Generalized Bernoulli Process and Fractional Binomial Distribution
Abstract
Recently, a generalized Bernoulli process (GBP) was developed as a stationary binary sequence whose covariance function obeys a power law. In this paper, we further develop generalized Bernoulli processes, reveal their asymptotic behaviors, and find applications. We show that a GBP can have the same scaling limit as the fractional Poisson process. Considering that the Poisson process approximates the Bernoulli process under certain conditions, the connection we found between GBP and the fractional Poisson process is thought of as its counterpart under long-range dependence. When applied to indicator data, a GBP outperforms a Markov chain in the presence of long-range dependence. Fractional binomial models are defined as the sum in GBPs, and it is shown that when applied to count data with excess zeros, a fractional binomial model outperforms zero-inflated models that are used extensively for such data in current literature.
keywords:
1 Introduction
The binomial and Poisson models are used for counting a number of events. Because of their common key assumptions on the memoryless property and constant rate of events, the Poisson distribution can approximate the binomial distribution. In practice, the assumptions often fail, resulting in overdispersion/excess zeros in count data. There have been numerous models developed in the past for such data, among them are zero-inflated models and generalized linear-type models Skellam (1948); Altham (1978); Kadane (2016); Wedderburn (1974); Consul (1989); Lambert (1992); Conway and Maxwell (1962).
Some models were developed through a correlated structure between events. In Rodrigues et al. (2013), the Markov-correlated Poisson process and Markov-dependent binomial distribution were developed through Markov-dependent Bernoulli trials. In Borges et al. (2012), a new class of correlated Poisson process and correlated weighted Poisson process was proposed with equicorrelated uniform random variables.
In Lee (2021b), a generalized Bernoulli process (GBP) was defined as a stationary binary sequence whose covariance function decreases slowly with a power law. This is called long-range dependence (LRD), also called long-memory property, and a stochastic process with LRD shows different large-scale behavior than the “usual” stationary process whose covariance function decays exponentially fast. LRD has been observed in many fields such as hydrology, econometrics, earth science, etc, and there have been several approaches to define LRD. For more information on LRD, see Samorodnitsky (2018). The estimation method for parameters in GBP and its application to earthquake data can be found in Lee (2021a),
In 2003, Nick Laskin discovered the fractional Poisson process by the fractional Kolmogorov-Feller equation that governs the non-Markov dependence structure. In the fractional Poisson process, events no longer independently occur, and inter-arrival time follows the first family of Mittag-Leffler distribution which is heavy-tail distribution Laskin (2003). Long-memory property of the fractional Poisson process was investigated in Biard and Saussereau (2014).
In this paper, we further develop generalized Bernoulli processes, investigate their asymptotic properties, and find applications. It turns out that there is an interesting connection between a GBP and the fractional Poisson process. Both can have the same scaling limit to the second family of Mittag-Leffler distribution, and in both GBP and fractional Poisson process, the interarrival time follows a heavy-tail distribution. Therefore, the large-scale behavior of the GBP is similar to that of the fractional Poisson process, and the GBP is considered to be a discrete-time counterpart of the fractional Poisson process.
In the application of GBPs to indicator data in economics, it is shown that a GBP outperforms a Markov-dependent Bernoulli process when LRD is present in the data. Fractional binomial models are defined as the sum of the first variables in the GBPs, and it is shown that when applied to count data with over-dispersion/excess zeros, a fractional binomial model outperforms zero-inflated models.
In Section 2, we will review the GBP proposed in Lee (2021b), and define a new generalized Bernoulli process. In Section 3, we will compare the GBPs and the fractional Poisson process by examining their asymptotic properties. In Section 4, we will continue to compare these distributions through simulations. Section 5 shows the applications of the GBPs and fractional binomial models to real data. All the proofs and technical results can be found in Supplementary material. Throughout this paper, we assume that and unless mentioned otherwise. For any set is the number of elements in , with means as For notational convenience, we denote by
2 Generalized Bernoulli processes and fractional binomial distributions
2.1 Generalized Bernoulli process I and fractional binomial distribution I
We first review the generalized Bernoulli process developed in Lee (2021b). We will call it the generalized Bernoulli process I (GBP-I) to differentiate it from what we will develop in this paper. The GBP-I, , was defined with parameters, that satisfy the following assumption.
Assumption 1.
and
Under Assumption 1, the GBP-I is well defined with the following probabilities.
and for any disjoint sets
| (1) |
and
| (2) |
The following operators were defined in Lee (2021b) to express the above probabilities more conveniently.
Definition 1.
Define the following operation on a set with
If , define , and if
Definition 2.
Define for disjoint sets, with
If
Using the operators, the probabilities in the GBP-I can be expressed as
for disjoint sets The GBP-I is a stationary process with covariance function
When the GBP-I possesses LRD since The sum of the first variables in the GBP-I was defined as the fractional binomial random variable whose mean is , and if its variance is asymptotically proportional to We will call it fractional binomial distribution I, and denote it by or simply . When becomes the regular binomial random variable whose parameters are
2.2 Generalized Bernoulli process II and fractional binomial distribution II
We define the generalized Bernoulli process II (GBP-II), , , that has three parameters and the fractional binomial random variable II, To ease our notation, and are used interchangeably, and will replace when there is no confusion. For the GBP-II, it is assumed that the parameters satisfy the following condition.
Assumption 2.
and
We will show that the GBP-II is well-defined under Assumption 2 with the following probabilities. For is defined with for and for any
| (3) |
where
Definition 3.
Define the following operation on a set
If , then we define If (when ), then
For example, if
Definition 4.
Define for disjoint sets such that and
If then
The joint probabilities in GBP-II is defined with (3) and (1-2) for any disjoint sets , i.e., by the inclusion-exclusion principle. This can be succinctly written as
| (4) |
To show that the GBP-II is well-defined, we have to verify that for any disjoint sets for any
Proposition 2.1.
Under Assumption 2, for any and any disjoint sets
From the result of Proposition 2.1, the GBP-II is well defined stationary binary sequence whose correlation function obeys a power law asymptotically.
Theorem 2.2.
For any defined with (4) under Assumption 2 is a stationary process with and
i)
for
ii) For any
iii) Define then , and as
We call the stationary process defined in Theorem 2.2 the generalized Bernoulli process II (GBP-II). Also, the sum of the first variables in the GBP-II, , is called the fractional binomial random variable II.
Remark 1.
If we use a correlation function and its asymptotic behavior to define long-range dependence (LRD), then we conclude that the GBP-II always possesses a long-memory property, since
therefore,
Alternatively, one can define LRD in the GBP-II using the asymptotic behavior of its covariance function. Since if then
and the GBP-II is considered to have LRD when .
3 GBP and fractional Poisson process
3.1 Comparison between the GBP-II and the fractional Poisson process
We will show the connection between GBP-II and the fractional Poisson process by using the moment generating function (mgf). First, we modify the GBP-II, and define such that
and in general, for
| (5) |
Note that where and Therefore, by Proposition 2.1, , and is well defined, which we will call GBP-II∗.
Roughly speaking, can be considered as what is observed after the first 1 in the GBP-II for large . In fact, the probability distribution (5) is the limiting distribution of the conditional probability of the GBP-II that is observed after the first observation of ”1”. If we define a random variable as the time when the first ”1” appears in the GBP-II, then for any
and for
which is the same as the distribution of defined in (5).
Define as the sum of the first variables in the GBP-II∗,
and call it the fractional binomial random variable II In both of the fractional binomial distributions-II, II∗, the moments are asymptotically proportional to the powers of
Theorem 3.1.
For any
as
i) the fractional binomial II has
where
ii) the fractional binomial II∗ has
where
It turns out that a scaled fractional binomial II∗ has the same limiting distribution as a scaled fractional Poisson distribution. More specifically, the scaled fractional binomial II∗ and scaled fractional Poisson, and converge in distribution to the second family of Mittag-Leffler random variable of order as
Theorem 3.2.
For the fractional binomial distribution II∗ with parameters that satisfy Assumption 2, and the fractional Poisson process with parameters the following holds: Both and converge in distribution, as to the second family of Mittag-Leffler random variable of order , , whose mgf is Mittag-Leffler function, i.e.,
where
3.2 Comparison between the GBP-I and the GBP-II
We will compare the asymptotic properties of GBPs through asymptotic moments and tail behavior of return time.
First, we define GBP-I∗ in a similar way that we defined the GBP-II∗. GBP-I∗, , is what is observed after the first “1” in the GBP-I. Then it has
for where is the first time when “1” appeared in the GBP-I. We also define as the sum of the first variables in the GBP-I∗, and call it the fractional binomial random variable I∗.
