GAN-Based Multi-View Video Coding with Spatio-Temporal EPI Reconstruction
Abstract.
The introduction of multiple viewpoints in video scenes inevitably increases the bitrates required for storage and transmission. To reduce bitrates, researchers have developed methods to skip intermediate viewpoints during compression and delivery, and ultimately reconstruct them using Side Information (SI). Typically, depth maps are used to construct SI. However, their methods suffer from inaccuracies in reconstruction and inherently high bitrates. In this paper, we propose a novel multi-view video coding method that leverages the image generation capabilities of Generative Adversarial Network (GAN) to improve the reconstruction accuracy of SI. Additionally, we consider incorporating information from adjacent temporal and spatial viewpoints to further reduce SI redundancy. At the encoder, we construct a spatio-temporal Epipolar Plane Image (EPI) and further utilize a convolutional network to extract the latent code of a GAN as SI. At the decoder side, we combine the SI and adjacent viewpoints to reconstruct intermediate views using the GAN generator. Specifically, we establish a joint encoder constraint for reconstruction cost and SI entropy to achieve an optimal trade-off between reconstruction quality and bitrates overhead. Experiments demonstrate significantly improved Rate-Distortion (RD) performance compared with state-of-the-art methods.
1. Introduction
To provide more immersive experience, multi-view video captures visual information from different positions and angles, and thereby leading a surge in the amount of data. How to reduce the coding bitrates while ensuring the reconstruction quality has become a critical issue. Recent efforts have confirmed the feasibility of deep learning-based video coding (Hu et al., 2021; Liu et al., 2020; Li et al., 2021a; Zhao et al., 2022; Zhang et al., 2020a). This is benefited from the training of large datasets coupled with the powerful nonlinear modeling capability of neural networks. Unfortunately, little research has been conducted on deep learning-based Multi-view Video Coding (MVC) (Tech et al., 2015), which is still an open problem.

Traditional MVC methods utilize the hybrid coding framework to encode each viewpoint. To further reduce the output bitrates, a feasible approach is to skip intermediate viewpoints at encoder side and reconstruct them at decoder side. To this aim, small amount of information, which we call Side Information (SI), is introduced to extract the features of intermediate viewpoint for compensation of skipped information. Recently, the depth values of 3D scenes are often employed as SI to synthesize virtual viewpoint images by depth-image-based rendering (Tian et al., 2009). This is the currently popular method called Multi-view plus Depth (MVD) (Müller et al., 2010). However, the depth information cannot be accurately recovered due to the difficulty of obtaining and calculating the precise depth information(Chan et al., 2020). To improve the reconstruction quality, the low-resolution images are utilized as the SI in (Hu et al., 2014). However, the compressed low-resolution images also lead to a high bitrate overhead, which limits its application. To address this issue, we propose to extract the spatio-temporal latent code of intermediate virtual viewpoint with Generative Adversarial Network (GAN) (Lipton and Tripathi, 2017), which reduces bitrates overhead while maintaining the reconstruction quality of videos.
It is commonly known that neural networks can extract high-level semantic features, while GAN succeeds in generating images according to prior knowledge of sample datasets. Therefore, we deploy a GAN-based viewpoint reconstruction at decoder side. Meanwhile, an attempt is made to apply the latent vectors of GAN as SI. Previous studies suggest latent codes have contributed to restore original images (Chen et al., 2016). However, the conventional GAN approaches do not provide an inverse mapping to project an image back into latent space. Recent years have witnessed a series of methods to extract latent code, including gradient descent (Creswell and Bharath, 2018) and adversarial feature learning (Donahue et al., 2016). Despite of these great efforts, they cannot be applied in our task due to the difficulty in establishing correlations between spatio-temporal and inter-view domains and lack of tradeoff between SI bitrates and reconstruction quality. As Epipolar Plane Image (EPI) method (Wu et al., 2018) can aggregate information across viewpoints, we construct spatio-temporal EPI as input to the framework instead of the direct viewpoint to exploit correlations between spatio-temporal and inter-view domains. As depicted in Fig. 1, we address the bitrate and reconstruction quality trade-off of SI with a compact latent code and a bitrate optimization, which are capable of improving reconstruction accuracy with a reduced bitrates.
Overall, we construct the spatio-temporal EPI as input to efficiently extract SI of the intermediate viewpoint and achieve better reconstruction quality. Furthermore, we use GAN to recover more details with high-level understanding across viewpoints. Finally, we use a hybrid cost function of reconstruction quality and bitrates to obtain the optimal SI while minimizing bitrates. In summary, the contributions of this paper are as follows:
-
•
We propose a multi-view video learning to exploiting the correlation between the spatio-temporal and inter-view domains to extract latent code as SI. The proposed method can effectively reduce the redundancy of SI.
-
•
We make the first attempt to introduce GAN coding network to reconstruct the intermediate viewpoint of MVC. The proposed method is able to accurately reconstruct intermediate viewpoint using latent code as SI.
-
•
We achieve a trade-off between reconstruct quality and SI bitrates by a bitrate optimization cost function. Experimental results show we achieve improved Rate-Distortion (RD) performance compared to the popular MVC methods.
2. Related work
This section focuses on current multi-view coding approaches and analyzes their shortcomings, including the MVC and deep-learning based MVC works.
2.1. Multi-view video coding
Multi-view video coding adds inter-view prediction to the standard of High Efficiency Video Coding (HEVC). It also introduces the concept of depth map, in which each viewpoint has an additional depth video. Therefore, we divide multi-view video coding into two categories: general multi-view video coding and depth map-based multi-view video coding.
General multi-view video coding. MV-HEVC is the sate-of-the-art standard, which inspires many improvements on its modules. Hannuksela et al. (Hannuksela et al., 2015) made a stage summary of multi-view extensions for HEVC and described the standard practices for multi-view video coding, which sets a milestone for the future work. Unlike the traditional RD model, Li et al. (Li et al., 2020) proposed a multi-view bit allocation method based on the exact target bit relationship between base view and dependent view. To reduce coding complexity, Khan et al. (Khan et al., 2021) propose an Efficient Inter-Prediction Mode Decision (EIPMD) technique utilizes the Coding Unit (CU) splitting information of the base view to find its relation with the prediction Modes. Xu et al. (Xu et al., 2021) proposed a flexible complexity optimization framework that reduces encoder complexity according to external-defined constraints by minimizing the cost of alternative partitioning using a probability-driven approach known as APC. This method dynamically adjusts local candidate partitions to meet the target local complexity constraint. Li et al. (Li et al., 2021b) proposed an RD optimization for the dependent viewpoint based on inter-viewpoint dependencies, and greatly improved its performance in MVC. In these general methods, the bitrates may increase sharply with the number of viewpoints, which is because the original video needs to be encoded in each viewpoint rather than the side information.
Depth map-based multi-view video coding. Various coding methods have been proposed for depth map sequences from different aspects such as RD optimization, enhancement, bit allocation, and virtual view synthesis for depth maps. Müller et al. (Müller et al., 2013) improved motion compensation module to encode depth map sequences, and thus proposed an extended method for depth map HEVC based on inter-view prediction. By synthesizing the intermediate view with depth map and adjacent views, this method greatly saved bitrates and thus set a major milestone in the development of MVC. To address the problem of degraded quality at boundaries of synthesized viewpoints, Rahaman et al. (Rahaman and Paul, 2017) used Gaussian Mixture Models (GMM) to separate the foreground and fills holes in synthesized views. Besides, the amount of data transmitted can be further reduced by frame interpolation. Considering the application of depth map in intermediate view construction, a feasible method to improve MVC is to obtain accurate depth maps. Yang et al. (Yang et al., 2018) recommended a cross-view multi-lateral filtering scheme, which enhances the quality of depth map using color and depth priors from adjacent views at different time-slots. To reduce the complexity in coding mode selection, Zhang et al. (Zhang et al., 2020b) proposed an efficient MVD scheme based on depth histogram projection and allowable depth distortion. Lin et al. (Lin et al., 2021) proposed to accelerate 3D-HEVC deep intra-frame coding using the characteristics of the human visual system. For the above methods, their qualities are limited by the quality of the depth map.
2.2. Deep learning-based MVC
Deep learning have been introduced into MVC with significantly improved performances. These works include deep learning-based MVC optimization and deep learning-based MVC post-processing.

