Generalized Maximum Likelihood Estimation for Perspective-n-Point Problem
Abstract
The Perspective-n-Point (PnP) problem has been widely studied in the literature and applied in various vision-based pose estimation scenarios. However, existing methods ignore the anisotropy uncertainty of observations, as demonstrated in several real-world datasets in this paper. This oversight may lead to suboptimal and inaccurate estimation, particularly in the presence of noisy observations. To this end, we propose a generalized maximum likelihood PnP solver, named GMLPnP, that minimizes the determinant criterion by iterating the GLS procedure to estimate the pose and uncertainty simultaneously. Further, the proposed method is decoupled from the camera model. Results of synthetic and real experiments show that our method achieves better accuracy in common pose estimation scenarios, GMLPnP improves rotation/translation accuracy by / on TUM-RGBD and / on KITTI-360 dataset compared to the best baseline. It is more accurate under very noisy observations in a vision-based UAV localization task, outperforming the best baseline by in translation estimation accuracy.
I INTRODUCTION
Perspective-n-Point (PnP) is a classic robotics and computer vision problem that aims to recover the 6-DoF pose given a set of 3D object points in the world frame and the corresponding 2D image projection points on a calibrated camera. It is critical in various vision and robotics applications, e.g., vision-based localization [1, 2], 3D reconstruction [3], etc.
In the literature, most PnP solvers ignore the anisotropy of observation noise. In the context of vision-based pose estimation with respect to sparse features, existing works assume that the observation of object points and their projection on the image is accurate or with an isotropic Gaussian noise, i.e., with the covariance formed [4, 5]. However, this may not hold in real-world data, as the observation of object points is derived from different sensors’ measurements and techniques, along with the propagation of image point noise, resulting in anisotropic uncertainty. In general cases, the distribution of the noise may not be known in advance, thus how to estimate the observation uncertainty is an essential issue. Furthermore, there is a practical need for the generalization of PnP methods to cope with omnidirectional camera models. Most existing works build upon the perspective camera model (e.g., pinhole camera) [6, 5, 7], while the omnidirectional camera (e.g., fisheye camera) is often used in vision-based localization. Coupling the solver with the camera model restricts the application of these methods.
In this paper, we propose a generalized maximum likelihood PnP (GMLPnP) solver that considers the anisotropy of observation uncertainty. The term generalized comes from two aspects: (1) generalized least squares and (2) generalization for the camera model. The contributions of this paper are:
-
1.
Show that many real-world data have the property of anisotropic uncertainty.
-
2.
Devise a novel PnP solver featuring:
-
•
Its solution is statically optimal in the sense of maximum likelihood.
-
•
It simultaneously estimates the distribution parameter of the observation uncertainty by iterated generalized least squares (GLS) procedure.
-
•
The estimation is consistent, i.e., convergent in probability.
-
•
The proposed PnP solver is decoupled from the camera model.
-
•
-
3.
The proposed method is evaluated by experiments including synthetic and real-world data. An application in UAV localization by vision is shown in section V-C, which is the original motivation behind our work.
II RELATED WORKS
In the past several decades, researchers have dedicated themselves to finding the optimal and more efficient solution for the PnP problem. Algorithms that depend on a fixed number of points [8, 9] are practically sub-optimal since they do not make full use of the information of all the observed points, and their stability under noisy measurements is limited. Among the non-iterative methods, the most well-known efficient solution is the EPnP [6], which solves the least squares formulation based on principal component analysis. In DLS [10], a nonlinear object space error is minimized by the least squares.
Iterative methods usually provide better precision while yielding more computational cost. Classic Gauss-Newton refinement [11], or motion-only bundle adjustment (BA) in some literature [12], minimizes the reprojection error defined in the image plane and is often minimized on the manifold of or , forming an unconstrant non-linear optimization problem [13]. REPPnP [14] includes algebraic outlier rejection that removes sequentially eliminating outliers exceeding some threshold. PPnP [15] formulates an anisotropic orthogonal Procrustes problem. The error between the object and the reconstructed image points is minimized in a block relaxation [16] scheme. SQPnP [7] obtains the global minimum from the regional minimum computed with a sequential quadratic programming scheme starting from several initials. CPnP [4], analyzes and subtracts the asymptotic bias of a closed-form least squares solution, resulting in a consistent estimate. A very recent EPnP-based work ACEPnP [17] integrates geometry constraints into control points formulation and reformulates the LS to quadratic constraints quadratic programming. In general, iteration methods yield better accuracy, but they require a good initialization to avoid trapping in a local minima. Hence, the combination of non-iterative initialization and iterative refinement is commonly used by the methods mentioned above.
Many solutions are only geometrically optimal since they do not consider the uncertainties of the observations. Methods that involve observation uncertainty have been explored by researchers recently and are most relevant to our work. MLPnP [18] is a maximum likelihood solution to the PnP problem incorporating image observation uncertainty, thus statistically optimal. CEPPnP [19] formulates the PnP problem as a maximum likelihood minimization approximated by an unconstrained Sampson error function that penalizes the noisy correspondences. EPnPU and DLSU [5] are uncertainty-aware pose estimation methods based on EPnP and DLS, a modified motion-only BA is introduced to take 3D and 2D uncertainties into account. In the above methods that incorporate observation uncertainty, noise distribution is acquired by feature detector, triangulation sequence of images or prior knowledge of sensors. We argue that these prior may not be available in real-world applications, but the uncertainty can be estimated directly from the residuals of the error function.
In addition, formulation decoupled from the camera model is essential in many modern applications incorporating various camera models, e.g., the fisheye camera is widely used in visual SLAM [1, 2]. UPnP [20] is a linear, non-iterative unified method that is decoupled from the camera model and extends the solution to the NPnP (Non-Perspective-n-Point) problem. It solves the problem by a closed-form computation of all stationary points of the sum of squared object space errors. The DLS, MLPnP, and gOp [21] also include projection rays and formulate errors in object space, which can be solved by providing the unprojection function passing from pixels to projection rays.
III Problem Formulation
Given a set of observed object points and their corresponding projection on image plane of an unknown camera frame, PnP is aimed to recover the motion, i.e., rotation and translation . This paper considers general cases when the number of points is from dozens to hundreds in common vision-based localization tasks. Existing methods primarily aim to minimize the reprojection error defined on the normalized image plane, known as the gold standard [11]. This method is restricted to a perspective camera, whereas we are seeking a formulation that is decoupled from the camera model.
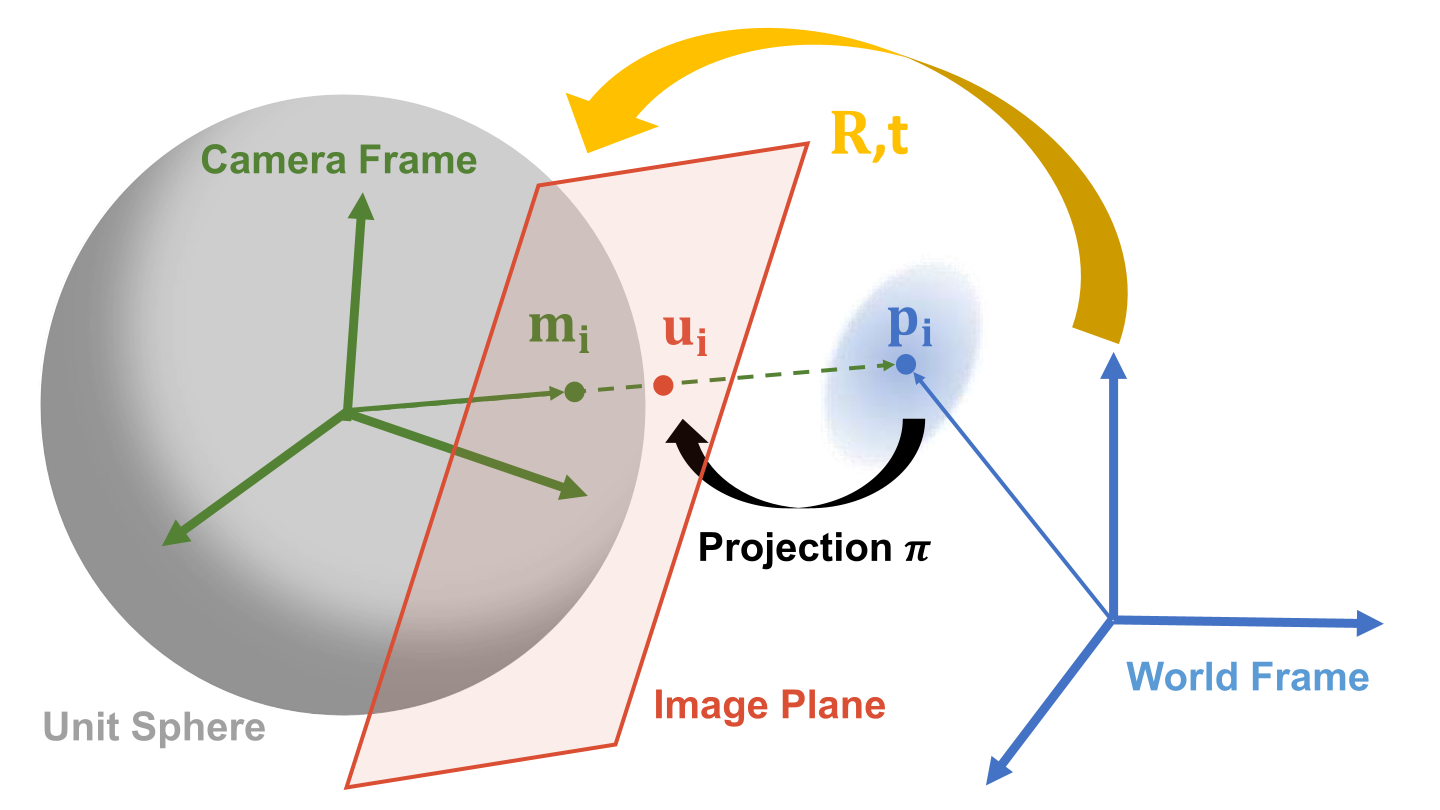
Considering the formulation in object space, define as the unit projection ray with , and as the scale factor (depth) of the corresponding point. The geometry relation is given by
| (1) |
where is the disturbance term. The unit projection ray is obtained by the image point and inverse projection function of the camera, e.g., for pinhole camera where is the intrinsic matrix. This is a similar formulation used in [18, 10, 22], shown in Fig. 1.
