GEM: Group Enhanced Model for Learning Dynamical Control Systems
Abstract
Learning the dynamics of a physical system wherein an autonomous agent operates is an important task. Often these systems present apparent geometric structures. For instance, the trajectories of a robotic manipulator can be broken down into a collection of its transitional and rotational motions, fully characterized by the corresponding Lie groups and Lie algebras. In this work, we take advantage of these structures to build effective dynamical models that are amenable to sample-based learning. We hypothesize that learning the dynamics on a Lie algebra vector space is more effective than learning a direct state transition model. To verify this hypothesis, we introduce the Group Enhanced Model (GEM). GEMs significantly outperform conventional transition models on tasks of long-term prediction, planning, and model-based reinforcement learning across a diverse suite of standard continuous-control environments, including Walker, Hopper, Reacher, Half-Cheetah, Inverted Pendulums, Ant, and Humanoid. Furthermore, plugging GEM into existing state of the art systems enhances their performance, which we demonstrate on the PETS system. This work sheds light on a connection between learning of dynamics and Lie group properties, which opens doors for new research directions and practical applications along this direction. Our code is publicly available at: https://tinyurl.com/GEMMBRL.
1 Introduction
The interaction between an autonomous agent and its environment can be modeled by a dynamical control system, where the environment’s current state and agent’s action are mapped by a dynamics function to the next state (Watter et al., 2015; Todorov & Li, 2005). When the system is unknown and complex, learning a reliable dynamical model from data samples is a notably challenging problem.
Reliable dynamical models are required in many important applications such as planning (Schrittwieser et al., 2020), model-based reinforcing learning (Moerland et al., 2020), system identification (Nelles, 2020), environment emulation (Castelletti et al., 2012), SimToReal (Tan et al., 2018), etc. Moreover, reliably predicting over long-time horizons remains a brutishly difficult problem as compared to a single-step prediction. Such long horizon prediction is particularly useful for downstream planning of robust behaviors (Chua et al., 2018; Rajeswaran et al., 2020; Hafner et al., 2020). Hence, there has been a growing research interest in enhancing the quality of sample-based methods for learning dynamical models (Brzeski et al., 2017; Fragkiadaki et al., 2015; Deisenroth, ).
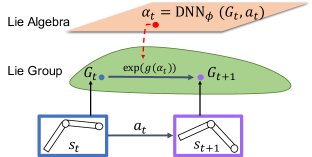
In general, the problem of learning a dynamical model is formulated as learning a predictive mapping from the present state and action to the future state (Schrittwieser et al., 2020). Usually, the outputs and the inputs in learning of this mapping are treated as general Euclidean vectors. However, such a view overlooks the intrinsic properties within the state space of a dynamical system. In fact, the states form a manifold structure (Strogatz, 2018; Agrachev & Sachkov, 2013). In this work we propose a novel approach to exploit this underlying structure and learn reliable dynamical models.
An important component for sample-based learning of dynamical models is the choice of priors, which usually comes from our understanding of the underlying physical laws (Greydanus et al., 2019; Miles et al., 2020). For example, the priors can be a prior distribution over the model parameters (Chua et al., 2018; Luo & Kareem, 2020) or a set of differential equations with undetermined physical parameters (Bahl et al., 2020; Chen et al., 2018). Here, we consider another type of priors, which are primitive geometric motions of dynamical system. These priors reflect the manifold structure of the state space of dynamical system, as explained below.
Primitive geometric priors describe what a dynamical system does, which is independent from any specific physical parameters (such as friction, mass, natural frequencies, etc) or physical laws. For example, by simply observing interactions between the agents and the environments, one may understand that a car rotates and translates linearly, a robotic arm rotates around rotation axes of its joints, and a humanoid translates its center of mass while rotating its hinge joints. Such information can be obtained either implicitly via cameras (Shi et al., 2020; Gothandaraman et al., 2020) or explicitly via hardware specifications (Todorov et al., 2012) with little extra cost. In contrast, many physical states need to be measured by elaborated motion capture or sensory systems (OpenAI et al., 2018).
To characterize these geometric priors, we follow the framework of Lie group theory, a powerful tool for studying manifolds with group structure (Hall & Hall, 2003)111This theory is well-known dating back to the XIX century, when mathematician Sophus Lie laid the foundations of the theory of continuous transformation groups.. To this end, we propose the Group Enhanced Models (GEMs) that incorporates the properties of the smooth manifold, which allows a neural network to effectively learn reliable dynamical models both in short and long horizons.
Central to GEMs is the one-to-one correspondence between elements from the manifold and those from an associated linear vector space, termed Lie Algebra. The significance of this correspondence is summarized in the following paragraph by Howe (1983):
“…The essential phenomenon of Lie theory is that one may associate in a natural way to a Lie group its Lie algebra . Thus for many purposes one can replace with g. Since is a complicated nonlinear object and is just a vector space, it is usually vastly simpler to work with …”
Hypothesis.
We hypothesize that it is more efficient and effective to learn a dynamical system on the linear vector space Lie algebra, , than on the original unstructured state space, , or on the complicated Lie group, .
To explore this hypothesis, we develop GEM to enable learning a dynamical system on the linear vector space of Lie algebra. Figure 1 provides an overview of GEM: after converting a raw state to a Lie group manifold, GEM outputs a Lie algebra action to evolve it to the target next state on the manifold that is equivalent to applying an action in the original raw space. In experiments, we evaluate GEM on various dynamical systems in different standard benchmark tasks. Our main contributions are:
-
•
We propose a new framework, the Group Enhanced Models, for learning dynamical models on Lie algebra.
-
•
We show that GEM outperforms the relevant baselines on the task of long horizon prediction for standard continuous control benchmarks.
-
•
We demonstrate the advantage of GEM for offline planning and model-based reinforcement learning on various dynamical systems.
In Section 2, we review the related prior works. Section 3 overviews the relevant background of Lie group theory. Section 4 introduces our method. Section 5 presents the experimental results. Finally, Section 6 summaries and provides a broader perspective.
2 Related Works
In this section, we review the related prior works, including generic methods of learning dynamics, dynamical models with physical priors and machine learning models with Lie theory elements.
2.1 Generic predictive models
The most common technique for learning dynamics is to fit either the forward model, , or the inverse-model, to the training samples of -step state-action trajectories, (Nguyen-Tuong & Peters, 2010, 2011; Schaal et al., 2002; Kocijan et al., 2004; Deisenroth, ).
Feed-forward networks are commonly used model classes to parametrize these forward models (Janner et al., 2019). The training objective is generally formulated as empirical loss minimization between the predicted next state and the true next state, given the present state and agent’s action:
| (1) |
where , and are the predicted next state, , and an appropriate loss function, such as mean squared error, respectively.
This generic approach manages to achieve decent results, and it is often adopted as the comparative baseline when proposing other novel approaches (Greydanus et al., 2019; Miles et al., 2020; Sanchez-Gonzalez et al., 2018; Lutter et al., 2019). Here, we also compare our proposed methods to the generic baseline.
2.2 Dynamical models with physical priors
Recently, a series of works have proposed to incorporate physical priors to model dynamics. One line of research takes advantage of the properties of the Hamiltonian and the Lagrangian function of dynamical systems (Greydanus et al., 2019; Miles et al., 2020; Lutter et al., 2019). Specifically, Greydanus et al. (2019) propose Hamiltonian Neural Networks (HNN) to explicitly use the Hamiltonian formalism and the canonical coordinates. The resulting Hamiltonian optimization objective better preserves energy and hence improves long horizon predictions.
A follow-up idea, Lagrangian Neural Networks (Miles et al., 2020) eliminates the need for the canonical coordinates. An extended Lagrangian formalism, including external forces, is proposed by Lutter et al. (2019) for learning inverse-models. These approaches improve the quality of sample-based learning of autonomous dynamical systems. In contrast, we consider dynamical control systems with external control signals. We also do not assume the knowledge of the Hamiltonian or Lagrangian formalisms but explore forward-dynamics models from the group theoretical viewpoint.
Another approach to incorporate physical priors is proposed by Sanchez-Gonzalez et al. (2018), based on Graph Neural Networks (GNN). The components of a dynamical system are embedded in a static and a dynamic graph with recurrent connections. The static graph represents the physical parameters (friction, mass, viscosity etc), and the dynamic represents instantaneous state. Our method, on the other hand, does not need to explicitly learn these physical parameters.
2.3 Models with Lie theory elements
Several existing works have leveraged the power of Lie group theories in machine learning applications, from image classification (Cohen & Welling, 2016), medical data preprocessing (Bekkers, 2019), to action recognition (Huang et al., 2017; Vemulapalli & Chellapa, 2016), etc. The language of Lie theory is also ubiquitous in robotics (Selig, 2004; Byravan & Fox, 2017) and geometric optimal control (Agrachev & Sachkov, 2013).
A common theme of these prior works suggest that utilizing the Lie group representations instead of the original observations leads to better training efficiency and better final performance. In addition, Quessard et al. (2020) learns disentangled representations by constraining the latent space to be a Lie group manifold. Similarly, Byravan & Fox (2017) employ the prediction of Lie group elements in the context of scene recognition and object segmentation for robotic manipulations, where the elements of are modeled by a neural network.
Unlike other machine learning frameworks using Lie theory elements, we consider both a Lie group manifold and its corresponding Lie algebra. In particular, the Lie algebra elements are modeled by a neural network and govern the transition between the present and the next points on the Lie group manifold.
3 Preliminaries
Our work considers rigid body dynamics (Tsai, 1999). Translations, rotations and their compositions are the primitive motions of such systems. This is a broad class of dynamical systems, used ubiquitously in artificial intelligence and optimal control (Todorov et al., 2012; Brockman et al., 2016; Selig, 2004). For example, the motion of a planar single pendulum, which is a two-dimensional non-linear dynamical system, is characterized by rotation with regard to its pivot. For another example, the motion of a humanoid, which is a high-dimensional system, is characterized by a composition of multiple limb rotations and translation of center of mass. An important feature of these primitive motions is that they are elements of the corresponding groups, or more precisely, Lie groups.
In this section, we first review the generic approach for sample-based dynamics learning and then review the relevant Lie group theories to our work.
3.1 Generic predictive dynamical models
A dynamics function, , is a map from the current state, and the current action, to the following state, 222in practice, following the previous works (Nagabandi et al., 2020), we model the change in state, .:
| (2) |
When the dynamics is unknown, learning an accurate becomes essential for e.g. planning and control (Nagabandi et al., 2018, 2020; Chua et al., 2018). Usually, this map is approximated by a parametric function, , through minimization of some loss between the predicted next state and the true next state :
| (3) |
This generic way of learning dynamics often ignores any geometric structure within the dynamical system but simply operates on the unstructured raw state space .
3.2 Elements of Lie group theory
A finite dimensional Lie group is a group and a differential manifold at the same time (Howe, 1983; Hall & Hall, 2003).
For every point on the manifold, there exists a tangent linear vector space . The tangent space at the identity element, , is special. It is called the Lie algebra, , of the Lie group, . The Lie group (manifold) and its algebra (linear vector space) are connected by:
| (10) |
where and can be calculated via the corresponding Taylor series. For instance, , , where and is a binary composition operator defined on .
The Lie algebra is a linear vector space spanned by a basis of elements, , where is the dimension of the manifold . Every vector in the algebra, , can be represented by an unique linear combination of the basis elements with scalars, :
| (11) |
The equations (10) and (11) read together as follows:
| (12) |
The composition axiom of group ensures that when a group element, e.g. , acts on another group element , we obtain another element within :
| (13) |
In other words, the coefficients of Lie algebra govern the transition between and . This property is core to our proposed framework. Specifically, can be viewed as the Lie group representation of the current state and the next state. In Section 4, we will formally introduce our method for learning of dynamical control systems through Lie algebra coefficients, .
3.2.1 Groups of rotation and translation
The Lie groups of 2D/3D spacial rotations, /, and translations, /, fully characterize the primitive geometric motion of rigid body, and are broadly used in robotics (Selig, 2004; Bourmaud et al., 2015; Featherstone, 2014). Both groups admit matrix representations (Hall & Hall, 2003). Here, the group composition operator, , is the standard matrix multiplication and the matrix exponential. We review the properties of these groups in the Supplementary Material. In this work, we assume the bases of and are known, which is a common setup in many robotic applications. In the case of unknown basis, it can potentially be learned as well (Quessard et al., 2020), which we leave for future investigation. In contrast to (Quessard et al., 2020), we utilize known group structures as a prior for learning of dynamical model (2) for planning.
Conversion from angle-axis representation The elements of can be constructed from a rotation axis, , and a rotation angle, (Selig, 2004)333In the robotic environments we use in the current work, state is represented either by angle-axis or quaternion, which we firstly transform to the corresponding Lie groups, such as SO and or SE. The transformation from angle-axis, (which is used in most of the environments in this work), to SO is provided for completeness.:
| (14) |
where is the identity matrix, the cross product, and the outer product. The axes of rotations can be revealed either from the hardware specification (Todorov et al., 2012), or by computer vision techniques (Shi et al., 2020; Gothandaraman et al., 2020).
4 Our Method
Now, we are ready to introduce Group Enhanced Model (GEM), which is a particular method for learning (13). The core component in our method is prediction of Lie algebra coefficients from data samples that connect two consequent points on the manifold, , and . Our method includes a novel objective, given by equation (15), a two-staged neural network architecture, shown at Figure (2), and its training algorithm, Algorithm (1).
Notations: Given a state observation, , the first stage models the Lie algebra coefficients, , that build the “static” component, , and the second stage models the “dynamic” component, , where “static” and “dynamic” represent position and velocity, or angle and angular velocity, respectively. The static components are represented by the corresponding group elements, which can be any combination of , , , (Hall & Hall, 2003). The full state vector is represented by stacking matrices of corresponding groups. For example, double pendulum is represented by stacking two rotation matrices. We refer to this collective group state as .
4.1 GEM Objective
Our goal is to train a neural network to predict the Lie algebra coefficients, , to construct the next state by applying the associated group action in (12) to the current state. To do so, we formulate the following objective function where is the parameters of our network and is its predicted coefficients :
| (15) | ||||
and we refer to the “algebraic loss”, which depends on a particular representation of a group. In the case of a group with matrix representation, this loss is a matrix norm.
