FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Abstract.
The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in and even challenging upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.Project page: https://isaac-paradox.github.io/FuseSR/

1. introduction
In the past few years, with the popularity of high-resolution and high-refresh-rate displays, as well as photographic realistic lighting and the advancement of real-time ray tracing techniques, the computational workload of real-time rendering has increased dramatically. The emergence of real-time raytracing has further increased the computational overhead of rendering for higher quality outputs. Even with the high-end consumer GPU, rendering high-quality images at 144 FPS and 4K resolution is still extremely challenging. As a result, users have to make trade-offs between rendering quality, resolution, and refresh rate.
A large number of techniques have been proposed to alleviate this problem. Real-time denoising techniques [Fan et al., 2021; Schied et al., 2017] render images at a low tracing budget and manage to reduce these images’ noise levels to produce plausible results. Frame extrapolation methods [Guo et al., 2021; Zeng et al., 2021] focus on reconstructing accurate shading results from historical frames reprojected with motion vectors to accelerate rendering. Foveated rendering methods [Kaplanyan et al., 2019] propose to reduce the resolution at the periphery of users’ vision without sacrificing perceived visual quality, thereby improving efficiency, but only for virtual reality headsets.
The most widely adopted and successful method is the super-resolution (SR) approaches, including DLSS [NVIDIA, 2018], FSR [AMD, 2021], XeSS [Intel, 2022], etc. Users can reduce the resolution of rendered images to decrease rendering time and upsample the low-resolution (LR) rendered image to obtain the final high-resolution (HR) image. However, they mainly consider upsampling factors less than , which limits higher performance improvement. NSRR [Xiao et al., 2020] pursues a more promising task that produces high-quality -upsampled reconstruction in real-time by utilizing historical frames, yet it struggles with recovering accurate high-frequency texture details and cannot support real-time experience at resolutions higher than 1080p.
The results of NSRR demonstrate that high-resolution SR is a tough challenge. On the one hand, many high-fidelity details are lost even in historical frames. In theory, a SR reconstruction requires at least 16 historical frames to cover every pixel of the HR target fully, and such a long temporal window makes the history-reusing scheme basically infeasible in dynamic scenes. An intuitive solution is to utilize HR G-buffers that contain full-resolution information, of which the rendering cost is negligible and only sub-linearly increases. On the other hand, the network performance is also a critical concern for real-time SR and the neural network inference time increases rapidly w.r.t. the input resolution. Therefore, the need to increase feature resolution and reduce network bandwidth is a pair of contradictions that are difficult to resolve, which slows down the development of high-resolution SR.
In this paper, we present FuseSR, an efficient and effective real-time super-resolution technique that is able to offer high-fidelity even upsampled reconstruction with significantly improved quality and performance compared to existing works. Besides using historical information, we utilize HR G-buffer to provide per-pixel cues for the HR target. We further decompose the shading results into pre-integrated BRDF and demodulated irradiance components, and train a network to predict the HR irradiance, to strike a better balance between quality and efficiency. Most importantly, we propose H-Net architecture to resolve the contradictions between HR features and LR bandwidth. In H-Net, we incorporate pixel shuffling and unshuffling [Shi et al., 2016; Gharbi et al., 2016] to losslessly align HR features with LR inputs and fuse the features into the LR network backbone, while preserving high-fidelity HR details. Our contributions can be summarized as follows:
-
•
Our method successfully utilizes high-resolution G-buffers to resolve the real-time super-resolution problem, which significantly outperforms existing methods in both time and quality. We are the first method to produce high-fidelity results in the challenging super-resolution task.
-
•
We propose H-Net, an efficient and effective network design to conduct lossless multi-resolution feature alignment and fusion with a low-resolution network backbone. We innovatively employ pixel shuffling and unshuffling pair into our network design to align and fuse multi-resolution features into the same screen space.
-
•
We introduce pre-integrated BRDF demodulation to resolve the super-resolution problem, improving detail preservation and reducing the redundancy of G-buffers.
2. related work
Real-time supersampling.
