Fundamental Convergence Analysis of Sharpness-Aware Minimization
Abstract
The paper investigates the fundamental convergence properties of Sharpness-Aware Minimization (SAM), a recently proposed gradient-based optimization method (Foret et al., 2021) that significantly improves the generalization of deep neural networks. The convergence properties including the stationarity of accumulation points, the convergence of the sequence of gradients to the origin, the sequence of function values to the optimal value, and the sequence of iterates to the optimal solution are established for the method. The universality of the provided convergence analysis based on inexact gradient descent frameworks Khanh et al. (2023b) allows its extensions to efficient normalized versions of SAM such as F-SAM (Li et al., 2024), VaSSO (Li and Giannakis, 2023), RSAM (Liu et al., 2022), and to the unnormalized versions of SAM such as USAM (Andriushchenko and Flammarion, 2022). Numerical experiments are conducted on classification tasks using deep learning models to confirm the practical aspects of our analysis.
1 Introduction
This paper concentrates on optimization methods for solving the standard optimization problem
| (1) |
where is a continuously differentiable (-smooth) function. We study the convergence behavior of the gradient-based optimization algorithm Sharpness-Aware Minimization (Foret et al., 2021) together with its efficient practical variants (Liu et al., 2022; Li and Giannakis, 2023; Andriushchenko and Flammarion, 2022). Given an initial point the original iterative procedure of SAM is designed as follows
| (2) |
for all , where and are respectively the stepsize (in other words, the learning rate) and perturbation radius. The main motivation for the construction algorithm is that by making the backward step , it avoids minimizers with large sharpness, which is usually poor for the generalization of deep neural networks as shown in (Keskar et al., 2017).
1.1 Lack of convergence properties for SAM due to constant stepsize
The consistently high efficiency of SAM has driven a recent surge of interest in the analysis of the method. The convergence analysis of SAM is now a primary focus on its theoretical understanding with several works being developed recently (e.g., Ahn et al. (2024); Andriushchenko and Flammarion (2022); Dai et al. (2023); Si and Yun (2023)). However, none of the aforementioned studies have addressed the fundamental convergence properties of SAM, which are outlined below where the stationary accumulation point in (2) means that every accumulation point of the iterative sequence satisfies the condition .
| (1) | |
|---|---|
| (2) | stationary accumulation point |
| (3) | |
| (4) | with |
| (5) | converges to some with |
The relationship between the properties above is summarized as follows:
(1) (2) (3) (5) (4).
The aforementioned convergence properties are standard and are analyzed by various smooth optimization methods including gradient descent-type methods, Newton-type methods, and their accelerated versions together with nonsmooth optimization methods under the usage of subgradients. The readers are referred to Bertsekas (2016); Nesterov (2018); Polyak (1987) and the references therein for those results. The following recent publications have considered various types of convergence rates for the sequences generated by SAM as outlined below:
(i) Dai et al. (2023, Theorem 1)
where is the Lipschitz constant of , and where is the constant of strong convexity constant for .
(ii) Si and Yun (2023, Theorems 3.3, 3.4)
where is the Lipschitz constant of We emphasize that none of the results mentioned above achieve any fundamental convergence properties listed in Table 1. The estimation in (i) only gives us the convergence of the function value sequence to a value close to the optimal one, not the convergence to exactly the optimal value. Additionally, it is evident that the results in (ii) do not imply the convergence of to . To the best of our knowledge, the only work concerning the fundamental convergence properties listed in Table 1 is Andriushchenko and Flammarion (2022). However, the method analyzed in that paper is unnormalized SAM (USAM), a variant of SAM with the norm being removed in the iterative procedure (2c). Recently, Dai et al. (2023) suggested that USAM has different effects in comparison with SAM in both practical and theoretical situations, and thus, they should be addressed separately. This observation once again highlights the necessity for a fundamental convergence analysis of SAM and its normalized variants.
Note that, using exactly the iterative procedure (2), SAM does not achieve the convergence for either , or , or to the optimal solution, the optimal value, and the origin, respectively. It is illustrated by Example 3.1 below dealing with quadratic functions. This calls for the necessity of employing an alternative stepsize rule for SAM. Scrutinizing the numerical experiments conducted for SAM and its variants (e.g., Foret et al. (2021, Subsection C1), Li and Giannakis (2023, Subsection 4.1)), we can observe that in fact the constant stepsize rule is not a preferred strategy. Instead, the cosine stepsize scheduler from (Loshchilov and Hutter, 2016), designed to decay to zero and then restart after each fixed cycle, emerges as a more favorable approach. This observation motivates us to analyze the method under diminishing stepsize, which is standard and employed in many optimization methods including the classical gradient descent methods together with its incremental and stochastic counterparts (Bertsekas and Tsitsiklis, 2000). Diminishing step sizes also converge to zero as the number of iterations increases, a condition satisfied by the practical cosine step size scheduler in each cycle.
1.2 Our Contributions
Convergence of SAM and normalized variants
We establish fundamental convergence properties of SAM in various settings. In the convex case, we consider the perturbation radii to be variable and bounded. This analysis encompasses the practical implementation of SAM with a constant perturbation radius. The results in this case are summarized in Table 2.
| Classes of function | Results |
|---|---|
| General setting | |
| Bounded minimizer set | stationary accumulation point |
| Unique minimizer | is convergent |
In the nonconvex case, we present a unified convergence analysis framework that can be applied to most variants of SAM, particularly recent efficient developments such as VaSSO (Li and Giannakis, 2023), F-SAM (Li et al., 2024), and RSAM (Liu et al., 2022). We observe that all these methods can be viewed as inexact gradient descent (IGD) methods with absolute error. This version of IGD has not been previously considered, and its convergence analysis is significantly more complex than the one in Khanh et al. (2023b, 2024a, a, 2024b), as the function value sequence generated by the new algorithm may not be decreasing. This disrupts the convergence framework for monotone function value sequences used in the aforementioned works. To address this challenge, we adapt the analysis for algorithms with nonmonotone function value sequences from Li et al. (2023), which was originally developed for random reshuffling algorithms, a context entirely different from ours.
We establish the convergence of IGD with absolute error when the perturbation radii decrease at an arbitrarily slow rate. Although the analysis of this general framework does not theoretically cover the case of a constant perturbation radius, it poses no issues for the practical implementation of these methods, as discussed in Remark 3.6. A summary of our results in the nonconvex case is provided in the first part of Table 3.
Convergence of USAM and unnormalized variants
Our last theoretical contribution in this paper involves a refined convergence analysis of USAM in Andriushchenko and Flammarion (2022). In the general setting, we address functions satisfying the -descent condition (4), which is even weaker than the Lipschitz continuity of as considered in Andriushchenko and Flammarion (2022). The summary of the convergence analysis for USAM is given in the second part of Table 3.
As will be discussed in Remark G.4, our convergence properties for USAM use weaker assumptions and cover a broader range of applications in comparison with those analyzed in (Andriushchenko and Flammarion, 2022). Furthermore, the universality of the conducted analysis allows us to verify all the convergence properties for the extragradient method (Korpelevich, 1976) that has been recently applied in (Lin et al., 2020) to large-batch training in deep learning.
| SAM and normalized variants | USAM and unnormalized variants | ||
|---|---|---|---|
| Classes of functions | Results | Classes of functions | Results |
| General setting | General setting | stationary accumulation point | |
| General setting | General setting | ||
| KL property | is convergent | is Lipschitz | |
| KL property | is convergent | ||
1.3 Importance of Our Work
Our work develops, for the first time in the literature, a fairly comprehensive analysis of the fundamental convergence properties of SAM and its variants. The developed approach addresses general frameworks while being based on the analysis of the newly proposed inexact gradient descent methods. Such an approach can be applied in various other circumstances and provides useful insights into the convergence understanding of not only SAM and related methods but also many other numerical methods in smooth, nonsmooth, and derivative-free optimization.