Deep learning-based MVC optimization. The deep learning-based MVC optimization approach introduces deep learning into specific modules of MVC framework. Lei et al. (Lei et al., 2022) put forward a deep reference frame generation method for MVC. This method employed a Disparity-Aware reference frame Generation Network (DAG-Net) to transform the disparity relationship between different viewpoints and generate a more reliable reference frame. Lei et al. (Lei et al., 2021) exploited spatial, temporal, and inter-view correlations and proposed a deep multi-domain prediction for 3D video coding. By employing CNNs to fuse multi-domain references, they achieved significant bitrates savings compared to 3D-HEVC. Peng et al. (Peng et al., 2023) proposed a multi-domain correlation learning module to recover the high frequency details of distorted frames by exploring multi-domain correlation. In addition, based on the block partition information generated in video coding, this method proposes a partition-constrained reconstruction module to better attenuate compression artifacts by designing partition losses. Chen et al. (Chen et al., 2022) proposed the first end-to-end optimized stereo video coding framework to reduce redundancy by iteratively using motion estimation and disparity estimation for left and right views in feature space.
Deep learning-based MVC post-processing. Deep learning-based methods are applied to the post-processing stage of the framework, which not only enhances quality of multi-view videos but also effectively removes compression artifacts. Recently, multi-frame quality enhancement approaches (Guan et al., 2019; Zhao et al., 2021; Luo et al., 2022) have been proposed. They significantly reduce quality fluctuations between compressed video frames by locating peak-quality frames and enhancing low quality frames with adjacent high quality frames. He et al. (He et al., 2020) recommended a graph-neural-network-based compression artifacts reduction method, which reduces compression artifacts by fusing adjacent viewpoint messages and suppressing misleading information. Pan et al. (Pan et al., 2021) proposed a Two-Stream Attention Network (TSAN)-based synthetic viewpoint quality enhancement method, which significantly improves the quality of synthetic viewpoints by extracting features at different scales using Multi-Scale Residual Attention Blocks (MSRAB) for enhancement. Zhang et al. (Zhang et al., 2022) modeled the elimination of temporal distortion as a perceptual video denoising problem and proposed a CNN-based synthetic viewpoint quality enhancement to reduce temporal flicker distortion while improving the perceptual quality of 3D synthetic viewpoint videos.
Inspired by these methods, we propose a method of multi-view latent code extraction and GAN-based multi-view video with spatio-temporal EPI reconstruction method to render new views by learning the least redundant latent code. The details of our proposed method are described as follows.
3. Proposed Multi-View Latent Code Learning
The existing MVC methods usually extract and represent features in single viewpoint, e.g., DCT coefficients, motion vectors and stereo depth maps, without regarding to simultaneous feature extraction and cross-viewpoint correlations. Capturing the correlation between multiple views simultaneously and leveraging the diversity in each view to achieve accurate original image reconstruction on the decoder side remains a critical and challenging issue.
3.1. Problem formulation
To facilitate the use of cross-viewpoint correlation, we employ the Epipolar Plane Image (EPI) method. On epipolar plane, an object projected into different viewpoints will appear on the same straight line of EPI. Using this approach, we group the corresponding data from different viewpoints into spatially adjacent locations in EPI, which enables us to exploit the inter-view correlation for subsequent processing. Then, the EPI is connected in temporal domain as the input of convolutional network to extract latent code.
We model the latent code extraction of EPI:
| (1) |
where and represent the original EPI and its high-level semantic features, respectively. represents a feature extraction network to extract the high-level semantic features of original EPI. To further reduce the bitrates of features, will be compressed by using a compression network before being transmitted to the decoder side:
| (2) |
At the decoder side, we recover the EPI information with and a generator .
Our task is to find an and its inverse operation to minimize the reconstruction error of EPI and the bitrates of latent code transmission:
| (3) |
In this work, we employ CNN and GAN to perform latent code extraction & compression and EPI reconstruction, respectively. The whole networks are co-trained in an end-to-end manner. As shown in Fig. 2, the whole framework consists of spatio-temporal EPI construction, latent code extraction & compression and GAN-based EPI reconstruction, which are elaborated as follows.
3.2. Spatio-temporal EPI construction
Traditional EPI with pixel rows of images cannot well reflect the spatio-temporal correlations of multi-view images. In this work, we construct a spatio-temporal EPI with the following two steps. Firstly, the multi-view images are decomposed and reassembled based on their spatial locations. Let , and denote the width, height and number of views of a multi-view video, respectively. As shown in Fig. 3, images of each view are divided into strips with all color channels, where the value 8 is chosen empirically(Bolles et al., 1987) and thus an image consists of strips. Then, all strips at the same spatial locations are grouped to formulate a spatial EPI with a dimension of . In total, there are spatial EPIs at a same time. Secondly, a spatio-temporal EPI is obtained by stacking successive spatial EPIs at time axis, in order to embed the temporal correlations. A spatio-temporal EPI is then with the dimension of . In particular, we set in this work.
In the following, we refer a spatio-temporal EPI as , where and denotes the temporal index. The spatio-temporal EPI is then fed into convolutional layers to extract latent code.

