FT-TDR: Frequency-guided Transformer and Top-Down Refinement Network
for Blind Face Inpainting
Abstract
Blind face inpainting refers to the task of reconstructing visual contents without explicitly indicating the corrupted regions in a face image. Inherently, this task faces two challenges: (1) how to detect various mask patterns of different shapes and contents; (2) how to restore visually plausible and pleasing contents in the masked regions. In this paper, we propose a novel two-stage blind face inpainting method named Frequency-guided Transformer and Top-Down Refinement Network (FT-TDR) to tackle these challenges. Specifically, we first use a transformer-based network to detect the corrupted regions to be inpainted as masks by modeling the relation among different patches. For improved detection results, we also exploit the frequency modality as complementary information and capture the local contextual incoherence to enhance boundary consistency. Then a top-down refinement network is proposed to hierarchically restore features at different levels and generate contents that are semantically consistent with the unmasked face regions. Extensive experiments demonstrate that our method outperforms current state-of-the-art blind and non-blind face inpainting methods qualitatively and quantitatively.
Index Terms:
Face Inpainting, Blind Inpainting, Visual Transformer, Top-Down Refinement Network.I Introduction
Face image inpainting aims to reconstruct the missing parts of the input face image based on valid contexts. It can be applied to various multimedia tasks, such as image restoration and face attribute editing. Generally, most existing face inpainting methods [1, 2, 3, 4, 5] require to take both the corrupted image and its corresponding mask as input. However, in most realistic scenarios, it is impractical to obtain the masks directly, and manual labeling is often time-consuming and inaccurate. Recently, [6] considered a new task to restore contents without specifying masks that indicate missing areas in an image, named blind image inpainting.
In this paper, we adopt the blind inpainting settings from [6] and focus on a more specific task: blind face inpainting. Compared with natural scenes, human faces have more complex structures and finer textures, thus requiring higher visual quality for the restoration results and is thought to be more challenging [1, 5]. Specifically, the input to our method is a corrupted face image that could be contaminated by various patterns. We aim to recognize the visually unreasonable regions in the input image and complete natural and pleasing contents within these regions. Figure 1 shows several inpainting results by our method on real cases, e.g., faces images occluded by graffiti and masks.

The challenges of blind face image inpainting are twofold. The first is how to detect various damage patterns. [6] uses a naive convolutional encoder-decoder architecture, where the encoder is for semantic feature extraction and the decoder is for pixel-wise classification. However, due to the limitation of convolution operations, such a structure may struggle to handle the long-range relation, thus failing to detect complex corruption patterns. We argue that modeling spatial long-range information is necessary to globally integrate the features of different regions and is crucial to recognizing corrupted regions in this task. In addition to long distance relation modeling for global information integration, local contextual information is of significant importance to enhance the boundary consistency of the prediction results. Based on the fact that visually abnormal areas are usually inconsistent with the surrounding contexts, pair-wise similarity of local patches can be utilized to effectively capture the inconsistency at the boundary. The patterns of corrupted regions in real scenes could be diverse, making global information modeling and local feature extraction in the RGB domain not adequate to detect some subtle damaged regions. Prior studies [7, 8] in Deepfake detection suggest that the artifacts of forged images can be perceived in the frequency domain in the form of unusual frequency distributions. Inspired by this, we further exploit the frequency modality for our mask detection.
Based on the above motivations, we first propose a Transformer-based Mask Detection Module for corrupted region prediction, using the self-attention mechanism to model the relation of different local regions. It is widely recognized that transformer-based architecture has recently demonstrated superior performance on a broad range of vision and language tasks [9, 10, 11, 12], mostly because of its strong capabilities in modeling long-range relation. To exploit the frequency domain, we also transform the corrupted image into frequency-aware components which preserve abnormal frequency signals based on Discrete Cosine Transform (DCT) and use stacked convolution layers to extract frequency modality features. These features are incorporated into the transformer encoder for information integration. Furthermore, we propose a Patch Similarity (PS) Block and embed it into the transformer encoder, which explicitly calculates the pair-wise similarity between neighboring local patches to capture the local semantic inconsistency. In general, we capture both frequency modality anomaly and contextual semantic incoherence based on a global relation-modeling transformer network to detect the corrupted regions on faces.
The second obstacle of this task is how to restore visual contents that are both consistent with the surrounding context and visually pleasing. To complete both the geometric structure and fine texture of the masked regions, a large group of works [13, 14, 4] use two encoder-decoders to separately learn structural and textural features. However, the independent learning of structure and texture reconstructions will produce artifacts in the final output. To avoid this, [15] uses the features from deep layers of the encoder to reconstruct structural semantics and the features extracted from shallow layers to reconstruct textural details. But additional information (i.e., ground-truth structure image generated by an edge-preserving smoothing method RTV [16]) is needed to supervise the effective feature extractions of two branches, which will greatly increase the complexity of the model.