For the noise , we have the following assumption:
Assumption 1.
The observation is corrupted by zero mean Gaussian noise , and all observation are i.i.d. with covariance positive-definite.
In the literature [4, 5], the covariance matrix is often considered isotropic, i.e., , where is the identity matrix and is the standard deviation. We instead relax this assumption and argue the covariance can be anisotropic as in Assumption 1. The uncertainty of image points can be propagated into the object space [13, 18, 5]. The resulting random noise, represented by in (1), is modelled by Assumption 1. It is reasonable to assume to be positive-definite because the covariance matrix is positive semidefinite and when , the space spanned by observation noise collapses into a plane or a line, which is unlikely to happen.
IV Method
In this section, we first consider the maximum likelihood estimation of the PnP problem in object space when the parameter of noise distribution is known. Then, the method is generalized to simultaneously estimate the pose and infer the covariance of the noise distribution without prior knowledge, named GMLPnP. Finally, we discuss the consistency and convergence of the GMLPnP solver.
IV-A Maximum Likelihood Estimation with Uncertainty Prior
Given the model of (1) and Assumption 1, we relax the scale constraint, treating each as a free parameter as in [10]. When the noise uncertainty is known, we introduce maximum likelihood estimation as
Proposition 1.
The maximum likelihood estimation of transformation in object space is given by minimizing the error function
| (2) |
where is the Mahalanobis norm, and is the covariance matrix of the known noise distribution.
Proof.
Denote observations , parameters , and residual , the joint distribution of is
| (3) |
With covariance known, the log-likelihood is given by
| (4) | ||||
Thus minimizing (2) is equivalent to maximizing the log likelihood. ∎
The parameters in (2) are naturally divided into two blocks, namely the pose parameters and the scale parameters . We can optimize these two blocks by block relaxation [16], where each group of variables is alternatively estimated while keeping others fixed. The rotation is often minimized on the manifold of [13], thus formulating an unconstrained nonlinear optimization problem. The Jacobians of with respective to and is given by
| (5) |
where is to take the skew-symmetric matrix of a vector.
For the optimization of scale, by setting the partial derivation of w.r.t. to zero, we obtain
| (6) |
IV-B Generalized Maximum Likelihood Estimation
In more general cases, the uncertainty of the noise is unknown. Hence we develop a PnP solver by generalized nonlinear least squares estimator, which simultaneously estimates the pose and the covariance. We consider the case when there is a rough initial hypothesis of rotation and translation. In this section, we brought the idea introduced by [23, 24] to solve the regression for multiresponse data under the assumptions that the disturbance terms in different observations are uncorrelated, but the disturbance terms for different responses in the same observation have a fixed unknown covariance. This is called the iterated GLS procedure in [25].
Treating the covariance matrix as an unknown parameter, the log-likelihood of (4) becomes
| (7) | ||||
The minimization of (7) can be finished in two steps as described in [25]. We first fix and minimize (7) w.r.t. to by setting the derivative to zero, providing the conditional estimation
| (8) |
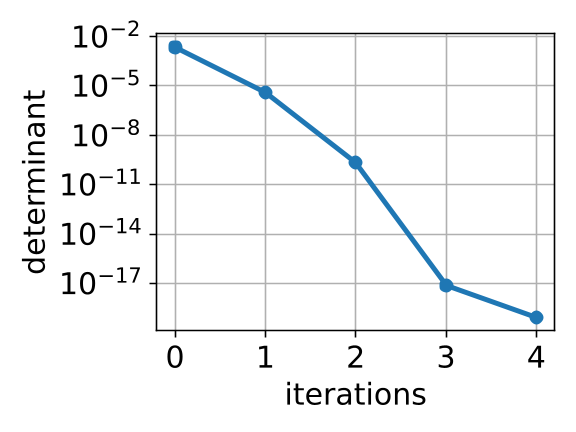
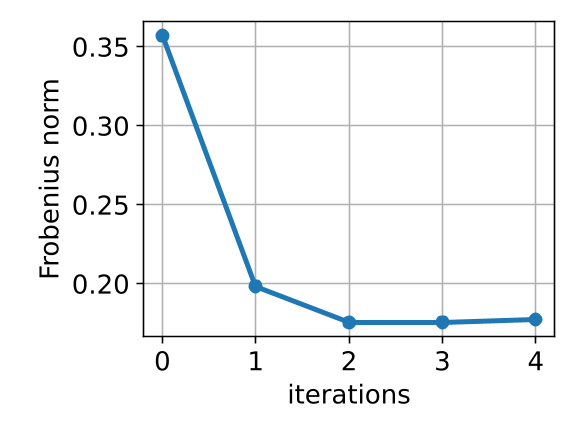
The resulting value of is then substituted back into (7), and the resulting function of is minimized with respect to , which is identical to minimizing (2). This technique of first eliminating to obtain a function of is called concentrating the likelihood [25]. We summarize the method in Algorithm 1. In practice, we found that two iterations are usually enough for convergence (as shown in Fig. 7), and the convergence threshold can be set as .
We introduce another interpretation of the minimization of (7). When substitute (8) into (7) gives the conditional log-likelihood
| (9) |
which is equivalent to directly minimizing . This is called the determinant criterion in [26]. Geometrically, corresponds to the square of the volume of the parallelepiped spanned by the residual vectors. Minimizing the determinant corresponds to minimizing the volume enclosed by the residual vectors.
IV-C Discussion on Consistency and Convergence
To discuss the asymptotic properties of the estimation of GMLPnP, consider our nonlinear model . Define set as the unit sphere in , so that . We rewrite the rotation as Lie algebra where . Then, the parameter is in a subset of denoted as , note here the scale factor is omitted as it depends on by (6). Denote the superscript as the true value. The generalized least squares estimator, is the value of which minimizes
| (10) |
where is a positive definite matrix, called iterated GLS procedure, where in our case it is the inverse of the covariance matrix (8),
We further make the following assumptions:
Assumption 2.
The function is continuous on .
Assumption 3.
and are closed, bounded (compact) subset of and respectively.
Assumption 3 is not a serious restriction, as most parameters are bounded by the physical constraints of the system being modeled [25]. In our case, it is reasonable to bound which avoids ambiguities related to multiple angle representations of the same rotation. The translation is bounded by the maximum measuring distance of the sensor (camera, LiDAR, etc.).
Assumption 4.
The observations are such that , where is the empirical distribution function and is a distribution function.
Assumption 4 indicates that the sample points is a random sample from some distribution with distribution function .
Assumption 5.
If , then .
It has been given by Malinvaud et al. [24] that if Assumptions 1 to 5 hold, then the estimation and
| (11) |
are consistent estimators of the true value and respectively, i.e.,
| (12) |
Furthermore, under these assumptions and certain conditions, Phillips et al. [27] show that the iterated GLS procedure converges for large enough and the limit point is independent of the starting value of .
