g3D-LF: Generalizable 3D-Language Feature Fields for Embodied Tasks
Abstract
We introduce Generalizable 3D-Language Feature Fields (g3D-LF), a 3D representation model pre-trained on large-scale 3D-language dataset for embodied tasks. Our g3D-LF processes posed RGB-D images from agents to encode feature fields for: 1) Novel view representation predictions from any position in the 3D scene; 2) Generations of BEV maps centered on the agent; 3) Querying targets using multi-granularity language within the above-mentioned representations. Our representation can be generalized to unseen environments, enabling real-time construction and dynamic updates. By volume rendering latent features along sampled rays and integrating semantic and spatial relationships through multiscale encoders, our g3D-LF produces representations at different scales and perspectives, aligned with multi-granularity language, via multi-level contrastive learning. Furthermore, we prepare a large-scale 3D-language dataset to align the representations of the feature fields with language. Extensive experiments on Vision-and-Language Navigation under both Panorama and Monocular settings, Zero-shot Object Navigation, and Situated Question Answering tasks highlight the significant advantages and effectiveness of our g3D-LF for embodied tasks. The code is available at https://github.com/MrZihan/g3D-LF.
1 Introduction
Embodied agents seek to understand 3D environments, enabling interaction with environments and human by performing tasks such as Question Answering [37, 4, 40], Navigation [6, 39, 62, 3, 27, 28], etc. To this end, various 3D scene representation models tailored for embodied tasks have been proposed, including point cloud-based models [73, 22, 11], 3D occupancy [34], hybrid voxel [14], and feature fields [49, 64, 57, 44].
For multimodal embodied tasks in large-scale scenes, 3D representation models typically need: 1) generalization to unseen scenes, 2) construct and update representations in real time, and 3) open-vocabulary semantic space. The generalizable 3D feature fields provides the above advantages and has been widely explored across various embodied tasks. Unlike point cloud-based models that depend on complete and low-noise point clouds which are less robust, the implicit representations of the feature fields are derived from the 2D foundation model, preserving semantic expressiveness even with few-shot observations from 3D scenes. As shown in Figure 1, the feature fields model uses RGB-D images as input to encode and update implicit scene representations, which are then used to predict novel view, panorama and BEV map representations associated with language through volume rendering. These predicted representations can assist embodied tasks such as navigation planning [57, 58, 44], etc.

However, several significant drawbacks remain in these feature fields models: 1) The supervision for the predicted representations comes from 2D foundation models, e.g., CLIP [45] and DINOv2 [42] greatly limits the understanding for 3D spatial relationships; 2) These models are trained without language supervision, resulting in a substantial gap with language semantics; 3) The large-scale representations, e.g., panorama and BEV map from feature fields is particularly challenging for long text understanding. These issues severely limit the potential of the feature fields model on language-guided embodied tasks.
To circumvent the above-mentioned issues, we introduce Generalizable 3D-Language Feature Fields (g3D-LF), a 3D representation model pre-trained on large-scale 3D-language dataset for embodied tasks. We first curate and consolidate a large amount of 3D-language data from previous works [23, 7, 66] to train our g3D-LF model. These data include 5K indoor scenes and almost 1M language descriptions of multiple granularities. The text annotations include object categories, object characteristics, object relationships, and the spatial layout of the entire scene, which are employed to supervise multiscale encoders of the g3D-LF model. We then design our g3D-LF model to learn generalizable 3D-language feature fields. To this end, we employ multi-level contrastive learning for multi-scale encoders to align predicted representations and language across different scales. For the regional representation within the novel view, a contrastive loss is calculated across 1,883 indoor object categories. For the predicted novel view representation, both the CLIP visual representations and language are employed for contrastive training to balance generalization ability and language alignment. For large-scale panorama and BEV representations, we propose the fine-grained contrastive learning based on the affinity matrix to achieve long text understanding.
The pre-trained g3D-LF model is subsequently evaluated on various embodied tasks, including vision-and-language navigation (monocular setting [58] and panorama setting [57]), zero-shot object navigation [62], and situated question answering [37], gains significant performance improvements. In this work, our main contributions include:
-
•
We organize a large-scale 3D-language dataset to train the feature fields model.
-
•
This work proposes the Generalizable 3D-Language Feature Fields (g3D-LF) with a multi-level contrastive learning framework to align the multi-scale representations of feature fields with multi-granularity language.
-
•
Our proposed g3D-LF model improves multiple baseline methods to state-of-the-art performance across various embodied tasks, thus validating the potential of our generalizable feature fields for Embodied AI.
2 Related Work
Generalizable 3D Feature Fields. The neural radiance field (NeRF) [41] has gained significant popularity in various AI tasks, which predicts the RGB image from an arbitrary viewpoint in a 3D scene. Furthermore, some works leverage NeRF-based methods to predict novel view representations instead of RGB values, enabling 3D semantic segmentation [51] and 3D language grounding [24]. However, these methods with implicit MLP networks can only synthesize novel view representations in seen scenes, which makes it difficult to generalize to unseen large-scale scenes and adapt to many embodied AI tasks (e.g., navigation). To this end, some works [57, 44, 50] attempt to encode 2D visual observations into 3D representations (called Generalizable 3D Feature Fields) via the depth map. Through volume rendering [41], these models decode novel view representations from the feature fields and align them with open-world features (e.g., CLIP embeddings [45]). The 3D feature fields can generalize to unseen scenes, enabling real-time construction and dynamic updates. However, the drawback of these models lies in the fact that the supervision of their predicted representations comes from 2D visual models, which limits their performance in language-guided embodied tasks. Our work offers a feasible approach to training the 3D feature fields model with large-scale 3D-language data.