3.3. Latent code extraction & compression
Latent code extraction. As shown in Fig. 2, the latent code extraction step transforms the spatio-temproal EPI to a latent vector , which is critical to reconstruct the intermediate viewpoint. In order to obtain more accurate latent code with low bitrates, we use latent code extraction module to remove the redundant information at the encoder end. Through iterative training of the whole network, the module extracts latent code from the spatio-temporal EPI based on a trade-off between the quality of the reconstructed EPI and the bitrates. In this work, we achieve this with Fully Convolutional Network (FCN) due to its capacity to effectively learn data distribution with a compact feature size.
For the extraction module, its input and output are the spatio-temporal EPIs and latent code of intermediate viewpoint, respectively. The extraction network includes 1 convolutional layer, 4 residual blocks and another 2 convolutional layers. Each residual block includes 2 convolutional layers, 2 Bach Normalization (BN) layers, a Rectified Linear Unit (ReLU) function and an elementwise sum. The residual blocks are connected with skip connections and elementwise sum, in order to ensemble diverse feature information that benefits the visual quality of viewpoint reconstruction. As a result, the final output of extraction is with a dimension of K due to we only need the latent code of intermediate viewpoint. As shown in Fig.4, the latent code contains structural information of intermediate viewpoint, which can be used as a priori information of the GAN network to guide the generator to reconstruct the intermediate viewpoint.

(a)

