FusionStitching: Boosting Memory Intensive Computations for
Deep Learning Workloads
Abstract
We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time (JIT) kernel fusion and code generation techniques have limitations, such as rough fusion plan exploration strategies and limited code generation ability. We propose FusionStitching , a deep learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and context switch overhead automatically. FusionStitching widens the range of operation combinations that fusion can target beyond previous JIT works by introducing data reuse of intermediate values. It explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. FusionStitching tunes the optimal stitching scheme with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to speedup compared to state-of-the-art, with 1.45 on average. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.
1 Introduction
Recent years have witnessed a surge of industry scale applications of deep learning models, ranging from images/videos, text/NLP, to billion scale search and recommendation systems[49]. Such workloads are typically expressed as computation graphs, and mapped to hardware through domain specific frameworks (TensorFlow[2], PyTorch[1], MXNet[10], etc). Given the flexibility and expressiveness of modern execution frameworks, there are still challenges regarding to transforming high level computation graphs into efficient kernels to maximize the underlying hardware execution efficiency.
Many current research works mainly focus on compute intensive operations, referring to GEMM and convolution in this paper, as compute intensive operations dominate the execution time for many DNN workloads [34, 46, 11, 39, 6], such as CNN[38, 20, 41]). Compute intensive operations are usually realized as efficient libraries (cuDNN, cuBLAS).
However, recent advancement of deep learning domain has resulted in many novel model structures in which memory intensive patterns occupies a large proportion of time. In this paper, we refer to operators that are not GEMM or convolution as memory intensive ops, such as element wise[42], transpose[44] and reduction[43]. In addition, the amount of memory intensive operators in modern machine learning models can be very large, causing notable GPU kernel launch and framework scheduling overhead. Table 2 contains the collected metrics of various models with TensorFlow implementation. The execution time of memory intensive ops can be more than that of compute intensive ops in some cases, and the kernel calls can be up to 10,406. Optimizing compute intensive ops alone is inadequate to unlock the full performance potential for these models.
It is not feasible to build library for memory intensive operations, because a single memory intensive op is too simple while the combination of such ops various in different models and changes fast as the model evolves. Thus, memory intensive ops are usually generated just-in-time with compilation techniques in modern machine learning frameworks.
A common approach to address memory intensive patterns is computation fusion. Prior works have explored the basic idea in AI workloads[8, 29], database[50], image processing[32, 34, 4], and HPC applications[48, 25] ahead-of-time (AOT). However, how to fuse kernels just-in-time (JIT) efficiently, with unpredictable varied dependencies and non-homogeneous parallelism, is still an open problem. Note that the rapidly evolving AI models introduce diverse and complex combination patterns of ops.
Existing JIT kernel fusion techniques use simple code generation and fusion exploration approach. As for XLA[26], state-of-the-art JIT optimization engine, it only focuses on memory access optimization for memory intensive ops, but lacks consideration of computation characteristics. In a fusion kernel generated by XLA, each thread is only capable of reading intermediate results produced by itself. If two threads require the same intermediate value, they will recompute it independently. It works good for light element-wise ops (like add, sub, mul), but introduces severer re-computation overhead for ops like reduction, tan, log and other expensive ops. XLA avoids re-computation overhead by only allowing expensive ops (reduction, tan, et.al.) appear in the tail of a fusion, that is not being a producer within a fusion. This trade-off limits the fusion exploration space. Meanwhile, XLA uses a conservative fusion exploration strategy. On one hand, it is a rule-based strategy which cannot cover the various combination of element wise ops and tensor shapes. On the other hand, it uses a greedy approach that is easily to fall into local solution.
We propose FusionStitching , a JIT optimization framework to systematically perform fusion space exploration and generate high-performance kernels efficiently. FusionStitching broadens the fusion exploration space by exploring data reuse between ops. If the intermediate data can be reused by a set of threads, these threads could exchange the intermediate data through register-shuffle and shared memory. This approach allows expensive ops to be fused in the middle of a kernel and widens the fusion possibility. With the expanded fusion exploration space, FusionStitching is able to compose a large set of ops with diverge and complex patterns into one GPU kernel. This is effective to reduce off-chip memory accesses and context switch overhead. Meanwhile, FusionStitching applies a more effective fusion exploration approach to find good fusion patterns. FusionStitching addresses two main challenges of large scope JIT fusion.
The first challenge is how to generate efficient GPU kernel given unpredictable complex fusion pattern just-in-time. A fusion pattern reveals a set of operators to be fused into a single GPU kernel. It is non trivial to handle a complex fusion pattern consisting of a broad range of memory intensive ops with various dependence relationships and tensor dimensions. We provide 4 types of stitching scheme abstractions covering the main patterns for memory intensive ops in machine learning workloads, including independent packing, re-computation, intra-warp reuse and intra-block reuse scenarios. With the stitching schemes, we design an approach that divides a fusion into several sub-groups. Different sub-groups use independent schedules and adjacent sub-groups communicate with proper stitching scheme. FusionStitching explores sub-group and stitching scheme settings automatically for a fusion pattern, along with launch dimension enumeration. Instead of using rule-based approach, we design a cost model for code generation tuning.
The second challenge is to find the optimal fusion plan given complex op graph. A fusion plan reveals how ops in a subgraph are grouped together to form a set of fusion patterns. Note that naive composition of multiple computations may cause notable performance slowdown, as different portions of the kernel may have conflicting memory layout, parallelization and on-chip resource requirements[56]. A deep learning computation graph usually brings huge search space about operation combinations. It is not feasible to evaluate all possible combinations with complexity of up to where is the number of ops in the computing graph. We formulate the fusion plan searching as an approximate dynamic programming problem with complexity of , where is the number of edges in the graph. The approximate dynamic programming process produces a limited set of promising fusion patterns with a light-weight cost model. FusionStitching applies beam search to generate the overall fusion plan with these fusion patterns.
We realize FusionStitching into TensorFlow as an optimization component beyond XLA. All the optimizations are opaque to users. FusionStitching supports JIT optimization for both training and inference.
We evaluate FusionStitching on a set of common machine learning models, ranging from natural language processing, OCR, speech recognition to searching and recommendation models. FusionStitching achieves up to 2.21 speedup compared with XLA, with 1.45 on average.
In summary, this work makes the following contributions:
-
•
It reveals the importance of memory intensive ops, and broadens the range of op combinations that JIT fusion targets by introducing data reuse of to-be-fused ops.
-
•
It provides a set of fusion scheme abstractions for memory intensive ops in machine learning workloads, and proposes an approach to generate efficient GPU kernels given very complex fusion patterns.
-
•
It proposes a technique to explore good fusion plans just-in-time in the expanded search space of op composition, along with a two-layer cost model of GPU kernels.
