From Intrinsic to Counterfactual: On the Explainability of Contextualized Recommender Systems
Abstract.
With the prevalence of deep learning based embedding approaches, recommender systems have become a proven and indispensable tool in various information filtering applications. However, many of them remain difficult to diagnose what aspects of the deep models’ input drive the final ranking decision, thus, they cannot often be understood by human stakeholders. In this paper, we investigate the dilemma between recommendation and explainability, and show that by utilizing the contextual features (e.g., item reviews from users), we can design a series of explainable recommender systems without sacrificing their performance. In particular, we propose three types of explainable recommendation strategies with gradual change of model transparency: whitebox, graybox, and blackbox. Each strategy explains its ranking decisions via different mechanisms: attention weights, adversarial perturbations, and counterfactual perturbations. We apply these explainable models on five real-world data sets under the contextualized setting where users and items have explicit interactions. The empirical results show that our model achieves highly competitive ranking performance, and generates accurate and effective explanations in terms of numerous quantitative metrics and qualitative visualizations.
1. Introduction
Recommendation plays an important role in many information filtering systems, such as e-commerce (Amazon, Walmart), streaming services (YouTube, Netflix), and business review services (Yelp, Trip Advisor), etc. Modern recommender systems (RS) provide personalized recommendation suggestions by learning from the historical user-item interactions, e.g., explicit interactions such as ratings or implicit interactions such as clicks. Recently, with the prevalence of embedding-based approaches, many recommender systems can accurately uncover the preference of users over unseen items. By learning the ranking model merely from the historical interactions data between users and items, a lot of successes have been observed in both industry and academia. Nevertheless, most (if not all) of these models suffer from a lack of model explainability. Over the last few years, the demand for explainability of recommender systems drastically increased because customers are no longer satisfied with only high-quality recommendations, but they also require intuitive explanations. Explaining the relationship, in a human-interpretable way, between the users and its ranking decisions is critical for transparency, effectiveness, and trustworthiness. By providing a personalized recommender algorithm that explains why the recommendation results are presented in such a specific way, could significantly improve user satisfaction.
Without using the explicit user-item interaction features (e.g., review text), the pioneering work of recommender systems that utilized item-based collaborative filtering methods are explainable to some degrees, e.g. “similar movies other users also watched” or “this product is similar to the products you purchased before”, etc. Later on, the content-based recommender system becomes prevalent since it is also human interpretable by modeling users and items with various shared content information, for example, “genre”, “actors”, and “duration” in the movie recommendation problem. Besides using simple models with good explainability such as regression-based or tree-based models, there exist multiple strategies to build content-based explanation recommender systems. With the success of more business-driven models being applied into productions, such as matrix factorization based models (Ma et al., 2008; Koren et al., 2009), neural collaborative filtering based models (He et al., 2017, 2018), generative adversarial network based models (Wang et al., 2017; Zhou et al., 2021), and graph-based models (He et al., 2020), the performance of recommender systems has dramatically improved over the last decade, but the lack of explainability is becoming a more severe concern.
The available solutions to the aforementioned issues mostly rely on incorporating contextualized features into the model learning process. In recent years, multiple efforts have been made in this direction, such as FM (Rendle, 2010), VBPR (He and McAuley, [n.d.]), DeepFM (Guo et al., [n.d.]), etc. The majority of such efforts are devoted to designing the learning mechanism of the high-order feature interactions. Typical contextualized features for users could be their meta-information (e.g., locations, age, gender), and those for items could come from other sources (e.g., images, item titles, item descriptions). However, since their contextualized features are isolated between users and items, these models are more suitable for “cold start” recommendations and personalized ranking with rich features. Another line of research, such as EFM (Zhang et al., 2014), utilized the user-item interaction features (text reviews) and aimed to learn the sentiment latent factors using matrix factorization. However, their learning objective is explicitly modeled for personalized sentiment attention instead of user preference. Therefore, it is difficult to directly apply to personalized ranking problems.
In this work, we propose to achieve the explainability of personalized ranking by building a series of models with various architecture transparency: an intrinsically interpretable model (whitebox model with feature attention); a model with partial transparency (greybox model with adversarial training); and a post-hoc explanations model (blackbox model with counterfactual augmentations). Intuitively, we could easily build a fully transparent model such as logistic regression or decision tree that has good explainability. However, they mostly have limited performance (due to model linearity or inclination to overfitting) under many application scenarios. In this work, we mainly focus on providing insights into the explainability regarding existing neural network based recommendation models and perform a horizontal comparison among all proposed strategies in terms of their characteristics and relationships.
The main contribution of this paper can be summarized as follows:
-
•
We provide a systematic overview of the explainable recommendation models based on the level of model transparency requirement in a descending order: intrinsic attention based recommendation, adversarial explainable recommendation, and counterfactual explainable recommendation.
-
•
We compare the advantages and disadvantages of these three types of models in terms of their effectiveness, suitable domains, as well as their explainability via various qualitative visualizations.
-
•
We verify our claims and quantitatively evaluate all three models on five publicly accessible data sets in terms of user explanation oriented metrics and user ranking oriented metrics.
The rest of the paper is organized as follows. Section 2 is the related work. Section 3 describes the proposed three explainable recommendation models, and Section 4 presents the analysis of these models from various perspectives. The experimental results are demonstrated in Section 5, and we conclude the paper in Section 6.
2. Related Work
In this section, we introduce the background knowledge regarding the explainable recommendation and other highly related domains: counterfactual explanation, adversarial ranking, and attention-based recommendation.