Vision-and-Language Navigation. Vision-and-Language Navigation (VLN) [3, 27, 69, 19, 9, 43, 54] requires the agent understand complex natural language instructions and navigate to the described destination using low-level actions, e.g., turn left 15 degrees, turn right 15 degrees, or move forward 0.25 meters. To address inefficiencies and poor performance in atomic action prediction, some works [26, 20, 58] develop waypoint predictors to generate several candidate waypoints around the agent. The navigation policy model can then select the optimal waypoint as the next sub-goal and execute atomic actions to move, greatly enhancing planning efficiency. In this context, how to represent waypoints and carry out planning have become critical. Some works use a topological map [10, 2] or BEV map [1, 56, 32] to represent semantic relationships between waypoints, while some [57, 58] explore feature fields to predict waypoint representations of novel views and improve navigation planning. Our g3D-LF model further improves the performance of methods using feature fields.
Zero-shot Object Navigation. In object-goal navigation [6, 47, 68], an agent is tasked with locating a specified object within indoor environments. Typically, reinforcement learning [72] is used to train a policy network that predicts actions, while object detection [52, 35] or segmentation models [25, 65, 18] help identify the object. However, these navigation models are often limited to specific objects, making open-vocabulary navigation challenging and hindering generalization in real-world applications [17]. To address this issue, zero-shot navigation methods have emerged [39, 71, 15, 62], leveraging Vision-and-Language Models (VLMs) [45, 31, 30] to identify potential directions or areas containing the target, followed by using the pre-trained pointgoal navigation models [59] to search the potential areas. Considering that general 2D VLMs are not fully suited for indoor 3D environments and to the best of our knowledge, we are the first to attempt using the indoor 3D feature fields model for zero-shot object navigation.
Situated Question Answering. The Embodied Question Answering tasks [4, 13, 40] require the agent to observe the 3D environment and answer questions from humans. Furthermore, Situated Question Answering [37] requires advanced 3D spatial understanding of the agent to answer the question and to interpret and locate the position and orientation of the textual description. Compared to previous works [22, 23, 14] using point clouds, we only use RGB-D images to encode feature fields and leverage their multi-scale representations for localization and question answering.
3 Our Method
3.1 3D-Language Data
We prepare a large-scale 3D-language dataset to align the representations of the feature fields with language. Our dataset includes about 5K 3D indoor scenes, mainly sourced from the single-room scans ScanNet [12], multi-room house scans of the Habitat-Matterport 3D dataset (HM3D) [46, 60], and the photo-realistic multi-room scenes of Structured3D [70]. The total number of language annotations is close to one million, which are mainly sourced from the SceneVerse dataset [23]. SceneVerse uses 3D scene graphs and large language models (LLMs) to automate high-quality object-level and scene-level descriptions. The annotations also includes the large set of human-annotated object referrals [7].
We organize the dataset as follows to streamline feature fields training: 1) For each 3D scene, the agent can observe numerous RGB-D images and its corresponding poses as inputs. 2) An instance-level point clouds mark each instance in the scene with an instance ID which can be used to retrieve associated language descriptions from the database. It is thus easy to get instances that are near any given point in the 3D scene and obtain their language descriptions. This enables the training code to efficiently obtain language annotations for specific regions within a novel view or a BEV map.
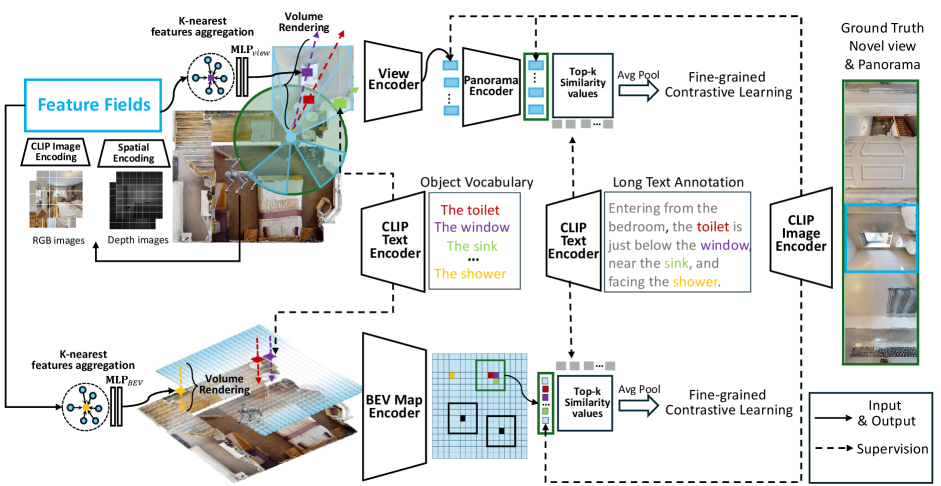
3.2 3D-Language Feature Fields
Feature Fields Encoding. As shown in Figure 2, our g3D-LF model follows HNR [57] to take a posed RGB image as input and uses the CLIP image encoder to extract fine-grained visual features . denotes the -th feature patch of the CLIP feature map extracted from -th frame observed by the agent. We then map to the corresponding 3D world coordinates using the depth map and camera parameters.
For each feature , the observed horizontal orientation and the regional size are also calculated and stored to enhance the spatial representation. The set of feature points can therefore be dynamically updated as:
| (1) |
Ray-View-Panorama Encoding. The network aggregates nearby features within feature fields and encode their spatial information [57] (i.e., relative positions and relative directions) to predict semantic representations and volume density at any point from any direction in the continuous fields.
For each novel view, our g3D-LF model generates a feature map by predicting subregion features through volume rendering within feature fields. The model samples points along the ray from the camera position to each subregion center to search for the k-nearest features and predicting volume density and latent representation , which then are composited into a subregion feature:
| (2) |
Here, represents volume transmittance and is the distance between sampled points. denotes the regional feature at the -th row and -th column of the novel view feature map R. We integrate context of the surrounding by feeding the feature map R together with a learnable view token into the transformer-based view encoder to obtain the encoded and novel view representation that represent the entire novel view. Furthermore, to reason relationships across multiple views within a panorama, our g3D-LF model predicts 12 novel views around the viewpoint at 30-degree intervals and combines them into a transformer-based panorama encoder to obtain .
