of wavelet bases and activation functions, the WNO model is trained to learn the operator with input and output . The complete process of learning the operator can be represented as an iterative process between the input and output can be represented as,
| (8) |
where the transformations and are defined in Section 2.1. Similarly the iterations are represented as,
| (9) |
where and are defined in the Section 2.1 conditioned over the activation operator and wavelet basis function given the network parameters . To calculate the reward, we consider the loss as the imbalance in inflow and outflow for each state in the flow network over the trajectory as,
| (10) |
During training, the loss becomes the objective function for tuning the parameters of the networks and . The training process may then be represented as,
| (11) |
For ease of understanding, a schematic representation of the proposed flow-induced wavelet neural operator is illustrated in Figure 1.
3.1 Initial setup
We instantiate the FWNO framework by selecting a sufficiently rich set of wavelets and non-linear activation operators . For the purpose of learning a policy to sample states of the wavelets and activation operators in the sets and , two neural networks and are set up as feed-forward neural networks. Here, a state is described as the sequence of basis and activation functions in the trajectory in (7). The base state here is an empty set. The terminal state is denoted as , where is the number of wavelet integral blocks needed for satisfactory convergence. The FWNO architecture is then generated sequentially by selecting a wavelet cum activation pair for each of the wavelet integral blocks based on the policy from and . During the architecture generation process, the current states are alternatively passed through and to probabilistically sample the wavelets and activation operators for the current state (see section 3.2). At the end of the policy learning, the terminal state provides us with the best-performing FWNO architecture, where is the wavelet basis function and is the non-linear activation operator for wavelet integral block and the state space contains such pairs of wavelets and activation operators.
3.2 Sequential construction of the architecture
At the beginning the initial state is passed to the to get a distribution over . We sample the set with a probability to get the first state . The sampled state is then passed into the network to get a distribution over the activation operator space . On sampling from the set with a probability we get the second state . This wavelet-activation pair constructs the first wavelet integral block . This state is sequentially passed to and till the terminal state is reached and all the wavelet and activation operator pairs are sampled with the highest probability. Note that we are training two neural networks and here and states of the form are the inputs for and states of the form are the inputs for , such that,
| (12) | ||||
3.3 Training the networks to learn flow
A trajectory is considered complete on reaching the terminal state . For a trajectory of the form in Eq. (7) we first calculate the inflow from state to . As defined before, we continue to use the notation to denote the result of action on state leading to state . Then we find the total outflow from which is given as where is the set of all actions possible on state . We also calculate the reward for given as , which is the inverse of the exponential of training loss for the WNO architecture given by if it is a terminal state and 0 otherwise. By including the inflow, outflow, and reward from WNO, we minimize the discrepancy in the information flow between the states. The objective function for a trajectory that is to be minimized is given as 10. The flow is parametrized by the neural network if is odd and by the neural network otherwise. Therefore, minimization of the objective function optimizes the network parameters of and while learning the policy to select the best-performing sequence of wavelets and activation operators. For ease of implementation, the algorithm of the proposed framework is given in Algorithm 1, which briefly illustrates the implementation steps of the proposed FWNO.
4 Numerical Results
In this section, we illustrate the performance of the proposed framework on four mechanics examples. The experiments include standard benchmarks like the 1D Burgers equation, the 2D Darcy flow equation, and a 2D incompressible Navier-Stokes equation. As previously stated, we illustrate the efficacy of the proposed generative flow-induced neural architecture search algorithm in learning the optimal neural architecture of WNO. The resulting WNO architecture is referred to as Flow-induced WNO (FWNO). The improvement achieved is reported against the vanilla WNO architecture-based results reported in [10]. During the training of FWNO, we calculate the reward for each generated architecture over 100 epochs only. The optimal architecture obtained is then trained for 500 epochs to obtain the optimal solution.
Hyperparameter settings.
The fully connected neural networks denoted as and , share identical hyperparameters across all cases except for the Darcy flow equation in a rectangular grid. For the former cases, these hyperparameters consist of a single hidden layer comprising 16 nodes, followed by the Leaky ReLU activation function. However, the Darcy equation deviates from this norm, featuring a hidden layer with 128 nodes instead. Both and undergo optimization using the Adam Optimizer, employing a fixed learning rate of . The training process spans 500 iterations for all scenarios except the Navier-Stokes equation, where it is limited to 100 iterations. Table 1 specifies the specific hyperparameters employed in the training of FWNO architectures across the various cases taken from [10].