1.4 Related Works
Variants of SAM. There have been several publications considering some variants to improve the performance of SAM. Namely, Kwon et al. (2021) developed the Adaptive Sharpness-Aware Minimization (ASAM) method by employing the concept of normalization operator. Du et al. (2022) proposed the Efficient Sharpness-Aware Minimization (ESAM) algorithm by combining stochastic weight perturbation and sharpness-sensitive data selection techniques. Liu et al. (2022) proposed a novel Random Smoothing-Based SAM method called RSAM that improves the approximation quality in the backward step. Quite recently, Li and Giannakis (2023) proposed another approach called Variance Suppressed Sharpness-aware Optimization (VaSSO), which perturbed the backward step by incorporating information from the previous iterations. As Li et al. (2024) identified noise in stochastic gradient as a crucial factor in enhancing SAM’s performance, they proposed Friendly Sharpness-Aware Minimization (F-SAM) which perturbed the backward step by extracting noise from the difference between the stochastic gradient and the expected gradient at the current step. Two efficient algorithms, AE-SAM and AE-LookSAM, are also proposed in Jiang et al. (2023), by employing adaptive policy based on the loss landscape geometry.
Theoretical Understanding of SAM. Despite the success of SAM in practice, a theoretical understanding of SAM was absent until several recent works. Barlett et al. (2023) analyzed the convergence behavior of SAM for convex quadratic objectives, showing that for most random initialization, it converges to a cycle that oscillates between either side of the minimum in the direction with the largest curvature. Ahn et al. (2024) introduces the notion of -approximate flat minima and investigates the iteration complexity of optimization methods to find such approximate flat minima. As discussed in Subsection 1.1, Dai et al. (2023) considers the convergence of SAM with constant stepsize and constant perturbation radius for convex and strongly convex functions, showing that the sequence of iterates stays in a neighborhood of the global minimizer while (Si and Yun, 2023) considered the properties of the gradient sequence generated by SAM in different settings.
Theoretical Understanding of USAM. This method was first proposed by Andriushchenko and Flammarion (2022) with fundamental convergence properties being analyzed under different settings of convex and nonconvex and optimization. Analysis of USAM was further conducted in Behdin and Mazumder (2023) for a linear regression model, and in Agarwala and Dauphin (2023) for a quadratic regression model. Detailed comparison between SAM and USAM, which indicates that they exhibit different behaviors, was presented in the two recent studies by Compagnoni et al. (2023) and Dai et al. (2023). During the final preparation of the paper, we observed that the convergence of USAM can also be deduced from Mangasarian and Solodov (1994), though under some additional assumptions, including the boundedness of the gradient sequence.
2 Preliminaries
First we recall some notions and notations frequently used in the paper. All our considerations are given in the space with the Euclidean norm . As always, signifies the collections of natural numbers. The symbol means that as with . Recall that is a stationary point of a -smooth function if . A function is said to posses a Lipschitz continuous gradient with the uniform constant , or equivalently it belongs to the class , if we have the estimate
| (3) |
This class of function enjoys the following property called the -descent condition (see, e.g., Izmailov and Solodov (2014, Lemma A.11) and Bertsekas (2016, Lemma A.24)):
| (4) |
for all Conditions (3) and (4) are equivalent to each other when is convex, while the equivalence fails otherwise. A major class of functions satisfying the -descent condition but not having the Lipschitz continuous gradient is given by Khanh et al. (2023b, Section 2) as where is an matrix, , and is a smooth convex function whose gradient is not Lipschitz continuous. There are also circumstances where a function has a Lipschitz continuous gradient and satisfies the descent condition at the same time, but the Lipschitz constant is larger than the one in the descent condition.
Our convergence analysis of the methods presented in the subsequent sections benefits from the Kurdyka-Łojasiewicz property taken from Attouch et al. (2010).
Definition 2.1 (Kurdyka-Łojasiewicz property).
We say that a smooth function enjoys the KL property at if there exist , a neighborhood of , and a desingularizing concave continuous function such that , is -smooth on , on , and for all with , we have
| (5) |
Remark 2.2.
It has been realized that the KL property is satisfied in broad settings. In particular, it holds at every nonstationary point of ; see Attouch et al. (2010, Lemma 2.1 and Remark 3.2(b)). Furthermore, it is proved at the seminal paper Łojasiewicz (1965) that any analytic function satisfies the KL property on with for some . Typical functions that satisfy the KL property are semi-algebraic functions and in general, functions definable in o-minimal structures; see Attouch et al. (2010, 2013); Kurdyka (1998).
We utilize the following assumption on the desingularizing function in Definition 2.1, which is employed in (Li et al., 2023). The satisfaction of this assumption for a general class of desingularizing functions is discussed in Remark G.1.
Assumption 2.3.
There is some such that whenever with , it holds that
3 SAM and normalized variants
3.1 Convex case
We begin this subsection with an example that illustrates SAM’s inability to achieve the convergence of the sequence of iterates to an optimal solution of strongly convex quadratic functions by using a constant stepsize. This emphasizes the necessity of avoiding this type of stepsize in our subsequent analysis.
Example 3.1 (SAM with constant stepsize and constant perturbation radius does not converge).
Let the sequence be generated by SAM in (2) applied to the strongly convex quadratic function , where is an symmetric, positive-definite matrix and Then for any fixed small constant perturbation radius and for some small constant stepsize together with an initial point close to the solution, the sequence generated by this algorithm does not converge to the optimal solution.
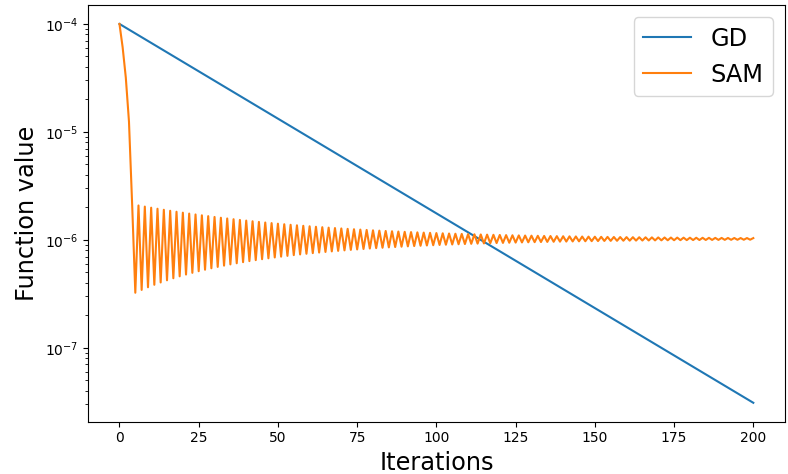
The details of the above example are presented in Appendix A.1. Figure 1 gives an empirical illustration for Example 3.1. The graph shows that, while the sequence generated by GD converges to , the one generated by SAM gets stuck at a different point.
As the constant stepsize does not guarantee the convergence of SAM, we consider another well-known stepsize called diminishing (see (7)). The following result provides the convergence properties of SAM in the convex case for that type of stepsize.
Theorem 3.2.
Let be a smooth convex function whose gradient is Lipschitz continuous with constant . Given any initial point , let be generated by the SAM method with the iterative procedure
| (6) |
for all with nonnegative stepsizes and perturbation radii satisfying the conditions
| (7) |
Assume that for all and that . Then the following assertions hold:
(i) .
(ii) If has a nonempty bounded level set, then is bounded, every accumulation point of is a global minimizer of , and converges to the optimal value of . If in addition has a unique minimizer, then the sequence converges to that minimizer.
Due to the space limit, the proof of the theorem is presented in Appendix C.1.
3.2 Nonconvex case
In this subsection, we study the convergence of several versions of SAM from the perspective of the inexact gradient descent methods.
Step 0.
Choose some initial point sequence of errors , and sequence of stepsizes For do the following
Step 1.
Set with .
This algorithm is motivated by while being different from the Inexact Gradient Descent methods proposed in (Khanh et al., 2023a, b, 2024b, 2024a). The latter constructions consider relative errors in gradient calculation, while Algorithm 1 uses the absolute ones. This approach is particularly suitable for the constructions of SAM and its normalized variants. The convergence properties of Algorithm 1 are presented in the next theorem.
Theorem 3.3.
Let be a smooth function whose gradient is Lipschitz continuous with some constant , and let be generated by the IGD method in Algorithm 1 with stepsizes and errors satisfying the conditions
| (8) |
Assume that . Then the following convergence properties hold:
(i) and thus every accumulation point of is stationary for
(ii) If is an accumulation point of the sequence , then
(iii) Suppose that satisfies the KL property at some accumulation point of with the desingularizing function satisfying Assumption 2.3. Assume in addition that
| (9) |
and that for sufficiently large . Then as . In particular, if is a global minimizer of , then either for some , or .
The proof of the theorem is presented in Appendix C.2. The demonstration that condition (9) is satisfied when with some and , and when and with for all , is provided in Remark G.3.