-
•
It provides an industry level realization that is opaque to users and evaluates with various modern machine learning models on production cluster.
2 Motivation and Challenge
2.1 Motivation
JIT fusion is the state-of-the-art technique to reduce context switch and memory access overhead of intensive memory operations for machine learning workloads. As the state-of-the-art fusion engine, XLA only supports thread-local data transferring for fusion, which relies on index analyzing and re-computation to improve thread locality. A bad case is to put a reduction in the middle of a fusion pattern. If different threads require the same value of reduction result, each thread needs to recompute the reduction independently and redundantly. To avoid this, XLA does not fuse operations that lead to middle-reductions. As a result, this strategy misses many optimization exploration space.

Figure 1 shows how XLA and FusionStitching perform fusion for layer normalization. XLA forms 4 fusions, where fusion.3 and fusion.7 end with reductions and fusion.2 ends with expensive operation. XLA does not do other fusion to avoid re-computation overhead, with the drawback of CPU-GPU context switch and off-chip memory access overhead. While FusionStitching generates only one kernel with all intermediate results residing in on-chip memory and involves no CPU-GPU switching. No re-computation is introduced in FusionStitching .
Static libraries are not feasible to solve this problem as a single memory intensive operation is lightweight and the combinations of them vary in different models. TVM [11, 55] mainly focuses on compute intensive operations but not fusion optimization, whereas XLA only provides simple rule-based fusion strategies for memory intensive ops. In addition, TVM relies on pre-defined schedules for code generation and usually requires a long time for tuning.
2.2 Observation
In this work, we have analyzed a variety of machine learning workloads (Section 7). we get two main observations.
Severe Context Switch Overhead Context switch overhead between CPU and GPU is a severe performance issue. Table 2 shows the breakdown analysis of a wide range of machine learning applications. The count of GPU kernel calls () for TensorFlow implementation can reach up to 10,406, which leads to large kernel launch overhead. Even fused with XLA, the kernel calls can be still up to 6,842. As a result, both scheduling and pre-/post-processing time on CPU brought by machine learning framework dominate the execution time for some models (like BERT inference, DIEN, ASR, and CRNN).
Large Portion of Memory-intensive Ops Also in Table 2, the execution time of memory intensive ops can be up to 40% in the overall time for some models. Off-chip memory traffic time usually occupies a large portion of the overall execution time of memory intensive ops. By fusing a large quantity of operations, our system is able to reduce CPU-GPU context switch overhead and leverage high speed on-chip memory to reuse intermediate data between ops.
2.3 Challenges
Although data reuse is a potential opportunity to fuse a large scope of ops together to avoid redundant re-computation, there are several main challenges for both applying reuse given a fusion pattern and deciding op fusion strategy.
As for applying reuse for a given fusion pattern to generate kernel:
-
•
The first challenge is how to evaluate reuse benefit. Reuse is not always better than re-computation. Reuse will lead to extra inter-thread data communication, whereas re-computation introduces redundant compute overhead but without inter-thread communication. Besides, introducing reuse with shared memory may hurt kernel occupancy, thus hurts parallelism.
-
•
The second challenge is how to apply reuse. There are two types of data reuse: intra-warp reuse and intra-block reuse. Intra-warp/block reuse means that threads within a warp/block reuses intermediate data produced by other threads within the same warp/block. The trade-off is that, intra-warp reuse has less memory access overhead while intra-block reuse has better parallelism.
For a given machine learning model, the challenge is to decide what ops should be fused together. XLA also tries to solve this challenge, but with limited exploration space. One main problem is that, forming a fusion pattern by data reuse is not always better than separate kernels. Reuse requires data locality within thread-block or warp, which can potentially limit parallelism. Take reduction as an example, reuse of reduction result requires to compute reduction within a block or warp. However, some reductions perform better with several blocks work together, which has higher parallelism. Not fusing such a reduction with its consumers may result in better performance, even with context switch and off-chip memory access overhead. Intra-block reuse may further hurt parallelism as it requires extra shared memory. Another typical problem is that, when operation A can be fused with either operation B or operation C, while B and C cannot be fused together due to some limitation, it is not always easy to decide which one to fuse for A. Rule-based approaches, like XLA, fail to find effective fusion plans for varied models.
3 Overview
3.1 Data Reuse
As described before, FusionStitching widens fusion possibilities by introducing data reuse, a rarely used method in state-of-the-art JIT fusion techniques. Data reuse can be applied when different threads processing operation requires the same value generated by operation . We assume is the consumer of . The threads requiring the same value can read the same data with inter-thread communication, but do not have to re-compute it redundantly like in XLA. We observe that tensor shapes of a sequence of memory intensive operations always shrink and broaden frequently due to operations like reduce, broadcast, gather, and slice. Thereby the opportunity to explore data reuse is large.
In our work, we explore both intra-warp reuse and intra-block reuse, corresponding to warp composition and block composition in figure 3. Take reduction as an example, intra-warp reuse means that each warp does reduction for a row of data and stores result in the register of the first lane of the warp. Consumers of the reduction read data with register-shuffle from the first lane. Intra-block reuse does reduction for the row with all threads in the block and stores results in shared memory. Consumers of the reduction read data from shared memory. This approach enables stitching operations with on-chip memory while avoiding re-computation. Data locality should be guaranteed for correct data reuse. Intra-warp reuse requires warp level data locality, and intra-block reuse requires block level data locality.

3.2 FusionStitching System
We divide optimization process into two stages in FusionStitching : fusion exploration and code generation. The two stages are conceptually independent but highly related.
As shown in figure 2, FusionStitching consists of fusion explorer and code generator. Fusion explorer generates possible fusion patterns that may enjoy data reuse. It then applies beam search to form several candidate fusion plans with these fusion patterns, and selects the best fusion plan from candidate plans with a cost model. Code generator generates GPU kernels for each fusion pattern produced by fusion explorer. We pre-define a set of schedules (i.e., templates) for each kind of operators. A schedule describes code generation about how an operation runs in parallel. Meanwhile, it indicates whether threads of an operation reuse data with other threads and the reuse scope, and whether this operation produces data for consumer’s reuse. FusionStitching divides operations of a fusion pattern into several groups, and enumerates all valid combinations of the schedules in the groups. With a cost model that estimates the performance of each schedule and launch dimension setting, FusionStitching selects the best configuration of the fusion pattern and generates GPU kernel code.
We design a two-level cost model in FusionStitching . Fusion explorer needs to search in large search space and applies delta-evaluator (5.4), which is fast but less accurate. Code generator operates on merged GPU kernels and needs more accurate performance estimation, and thus we apply latency-evaluator (4.3) which is more accurate but slower.