2.1. Explainable Recommendation
Recommender systems point the online users to a certain list of items with potential interests, thereby increasing the cross-sales and customer engagement. Many efforts have been devoted to this direction with the booming growth of e-commerce and online streaming services. Recent years have seen significant improvement in performance with the emergence of more sophisticated models. However, only showing the recommended ranking list of items can hardly gain the trust and satisfaction of users. The reason is that many modern recommendation models are difficult to support the end-users in the decision-making processes by providing useful and meaningful explanations (Tintarev and Masthoff, 2015; Gedikli et al., 2014; Zhang and Chen, 2020). Traditional explainable models such as collaborative filtering (Herlocker et al., 2000; Sarwar et al., 2001), factorization-based model (Zhang et al., 2014; Wang et al., 2018b; Pan et al., 2020a), and tree-based models (Wang et al., 2018a) can leverage the explanations from user/item features (Polleti and Cozman, 2019), opinions (McAuley and Leskovec, 2013), and summarized topics (Wu and Ester, 2015). However, they usually have limited performance and lack the ability to extend to complicated scenarios. Recently, various types of neural network based explainable recommendation models have been proposed. A2CF (Chen et al., 2020) is an attribute-aware model that uses the residual network to model user-item reviews with joint sentiment analysis; SAERS (Hou et al., 2019) leveraged the power of gradient-weighted class activation mapping (Selvaraju et al., 2020) and used the backpropagated ranking loss to generate item image’s saliency map as visual explanations; AMCF (Pan et al., 2020b) maps the uninterpretable features into the interpretable aspect features by minimizing both ranking loss and interpretation loss, etc. Various kinds of explanation models are emerging every year, e.g., set operation based model (Balog et al., 2019), knowledge graph based explanation model (Ai et al., 2018), disentangled embedding explanation (Ma et al., 2019), and many others.
These existing approaches generate explanations in different ways but lack the systemic analysis regarding explainable recommendation models from multiple perspectives. Based on the classification of explainable models (Zhang and Chen, 2020), they can be either information source dependent (displaying explainable content that is human-readable as the justification of the ranking model’s decision) or model architecture-dependent (deliberately designing the machine learning model with the ability to explain). In our work, we have considered both directions and studied three types of models that are coherently connected as well as complying with this classification taxonomy.
2.2. Attention Based Recommendation
Attention models are one type of input processing technique that allows the neural network to focus on certain parts of a complex input by assigning various modular learned weights. In this way, it allows the neural networks to approximate the visual attention mechanism humans use and the output can be calculated as an attention-weighted sum of the input. It has gained a lot of successes in multiple domains especially natural language processing and computer vision. In recent years, various works (Chen et al., 2018; Wu et al., 2019; Li et al., 2020, 2021; Gao et al., 2019) have been proposed to use attention in recommender systems. Intuitively, different users may interact with the same item with attention to different aspects, e.g., words in the text, saliency areas in images, etc. NPA (Wu et al., 2019) and NRPA (Liu et al., 2019) use two-level attention models of both word-attention and document-attention to personalize news recommendation; NETE (Li et al., 2020) learned template-controlled sentences from data to describe word features; VECF (Chen et al., 2019) utilized both attention-weighted visual features and GRU-based weak supervised learning to increase the model explanation on personalized ranking. In this work, we adopt a similar strategy where the attention weights are learned with ID embeddings and feature embeddings. However, for the sake of explanation, the attentions are applied to features instead of their embeddings.
2.3. Adversarial Personalized Ranking
Despite the successes of recommendation models, numerous works have reported that they can be vulnerable when exposed to adversarial perturbations or even random perturbations (He et al., 2018; Deldjoo et al., 2021). Thus, two types of adversarial recommendation models have been proposed: adversarial learning (Goodfellow et al., 2015; Madry et al., 2018) based RS and GAN-based RS. Among the first type: APR (He et al., 2018) proposed to add adversarial perturbations on user/item embeddings to improve BPR(Rendle et al., 2009) performance; AMR (Tang et al., 2020) leverages the adversarial training by adding adversarial perturbations to target image features. For the second type: IRGAN (Wang et al., 2017), for the first time, formulated the IR tasks as a minimax game where the generator learns the discrete relevance distribution of entities and the discriminator is the ranking model that decides whether the user-item pair is relevant or not; CFGAN (Chae et al., 2018) relaxed the discrete constraints of IRGAN by introducing a generator with the ability to perform continuous embedding space synthesizing; PURE (Zhou et al., 2021) further enriched the CFGAN by performing a positive-unlabeled sampling strategy and reached state-of-the-art performance. Nevertheless, none of them have the ability to provide explanations for the decisions made by the ranking model. Our work bridges the gap by introducing an explanation to the ranking model via adversarial training.
2.4. Counterfactual Explanation
Counterfactual explanation is a specific class of explanation model that provides the reasoning between decision making and input modifications. In recommendations, counterfactual explanations provide perturbations to user input features and these modifications can help the ranking model’s transition to the desirable decision boundary, e.g., flipping the original relevance preference over pair of items. Multiple efforts have been made to categorize and evaluate the counterfactual explanation models (Verma et al., 2020a; Wachter et al., 2017) and they have found successful applications in multiple domains, including natural language processing, computer vision (Goyal et al., 2019), and recommender systems (Tan et al., 2021; Wang et al., 2021; Tran et al., 2021; Ghazimatin et al., 2020). This is an emerging domain in recent years, and our work extends the existing work with multi-pass counterfactual augmentations.
3. Proposed Model
3.1. Problem Definition
In this paper, we study the contextual recommendation problem where , , and are the set of users, items, and features, respectively. Given a user , a list of relevant items and their corresponding interactions are recorded. For each user-item pair , there exists a group of raw features that can be used as the source of explanation to describe the interaction between the user and the item . A good source of features is the review text from the user for the specific items. Compared with many existing works that only utilized the isolated features from either the user (e.g., biographical information) or the item (e.g., item title description or item image), the text review features have the explicit interactions between user and item, thus, it is more informative in terms of building an explainable ranking model. We further assume to be the index set of observed user-item-feature interactions where we denote as the observed review features within one specific application domain (e.g., electronics, fashion). Here, the corresponding user id, item id, as well as their review features should satisfy and .
Then, our recommendation problem is formulated as follows:
Definition 1 (Contextualized Explainable Recommendation).
Given: A set of users , a set of items , a set of raw features , the observed user-item-feature interaction sets .
Output: The estimated interaction scores of the unobserved items for each user in as well as their corresponding feature explanations.
It should be noted that under this problems setting, the features being utilized for users are not isolated from these ones from items, this is different from the traditional contextualized recommender systems (Guo et al., [n.d.]; He and McAuley, [n.d.]; Rendle, 2010). Similar to (Zhang et al., 2014; Tan et al., 2021), we decompose the review features (where ) into user feature vector and item feature vector w.r.t. the -th review feature as shown in Equation (1). Intuitively, the user tends to comment on the features they care more about, thus, the user feature is merely a frequency-based vector. However, for items, their qualities can be accurately reflected in the review sentiments from multiple users. Therefore, we formulate the item features by considering both review feature frequency and average sentiment.
| (1) |
where is the maximum review scores a user can give to an item, is the frequency that user mentioned review feature toward item , and is the average sentiment on review feature toward item . After transformation, all entries of these feature vectors are mapped into the range of and the the indexed set becomes .