The loss in (15) is used to train the model to predict the static components, , via the Lie algebra coefficients, . The velocity loss is mean square error between true delta, , and predicted delta velocity, , as shown in Algorithm (1). In Section 6 we discuss an alternative to this approach for predicting velocity.
4.2 GEM Architecture
In this section, we introduce an architecture for predicting the full state, including both static and dynamic state components. The architecture of GEM, shown in Figure 2, consists of two parts: Coefficient Model and Velocity Model , and . The Coefficient Model is a neural network, parameterized by , with an arbitrary architecture that maps the Lie Group state , the velocity , and the action at time into Lie Algebra coefficients that describe the change of motion undergone by the primitive geometry. The Velocity Model, also an arbitrary neural network, parameterized by , then maps , , , and action to . From equation (11) and (13), we compute the final prediction of using coefficients. We hypothesised that the predicted coefficients could aid in predicting future velocities, which we confirm by the experiments. However, one can combine the coefficient model and velocity model into a single network without loss of the superiority of GEM. This is demonstrated by PETS comparison experiment in Section 5.4.
In the current work, we explore feed-forward networks for modeling of Lie algebra coefficients and velocities. However, other frameworks are possible, including recurrent networks, transformer networks, graph networks, etc, as we discuss in Section 6.
4.3 GEM Training Algorithm
Algorithm (1) summarizes the GEM training process. The algorithm receives - training samples, (, ) - initial models, - learning rate, and - number of iterations. Each training sample comprises of the state observation, , and agent’s action, . The state observation includes the angular and translation component, , and the velocity component, . The angular and translation component, is converted to by (14), which is used in the loss (15). This transformation depends on the groups that make up the environment. For example, 2D joint angles are converted into group space. The supplementary materials contains an walk-through of this transformation for a particular environment.
5 Experiments
We now evaluate GEM on a standard set of continuous control dynamical systems, namely Inverted Pendulum, Inverted Double Pendulum, Reacher, Hopper, Walker, Half Cheetah, Ant, and Humanoid. These environments incorporate a diverse set of challenging geometries and motions (Todorov et al., 2012; Tassa et al., 2018), making them a suitable testbed for GEMs.
In all the experiments, we use feed-forward multilayer perceptrons with consistent hyperparameters for the baseline model and GEM.444We use this over more advanced architectures initially to keep confounding variables to a minimum and provide a simple ablated test bed to study the effects of the geometric prior alone. If complex architectures were initially used, it would be harder to assess the results, and additional (unrelated to geometric priors) ablation experiments would be required. To make sure the benefits carry on to more advanced architectures, we also apply ensembling to both the baseline and GEM, so as to evaluate how GEM performs against the improved ensembles. We perform hyperparameter tuning over the number of hidden units, layers, and learning rates, and then select the best performing ones for both the baseline and GEM555The experiment details are provided in Supplementary Materials. The code is available at: https://tinyurl.com/GEMMBRL. When evaluating the networks we test on online and offline data input settings.
The experiments address the following research questions:
-
Q1.
Does GEM achieve better long horizon prediction?
-
Q2.
Does GEM help better solve downstream tasks?
5.1 Long horizon prediction
Long horizon prediction is a commonly used task to test the quality of learned dynamical models (Sanchez-Gonzalez et al., 2018; Lutter et al., 2019; Greydanus et al., 2019; Miles et al., 2020; Janner et al., 2019).
To compare the performance of the models in this task, we first collect data in the environment using soft actor critic (Haarnoja et al., 2018). Then we train GEMs following Algorithm (1), while the baseline models are trained with the original states.
After the training, we keep both models fixed and apply action sequences with different time horizons, . These sequences are derived from the same trained soft actor critic policy used before. We calculate the average step-wise error between the true state trajectory for an action sequence and the corresponding state trajectory produced by GEM model or the baseline model. To get a single number to represent the overall performance, the step-wise error is averaged over different time horizons and normalized relative to largest error between the models.
Figure 3 displays the normalized relative error in all the environments averaged over five random model instantiations. It is evident that GEM outperforms its comparative baseline in the task of long horizon prediction in all the environments both as in a single model and in a model ensemble, averaging about half the error.
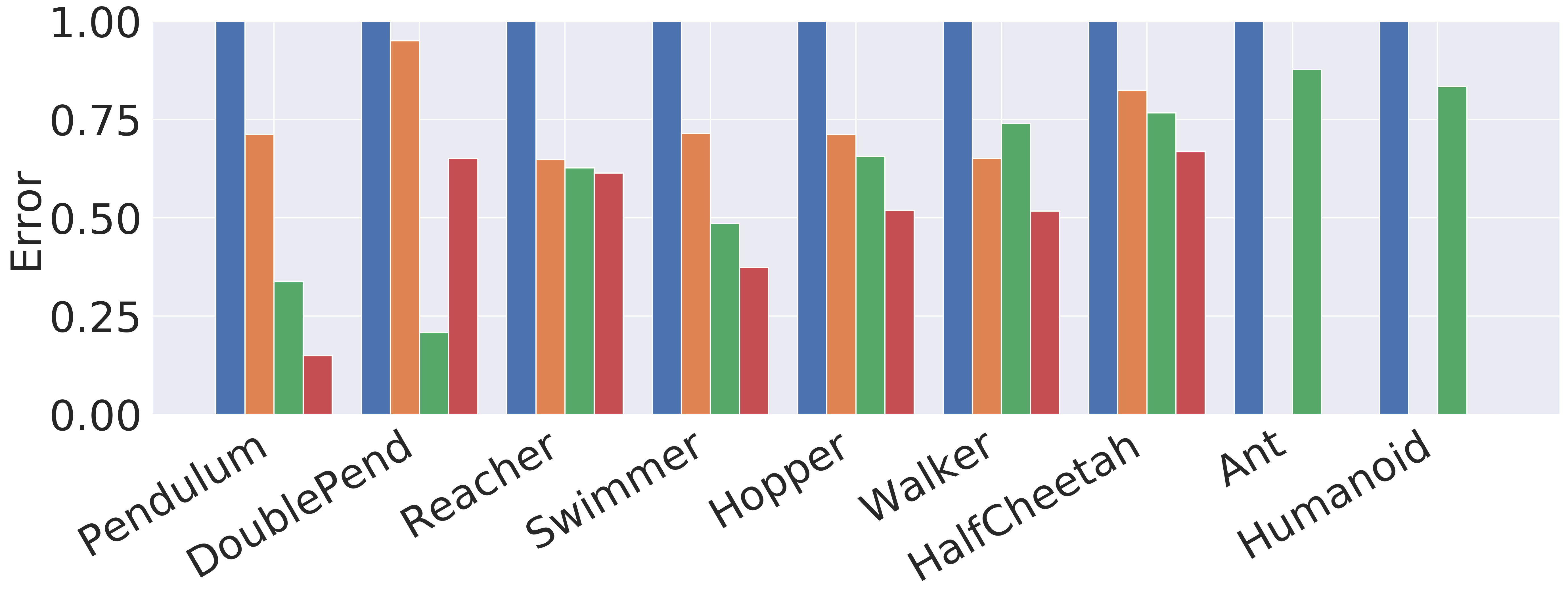
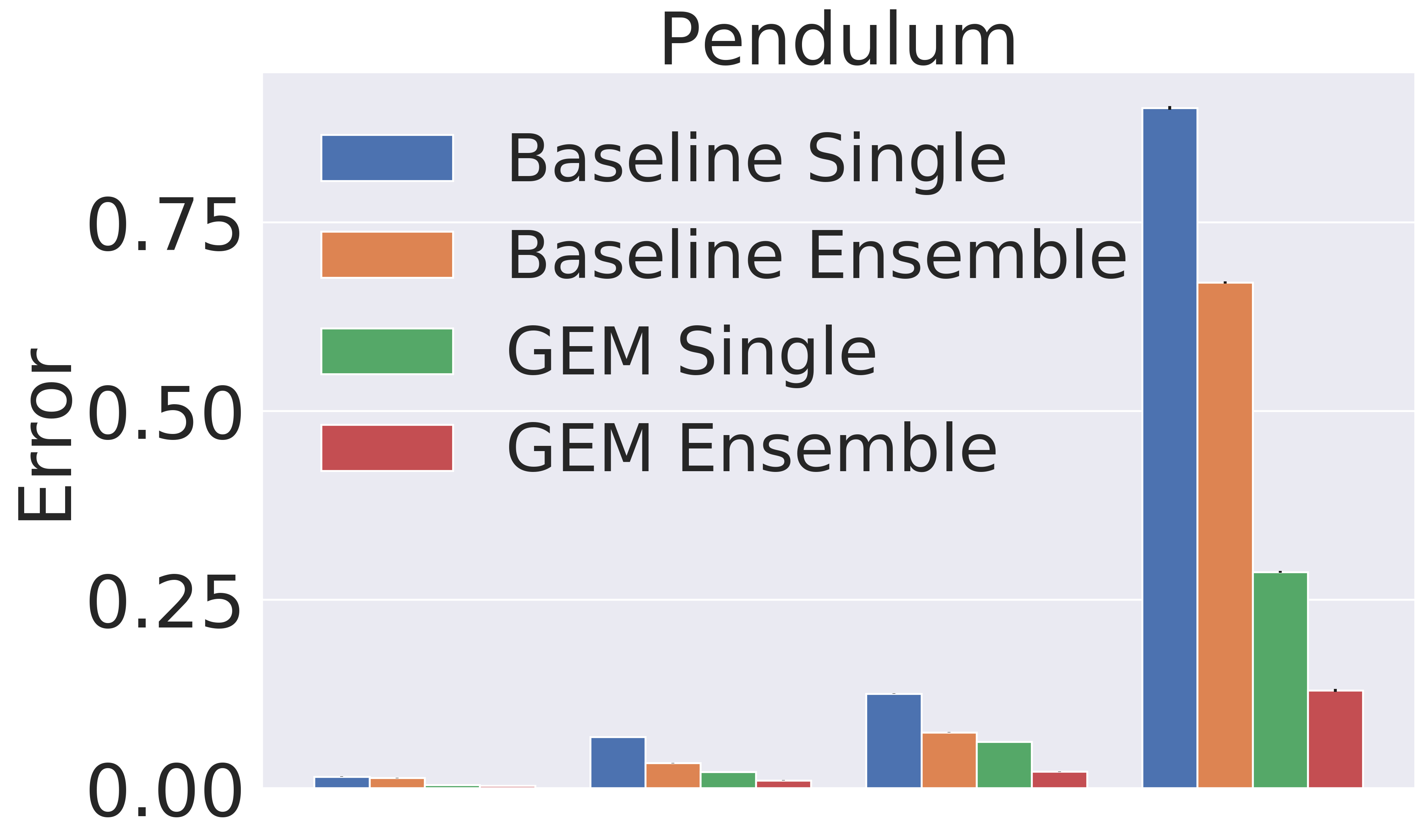
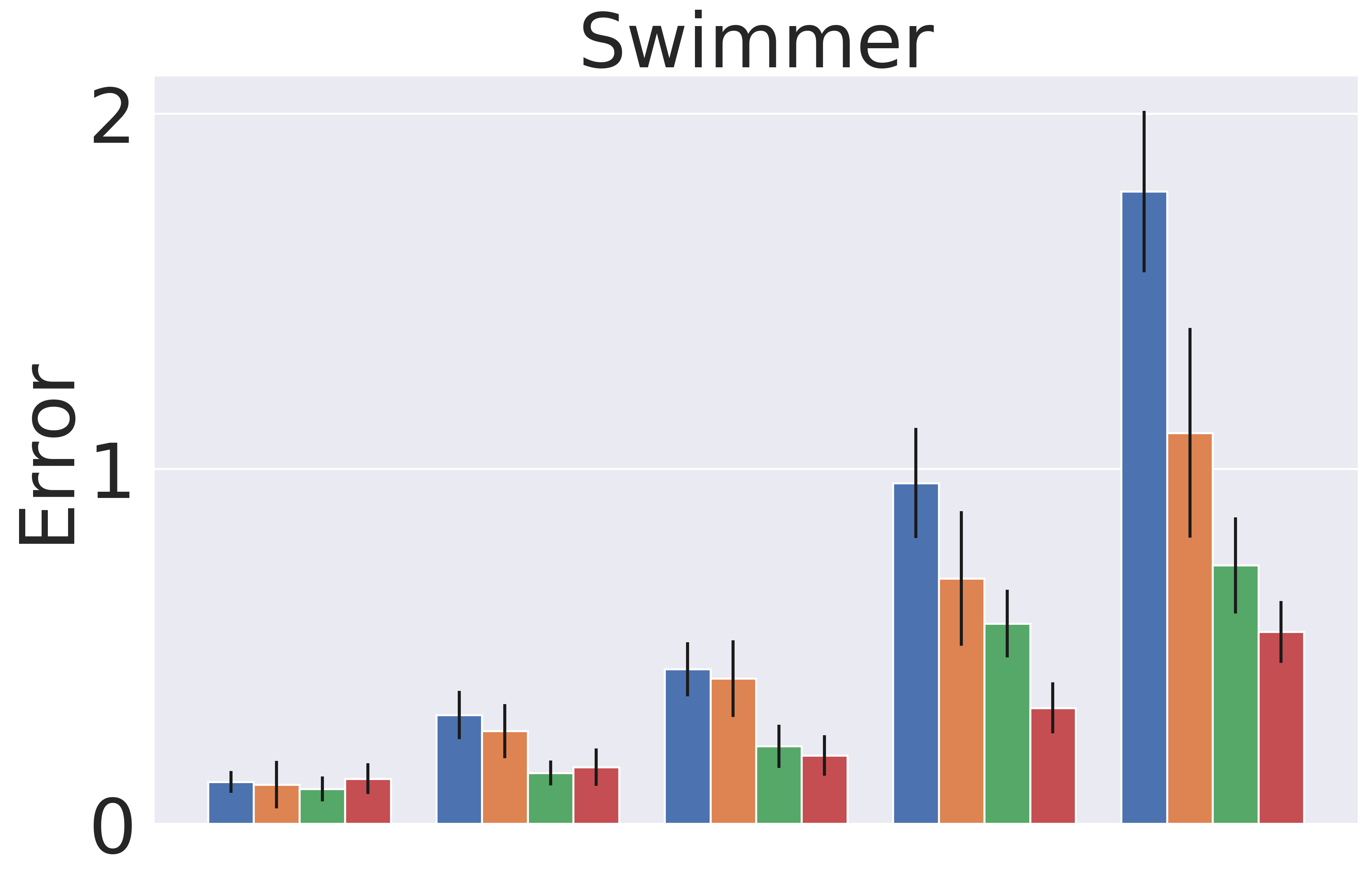
Figure 4 shows the detailed absolute error results for the different time horizons. We note that single step prediction performance is similar across all models. However, when scaling up the length of prediction, GEM significantly outperforms the baselines. This highlights the utility of GEM for accurate prediction of long-horizon behavior.