To address the above issues, we propose a Top-Down Refinement (TDRefine) Module which consists of a bottom-up path and a top-down path. The bottom-up path captures rich textural information from low-level features and structure knowledge from high-level features. Then in the top-down path, the encoded structural features are merged with the low-level features by the top-down refinement fusion lock. In this way, the texture and structure information is jointly utilized in a single network.
In summary, our proposed method addresses the technical challenges of blind face image inpainting following a two-stage pipeline. First, it can detect the corrupted areas with decent performance even when the corruption patterns are unseen to the trained model. Second, it can generate visually reasonable and pleasing contents within the predicted or given masked regions.
Our contributions can be summarized as follows:
-
•
We propose a novel Transformer-based Mask Detection Module to detect the corrupted regions based on both frequency modality anomaly and contextual incoherence, which better utilizes the information contained in face images with a transformer architecture.
-
•
We design a Top-Down Refinement (TDRefine) Module to restore the hierarchical features of the masked regions implicitly using a top-down refinement architecture, and finally generate both realistic and high-quality images.
-
•
Extensive experiment results demonstrate our model outperforms previous state-of-the-art non-blind facial inpainting methods both qualitatively and quantitatively.

II Related Work
II-A Deep Image Inpainting
Recently, deep learning based methods have become prevalent in image inpainting. [17] puts forward an approach which can generate inpainted images that are both locally and globally consistent with the surrounding areas by using a global and local context discriminator. [18] formulates the image inpainting problem as an energy optimization problem, and exploits an EM-like approach based on homography transformations to solve it . [2, 4] propose novel convolution methods and mask updating mechanisms to make networks adaptive to the masked input. [19] uses predicted prior to guide the inpainting network for better retention of the structure of the object to be restored. Besides, [20, 21] explore to produce multiple plausible results for a given masked input based on conditional probability models.
Face inpainting is more challenging compared with general image inpainting tasks because facial attributes have strong visual consistency to preserve and contain large appearance variations. [22] uses estimated facial landmark heatmaps and parsing maps to guide a generator of encoder-decoder structure to complete a face image conditioned on both the uncorrupted regions and the estimated facial geometry images. However, [5] argues that redundant face geometry like parsing maps may degenerate the performance when feeding slightly inaccurate information into the inpainting module, instead, they use facial landmarks as the indicator to reconstruct the missing regions. Although these prior guided methods could recover natural contents, the synthesized faces still lack of high-frequency details. To address this problem, [23] proposes a recurrent generative adversarial network to hierarchically restore the textures within masked regions. [24] utilizes a Laplacian pyramid adversarial network to complete the multi-scale information of missing face regions in a coarse-to-fine manner.
II-B Blind Image Inpainting
Existing blind image inpainting works [25, 26] are based on the assumption that the corrupted areas are filled with simple data distributions, such as thin stroke masks filled with constant values or regular masks filled with Gaussian noise. This setting is different from most scenarios in real life, which limits the application scope of the proposed approach. In addition, the pixels in the masked area are significantly different from those in other areas, which makes the network easily develop the capability to identify abnormal areas and overfit to the specific mask patterns. Comparatively, we adopt more complex mask filling patterns that are closer to the real-life data distributions. Recently, [6] proposes a novel data generation strategy to enrich the training data as much as possible, and formulate the versatile blind inpainting task. Following [6], we additionally incorporate the frequency modality and contextual incoherence into mask prediction, and focus on the more challenging face inpainiting task.
II-C Visual Transformer
Exemplary performance of Transformer models [27] in natural language processing have intrigued the vision community to apply them in vision problems. [28, 9] purely use transformer for image classification. [10, 29] use the self-attention mechanism in the transformer to enhance the specific modules of traditional object detectors. [30] proposes to use a multi-scale transformer to detect local inconsistency in forged images at different scales. The above methods extract the features of input images through transformer encoders, and output low-dimensional predictions. Comparatively, [31] proposes a spatial-temporal transformer network for video inpainting, while [32] adopts a pure transformer to encode the image as a sequence of patches and further predict the segmentation map by a decoder. In this paper, we propose a novel Transformer-based Mask Detection Module to detect the damaged regions of face images, guided by the frequency modality features.
III METHODOLOGY
In this section, we introduce our proposed blind face inpainting method named FT-TDR. As shown in Figure 2, it consists of two parts, i.e., Transformer-based Mask Detection Module and TDRefine Inpainting Module.
III-A Training Data Generation
Let be the uncorrupted ground truth face image. Under blind inpainting setting, we generate the masked image for training following the strategy proposed by [6]:
| (1) |
where is a binary mask (with value 0 for valid pixels and 1 for otherwise), is a noisy visual signal (i.e., constant value or real-world images), and is Hadmard product operator. Note that during the process of training, both and are randomly selected for and there is no correspondence between them.