In real-time rendering, each pixel of rendered images is point sampled. Therefore, the SR of rendered images can be conceived as a supersampling problem with upscaling. Supersampling-based antialiasing techniques [Akeley, 1993; Young, 2006] and temporal antialiasing methods [Karis, 2014; Yang et al., 2020] manage to conduct supersampling in spatial and temporal domain. These aforementioned antialiasing techniques supersample without resolution changing. On the other hand, deep learning-based supersampling with upscaling has gained increasing attention recently. Deep learning super sampling (DLSS) [NVIDIA, 2018] utilizes neural networks to upscale LR frames, significantly reducing the rendering cost of HR frames and enabling high-quality rendering at high resolution in real-time. It inspired a series of similar works, including FSR [AMD, 2021], TAAU [Epic Games, 2020a], and XeSS [Intel, 2022]. However, these methods focus on tasks with upsampling factors smaller than , limiting further performance improvement. NSRR [Xiao et al., 2020] is the closest to our method, which uses temporal dynamics and G-buffer to provide compelling results in the challenging 44 upsampling case, but it cannot accurately recover HR details and is unable to support real-time rendering at high resolutions such as 2K and 4K. MNSS [Yang et al., 2023] also leverages historical frames, and achieves competitive runtime performance due to its lightweight network design.
Pixel Shuffling.
ESPCN [Shi et al., 2016] firstly designs pixel shuffling as an efficient upscaling operation in their super-resolution network, which keeps most convolutional layers in low resolution to reduce network computational overhead. Gharbi et al. [2016] further design a pixel unshuffling-shuffling pair in their denoising network architecture, with the purpose of converting pixel-wise noise patterns into channel-wise for better denoising processing. Inspired by these methods, our approach adopt pixel shuffling for high speed and pixel unshuffling for the alignment and fusion of multi-resolution input features.
BRDF demodulation.
Materials with fine details can increase rendering realism but also make reconstruction tasks (e.g., denoising and supersampling) more challenging. Demodulating BRDF is a common practice for preserving details in reconstruction tasks. Bako et al. [2017] and SVGF [Schied et al., 2017] demodulate the diffuse albedo from the noisy image and then modulate it with the denoised result to alleviate the blurring problem. Guo et al. [2021] found that such demodulation was also beneficial for extrapolated rendering. Pre-integrated BRDF demodulation [Zhuang et al., 2021] is also proven effective for real-time denoising. Inspired by these methods, our approach introduces demodulation similar to [Zhuang et al., 2021] to decompose the color frames SR into the SR tasks of corresponding pre-integrated BRDF maps and demodulated irradiance maps, wherein the demodulated irradiance map tends to be smoother than the original color, thus reducing the SR difficulty.
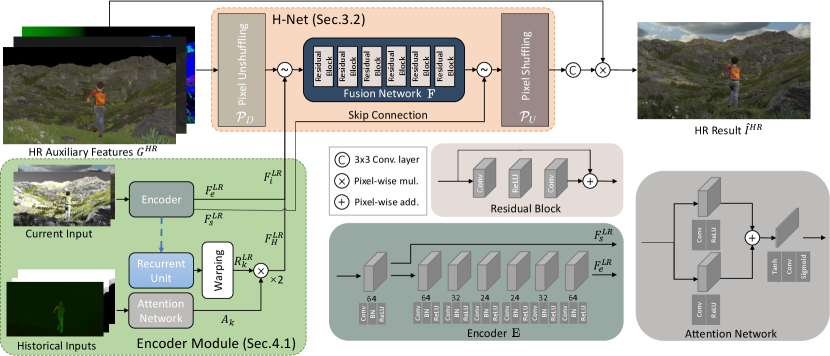
3. Method
The goal of our work is to reconstruct upsampled HR frames from the corresponding LR frames in real-time rendering. Unfortunately, the SR problem that relied entirely on LR color frames is ill-posed because of the lack of HR details. Inspired by previous works [Guo et al., 2021], we take HR G-buffers as SR cues to make the problem more tractable. G-buffer is a commonly used rendering byproduct containing rich scene information (e.g., depths, normals, and texture details), and its acquisition is significantly cheaper (several milliseconds for each 1080p frame) than heavy shading and potential post-processing tasks.
To utilize material information from G-Buffer, we employ pre-integrated BRDF demodulation (Section 3.1) to explicitly filter out HR details, turning the color frame SR to an easier demodulated irradiance SR problem. We further design our H-Net architecture employing pixel shuffling operations (Section 3.2) to effectively and efficiently align and fuse HR and LR information. Our design demonstrates significantly improved quality and performance compared with other advanced works.
To be precise, we describe our task as follows:
| (1) |
where and denote LR and HR G-buffers respectively, which are taken as auxiliary input features to enrich the input information for better predictions.