| Example | Levels of Wavelet | Batch Size | Learning | Scheduler (Learning Rate) | Weight | |
|---|---|---|---|---|---|---|
| Decomposition | Rate | Step Size | Decay | |||
| Burgers’ diffusion dynamics | 8 | 10 | 100 | 0.5 | ||
| Darcy equation (square domain) | 4 | 20 | 50 | 0.75 | ||
| Darcy equation (with notch) | 3 | 25 | 50 | 0.75 | ||
| Navier-Stokes equation | 3 | 20 | 50 | 0.75 | ||
4.1 Burgers diffusion dynamics
The first example we consider for the numerical illustration is the 1D Burgers equation used in modeling flow in fluid mechanics, traffic flow, and acoustics. The following parabolic partial differential equation describes the Burgers diffusion dynamics,
| (13) | ||||
where we consider periodic boundary conditions. In the above equation, defines the viscosity of the flow. The training dataset is generated for different initial conditions , where is modeled as a Gaussian Random field [9]. We utilize 1000 training and 100 testing samples to test the performance of the proposed framework on a spatial grid of 1024. Although the Burgers equation is a time-dependent differential equation, following the original problem statement in [9], we aim to learn the solution operator , i.e., the integral operator which maps the initial conditions to the solution at s. The exploration space for the wavelet basis functions in the FWNO follows the following set {6, 6, 6.8, 6.8, 6}, where refers to Daubechies, refers to Coiflet, refers to Biorthogonal, refers to Reverse Biorthogonal, and refers to Symlet wavelet family. The exploration space for the activation functions has the following set {GeLU, ELU, Leaky ReLU, SELU, Sigmoid}. Neural network is initialized with the db6 wavelet, and is initialized with the GeLU activation for each wavelet integral layer.
After the training, among the states sampled by the FWNO, we found the best-performing architecture to be constructed by the state {6.8, GeLU, 6, GeLU, 6.8, GeLU, 6, ELU}. This indicates that for the first wavelet integral layer, the wavelet basis and activation pair {6.8, GeLU} is the most probable pair that maximizes the reward and minimizes the flow discrepancy between the first two layers. Similarly, for the second, third, and fourth layers, the combinations {6, GeLU}, {6.8, GeLU}, and {6, ELU} are found to be the most optimal pairs. The prediction results for four different representative initial conditions are illustrated in Fig. 2. The mean relative error norm over the entire set of testing dataset is given in Table 2. It is evident that the proposed FWNO clearly outperforms the vanilla WNO. A quantitative representation of the results obtained using the proposed approach is shown in Fig. 2.


In operator learning, a major point of interest lies in performance under higher resolution from what the operator is trained on during testing, also called super-resolution. Fig. 3 illustrates the experiments we conducted for different resolutions using the generated architecture for this example. It is clearly observed from Fig. 3 that despite being trained at a lower resolution, the generated architecture manages to produce highly accurate results on higher-resolution inputs as well.

4.2 Darcy’s flow equation
In the second problem, we consider the Darcy flow equation in a rectangular domain, which plays an important role in modeling the fluid flow through porous mediums. The partial differential description of the Darcy equation is given as,
| (14) | ||||
where represents the pressure field, represents the permeability field, represents the source field, and represents the boundary of the domain. The training data set is generated for different permeability fields , where is a pointwise push-forward operation that takes a value of 12 for the positive part of real line and 3 on the negative part [9]. The aim in this example is to learn the solution operator , i.e., the integral operator which maps the permeability fields to the pressure fields. The wavelet basis search space is taken as the set {4, 6, 6.8, 6.8, 6}, where the prefix of the bases are defined in the previous example. The search space of the activation operator is {GeLU, ELU, Leaky ReLU, SELU, Sigmoid}. Similar to the Burgers example, we use two feed-forward neural networks, and , to choose the wavelet basis and activation operators from these sets.
| PDE examples | Burgers’ equation | Darcy equation | Darcy (Triangular) | Navier-Stokes equation |
|---|---|---|---|---|
| WNOa | 1.75% | ∗1.8% | 0.88% | 3.43% |
| FWNOb | 1.44% | 1.58% | 0.59% | 2.35% |
-
a,b
WNO results are obtained on an uplifting dimension of 64. Similarly, the FWNO was trained for WNO architectures of width 64. ∗However, FWNO provides better accuracy on the Darcy equation, where WNO was trained on an uplifting dimension of 128 [10].