(b)
Latent code compression. For the compression module , we employ an auto-encoder with three downsampling layers and three upsampling layers that are implemented with convolutions and deconvolutions, respectively. The extracted latent code will be compressed and quantized as a compact representation , and then reconstructed as .
Entropy coding. The quantized latent code will be transformed into bit-streams by performing entropy coding. In this work, we employ the hyperprior entropy model presented in (Lu et al., 2019) for an accurate bitrates estimation. During the training process, the calculated bitrate is used as a part of the loss function.
3.4. GAN-based EPI reconstruction
By using a compact representation of EPI features, we provide multi-view video at a lower bitrate. At the receiver side, we reconstruct the generated EPI from , , where denotes the function of reconstruction process. To ensure that the reconstructed EPI is as close as possible to the original EPI , we refer to the GAN framework to introduce the discrimination function . Through the interaction between and , the EPI generated by can increasingly approximate the original EPI . As shown in Fig. 2, the EPI reconstruction is composed of two modules: reconstruction and discrimination, as well as an interaction mechanism.
The reconstruction module uses a neural network with convolution as the generator. We consider the following two distributions: Joint probability density function in latent code extraction ; Joint probability density function in reconstruction . In these distributions, is the prior probability function of the original EPI, is the probability density function of the latent code and is the probability density function of the compressed latent code. In the latent code extraction & compression process, the extraction network maps the original EPI to the latent code : and the compression network compresses to , while in the reconstruction process, the generator network maps the samples of the compressed prior to the input space . To accurately reconstruct the EPI, it is necessary to make the conditional probability coincide with the prior probability as much as possible.
The discrimination module determines whether the input EPI is the original EPI by a classification network. To better discriminate whether the input image is the original EPI, the training goal is to make the value of as large as possible and the value of as small as possible. Unlike the GAN network which only discriminates the input image, our discriminator network needs to discriminate both the image and the latent code.
The interaction mechanism uses the discrimination results to guide the generator to reconstruct images closer to the original EPI, and also to navigate the discriminator to better identify differences between the generator’s output and the original EPI. To this end, we design this mechanism with an adversarial game in which the discriminator and the generator are trained alternately. The discriminator is trained to distinguish between sample pairs from the encoder and sample pairs from the generator , both of which satisfy the joint probability distribution or . The generators are trained to fool the discriminators obtained from the previous training. At this point, the discriminant value is as large as possible.
Pretrain and initialize networks , and , and then train the network with the data sets samples of EPIs as follows:
3.5. The objective function
The latent code extraction & compression and GAN-based EPI reconstruction are co-trained within a network flow. A joint objective function is thereby designed and utilized to optimize both the bitrates of latent code and the visual quality of reconstructed videos. As discussed above, the spatio-temporal EPI is extracted as latent code by convolutional network , compressed to by compression module and finally reconstructed as by generator . A discriminator is deployed to identify the reconstruction performance. Inspired by GAN, the objective function of whole network can be expressed as:
| (4) |
where and denote the distributions of spatio-temporal EPI and latent code respectively. denotes the distortion loss and denote the numbers of bits used to encode latent code. is a hyper parameter used to control the rate-distortion trade-off.
We calculate the distortion and bitrates losses based on distance and entropy, respectively. The distortion loss is calculated between the original and reconstructed spatio-temproal EPIs,
| (5) |
where the distance is obtained as a combination of pixel-domain Mean Squared Error (MSE) and feature-domain VGG loss,
| (6) |
Here and represent the dimension of EPI. denotes the operation of the VGG network to extract the feature map.
As depicted in Section 3.3, we can use the entropy model to accurately estimate the bitrates of the compressed and quantized latent code :
| (7) |
3.6. The overall algorithm
With the loss function defined in Section 3.5, we are able to train the whole network consisting of the extraction module , the compression module , the generator and the discriminator . The whole training process is summarized in the Algorithm1.
4. Experiments
4.1. Experiment setup
Datasets. We train our method, which is named as MVLL for the sake of simplicity, with 5 typical multi-view sequences including Scence_Door_Flowers (1024 768), Scence_Leaving_Laptop (1024 768), Scence_Outdoor (1024 768), Champagne_Tower (1280 960) and Dog (1280 960). Each of them is with 5 views. They are further split into EPI images, according to the steps shown in Section 3.2. We selected 12,800 EPIs from each produced EPI sequence, and a total of 64,000 EPIs were used for training. To examine the performance of our method, we test on the Common Test Conditions (CTC) of MVC (Müller and Vetro, 2014). The details are listed in Table 1. We selected 30 frames of video from each sequence for the EPI construction and put them to the test.
| Sequence | Resolution | Viewpoints | Frame Rate |
|---|---|---|---|
| Balloons | 1024768 | 1, 2, 3 | 30 |
| Bookarrival | 1024768 | 6, 7, 8 | 16.67 |
| Kendo | 1024768 | 1, 2, 3 | 30 |
| Lovebord1 | 1024768 | 4, 5, 6 | 30 |
| Newspaper | 1024768 | 2, 3, 4 | 30 |
| Pantomime | 1280960 | 37, 38, 39 | 30 |
| Dancer | 19201088 | 1, 5, 9 | 25 |
| Poznan_Street | 19201088 | 3, 4, 5 | 25 |
Baseline codecs. There are four other methods implemented for performance comparison. The state-of-the-art multi-view video coding standard, MV-HEVC (Hannuksela et al., 2015). The multi-view video plus depth standard method, MVD (Tech et al., 2015), uses the depth maps as the auxiliary information. The deep-learning based video coding method, DCVC (Li et al., 2021a), used conditional coding to replace the traditional predictive coding paradigm. The deep-learning based multi-view video enhancement method, TSAN (Pan et al., 2021), used a dual-stream attention network to improve the synthesized view quality. To make a fair comparison, for MV-HEVC, we use the HTM-16.3 software with baseCfg_3view.cfg configuration setting and set the QP to {30, 35, 40, 45}, while for MVD, we use the HTM-16.3 software and VSRS3.5 view synthesis software with baseCfg_2view+depth.cfg configuration and setting the QP pairs of for texture and depth videos, i.e. (30, 39), (35, 42), (40, 45) and (45, 48). For the DCVC method, we use the HTM16.3 software with baseCfg_2view.cfg configuration setting to encode the left and right views, and use the DCVC method with their pre-trained models to compress the intermediate view. For the TSAN method, we use their pre-trained models to perform quality enhancement on the intermediate view synthesized by the MVD method.
Metrics. The popular video coding criteria are employed to evaluate and compare all the above four methods. These criteria include the PSNR-aware measurements (rate-PSNR curves, the BDPSNR and BDBR (Bjontegaard, 2001)) and the SSIM-aware measurements (rate-SSIM curves, the ADSSIM and ADBR (Zhao et al., 2015)).
Implementation details. In our implementation, we use the HTM-16.3 software with baseCfg_2view.cfg configuration setting to encode the left and right views, and compress the intermediate view using our proposed method. We train four models with different values ( = 512, 1024, 2048, 4096). The other parameters for training are set as follows: epochs=50, iterations=64000, batchsize=1.
(a) Balloons