3.2. Intrinsic Explanation
In this subsection, we introduce the neural attention recommendation (NAR) in detail. NAR is a white box recommendation model with intrinsically explainable designs and it has two major components: a user (item) network to learn user (item) representations, and a final prediction network to predict the relevance scores. The overview of the NRA model is shown in Figure 1.
3.2.1. User (item) embedding network
For the embedding network, it maps each user and item into lower-dimensional representations and via an embedding layer based on their IDs. Under the contextualized setting, we also have the decomposed feature vectors and available for each user and each item . Given one feature vector or , we embed each word within it to a lower dimensional representation (denoted in bold) via word embeddings.
Within a specific application domain, each user will have attentions on a few features. Based on this intuition, we highlight the crucial features by designing the attention network as:
| (2) |
where is the attention mapping matrix between user embedding and word embedding. Thus, the attention weights of each user on -th word will be . Each item can also obtain its attention weights in a similar manner with a different attention mapping matrix .
3.2.2. Prediction network
To incorporate the review features into the prediction, one naive solution is to let the user and item share the same feature vector . In our design, different mapping functions, i.e., Equation (1), are applied to transform to the user as and to the item as , respectively. After the embedding network, we obtain the attention aggregated representations of users and items as follows.
| (3) |
In the end, we concatenate the user and item embeddings and attention aggregated representations. Then, the final relevance prediction between the user and item can be retrieved by passing the concatenated vector representation into a multi-layer perceptron (MLP) layer111We could also use factorization machine to learn the high-order interactions, but without loss of generality, we adopt MLP as the final layer for all baselines to assure an easy and fair comparison between various models.
| (4) |
where is the concatenation of two vectors and is the element-wise product of two vectors.

3.3. Adversarial Explanation
In this section, we introduce the contextualized adversarial ranking model (CAR) in detail. CAR is a gray box recommendation model with a partial transparency requirement on the feature gradients and it allows the ranking model to be retrained with adversarial augmentations. Specifically, CAR has the same user (item) embedding network as NAR. In addition, CAR also has two distinct components: an adversarial augmentation network, and the final prediction network. The overview of the NRA model is shown in Figure 2.
3.3.1. Prediction network
To incorporate the feature signal into the ranking prediction, a common practice is first to convert user features and item features to latent embeddings, then, infuse them with the user (item) ID embeddings as a single latent vector representation.
| (5) |
where and are the mapping matrices that convert the normalized user feature vector and item feature vector into the same latent space.
3.3.2. Adversarial augmentation network
Considering that we aim to use adversarial perturbation for generating the explainable perturbations, the first step is to learn the base recommendation model222For a fair comparison, all baselines are modified to use the pairwise loss on top of the neural Bayesian personalized ranking (BPR) architecture and all optimization hyper-parameters are set to be the same, e.g., learning rate, embedding size.. Then, we generate the adversarial perturbations that aim to maximize the loss of our model. Assuming that the BPR loss is , then, the corresponding perturbations could be generated using the fast gradient sign method (FGSM (Goodfellow et al., 2015)):
| (6) |
where is the perturbation estimated by calculating the gradient of the BPR loss w.r.t. the user feature vectors. This assumes that our loss is the first-order derivative around . Meanwhile, the adversarial perturbation is under the max-norm constraint. In other words, after the L2 normalization, each dimension of should be constrained under the magnitude of in order to get a scale-controllable minimum perturbation.
Next, we augment the original training set with adversarial perturbations on top of the user features. Notice that adversarial augmentation with retraining could in general make the ranking model less sensitive to the adversarial perturbations, hence increasing the model robustness. In our contextualized setting, we could augment the data set with item features or even user (item) id embedding as well. However, as the target is to provide explanations for personalized rankings, we only need to perturb the user feature vector to serve this purpose. Eventually, our adversarial augmented prediction network will be trained in the following manner:
| (7) |
From another perspective, we can think of the loss of the adversarial augmentations as a regularization term to control the trade-off between the ranking model that optimizes the pairwise loss and the attacking model that finds the most effective perturbations against the current ranking model. This trade-off can be balanced by introducing a hyper-parameter :
| (8) |
where is the ranking model’s parameter and is the user-item-feature set where the user feature vector has its adversarial perturbation being added on user features.

3.4. Counterfactual Explanation
In this section, we introduce the counterfactual neural recommendation model (CNR) in detail. CNR is a blackbox recommendation model with model-agnostic designs to generate explanations for rankings. Similar to the CAR model, CNR has exactly the same user (item) embedding network and final prediction network. Nevertheless, its augmentation network is designed by following the counterfactual thinking (Tan et al., 2021; Verma et al., 2020b): ‘‘User X purchased item A over item B because feature variables have values () associated with X. If user X has a few feature variables () changed and all other variables remained the same, user X would purchase item B over item A instead’’.
One should note that many such explanations exist, our objective is to find a counterfactual perturbation that alters features as little as possible but returns the closest world where the ranking decision has been flipped. Based on the above principle, we can find the counterfactual perturbation and an optimum solution for the ranking model by solving the following minimax problem:
| (9) |
where is the counterfactual perturbation of user features by fixing the model parameter and minimizing this objective. is the distance function that measures the difference between original user features and perturbed user features. Meanwhile, the ranking loss should be maximized since the ranking decision is designed to be flipped after the feature perturbations are applied. In practice, we should initialize by training the ranking model without any perturbations, and then we can iteratively update and until a perturbation has been found that is sufficiently small to flip the ranking predictions. For example, under the pairwise learning setting, will become if the counterfactual perturbation is applied on user features .
The distance term is critical in counterfactual recommendations, especially when we aim to generate human interpretable explanations. Namely, only a small number of features should be changed and the rest remain untouched. In this way, these counterfactual perturbations are easier for humans to interpret. Thus, various distance functions can be defined to support our goal. One straightforward definition is L2 distance , which can be used to guarantee the user features are minimally perturbed. For the sake of introducing sparsity to so that humans can understand such explanation, we also introduce the L1 norm . This is also called elastic net regularization, which combines ridge and lasso regularization.
| Model Transparency | Data Augmentation | Constraint | Learning Objective | Extensibility | |
| Intrinsic Model | Fully | False | — | Minimize log loss | Low |
| Adversarial Model | Partial | True | Max-norm bounded | Maximize loss gradient | High |
| Counterfactual Model | Model agnostic | True | P-norm regularized | Flip ranking decision | High |
4. Model Analyses
We compare all three types of explanation models in various aspects: model transparency, data manipulation, explanation constraints, learning objectives, and extensibility. Specially they all share certain commonalities but have a significant difference in terms of their explanation generating mechanisms. The high-level summary is presented in Table 1.