Ray-BEV Encoding. The novel view and panorama representations are insufficient for larger-scale scene understanding. To circumvent this problem, we propose to construct BEV map representation via our g3D-LF as shown in Figure 2. Unlike novel view prediction where rays are emitted from the viewpoint along the viewing cone, the rendering rays for the BEV map are rendered vertically from top to bottom. The starting point of the rendered ray is set slightly below the ceiling to avoid being blocked.
Specifically, the network is used to aggregate the nearest feature points to the sampled point and predict its semantic representation and volume density in the continuous field. Subsequently, the ray representation can be obtained using the similar volume rendering method of Equation 2, where denotes the -th row and -th column of the BEV map . To cover the large scene, the BEV map encompasses a area centered on the agent. After downsampling the BEV map to through a non-overlapping convolution layer, the transformer-based BEV map encoder captures semantic relationships between different regions to get the encoded BEV map representations .
3.3 Multi-level Contrastive Learning
Balanced Object-level Alignment. We apply contrastive supervision using an object vocabulary that spans 1,883 indoor object categories for supervision of the and networks to predict latent features in feature fields. For ray representations R obtained via volume rendering, the cosine similarities are computed with each vocabulary embedding. The training objective is to maximize and minimize similarity for the correct and other object category, respectively, i.e.:
| (3) |
where denotes the ground-truth category and is the temperature coefficient for contrastive learning. Similarly, the object alignment loss for the ray representations of the BEV map denoted as can also be calculated.
We notice the network struggles to recognize smaller objects such as the lamp due to the dominance of some objects (e.g., floor and walls) leading to long-tailed distribution in the indoor scenes. To address this issue, we implement a balanced loss that emphasizes harder-to-recognize objects. Specifically, the weight of loss for the rays of top 10% cross entropy are significantly increased using a scaling factor for ray representations within the novel view or BEV map. In short, rays with higher cross entropy indicate harder-to-recognize objects and therefore have a higher loss weight.
Fine-grained Contrastive for Long Text. To enable our g3D-LF model to understand object relationships and spatial layouts, we propose a fine-grained contrastive learning method for long text alignment. As shown in Figure 2, our g3D-LF aligns the BEV features in a window (e.g., ) with the long text features to enhance the representation of the BEV map for spatial semantics. Specifically, centered on an instance, the BEV features within the window are associated with word features from the CLIP text encoder through an affinity matrix :
| (4) |
The highest similarity scores (equal to the number of words) are extracted from the affinity matrix , and their average is used as the fine-grained similarity score between the BEV window and the long text features:
| (5) |
Denoting the BEV features within the -th window as and the -th text features as , the fine-grained contrastive learning loss can be calculated as:
| (6) |
Similarly, our g3D-LF model performs fine-grained contrastive learning between encoded panoramic representations and long-text features to compute the fine-grained contrastive loss .
CLIP Knowledge Distillation. Since the 3D-language data is orders of magnitude smaller than image-language data (millions vs. billions [45]), our g3D-LF model still distills visual features from CLIP model [45] to ensure robust generalization. Specifically, our g3D-LF uses CLIP features extracted from the ground-truth novel view or corresponding region image for contrastive supervision on the predicted new view representation , the panorama representation , and the BEV map representation , i.e.:
| (7) |
where denotes the ground truth CLIP feature for -th novel view representation . Similarly, the contrastive loss for the panoramic representation and for the BEV map can also be computed.
3.4 Embodied Tasks
To verify the effectiveness of our g3D-LF model for embodied tasks, we integrate the predicted representations from our model into existing baseline methods and evaluates performance on Vision-and-Language Navigation, Zero-shot Object Navigation, and Situated Question Answering tasks.
Vision-and-Language Navigation. We evaluate the g3D-LF model on VLN tasks with two settings. The first setting is with the monocular camera, which only allows the agent to observe the forward-facing view. As shown in Figure 3, the VLN-3DFF [58] is a monocular VLN model that predicts candidate waypoints around the agent using a semantic map, and predicts each candidate’s representation with generalizable feature fields [57] and then selects the optimal waypoint to move through a cross-modal graph encoder [10, 2]. Based on this baseline method, we incorporate novel view representations from our g3D-LF model and input the BEV map into the cross-modal graph encoder following GridMM [56] to enhance spatial layout understanding. The second setting is with the panorama camera, in which the agent can observe 12 RGB-D view images within the panorama. Following HNR [57], a waypoint predictor [20] is used to predict candidate waypoints, and our g3D-LF model generates panorama representations of these waypoints for navigation planning.

Zero-shot Object Navigation. As shown in Figure 4, unlike the baseline method VLFM [62] that uses the 2D foundation model BLIP-2 [30] to calculate the similarity between the target object and visual observations to construct the value map, we use our g3D-LF to predict the value of potential regions. Although the monocular agent can only observe the forward view, our g3D-LF predicts 12 novel view feature maps surrounding the agent within panorama based on historical observations, and calculates max similarity in feature map with the target object. The text features of the target object are also used to calculate the similarity with each region representation on the BEV map to obtain a larger-scale value map. Combining these two value maps, the navigation agent prioritizes traveling to the candidate waypoint with the highest similarity score.

Situated Question Answering. A three-stage framework is shown in Figure 5, where we use our g3D-LF to train three transformer-based decoders for position, orientation and answer predictions. First, the Localization Decoder predicts the heatmap for location of the textual description based on the BEV map. Our g3D-LF model generates the panorama representations around the predicted location, which are then processed by the Orientation Decoder to predict the orientation. Finally, the textual description, question, BEV map, and panorama representations are fed into the Answer Decoder to generate the final answer.

4 Experiments
4.1 Experiment Setup and Metrics
g3D-LF Pre-training. We pre-train our g3D-LF model shown in Figure 2 on 5K 3D scenes. During training, 30 frames are uniformly sampled from the RGB-D video of each scene in the ScanNet [12] dataset to construct the feature fields, with an additional frame randomly selected as the novel view for prediction. The g3D-LF then predicts the panorama representation and BEV map centered on the camera of this novel view. For each ray in the novel view or BEV map, the corresponding instance ID can be searched by calculating the nearest instance point to the rendered surface within the annotated instance point cloud. The language annotations of the novel view, panorama, and BEV map can thus be obtained by retrieving language annotations with their instance IDs from the database for training. Due to the limited number of images per scene (fewer than 20), we use all available images from the Structured3D [70] dataset for training. We follow HNR [57] for the HM3D [46, 60] dataset using the Habitat simulator [48] to randomly sample navigation trajectories and the observed RGB-D images to predict the novel views and panoramas around candidate waypoints, and construct the BEV map centered on the agent. The multi-level contrastive losses described in Section 3.3 are utilized to optimize the g3D-LF model.