V Experiments
We conduct synthetic and real data experiments to evaluate our method, GMLPnP, by comparing with iterative and non-iterative PnP solvers listed in Table I. All experiments are conducted via a desktop with Intel Core i7-9700F CPU. The GMLPnP algorithm is implemented in a graph optimization manner with [28] library, and the initial guess is given by MLPnP [18].
| Method | Iterative | Uncertainty | Camera | Impl. |
|---|---|---|---|---|
| EPnP [6] | Perspective | C++ | ||
| BA [11] | ✓ | Perspective | C++ | |
| PPnP [15] | ✓ | Perspective | C++ | |
| SQPnP [7] | ✓ | Perspective | C++ | |
| CPnP [4] | (✓) | Perspective | C++ | |
| UPnP [20] | (✓) | Decoupled | C++ | |
| MLPnP [18] | (✓) | ✓ | Decoupled | C++ |
| REPPnP [14] | ✓ | Perspective | MATLAB | |
| EPnPU [5] | (✓) | ✓ | Perspective | MATLAB |
| DLSU [5] | (✓) | ✓ | Perspective | MATLAB |
| GMLPnP(ours) | ✓ | ✓ | Decoupled | C++ |
V-A Synthetic Experiments
V-A1 Experiment setup
In the simulation, we assume a pinhole camera with a focal length of pixels, resolution pixels, and principal point in the image center. A point cloud is randomly generated in front of the camera within the range of in the camera frame. The world frame’s origin is set at the center of the point cloud under a random rotation to the camera frame. The 3D-2D correspondences are obtained by projecting the point cloud to the image plane. We disturb the observation of each object point with i.i.d. zero-mean Gaussian noise with anisotropic covariance , which are composed of randomly generated rotation and randomly drawn within the interval . The 2D projection noise is generated analogously and added to the image points. We show a reference by bringing a method GMLPnP∗ that minimizes (2) with the true covariance matrix known and fixed. The methods that incorporate uncertainties, namely the MLPnP, EPnPU and DLSU, are fed with ground truth covariance. All the simulations are run 500 times, and the results are taken as the mean value.
V-A2 Metrics
Absolute rotation error and relative translation error [19, 14, 20, 4] are used to evaluate estimation accuracy. The absolute rotation error is defined as in degrees, where and are the -th column of the ground truth rotation matrix and PnP estimation . The relative translation error is defined as , where and are the ground truth and estimated translation vector.
V-A3 Results
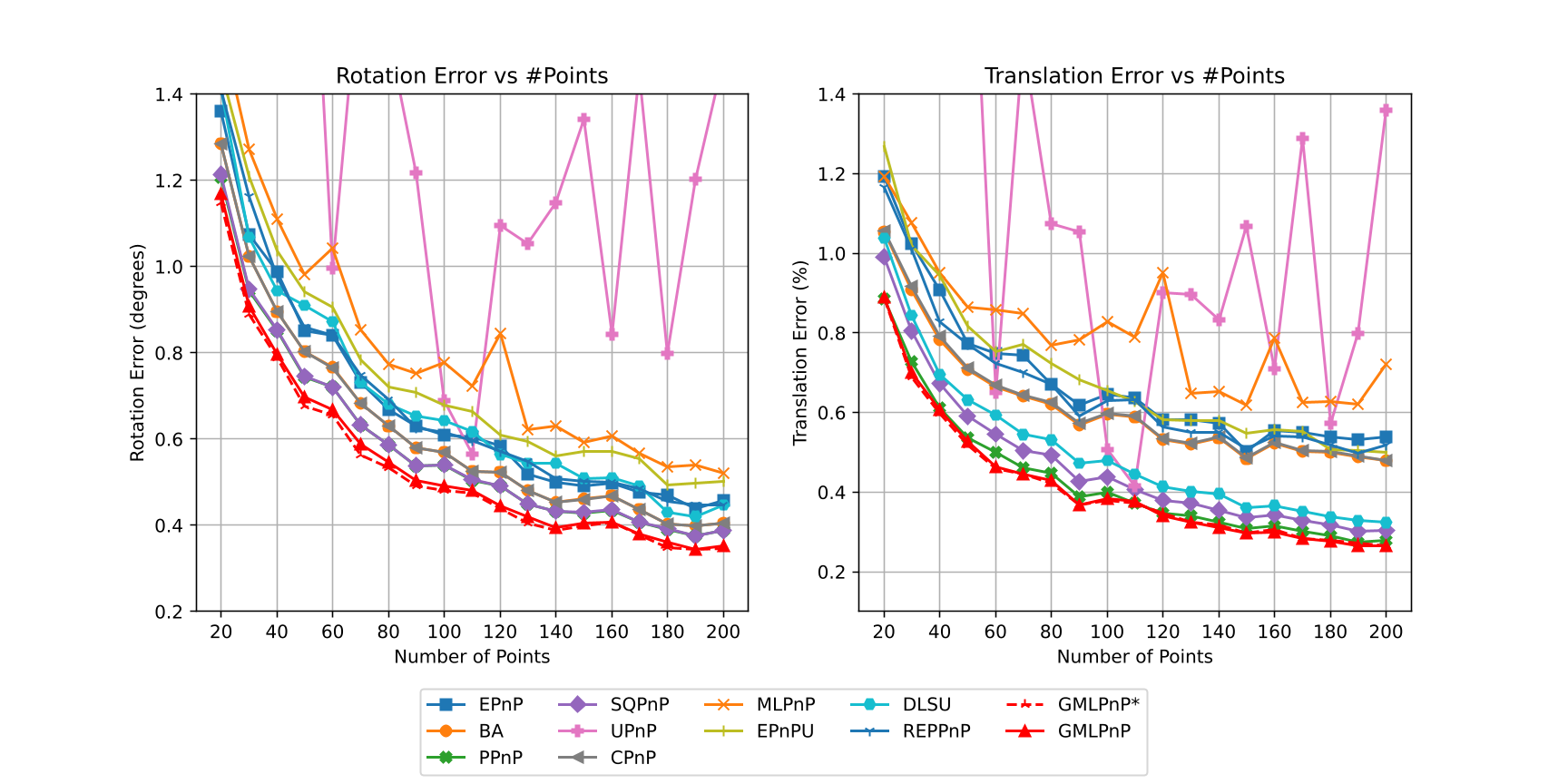
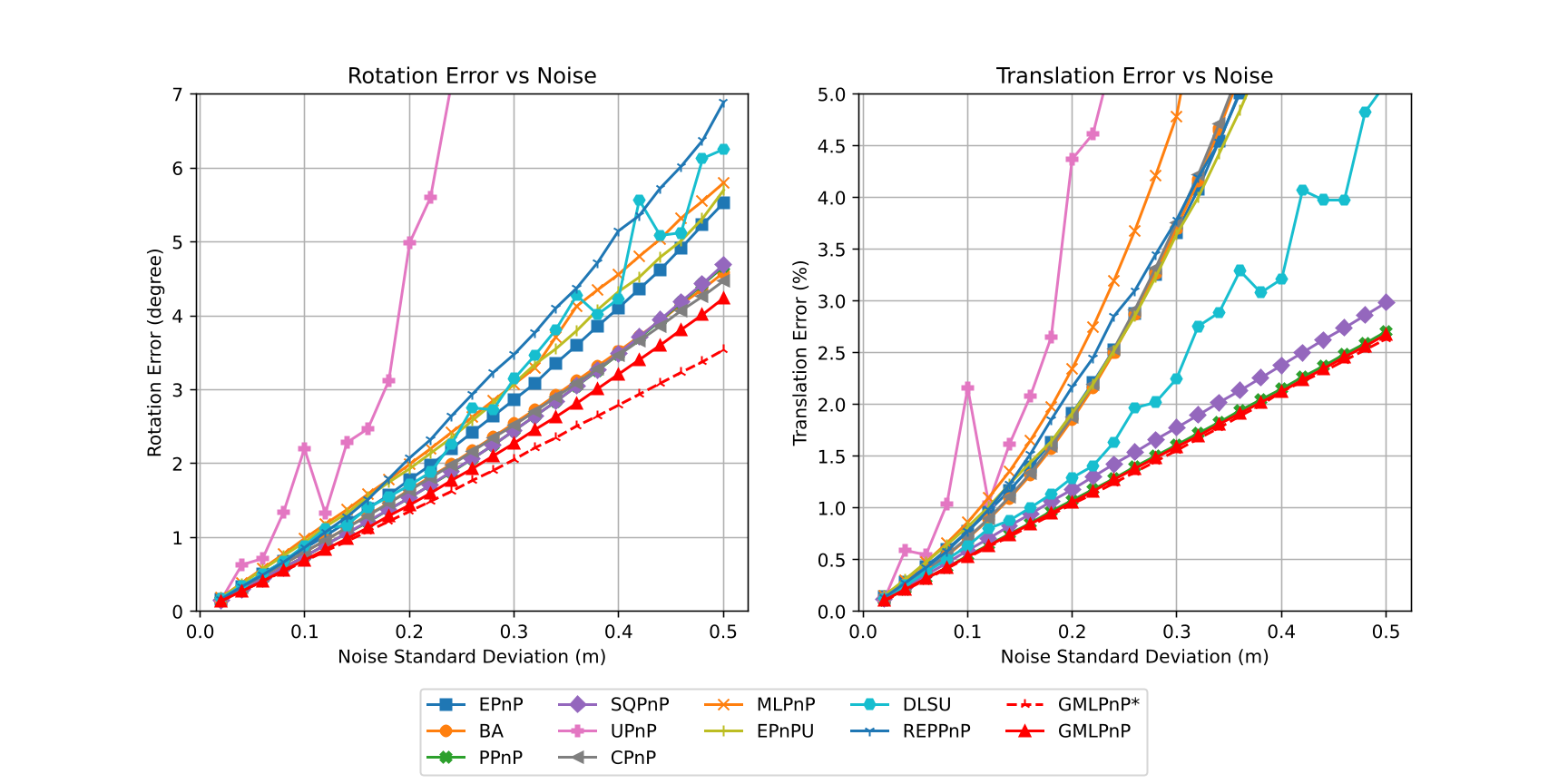
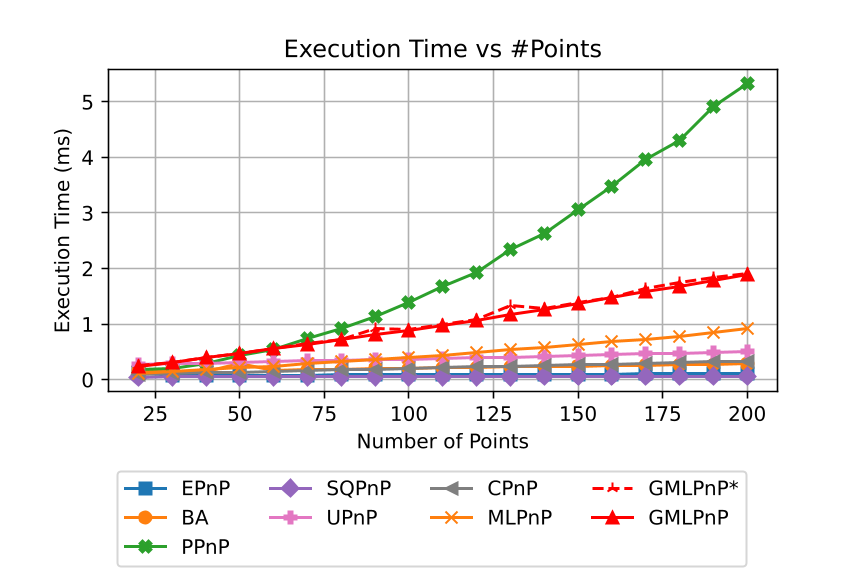
Fig. 2 shows the pose estimation error with respect to the number of points. The is set to be meters for object point noise and pixel for the image point noise. Our methods achieve the best accuracy. The estimation accuracy with respect to noise level is shown in Fig. 3, the number of points is set to be , and object point noise varies from 0.02 to 0.5 meters, the corresponding image point noise varies from 0.2 pixels to 5 pixels accordingly. GMLPnP∗ reasonably achieves the highest precision with the prior knowledge of uncertainty. GMLPnP does not lag behind by too much due to the simultaneous estimation of pose and uncertainty and is more accurate than all other methods in both synthetic experiments above. As the noise level increases in Fig. 3, the accuracy of our method can still remain relatively high. We compare the computing time of the algorithms implemented in C++, as the MATLAB code is much more inefficient and not comparable, results are shown in Fig. 4. The execution time of GMLPnP grows linearly and is fast enough for real-time use.
