FreqBlender: Enhancing DeepFake Detection by Blending Frequency Knowledge
Abstract
Generating synthetic fake faces, known as pseudo-fake faces, is an effective way to improve the generalization of DeepFake detection. Existing methods typically generate these faces by blending real or fake faces in spatial domain. While these methods have shown promise, they overlook the simulation of frequency distribution in pseudo-fake faces, limiting the learning of generic forgery traces in-depth. To address this, this paper introduces FreqBlender, a new method that can generate pseudo-fake faces by blending frequency knowledge. Concretely, we investigate the major frequency components and propose a Frequency Parsing Network to adaptively partition frequency components related to forgery traces. Then we blend this frequency knowledge from fake faces into real faces to generate pseudo-fake faces. Since there is no ground truth for frequency components, we describe a dedicated training strategy by leveraging the inner correlations among different frequency knowledge to instruct the learning process. Experimental results demonstrate the effectiveness of our method in enhancing DeepFake detection, making it a potential plug-and-play strategy for other methods.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/60dd9615-2eb3-4f4e-99ac-19077aa29fbd/x1.png)
1 Introduction
DeepFake refers to face forgery techniques that can manipulate facial attributes, such as identity, expression, and lip movement [1]. The recent advancement of deep generative models [2, 3] has greatly sped up the evolution of DeepFake techniques, enabling the creation of highly realistic and visually imperceptible manipulations. However, the misuse of these techniques can pose serious security concerns [4], making DeepFake detection more pressing than ever before.
There have been many methods proposed for detecting DeepFakes, showing their effectiveness on public datasets [5, 6, 7, 8, 9]. However, with the continuous growth of AI techniques, new types of forgeries constantly emerge, posing a challenge for current detectors to accurately expose unknown forgeries. To address this challenge, recent efforts [10, 11, 12, 13] have focused on improving the generalizability of detection, i.e., the ability to detect unknown forgeries based on known examples. One effective approach to address this problem is to enhance the training data by generating synthetic fake faces, known as pseudo-fakes [14, 15, 16]. The intuition behind this approach is that the DeepFake generation process introduces artifacts in the step of blending faces, and these methods generate pseudo-fake faces by simulating various blending artifacts. By training on these pseudo-fake faces, the models can be driven to learn corresponding artifacts. However, existing methods concentrate on simulating the spatial aspects of face blending (see Fig. 1 (right)). While they can make the pseudo-fake faces resemble the distribution of wild fake faces in the spatial domain, they do not explore the distribution in the frequency domain. Thus, current pseudo-fake faces lack frequency-based forgery clues, limiting the models to learn generic forgery features.
In this paper, we shift our attention from the spatial domain to the frequency domain and propose a new method called FreqBlender to generate pseudo-fake faces by blending frequency knowledge (see Fig. 1 (left)). To achieve this, we analyze the composition of the frequency domain and accurately identify the range of forgery clues falling into. Then we replace this range of real faces with the corresponding range of fake faces to generate pseudo-fake faces. However, identifying the frequency range of forgery clues is challenging due to two main reasons: 1) this range varies across different fake faces due to its high dependence on face content, and 2) forgery clues may not be concentrated on a single frequency range but could be an aggregation of various portions across multiple ranges. Thus, general low-pass, high-pass, or band-pass filters are incapable of precisely pinpointing the distribution.
To address this challenge, we propose a Frequency Parsing Network (FPNet) that can adaptively partition the frequency domain based on the input faces. Specifically, we hypothesize that the faces are composed of three frequency knowledge, which represents semantic information, structural information, and noise information, respectively, and the forgery traces are likely hidden in structural information. This hypothesis is validated in our preliminary analysis (refer to Sec. 3 for details). Based on this footstone, we design the network consisting of a shared encoder and three decoders to extract corresponding frequency knowledge. The encoder transforms the input data into a latent frequency representation, while the decoders estimate the probability map of the corresponding frequency knowledge.