Theorem 3.3.
For the fractional binomial I, and the fractional binomial I we have the following asymptotic properties as
i) For the fractional binomial I, the central moments are
where and is the largest integer smaller than or equal to .
ii) For the fractional binomial I
where
and
For the non-central moments, and for
Let’s consider the number of 0’s between two successive 1’s plus one as a return time, also called interarrival time, and denote the return time from the 1 to the 1 in the GBP-I as In the GBP-I, return times, are i.i.d. with
We will drop the subscript and use as a random variable for return time in the GBP-I.
In the GBP-II , we define a return time in the same way and denote as the return time to the 1. Note that are independent but not identically distributed, since the length of the sequence is fixed as . However, they are asymptotically i.i.d. when with its limiting distribution
| (6) |
which is in fact the distribution of return time in the GBP-II∗, if we define return time in the GBP-II∗, in the same way. In the GBP-II∗, denote as the return time to the 1, it is easily derived that return times are i.i.d. with distribution (6).
It is found that the return time of the GBP-I has a finite mean, whereas the return time of the GBP-II∗ has an infinite mean. Also, the return time follows heavy-tail distribution in both the GBP-I and the GBP-II∗ with
for a large , some constant , and for the GBP-I, and for the GBP-II.
Theorem 3.4.
In the GBP-I, If and if Furthermore,
for where is a slowly varying function that depends on the parameters of the GBP-I.
Theorem 3.5.
In the GBP-II, and
for where is a slowly varying function that depends on the parameters of the GBP-II.
4 Simulation
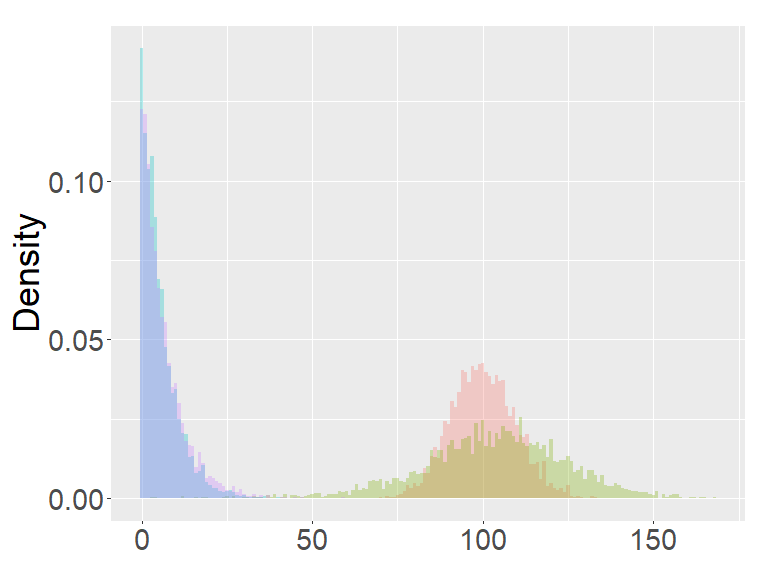
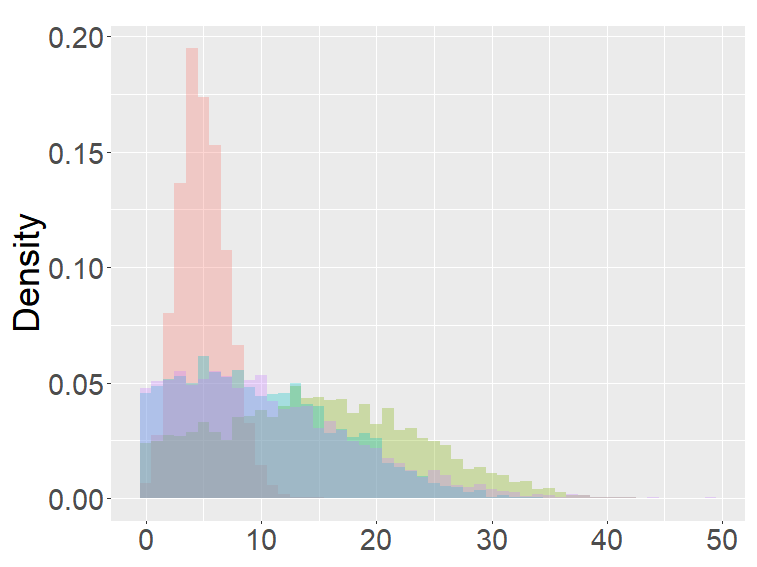
