General Place Recognition Survey: Towards Real-World Autonomy
Abstract
In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community’s remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics.
This paper begins with an exploration of PR’s formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR’s potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR’s future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
Index Terms:
Place Recognition, Multi-sensor modalities, Long-term Navigation, DatasetsI Introduction
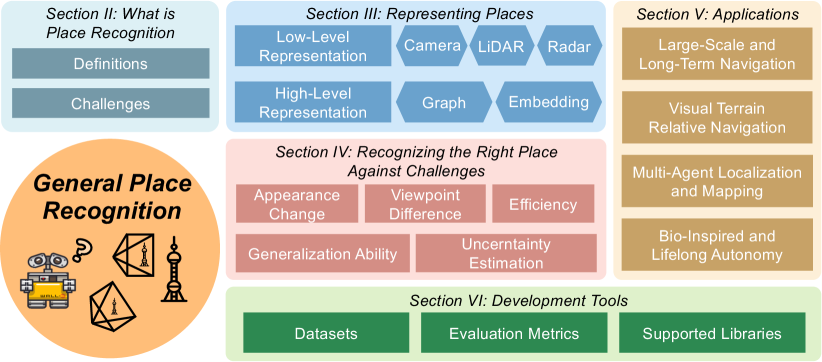
I-A Background
In recent decades, mobile robot systems have gained significant interest for their roles in diverse applications, such as autonomous driving, last-mile delivery, search-and-rescue operations, and warehouse logistics. These robots are increasingly woven into the fabric of our daily routines, facing growing demands for navigating complex environments. This evolution prompts a critical inquiry: How can robots achieve lifelong autonomy with the capability of zero-shot or few-shot transferring to new environments and tasks?
As the foundamental module in navigation, SLAM enables a robot to estimate its ego-motion while simultanously constructing a map of its surroundion environments. As a distant yet exciting frontier in the community, lifelong navigation raises new performance requirements of SLAM beyond accuracy from several aspects including large-scale and long-term localization, map maintainance in dynamic environments, active perception, and self-evolution. This indicates that we are entering the SLAM2.0 era: distinguished from traditional SLAM [1], SLAM2.0 emphasizes the integration of advanced algorithms in robotics and AI to support the scalable, adaptable, and efficient realization of lifelong robotic autonomy.
As the core of advancing to SLAM2.0, PR, now is becoming more essential than ever, which enables robots to identify previously visited areas despite changes in environmental conditions and viewpoints. Essentially, PR’s ability hinges on creating short-term or long-term association between current observations and a robot’s internal “memory”. In visual SLAM (VSLAM), “memory” typically refers to a database of stored visual information. For decision making, PR enables robots to apply lessons from past experiences to current situation. Thus, PR’s role extends beyond merely loop closure detection (LCD) in SLAM. Its applications now span failure recovery, global localization, multi-agent coordination, and more.
Over the years, PR methodologies have evolved significantly, as evidenced by facts such as: (1) there are more than published papers within this area; (2) the complexity of the operational scope for robots escalates markedly when transitioning from controlled indoor environments to the unpredictable conditions of outdoor fields, which brings new performance requirements; and (3) there have been several massive PR competitions, such as the CVPR 2020 Long-term Visual PR (VPR) competition and our previous ICRA 2022 General PR competition for City-scale UGV Localization and Visual Terrain Relative Navigation (VTRN). Thus, PR has drawn huge interest from the robotics and computer vision (CV) research communities, leading to a large number of PR techniques proposed over the past many years.
I-B Summary of Previous Surveys
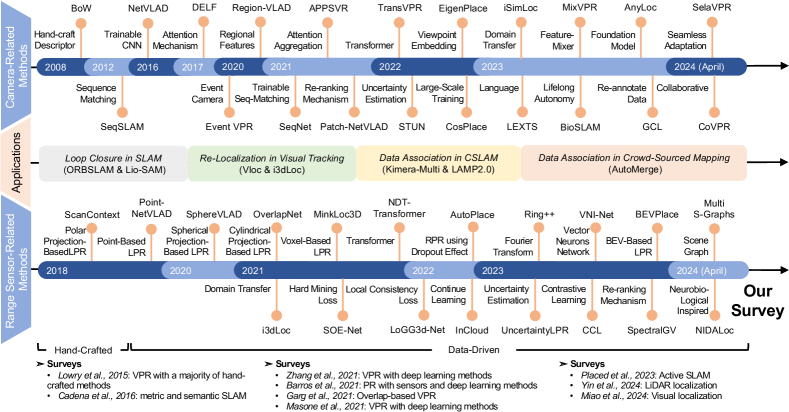
The evolution of PR visualized as the timeline in Fig. 2. A comprehensive historical analysis up to the year on the PR issue is meticulously provided by Lowry et al.[2], emphasizing vision-based methodologies. This seminal survey articulates the VPR challenge, delineates the core components of recognition systems, and reviews solutions to tackle variations in appearance. It distills the essence of a PR system into three fundamental modules: (1) an image processing module for visual input abstraction, (2) a map representing the robot’s understanding of the world, and (3) a belief generation module to evaluate the likelihood of the robot being in a previously encountered or new location. This architecture has served as the foundations of modern PR solutions. The evolution in PR methodology has been profound, transitioning from manual feature extraction to deep learning-based approaches, as comprehensively discussed in prominent studies [3, 4, 5]. However, as Zaffar et al. [6] note, the PR field has seen a growing divergence, particularly as the robotics and CV communities have developed distinct performance benchmarks for PR. This divergence has rendered direct comparisons between PR methods problematic, owing to the significant variability in benchmark datasets and evaluation metrics. To address this issue, they introduced an open-source, standardized framework for PR evaluation, with a particular emphasis on VPR [6]. And there are related works concentrate on visual [7] or LiDAR localization [8], where several literation on VPR and LiDAR-based PR (LPR) are covered.
I-C Contributions and Paper Organization
Given new approaches and applications along with development of robots and AI, the field of PR is active. However, existing literature lacks comprehensive surveys that explore the diverse aspects of place representations, the underlying challenges, and the applications that highlight potential opportunities in place recognition research. In contrast, our goal is to address and fill this gap. Additionally, this paper emphasizes “General PR” (GPR) as it extends beyond VPR and LPR to cover a broader range of topics within the field. This includes the utilization of multi-modal information, such as language, graphs, and implicit embeddings, to enhance PR. The timing for such a survey is particularly fortuitous given major events across these related fields: for example, the emerging large-language models (LLM) such as the ChatGPT [9] exhibit a remarkable ability, neural mapping-related methods [10] evolve the way of environmental representation and scene rendering, and widespread presence in robots. In overall, this paper is structured in Fig. 1 and summarized as follow:
-
•
Section II details two widely accepted definitions of PR: the position-based and the overlap-based approaches. Adhering to the position-based definition to narrow the focus, this paper then proceeds to offer a more precise problem definition (Section II-A) and to highlight the key challenges involved (Section II-B).
-
•
Section III reviews existing representation approaches in PR, covering the core solutions prevalent in the field. Intuitively, PR extends beyond mere image-based approches, encompassing a variety of solutions. At a low level, detailed in Section III-A, a “place” can be captured through sensors, such as cameras, LiDARs and Radars. It’s generally expected that identical locations will produce similar sensor data. On a more abstract and higher level, as discussed in Section III-B, a “place” may also be represented through compact data forms, like scene graphs and implicit embeddings.
-
•
Section IV delves into the primary challenges faced by PR, exploring how contemporary solutions are tailored to achieve key attributes such as invariance to conditions and viewpoints, great generalization ability, high efficiency, and uncertainty awareness.
-
•
Section V concentrates on the deployment of PR techniques for achieving real-world autonomy. It highlights opportunities from these aspects: large-scale and long-term navigation (Section V-A), visual terrain relative navigation (VTRN) (Section V-B), multi-agent localization and mapping (Section V-C), and lifelong navigation (Section V-D). We posit that PR is poised to become a cornerstone in modern robotics, with its applications and related research beyond the realms of SLAM.
-
•
Section VI reviews the leading datasets and benchmarks in the field of PR. It introduces a new perspective on property analysis that complements to primary metrics for quality assessment. Addtionally, this section showcases open-source PR libraries, featuring our in-development library dedicated to GPR research.
-
•
Section VII provides a thorough conclusion of this survey and outlines potential directions for future research.
II Definition of Place Recognition and Challenges
Before exploring specific solutions in PR, it is crucial to address two basic questions:
-
1.
What is the rigorous definition of PR?
-
2.
What are the primary challenges encountered in PR?
II-A Definition: What is Place Recognition?
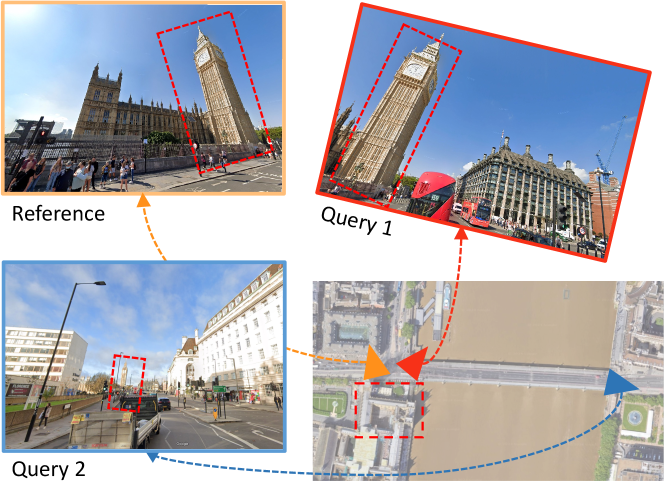
There primarily exist two prevalent PR definitions: position-based and overlap-based. They diverge in their definitions of a “place”, evaluation metrics, objectives. Fig. 3 visualizes the key differences between these definitions.
O’Keefe’s identification of ”place cells” within the hippocampus, a finding that contributed to winning the Nobel Prize in 2014 [11] in neuroscience, inspiring the concept of PR in robotics. Building on this discovery, Lowry et al. defined the position-based PR as a robot’s capability to identify previously visited areas, despite changes in environmental conditions or viewpoint [2]. This perspective treats a “place” akin to a region, though its precise definition can vary with the context of navigation-sometimes seen as a specific location, other times as a broader area. Essentially, the challenge of PR revolves around determining if the current location is within proximity to a previously encountered region. Alternatively, Garg et al. introduce the concept of overlap-based PR, where the focus is on identifying potential matches through visual similarities [12]. According to this approach, even if an exact location is viewed from markedly different angles, it’s considered a distinct place. This method closely parallels the task of content-based image retrieval in the computer vision field [13], which involves searching a large database to find the image most similar to a provided query image.
The overlap-based approach aligns with the visual retrieval methods prevalent in the computer vision community. However, from a robotics standpoint, these methods don’t seamlessly translate to SLAM and navigation due to the unclear relationship between visual overlap and the precise position of retrievals. This ambiguity is exemplified in Fig. 3, where despite the top-left and bottom images viewing the same landmark (i.e., the building) within their overlapping field of view (FoV), determining their relative transformation based on visual overlap alone is challenging. For subsequent tasks such as pose graph optimization (PGO) [14] that focuses on maximizing inlier ratios, the position-based definition is clearer and more advantageous. Consequently, this paper will focus on this definition, starting with its mathematical formulation and exploring relevant research in the field.
II-A1 Problem Formulation
A fundamental assumption underlying position-based PR is that two geographically close places share similar layout which can be partially observed by sensors such as cameras. Let represent the current place of the robot, let denote a set of previously visited places, and let indicate the geographically close place to . If a place’s layout can be abstracted as a global descriptor , the above assumption is formulated as
| (1) |
where represents geometric distance like Euclidean distance between the place as well as and is the threshold. The value of is manually set since the definition of a specific place depends on subsequent tasks. Modern position-based PR solutions, predominantly framed within end-to-end learning paradigm, follow the above assumption and optimize modal parameters for the most correct place such as
| (2) |
where is a distance in the feature space (typicall ).

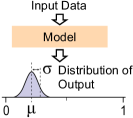
II-B Challenges
As summarized in Fig. 4, solving the position-based PR problem for real-world robot autonomy requires addressing five specific categories of practical challenges:
-
1.
Appearance Change: Compared to short-term navigation, long-term operation may contain appearance changes under different illumination conditions or structural changes (i.e., parking lot and construction sites), which will introduce further localization failures.
-
2.
Viewpoint Difference: This issue arises from differences in how sensors capture an environment’s perspective. For example, a building’s frontal view exposes its full shape, whereas a top-down perspective highlights the layout and roof design. Such viewpoint variations are especially noticeable when a robot revisits a location from a different angle or altitude. This challenge is ubiquitous across sensor types, necessitating PR systems to incorporate robust modules for feature extraction and matching to accommodate these perspective shifts.
-
3.