(b) Bookarrival

(c) Kendo

(d) Lovebird1

(e) Newspaper

(f) Pantomime

(g) Dancer

(h) PoznanStreet

(a) Balloons

(b) Bookarrival
(c) Kendo

(d) Lovebird1

(e) Newspaper

(f) Pantomime

(g) Dancer

(h) PoznanStreet
| Balloons | Bookarrival | Kendo | Lovebird1 | Newspaper | Pantomime | Dancer | PoznanStreet | Average | ||
|---|---|---|---|---|---|---|---|---|---|---|
| BDBR() | MV-HEVC | -23.7886 | -17.1885 | -17.9240 | -13.5281 | -6.9199 | -32.7008 | -68.3621 | -36.1006 | -20.4410 |
| MVD | -40.1095 | -71.2063 | -39.8545 | -57.4701 | -65.5207 | -38.2222 | -17.6076 | -25.7746 | -44.1407 | |
| DCVC | -36.4340 | -31.4592 | –28.8073 | -59.2842 | -26.7557 | -27.6334 | -41.8136 | -38.0574 | -36.2806 | |
| TSAN | -20.5295 | -56.2097 | -10.9087 | -28.1795 | -43.8484 | -14.1459 | -9.9345 | -7.1604 | -23.8646 | |
| BDPSNR | MV-HEVC | 1.1203 | 0.6381 | 0.7341 | 0.6249 | 0.4609 | -0.0827 | 1.3435 | 0.9945 | 0.7290 |
| MVD | 1.5722 | 2.6093 | 1.4409 | 2.1399 | 2.9809 | 1.4293 | 0.4759 | 0.7446 | 1.6741 | |
| DCVC | 1.8429 | 1.0744 | 1.3624 | 2.6531 | 1.2096 | 1.5557 | 1.7062 | 1.2880 | 1.5804 | |
| TSAN | 0.8242 | 1.9015 | 0.4191 | 0.9056 | 1.7666 | 0.3368 | 0.2444 | 0.1538 | 0.8190 |
| Balloons | Bookarrival | Kendo | Lovebird1 | Newspaper | Pantomime | Dancer | PoznanStreet | Average | ||
|---|---|---|---|---|---|---|---|---|---|---|
| ADBR() | MV-HEVC | -18.9829 | -33.6628 | -19.5974 | -14.5925 | -18.8311 | 5.8075 | -25.1623 | -25.5533 | -18.8219 |
| MVD | -69.4709 | -37.1942 | -24.0581 | -11.8847 | -45.6205 | -13.5243 | -30.2773 | -28.6590 | -32.5861 | |
| DCVC | -41.1030 | -19.7054 | -24.2316 | -11.8847 | -45.6205 | -13.5243 | -30.2773 | -25.4233 | -16.6478 | |
| TSAN | -61.8296 | -31.1066 | -71.1281 | -7.5817 | -37.7603 | -1.9382 | -28.6742 | -23.1616 | -32.8975 | |
| ADSSIM | MV-HEVC | 0.0030 | 0.0178 | 0.0044 | 0.0066 | 0.0095 | 0.0010 | 0.0426 | 0.0163 | 0.0124 |
| MVD | 0.0288 | 0.0144 | 0.0041 | 0.0056 | 0.0303 | 0.0028 | 0.0289 | 0.0166 | 0.0505 | |
| DCVC | 0.0064 | 0.0063 | 0.0036 | 0.0044 | 0.0020 | -0.0009 | 0.0034 | 0.0122 | 0.0047 | |
| TSAN | 0.0248 | 0.0108 | 0.0008 | 0.0036 | 0.0242 | 0.0004 | 0.0268 | 0.0130 | 0.0131 |
4.2. Experimental results
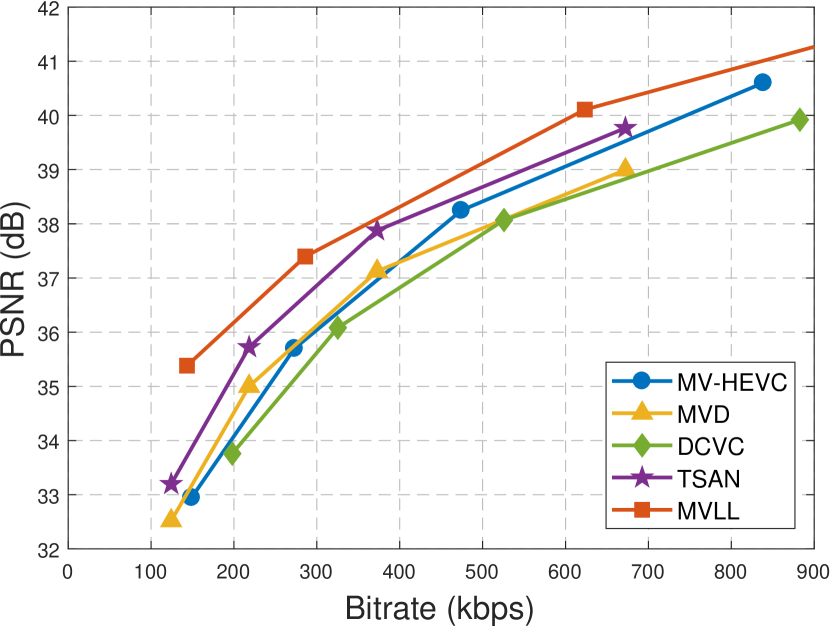
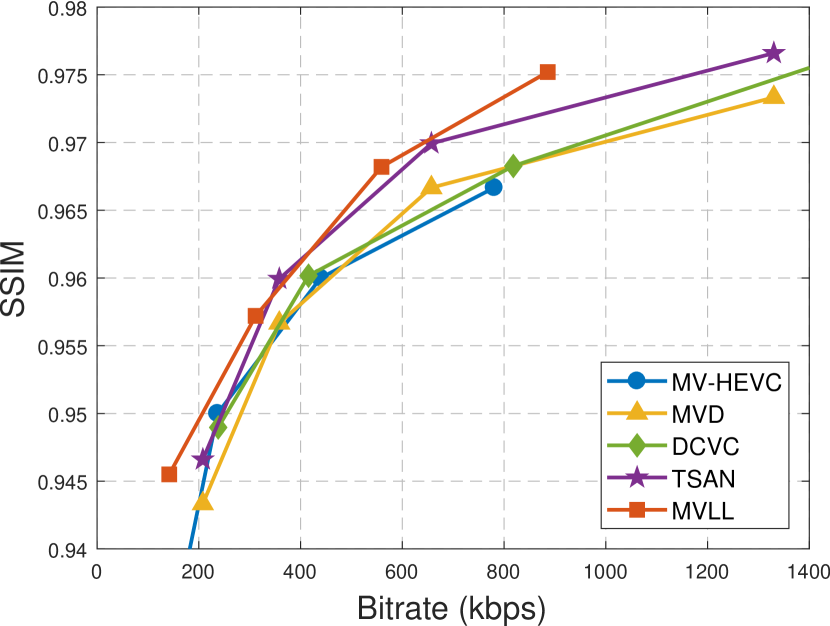
Fig. 5 shows the rate-PSNR curves of all compared methods: MV-HEVC, MVD, DCVC, TSAN and MVLL. In each curve, the four data samples correspond to the four Qp settings; while in each data sample, the rate-PSNR performances are obtained as the averaged results of all views. Fig. 6 shows the rate-SSIM curves of these methods, where the SSIM index is considered is more consistent with human vision system than PSNR.
From Figs. 5-6 we can get several conclusions. Firstly, all methods achieve good performances in terms of R-Q curves, by retaining a high compression ratios at the acceptable visual quality. Generally speaking, they are still superior to the original encoder without optimizations. Secondly, the MV-HEVC methods achieve superior performance than MVD in most sequences, which may be due to the extra bitrates for depth maps in MVD. In case of multi-view plus depth coding, the MVD method is still preferred. Thirdly, the DCVC achieves acceptable performance but still inferior to our MVLL. This method was designed for general video coding and thus do not exploit the inter-view correlations between multi-view videos. Fourthly, the TSAN methods enhances the quality of synthetic view of the MVD method, thus achieves superior performance than MVD in all sequences. Fifthly, our MVLL method outperforms the compared methods in most sequences, which is contributed to its GAN-based inter-view prediction.