4 Code Generation
Code generator takes a fusion pattern as input, and produces a GPU kernel that implements the fused operators. It is nontrivial to fuse multiple ops into one high performance GPU kernel due to various dependence scenarios and parallelism incompatibilities.
The combination patterns of memory intensive operators in machine workload are numerous, but basic kinds of memory intensive ops are limited. We made three classifications: light element-wise (most elem-wise ops), expensive element-wise (tan, exponential, et.al.), and reduction ops. We pre-define a set of schedules for each kind of memory intensive ops. The left problem of code generation is how to stitch different operators into one kernel and what schedule each individual op applies.
We first systematically investigate four kernel composition schemes (4.1) that covers common execution patterns for memory intensive operations. With these composition schemes, we used an automatic generation solution based on performance modeling (4.3) to find good schedules and generate code for the fusion pattern (4.2).
4.1 Kernel Composition Schemes
We study about four kernel composition schemes, which indicate main behaviors of common memory intensive ops. Different scheme indicates different data dependence and parallel behaviors of kernels to fuse, ranging from no dependence to complex cross-thread dependence, and from uniformed parallelism to non-homogeneous computations. Figure 3 illustrates the four kind of composition schemes.

Kernel Packing packs computations of ops with no data dependence. This scheme is instrumental in reducing context switch overhead of kernel launch and framework scheduling. It also reduces loop control overheads in instruction level. To reduce control flow overhead, we perform aggressive loop fusion [5, 18] to merge as many element-wise ops as possible into a single loop structure when these ops have the same parallelism dimension.
Thread Composition fuses dependent ops and transfer intermediate results via registers within a local thread context. This is the fusion scheme XLA applies. This may introduce redundant computations between threads requiring the same value.
Warp Composition fuses dependent operators and apply intra-warp reuse. This scheme employs register shuffle to communicate between threads within a warp. A typical case is warp reduction and its consumers, which applies warp level reduction and leverages registers to transfer intermediate results to threads of its consumers.
Block Composition applies intra-block reuse and unlocks the potential to enable composing non-homogeneous computations into large fused kernels, as long as these computations can communicate within block level. It makes use of shared memory to transfer intermediate results for data reuse.
Warp composition and block composition are flexible schemes as they allow different ops to execute in independent schedules in the fused kernel. The only requirement is to keep warp/block locality between producers and consumers. These two schemes are essential to compose a broad range of op kinds with various parallelism characteristics and dependence relationships efficiently.
As far as we know, FusionStitching is the first work to thoroughly study about all above composition techniques for just-in-time compilation of memory intensive operations for machine learning workloads. XLA only realizes kernel packing and thread composition. We do not stitch ops that involves inter-block communications as it results in global memory level synchronization and introduces high overhead.
4.2 Kernel Generation
Code generation in FusionStitching is not as straightforward as XLA, because of the trade-off of composition schemes we discussed above. We use a cost model based tuning approach in FusionStitching , and ease the process by op grouping.
According to the four types of composition schemes, we pre-define a set of schedules for each kind of operators (light element-wise, expensive element-wise, and reduction ops). Specifically, we define a single template for light element-wise ops representing kernel packing and thread composition. Note that we find kernel packing and thread composition can be described with the same schedule. We define three schedules for expensive element-wise ops and reduction ops. The first one represents kernel packing and thread composition. The second one stores intermediate result to the register of the first lane in each warp, representing warp composition. The third one stores intermediate result to shared memory, representing block composition.
FusionStitching enumerates all schedule combinations of ops. It estimates these combinations according to cost model (sec 4.3). To ease the enumeration process, we divide ops in a fusion pattern into several groups. Each group applies one schedule and different groups transfer intermediate data with warp/block level reuse.
We group ops according to op types. Given a fusion pattern, we enumerate a small set of grouping strategies. We call sub-root as the output op of a group, and root as the output of the fusion. We first identify sub-roots and generate groups rooted from sub-roots and root. Reduce ops are always regarded as sub-root. Expensive element-wise ops are enumerated to both sub-roots and non sub-roots. Other ops are neither sub-roots. This leads to a set of groups rooted from reduction, expensive element-wise and root ops.
The insight of the grouping approach is that, the schedule of non sub-roots can be determined by the schedule of sub-roots by tensor indices propagation. Thus we only need to enumerate the schedule of sub-roots and root ops, and we can propagate to get schedules of all ops.
FusionStitching enumerates grouping strategies, and emulates schedules of every sub-root/root op and launch dimension of the fused kernel. As data reuse requires correct data locality in the reuse scope, schedules do not match data locality requirement are discarded. After estimating the performance of each enumeration with latency-evaluator, FusionStitching selects code generation strategy with the best estimated performance.
4.3 Kernel Evaluation: Latency-Evaluator
FusionStitching requires an accurate estimation for kernel performance for code generation strategy. Fortunately, as the searching space of code generation is not very large, we can tolerate a relative slow cost model.
We build latency-evaluator as in equation 1, where is the estimated execution cycles of a fused kernel.
| (1) | |||
means how many waves of warps that will be processed by a GPU, noting that the warps for a large GPU kernel will be spitted into several waves to be executed on a GPU where warps in the same wave executes concurrently. means the latency (cycles) a single warp spends in the fused kernel. The multiply of and stands for the total cycles to execute the fused kernel.
We estimate with the total number of warps to issue () and the occupancy of the fused kernel (). is calculated with launch dimension and tensor shape. We calculate with launch dimension, shared memory usage (Sec. 4.4) and estimated register usage. We estimate the register usage by analyzing the life time of every intermediate value and get the maximum register usage for a thread. Also, we estimate shared memory usage by life time analyzing. This approach is accurate enough for us to calculate .
4.4 Shared Memory Optimization
It is essential to use shared memory moderately as large amount of shared memory usage hurts kernel parallelism, especially for large granularity compositions. To use as much shared memory as possible while not hurting parallelism, we explore a dataflow based shared memory sharing technique. The insight is that, FusionStitching reuses previous allocated shared memory as much as possible to reduce unnecessary shared memory allocation.
We use dominance tree algorithm[12] for shared memory dataflow analysis. The approach takes a computation graph and shared memory requests as input, and outputs an allocation map. To optimize shared space sharing, we traverse ops of the computation graph in topological order. When an op does not need shared space, previous allocation information will be propagated forward. If an op needs shared space, we merge allocation information of all its operands, test the dominance relation to check if we can share any previously allocated space for current op, and reuse the space if possible.