In this section, we examine and compare the shape of the fractional binomial distributions (FB) and the fractional Poisson distribution through simulations. Each histogram in Figures 1-4 was made of 3000 simulated random variables of the corresponding distribution. Figure 1 shows the histograms of the scaled FB-II∗, and the scaled fractional Poisson random variable, for various parameters It is observed that when the histograms of the scaled FB-II∗ and the scaled fractional Poisson random variable are fairly close to the pdf of the second family of Mittag-Leffler distribution. The approximation is better for larger This result reflects well Theorem 3.2.
Figure 2 shows the histograms of the FB-II, II∗ and the fractional Poisson distribution for various parameters. It is seen that the histograms of FB-II∗ and the fractional Poisson largely overlap, which is not surprising given the fact that their scaled distributions have the same limiting distribution. However, the FB-II behaves quite differently than the other two distributions as it has a high peak near 0.
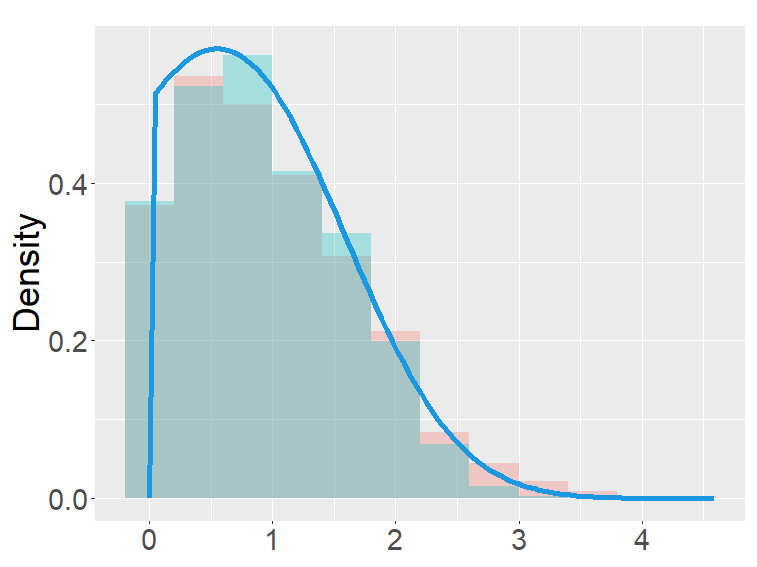
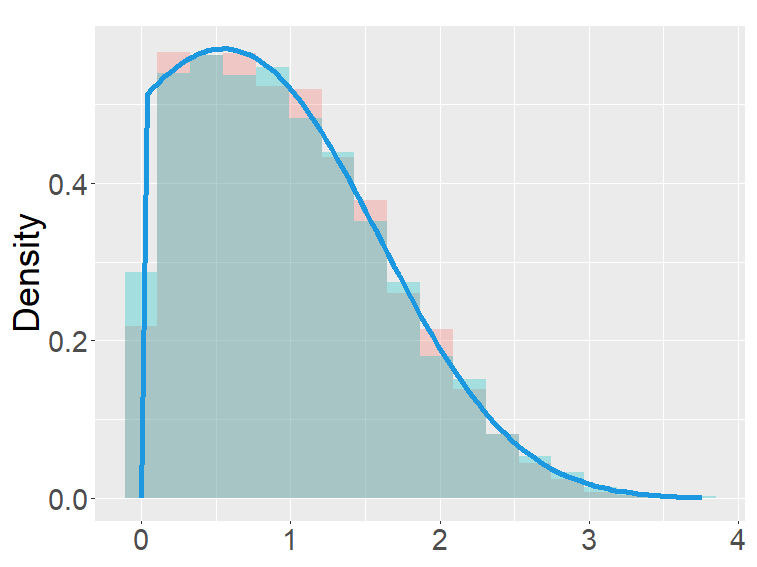
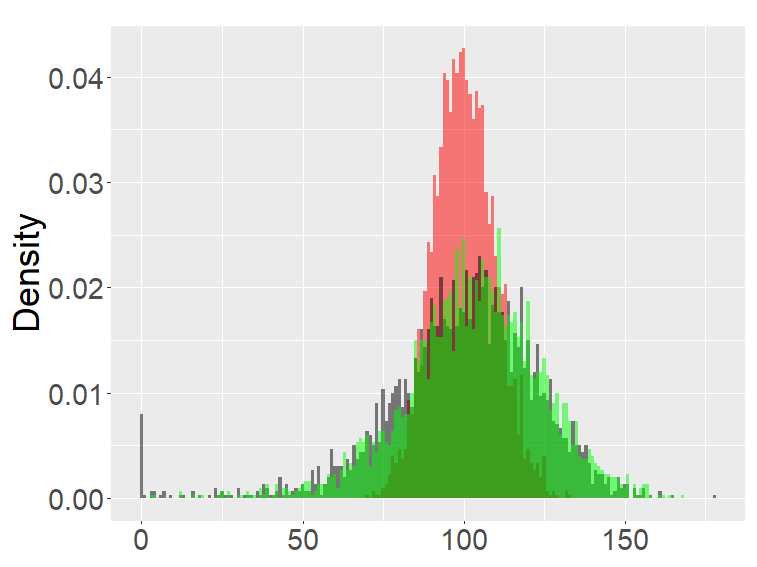
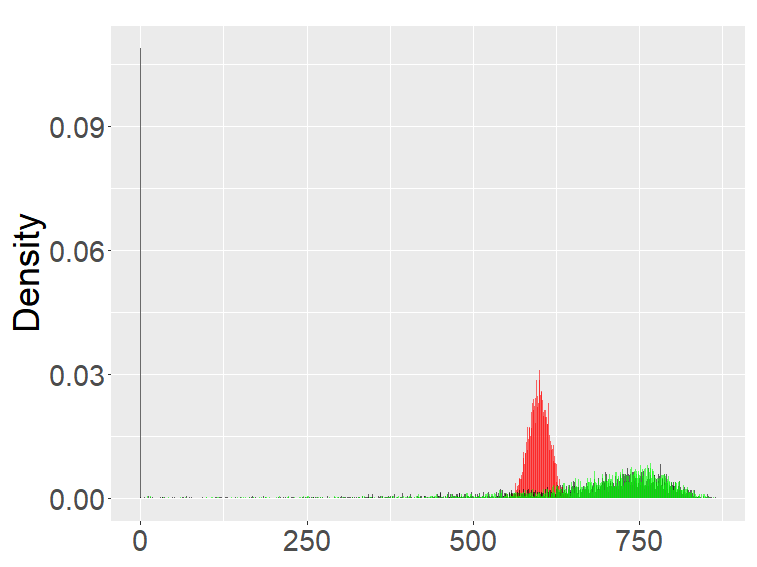
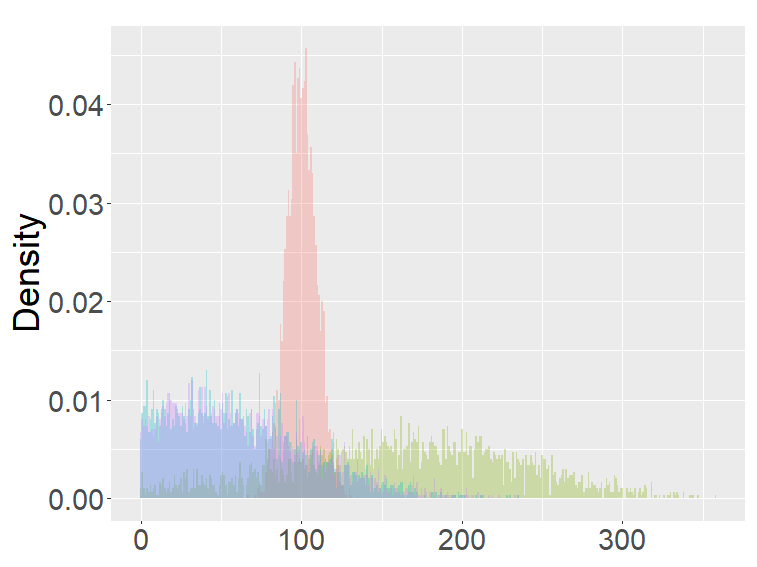
The FB-I, I∗ and the binomial distribution are compared in Figure 3. The binomial distribution is roughly symmetric and bell-shaped for each set of parameters as expected from the central limit theorem, whereas the FBs show various shapes and larger variability than the binomial distribution. Unlike the FB-I∗, the FB-I has a large probability near 0, a similar phenomenon observed in Figure 2 for the FB-II.
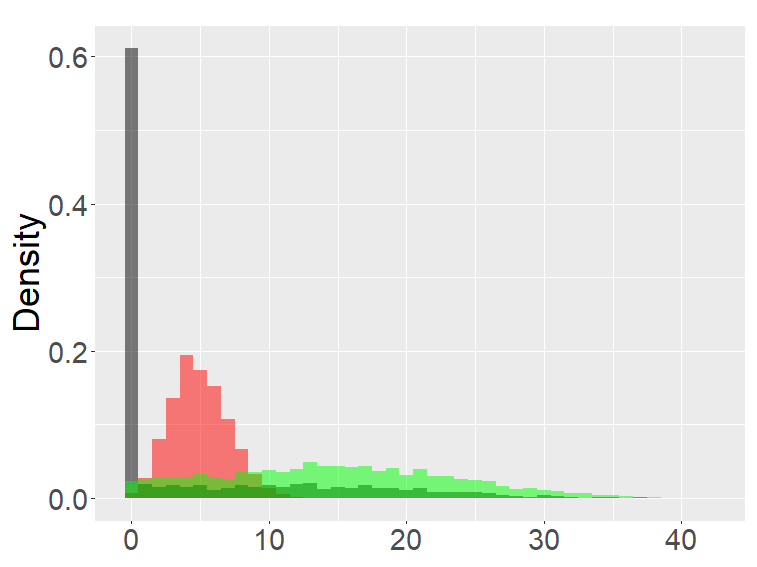
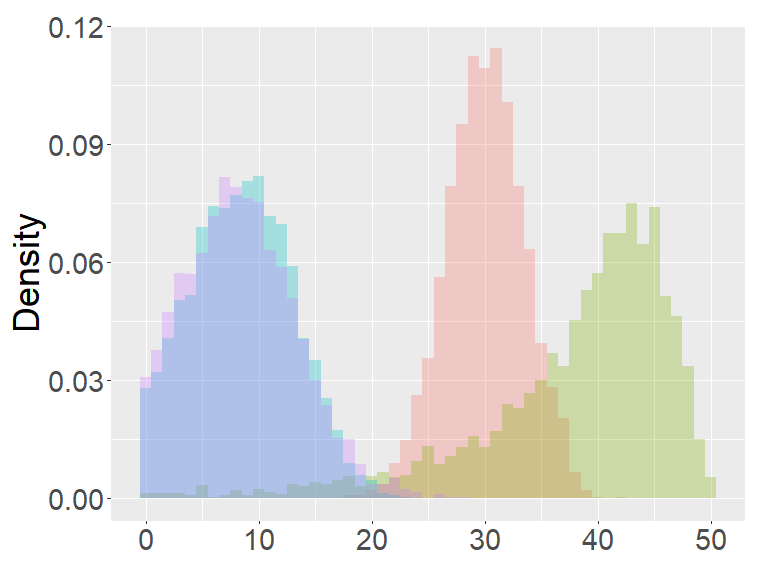
Figure 4 are the combined results of Figures 2, 3, putting together the histograms of the binomial, FB-I∗, II∗, and fractional Poisson distributions for each set of parameters. The FB- II∗ and the fractional Poisson distributions are similar to each other, and the shape and the range of these distributions are neither close to the binomial nor the FB- I∗.