Tables 2 and 3 presents the quantitative comparisons of R-Q performances, where the efficiency of our MVLL is evaluated with MV-HEVC, MVD, DCVC and TSAN as the benchmarks. The terms BDBR and ADBR indicate the average bitrates savings at the same PSNR and SSIM, respectively. The terms BDPSNR and ADSSIM indicate the average quality increments at the same bitrates, respectively. From the tables, we can see the quantitative comparison results are consistent with those in Figs. 5-6. Compared with the other methods, our MVLL reduces 20.44%, 44.14%, 36.28% and 23.86% bitrates at the same PSNR, or 18.82%, 32.59%, 16.65% and 32.90% bitrates at the same SSIM. It also significantly improves the video quality in terms of PSNR and SSIM at the same bitrates. These results demonstrate the efficiency and effectiveness of our proposed method.
As for the computational complexity, we use the balloons sequence to evaluate our encoder time on the machine with a single 2080TI GPU (11GB Memory). The coding time of our proposed method is 0.204s per frame, which is faster than the traditional hand-crafted MVC standard MV-HEVC or 3D-HEVC.
4.3. Ablation study
The main contributions of the proposed method consist of two parts: the spatio-temporal EPI structure, and the GAN based autoencoder network structures. Therefore, to validate their effectiveness, the ablation experiments are performed.
Contribution of spatio-temporal EPI structure: To analyze the effect of the structure of EPI on the results of MVLL, we compare the algorithm performance of three different input structures: traditional EPI, spatial EPI and spatio-temporal EPI. In the traditional EPI structure, we set the width of the column occupied by each viewpoint in the EPI to 1. In the spatial EPI, the column width occupied by each viewpoint in the EPI is 8. And in the spatio-temporal EPI, we stack the time-domain information of the 3 spatial EPIs on 9 different channels in the intermediate viewpoint. With other experimental conditions being consistent, Fig. 7 represents the rate distortion results of the algorithmic based on the three EPI structures, where the horizontal axis is the bitrates of the latent code in the intermediate viewpoint. Since applying a different EPI structure requires retraining the neural network model, we use a training data set of size 8000 to reduce the computational complexity. As can be seen in Fig. 7, with the increase of the bitrates of the latent code, the image quality of the reconstructed image results from the algorithm of the traditional EPI structure grows slowly. However, the image quality growths of the results from both the algorithm of the spatial EPI and the spatio-temporal EPI structures are more obvious. Furthermore, the image quality of the spatio-temporal EPI structure is superior to the performance of the spatial EPI. Therefore, we choose to use the structure of spatio-temporal EPI in this paper.