Finally, we combine scenes from all datasets and pretrain our g3D-LF model for 50K episodes (about 10 days) on two RTX 6000 Ada GPUs. To ensure fair comparisons on downstream tasks, all training data only includes the train split, the val and test splits are removed.
Vision-and-Language Navigation. We evaluate the VLN model on the VLN-CE dataset [27] in both monocular [58] and panorama [57] settings. R2R-CE is collected based on the Matterport3D [5] scenes with the Habitat simulator [48]. The R2R-CE dataset includes 5,611 trajectories divided into train, validation seen, validation unseen, and test unseen splits. Each trajectory has three English instructions with an average path length of 9.89 meters and an average instruction length of 32 words. Several standard metrics [3] are used to evaluate VLN performance: Navigation Error (NE), Success Rate (SR), SR given the Oracle stop policy (OSR), Success Rate weighted by normalized inverse Path Length (SPL).
Zero-shot Object Navigation. For object navigation, we evaluate our approach using the Habitat simulator [48] on the validation splits of two different datasets HM3D [46] and MP3D [5]. The HM3D validation split contains 2,000 episodes across 20 scenes and 6 object categories. The MP3D validation split contains 2,195 episodes across 11 scenes and 21 object categories. The main metrics [3] include Success Rate (SR) and Success Rate weighted by normalized inverse Path Length (SPL).
Situated Question Answering. Following ScanNet [12], the SQA3D dataset comprises 20.4k descriptions and 33.4k diverse questions, which is splited into train, val, and test sets. The main metric is the Exact Match (EM@1) of the answer. Additionally, for localization evaluation, [email protected] and [email protected] metric means the prediction is counted as correct when the predicted position is within 0.5 meter and 1.0 meter range to the ground truth position. The Acc@15° and Acc@30° metric means the prediction is counted as correct when the prediction orientation is within 15° and 30° range to the ground truth orientation.
4.2 Comparison with SOTA Methods
As shown in Table 1 and Table 2, we evaluate the VLN performance of our g3D-LF model on the R2R-CE dataset in both monocular and panorama settings, respectively. Table 1 shows that our g3D-LF significantly outperforms previous monocular VLN methods on the Success Rate (SR) metric, even compared to LLM-based methods such as NaVid [67] and InstructNav [36]. Compared to the panorama setting, monocular VLN has the advantage of being compatible with a broader range of real-world monocular robots. Our g3D-LF model overcomes the limitations of monocular cameras, enhancing the multi-view and BEV perception capabilities of the agent for monocular VLN.
| Methods | LLM | Val Unseen | Test Unseen | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NE↓ | OSR↑ | SR↑ | SPL↑ | NE↓ | OSR↑ | SR↑ | SPL↑ | ||
| CM2 [16] | 7.02 | 41.5 | 34.3 | 27.6 | 7.7 | 39 | 31 | 24 | |
| WS-MGMap [8] | 6.28 | 47.6 | 38.9 | 34.3 | 7.11 | 45 | 35 | 28 | |
| NaVid [67] | ✓ | 5.47 | 49.1 | 37.4 | 35.9 | - | - | - | - |
| InstructNav∗ [36] | ✓ | 6.89 | - | 31 | 24 | - | - | - | - |
| VLN-3DFF [58] | 5.95 | 55.8 | 44.9 | 30.4 | 6.24 | 54.4 | 43.7 | 28.9 | |
| g3D-LF (Ours) | 5.70 | 59.5 | 47.2 | 34.6 | 6.00 | 57.5 | 46.3 | 32.2 | |
We follow HNR [57] to perform lookahead exploration through predicted candidate waypoint representations for the panorama setting in Table 2. Although the results show minor performance gains and the advanatges are not as pronounced as its monocular counterpart in Table 1, our g3D-LF model still achieves SOTA performance on the SPL metric and demonstrated competitive results on the SR metric.
| Methods | LLM | Val Unseen | Test Unseen | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NE↓ | OSR↑ | SR↑ | SPL↑ | NE↓ | OSR↑ | SR↑ | SPL↑ | ||
| Sim2Sim [26] | 6.07 | 52 | 43 | 36 | 6.17 | 52 | 44 | 37 | |
| VLN-BERT [20] | 5.74 | 53 | 44 | 39 | 5.89 | 51 | 42 | 36 | |
| GridMM [56] | 5.11 | 61 | 49 | 41 | 5.64 | 56 | 46 | 39 | |
| Ego2-Map [21] | 4.94 | - | 52 | 46 | 5.54 | 56 | 47 | 41 | |
| DREAM [53] | 5.53 | 59 | 49 | 44 | 5.48 | 57 | 49 | 44 | |
| ScaleVLN [55] | 4.80 | - | 55 | 51 | 5.11 | - | 55 | 50 | |
| ETPNav [2] | 4.71 | 65 | 57 | 49 | 5.12 | 63 | 55 | 48 | |
| BEVBert [1] | 4.57 | 67 | 59 | 50 | 4.70 | 67 | 59 | 50 | |
| HNR [57] | 4.42 | 67 | 61 | 51 | 4.81 | 67 | 58 | 50 | |
| Energy [33] | 4.69 | 65 | 58 | 50 | 5.08 | 64 | 56 | 48 | |
| g3D-LF (Ours) | 4.53 | 68 | 61 | 52 | 4.78 | 68 | 58 | 51 | |
In Table 3 for the Zero-shot Object Navigation, our g3D-LF achieves SOTA performance in the SPL metric and achieves competitive results in the SR metric. Notably, our g3D-LF is the only method that queries targets using feature fields instead of VLM. Replacement of BLIP-2 [30] in VLFM [62] with g3D-LF improves the navigation success rate (SR) by nearly 3%. Although the MP3D benchmark includes some targets outside the g3D-LF object vocabulary, our model still performs well, demonstrating strong generalization. Compared to methods using LLM: InstructNav [36] and SG-Nav [61], our g3D-LF also offers significant advantages in response time and computational cost.