4.5 Computation Reuse Optimizations
Beside the reuse of intermediate result between producers and consumers with shared memory and register shuffles, FusionStitching also reduces thread local redundant calculations. Thread local redundant calculations mainly come from memory access index calculations and thread local intermediate values. It is because different parts in a fusion kernel may use different schedules, and index and some intermediate values are generated independently within each schedule, even in the same thread. Before generating the code, FusionStitching first analyzes the overall index and intermediate value characteristics and then organizes the output code to reuse computations and data as much as possible.
5 Fusion Exploration
As noted before, rule-based approach in XLA is not adequate to handle complex fusion decisions. We use a cost-based searching approach to find good fusion plans. We propose an approximate dynamic programming approach to search for a set of promising fusion patterns(5.2) which may overlap with each other. The searching process is guided by a light-weight domain-specific cost model(5.4). FusionStitching finally generates the overall fusion plan by selecting fusion patterns(5.3).
5.1 Fusion Problem Definition
We formulate fusion exploration as a subgraph searching problem. For computation graph , where and are sets of vertices and edges respectively. We define a fusion pattern as a subgraph of , with , . A fusion plan is a set of disjoint fusion patterns . The score function of is annotated as . The higher the performance is, the larger is. So the goal of computation fusion problem is to find fusion plan with maximal .
5.2 Explore Fusion Patterns
A Brute-force way to enumerate all fusion patterns has a complexity of up to without pruning. We proposed an approximate dynamic programming approach with complexity of to find good fusion patterns.
The basic idea of fusion exploration is that, we generate candidate-patterns starting from each vertex in post-order in the graph, and select and compose final fusion plan with these candidate patterns. The candidate-patterns starting from vertex is the set of fusion patterns whose producer node is . We describe how we generate candidate-patterns for each vertex in this section and describe how to compose the final fusion plan in section 5.3
Given a computation graph , we get a topological sorting list. We generate candidate-patterns for vertices in post-order, from the last vertex to the first vertex. This is to guarantee that each searching results in a fusion pattern with current vertex as producer.
Equation 2 shows the approximate dynamic programming process. is the set of all consumers of . PatternReduction is the approach to get candidate patterns of according to all its consumers’ candidate pattens.
| (2) |

We describe PatternReduction approach with an example shown in Figure 4, where is the root vertex who produces the output of whole graph. Assume that candidate-patterns for vertices before have already been generated. (We only explore top patterns in candidate-patterns for each vertex according to score function . We set as 3 in this case.) We will generate candidate-patterns for with its consumers’ information. A naive approach is to append to all possible combinations of patterns in its consumers’ candidate-patterns sets, and select the top 3 patterns within the appended combinations. However, the combinations will be huge when the consumer number and top setting is large, noting that JIT approach requires timely optimization. Instead, we design an approximate divide-and-conquer process to find top 3 patterns with limited complexity as PatternReduction.
We first divide the consumers of into several groups and find candidate-patterns for considering these groups independently, and finally compose final candidate-patterns by reducing the above results of all groups. We assume the group number in this case is 2 (group {, } and group {}). For group {}, we enumerate all possible combinations of patterns in candidate-patterns of and . Specifically, there are 15 possible combinations between and , including empty set. We append to each of the 15 combinations and select the top 3 patterns as the temporary candidates associated to group {}. We get another top 3 patterns considering group {} as temporary candidates. We finally select the final top 3 patterns as candidate-patterns for from all above 6 temporary candidates. Note we validate top patterns according to score function .
The PatternReduction process above is recursive if consumers number of a vertex is very large. We first divide the consumers into two groups. To get candidate patterns of a group, we divide the group further until it is small enough.
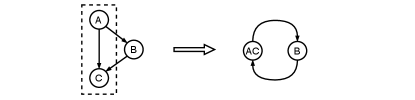
A constraint of a fusion pattern is that, no cyclic dependence is allowed. Figure 6 shows an example that a cyclic dependence occurs after fusion. FusionStitching discards patterns with cyclic during the searching process. Meanwhile, FusionStitching only explores fusion patterns that the code generator can process. It does not form fusion patterns with cross-block communication requirement.

Remote Fusion To further reduce the context switch overhead between CPU and GPU, we try to merge fusion patterns that are not adjacent in the graph after above procedures. As is shown in Figure 5, we add a virtual vertex as the producer for all vertices and apply PatternReduction. We finally get the candidate-patterns of , which includes the fusion of remote patterns that are not adjacent. The remote pattern fusion helps to reduce generated kernels and thus reduces the context switch overhead. Remote fusion results in kernel packing for code generation.
5.3 Generate Overall Fusion Plan
All candidate-patterns of all vertices, which may overlap with each other, form a new set . The insight of forming good fusion plan is to select non-overlapped patterns from with high score of . Note means how much cost the pattern saves (sec 5.4).
FusionStitching uses beam search [17] to generate top-3 (width of the beam) candidate fusion plans, and finally selects the best plan within the 3 candidates with latency-evaluator (sec 4.3).
Specifically, FusionStitching maintains 3 buffer sets to store candidate fusion plans. It traverses from the producer vertex to the consumer vertex in op graph , and try to append each candidate pattern of each vertex to each buffer set in turn if it introduces no overlapping. It may result in more than 3 temporal sets after appending in each iteration, and will select top-3 with highest accumulated as new buffer sets.
After traversing all vertices, each buffer set forms a candidate fusion plan. FusionStitching will use the more accurate cost model latency-evaluator to estimate which candidate plan performs the best. The best one is the final fusion plan.
5.4 Fusion Evaluation: Delta-Evaluator
FusionStitching applies delta-evaluator to form the score function . One insight is that, we only need to estimate the performance gain or loss when forming a fusion pattern, but do not require accurate estimation of the overall execution time. With this insight, the score function represents the performance gain or loss of a fusion pattern only.
There are three main factors in delta-evaluator: reduced memory access latency, reduced CPU-GPU context switch overhead, and performance penalty of kernel fusion. The score function is the summary of these three parts, shown in equation 3.
| (3) |
We estimate reduced memory access latency () with two factors. The first is the amount of memory traffics between operators to be fused, which can be calculated according to the shape and type of input and output tensors. And the second is the change of memory type to store the intermediate values between operations. We build a regression model to predict the reduced memory access latency when changing the memory type from global memory to register or shared memory, when given memory traffic amount. The regression model is based on latency data we collected offline on various GPU vendors with various amount of data traffic.
can be easily estimated by multiplying the number of fused kernels with a fixed value representing average CPU-GPU context switch time we collected.
The performance penalty () is estimated by a simplified version of latency-evaluator (sec 4.3). As fusion plan exploration faces a very large searching space, using latency-evaluator directly takes too long time for JIT optimization. The most time consuming part of latency-evaluator is the estimation of . To estimate fast, we use a fixed number (16) as registers number, and use the maximal shared memory usage in and between any ops within a fusion pattern as the overall shared memory usage. Life time analyzing of registers and shared memory is discarded in delta-evaluator.