The next example discusses the necessity of the last two conditions in (8) in the convergence analysis of IGD while demonstrating that employing a constant error leads to the convergence to a nonstationary point of the method.
Example 3.4 (IGD with constant error converges to a nonstationary point).
Let be defined by for . Given a perturbation radius and an initial point , consider the iterative sequence
| (10) |
where and . This algorithm is in fact the IGD applied to with . Then converges to which is not a stationary point of
The details of the example are presented in Appendix A.2. We now propose a general framework that encompasses SAM and all of its normalized variants including RSAM (Liu et al., 2022), VaSSO (Li and Giannakis, 2023) and F-SAM (Li et al., 2024). Due to the page limit, we refer readers to Appendix D for the detailed constructions of those methods. Remark D.1 in Appendix D also shows that all of these methods are special cases of Algorithm 1a, and thus all the convergence properties presented in Theorem 3.3 follow.
Step 0.
Choose , and For do the following:
Step 1.
Set .
Corollary 3.5.
The proof of this result is presented in Appendix C.5.
Remark 3.6.
Note that the conditions in (11) do not pose any obstacles to the implementation of a constant perturbation radius for SAM in practical circumstances. This is due to the fact that a possible selection of and satisfying (11) is and for all (almost constant), where . Then the initial perturbation radius is , while after million iterations, it remains greater than . This phenomenon is also confirmed by numerical experiments in Appendix E on nonconvex functions. The numerical results show that SAM with almost constant radii has a similar convergence behavior to SAM with a constant radius . As SAM with a constant perturbation radius has sufficient empirical evidence for its efficiency in Foret et al. (2021), this also supports the practicality of our almost constant perturbation radii.
4 USAM and unnormalized variants
In this section, we study the convergence of various versions of USAM from the perspective of the following Inexact Gradient Descent method with relative errors.
Step 0.
Choose some , and For do the following:
Step 1.
Set , where .
This algorithm was initially introduced in Khanh et al. (2023b) in a different form, considering a different selection of error. The form of IGDr closest to Algorithm 2 was established in Khanh et al. (2024a) and then further studied in Khanh et al. (2024a, 2023a, b). In this paper, we extend the analysis of the method to a general stepsize rule covering both constant and diminishing cases, which was not considered in Khanh et al. (2024a).
Theorem 4.1.
Let be a smooth function satisfying the descent condition for some constant and let be the sequence generated by Algorithm 2 with the relative error , and the stepsizes satisfying
| (12) |
for sufficiently large and for some . Then either , or we have the assertions:
(i) Every accumulation point of is a stationary point of the cost function .
(ii) If the sequence has any accumulation point , then .
(iii) If , then
(iv) If satisfies the KL property at some accumulation point of , then .
(v) Assume in addition to (iv) that the stepsizes are bounded away from , and the KL property in (iv) holds with the desingularizing function with and . Then either stops finitely at a stationary point, or the following convergence rates are achieved:
If , then , converge linearly as to , , and .
If , then
Although the ideas for proving this result is similar to the one given in Khanh et al. (2024a), we do provide the full proof in the Appendix C.3 for the convenience of the readers. We now show that using this approach, we derive more complete convergence results for USAM in Andriushchenko and Flammarion (2022) and also the extragradient method by Korpelevich (1976); Lin et al. (2020).
Step 0.
Choose , and For do the following:
Step 1.
Set .
Step 0.
Choose , and For do the following:
Step 1.
Set .
We are ready now to derive convergence of the two algorithms above. The proof of the theorem is given in Appendix C.4
5 Numerical Experiments
To validate the practical aspect of our theory, this section compares the performance of SAM employing constant and diminishing stepsizes in image classification tasks. All the experiments are conducted on a computer with NVIDIA RTX 3090 GPU. The three types of diminishing stepsizes considered in the numerical experiments are (Diminish 1), (Diminish 2), and (Diminish 3), where is the initial stepsize, represents the number of epochs performed, and . The constant stepsize in SAM is selected through a grid search over 0.1, 0.01, 0.001 to ensure a fair comparison with the diminishing ones. The algorithms are tested on two widely used image datasets: CIFAR-10 (Krizhevsky et al., 2009) and CIFAR-100 (Krizhevsky et al., 2009).
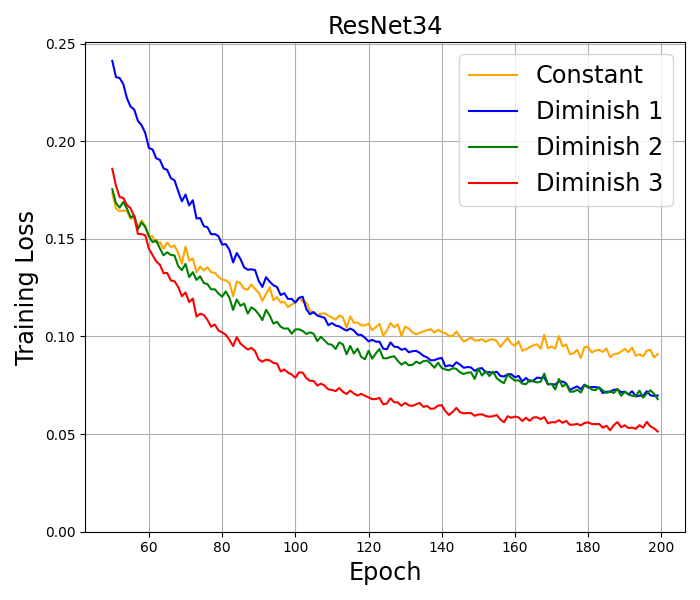
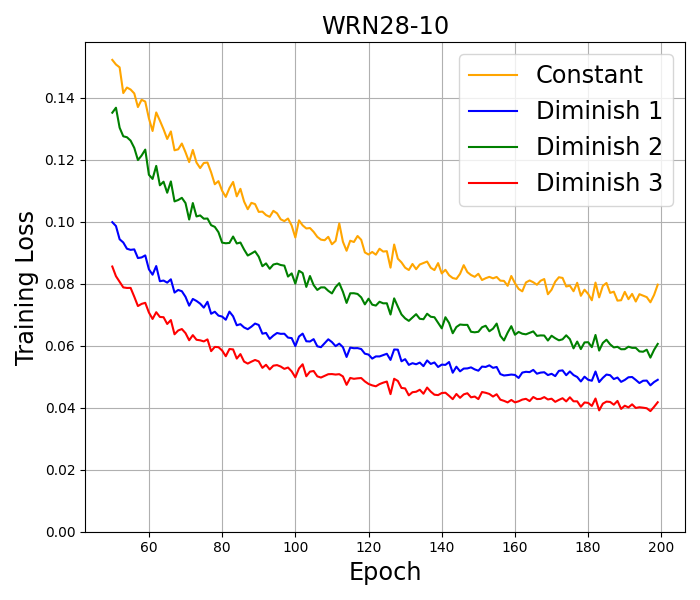
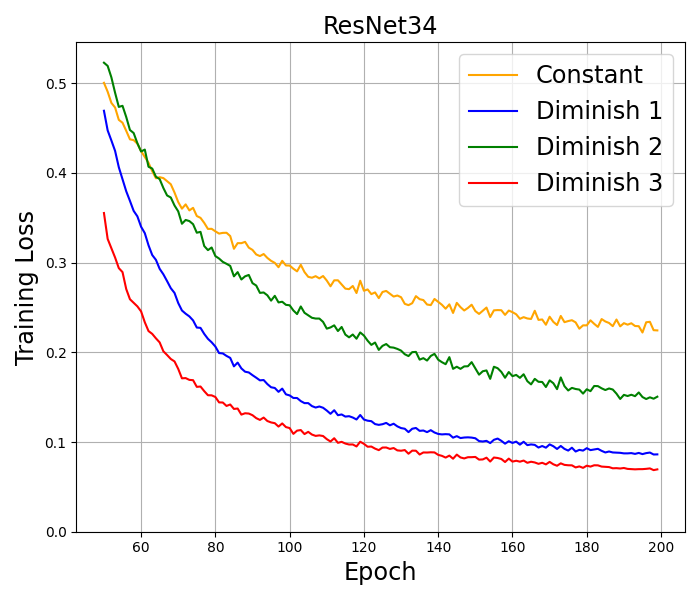
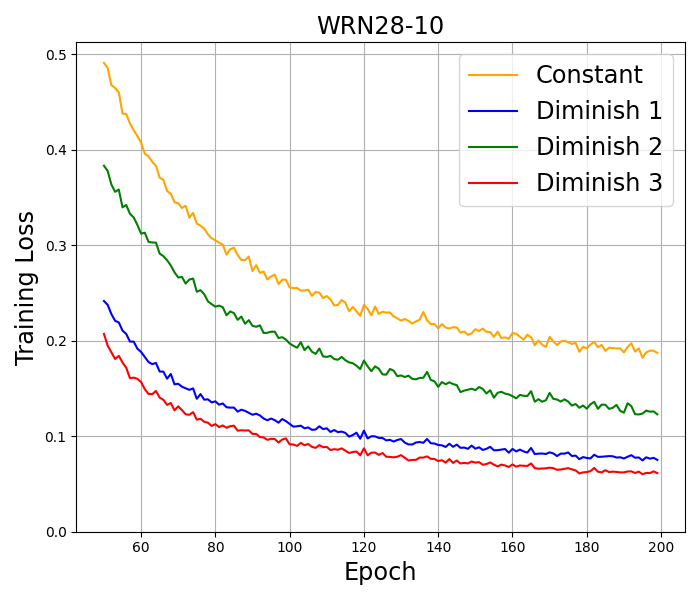
CIFAR-10. We train well-known deep neural networks including ResNet18 (He et al., 2016), ResNet34 (He et al., 2016), and WideResNet28-10 (Zagoruyko and Komodakis, 2016) on this dataset by using 10% of the training set as a validation set. Basic transformations, including random crop, random horizontal flip, normalization, and cutout (DeVries and Taylor, 2017), are employed for data augmentation. All the models are trained by using SAM with SGD Momentum as the base optimizer for epochs and a batch size of . This base optimizer is also used in the original paper (Foret et al., 2021) and in the recent works on SAM Ahn et al. (2024); Li and Giannakis (2023). Following the approach by Foret et al. (2021), we set the initial stepsize to , momentum to , the -regularization parameter to , and the perturbation radius to . Setting the perturbation radius to be a constant here does not go against our theory, since by Remark 3.6, SAM with a constant radius and our almost constant radius have the same numerical behavior. We also conducted the numerical experiment with an almost constant radius and got the same results. Therefore, for simplicity of presentation, a constant perturbation radius is chosen. The algorithm with the highest accuracy, corresponding to the best performance, is highlighted in bold. The results in Table 4 report the mean and 95% confidence interval across the three independent runs. The training loss in several tests is presented in Figure 2.