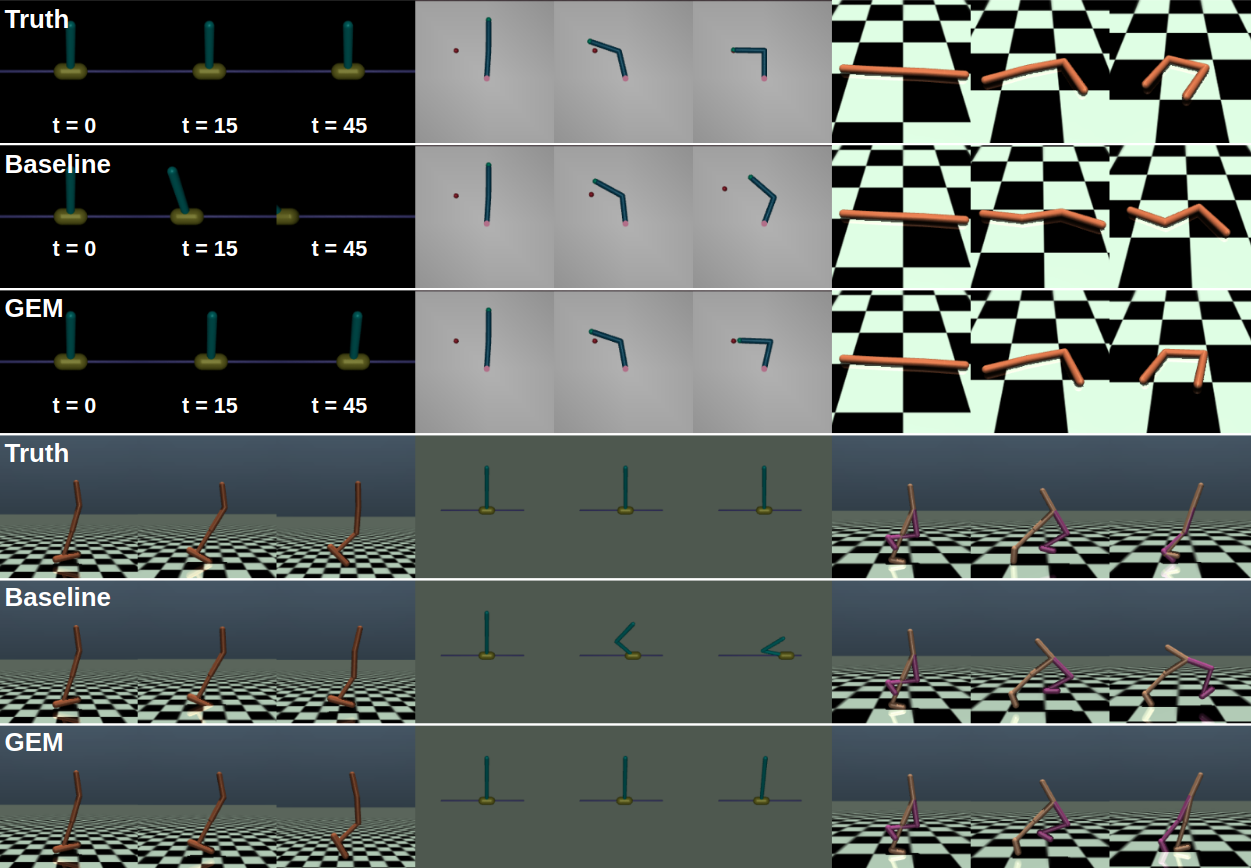
Qualitative comparison: Figure 7 presents samples of trajectories to demonstrate the evolution of model prediction. These images help us qualitatively understand the quantitative errors in Figure 3 and 4. Figure 7 shows that GEM is closer to the true model, while the baseline is much degraded, especially for the long time horizon, t=45. This observation agrees with the results presented in Figure 4.
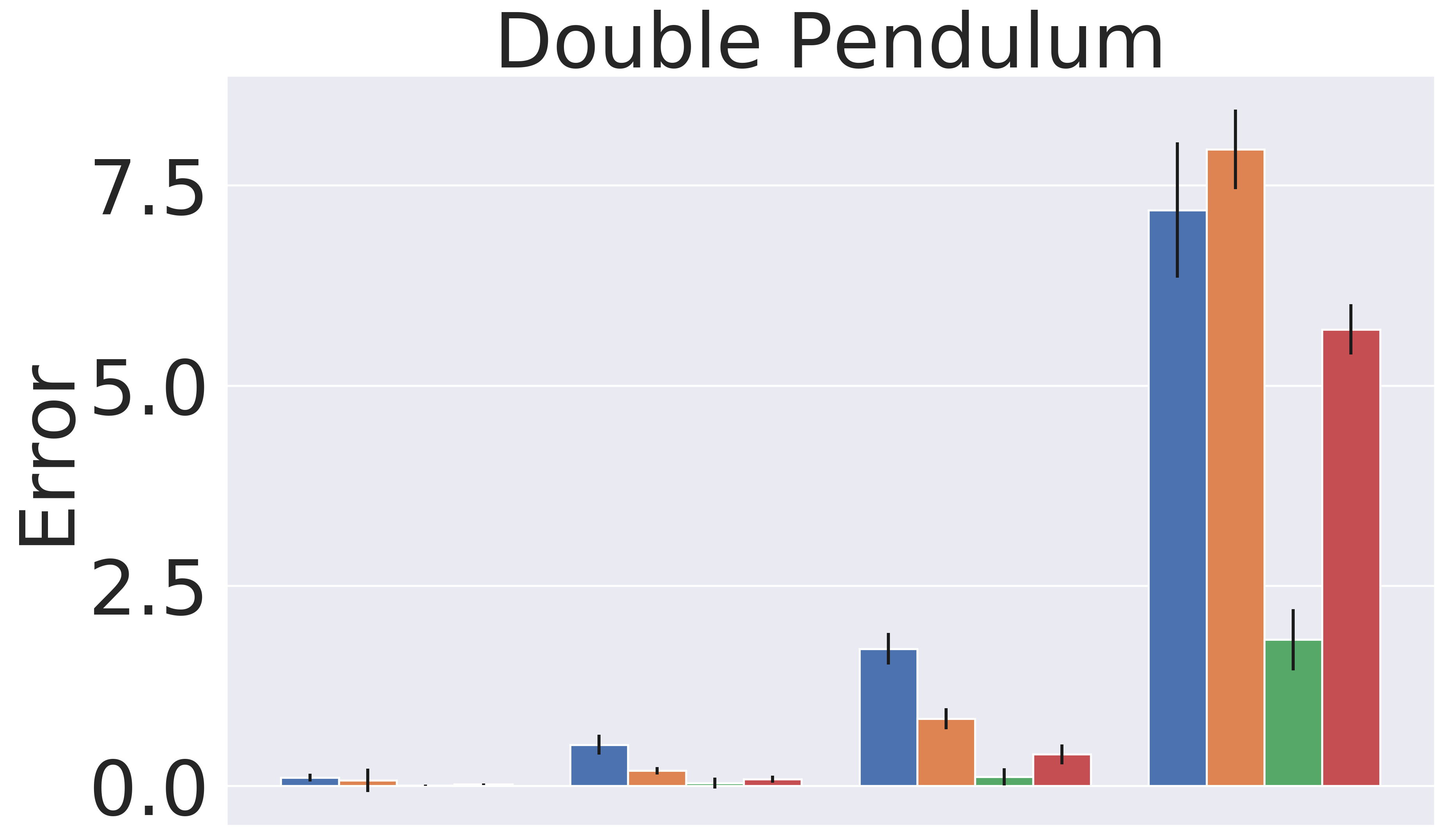
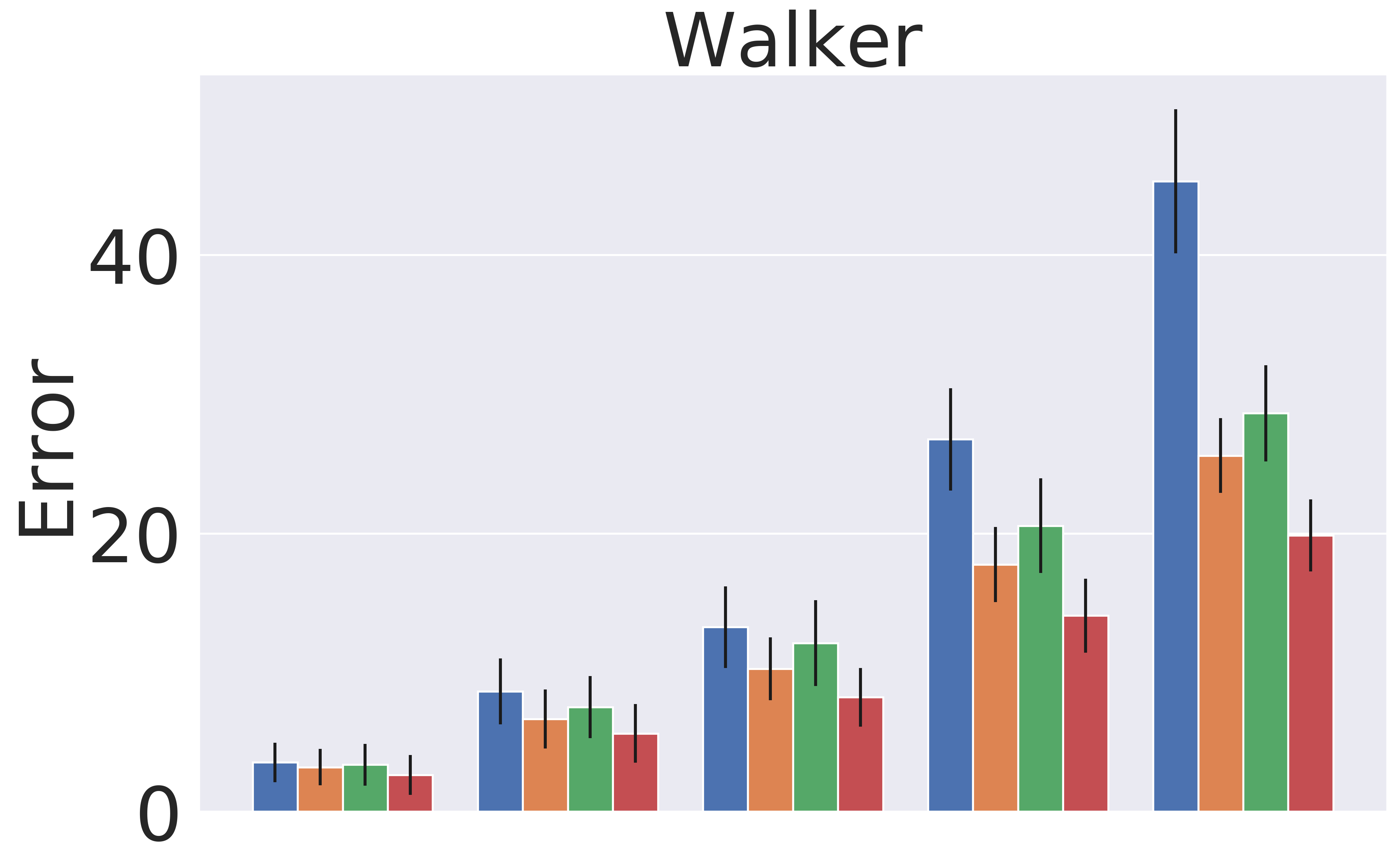
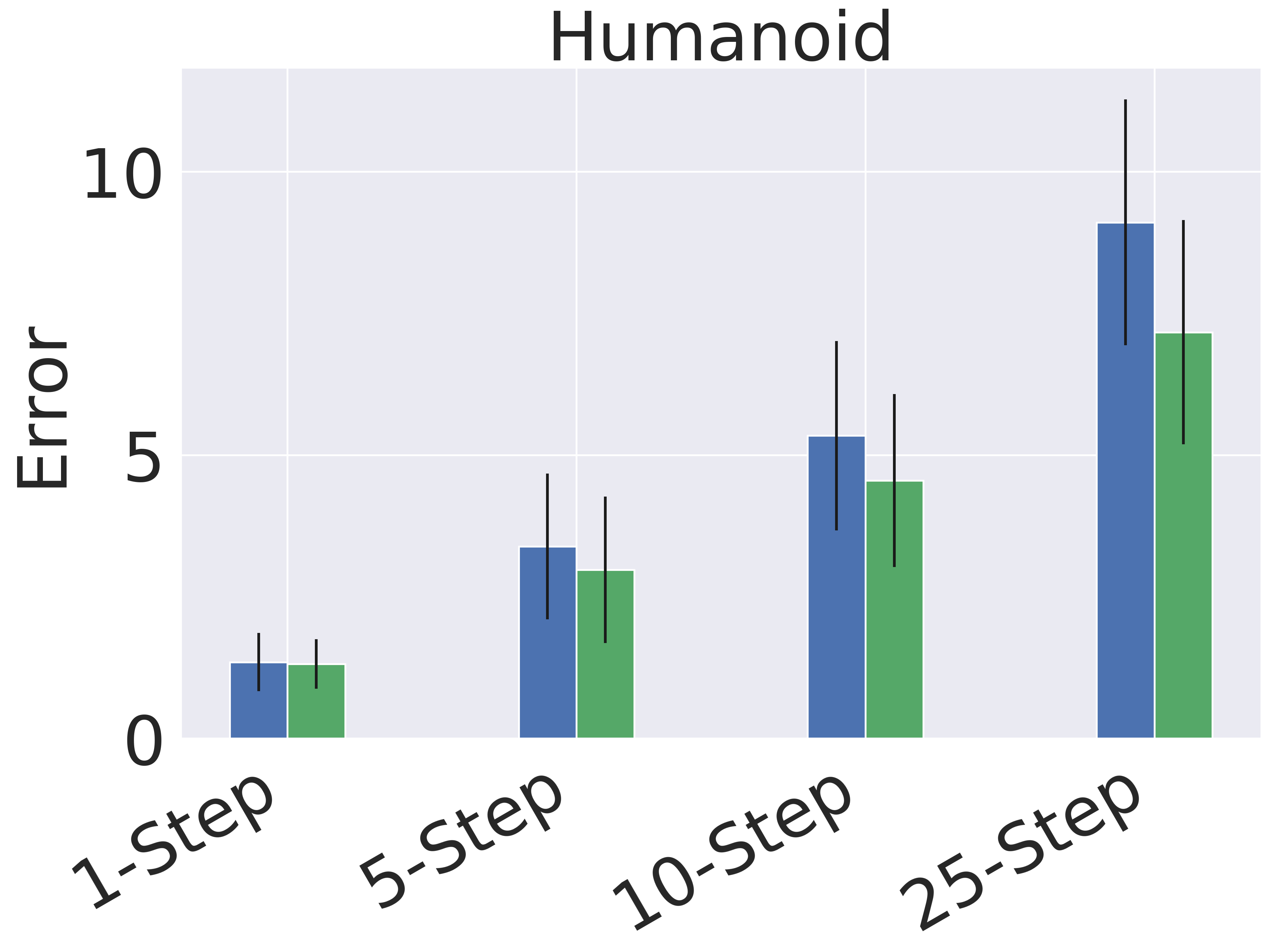
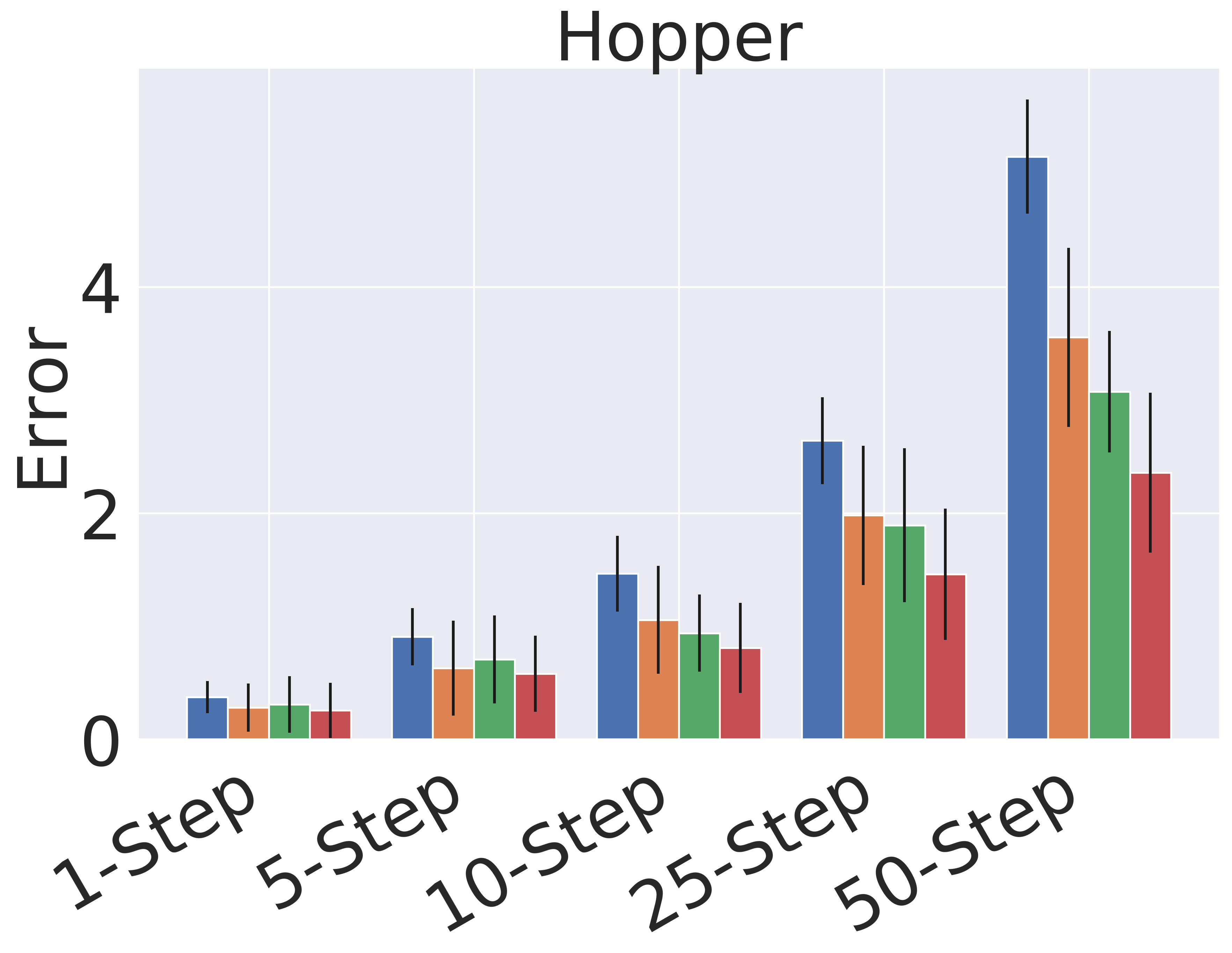
5.2 Planning
In this section we demonstrate planning experiments in order to confirm that GEM is advantageous not only for long term prediction, but also in downstream control tasks. Importantly, to decouple the effects of exploration, here, we evaluate the pre-trained models without continual updates from the environment. This property can be useful, for instance, in distributed model-based reinforcement learning, where the dynamical model is updated on a remote server, while an agent acts according to the previous model until a better model is available.
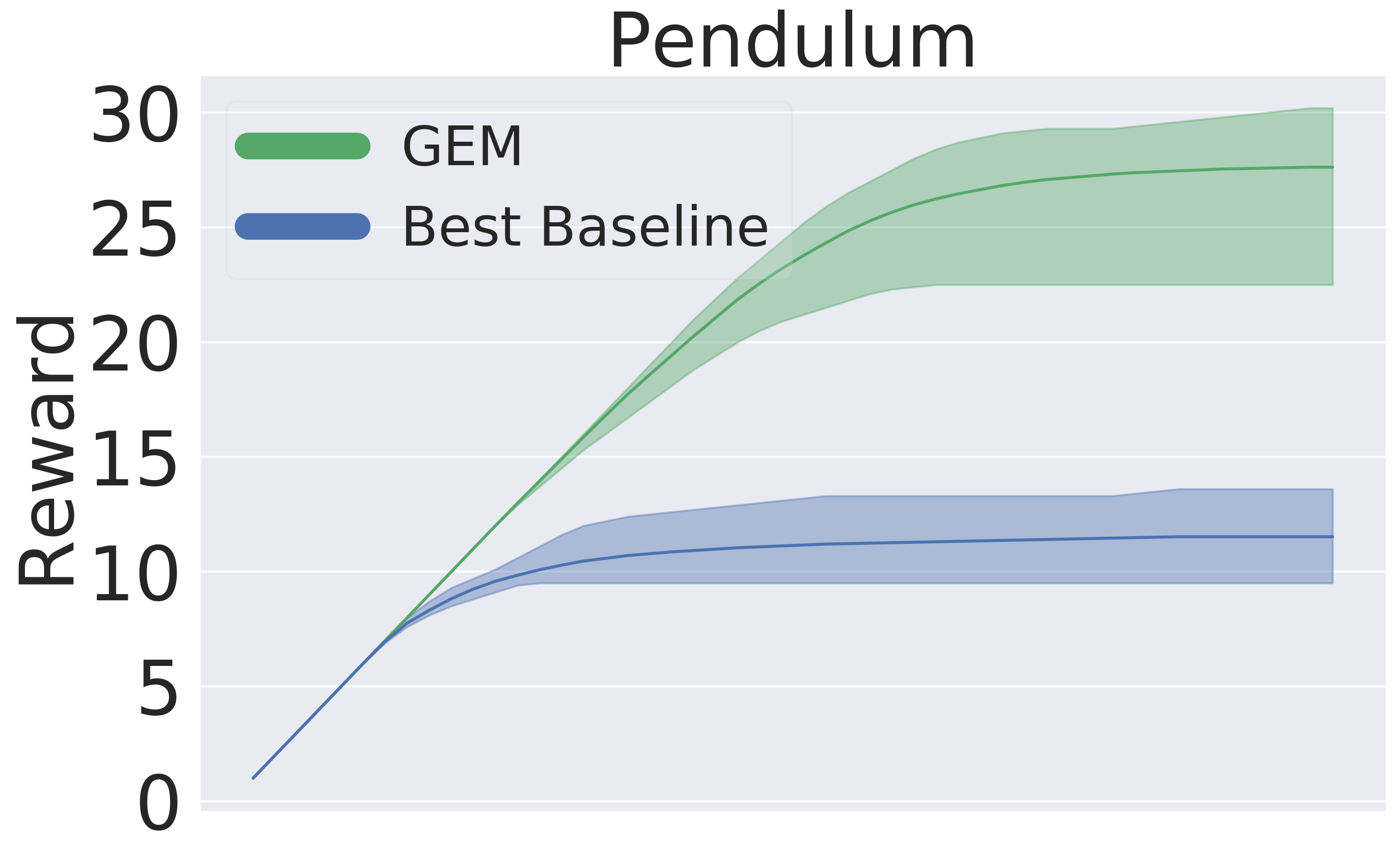
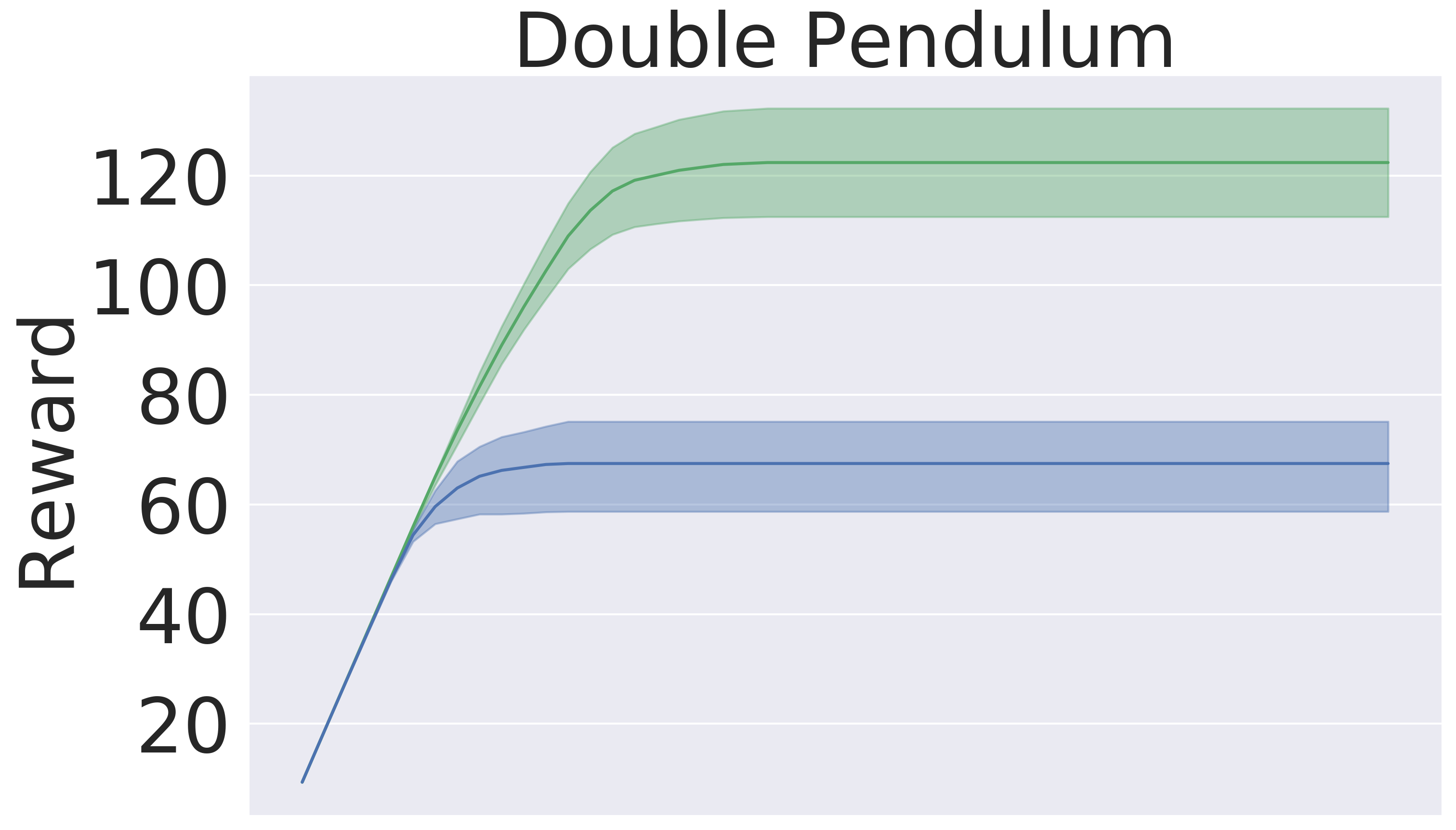
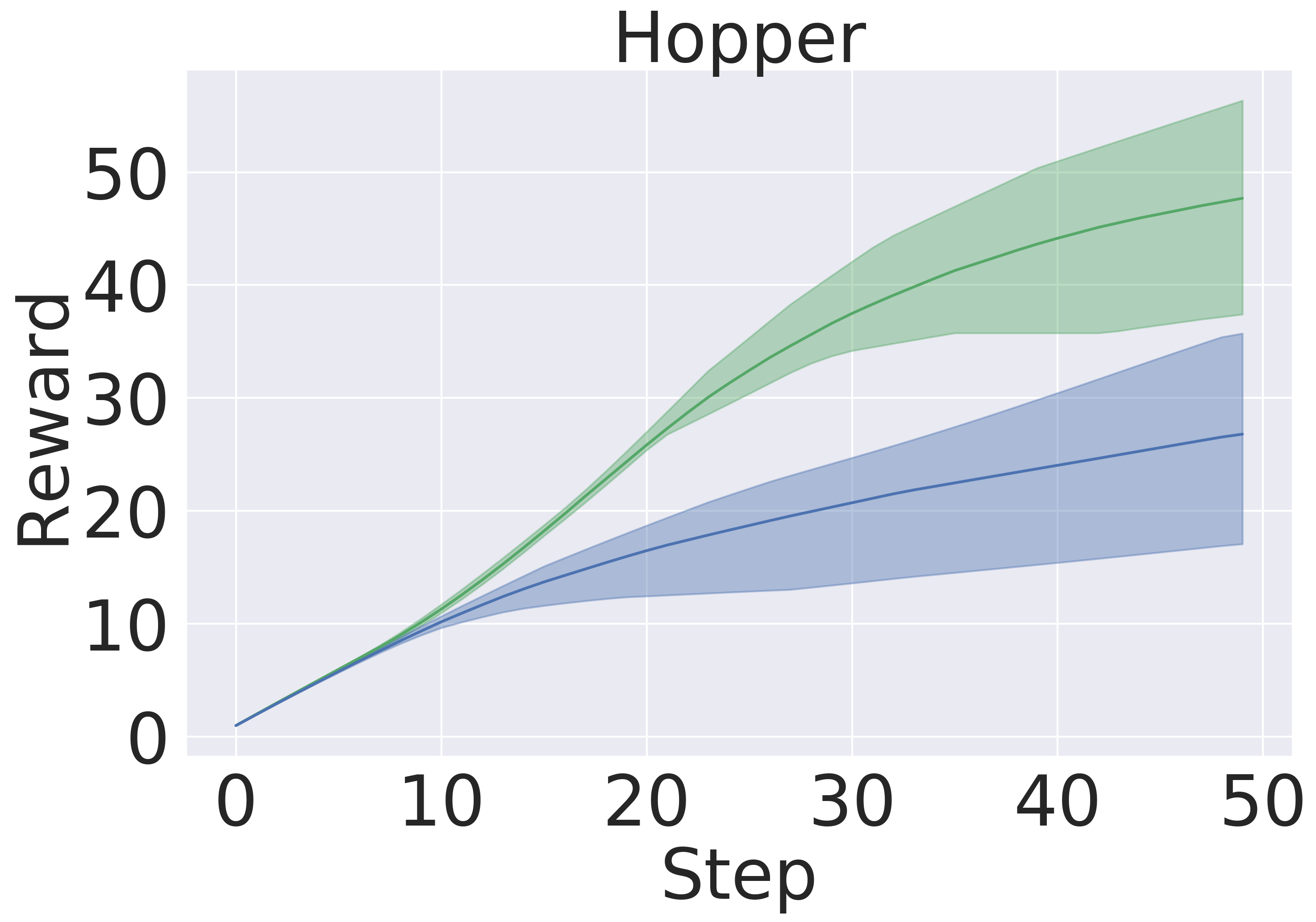
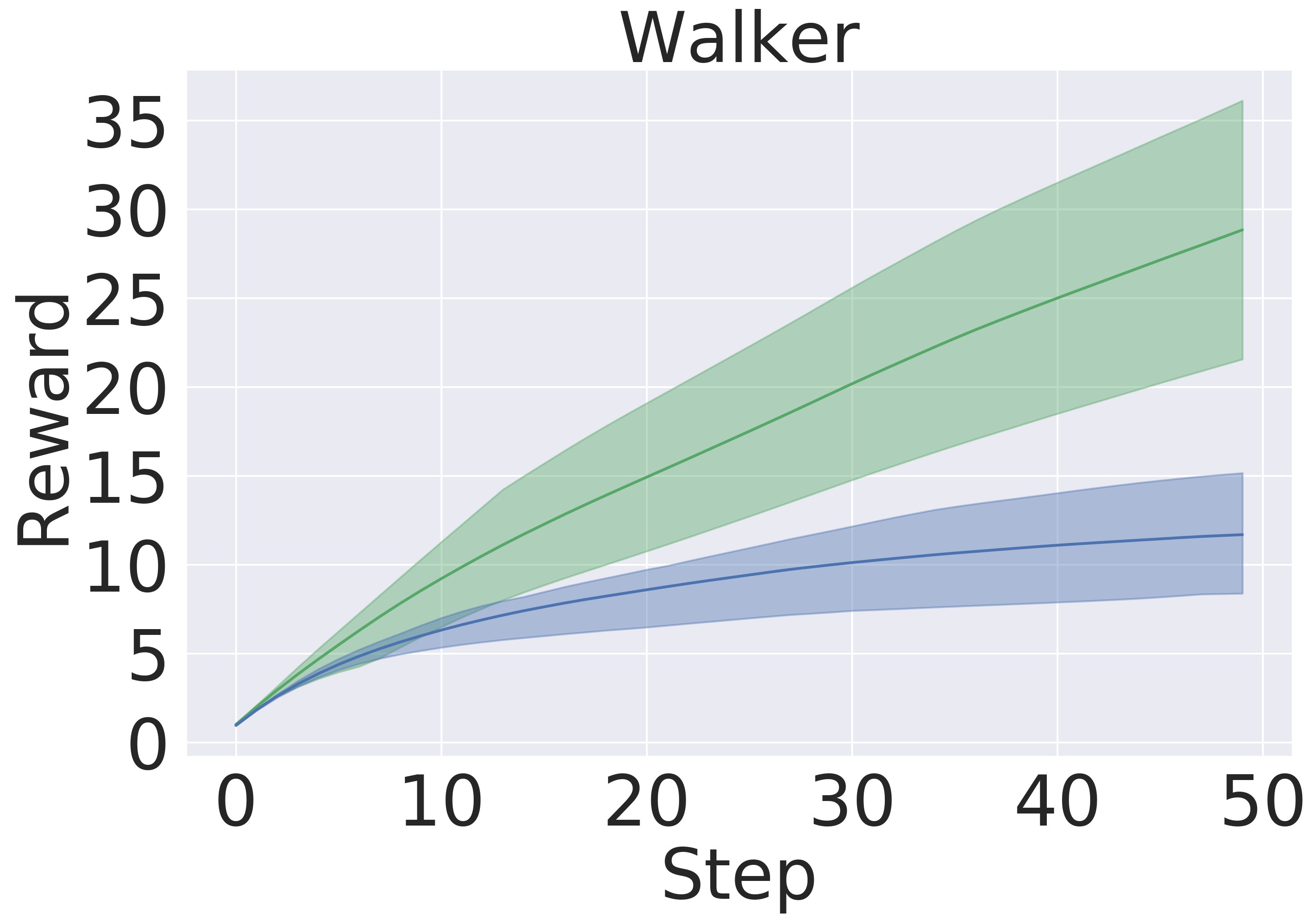
Here, we pre-train the models in the same fashion as in Section 5.1. Then, we use the models to plan in open loop over 50-step trajectories using an MPPI planner (Tassa et al., 2018). We apply the set of actions returned by the planner and track rewards over these 50 steps. The results are averaged over five seeds . Figure 5 presents the averaged reward over a trajectory with length 50 step within the variance due to five random initialization of initial models in pre-training. In this experiment, GEM achieves higher rewards across all tasks as well.