6 Implementation
The fusion exploration and code generation techniques we studied requires heavy implementation efforts and will be a burden if left to users. Meanwhile, TensorFlow evolves fast and porting the realization of FusionStitching from one TensorFlow version to another one is heavy.
To ease the using of FusionStitching and make it portable to any version of TensorFlow, we build FusionStitching as a stand alone add-on. Users can make use of all the techniques without changing any model script, but only need to specify FusionStitching path and setup environment to enable FusionStitching beyond TensorFlow XLA.
Specifically, we add FusionStitching as an extra pass upon XLA framework. After XLA finishes all its optimizations, including its basic fusion pass, we feed the fusion results of XLA into fusion explorer to get larger scope fusions. We do not disable the basic XLA fusion pass as there is no conflict to apply FusionStitching based on the naive fusions and a basic fusion reduces optimization time of FusionStitching .
We realize a GPU IR emitter module with the techniques of code generator in FusionStitching . The fusion plan generated by fusion explorer goes through this IR emitter. The IR emitter will compile fusion patterns into llvm IR, GPU ptx IR, and finally GPU binary sequentially.
Note that the input of FusionStitching is the basic fusion results of XLA, and not every basic fusion will be merged into a FusionStitching fusion pattern as a result. The basic fusions not merged into larger fusions by FusionStitching will finally go through basic compilation pass of XLA.
All the above implementations are realized as a hook of TensorFlow, and will be called if FusionStitching is loaded and environment is set.
To hide the optimization tuning time, we develop async-compilation mode in FusionStitching library. As for training, if users set environment as async-optimization, the first several iterations will not execute binaries generated by FusionStitching while FusionStitching is still running in background asynchronously. After FusionStitching generates optimized kernels for the model, the non-optimized ops will be replaced with that of FusionStitching in latter iterations.
7 Evaluation
7.1 Experimental Setup
In this section, we evaluate FusionStitching using a variety of machine learning applications with different characteristics in different fields. Table 1 summarizes the various fields of the evaluated applications and the characteristics of these applications. These applications range from images (CRNN[37]), speech (ASR[52]), NLP (Transformer[47], BERT[15]), to internet scale E-commerce search and recommendation systems (DIEN[57]). The building blocks of these workloads include perceptron, attention, convolution, RNN and a broad range of memory intensive operators.
| Model | Field | Mode | Batch Size |
| BERT | NLP | Both | 32 |
| DIEN | Recommendation | Both | 256 |
| Transformer | NLP | Training | 4096 |
| ASR | Speech Recognition | Inference | 8 |
| CRNN | OCR | Inference | 8 |
To demonstrate the benefits of FusionStitching over previous work, we compare it with the default TensorFlow implementation and XLA (up-to-date with community functions). All evaluation results are collected on NVIDIA V100 GPU with 16 GB device memory. The server runs Red Hat Enterprise Linux 7.2 with CUDA toolkit 10.2 and cuDNN 7.6.
7.2 Overview
We evaluate the speedup of FusionStitching by comparing inference cost or the training time of one iteration for TF, XLA and FusionStitching with the same batch-size. During our test, the accuracy in each iteration of training and the result of inference are the same with TF and XLA. We repeat 10 times and use the average performance to validate speedup. As for training workloads, we collect the execution time from the 11th iteration to the 20th (guaranteed to be stable), to avoid the initialization overhead of the early training iterations.

We show the speedup of FusionStitching in figure 7, where the execution time of TensorFlow is normalized to 1. Compared to TensorFlow, our approach achieves up to speedup, with 1.66 on average. Compared to XLA, our approach achieves up to speedup, with 1.45 on average. Note XLA shows performance degradation for DIEN (both training and inference), while FusionStitching does not show negative optimization in any of these cases.
We also test the inference workloads on NVIDIA T4 GPU and get the similar speedup.
We apply FusionStitching in production and measure the performance benefits. It shows that FusionStitching saves about 7,000 GPU hours for about 30,0000 tasks in a month. The performance result on the cluster shows FusionStitching is robust. Note that XLA, as state-of-the-art JIT engine, cannot be enabled default as it suffers from negative optimizations for many cases.
Overall, the performance benefit of FusionStitching comes from both reduced CPU-GPU context switch and off-chip memory access. FusionStitching gives a good solution to the problems we found (sec 2.2). We provide performance breakdown information in the following section.
7.3 Performance Breakdown
Table 2 shows the kernel breakdown information, including execution time (T) of memory intensive ops (Mem), compute intensive ops (Math), CPU time (CPU, kernel launch and framework scheduling), CUDA memcpy/memset activities (Cpy) and kernel call times (#). Note that the breakdown profiling process is different with the process to measure the end-to-end performance. This is because profiling introduces some overhead and makes the end-to-end time not accurate. We profile Mem, Math, Cpy time directly, and get CPU time by dividing other time from end-to-end time.
Before we analyze the effect of our technique, we need to point out that XLA affects the behavior of Matrix operations (GEMM and GEMV). It tends to fuse GEMVs into GEMM, and GEMMs to larger GEMM when there are Matrices sharing common input. Some other algebra transformation and loop-invariant code motion also reduces GEMM count. The difference in GEMM count in table 2 is caused by such reasons. Meanwhile, XLA affects the runtime behavior of TensorFlow and leads to more or less CUDA memcpy/memset activities. FusionStitching is built upon XLA and exhibits the same behavior.