Model transparency
From the intrinsic model to the adversarial model and then the counterfactual model, the requirements for model transparency gradually decrease. The intrinsic model (NAR) usually requires full transparency of the ranking model architecture and a well-designed attention mechanism with extra attention weights on user features. The adversarial model (CAR) only requires the gradient w.r.t. the features that need to be explained, and it is more like a partially transparent model. The counterfactual model (CNR) bypasses the substantial challenges of exploring the internal logic of the complex ranking systems. Therefore, counterfactual models can explain the rationale of the ranking decision-making process to a certain extent without opening the “black box”, and it is a model agnostic explanation approach.
Learning objectives
The learning objectives of all three types of models will be the same as any popular ranking models where we usually minimize the log loss of the observed user-item interactions regardless of whether it is under the pointwise or the pairwise setting. The major difference is reflected in their explanation components: for the intrinsic model, the explanation is instantiated using attention weights, thus, no modification is needed in the objective; for the adversarial model, the perturbation is designed to be the gradient w.r.t. the user features that can maximize the log loss; for the counterfactual model, the perturbation is learned to serve the purpose of flipping the pre-trained ranking model’s decision, do it does not necessarily need to be the largest gradient w.r.t. the log loss.
Explanation constraints
The intrinsic model has no constraints on the learning process. The adversarial model’s perturbation is max-norm bounded by the magnitude of on the loss’s gradient. The counterfactual model’s perturbation is usually L2-norm regularized (and L1-norm regularized sometimes for the sake of explanation sparsity) but not strictly bounded.
Data manipulations
The intrinsic model does not require any data augmentations since it is inherently designed to be explainable by attention weights. Both the adversarial model and counterfactual model require data augmentation to increase the model expressiveness and alleviate the data sparsity issue by adding more data points near the ranking decision boundary in latent feature space.
Extensibility
The adversarial model and counterfactual model require very little or no effort to modify the existing model architectures. Therefore, they can be easily extended from any contextualized recommender systems. On the other hand, the intrinsic model requires a dedicated design for the attention mechanism.
5. Experimental Results
In this section, we aim to answer the following questions:
RQ1: Do the learned models give competitive and human interpretable results?
RQ2: Are the explainable mechanisms helpful with the ranking performance?
RQ3: How do we evaluate the explanation results both quantitatively and qualitatively?
| Dataset | # Users | # Items | # Interactions | Density | # Features |
|---|---|---|---|---|---|
| Instrument | 1,276 | 843 | 3,581 | 0.33% | 325 |
| Video | 4,333 | 1,486 | 11,759 | 0.18% | 350 |
| Music | 5,339 | 3,538 | 40,315 | 0.21% | 1,366 |
| Beauty | 21,472 | 11,897 | 105,659 | 0.04% | 1,985 |
| Clothing | 37,703 | 22,647 | 142,553 | 0.02% | 1,462 |
5.1. Experiment Settings
5.1.1. Data sets
We conduct the experiments on five publicly accessible data sets333 http://jmcauley.ucsd.edu/data/amazon/index_2014.html with various sizes: Instrument, Video, Music, Beauty, and Clothing. For the preprocessing steps, we keep the user-item interaction pairs that have text reviews. To perform the negative sampling, we treat the 4-star and 5-star reviews as the positive feedback and the rest are unlabeled feedback (Wang et al., 2017; Zhou et al., 2021). Following this pro-processing protocol, all user and item interactions are eventually stored into the interaction matrix with entries of values 0 and 1. The details of all data set are summarized in Table 2. We utilize the Sentire444https://github.com/lileipisces/Sentires-Guide package to further process each data set in order to get the word and sentiment pairs for each user from the review text.
5.1.2. Evaluation protocols
For the purpose of evaluation, we have adopted the train and test random split on each user when the number of positive examples is larger than 5. Otherwise, there will be no positive examples in testing. Similar to the existing work, we also perform the sampled evaluation (Krichene and Rendle, 2020; He et al., 2017) to speed up the computation where each positive test item will be randomly assigned with a candidate item pool of size 100. The final performance evaluation uses both classification and ranking-based metrics, i.e., Precision, Recall, F1, Hit rate, NDCG, and MRR. Specifically, MRR has the cutting threshold of 1 (i.e., MRR@1) and all the rest of the evaluation metrics have the cutting threshold of 10 (e.g., NDCG@10).
It is also very important that we can quantitatively evaluate the explanations generated by our models. Therefore, besides the model-based performance evaluation, we also perform the user-based evaluation. Intuitively, we aim to evaluate how good our model’s explanation is when matched with users’ sentiment in terms of the features. Let us assume that user has ground truth features . Here, a feature will be added to only if user has already given sentiments (positive and negative) on this feature regarding all items. Meanwhile, for our ranking model, we have generated an explanation vector , i.e., attention weight vector in NAR or perturbation vector in CAR and CNR. We can sort this explanation vector in descending order and compare with users’ sentiment vector in terms of precision and recall at different cutting thresholds .
| (10) |
Furthermore, F1@k is computed on top of precision and recall and NDCG@k will be straight forward to compute as well.
| Instrument | Video | Music | Beauty | Clothing | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | NDCG | F1 | NDCG | F1 | NDCG | F1 | NDCG | F1 | NDCG | |
| NAR | 0.2028 | 0.3124 | 0.2106 | 0.2991 | 0.3145 | 0.5585 | 0.2286 | 0.3416 | 0.2365 | 0.3302 |
| CAR | 0.0160 | 0.0252 | 0.0129 | 0.0220 | 0.0147 | 0.0354 | 0.0163 | 0.0257 | 0.0150 | 0.0200 |
| CNR | 0.1858 | 0.2580 | 0.2204 | 0.3417 | 0.3437 | 0.5821 | 0.2279 | 0.3336 | 0.1889 | 0.2535 |
5.1.3. Baselines
We have considered various state-of-the-art baselines for the model performance evaluations:
-
•
Neural collaborative filtering (NCF) (He et al., 2017): The most popular two tower based neural network recommendations.