Training this network is non-trivial since no ground truth of frequency distribution is provided. Therefore, we propose a novel training strategy that leverages the inner correlations among different frequency knowledge. To be specific, we describe dedicated-crafted objectives that are performed on various blending combinations of the output from each decoder and emphasize the properties of each frequency knowledge. The experimental results demonstrate that the network successfully parses the desired frequency knowledge within the proposed training strategy.
Once the network is trained, we can parse the frequency component corresponding to the structural information of a fake face, and blend it with a real face to generate a pseudo-fake face. It is important to note that our method is not in conflict with existing spatial blending methods, but rather complements them by addressing the defect in the frequency domain. Our method is validated on multiple recent DeepFake datasets (e.g., FF++ [5], CDF [6], DFDC [8], DFDCP [7], FFIW [9]) and compared with many state-of-the-art methods, demonstrating the efficacy of our method in improving detection performance.
The contributions of this paper are summarized in three-fold: 1) To the best of our knowledge, we are the first to generate pseudo-fake faces by blending frequency knowledge. Our method pushes pseudo-fake faces closer to the distribution of wild fake faces, enhancing the learning of generic forgery features in DeepFake detection.2) We propose a Frequency Parsing Network that can adaptively partition the frequency components corresponding to semantic information, structural information, and noise information, respectively. Since no ground truth is provided, we design dedicated objectives to train this network. 3) Extensive experimental results on several DeepFake datasets demonstrate the efficacy of our method and its potential as a plug-and-play strategy for existing methods.
2 Related Works
The rapid progress of AI generative models has spawned the development of DeepFake detection methods. These methods mainly rely on deep neural networks to identify the inconsistency between real and fake faces using various features, including biological signals [17], spatial artifacts [14, 15, 16], frequency abnormality [13, 18, 19], auto-learned clues from dedicated-designed models [20, 21]. These methods have shown promising results on public datasets. However, some of their performance significantly deteriorates when confronted with unknown DeepFake faces due to the large distribution discrepancy resulting from limited training datasets. To tackle this issue, many methods have been proposed to improve their generalizability by learning the generic DeepFake traces, e.g., [10, 14, 15, 16, 12, 22, 23]. One effective approach is to create synthetic fake faces during training, known as pseudo-fake faces, e.g., [10, 14, 15, 16]. FWA [10] is a pioneering method that conducts self-blending to simulate fake faces. Several extended variants (Face X-ray [14], PCL [15], SBI [16], BiG-Arts [24]) have been proposed to blend faces using curated strategies, further improving detection performance. By increasing the diversity of training faces, the gap in the distribution of wild fake faces can be reduced, allowing the models to learn the invariant DeepFake traces across different distributions. To generate the pseudo-fake faces, existing methods usually design spatial blending operations to combine different faces. This involves extracting the face region from a source image and blending it into a target image. However, these methods overlook the distribution of wild fake faces in the frequency domain. While the synthetic faces may resemble the spatial-based distribution, the lack of consideration for frequency perspective hinders the models from learning the fundamental generic DeepFake traces.
3 Preliminary Analysis
We perform a statistical analysis of the frequency distribution of real and fake faces and present preliminary results for the main frequency components corresponding to semantic information, structural formation, and noise information, respectively.
Inspiration and Verification. The investigation in previous works [25, 26] has indicated that the forgery traces mainly exist in high-frequency areas. However, the precise range of these areas has not been described, driving us to re-investigate the frequency distribution of forgery traces.