Generalization Ability: For lifelong navigation, the boundless complexity of environments makes generalization to unseen areas a critical challenge for PR methods. Additionally, these methods must support online learning to adapt over time, a crucial requirement for missions like space exploration, where robots investigate other planets long-term with minimal human supervision. Robots should possess the capability to continuously learn and adapt to new environments.
-
4.
Efficiency on Resource-Constrained Platforms: Adapting PR algorithms that mainly use neural networks for robots with limited computational resources poses a significant challenge, particularly for drones. Effective algorithms should balance accuracy with computational efficiency. This becomes a necessity for both single and multi-robot systems which face bandwidth constraints and potential communication disruptions.
-
5.
Uncertainty Estimation: Generating a belief distribution for assessing likelihood or confidence, identifying out-of-distribution data, and evaluating PR algorithm reliability is crucial for downstream navigation tasks like PGO and mapping. But accurately estimating and qualifying the likelihood function is challenging.
Building from our overview of PR’s definitions and challenges, the next sections will delve into associate studies.
III Describing Places: Data Representation

The pivotal aspect, and indeed the foundation of PR, lies in representing a place with compact features while preserving key distinctions. Therefore, this section delves into the various formats of representations employed in prevalent PR methods, ranging from low-level, sensor-specific representations to high-level, sensor-independent representations.
III-A Low-Level Representations
III-A1 Sensor Selection Criteria
Cameras, LiDAR (Light Detection and Ranging), and Radar (Radio Detection and Ranging) are essential sensors in place recognition (PR). Important selection criteria include field of view (FoV), information density, and robustness under various conditions. Frame cameras provide high-resolution images, while event cameras perform better in low-light and reduce motion blur. LiDARs generate precise 3D point clouds but have lower resolution. Radars offer long-range capabilities and excel in poor weather, also measuring relative velocity via the Doppler effect. Selecting between cameras, LiDARs, and Radars depends on the specific needs for precision, range, and environmental suitability.
III-A2 Camera-Related Approaches
VPR is the most thoroughly investigated problem. As highlighted in previous surveys (Section I-B), it has been comprehensively explored through both traditional and learning-based methodologies.
Handcrafted VPR Methods: Traditional handcrafted methods like[23], [24] are well reviewed and extensively used in commercial robotics systems. However, data-driven approaches, leveraging the power of deep-learning algorithms, consistently outperforms their counterparts in terms of accuracy and robustness. This superior performance has catalyzed data-driven approaches as the preferred choise for PR.
Data-Driven VPR Methods: Data-driven approaches, particularly those utilizing deep neural networks (DNNs), provide the unique benefit of automatically learning features directly from training data, shifting from the handcrafted methods that require significant engineering and domain expertise. The capability of DNNs to derive distinct features has been significantly improved, thereby advancing PR across various complex scenarios. Moreover, utilizing DNNs allows for the end-to-end training of PR models. The trend indicates that VPR tasks continue to adopt novel image learning methods.
The emergence of NetVLAD[25] marked a significant advance in data-driven methods, utilizing CNNs as local feature extractors and introducing differentiable VLAD (Vector of Locally Aggregated Descriptors) layers for feature aggregation. Subsequent developments enhanced both feature extractors and aggregators. Notably, Regional Maximum Activations of Convolutions (R-MAC)[26] and Generalized Mean (GeM) [27, 28] emerged as effective alternatives to VLAD for feature aggregation. With the rise of vision transformers, which surpass CNNs in performance, TransVPR[29] was developed, incorporating multi-level attention mechanisms to improve image understanding. However, the adoption of vision transformers significantly increases the model size, requiring more computational resources for end-to-end training. Foundation models, pre-trained on extensive datasets, demonstrate robust zero or few-shot capabilities in various vision tasks[30] and are directly applicable to VPR tasks. AnyLoc[31] utilizes the ViT-based DINOv2[30] to achieve state-of-the-art performance, underscoring the potential of foundation models.
Various research efforts have broadened scope by integrating diverse cues such as semantic, geometric, event data to boost the place representation. The utilization of semantics includes the way of filtering specific pixels [32] and adjusting the weight of feature embeddings [33]. Geometric cues, such as the 3D position of landmarks and ego-motion obtained from monocular image sequences or multiple cameras, also contribute to PR accuracy [34, 35]. Oertel et al. [34] introduced a fusion-based VPR method that leverages both 2D imagery and 3D points from structure-from-motion, Furthermore, event cameras, surpassing frame cameras in dynamic range, prove advantageous for VPR in fluctuating lighting conditions. Lee et al. [36] proposed to use event cameras to capture texture information under low-light condition, constructed edge-based images from event data to achieve PR.
III-A3 Range Sensor-Related Approaches
Research on LPR has significantly progressed, driven by the extensive application of LiDARs in autonomous vehicles and surveying fields. However, LiDAR measurements are predominantly stored as point clouds, which are characterized by their sparsity and lack of orderly structure. These attributes present challenges for traditional 2D convolution operations. To leverage CNN, LPR solutions employ advanced point cloud learning architectures, including PointNet [37] and the Minkowski Engine[38]. Radar-based PR (RPR) research, though less mature, is growing, with efforts concentrating on enhancing Radar perception for all-weather functionality. The forthcoming sections will highlight diverse representation techniques in LPR and then introduce initial progress in RPR research.
Handcraft LPR Methods: ScanContext [39] and ScanContext++ [40] transform LiDAR point clouds into bird-eye-view (BEV) images that encode height in each pixel. Building on this, Wang et al. [41] developed the LiDAR IRIS, enhancing rotation invariance using the LoG-Gabor filter. Ring++ [42] utilizes Radon and Fourier transforms on BEV images for improved representation. In BTC [43], key points of a point cloud are projected onto planes to form triangles whose side lengths serve as triangle descriptors.
Data-Driven LPR Methods: The shift towards feature learning in VPR is similarly observed in LPR, where deep learning methods are increasingly favored. Employing neural networks, including CNNs and Transformers, on point cloud data demands the formulation of specialized network architectures for point clouds or the implementation of extra preprocessing steps to align the data with the original network designs.
The initial advancements in LPR are point-based methods, exemplified by PointNet [37] and PointSift [44], which directly process point clouds to extract features without quantization. PointNetVLAD [45] pioneered this direction by combining PointNet [37] with NetVLAD [25] as the description computation. LPD-Net [46] utilized a graph-based approach for spatial distribution analysis; and SOE-Net [47] proposed an orientation embedding based on PointSift [44] and features are enhaned with self-attention; However, the PointNet structure struggles with orientation invariance, showing reduced performance on significantly rotated point clouds [46]. Addressing this, RPR-Net [48] leveraged SPRIN [49] to derive rotation-invariant features, demonstrating promising outcomes. Nonetheless, a critical drawback of point-wise methods is their escalating computational complexity with increasing point count, posing challenges for real-time application efficiency.
Rather than directly manipulating points within neural networks, two alternative categories of LPR methods utilizes voxelization [50, 51, 52] and projection-based techniques [53, 54, 55]. These methods transform point clouds into 3D voxels and 2D grids respectively, serving as a preparatory phase prior to network input. Regarding the former category, MinkLoc3D [50] employs sparse 3D convolution on voxelized point clouds for place descriptor extraction, achieving substantial enhancements over PointNet-based techniques. Its successor, MinkLoc3D-SI [51], incorporates spherical coordinates and intensity data for each 3D point. Besides leveraging the sparse convolution, LoGG3D-Net [52] additionally introduces a local consistency loss that steers the network to consistently learn local features during revisits.
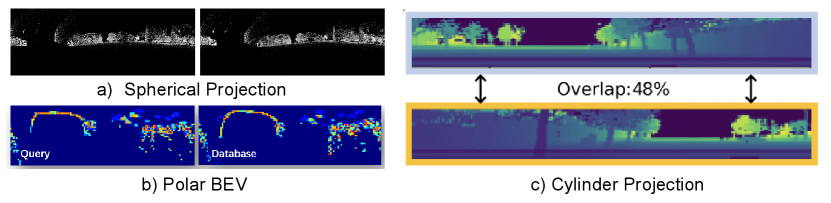
Projection-based methods come in multiple variations. Cylindrical projection transforms point cloud rotations into translations on a 2D image, and thus is yaw-invariant for subsequent convolutional operations. OverlapNet [21] leverages this method for point cloud pre-processing, generating multi-channel images that encapsulate range, intensity, normals, and semantic information. OverlapTransformer [56] extends this approach, applying transformer networks for image analysis. RINet [57] advanced the model by leveraging semantics and geometric features and attention mechanism to build a discriminative global descriptor. Spherical projection, utilized in the SphereVLAD series [53, 58, 54], offers -DoF rotation invariance, crucial for reliable 3D coordinate encoding. Its successor, SphereVLAD++ [58], applied attention mechanism on features after the spherical projection. There are projection methods: DiSCO [59] proposed a differentiable ScanContext-like representation using the polar projection, while BEVPlace [55] transforms point clouds into BEV images and designed the corresponding rotation-invariant network.
Data-Driven RPR Methods: RPR techniques predominantly utilize polar and Cartesian images derived from Radar measurements. Kidnapped Radar [60] leverages a CNN backbone to process polar images for feature extraction. AutoPlace [61] enhances accuracy by employing Doppler measurements to eliminate moving objects and applies a specialized network to encode Radar point clouds, integrating spatial and temporal dimensions, and further refines matches using Radar Cross Section histograms. mmPlace [62] designed a rotating single-chip Radar platform to enhance the perception FoV. Additionally, advancements in RPR have been made through exploring sequence matching [63], self-supervised fusion [64], and data augmentation [65] strategies to enhnace PR precision.
III-B High-Level Representations in Various Formats
High-level representations offer a sophisticated abstraction of a place’s layout, distinguishing themselves from low-level, sensor-dependent models by focusing on advanced constructs like graph structures and embedding vectors. Graphs are adopted to modal implicit relationship among objects, while embeddings can be understood as a high-level feature vectors that are directly processed by deep learning models. An interesting property is that a set of same-size embeddings can be concatenated, regardless that they are generated from images, point clouds or text. This section aims to detail the construction of high-level representations and examine their application in existing PR works, unveiling their evolution and role in boosting PR performance.
III-B1 Graph
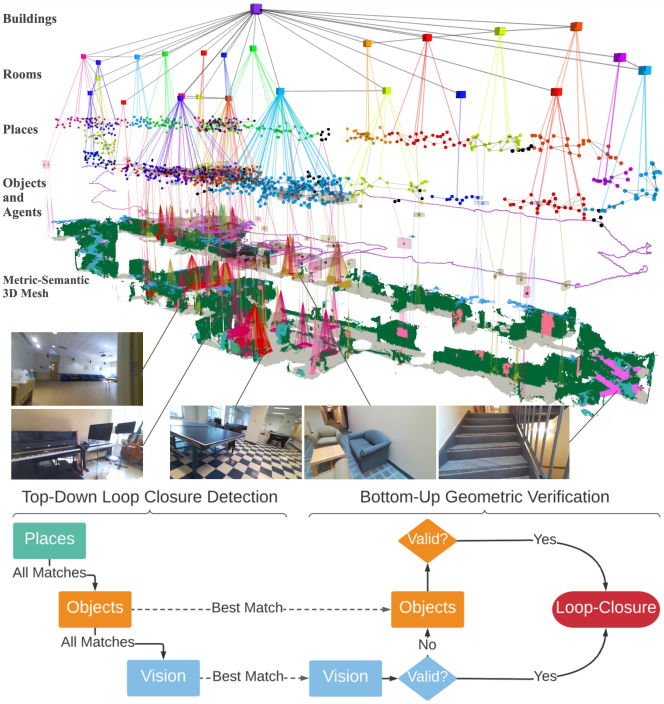
Graphs, including object-based graphs and 3D scene graphs, have recently emerged as a powerful representation of a place. A graph is a mathematical structure that is used to model pairwise relations between objects [67]. It consists of vertices (also called nodes) and edges, where the vertices represent the objects and the edges represent the connections or relationships between them. In the context of PR, these entities can be features, landmarks, or regions, and the edges can denote spatial or topological relations. Graph representations offer several advantages, including robustness to viewpoint changes, occlusions, and dynamic scenes. They can also store semantic labels [66] to enhance PR accuracy.
Recent studies [68, 69, 70, 66, 71] have introduced various graph models to depict places and environments. Co-visibility graphs depict the relationships between landmarks and the different viewpoints from which sensors observe these landmarks [68]. Kong et al. [69] constructed the semantic graph which abstracts object instances and their relative position. LOCUS [70] employed the spatio-temporal higher-order pooling graphs to merge various features including appearance, topology, and temporal links for a unified scene depiction. The topological semantic graph is designed to enable the goal-directed exploration [71]. The Hydra [66] system construct 3D scene graph to represent places with a hierarchical graph structure from low-level metric maps to high-level object semantics. Comparing the similarity of two graphs become the key challenge in PR. Related solutions including graph kernel formulation [68], inner product of features from graph neural network [69], Euclidean distance after feature pooling [70], and hierarchical descriptor matching [66] have been proposed.