III-B Transformer-based Mask Detection Module
The target of our Transformer-based Mask Detection Module (TMDM) (parameterized by ) is to recognize the visually abnormal areas on a face image and predict a binary mask :
| (2) |
Then a binary-masked face image is obtained by blending the corrupted image and the predicted mask :
| (3) |
Specifically, TMDM consists of two components: a Frequency Anomaly Detector (FAD) and a Convolutional Vision Transformer (CViT). The detailed architecture is illustrated in Figure 3.

III-B1 Frequency Anomaly Detector
Considering DCT has the property that the high and low frequency components of the resulting signals distribute in different locations, we first apply DCT to transform from RGB domain to frequency domain and use a hand-crafted filter [33] to filter out the low-frequency information and amplify visually unreasonable signals:
| (4) |
where is a high-pass filter, is the manually-chosen threshold which controls the frequency components to be filtered out, and is the high frequency component of the input corrupted image . Then to preserve shift invariance and local consistency of natural images and use the representation learning capability of CNN to extract features, we then invert the filtered signals back into RGB space via inverse DCT to obtain the frequency-aware representation: , where .
III-B2 Convolutional Vision Transformer
As previously discussed, we process the mask detection input in a sequence-to-sequence manner to capture the relation of different regions. First, we reshape the input image into a sequence of flattened patches and embed them into 1D feature embeddings , where and is the length of sequence. In this paper, we set to , and to . Then we add position embeddings to these features to obtain feature vectors for each patch, and input them to stacked transformer encoders. Each encoder layer has a standard architecture that consists of a multi-head attention block and a multi-layer perceptron. Specifically, For each head , we use fully connected layers to map the feature vectors into query, key, and value embeddings , , and respectively. Then matrix multiplication and function are implemented to calculate the attention for different heads :
| (5) |
where i,j is the position index. Then the resulting attention maps of different heads are concatenated along the first dimension to obtain the final self-attention map , and is the number of heads. Then we use several convolutional layers to encode the frequency-aware representation into a frequency modality attention map . It is then fused with the attention map of the visual features so that complementary information of the frequency modality can be utilized to better recognize corrupted regions.
| (6) |
where denotes concatenating along the first dimension and denotes the convolution that squeezes the number of channels back to . With the dual attention map , we obtain the output for each query by computing the weighted summation of the attention weights and values of relevant patches. The outputs are added to the input feature embeddings by a residual connection, and then fed to a MLP. With stacked transformer encoders, we obtain the features that are aware of the region-wise relation and sensitive to subtle signals in the frequency domain, we then reassemble it to a 2D feature map .
In addition, we introduce a Patch Similarity Block (PS Block in Figure 3) on top of the transformer. Based on the fact the visually abnormal regions are usually incoherent with the surrounding context along the edges, we calculate the similarity between different feature vectors within a local patch to further enhance the edge consistency of the predicted results, and obtain the edge map :
| (7) |
where denotes a small neighboring patch in the feature map around (in this paper we set the size of to 9). The similarity measurement function that we use is cosine similarity. Then we add the edge map and the input feature map to obtain an edge-preserving feature map .
Finally, we use consecutive bilinear upsampling layers and convolutional layers to progressively increase the spatial resolution of and obtain the mask detection results . Cross-entropy loss and dice loss are combined to supervise the learning of .
III-C TDRefine Inpainting Module
Our Top-Down Refinement Inpainting Module follows the encoder-decoder [34] based architecture. Generally, takes the binary-masked image , the predicted mask from the mask detection module as inputs, and outputs a restored image :
| (8) |
where denotes the network parameters.
Specifically, taking as inputs, we first adopt the Landmark Prediction Module proposed by [5] to obtain the predicted facial landmarks . We further concatenate with and , and input them to the first TDRB block. 111The effectiveness of landmark detection on corrupted face images is shown in the Supplementary Materials.. The bottom-up path of the TDRefine module contains an encoder that gradually down-sample twice, followed by 7 residual blocks with dilated convolutions and a long-short term attention block [35]. The stacked dilated blocks can enlarge the receptive field, and the long-short attention layer is used to merge the features before and after residual blocks.
In the top-down path are several Top-Down Refinement Fusion Blocks (TDRB), in addition to up-sampling the feature maps, the TDRB is also responsible for connecting the decoder layers with the successive encoder layers at different levels, so that the low-level texture information can be integrated into the high-level structure information in the top-down path. The TDRB can be formulated as:
| (9) |
where denotes the feature maps generated in the top-down pass, denotes the feature maps of the encoder layer, and is the predicted mask indicating the regions to be inpainted. Concretely, we first use de-convolution layers to up-sample to the same size as , and adaptively fuse them according to the mask :
| (10) |
Then we equalize the features inside and outside the mask areas of using the region normalization algorithm [36]:
| (11) |
Finally, we pass through a convolutional layer to generate the refined features . Note that we use resized as the mask in different refinement blocks. Multiple such modules are stacked and the final output of our network is up-sampled to the same resolution as the input image. This hierarchical generation and refinement process effectively fuses textural and structural information from the deep and shallow layers of the encoder-decoder to generate better face images.