| Methods | LLM | VLM | Feature Fields | HM3D | MP3D | ||
| SR↑ | SPL↑ | SR↑ | SPL↑ | ||||
| ZSON [39] | ✓ | 25.5 | 12.6 | 15.3 | 4.8 | ||
| ESC [71] | ✓ | ✓ | 39.2 | 22.3 | 28.7 | 14.2 | |
| VLFM [62] | ✓ | 52.5 | 30.4 | 36.4 | 17.5 | ||
| InstructNav [36] | ✓ | ✓ | 58.0 | 20.9 | - | - | |
| GAMap [63] | ✓ | ✓ | 53.1 | 26.0 | - | - | |
| SG-Nav [61] | ✓ | ✓ | 54.0 | 24.9 | 40.2 | 16.0 | |
| g3D-LF (Ours) | ✓ | 55.6 | 31.8 | 39.0 | 18.8 | ||
In Table 4 for the Situated Question Answering task, our g3D-LF achieves good localization performance in metrics of [email protected], Acc@1m, Acc@15° and Acc@30°. Although our performance on the answering accuracy (EM@1) is significantly lower than that of LLM-based methods: LEO [22] and Scene-LLM [14], it is worth noting that our g3D-LF only uses images as input without low-noise 3D point clouds. This actually offers a significant advantage in agent-centered embodied tasks since it is more adaptable to unseen dynamic real-world environments, where the low-noise point clouds are difficult to collect.
| Methods | LLM | PCD | Image | Position | Orientation | Answer | ||
|---|---|---|---|---|---|---|---|---|
| 0.5m | 1.0m | 15° | 30° | EM@1 | ||||
| ClipBERT [29] | ✓ | - | - | - | - | 43.3 | ||
| ScanQA [4] | ✓ | - | - | - | - | 46.6 | ||
| SQA3D [37] | ✓ | 14.6 | 34.2 | 22.4 | 42.3 | 47.2 | ||
| 3D-VisTA [73] | ✓ | - | - | - | - | 48.5 | ||
| SceneVerse [23] | ✓ | - | - | - | - | 49.9 | ||
| LEO [22] | ✓ | ✓ | - | - | - | - | 52.4 | |
| Scene-LLM [14] | ✓ | ✓ | ✓ | - | - | - | - | 54.2 |
| g3D-LF (Ours) | ✓ | 23.4 | 45.7 | 29.8 | 54.7 | 47.7 | ||
4.3 Ablation Study
Perfromance impact of g3D-LF on embodied tasks. In row 1 of Table 5, the performance of monocular VLN and object navigation drops significantly without representations from g3D-LF. In this setting, the VLN model only uses the CLIP features from the forward-facing view with features of all other directions set to zero. The object navigation model uses BLIP-2 [30] instead of g3D-LF to construct the value map. Examining rows 2 and 3 shows that removing either the novel view or the BEV map reduces the performance of both two tasks, highlighting the role of each g3D-LF module.
Novel views are crucial for monocular VLN. As shown in row 1 and row 2 of Table 5, the novel view representations significantly boost VLN performance by overcoming the narrow perception of the monocular camera [58], enabling the monocular agent to have panoramic perception capabilities. To some extent, this confirms that novel view prediction is a very important and valuable capability for monocular agents. Based on this capability, the g3D-LF model predicts the novel view representations of candidate waypoints around the agent to construct the topological map for better navigation planning.
Object navigation requires balancing local and global targets. As shown in row 3 of Table 5, we observe that relying solely on BEV representation significantly reduces object navigation performance. This decline occurs because the global value map from the BEV map fails to select optimal nearby waypoints if the target is far from these waypoints. In this case, a local value map constructed from novel views is also essential to identify the optimal short-term goal, i.e., nearby waypoints around the agent.
| View & Pano | BEV | Monocular VLN | Object Nav. | ||||
|---|---|---|---|---|---|---|---|
| NE↓ | OSR↑ | SR↑ | SPL↑ | SR↑ | SPL↑ | ||
| 6.54 | 44.6 | 33.1 | 23.4 | 52.5 | 30.4 | ||
| ✓ | 5.78 | 58.3 | 46.9 | 32.7 | 53.9 | 30.8 | |
| ✓ | 6.02 | 53.1 | 42.8 | 26.5 | 50.2 | 27.1 | |
| ✓ | ✓ | 5.70 | 59.5 | 47.2 | 34.6 | 55.6 | 31.8 |
| OBJ-CL | CLIP-CL | FG-CL | Monocular VLN | Object Nav. | ||||
|---|---|---|---|---|---|---|---|---|
| NE↓ | OSR↑ | SR↑ | SPL↑ | SR↑ | SPL↑ | |||
| 6.21 | 50.2 | 40.7 | 24.9 | 34.2 | 13.9 | |||
| ✓ | 5.84 | 56.1 | 44.6 | 31.1 | 47.6 | 27.8 | ||
| ✓ | ✓ | 6.01 | 53.5 | 42.4 | 26.7 | 55.8 | 31.6 | |
| unbalanced | ✓ | ✓ | 5.73 | 58.3 | 46.6 | 33.0 | 51.7 | 28.8 |
| ✓ | ✓ | coarse | 5.81 | 57.1 | 45.7 | 33.2 | 55.5 | 31.2 |
| ✓ | ✓ | ✓ | 5.70 | 59.5 | 47.2 | 34.6 | 55.6 | 31.8 |
Pre-training is essential for generalizable feature fields model. Table 6 analyzes the impact of multi-level contrastive pre-training on downstream embodied tasks. As shown in row 1 of Table 6, the performance on VLN and object navigation drops significantly when the model is optimized solely by the navigation loss [2] without pre-training.