III-B2 Embeddings
Implicit embeddings, often referred to as latent codes in the literature, differ from the global descriptors discussed in Section III-A. These embeddings are outputs from intermediate layers of neural networks that are not specifically designed for PR. Although they have been seldom mentioned in previous literature, we have found that implicit embeddings demonstrate significant potential for PR. The RNR-Map [72], for instance, leverages image-based embeddings to construct a 2D grid map that is not only abstract and descriptive but also generalizable and capable of real-time performance. These embeddings, originating from image observations, enable image rendering via volume rendering techniques, yielding a visually rich map useful for localization and navigation. Given their capacity to retain the appearance of places, these embeddings can be directly applied in PR through cross-correlation.
Recent works have explored image-language descriptors for PR, leveraging Visual Language Models (VLM) to link visual and textual information. The CLIP method [73], for instance, transforms images and natural language prompts into a shared embedded space, facilitating comparison between visual and textual representations [74, 75]. LEXTS [74] further integrates CLIP features with topological graph nodes for indoor, room-level PR, employing cosine similarity to gauge distances between image and room text encodings. These approaches enable the language-based data fusion in PR, demonstrating with enhanced resilience to changes in conditions, viewpoints, and overall generalizability. Moreover, the flexibility of embeddings surpasses traditional string comparison [76], mitigating the noise often present in LLM outputs. For instance, LLM may label a single location with synonyms like “corridor” and “hallway”, despite being different terms, share similar embedded representations.
III-C Summary
The methodologies employed to accurately represent places have undergone considerable evolution. Initially, these methods relied heavily on handcrafted techniques necessitating extensive engineering and domain-specific knowledge. The field then shifted towards leveraging pre-trained neural network models for the task of feature extraction, paving the way for the development of innovative end-to-end solutions such as NetVLAD, specifically designed for PR tasks. High-level representations provide a new aspect to place abstraction, demonstrating robustness against conditional and viewpoint changes, along with enhanced flexibility in multi-modal information fusion. Recent advancements in ViTs and foundation models, which are pre-trained on extensive datasets, have significantly enhanced zero-shot generalization ability in feature extraction across various domains. The next section presents methods for determining whether a place has been previously visited, utilizing proper representation and considering various practical factors relevant to robotic navigation.
| Challenges | Categories of Solutions |
|
Appearance
Change |
Place Modeling: semantics [33], domain transfer [77], event cameras [36]
Place Matching with Sequences: sequence matching [78], dynamic time warping [79] |
|
Viewpoint
Difference |
Geometric: cylinder projection [21, 59], multi-view projection [80], rotation-invariant descriptor [50]
Appearance: semantics [81], global descriptor [25, 29, 82], multi-scale feature fusion [83] Others: hybrid method [84], omnidirectional sensors [54] |
|
Generalization
Ability |
Network Capability: transformer [29], foundation model [31, 30]
Loss Functions: rotation triplet [53], angular [85], divergence [86], soft binary-cross entrpy [57] Incremental Learning: loss functions [87, 88], HMM [89], dual-memory mechanism [17] Other Methods: multi-modal information [90, 35, 91], domain transfer [77] |
| Efficiency |
Optimal Architecture: efficient backbone [92, 93]
Novel Network Design: spiking neural network [94] Non-Learning Method: context encoding [39], planar features [95] Effient Sequence Matching: particle filter [96], approximate world’s nearest neighbor [97], and HMM [98] |
|
Uncertainty
Estimation |
Employed in PR: MC Dropout [99], deep ensembles [100],
probabilistic place embedding [101], self-teaching uncertainty [102]
Employed in Other Tasks: Laplace approximation [103] |
IV Recognizing the Right Place Aginst Challenges
As we stated in Section. II, the primary challenges for place recognition can be categorized into five types: (1) Appearance Change, (2) Viewpoint Difference, (3) Generalization Ability, (4) Efficiency, and (5) Uncertainty Estimation. We will investigate them and review existing solutions separately.
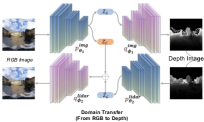
IV-A Appearance Change
Appearance changes can introduce recognition failures for the same areas and perceptual aliasing where different places generate similar observations. Two types of appearance changes are commonly presented in PR:
-
•
Conditional changes, contains the appearance changes caused by environmental conditions, such as illumination, weather, and seasons. This change will mainly affect visual observations over time, causing perceptual aliasing and wrong data association.
-
•
Structural changes, contains the dynamic objects, geometric transformations, and landform changes over short-term or long-term navigation. These changes can be due to natural phenomena, such as seasonal variations and weather conditions, or human activities, including construction and urban development.
Two categories of solutions with complementary strengths exist to address appearance changes [105]: (1) place modeling, which aims to extracing condition-invariant features to represent a place, and (2) place mathcing with sequences, which estimates the place similarity with a sequence of observations.
IV-A1 Place Modeling
Existing solutions have investigated these strategies: utilization of additional metric and semantic cues [106, 33], multi-scale feature fusion [83], and domain transformation (e.g., transform night-time images into day-time visuals) [107]. CALC2.0 [106] enhances keypoint extraction by incorporating semantic loss, ensuring the keypoints are semantically contextualized, while SRALNet [33] uses semantics as the weight to reinforce local CNN features. Patch-NetVLAD [83] extends NetVLAD by designing a multi-scale patch feature fusion mechanism, focusing on local details. Yin et al. [107] proposed a conditional domain transfer module (CDTM) to transform raw image into simulated image that is condition-invariant. This solution is also beneficial to cross-modality [54] and cross-view [77] localization.
But several challenges remain in place modeling-based solutions. For conditional changes, methods have difficulty in generalizing better across a wider range of environmental conditions, especially when training data is limited. For large structural changes that significantly reshape the spatial layout of a place (e.g., construction sites), systems may fail to detect and adapt to changes during the mission without human intervention. As a supplement, methods leveraging sequential data can avoid mismatching during single-frame matching.
IV-A2 Place Mathcing with Sequences
Since in robot navigation, data is always captured in sequence, Milford et al. established a benchmark [78] based on image sequences instead of single frame such as FAB-MAP. It aggregates scores across defined paths to ascertain the most accurate match, enhancing PR performance significantly, even with basic image intensity normalization. SeqSLAM’s methodology has inspired a vast array of research [108, 109, 110, 111, 104], fostering advancements in addressing more intricate challenges. The original SeqSLAM design presents several limitations. A significant hurdle is its computational demand, which intensifies with the expansion of the reference database and the image sequence’s length. FastSeqSLAM [108] addresses this by employing an approximate nearest neighbor (ANN) search, offering a more efficient alternative to exhaustive search methods. Moreover, Bampis et al. [109] enhance sequence matching with a BoW that includes a temporal consistency filter for improved accuracy. A further complication arises from SeqSLAM’s assumption of constant sensor velocity, making it vulnerable to velocity fluctuations. The efficacy of sequence-based recognition also heavily relies on the quality of single-image descriptors, which may falter under drastic visual changes.
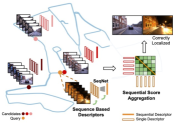
IV-B Viewpoint Difference
This challenge is caused by the variation in the perspective from which an environment is observed by sensors. For instance, observing a building from the front view reveals its full shape, while a top-down view showcases its layout and roof design. Viewpoint differences also encounter when a robot revisits a location from a different angle or altitude [77]. This issue is common in all kinds of sensor modalities and should be handled by PR systems that consist of robust feature extraction and matching modules.
PR solutions to address viewpoint differences can be categorized into three primary groups: geometric, appearance-based, and hybrid approaches, each leveraging different input types. Geometric methods, predominantly utilized in LPR systems, include innovations like OverlapNetTransformer [56], which transforms yaw differences in point clouds into translational differences on images via cylinder projection, addition to translation-invariant CNN to extract features. RPR-Net[48] achieves rotation-invariant LPR by utilizing SPRIN[112] rotation-invariant local features and geometry constrains which are consistent within different viewpoints. Appearance-based methods aim to identify visual cues immune to viewpoint shifts. Semantics-aware PR methods, as proposed by Garg et al., facilitate PR across inverse directions. Techniques such as MixVPR [82] utilize global descriptors with attention-weighted patch tokens and isotropic MLP stacks, respectively, to maintain consistent performance despite viewpoint changes. Patch-NetVLAD [83] focuses on extracting patch-level features for global descriptor computation, enhancing viewpoint invariance through a multi-scale patch feature fusion strategy. Hybrid methods, like AutoMerge [84], incorporating both point-based (geometry) and projection-based (appearance) feature extraction. This combination addresses the issue caused by translation and orientation disparities, offering a robust framework for PR under varied viewpoints.
Large viewpoint differences may lead to limited overlap between observations, particularly when using pinhole cameras positioned in opposite directions. Besides above solutions, this challenge can be also mitigated by employing omnidirectional sensors like panorama cameras, LiDARs, and Radars. Existing studies concentrate on deriving rotation-invariant features and descriptors, employing methods like polar context projection [39], spherical harmonic functions [54], and multi-view fusion [80] to enhance PR under significant viewpoint variations.
IV-C Generalization Ability
Generalization ability refers to a system’s capacity to recognize places that it is not included during training, which is especially challenging if the unseen environment has drastic variations from the training data [113]. However, infinite real-world environments make it impossible to train data covering all types of scenarios. Enhancing the generalization ability of robots is essential for their autonomous operation, particularly in applications such as autonomous navigation, where they must adeptly navigate through entirely novel environments.
In Section III, the transformative impact of deep learning on place representation is thoroughly explored, highlighting the integration of pre-trained CNN architectures [114], adaptable and trainable frameworks [25], attention mechanisms [58], and ViTs [31]. A notable trend is the enhancement of feature extraction generalization across diverse domain datasets through the augmentation of network capacity (e.g., increased model depth and a greater number of trainable parameters) and the expansion of training data scale. However, as explained in Section IV-D, this augmentation in network size introduces significant efficiency challenges to real-time applications.
Semantics that encode high-level human knowledge can help PR for better inference. PSE-Match [86] designed a semantic feature encoding to extracts the different types of semantics (tree, building, etc.). Paolicelli et al. [91] combined the visual appearance and semantic context through a multi-scale attention module for robust feature embedding. Visual-LiDAR fusion, as demonstrated in AdaFusion [90] and MinkLoc++ [35], enhances generalization capability in PR, surpassing what a single sensor alone can achieve.
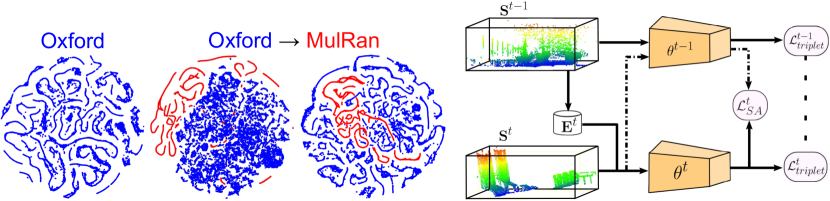
Loss functions play a crucial role in training generalized PR models. Triplet loss, a well-established metric, aims to reduce the distance between query-positive pairs while increasing the separation from negative pairs [25, 45]. To enhance orientation invariance, Yin et al. [53] proposed the rotation triplet loss. Angular loss, leveraging cosine similarity, offers robustness against similarity transformations and is effective in handling spatial discrepancies [85]. However, these metrics predominantly concentrate on the relational distances within and between clusters, somewhat overlooking the multifaceted nature of PR challenges. Alternatively, divergence loss, introduced by Yin et al. [86], targets varying semantic structures. Meanwhile, classification-based strategies like RINet [57] formulate PR as classification problem, presenting a soft binary-cross entropy loss for the model training.
Rather than expanding models’ capacity to address PR by training on extensive datasets like Anyloc, lifelong or continual learning chooses to incrementally update agents’ knowledge during missions while utilizing a standard-sized model. AirLoop [87] proposed two loss fucntions to protect the model from catastrophic forgetting when being adapted to a new domain: (1) the relational memory-aware synapses loss, which assigns an importance weight to each model parameter, thus regularizing the parameters’ adjustments throughout the training process; (2) the relational knowledge distillation (RKD) loss, designed to preserve the embedding space structure. In contrast to the RKD loss, InCloud [88] designed a higher-order angular distillation loss. Fig. 10 visulized the key insight of InCloud. HM4 [89] developed a Hidden Markov Model featuring a dual-tier memory management system. Additionally, Bio-SLAM [17] took inspiration from human memory mechanisms to propose a lifelong PR system capable of incremental learning across new domains.