CIFAR-100. The training configurations for this dataset are similar to CIFAR10. The accuracy results are presented in Table 4, while the training loss results are illustrated in Figure 2.
| CIFAR-10 | CIFAR-100 | |||||
| Model | ResNet18 | ResNet34 | WRN28-10 | ResNet18 | ResNet34 | WRN28-10 |
| Constant | 94.10 0.27 | 94.38 0.47 | 95.33 0.23 | 71.77 0.26 | 72.49 0.23 | 74.63 0.84 |
| Diminish 1 | 93.95 0.34 | 93.94 0.40 | 95.18 0.03 | 74.43 0.12 | 73.99 0.70 | 78.59 0.03 |
| Diminish 2 | 94.60 0.09 | 95.09 0.16 | 95.75 0.23 | 73.40 0.24 | 74.44 0.89 | 77.04 0.23 |
| Diminish 3 | 94.75 0.20 | 94.47 0.08 | 95.88 0.10 | 75.65 0.44 | 74.92 0.76 | 79.70 0.12 |
The results on CIFAR-10 and CIFAR-100 indicate that SAM with Diminish 3 stepsize usually achieves the best performance in both accuracy and training loss among all tested stepsizes. In all the architectures used in the experiment, the results consistently show that diminishing stepsizes outperform constant stepsizes in terms of both accuracy and training loss measures. Additional numerical results on a larger data set and without momentum can be found in Appendix F.
6 Discusison
6.1 Conclusion
In this paper, we provide a fundamental convergence analysis of SAM and its normalized variants together with a refined convergence analysis of USAM and its unnormalized variants. Our analysis is conducted in deterministic settings under standard assumptions that cover a broad range of applications of the methods in both convex and nonconvex optimization. The conducted analysis is universal and thus can be applied in different contexts other than SAM and its variants. The performed numerical experiments show that our analysis matches the efficient implementations of SAM and its variants that are used in practice.
6.2 Limitations
Our analysis is only conducted in deterministic settings, which leaves the stochastic and random reshuffling developments to our future research. The analysis of SAM coupling with momentum methods is also not considered in this paper. Another limitation pertains to numerical experiments, where only SAM was tested on three different architectures of deep learning.
Acknowledgment
Pham Duy Khanh, Research of this author is funded by the Ministry of Education and Training Research Funding under the project B2024-SPS-07. Boris S. Mordukhovich, Research of this author was partly supported by the US National Science Foundation under grants DMS-1808978 and DMS-2204519, by the Australian Research Council under grant DP-190100555, and by Project 111 of China under grant D21024. Dat Ba Tran, Research of this author was partly supported by the US National Science Foundation under grants DMS-1808978 and DMS-2204519.
The authors would like to thank Professor Mikhail V. Solodov for his fruitful discussions on the convergence of variants of SAM.
References
- Agarwala and Dauphin [2023] A. Agarwala and Y. N. Dauphin. Sam operates far from home: eigenvalue regularization as a dynamical phenomenon. arXiv preprint arXiv:2302.08692, 2023.
- Ahn et al. [2024] K. Ahn, A. Jadbabaie, and S. Sra. How to escape sharp minima with random perturbations. Proceedings of the 38th International Conference on Machine Learning, 2024.
- Andriushchenko and Flammarion [2022] M. Andriushchenko and N. Flammarion. Towards understanding sharpness-aware minimization. Proceedings of International Conference on Machine Learning, 2022.
- Attouch et al. [2010] H. Attouch, J. Bolte, P. Redont, and A. Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems. Mathematics of Operations Research, pages 438–457, 2010.
- Attouch et al. [2013] H. Attouch, J. Bolte, and B. F. Svaiter. Convergence of descent methods for definable and tame problems: Proximal algorithms, forward-backward splitting, and regularized gauss-seidel methods. Mathematical Programming, 137:91–129, 2013.
- Barlett et al. [2023] P. L. Barlett, P. M. Long, and O. Bousquet. The dynamics of sharpness-aware minimization: Bouncing across ravines and drifting towards wide minima. Journal of Machine Learning Research, 24:1–36, 2023.
- Behdin and Mazumder [2023] K. Behdin and R. Mazumder. On statistical properties of sharpness-aware minimization: Provable guarantees. arXiv preprint arXiv:2302.11836, 2023.
- Bertsekas [2016] D. Bertsekas. Nonlinear programming, 3rd edition. Athena Scientific, Belmont, MA, 2016.
- Bertsekas and Tsitsiklis [2000] D. Bertsekas and J. N. Tsitsiklis. Gradient convergence in gradient methods with errors. SIAM Journal on Optimization, 10:627–642, 2000.
- Compagnoni et al. [2023] E. M. Compagnoni, A. Orvieto, L. Biggio, H. Kersting, F. N. Proske, and A. Lucchi. An sde for modeling sam: Theory and insights. Proceedings of International Conference on Machine Learning, 2023.
- Dai et al. [2023] Y. Dai, K. Ahn, and K. Sra. The crucial role of normalization in sharpness-aware minimization. Advances in Neural Information Processing System, 2023.
- DeVries and Taylor [2017] Terrance DeVries and Graham W. Taylor. Improved regularization of convolutional neural networks with cutout. https://arxiv.org/abs/1708.04552, 2017.
- Du et al. [2022] J. Du, H. Yan, J. Feng, J. T. Zhou, L. Zhen, R. S. M. Goh, and V. Y. F.Tan. Efficient sharpness-aware minimization for improved training of neural networks. Proceedings of International Conference on Learning Representations, 2022.
- Foret et al. [2021] P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization. Proceedings of International Conference on Learning Representations, 2021.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Izmailov and Solodov [2014] A. F. Izmailov and M. V. Solodov. Newton-type methods for optimization and variational problems. Springer, 2014.
- Jiang et al. [2023] W. Jiang, H. Yang, Y. Zhang, and J. Kwok. An adaptive policy to employ sharpness-aware minimization. Proceedings of International Conference on Learning Representations, 2023.
- Keskar et al. [2017] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp mininma. Proceedings of International Conference on Learning Representations, 2017.