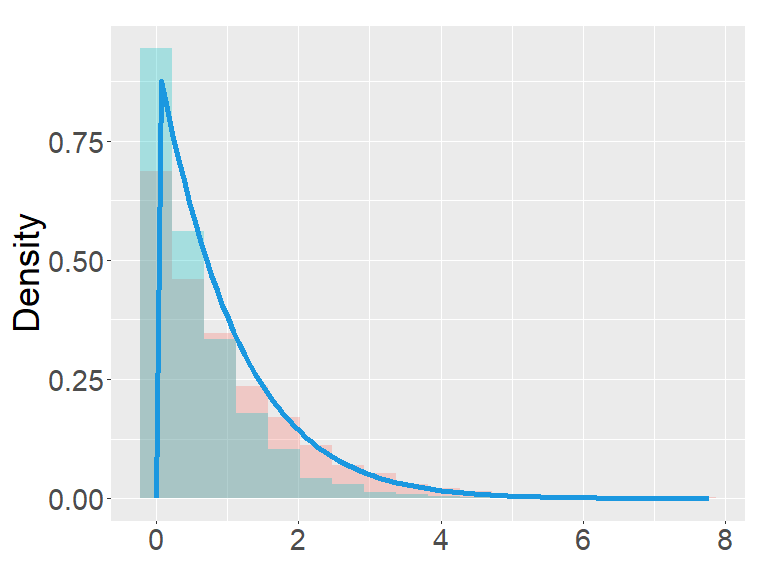
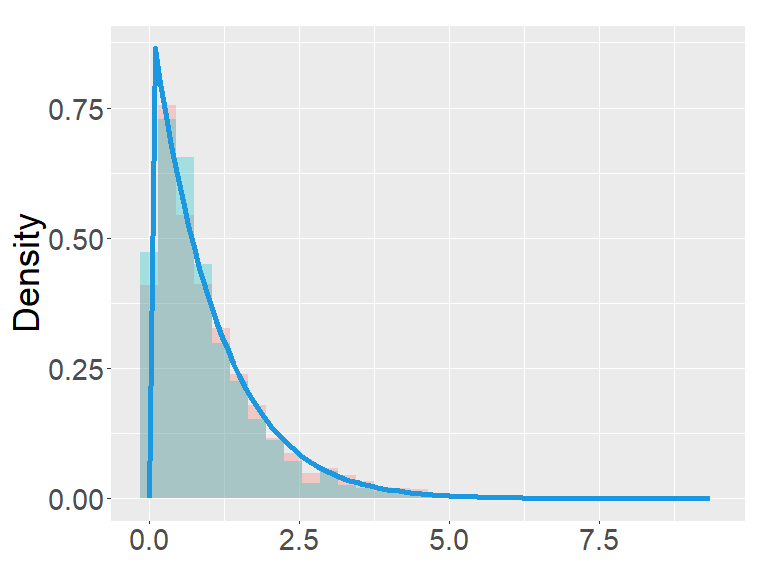
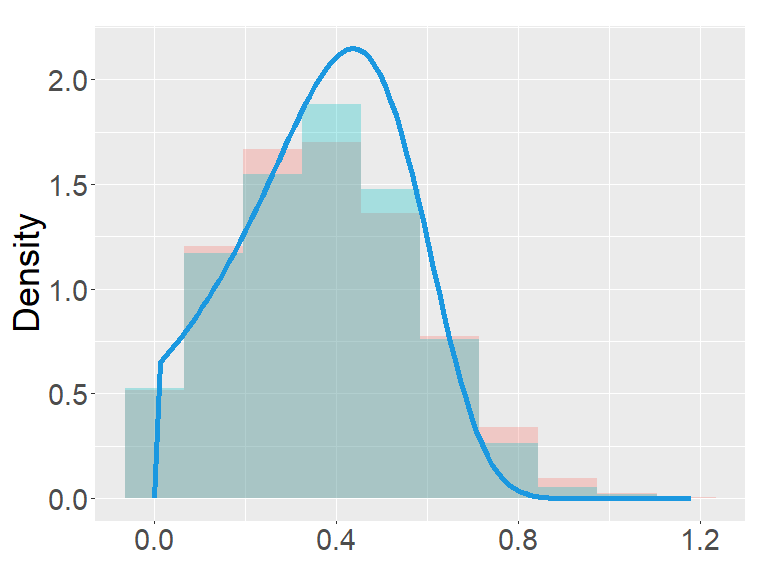
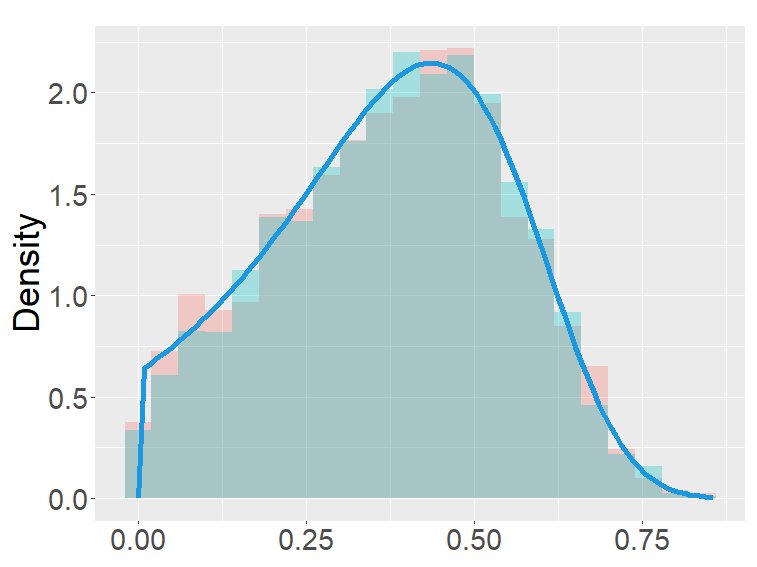
the second row: with (left), 1000 (right),
the third row: with (left), 1000 (right).
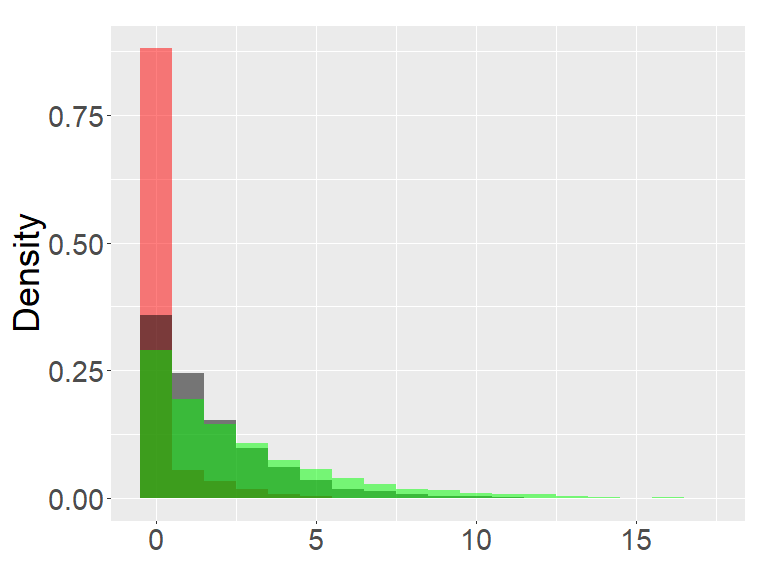
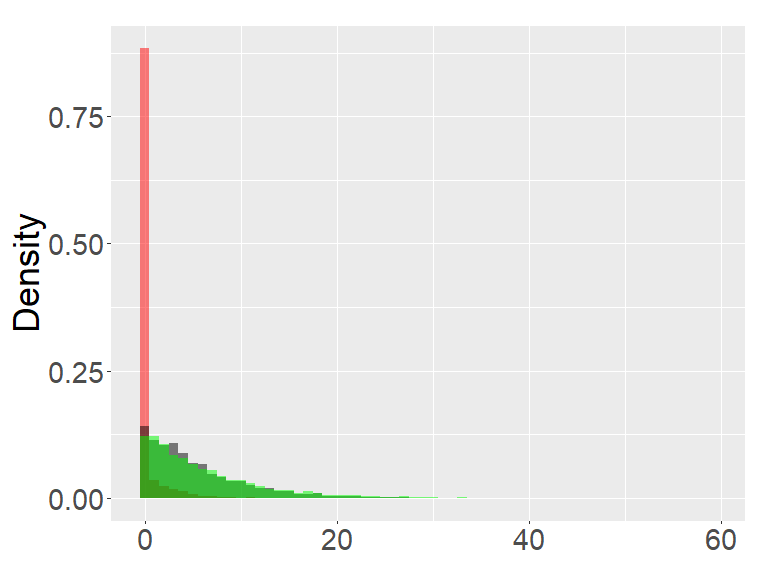
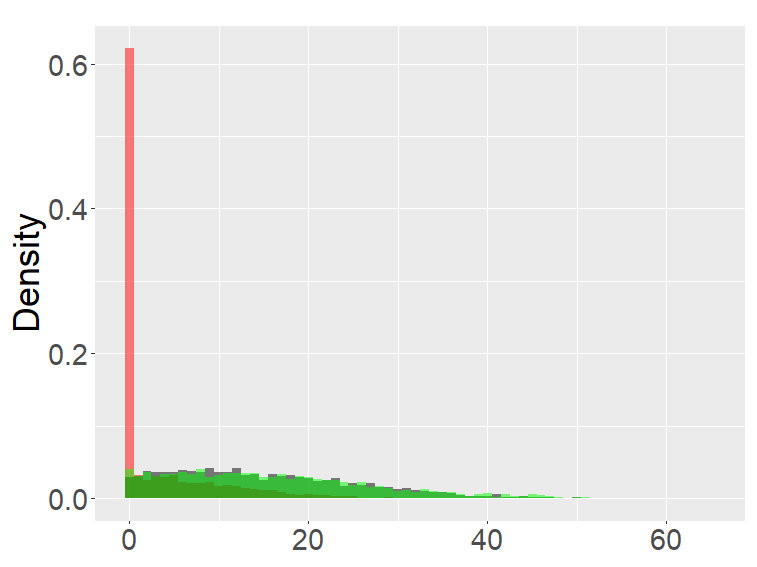
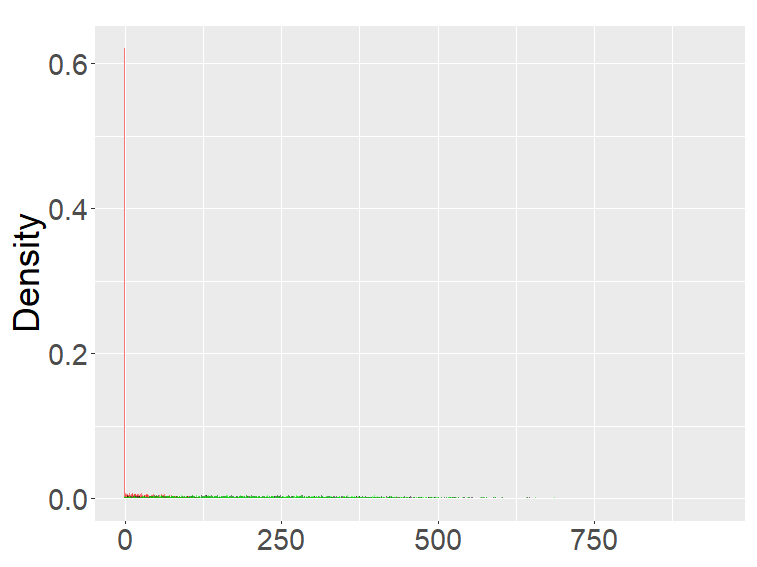