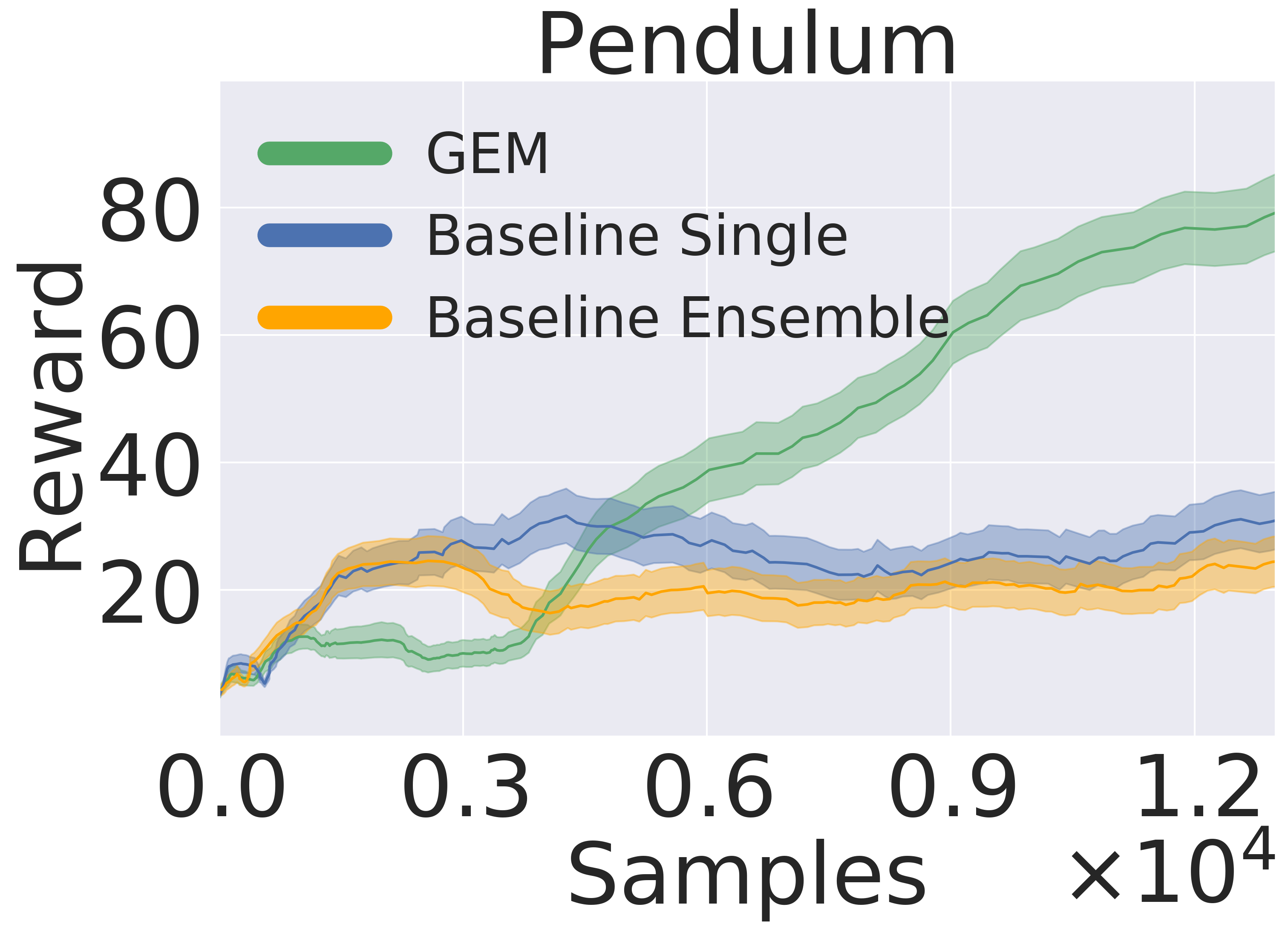
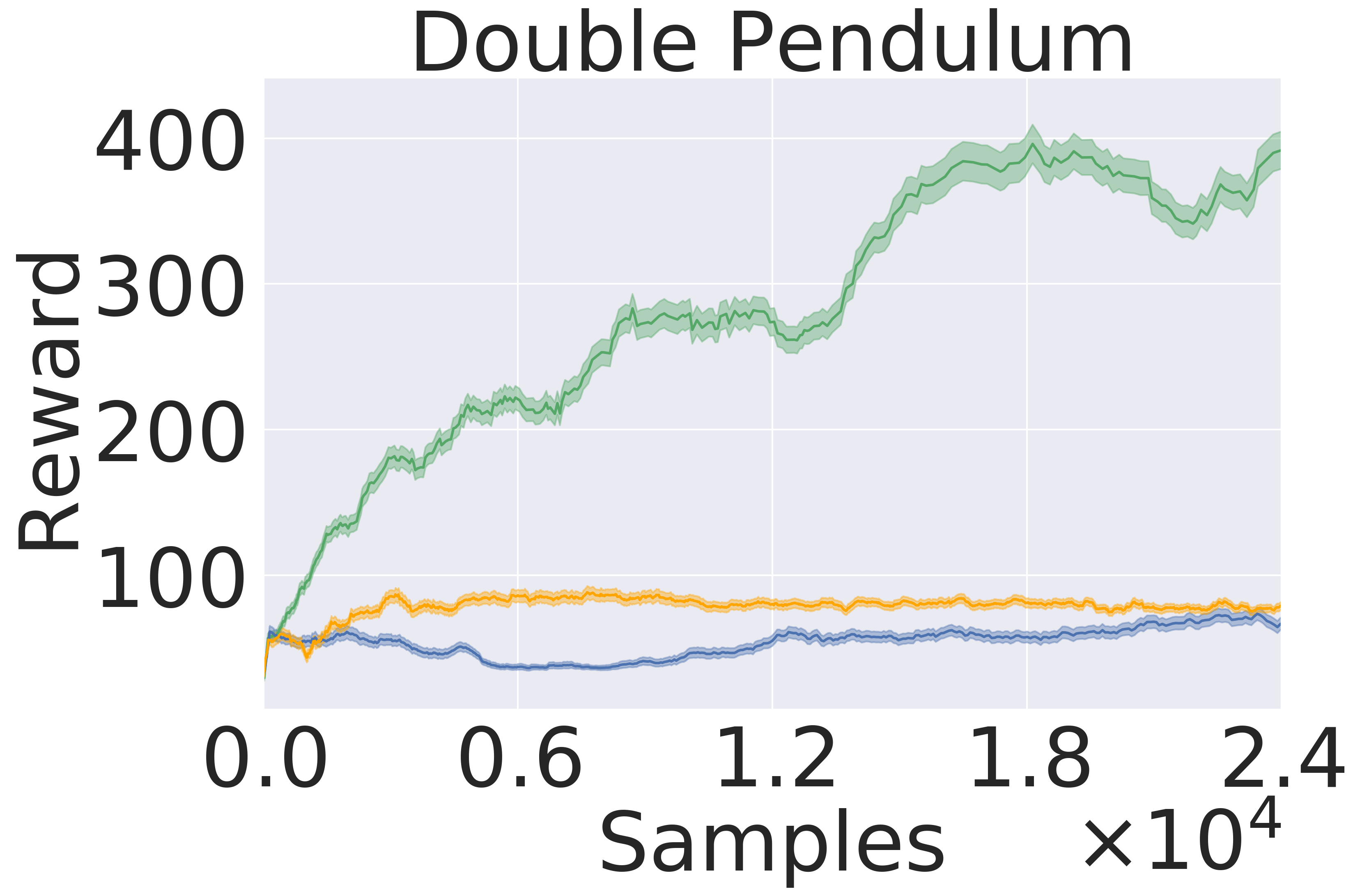
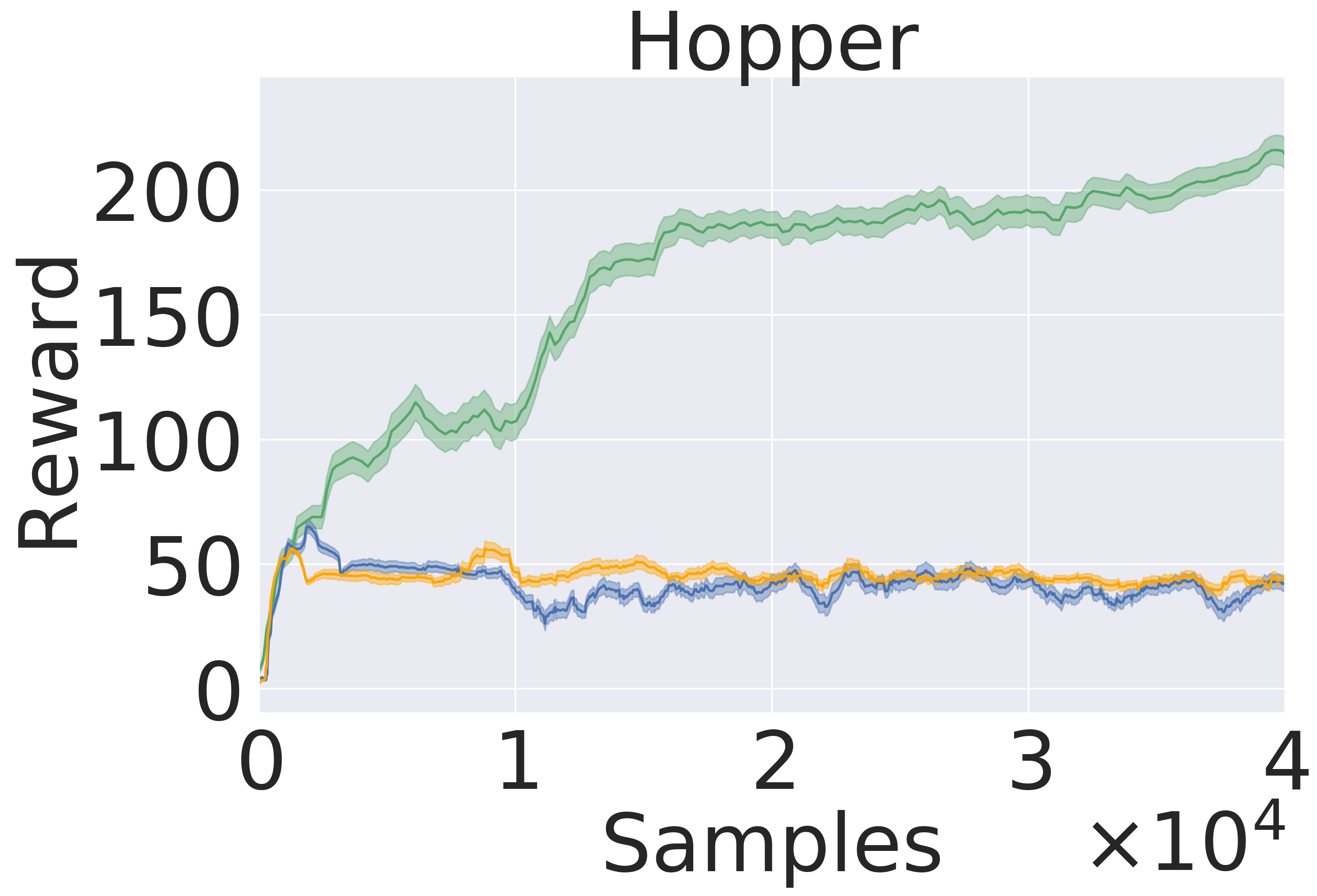
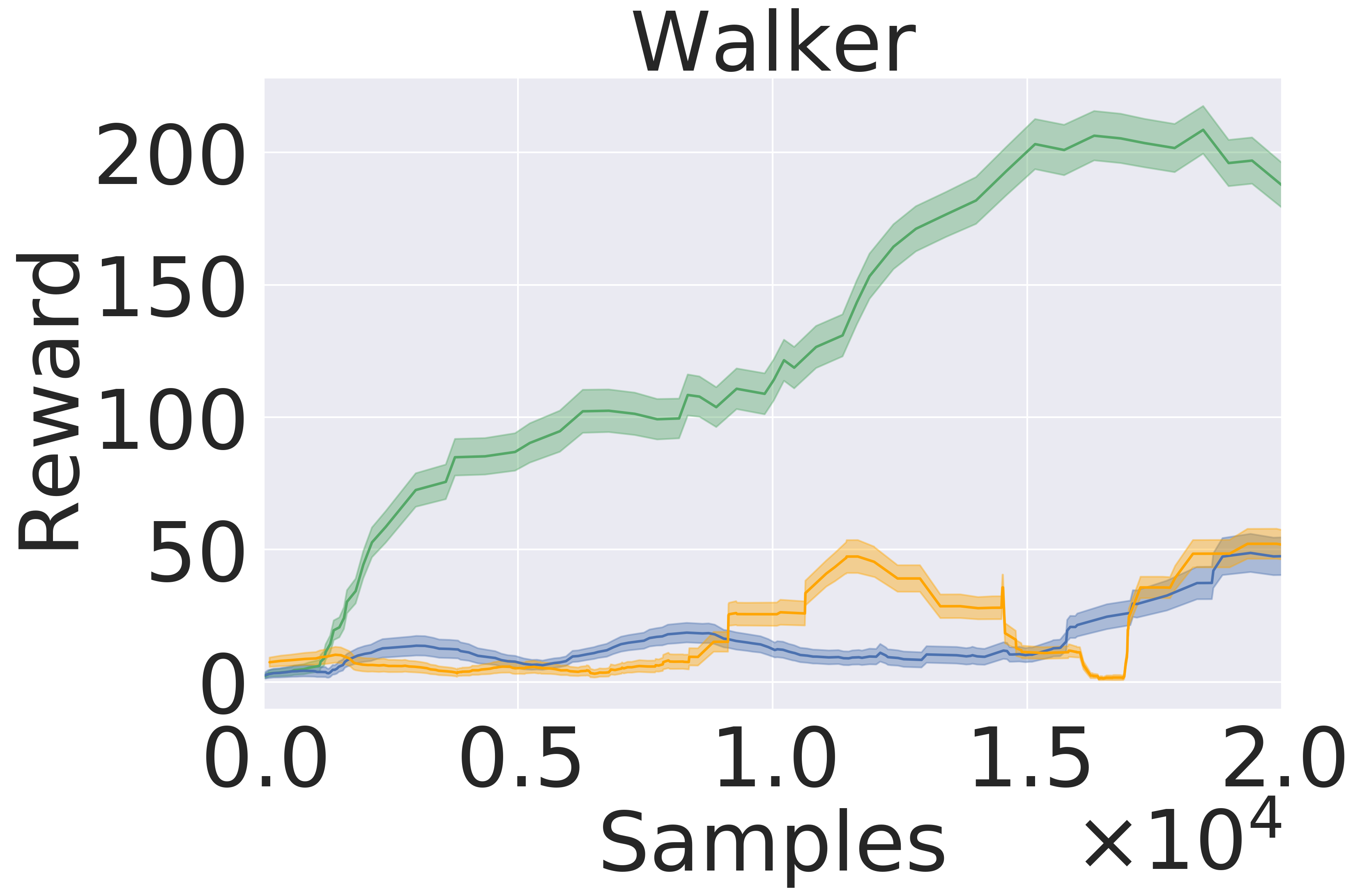
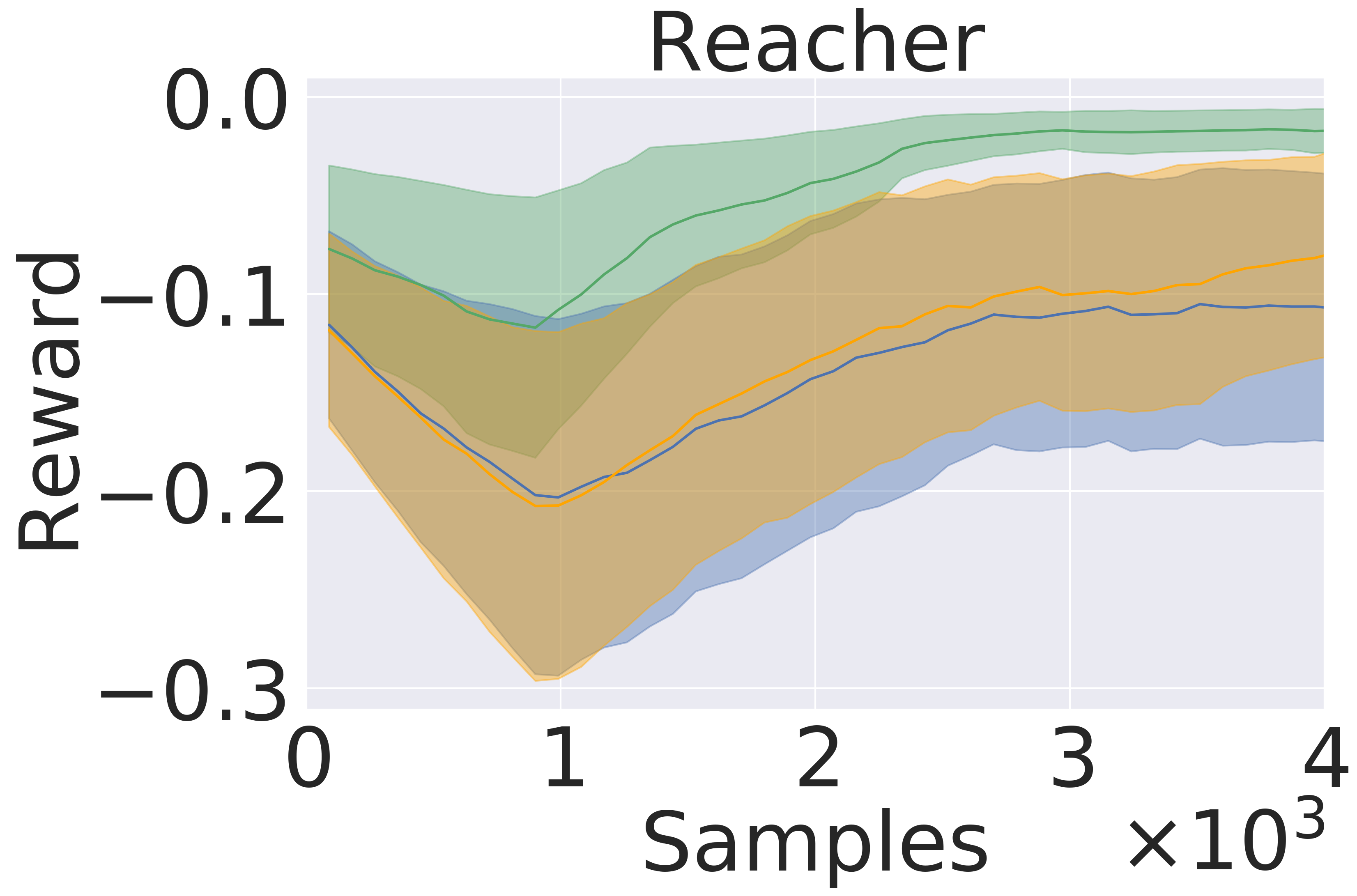
5.3 Model-Based Reinforcement Learning
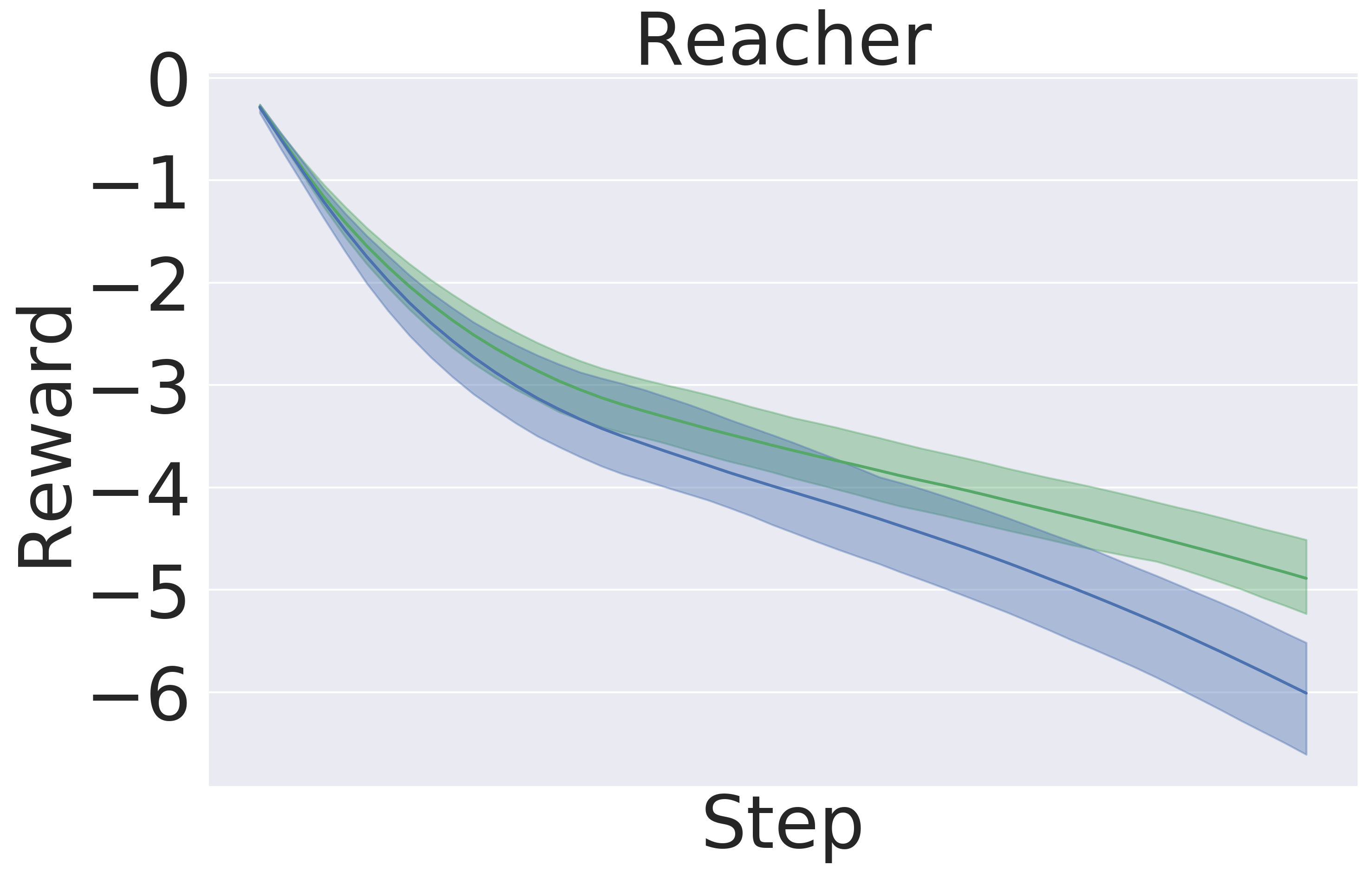
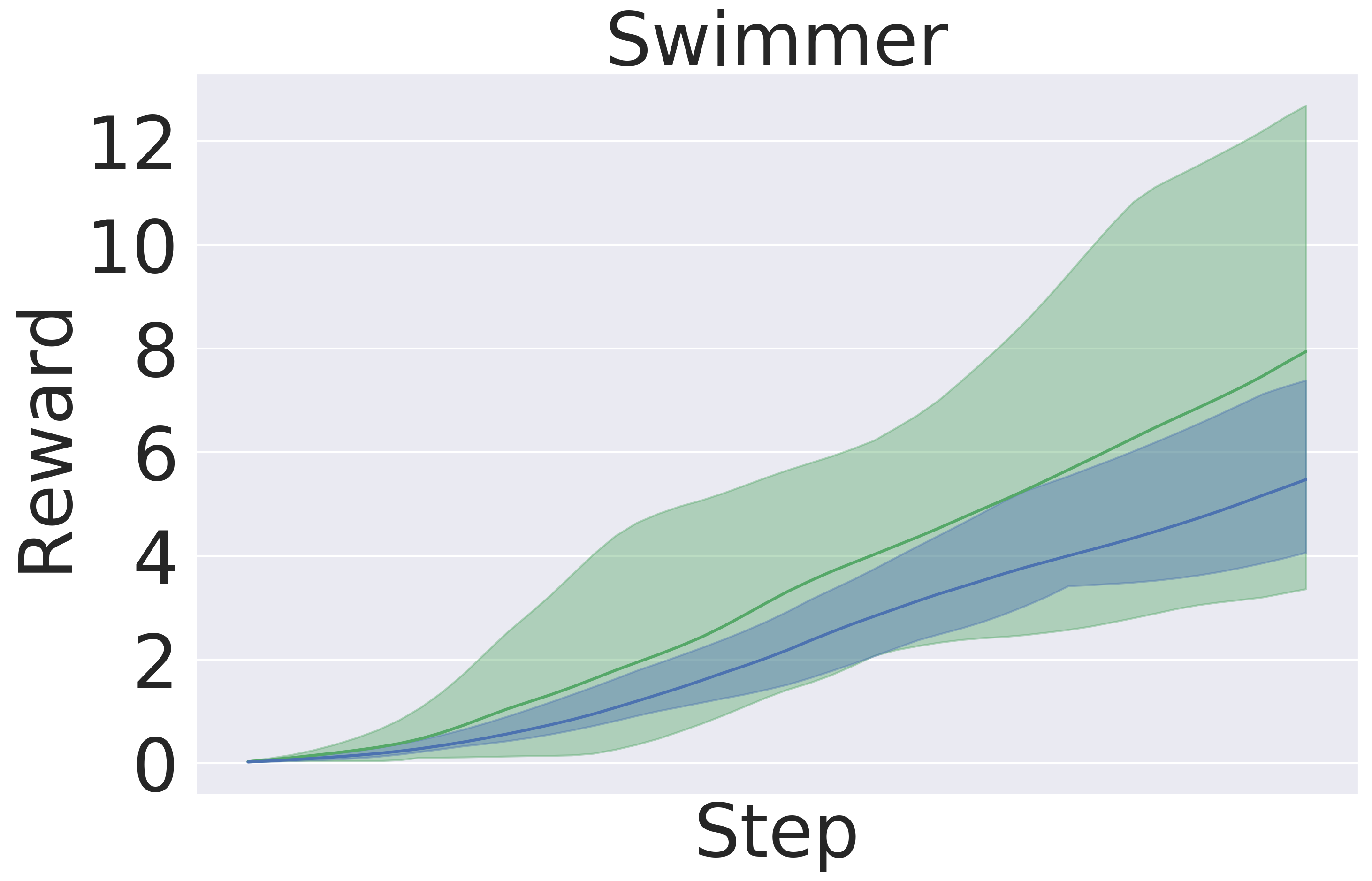
In this section we evaluate the models’ performance in the setting of MBRL, where both the model and the policy are updated iteratively (Nagabandi et al., 2018, 2020; Chua et al., 2018; Rajeswaran et al., 2020; Babaeizadeh et al., 2020). Importantly, observation update during execution of a trajectory happens only every fifth step in the trajectory. Figure (8) shows that GEM achieves higher rewards in all the environment with the same amount of data.
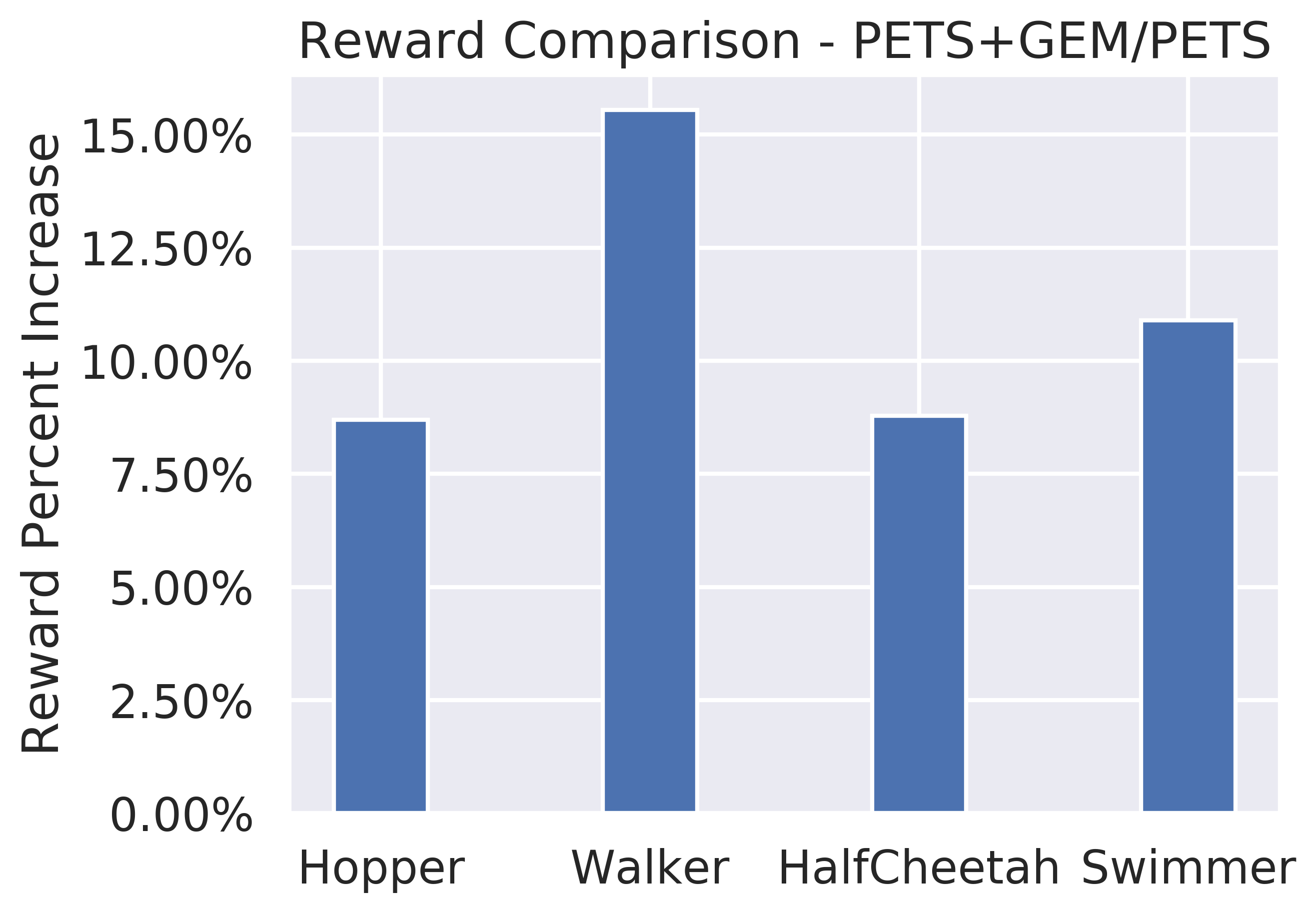
5.4 Enhancing PETS by GEM
The feed forward MLP (FFMLP) architecture used in the previous experiments is effective for testing the impact of GEM on RL and state prediction. Though it is not a SOTA architecture for model based RL. To show that GEM can improve upon SOTA we integrate GEM to PETS (Chua et al., 2018), which is often used as a sophisticated baseline for MBRL. This section experiments stand to confirm that the results from the FFMLP are transferable into more advanced architectures, which can be even stochastic. Figure 6 shows that GEM+PETS consistently achieves higher rewards on complex environments compared to PETS alone on a similar number of trained samples and networks’ parameters.