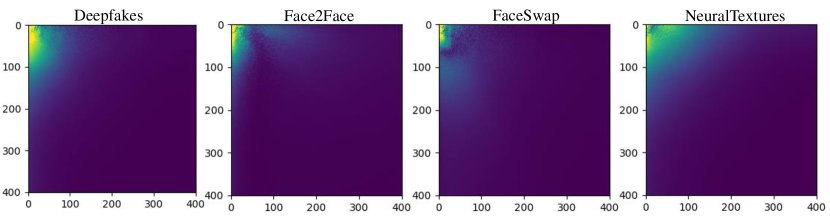
Specifically, we conduct verification experiments using FaceForensics++ (FF++) [5] datasets. We extract the frames from all videos and randomly select real images and fake images for each manipulation method (e.g., DF, F2F, FS, and NT). Then we crop out the face region in these selected images using a face detector [27] and apply DCT [28] to generate frequency maps. For analysis, we sum up all frequency maps of real and fake images and adopt the visualization process of azimuthal average described in previous work [29, 26]. This process involves logarithmic transformation and the calculation of azimuthally-averaged flux in circular annuli apertures. By placing the center of the circular annuli aperture at the top-left corner of the frequency map, we can obtain a one-dimensional array representing the spectrum diagram. The visual results of their distribution are shown in Fig. 2 (top). It can be observed that this figure is consistent with the results in [25]. However, when we directly plot their distribution differences without logarithmic operation, the results do not match the previous figure. It can be seen that the disparities in high-frequency regions are not as substantial as expected, while the differences in the lower range become more noticeable (see Fig. 2 (bottom)). This is because the logarithmic operation mitigates the degree of differences in lower frequency ranges, causing the illusion that only the high-frequency range exhibits differences between real and fake faces. Therefore, we conjecture that the forgery traces may not only be concentrated in a very high-frequency range but could possibly spread to the low-frequency range.

Hypothesis and Validation. As shown in Fig. 2, the most significant difference can be observed in the range of very low frequency. Given the significant dissimilarity in appearance between real and fake faces, we hypothesize that the semantic information is mainly represented in this low-frequency band. Moreover, we hypothesize that the mid-to-high frequency components capture the structural information, making them more susceptible to containing forgery traces. Furthermore, we hypothesize that the highest frequency components likely correspond to the noise introduced by various video preprocessing operations, such as compression, decompression, and encoding.

To validate our hypothesis, we directly visualize the difference between real and fake faces on their frequency maps in Fig. 3. By observing these results, we empirically split the frequency map into three non-overlap bands. The split operations follow the general band-pass filters. Denote the position in the frequency map as , where denotes the top-left corner and bottom-right corner. Specifically, we identify the region where as containing semantic information, the region where as containing structural information, and the region where as containing noise information. The corresponding results are visualized in Fig. 4, validating that these three ranges provide empirical evidence that aligns with our frequency distribution hypothesis.
4 FreqBlender
We describe a new method to create pseudo-fakes by blending specific frequency knowledge. The motivation is that existing methods only focus on spatial domain blending, which overlook the disparity between real and fake faces in the frequency domain. By considering the frequency distribution, the pseudo-fakes can closely resemble the fake faces. To achieve this, we propose a Frequency Parsing Network (FPNet) to partition the frequency domain into three components, corresponding to semantic information, structural information, and noise information, respectively. We then blend the structural information of fake faces with the real faces to generate the pseudo-fakes. The details of the Frequency Parsing Network are elaborated in Sec. 4.1, and the objective and training process for this network is described in Sec. 4.2. Then we introduce the deployment of our method with existing methods in Sec. 4.3.
4.1 Frequency Parsing Network
Overview. The Frequency Parsing Network (FPNet) is composed of one shared encoder and three independent decoders. The encoder transforms the input faces into frequency-critical features and the decoders aim to decompose the feature from the encoder and extract the respective frequency components.
Denote the encoder as and three decoders as respectively. Given an input face image , we first convert this face to the frequency map as , where denotes the operations of Discrete Cosine Transform (DCT). Then we send this frequency map into model and generate three distribution maps as ,, and respectively. Each distribution map indicates the probability of the corresponding frequency component distributed in the frequency map. Given these distribution maps, we can select the corresponding frequency components conveniently. For example, the frequency component corresponding to semantic information can be selected by and the same is for other two frequency components, i.e., and . The overview of FPNet is shown in Fig. 5 (left).

4.2 Objective Design for FPNet
The most challenging and crucial aspect of our method is to train the network for frequency parsing, as there is no ground truth available for the different frequency components. Note that the only available resources for supervising the training are the preliminary analysis results in Section 3. Nevertheless, these results are not precise and can not be adaptive to different inputs, which are insufficient for model training. Therefore, we meticulously craft a couple of auxiliary objectives to instruct the learning of networks, allowing for the self-refinement of the network.