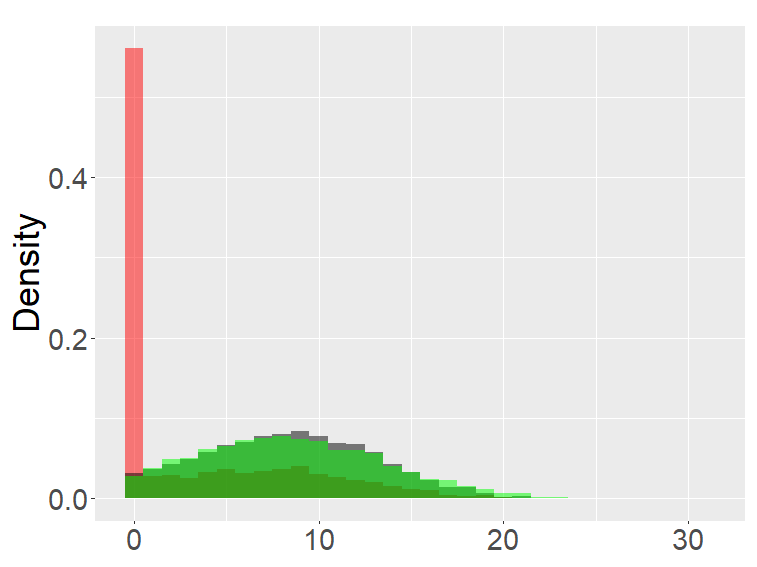
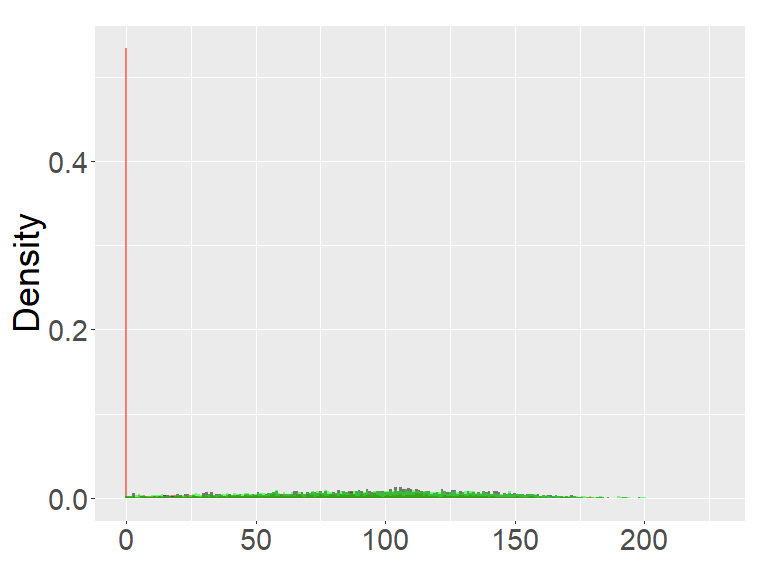

the second row: with (left), 1000 (right),
the third row: with (left), 1000 (right). ( for all graphs.)
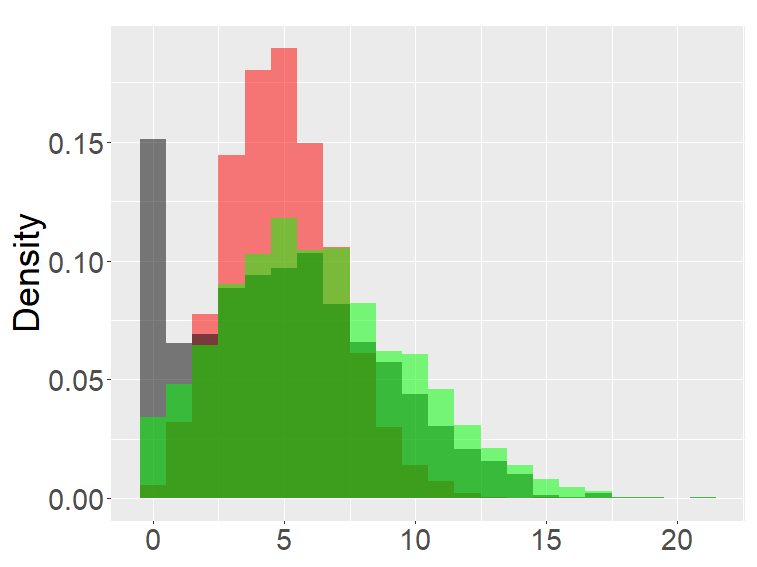
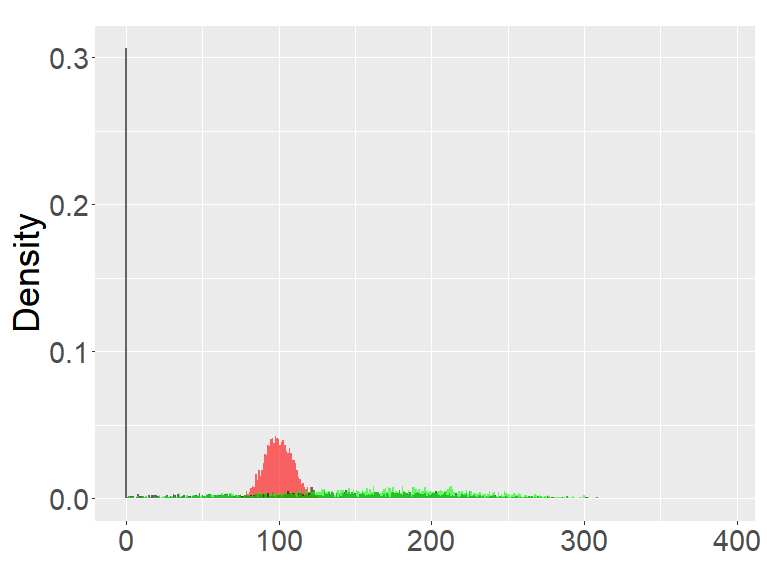
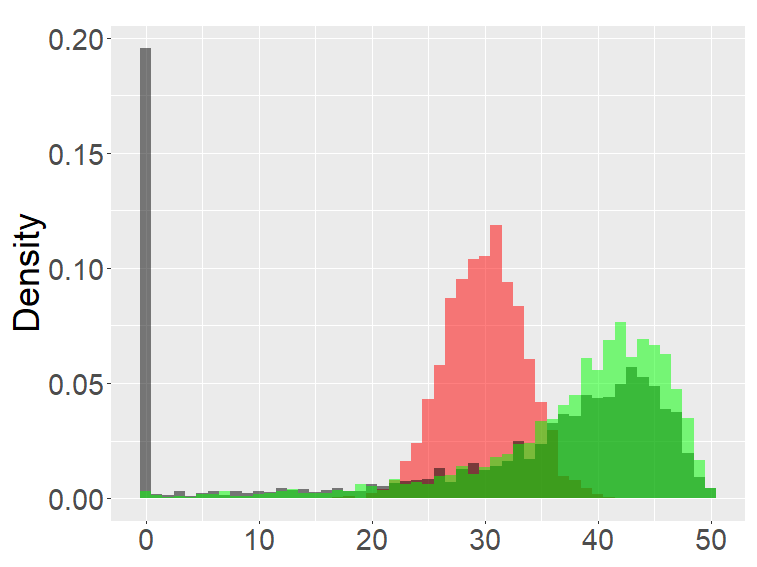

the second row: with (left), 1000 (right),
the third row: with (left), 1000 (right).