-
•
Visual Bayesian personalized ranking (VBPR) (He and McAuley, [n.d.]): A modified version of the original VBPR by using the neural network based embeddings along with the contextual features.
-
•
Counterfactual explainable recommendation (CER) (Tan et al., 2021): The latest counterfactual explainable recommendation model.
-
•
Neural attention recommendation (NAR): Our proposed attention based intrinsic recommendation model.
-
•
Contextualized adversarial recommendation (CAR): Our proposed personalized ranking model with adversarial explanation.
-
•
Counterfactual neural recommendation (CNR): Our proposed iterative counterfactual explainable recommendation model.
5.1.4. Reproducible setting
To guarantee a fair comparison, we fix both ID embedding and feature embedding to be 350 for all models on all data sets. Meanwhile, all models’ feature input regarding users and items will be kept the same across different models. We optimize ball baselines using Adam with a fixed learning rate of 0.001 and the number of training epochs is set to 50. For CNR, the number of the outer loop iteration for the minimax problem (9) is set to 20. For the regularization parameters for CAR and for CNR. The source code (pre-processing and modeling) will be released upon acceptance.
| Instrument | Precision | Recall | F1 | Hit Rate | NDCG | MRR |
|---|---|---|---|---|---|---|
| NCF | 0.0316 | 0.3047 | 0.0570 | 0.3113 | 0.1773 | 0.1405 |
| VBPR | 0.0418 | 0.4006 | 0.0753 | 0.4088 | 0.2344 | 0.1871 |
| CER | 0.0419 | 0.3984 | 0.0753 | 0.4088 | 0.2342 | 0.1881 |
| NAR | 0.0284 | 0.2724 | 0.0513 | 0.2799 | 0.1545 | 0.1206 |
| CAR | 0.0457 | 0.4355 | 0.0822 | 0.4455 | 0.2538 | 0.2025 |
| CNR | 0.0428 | 0.4077 | 0.0769 | 0.4172 | 0.2406 | 0.1922 |
| Video | Precision | Recall | F1 | Hit Rate | NDCG | MRR |
|---|---|---|---|---|---|---|
| NCF | 0.0535 | 0.5106 | 0.0962 | 0.5222 | 0.2986 | 0.2356 |
| VBPR | 0.0595 | 0.5638 | 0.1068 | 0.5773 | 0.3362 | 0.2668 |
| CER | 0.0576 | 0.5482 | 0.1035 | 0.5613 | 0.3226 | 0.2561 |
| NAR | 0.0511 | 0.4893 | 0.0920 | 0.5005 | 0.2875 | 0.2278 |
| CAR | 0.0596 | 0.5662 | 0.1071 | 0.5800 | 0.3342 | 0.2701 |
| CNR | 0.0579 | 0.5519 | 0.1041 | 0.5666 | 0.3275 | 0.2626 |
| Music | Precision | Recall | F1 | Hit Rate | NDCG | MRR |
|---|---|---|---|---|---|---|
| NCF | 0.0628 | 0.3857 | 0.0983 | 0.4753 | 0.2314 | 0.2104 |
| VBPR | 0.1037 | 0.6300 | 0.1622 | 0.7001 | 0.4520 | 0.4288 |
| CER | 0.0941 | 0.5634 | 0.1463 | 0.6416 | 0.3843 | 0.3609 |
| NAR | 0.1006 | 0.6106 | 0.1573 | 0.6841 | 0.3989 | 0.3614 |
| CAR | 0.1081 | 0.6567 | 0.1693 | 0.7244 | 0.4796 | 0.4567 |
| CNR | 0.0974 | 0.5821 | 0.1515 | 0.6584 | 0.4176 | 0.4021 |
| Beauty | Precision | Recall | F1 | Hit Rate | NDCG | MRR |
|---|---|---|---|---|---|---|
| NCF | 0.0534 | 0.3737 | 0.0885 | 0.4112 | 0.2214 | 0.1881 |
| VBPR | 0.0775 | 0.5758 | 0.1301 | 0.6074 | 0.3778 | 0.3293 |
| CER | 0.0665 | 0.4794 | 0.1107 | 0.5110 | 0.3159 | 0.2778 |
| NAR | 0.0617 | 0.4358 | 0.1020 | 0.4652 | 0.2820 | 0.2465 |
| CAR | 0.0778 | 0.5791 | 0.1306 | 0.6094 | 0.3776 | 0.3283 |
| CNR | 0.0734 | 0.5324 | 0.1221 | 0.5642 | 0.3547 | 0.3121 |
| Clothing | Precision | Recall | F1 | Hit Rate | NDCG | MRR |
|---|---|---|---|---|---|---|
| NCF | 0.0364 | 0.3305 | 0.0650 | 0.3504 | 0.1928 | 0.1569 |
| VBPR | 0.0564 | 0.5252 | 0.1012 | 0.5440 | 0.3112 | 0.2524 |
| CER | 0.0479 | 0.4409 | 0.0856 | 0.4598 | 0.2665 | 0.2192 |
| NAR | 0.0403 | 0.3707 | 0.0719 | 0.3888 | 0.2146 | 0.1732 |
| CAR | 0.0578 | 0.5373 | 0.1035 | 0.5562 | 0.3210 | 0.2613 |
| CNR | 0.0513 | 0.4715 | 0.0917 | 0.4920 | 0.2879 | 0.2387 |
5.2. Performance Evaluation
For the recommendation evaluation, the comparison results are summarized in Tables 4-8. We observe that regardless of the data set size or the application domain, the adversarial perturbation and augmentation based method CAR always outperforms all other baselines. Meanwhile, we also observe that the counterfactual-based models, such as CER and CNR, also have competitive results. Specifically, CNR consistently beats CER in every aspect. This is because CNR is the minimax version of CER and it has multiple rounds of optimizations to find the best counterfactual perturbations and keeps improving the ranking decision boundaries constantly. As a direct comparison, CAR also generates perturbations and retrains the ranking model on top. Nevertheless, the objective of CAR is to directly optimize the ranking performance. With more near-boundary perturbation examples generated, the embedded feature space will be further covered for the scenarios where the data set is extremely sparse. Similar phenomena have been observed in multiple recent works that use adversarial augmentation (He et al., 2018; Zhou et al., 2021; Chae et al., 2018). For the attention-based model NAR, due to its high model complexity, it does not perform well for small-scaled data sets because of model overfitting. But its performance gets significantly improved on large-scale data sets and becomes very competitive on them. The VBPR and NCF models in general are quite stable in terms of their performance, but due to the lack of a module for explanation, their prediction results are hardly interpretable.