These objectives are designed based on the following proposition.
Proposition 1.
Each frequency component exhibits the following properties:
-
1.
Semantic information can reflect the facial identity.
-
2.
Structural information serves as the carrier of forgery traces.
-
3.
Noise information has minimal impact on visual quality.
-
4.
The preliminary analysis findings are generally applicable.
Corollary 1.
For a given face , the transformed face based on its semantic information will retain the same facial identity as , i.e., , where denotes a face recognition model and denotes the Inverse Discrete Cosine Transform (IDCT).
Facial Fidelity Loss. We introduce a facial fidelity loss to penalize the discrepancy in identity between the input face image and the spatial content represented by semantic information. To measure the identity discrepancy, we employ the MobileNet [31] as our face recognition model and train it using ArcFace [32, 33]. We select MobileNet for its balance between computational efficiency and recognition accuracy. Let be the MobleNet and be the facial features extracted from the face image . The facial fidelity loss can be defined as
| (1) |
Note that the input face can be either real or fake, as the identity information is present in both cases.
Corollary 2.
For a given real face , it can be detected as fake if and only if it is inserted the structural information from a fake face , i.e., , where denotes a Deepfake detector with labels of fake and real in , indicates the inserting operation.
Authenticity-determinative Loss. This loss is designed to emphasize the determinative role of structural information. To evaluate the authenticity of faces, we develop a DeepFake detector , which is implemented using a ResNet-34 [34] trained on real and fake faces. Then we construct two sets of faces by blending frequency components.
The first set contains three types of faces transformed from frequency components corresponding to 1) the semantic information of the real face, 2) the semantic information of the fake face, and 3) the semantic information of the real face blended with the structural information of the real face. We denote this set as . Since there is no structural information from fake faces in this set, all the faces should be detected as real.
Similarly, the second set contains two types of faces: 1) blending the semantic information of the fake face with the structural information of the fake face, and 2) blending the semantic information of the real face with the structural information of the fake face. We denote this set as . Since all blended faces in this set contain the structural information of fake faces, they should be detected as fake. Thus the authenticity-determinative loss can be written as
| (2) |
where CE denotes the cross-entropy loss.
Corollary 3.
The face should exhibit no visible change if the frequency component of noise information is removed, i.e., , where indicates the removing operation.
Quality-agnostic Loss. As noise information does not contain decisive details for the overall depiction of the image, the face image is expected to be similar to the face image transformed using the frequency components of semantic and structural information. This similarity can be quantified using the quality-agnostic Loss , defined as
| (3) |
where the face can be either real or fake.
Corollary 4.
Each frequency component is bound by the preliminary results, i.e., there should be no significant deviation between the predicted frequency component and the approximate frequency distribution in preliminary analysis.
Prior and Integrity Loss. According to our analysis in the Preliminary Analysis section, we have an initial understanding of the approximate frequency distribution. Denote the initial frequency maps for semantic, structural, and noise information as , respectively. These maps are utilized to accelerate the convergence of the model towards the desired direction. Moreover, we add a constraint on the integrity of their distributions, ensuring that their combination covers all elements of the frequency map. This loss can be expressed as
| (4) | ||||
where denotes a mask where all the elements in it is .
Overall Objectives. The overall objectives are the summation of all these loss terms, as
| (5) |
where are the weights for different loss terms.
4.3 Deployment of FreqBlender
Given a fake face and a real face , we can generate a pseudo-fake face by
| (6) |
Note that in our method, it is not necessary to perform the blending using wild fake faces. Instead, we can tactfully substitute wild fake faces with the pseudo-fake faces generated by existing spatial face blending methods. It allows us to overcome the limitations in the frequency distribution of existing pseudo-fake faces.