IV-D Efficiency
Efficiency in PR involves the system’s ability to quickly and accurately recognize previously visited places, which is essential for real-time robotics applications such as loop closure and multi-agent exploration. Traditional handcrafted methods, including DBoW [115] and the ScanContext series [39, 116, 40], have been widely adopted in real-time SLAM due to their high efficiency. Conversely, data-driven approaches, though they meet the required performance metrics for large-scale and long-duration navigation tasks, tend to impose substantial computational burdens. This raises a demand of addressing the efficiency issue. Overall, the pursuit of efficiency encompasses several dimensions: minimizing time latency, reducing memory usage, and ensuring effective operation on resource-constrained devices without compromising accuracy.
Various strategies have been explored to enhance the efficiency of PR systems, which can be broadly categorized into three primary approaches: Architectures optimized for mobile inference, focusing on designing systems that are lightweight and capable of running on devices with limited computational resources. Innovative neural network structures, introducing novel architectures that aim to reduce computational complexity without compromising on the system’s ability to accurately recognize places. Accelerated matching with the prior knowledge integration, leveraging additional information to streamline the recognition process, thus balancing computational demands with recognition accuracy.
Architectural optimization enhances neural network models for greater efficiency [92]. MobileNetV2, designed for mobile devices, introduces inverted residual blocks with linear bottlenecks, optimizing both performance and memory efficiency for various vision tasks [92]. FlopplyNet [117] proposed the binary neural network with depth reduction and network tunning for VPR. Oliver et al. [118] provide an exhaustive analysis of PR efficiency, exploring architectural optimization, pooling methods, descriptor size, and quantization schemes. Their findings suggest that a balance between recall performance and resource consumption is achievable, offering design recommendations for PR systems facing resource constraints.
Researchers have explored the Spiking Neural Network (SNN) [119] for PR, leveraging its ability to process information through discrete spikes. This event-driven computation in SNNs, triggered only by significant input changes, drastically reduces energy consumption and computational load, making it ideal for robotics where energy efficiency and real-time processing are paramount. VPRTempo [94] enhances PR efficiency by using temporal coding for spike timing based on pixel intensity, enabling rapid training and querying suitable for resource-limited platforms. Further, Hussaini et al. [120] introduce three key SNN advancements: modular architecture, ensemble techniques, and sequence matching.
Although sequence matching improves matching accuracy, the brute-force method used in SeqSLAM [78] is time-consuming. Including odometry and movement information may help enhance performance. Various approaches have been proposed to boost SeqSLAM’s efficiency, such as particle filters [96], approximate nearest neighbor searches [97], and Hidden Markov Models [98]. However, these methods largely rely on environmental conditions, limiting their robustness in dynamic and challenging settings. Recent works [121] and [111] have introduced frameworks that balance efficiency and accuracy by refining SeqSLAM with a coarse-to-fine search strategy. Similarly, in several SLAM systems, odometry information can constrain the search space for PR, thereby providing a starting point for the place node identification.
IV-E Uncertainty Estimation
Uncertainty estimation allows PR systems to assess the reliability of their results, highlighting instances where the model’s predictions are less certain. Uncertainty can be used to determine whether the PR systems perform poorly or if the input data are out-of-distribution. The sources of uncertainty mainly include the sensor noise, models, and environments (e.g., repetitive environments and conditional changes). Obtaining uncertainty is sometimes equally important to the recognition outcomes due to requirements raised by downstream tasks such as PGO [14], graph merging [84], and localization [122]. PGO typically needs to solve a large optimization problems that involve thousand of variables, which requires accurate weighting scores and robust outlier rejection to prevent local minima.
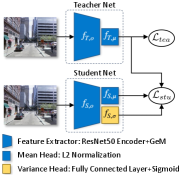

The Bayesian neural network framework is one the pioneering methods in uncertainty estimation for neural networks. The posterior distribution of network weights can be approximated through Monte-Carlo (MC) Dropout, Deep Ensembles, and Laplace approximation methods [99, 123, 100, 103]. Additionally, some of these methods have been applied to tasks such as semantic segmentation [123] and 3D object detection [103]. However, they require intensive computational sampling during inference. Another solution is to integrate evidential theory into neural networks [124]. By optimizing the distribution’s hyper-parameters, this approach enables precise uncertainty estimation in a single forward pass, thereby eliminating the need for sampling during inference.
Some of these approaches are used to estimate the uncertainty in PR. Cai et al. [102] formulated the problem into estimating the distribution of embeddings within the metric space. They proposed a Student-Teacher Network (STUN), in which a variance-enhanced student network, under the guidance of a pre-trained teacher, refines embedding priors to assess uncertainty at an individual sample level. Keita et al. [125] benchmarked existing uncertainty estimation for LPR, including: negative MC-Dropout [99], Deep Ensembles [100], cosine similarity, Probabilistic Place Embedding (PPE) [101], and STUN [102]. Their findings suggest that, although Ensembles consistently surpass other methods in terms of performance on key LPR datasets, they also demand significant computational resources.
Uncertainty estimation remains a critical and unresolved challenge in PR, characterized by a gap between theory and application. This complexity arises from several key issues: (1) Balancing the computational cost with the accuracy of uncertainty estimation for real-time applications. (2) Avoiding overestimation or underestimation of uncertainty. (3) Estimation methods for novel foundation model-based PR approaches. (4) Accurately assessing the uncertainty for sequence-based PR. Addressing these challenges improve the accuracy and reliability of PR, empowering robots to make informed decisions for subsequent navigation tasks.


V Application & Trends
Looking towards the horizon of future applications, multiple potential avenues are currently unfolding withitn the field of PR. This sectioin delineates four pivotal directions: (1) Long-Term and Large-Scale Navigation for mobile robots, (2) Visual Terrain Relative Navigation for aerial robots, (3) Multi-Agent Localization and Mapping, and (4) potential pathways to achieve the Lifelong Autonomy. For each direction, we dive into current status and future opportunities.
V-A Long-Term & Large-Scale Navigation
The most in-demand robotic tasks requiring PR is the autonomous navigation, including applications such as autonomous driving [128] and subterranean search [129]. PR enables robots to obtain their global location with precision up to the topological level in a known environment, despite condition changes of environments. This capability is crucial to safe and reliable navigation, as it allows robots to (1) determine whether this place is visited before, (2) recorver from failure against the kidnapped problem, and (3) progressively update and enhance their navigational maps over time.
V-A1 Brief Survey
Large-scale SLAM often benefits from PR solutions that enable robots to recognize previously visited locations against significant environmental changes or different viewpoints, thereby correcting drift errors and enhancing map accuracy. Typical SLAM systems such as ORB-SLAM [130] and VINS-Mono [131] are designed with the PR module to maintain the global consistency of poses, mainly rely on the DBoW2 library [115] and use the BoW representation with specific global descriptors to quickly detect loop candidates. The additional RANSAC-based verification algorithms is also coupled to reject wrong place candidates. LiDAR- and Radar-based SLAM [132, 133] also benefits from the development of LPR and RPR approaches, where the need for an extra camera to find a loop is eliminated.
Tracking failure, which often refers to a situation where the system fails to correctly associate across adjacent frames, is the primary cause to make SLAM collapse and induce the kidnapped problem. It may encouter in practice due to reasons such as motion blur, occlusion, and hardware disconnection. Recovering from failure by relocalizing the robot in the previously built map necessitates solving a more complex PR problem than loop detection since odometry prior is unavailable. Chen et al. [134] developed a submap-based SLAM system that enhances resilience and mapping integrity by initiating a new process to manage a submap upon failure, which is integrated into the main map after detecting a loop closure using DBoW2 to ensure continuous and accurate mapping. Kuse and Shen [135] streamlined the training of NetVLAD [45] for VPR by introducing an all-pair loss function and decoupled convolutions. This innovation leads to quicker training convergence and reduced the number of learnable parameters. And the enhanced NetVLAD method was effectively integrated into a stereo-inertial SLAM system, achieving real-time loop closure detection and failure recovery in complex indoor settings.
Global localization broadly encompasses the challenge of determining a global position within a pre-mapped area, especially where GNSS is unreliable. This context implies a significant initial uncertainty in pose estimation. Leveraging deep-feature extraction advancements [136], Sarlin et al. [137] introduced a hierarchical localization approach using a unified CNN architecture that integrates both local geometric features and a global descriptor for precise -DoF localization in vast environments. Yin et al. [54] presented a cross-modality visual localization technique tailored for extensive campus areas, employing cross-domain transfer networks. These networks harness condition-invariant features from visual inputs and learn geometric similarities to LiDAR projections, enhancing long-term navigational robustness in dynamically changing environments. Regarding the localization in a larger-scale urban road, Liu et al. [138] tackled the problem by introducing cross-view matching for large-scale geo-localization. Their method, which incorporates both orientation and geometric data, significantly enhances recall rates in spatial localization.
The Teach-and-Repeat (T&R) framework is an efficient navigation solution for diverse mobile robots [139, 140]. Without the requirement of constructing a precise global map, it has achieved great performance in applications such as long-range navigation and planet exploration. During the teach phase, a robot is manually guided along a specific path to generate a topological map, optionally incorporating local metric data. Subsequently, in the repeat phase, the robot autonomously localizes itself within this map to follow the established route, demonstrating an efficient method for traversing pre-determined paths even in changing environments. Therefore, T&R systems necessitate a robust PR module to guarantee the precise localization at the topological level. Chen et al. [141] introduced the sequence matching scheme for enduring T&R operations. Mattamala et al. [140] proposed to dynamically choose the most informative camera during the repeat phase under a multi-camera configuration, mitigating the impact of sudden PR variations. And PlanNav [142] used PR to limit the number of sub-goal candidates for topological navigation.
V-A2 Opportunities
PR is essential for large-scale and long-term navigation, evolving from mere loop closure detection to a broad spectrum of applications including global positioning, failure recovery, and T&R navigation. As PR technology advances, it is timely to revisit navigation system designs, positioning PR as a central element in modern robotic frameworks to enhance navigation in challenging environments. The evolution of mobile robots introduces new challenges for PR, particularly in environments with repetitive features such as multi-floor buildings and underground parking lots. Recent innovations like the hierarchical 3D scene graph proposed by Hughes et al. [66] provide novel PR solutions. Additionally, PR has the potential to enhance the construction of 3D scene graphs by improving spatial segmentation through place similarity comparisons and facilitating efficient exploration in tasks such as object/image-directed exploration (e.g., finding a chair in an office) [143]. These investigations are crucial for advancing dynamic and long-term navigation strategies in complex environments.
V-B Visual Terrain Relative Navigation
VTRN is another representative application of PR by comparing onboard camera images (as the observation) with pre-acquired geo-referenced satellite imagery (as the database) [144]. VTRN proves especially valuable in GNSS-denied environments by utilizing lightweight cameras and widely accessible satellite data, making it applicable to a broad range of robots, including drones and vehicles. But challenges including changes in environmental conditions (Section IV-A), differences in viewpoints (Section IV-B), and constrained model’s generalization ability (Section IV-C) are presented.
V-B1 Brief Survey
The temporal disparities between capturing satellite images and onboard sensor images often span years. Therefore, the conditional changes are mainly attributed to day-night transitions and seasonal variances such as lighting conditions, changes in vegetation, and snow coverage. Current strategies to mitigate these changes [145, 77] include image transformation and feature matching.
Bhavit et al. [146] explored the efficacy of the Normalized Information Distance for aligning Google Earth (GE) satellite images with unmanned aerial vehicle images, demonstrating its superiority over traditional photometric error measurements in day-night scenarios. Following this, an auto-encoder network was developed to map raw images into an embedding space, enhancing robustness against environmental changes by simplifying optimization and storage processes [145]. For addressing seasonal variations, Anthony et al. [144] utilized the U-Net image transform model to align cross-seasonal image pairs. This approach excels at high altitudes, where invariant geometric features prevail across seasons.
However, the majority of previous studies overlooks viewpoint differences (orientation and altitude). iSimLoc [77] utilizes NetVLAD for clustering local features into comprehensive global place descriptors, enhancing feature matching with sequential data. VTRN extends beyond UAVs to ground robots, tackling substantial viewpoint shifts known as “cross-view localization” [138, 147, 148, 149]. An example is visualized in Fig. 4(b). Liu et al. [138] innovated a Siamese network that encodes image pixel orientations, bolstering feature discrimination for localization. SNAP [147] introduced neural representations for Ground Elevation images, dependent solely on ego-view images and camera poses for training, spontaneously generating significant semantics. Shi et al. [148] created a geometry-enhanced cross-view transformer for establishing correspondence across views. In addressing range sensors, Tang et al. [149] developed a representation transforming GE images into 2D point collections for direct comparison with BEV images from LiDAR data.
V-B2 Opportunities
Integrating advanced PR algorithms into VTRN unlocks new possibilities for cutting-edge applications across multiple fields. In particular, this enhancement improves the reliability of autonomous mobile robot navigation in environments where GNSS signals are blocked [77]. PR also benefits planetary exploration [150, 151], providing a consistent global position as complemerty to visual odometry. Furthermore, aerial-ground coordination introduces new prospects for advanced robotic applications, such as environmental reconstruction and cooperative exploration. Aerial imagery contributes valuable prior knowledge for global path planning and mapping. By linking aerial with ground images, PR algorithms facilitate an integrated aerial-ground collaboration, evolving the functionality of these systems [152].
V-C Multi-Agent Localization and Mapping
Multi-agent systems bring a pivotal shift in addressing complex and dynamic tasks that are beyond the capability of a single agent. The collaboration among robots significantly increase the efficiency to achieve common goals such as cooperative scene exploration [153] and reconstruction [154]. However, one of major challenges in realizing decentralized multi-agent cooperation is to obtain real-time relative coordinates w.r.t. each robot, which become serious in environments characterized by uncertainty and high complexity. PR methods provide a series of solutions, but as pointed out in Section. IV-A and Section. IV-B, the appearance and viewpoint difference from different agents will cause data association to fail for multi-agent cooperation.
V-C1 Brief Survey
Recent advancements in multi-agent systems (MAS) have showcased diverse PR approaches to collaborative mapping and localization. Van et al. [155] introduced a collaborative SLAM system that compresses visual features, allowing for efficient multi-session mapping on the KITTI dataset. Sasaki et al. [156] developed a rover-copter-orbiter cooperative system, leveraging satellite images for coordinated localization among agents and enabling the generation of optimized paths for rover robots through rich textures captured by the copter. Ebadi et al. [157] proposed a geometric-based multi-agent SLAM system for unstable underground environments, employing a robust filtering mechanism to reject noise in data association, demonstrating the critical role of 3D geometric features in the robustness of point-based approaches. Tian et al. [154] introduced the distributed multi-agent metric-semantic SLAM system called Kimera-Multi, where a distributed loop closure detection based on DBoW2 is implemented. Its following work Hydra-Multi [158] employed a multi-robot team to collaboratively construct a 3D scene graph, where scene-graph-based hierarchical loop closure detection is designed. Labbé et al. [159] focused on visual appearance-based loop closure detection methods for multi-session mapping, allowing a single robot to map separate areas across different sessions without requiring initial transformations between trajectories.
These methodologies underscore the evolving landscape of multi-agent localization, setting the groundwork for future cross-disciplinary research [160]. However, challenges remain, particularly in large-scale map merging, where significant perspective and appearance differences pose hurdles. The most recent contribution by Yin et al. [84] addresses these challenges with a framework for large-scale data association and map merging, extracting viewpoint-invariant place descriptors and filtering unreliable loop closures, marking a significant step forward in the field. This body of work not only highlights the potential for multi-agent cooperation but also underscores the necessity of innovative solutions for PR and large-scale data integration in achieving effective map merging and localization.
V-C2 Opportunities
The field of MAS is approaching a period of notable developments, with PR contributing significantly to the evolution of autonomous technologies. Among the most promising avenues is the integration of Neural mapping such as NeRF [10] and 3D Gaussian Splatting [161], offering a groundbreaking approach to rendering photo-realistic and three-dimensional environments from sparse and unstructured data. The PR technique, when applied within systems such as virtual and augmented reality, can enable seamless and immersive interactions between users such as real-world massively multiplayer online games.
Furthermore, PR methods facilitate the applications of MAS in GNSS-denied environments such as subterranean scenes [153], factories, and forests, as demonstrated in the drone swarm system [160]. Exploiting the coordination and communication capabilities of MAS enables safer and more efficient operations in hazardous environments, ranging from deep-sea explorations to space missions and disaster zones, thereby lessening the heavy reliance on communication infrastructure. The collaborative nature of MAS also opens up innovative approaches to crowd-sourcing data collection in robots. Taking the Tesla FSD system [162] as an example, by leveraging a network of vehicles equipped with sensory technologies, a more comprehensive and dynamic mapping of urban roads can be achieved. This provides a large amount of data for algorithm training and thus enhances the safety and reliability of autonomous navigation systems.
V-D Bio-Inspired and Lifelong Autonomy
Recent advancements in space robotics, as evidenced by NASA’s new Mars rover Perseverance [150] and CNSA’s teleoperated Yutu-2 rover on the Moon [151], have underscored the challenges of remote operations and the limits of real-time communication. These challenges make long-term and real-world autonomy a critical requirement for future robots. PR serves as a critical component in space and underground exploration, facilitating consistent localization of robots within a global coordinate system. This capability is essential to long-horizon planning and decision-making. However, the computational resources available to robots are limited, and the performance of PR models often degrade when faced with new environments. Thus, developing a lifelong PR system is imperative for sustaining real-world autonomy. Building on the discussion in Section IV-C, this section further details how PR enhances the capability of lifelong robotic systems.
V-D1 Brief Survey
Tipaldi et al. [163] introduced a traditional probability-based approach to lifelong localization, leveraging a combination of a particle filter with a hidden Markov model to assess dynamic changes in local maps effectively. Zhao et al. [164] proposed a novel lifelong LiDAR SLAM framework tailored for extended indoor navigation tasks. This framework primarily employs a multiple-session mapping strategy to construct and refine maps while concurrently optimizing memory usage through a Chow-Liu tree-based method [165]. Notably, real-world SLAM implementations tend to struggle more significantly with less dynamic objects, such as parked cars, compared to highly dynamic ones, like moving vehicles. Drawing inspiration from this challenge, Zhu et al. [166] have developed a semantic mapping-enhanced lifelong localization framework that seamlessly integrates existing object detection techniques to update maps continually.
Lifelong place feature learning is crucial for navigation and recognition systems, often challenged by the issue of catastrophic forgetting. This issue arises when systems fail to retain knowledge over long periods, particularly problematic in dynamic or evolving environments. Most existing PR methods focus on short-term or static cases, lacking the ability to adapt and learn continuously without losing previous knowledge. The benchmark on VPR highlights this gap, emphasizing the need for more resilient approaches [167]. An early work to address these challenges was presented by Mactavish et al. [168] A vision-in-the-loop navigation system that incorporates a visual T&R was introduced. This system facilitates long-term, online visual place feature learning and employs a multi-experience localization mechanism. This mechanism assists in matching current observations with relevant past experiences, enhancing the system’s ability to navigate and recognize places over extended periods.
However, real-world applications often involve infinite data streams, leading to scalability challenges. Doan et al. [89] addressed the challenge by integrating a HMM with an innovative two-tiered memory management strategy. This approach effectively segregates active memory from passive storage, facilitating dynamic image transfers essential for lifelong autonomy. Their methodology presents a pragmatic solution for managing long-term navigation tasks, maintaining steady performance without notably elevating time or space demands. Yin et al. [17] proposed BioSLAM, a bio-inspired lifelong learning framework tailored for PR. This innovative framework incorporates a dual-memory system to bolster a robot’s PR capabilities incrementally while mitigating catastrophic forgetting. It encompasses: (1) a dynamic memory for the agile assimilation of new observations; and (2) a static memory to balance fresh insights with established knowledge, guaranteeing consistent PR performance. Furthermore, to evaluate the performance of lifelong systems, two novel evaluation metrics were proposed: adaptation efficiency and retention ability.
V-D2 Opportunities
Although lifelong PR is a relatively nascent area compared to other research direction, it presents significant opportunities, particularly in memory management for long-term navigation tasks. Motivated by advancements in embodied AI, PR methods diverge from traditional couterpart that depend on pre-trained models using offline databases. lifelong PR leverages embodied intelligence, enabling robots to engage directly with their environment, accumulate rewards, and learn from ongoing data and experiences. This capability allows robots to execute more complex tasks and navigate more effectively in dynamic settings, ranging from urban landscapes to unstructured terrains like disaster areas or extraterrestrial environments.
VI Datasets & Evaluation
Open datasets introducing new sensor modalities, challenging scenarios, and diverse challenges are instrumental in driving the development of PR approaches. To fairly assess the performance of various PR algorithms and identify their limitations, well-designed evaluation metrics are crucial. In this section, we briefly introduce several public PR datasets, propose a new perspective for evaluation, and discuss open-source libraries relevant to PR. We additionally present our open-source package for general PR research.
| Dataset | Scenarios | Geographical Coverage | Sensors | Appearance Diversity | Viewpoint Diversity | Dynamic Diversity |
| Nordland [169] | Train ride | PinC | Four seasons | ✗ | ✗ | |
| KITTI [170] | Urban Street | L, PinC | Day-time | ✗ | ✔ | |
| Oxford RobotCar [171] | Urban + Suburban | L, PinC | All kinds | ✗ | ✔ | |
| Mapillary [16] | Urban + Suburban | PinC | All kinds | ✔ | ✔ | |
| KITTI360 [172] | Urban Street | L, PinC, PanC | Day-time | ✗ | ✔ | |
| ALTO [173](States) | Urban+Rural+Nature | Top-down PinC | Day-time | ✔ | ✗ | |
| ALITA [126](City) | Urban + Terrain | L | Day time | ✔ | ✔ | |
| ALITA [126](Campus) | Campus | L, PanC | Day/Night | ✔ | ✔ | |
| Oxford Radar RoboCar [174] | Urban | L, R, PinC | Day/Night, Weather, Traffic | ✔ | ✗ | |
| # L: LiDAR. R: Radar. PinC: Pinhole Camera. PanC: Panoramas Camera. | ||||||
VI-A Public Datasets
Table II provides a summary of several commonly utilized PR datasets, emphasizing key factors such as scenarios, scale, sensor types, and the associated challenges.
VI-A1 VPR Datasets
Related datasets predominantly cater to various environmental conditions, including illumination [107] and seasons [169]. The Nordland dataset [169], captured using a train-mounted camera, is particularly notable for benchmarking condition-invariant or large-scale PR tasks. In the realm of lifelong PR, Warburg et al. [16] introduced the most extensive VPR dataset to date, covering urban and suburban settings over a span of seven years and documenting various condition changes. The ALIO dataset [173] presents a comprehensive dataset for the VTRN task, including raw aerial visuals and corresponding satellite imagery. Furthermore, Project Aria [175] utilizes AR glasses to provide a dataset of sequences over months from a construction site, which is crucial for exploring lifelong PR with structural and appearance changes.
VI-A2 LPR Datasets
The datasets discussed herein extensively overlap with those for VPR, with a primary focus on urban environments. Notable autonomous driving datasets, including KITTI [170] and Oxford RobotCar [171], are particularly valuable for evaluating PR in diverse open-street contexts. The Newer College dataset [176] is a campus-scene dataset that features LiDAR and stereo-inertial sensors, which is well-suited for VPR, PR, and cross-modal PR evaluations. Additionally, the ALITA dataset presents large-scale, LiDAR-centric data encompassing city-scale trajectories with overlaps and campus-scale trajectories with overlaps. This dataset is versatile, supporting a broad spectrum of algorithm evaluations, including large-scale and cross-domain PR, multi-agent map merging, and lifelong learning.
VI-A3 RPR Datasets
RPR datasets typically feature extreme environments under various weather conditions, including foggy and snowy days, where Radar technology demonstrates significant advantages. Key datasets such as the Oxford RoboCar Radar [174] and Boreas [15] showcase Radar’s unique capabilities in challenging visibility conditions.
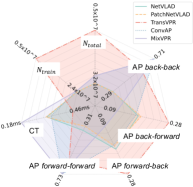
VI-B New Perspective of Evaluation
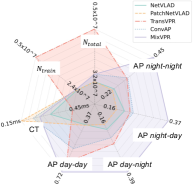
As outlined in Section II, the essential properties of PR encompass condition-invariance, viewpoint-invariance, recognition accuracy, generalization ability, and both training and inference costs. Utilizing a set of evaluation metrics from VPR-Bench [167], we propose a comprehensive comparison of methods based on these properties. We choose the following metrics Average Precision (AP), Network Parameters (NP), and Computational Time (CT). to illuminate the key characteristics of PR methods:
-
•
Condition Invariant Property: AP of PR under different environmental conditions like illumination and weather changes, e.g., comparing night query images against a daytime database.
-
•
Viewpoint Invariant Property: AP of PR across varying viewpoints, e.g., forward and backward. We consider that environmental conditions and sensors are fixed between the database and query.
-
•
Generalization Ability: AP of RP in unseen environments after model training, e.g., evaluating how an indoor-trained method performs in urban settings.
-
•
Training and Inference Cost: Analyzes computational demands, including NP and CT required by a PR algorithm.
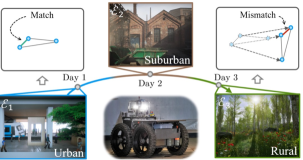
Fig. 12 illustrates two star diagrams comparing the properties of five SOTA PR methods (without fine-tuning) using two subsets of the ALITA-campus dataset [126]. We created the Dataset by selecting two sequences from the same location captured during daytime and nighttime, respectively, to assess the condition-invariant property and generalization ability of the PR methods. The notation “day-night” indicates the test setting that daytime images serve as the database, while nighttime images form the query set. Unless specified, database and query images are chosen randomly. The Dataset follows a similar structure but focuses on evaluating the viewpoint-invariant property. To aid researchers in developing novel PR methods, we provide a standardized implementation and evaluation framework detailed at GPRS-core111https://github.com/MetaSLAM/GPRS_core, which will be further explained in the subsequent section.
VI-C Supported Libraries
Recent advancements have led to the development of several comprehensive libraries aimed at enhancing long-term PR systems. OpenSeqSLAM2.0 [177] enhances sequence matching by providing a detailed analysis of SeqSLAM’s key components. VPR-Bench [6] integrates datasets and VPR methods, complete with evaluation metrics to benchmark new PR techniques. Additionally, Kapture [178] is an open-source library that supports visual localization and structure-from-motion, including implementations of VPR.
We publicly release the GPRS-core, which is a versatile framework taliored for PR benchmarking and support multiple input modalities such as point clouds and images. The usage of GPRS-core involves three main steps: (1) training a PR model and saving the weights; (2) applying these weights across multiple datasets; and (3) evaluating model performance with diverse metrics for benchmark comparisons. Notably, GPRS-core reimplements over SOTA methods: (1) VPR Methods: NetVLAD [25], CosPlace [28], MixVPR [82], SVTNet [93], and TransVPR [29]. (2) LPR Methods: BEVPlace [55], LoGG3D [52], MinkLoc3D [50], MinkLoc3Dv2 [179], and PointNetVLAD [45]. (3) Fusion-Based Method: MinkLoc++ [35]. We invite the academic community to contribute to enhancing the package, thereby advancing PR research.
VII Conclusion
The escalating complexity of mobile robots necessitates the development of lifelong navigation systems capable of autonomous, long-term operations in large-scale environments. PR, which enables robots to identify previously visited locations under appearance changes and viewpoint differences, has emerged as an essential technology for robotic autonomy. This paper has charted significant advancements in PR over recent decades, including the discussion of the definition of PR and typical methods on representations, strategies against challenges, and applications. We start providing a clear problem formulation that is closed to the need of robotic navigation of position-based PR. This sidesteps the ambiguities associated with overlap-based PR definitions which are aligned with image retrieval tasks.
Addressing the critical question of “representing a place”, we explore the evolution from handcrafted feature extraction to data-driven methodologies. Methods of place representation is benefiting from research in other fields, particularly the great strides being achieved in computer vision and nature language processing in the fields of novel neural network architectures, open-set object detection, semantic segmentation, and so on. Developments in high-level place representations (i.e., graphs and implicit embedding) have collectively fostered the paradigm shift. This shift not only simplifies the PR challenges but also enhances model generalization abilities and provides more opportunities to define PR architectures.
The challenge of accurately “recognizing the correct place” for real-world robots introduces five fundamental challenges: appearance change, viewpoint difference, model generalization, efficiency on resource-constrained platforms, and uncertainty estimation of the methods’ output. Key solutions are reviewed, while unsolved issues still exist. The trend shows that the development of methods from the precision race in open-datasets to solution of real-world problems encountered.
In recent years, the development of PR has advanced in parallel with SLAM algorithms. Fortunately, an increasing number of studies are now proposing or incorporating SOTA PR methods to enhance navigation systems. Looking towards real-world navigation, we question ”how to bridge the gap between PR algorithms and applications?” Highlighting PR’s vast potential, we showcase applications from large-scale navigation and visual terrain navigation to multi-agent systems and beyond, including VR/AR and crowd-sourced mapping. This field presents numerous opportunities for exploration. Additionally, the indispensable contributions of PR datasets, evaluation metrics, and open-source libraries in expediting the advancement of PR are discussed.
In conclusion, we underscore the immense potential of PR in shaping the future of robotic navigation and autonomy. By inviting researchers to engage with our open-source projects, we aim to collectively advance towards the realization of generalized PR, a goal that holds promise for transforming both robotic systems and their applications in our world.
References
- [1] C. Cadena, L. Carlone, H. Carrillo, Y. Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,” IEEE Transactions on Robotics, vol. 32, no. 6, pp. 1309–1332, 2016.
- [2] S. Lowry, N. Sünderhauf, P. Newman, J. J. Leonard, D. Cox, P. Corke, and M. J. Milford, “Visual place recognition: A survey,” ieee transactions on robotics, vol. 32, no. 1, pp. 1–19, 2015.
- [3] X. Zhang, L. Wang, and Y. Su, “Visual place recognition: A survey from deep learning perspective,” Pattern Recognition, vol. 113, p. 107760, 2021.
- [4] T. Barros, R. Pereira, L. Garrote, C. Premebida, and U. J. Nunes, “Place recognition survey: An update on deep learning approaches,” arXiv preprint arXiv:2106.10458, 2021.
- [5] S. Garg, T. Fischer, and M. Milford, “Where is your place, visual place recognition?” arXiv preprint arXiv:2103.06443, 2021.
- [6] M. Zaffar, S. Garg, M. Milford, J. Kooij, D. Flynn, K. McDonald-Maier, and S. Ehsan, “Vpr-bench: An open-source visual place recognition evaluation framework with quantifiable viewpoint and appearance change,” Int. J. Comput. Vision, vol. 129, no. 7, pp. 2136–2174, jul 2021.
- [7] J. Miao, K. Jiang, T. Wen, Y. Wang, P. Jia, X. Zhao, Z. Xiao, J. Huang, Z. Zhong, and D. Yang, “A survey on monocular re-localization: From the perspective of scene map representation,” arXiv preprint arXiv:2311.15643, 2023.
- [8] H. Yin, X. Xu, S. Lu, X. Chen, R. Xiong, S. Shen, C. Stachniss, and Y. Wang, “A survey on global lidar localization: Challenges, advances and open problems,” International Journal of Computer Vision, pp. 1–33, 2024.
- [9] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [10] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021.
- [11] J. O’Keefe, “Place units in the hippocampus of the freely moving rat,” Experimental neurology, vol. 51, no. 1, pp. 78–109, 1976.
- [12] S. Garg, T. Fischer, and M. Milford, “Where is your place, visual place recognition?” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, aug 2021.
- [13] T. Weyand, A. Araujo, B. Cao, and J. Sim, “Google landmarks dataset v2 - a large-scale benchmark for instance-level recognition and retrieval,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2572–2581.
- [14] L. Carlone, G. C. Calafiore, C. Tommolillo, and F. Dellaert, “Planar pose graph optimization: Duality, optimal solutions, and verification,” IEEE Transactions on Robotics, vol. 32, no. 3, pp. 545–565, 2016.
- [15] K. Burnett, D. J. Yoon, Y. Wu, A. Z. Li, H. Zhang, S. Lu, J. Qian, W.-K. Tseng, A. Lambert, K. Y. Leung et al., “Boreas: A multi-season autonomous driving dataset,” The International Journal of Robotics Research, vol. 42, no. 1-2, pp. 33–42, 2023.
- [16] F. Warburg, S. Hauberg, M. López-Antequera, P. Gargallo, Y. Kuang, and J. Civera, “Mapillary street-level sequences: A dataset for lifelong place recognition,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2623–2632.
- [17] P. Yin, A. Abuduweili, S. Zhao, L. Xu, C. Liu, and S. Scherer, “Bioslam: A bioinspired lifelong memory system for general place recognition,” IEEE Transactions on Robotics, 2023.
- [18] J. M. Dolezal, A. Srisuwananukorn, D. Karpeyev, S. Ramesh, S. Kochanny, B. Cody, A. S. Mansfield, S. Rakshit, R. Bansal, M. C. Bois et al., “Uncertainty-informed deep learning models enable high-confidence predictions for digital histopathology,” Nature communications, vol. 13, no. 1, p. 6572, 2022.
- [19] D. Scaramuzza, Omnidirectional Camera. Boston, MA: Springer US, 2014, pp. 552–560.
- [20] J. Jiao, H. Wei, T. Hu, X. Hu, Y. Zhu, Z. He, J. Wu, J. Yu, X. Xie, H. Huang et al., “Fusionportable: A multi-sensor campus-scene dataset for evaluation of localization and mapping accuracy on diverse platforms,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 3851–3856.
- [21] X. Chen, T. Läbe, A. Milioto, T. Röhling, O. Vysotska, A. Haag, J. Behley, and C. Stachniss, “Overlapnet: Loop closing for lidar-based SLAM,” CoRR, vol. abs/2105.11344, 2021.
- [22] Z. Hong, Y. Petillot, A. Wallace, and S. Wang, “Radarslam: A robust simultaneous localization and mapping system for all weather conditions,” The International Journal of Robotics Research, vol. 41, no. 5, pp. 519–542, 2022.
- [23] M. Zaffar, S. Ehsan, M. Milford, and K. McDonald-Maier, “Cohog: A light-weight, compute-efficient, and training-free visual place recognition technique for changing environments,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1835–1842, 2020.
- [24] D. Galvez-López and J. D. Tardos, “Bags of binary words for fast place recognition in image sequences,” IEEE Transactions on Robotics, vol. 28, no. 5, pp. 1188–1197, 2012.
- [25] R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5297–5307.
- [26] G. Tolias, R. Sicre, and H. Jégou, “Particular object retrieval with integral max-pooling of cnn activations,” arXiv preprint arXiv:1511.05879, 2015.
- [27] F. Radenović, G. Tolias, and O. Chum, “Fine-tuning cnn image retrieval with no human annotation,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 7, pp. 1655–1668, 2018.
- [28] G. Berton, C. Masone, and B. Caputo, “Rethinking visual geo-localization for large-scale applications,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4878–4888.
- [29] R. Wang, Y. Shen, W. Zuo, S. Zhou, and N. Zheng, “Transvpr: Transformer-based place recognition with multi-level attention aggregation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 648–13 657.
- [30] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby et al., “Dinov2: Learning robust visual features without supervision,” arXiv preprint arXiv:2304.07193, 2023.
- [31] N. Keetha, A. Mishra, J. Karhade, K. M. Jatavallabhula, S. Scherer, M. Krishna, and S. Garg, “Anyloc: Towards universal visual place recognition,” IEEE Robotics and Automation Letters, 2023.
- [32] N. Piasco, D. Sidibé, V. Gouet-Brunet, and C. Demonceaux, “Learning scene geometry for visual localization in challenging conditions,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 9094–9100.
- [33] G. Peng, Y. Yue, J. Zhang, Z. Wu, X. Tang, and D. Wang, “Semantic reinforced attention learning for visual place recognition,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 13 415–13 422.
- [34] A. Oertel, T. Cieslewski, and D. Scaramuzza, “Augmenting visual place recognition with structural cues,” IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 5534–5541, 2020.
- [35] J. Komorowski, M. Wysoczańska, and T. Trzcinski, “Minkloc++: lidar and monocular image fusion for place recognition,” in 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8.
- [36] A. J. Lee and A. Kim, “Eventvlad: Visual place recognition with reconstructed edges from event cameras,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 2247–2252.
- [37] R. Q. Charles, H. Su, M. Kaichun, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 77–85.
- [38] C. Choy, J. Gwak, and S. Savarese, “4d spatio-temporal convnets: Minkowski convolutional neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 3075–3084.
- [39] G. Kim and A. Kim, “Scan context: Egocentric spatial descriptor for place recognition within 3d point cloud map,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 4802–4809.
- [40] G. Kim, S. Choi, and A. Kim, “Scan context++: Structural place recognition robust to rotation and lateral variations in urban environments,” IEEE Transactions on Robotics, vol. 38, no. 3, pp. 1856–1874, 2022.
- [41] Y. Wang, Z. Sun, C.-Z. Xu, S. E. Sarma, J. Yang, and H. Kong, “Lidar iris for loop-closure detection,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 5769–5775.
- [42] X. Xu, S. Lu, J. Wu, H. Lu, Q. Zhu, Y. Liao, R. Xiong, and Y. Wang, “Ring++: Roto-translation invariant gram for global localization on a sparse scan map,” IEEE Transactions on Robotics, vol. 39, no. 6, pp. 4616–4635, 2023.
- [43] C. Yuan, J. Lin, Z. Liu, H. Wei, X. Hong, and F. Zhang, “Btc: A binary and triangle combined descriptor for 3-d place recognition,” IEEE Transactions on Robotics, vol. 40, pp. 1580–1599, 2024.
- [44] M. Jiang, Y. Wu, T. Zhao, Z. Zhao, and C. Lu, “Pointsift: A sift-like network module for 3d point cloud semantic segmentation,” arXiv preprint arXiv:1807.00652, 2018.
- [45] M. A. Uy and G. H. Lee, “Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4470–4479.
- [46] Z. Liu, S. Zhou, C. Suo, P. Yin, W. Chen, H. Wang, H. Li, and Y. Liu, “Lpd-net: 3d point cloud learning for large-scale place recognition and environment analysis,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 2831–2840.