Upon training, among the states sampled by the network, the best-performing network architecture for the Darcy flow equation is found to be constructed by the state {6, GeLU, 4, GeLU, 6, GeLU, 4, Leaky ReLU}. We observe that only in the second wavelet integral layer, the wavelet basis and activation operator pair {4, GeLU}, which was used in the vanilla WNO paper, obtains the highest probability among other states. In the other layers, new combinations with the wavelet basis 4 and Leaky ReLU are found to be optimal for maintaining flow between network layers. The prediction results of pressure fields for four representative permeability fields are illustrated in Fig. 4. The associated relative error norms are provided in Table 2. It is seen that our method outperforms the results obtained using vanilla WNO as reported in [10].

4.3 Darcy’s flow equation in triangular geometry with a notch
As a follow-up to the previous Darcy equation in the rectangular domain, we further consider the same partial differential equation with a triangular domain and an added notch in the flow medium. In this example, our aim is to learn the operator , which maps the boundary conditions to the pressure field. Due to the presence of the notch and the triangular domain, predicting the pressure field from boundary conditions becomes difficult. Different boundary conditions for the training dataset are modeled as random fields with the radial basis function kernel as,
| (15) | ||||
where for data generation is considered. The permeability field and the forcing function are kept equal to and , respectively [34]. The search space for the wavelets and activation operators consists of the set {6, 6, 6.8, 6.8, 6} and {GeLU, ELU, Leaky ReLU, SELU, Sigmoid}, respectively. Among all states sampled, the best-performing state was {6, GeLU, 6.8, ELU, 6, ELU, 6, GeLU}. While the pair {6, GeLU}, which was used in the vanilla WNO paper, has the highest probability in the first wavelet integral layer, the FWNO adapts the initial choices to the best possible combination as the training of FWNO progresses. The prediction results of pressure fields for four representative boundary conditions are illustrated in Fig. 5. The mean estimate of the relative prediction error over the testing dataset is provided in Table 2. The predictions and absolute error plots in Fig. 5 indicate an improvement of the vanilla WNO architecture, where all the wavelet integral layers use the same wavelet-activation pair.
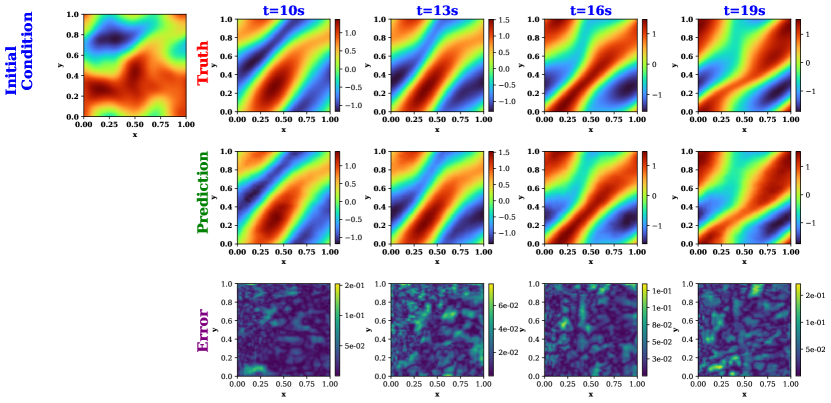
4.4 Navier-Stokes viscous fluid dynamics
The Navier-Stokes equation is a nonlinear coupled second-order partial differential equation that plays a fundamental role in describing the dynamic behavior of viscous fluid flow. These equations have widespread applications, playing a crucial role in aerodynamics for aircraft design, numerical simulations of weather patterns, and the study of physiological phenomena like blood circulation in biological systems. Due to the nonlinear divergence and diffusion terms, simulating the velocity fields of the Navier-Stokes equation becomes highly challenging. To that end, we consider the 2D incompressible Navier-Stokes equation in its vorticity form, given as,
| (16) | |||||
where is the positive viscosity coefficient of the viscous flow, is the velocity of the viscous flow, is the vorticity field, and the is the source field. For training data generation, the viscosity is taken as , and the force field is defined as . The datasets are generated for different initial vorticity fields, which are modeled as random Gaussian fields as [9]. The vorticity fields are obtained at resolutions . The aim is to learn a time-dependent operator , that maps the vorticity fields at first ten-time steps to next ten time steps for arbitrary initial vorticity fields. For constructing the best architecture, we construct the search space of wavelet basis as {4, 6, 6.8, 6.8, 6} and {GeLU, ELU, Mish, SELU, Sigmoid} for the activation operators. Each wavelet integral layer of the WNO operator is initialized on a 4 wavelet basis and with a GeLU activation operator for each layer of the WNO.