5 Experiments
5.1 Experimental Setups
DataSets. Our method is evaluated using several standard datasets, including FaceForensics++ [5] (FF++), Celeb-DF (CDF) [6], DeepFake Detection Challenge (DFDC) [8], DeepFake Detection Challenge Preview (DFDCP) [7], and FFIW-10k (FFIW) [9] datasets. Specifically, the FF++ dataset consists of pristine videos and manipulated videos corresponding to four different manipulation methods, that are Deepfakes (DF), Face2Face (F2F), FaceSwap (FS), and NeuralTextures (NT). CDF dataset comprises pristine videos and high-quality fake videos created from DeepFake alterations of celebrity videos available on YouTube. DFDC is a large-scale deepfake dataset, that consists of video clips, and DFDCP is a preview version of DFDC, which is also widely used in evaluation. The FFIW dataset contains pristine videos and DeepFake videos with multi-face scenarios. We follow the original training and testing split provided by the datasets for experiments.
Implementation Details. Our method is implemented using PyTorch 2.0.1 [35] with a Nvidia 3090ti. In the training stage of FPNet, the image size is set to . The batch size is set to and the Adam optimizer is utilized with an initial learning rate of . The training epoch is set to . The hyperparameters in the objective function in Eq. (5) are set as follows: . For DeepFake detection, we employ the vanilla EfficientNet-b4 [36] as our model following [16]. In the training phase, we create pseudo-fake faces on-the-fly. We first generate synthetic faces using the spatial-blending method [16] and then blend them with real faces using our method with a probability of . Other training and testing settings are the same as [16]. More analysis of parameters are provided in Supplementary.
| Method | Input Type | Training Set | Test Set AUC (%) | ||||
|---|---|---|---|---|---|---|---|
| Real | Fake | CDF | DFDC | DFDCP | FFIW | ||
| Two-branch (ECCV’20) [37] | Video | ✓ | ✓ | 76.65 | - | - | - |
| DAM (CVPR’21) [9] | Video | ✓ | ✓ | 75.3 | - | 72.8 | - |
| LipForensics (CVPR’21) [1] | Video | ✓ | ✓ | 82.4 | 73.50 | - | - |
| FTCN (ICCV’21) [38] | Video | ✓ | ✓ | 86.9 | 71.00 | 74.0 | 74.47 |
| SST (CVPR’24) [23] | Video | ✓ | ✓ | 89.0 | - | - | - |
| DSP-FWA (CVPRW’19 [10]) | Frame | ✓ | ✓ | 69.30 | - | - | - |
| Face X-ray (CVPR’20) [14] | Frame | ✓ | - | - | - | 71.15 | - |
| Face X-ray (CVPR’20) [14] | Frame | ✓ | ✓ | - | - | 80.92 | - |
| F3-Net (ECCV’20) [28] | Frame | ✓ | ✓ | 72.93 | 61.16 | 81.96 | 61.58 |
| LRL (AAAI’21) [39] | Frame | ✓ | ✓ | 78.26 | - | 76.53 | - |
| FRDM (CVPR’21) [40] | Frame | ✓ | ✓ | 79.4 | - | 79.7 | - |
| PCL+I2G (ICCV’21) [15] | Frame | ✓ | - | 90.03 | 67.52 | 74.37 | - |
| DCL (AAAI’22) [41] | Frame | ✓ | ✓ | 82.30 | - | 76.71 | 71.14 |
| SBI∗ (CVPR’22) [16] | Frame | ✓ | - | 92.94 | 72.08 | 85.51 | 85.99 |
| SBI (CVPR’22) [16] | Frame | ✓ | - | 93.18 | 72.42 | 86.15 | 84.83 |
| TALL-Swin (ICCV’23) [21] | Frame | ✓ | ✓ | 90.79 | 76.78 | - | - |
| UCF (ICCV’23) [12] | Frame | ✓ | ✓ | 82.4 | 80.5 | - | - |
| BiG-Arts (PR’23) [24] | Frame | ✓ | ✓ | 77.04 | - | 80.48 | - |
| F-G (CVPR’24) [42] | Frame | ✓ | ✓ | 74.42 | 61.47 | - | - |
| LSDA (CVPR’24) [22] | Frame | ✓ | ✓ | 83.0 | 73.6 | 81.5 | - |
| FreqBlender (Ours) | Frame | ✓ | - | 94.59 | 74.59 | 87.56 | 86.14 |
5.2 Results
To showcase the effectiveness of our method, we train our method solely on the FF++ dataset and test it on the other different datasets. We employ the Area Under the Receiver Operating Characteristic Curve (AUC) as the evaluation metric following previous work [16]. Our method is compared with five video-based detection methods, including Two-branch [37], DAM [9], LipForensics [1], FTCN [38] and SST [23]. Moreover, we involve thirteen frame-level state-of-the-art methods for comparison, which are DSP-FWA [10], Face X-ray [14], F3-Net [28], LRL [39], FRDM [40], PCL [15], DCL [41], SBI [16], TALL-Swin [21], UCF [12], SST [23], F-G [42], LSDA [22],respectively.