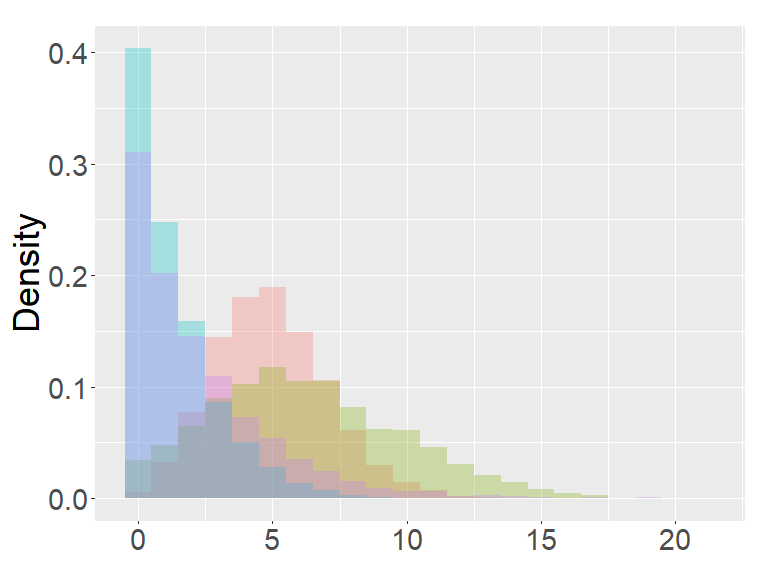
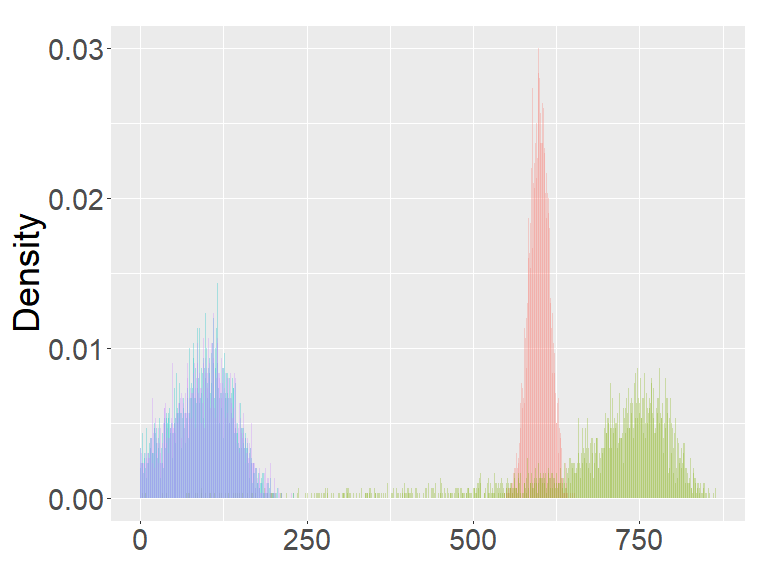

the second row: with (left), 1000 (right),
the third row: with (left), 1000 (right).
5 Applications
5.1 Application of GBP
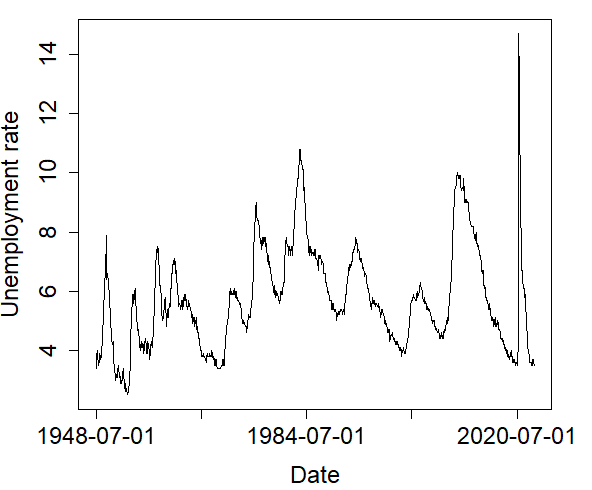
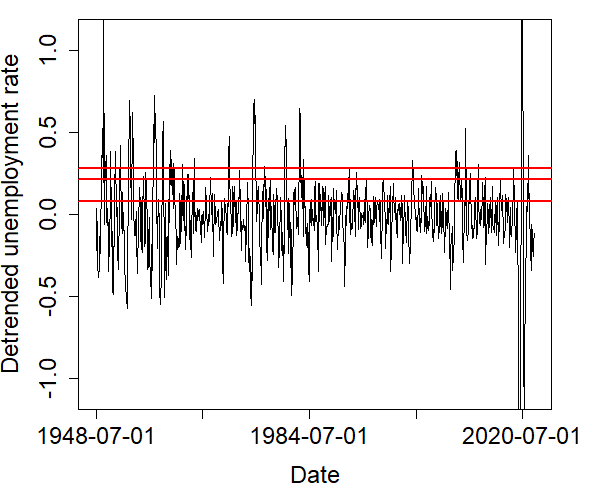
The monthly unemployment rate (seasonally adjusted, percent) from January 1948 to December 2022 was obtained from the U.S. Bureau of Labor Statistics (https://fred.stlouisfed.org/series/UNRATE) and shown in the left graph of Figure 5. Using the decomposition method, the trend of the time series of the unemployment rate was extracted, and the remaining component of the detrended unemployment rate was used for data analysis. With the detrended time series, a sequence of indicator variables was made to specify if the detrended unemployment rate is above a cutoff (indicator 1) or not (indicator 0) at each time. We tried three cutoffs, .08%, .21%, .28%, and three indicator sequences were obtained. In Figure 5, the graph on the right shows the detrended unemployment rates and horizontal lines at the three cutoffs.
For each indicator sequence, we checked its autocorrelation in the left graphs of Figure 6. It is observed that in the indicator sequence with cutoff .08, the correlation decreases relatively fast, and as the cutoff increases, the decay rate of the correlation slows down.