Among all the sampled states, the best-performing state is found to be {4, GeLU, 6, GeLU, 6.8, GeLU, 4, GeLU}. While the states with the highest probability are dominated by the Daubechies wavelets and GeLU activation function, the best-performing state is participated by three different wavelet basis functions. These prediction results of the vorticity fields from the proposed FWNO architecture are illustrated in Fig. 6. The mean estimate of the relative error norm over the test dataset is provided in Table 2. In Fig. 6, we observe a similar performance as the previous examples. The architecture constructed by the best-performing state maintains a consistent accuracy over all the prediction time steps. The mean error values in Table 2 are also evidence that the proposed framework outperforms the vanilla WNO architecture.
5 Conclusions
In this article, we proposed a generative flow-based neural architecture search algorithm for neural operators. The neural search architecture is implemented on the recently proposed WNO, thereby introducing the flow-induced wavelet neural operator (FWNO). The resulting framework generates its own architecture by generating the sequence of the best-performing pairs of wavelet basis and activation operators in the vanilla WNO. The sequence is generated by learning stochastic policies through simple feed-forward neural networks and can also be extended to other network hyperparameters. Compared to the computationally involved grid search-reliant hyperparameters tuning algorithm, the FWNO employs a flow cum reward-based strategy, where the flow discrepancy between two states is reduced, and the reward from the terminal state is increased to learn a probabilistic policy to generate the most appropriate sequence of wavelet basis and activation operators. Once the training succeeds, the learned policies sample the states (wavelet bases and activation operators) in proportion to the reward at the terminal state so as to deliver the best-performing architectures among the diverse set of possible sequences. At the terminal state, i.e., the WNO model, we return the exponent of the negative of the prediction loss on the validation dataset.
On a broader level, the FWNO inherits all the properties of the WNO and learns a discretization invariant functional mapping between infinite-dimensional function spaces using the frequency-space localization property wavelet decomposition. Therefore, with a single training, it can deployed for reliable prediction of solutions on a different grid size for a family of parametric PDEs. We exemplified the efficacy of the proposed framework on four operator learning benchmarks. In each example, we found reductions in error when compared with the vanilla WNO. In the case of Burger’s equation, our method reduces the relative error from 1.75% to 1.44%. On the Darcy flow equation, the error reduces from 1.8% to 1.58% on a rectangular grid while it drops from 0.88% to 0.59% on a triangular grid, showcasing it has preserved all the properties of vanilla WNO. For the incompressible Navier Stokes equation, FWNO reduces errors significantly from 3.43% to 2.35%, with over an entire percentage change when compared with the vanilla WNO.
Before concluding the discussion, we summarise the contribution of this study in the following points,
-
•
We have illustrated a generative flow-based architectural search algorithm for neural operators. By setting the flow consistency between integral layers of neural operators, the proposed framework learns policies to sample a best-performing set of network hyperparameters in proportion to the positive rewards of the actions taken.
-
•
We have showcased the efficacy of the framework on the WNO, which contains a multitude of hyperparameters like the wavelet basis and activation operator. Instead of selecting a fixed set of wavelets and activation operators like in vanilla WNO, the proposed framework selects layers-specific pairs of wavelets and activation operators.
To conclude, we note that while the implementation of the flow-based strategy is limited to the wavelet neural operator in this paper, the method proposed can be seamlessly integrated with other neural operators and neural networks as well. Future work on the same could incorporate other hyper-parameters, such as the number of convolution layers and the number of layers for wavelet decomposition.
Code and data availability
Upon acceptance, all the source codes to reproduce the results in this study will be made available to the public on GitHub by the corresponding author.
References
- [1] Michael Renardy and Robert C Rogers. An introduction to partial differential equations, volume 13. Springer Science & Business Media, 2006.
- [2] Arnold Sommerfeld. Partial differential equations in physics. Academic press, 1949.
- [3] Thomas JR Hughes. The finite element method: linear static and dynamic finite element analysis. Courier Corporation, 2012.
- [4] Robert Eymard, Thierry Gallouët, and Raphaèle Herbin. Finite volume methods. In Handbook of numerical analysis, volume 7, pages 713–1018. 2000.
- [5] Tianping Chen and Hong Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Transactions on Neural Networks, 6(4):911–917, 1995.
- [6] Lu Lu, Pengzhan Jin, and George Em Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193, 2019.
- [7] Sifan Wang, Hanwen Wang, and Paris Perdikaris. Learning the solution operator of parametric partial differential equations with physics-informed deeponets. Science advances, 7(40):eabi8605, 2021.
- [8] Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations. 2020.
- [9] Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. 2020.
- [10] Tapas Tripura and Souvik Chakraborty. Wavelet neural operator for solving parametric partial differential equations in computational mechanics problems. Computer Methods in Applied Mechanics and Engineering, 404:115783, 2023.