Both CLIP distillation and language supervision are indispensable. For row 3 of Table 6 without supervision from the CLIP visual features, the VLN performance lags behind the model distilled by CLIP. This suggests that millions of language annotations are still far from sufficient for g3D-LF pre-training, and distilling representations from 2D foundation models to enhance semantic generalization remains necessary. However, in Table 6, we can also see that language supervision significantly improves g3D-LF performance on embodied tasks , the model performs poorly in row 2 when using only CLIP distillation.
Long-tail distribution limits object-level semantic learning. As shown in row 4 of Table 6, the performance of object navigation decreases drastically without the balanced loss mentioned in Section 3.3. The long-tail distribution of object categories in indoor environments leads models to overlook of rare or small objects such as towels and cups, significantly limiting the ability of our g3D-LF model to query target objects. Fortunately, row 6 of Table 6 shows that the balanced object alignment works well by balancing the weight for loss of hard-to-recognize objects.
Fine-grained contrastive benefits long text understanding. In the row 5 of Table 6, we use the [SEP] feature (single vector) from the CLIP text encoder to supervise panorama and BEV representations. However, compared to the fine-grained contrastive learning in row 6, compressing long text into a coarse vector significantly limits g3D-LF’s performance on long-text understanding tasks such as VLN. As shown in Figure 2, fine-grained contrastive learning between long texts and windows within the BEV map helps g3D-LF understand spatial layouts, overcoming the limitations of semantic representation in large-scale scenes.
| Rays for View | View | Panorama | Rays for BEV | BEV |
| 73.6 FPS | 71.1 FPS | 5.9 FPS | 6.3 FPS | 6.1 FPS |
g3D-LF enables real-time inference. As shown in Table 7, we calculate the inference time of our g3D-LF model on the val unseen split of the R2R-CE dataset in the VLN task. Our g3D-LF achieves novel view volume rendering at 73.6 FPS, which slightly drops to 71.1 FPS when rays are further encoded by the View Encoder. For a panorama containing 12 views, the inference speed is 5.9 FPS. Due to the large rendered range, our g3D-LF renders BEV maps at 6.3 FPS, which drops slightly to 6.1 FPS with the BEV Map Encoder. Our g3D-LF model adopts the same sparse sampling strategy as in HNR [57], where the MLP network is only used to render sampled regions containing feature points nearby, while skipping empty regions. This reduces rendering time by over 10 times, enabling real-time embodied tasks.
5 Conclusion
In this work, we propose Generalizable 3D-Language Feature Fields (g3D-LF), a 3D representation model pre-trained on large-scale 3D-language data for embodied tasks. We organize the first large-scale 3D-language dataset for feature fields training, demonstrating the feasibility of using generalizable feature fields for large-scale scene understanding, i.e., panorama and BEV. Our proposed g3D-LF leverages multi-level contrastive learning strategies such as balanced object semantic alignment, fine-grained text alignment, and CLIP knowledge distillation to optimize generalized feature fields. More importantly, the value of g3D-LF has been widely evaluated in multiple embodied tasks. We believe that our g3D-LF can provide sufficient inspiration for subsequent research on feature fields and embodied AI.
Limitations and future works. Our g3D-LF still has some limitations with significant potential for future research: 1) g3D-LF cannot be adapted to dynamic environments, where objects or people are moving in real time. This requires better update strategies for implicit representations. 2) g3D-LF has not been evaluated on dynamic tasks such as object manipulation. 3) The scale and quality of 3D-language data used for training g3D-LF remain limited, which essentially restricts the ability of generalizable feature field models. 4) The 3D feature fields combined with LLM can enable better text generation. These may become the guiding directions for the next phase of generalizable feature fields.
References
- An et al. [2023] Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. Bevbert: Multimodal map pre-training for language-guided navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2737–2748, 2023.
- An et al. [2024] Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. Etpnav: Evolving topological planning for vision-language navigation in continuous environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- Anderson et al. [2018] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018.
- Azuma et al. [2022] Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022.
- Chang et al. [2017] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In International Conference on 3D Vision (3DV), 2017.
- Chaplot et al. [2020] Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems, 33:4247–4258, 2020.
- Chen et al. [2020] Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. In European conference on computer vision, pages 202–221. Springer, 2020.
- Chen et al. [2022a] Peihao Chen, Dongyu Ji, Kunyang Lin, Runhao Zeng, Thomas Li, Mingkui Tan, and Chuang Gan. Weakly-supervised multi-granularity map learning for vision-and-language navigation. Advances in Neural Information Processing Systems, 35:38149–38161, 2022a.
- Chen et al. [2021] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. Advances in neural information processing systems, 34:5834–5847, 2021.
- Chen et al. [2022b] Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16537–16547, 2022b.
- Chen et al. [2024] Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, and Jiangmiao Pang. Grounded 3d-llm with referent tokens. arXiv preprint arXiv:2405.10370, 2024.
- Dai et al. [2017] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017.
- Das et al. [2018] Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. Embodied question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–10, 2018.
- Fu et al. [2024] Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning. arXiv preprint arXiv:2403.11401, 2024.
- Gadre et al. [2023] Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Ilharco, Ludwig Schmidt, and Shuran Song. Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23171–23181, 2023.
- Georgakis et al. [2022] Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. Cross-modal map learning for vision and language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15460–15470, 2022.
- Gervet et al. [2023] Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world. Science Robotics, 8(79):eadf6991, 2023.
- He et al. [2017] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- Hong et al. [2021] Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould. Vln bert: A recurrent vision-and-language bert for navigation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 1643–1653, 2021.
- Hong et al. [2022] Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Hong et al. [2023] Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan. Learning navigational visual representations with semantic map supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3055–3067, 2023.
- Huang et al. [2024] Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. In Proceedings of the International Conference on Machine Learning (ICML), 2024.