- Khanh et al. [2023a] P. D. Khanh, B. S. Mordukhovich, V. T. Phat, and D. B. Tran. Inexact proximal methods for weakly convex functions. https://arxiv.org/abs/2307.15596, 2023a.
- Khanh et al. [2023b] P. D. Khanh, B. S. Mordukhovich, and D. B. Tran. Inexact reduced gradient methods in smooth nonconvex optimization. Journal of Optimization Theory and Applications, doi.org/10.1007/s10957-023-02319-9, 2023b.
- Khanh et al. [2024a] P. D. Khanh, B. S. Mordukhovich, and D. B. Tran. A new inexact gradient descent method with applications to nonsmooth convex optimization. Optimization Methods and Software https://doi.org/10.1080/10556788.2024.2322700, pages 1–29, 2024a.
- Khanh et al. [2024b] P. D. Khanh, B. S. Mordukhovich, and D. B. Tran. Globally convergent derivative-free methods in nonconvex optimization with and without noise. https://optimization-online.org/?p=26889, 2024b.
- Korpelevich [1976] G. M. Korpelevich. An extragradient method for finding saddle points and for other problems. Ekon. Mat. Metod., page 747–756, 1976.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. technical report, 2009.
- Kurdyka [1998] K. Kurdyka. On gradients of functions definable in o-minimal structures. Annales de l’institut Fourier, pages 769–783, 1998.
- Kwon et al. [2021] J. Kwon, J. Kim, H. Park, and I. K. Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. Proceedings of the 38th International Conference on Machine Learning, pages 5905–5914, 2021.
- Li and Giannakis [2023] B. Li and G. B. Giannakis. Enhancing sharpness-aware optimization through variance suppression. Advances in Neural Information Processing System, 2023.
- Li et al. [2024] Tao Li, Pan Zhou, Zhengbao He, Xinwen Cheng, and Xiaolin Huang. Friendly sharpness-aware minimization. Proceedings of Conference on Computer Vision and Pattern Recognition, 2024.
- Li et al. [2023] X. Li, A. Milzarek, and J. Qiu. Convergence of random reshuffling under the kurdyka-łojasiewicz inequality. SIAM Journal on Optimization, 33:1092–1120, 2023.
- Lin et al. [2020] T. Lin, L. Kong, S. U. Stich, and M. Jaggi. Extrapolation for large-batch training in deep learning. Proceedings of International Conference on Machine Learning, 2020.
- Liu et al. [2022] Y. Liu, S. Mai, M. Cheng, X. Chen, C-J. Hsieh, and Y. You. Random sharpness-aware minimization. Advances in Neural Information Processing System, 2022.
- Łojasiewicz [1965] S. Łojasiewicz. Ensembles semi-analytiques. Institut des Hautes Etudes Scientifiques, pages 438–457, 1965.
- Loshchilov and Hutter [2016] I. Loshchilov and F. Hutter. Sgdr: stochastic gradient descent with warm restarts. Proceedings of International Conference on Learning Representations, 2016.
- Mangasarian and Solodov [1994] O. Mangasarian and M. V. Solodov. Serial and parallel backpropagation convergence via nonmonotone perturbed minimization. Optimzation Methods and Software, 4, 1994.
- Nesterov [2018] Y. Nesterov. Lectures on convex optimization, 2nd edition,. Springer, Cham, Switzerland,, 2018.
- Polyak [1987] B. Polyak. Introduction to optimization. Optimization Software, New York,, 1987.
- Ruszczynski [2006] A. Ruszczynski. Nonlinear optimization. Princeton university press, 2006.
- Si and Yun [2023] D. Si and C. Yun. Practical sharpness-aware minimization cannot converge all the way to optima. Advances in Neural Information Processing System, 2023.
- Zagoruyko and Komodakis [2016] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
Appendix A Counterexamples illustrating the Insufficiency of Fundamental Convergence Properties
A.1 Proof of Example 3.1
Proof.
Since , the gradient of and the optimal solution are given by
Let be the minimum, maximum eigenvalues of , respectively and assume that
| (13) |
The iterative procedure of (6) can be written as
| (14) |
Then satisfies the inequalities
| (15) |
It is obvious that (15) holds for Assuming that this condition holds for any let us show that it holds for We deduce from the iterative update (14) that
| (16) |
In addition, we get
where the last inequality follows from from (13). Thus, (15) is verified. It follows from (A.1) that ∎
A.2 Proof of Example 3.4
Proof.
Observe that for all Indeed, this follows from , , and
In addition, we readily get
| (17) |
Furthermore, deduce from that Indeed, we have
This tells us by (17) and the classical squeeze theorem that as . ∎
Appendix B Auxiliary Results for Convergence Analysis
We first establish the new three sequences lemma, which is crucial in the analysis of both SAM, USAM, and their variants.
Lemma B.1 (three sequences lemma).
Let be sequences of nonnegative numbers satisfying the conditions
| (a) | |||
| (b) |
Then we have that as .
Proof.
First we show that Supposing the contrary gives us some and such that for all . Combining this with the second and the third condition in (b) yields
which is a contradiction verifying the claim. Let us now show that in fact Indeed, by the boundedness of define and deduce from (a) that there exists such that
| (18) |
Pick and find by and the two last conditions in (b) some with , ,
| (19) |
It suffices to show that for all Fix and observe that for the desired inequality is obviously satisfied. If we use and find some such that and
Then we deduce from (18) and (19) that
As a consequence, we arrive at the estimate
which verifies that as sand thus completes the proof of the lemma. ∎
Next we recall some auxiliary results from Khanh et al. [2023b].
Lemma B.2.
Let and be sequences in satisfying the condition
If is an accumulation point of the sequence and is an accumulation points of the sequence , then there exists an infinite set such that we have
| (20) |
Proposition B.3.
Let be a -smooth function, and let the sequence satisfy the conditions:
-
(H1)
(primary descent condition). There exists such that for sufficiently large we have
-
(H2)
(complementary descent condition). For sufficiently large , we have
If is an accumulation point of and satisfies the KL property at , then as .
When the sequence under consideration is generated by a linesearch method and satisfies some conditions stronger than (H1) and (H2) in Proposition B.3, its convergence rates are established in Khanh et al. [2023b, Proposition 2.4] under the KL property with as given below.
Proposition B.4.
Let be a -smooth function, and let the sequences satisfy the iterative condition for all . Assume that for all sufficiently large we have and the estimates
| (21) |
where . Suppose in addition that the sequence is bounded away from i.e., there is some such that for large , that is an accumulation point of , and that satisfies the KL property at with for some and . Then the following convergence rates are guaranteed:
-
(i)
If , then the sequence converges linearly to .
-
(ii)
If , then we have the estimate
Yet another auxiliary result needed below is as follows.
Proposition B.5.
Let be a -smooth function satisfying the descent condition (4) with some constant . Let be a sequence in that converges to , and let be such that
| (22) |
Consider the following convergence rates of
-
(i)
linearly.
-
(ii)
, where as
Then (i) ensures the linear convergences of to , and to , while (ii) yields and as .
Proof.
Condition (22) tells us that there exists some such that for all As , we deduce that with for Letting in (22) and using the squeeze theorem together with the convergence of to and the continuity of lead us to It follows from the descent condition of with constant and from (4) that
This verifies the desired convergence rates of Employing finally (22) and , we also get that
This immediately gives us the desired convergence rates for and completes the proof. ∎
Appendix C Proof of Convergence Results
C.1 Proof of Theorem 3.2
Proof.
To verify (i) first, for any define and get
| (23) |
where Using the monotonicity of due to the convexity of ensures that
| (24) |
With the definition of the iterative procedure (6) can also be rewritten as for all . The first condition in (7) yields which gives us some such that for all . Take some such . Since is Lipschitz continuous with constant , it follows from the descent condition in (4) and the estimates in (C.1), (C.1) that
| (25) |
Rearranging the terms above gives us the estimate
| (26) |
Select any define , and get by taking into account that
Letting yields Let us now show that Supposing the contrary gives us and such that for all , which tells us that
This clearly contradicts the second condition in (7) and this justifies (i).
To verify (ii), define and deduce from the first condition in (7) that as With the usage of estimate (26) is written as
which means that is nonincreasing. It follows from and that is convergent, which means that the sequence is convergent as well. Assume now has some nonempty and bounded level set. Then every level set of is bounded by Ruszczynski [2006, Exercise 2.12]. By (26), we get that
Proceeding by induction leads us to
which means that for all and thus justifies the boundedness of .