- [11] N Navaneeth, Tapas Tripura, and Souvik Chakraborty. Physics informed wno. Computer Methods in Applied Mechanics and Engineering, 418:116546, 2024.
- [12] Jacob H. Seidman, Georgios Kissas, Paris Perdikaris, and George J. Pappas. Nomad: Nonlinear manifold decoders for operator learning, 2022.
- [13] Qianying Cao, Somdatta Goswami, and George Em Karniadakis. Lno: Laplace neural operator for solving differential equations, 2023.
- [14] V. S. Fanaskov and I. V. Oseledets. Spectral neural operators. Doklady Mathematics, 108(Suppl 2):S226–S232, 2023.
- [15] Martin Wistuba, Ambrish Rawat, and Tejaswini Pedapati. A survey on neural architecture search. arXiv preprint arXiv:1905.01392, 2019.
- [16] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, 20(55):1–21, 2019.
- [17] Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-yao Huang, Zhihui Li, Xiaojiang Chen, and Xin Wang. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Comput. Surv., 54(4), may 2021.
- [18] Yuqiao Liu, Yanan Sun, Bing Xue, Mengjie Zhang, Gary G Yen, and Kay Chen Tan. A survey on evolutionary neural architecture search. IEEE transactions on neural networks and learning systems, 34(2):550–570, 2021.
- [19] Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, and Jeff Dean. Efficient neural architecture search via parameters sharing. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 4095–4104. PMLR, 10–15 Jul 2018.
- [20] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In Proceedings of the European conference on computer vision (ECCV), pages 19–34, 2018.
- [21] Z. Zhong, J. Yan, W. Wu, J. Shao, and C. Liu. Practical block-wise neural network architecture generation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2423–2432, Los Alamitos, CA, USA, jun 2018. IEEE Computer Society.
- [22] Bowen Baker, Otkrist Gupta, Nikhil Naik, and Ramesh Raskar. Designing neural network architectures using reinforcement learning, 2017.
- [23] Barret Zoph and Quoc Le. Neural architecture search with reinforcement learning. In International Conference on Learning Representations, 2017.
- [24] Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network based generative models for non-iterative diverse candidate generation. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 27381–27394. Curran Associates, Inc., 2021.
- [25] Yoshua Bengio, Salem Lahlou, Tristan Deleu, Edward J. Hu, Mo Tiwari, and Emmanuel Bengio. Gflownet foundations. J. Mach. Learn. Res., 24(1), mar 2024.
- [26] Moksh Jain, Emmanuel Bengio, Alex Hernandez-Garcia, Jarrid Rector-Brooks, Bonaventure F. P. Dossou, Chanakya Ajit Ekbote, Jie Fu, Tianyu Zhang, Michael Kilgour, Dinghuai Zhang, Lena Simine, Payel Das, and Yoshua Bengio. Biological sequence design with GFlowNets. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 9786–9801. PMLR, 17–23 Jul 2022.
- [27] Moksh Jain, Sharath Chandra Raparthy, Alex Hernández-García, Jarrid Rector-Brooks, Yoshua Bengio, Santiago Miret, and Emmanuel Bengio. Multi-objective GFlowNets. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 14631–14653. PMLR, 23–29 Jul 2023.
- [28] Navaneeth N. and Souvik Chakraborty. Waveformer for modeling dynamical systems. Mechanical Systems and Signal Processing, 211:111253, 2024.
- [29] Tapas Tripura, Abhilash Awasthi, Sitikantha Roy, and Souvik Chakraborty. A wavelet neural operator based elastography for localization and quantification of tumors. Computer Methods and Programs in Biomedicine, 232:107436, 2023.
- [30] Akshay Thakur, Tapas Tripura, and Souvik Chakraborty. Multi-fidelity wavelet neural operator with application to uncertainty quantification. arXiv preprint arXiv:2208.05606, 2022.
- [31] Tapas Tripura and Souvik Chakraborty. A foundational neural operator that continuously learns without forgetting. arXiv preprint arXiv:2310.18885, 2023.
- [32] Jyoti Rani, Tapas Tripura, Hariprasad Kodamana, and Souvik Chakraborty. Generative adversarial wavelet neural operator: Application to fault detection and isolation of multivariate time series data. arXiv preprint arXiv:2401.04004, 2024.
- [33] Souvik Chakraborty et al. Dpa-wno: A gray box model for a class of stochastic mechanics problem. arXiv preprint arXiv:2309.15128, 2023.
- [34] Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data. Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022.