| Instrument | Video | Music | Beauty | Clothing | |
| GT | {vocal, tone, display, pedal, sound} | {character, drama, season, performances, adventures} | {hits, artist, performance, playing, charm} | {hair, pumps, frizzy, scents, salon} | {size, material, arch support, strap, velcro} |
| NAR | {tune, hum, tab, tube, styles} | {effing, murder mystery, outdoors, storytelling, satire} | {lyricist, outtakes, comeback, hook, studio} | {curler, tingle, cover, itch, pore} | {dressy, cushion, knee, fit, calf} |
| CAR | {processor, bucks, neck, overdrive, plugs} | {performance, fans, cabin, twists, performer} | {york, grooves, riffs, intro, sounds} | {smell, iron, scars, chip, skin tone} | {fits, boxers, gloves, lining, sleeve} |
| CNR | {noise, epiphone, cord, holder, pickup} | {adventures, seasons, artistry, dramas, series} | {album, smash, guitar playing, guitar work, songwriters} | {hair, drugstore, pencil, perfume smell, customer} | {bikini, thickness, heels, footbed, padding} |
5.3. Explanation Evaluation
In terms of the user-orientated evaluation w.r.t. the explanations, we mainly focus on horizontally comparing all three proposed models. As shown in Figure 3, we observe that neural attention model NAR and counterfactual model CNR perform relatively well, but the adversarial perturbation model CAR has low scores across all five data sets. The reason is that NAR and CNR are more suitable for model explanations: NAR has an explicitly designed architecture for learning the attention weights of the input features; CNR uses the counterfactual perturbation to alter the ranking decision, therefore, these perturbations are also explainable in terms of making a ranking decision. As a sharp contrast, CAR learns its adversarial perturbations to maximize the ranking loss and they have weak correlations with explanation because these perturbations do not guarantee to change the model ranking.
5.4. Visualizations Results
In this section, we compare and connect all three explanation models, NAR, CAR, and CNR, by conducting various visualizations. These visualization show that quantitative evaluations and qualitative visualization are well aligned. Since the users are inclined to give reviews to items with positive or negative sentiment, then, the word-sentiment pairs of each user are one reliable proxy of ground truth (GT) for explanation evaluations.
5.4.1. Explanation correlation analysis
In Figure 4, we compute the average Pearson correlations of GT, NAR, CAR, and CNR in a pairwise manner and demonstrate them as the heatmaps. We observe that comparing GT, NAR and CNR have the most correlated explanations. Since the feature dimension is relatively high, and GT features are extremely sparse (only a few explanation words per user), therefore, the correlation computed w.r.t. GT are in general low as expected. However, the correlations between the proposed explanation models are relatively high. NAR and CNR are also strongly correlated with each other.
5.4.2. Explanation clustering analysis
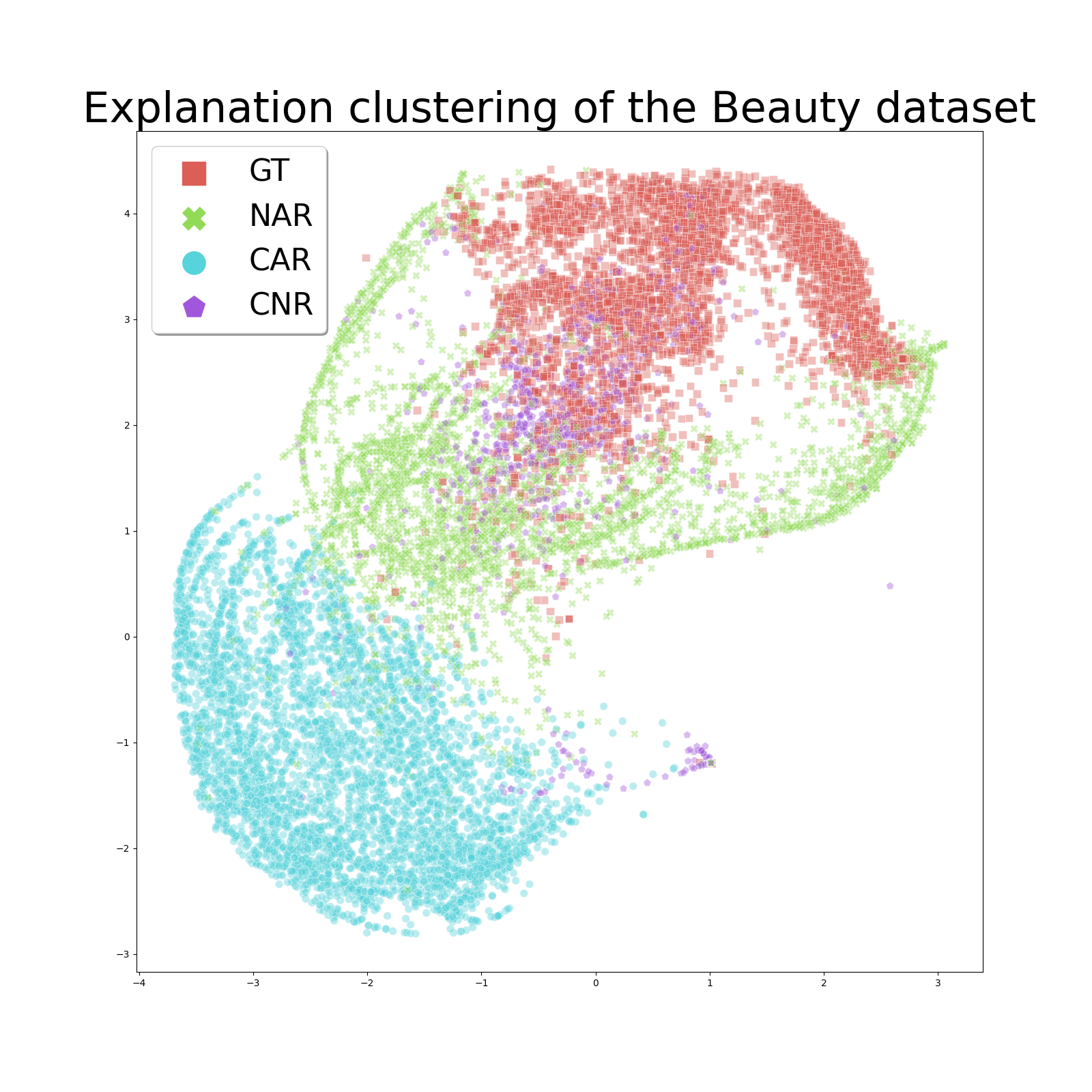
In Figure 5, we transform all the explanation vectors of users into two-dimensional representations using t-SNE (Van der Maaten and Hinton, 2008). We observe that the users group together within the same model. CNR usually has a cluster of users that are close to the GT user clusters. The NAR clusters are slightly further distanced compared with CNR. CAR always has the most distanced group of users.