We also introduce a PatchGAN [37] with spectral normalization [38] as a discriminator to further improve the visual quality of the inpainted images. It takes an inpainted image as input and determines whether the image patches of with size of are real. (For the sake of clarity, the discriminator is not shown in Figure 2). Additionally, the discriminator also takes the landmarks as input, which could regularize the network to pay more attention to the structurally important regions of human faces.
III-D Objective Functions
Finally, our inpainting module is trained with a joint loss that consists of a reconstruction loss, an adversarial loss, a perceptual loss, a style loss, and a total variation loss.
The reconstruction loss is defined as follows:
| (12) |
We follow [3] to calculate the reconstruction loss only on masked regions and is the number of masked pixels. Additionally, denotes the norm.
The adversarial loss that we use follows the LSGAN [39], which has demonstrated its ability in stabilizing the training process and improve the visual quality of the images:
| (13) |
where denotes the ground-truth landmarks and is the discriminator network. As are unavailable for both the CelebA-HQ dataset [40] and CelebA dataset [41], we apply FAN [42] to generate them.
The perceptual loss penalizes the restored results that are not perceptually similar to ground-truth images by measuring the distance between their activation maps:
| (14) |
where denotes the features maps with size of of the layer from the pre-trained network. In this work, , , , and of the pretrained VGG-19 network are used to calculate the perceptual loss.
The style loss similarly computes the style distance between two images:
| (15) |
where denotes the Gram Matrix corresponding to . It is validated by [43] to be effective in combating the checkerboard effects.
The total variation loss is used to make the restored results visually smoother:
| (16) |
where is the number of pixels of image , and denotes the first order derivative, including the horizontal and vertical directions.
The overall loss is a weighted combination of the above:
| (17) |
In this work, we empirically use , , , , and when training the inpainting module on CelebA-HQ dataset and adjust to 5 on CelebA dataset.
IV Experiments
We first compare our method with the state-of-the-art blind inpainting method VCNet [6] to evaluate the performance of our complete method. Then we use the ground-truth mask to independently evaluate the TDRefine Inpainting Module under non-blind setting and compare it with state-of-the-art methods. Finally, we perform ablation studies to validate the contribution of the frequency modality and the Patch Similarity Block in our Transformer-based Mask Detection Module, and the effectiveness of TDRB in our TDRefine Inpainting Module.
IV-A Experiment Setup
Datasets. We evaluate our method on the CelebA-HQ dataset [40] and CelebA dataset [41]. The mask shapes that we use for training include both randomly generated block masks and free-form strokes adopted from [4]. When testing, we use the irregular mask dataset [2] which has been grouped into six intervals according to the mask area, i.e., 0-10%, 10-20%, 20-30%, 30-40%, 40-50%, and 50-60%, and each interval has 2,000 masks. The filling contents in our masks for both training and testing are constant values and ground-truth images from the Places2 dataset [44]. All the masks and images for training and testing are resized to 256 256, and the block masks that we generate have the size of 128 128.
Evaluation Metrics. We apply peak signal-to-noise ratio (PSNR) and structural similarity index metrics (SSIM) as our evaluation metrics, which are common used in painting results evaluation [3, 45, 5, 6].


Implementation Details. We conduct experiments to evaluate the performance of our method under both blind inpainting setting and non-blind inpainting setting. For blind face inpainting, we use a two-stage training strategy. First, we train the mask detection module independently. Then we train the mask detection module and inpainting module jointly in an end-to-end manner. The batch sizes are 16 and 8 for the first and second stages, respectively. For non-blind face inpainting, we independently train the inpainting module using ground-truth masks. The learning rates of the generator and discriminator in are set to and , respectively. The learning rate of is set to . All the parameters are optimized by the Adam optimizer with and .