3.1. BRDF Demodulation for Superresolution
Today’s production-ready 3D scenes are becoming more and more exquisite, making the superresolution task, especially those with high-frequency features, more challenging. Inspired by Zhuang et al. [2021], we perform BRDF demodulation to filter out high-frequency material details for better overall quality and detail preservation. Specifically, we reformulate the rendering equation [Kajiya, 1986] into the multiplication of the pre-integrated BRDF term and the demodulated irradiance term :
| (2) | ||||
| (3) |
where denotes the incoming and outgoing directions, respectively, represents the bidirectional reflectance distribution function (BRDF) at the shading point, the lighting function describes incident radiance at the shading point, is the cosine term, and is the outgoing radiance. This demodulation decomposes the radiance of a pixel into two terms: and . Hence the superresolution task turns into estimating the corresponding HR and HR maps.
We adopt the precomputation approach proposed by Karis et al. [2013] (known as split-sum approximation) to acquire maps at a negligibly low cost. In the precomputation stage, the BRDF integrals to each normal and light direction combination on varying roughness values are computed and stored in a 2D lookup texture (LUT). After that, we can easily obtain maps with arbitrary resolutions by querying the LUT according to each pixel’s roughness and view direction that are provided in the G-buffers. We refer readers to the original paper [Karis, 2013] for more details.
Then, we leverage a neural network to predict the HR demodulated irradiance map and multiply it with the HR pre-integrated BRDF map pixel-by-pixel to obtain the SR outcome. Thus Eq. 1 can be rewritten as:
| (4) |
where denotes pixel-wise multiplication. The LR demodulated irradiance map can be easily computed by dividing the LR color map by the LR pre-integrated BRDF map pixel-by-pixel, while can be easily pre-computed from HR G-buffers . Note that we omit the emitted radiance term in the rendering equation because its HR version is available in the G-buffers.
Please refer to our supplementary for the visualization of map with high-frequency details and map smoother than the original pixel color. We believe that estimating the smoother map instead of the original color frame is conducive to improving the quality and generalizability. Our experiments confirmed this choice (see Section 5.4.1).
3.2. H-Net: An Effective and Efficient Network for Multi-Resolution Alignment and Fusion
Given that our network takes multi-resolution features (LR image and HR G-buffers) as input, to make full use of the HR auxiliary inputs, an efficient network is required to organize the features at different resolution levels. Aligning pixels that share the same screen space position can preserve correct spatial correlation between multi-resolution input features. After that, our network fuses the aligned multi-resolution features to finish the SR task.
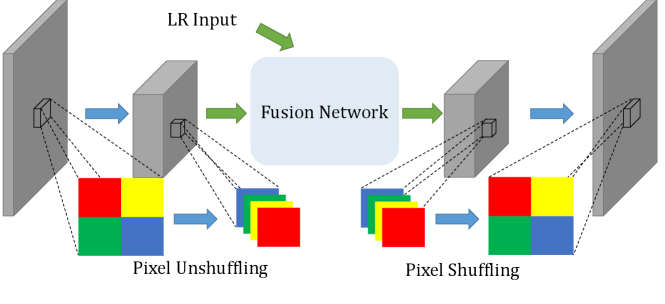
Multi-resolution feature alignment.
To align pixels sharing the same screen space position, upsampling and pooling are two common strategies, where the former aligns at HR level and the latter aligns at LR level. Considering that the performance of convolutional networks degrades sharply as the input resolution increases, the upsampling alignment contradicts with the need of real-time performance, while pooling is a more feasible choice.
Pooling operations are commonly used in neural networks, including maximum pooling and average pooling. However, these pooling operations inevitably damage the spatial details such as HR edges and textures, which are key information for SR quality improvements. Therefore, instead of lossy pooling operations, we adopt pixel unshuffling operation [Shi et al., 2016; Gharbi et al., 2016] to align an HR feature to LR without information loss. We find that pixel unshuffling can losslessly shrink an HR feature map into LR space, converting pixel-wise spatial information into channel-wise deep information. Specifically, this operation divides the HR map into blocks of size ( is the downscaling factor) and concatenates the features of all pixels within each block to form pixels of the LR version, i.e. transforming a map of shape into an LR map of shape without information loss.
H-Net
We propose an H-Net architecture with a pixel unshuffling-shuffling pair, to efficiently align and fuse LR and HR information to faithfully preserve HR details during the alignment and fusion. The architecture of H-Net is shown in Fig. 3:
-
(1)
We use pixel unshuffling to downscale and concatenate it with other LR inputs.