Cross-dataset Evaluation. We evaluate the cross-dataset performance of our method compared to other counterparts in Table 1. The best performance is highlighted in blue and the second-best is marked by red. It should be noted that our method operates on pseudo-fake faces generated by SBI, thus we do not need fake faces. In comparison to video-level methods, our method achieves the best performance, which outperforms all the methods by a large margin.
When compared to frame-level methods, our method still outperforms the others. For example, our method improves upon the performance of the most relevant counterpart SBI by , , , on CDF, DFDC, DFDCP, and FFIW respectively. This improvement can be attributed to the incorporation of frequency knowledge in pseudo-fake faces, enhancing the generalization of detection models. Note that the performance of the compared methods (except SBI* and F3-Net) is extracted from their original papers. SBI* denotes the performance obtained using the officially released codes, and F3-Net is reproduced using the codes implemented by others 111F3-Net:https://github.com/Leminhbinh0209/F3Net. The results closely align with the reported scores, which verifies the correctness of our configuration of their codes. In subsequent experiments, we employ their release codes for comparison.
Cross-manipulation Evaluation. Since SBI is the most recent and effective method, we compare our method with it for demonstration. Specifically, we compare our method with two variants of the SBI method. The first is trained using the raw set of real videos in the FF++ dataset, while the second is trained using the c23 set. According to the standard protocols, all methods are tested on c23 videos. The results are shown in Table 2. It can be seen that our method outperforms SBI-raw by and SBI-c23 by , demonstrating the efficacy of our method on cross-manipulation scenarios.
5.3 Analysis
| Setting | CDF | DFDC | DFDCP | Avg |
|---|---|---|---|---|
| Baseline | 91.69 | 72.69 | 86.67 | 83.68 |
| w/o | 94.01 | 74.30 | 86.86 | 85.06 |
| w/o | 93.31 | 72.97 | 86.32 | 84.20 |
| w/o | 94.28 | 74.42 | 87.25 | 85.32 |
| w/o | 93.78 | 74.03 | 85.99 | 84.60 |
| All | 94.59 | 74.59 | 87.56 | 85.58 |
| Method | FF++ | CDF | DFDCP | FFIW | Avg |
|---|---|---|---|---|---|
| DSP-FWA [10] | 48.14 | 62.91 | 60.74 | 40.65 | 53.11 |
| DSP-FWA [10] + Ours | 49.46 | 65.47 | 56.18 | 41.81 | 53.23 |
| I2G [15] | 59.56 | 53.55 | 48.02 | 46.75 | 51.97 |
| I2G [15] + Ours | 63.84 | 48.89 | 49.53 | 48.96 | 52.81 |
| Face X-ray [14] | 82.26 | 67.99 | 65.00 | 63.65 | 69.73 |
| Face X-ray [14] + Ours | 84.03 | 76.05 | 63.90 | 67.24 | 72.81 |
Effect of Each Objective Term. This part studies the effect of each objective term on CDF, DFDC, and DFDCP datasets. The results are shown in Table 4. Note that Baseline denotes only using prior and integrity loss and “w/o” denotes without. It can be seen that without one certain objective term, the performance drops on all datasets, which demonstrates that different objective terms have distinct impacts, and their collective contributes most to our method.