6 Discussion and Conclusions
In this work, we propose a framework, Group Enhanced Model, for dynamical control systems. This framework is built on the intuition that the geometric and physical properties of dynamics are naturally separable. The former can be revealed by simple visual observation, while the later requires detailed and rigours measurement. We use the language of Lie group theory to characterise the geometric properties of rigid body dynamics. The core in our formalism is a correspondence between Lie group and Lie algebra, which allows us to map points on the manifold, (e.g., rotations and translation of rigid body), to the Lie algebra vector space, and to train a dynamical model on this vector space. We experimentally assess GEM on various robotic systems by extensive comparison to the baseline models and provide answers to the research questions from Section 5.
Q1: GEM achieves better long horizon prediction than the generic approach both as single model and as ensemble, shown in Figure 3 and 4. In addition, Figure 7 qualitatively highlights that while the generic baseline can manage relatively short term prediction but fails in the long run, GEM consistently outputs close-to-truth predictions.
Q2: GEM outperforms the generic baseline in downstream tasks, namely planning and model-based RL. Figure 5 and Figure 8 clearly exhibits the advantages of using GEM in terms of final performance. Also, GEM is more sample-efficient —reaching the same level of baseline performance significantly faster.
The current limitation of GEM is an implicit modeling of velocities through the predicted Lie algebra coefficients, rather than their direct derivation and prediction from the properties of the differential manifold. Future research could continue to explore how to tune networks with Lie algebra.
Our advantage does not come for free, but rather we assume that we can observe what a dynamical system does - a systems core geometry and its motions -, which, however, is often apparent, as mentioned in the abstract. We speculate that this additional knowledge will give us the advantage in comparison to learning dynamical models without knowledge of the systems geometry. A rigorous research of this hypothesis is a promising new research direction. We believe GEM provides a step towards structured-RL and opens up future research on the connection between the manifold’s structure and perception action cycle (Tishby & Polani, 2011; Tiomkin & Tishby, 2017).
References
- Agrachev & Sachkov (2013) Agrachev, A. A. and Sachkov, Y. Control theory from the geometric viewpoint, volume 87. Springer Science & Business Media, 2013.
- Babaeizadeh et al. (2020) Babaeizadeh, M., Saffar, M., Hafner, D., Kannan, H., Finn, C., Levine, S., and Erhan, D. Models, pixels, and rewards: Evaluating design trade-offs in visual model-based reinforcement learning. ArXiv, abs/2012.04603, 2020.
- Bahl et al. (2020) Bahl, S., Mukadam, M., Gupta, A., and Pathak, D. Neural dynamic policies for end-to-end sensorimotor learning. arXiv preprint arXiv:2012.02788, 2020.
- Bekkers (2019) Bekkers, E. J. B-spline cnns on lie groups. arXiv preprint arXiv:1909.12057, 2019.