IV-B Blind Inpainting Evaluation
IV-B1 Mask Prediction Results
We first evaluate the mask detection performance using MAE loss (lower is better) and IoU (higher is better) on the irregular mask dataset, and report the quantitative results in Table I. As the table shows, our transformer-based mask detection module can accurately predict the masks of different sizes. Further analysis on the mask detection module will be provided in Section IV-D.
| Metric | 10-20% | 20-30% | 30-40% | 40-50% | |
|---|---|---|---|---|---|
| MAE | 1.93 | 2.01 | 2.13 | 2.24 | |
| IoU | 91.04% | 92.37% | 94.17% | 96.33% |
| Metric | Mask | VCNet [6] | Ours⋆ | ||
|---|---|---|---|---|---|
| PSNR | 10-20% | 30.82 | 31.61 | ||
| 40-50% | 24.11 | 24.39 | |||
| Center | 25.47 | 26.01 | |||
| SSIM | 10-20% | 0.969 | 0.974 | ||
| 40-50% | 0.867 | 0.877 | |||
| Center | 0.883 | 0.908 |
IV-B2 Inpainting Results Comparison
Quantitative Comparisons. Previous blind inpainting methods [25, 26] have not published their code, therefore, we compare our method with the most recent state-of-the-art method, VCNet [6], and report the results in Table II. The results clearly demonstrate that our method outperforms VCNet for various types of masks applied to the face images, i.e., about 2.6%, 1.2%, and 2.1% performance gain in PSNR score on the 10-20%, 40-50%, and Center masks, respectively.
Qualitative Comparisons. We further compare the inpainting results of VCNet [6] and our method qualitatively and show some examples in Figure 4. We can see that the restored contents by VCNet and our method are basically visually reasonable, but our proposed method can produce the most visually natural and pleasing details which are consistent with the surrounding context. Except from the high-quality mask predictions, this is mainly because 1) the multiple refinement fusion blocks fuse the information at different levels more effectively and 2) the generator also uses proper structural priors as guidance.
IV-C Non-blind Inpainting Evalution
Quantitative Comparisons. To specifically demonstrate the effectiveness of our inpainting module, we compare our method with state-of-the-art non-blind inpainting methods: EC [3], RFR [45], and Lafin [5] on the CelebA-HQ dataset and report the results in Table III. It can be seen that our method achieves 31.75, 28.75, 26.40, 24.45, 21.75, and 26.16 in PSNR on the 10-20%, 20-30%, 30-40%, 40-50%, 50%+, and Center masks, respectively, which outperforms the current state-of-the-art methods. In addition, further quantitative comparisons with CE [46], EC [3], andLafin [5] on center masks on the CelebA dataset are shown in Table IV. We also achieve the best results.
| Metric | Mask | EC [3] | RFR [45] | Lafin [5] | Ours | ||
|---|---|---|---|---|---|---|---|
| PSNR | 10-20% | 30.73 | 30.92 | 31.48 | 31.75 | ||
| 20-30% | 27.56 | 28.02 | 28.31 | 28.57 | |||
| 30-40% | 25.34 | 25.79 | 26.14 | 26.40 | |||
| 40-50% | 23.44 | 23.96 | 24.22 | 24.45 | |||
| 50%+ | 20.71 | 21.33 | 21.61 | 21.75 | |||
| Center | 24.82 | 25.47 | 25.92 | 26.16 | |||
| SSIM | 10-20% | 0.971 | 0.972 | 0.975 | 0.978 | ||
| 20-30% | 0.942 | 0.948 | 0.951 | 0.959 | |||
| 30-40% | 0.907 | 0.915 | 0.922 | 0.932 | |||
| 40-50% | 0.859 | 0.870 | 0.883 | 0.885 | |||
| 50%+ | 0.754 | 0.773 | 0.805 | 0.811 | |||
| Center | 0.874 | 0.883 | 0.905 | 0.912 |
| Metric | Mask | w/o DA | w/o FAD | w/o PS | Ours | ||
|---|---|---|---|---|---|---|---|
| MAE | 10-20% | 2.58 | 2.13 | 2.21 | 1.93 | ||
| 40-50% | 2.72 | 2.41 | 2.47 | 2.24 | |||
| IoU | 10-20% | 85.39% | 89.16% | 89.55% | 91.04% | ||
| 40-50% | 92.18% | 95.06% 91. | 95.32% | 96.33% |


Qualitative Comparisons. We present qualitative results of our method and state-of-the-art methods in Figure 6, which shows the images inpainted by EC [3], RFR [45], Lafin [5], and ours (using ground-truth masks) on the CelebA-HQ dataset. Note that for EC, the pre-trained models on CelebA-HQ dataset are not provided by the authors, so we use the code that they provide to train on the CelebA-HQ dataset by ourselves. It can be seen that EC [3] and RFR [45] generate blurred results when the faces have rich expressions and postures because they do not use suitable structural guidance to facilitate face restoration. Just as [5] suggests, the redundancy of edge information may even degrade the performance. Lafin [5] mitigate this problem to some extent but struggle to preserve the properties of facial attributes, e.g., eyes and mouths. Comparatively, we tackle the problem by the refinement fusion blocks to hierarchically restore features, and our method generates the most natural and visually pleasant contents.
IV-D Ablation Study
Mask detection results w/o FAD and PS block. In addition, we show the mask detection results on face images wearing real masks without FAD and PS block in Figure 5. The comparison results demonstrate that using PS block and FAD enables our mask detection module to not only accurately detect the visually abnormal regions on face images, but also develop sharp capability in edge perception.