5.4.3. Top explainable words
As we can see in Table 9, we randomly pick the users for visualization and observe that the top-5 words of various explanation models are quite different. Nevertheless, they belong to the specific application domains as expected. In general, the retrieved explainable words for all three models also have large variations compared with GT. However, since we are only focusing on the top words, with large values being selected, we begin to see more overlaps of explainable words.
6. Conclusion
In this paper, we propose three explainable recommendation models with various transparencies and perform a systematic and extensive comparison between them in terms of both quantitative evaluations and qualitative visualizations. The overall takeaway message for all these proposed models is: CAR has outstanding recommendation performance but does not have sufficient ability to explain; NAR explains well but could easily overfit in small-scale data sets and has reasonably recommendation results on large-scale data sets; CNR is the winner model which balances well in terms of both recommendation performance and explanation. Besides those, CNR is also a blackbox explainable ranking model and it can be easily extended to any existing ranking architecture.
References
- (1)
- Ai et al. (2018) Qingyao Ai, Vahid Azizi, Xu Chen, and Yongfeng Zhang. 2018. Learning Heterogeneous Knowledge Base Embeddings for Explainable Recommendation. Algorithms 11, 9 (2018), 137.
- Balog et al. (2019) Krisztian Balog, Filip Radlinski, and Shushan Arakelyan. 2019. Transparent, Scrutable and Explainable User Models for Personalized Recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR. ACM, 265–274.
- Chae et al. (2018) Dong-Kyu Chae, Jin-Soo Kang, Sang-Wook Kim, and Jung-Tae Lee. 2018. CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM. ACM, 137–146.
- Chen et al. (2018) Chong Chen, Min Zhang, Yiqun Liu, and Shaoping Ma. 2018. Neural Attentional Rating Regression with Review-level Explanations. In Proceedings of the 2018 World Wide Web Conference on World Wide Web WWW. ACM, 1583–1592.
- Chen et al. (2020) Tong Chen, Hongzhi Yin, Guanhua Ye, Zi Huang, Yang Wang, and Meng Wang. 2020. Try This Instead: Personalized and Interpretable Substitute Recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR. ACM, 891–900.
- Chen et al. (2019) Xu Chen, Hanxiong Chen, Hongteng Xu, Yongfeng Zhang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2019. Personalized Fashion Recommendation with Visual Explanations based on Multimodal Attention Network: Towards Visually Explainable Recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR. ACM, 765–774.
- Deldjoo et al. (2021) Yashar Deldjoo, Tommaso Di Noia, and Felice Antonio Merra. 2021. A Survey on Adversarial Recommender Systems: From Attack/Defense Strategies to Generative Adversarial Networks. ACM Comput. Surv. 54, 2 (2021), 35:1–35:38.
- Gao et al. (2019) Jingyue Gao, Xiting Wang, Yasha Wang, and Xing Xie. 2019. Explainable Recommendation through Attentive Multi-View Learning. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI. AAAI Press, 3622–3629.
- Gedikli et al. (2014) Fatih Gedikli, Dietmar Jannach, and Mouzhi Ge. 2014. How should I explain? A comparison of different explanation types for recommender systems. Int. J. Hum. Comput. Stud. 72, 4 (2014), 367–382.
- Ghazimatin et al. (2020) Azin Ghazimatin, Oana Balalau, Rishiraj Saha Roy, and Gerhard Weikum. 2020. PRINCE: Provider-side interpretability with counterfactual explanations in recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining, WSDM. 196–204.
- Goodfellow et al. (2015) Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In 3rd International Conference on Learning Representations, ICLR.
- Goyal et al. (2019) Yash Goyal, Ziyan Wu, Jan Ernst, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Counterfactual Visual Explanations. In Proceedings of the 36th International Conference on Machine Learning, ICML (Proceedings of Machine Learning Research, Vol. 97). 2376–2384.
- Guo et al. ([n.d.]) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. [n.d.]. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI. 1725–1731.
- He and McAuley ([n.d.]) Ruining He and Julian J. McAuley. [n.d.]. VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. 144–150.
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR. 639–648.
- He et al. (2018) Xiangnan He, Zhankui He, Xiaoyu Du, and Tat-Seng Chua. 2018. Adversarial Personalized Ranking for Recommendation. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR. 355–364.
- He et al. (2017) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, WWW. 173–182.
- Herlocker et al. (2000) Jonathan L. Herlocker, Joseph A. Konstan, and John Riedl. 2000. Explaining collaborative filtering recommendations. In CSCW, Proceeding on the ACM 2000 Conference on Computer Supported Cooperative Work. ACM, 241–250.
- Hou et al. (2019) Min Hou, Le Wu, Enhong Chen, Zhi Li, Vincent W. Zheng, and Qi Liu. 2019. Explainable Fashion Recommendation: A Semantic Attribute Region Guided Approach. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI. 4681–4688.
- Koren et al. (2009) Yehuda Koren, Robert M. Bell, and Chris Volinsky. 2009. Matrix Factorization Techniques for Recommender Systems. Computer 42, 8 (2009), 30–37.
- Krichene and Rendle (2020) Walid Krichene and Steffen Rendle. 2020. On Sampled Metrics for Item Recommendation. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). 1748–1757.
- Li et al. (2020) Lei Li, Yongfeng Zhang, and Li Chen. 2020. Generate Neural Template Explanations for Recommendation. In The 29th ACM International Conference on Information and Knowledge Management CIKM. ACM, 755–764.
- Li et al. (2021) Lei Li, Yongfeng Zhang, and Li Chen. 2021. Personalized Transformer for Explainable Recommendation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP. 4947–4957.
- Liu et al. (2019) Hongtao Liu, Fangzhao Wu, Wenjun Wang, Xianchen Wang, Pengfei Jiao, Chuhan Wu, and Xing Xie. 2019. NRPA: Neural Recommendation with Personalized Attention. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR. ACM, 1233–1236.
- Ma et al. (2008) Hao Ma, Haixuan Yang, Michael R. Lyu, and Irwin King. 2008. SoRec: social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, CIKM. 931–940.
- Ma et al. (2019) Jianxin Ma, Chang Zhou, Peng Cui, Hongxia Yang, and Wenwu Zhu. 2019. Learning Disentangled Representations for Recommendation. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS. 5712–5723.
- Madry et al. (2018) Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. In 6th International Conference on Learning Representations, ICLR.
- McAuley and Leskovec (2013) Julian J. McAuley and Jure Leskovec. 2013. Hidden factors and hidden topics: understanding rating dimensions with review text. In Seventh ACM Conference on Recommender Systems, RecSys. ACM, 165–172.
- Pan et al. (2020a) Deng Pan, Xiangrui Li, Xin Li, and Dongxiao Zhu. 2020a. Explainable Recommendation via Interpretable Feature Mapping and Evaluation of Explainability. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI. 2690–2696.
- Pan et al. (2020b) Deng Pan, Xiangrui Li, Xin Li, and Dongxiao Zhu. 2020b. Explainable Recommendation via Interpretable Feature Mapping and Evaluation of Explainability. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI. 2690–2696.
- Polleti and Cozman (2019) Gustavo Padilha Polleti and Fábio Gagliardi Cozman. 2019. Explaining Content-Based Recommendations with Topic Models. In 8th Brazilian Conference on Intelligent Systems, BRACIS. IEEE, 800–805.
- Rendle (2010) Steffen Rendle. 2010. Factorization Machines. In ICDM 2010, The 10th IEEE International Conference on Data Mining. 995–1000.
- Rendle et al. (2009) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence UAI. 452–461.
- Sarwar et al. (2001) Badrul Munir Sarwar, George Karypis, Joseph A. Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In Proceedings of the Tenth International World Wide Web Conference WWW. ACM, 285–295.
- Selvaraju et al. (2020) Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2020. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 128, 2 (2020), 336–359.
- Tan et al. (2021) Juntao Tan, Shuyuan Xu, Yingqiang Ge, Yunqi Li, Xu Chen, and Yongfeng Zhang. 2021. Counterfactual Explainable Recommendation. CoRR abs/2108.10539 (2021).
- Tang et al. (2020) Jinhui Tang, Xiaoyu Du, Xiangnan He, Fajie Yuan, Qi Tian, and Tat-Seng Chua. 2020. Adversarial Training Towards Robust Multimedia Recommender System. IEEE Trans. Knowl. Data Eng. 32, 5 (2020), 855–867.
- Tintarev and Masthoff (2015) Nava Tintarev and Judith Masthoff. 2015. Explaining Recommendations: Design and Evaluation. In Recommender Systems Handbook. Springer, 353–382.
- Tran et al. (2021) Khanh Hiep Tran, Azin Ghazimatin, and Rishiraj Saha Roy. 2021. Counterfactual Explanations for Neural Recommenders. arXiv:2105.05008 (2021).
- Van der Maaten and Hinton (2008) Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, 11 (2008).
- Verma et al. (2020a) Sahil Verma, John P. Dickerson, and Keegan Hines. 2020a. Counterfactual Explanations for Machine Learning: A Review. CoRR abs/2010.10596 (2020).
- Verma et al. (2020b) Sahil Verma, John P. Dickerson, and Keegan Hines. 2020b. Counterfactual Explanations for Machine Learning: A Review. CoRR abs/2010.10596 (2020).
- Wachter et al. (2017) Sandra Wachter, Brent D. Mittelstadt, and Chris Russell. 2017. Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR. CoRR abs/1711.00399 (2017).
- Wang et al. (2017) Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang, and Dell Zhang. 2017. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR. ACM, 515–524.
- Wang et al. (2018b) Nan Wang, Hongning Wang, Yiling Jia, and Yue Yin. 2018b. Explainable Recommendation via Multi-Task Learning in Opinionated Text Data. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR. ACM, 165–174.
- Wang et al. (2018a) Xiang Wang, Xiangnan He, Fuli Feng, Liqiang Nie, and Tat-Seng Chua. 2018a. TEM: Tree-enhanced Embedding Model for Explainable Recommendation. In Proceedings of the 2018 World Wide Web Conference on World Wide Web WWW. ACM, 1543–1552.
- Wang et al. (2021) Zhenlei Wang, Jingsen Zhang, Hongteng Xu, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. Counterfactual Data-Augmented Sequential Recommendation. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 347–356.
- Wu et al. (2019) Chuhan Wu, Fangzhao Wu, Mingxiao An, Jianqiang Huang, Yongfeng Huang, and Xing Xie. 2019. NPA: Neural News Recommendation with Personalized Attention. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD. ACM, 2576–2584.
- Wu and Ester (2015) Yao Wu and Martin Ester. 2015. FLAME: A Probabilistic Model Combining Aspect Based Opinion Mining and Collaborative Filtering. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, WSDM. ACM, 199–208.
- Zhang and Chen (2020) Yongfeng Zhang and Xu Chen. 2020. Explainable Recommendation: A Survey and New Perspectives. Found. Trends Inf. Retr. 14, 1 (2020), 1–101.
- Zhang et al. (2014) Yongfeng Zhang, Guokun Lai, Min Zhang, Yi Zhang, Yiqun Liu, and Shaoping Ma. 2014. Explicit factor models for explainable recommendation based on phrase-level sentiment analysis. In The 37th International ACM SIGIR Conference on Research and Development in Information Retrieval SIGIR. ACM, 83–92.
- Zhou et al. (2021) Yao Zhou, Jianpeng Xu, Jun Wu, Zeinab Taghavi Nasrabadi, Evren Körpeoglu, Kannan Achan, and Jingrui He. 2021. PURE: Positive-Unlabeled Recommendation with Generative Adversarial Network. In KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2409–2419.