- [47] Y. Xia, Y. Xu, S. Li, R. Wang, J. Du, D. Cremers, and U. Stilla, “Soe-net: A self-attention and orientation encoding network for point cloud based place recognition,” in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2021, pp. 11 348–11 357.
- [48] Z. Fan, Z. Song, W. Zhang, H. Liu, J. He, and X. Du, “Rpr-net: A point cloud-based rotation-aware large scale place recognition network,” in European Conference on Computer Vision. Springer, 2022, pp. 709–725.
- [49] Y. You, Y. Lou, R. Shi, Q. Liu, Y.-W. Tai, L. Ma, W. Wang, and C. Lu, “Prin/sprin: On extracting point-wise rotation invariant features,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9489–9502, 2021.
- [50] J. Komorowski, “Minkloc3d: Point cloud based large-scale place recognition,” in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), 2021, pp. 1789–1798.
- [51] K. Żywanowski, A. Banaszczyk, M. R. Nowicki, and J. Komorowski, “Minkloc3d-si: 3d lidar place recognition with sparse convolutions, spherical coordinates, and intensity,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1079–1086, 2022.
- [52] K. Vidanapathirana, M. Ramezani, P. Moghadam, S. Sridharan, and C. Fookes, “Logg3d-net: Locally guided global descriptor learning for 3d place recognition,” in 2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 2215–2221.
- [53] P. Yin, F. Wang, A. Egorov, J. Hou, Z. Jia, and J. Han, “Fast sequence-matching enhanced viewpoint-invariant 3-d place recognition,” IEEE Transactions on Industrial Electronics, vol. 69, no. 2, pp. 2127–2135, 2022.
- [54] P. Yin, L. Xu, J. Zhang, H. Choset, and S. Scherer, “i3dloc: Image-to-range cross-domain localization robust to inconsistent environmental conditions,” in Proceedings of Robotics: Science and Systems (RSS ’21). Robotics: Science and Systems 2021, 2021.
- [55] L. Luo, S. Zheng, Y. Li, Y. Fan, B. Yu, S.-Y. Cao, J. Li, and H.-L. Shen, “Bevplace: Learning lidar-based place recognition using bird’s eye view images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8700–8709.
- [56] J. Ma, J. Zhang, J. Xu, R. Ai, W. Gu, and X. Chen, “Overlaptransformer: An efficient and yaw-angle-invariant transformer network for lidar-based place recognition,” IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6958–6965, 2022.
- [57] L. Li, X. Kong, X. Zhao, T. Huang, W. Li, F. Wen, H. Zhang, and Y. Liu, “Rinet: Efficient 3d lidar-based place recognition using rotation invariant neural network,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4321–4328, 2022.
- [58] S. Zhao, P. Yin, G. Yi, and S. Scherer, “Spherevlad++: Attention-based and signal-enhanced viewpoint invariant descriptor,” 2022.
- [59] X. Xu, H. Yin, Z. Chen, Y. Li, Y. Wang, and R. Xiong, “Disco: Differentiable scan context with orientation,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2791–2798, 2021.
- [60] S. Saftescu, M. Gadd, D. De Martini, D. Barnes, and P. Newman, “Kidnapped radar: Topological radar localisation using rotationally-invariant metric learning,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 4358–4364.
- [61] K. Cait, B. Wang, and C. X. Lu, “Autoplace: Robust place recognition with single-chip automotive radar,” in 2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 2222–2228.
- [62] C. Meng, Y. Duan, C. He, D. Wang, X. Fan, and Y. Zhang, “mmplace: Robust place recognition with intermediate frequency signal of low-cost single-chip millimeter wave radar,” IEEE Robotics and Automation Letters, 2024.
- [63] M. Gadd, D. De Martini, and P. Newman, “Look around you: Sequence-based radar place recognition with learned rotational invariance,” in 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), 2020, pp. 270–276.
- [64] T. Y. Tang, D. D. Martini, S. Wu, and P. Newman, “Self-supervised learning for using overhead imagery as maps in outdoor range sensor localization,” The International Journal of Robotics Research, vol. 40, no. 12-14, pp. 1488–1509, 2021, pMID: 34992328.
- [65] M. Gadd, D. De Martini, and P. Newman, “Contrastive learning for unsupervised radar place recognition,” in 2021 20th International Conference on Advanced Robotics (ICAR), 2021, pp. 344–349.
- [66] N. Hughes, Y. Chang, and L. Carlone, “Hydra: A real-time spatial perception system for 3d scene graph construction and optimization,” arXiv preprint arXiv:2201.13360, 2022.
- [67] R. J. Trudeau, Introduction to graph theory. Courier Corporation, 2013.
- [68] E. Stumm, C. Mei, S. Lacroix, J. Nieto, M. Hutter, and R. Siegwart, “Robust visual place recognition with graph kernels,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4535–4544.
- [69] X. Kong, X. Yang, G. Zhai, X. Zhao, X. Zeng, M. Wang, Y. Liu, W. Li, and F. Wen, “Semantic graph based place recognition for 3d point clouds,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 8216–8223.
- [70] K. Vidanapathirana, P. Moghadam, B. Harwood, M. Zhao, S. Sridharan, and C. Fookes, “Locus: Lidar-based place recognition using spatiotemporal higher-order pooling,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 5075–5081.
- [71] N. Kim, O. Kwon, H. Yoo, Y. Choi, J. Park, and S. Oh, “Topological semantic graph memory for image-goal navigation,” in Conference on Robot Learning. PMLR, 2023, pp. 393–402.
- [72] O. Kwon, J. Park, and S. Oh, “Renderable neural radiance map for visual navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9099–9108.
- [73] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [74] C. Kassab, M. Mattamala, L. Zhang, and M. Fallon, “Language-extended indoor slam (lexis): A versatile system for real-time visual scene understanding,” arXiv preprint arXiv:2309.15065, 2023.
- [75] J. Chen, D. Barath, I. Armeni, M. Pollefeys, and H. Blum, “” where am i?” scene retrieval with language,” arXiv preprint arXiv:2404.14565, 2024.
- [76] Z. Hong, Y. Petillot, D. Lane, Y. Miao, and S. Wang, “Textplace: Visual place recognition and topological localization through reading scene texts,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 2861–2870.
- [77] P. Yin, I. Cisneros, S. Zhao, J. Zhang, H. Choset, and S. Scherer, “isimloc: Visual global localization for previously unseen environments with simulated images,” IEEE Transactions on Robotics, 2023.
- [78] M. J. Milford and G. F. Wyeth, “Seqslam: Visual route-based navigation for sunny summer days and stormy winter nights,” in 2012 IEEE International Conference on Robotics and Automation, 2012, pp. 1643–1649.
- [79] F. Lu, B. Chen, X.-D. Zhou, and D. Song, “Sta-vpr: Spatio-temporal alignment for visual place recognition,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4297–4304, 2021.
- [80] P. Yin, L. Xu, J. Zhang, and H. Choset, “Fusionvlad: A multi-view deep fusion networks for viewpoint-free 3d place recognition,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2304–2310, 2021.
- [81] S. Garg, N. Suenderhauf, and M. Milford, “Don’t look back: Robustifying place categorization for viewpoint- and condition-invariant place recognition,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 3645–3652.
- [82] A. Ali-Bey, B. Chaib-Draa, and P. Giguere, “Mixvpr: Feature mixing for visual place recognition,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 2998–3007.
- [83] S. Hausler, S. Garg, M. Xu, M. Milford, and T. Fischer, “Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14 136–14 147.
- [84] P. Yin, S. Zhao, H. Lai, R. Ge, J. Zhang, H. Choset, and S. Scherer, “Automerge: A framework for map assembling and smoothing in city-scale environments,” IEEE Transactions on Robotics, 2023.
- [85] T. Barros, L. Garrote, R. Pereira, C. Premebida, and U. J. Nunes, “Attdlnet: Attention-based dl network for 3d lidar place recognition,” 2021.
- [86] P. Yin, L. Xu, Z. Feng, A. Egorov, and B. Li, “Pse-match: A viewpoint-free place recognition method with parallel semantic embedding,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–12, 2021.
- [87] D. Gao, C. Wang, and S. Scherer, “Airloop: Lifelong loop closure detection,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 664–10 671.
- [88] J. Knights, P. Moghadam, M. Ramezani, S. Sridharan, and C. Fookes, “Incloud: Incremental learning for point cloud place recognition,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 8559–8566.
- [89] A.-D. Doan, Y. Latif, T.-J. Chin, and I. Reid, “Hm4: Hidden markov model with memory management for visual place recognition,” IEEE Robotics and Automation Letters, vol. 6, no. 1, pp. 167–174, 2021.
- [90] H. Lai, P. Yin, and S. Scherer, “Adafusion: Visual-lidar fusion with adaptive weights for place recognition,” 2021.
- [91] V. Paolicelli, A. Tavera, C. Masone, G. Berton, and B. Caputo, “Learning semantics for visual place recognition through multi-scale attention,” in Image Analysis and Processing – ICIAP 2022, S. Sclaroff, C. Distante, M. Leo, G. M. Farinella, and F. Tombari, Eds. Cham: Springer International Publishing, 2022, pp. 454–466.
- [92] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [93] Z. Fan, Z. Song, H. Liu, Z. Lu, J. He, and X. Du, “Svt-net: Super light-weight sparse voxel transformer for large scale place recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 1, 2022, pp. 551–560.
- [94] A. D. Hines, P. G. Stratton, M. Milford, and T. Fischer, “Vprtempo: A fast temporally encoded spiking neural network for visual place recognition,” arXiv preprint arXiv:2309.10225, 2023.
- [95] L. He, X. Wang, and H. Zhang, “M2dp: A novel 3d point cloud descriptor and its application in loop closure detection,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 231–237.
- [96] Y. Liu and H. Zhang, “Towards improving the efficiency of sequence-based slam,” in 2013 IEEE International Conference on Mechatronics and Automation, 2013, pp. 1261–1266.
- [97] S. M. Siam and H. Zhang, “Fast-seqslam: A fast appearance based place recognition algorithm,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 5702–5708.
- [98] P. Hansen and B. Browning, “Visual place recognition using hmm sequence matchingv,” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2014, pp. 4549–4555.
- [99] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in International Conference on Machine Learning, 2016, pp. 1050–1059.
- [100] B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” Advances in neural information processing systems, vol. 30, 2017.
- [101] Y. Shi and A. K. Jain, “Probabilistic face embeddings,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6902–6911.
- [102] K. Cai, C. X. Lu, and X. Huang, “Stun: Self-teaching uncertainty estimation for place recognition,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 6614–6621.
- [103] P. Yun and M. Liu, “Laplace approximation based epistemic uncertainty estimation in 3d object detection,” in Conference on Robot Learning. PMLR, 2023, pp. 1125–1135.
- [104] S. Garg and M. Milford, “Seqnet: Learning descriptors for sequence-based hierarchical place recognition,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4305–4312, 2021.
- [105] X. Zhang, L. Wang, and Y. Su, “Visual place recognition: A survey from deep learning perspective,” Pattern Recognition, vol. 113, p. 107760, 2021.
- [106] N. Merrill and G. Huang, “Calc2.0: Combining appearance, semantic and geometric information for robust and efficient visual loop closure,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 4554–4561.
- [107] P. Yin, L. Xu, X. Li, C. Yin, Y. Li, R. A. Srivatsan, L. Li, J. Ji, and Y. He, “A multi-domain feature learning method for visual place recognition,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 319–324.
- [108] S. M. Siam and H. Zhang, “Fast-seqslam: A fast appearance based place recognition algorithm,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 5702–5708.
- [109] L. Bampis, A. Amanatiadis, and A. Gasteratos, “Fast loop-closure detection using visual-word-vectors from image sequences,” The International Journal of Robotics Research, vol. 37, no. 1, pp. 62–82, 2018.
- [110] Z. Liu, C. Suo, S. Zhou, F. Xu, H. Wei, W. Chen, H. Wang, X. Liang, and Y.-H. Liu, “Seqlpd: Sequence matching enhanced loop-closure detection based on large-scale point cloud description for self-driving vehicles,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 1218–1223.
- [111] P. Yin, F. Wang, A. Egorov, J. Hou, J. Zhang, and H. Choset, “Seqspherevlad: Sequence matching enhanced orientation-invariant place recognition,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 5024–5029.
- [112] Y. You, Y. Lou, R. Shi, Q. Liu, Y.-W. Tai, L. Ma, W. Wang, and C. Lu, “Prin/sprin: On extracting point-wise rotation invariant features,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9489–9502, 2022.
- [113] B. Neyshabur, S. Bhojanapalli, D. McAllester, and N. Srebro, “Exploring generalization in deep learning,” Advances in neural information processing systems, vol. 30, 2017.
- [114] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2015.
- [115] D. Gálvez-López and J. D. Tardos, “Bags of binary words for fast place recognition in image sequences,” IEEE Transactions on Robotics, vol. 28, no. 5, pp. 1188–1197, 2012.
- [116] H. Wang, C. Wang, and L. Xie, “Intensity scan context: Coding intensity and geometry relations for loop closure detection,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 2095–2101.
- [117] B. Ferrarini, M. J. Milford, K. D. McDonald-Maier, and S. Ehsan, “Binary neural networks for memory-efficient and effective visual place recognition in changing environments,” IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2617–2631, 2022.
- [118] O. Grainge, M. Milford, I. Bodala, S. D. Ramchurn, and S. Ehsan, “Design space exploration of low-bit quantized neural networks for visual place recognition,” arXiv preprint arXiv:2312.09028, 2023.
- [119] W. Maass, “Networks of spiking neurons: the third generation of neural network models,” Neural networks, vol. 10, no. 9, pp. 1659–1671, 1997.
- [120] S. Hussaini, M. Milford, and T. Fischer, “Applications of spiking neural networks in visual place recognition,” arXiv preprint arXiv:2311.13186, 2023.
- [121] P. Yin, R. A. Srivatsan, Y. Chen, X. Li, H. Zhang, L. Xu, L. Li, Z. Jia, J. Ji, and Y. He, “Mrs-vpr: a multi-resolution sampling based global visual place recognition method,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 7137–7142.
- [122] X. Hu, L. Zheng, J. Wu, R. Geng, Y. Yu, H. Wei, X. Tang, L. Wang, J. Jiao, and M. Liu, “Paloc: Advancing slam benchmarking with prior-assisted 6-dof trajectory generation and uncertainty estimation,” arXiv preprint arXiv:2401.17826, 2024.
- [123] A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?” Advances in neural information processing systems, vol. 30, 2017.
- [124] M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,” Advances in neural information processing systems, vol. 31, 2018.
- [125] K. Mason, J. Knights, M. Ramezani, P. Moghadam, and D. Miller, “Uncertainty-aware lidar place recognition in novel environments,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 3366–3373.
- [126] P. Yin, S. Zhao, R. Ge, I. Cisneros, R. Fu, J. Zhang, H. Choset, and S. Scherer, “Alita: A large-scale incremental dataset for long-term autonomy,” 2022.
- [127] Y. Tian, Y. Chang, L. Quang, A. Schang, C. Nieto-Granda, J. P. How, and L. Carlone, “Resilient and distributed multi-robot visual slam: Datasets, experiments, and lessons learned,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 11 027–11 034.
- [128] L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” arXiv preprint arXiv:2306.16927, 2023.
- [129] M. Tranzatto, T. Miki, M. Dharmadhikari, L. Bernreiter, M. Kulkarni, F. Mascarich, O. Andersson, S. Khattak, M. Hutter, R. Siegwart et al., “Cerberus in the darpa subterranean challenge,” Science Robotics, vol. 7, no. 66, p. eabp9742, 2022.
- [130] C. Campos, R. Elvira, J. J. G. Rodríguez, J. M. Montiel, and J. D. Tardós, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,” IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021.
- [131] T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018.
- [132] T. Shan, B. Englot, C. Ratti, and D. Rus, “Lvi-sam: Tightly-coupled lidar-visual-inertial odometry via smoothing and mapping,” in 2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021, pp. 5692–5698.
- [133] D. Adolfsson, M. Karlsson, V. Kubelka, M. Magnusson, and H. Andreasson, “Tbv radar slam–trust but verify loop candidates,” IEEE Robotics and Automation Letters, 2023.
- [134] W. Chen, L. Zhu, Y. Guan, C. R. Kube, and H. Zhang, “Submap-based pose-graph visual slam: A robust visual exploration and localization system,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 6851–6856.
- [135] M. Kuse and S. Shen, “Learning whole-image descriptors for real-time loop detection and kidnap recovery under large viewpoint difference,” Robotics and Autonomous Systems, vol. 143, p. 103813, 2021.
- [136] D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self-supervised interest point detection and description,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236.
- [137] P.-E. Sarlin, C. Cadena, R. Siegwart, and M. Dymczyk, “From coarse to fine: Robust hierarchical localization at large scale,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12 708–12 717.
- [138] L. Liu and H. Li, “Lending orientation to neural networks for cross-view geo-localization,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5617–5626.
- [139] F. Gao, L. Wang, B. Zhou, X. Zhou, J. Pan, and S. Shen, “Teach-repeat-replan: A complete and robust system for aggressive flight in complex environments,” IEEE Transactions on Robotics, vol. 36, no. 5, pp. 1526–1545, 2020.
- [140] M. Mattamala, M. Ramezani, M. Camurri, and M. Fallon, “Learning camera performance models for active multi-camera visual teach and repeat,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 14 346–14 352.
- [141] Y. Chen and T. D. Barfoot, “Self-supervised feature learning for long-term metric visual localization,” IEEE Robotics and Automation Letters, vol. 8, no. 2, pp. 472–479, 2022.
- [142] L. Suomela, J. Kalliola, A. Dag, H. Edelman, and J.-K. Kämäräinen, “Placenav: Topological navigation through place recognition,” arXiv preprint arXiv:2309.17260, 2023.
- [143] O. Michel, A. Bhattad, E. VanderBilt, R. Krishna, A. Kembhavi, and T. Gupta, “Object 3dit: Language-guided 3d-aware image editing,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [144] A. T. Fragoso, C. T. Lee, A. S. McCoy, and S.-J. Chung, “A seasonally invariant deep transform for visual terrain-relative navigation,” Science Robotics, vol. 6, no. 55, p. eabf3320, 2021.
- [145] M. Bianchi and T. D. Barfoot, “Uav localization using autoencoded satellite images,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1761–1768, 2021.
- [146] B. Patel, T. D. Barfoot, and A. P. Schoellig, “Visual localization with google earth images for robust global pose estimation of uavs,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 6491–6497.
- [147] P.-E. Sarlin, E. Trulls, M. Pollefeys, J. Hosang, and S. Lynen, “Snap: Self-supervised neural maps for visual positioning and semantic understanding,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [148] Y. Shi, F. Wu, A. Perincherry, A. Vora, and H. Li, “Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 516–21 526.
- [149] T. Y. Tang, D. De Martini, and P. Newman, “Get to the point: Learning lidar place recognition and metric localisation using overhead imagery,” Proceedings of Robotics: Science and Systems, 2021, 2021.
- [150] A. Witze et al., “Nasa has launched the most ambitious mars rover ever built: Here’s what happens next,” Nature, vol. 584, no. 7819, pp. 15–16, 2020.
- [151] L. Ding, R. Zhou, Y. Yuan, H. Yang, J. Li, T. Yu, C. Liu, J. Wang, S. Li, H. Gao, Z. Deng, N. Li, Z. Wang, Z. Gong, G. Liu, J. Xie, S. Wang, Z. Rong, D. Deng, X. Wang, S. Han, W. Wan, L. Richter, L. Huang, S. Gou, Z. Liu, H. Yu, Y. Jia, B. Chen, Z. Dang, K. Zhang, L. Li, X. He, S. Liu, and K. Di, “A 2-year locomotive exploration and scientific investigation of the lunar farside by the yutu-2 rover,” Science Robotics, vol. 7, no. 62, p. eabj6660, 2022.
- [152] I. D. Miller, F. Cladera, T. Smith, C. J. Taylor, and V. Kumar, “Stronger together: Air-ground robotic collaboration using semantics,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9643–9650, 2022.
- [153] J. Yan, X. Lin, Z. Ren, S. Zhao, J. Yu, C. Cao, P. Yin, J. Zhang, and S. Scherer, “Mui-tare: Multi-agent cooperative exploration with unknown initial position,” arXiv preprint arXiv:2209.10775, 2022.
- [154] Y. Tian, Y. Chang, F. H. Arias, C. Nieto-Granda, J. P. How, and L. Carlone, “Kimera-multi: Robust, distributed, dense metric-semantic slam for multi-robot systems,” IEEE Transactions on Robotics, pp. 1–17, 2022.
- [155] D. Van Opdenbosch and E. Steinbach, “Collaborative visual slam using compressed feature exchange,” IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 57–64, 2019.
- [156] T. Sasaki, K. Otsu, R. Thakker, S. Haesaert, and A.-a. Agha-mohammadi, “Where to map? iterative rover-copter path planning for mars exploration,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2123–2130, 2020.
- [157] K. Ebadi, Y. Chang, M. Palieri, A. Stephens, A. Hatteland, E. Heiden, A. Thakur, N. Funabiki, B. Morrell, S. Wood, L. Carlone, and A.-a. Agha-mohammadi, “Lamp: Large-scale autonomous mapping and positioning for exploration of perceptually-degraded subterranean environments,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 80–86.
- [158] Y. Chang, N. Hughes, A. Ray, and L. Carlone, “Hydra-multi: Collaborative online construction of 3d scene graphs with multi-robot teams,” arXiv preprint arXiv:2304.13487, 2023.
- [159] M. Labbé and F. Michaud, “Rtab-map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation,” Journal of Field Robotics, vol. 36, no. 2, pp. 416–446, 2019.
- [160] H. Xu, Y. Zhang, B. Zhou, L. Wang, X. Yao, G. Meng, and S. Shen, “Omni-Swarm: A decentralized omnidirectional visual–inertial–uwb state estimation system for aerial swarms,” IEEE Transactions on Robotics, vol. 38, no. 6, pp. 3374–3394, 2022.
- [161] B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” ACM Transactions on Graphics, vol. 42, no. 4, pp. 1–14, 2023.
- [162] Tesla, Inc., “Autopilot support,” 2023, accessed: 2023-03-30. [Online]. Available: https://www.tesla.com/en_gb/support/autopilot
- [163] G. D. Tipaldi, D. Meyer-Delius, and W. Burgard, “Lifelong localization in changing environments,” The International Journal of Robotics Research, vol. 32, no. 14, pp. 1662–1678, 2013.
- [164] M. Zhao, X. Guo, L. Song, B. Qin, X. Shi, G. H. Lee, and G. Sun, “A general framework for lifelong localization and mapping in changing environment,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 3305–3312.
- [165] C. Chow and C. Liu, “Approximating discrete probability distributions with dependence trees,” IEEE transactions on Information Theory, vol. 14, no. 3, pp. 462–467, 1968.
- [166] S. Zhu, X. Zhang, S. Guo, J. Li, and H. Liu, “Lifelong localization in semi-dynamic environment,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 14 389–14 395.
- [167] M. Zaffar, S. Garg, M. Milford, J. Kooij, D. Flynn, K. McDonald-Maier, and S. Ehsan, “VPR-bench: An open-source visual place recognition evaluation framework with quantifiable viewpoint and appearance change,” International Journal of Computer Vision., vol. 129, no. 7, pp. 2136–2174, May 2021.
- [168] K. MacTavish, M. Paton, and T. D. Barfoot, “Visual triage: A bag-of-words experience selector for long-term visual route following,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 2065–2072.
- [169] N. Sünderhauf, P. Neubert, and P. Protzel, “Are we there yet? challenging seqslam on a 3000 km journey across all four seasons,” in Proc. of workshop on long-term autonomy, IEEE international conference on robotics and automation (ICRA), 2013, p. 2013.
- [170] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013.
- [171] W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 year, 1000 km: The oxford robotcar dataset,” The International Journal of Robotics Research, vol. 36, no. 1, pp. 3–15, 2017.
- [172] Y. Liao, J. Xie, and A. Geiger, “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,” CoRR, vol. abs/2109.13410, 2021.
- [173] C. Ivan, P. Yin, J. Zhang, H. Choset, and S. Scherer, “Alto: A large-scale dataset for uav visual place recognition and localization,” arXiv preprint arXiv:2205.30737, 2022.
- [174] D. Barnes, M. Gadd, P. Murcutt, P. Newman, and I. Posner, “The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 6433–6438.
- [175] K. Somasundaram, J. Dong, H. Tang, J. Straub, M. Yan, M. Goesele, J. J. Engel, R. De Nardi, and R. Newcombe, “Project aria: A new tool for egocentric multi-modal ai research,” arXiv preprint arXiv:2308.13561, 2023.
- [176] M. Ramezani, Y. Wang, M. Camurri, D. Wisth, M. Mattamala, and M. Fallon, “The newer college dataset: Handheld lidar, inertial and vision with ground truth,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 4353–4360.
- [177] B. Talbot, S. Garg, and M. Milford, “Openseqslam2.0: An open source toolbox for visual place recognition under changing conditions,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 7758–7765.
- [178] M. Humenberger, Y. Cabon, N. Guerin, J. Morat, V. Leroy, J. Revaud, P. Rerole, N. Pion, C. de Souza, and G. Csurka, “Robust image retrieval-based visual localization using kapture,” 2020.
- [179] J. Komorowski, “Improving point cloud based place recognition with ranking-based loss and large batch training,” in 2022 26th International Conference on Pattern Recognition (ICPR). IEEE, 2022, pp. 3699–3705.