Taking into account gives us an infinite set such that As is bounded, the sequence is also bounded, which gives us another infinite set and such that By
and the continuity of , we get that ensuring that is a global minimizer of with the optimal value Since the sequence is convergent and since is an accumulation point of , we conclude that is the limit of . Now take any accumulation point of and find an infinite set with As converges to , we deduce that
which implies that is also a global minimizer of Assuming in addition that has a unique minimizer and taking any accumulation point of we get that is a minimizer of i.e., This means that is the unique accumulation point of , and therefore as . ∎
C.2 Proof of Theorem 3.3
Proof.
By (8), we find some , and such that
| (27) |
Let us first verify the estimate
| (28) |
To proceed, fix and deduce from the Cauchy-Schwarz inequality that
| (29) |
Since is Lipschitz continuous with constant , it follows from the descent condition in (4) and the estimate (C.2) that
Combining this with (27) gives us (28). Defining for , we get that as and for all Then (28) can be rewritten as
| (30) |
To proceed now with the proof of (i), we deduce from (30) combined with and as that
Next we employ Lemma B.1 with , , and for all to derive Observe first that condition (a) is satisfied due to the the estimates
Further, the conditions in (b) hold by (8) and As all the assumptions (a), (b) are satisfied, Lemma B.1 tells us that as
To verify (ii), deduce from (30) that is nonincreasing. As and we get that is bounded from below, and thus is convergent. Taking into account that , it follows that is convergent as well. Since is an accumulation point of the continuity of tells us that is also an accumulation point of which immediately yields due to the convergence of
It remains to verify (iii). By the KL property of at we find some a neighborhood of , and a desingularizing concave continuous function such that , is -smooth on , on , and we have for all with that
| (31) |
Let be natural number such that for all . Define for all , and let be such that . Taking the number from Assumption 2.3, remembering that is an accumulation point of and using , as together with condition (9), we get by choosing a larger that and
| (32) |
Let us now show by induction that for all The assertion obviously holds for due to (32). Take some and suppose that for all We intend to show that as well. To proceed, fix some and get by that
| (33) |
Combining this with and gives us
| (34a) | ||||
| (34b) | ||||
| (34c) | ||||
| (34d) | ||||
where (34a) follows from the concavity of , (34b) follows from (30), (34c) follows from Assumption 2.3, and (34d) follows from (33). Taking the square root of both sides in (34d) and employing the AM-GM inequality yield
| (35) |
Using the nonincreasing property of due to the concavity of and the choice of ensures that
Rearranging terms and taking the sum over of inequality (C.2) gives us
The latter estimate together with the triangle inequality and (32) tells us that
By induction, this means that for all Then a similar device brings us to
which yields . Therefore,
which justifies the convergence of and thus completes the proof of the theorem. ∎
C.3 Proof of Theorem 4.1
Proof.
Using gives us the estimates
| (36) | ||||
| (37) | ||||
| (38) | ||||
which in turn imply that
| (39) |
Using condition (12), we find so that for all Select such a natural number and use the Lipschitz continuity of with constant to deduce from the descent condition (4), the relationship , and the estimates (36)–(38) that
| (40) |
It follows from the above that the sequence is nonincreasing, and hence the condition ensures the convergence of . This allows us to deduce from (40) that
| (41) |
Combining the latter with (39) and gives us
| (42) |
Now we are ready to verify all the assertions of the theorem. Let us start with (i) and show that in an accumulation point of . Indeed, supposing the contrary gives us and such that for all , and therefore
which is a contradiction justifying that is an accumulation point of . If is an accumulation point of then by Lemma B.2 and (42), we find an infinite set such that and The latter being combined with (39) gives us , which yields the stationary condition
To verity (ii), let be an accumulation point of and find an infinite set such that Combining this with the continuity of and the fact that is convergent, we arrive at the equalities
which therefore justify assertion (ii).
To proceed with the proof of the next assertion (iii), assume that is Lipschitz continuous with constant and employ Lemma B.1 with , , and for all to derive that Observe first that condition (a) of this lemma is satisfied due to the the estimates
The conditions in (b) of the lemma are satisfied since is bounded, by (12), , and
where the inequality follows from (41). Thus applying Lemma B.1 gives us as .
To prove (iv), we verify the assumptions of Proposition B.3 for the sequences generated by Algorithm 2. It follows from (40) and that
| (43) |
which justify (H1) with . Regarding condition (H2), assume that and get by (40) that , which implies by that Combining this with gives us which verifies (H2). Therefore, Proposition B.3 tells us that is convergent.
Let us now verify the final assertion (v) of the theorem. It is nothing to prove if stops at a stationary point after a finite number of iterations. Thus we assume that for all The assumptions in (v) give us and such that for all Let us check that the assumptions of Proposition B.4 hold for the sequences generated by Algorithm 2 with and for all . The iterative procedure can be rewritten as . Using the first condition in (39) and taking into account that for all we get that for all Combining this with and for all tells us that for all It follows from (40) and (39) that
| (44) |
This estimate together with the second inequality in (39) verifies (21) with . As all the assumptions are verified, Proposition B.4 gives us the assertions:
-
•
If , then the sequence converges linearly to .
-
•
If , then we have the estimate
The convergence rates of and follow now from Proposition B.5, and thus we are done. ∎
C.4 Proof of Theorem 4.2
Proof.
Let be the sequence generated by Algorithm 2a. Defining and utilizing , we obtain
which verifies the inexact condition in Step 2 of Algorithm 2. Therefore, all the convergence properties in Theorem 4.1 hold for Algorithm 2a. The proof for the convergence properties of Algorithm 2b can be conducted similarly. ∎
C.5 Proof of Corollary 3.5
Proof.
Considering Algorithm 1a and defining , we deduce that
Therefore, Algorithm 1a is a specialization of Algorithm 1 with Combining this with (11) also gives us (8), thereby verifying all the assumptions in Theorem 3.3. Consequently, all the convergence properties outlined in Theorem 3.3 hold for Algorithm 1a. ∎
Appendix D Efficient normalized variants of SAM
In this section, we list several efficient normalized variants of SAM from [Foret et al., 2021, Liu et al., 2022, Li and Giannakis, 2023, Li et al., 2024] that are special cases of Algorithm 1a. As a consequence, all the convergence properties in Theorem 3.3 are satisfied for these methods.
Step 0.
Choose , and For do the following:
Step 1.
Set .
Step 0.
Choose , and For do the following:
Step 1.
Construct a random vector and set
Step 2.
Set .
Step 0.
Choose , , , For do the following:
Step 1.
Set
Step 2.
Set
Step 0.
Choose , , , , , For :
Step 1.
Set
Step 2.
Set
Step 3.