-
(2)
The concatenated feature is fed into a fusion network backbone . Note that runs at LR level, which prevents significant HR computational overhead.
-
(3)
The output of is transformed to HR space using pixel shuffling to obtain the HR output .
Formally, the process can be expressed as follows:
| (5) |
where represents concatenation, and is the encoder used to obtain the LR feature map (Section 4). The name “H-Net” is motivated by the shape of the network with two HR ends and an LR bottleneck, resembling an “H”.
With the use of pixel unshuffling, our method can faithfully preserve the HR details, thus facilitating high-quality SR outcomes. Moreover, since neighboring pixels are usually highly correlated, aggregating neighboring pixels of the HR map together via allows obtaining more compact implicit representations in the following fusion network, which is beneficial for reducing data redundancy and enhancing efficiency. Our experiments show that our alignment strategy even achieves better quality than the naïve HR upsampling alignment strategy (see Section 5.4.2).
4. Network and Training
In this section, we first provide the specific architecture of our network in Section 4.1, and then describe details of the implementation and training in Section 4.2.
4.1. Network Architecture
Here we explain the architectural details of each component involved in Eq. 5, including the encoder , fusion network , and a pixel unshuffling-shuffling pair and . Unless otherwise stated, all convolutional layers are set by default to a convolution with a kernel size, a stride of 1, zero padding, and a subsequent ReLU activation. Please refer to our supplementary material for detailed network configurations.
Encoder
The encoder module takes LR irradiance and G-buffers as input and outputs an LR feature map as part of the input of our H-Net (Eq. 5). Following existing works , we also utilize LR historical frames to encourage temporal consistency. The architecture of the encoder is shown in the bottom left corner of Fig. 2, and please refer to our supplementary material for details on how we encode LR current frame and historical frames.
Formally, the encoder takes the LR irradiance along with G-buffers of current frame and 2 previous frames as input, and output 2 LR feature maps and :
| (6) |
where is the current frame index, is the output of the first layer of used for skip connection later, and is the final output as an input of the fusion network.
Fusion network
In our fusion network , the LR feature from encoder , and the unshuffled HR auxiliary features are concatenated and fed into a subsequent network to obtain an LR fused feature map :
| (7) |
Final upscaling module.
In this module, we skip-connect the first layer output of the encoder with the fused feature map and then upscale this concatenated feature map via the pixel shuffling operation . Finally, the upscaled feature map is processed by a single-layer convolutional network to obtain the RGB prediction of demodulated irradiance (Section 3.1):
| (8) |
After obtaining , we can compute the final color prediction by remodulating with as described in Eq. 4.
4.2. Training
We train our network with the supervision of ground truth high-resolution images, and the training process is end-to-end.
loss
We directly apply loss between HR ground truth and the predicted HR image to supervise the training:
| (9) |
Perceptual loss
Introduced by Johnson et al. [2016], we use a pretrained VGG-16 network to compute perceptual loss to enhance semantic consistency:
| (10) |
where represents the i-th layer of pre-trained VGG network, and denotes the set of selected layers.
SSIM loss
Total loss
To summarize, the total loss is the weighted combination of all losses mentioned above:
| (12) |
We empirically set and in our experiments.
5. Experiment
| Ours | Ours ↯ | NSRR | MNSS | LIIF | FSR | XeSS | Ours-8x | NSRR-8x | MNSS-8x | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | Kite | 32.33 | 31.22 | 27.74 | 28.00 | 26.47 | 29.12 | 28.30 | 30.21 | 25.00 | 25.72 |
| Showdown | 36.32 | 31.42 | 30.27 | 29.17 | 30.33 | 26.29 | 29.31 | 33.61 | 29.17 | 25.62 | |
| Slay | 37.02 | 34.41 | 35.42 | 35.39 | 31.12 | 32.39 | 34.94 | 34.26 | 32.12 | 33.47 | |
| City | 28.94 | 28.66 | 27.65 | 28.23 | 26.56 | 26.63 | 27.15 | 27.20 | 25.95 | 26.46 | |
| SSIM | Kite | 0.933 | 0.900 | 0.832 | 0.829 | 0.817 | 0.887 | 0.893 | 0.899 | 0.765 | 0.770 |
| Showdown | 0.976 | 0.949 | 0.945 | 0.914 | 0.942 | 0.866 | 0.917 | 0.955 | 0.914 | 0.813 | |
| Slay | 0.972 | 0.958 | 0.962 | 0.963 | 0.962 | 0.928 | 0.944 | 0.957 | 0.939 | 0.943 | |
| City | 0.921 | 0.901 | 0.899 | 0.896 | 0.874 | 0.836 | 0.888 | 0.916 | 0.873 | 0.873 |
In this section, we will demonstrate the comprehensive experimental results of our method. We first introduce implementation details of our network and datasets used in training and testing (Section 5.1). Then, we compare our method with state-of-the-art methods in quality and performance (Section 5.2). We further make a discussion on the performance and quality of integrating our method into rendering pipelines compared to native HR rendering in Section 5.3. At last, experiments are conducted to validate the effectiveness of each design (Section 5.4).