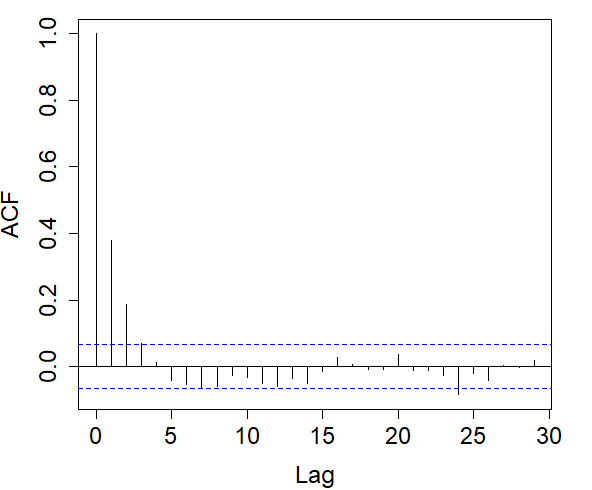
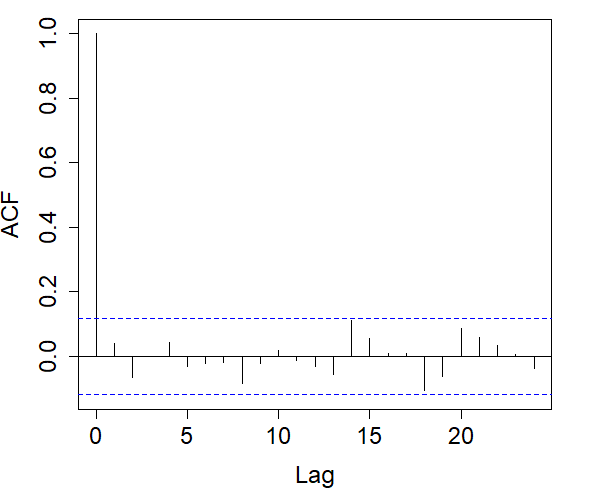
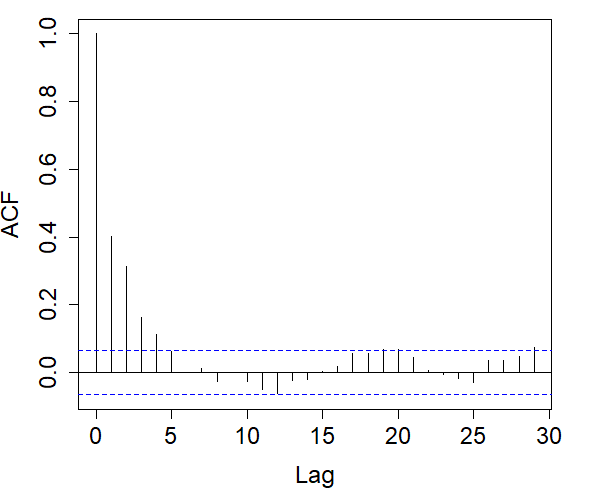
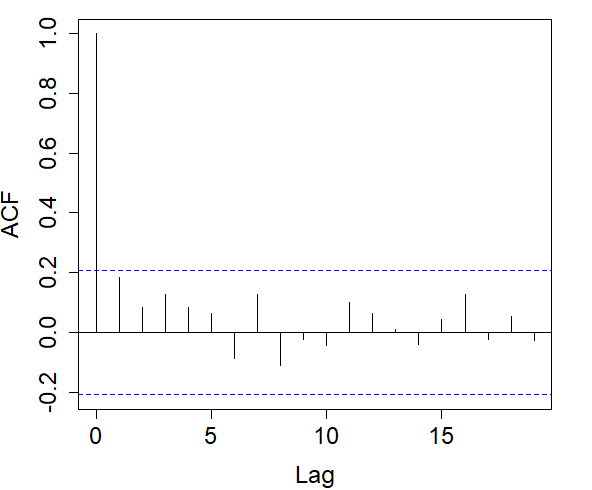
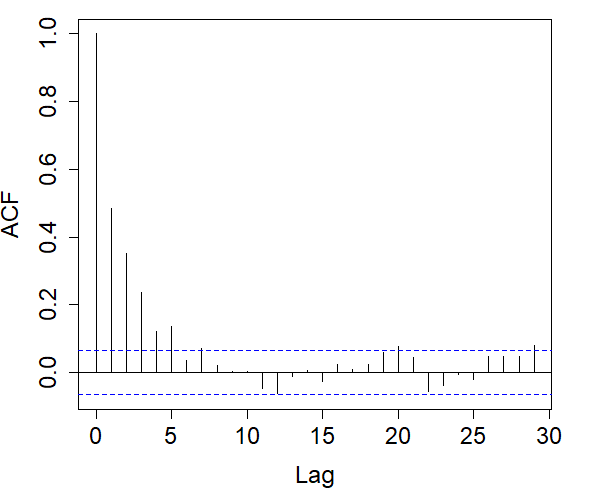
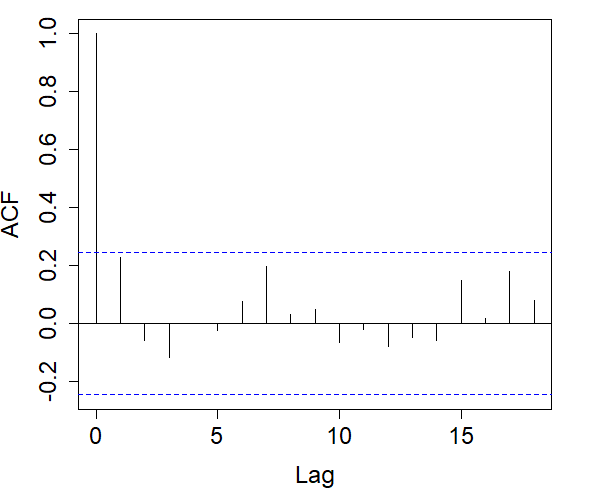
Right: Autocorrelograms of return times in the indicator sequence with cutoff .08% (top), .21% (middle), .28% (bottom).
The GBP-I, GBP-II, Bernoulli process, and Markov chains were applied to each indicator sequence. In each of the four stochastic models, the return times, times between successive 1’s, are independent and identically distributed as
| (7) |
where , , and are indicator variables.
In each indicator sequence, we checked whether the return times were correlated. Autocorrelograms on the right in Figure 6 show that at a 5% significance level, there is no significant evidence that return times are correlated. Therefore, we could proceed to fit each of the distributions in (7) to the return times of each indicator sequence.
The results on the MLE of the parameters and the AIC of each model are shown in Tables 1-3. From Table 1, when the cutoff is .08, the Markov chain shows the best fit, having the smallest AIC, followed by the GBP-I. Table 2 shows that with the cutoff of .21, GBP-I has the smallest AIC, although the difference from the second smallest AIC from the Markov chain is very small. In Table 3, when the cutoff is .28, the GBP-I best fits the data, followed by the GBP-II and the Markov chain, in that order. The graphs in Figure 7 show the histogram of the return time overlaid with the fitted probability models.
| Probability model | Parameters | MLE | AIC |
|---|---|---|---|
| GBP-I | () | (.30, .11, .23) | 974.68 |
| GBP-II | () | (.85, .56) | 1027.04 |
| Bernoulli process | .31 | 1079.06 | |
| Markov chain | () | (.57, .19) | 961.55 |
| Probability model | Parameters | MLE | AIC |
|---|---|---|---|
| GBP-I | () | (.09, .46, .33) | 479.76 |
| GBP-II | () | (.77, .45) | 496.18 |
| Bernoulli process | .10 | 570.96 | |
| Markov chain | () | (.47, .06) | 480.38 |
| Probability model | Parameters | MLE | AIC |
|---|---|---|---|
| GBP-I | () | (.06, .58, .42) | 340.56 |
| GBP-II | () | (.75, .53) | 346 |
| Bernoulli process | .07 | 458.44 | |
| Markov chain | () | (.53, .04) | 348.41 |
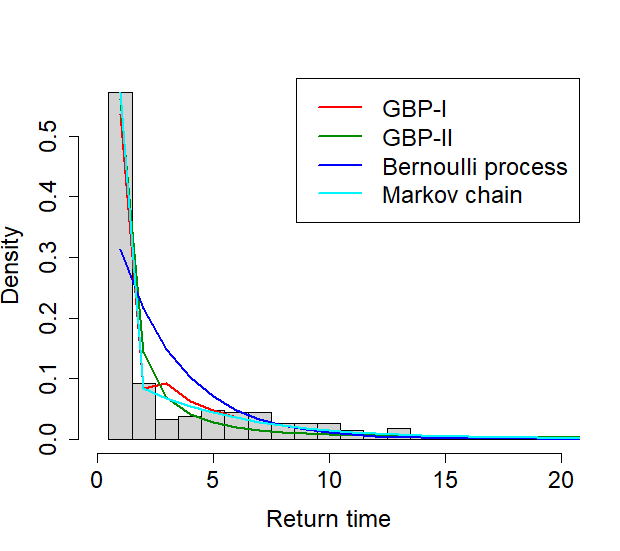
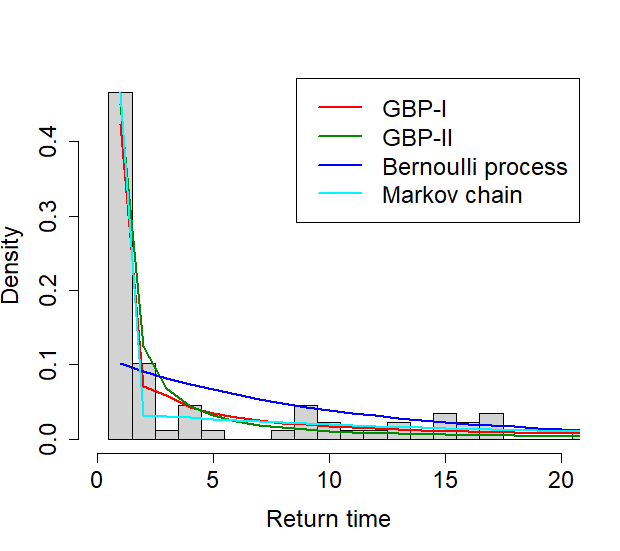
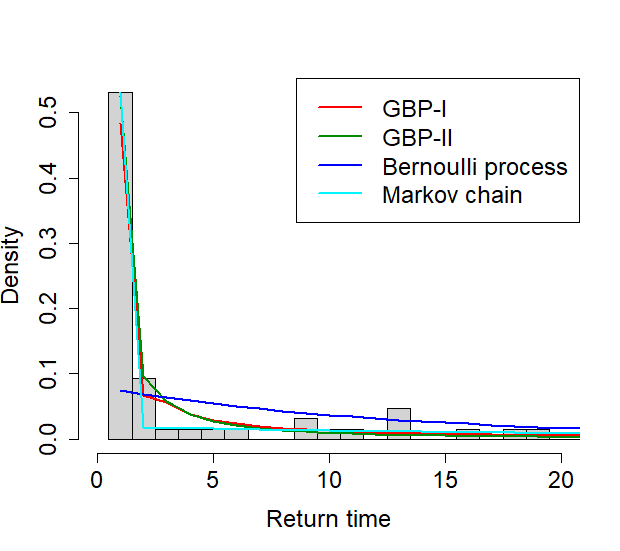
From the results, it is observed that the relative performance of the GBP-I to the Markov chain improves as the cutoff increases. It seems to be related to the fact that as the cutoff increases, the estimated parameter of in the GBP-I also increases. Especially, with the largest cutoff, the estimate of was , which indicates the presence of long-range dependence (LRD) in the indicator sequence. Since GBPs can incorporate LRD in a binary sequence unlike a Markov chain, it is not surprising that GBP shows a better fit than a Markov chain in the presence of LRD.