Effects of different components in TMDM. The Frequency Anomaly Detector (FAD) is utilized to detect the visually abnormal signals of face images in the frequency domain, while the Dual Attention (DA) combines the self-attention map and the frequency modality attention map to locate the masked regions. To evaluate the effects of FAD and DA, we separately remove them from TMDM and show the performance degradation in Table V. In addition, we also remove the Patch Similarity Block to validate its contribution in mask detection. The quantitative comparison results validates that different components can effectively improve the performance of our mask detection module by a large margin, e.g., the use of DA, FAD and PS increases the IoU values by about 6.6%, 2.1% and 1.7% on the 10-20% masks.
| Metric | DC | DCC | Ours | |
|---|---|---|---|---|
| PSNR | 24.85 | 25.32 | 26.16 | |
| SSIM | 0.881 | 0.893 | 0.912 |
Effects of the TDRB. We demonstrate the contributions of top-down refinement fusion blocks (TDRB) by 1) replacing them with (Deconv+11 Conv) blocks for up-sampling 2) using (Deconv+11 Conv) blocks for up-sampling and concatenation for naive fusion. The quantitative results in Table VI show that both variants achieve lower performances (i.e., 5.0% and 3.2% performance degradation in terms of PSNR value, respectively), this validates that our refinement fusion block can improve the quality of output images by effectively merging the structural information from deep layers with textural information from shallow layers.
Landmark prediction results on masked images. For our proposed inpainting method, the landmark prediction module is just a tool to provide geometry information to the generator, instead of our main contribution. Therefore, we adopted the method of Lafin [5]. We demonstrate the performance of the landmark prediction module below (Figure 7), and the results validate it could detect landmarks accurately even on the damaged images. The restored results by FT-TDR are also shown in the rightmost column.
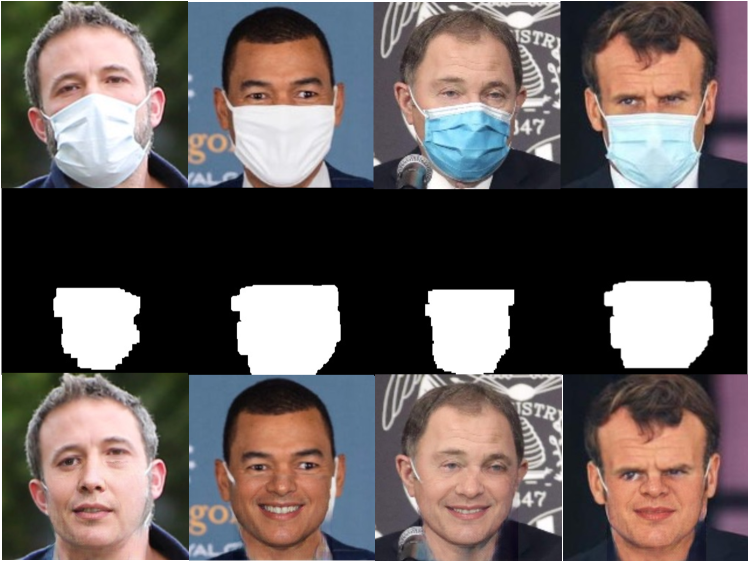
Evalutaion on the In-the-wild data. In order to further validate the effectiveness of FT-TDR on real-world masked images, we evaluate our method on a public masked face image dataset MFR2 [47], and demonstrate the predicted masks and inpainted results in Figure 8. Note that both ground-truth masks and ground-truth uncorrupted face images are not available. We can observe that although the patterns of these masks are not included in our training data, FT-TDR can still locate the mask regions, and the restored contents are visually reasonable.
Visualization of the frequency attention and edge map. In addition, we visualize the frequency attention and the edge map produced by the PS Block in Figure 9. The visualization results demonstrate that the frequency information can roughly locate the visually abnormal regions, while the edge information can provide additional assistance to develop sharp capability in edge perception.

Evaluation of the identity retention capability. In order to assess the identity retention capability of different face inpainting methods, we propose to leverage ICS to compute the cosine similarity of the features extracted from the restored images and the ground-truth images. ICS is defined as:
| (18) |
where denotes the cosine similarity function, and the feature extraction network that we use is Inception-V3 [48]. We report the comparison results with state-of-the-art face inpainting methods in Table VII, which demonstrate that the restored results by FT-TDR could effectively preserve identity information.
Additional qualitative results. We provide additional results produced by our model on the CelebA-HQ and CelebA datasets in Figure 10 and Figure 11, respectively.