5.1. Implementation Details and Datasets
Implementation details.
Our model is implemented and trained using PyTorch [Paszke et al., 2019]. All training and testing are performed on a single NVIDIA RTX 3090 GPU. For the best trade-off between performance and quality, we evaluate two implementations of our FuseSR model, namely Ours and Ours ↯. “Ours” version provides full network implementation with optimal quality. “Our ↯” version is more performance-oriented. It cuts off the history reusing module in the encoder (Section 4.1), reduces the number of hidden channels of all layers in fusion network F by half, and replaces all convolutional layers in F with faster DWS layers [Sandler et al., 2018] to improve the performance at a slight sacrifice of quality.
Datasets.
We have constructed a large-scale dataset using four virtual scenes selected from Unreal Engine marketplace111https://unrealengine.com/marketplace We select 2 scenes from Unreal Engine 4 (Kite and Showdown), and 2 scenes from Unreal Engine 5 (Slay and City). These scenes contain extensively complex geometry and lighting conditions with dynamic objects. Each scene contains 1080 continuous frames, of which 960 frames are used for training and 120 are used for testing. To show our method’s ability for high-quality rendering, the 2 scenes from UE 5 are rendered by real-time raytracing to achieve photorealistic appearances. We choose 4K () as the resolution of the target HR frame and the LR frames are downscaled according to scale factor. All frames are generated using UE 4 [2020b] and 5 [2021] with customized shaders to compute the required G-buffers, pre-integrated BRDF, and motion vectors.
Metrics.
Our evaluation comprises two aspects: performance and quality. We report the runtime of networks in milliseconds (ms) as a straightforward metric in performance. In terms of quality, we report two widely-used image metrics: peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) [Wang et al., 2004]. For both PSNR and SSIM, higher is better.
5.2. Results and Comparisons
5.2.1. Quality evaluation.
We compare our method with several state-of-the-art super-resolution methods in both academia and industry, including SOTA single image super-resolution method LIIF [Chen et al., 2021], real-time rendering super-resolution methods NSRR [Xiao et al., 2020] and MNSS [Yang et al., 2023], and methods widely used in the gaming industry including AMD’s FidelityFX™ Super Resolution (FSR) [AMD, 2021] and Intel Xe Super Sampling (XeSS) [Intel, 2022].
In Table 1, we compare PSNR and SSIM metrics averaged over all frames from 4 scenes of our dataset . Our method significantly outperforms other baselines in all scenes quantitatively. We also provide qualitative comparisons in Fig. 7. Our method faithfully produces HR details such as sharp edges and complex textures, owing to our exploitation of BRDF demodulation and effective H-Net design.
5.2.2. Runtime performance.
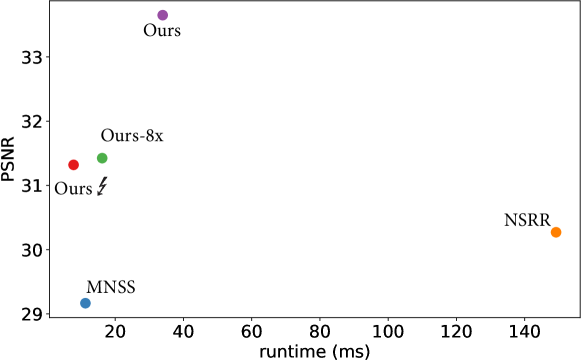
The performance of a super-resolution method is crucial for its application to real-time high-resolution rendering. After training, the optimized models are accelerated by NVIDIA TensorRT [2018] with 16-bit mixed precision for optimal inference speed. In Table 2, we report the total runtime of our method and baselines at different resolutions. Benefiting from our carefully designed H-Net architecture, both of our two versions achieve superior performance to NSRR at all configurations.
