Generating Synthetic Datasets by
Interpolating along Generalized Geodesics
Abstract
Data for pretraining machine learning models often consists of collections of heterogeneous datasets. Although training on their union is reasonable in agnostic settings, it might be suboptimal when the target domain —where the model will ultimately be used— is known in advance. In that case, one would ideally pretrain only on the dataset(s) most similar to the target one. Instead of limiting this choice to those datasets already present in the pretraining collection, here we explore extending this search to all datasets that can be synthesized as ‘combinations’ of them. We define such combinations as multi-dataset interpolations, formalized through the notion of generalized geodesics from optimal transport (OT) theory. We compute these geodesics using a recent notion of distance between labeled datasets, and derive alternative interpolation schemes based on it: using either barycentric projections or optimal transport maps, the latter computed using recent neural OT methods. These methods are scalable, efficient, and —notably— can be used to interpolate even between datasets with distinct and unrelated label sets. Through various experiments in transfer learning in computer vision, we demonstrate this is a promising new approach for targeted on-demand dataset synthesis.
1 Introduction
Recent progress in machine learning has been characterized by the rapid adoption of large pretrained models as a fundamental building block [Brown et al., 2020]. These models are typically pretrained on large amounts of general-purpose data and then adapted (e.g., fine-tuned) to a specific task of interest. Such pretraining datasets usually draw from multiple heterogeneous data sources, e.g., arising from different domains or sources. Traditionally, all available datasets are used in their entirety during pretraining, for example by pooling them together into a single dataset (when they all share the same label sets) or by training in all of them sequentially one by one. These strategies, however, come with important disadvantages. Training on the union of multiple datasets might be prohibitive or too time-consuming, and it might even be detrimental — indeed, there is a growing line of research showing that removing pretraining data sometimes improves transfer performance [Jain et al., 2022]. On the other hand, sequential learning (i.e., consuming datasets one by one) is infamously prone to catastrophic forgetting [McCloskey and Cohen, 1989, Kirkpatrick et al., 2017]: the information from earlier datasets gradually vanishing as the model is trained on new datasets. The pitfalls of both of these approaches suggest training instead on a subset of the available pretraining datasets, but how to choose that subset is unclear. However, when the target dataset on which the model is to be used is known in advance, the answer is much easier: intuitively, one would train only of those relevant to the target one: e.g., those most similar to it. Indeed, recent work has shown that selecting pretraining datasets based on the distance to the target is a successful strategy [Alvarez-Melis and Fusi, 2020, Gao and Chaudhari, 2021]. However, such methods are limited to selecting (only) among individual datasets already present in the collection.
In this work, we propose a novel approach to generate synthetic pretraining datasets as combinations of existing ones. In particular, this method searches among all possible continuous combinations of the available datasets and thus is not limited to selecting specifically one of them. When given access to the target dataset of interest, we seek among all such combinations the one closest (in terms of a metric between datasets) to the target. By characterizing datasets as sampled from an underlying probability distribution, this problem can be understood as a generalization (from Euclidean to probability space) of the problem of finding among the convex hull of a set of reference points, that which is closest to a query point. While this problem has a simple closed-form solution in Euclidean space (via an orthogonal projection), solving it in probability space is —as we shall see here— significantly more challenging.
We tackle this problem from the perspective of interpolation. Formally, we model the combination of datasets as an interpolation between their distributions, formalized through the notion of geodesics in probability space endowed with the Wasserstein metric [Ambrosio et al., 2008, Villani, 2008]. In particular, we rely on generalized geodesics [Craig, 2016, Ambrosio et al., 2008]: constant-speed curves connecting a pair (or more) distributions parametrized with respect to a ‘base’ distribution, whose role is played by the target dataset in our setting. Computing such geodesics requires access to either an optimal transport coupling or a map between the base distribution and every other reference distribution. The former can be computed very efficiently with off-the-shelf OT solvers, but are limited to generating only as many samples as the problem is originally solved on. In contrast, OT maps allow for on-demand out-of-sample mapping and can be estimated using recent advances in neural OT methods [Fan et al., 2020, Korotin et al., 2022b, Makkuva et al., 2020]. However, most existing OT methods assume unlabeled (feature-only) distributions, but our goal here is to interpolate between classification (i.e., labeled) datasets. Therefore, we leverage a recent generalization of OT for labeled datasets to compute couplings [Alvarez-Melis and Fusi, 2020] and adapt and generalize neural OT methods to the labeled setting to estimate OT maps.
In summary, the contributions of this paper are: (i) a novel approach to generate new synthetic classification datasets from existing ones by using geodesic interpolations, applicable even if they have disjoint label sets, (ii) two efficient methods to solve OT between labeled datasets, which might be of independent interest, (iii) empirical validation of the method in various transfer learning settings.
2 Related work
Mixup and related In-Domain Interpolation
Generating training data through convex combinations was popularized by mixup [Zhang et al., 2018]: a simple data augmentation technique that interpolates features and labels between pairs of points. This and other works based on it [Zhang et al., 2021, Chuang and Mroueh, 2021, Yao et al., 2021] use mixup to improve in-domain model robustness [Zhu et al., 2023] and generalization by increasing the in-distribution diversity of the training data. Although sharing some intuitive principles with mixup, our method interpolates entire datasets —rather than individual datapoints— with the goal of improving across-distribution diversity and therefore out-of-domain generalization.
Dataset synthesis in machine learning
Generating data beyond what is provided as a training dataset is a crucial component of machine learning in practice. Basic transformations such as rotations, cropping, and pixel transformations can be found in most state-of-the-art computer vision models. More recently, Generative Adversarial Nets (GAN) have been used to generate synthetic data in various contexts [Bowles et al., 2018, Yoon et al., 2019], a technique that has proven particularly successful in the medical imaging domain [Sandfort et al., 2019]. Since GANs are trained to replicate the dataset on which they are trained, these approaches are typically confined to generating in-distribution diversity and typically operate on features only.
Discrete OT, Neural OT, Gradient Flows
Barycentric projection [Ambrosio et al., 2008, Perrot et al., 2016] is a simple and effective method to approximate an optimal transport map with discrete regularized OT. On the other hand, there has been remarkable recent progress in methods to estimate OT maps in Euclidean space using neural networks [Makkuva et al., 2020, Fan et al., 2021, Rout et al., 2022], which have been successfully used for image generation [Rout et al., 2022], style transfer [Korotin et al., 2022b], among other applications. However, the estimation of an optimal map between (labeled) datasets has so far received much less attention. Some conditional Monge map solvers [Bunne et al., 2022a] utilize the label information in a semi-supervised manner, where they assume the label-to-label correspondence between two distributions is known. Our method differs from theirs in that we do not require a pre-specified label-to-label mapping, but instead estimate it from data. Geodesics and interpolation in general metric spaces have been studied extensively in the optimal transport and metric geometry literature [McCann, 1997, Agueh and Carlier, 2011, Ambrosio et al., 2008, Santambrogio, 2015, Villani, 2008, Craig, 2016], albeit mostly in a theoretical setting. Gradient flows [Santambrogio, 2015], increasingly popular in machine learning to model existing processes [Bunne et al., 2022b, Mokrov et al., 2021, Fan et al., 2022, Hua et al., 2023] or solving optimization problems over datasets [Alvarez-Melis and Fusi, 2021], provide an alternative approach for interpolation between distributions but are computationally expensive.