Set
Appendix E Numerical experiments on SAM constant and SAM almost constant
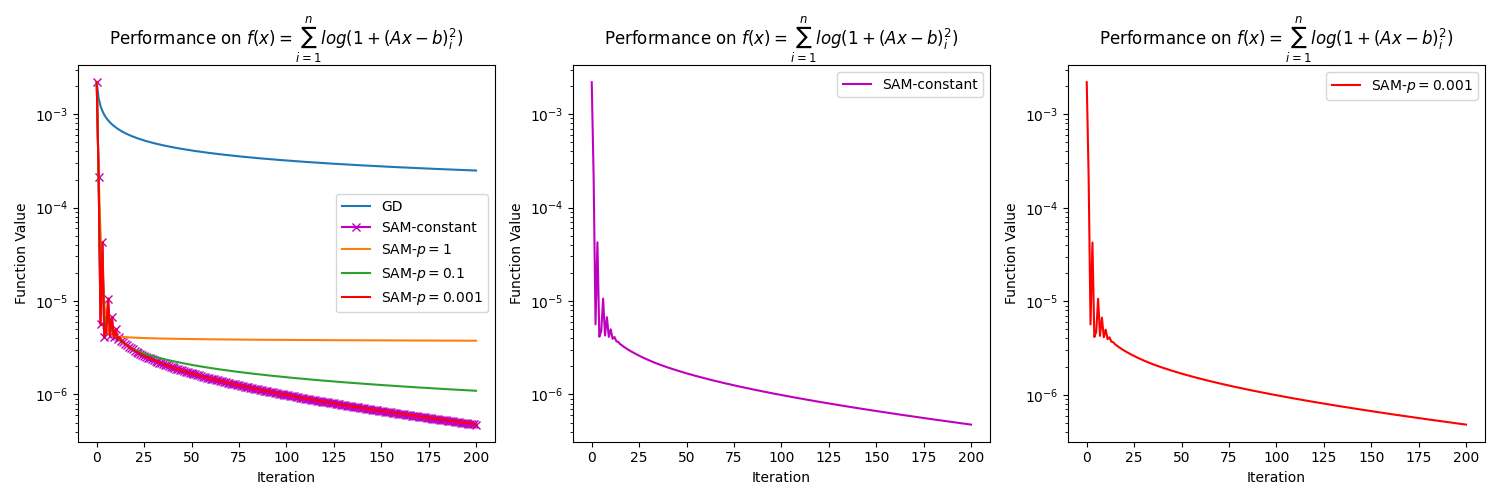
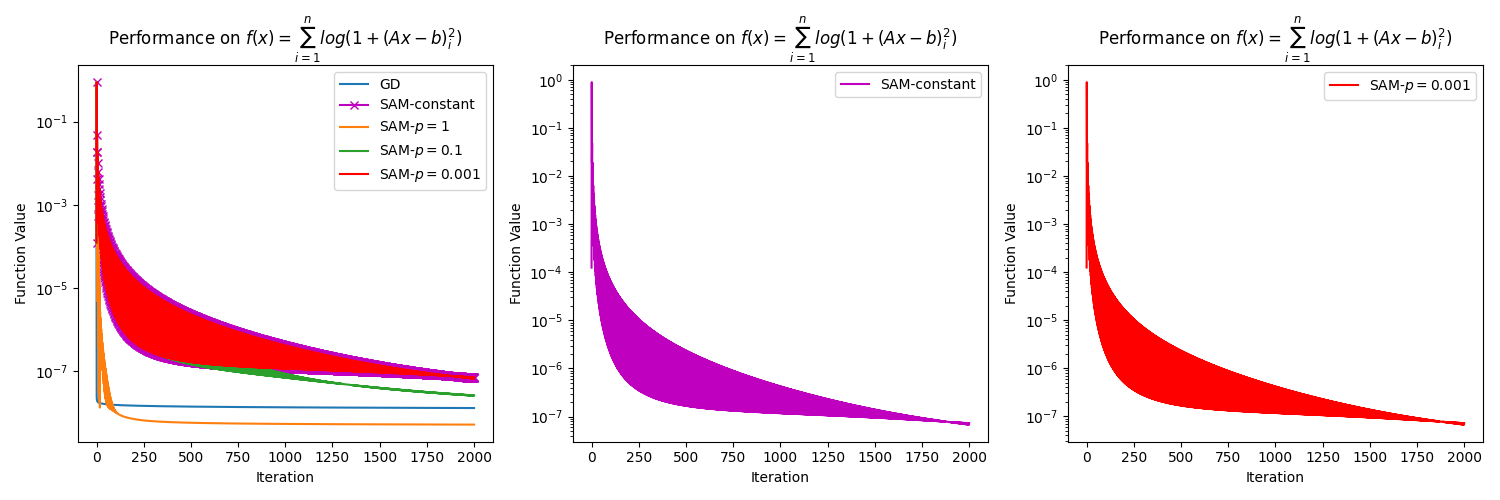
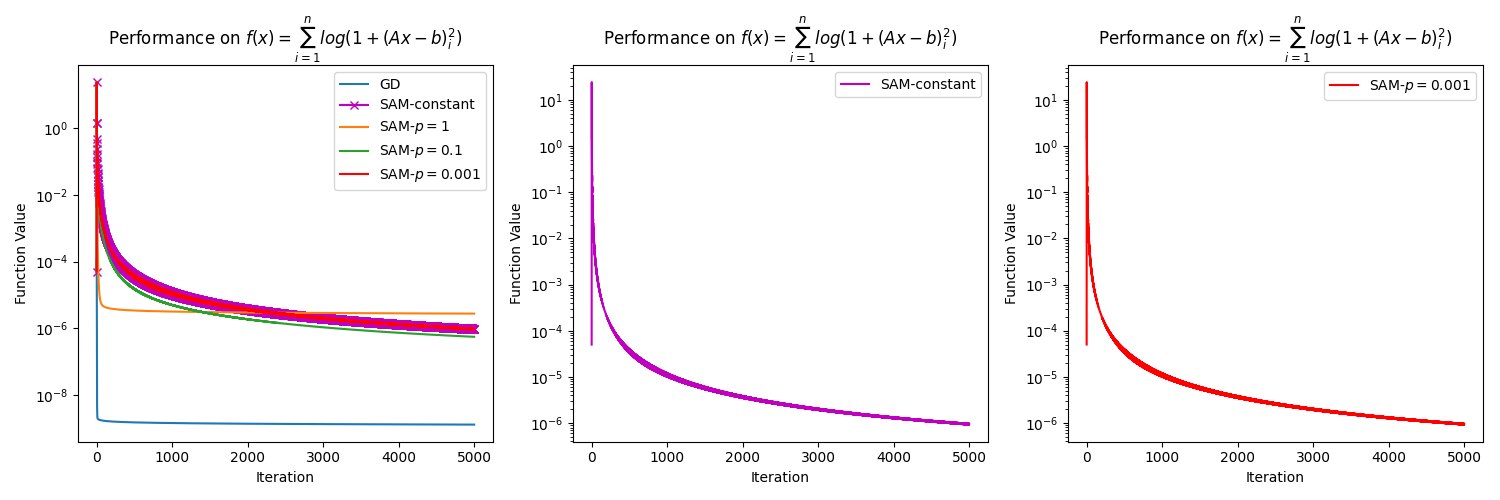
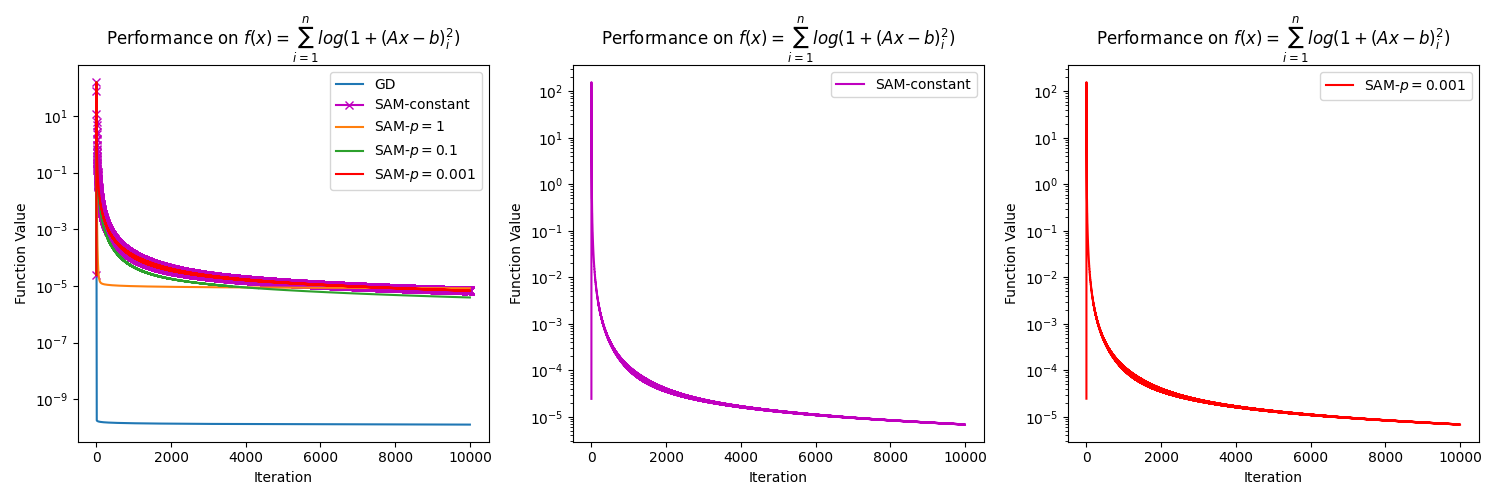
In this section, we present numerical results to support our claim in Remark 3.6 that SAM with an almost constant perturbation radius for close to , e.g., , generates similar results to SAM with a constant perturbation radius . To do so, we consider the function , where is an matrix, and is a vector in . In the experiment, we construct and randomly with . The methods considered in the experiment are GD with a diminishing step size, SAM with a diminishing step size and a constant perturbation radius of , and lastly, SAM with a diminishing step size and a variable radius , for . We refer to the case as the "almost constant" case, as is numerically similar to when we consider a small number of iterations. The diminishing step size is chosen as at the iteration, where is the dimension of the problem. To make the plots clearer, we choose the initial point near the solution, which is , where is a solution of , and is the all-ones vector in . All the algorithms are executed for iterations. The results presented in Figure 3 show that SAM with a constant perturbation and SAM with an almost constant perturbation have the same behavior regardless of the dimension of the problem. This is simply because is almost the same as . This also tells us that the convergence rate of these two versions of SAM is similar. Since SAM with a constant perturbation radius is always preferable in practice [Foret et al., 2021, Dai et al., 2023], this highlights the practicality of our development.