- Jia et al. [2024] Baoxiong Jia, Yixin Chen, Huangyue Yu, Yan Wang, Xuesong Niu, Tengyu Liu, Qing Li, and Siyuan Huang. Sceneverse: Scaling 3d vision-language learning for grounded scene understanding. In European Conference on Computer Vision (ECCV), 2024.
- Kerr et al. [2023] Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19729–19739, 2023.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023.
- Krantz and Lee [2022] Jacob Krantz and Stefan Lee. Sim-2-sim transfer for vision-and-language navigation in continuous environments. In European Conference on Computer Vision (ECCV), 2022.
- Krantz et al. [2020] Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16, pages 104–120. Springer, 2020.
- Kwon et al. [2023] Obin Kwon, Jeongho Park, and Songhwai Oh. Renderable neural radiance map for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9099–9108, 2023.
- Lei et al. [2021] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7331–7341, 2021.
- Li et al. [2023] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023.
- Li et al. [2022] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10965–10975, 2022.
- Liu et al. [2023a] Rui Liu, Xiaohan Wang, Wenguan Wang, and Yi Yang. Bird’s-eye-view scene graph for vision-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10968–10980, 2023a.
- Liu et al. [2024a] Rui Liu, Wenguan Wang, and Yi Yang. Vision-language navigation with energy-based policy. In Advances in Neural Information Processing Systems, 2024a.
- Liu et al. [2024b] Rui Liu, Wenguan Wang, and Yi Yang. Volumetric environment representation for vision-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16317–16328, 2024b.
- Liu et al. [2023b] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023b.
- Long et al. [2024] Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment. In 8th Annual Conference on Robot Learning, 2024.
- Ma et al. [2023] Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. In The Eleventh International Conference on Learning Representations, 2023.
- Maas et al. [2013] Andrew L Maas, Awni Y Hannun, Andrew Y Ng, et al. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml, page 3. Atlanta, GA, 2013.
- Majumdar et al. [2022] Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. Zson: Zero-shot object-goal navigation using multimodal goal embeddings. Advances in Neural Information Processing Systems, 35:32340–32352, 2022.
- Majumdar et al. [2024] Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16488–16498, 2024.
- Mildenhall et al. [2021] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- Oquab et al. [2024] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal, pages 1–31, 2024.
- Qiao et al. [2023] Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, and Qi Wu. Hop+: History-enhanced and order-aware pre-training for vision-and-language navigation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(7):8524–8537, 2023.
- Qiu et al. [2024] Ri-Zhao Qiu, Yafei Hu, Ge Yang, Yuchen Song, Yang Fu, Jianglong Ye, Jiteng Mu, Ruihan Yang, Nikolay Atanasov, Sebastian Scherer, et al. Learning generalizable feature fields for mobile manipulation. arXiv preprint arXiv:2403.07563, 2024.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [46] Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- Ramakrishnan et al. [2022] Santhosh Kumar Ramakrishnan, Devendra Singh Chaplot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18890–18900, 2022.
- Savva et al. [2019] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019.
- Shen et al. [2023] William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. Distilled feature fields enable few-shot language-guided manipulation. In Proceedings of The 7th Conference on Robot Learning, pages 405–424. PMLR, 2023.
- Taioli et al. [2023] Francesco Taioli, Federico Cunico, Federico Girella, Riccardo Bologna, Alessandro Farinelli, and Marco Cristani. Language-enhanced rnr-map: Querying renderable neural radiance field maps with natural language. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4669–4674, 2023.
- [51] Suhani Vora, Noha Radwan, Klaus Greff, Henning Meyer, Kyle Genova, Mehdi SM Sajjadi, Etienne Pot, Andrea Tagliasacchi, and Daniel Duckworth. Nesf: Neural semantic fields for generalizable semantic segmentation of 3d scenes. Transactions on Machine Learning Research.
- Wang et al. [2023a] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7464–7475, 2023a.
- Wang et al. [2023b] Hanqing Wang, Wei Liang, Luc Van Gool, and Wenguan Wang. Dreamwalker: Mental planning for continuous vision-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10873–10883, 2023b.
- Wang et al. [2024a] Liuyi Wang, Zongtao He, Ronghao Dang, Mengjiao Shen, Chengju Liu, and Qijun Chen. Vision-and-language navigation via causal learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13139–13150, 2024a.
- Wang et al. [2023c] Zun Wang, Jialu Li, Yicong Hong, Yi Wang, Qi Wu, Mohit Bansal, Stephen Gould, Hao Tan, and Yu Qiao. Scaling data generation in vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12009–12020, 2023c.
- Wang et al. [2023d] Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15625–15636, 2023d.
- Wang et al. [2024b] Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Junjie Hu, Ming Jiang, and Shuqiang Jiang. Lookahead exploration with neural radiance representation for continuous vision-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13753–13762, 2024b.
- Wang et al. [2024c] Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Sim-to-real transfer via 3d feature fields for vision-and-language navigation. In 8th Annual Conference on Robot Learning, 2024c.
- Wijmans et al. [2019] Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357, 2019.
- Yadav et al. [2023] Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, et al. Habitat-matterport 3d semantics dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4927–4936, 2023.
- Yin et al. [2024] Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation. In Advances in Neural Information Processing Systems, 2024.
- Yokoyama et al. [2024] Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024.
- Yuan et al. [2024] Shuaihang Yuan, Hao Huang, Yu Hao, Congcong Wen, Anthony Tzes, and Yi Fang. Gamap: Zero-shot object goal navigation with multi-scale geometric-affordance guidance. In Advances in Neural Information Processing Systems, 2024.
- Ze et al. [2023] Yanjie Ze, Ge Yan, Yueh-Hua Wu, Annabella Macaluso, Yuying Ge, Jianglong Ye, Nicklas Hansen, Li Erran Li, and Xiaolong Wang. Gnfactor: Multi-task real robot learning with generalizable neural feature fields. In Conference on Robot Learning, pages 284–301. PMLR, 2023.
- Zhang et al. [2023] Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023.
- Zhang et al. [2024a] Haochen Zhang, Nader Zantout, Pujith Kachana, Zongyuan Wu, Ji Zhang, and Wenshan Wang. Vla-3d: A dataset for 3d semantic scene understanding and navigation. arXiv preprint arXiv:2411.03540, 2024a.