MNSS achieves competitive runtime performance due to its lightweight network design, especially at low resolutions. However, it requires network computations at HR level, leading to a more steep increase in running time compared to ours. With G-buffer generation time included, Ours ↯surpasses MNSS above 2K resolution.
The performance of our method is highly dependent on the upscaling factor, because our fusion network runs at LR level thanks to our pixel unshuffling alignment strategy. “Ours-8x” achieves superior performance to “Ours”, especially for high resolutions.
“Ours ↯” version indeed leads to a slight decrease in quality, which is reasonable due to the reduced network capacity. Nevertheless, it still performs on par with or better than other baselines. Fig. 4 displays the trade-off between performance and quality.
| 720p | 1080p | 2K | 4K | |
|---|---|---|---|---|
| HR G-buffer | 0.83 | 0.93 | 1.97 | 2.35 |
| Ours | 6.21 | 8.44 | 15.09 | 33.93 |
| Ours-8x | 6.20 | 7.57 | 8.79 | 16.20 |
| Ours ↯ | 2.66 | 2.88 | 3.96 | 7.82 |
| NSRR | 13.53 | 26.29 | 64.02 | 149.20 |
| MNSS | 2.26 | 3.57 | 5.52 | 11.29 |
5.2.3. Upsampling Factor
Besides super-resolution, we also evaluate our method on a more challenging task, which requires the network to predict 64 HR sub-pixel colors from a single LR pixel. Such a high upsampling rate makes it nearly impossible for previous methods with the absence of HR cues to recover any details, while our method still predicts high-fidelity results thanks to the demodulation and multi-resolution fusion. Table 1 (Right) and Fig. 8 demonstrates quantitative and qualitative results of our method and SOTA baselines.
5.3. Discussion on Real-time Rendering
G-buffer generation.
We test G-buffer generation time by recording the rendering state via the UE built-in profiling tool. For each scene, we measure the average G-buffer time on a sequence of dynamic frames and take 10 samples to cover as many scenarios as possible. Notably, G-buffer generation time is affected by various factors and there is a variance between certain frames within four orders of magnitude ranging from 0.01 ms to less than 10 ms. In general, the average G-buffer time is significantly lower than network time (as reported in the first row of Table 2). In modern game engines, simplification techniques, such as LOD or new techniques like Nanite in UE5, can further reduce the overhead of G-Buffer generation to a stably low cost.
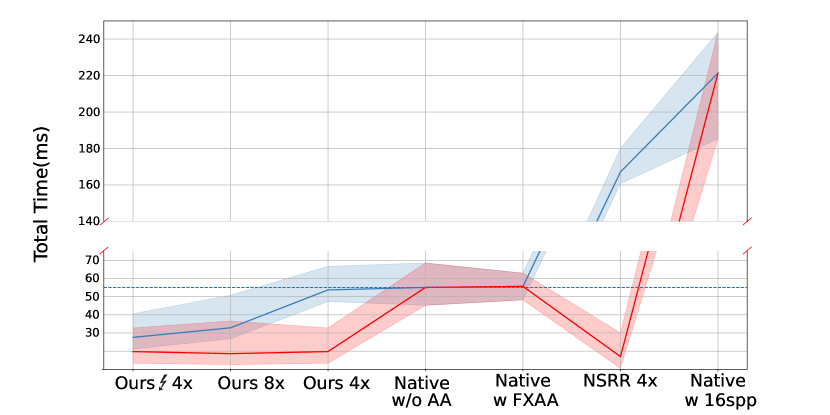
Comparisons to HR native rendering.
The ultimate goal of SR for real-time rendering is to reduce computational overhead by avoiding native rendering of HR images by the rendering engine. The performance of native rendering is affected by multiple factors including resolution and anti-aliasing options. In Fig. 5, we compare the runtime of HR native rendering with the total runtime of rendering an LR image and then super-resolving it into HR by our method. We report native rendering runtimes with different anti-aliasing levels (w/o AA, FXAA, and SSAA), and our results with different network configurations (Ours and Ours ↯) and different SR upscaling factors (4x and 8x). Results show that integrating our method into the rendering pipeline indeed reduces computational overhead compared to native rendering.
Scene complexity
The native rendering overhead typically depends on the complexity of scenes and lighting conditions, while the inference time of SR network basically remains constant among varying scenes. Integrating SR into rendering pipelines can increase the potential of designing more complex scenes for modern games without noticeable degradation of rendering performance.