V Discussion
Benefited from the transformer’s capability to capture contextual inconsistencies, our mask detection module can identify unusual visual areas such as graffiti and masks that do not appear on most face images. However, one remaining challenge and limitation of blind inpainting methods (including ours) is that it is difficult to recognize small items like beards and jewelry. This is in part due to the dataset bias. Under the blind inpainting setting, original images in the face image datasets are defined as uncorrupted face images. However, some uncorrupted face images can also contain abnormal visual areas like caps and beards and these won’t be marked as masks during the training process, thus the resulting model is not able to complete these areas. Such dataset bias may be addressed in the future by constructing a cleaner dataset for face inpainting.
VI Conclusion
In this work, we propose a new method FT-TDR for the task of blind face inpainting, which completes visual contents on a corrupted face image without specifying the damaged regions. Our method first accurately detects the corrupted region and then fills these regions with coherent contents. Specifically, the proposed transformer-based mask detection module operates on image patches in a sequence-to-sequence manner, it also incorporates frequency modality information and captures contextual inconsistency among the patches. Then in the image generation stage, an encoder-decoder generator with a stack of top-down refinement blocks is used to hierarchically restore features within the masked regions. Texture and structure information is properly combined in the bottom-up and top-down paths. Extensive experimental results on the widely used CelebA-HQ and CelebA datasets have demonstrated our proposed model can outperform state-of-the-art face image inpainting methods with both ground-truth and predicted masks.
VII Acknowledgment
The authors would like to thank the anonymous referees for their valuable comments and helpful suggestions. This work was supported in part by NSFC project (#62032006).
References
- [1] Y. Li, S. Liu, J. Yang, and M.-H. Yang, “Generative face completion,” in CVPR, 2017.
- [2] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro, “Image inpainting for irregular holes using partial convolutions,” in ECCV, 2018.
- [3] K. Nazeri, E. Ng, T. Joseph, F. Z. Qureshi, and M. Ebrahimi, “Edgeconnect: Generative image inpainting with adversarial edge learning,” arXiv preprint arXiv:1901.00212, 2019.
- [4] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Free-form image inpainting with gated convolution,” in ICCV, 2019.
- [5] Y. Yang, X. Guo, J. Ma, L. Ma, and H. Ling, “Lafin: Generative landmark guided face inpainting,” arXiv preprint arXiv:1911.11394, 2019.
- [6] Y. Wang, Y.-C. Chen, X. Tao, and J. Jia, “Vcnet: A robust approach to blind image inpainting,” arXiv preprint arXiv:2003.06816, 2020.
- [7] N. Yu, L. S. Davis, and M. Fritz, “Attributing fake images to gans: Learning and analyzing gan fingerprints,” in ICCV, 2019.
- [8] R. Durall, M. Keuper, F.-J. Pfreundt, and J. Keuper, “Unmasking deepfakes with simple features,” arXiv preprint arXiv:1911.00686, 2019.
- [9] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [10] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in ECCV, 2020.
- [11] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale vision transformers,” arXiv preprint arXiv:2104.11227, 2021.
- [12] J. Wang, X. Yang, H. Li, Z. Wu, and Y.-G. Jiang, “Efficient video transformers with spatial-temporal token selection,” arXiv preprint arXiv:2111.11591, 2021.
- [13] Y. Song, C. Yang, Z. Lin, X. Liu, Q. Huang, H. Li, and C.-C. Jay Kuo, “Contextual-based image inpainting: Infer, match, and translate,” in ECCV, 2018.
- [14] Y. Ren, X. Yu, R. Zhang, T. H. Li, S. Liu, and G. Li, “Structureflow: Image inpainting via structure-aware appearance flow,” in ICCV, 2019.
- [15] H. Liu, B. Jiang, Y. Song, W. Huang, and C. Yang, “Rethinking image inpainting via a mutual encoder-decoder with feature equalizations,” arXiv preprint arXiv:2007.06929, 2020.
- [16] L. Xu, Q. Yan, Y. Xia, and J. Jia, “Structure extraction from texture via relative total variation,” TOG, 2012.
- [17] S. Iizuka, E. Simo-Serra, and H. Ishikawa, “Globally and locally consistent image completion,” ToG, 2017.
- [18] J. Liu, S. Yang, Y. Fang, and Z. Guo, “Structure-guided image inpainting using homography transformation,” TMM, 2018.
- [19] A. Lahiri, A. K. Jain, S. Agrawal, P. Mitra, and P. K. Biswas, “Prior guided gan based semantic inpainting,” in CVPR, 2020.
- [20] L. Zhao, Q. Mo, S. Lin, Z. Wang, Z. Zuo, H. Chen, W. Xing, and D. Lu, “Uctgan: Diverse image inpainting based on unsupervised cross-space translation,” in CVPR, 2020.
- [21] W. Cai and Z. Wei, “Piigan: Generative adversarial networks for pluralistic image inpainting,” Access, 2020.