Complementary to Spatial-blending Methods. To validate the complementary of our method, we replace the SBI method with other spatial-blending methods and study if the performance is improved. Specifically, we reproduce the pseudo-fake face generation operations in DSP-FWA, I2G, and Face X-ray, and combine them with our method. Note that I2G and Face X-ray have not released their codes, we re-implement them rigorously following their original settings. The results on FF++, CDF, DFDCP, FFIW datasets are presented in Table 4. It can be seen that by combining with DSP-FWA, our method improves averagely. A similar trend is also observed in the I2G, which improves on average. For Face X-ray, we improve the performance by on average. It is noteworthy that I2G and Face X-ray have not released their codes yet. We rigorously follow the instructions as in their papers and run the codes widely used by others222I2G: https://github.com/jtchen0528/PCL-I2G 333Face X-ray: https://github.com/AlgoHunt/Face-Xray.
Different Network Architectures. This part validates the effectiveness of our method on different networks, including ResNet-50 [34], EfficientNet-b1 [36], VGG16 [43], Xception [44], ViT [45], F3-Net [28], and GFFD[40]. We compare our method with SBI on these networks, which are tested on CDF, FF++, DFDCP, and FFIW datasets. The results are shown in Table 5. It can be observed that our method improves the performance by , , , , , and averagely on ResNet-50, EfficientNet-b1, Xception, Vit networks, F3-Net, and GFFD networks respectively. It is noteworthy that our method slightly reduces the performance of VGG16 by . It is possibly because the capacity of VGG16 is limited than other networks, and learning spatial pseudo-fake faces almost fills up this capacity, leaving no room for the learning of frequency knowledge.
| Method | CDF | FF++ | DFDCP | FFIW | Avg |
|---|---|---|---|---|---|
| ResNet-50 [34] + SBI | 84.82 | 95.39 | 73.51 | 81.67 | 83.85 |
| ResNet-50 [34] + Ours | 85.44 | 94.61 | 76.16 | 86.32 | 85.63 |
| EfficientNet-b1 [36] + SBI | 90.25 | 94.66 | 87.54 | 82.55 | 88.75 |
| EfficientNet-b1 [36] + Ours | 90.53 | 94.65 | 87.70 | 83.76 | 89.16 |
| VGG16 [43] + SBI | 78.22 | 93.05 | 74.13 | 87.26 | 83.16 |
| VGG16 [43] + Ours | 78.38 | 93.10 | 73.47 | 87.63 | 83.15 |
| Xception [44] + SBI | 87.00 | 91.40 | 75.68 | 70.24 | 81.08 |
| Xception [44] + Ours | 90.52 | 93.32 | 76.07 | 70.43 | 82.59 |
| ViT [45] + SBI | 85.85 | 96.09 | 87.71 | 86.05 | 88.92 |
| ViT [45] + Ours | 86.34 | 96.10 | 87.17 | 86.88 | 89.12 |
| F3-Net [28] + SBI | 84.94 | 93.42 | 79.29 | 73.42 | 82.77 |
| F3-Net [28] + Ours | 88.10 | 95.16 | 84.32 | 74.49 | 85.52 |
| GFFD [40] + SBI | 81.34 | 91.81 | 77.19 | 65.53 | 78.97 |
| GFFD [40] + Ours | 86.71 | 92.18 | 78.25 | 77.45 | 83.65 |

Saliency Visualization. We employ Grad-CAM [46] to visualize the attention of our method compared to SBI on four manipulations in the FF++ dataset. Compared to SBI, our method concentrates more on the structural information, such as the manipulation boundaries. For example, our method highlights the face outline in DF, F2F, and FS, while focusing on the mouth contour in NT.
Effect of Using Wild Fake or Spatial Pseudo-fake Faces. As described in Sec. 4.3, our method is performed using real and spatial-blending pseudo-fake (SP-fake) faces. The rationale is that SP-fake faces are greatly diversified, containing more spatial forgery traces. Applying our method to these faces can consider both frequency and spatial traces effectively. To verify this, we directly perform our method on real and wild fake faces. The results in Table 6 indicate a notable performance drop when only wild fakes are used.
| SP-fake | CDF | DFDC | DFDCP | FFIW | Avg |
|---|---|---|---|---|---|
| 75.79 | 66.30 | 66.30 | 67.70 | 72.95 | |
| ✓ | 94.59 | 74.59 | 74.59 | 86.14 | 85.72 |
Limitations. Our method is designed to address the drawbacks of existing spatial-blending methods. Hence, it inherits the assumption that the faces are forged by face-swapping techniques. Further research is needed to validate our performance on other types of forgery operations, such as whole-face synthesis and attribute editing.