5.4. Ablation Studies
5.4.1. Network modules
In Table 3, we report ablation experiments on our BRDF demodulation (Section 3.1) and HR G-buffer fusion (Section 3.2). The results confirm the effectiveness of our design.
| HR G-Buffer | Demodulation | PSNR(dB) | SSIM |
|---|---|---|---|
| ✗ | ✗ | 31.88 | 0.891 |
| ✓ | ✗ | 33.74 | 0.941 |
| ✗ | ✓ | 33.05 | 0.926 |
| ✓ | ✓ | 34.67 | 0.952 |
5.4.2. Alignment strategy
Tables 4 and 6 shows the comparisons between different alignment strategies used before the fusion network. Our strategy significantly outperforms maximum pooling and average pooling due to the preservation of HR details. Our strategy even outperforms the upsampling alignment strategy (where the fusion network runs much slower at HR level), showing the effectiveness of compact LR implicit representations.
| Ours | Avg-Pool | Max-Pool | Upsampling | |
|---|---|---|---|---|
| Kite | 32.33 | 32.14 | 31.87 | 32.09 |
| Slay | 37.02 | 36.32 | 36.11 | 36.69 |
\stackinsetl1ptt1ptOurs
|
\stackinsetl1ptt1ptUpsampling
|
\stackinsetl1ptt1ptReference
|
\stackinsetl1ptt1ptOurs
|
\stackinsetl1ptt1ptAvg-Pool
|
\stackinsetl1ptt1ptReference
|
6. Discussion and Conclusion
Integration cost.
While HR G-buffers provide a good guidance for upscaling and the demodulation further helps with the quality, these additional inputs require major modifications to modern game engines to integrate FuseSR. For example, to provide pre-integrated BRDF term , the engine should generate pre-integrated BRDF LUT for each material asset. To reduce integration costs, some rational trade-offs may be considered such as using FuseSR without demodulation or replacing with albedo.
Material Generalization.
Split-sum approximation offers an efficient means for BRDF demodulation, but it also limits the material types we can support. Materials that violate the assumptions of split-sum approximation, such as translucent and anisotropic materials, are not available in our method. Therefore, finding a more general BRDF demodulation method is an important direction for our future research.
Potential of H-Net.
We believe that our H-Net design are flexible and scalable, with the potential to be extended to more resolution levels and more multi-resolution tasks such as multi-scale object detection. We leave it as an interesting future work.
Conclusion
We present FuseSR, an efficient and effective super-resolution network that predicts high-quality (even ) upsampled reconstructions according to the corresponding low-resolution frames. With introducing pre-integrated BRDF demodulation and H-Net design, our method achieves a new SOTA for real-time superresolution. The experiments show that our method not only strikes an outstanding balance strikes an excellent balance between quality and performance, but also exhibits excellent generalizability and temporal stability. We hope our work will stimulate further developments of neural superresolution.
Acknowledgements.
The work was partially supported by Key R&D Program of Zhejiang Province (No. 2023C01039), Zhejiang Lab (121005-PI2101), and Information Technology Center and State Key Lab of CAD&CG, Zhejiang University.References
- [1]
- Akeley [1993] Kurt Akeley. 1993. Reality engine graphics. In Proceedings of the 20th annual conference on Computer graphics and interactive techniques. 109–116.
- AMD [2021] AMD. 2021. AMD FidelityFX™ Super Resolution. https://www.amd.com/en/technologies/fidelityfx-super-resolution/
- Bako et al. [2017] Steve Bako, Thijs Vogels, Brian McWilliams, Mark Meyer, Jan Novák, Alex Harvill, Pradeep Sen, Tony Derose, and Fabrice Rousselle. 2017. Kernel-predicting convolutional networks for denoising Monte Carlo renderings. ACM Trans. Graph. 36, 4 (2017), 97–1.
- Chen et al. [2021] Yinbo Chen, Sifei Liu, and Xiaolong Wang. 2021. Learning continuous image representation with local implicit image function. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8628–8638.
- Epic Games [2020a] Epic Games. 2020a. Screen Percentage with Temporal Upscale in Unreal Engine. https://docs.unrealengine.com/en-US/screen-percentage-with-temporal-upscale-in-unreal-engine/
- Epic Games [2020b] Epic Games. 2020b. Unreal Engine. https://www.unrealengine.com/
- Epic Games [2021] Epic Games. 2021. Unreal Engine. https://www.unrealengine.com/en-US/unreal-engine-5.