Appendix F Numerical experiments on SAM with SGD without momentum as base optimizer
CIFAR-10, CIFAR-100, and Tiny ImageNet. The training configurations for these datasets follow a similar structure to Section 5, excluding momentum, which we set to zero. The results in Table 5 report test accuracy on CIFAR-10 and CIFAR-100. Table 6 shows the performance of SAM on momentum and without momentum settings. Each experiment is run once, and the highest accuracy for each column is highlighted in bold.
| CIFAR-10 | CIFAR-100 | |||||
| Model | ResNet18 | ResNet34 | WRN28-10 | ResNet18 | ResNet34 | WRN28-10 |
| Constant | 93.64 | 94.26 | 93.04 | 72.07 | 72.57 | 71.11 |
| Diminish 1 | 88.87 | 89.79 | 86.81 | 65.99 | 67.04 | 51.31 |
| Diminish 2 | 94.56 | 94.44 | 93.66 | 74.24 | 74.95 | 74.23 |
| Diminish 3 | 90.84 | 91.23 | 88.70 | 69.69 | 70.54 | 60.64 |
| Tiny ImageNet | Momentum | Without Momentum | ||||
| Model | ResNet18 | ResNet34 | WRN28-10 | ResNet18 | ResNet34 | |
| Constant | 48.58 | 48.34 | 53.34 | 54.90 | 57.36 | |
| Diminish 1 | 50.36 | 51.24 | 58.37 | 55.82 | 55.96 | |
| Diminish 2 | 48.70 | 49.06 | 52.74 | 57.30 | 60.00 | |
| Diminish 3 | 51.46 | 53.98 | 58.68 | 57.86 | 57.82 |
Appendix G Additional Remarks
Remark G.1.
Assumption 2.3 is satisfied with constant for with and . Indeed, taking any with , we deduce that and hence
Remark G.2.
Construct an example to demonstrate that the conditions in (11) do not require that converges to . Let be a Lipschitz constant of , let be a positive constant such that , let be the set of all perfect squares, let for all , and let be constructed as follows:
It is clear from the construction of that , which implies that does not convergence to We also immediately deduce that and which verifies the first three conditions in (11). The last condition in (11) follows from the estimates
Remark G.3 (on Assumption (9)).
Supposing that with and letting , we get that is an increasing function. If and with , we have
which yields the relationships
Therefore, we arrive at the claimed conditions
Remark G.4.
Let us finally compare the results presented in Theorem 4.1 with that in Andriushchenko and Flammarion [2022]. All the convergence properties in Andriushchenko and Flammarion [2022] are considered for the class of functions, which is more narrow than the class of -descent functions examined in Theorem 4.1(i). Under the convexity of the objective function, the convergence of the sequences of the function values at averages of iteration is established in Andriushchenko and Flammarion [2022, Theorem 11], which does not yield the convergence of either the function values, or the iterates, or the corresponding gradients. In the nonconvex case, we derive the stationarity of accumulation points, the convergence of the function value sequence, and the convergence of the gradient sequence in Theorem 4.1. Under the strong convexity of the objective function, the linear convergence of the sequence of iterate values is established Andriushchenko and Flammarion [2022, Theorem 11]. On the other hand, our Theorem 4.1 derives the convergence rates for the sequence of iterates, sequence of function values, and sequence of gradient under the KL property only, which covers many classes of nonconvex functions. Our convergence results address variable stepsizes and bounded radii, which also cover the case of constant stepsize and constant radii considered in Andriushchenko and Flammarion [2022].
NeurIPS Paper Checklist
-
1.
Claims
-
Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
-
Answer: [Yes]
-
Guidelines:
-
•
The answer NA means that the abstract and introduction do not include the claims made in the paper.
-
•
The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
-
•
The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
-
•
It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
-
•
-
2.
Limitations
-
Question: Does the paper discuss the limitations of the work performed by the authors?
-
Answer: [Yes]
-
Justification: See Section 6.
-
Guidelines:
-
•
The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
-
•
The authors are encouraged to create a separate "Limitations" section in their paper.
-
•
The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
-
•
The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
-
•
The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
-
•
The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
-
•
If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
-
•
While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
-
•
-
3.
Theory Assumptions and Proofs
-
Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
-
Answer: [Yes]
-
Justification: All the assumptions are given in the main text while the full proofs are provided in the appendices.
-
Guidelines:
-
•
The answer NA means that the paper does not include theoretical results.
-
•
All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
-
•
All assumptions should be clearly stated or referenced in the statement of any theorems.
-
•
The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
-
•
Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
-
•
Theorems and Lemmas that the proof relies upon should be properly referenced.
-
•
-
4.
Experimental Result Reproducibility
-
Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
-
Answer: [Yes]
-
Justification: See Section 5
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
-
•
If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
-
•
Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
-
•
While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
-
(a)
If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
-
(b)
If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
-
(c)
If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
-
(d)
We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
-
(a)
-
•
-
5.
Open access to data and code
-
Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
-
Answer: [Yes] .
-
Justification: See the supplementary material.
-
Guidelines:
-
•
The answer NA means that paper does not include experiments requiring code.
-
•
Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
-
•
The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
-
•
The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
-
•
At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
-
•
Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
-
•
-
6.
Experimental Setting/Details
-
Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
-
Answer: [Yes]
-
Justification: See Section 5
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
-
•
The full details can be provided either with the code, in appendix, or as supplemental material.
-
•
-
7.
Experiment Statistical Significance
-
Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
-
Answer: [Yes]
-
Justification: See Section 5
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
-
•
The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
-
•
The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
-
•
The assumptions made should be given (e.g., Normally distributed errors).
-
•
It should be clear whether the error bar is the standard deviation or the standard error of the mean.
-
•
It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
-
•
For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
-
•
If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
-
•
-
8.
Experiments Compute Resources
-
Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
-
Answer: [Yes]
-
Justification: We mentioned an RTX 3090 computer worker.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
-
•
The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
-
•
The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
-
•
-
9.
Code Of Ethics
-
Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
-
Answer: [Yes]
-
Justification: Our paper conform with the NeurIPS Code of Ethics.
-
Guidelines:
-
•
The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
-
•
If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
-
•
The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
-
•
-
10.
Broader Impacts
-
Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
-
Answer: [N/A]
-
Justification: This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none of which are specifically highlighted here.
-
Guidelines:
-
•
The answer NA means that there is no societal impact of the work performed.
-
•
If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
-
•
Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
-
•
The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
-
•
The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
-
•
If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
-
•
-
11.
Safeguards
-
Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
-
Answer: [N/A]
-
Justification: Our paper is a theoretical study.
-
Guidelines:
-
•
The answer NA means that the paper poses no such risks.
-
•
Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
-
•
Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
-
•
We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
-
•
-
12.
Licenses for existing assets
-
Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
-
Answer: [Yes]
-
Justification: See Section 5.
-
Guidelines:
-
•
The answer NA means that the paper does not use existing assets.
-
•
The authors should cite the original paper that produced the code package or dataset.
-
•
The authors should state which version of the asset is used and, if possible, include a URL.
-
•
The name of the license (e.g., CC-BY 4.0) should be included for each asset.
-
•
For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
-
•
If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
-
•
For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
-
•
If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
-
•
-
13.
New Assets
-
Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
-
Answer: [N/A]
-
Justification: Our paper is a theoretical study.
-
Guidelines:
-
•
The answer NA means that the paper does not release new assets.
-
•
Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
-
•
The paper should discuss whether and how consent was obtained from people whose asset is used.
-
•
At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
-
•
-
14.
Crowdsourcing and Research with Human Subjects
-
Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
-
Answer: [N/A]
-
Justification:
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
-
•
According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
-
•
-
15.
Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
-
Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
-
Answer: [N/A]
-
Justification:
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
-
•
We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
-
•
For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.
-
•