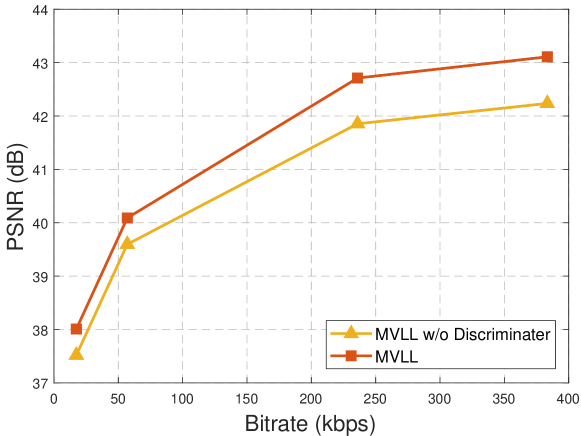
Comparison of GAN and autoencoder network structures: To analyze the contribution of the GAN network structure, we compared the performance of both GAN and autoencoder network structures. Since the difference between these two network structures is whether they have a discriminator network or not, we implement the two different algorithms by adding or subtracting the discriminator network from the original network structure. With all other experimental conditions being equal, Fig. 8 represents the rate distortion performance results of the multi-view video coding algorithm based on latent code learning for two network structures, GAN and autoencoder network. We can see that the rate distortion performance of the algorithm with discriminator network structure is higher. Therefore, in this paper we use a GAN structure with discriminator network for multi-view video coding.
5. Conclusion
Nowadays, there exists a bottleneck to further compress video streams with the traditional hybrid model. Researchers have been contributing to deep-learning-based video compression, where the motion prediction/compensation, RD optimization or entropy coding is realized by deep network. In this paper, we made the first attempt to combine deep GAN model with multi-view video coding. We utilized the latent code of GAN as SI in an RD-optimal manner. The latent code is generated with a deep network and further utilized to reconstruct the intermediate views, thereby saving the streaming bitrates of multi-view videos. Experimental results show a significant performance gain over the state-of-the-art schemes using depth map as SI. We hope this work can provide an innovative methodology to deep-learning-based multi-view video coding.
References
- (1)
- Bjontegaard (2001) Gisle Bjontegaard. 2001. Calculation of average PSNR differences between RD-curves. VCEG-M33 (2001).
- Bolles et al. (1987) Robert C Bolles, H Harlyn Baker, and David H Marimont. 1987. Epipolar-plane image analysis: An approach to determining structure from motion. International journal of computer vision 1, 1 (1987), 7–55.
- Chan et al. (2020) Yui-Lam Chan, Chang-Hong Fu, Hao Chen, and Sik-Ho Tsang. 2020. Overview of current development in depth map coding of 3D video and its future. IET Signal Processing 14, 1 (2020), 1–14. https://doi.org/10.1049/iet-spr.2019.0063 arXiv:https://ietresearch.onlinelibrary.wiley.com/doi/pdf/10.1049/iet-spr.2019.0063
- Chen et al. (2016) Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. 2016. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in neural information processing systems. 2172–2180.
- Chen et al. (2022) Zhenghao Chen, Guo Lu, Zhihao Hu, Shan Liu, Wei Jiang, and Dong Xu. 2022. LSVC: A Learning-based Stereo Video Compression Framework. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6063–6072. https://doi.org/10.1109/CVPR52688.2022.00598
- Creswell and Bharath (2018) Antonia Creswell and Anil Anthony Bharath. 2018. Inverting the generator of a generative adversarial network. IEEE transactions on neural networks and learning systems 30, 7 (2018), 1967–1974.
- Donahue et al. (2016) Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. 2016. Adversarial feature learning. arXiv preprint arXiv:1605.09782 (2016).
- Guan et al. (2019) Zhenyu Guan, Qunliang Xing, Mai Xu, Ren Yang, Tie Liu, and Zulin Wang. 2019. MFQE 2.0: A new approach for multi-frame quality enhancement on compressed video. IEEE transactions on pattern analysis and machine intelligence (2019).
- Hannuksela et al. (2015) Miska M Hannuksela, Ye Yan, Xuehui Huang, and Houqiang Li. 2015. Overview of the multiview high efficiency video coding (MV-HEVC) standard. In 2015 IEEE International Conference on Image Processing (ICIP). IEEE, 2154–2158.
- He et al. (2020) Xin He, Qiong Liu, and You Yang. 2020. MV-GNN: Multi-view graph neural network for compression artifacts reduction. IEEE Transactions on Image Processing 29 (2020), 6829–6840.
- Hu et al. (2014) Wei Hu, Gene Cheung, Antonio Ortega, and Oscar C Au. 2014. Multiresolution graph fourier transform for compression of piecewise smooth images. IEEE Transactions on Image Processing 24, 1 (2014), 419–433.
- Hu et al. (2021) Zhihao Hu, Guo Lu, and Dong Xu. 2021. FVC: A New Framework Towards Deep Video Compression in Feature Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1502–1511.
- Khan et al. (2021) Shahid Nawaz Khan, Khurram Khan, Nazeer Muhammad, and Zahid Mahmood. 2021. Efficient Prediction Mode Decisions for Low Complexity MV-HEVC. IEEE Access 9 (2021), 150234–150251. https://doi.org/10.1109/ACCESS.2021.3125962
- Lei et al. (2021) Jianjun Lei, Yanan Shi, Zhaoqing Pan, Dong Liu, Dengchao Jin, Ying Chen, and Nam Ling. 2021. Deep multi-domain prediction for 3D video coding. IEEE Transactions on Broadcasting 67, 4 (2021), 813–823.
- Lei et al. (2022) Jianjun Lei, Zongqian Zhang, Zhaoqing Pan, Dong Liu, Xiangrui Liu, Ying Chen, and Nam Ling. 2022. Disparity-Aware Reference Frame Generation Network for Multiview Video Coding. IEEE transactions on image processing (2022). https://doi.org/10.1109/tip.2022.3183436
- Li et al. (2021a) Jiahao Li, Bin Li, and Yan Lu. 2021a. Deep contextual video compression. Advances in Neural Information Processing Systems 34 (2021).
- Li et al. (2020) Tiansong Li, Li Yu, Hongkui Wang, and Zhuo Kuang. 2020. A Bit Allocation Method Based on Inter-View Dependency and Spatio-Temporal Correlation for Multi-View Texture Video Coding. IEEE Transactions on Broadcasting (2020).