- Zhang et al. [2024b] Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. In Proceedings of Robotics: Science and Systems (RSS), 2024b.
- Zhang et al. [2021] Sixian Zhang, Xinhang Song, Yubing Bai, Weijie Li, Yakui Chu, and Shuqiang Jiang. Hierarchical object-to-zone graph for object navigation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 15130–15140, 2021.
- Zhang et al. [2024c] Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, and Parisa Kordjamshidi. Vision-and-language navigation today and tomorrow: A survey in the era of foundation models. arXiv preprint arXiv:2407.07035, 2024c.
- Zheng et al. [2020] Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3d: A large photo-realistic dataset for structured 3d modeling. In Proceedings of The European Conference on Computer Vision (ECCV), 2020.
- Zhou et al. [2023] Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. Esc: Exploration with soft commonsense constraints for zero-shot object navigation. In International Conference on Machine Learning, pages 42829–42842. PMLR, 2023.
- Zhu et al. [2017] Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In 2017 IEEE international conference on robotics and automation (ICRA), pages 3357–3364. IEEE, 2017.
- Zhu et al. [2023] Ziyu Zhu, Xiaojian Ma, Yixin Chen, Zhidong Deng, Siyuan Huang, and Qing Li. 3d-vista: Pre-trained transformer for 3d vision and text alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2911–2921, 2023.
Supplementary Material
Appendix A More Details of the g3D-LF Model
Model structure.
Figure 6 illustrates the structure of main modules in the g3D-LF model. Compared to HNR [57], g3D-LF improve the MLP network for volume rendering by adding residual connections and replacing ReLU with LeakyReLU, which helps alleviate gradient explosion and neuron death issues during HNR training. Since the number of k-nearest features is set to 4 and the dimension of each aggregated feature is 768, the input dimension of both and networks is 3072. As shown in Figure 6, all transformer-based encoders consist of four-layer transformers.
Settings of novel view prediction.
For each sampled point in the rendered ray, we set the search radius for k-nearest features as 0.5 meter. Using sparse sampling [57], if no nearby feature points are found within a sampled point’s search radius, the latent feature and volume density are set to zero. The rendered ray is uniformly sampled from 0 to 10 meters, and the number of sampled points is set as 501. After volume rendering, the number of rays within a novel view is set as 1212.
Settings of BEV map prediction.
The search radius for k-nearest features is set as 0.4 meter. The rendered ray is uniformly sampled from 0 to 1.6 meters (i.e., vertically from the camera’s position to bottom), and the number of sampled points is set as 17. After volume rendering, the number of rays within a BEV map is set as 168168.

Loss functions.
As illustrated in Figure 7 and 8, we present the code for the primary loss functions used in g3D-LF pre-training to provide further details. During training, we apply constant coefficients to balance the contributions of each loss, ensuring they remain within the same order of magnitude.


Appendix B Visualization of the Training Data
As shown in Figure 9, we present a 3D scene from our dataset along with some associated language annotations (scene 00800-TEEsavR23oF from HM3D [46]). The instance-level point cloud precisely annotates instances within the 3D scene, allowing retrieval of language annotations for any position by calculating its neighboring instance points and using the instance IDs.

Appendix C Visualization of the g3D-LF model
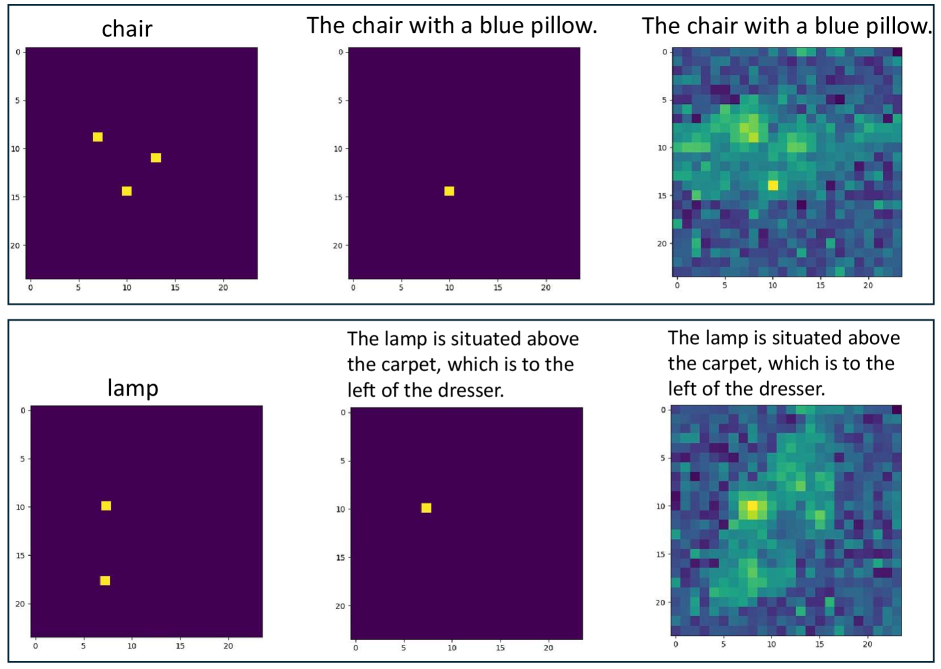
As shown in Figure 10 and 11, the g3D-LF model query targets with language on the BEV map. In Figure 10, the left side of each example shows the position of the ground-truth target, while the right side displays the result of querying objects on rays of the BEV map during navigation. The BEV map accurately recognizes both large objects, like window and sofa, and smaller objects, like table lamp and tap, by calculating the cosine similarity between ray representations and target text features.
In Figure 11, the left side of each example shows the position of the objects, the middle is the ground-truth position of the long text that contains the target object, while the right side displays the result of querying the long text on the BEV map during navigation. In the 3D scene, multiple objects of the same category often appear. With the excellent ability to understand long texts, our g3D-LF model can achieve more fine-grained long-text queries, distinguishing different instances of the same object category.