6 Conclusion
This paper describes a new method called FreqBlender that can generate pseudo-fake faces by blending frequency knowledge. To achieve this, we propose a Frequency Parsing Network that adaptively extracts the frequency component corresponding to structural information. Then we can blend this information from fake faces into real faces to create pseudo-fake faces. The extensive Experiments demonstrate the effectiveness of our method and can serve as a complementary module for existing spatial-blending methods.
Acknowledgement. This work is supported in part by the National Natural Science Foundation of China (No.62402464), Shandong Natural Science Foundation (No.ZR2024QF035), and China Postdoctoral Science Foundation (No.2021TQ0314; No.2021M703036). Jiaran Zhou is supported by the National Natural Science Foundation of China (No.62102380) and Shandong Natural Science Foundation (No.ZR2021QF095, No.ZR2024MF083). Baoyuan Wu is supported by Guangdong Basic and Applied Basic Research Foundation (No.2024B1515020095), National Natural Science Foundation of China (No. 62076213), and Shenzhen Science and Technology Program (No. RCYX20210609103057050). Bin Li is supported in part by NSFC (Grant U23B2022, U22B2047).
References
- [1] Alexandros Haliassos, Konstantinos Vougioukas, Stavros Petridis, and Maja Pantic. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5039–5049, 2021.
- [2] Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. Forgerynet: A versatile benchmark for comprehensive forgery analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 4360–4369, 2021.
- [3] Kunlin Liu, Ivan Perov, Daiheng Gao, Nikolay Chervoniy, Wenbo Zhou, and Weiming Zhang. Deepfacelab: Integrated, flexible and extensible face-swapping framework. Pattern Recognition(PR), 141:109628, 2023.
- [4] Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (ToG), 36(4):1–13, 2017.
- [5] Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF international conference on computer vision (ICCV), pages 1–11, 2019.
- [6] Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 3207–3216, 2020.
- [7] Brian Dolhansky, Russ Howes, Ben Pflaum, Nicole Baram, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) preview dataset. arXiv preprint arXiv:1910.08854, 2019.
- [8] Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset. arXiv preprint arXiv:2006.07397, 2020.
- [9] Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. Face forensics in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 5778–5788, 2021.
- [10] Yuezun Li and Siwei Lyu. Exposing deepfake videos by detecting face warping artifacts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2019.
- [11] Jiaming Li, Hongtao Xie, Jiahong Li, Zhongyuan Wang, and Yongdong Zhang. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 6458–6467, 2021.
- [12] Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. Ucf: Uncovering common features for generalizable deepfake detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22412–22423, 2023.
- [13] Yuan Wang, Kun Yu, Chen Chen, Xiyuan Hu, and Silong Peng. Dynamic graph learning with content-guided spatial-frequency relation reasoning for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7278–7287, 2023.
- [14] Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 5001–5010, 2020.
- [15] Tianchen Zhao, Xiang Xu, Mingze Xu, Hui Ding, Yuanjun Xiong, and Wei Xia. Learning self-consistency for deepfake detection. In Proceedings of the IEEE/CVF international conference on computer vision (ICCV), pages 15023–15033, 2021.
- [16] Kaede Shiohara and Toshihiko Yamasaki. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18720–18729, 2022.
- [17] Yipin Zhou and Ser-Nam Lim. Joint audio-visual deepfake detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14800–14809, 2021.
- [18] Changtao Miao, Zichang Tan, Qi Chu, Nenghai Yu, and Guodong Guo. Hierarchical frequency-assisted interactive networks for face manipulation detection. IEEE Transactions on Information Forensics and Security (TIFS), 17:3008–3021, 2022.
- [19] Qiqi Gu, Shen Chen, Taiping Yao, