GEM-VPC: A dual Graph-Enhanced Multimodal integration for Video Paragraph Captioning
Abstract
Video Paragraph Captioning (VPC) aims to generate paragraph captions that summarises key events within a video. Despite recent advancements, challenges persist, notably in effectively utilising multimodal signals inherent in videos and addressing the long-tail distribution of words. The paper introduces a novel multimodal integrated caption generation framework for VPC that leverages information from various modalities and external knowledge bases. Our framework constructs two graphs: a ‘video-specific’ temporal graph capturing major events and interactions between multimodal information and commonsense knowledge, and a ‘theme graph’ representing correlations between words of a specific theme. These graphs serve as input for a transformer network with a shared encoder-decoder architecture. We also introduce a node selection module to enhance decoding efficiency by selecting the most relevant nodes from the graphs. Our results demonstrate superior performance across benchmark datasets.
1 Introduction
Dense video captioning (DVC) [23] is a sub-branch of video captioning, which requires the model to first localise the important events in the video and then generate the associated captions. Video paragraph captioning (VPC) [33] is a simplified version of DVC where the event segments in a video are assumed given; therefore, the event proposal generation step is not needed, and the ultimate goal is to generate better paragraph captions with the known events. While research in video captioning is recently becoming more popular, numerous challenges still persist. Firstly, most VPC works solely use visual information for generating captions [33, 41]. However, they overlook that videos naturally contain rich content with multimodal signals such as additional speech text and an audio soundtrack. Incorporating these extra modalities and unravelling their interactions can provide vital cues for video understanding. Another challenge is overcoming the long-tail distribution of words, whereby the model tends to overfit on frequent terms while neglecting objects, properties or behaviours that rarely appear in the training data. Past natural language generation works have shown that exploiting external data from knowledge graphs can alleviate this issue and encourage more diverse generated text [63]. Finally, existing studies [17, 24] simply feed the video’s feature embeddings into the captioning model directly, leading to two problems: 1) the model cannot effectively handle the long sequence, and 2) it struggles to select the relevant context from the long input stream.
As such, we address the aforementioned challenges by introducing GEM-VPC, a graph-based novel framework for VPC that integrates information from various modalities. Unlike past works [17, 16], rather than purely feeding in the raw features as a long input stream, we first convert the videos into a graphical structure to capture high-level salient features and context. We construct two types of graphs. The first is a ‘video-specific’ temporal graph, which aims to depict the major events of the video in chronological order whilst simultaneously representing interactions between various multimodal information and related commonsense knowledge. In particular, nodes are represented using language class labels to provide key details about the video contents instead of using raw feature embeddings, which may contain noisy information. To this end, we leverage pretrained action/audio/object recognition models and text parsers to extract linguistic information such as the action label, sound label or object label from the visual features, audio features and speech transcript to be used as nodes in the graph. To alleviate the long-tail problem, we further enhance the graph by incorporating language features from an external knowledge data source. While other VPC studies [10] using knowledge graphs typically employ static graphs like ConceptNet [42], we use a neural knowledge model trained on existing commonsense knowledge graph datasets to generate diverse commonsense about human everyday experiences on-demand. These nodes are then connected with informative edge labels. We utilise sentences from the corpus to create a ‘theme graph’ to represent correlations between words relating to a specific theme with the motivation of providing corpus-level information for each sample during training. In the model training stage, both graphs are finally fed as supporting information into a transformer network. As some nodes in the graph may be noisy, we propose a node selection module to select only the most useful nodes from the video-specific and theme graphs when decoding the caption.
The main contributions are to: 1) introduce a novel framework for VPC that leverages multimodal commonsense knowledge to enhance video understanding. It incorporates heterogeneous video and theme graphs derived from various modalities, including visual, audio, and textual data, along with commonsense knowledge. 2) demonstrate the superior performance of our model compared to state-of-the-art methods on two widely used benchmarks. 3) conduct a comprehensive ablation analysis to dissect the contribution of different components.
2 Related Work111The main integration methods of past works are highlighted in Table 1 and 2
2.1 Video Paragraph Captioning
Earlier works for VPC often employ an LSTM-based model for generating the captions [50, 58, 60]. [33] adopts adversarial training in their LSTM model by proposing a hybrid discriminator to measure the language characteristics, relevance to a video segment, and coherence of their generated captions. Transformer-based [45] methods have become increasingly popular [8, 49, 53, 10]. This was first introduced by [61] for DVC and VPC, and each event in the video is decoded separately, resulting in context fragmentation and poor inter-event coherency. Later works have tried to alleviate this issue such as in MART [24], which modified Transformer-XL [6] and proposed a memory module for remembering the video segments and the sentence history to improve future caption predictions with respect to coherence and repetition aspects. [53] extracts local and global visual features and linguistic scene elements and leverages a Transformer to simultaneously model the long-range dependencies between features at an intra- and inter-event level.
2.2 Multimodal Video Captioning
Existing studies have integrated multimodal features as extra information for video captioning. Most works consider the audio modality, with their frameworks first encoding the modalities separately with modality-specific encoders, followed by a fusion unit to combine the multiple streams together [51, 37, 16]. Other than video and audio modalities, previous studies have suggested that considering speech features can enhance model outputs [17]. In [12] and [40], automatic speech recognition (ASR) was used to extract human speech from narrated instructional cooking videos for DVC while in [10], commonsense from knowledge graphs was incorporated into their captioning model where the ASR was used as a source for constructing the graph. Inspired by these methods, we consider the audio and speech modality as model inputs. Unlike the aforementioned approaches, we convert the videos into a heterogeneous graph from language labels extracted from the raw modality segments to represent relationships between key temporal events and different modality information, and propose a novel approach for explicitly incorporating the external commonsense knowledge into the graph.
Some studies propose pretraining tasks to explicitly align the different modalities for improving feature representation, after which the model is fine-tuned to the captioning task. Common pretraining objectives involve predicting whether an ASR and video segment are aligned or predicting masked speech segments and frames [14, 28, 26]. Generative pretraining objectives have been explored in [54] and [38], which proposed predicting the transcribed speech given related video frames to jointly train the visual encoder and text decoder. Our framework requires no pretraining, but can achieve comparable scores to VPC models that utilise such methods.
2.3 Graphs for Video Analysis
Graph structures have been widely used in video-related tasks from video scene graph classification [1], temporal action localisation [57] to video question answering [21] and visual storytelling [48]. Several studies have delved into ‘spatio-temporal’ graphs that try to represent interactions of features at a static time and relations between features across time. For the spatial component, numerous works connect objects and regions together within a timeframe and then connect identical or similar objects across time for the temporal component [31, 59, 22, 30]. In VPC, [19] proposed a multimodal heterogeneous graph that connects visual and text features within the same event. While they use the raw feature embeddings for node representation, which create large graphs with noisy information, we utilise the linguistic labels to provide a more high-level representation of the key semantic contents of the video and further propose a node selection module to filter out irrelevant nodes.
3 Method
Problem Definition: Given an untrimmed video with temporally ordered events where is the event at timestep defined by a starting and ending timestamp () and is the total number of events in the video, the task of VPC is to generate where is a matching textual description for .
We first describes constructing the graphs as input for our VPC model. Two graphs (Section 3.1 and 3.2) are built: 1) a commonsense-enhanced video-specific graph (VG), representing the main sequential events in the video with related commonsense and contextual information, and 2) a theme graph (TG) representing relationships between vocabulary of a specific theme. For the video-specific graphs, we propose two ways to construct the primary nodes: 1) Utilising the video’s visual information (‘VF-method’) and 2) extracting information from the speech transcript (‘ASR-method’).
3.1 Video-Specific Graph Creation
3.1.1 Creating the Nodes - VF-Method
Graphs created using the VF-method have 3 main node types: action, context (consisting of location, object, audio nodes), and commonsense nodes.
Action Nodes: The action nodes describe the main actions at each key event and are represented using linguistic action class labels. To obtain these labels, we download the video frames at 5fps. For each event , we uniformly sample frames between the event’s starting and ending frames with a step size of 10 and then feed every 16 frames into a pretrained video action classification model for each 16-frame segment. As the agent does not always perform a specific action (e.g. just standing or no human agent in the video segment), we replace the class label with ‘no action’ if the predicted class probability is less than a threshold. When less than the threshold and speech is detected by the audio node, we replace the label with ‘speaking’.
Context Nodes: For extra scene context, we include location, object and audio nodes. For the location and object nodes, we take the centre and last frame of each event and leverage a Visual Question Answering (VQA) model to extract open-ended answers about the images. For the location node, we ask the VQA model ‘what is the location?’ for each of the 3 images and take the most common answer as the location for each event. For the object nodes, we obtain the object labels by asking 3 questions: ‘what objects are in this image?’, what is in the background?’ and ‘who is in this image?’. We further expand this object set by employing an object detection model to detect objects from the frames. Finally, the audio nodes represent the sound information and can provide vital cues for video understanding in addition to the visual information. We sample 10 second segments of audio data from the video and obtain the the top 2 predicted audio classes by confidence score for each segment via a pretrained audio classifier.
Commonsense Nodes We also add external commonsense knowledge for richer graphs. Comet-ATOMIC2020 [15], a neural knowledge model capable of dynamically generating commonsense about everyday events is adopted. Given a head phrase and relation (e.g. cut a cake CapableOf), Comet-ATOMIC2020 can produce a tail phrase on-demand (e.g. celebrate birthday). We use the action node class labels as the head phrase and append 11 different relation tokens to generate 5 commonsense inferences per relation. The relation is described in Appendix E.
3.1.2 Creating the Nodes - ASR-Method
For videos where the speech modality is considered vital for video understanding, we introduce the ASR-method for creating the VG nodes. This is useful for how-to or cooking videos, where actions are explicitly described in the speech transcript, and visual information such as the location/scene may not be as important. There are 3 node types:
Action Nodes: We extract the ASR between each event and use a pretrained Open Information Extraction (OpenIE) model to breakdown the syntactically complex speech sentences into a list of verbs (V) and related arguments (ARG). Given the sentence ‘I chop the onions and put the meat in the frying pan’, OpenIE can extract related arguments for the 2 verbs (‘chop’ and ‘put’): ARG0, V, ARG1 = I, chop, onions and ARG0, V, ARG1, ARG2 = I, put, meat, in the frying pan. The extracted verb and argument tuples from the speech segments within each event are then used as the action nodes for event . As the speech may contain irrelevant content, we tag the verbs in the ground-truth annotations and only retain tuples if the extracted verb has a high word embedding similarity score with at least one of the tagged verbs in the annotations. Moreover, we only retain words from the extracted arguments if it is a noun/adverb in the training annotations.
Context Nodes: Instead of location nodes as introduced in the VF-method, we concatenate the action node labels within the same event to form a ‘contextual phrase node’. This represents similar information to the action nodes, but at a less fine-grained level with more context about surrounding actions. For the object nodes, we tag the nouns from the ASR segment, retaining only the tagged nouns if they appear in the training ground-truth annotations. The audio nodes are retrieved in the same way as the VF-method except we filter out any irrelevant sound labels. For example, with cooking videos, we retain cooking-related sounds (‘boiling’, ‘sizzling’, ‘frying’, ‘chopping’ etc).
Commonsense Nodes We follow the VF-method but instead of using the action node information as the head phrase, we find that better commonsense is generated when using the linguistic information inside the contextual phrase node to query Comet-ATOMIC2020.
3.1.3 Connecting the VG Nodes
For event , let be the action nodes, be the corresponding location node when the VF-method is used, or be the contextual phrase node when the ASR-method is used, are the commonsense nodes, are the object nodes, and are the audio nodes.
To form the graph, all action nodes are first connected in temporal order. To capture forward information, we add a directed edge with the label occursAfter between each consecutive action node and further capture backwards information by adding a reversed edge with the label occursBefore. Each location node or contextual phrase node is then connected to all the nodes in with the edge label atLocation or hasContext. Next, commonsense nodes from are connected to the corresponding action nodes from that were used to generate the commonsense, using the commonsense relation token as the edge label. For the object and audio nodes, each node in and is connected with or with the edge label inScene and hasSound respectively. For the VF-method, we additionally filter out any irrelevant commonsense if the predicted action class confidence score used to generate that commonsense does not exceed a particular threshold. Noisy audio or object labels are disregarded at each timestep by converting the class labels to a text embedding and only retaining those that have a high cosine similarity score with any of the nodes in , or . A depiction of the final graphs using the VF- and ASR-method is in Appendix I.

3.2 Theme Graph Creation
We also create a theme graph for each action class to incorporate corpus-level information. Given an action predicted at , we collect the corresponding ground-truth training sentence at and tag the nouns, verbs and adverbs to build a vocabulary for each action class. With the ASR-method, the action classes are created by the -means algorithm to cluster the text embeddings of the action nodes. We retain the top- most frequent words for each action class vocabulary and following [55], the individual words are connected based on word co-occurrence statistics to form a graph.
| (1) |
| (2) |
We utilise the normalised point-wise mutual information score (NPMI), where a positive score implies high semantic correlation between words. Here, , and where is the number of sentences in the corpus that contain word , is the number of sentences that contain both words and is the number of sentences in the corpus. For the corpus, we use the ground-truth sentences from external datasets (see Section 4). A word-to-word connection is made only if the NPMI score exceeds 0.10. A theme graph example is in Appendix F.
3.3 VPC Model
GEM-VPC (Figure 1) adopts a transformer-based shared encoder-decoder augmented with an external memory module to model temporal dependencies between events.
1) Visual Stream:
At each timestep related to event , we concatenate the visual features and predicted video captions from . A [CLS] token is also prepended to learn the sequence representation. We denote the concatenated sequence as . is fed into a transformer with learnt positional and token type embeddings (for indicating the token’s modality type), which applies multi-head self attention (MHA):
| (3) |
where , , , , , and are learnable parameters, and is a masked matrix to prevent the model from attending to future words. The outputted intermediate hidden state is then fed into another attention layer that performs MHA between and past memory states for capturing history information.
2) Node Stream:
For each event (timestep), a representative action is extracted by using the predicted action label with the highest confidence score out of the predicted actions from . The matching theme graph for that action class is then obtained and fed through a Graph Attention Network (GAT) to learn theme node embeddings. For encoding the video-specific graph information, we feed the entire graph into another GAT and extract the node embeddings corresponding to timestep . We denote the theme and video-specific graph node embeddings as and , where , are the number of nodes and is the embedding dimension. Specifically, we compute:
| (4) |
| (5) |
where is the [CLS] representation from the visual stream at time , and are learnable, is either or and contains probability scores for each node. The top- nodes yielding the highest probabilities from each and are then selected to be inputs for the node stream. Finally, we concatenate the selected nodes with the predicted captions and feed through another transformer analogous to the one used in the visual stream. We do not add positional embeddings here as the selected nodes have no temporal order.
3) Decoding the Caption
Visual and node streams exchange information with cross attention:
| (6) |
Here, and are the outputs from the visual and node stream respectively at time while and are node attended visual features and visual attended node features respectively. The concatenation of and is finally fed into a linear (MLP) layer and the next word predicted word is the of the output.
4) Encoding Recurrence
To capture temporal dependencies between events from previous timesteps, recent methods for encoding recurrence into transformer models are adopted for our visual and node stream.
A) MART: memory augmented recurrent transformer [24], using multi-head attention to encode the memory state. Given the intermediate hidden state , the memory updated intermediate hidden state is computed:
| (7) |
where is the past memory calculated by:
| (8) |
| (9) |
| (10) |
where is the Hadamard product, , , , are trainable weights, and are trainable bias, is the internal cell state and is the update gate that controls which information to retain from previous memory states. B) TinT: proposed by [53], utilising Hybrid Attention Mechanism (HAM) [47] to select information from previous hidden states:
| (11) |
| (12) |
| (13) |
Here, ‘;’ denotes concatenation along a new dimension, is self-attention applied on the new dimension and reduced by the mean operation, is the memory information at time () and is defined as above.
4 Evaluation Setup333Implementation details can be found in Appendix G
4.1 Datasets
1) ActivityNet Captions [23] consists of 10,009 training and 4,917 validation videos on people performing complex activities. On average, each video contains 3.65 event segments covering 36 seconds. We follow previous works [24] and split the original validation set into ae-val and ae-test.
2) YouCook2 [61] is for dense video procedural captioning in the recipe domain. It contains 1,333 training and 457 validation samples comprised specifically of instructional cooking videos. On average, videos are 5.26 minutes long with 7.7 event segments and each annotation for an event is a language description of the procedure’s step covering 1.96 seconds. We report our results on the validation set (‘yc2-val’).
3) RecipeNLG [4] is for recipe generation, consisting of 2,231,142 cooking recipes and food entities from the recipes extracted using Named Entity Recognition. We use RecipeNLG as a supporting dataset to compute the NPMI scores when constructing the theme graphs for the YouCook2.
| ae-test | |||||||||
| Model | Conference | Year | Modalities | Integration Method | B4 | M | C | R | R4 |
| VTrans [61] | CVPR | 2018 | V+F | Concatenation | 9.31 | 15.54 | 21.33 | 28.98 | - |
| Trans-XL [6] | ACL | 2019 | V+F | Concatenation | 10.25 | 14.91 | 21.71 | 30.25 | 8.54 |
| MDVC [17] † | CVPR | 2020 | V+S+A | Concatenation | 8.50 | 14.28 | 17.57 | 25.48 | - |
| BMT [16] † | BMVC | 2020 | V+A | CM Attention | 8.42 | 14.08 | 15.41 | 25.44 | - |
| MART [24] | ACL | 2020 | V+F | Concatenation | 9.78 | 15.57 | 22.16 | - | 5.44 |
| MART-COOT [8] | NeurIPS | 2020 | V+L | Joint CM Space | 10.85 | 15.99 | 28.19 | - | - |
| Trans-XLRG [24] | ACL | 2020 | V+F | Concatenation | 8.85 | 10.07 | 14.58 | 20.34 | - |
| Motion-Aware [13] | ICASSP | 2023 | V+O | CM Attention | 11.90 | 16.54 | 30.13 | - | 4.12 |
| Memory Trans. [41] | CVPR | 2021 | V+F | Concatenation | 11.74 | 15.64 | 26.55 | - | 2.75 |
| VLCAP [52] | ICIP | 2022 | V+L | CM Attention | 13.38 | 17.48 | 31.29 | 35.99 | 4.18 |
| VLTinT w/ CL [53] | AAAI | 2023 | V+L+O | CM Attention | 14.50 | 17.97 | 31.13 | 36.56 | 4.75 |
| VLTinT w/ CL∗ [53] | AAAI | 2023 | V+L+O | CM Attention | 14.32 | 17.84 | 31.83 | 36.51 | 5.16 |
| VLTinT w/o CL [53] | AAAI | 2023 | V+L+O | CM Attention | 13.80 | 17.72 | 30.59 | 36.11 | - |
| VGCSN+CHPG [56] | ICASSP | 2024 | V+L+O+C | CM Attention | 11.80 | 16.51 | 29.69 | - | 4.02 |
| GEM-VPC w/ No Recurrence | - | 2024 | V+G(V+A+C) | CM Attention | 12.82 | 17.4 | 26.97 | 33.45 | 7.28 |
| GEM-VPC w/ MART decoder | - | 2024 | V+G(V+A+C) | CM Attention | 13.47 | 17.38 | 30.38 | 35.8 | 5.93 |
| GEM-VPC w/ TinT decoder | - | 2024 | V+G(V+A+C) | CM Attention | 14.54 | 17.99 | 32.62 | 36.51 | 5.17 |
| yc2-val | ||||||||||
| Model | Conference | Year | Modalities | Pretraining | Integration Method | B4 | M | C | R | R4 |
| VTrans [61] | CVPR | 2018 | V+F | ✗ | Concatenation | 7.62 | 15.65 | 32.26 | - | 7.83 |
| Trans-XL [6] | ACL | 2019 | V+F | ✗ | Concatenation | 6.56 | 14.76 | 26.35 | - | 6.30 |
| MART [24] | ACL | 2020 | V+F | ✗ | Concatenation | 8.00 | 15.90 | 35.74 | - | 4.39 |
| MART-COOT [8] | NeurIPS | 2020 | V+L | ✗ | Joint CM Space | 9.44 | 18.17 | 46.06 | - | 6.30 |
| Trans-XLRG [24] | ACL | 2019 | V+F | ✗ | Concatenation | 6.63 | 14.74 | 25.93 | - | 6.03 |
| VLCAP [52] | ICIP | 2022 | V+L | ✗ | CM Attention | 9.56 | 17.95 | 49.41 | 35.17 | 5.16 |
| VLTinT [53] | AAAI | 2023 | V+L | ✗ | CM Attention | 9.40 | 17.94 | 48.70 | 34.55 | 4.29 |
| VGCSN+CHPG [56] | ICASSP | 2024 | V+L+O+C | ✗ | CM Attention | 6.80 | 14.50 | 27.21 | - | - |
| DECEMBERT [44] | NAACL | 2021 | V+L+S | ✓ | CM Pretraining | 11.92 | 20.01 | 58.02 | 40.22 | - |
| MTrans+COOT+MIL-NCE PT [44] | NAACL | 2021 | V+L | ✓ | Joint CM Space | 11.05 | 19.79 | 55.57 | 37.51 | - |
| MART+COOT+MIL-NCE PT[44] | NAACL | 2021 | V+L | ✓ | Joint CM Space | 11.30 | 19.85 | 57.24 | 37.94 | - |
| GEM-VPC w/ No Recurrence | - | 2024 | V+G(S+A+C) | ✗ | CM Attention | 11.03 | 20.01 | 58.49 | 36.89 | 4.64 |
| GEM-VPC w/ MART decoder | - | 2024 | V+G(S+A+C) | ✗ | CM Attention | 11.01 | 19.86 | 54.84 | 36.81 | 4.47 |
| GEM-VPC w/ TinT decoder | - | 2024 | V+G(S+A+C) | ✗ | CM Attention | 11.47 | 19.72 | 56.00 | 37.48 | 4.91 |
4.2 Evaluation Metrics
5 Results555Appendix J shows qualitative examples of generated captions from our model versus state-of-the-art
5.1 Performance Against SOTA
We compare GEM-VPC with prior SOTA on ActivityNet Captions’s ae-test split (Table 1) and YouCook2’s validation split (Table 2).
Our best model (GEM-VPC w/ TinT decoder) evidently outperforms most of the existing baselines. VLTinT w/ CL and w/o CL is the VLTinT model trained with their novel contrastive loss (in addition to the classic MLE loss) and without their contrastive loss respectively. Specifically, GEM-VPC w/ TinT decoder outperforms VLTinT w/ CL on BLEU-4, METEOR and CIDEr and all metrics when considering the VLTinT w/o CL variant which is optimised using the same MLE loss as our model. For a more accurate comparison, we rerun VLTinT w/ CL (with their optimal parameters) in our own environment and record the results under VLTinT w/ CL∗. As shown, GEM-VPC w/ TinT decoder yields higher BLEU-4, METEOR and CIDEr scores than VLTinT w/ CL∗ with similar ROUGE and R4. While R4 does not outperform some baselines, the lower repetition does not necessarily mean good caption quality as lower repetition can be simply achieved by generating words unrelated to the video content. Hence, a strong model should have a balance of high -gram metrics and a low repetition score. Examining YouCook2, our model variants achieve higher -gram scores with relatively low repetition of 4.6-4.9 compared to baselines with no pretraining (first 6 baselines). Even when comparing with the last 3 baselines with pretraining methods and a large separate instructional video dataset (HowTo100M [29]), we achieve similar scores with our best CIDEr score (58.49) outperforming all baselines.
5.2 Ablation Studies
Different Input Modalities: Our model is examined with different modality settings in Table 3. Using visual features alone (Exp # ①) for both datasets yields the worst performance with the lowest scores across all -gram metrics. Using nodes only (Exp # ②) can substantially improve the scores, although this produces higher repetition and lower diversity. We also find that the setting using visual features combined with node features results in significant performance improvement across all metrics (Exp # ⑤). Comparing ③ and ④, inputting visual+VG features exhibit higher -gram metrics than using visual+TG features for both datasets, indicating that the VG provide more useful information representative of the video content. R4 and Div2 scores remain similar for ActivityNet, but that for YouCook2 yields lower repetition/higher diversity. However as previously noted, lower repetition/higher diversity does not mean good caption quality if the -gram metrics are also low. Overall, we show that incorporating video-specific information and the TG corpus-level information (Exp # ⑤) is superior. We further experimented by adding a separate stream to process the raw audio features. Comparing ⑤ and ⑥ for both datasets, adding audio information slightly improves the repetition/diversity at the cost of lower B4 and CIDEr. This could be due to a misalignment in the audio track and the video’s topic e.g. there are cases where users upload background music unrelated to the video contents. Moreover, we examine noisy background audio that could potentially confuse the model. For YouCook2, by examining unprocessed speech features (Exp # ⑦), inputting the visual and speech transcript can produce competitive performance. However, this can be further enhanced by incorporating node information from VG and TG as seen in ⑧ which yields the highest B4 and CIDEr out of all the settings whilst maintaining competitive Div2 and R4.
| ActivityNet (ae-test) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Exp | V | VG | TG | A | S | B4 | M | C | Div2 | R4 |
| ① | ✓ | ✗ | ✗ | ✗ | ✗ | 12.90 | 16.92 | 28.27 | 75.65 | 6.00 |
| ② | ✗ | ✓ | ✓ | ✗ | ✗ | 10.63 | 16.51 | 20.75 | 74.83 | 7.66 |
| ③ | ✓ | ✓ | ✗ | ✗ | ✗ | 13.27 | 17.24 | 28.99 | 74.29 | 6.93 |
| ④ | ✓ | ✗ | ✓ | ✗ | ✗ | 13.12 | 17.09 | 27.97 | 75.02 | 7.01 |
| ⑤ | ✓ | ✓ | ✓ | ✗ | ✗ | 13.47 | 17.38 | 30.38 | 75.74 | 5.93 |
| ⑥ | ✓ | ✓ | ✓ | ✓ | ✗ | 13.16 | 17.40 | 29.88 | 76.24 | 5.80 |
| YouCook2 (yc2-val) | ||||||||||
| ① | ✓ | ✗ | ✗ | ✗ | ✗ | 7.12 | 15.25 | 30.12 | 70.75 | 3.66 |
| ② | ✗ | ✓ | ✓ | ✗ | ✗ | 9.91 | 18.65 | 44.50 | 65.38 | 6.33 |
| ③ | ✓ | ✓ | ✗ | ✗ | ✗ | 10.82 | 19.42 | 54.73 | 67.11 | 4.65 |
| ④ | ✓ | ✗ | ✓ | ✗ | ✗ | 8.06 | 16.35 | 36.68 | 69.96 | 3.72 |
| ⑤ | ✓ | ✓ | ✓ | ✗ | ✗ | 11.03 | 20.01 | 58.49 | 67.08 | 4.64 |
| ⑥ | ✓ | ✓ | ✓ | ✓ | ✗ | 9.73 | 18.50 | 53.33 | 68.22 | 4.36 |
| ⑦ | ✓ | ✗ | ✗ | ✗ | ✓ | 10.94 | 19.90 | 57.45 | 71.55 | 1.94 |
| ⑧ | ✓ | ✓ | ✓ | ✗ | ✓ | 11.56 | 19.98 | 58.70 | 70.46 | 2.61 |
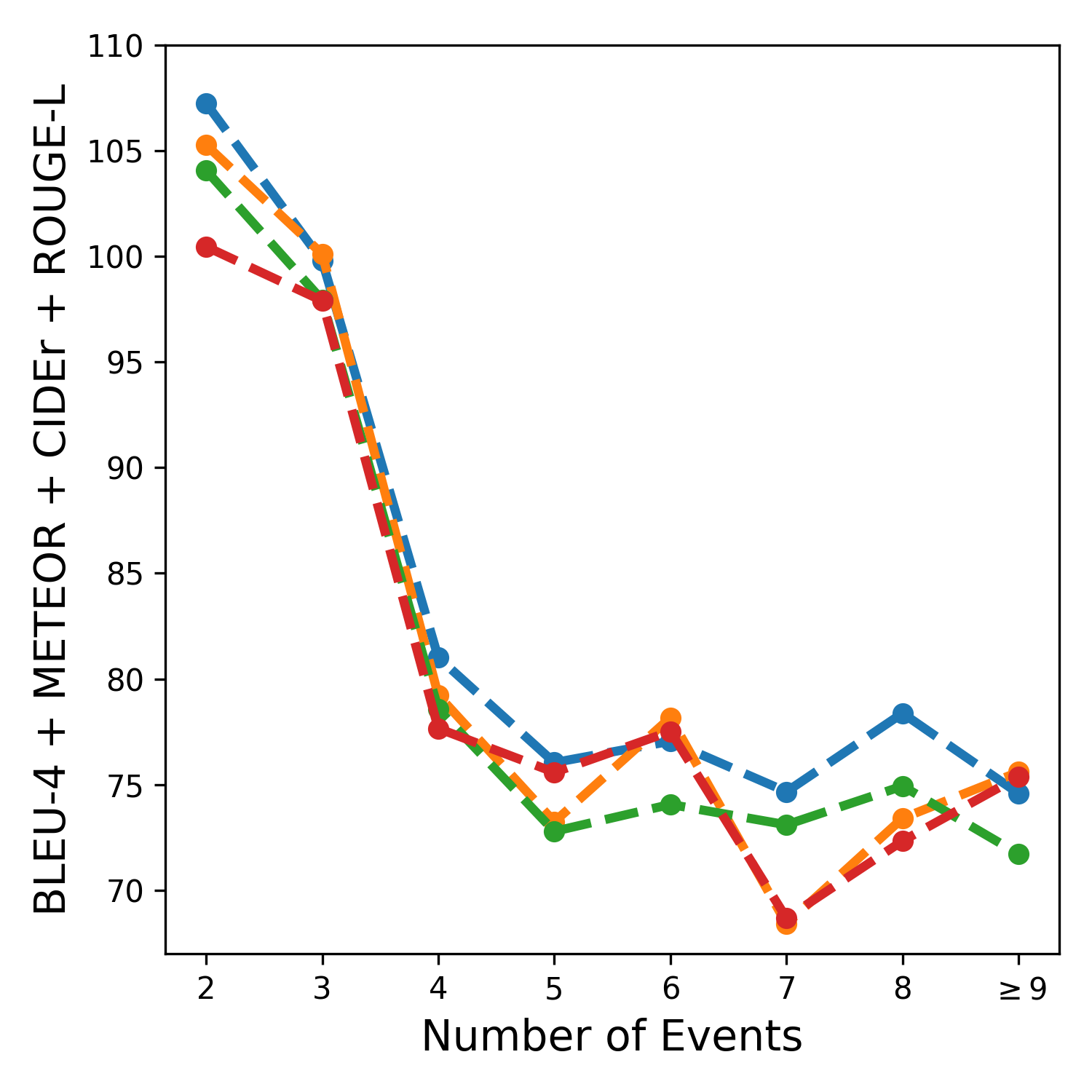
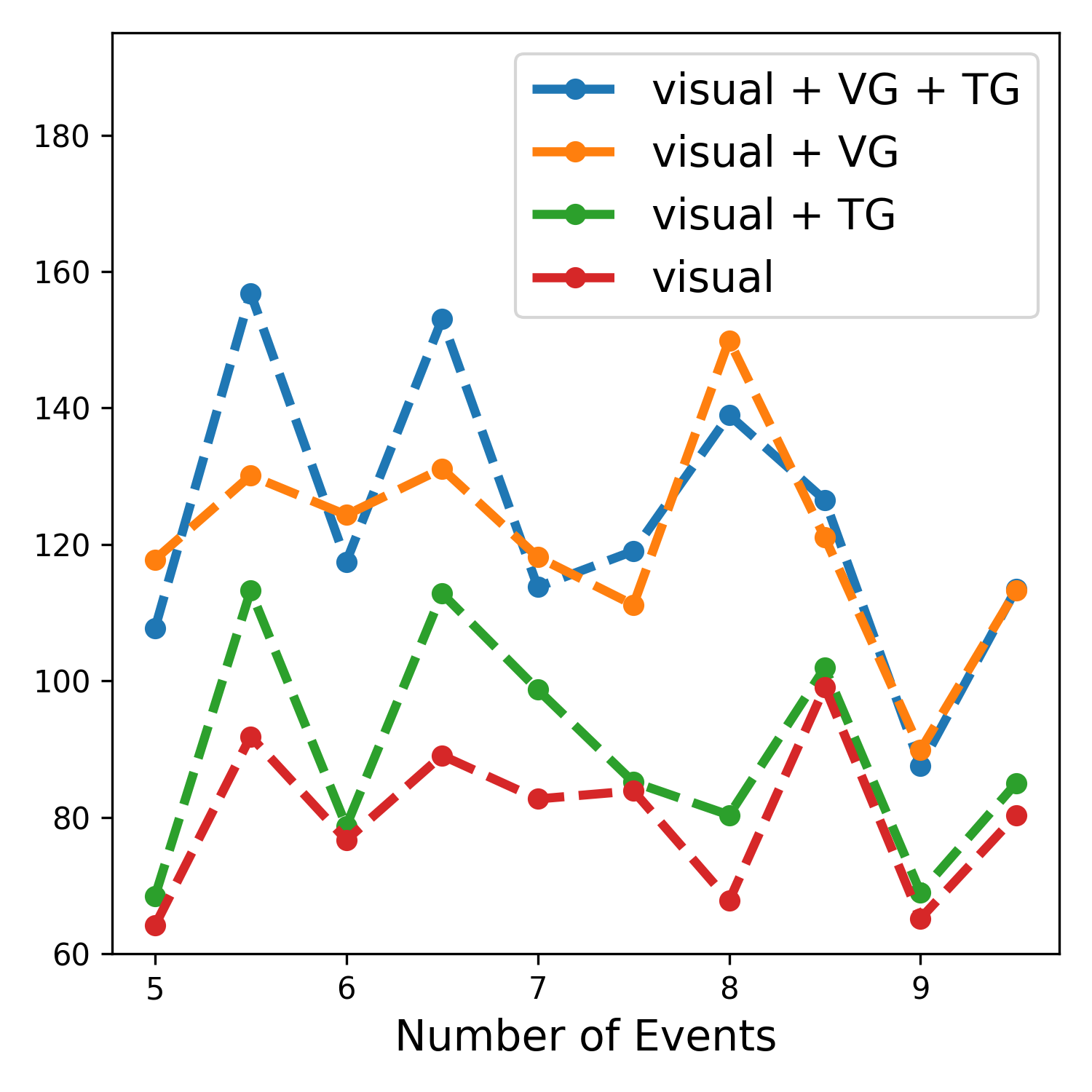
Different Decoders: We evaluated different methods for encoding recurrence using MART, TinT, and a ‘No Recurrence’ setting, as in the last three rows of Table 1/2 for ActivityNet/YouCook2. For ActivityNet, the TinT decoder achieved the best results across all metrics, followed by MART, with the No Recurrence setting performing the worst, indicating the importance of a recurrent memory module. Conversely, YouCook2 results showed that the No Recurrence setting yielded the highest METEOR (20.0) and CIDEr (58.5) scores, while TinT improved BLEU-4 and ROUGE-L but had the lowest METEOR and R4. This suggests that encoding recurrence benefits captioning if the current timestep relies on past information. We analysed samples by their total timesteps and plotted the average sum of -gram metrics for each group in Figure 2. For YouCook2, even without recurrence, decoding captions for samples with more timesteps wasn’t necessarily more complex. However, for ActivityNet, scores decreased with more timesteps, highlighting the need for recurrent information. This aligns with the MART paper’s findings on ActivityNet, though YouCook2 wasn’t tested in their study [24].