- Fan et al. [2021] Hangming Fan, Rui Wang, Yuchi Huo, and Hujun Bao. 2021. Real-time Monte Carlo Denoising with Weight Sharing Kernel Prediction Network. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 15–27.
- Gharbi et al. [2016] Michaël Gharbi, Gaurav Chaurasia, Sylvain Paris, and Frédo Durand. 2016. Deep joint demosaicking and denoising. ACM Transactions on Graphics (ToG) 35, 6 (2016), 1–12.
- Guo et al. [2021] Jie Guo, Xihao Fu, Liqiang Lin, Hengjun Ma, Yanwen Guo, Shiqiu Liu, and Ling-Qi Yan. 2021. ExtraNet: real-time extrapolated rendering for low-latency temporal supersampling. ACM Transactions on Graphics (TOG) 40, 6 (2021), 1–16.
- Intel [2022] Intel. 2022. Intel Xe Super Sampling. https://www.intel.com/content/www/us/en/products/docs/arc-discrete-graphics/xess.html/
- Johnson et al. [2016] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision. Springer, 694–711.
- Kajiya [1986] James T Kajiya. 1986. The rendering equation. In Proceedings of the 13th annual conference on Computer graphics and interactive techniques. 143–150.
- Kaplanyan et al. [2019] Anton S Kaplanyan, Anton Sochenov, Thomas Leimkühler, Mikhail Okunev, Todd Goodall, and Gizem Rufo. 2019. DeepFovea: Neural reconstruction for foveated rendering and video compression using learned statistics of natural videos. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–13.
- Karis [2013] Brian Karis. 2013. Real shading in unreal engine 4. In SIGGRAPH Courses: Physically Based Shading in Theory and Practice.
- Karis [2014] Brian Karis. 2014. High Quality Temporal Anti-Aliasing. In SIGGRAPH Courses: Advances in Real-Time Rendering.
- NVIDIA [2018] NVIDIA 2018. Deep Learning Super Sampling (DLSS) Technology — NVIDIA. NVIDIA. https://www.nvidia.com/en-us/geforce/technologies/dlss/
- NVIDIA [2018] NVIDIA. 2018. TensorRT. https://developer.nvidia.com/tensorrt/
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
- Sandler et al. [2018] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4510–4520.
- Schied et al. [2017] Christoph Schied, Anton Kaplanyan, Chris Wyman, Anjul Patney, Chakravarty R Alla Chaitanya, John Burgess, Shiqiu Liu, Carsten Dachsbacher, Aaron Lefohn, and Marco Salvi. 2017. Spatiotemporal variance-guided filtering: real-time reconstruction for path-traced global illumination. In Proceedings of High Performance Graphics. 1–12.
- Shi et al. [2016] Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. 2016. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1874–1883.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13, 4 (2004), 600–612.
- Xiao et al. [2020] Lei Xiao, Salah Nouri, Matt Chapman, Alexander Fix, Douglas Lanman, and Anton Kaplanyan. 2020. Neural supersampling for real-time rendering. ACM Transactions on Graphics (TOG) 39, 4 (2020), 142–1.
- Yang et al. [2020] Lei Yang, Shiqiu Liu, and Marco Salvi. 2020. A survey of temporal antialiasing techniques. In Computer graphics forum, Vol. 39. Wiley Online Library, 607–621.
- Yang et al. [2023] Sipeng Yang, Yunlu Zhao, Yuzhe Luo, He Wang, Hongyu Sun, Chen Li, Binghuang Cai, and Xiaogang Jin. 2023. MNSS: Neural Supersampling Framework for Real-Time Rendering on Mobile Devices. IEEE Transactions on Visualization and Computer Graphics (2023), 1–14. https://doi.org/10.1109/TVCG.2023.3259141
- Young [2006] Peter Young. 2006. Coverage sampled anti-aliasing. Technical Report. NVIDIA Corporation.
- Zeng et al. [2021] Zheng Zeng, Shiqiu Liu, Jinglei Yang, Lu Wang, and Ling-Qi Yan. 2021. Temporally Reliable Motion Vectors for Real-time Ray Tracing. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 79–90.
- Zhuang et al. [2021] Tao Zhuang, Pengfei Shen, Beibei Wang, and Ligang Liu. 2021. Real-time Denoising Using BRDF Pre-integration Factorization. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 173–180.
 |
 |
 |
 |
 |
 |