- Bourmaud et al. (2015) Bourmaud, G., Mégret, R., Arnaudon, M., and Giremus, A. Continuous-discrete extended kalman filter on matrix lie groups using concentrated gaussian distributions. Journal of Mathematical Imaging and Vision, 51(1):209–228, 2015.
- Brockman et al. (2016) Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., and Zaremba, W. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Brzeski et al. (2017) Brzeski, P., Wojewoda, J., Kapitaniak, T., Kurths, J., and Perlikowski, P. Sample-based approach can outperform the classical dynamical analysis-experimental confirmation of the basin stability method. Scientific reports, 7(1):1–10, 2017.
- Byravan & Fox (2017) Byravan, A. and Fox, D. Se3-nets: Learning rigid body motion using deep neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 173–180. IEEE, 2017.
- Castelletti et al. (2012) Castelletti, A., Galelli, S., Restelli, M., and Soncini-Sessa, R. Data-driven dynamic emulation modelling for the optimal management of environmental systems. Environmental Modelling & Software, 34:30–43, 2012.
- Chen et al. (2018) Chen, R. T., Rubanova, Y., Bettencourt, J., and Duvenaud, D. Neural ordinary differential equations. arXiv preprint arXiv:1806.07366, 2018.
- Chua et al. (2018) Chua, K., Calandra, R., McAllister, R., and Levine, S. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. arXiv preprint arXiv:1805.12114, 2018.
- Cohen & Welling (2016) Cohen, T. and Welling, M. Group equivariant convolutional networks. In International conference on machine learning, pp. 2990–2999. PMLR, 2016.
- (13) Deisenroth, M. P. Learning to control a low-cost manipulator using data-efficient reinforcement learning. In Robotics: Science and Systems VII, volume 7, pp. 57–64.