- Li et al. (2021b) Tiansong Li, Li Yu, Hongkui Wang, and Zhuo Kuang. 2021b. An efficient rate–distortion optimization method for dependent view in MV-HEVC based on inter-view dependency. Signal Processing: Image Communication 94 (2021), 116166.
- Lin et al. (2021) Jie-Ru Lin, Mei-Juan Chen, Chia-Hung Yeh, Yong-Ci Chen, Lih-Jen Kau, Chuan-Yu Chang, and Min-Hui Lin. 2021. Visual perception based algorithm for fast depth intra coding of 3D-HEVC. IEEE Transactions on Multimedia (2021).
- Lipton and Tripathi (2017) Zachary C Lipton and Subarna Tripathi. 2017. Precise recovery of latent vectors from generative adversarial networks. arXiv preprint arXiv:1702.04782 (2017).
- Liu et al. (2020) Dong Liu, Yue Li, Jianping Lin, Houqiang Li, and Feng Wu. 2020. Deep learning-based video coding: A review and a case study. ACM Computing Surveys (CSUR) 53, 1 (2020), 1–35.
- Lu et al. (2019) Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. 2019. Dvc: An end-to-end deep video compression framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11006–11015.
- Luo et al. (2022) Dengyan Luo, Mao Ye, Shuai Li, and Xue Li. 2022. Coarse-to-Fine Spatio-Temporal Information Fusion for Compressed Video Quality Enhancement. IEEE Signal Processing Letters 29 (2022), 543–547. https://doi.org/10.1109/LSP.2022.3147441
- Müller et al. (2010) Karsten Müller, Philipp Merkle, and Thomas Wiegand. 2010. 3-D video representation using depth maps. Proc. IEEE 99, 4 (2010), 643–656.
- Müller et al. (2013) Karsten Müller, Heiko Schwarz, Detlev Marpe, Christian Bartnik, Sebastian Bosse, Heribert Brust, Tobias Hinz, Haricharan Lakshman, Philipp Merkle, Franz Hunn Rhee, et al. 2013. 3D high-efficiency video coding for multi-view video and depth data. IEEE transactions on image processing 22, 9 (2013), 3366–3378.
- Müller and Vetro (2014) Karsten Müller and Anthony Vetro. 2014. Common test conditions of 3DV core experiments. ITU-T SG 16 (2014), 1–7.
- Pan et al. (2021) Zhaoqing Pan, Weijie Yu, Jianjun Lei, Nam Ling, and Sam Kwong. 2021. TSAN: Synthesized view quality enhancement via two-stream attention network for 3D-HEVC. IEEE Transactions on Circuits and Systems for Video Technology 32, 1 (2021), 345–358.
- Peng et al. (2023) Bo Peng, Renjie Chang, Zhaoqing Pan, Ge Li, Nam Ling, and Jianjun Lei. 2023. Deep In-Loop Filtering via Multi-Domain Correlation Learning and Partition Constraint for Multiview Video Coding. IEEE Transactions on Circuits and Systems for Video Technology 33, 4 (2023), 1911–1921. https://doi.org/10.1109/TCSVT.2022.3213515
- Rahaman and Paul (2017) DM Motiur Rahaman and Manoranjan Paul. 2017. Virtual view synthesis for free viewpoint video and multiview video compression using Gaussian mixture modelling. IEEE Transactions on Image Processing 27, 3 (2017), 1190–1201.
- Tech et al. (2015) Gerhard Tech, Ying Chen, Karsten Müller, Jens-Rainer Ohm, Anthony Vetro, and Ye-Kui Wang. 2015. Overview of the multiview and 3D extensions of high efficiency video coding. IEEE Transactions on Circuits and Systems for Video Technology 26, 1 (2015), 35–49.
- Tian et al. (2009) Dong Tian, Po-Lin Lai, Patrick Lopez, and Cristina Gomila. 2009. View synthesis techniques for 3D video. In Applications of Digital Image Processing XXXII, Vol. 7443. International Society for Optics and Photonics, 74430T.
- Wu et al. (2018) Gaochang Wu, Yebin Liu, Lu Fang, Qionghai Dai, and Tianyou Chai. 2018. Light field reconstruction using convolutional network on EPI and extended applications. IEEE transactions on pattern analysis and machine intelligence 41, 7 (2018), 1681–1694.
- Xu et al. (2021) Yiwen Xu, Kaiying Xing, Hang Liu, Tiesong Zhao, and Sam Kwong. 2021. Flexible Complexity Optimization in Multiview Video Coding. IEEE Transactions on Circuits and Systems for Video Technology 31, 10 (2021), 4096–4106. https://doi.org/10.1109/TCSVT.2020.3043005
- Yang et al. (2018) You Yang, Qiong Liu, Xin He, and Zhen Liu. 2018. Cross-view multi-lateral filter for compressed multi-view depth video. IEEE Transactions on Image Processing 28, 1 (2018), 302–315.
- Zhang et al. (2022) Huan Zhang, Yun Zhang, Linwei Zhu, and Weisi Lin. 2022. Deep Learning-based Perceptual Video Quality Enhancement for 3D Synthesized View. IEEE Transactions on Circuits and Systems for Video Technology (2022).
- Zhang et al. (2020a) Yun Zhang, Sam Kwong, and Shiqi Wang. 2020a. Machine learning based video coding optimizations: A survey. Information Sciences 506 (2020), 395–423.
- Zhang et al. (2020b) Yun Zhang, Linwei Zhu, Raouf Hamzaoui, Sam Kwong, and Yo-Sung Ho. 2020b. Highly Efficient Multiview Depth Coding Based on Histogram Projection and Allowable Depth Distortion. IEEE Transactions on Image Processing 30 (2020), 402–417.
- Zhao et al. (2021) Minyi Zhao, Yi Xu, and Shuigeng Zhou. 2021. Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction. ACM Multimedia (2021). https://doi.org/10.1145/3474085.3475710
- Zhao et al. (2022) Tiesong Zhao, Weize Feng, HongJi Zeng, Yiwen Xu, Yuzhen Niu, and Jiaying Liu. 2022. Learning-Based Video Coding with Joint Deep Compression and Enhancement. ACM Multimedia (2022). https://doi.org/10.1145/3503161.3548314
- Zhao et al. (2015) Tiesong Zhao, Zhou Wang, Sam Kwong, and Chang Wen Chen. 2015. On SSIM-bit rate comparison of HEVC encoders. In 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE, 246–251.