- [22] L. Song, J. Cao, L. Song, Y. Hu, and R. He, “Geometry-aware face completion and editing,” in AAAI, 2019.
- [23] Q. Wang, H. Fan, G. Sun, W. Ren, and Y. Tang, “Recurrent generative adversarial network for face completion,” TMM, 2020.
- [24] Q. Wang, H. Fan, G. Sun, Y. Cong, and Y. Tang, “Laplacian pyramid adversarial network for face completion,” PR, 2019.
- [25] N. Cai, Z. Su, Z. Lin, H. Wang, Z. Yang, and B. W.-K. Ling, “Blind inpainting using the fully convolutional neural network,” The Visual Computer, 2017.
- [26] Y. Liu, J. Pan, and Z. Su, “Deep blind image inpainting,” in ICISBDE, 2019.
- [27] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017.
- [28] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in ICML, 2020.
- [29] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020.
- [30] J. Wang, Z. Wu, J. Chen, and Y.-G. Jiang, “M2tr: Multi-modal multi-scale transformers for deepfake detection,” arXiv preprint arXiv:2104.09770, 2021.
- [31] Y. Zeng, J. Fu, and H. Chao, “Learning joint spatial-temporal transformations for video inpainting,” in ECCV, 2020.
- [32] S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, Y. Fu, J. Feng, T. Xiang, P. H. Torr et al., “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,” arXiv preprint arXiv:2012.15840, 2020.
- [33] S. Chen, T. Yao, Y. Chen, S. Ding, J. Li, and R. Ji, “Local relation learning for face forgery detection,” in AAAI, 2021.
- [34] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in ECCV, 2016.
- [35] C. Zheng, T.-J. Cham, and J. Cai, “Pluralistic image completion,” in CVPR, 2019.
- [36] T. Yu, Z. Guo, X. Jin, S. Wu, Z. Chen, W. Li, Z. Zhang, and S. Liu, “Region normalization for image inpainting.” in AAAI, 2020.
- [37] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in CVPR, 2017.
- [38] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018.
- [39] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley, “Least squares generative adversarial networks,” in ICCV, 2017.
- [40] C.-H. Lee, Z. Liu, L. Wu, and P. Luo, “Maskgan: Towards diverse and interactive facial image manipulation,” in CVPR, 2020.
- [41] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in ICCV, 2015.
- [42] A. Bulat and G. Tzimiropoulos, “How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks),” in ICCV, 2017.
- [43] M. S. Sajjadi, B. Scholkopf, and M. Hirsch, “Enhancenet: Single image super-resolution through automated texture synthesis,” in ICCV, 2017.
- [44] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” TPAMI, 2017.
- [45] J. Li, N. Wang, L. Zhang, B. Du, and D. Tao, “Recurrent feature reasoning for image inpainting,” in CVPR, 2020.
- [46] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in CVPR, 2016.
- [47] A. Anwar and A. Raychowdhury, “Masked face recognition for secure authentication,” arXiv preprint arXiv:2008.11104, 2020.
- [48] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” arXiv preprint arXiv:1512.00567, 2015.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3b70adda-0205-40af-b75a-16edc2e23a07/Junke_Wang.jpg) |
Junke Wang received the B.E. degree from Fudan University, Shanghai, China, in 2021. He is currently pursuing his Ph.D. degree in Computer Science at Fudan University. His research interests include video understanding and media forensics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3b70adda-0205-40af-b75a-16edc2e23a07/Shaoxiang_Chen.jpg) |
Shaoxiang Chen is currently a PhD student in the School of Computer Science of Fudan University. Shaoxiang received his B.S. degree from the School of Computer Science of Fudan University. His research is focused on multimedia and deep learning, with respect to video captioning and temporal sentence localization in videos. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3b70adda-0205-40af-b75a-16edc2e23a07/Zuxuan_Wu.jpg) |
Zuxuan Wu received his Ph.D. in Computer Science from the University of Maryland with Prof. Larry Davis in 2020. He is currently an Associate Professor in the School of Computer Science at Fudan University. His research interests are in computer vision and deep learning. His work has been recognized by an AI 2000 Most Influential Scholars Honorable Mention in 2021, a Microsoft Research PhD Fellowship in 2019 and a Snap PhD Fellowship in 2017. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3b70adda-0205-40af-b75a-16edc2e23a07/Yu-Gang_Jiang.jpg) |
Yu-Gang Jiang received the Ph.D. degree in Computer Science from City University of Hong Kong in 2009 and worked as a Postdoctoral Research Scientist at Columbia University, New York during 2009-2011. He is currently a Professor and Dean at School of Computer Science, Fudan University, Shanghai, China. His research lies in the areas of multimedia, computer vision and trustworthy AI. His work has led to many awards, including the inaugural ACM China Rising Star Award, the 2015 ACM SIGMM Rising Star Award, and the research award for excellent young scholars from NSF China. |