5.2 Application of fractional binomial distribution
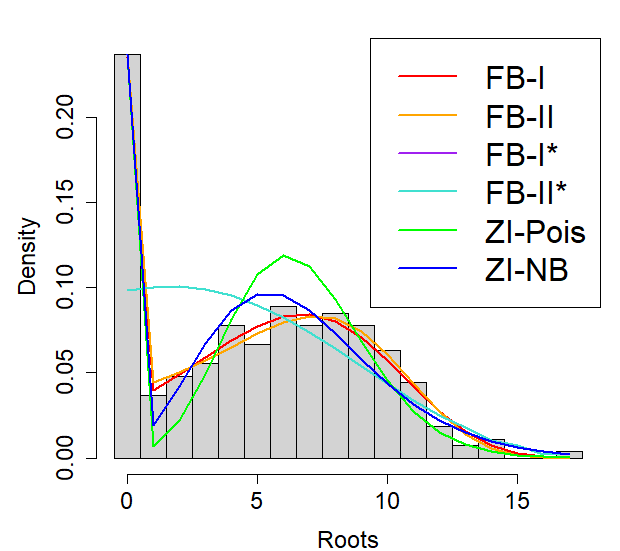
We use a dataset in horticulture in Ridout et al. (1998). The dataset contains the number of roots produced by 270 micropropagated shoots of the columnar apple cultivar Trajans which were cultured under different experimental conditions, and the distribution of the number of roots is over-dispersed and has excess zeros. In Ridout et al. (1998), it was shown that zero-inflated Poisson (ZIP) and zero-inflated negative binomial (ZINB) models fitted the data better than Poisson and negative binomial models with covariates on the experimental conditions. Here we only use data on the number of roots without covariates, and fit fractional binomial models, ZIP, and ZINB. The results on the MLE of parameters and AIC of each model are provided in Table 4. The FB-I shows the lowest AIC, followed by the FB-II, zero-inflated models, FB-II∗, and FB-I∗, in that order. Figure 8 shows the fitted distribution of each model with the data distribution. It was observed that FB-I and FB-II fitted the data well over the entire range of distribution, whereas the zero-inflated models overestimated the variable around the middle of the range and underestimated it in the latter half of the range. FB-I∗, II∗ show the worst fit to the data distribution, and also since the estimated is almost zero in FB-I∗, the fitted distribution of FB-I∗ and FB-II∗ becomes almost identical.
| Probability model | Parameters | MLE | AIC |
|---|---|---|---|
| FB-I | () | (.30, .74 ,.31) | 1348.44 |
| FB-II | () | (.47, .92, .57) | 1350.1 |
| ZINB | (6.59, 9.97, .23) | 1358.6 | |
| ZIP | () | (6.62, .24) | 1381.6 |
| FB-II∗ | () | (.77, .70) | 1420.24 |
| FB-I∗ | () | (.00, .77, .70) | 1422.24 |
6 Conclusion
We proposed generalized Bernoulli processes that are stationary binary sequences and found a connection to the fractional Poisson process. GBPs can possess long-range dependence, and the interarrival time of GBPs follows a heavy-tailed distribution. Since a GBP can have the same scaling limit as the fractional Poisson process, it can be considered as a discrete-time analog of the fractional Poisson process. Fractional binomial distributions are defined from the sum in GBPs and possess various shapes, from highly skewed to flat.
GBPs were applied to economic data with indicator variables, and the model fit of the GBPs was compared to the model fit of a Markov chain. It turned out that in the presence of LRD, the GBPs outperformed the Markov chain, which can be explained by the fact that the GBPs can incorporate LRD. It was noted that LRD appeared in the dataset when the higher cutoff was used for the indicator sequence, which suggests a connection between rare events and LRD, and this shows potential for the applicability of GBPs for modeling LRD in rare events.
Fractional binomial models were applied to count data with excess zeros. It was shown that a fractional binomial model fitted the data better than zero-inflated models that are extensively used for overdispersed, excess zero count data.
Generalized Bernoulli process and fractional Poisson process: supplemental document \sdescriptionAll the proofs of the proposition and theorems of this article are included in the supplementary material.
Computer code for simulations and data applications \sdescriptionCode for simulations can be found in J. Lee, frbinom, (2023), GitHub repository, https://github.com/leejeo25/frbinom. Computer code used in the application of Section 5 is provided in J. Lee, GBP_FB, (2023), GitHub repository, https://github.com/leejeo25/GBP_FB
References
- Altham (1978) Altham, P. M. E. (1978). Two generalizations of the binomial distribution. Journal of the Royal Statistical Society. Series C (Applied Statistics) 27(2), 162–167.
- Biard and Saussereau (2014) Biard, R. and B. Saussereau (2014). Fractional poisson process: Long-range dependence and applications in ruin theory. Journal of Applied Probability 51(03), 727–740.
- Borges et al. (2012) Borges, P., J. Rodrigues, and N. Balakrishnan (2012). A class of correlated weighted poisson processes. Journal of Statistical Planning and Inference 142(1), 366–375.
- Consul (1989) Consul, P. C. (1989). Generalized poisson distributions: Properties and applications. Dekker.
- Conway and Maxwell (1962) Conway, R. W. and W. L. Maxwell (1962). A queuing model with state dependent service rates. Journal of Industrial Engineering 12, 132–136.
- Kadane (2016) Kadane, J. B. (2016). Sums of possibly associated bernoulli variables: The conway–maxwell-binomial distribution. Bayesian Analysis 11(2).
- Lambert (1992) Lambert, D. (1992). Zero-inflated poisson regression, with an application to defects in manufacturing. Technometrics 34(1), 1–14.
- Laskin (2003) Laskin, N. (2003). Fractional poisson process. Communications in Nonlinear Science and Numerical Simulation 8(3), 201–213. Chaotic transport and compexity in classical and quantum dynamics.
- Lee (2021a) Lee, J. (2021a). Generalized bernoulli process: simulation, estimation, and application. Dependence Modeling 9(1), 141–155.
- Lee (2021b) Lee, J. (2021b). Generalized bernoulli process with long-range dependence and fractional binomial distribution. Dependence Modeling 9(1), 1–12.
- Ridout et al. (1998) Ridout, M. S., C. G. B. Demétrio, and J. P. Hinde (1998). Models for count data with many zeros.
- Rodrigues et al. (2013) Rodrigues, J., N. Balakrishnan, and P. Borges (2013). Markov-correlated poisson processes. Communications in Statistics - Theory and Methods 42(20), 3696–3703.
- Samorodnitsky (2018) Samorodnitsky, G. (2018). Stochastic processes and long range dependence. Springer International Publishing.
- Skellam (1948) Skellam, J. G. (1948). A probability distribution derived from the binomial distribution by regarding the probability of success as variable between the sets of trials. Journal of the Royal Statistical Society: Series B (Methodological) 10(2), 257–261.
- Wedderburn (1974) Wedderburn, R. W. M. (1974). Quasi-likelihood functions, generalized linear models, and the gauss-newton method. Biometrika 61(3), 439–447.