5.3 Qualitative Examples
Qualitative Examples for the start-of-the art methods versus GEM-VPC are shown in Figure 3 and Appendix J. We collect the top-10 selected nodes by confidence score at each timestep during inference and display the selected nodes and their types in the table after each example. Highlighted blue words indicate information related to the video’s theme. Evidently, the commonsense-enhanced video graph and theme graph assists our model in producing concepts and phrases relevant to the video segment. For instance in Figure 3, GEM-VPC mentions relevant phrases like ‘smiling to the camera’ and ‘putting ornaments on the tree’ which were perhaps derived from selected nodes such as ‘happy’, ‘decoration’ and ‘jingle’. Conversely, other baselines (see Appendix J) will sometimes mention irrelevant concepts such as in the last instance where BMT incorrectly outputs ‘brushing his face’ in contrast to our model which is capable of recognising the action of a person shaving his beard.

6 Conclusion
We introduced GEM-VPC, a novel framework for video captioning (VPC) that leverages multimodal information and external knowledge. We construct a commonsense-enhanced video-specific graph for key events and context, and a theme graph from ground-truth captions to represent word relationships. These graphs are processed by separate GNNs, and a node selection module identifies useful nodes for caption decoding. The selected nodes and supporting information (visual, audio, etc.) are fed into a transformer with multiple streams for different modalities, followed by a cross-attention module for inter-stream information exchange. Experiments on benchmark datasets demonstrate that GEM-VPC outperforms existing baselines, generating coherent and visually-grounded captions.
References
- [1] Anurag Arnab, Chen Sun, and Cordelia Schmid. Unified graph structured models for video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8117–8126, 2021.
- [2] Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005.
- [3] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? In ICML, volume 2, page 4, 2021.
- [4] Michał Bień, Michał Gilski, Martyna Maciejewska, Wojciech Taisner, Dawid Wisniewski, and Agnieszka Lawrynowicz. Recipenlg: A cooking recipes dataset for semi-structured text generation. In Proceedings of the 13th International Conference on Natural Language Generation, pages 22–28, 2020.
- [5] Shaked Brody, Uri Alon, and Eran Yahav. How attentive are graph attention networks? In International Conference on Learning Representations, 2021.
- [6] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019.
- [7] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 776–780. IEEE, 2017.
- [8] Simon Ging, Mohammadreza Zolfaghari, Hamed Pirsiavash, and Thomas Brox. Coot: Cooperative hierarchical transformer for video-text representation learning. Advances in neural information processing systems, 33:22605–22618, 2020.
- [9] Yuan Gong, Yu-An Chung, and James Glass. Ast: Audio spectrogram transformer. Interspeech Conference, 2021.
- [10] Xin Gu, Guang Chen, Yufei Wang, Libo Zhang, Tiejian Luo, and Longyin Wen. Text with knowledge graph augmented transformer for video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18941–18951, 2023.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [12] Jack Hessel, Bo Pang, Zhenhai Zhu, and Radu Soricut. A case study on combining asr and visual features for generating instructional video captions. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 419–429, 2019.
- [13] Yimin Hu, Guorui Yu, Yuejie Zhang, Rui Feng, Tao Zhang, Xuequan Lu, and Shang Gao. Motion-aware video paragraph captioning via exploring object-centered internal knowledge. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
- [14] Gabriel Huang, Bo Pang, Zhenhai Zhu, Clara Rivera, and Radu Soricut. Multimodal pretraining for dense video captioning. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, pages 470–490, 2020.
- [15] Jena D Hwang, Chandra Bhagavatula, Ronan Le Bras, Jeff Da, Keisuke Sakaguchi, Antoine Bosselut, and Yejin Choi. (comet-) atomic 2020: on symbolic and neural commonsense knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 6384–6392, 2021.
- [16] Vladimir Iashin and Esa Rahtu. A better use of audio-visual cues: Dense video captioning with bi-modal transformer. In The 31st British Machine Vision Virtual Conference. BMVA Press, 2020.
- [17] Vladimir Iashin and Esa Rahtu. Multi-modal dense video captioning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 958–959, 2020.
- [18] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. pmlr, 2015.
- [19] Lei Ji, Rongcheng Tu, Kevin Lin, Lijuan Wang, and Nan Duan. Multimodal graph neural network for video procedural captioning. Neurocomputing, 488:88–96, 2022.
- [20] Shuiwang Ji, Wei Xu, Ming Yang, and Kai Yu. 3d convolutional neural networks for human action recognition. IEEE transactions on pattern analysis and machine intelligence, 35(1):221–231, 2012.
- [21] Pin Jiang and Yahong Han. Reasoning with heterogeneous graph alignment for video question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11109–11116, 2020.
- [22] Weike Jin, Zhou Zhao, Xiaochun Cao, Jieming Zhu, Xiuqiang He, and Yueting Zhuang. Adaptive spatio-temporal graph enhanced vision-language representation for video qa. IEEE Transactions on Image Processing, 30:5477–5489, 2021.
- [23] Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on computer vision, pages 706–715, 2017.
- [24] Jie Lei, Liwei Wang, Yelong Shen, Dong Yu, Tamara Berg, and Mohit Bansal. Mart: Memory-augmented recurrent transformer for coherent video paragraph captioning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020.
- [25] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- [26] Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu. Hero: Hierarchical encoder for video+ language omni-representation pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 2020.
- [27] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- [28] Huaishao Luo, Lei Ji, Botian Shi, Haoyang Huang, Nan Duan, Tianrui Li, Jason Li, Taroon Bharti, and Ming Zhou. Univl: A unified video and language pre-training model for multimodal understanding and generation. arXiv preprint arXiv:2002.06353, 2020.
- [29] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640, 2019.
- [30] Kyle Min, Sourya Roy, Subarna Tripathi, Tanaya Guha, and Somdeb Majumdar. Learning long-term spatial-temporal graphs for active speaker detection. In European Conference on Computer Vision, pages 371–387. Springer, 2022.
- [31] Boxiao Pan, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, and Juan Carlos Niebles. Spatio-temporal graph for video captioning with knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10870–10879, 2020.
- [32] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- [33] Jae Sung Park, Marcus Rohrbach, Trevor Darrell, and Anna Rohrbach. Adversarial inference for multi-sentence video description. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6598–6608, 2019.
- [34] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- [35] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [36] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, pages 28492–28518. PMLR, 2023.
- [37] Tanzila Rahman, Bicheng Xu, and Leonid Sigal. Watch, listen and tell: Multi-modal weakly supervised dense event captioning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8908–8917, 2019.
- [38] Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. End-to-end generative pretraining for multimodal video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17959–17968, 2022.
- [39] Rakshith Shetty, Marcus Rohrbach, Lisa Anne Hendricks, Mario Fritz, and Bernt Schiele. Speaking the same language: Matching machine to human captions by adversarial training. In Proceedings of the IEEE international conference on computer vision, pages 4135–4144, 2017.
- [40] Botian Shi, Lei Ji, Yaobo Liang, Nan Duan, Peng Chen, Zhendong Niu, and Ming Zhou. Dense procedure captioning in narrated instructional videos. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 6382–6391, 2019.
- [41] Yuqing Song, Shizhe Chen, and Qin Jin. Towards diverse paragraph captioning for untrimmed videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11245–11254, 2021.
- [42] Robyn Speer, Joshua Chin, and Catherine Havasi. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirty-first AAAI conference on artificial intelligence, 2017.
- [43] Gabriel Stanovsky, Julian Michael, Luke Zettlemoyer, and I. Dagan. Supervised open information extraction. In NAACL-HLT, 2018.
- [44] Zineng Tang, Jie Lei, and Mohit Bansal. Decembert: Learning from noisy instructional videos via dense captions and entropy minimization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2415–2426, 2021.
- [45] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [46] Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015.
- [47] Khoa Vo, Hyekang Joo, Kashu Yamazaki, Sang Truong, Kris Kitani, Minh-Triet Tran, and Ngan Le. Aei: Actors-environment interaction with adaptive attention for temporal action proposals generation. arXiv preprint arXiv:2110.11474, 2021.
- [48] Eileen Wang, Caren Han, and Josiah Poon. SCO-VIST: Social interaction commonsense knowledge-based visual storytelling. In Yvette Graham and Matthew Purver, editors, Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1602–1616, St. Julian’s, Malta, Mar. 2024. Association for Computational Linguistics.
- [49] Teng Wang, Ruimao Zhang, Zhichao Lu, Feng Zheng, Ran Cheng, and Ping Luo. End-to-end dense video captioning with parallel decoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6847–6857, 2021.
- [50] Yilei Xiong, Bo Dai, and Dahua Lin. Move forward and tell: A progressive generator of video descriptions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 468–483, 2018.
- [51] Jun Xu, Ting Yao, Yongdong Zhang, and Tao Mei. Learning multimodal attention lstm networks for video captioning. In Proceedings of the 25th ACM international conference on Multimedia, pages 537–545, 2017.
- [52] Kashu Yamazaki, Sang Truong, Khoa Vo, Michael Kidd, Chase Rainwater, Khoa Luu, and Ngan Le. Vlcap: Vision-language with contrastive learning for coherent video paragraph captioning. In 2022 IEEE International Conference on Image Processing (ICIP), pages 3656–3661. IEEE, 2022.
- [53] Kashu Yamazaki, Khoa Vo, Quang Sang Truong, Bhiksha Raj, and Ngan Le. Vltint: Visual-linguistic transformer-in-transformer for coherent video paragraph captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 3081–3090, 2023.
- [54] Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, Antoine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid. Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10714–10726, 2023.
- [55] Liang Yao, Chengsheng Mao, and Yuan Luo. Graph convolutional networks for text classification. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 7370–7377, 2019.
- [56] Guorui Yu, Yimin Hu, Yiqian Xu, Yuejie Zhang, Rui Feng, Tao Zhang, and Shang Gao. Exploring object-centered external knowledge for fine-grained video paragraph captioning. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11786–11790. IEEE, 2024.
- [57] Runhao Zeng, Wenbing Huang, Mingkui Tan, Yu Rong, Peilin Zhao, Junzhou Huang, and Chuang Gan. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7094–7103, 2019.
- [58] Bowen Zhang, Hexiang Hu, and Fei Sha. Cross-modal and hierarchical modeling of video and text. In Proceedings of the european conference on computer vision (ECCV), pages 374–390, 2018.
- [59] Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it exist: Spatio-temporal video grounding for multi-form sentences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10668–10677, 2020.
- [60] Luowei Zhou, Yannis Kalantidis, Xinlei Chen, Jason J Corso, and Marcus Rohrbach. Grounded video description. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6578–6587, 2019.
- [61] Luowei Zhou, Yingbo Zhou, Jason J Corso, Richard Socher, and Caiming Xiong. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8739–8748, 2018.
- [62] Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Krähenbühl, and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. In European Conference on Computer Vision, pages 350–368. Springer, 2022.
- [63] Yimin Zhou, Yiwei Sun, and Vasant Honavar. Improving image captioning by leveraging knowledge graphs. In 2019 IEEE winter conference on applications of computer vision (WACV), pages 283–293. IEEE, 2019.
- [64] Andrew Zisserman, Joao Carreira, Karen Simonyan, Will Kay, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, et al. The kinetics human action video dataset. 2017.
Appendix A Video-Specific Graph Statistics
Total count for the different node types for the ActivityNet and YouCook2 video-specific graphs. On average, the ActivityNet and YouCook2 graphs have 57.04 and 127.83 nodes respectively with the largest graphs containing 259 and 304 nodes respectively.
| Node Type | ActivityNet | YouCook2 |
|---|---|---|
| Action | 74,017 | 43,555 |
| Location | 54,802 | - |
| Contextual Phrase | - | 13,464 |
| Object | 198,905 | 64,379 |
| Audio | 49,496 | 2,848 |
| Commonsense | 472,534 | 97,147 |
Appendix B Node Type Importance
To examine the importance of different node types in the video-specific graph, for each video sample during inference, we extract the top-10 selected nodes chosen by our node selection module at each event timestep. Then, for each node type, we count the frequency of selected nodes across the timesteps and divide the count by the total number of nodes (of that same type) that are present in the video-specific graph to get the proportion (normalised count). Finally, the proportions computed from each video sample is averaged across the validation set. This number reflects the expected probability that a node of a specific type will be selected to be part of the top-10 nodes. The results for both datasets is shown in the table below. For example, 48.99% in the table means that for ActivityNet video-specific graphs, if the node is an action node, then it has 48.99% chance to be in the top-10 nodes as ranked by our node selection module.
| Node Type | ActivityNet (%) | YouCook2 (%) |
|---|---|---|
| Action | 48.99 | 51.48 |
| Location | 54.30 | - |
| Contextual Phrase | - | 55.56 |
| Object | 39.79 | 43.61 |
| Audio | 54.24 | 59.76 |
| Commonsense | 30.80 | 10.74 |
Examining Table 5, for both ActivityNet and YouCook2, the node types with the highest average selected proportions were the location/contextual phrase, audio and action nodes, indicating that these node types tend to be more vital for video understanding. Action nodes having a high chance of being selected is not surprising, as this node captures information closely aligned with the VPC task where the aim is to generate captions describing the action and events in the video segment. Similarly for ActivityNet, the location nodes may be important as the action/events happening in the video are often closely related to location e.g. videos about water skiing often happen in locations with water. Moreover, for YouCook2, the contextual phrase nodes are most likely significant as they provide similar information to the action nodes. The large percentage of audio nodes selected for both datasets may be unexpected at first as raw video sounds tend to contain noisy background information. However, as mentioned in Section 3.1 of the main paper, we already perform extra post-processing in an attempt to retain only the relevant audio labels. For both datasets, the node type with the second least selection probability are object nodes with on average, 39-44% considered as important. This is however still a relatively large proportion, suggesting that object nodes are significant for VPC. Finally, we observe that a majority of the commonsense nodes were not useful, especially for YouCook2, despite the large count of commonsense nodes in both graphs (see Appendix A). This is perhaps attributed to the fact that Comet-ATOMIC2020 focuses on generating social commonsense such as people’s reactions, intents and desires relating to a specific event. However, we find that the ground-truth captions are often limited in detail whereby annotators do not always describe such information but mainly just simply focus on stating what is visually happening in the video. Nevertheless, a relatively large proportion of 30.8% is still selected from the ActivityNet video-specific graphs, suggesting that this social commonsense knowledge can still provide useful contextual cues for videos that are similar in nature to the ones in ActivityNet.
Appendix C Number of Nodes Selected
We report the performance of our model when changing the different maximum number of nodes that can be selected from each video-specific graph and each theme graph per timestep. Results for the ActivityNet and YouCook2 dataset are displayed in Table 6 and Table 7 respectively. For ActivityNet, the best -gram and repetition scores can be achieved when using 20 nodes (10 nodes selected from each of the video-specific and theme graphs at each timestep) or 40 nodes (20 nodes selected from each graph at each timestep). For YouCook2, we find that the best performance stabilises at around 60-80 total nodes.
| ActivityNet | ||||||
|---|---|---|---|---|---|---|
| # Nodes | B4 | M | C | R | Div2 | R4 |
| 10 | 13.80 | 17.40 | 31.21 | 35.88 | 75.22 | 6.50 |
| 20 | 13.91 | 17.40 | 31.45 | 36 | 75.19 | 6.41 |
| 40 | 13.91 | 17.47 | 30.68 | 35.97 | 75.75 | 6.18 |
| 60 | 13.51 | 17.38 | 30.74 | 35.82 | 75.21 | 6.42 |
| YouCook2 | ||||||
|---|---|---|---|---|---|---|
| # Nodes | B4 | M | C | R | Div2 | R4 |
| 10 | 10.39 | 18.82 | 52.24 | 35.52 | 65.87 | 5.47 |
| 20 | 10.73 | 19.27 | 54.21 | 35.97 | 67.63 | 4.80 |
| 40 | 10.88 | 19.58 | 57.38 | 36.69 | 66.03 | 5.40 |
| 60 | 11.03 | 20.01 | 58.49 | 36.89 | 67.08 | 4.64 |
| 80 | 11.23 | 20.04 | 57.84 | 36.78 | 67.77 | 4.75 |
| Relation | Description | Example (headrelationtail) |
|---|---|---|
| ObjectUse | describes everyday affordances or uses of objects | put into pan ObjectUse frying |
| MadeUpOf | describes a part, portion or makeup of an entity | making cake MadeUpOf eggs |
| HasProperty | describes entities’ general characteristics | boiling water HasProperty heat |
| CapableOf | describe abilities and capabilities of everyday living entities | cut cake CapableOf celebrate birthday |
| isAfter | events that can follow an event | mop the floor isAfter sweep the floor |
| HasSubEvent | provides the internal structure of an event | boil the dumplings HasSubEvent boils water |
| isBefore | events that can precede an event | opens a gift isBefore rips wrapping paper |
| xNeed | describes a precondition for an agent to achieve the event | give a gift xNeed buys the presents |
| xAttr | describes personas or attributes perceived by others given an event | decorates Christmas tree xAttr festive |
| xEffect/oEffect | actions that happen to an agent that may occur after the event | gives a present xEffect gets thanked |
| xReact/oReact | emotional reactions of participants in an event | gives a present xReact feels happy |
| xWant/oWant | postcondition desires after an event | gives a present xWant wants to hug |
| xIntent | defines the likely intent of an agent | pour sauce on food xIntent add flavour |
Appendix D Performance Across Different Video Categories
To examine how our model performs across different types of videos, we compute the average sum of BLEU-4, METEOR, CIDEr and ROUGE-L across 14 different categories for the ActivityNet validation and testing split. These categories are provided by the user when uploading the video and roughly represent the video’s main topic. For this experiment, 3 different types of input modalities are tested: 1) using video visual features only (visual), 2) using visual features combined with node features chosen by the node selection module (visual + nodes), and 3) using visual features combined with node features and audio features (visual + nodes + audio).
Examining Figure 4, when comparing video versus visual + nodes, we find that visual + nodes does better than visual only in all categories except for ‘Travel & Events’, ‘Autos & Vehicles’, and ‘Science & Technology’. In particular, the largest gap occurs in the 2 latter categories. A reason for this may be due to a lack of action classes related to these categories in which the TimeSformer model is capable of predicting, which subsequently affects the quality of the nodes in the video-specific graph. For instance, there are no specific action classes that are related to ‘Science & Technology’ in the Kinetics600 dataset in which the TimeSformer model was trained on, while there are only 4 action classes that are related to ‘auto maintenance’ (‘changing oil’, ‘changing wheel’, ‘checking tires’, ‘pumping gas’). Furthermore, we observe that adding audio features to the model does not necessarily provide useful context cues for all categories. This is perhaps due to a misalignment between the audio track and video’s topic. For example, people will often put a sound track with music even when the video itself is not about ‘Music’. However, we do find that audio helps in improving performance for categories related to ‘Education’, ‘Travel & Events’, ‘Howto & Style’, and ‘Comedy’.
In summary, visual + nodes performs the best in general, outperforming the other 2 model variants for 7 out of the 14 categories. This aligns with the findings from Section 5.2. Visual + nodes + audio is the second-best with superior performance in 5 categories. This is finally followed by the visual only setting, whereby visual features alone clearly does not provide enough contextual information to generate high quality captions and thus, only benefits 2 out of the 14 categories.

Appendix E Relation Description
The relation tokens used to extract knowledge from the Comet-ATOMIC2020 neural knowledge model for the commonsense nodes in the video-specific graphs and their corresponding descriptions are detailed in Table 8. The descriptions are taken from the official Comet-ATOMIC2020 paper [15]. For the ActivityNet graphs, all relations below were used except for isAfter, isBefore, MadeUpOf, ObjectUse and HasProperty. Although isAfter and isBefore relations may be useful, we find that the commonsense generated using these relations for the ActivityNet data tends to produce similar results to xNeed and xEffect/oEffect and so we disregard these relations to help reduce the number of commonsense nodes in the graphs. MadeUpOf, ObjectUse and HasProperty are further ignored as information about properties, compositions or characteristics of entities are not closely aligned with the content in the ActivityNet captions. For the YouCook2 graphs, all relations below were used except for xReact/oReact, xAttr and xWant/oWant as we believe information about an event’s attributes and individual’s subjective reactions/desires may not be useful for captioning instructional cooking videos.
Appendix F Theme Graph Example
The image below shows an example of what a snippet from the theme graph corresponding to the action class carving pumpkins’ would look like. Nodes represent tagged nouns, verbs, and adverbs from the ground-truth training annotations. All edges in the graph are undirected and weighted by normalised point mutual information scores.

| ae-val | |||||||||
| Model | Conference | Year | Modalities | Integration Method | B4 | M | C | R | R4 |
| VTrans [61] | CVPR | 2018 | V+F | Concatenation | 9.75 | 15.64 | 22.16 | 28.9 | 7.79 |
| HSE [58] | ECCV | 2018 | V | - | 9.84 | 13.78 | 18.78 | - | |
| AdvInf [33] | CVPR | 2019 | V+F+O | Concatenation | 10.04 | 15.93 | 27.27 | - | 5.76 |
| GVD [60] | CVPR | 2019 | V+F+O | CM Attention | 11.04 | 15.71 | 22.95 | - | 8.76 |
| GVDsup [60] | CVPR | 2019 | V+F+O | CM Attention | 11.30 | 16.41 | 22.94 | - | 7.04 |
| Trans-XL [6] | ACL | 2019 | V+F | Concatenation | 10.39 | 15.09 | 21.67 | 30.18 | 8.79 |
| Trans-XLRG [24] | ACL | 2020 | V+F | Concatenation | 10.17 | 14.77 | 20.40 | - | |
| MDVC [17] † | CVPR | 2020 | V+S+A | Concatenation | 9.12 | 14.69 | 17.57 | 25.85 | - |
| BMT [16] † | BMVC | 2020 | V+A | CM Attention | 9.00 | 14.49 | 16.46 | 26.11 | - |
| MART [24] | ACL | 2020 | V+F | Concatenation | 10.33 | 15.68 | 23.42 | - | 5.18 |
| PDVC [49] | ICCV | 2021 | V+F | Concatenation | 11.8 | 15.93 | 27.27 | - | - |
| VLCAP [52] | ICIP | 2022 | V+L | CM Attention | 14.00 | 17.78 | 32.58 | 36.37 | 4.42 |
| Motion-Aware [13] | ICASSP | 2023 | V+O | CM Attention | 12.07 | 16.81 | 29.32 | - | 4.28 |
| Text-KG [10] | CVPR | 2023 | V+O+S+G(S+C) | CM Attention | 11.30 | 16.50 | 26.60 | - | 6.30 |
| VLTinT w/ CL [53] | AAAI | 2023 | V+L+O | CM Attention | 14.93 | 18.16 | 33.07 | 36.86 | 4.87 |
| VLTinT w/ CL∗ [53] | AAAI | 2023 | V+L+O | CM Attention | 14.89 | 18.09 | 33.07 | 36.76 | 5.11 |
| VGCSN+CHPG [56] | ICASSP | 2024 | V+L+O+C | CM Attention | 12.20 | 16.69 | 29.98 | - | 4.32 |
| GEM-VPC w/ No Recurrence | - | 2024 | V+G(V+A+C) | CM Attention | 13.16 | 17.56 | 27.50 | 33.85 | 7.86 |
| GEM-VPC w/ MART decoder | - | 2024 | V+G(V+A+C) | CM Attention | 13.91 | 17.47 | 30.68 | 35.97 | 6.18 |
| GEM-VPC w/ TinT decoder | - | 2024 | V+G(V+A+C) | CM Attention | 14.73 | 18.02 | 32.93 | 36.71 | 5.41 |
Appendix G Implementation Details
Graph Construction: The TimeSformer [3] pretrained on the Kinetics600 dataset [64] was used as the action classification model for constructing the action nodes for the VF-method. The model is capable of predicting 600 unique action classes. We leveraged the Audio Spectrogram Transformer [9] pretrained on AudioSet [7] (capable of predicting 632 audio event classes) as the audio classification model to create the audio nodes for the VF and ASR-method. Commonsense nodes are generated by Comet-ATOMIC2020 [15] using the ‘comet_atomic2020_bart’ implementation. Object and location nodes for the VF-method are generated by the BLIP-VQA base model as proposed in [25], with the object nodes further expanded using Detic’s [62] object detection model. ASR from the YouCook2 videos was extracted using OpenAI’s Whisper [36] while we used AllenNLP’s OpenIE model [43] for creating the action nodes in the ASR-method. All part-of-speech tagging is done with the NLTK toolkit.
For each set of commonsense knowledge generated by its corresponding action node, we filter out any similar generated commonsense to avoid adding duplicate commonsense into the video-specific graph at the same timestep. Specifically, we removed any similar commonsense if its Levenshtein Distance ratio with another commonsense is greater than 0.70. As mentioned in Section 3.1 of the main paper, we also did not add the commonsense into the graph if the action class used to generate that commonsense had a confidence score of less than 0.5 so as to avoid incorporating irrelevant external knowledge. The threshold for filtering out any noisy object and audio labels was 0.25 and 0.3 respectively while the threshold to determine whether an action node contained ‘no action’ was 0.35. For creating the theme graphs in the case when the ASR-method is used, -means clustering with and 10 repetitions was used to create the action classes. The theme graphs contain the top-100 most occurring words within that action class/theme.
Model Training: The 2048D visual features for the ActivityNet were extracted using a 3D-CNN backbone [20]. For YouCook2, we used 2048D ResNet-200 [11] visual features concatenated with 1024D optical flow features from BNInception [18]. The node/edge linguistic features for the video-specific and theme graphs are represented using CLIP textual embeddings [35].
We train the modules in an end-to-end fashion with teacher forcing to optimise the Kullback–Leibler divergence loss with the best model using a label smoothing of 0.3. The word embedding matrix of the models is initialised with GloVe embeddings of dimension 300 [34]. Inputs into each transformer stream are added with fixed positional embeddings (only for the visual stream) and learnt token type embeddings. The token type embedding matrix was size 10 to incorporate for different modality types such as visual, audio or type of node e.g. location, commonsense etc. We use 2 hidden transformer layers with 12 attention heads where the hidden and intermediate size was 768. For the theme graph encoder, 2 GATv2Conv layers [5] were used while the video-specific graph encoder used 1 GATv2Conv layer with all layers using 4 attention heads. Adam optimizer was used to train our model with an initial learning rate of 1e-4, and = 0.999, weight decay of 0.01, learning rate warmup over the first 5 epochs and batch size of 2. Early stopping was applied after no improvement was seen in the validation CIDEr score in 3 consecutive epochs. For decoding the caption at inference, nucleus sampling with 0.6 top- and 0.5 temperature was used.
Appendix H ActivityNet Validation Set Quantitative Results
Table 9 shows the -gram metrics and repetition scores of baselines and GEM-VPC for the ActivityNet ae-val split. In the ‘Modalities’ column, the abbreviations are defined as follows: V=visual, F=optical flow, O=bounding box object visual features, A=audio, S=speech, L=language, G(V+A+C)=graph built with visual, audio modality and commonsense, G(S+C)=graph build with speech modality and commonsense. † indicates results computed by ourselves using VPC evaluation mode. indicates results computed from the model that was reran with the same environment as this research. The ‘Integration Method’ column indicates the model’s main approach for integrating the distinct modalities. ‘Concatenation’ refers to a simple concatenation of different modality vectors which are then fed into a single stream, ‘CM Attention’ refers to cross-modal attention employed between modules processing different modality inputs, and ‘Joint CM Space’ indicates that the model attempts to learn a common space for different modalities.
Our best model (GEM-VPC w/ TinT decoder) achieves comparable performance with the strongest baselines (VLTinT w/ CL and VLTinT w/ CL∗). Note that while we underperform slightly on the validation set, we outperform VLTinT in a majority of the metrics when evaluating on the testing set (see Table 1 of the main paper).
Please note that the appendix continues on the next page.
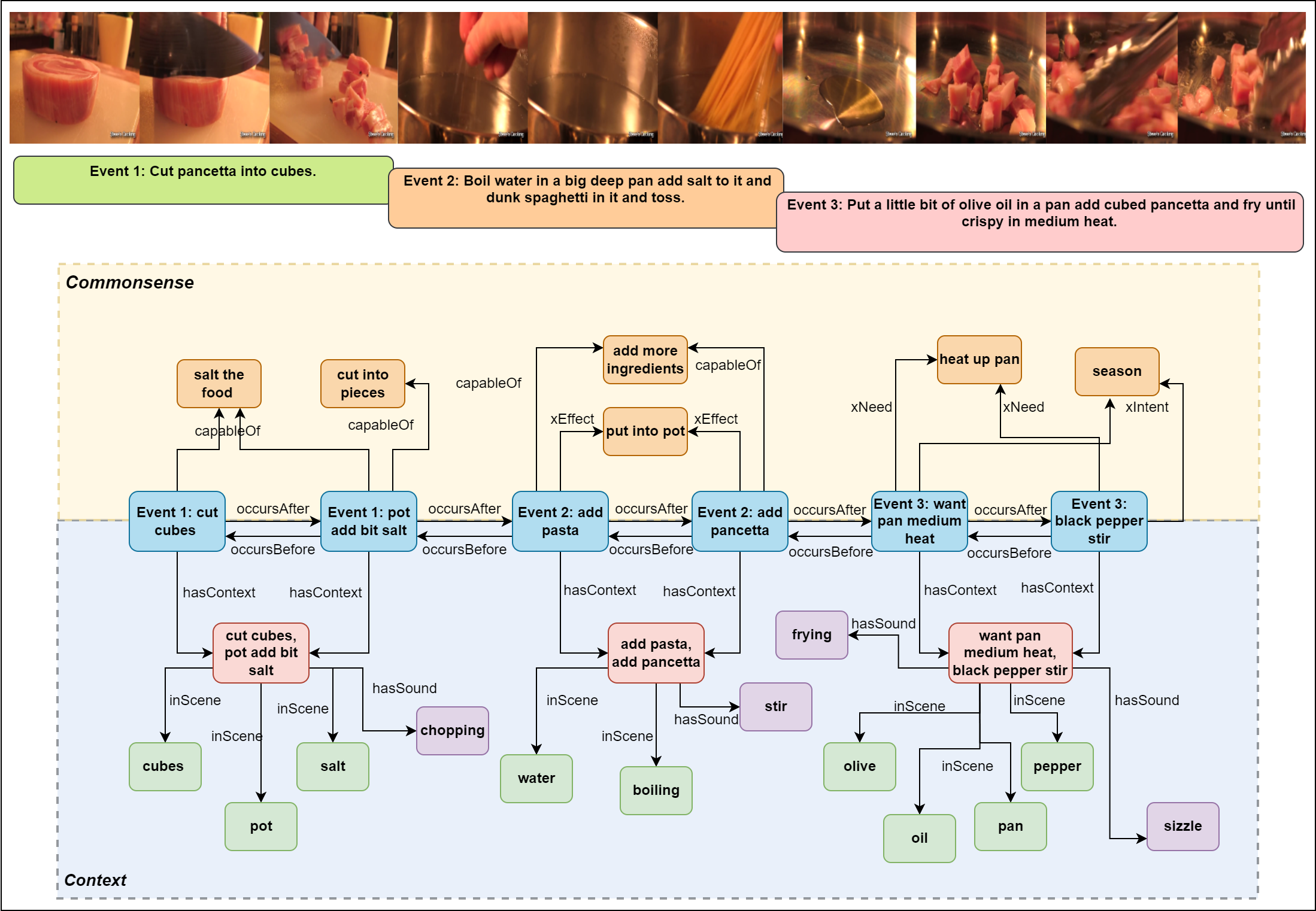
Appendix I Video-Specific Graph Visual Examples
Visual depiction of what the video-specific graphs would look like using the VF and ASR-method for an example ActivityNet and YouCook2 video. Blue nodes represent the action nodes, red nodes are the location/contextual phrase nodes, green nodes are object nodes, purple nodes are audio nodes and orange nodes are the commonsense nodes. Note that due to size of the graphs, not all nodes are presented and graphs would be larger in reality. Sentences under the video frames are the matching ground-truth captions.

Appendix J Qualitative Examples (Ours vs SOTA)
Qualitative Examples for the start-of-the art methods versus ours (GEM-VPC) are shown in Figure 8. The first example is from YouCook2 while the last is from ActivityNet. Blue words in the machine-generated captions are visually grounding to the video, while red words represent irrelevant words that are ‘hallucinated’ by the model. We collect the top-10 selected nodes by confidence score at each timestep during inference and display the selected nodes and their types in the table after each example. Highlighted blue words in the table indicate information related to the theme of the video.

Appendix K More Qualitative Examples