| Model | Tech | T/# | CPU | Math | Mem | Cpy | E2E |
| BERT -train | TF | T | 1.55 | 41.69 | 28.45 | 0.15 | 71.84 |
| # | - | 98 | 561 | 102 | 761 | ||
| XLA | T | 2.3 | 41.89 | 9.56 | 0.15 | 53.9 | |
| # | - | 98 | 200 | 97 | 395 | ||
| FS | T | 2.8 | 42.11 | 7.02 | 0.03 | 51.96 | |
| # | - | 98 | 98 | 20 | 216 | ||
| BERT -infer | TF | T | 3.24 | 1.65 | 0.83 | 0.14 | 5.86 |
| # | - | 70 | 365 | 106 | 541 | ||
| XLA | T | 0.78 | 2.50 | 0.60 | 0.13 | 4.02 | |
| # | - | 98 | 277 | 94 | 469 | ||
| FS | T | 0.59 | 2.46 | 0.40 | 0.04 | 3.49 | |
| # | - | 98 | 77 | 30 | 205 | ||
| DIEN -train | TF | T | 90.13 | 7.77 | 32.54 | 7.12 | 137.56 |
| # | - | 1218 | 10406 | 1391 | 13015 | ||
| XLA | T | 124.04 | 9.06 | 37.50 | 6.56 | 177.16 | |
| # | - | 1215 | 6842 | 1996 | 10053 | ||
| FS | T | 48.42 | 7.91 | 35.84 | 5.55 | 97.72 | |
| # | - | 1215 | 2109 | 1395 | 4719 | ||
| DIEN -infer | TF | T | 27.36 | 2.58 | 7.55 | 1.99 | 39.48 |
| # | - | 406 | 3680 | 225 | 4311 | ||
| XLA | T | 44.21 | 2.24 | 6.12 | 0.94 | 53.51 | |
| # | - | 405 | 2585 | 627 | 3617 | ||
| FS | T | 17.54 | 2.45 | 3.51 | 0.7 | 24.20 | |
| # | - | 405 | 815 | 422 | 1642 | ||
| Trans former | TF | T | 5.92 | 107.04 | 81.03 | 1.14 | 195.37 |
| # | - | 399 | 2497 | 522 | 3418 | ||
| XLA | T | 11.59 | 106.58 | 38.33 | 1.20 | 157.70 | |
| # | - | 405 | 903 | 577 | 1885 | ||
| FS | T | 7.43 | 107.16 | 30.26 | 0.80 | 145.65 | |
| # | - | 400 | 423 | 369 | 1212 | ||
| ASR | TF | T | 9.36 | 2.84 | 3.06 | 0.63 | 15.89 |
| # | - | 76 | 1359 | 439 | 1942 | ||
| XLA | T | 6.61 | 0.09 | 4.00 | 0.40 | 11.10 | |
| # | - | 4 | 386 | 257 | 647 | ||
| FS | T | 5.51 | 0.11 | 3.10 | 0.45 | 9.18 | |
| # | - | 4 | 187 | 284 | 475 | ||
| CRNN | TF | T | 23.31 | 6.05 | 6.14 | 1.60 | 37.10 |
| # | - | 256 | 3674 | 890 | 4820 | ||
| XLA | T | 12.17 | 0.30 | 11.37 | 1.04 | 24.88 | |
| # | - | 7 | 993 | 406 | 1406 | ||
| FS | T | 6.35 | 0.31 | 7.69 | 1.01 | 15.36 | |
| # | - | 8 | 311 | 388 | 707 |
According to Table 2, we have the following observations.
Reduced context switch overhead. FusionStitching effectively reduces the memory intensive kernel calls of all workloads, which results in reduced kernel launch and framework scheduling overhead. As is shown in Table 2, the number of memory intensive kernel calls with FusionStitching is 38.0% of that with XLA in average, ranging from 27.8% to 48.4%. Meanwhile, FusionStitching reduces CUDA memcpy/memset activities (Cpy time) than XLA, with 34.3% decrease in average. This is because we fuse more ops together into larger kernels than XLA and many CUDA memcpy/memset are combined together. The CPU time difference in table 2 indicates the reduced time due to the decrease of kernel calls and CUDA memcpy/memset activities. FusionStitching achieves up to 61.0% saving of the time comparing with XLA, 41.0% in average.
Take DIEN-train as an example, the kernel call number for memory intensive ops is 2109 with FusionStitching , and 6842 with XLA. Meanwhile, the CUDA memcpy/memset activities is reduced to 1395, comparing to 1996 with XLA. The final time with FusionStitching is significantly less than both TF and XLA, thanks for the reduced kernel calls. Note that XLA increases CUDA memcpy/memset activities and results in severe performance drop here. FusionStitching avoids the increased memcpy/memset calls due to larger kernel granularity and do not suffer from the drawback. DIEN-infer has the similar behavior. Optimizing kernel fusions while considering runtime behaviors (like memcpy activities) could be a future research topic.
Reduced memory intensive op execution time. FusionStitching reduces the total execution time for memory-intensive operations. The speedup of memory-intensive ops for all workloads is in average comparing with XLA, and up to . The performance speedup mainly comes from reduced global memory access. By fusing memory-intensive operations aggressively, the intermediate values can be cached in registers and shared memory.
Take CRNN as an example, it reads 667.6 MB global memory with XLA, while FusionStitching reduces the traffic to 225.8 MB. About 66% global memory access has been reduced for memory intensive ops. The execution time of all memory intensive computations thus achieves speedup than XLA.
Overall speaking, FusionStitching supports more complex fusion patterns than XLA with effective kernel generation, which relaxes the fusion conditions and thus reduces the final kernel numbers and intermediate global memory transactions. These two factors are essential for the performance of memory intensive ops (sec 2.2). Meanwhile, with well controlled performance estimation and reduced runtime memcpy activities than XLA, FusionStitching is less likely to result in bad case about optimization.
7.4 Fusion Pattern Analysis
We take the Layer Normalization case in Figure 1 again to analyze the fusion result of XLA and FusionStitching . Note Layer Normalization is a very common component in deep learning models.
XLA forms four different fusion kernels. While FusionStitching is able to fuse them all and generate a more efficient kernel. We collect the performance of all kernels of the two version. The single kernel with FusionStitching achieves a speedup of comparing with the sum of all 4 kernels with XLA. For this test, we do not count the context switch overhead for the 4 kernels in XLA version, which further hurts the performance of XLA.
There are two factors that prevents XLA to fuse operators with a larger granularity in this case. The first reason is reduce op in xla-fusion.7 and xla-fusion.3. As we discussed before, XLA does not explore reuse of intermediate results of producer op. Fusing reduce op in the middle of a kernel results redundant computation of the same value in different threads, thus hurts the performance. The second reason is expensive element-wise ops with small tensor shape (xla-fusion.2). XLA does not tend to fuse expensive ops processing small tensors in the middle of a kernel as the fusion will introduce redundant computations of expensive instructions.
Instead, FusionStitching finds notable potential for larger granularity fusion in this case and fuses all operators into one kernel. It applies data reuse to prevent redundant computation. In this way, the intermediate global memory transaction and CPU-GPU context switch is avoided.
7.5 Overhead Analysis
Similar with XLA, FusionStitching is designed for tune-once-run-many-times scenarios, which is a basic characteristic of deep learning workloads. For the training that could take up to several days, FusionStitching only needs to run in the first training iteration. For an inference task, the executable kernels can be prepared once and run many times in the future.
We measure the one-time overhead introduced by FusionStitching compared to XLA for training. The value is the JIT compilation time of FusionStitching minus that with XLA. Results show that the extra overhead is less than 30 minutes for the workloads we evaluated in this paper, which is far less than the overall training time.
As for cost models, we tried to use complete latency-evaluator to estimate in delta-evaluator. The results show a much longer tuning time, but do not show better performance of tuning results. It demonstrates the simplified cost model works good for fusion exploration.
A problem of both FusionStitching and XLA is that, they cannot handle dynamic shapes, appears in some deep learning workloads, with low tuning overhead. The reason is that the design of XLA service framework is not friendly to dynamic shape, while FusionStitching is implemented based on XLA service framework. This implementation problem does not affect the insight that FusionStitching shows.
8 Related Work
Many current AI compilation optimization works mainly focus on compute intensive ops[11, 34, 29, 30, 13, 24, 45], but do not pay attention to memory intensive ops. XLA[26] is one work optimizing memory intensive ops in depth. It provides an just-in-time fusion engine to reduce context switch and off-chip memory access overhead. However, XLA lacks to explore data reuse of intermediate value and limits the fusion exploration space. Besides, it uses simple rules to explore fusion strategy, which is not adaptive to varied combinations of ops and tensor shapes. FusionStitching reveals the data reuse opportunity for JIT fusion and proposes cost-based approach for fusion searching and code generation tuning.
Some works study about fusion optimization of machine learning workloads for static patterns. Li et al.[27] explores horizontal fusion for GPU Kernels to increase thread-level parallelism. Appleyard et al.[7], Diamos et al.[16] study about kernel fusion technique to speedup RNN workloads. These works do not study about just-in-time fusion problem that processes fusion patterns unknown ahead. Neither do they explore op combination strategy. Abdolrashidi et al.[3] explores op combination strategies with Proximal Policy Optimization[36] algorithm. This is an ahead-of-time tuning approach that searches in simple fusion rules similar with XLA, and does not explore fusion of complex patterns.
Some works focusing on compute intensive ops have ability of op fusion. Recent TVM[11] and Ansor[55] implementation have fusion ability with simple rules for simple patterns. These two works usually requires a long time tuning process given a static computation description, but are not designed to handle varied combinations of ops timely. Tiramisu[9] applies a similar fusion approach with TVM. Tensor Comprehensions[46] provides a polyhedral based JIT compiler capable of fusing ops together. It focuses on the trade-off of parallelism and data locality. Glow[35] and Latte[45] supports basic fusion and does not explore complex combination scenarios. Astra[40] and Ashari et al.’s work[8] support GEMM and basic element-wise op fusion. None of these works reveal the fusion chance with intermediate data reuse between to-be-fused ops through shared memory and register shuffle just-in-time. They also lacks of a thoroughly study about just-in-time fusion strategy exploration.
Fusion approach has also been applied to a wide range of domains given a static computation description, like HPC[48], database[50], image processing[32, 33]. They meet different challenges comparing with just-in-time compilation of AI workloads. Specifically, they do not fuse kernels that are not known ahead and do not face the choice of fusing which ops together in a huge searching space.
9 Conclusion
This work tackles the problem of optimizing memory intensive operators in machine learning workloads. We show that memory intensive ops are vital to end-to-end performance of various deep learning models. We propose FusionStitching that supports to fuse operators, with complex dependence and non-homogeneous parallelism, to reduce memory access and context switch overhead just-in-time. FusionStitching broadens the fusion possibility beyond state-of-the-art JIT techniques by introducing reuse scheme. FusionStitching consists of fusion explorer and code generator. The fusion explorer selects candidate fusion patterns from the large searching space with appropriate computing complexity, and produces a fusion plan with promising performance expected. We provide a set of kernel composition schemes, with which code generator stitches operators and reuses intermediate values with on-chip memory as much as possible, and tunes the schedules to emit high performance GPU code for a given fusion pattern. A two-layer cost model helps the searching and tuning process of FusionStitching . Results show that FusionStitching outperforms state-of-the-art JIT techniques with up to 2.21 speedup, 1.45 on average.
References
- [1] Torch nn, 2015.
- [2] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems, 2016.
- [3] Amirali Abdolrashidi, Qiumin Xu, Shibo Wang, Sudip Roy, and Yanqi Zhou. Learning to fuse. NeurIPS, 2019.
- [4] Asif M Adnan, Sridhar Radhakrishnan, and Suleyman Karabuk. Efficient kernel fusion techniques for massive video data analysis on gpgpus, 2015.
- [5] Randy Allen and Ken Kennedy. Optimizing compilers for modern architectures: a dependence-based approach. Taylor & Francis US, 2002.
- [6] Andrew Anderson and David Gregg. Optimal dnn primitive selection with partitioned boolean quadratic programming. In Proceedings of the 2018 International Symposium on Code Generation and Optimization, pages 340–351, 2018.
- [7] Jeremy Appleyard, Tomas Kocisky, and Phil Blunsom. Optimizing performance of recurrent neural networks on gpus. arXiv preprint arXiv:1604.01946, 2016.
- [8] Arash Ashari, Shirish Tatikonda, Matthias Boehm, Berthold Reinwald, Keith Campbell, John Keenleyside, and P Sadayappan. On optimizing machine learning workloads via kernel fusion. volume 50, pages 173–182. ACM New York, NY, USA, 2015.
- [9] Riyadh Baghdadi, Jessica Ray, Malek Ben Romdhane, Emanuele Del Sozzo, Patricia Suriana, Abdurrahman Akkas, Shoaib Kamil, Yunming Zhang, and Saman Amarasinghe. Tiramisu: A polyhedral compiler with a scheduling language for targeting high performance systems.
- [10] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. CoRR, abs/1512.01274, 2015.
- [11] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. TVM: An automated end-to-end optimizing compiler for deep learning. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 578–594, 2018.
- [12] Keith D Cooper, Timothy J Harvey, and Ken Kennedy. A simple, fast dominance algorithm, 2001.
- [13] Meghan Cowan, Thierry Moreau, Tianqi Chen, James Bornholt, and Luis Ceze. Automatic generation of high-performance quantized machine learning kernels. In Proceedings of the 18th ACM/IEEE International Symposium on Code Generation and Optimization, pages 305–316, 2020.
- [14] Zheng Cui, Yun Liang, Kyle Rupnow, and Deming Chen. An accurate gpu performance model for effective control flow divergence optimization. In 2012 IEEE 26th International Parallel and Distributed Processing Symposium, pages 83–94. IEEE, 2012.
- [15] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [16] Greg Diamos, Shubho Sengupta, Bryan Catanzaro, Mike Chrzanowski, Adam Coates, Erich Elsen, Jesse Engel, Awni Hannun, and Sanjeev Satheesh. Persistent rnns: Stashing recurrent weights on-chip. In International Conference on Machine Learning, pages 2024–2033, 2016.
- [17] David Furcy and Sven Koenig. Limited discrepancy beam search. In IJCAI, 2005.
- [18] G Gao, Russ Olsen, Vivek Sarkar, and Radhika Thekkath. Collective loop fusion for array contraction. In International Workshop on Languages and Compilers for Parallel Computing, pages 281–295. Springer, 1992.
- [19] A Gray. Getting started with cuda graphs. URL: https://devblogs. nvidia. com/cudagraphs, 2019.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. pages 770–778, 2016.
- [21] Zhe Jia, Marco Maggioni, Jeffrey Smith, and Daniele Paolo Scarpazza. Dissecting the nvidia turing t4 gpu via microbenchmarking. arXiv preprint arXiv:1903.07486, 2019.
- [22] Zhe Jia, Marco Maggioni, Benjamin Staiger, and Daniele P Scarpazza. Dissecting the nvidia volta gpu architecture via microbenchmarking. arXiv preprint arXiv:1804.06826, 2018.
- [23] Samuel J Kaufman, Phitchaya Mangpo Phothilimthana, Yanqi Zhou, and Mike Burrows. A learned performance model for the tensor processing unit. arXiv preprint arXiv:2008.01040, 2020.
- [24] Jinsung Kim, Aravind Sukumaran-Rajam, Vineeth Thumma, Sriram Krishnamoorthy, Ajay Panyala, Louis-Noël Pouchet, Atanas Rountev, and Ponnuswamy Sadayappan. A code generator for high-performance tensor contractions on gpus. In 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 85–95. IEEE, 2019.
- [25] Matthias Korch and Tim Werner. Accelerating explicit ode methods on gpus by kernel fusion. Concurrency and Computation: Practice and Experience, 30(18):e4470, 2018.
- [26] Chris Leary and Todd Wang. Xla: Tensorflow, compiled, 2017.
- [27] Ao Li, Bojian Zheng, Gennady Pekhimenko, and Fan Long. Automatic horizontal fusion for gpu kernels. arXiv preprint arXiv:2007.01277, 2020.
- [28] Sangkug Lym, Donghyuk Lee, Mike O’Connor, Niladrish Chatterjee, and Mattan Erez. Delta: Gpu performance model for deep learning applications with in-depth memory system traffic analysis. In 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 293–303. IEEE, 2019.
- [29] Lingxiao Ma, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenxiang Hu, Fan Yang, Lintao Zhang, and Lidong Zhou. Rammer: Enabling holistic deep learning compiler optimizations with rtasks. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 881–897, 2020.
- [30] Matthew W Moskewicz, Ali Jannesari, and Kurt Keutzer. Boda: A holistic approach for implementing neural network computations. In Proceedings of the Computing Frontiers Conference, pages 53–62, 2017.
- [31] Alberto Parravicini, Arnaud Delamare, Marco Arnaboldi, and Marco D Santambrogio. Dag-based scheduling with resource sharing for multi-task applications in a polyglot gpu runtime. arXiv preprint arXiv:2012.09646, 2020.
- [32] Bo Qiao, Oliver Reiche, Frank Hannig, and Jïrgen Teich. From loop fusion to kernel fusion: a domain-specific approach to locality optimization. In 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 242–253. IEEE, 2019.
- [33] Bo Qiao, Oliver Reiche, Frank Hannig, and Jürgen Teich. Automatic kernel fusion for image processing dsls. In Proceedings of the 21st International Workshop on Software and Compilers for Embedded Systems, pages 76–85, 2018.
- [34] Jonathan Ragan-Kelley, Andrew Adams, Dillon Sharlet, Connelly Barnes, Sylvain Paris, Marc Levoy, Saman Amarasinghe, and Frédo Durand. Halide: decoupling algorithms from schedules for high-performance image processing. Communications of the ACM, 61(1):106–115, 2017.
- [35] Nadav Rotem, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein, et al. Glow: Graph lowering compiler techniques for neural networks. arXiv preprint arXiv:1805.00907, 2018.
- [36] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- [37] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11):2298–2304, 2016.
- [38] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [39] Muthian Sivathanu, Tapan Chugh, Sanjay S Singapuram, and Lidong Zhou. Astra: Exploiting predictability to optimize deep learning. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 909–923, 2019.
- [40] Muthian Sivathanu, Tapan Chugh, Sanjay S Singapuram, and Lidong Zhou. Astra: Exploiting predictability to optimize deep learning. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 909–923, 2019.
- [41] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. pages 2818–2826, 2016.
- [42] TensorFlow team. tf.math.multiply.
- [43] TensorFlow XLA team. Hlo reduce operation.
- [44] TensorFlow XLA team. Hlo transpose operation.
- [45] Leonard Truong, Rajkishore Barik, Ehsan Totoni, Hai Liu, Chick Markley, Armando Fox, and Tatiana Shpeisman. Latte: a language, compiler, and runtime for elegant and efficient deep neural networks. In Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 209–223, 2016.
- [46] Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. Tensor comprehensions: Framework-agnostic high-performance machine learning abstractions, 2018.
- [47] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [48] Mohamed Wahib and Naoya Maruyama. Scalable kernel fusion for memory-bound gpu applications. In SC’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 191–202. IEEE, 2014.
- [49] Jizhe Wang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 839–848, 2018.
- [50] Haicheng Wu, Gregory Diamos, Srihari Cadambi, and Sudhakar Yalamanchili. Kernel weaver: Automatically fusing database primitives for efficient gpu computation. In 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, pages 107–118. IEEE, 2012.
- [51] Xuan Yang, Zhengrui Zhang, Guoliang Chen, Rui Mao, et al. A performance model for gpu architectures that considers on-chip resources: application to medical image registration. IEEE Transactions on Parallel and Distributed Systems, 30(9):1947–1961, 2019.
- [52] Dong Yu and Li Deng. AUTOMATIC SPEECH RECOGNITION. Springer, 2016.
- [53] Xiuxia Zhang, Guangming Tan, Shuangbai Xue, Jiajia Li, Keren Zhou, and Mingyu Chen. Understanding the gpu microarchitecture to achieve bare-metal performance tuning. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 31–43, 2017.
- [54] Yao Zhang and John D Owens. A quantitative performance analysis model for gpu architectures. In 2011 IEEE 17th international symposium on high performance computer architecture, pages 382–393. IEEE, 2011.
- [55] Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, et al. Ansor: Generating high-performance tensor programs for deep learning. arXiv preprint arXiv:2006.06762, 2020.
- [56] Zhen Zheng, Chanyoung Oh, Jidong Zhai, Xipeng Shen, Youngmin Yi, and Wenguang Chen. Versapipe: a versatile programming framework for pipelined computing on gpu. In 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 587–599. IEEE, 2017.
- [57] Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 5941–5948, 2019.