- Featherstone (2014) Featherstone, R. Rigid body dynamics algorithms. Springer, 2014.
- Fragkiadaki et al. (2015) Fragkiadaki, K., Levine, S., Felsen, P., and Malik, J. Recurrent network models for human dynamics. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4346–4354, 2015.
- Gothandaraman et al. (2020) Gothandaraman, R., Jha, R., and Muthuswamy, S. Reflectional and rotational symmetry detection of cad models based on point cloud processing. In 2020 IEEE 4th Conference on Information & Communication Technology (CICT), pp. 1–5. IEEE, 2020.
- Greydanus et al. (2019) Greydanus, S., Dzamba, M., and Yosinski, J. Hamiltonian neural networks. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32, pp. 15379–15389. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/26cd8ecadce0d4efd6cc8a8725cbd1f8-Paper.pdf.
- Haarnoja et al. (2018) Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pp. 1861–1870. PMLR, 2018.
- Hafner et al. (2020) Hafner, D., Lillicrap, T., Norouzi, M., and Ba, J. Mastering atari with discrete world models. arXiv preprint arXiv:2010.02193, 2020.
- Hall & Hall (2003) Hall, B. and Hall, B. Lie Groups, Lie Algebras, and Representations: An Elementary Introduction. Graduate Texts in Mathematics. Springer, 2003. ISBN 9780387401225. URL https://books.google.com/books?id=m1VQi8HmEwcC.
- Howe (1983) Howe, R. Very basic lie theory. The American Mathematical Monthly, 90(9):600–623, 1983.
- Huang et al. (2017) Huang, Z., Wan, C., Probst, T., and Van Gool, L. Deep learning on lie groups for skeleton-based action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6099–6108, 2017.
- Janner et al. (2019) Janner, M., Fu, J., Zhang, M., and Levine, S. When to trust your model: Model-based policy optimization. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32, pp. 12519–12530. Curran Associates, Inc., 2019.
- Kocijan et al. (2004) Kocijan, J., Murray-Smith, R., Rasmussen, C. E., and Girard, A. Gaussian process model based predictive control. In Proceedings of the 2004 American control conference, volume 3, pp. 2214–2219. IEEE, 2004.
- Luo & Kareem (2020) Luo, X. and Kareem, A. Bayesian deep learning with hierarchical prior: Predictions from limited and noisy data. Structural Safety, 84:101918, 2020.
- Lutter et al. (2019) Lutter, M., Ritter, C., and Peters, J. Deep lagrangian networks: Using physics as model prior for deep learning. International Conference on Learning Representations (ICLR), 2019.
- Miles et al. (2020) Miles, C., Sam, G., Stephan, H., Peter, B., David, S., and Shirley, H. Lagrangian neural networks. In International Conference on Learning Representations, Workshop on Deep Differential Equations. ICLR, 2020.
- Moerland et al. (2020) Moerland, T. M., Broekens, J., and Jonker, C. M. Model-based reinforcement learning: A survey. arXiv preprint arXiv:2006.16712, 2020.
- Nagabandi et al. (2018) Nagabandi, A., Kahn, G., Fearing, R. S., and Levine, S. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 7559–7566. IEEE, 2018.
- Nagabandi et al. (2020) Nagabandi, A., Konolige, K., Levine, S., and Kumar, V. Deep dynamics models for learning dexterous manipulation. In Conference on Robot Learning, pp. 1101–1112. PMLR, 2020.
- Nelles (2020) Nelles, O. Nonlinear System Identification: From Classical Approaches to Neural Networks, Fuzzy Models, and Gaussian Processes. Springer Nature, 2020.
- Nguyen-Tuong & Peters (2010) Nguyen-Tuong, D. and Peters, J. Using model knowledge for learning inverse dynamics. In 2010 IEEE international conference on robotics and automation, pp. 2677–2682. IEEE, 2010.
- Nguyen-Tuong & Peters (2011) Nguyen-Tuong, D. and Peters, J. Model learning for robot control: a survey. Cognitive processing, 12(4):319–340, 2011.
- OpenAI et al. (2018) OpenAI, Andrychowicz, M., Baker, B., Chociej, M., Józefowicz, R., McGrew, B., Pachocki, J., Petron, A., Plappert, M., Powell, G., Ray, A., Schneider, J., Sidor, S., Tobin, J., Welinder, P., Weng, L., and Zaremba, W. Learning dexterous in-hand manipulation. CoRR, abs/1808.00177, 2018.
- Quessard et al. (2020) Quessard, R., Barrett, T. D., and Clements, W. R. Learning group structure and disentangled representations of dynamical environments. Advances in Neural Information Processing System, 2020.
- Rajeswaran et al. (2020) Rajeswaran, A., Mordatch, I., and Kumar, V. A game theoretic framework for model based reinforcement learning. In International Conference on Machine Learning, pp. 7953–7963. PMLR, 2020.
- Sanchez-Gonzalez et al. (2018) Sanchez-Gonzalez, A., Heess, N., Springenberg, J. T., Merel, J., Riedmiller, M., Hadsell, R., and Battaglia, P. Graph networks as learnable physics engines for inference and control. In International Conference on Machine Learning, pp. 4470–4479. PMLR, 2018.
- Schaal et al. (2002) Schaal, S., Atkeson, C. G., and Vijayakumar, S. Scalable techniques from nonparametric statistics for real time robot learning. Applied Intelligence, 17(1):49–60, 2002.
- Schrittwieser et al. (2020) Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020.
- Selig (2004) Selig, J. M. Lie groups and lie algebras in robotics. In Computational Noncommutative Algebra and Applications, pp. 101–125. Springer, 2004.
- Shi et al. (2020) Shi, Y., Huang, J., Zhang, H., Xu, X., Rusinkiewicz, S., and Xu, K. Symmetrynet: Learning to predict reflectional and rotational symmetries of 3d shapes from single-view rgb-d images. ACM Trans. Graph., 39(6), 2020. doi: 10.1145/3414685.3417775.
- Strogatz (2018) Strogatz, S. H. Nonlinear dynamics and chaos with student solutions manual: With applications to physics, biology, chemistry, and engineering. CRC press, 2018.
- Tan et al. (2018) Tan, J., Zhang, T., Coumans, E., Iscen, A., Bai, Y., Hafner, D., Bohez, S., and Vanhoucke, V. Sim-to-real: Learning agile locomotion for quadruped robots. arXiv preprint arXiv:1804.10332, 2018.
- Tassa et al. (2018) Tassa, Y., Doron, Y., Muldal, A., Erez, T., Li, Y., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
- Tiomkin & Tishby (2017) Tiomkin, S. and Tishby, N. A unified bellman equation for causal information and value in markov decision processes. arXiv preprint arXiv:1703.01585, 2017.
- Tishby & Polani (2011) Tishby, N. and Polani, D. Information theory of decisions and actions. In Perception-action cycle, pp. 601–636. Springer, 2011.
- Todorov & Li (2005) Todorov, E. and Li, W. A generalized iterative lqg method for locally-optimal feedback control of constrained nonlinear stochastic systems. In Proceedings of the 2005, American Control Conference, 2005., pp. 300–306. IEEE, 2005.
- Todorov et al. (2012) Todorov, E., Erez, T., and Tassa, Y. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 5026–5033. IEEE, 2012.
- Tsai (1999) Tsai, L.-W. Robot analysis: the mechanics of serial and parallel manipulators. John Wiley & Sons, 1999.
- Vemulapalli & Chellapa (2016) Vemulapalli, R. and Chellapa, R. Rolling rotations for recognizing human actions from 3d skeletal data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4471–4479, 2016.
- Watter et al. (2015) Watter, M., Springenberg, J. T., Boedecker, J., and Riedmiller, M. Embed to control: A locally linear latent dynamics model for control from raw images. arXiv preprint arXiv:1506.07365, 2015.
Supplementary Materials
In the supplementary materials, we provide a) additional details of the Lie groups used in our work, b) a working example of performing calculations with these groups, c) hyperparameters used in our experiments. The supplementary materials are not mandatory for understanding the main ideas in the paper.666The line numbers, the equation references, and the citations continue/refer those in the main paper.
7 Special Orthogonal Group
A relevant example for applications in our work is the group of rotations in 3D space—Special Orthogonal group, . This section provides a detailed overview of . Derived from representation theory (Hall & Hall, 2003), the elements of are orthogonal matrices with unit determinant. The corresponding Lie algebra, , is a 3-dimensional vector space. A commonly used basis for is:
| (16) |
From (11) in the main text, any element in can be represented by some coefficient vector , i.e. . The matrix representation of allows us to conveniently use the standard matrix multiplication for the composition operator and the standard matrix exponential for in equation (13) from the main text.
Alternatively, the elements of can be constructed from the axis-angle representation, given by a rotation axis vector, , and a corresponding angle, :
| (17) |
where , , and are the identity matrix with dimension 3 by 3, the cross product, and and the outer product, respectively. Then, the angular components of a dynamical system state can be represented by rotation matrices, provided one knows the primitive geometric motions such as axes of rotations. The later can be revealed either from the hardware specification (Todorov et al., 2012), or by computer vision techniques (Shi et al., 2020; Gothandaraman et al., 2020). .
and in GEM: given a state, we represent it by rotation 777and/or translation matrices, ., and predict the Lie algebra coefficient vector, . Thus, the predicted rotation matrix, , is given by Eq. (13): . The coefficient vector, , is represented by deep neural network with parameters .
8 Special Euclidean Group
For completeness, we overview the Special Euclidean group, in Supplementary Material. These two groups characterize the primitive geometric motion of rigid body. Derived from representation theory (Hall & Hall, 2003), the elements of are essentially matrices that contain coordinates for transformations. The corresponding Lie algebra, , is a 6-dimensional vector space. A commonly used basis for is:
| (18) |
| (19) |
From (11) in the main text, any element in can be represented by some coefficient vector , i.e. . The matrix representation of allows us to conveniently use the standard matrix multiplication for the composition operator and the standard matrix exponential for in equation (13) from the main text.
9 An example: Reacher
We provide an example of an environment as it goes through the GEM process.
System description: Reacher is a task of guiding a robotic arm to a randomized goal point. This arm is built from a limb that rotates relative to a fixed center point, the second limb rotates relative to the end of the first limb. Reacher will be built from two rotational groups ( is a subset of discussed in 3 where angles are just in two dimensions) - one group will represent the angle of the primary limb position relative to its center pivot (), and the second group will represent the angle of the second limb position relative to the joint between the two limbs (). The angles form the static state of reacher (). There are also two angular velocities for each limb respectively that form the dynamic state () and two applied torques that make up the action ().
Reacher Initial Angles converted to Lie Group representation , contains both angles and we apply each angle sequentially:
| (20) |
| (21) |
The coefficients are applied to the basis matrix of the algebra for SO2, and an exponential map is taken to produce the relevant rotational matrix described in 12. Then a matrix multiplication is performed for each group to predict the future position of the limb as described in equation 13.
| (22) |
| (23) |
These coefficients are first order derivatives of position, if one were to apply the coefficient to the first limb, it would rotate the limb 90 degrees counterclockwise. This essentially means we apply a rotational matrix of magnitude radians to our group.
After predicting coefficients, the velocity model predicts future velocities.
| (24) |
GEMs forward prediction is complete. The loss is takes as sum of a frobenius norm difference between true delta resultant state and predicted delta resultant state as well as a two norm difference of the true resultant and the predicted .
| (25) |
10 Experiment details
The environments utilized in our experiments are from the MuJoCo control suite (Todorov et al., 2012). All experiments are run over 5 random seeds and we report the average and standard deviation. The code to run the experiments can found at https://tinyurl.com/GEMMBRL.
10.1 Hyperparameters
Our neural networks are multi-layer perceptions (MLPs) built using pytorch. For each task, we search over multiple hidden sizes for each model. For all tasks but ant and humanoid, the hidden sizes searched over are . For ant and humanoid they are . The best performing ones are used in our experiments. For optimizer we use Adam with learning rate . A batch size of is used for all experiments. Offline data samples are collected using Soft Actor Critic. For the models trained in the offline setting, we train until convergence which take 10000 training iterations or 100000 training samples. Validation set contain 10000 samples and testing set 20000.
10.2 Ensemble Details
For the ensemble experiments, we took 5 base models and outputted their average. They were trained in unison via total loss from all networks.
10.3 Planning Algorithm
We used MPPI optimizer for planning (Link to codebase: https://github.com/kzl/lifelong_rl). Actions were taken by planning via MPC on trained dynamics model.
10.4 Trajectory Prediction Experiments
The models in this experiment are trained in an offline setting. We compare prediction power on trajectories gathered from Soft Actor Critic. In the trajectory, we pick a random starting position and take the actions from the ground truth trajectory, and move the dynamics forward based on our trained dynamics model, while keeping track of the deviation from the ground truth state. Then average per step error is reported for each prediction horizon in figure 3 and 4. Images were sampled from these trajectories as well.
10.5 Planning Experiments
The models in this experiment were trained in an offline setting. Planning was done in an open loop setting: once an environments is initialized, the planner and model never receive an update from the environment besides the first initial state. Rewards are then tracked from each step in the trajectory. Both GEM and the baselines are given the reward function, which is a function of the state.
10.6 Model Based Reinforcement Learning Experiments
The models in this experiment were trained in an online setting. The models iterate between planning out trajectories while collecting data and training on the collected data, this was done for 300 iterations. Though, we plot samples trained on to maintain fair comparison between models. In the planning and data collection portion, the model is only updated from the environment every fifth step. Average final rewards over five random seeds are tracked relative to number of samples collected. This code is under MBRL experiments in ExperimentScripts at https://tinyurl.com/GEMMBRL.
10.7 PETS Experiments
We take the original PETS (Chua et al., 2018) code (pytorch implementation used: https://github.com/quanvuong/handful-of-trials-pytorch) and modify the input and objective of the dynamics model which is done by adding the observation to group transformation for the input, and predicting coefficients for output. The input takes in group state and velocity (similar to PETS alone). Instead of predicting direct delta state, the probabilistic ensemble is trained to predict in coefficient (algebra) space as well as delta velocity. From there, we apply (13) to get the next predicted state from the coefficients. Though there is no two step network, just one ensemble network. This was done to not change the other structures in the original PETs code. The rest of the code is the same. GEM+PET experiment appears under the PETS folder in https://tinyurl.com/GEMMBRL. Figure 6 shows the comparison results for different environments.