3 Background
3.1 Distribution interpolation with OT
Consider the space of probability distributions with finite second moments over some Euclidean space . Given , the Monge formulation optimal transport problem seeks a map that transforms into at a minimal cost. Formally, the objective of this problem is where the minimization is over all the maps that pushforward distribution into distribution . While a solution to this problem might not exist, a relaxation due to Kantorovich is guaranteed to have one. This modified version yields the Wasserstein-2 distance: where now the constraint set contains all couplings with marginals and . The optimal such coupling is known as the OT plan. A celebrated result by Brenier [1991] states that whenever has density with respect to the Lebesgue measure, the optimal exists and is unique. In that case, the Kantorovich and Monge formulations coincide and their solutions are linked by where is the identity map. The Wasserstein-2 distance enjoys many desirable geometrical properties compared to other distances for distributions [Ambrosio et al., 2008]. One such property is the characterization of geodesics in probability space [Agueh and Carlier, 2011, Santambrogio, 2015]. When is equipped with metric , the unique minimal geodesic between any two distributions and is fully determined by , the optimal transport plan between them, through the relation:
| (1) |
known as displacement interpolation. If the Monge map from to exists, the geodesic can also be written as
| (2) |
and is known as McCann’s interpolation [McCann, 1997]. It is easy to see that and .
Such interpolations are only defined between two distributions. When there are marginal distributions , the Wasserstein barycenter
| (3) |
generalizes McCann’s interpolation [Agueh and Carlier, 2011]. Intuitively, the interpolation parameters determine the ‘mixture proportions’ of each dataset in the combination, akin to the weights in a convex combination of points in Euclidean space. In particular, when is a one-hot vector with , then , i.e., the barycenter is simply the -th distribution. Barycenters have attracted significant attention in machine learning recently [Srivastava et al., 2018, Korotin et al., 2021], but they remain challenging to compute in high dimension [Fan et al., 2020, Korotin et al., 2022a].
Another limitation of these interpolation notions is the non-convexity of along them. In Euclidean space, given three points , the function , where is the interpolation , is convex. In contrast, in Wasserstein space, neither the function or are guaranteed to be convex [Santambrogio, 2017, §4.4]. This complicates their theoretical analysis, such as in gradient flows. To circumvent this issue, Ambrosio et al. [2008] introduced the generalized geodesic of with base :
| (4) |
where is the optimal map from to .
Lemma 1.
The functional is convex along the generalized geodesics, and
Thus, unlike the barycenter, the generalized geodesic does yield a notion of convexity satisfied by the Wasserstein distance and is easier to compute. The proof of Lemma 1 is postponed to §A. For these reasons, we adopt this notion of interpolation for our approach. It remains to discuss how to use it on (labeled) datasets.
3.2 Dataset distance
Consider a dataset . The Optimal Transport Dataset Distance (OTDD) [Alvarez-Melis and Fusi, 2020] measures its distance to another dataset as:
| (5) |
which defines a proper metric between datasets. Here, are class-conditional measures corresponding to and . This distance is strongly correlated with transfer learning performance, i.e., the accuracy achieved when training a model on and then fine-tuning and evaluating on . Therefore, it can be used to select pretraining datasets for a given target domain. Henceforth we abuse the notation to represent both a dataset and its underlying distribution for simplicity. To avoid confusion, we use and to represent distributions in the feature space (typically ) and use to represent distributions in the product space of features and labels.
4 Dataset interpolation along generalized geodesic
Our method consists of two steps: estimating optimal transport maps between the target dataset and all training datasets (§4.1), and using them to generate a convex combination of these datasets by interpolating along generalized geodesics (§4.2). The OT map estimation is in feature space or original space depending on the dataset’s dimension. For some downstream applications, we will additionally project the target dataset into the ‘convex hull’ of the training datasets (§4.3).
4.1 Estimating optimal maps between labeled datasets
The OTDD is a special case of Wasserstein distance, so it is natural to consider the alternative Monge (map-based) formulation to (3.2). We propose two methods to approximate the OTDD map, one using the entropy-regularized OT and another one based on neural OT.
OTDD barycentric projection.
Barycentric projections [Ambrosio et al., 2008, Pooladian and Niles-Weed, 2021] can be efficiently computed for entropic regularized OT using the Sinkhorn algorithm [Sinkhorn, 1967]. Assume that we have empirical distributions and , where is the Dirac function at . Denote all the samples compactly as matrices: . After solving the optimal coupling , the barycentric projection can be expressed as We extend this method to two datasets , where we have additional one-hot label data . and are the number of classes in dataset and . We solve the optimal coupling for OTDD (3.2) following the regularized scheme in Alvarez-Melis and Fusi [2020]. The barycentric projection can then be written as:
| (6) |
The visualization of barycentric projected data appears in Figure 1.

However, this approach has two important limitations: it can not naturally map out-of-sample data and it does not scale well to large datasets (due to the quadratic dependency on sample size). To relieve the scaling issue, we will use batchified version of OTDD barycentric projection in this paper (see complexity discussion in §6).
OTDD neural map.
Inspired by recent approaches to estimate Monge maps using neural networks [Rout et al., 2022, Fan et al., 2021], we design a similar framework for the OTDD setting. Fan et al. [2021] approach the Monge OT problem with general cost functions by solving its max-min dual problem
We extend this method to the distributions involving labels by introducing an additional classifier in the map. Given two datasets , we parameterize the map as
| (7) |
where is the pushforward feature map, and the is a frozen classifier that is pre-trained on the dataset . Notice that, with the cost , the Monge formulation of OTDD (3.2) reads We therefore propose to solve the max-min dual problem
| (8) |

Implementation details are provided in §B. Compared to previous conditional Monge map solvers [Bunne et al., 2022a, Asadulaev et al., 2022], the two methods proposed here: (i) do not assume class overlap across datasets, allowing for maps between datasets with different label sets; (ii) are invariant to class permutation and re-labeling; (iii) do not force one-to-one class alignments, e.g., samples can be mapped across similar classes.
4.2 Convex combination in dataset space
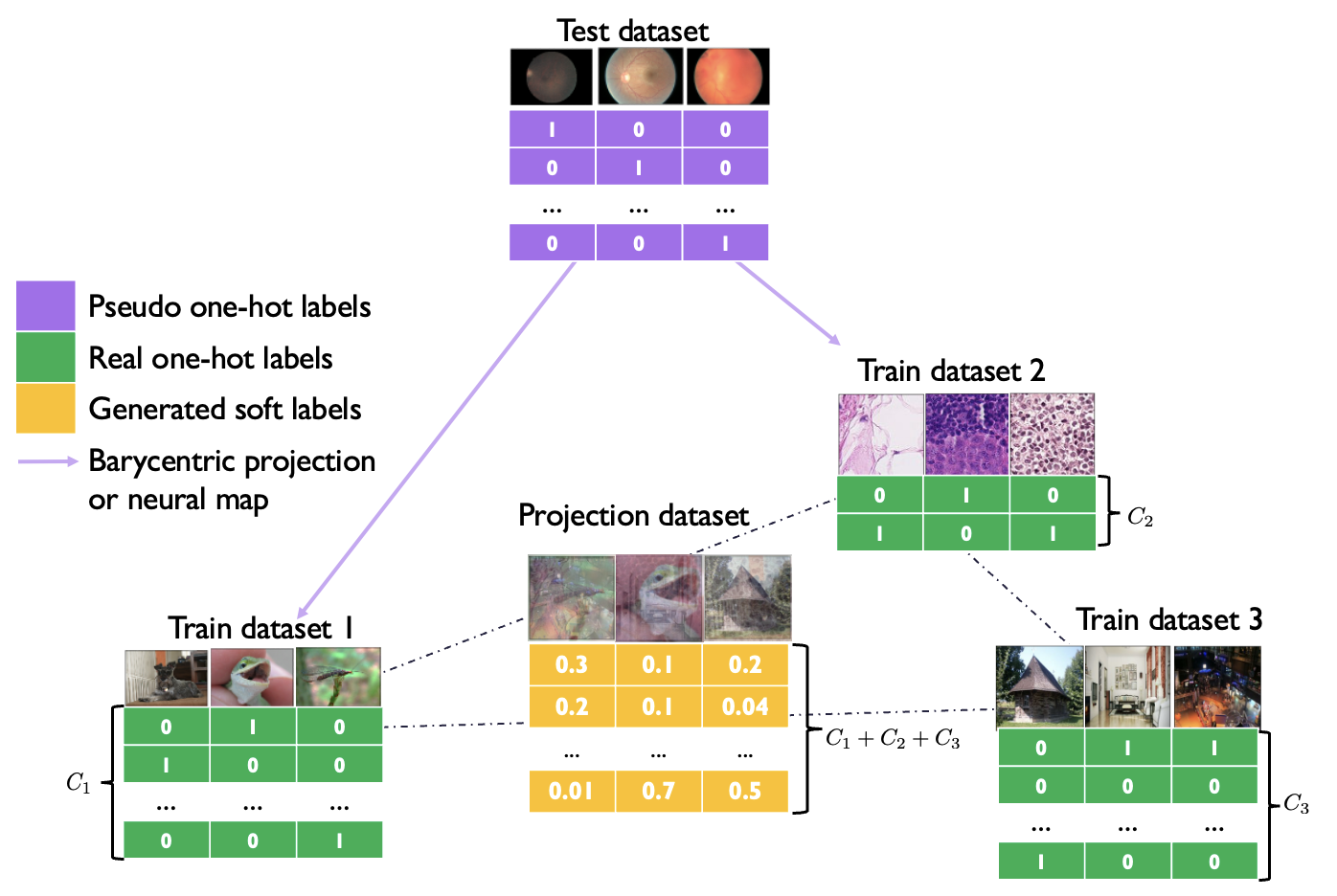
Computing generalized geodesics requires constructing convex combinations of datapoints from different datasets. Given a weight vector , features can be naturally combined as . But combining labels is not as simple because: (i) we allow for datasets with a different number of labels, so adding them directly is not possible; (ii) we do not assume different datasets have the same label sets, e.g. MNIST (digits) vs CIFAR10 (objects). Our solution is to represent all labels in the same dimensional space by padding them with zeros in all entries corresponding to other datasets. As an example, consider three datasets with , and classes respectively. Given a label vector for the first one, we embed it into as Defining analogously, we compute their combination as . This representation is lossless and preserves the distinction of labels across datasets. The visualization of our convex combination is in Figure 3.


4.3 Projection onto generalized geodesic of datasets
We now put together the components in Sec 4.1 and 4.2 to construct generalized geodesics between datasets in two steps. First, we compute OTDD maps between and all other datasets using the discrete or neural OT approaches. Then, for any interpolation vector we identify a dataset along the generalized geodesic via
| (9) |
By using the convex combination method in §4.2 for labeled data, we can efficiently sample from .
Next, we find the dataset that minimizes the distance between and , i.e. the projection of onto the generalized geodesic. We first approach this problem from a Euclidean viewpoint. Suppose there are several distributions and an additional distribution on Euclidean space . Lemma 1 guarantees there exists a unique parameter that minimizes . However, finding is far from trivial because there is no closed-form formula of the map and it can be expensive to calculate for all possible . To solve this problem, we resort to another transport distance: the (2,)-transport metric.
Definition 1 (Craig [2016]).
Given distributions , the (2,)-transport metric between them is given by
where is the optimal map from to .
When has a density with respect to Lebesgue measure is a valid metric [Craig, 2016, Prop. 1.15]. Moreover, we can derive a closed-form formula for the map .
Proposition 1.
This equation implies that given distributions in Euclidean space, we can trivially solve the optimal that minimizes by a quadratic programming solver†††We use the implementation https://github.com/stephane-caron/qpsolvers. The proof (§A ) relies on Brenier’s theorem. Inspired by this, we also define a transport metric for datasets:
Definition 2.
The squared (2,)-dataset distance is
where and is the OTDD map from to .
Denote as the set of all probability measures that satisfy and the OTDD map from to exists. The following result shows that (2,)-dataset distance is a proper distance. The proof is again deferred to §A.
Proposition 2.
is a valid metric on .
Unfortunately, in this case does not have an analytic form like before because Brenier’s theorem may not hold for a general transport cost problem. However, we still borrow this idea and define an approximated projection as the minimizer of function
| (10) |
which is an analog of Proposition 1. Since is defined by its interpolation weight , solving is equivalent to finding a weight
| (11) |
which is a simple quadratic programming problem. Unlike the Wasserstein distance, is easier to compute because it does not involve optimization, so it is relatively cheap to find the minimizer of . Experimentally, we observe that is predictive of model transferability across tasks. Figure 4(a) illustrates this projection on toy 3D datasets, color-coded by class.
5 Experiments
5.1 Learning OTDD maps
In this section, we visualize the quality of the learnt OTDD maps on both synthetic and realistic datasets.
Synthetic datasets
Figure 4 (b) illustrates the role of the optimal map in estimating the projection of a dataset into the generalized geodesic hull of three others. Using maps estimated via barycentric projection (6) results in better preservation of the four-mode class structure, whereas using non-optimal maps based on random couplings (as the usual mixup does) destroys the class structure.
*NIST datasets

In Figure 5, we provide qualitative results of OTDD map from EMNIST (letter) [Cohen et al., 2017] dataset to all other *NIST dataset and USPS dataset. At this point, we can confirm three traits of OTDD map, which are mentioned at the end of §4.1.
1) We don’t assume a known source label to target label correspondence. So we can map between two irrelevant datasets such as EMNIST and FashionMNIST. 2) The map is invariant to the permutation of label assignment. For example, we show two different labelling in Figure 7, and the final OTDD map will be the same. 3) It doesn’t enforce the label-to-label mapping but would follow the feature similarity. From Figure 5, we notice many cross-class mapping behaviors. For example, when the target domain is USPS [Hull, 1994] dataset, the lower-case letter "l" is always mapped to digit 1, and the capital letter "L" is mapped to other digits such as 6 or 0 because the map follows the feature similarity.
5.2 Transfer learning on *NIST datasets
Next, we use our framework to generate new pretraining datasets for transfer learning. Preceding works illustrate that the transfer learning performance can be quite sensitive to the type of test datasets if there is abundant training data from the test task [Zhai et al., 2019, Table 1]. Thus, we will focus on the few-shot setting, where we only have few labeled data from the test task. We first show that the generalization ability of training models has a strong correlation with the distance . Then we compare our framework with several baseline methods.
Setup
Given labeled pretraining datasets , we consider a few-shot task in which only a limited amount of data from the target domain is labeled, e.g. 5 samples per class. The goal is to find a single dataset of size comparable to any individual that yields the best generalization to the target domain when pre-training a model on it and fine-tuning on the target few-shot data. Here, we seek this training dataset within those generated by generalized geodesics , which can be understood as weighted interpolations of the training datasets . Note this includes individual datasets as particular cases when is a one-hot vector.
| Methods | MNIST-M | EMNIST | MNIST | FMNIST | USPS | KMNIST |
|---|---|---|---|---|---|---|
| OTDD barycentric projection | 42.104.37 | 67.062.55 | 93.741.46 | 70.123.02 | 86.011.50 | 52.552.73 |
| OTDD neural map | 40.064.75 | 65.321.80 | 88.783.85 | 70.022.59 | 83.801.60 | 50.323.10 |
| Mixup with weights | 33.852.22 | 60.951.38 | 88.681.57 | 66.743.79 | 88.612.00 | 48.163.38 |
| Train on few-shot dataset | 19.103.57 | 53.601.18 | 72.803.10 | 60.503.07 | 80.732.07 | 41.672.11 |
| 1-NN on few-shot dataset | 20.951.39 | 39.700.57 | 64.503.32 | 60.922.42 | 73.642.35 | 40.183.09 |
Connection to generalization
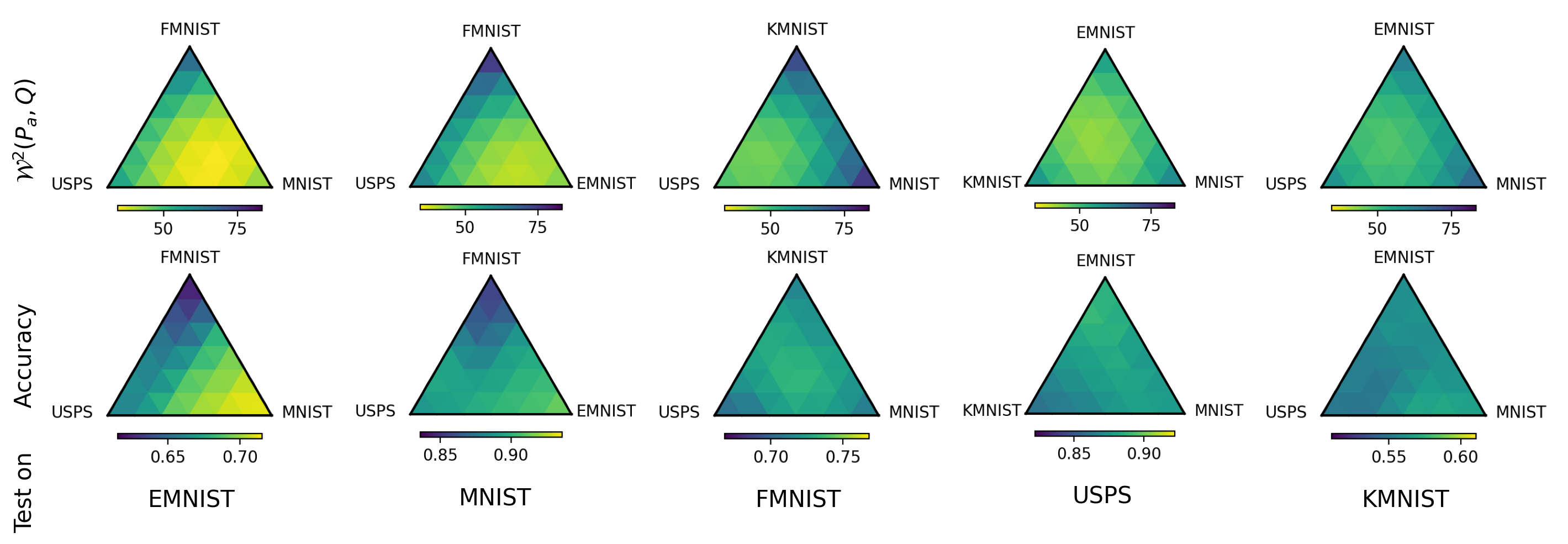
The closed-form expression of (Prop. 1) provides a distance between a base distribution and the distribution along generalized geodesic in Euclidean space. We study its analog (4.3) for labeled datasets and and visualize it in Figure 6 (first row). To investigate the generalization abilities of models trained on different datasets, we discretize the simplex to obtain interpolation parameters , and train a 5-layer LeNet classifier on each . Then we fine-tune all of these classifiers on the few-shot test dataset with only 20 samples per each class. We control the same number of training iterations and fine-tuning iterations across all experiments. The second row of Figure 6 shows fine-tuning accuracy. Comparing the first row and the second, we find the accuracy and are highly correlated. This implies that the model trained on the minimizer dataset of tends to have a better generalization ability. We fix the same colorbar range for all heatmaps across datasets to highlight the impact of training dataset choice. A more concrete visualization of the correlation between and accuracy is shown in Figure 11.
For some test datasets, the choice of training dataset strongly affects the fine-tuning accuracy. For example, when is EMNIST and the training dataset is FMNIST, the fine-tuning accuracy is only , but this can be improved to by choosing an interpolated dataset closer to MNIST. This is reasonable because MNIST is more similar to EMNSIT than FMNIST or USPS. To some test datasets like FMNIST and KMNIST, this difference is not so obvious because all training datasets are all far away from the test dataset.
Comparison with baselines.
Next, we compare our method with several baseline methods on NIST datasets. In each set of experiments, we select one *NIST dataset as the target domain, and use the rest for pre-training. We consider a 5-shot task, so we randomly choose 5 samples per class to be the labeled data, and treat the remaining samples as unlabeled. Our method first trains a model on , and fine-tunes the model on the 5-shot target data. To obtain , we use barycentric projection or neural map to approximate the OTDD maps from the test to training datasets. Our results are shown in the first two rows in Table 1. Overall, transfer learning can bring additional knowledge from other domains and improve the test accuracy by at most 21. Among the methods in the first block, training on datasets generated by OTDD barycentric projection outperforms others except USPS dataset, where the difference is only about 2.6.
5.3 Transfer learning on VTAB datasets
Finally, we use our method for transfer learning with large-scale VTAB datasets [Zhai et al., 2019]. In particular, we take Oxford-IIIT Pet dataset as the target domain, and use Caltech101, DTD, and Flowers102 for pre-training. To encode a richer geometry in our interpolation, we embed the datasets using a masked auto encoder (MAE) [He et al., 2022] and learn the OTDD map in this (200K dimensional) latent space. Since OTDD barycentric projection consistently works better than OTDD neural map (see Table 1), we only use barycentric projection in this section. We use ResNet-18 as the model architecture and pre-train the model on decoded MAE images (interpolated dataset) or original images (single dataset). Meanwhile, Mixup baseline is over pixel space and therefore does not utilize embeddings at all.
| Pre-Training | Map | Weights | Rel. Improv. () |
|---|---|---|---|
| Caltech101 | 59.68 41.44 | ||
| DTD | -1.17 9.52 | ||
| Flowers102 | -2.45 26.25 | ||
| Pooling | 28.96 18.29 | ||
| Sub-pooling | 3.00 19.10 | ||
| Interpolation | Mixup | uniform | 33.26 21.30 |
| Interpolation | Mixup | 51.99 34.10 | |
| Interpolation | OTDD | uniform | 82.61 25.93 |
| Interpolation | OTDD | 95.17 20.57 |
The pre-training interpolation dataset generated by our method has ‘optimal’ mixture weights for (Caltech101, dtd, Flowers102), suggesting a stronger similarity between the first of these and the target domain (Pets). This is consistent with the single-dataset transfer accuracies shown in Table 2. However, their interpolation yields better transfer than any single dataset, particularly when using our full method (interpolating using OTDD map with optimal mixture weights).
In Table 2, we compute relative improvement per run, and then average these across runs; in other words, we compute the mean of ratios (MoR) rather than the ratio of means (RoM). Our reasoning for doing this was (i) controlling for the ‘hardness’ inherent to the randomly sampled subsets of Pet by relativizing before averaging and (ii) our observation that it is common practice to compute MoR when the denominator and numerator correspond to paired data (as is the case here), and the terms in the sum are sampled i.i.d. (again, satisfied in this case by the randomly sampled subsets of the target domain).
Table 2 shows a high deviation due to a particularly good result generated by the non-transfer learning baseline with seed 2, while other methods such as Caltech101 pretraining and Flowers102 pretraining had particularly bad results with the same seed.
6 Conclusion and discussion
The method we introduce in this work provides, as shown by our experimental results, a promising new approach to generate synthetic datasets as combinations of existing ones. Crucially, our method allows one to combine datasets even if their label sets are different, and is grounded on principled and well-understood concepts from optimal transport theory. Two key applications of this approach that we envision are:
-
•
Pretraining data enrichment. Given a collection of classification datasets, generate additional interpolated datasets to increase diversity, with the aim of achieving better out-of-distribution generalization. This could be done even without knowledge of the specific target domain (as we do here) by selecting various datasets to play the role of the ‘reference’ distribution.
-
•
On-demand optimized synthetic data generation. Generate a synthetic dataset, by combining existing ones, that is ‘optimized’ for transferring a model to a new (data-limited) target domain.
Complexity
The complexity of solving OTDD barycentric projection by Sinkhorn algorithm is [Dvurechensky et al., 2018], where is the number of data in both datasets. This can be expensive for large-scale datasets. In practice, we solve the batched barycentric projection, i.e. take a batch from both datasets and solve the projection from source to target batch, and we normally fix batch size as . This reduces the complexity from to . The complexity of solving OTDD neural map is , where is number of iterations, and is the size of the network. We always choose in the experiments. The complexity of solving all the -dataset distances in (4.3) is since we need to solve the dataset distance between each pair of training datasets. Putting these pieces together, the complexity of approximating the interpolation parameter for the minimizer of (4.3) is .
Memory
As the number of pre-training tasks () increases, our method, which generates an interpolated label by concatenating labels from all tasks, creates an increasingly sparse vector. Consequently, the memory demands of the classifier’s output layer, which is proportional to , could rise significantly.
Barycentric projection vs Neural map
These two versions of our method offer complementary advantages. While estimating the OT map allows for easy out-of-sample mapping and continuous generation, the barycentric projection approach often yields better downstream performance (Table 1). We hypothesize this is due to the barycentric projection relying on (re-weighted) real data, while the neural map generates data which might be noisy or imperfect.
Pixel space vs feature space
We present results with OTDD mapping in both pixel space (§5.2) and feature space (§5.3). For the VTAB datasets with regular-sized images (e.g. ), we found that the feature space is more appropriate for measuring data distance. For small-scale images like NIST, feature space may be overkill because most foundation models are trained on images with a larger size. In our preliminary experiments with NIST datasets, we attempted a feature space approach using an off-the-shelf ResNet-18 model. However, we encountered challenges in achieving convergence when training OTDD neural maps with PyTorch ResNet-18 features.
High variance issue
Our method is not limited to the data scarcity regime, but indeed this is the most interesting one from the transfer learning perspective, which is why we assume limited labeled data (but potentially much more unlabeled data) from the target domain distribution. This is a typical few-shot learning scenario. The quality of a learned OT map will likely depend on the number of samples used to fit it, and might suffer from high variance. To mitigate this in our setting, we opt for augmenting our dataset by generating additional pseudo-labeled data via kNN (Fig. 3). Recall that we do have access to more unlabeled data from the target domain, which is a common situation in practice.
Limitations
Our method for generating a synthetic dataset relies on solving OTDD maps from the test dataset to each training dataset. These OTDD maps are tailored to the considered test dataset and can not be reused for a new test dataset. Another limitation is our framework is based on model training and fine-tuning pipeline. This can be resource-demanding for large-scale models, like GPT [Brown et al., 2020] or other similar models. Finally, if at least one of the datasets is imbalanced, our OTDD map will struggle to match the class with similar marginal distributions.
Acknowledgements.
We thank Yongxin Chen and Nicolò Fusi for their invaluable comments, ideas, and feedback. We extend our gratitude to the anonymous reviewers for their useful feedback that significantly improved this work.References
- Agueh and Carlier [2011] M. Agueh and G. Carlier. Barycenters in the wasserstein space. SIAM Journal on Mathematical Analysis, 43(2):904–924, 2011.
- Alvarez-Melis and Fusi [2020] D. Alvarez-Melis and N. Fusi. Geometric dataset distances via optimal transport. Advances in Neural Information Processing Systems, 33:21428–21439, 2020.
- Alvarez-Melis and Fusi [2021] D. Alvarez-Melis and N. Fusi. Dataset dynamics via gradient flows in probability space. In International Conference on Machine Learning, pages 219–230. PMLR, 2021.
- Ambrosio et al. [2008] L. Ambrosio, N. Gigli, and G. Savaré. Gradient flows: in metric spaces and in the space of probability measures. Springer Science & Business Media, 2008.
- Asadulaev et al. [2022] A. Asadulaev, A. Korotin, V. Egiazarian, and E. Burnaev. Neural optimal transport with general cost functionals. arXiv preprint arXiv:2205.15403, 2022.
- Bowles et al. [2018] C. Bowles, L. Chen, R. Guerrero, P. Bentley, R. Gunn, A. Hammers, D. A. Dickie, M. V. Hernández, J. Wardlaw, and D. Rueckert. GAN augmentation: Augmenting training data using generative adversarial networks, Oct. 2018.
- Brenier [1991] Y. Brenier. Polar factorization and monotone rearrangement of vector-valued functions. Communications on pure and applied mathematics, 44(4):375–417, 1991.
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are Few-Shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020.
- Bunne et al. [2022a] C. Bunne, A. Krause, and M. Cuturi. Supervised training of conditional monge maps. arXiv preprint arXiv:2206.14262, 2022a.
- Bunne et al. [2022b] C. Bunne, L. Papaxanthos, A. Krause, and M. Cuturi. Proximal optimal transport modeling of population dynamics. In G. Camps-Valls, F. J. R. Ruiz, and I. Valera, editors, Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 of Proceedings of Machine Learning Research, pages 6511–6528. PMLR, 2022b.
- Chuang and Mroueh [2021] C.-Y. Chuang and Y. Mroueh. Fair mixup: Fairness via interpolation. In International Conference on Learning Representations, 2021.
- Cohen et al. [2017] G. Cohen, S. Afshar, J. Tapson, and A. Van Schaik. Emnist: Extending mnist to handwritten letters. In 2017 international joint conference on neural networks (IJCNN), pages 2921–2926. IEEE, 2017.
- Craig [2016] K. Craig. The exponential formula for the wasserstein metric. ESAIM: Control, Optimisation and Calculus of Variations, 22(1):169–187, 2016.
- Dvurechensky et al. [2018] P. Dvurechensky, A. Gasnikov, and A. Kroshnin. Computational optimal transport: Complexity by accelerated gradient descent is better than by sinkhorn’s algorithm. In International conference on machine learning, pages 1367–1376. PMLR, 2018.
- Fan et al. [2020] J. Fan, A. Taghvaei, and Y. Chen. Scalable computations of wasserstein barycenter via input convex neural networks. arXiv preprint arXiv:2007.04462, 2020.
- Fan et al. [2021] J. Fan, S. Liu, S. Ma, H. Zhou, and Y. Chen. Neural monge map estimation and its applications. arXiv preprint arXiv:2106.03812, 2021.
- Fan et al. [2022] J. Fan, Q. Zhang, A. Taghvaei, and Y. Chen. Variational Wasserstein gradient flow. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 6185–6215. PMLR, 2022.
- Gao and Chaudhari [2021] Y. Gao and P. Chaudhari. An Information-Geometric distance on the space of tasks. In Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021.
- He et al. [2022] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022.
- Hua et al. [2023] X. Hua, T. Nguyen, T. Le, J. Blanchet, and V. A. Nguyen. Dynamic flows on curved space generated by labeled data. arXiv preprint arXiv:2302.00061, 2023.
- Hull [1994] J. J. Hull. A database for handwritten text recognition research. IEEE Transactions on pattern analysis and machine intelligence, 16(5):550–554, 1994.
- Jain et al. [2022] S. Jain, H. Salman, A. Khaddaj, E. Wong, S. M. Park, and A. Madry. A data-based perspective on transfer learning. arXiv preprint arXiv:2207.05739, 2022.
- Kabir et al. [2022] H. D. Kabir, M. Abdar, A. Khosravi, S. M. J. Jalali, A. F. Atiya, S. Nahavandi, and D. Srinivasan. Spinalnet: Deep neural network with gradual input. IEEE Transactions on Artificial Intelligence, 2022.
- Kirkpatrick et al. [2017] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell. Overcoming catastrophic forgetting in neural networks. PNAS, 114(13):3521–3526, mar 2017.
- Korotin et al. [2021] A. Korotin, L. Li, J. Solomon, and E. Burnaev. Continuous wasserstein-2 barycenter estimation without minimax optimization. arXiv preprint arXiv:2102.01752, 2021.
- Korotin et al. [2022a] A. Korotin, V. Egiazarian, L. Li, and E. Burnaev. Wasserstein iterative networks for barycenter estimation. arXiv preprint arXiv:2201.12245, 2022a.
- Korotin et al. [2022b] A. Korotin, D. Selikhanovych, and E. Burnaev. Neural optimal transport. arXiv preprint arXiv:2201.12220, 2022b.
- Liu et al. [2019] H. Liu, X. Gu, and D. Samaras. Wasserstein gan with quadratic transport cost. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4832–4841, 2019.
- Makkuva et al. [2020] A. Makkuva, A. Taghvaei, S. Oh, and J. Lee. Optimal transport mapping via input convex neural networks. In International Conference on Machine Learning, volume 37, 2020.
- McCann [1995] R. J. McCann. Existence and uniqueness of monotone measure-preserving maps. Duke Mathematical Journal, 80(2):309–323, 1995.
- McCann [1997] R. J. McCann. A convexity principle for interacting gases. Advances in mathematics, 128(1):153–179, 1997.
- McCloskey and Cohen [1989] M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In G. H. Bower, editor, Psychology of Learning and Motivation, volume 24, pages 109–165. Academic Press, Jan. 1989. 10.1016/S0079-7421(08)60536-8.
- Mokrov et al. [2021] P. Mokrov, A. Korotin, L. Li, A. Genevay, J. M. Solomon, and E. Burnaev. Large-Scale wasserstein gradient flows. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. S. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 15243–15256. Curran Associates, Inc., 2021.
- Perrot et al. [2016] M. Perrot, N. Courty, R. Flamary, and A. Habrard. Mapping estimation for discrete optimal transport. Advances in Neural Information Processing Systems, 29, 2016.
- Pooladian and Niles-Weed [2021] A.-A. Pooladian and J. Niles-Weed. Entropic estimation of optimal transport maps. arXiv preprint arXiv:2109.12004, 2021.
- Ronneberger et al. [2015] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- Rout et al. [2022] L. Rout, A. Korotin, and E. Burnaev. Generative modeling with optimal transport maps. In International Conference on Learning Representations, 2022.
- Sandfort et al. [2019] V. Sandfort, K. Yan, P. J. Pickhardt, and R. M. Summers. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep., 9(1):16884, Nov. 2019. ISSN 2045-2322. 10.1038/s41598-019-52737-x.
- Santambrogio [2015] F. Santambrogio. Optimal transport for applied mathematicians. Birkäuser, NY, 55(58-63):94, 2015.
- Santambrogio [2017] F. Santambrogio. Euclidean, metric, and Wasserstein gradient flows: an overview. Bulletin of Mathematical Sciences, 7(1):87–154, 2017.
- Sinkhorn [1967] R. Sinkhorn. Diagonal equivalence to matrices with prescribed row and column sums. The American Mathematical Monthly, 74(4):402–405, 1967.
- Srivastava et al. [2018] S. Srivastava, C. Li, and D. B. Dunson. Scalable bayes via barycenter in wasserstein space. The Journal of Machine Learning Research, 19(1):312–346, 2018.
- Villani [2008] C. Villani. Optimal transport, Old and New, volume 338. Springer Science & Business Media, 2008. ISBN 9783540710493.
- Yao et al. [2021] H. Yao, L. Zhang, and C. Finn. Meta-learning with fewer tasks through task interpolation. arXiv preprint arXiv:2106.02695, 2021.
- Yeaton et al. [2022] A. Yeaton, R. G. Krishnan, R. Mieloszyk, D. Alvarez-Melis, and G. Huynh. Hierarchical optimal transport for comparing histopathology datasets. arXiv preprint arXiv:2204.08324, 2022.
- Yoon et al. [2019] J. Yoon, J. Jordon, and M. van der Schaar. PATE-GAN: Generating synthetic data with differential privacy guarantees. In International Conference on Learning Representations, 2019.
- Zhai et al. [2019] X. Zhai, J. Puigcerver, A. Kolesnikov, P. Ruyssen, C. Riquelme, M. Lucic, J. Djolonga, A. S. Pinto, M. Neumann, A. Dosovitskiy, et al. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867, 2019.
- Zhang et al. [2018] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz. mixup: Beyond empirical risk minimization. In International Conference on Learning Representations, 2018.
- Zhang et al. [2021] L. Zhang, Z. Deng, K. Kawaguchi, A. Ghorbani, and J. Zou. How does mixup help with robustness and generalization? In International Conference on Learning Representations, 2021.
- Zhu et al. [2023] J. Zhu, J. Qiu, A. Guha, Z. Yang, X. Nguyen, B. Li, and D. Zhao. Interpolation for robust learning: Data augmentation on geodesics. arXiv preprint arXiv:2302.02092, 2023.
Appendix A Proofs
Proof of Lemma 1.
Proof of Proposition 1.
Proof of Proposition 2.
Firstly, is symmetric and nonnegative by definition. It is non-degenerate since and is a metric. Finally, we show it satisfies the triangular inequality. Indeed,
| (19) | |||
| (20) | |||
| (21) | |||
| (22) | |||
| (23) |
where the first inequality is the triangular inequality and the second inequality is the Minkowski inequality. ∎
Appendix B Implementation details of OTDD map
OTDD barycentric projection
We use the implementation https://github.com/microsoft/otdd to solve OTDD coupling. The rest part is straightforward.
OTDD neural map
To solve the problem (4.1), we parameterize to be three neural networks. In NIST dataset experiments, we parameterize as ResNet ‡‡‡https://github.com/harryliew/WGAN-QC from WGAN-QC [Liu et al., 2019], and take feature map to be UNet§§§https://github.com/milesial/Pytorch-UNet [Ronneberger et al., 2015]. We generate the labels with a pre-trained classifier , and use a LeNet or VGG-5 with Spinal layers¶¶¶https://github.com/dipuk0506/SpinalNet [Kabir et al., 2022] to parameterize . In 2D Gaussian mixture experiments, we use Residual MLP to represent all of them.
We remove the discriminator’s condition on label to simplify the loss function as
| (24) |
In this formula, we assume both and are hard labels, but in practice, the output of is a soft label. Simply taking the argmax to get a hard label can break the computational graph, so we replace the label loss by , where is the one-hot label from dataset . And is the label-to-label matrix where The matrix is precomputed before the training, and is frozen during the training.
We pre-train the feature map to be an identity map before the main adversarial training. We use the Exponential Moving Average∥∥∥https://github.com/fadel/pytorch_ema of the trained feature maps as the final feature map.
Data processing
For all the *NIST datasets, we rescale the images to size , and repeat their channel 3 times and obtain 3-channel images. We use the default train-test split from torchvision. For the VTAB datasets, we use a masked auto-encoder with 196 batches and 1024 embed dimension based on ViT-Large. So the final embedding dimension is . We also use the default train-test split from torchvision.
Hyperparameters
For the experimental results in §5.2, we use the OTDD neural map and train them using Adam optimizer with learning rate and batch size 64. We train a LeNet for 2000 iterations, and fine-tune for 100 epochs. Regarding the comparison with other baselines in §5.2, for transfer learning methods, we train a SpinalNet for iterations, and fine-tune it for iterations on the test dataset. Training from scratch on the test dataset takes also 2000 iterations. For the results in §5.3, we pre-train the ResNet-18 model for 5 epochs, then fine-tune the model on the few-shot dataset for 10 epochs. During fine-tuning, we still let the whole network tunable. The batch size is 128, and the learning rate is .
Appendix C Discussions over complexity-accuracy trade-off
We agree that our method is more computationally demanding than Mixup in general. Specifically, we consider Mixup and our methods to occupy different points of a compute-accuracy trade-off characterized by the expressivity of the geodesics between datasets they define. That being said, the trade-off is nevertheless not a prohibitive one, as shown by the fact that we can scale our method to VTAB-sized datasets with a very standard GPU setup.
‘Vanilla’ mixup with uniform dataset weights is indeed quite cheap (but, as shown in Table 2, considerably worse than alternatives). On the other hand, the version of Mixup that uses the ‘optimal’ mixture weights (labeled Mixup - optimal in Table 2, and the only Mixup version in Table 1) requires solving Eq. (4.3), which involves non-trivial computing to obtain OTDD maps. In the context of the trade-off spectrum described above, Mixup with optimal weights is strictly in between vanilla Mixup and OTDD interpolation.
Appendix D Additional results

D.1 OTDD neural map visualization
We show the OTDD neural map between 2D Gaussian mixture models with 16 components in Figure 8. This example is very special so that we have the closed-form solution of OTDD map. The feature map is a identity map and the pushforward label is equal to the corresponding class that has the same conditional distribution as source label. For example, the sample from top left corner cluster is still mapped to the top left corner cluster, and the label is changed from blue to orange. This map achieves zero transport cost. Since the transport cost is always non-negative, this map is the optimal OTDD map. However, Asadulaev et al. [2022], Bunne et al. [2022a] enforce mapping to preserve the labels, so with their methods, the blue cluster would still map to the blue cluster. Thus their feature map is highly non-convex and more difficult to learn. We refer to Figure 5 in Asadulaev et al. [2022] for their performance on the same example. Compared with them, our pushforward dataset aligns with the target dataset better.

D.2 McCann’s interpolation between datasets
Our OTDD map can be extended to generate McCann’s interpolation between datasets. We propose an anolog of McCann’s interpolation (2) in the dataset space. We define McCann’s interpolation between datasets and as
| (25) |
where is the optimal OTDD map from to and is the interpolation parameter. The superscript of means McCann. We use the same convex combination method in §4.2 to obtain samples from . Assume and contain 7, 3 classes respectively, i.e. . Then the combination of features is , and the combination of labels is
| (26) |
Thus is a sample from . We visualize McCann’s interpolation between two Gaussian mixture distributions in Figure 9. This method can map the labeled data from one dataset to another, and do the interpolation between them. Thus we can use it to map abundant data from an external dataset, to a scarce dataset for data augmentation. For example, in Figure 10, the target dataset only has 30 samples, but the source dataset has 60000 samples. We learn the OTDD neural map between them and solve their interpolation. We find that creates new data out of the domain of the original target distribution, which Mixup [Zhang et al., 2018] can not achieve. Thus, the data from for close to 1.0 can enrich the target dataset, and be potentially used in data augmentation for classification tasks.


D.3 Correlation study of *NIST experiments
A more concrete visualization of the correlation between and *NIST transfer learning test accuracy is shown in Figure 11. Among all datasets, USPS and KMNIST lack correlation. We believe it’s caused by (i) small variance in the distances from pretraining dataset to target dataset, implying a limited relative diversity of datasets on which to draw on and (ii) (in the case of USPS) a very simple task where baseline accuracy is already very high and hard to improve upon via transfer.

D.4 Fine-grained analysis over in *NIST experiments
In Table 3, we provide a more fine-grained analysis for different aspects of and their effect on transfer accuracy. To do so, we provide the min, median, range, and standard deviation of in the table below. In addition, as a proxy for the hardness / best possible gain from transfer learning, we show in the last column OTDD accuracy minus few shot accuracy, where OTDD accuracy and few shot accuracy are the mean accuracies in Rows 1 and 4, respectively, in Table 1.
Based on these statistics, we make the following observations on the relation between and transfer accuracy:
-
•
The accuracy improvement is strongly driven by . EMNIST and MNIST are with relatively smaller and share the largest improvement margin. On the other hand, FMNIST and KMNIST as have the largest to the other pre-training datasets, and have relatively smaller accuracy gain. In other words, the correlation between distance and accuracy is stronger in the part of the convex dataset polytope that is closest to the target dataset.
-
•
The strength of the correlation between and accuracy seems to depend on the range and standard deviation of he former. On the one hand, settings with low dynamic range in (like USPS and EMNIST) make it harder to observe meaningful differences in accuracy. On the other hand, this indicates that those datasets are roughly (or at least more) equidistant from all pretraining datasets, and therefore any convex combination of them will also be close to equidistant from the target, yielding no visible improvement.
-
•
Intrinsic task hardness matters. Consider USPS: all pretraining datasets, regardless of distance, seem to yield very similar accuracy on it, and it has the lowest accuracy gain (only 5%) among 5 tasks. But considering that the no-transfer (i.e. 5-shot) accuracy is already almost 81%, it is clear that the benefit from transfer learning is “a priori” limited, and therefore all pretraining datasets yield a similar minor improvement.
| Test dataset |
|
|
|
|
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EMNIST | 34.41 | 43.71 | 39.58 | 9.94 | 13.46 | ||||||||||
| MNIST | 39.13 | 49.04 | 44.17 | 11.35 | 20.94 | ||||||||||
| FMNIST | 44.19 | 54.75 | 39.11 | 10.64 | 10.62 | ||||||||||
| USPS | 42.04 | 48.32 | 23.49 | 6.13 | 5.28 | ||||||||||
| KMNIST | 47.65 | 53.92 | 24.83 | 6.19 | 10.88 |
D.5 Full results of VTAB experiments
In Section 5.3, we only showed the relative improvement of the test accuracy compared to non-pretraining. Here we will show the full test accuracy results. We keep the hyper-parameters consistent through all pre-training datasets. Table 4 clearly shows that the interpolation dataset with optimal weight assigned by our method can have a better performance than a naïve uniform weight. And with the same weight, our OTDD map will give a higher accuracy than Mixup because Mixup does not use the information from the reference dataset (see Figure 4).
Poor sub-pooling performance
We show the sub-pooling baseline as a non-trivial method to combine datasets. However, it performs poorly, and we believe there are two main reasons for this. First, this baseline wastes relevant label data, by discarding the original labels of the pretraining dataset and replacing them with the inputted nearest-neighbor label from the target examples. Secondly, it only uses the neighbors of the pet dataset, leaving all other datapoints unused.
| Transfer learning | OTDD map (optimal weight) | 22.60 1.01 |
| OTDD map (uniform weight) | 21.06 0.45 | |
| Mixup (optimal weight) | 17.45 2.2 | |
| Mixup (uniform weight) | 15.4 1.56 | |
| Caltech101 | 18.24 3.42 | |
| DTD | 11.46 0.68 | |
| Flowers102 | 11.11 1.92 | |
| Pooling | 14.88 0.57 | |
| Sub-pooling | 14.88 0.57 | |
| Non-transfer learning | 11.71 1.65 | |