V-A4 Convergence and residual analysis
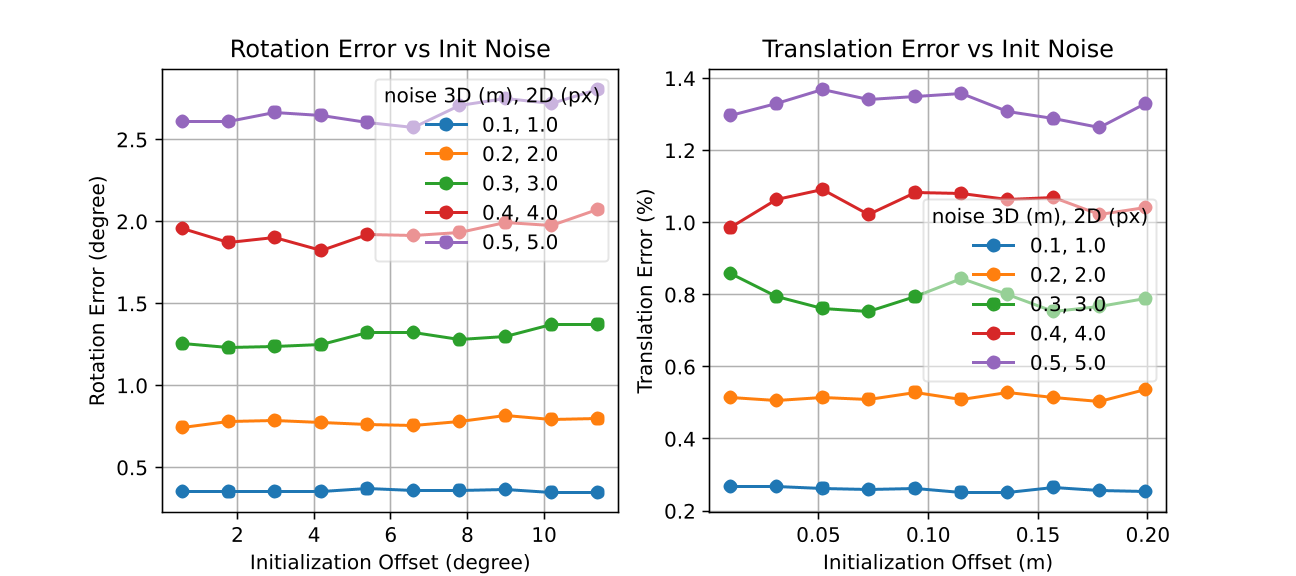
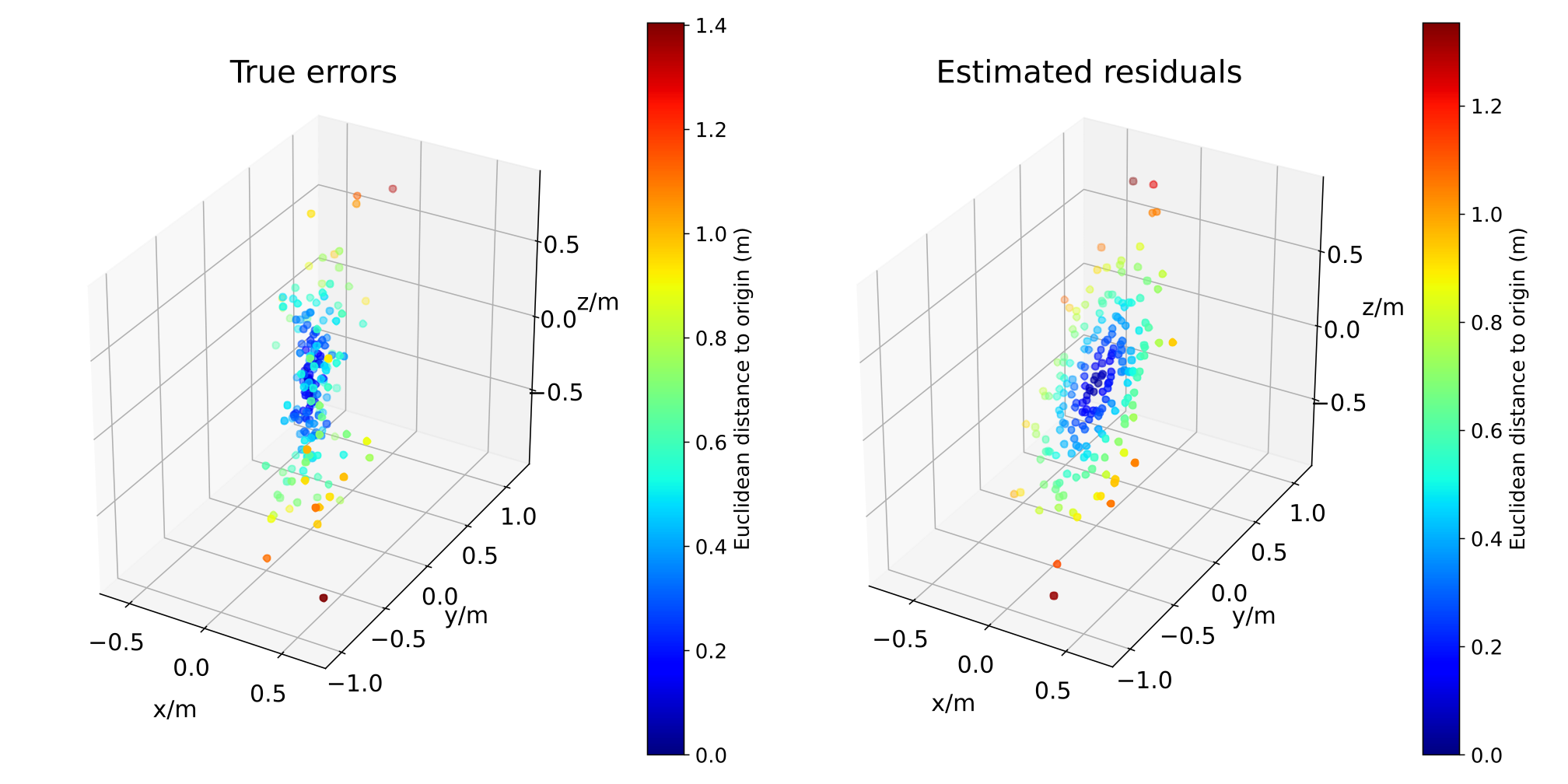
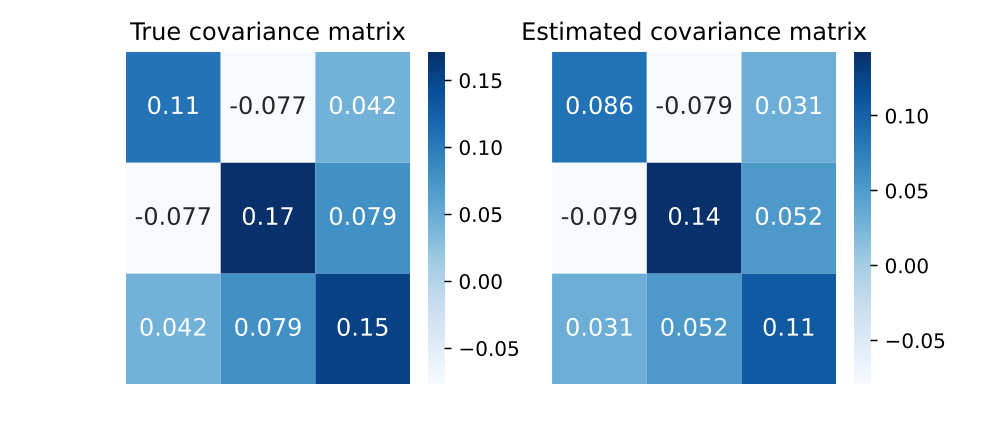
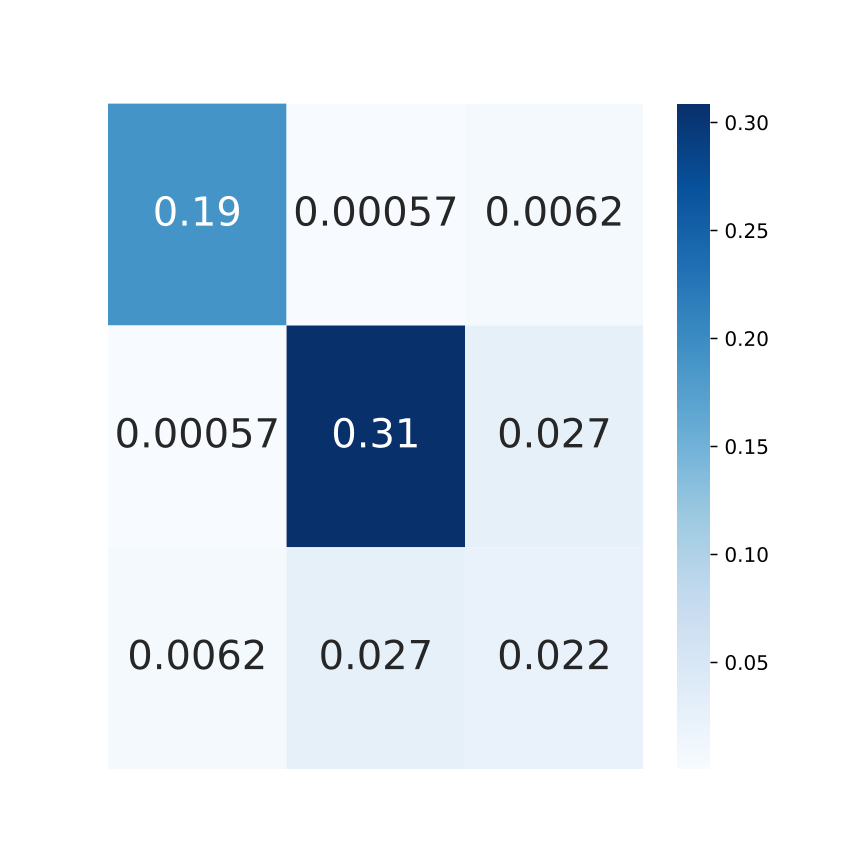
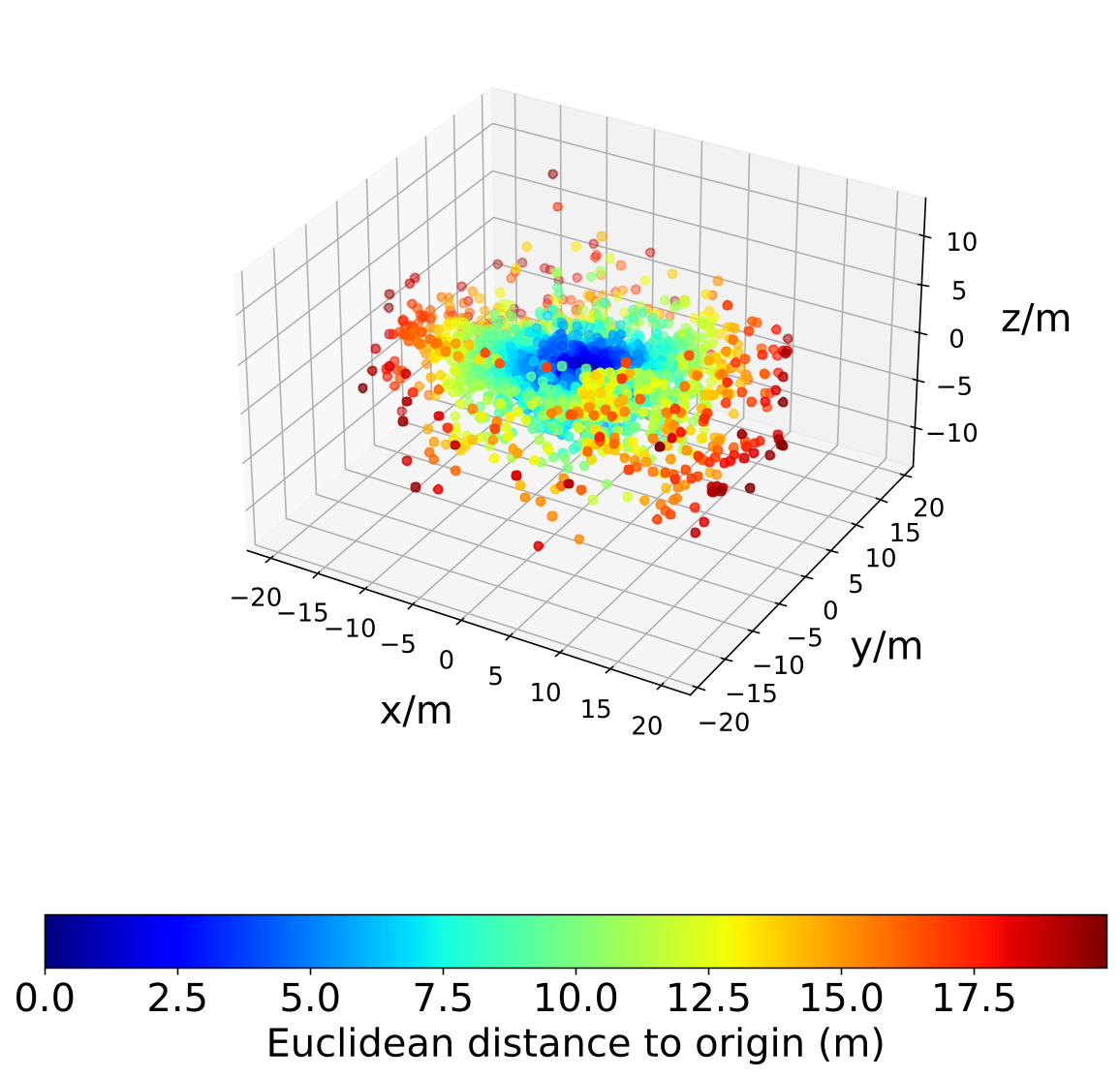
We conduct a convergence and residual analysis experiment setup with 200 points and to analyse the uncertainty estimation ability and convergence speed of GMLPnP. These simulations are performed 500 trials, and mean values are reported. Fig. 7 shows the determinate of the estimated covariance, which is minimized iteratively and matches (9). Fig. 7 shows the Frobenius norm of the difference between the estimated covariance and true covariance, i.e., . These results indicate that our algorithm typically converges in two iterations. Fig. 8 visualizes a specific case in the synthetic experiment. Fig. 8(a) plots the true noise added on the object point observations and the residuals when our algorithm converges, demonstrating that the residuals may contain important information about the uncertainties that the previous works ignore. Fig. 8(b) shows the true and estimated covariance, which indicates our algorithm can recover the uncertainty well. As an iterative method, we test its robustness to the initialization value in Fig 5. Results indicate that our method converges consistently under random initial offset and noisy observation.
V-B Motion Estimation with Real Data
Two real-world datasets, TUM-RGBD [29] (with pinhole camera) and KITTI-360 [30] (with fisheye camera), are used to evaluate the performance of our proposed method. We report the absolute rotation and translation error.
V-B1 TUM-RGBD dataset
In the TUM-RGBD dataset, the images are recorded by a handheld or robot-mounted RGB-D camera, the RGB camera is a pinhole camera. We sample image pairs with a temporal interval of 0.1 seconds from the freiburg1 sequences of the dataset. A total of 1662 pairs are sampled. In each pair, the pixel correspondences are registered by ORB descriptor and are brute-force matched with RANSAC outlier rejection. We associate the temporal first image with its corresponding depth map to get the object point observations. Then relative motion between the two frames is estimated by PnP solvers. Note that since we have little prior knowledge about the observation uncertainty, we initiate it as isotropic, i.e., the covariance . The estimation errors are shown in Table II. GMLPnP achieves the best precision, promoting the best baseline by in rotation (compared with BA) and in translation (compared with SQPnP).
| TUM-RGBD | KITTI-360 | |||
| (∘) | (cm) | (∘) | (cm) | |
| EPnP | 1.532 | 1.872 | - | - |
| BA | 0.915 | 1.728 | - | - |
| PPnP | 1.060 | 2.334 | - | - |
| SQPnP | 1.294 | 1.712 | - | - |
| UPnP | 0.992 | 1.843 | 0.105 | 1.365 |
| CPnP | 0.974 | 1.849 | - | - |
| MLPnP | 1.173 | 1.938 | 0.086 | 1.200 |
| EPnPU | 1.461 | 1.771 | - | - |
| DLSU | 0.994 | 1.880 | - | - |
| REPPnP | 1.885 | 2.357 | - | - |
| GMLPnP(ours) | 0.872 | 1.677 | 0.070 | 0.979 |
V-B2 KITTI-360 dataset
In the KITTI-360 dataset, a ground vehicle is mounted with omnidirectional fisheye cameras (camera 3, calibrated with MEI model [31]) along with LiDAR. Analogous to the TUM-RGBD setup, we sample image pairs in a sequence captured by a monocular camera with a temporal interval of 3 consecutive frames. The LiDAR points captured along with the first frame are projected on the corresponding frame and tracked on the second frame with Lucas-Kanade Optical Flow. We sample from sequences 00 to 10, a total of 2138 pairs are used to evaluate. Only methods decoupled from camera model are evaluated. The results are shown in Table II. GMLPnP generalizes well on the omnidirectional camera, outperforming the best baseline MLPnP by and in rotation and translation error respectively.
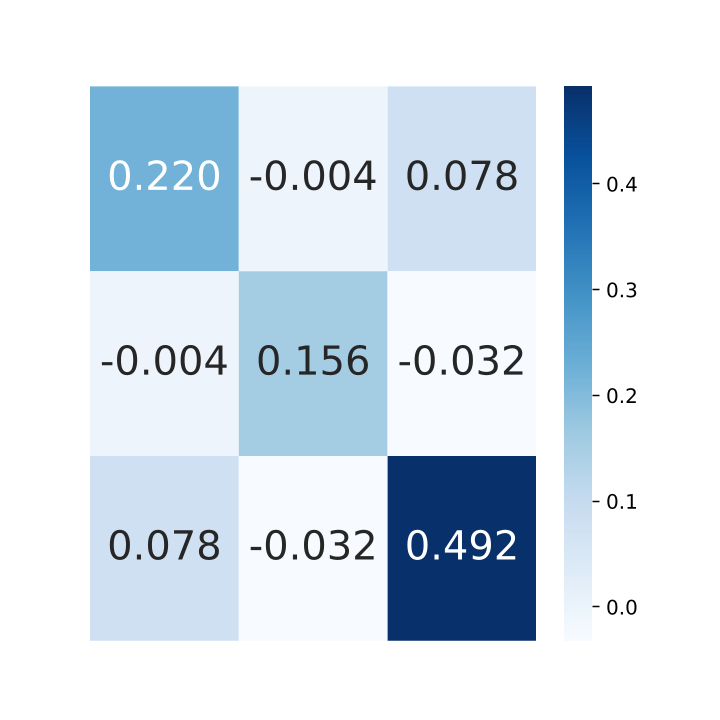
V-B3 Anisotropic uncertainties of real-world data
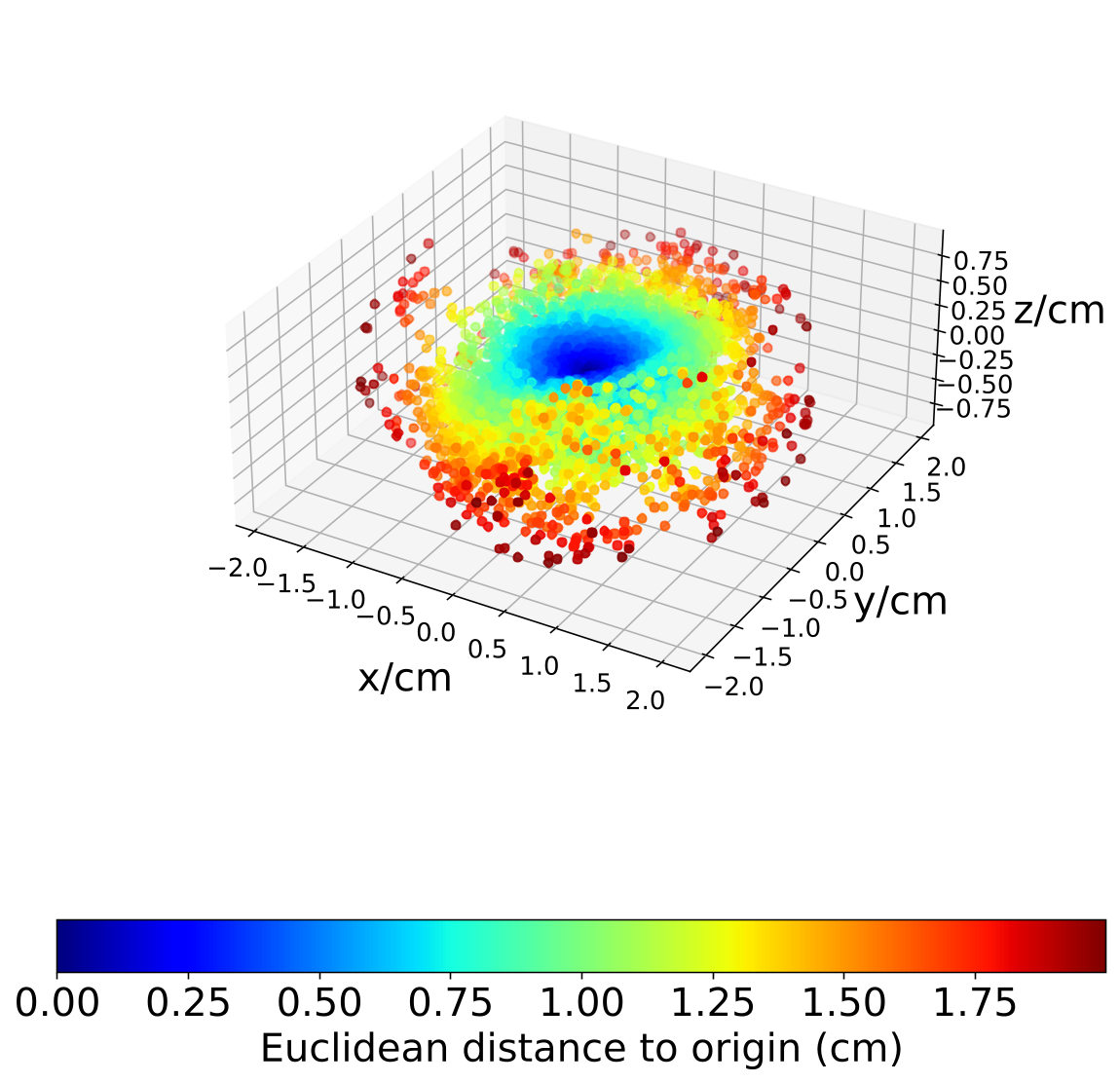
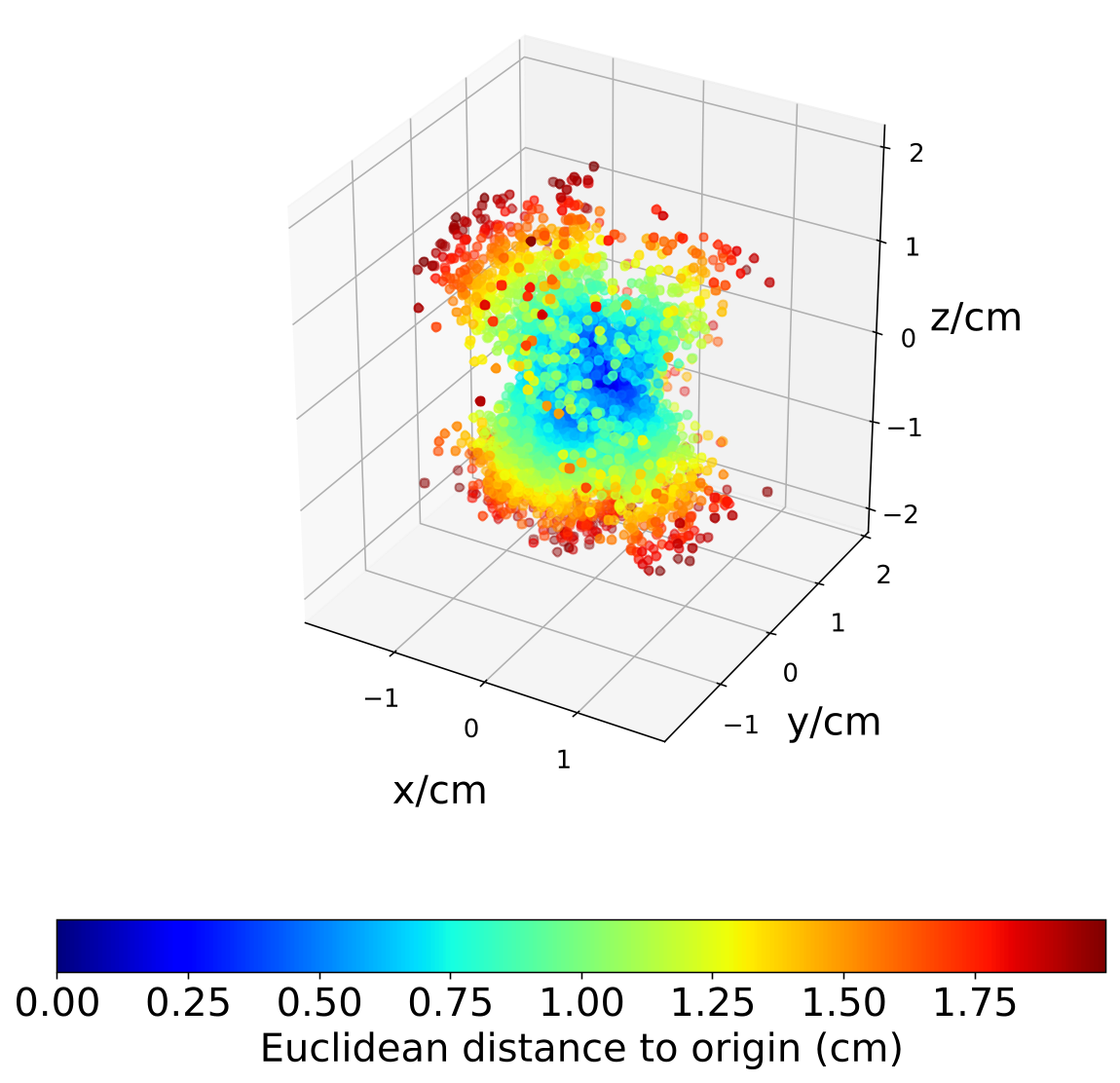
We show the anisotropic uncertainties of real-world data in Fig. 9 by plotting the residuals and covariance matrix. The object points observed in the first frame are transformed to the second frame by ground truth relative motion to obtain the depth of these points in the second frame. Then, the object points in the second frame are reconstructed by the relative motion, projection rays and the corresponding depths. We get the object point residuals by the observation in the first frame and reconstruction in the second frame. The resulting residuals and covariance show an obvious anisotropic property in these RGB-D and RGB-LiDAR data.
V-C Application in Vision-based UAV localization
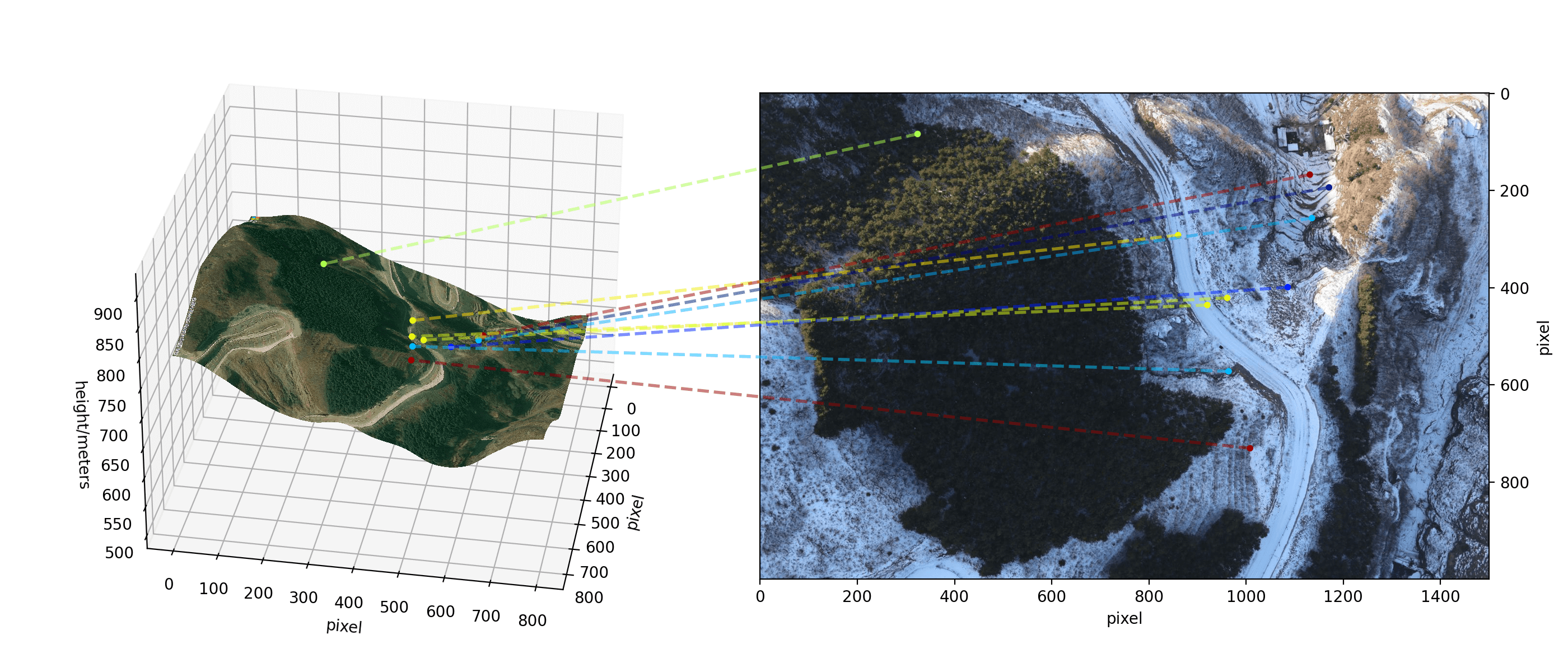
Vision-based localization with a monocular camera is a promising navigation technique that is low-cost, low-weight and low-power. It can be complementary when GNSS fails [32, 33, 34, 35]. This section presents a vision-based localization method relying on geo-tagged satellite images and a digital elevation model (DEM), as demonstrated in Fig. 10(a). We assume the reference satellite image is first retrieved by geo-localization technique [33, 36]. By combining the geo-tag of the satellite image and the DEM model, we observe each pixel’s longitude, latitude and elevation, as shown on the left in Fig. 10(a). Then, cross-domain image registration is applied between the satellite image and the onboard camera recorded image (right in Fig. 10(a)) by utilizing the state-of-the-art feature extractor SuperPoint [37] and matcher LightGlue [38]. Finally, this UAV visual localization problem is essentially concluded as a PnP problem. Note that the precision of the DEM (providing the elevation) and the satellite images’ geo-tag (providing the geodetic position) are inconsistent since they are measured by different techniques, resulting in the uncertainty of the observation anisotropic.
V-C1 Data Collection and Preparation
The data was recorded by a fixed-wing UAV’s onboard sensors on a flight in Fangshan, Beijing, on January 4th 2024, at 200 to 400 meters above the ground, covering a distance of kilometers. Images were collected by a downward-facing SLR camera mounted strap-down on the belly of the aircraft. 196 images are recorded with resolution pixels and down-sampled to pixels. Ground truth poses are obtained by a set of GNSS-INS navigation devices. Reference satellite images are collected using the Bing Maps API, with a ground resolution of around 0.4 meters per pixel. The DEM data is from Copernicus DEM GLO-30 with a 30-meter resolution (4 meters vertical accuracy) and interpolated to align with the satellite image.
V-C2 Results
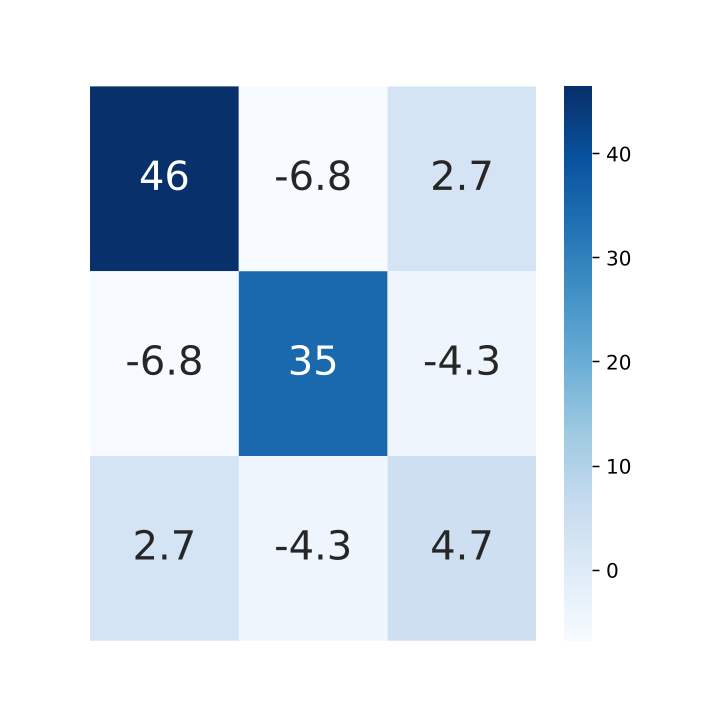
The localization errors by different methods are shown in Table III, among which GMLPnP achieves the best results, especially for the estimation of the elevation. The overall translation is more accurate than the best baseline PPnP by , particularly in elevation. Some methods fail to localize due to the noisy observation, while our method are robust to provide more accurate results. The uncertainty of the data is also shown in Fig. 10(b) and Fig. 10(c) with the same setup in section V-B3. This experiment presents a method for the localization of UAV which is promising to be the complementary or replacement of onboard GNSS system in the event of a noisy or unreliable GNSS signal.
| rotation (degrees) | translation (meters) | |||||
| roll | pitch | yaw | east | north | elevation | |
| EPnP | 13.6 | 17.8 | 20.3 | 8.6 | 9.5 | 28.0 |
| BA | 11.6 | 14.0 | 15.8 | 6.7 | 9.1 | 28.3 |
| PPnP | 11.6 | 14.0 | 15.7 | 6.6 | 9.1 | 27.9 |
| SQPnP | 12.0 | 16.0 | 17.5 | 7.8 | 8.5 | 27.4 |
| UPnP | 33.8 | 35.8 | 40.0 | 16.8 | 17.2 | 93.3 |
| CPnP | 48.1 | 56.4 | 94.6 | 13.7 | 12.9 | 761.5 |
| MLPnP | 95.4 | 94.1 | 29.3 | 11.1 | 13.1 | 120.2 |
| EPnPU | 38.3 | 40.4 | 20.1 | 8.9 | 10.0 | 135.5 |
| DLSU | 25.0 | 33.4 | 40.9 | 14.3 | 19.8 | 52.6 |
| REPPnP | 31.4 | 26.8 | 33.7 | 11.7 | 11.4 | 83.0 |
| GMLPnP(ours) | 11.0 | 12.9 | 14.6 | 7.2 | 7.8 | 18.3 |
VI Conclusion
In this paper, we propose GMLPnP, a generalized maximum likelihood PnP solver under the discovery of anisotropy uncertainty in many real-world data. The proposed method incorporates the anisotropic uncertainty of feature points into the PnP problem. Experimental results demonstrate increased accuracy in both synthetic and real data. This work is motivated initially by the vision-based localization of UAVs and is meant to explore a more accurate estimation under circumstances where the observations are very noisy. However, our work only considers the case of one central camera and supposes an initial guess is available for pose estimation. Methods for multiple camera systems with both central and non-central cameras are needed for further exploration.
References
- [1] C. Campos, R. Elvira, J. J. G. Rodríguez, J. M. M. Montiel, and J. D. Tardós, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,” IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021.
- [2] T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018.
- [3] J. L. Schönberger and J.-M. Frahm, “Structure-from-motion revisited,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [4] G. Zeng, S. Chen, B. Mu, G. Shi, and J. Wu, “Cpnp: Consistent pose estimator for perspective-n-point problem with bias elimination,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 1940–1946.
- [5] A. Vakhitov, L. Ferraz, A. Agudo, and F. Moreno-Noguer, “Uncertainty-aware camera pose estimation from points and lines,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 4659–4668.
- [6] V. Lepetit, F. Moreno-Noguer, and P. Fua, “Epnp: An accurate o(n) solution to the pnp problem,” International journal of computer vision, vol. 81, pp. 155–166, 2009.
- [7] G. Terzakis and M. Lourakis, “A consistently fast and globally optimal solution to the perspective-n-point problem,” in Computer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer International Publishing, 2020, pp. 478–494.
- [8] L. Kneip, D. Scaramuzza, and R. Siegwart, “A novel parametrization of the perspective-three-point problem for a direct computation of absolute camera position and orientation,” in CVPR 2011, 2011, pp. 2969–2976.
- [9] M. Bujnak, Z. Kukelova, and T. Pajdla, “A general solution to the p4p problem for camera with unknown focal length,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008, pp. 1–8.
- [10] J. A. Hesch and S. I. Roumeliotis, “A direct least-squares (dls) method for pnp,” in 2011 International Conference on Computer Vision, 2011, pp. 383–390.
- [11] R. Hartley and A. Zisserman, Multiple view geometry in computer vision. Cambridge university press, 2003.
- [12] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardós, “Orb-slam: A versatile and accurate monocular slam system,” IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
- [13] W. Förstner, “Minimal representations for uncertainty and estimation in projective spaces,” in Asian Conference on Computer Vision. Springer, 2010, pp. 619–632.
- [14] L. Ferraz, X. Binefa, and F. Moreno-Noguer, “Very fast solution to the pnp problem with algebraic outlier rejection,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 501–508.
- [15] V. Garro, F. Crosilla, and A. Fusiello, “Solving the pnp problem with anisotropic orthogonal procrustes analysis,” in 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, 2012, pp. 262–269.
- [16] J. De Leeuw, “Block-relaxation algorithms in statistics,” in Information Systems and Data Analysis: Prospects—Foundations—Applications. Springer, 1994, pp. 308–324.
- [17] Q. Sun, T. Zhang, G. Zhang, K. Wang, D. Zhu, J. Li, and X. Zhang, “Efficient solution to pnp problem based on vision geometry,” IEEE Robotics and Automation Letters, vol. 9, no. 4, pp. 3100–3107, 2024.
- [18] S. Urban, J. Leitloff, and S. Hinz, “Mlpnp - a real-time maximum likelihood solution to the perspective-n-point problem,” ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. III-3, pp. 131–138, 2016. [Online]. Available: https://isprs-annals.copernicus.org/articles/III-3/131/2016/
- [19] L. Ferraz Colomina, X. Binefa, and F. Moreno-Noguer, “Leveraging feature uncertainty in the pnp problem,” in Proceedings of the BMVC 2014 British Machine Vision Conference, 2014, pp. 1–13.
- [20] L. Kneip, H. Li, and Y. Seo, “Upnp: An optimal o(n) solution to the absolute pose problem with universal applicability,” in Computer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 127–142.
- [21] K. SHREE, “A general imaging model and a method for finding its parameters,” in Proceedings of ICCV, 2001, 2001.
- [22] G. Schweighofer and A. Pinz, “Globally optimal o (n) solution to the pnp problem for general camera models.” in BMVC. Citeseer, 2008, pp. 1–10.
- [23] A. Zellner, “An efficient method of estimating seemingly unrelated regressions and tests for aggregation bias,” Journal of the American Statistical Association, vol. 57, no. 298, pp. 348–368, 1962. [Online]. Available: http://www.jstor.org/stable/2281644
- [24] E. Malinvaud, Statistical Methods of Econometrics. North-Holland Publishing Company, 1980.
- [25] G. A. Seber and C. J. Wild, “Nonlinear regression. hoboken,” New Jersey: John Wiley & Sons, vol. 62, no. 63, p. 1238, 2003.
- [26] D. Bates, “Nonlinear regression analysis and its applications,” Wiley Series in Probability and Statistics, 1988.
- [27] P. C. B. Phillips, “The iterated minimum distance estimator and the quasi-maximum likelihood estimator,” Econometrica, vol. 44, pp. 449–460, 1976.
- [28] R. Kümmerle, G. Grisetti, H. Strasdat, K. Konolige, and W. Burgard, “G2o: A general framework for graph optimization,” in 2011 IEEE International Conference on Robotics and Automation, 2011, pp. 3607–3613.
- [29] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in Proc. of the International Conference on Intelligent Robot Systems (IROS), Oct. 2012.
- [30] Y. Liao, J. Xie, and A. Geiger, “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,” Pattern Analysis and Machine Intelligence (PAMI), 2022.
- [31] C. Mei and P. Rives, “Single view point omnidirectional camera calibration from planar grids,” in Proceedings 2007 IEEE International Conference on Robotics and Automation, 2007, pp. 3945–3950.
- [32] H. Goforth and S. Lucey, “Gps-denied uav localization using pre-existing satellite imagery,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 2974–2980.
- [33] A. Shetty and G. X. Gao, “Uav pose estimation using cross-view geolocalization with satellite imagery,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 1827–1833.
- [34] B. Patel, T. D. Barfoot, and A. P. Schoellig, “Visual localization with google earth images for robust global pose estimation of uavs,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 6491–6497.
- [35] J. Kinnari, F. Verdoja, and V. Kyrki, “Season-invariant gnss-denied visual localization for uavs,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 232–10 239, 2022.
- [36] T. Wang, Z. Zheng, C. Yan, J. Zhang, Y. Sun, B. Zheng, and Y. Yang, “Each part matters: Local patterns facilitate cross-view geo-localization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 2, pp. 867–879, 2022.
- [37] D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self-supervised interest point detection and description,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018.
- [38] P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “LightGlue: Local Feature Matching at Light Speed,” in ICCV, 2023.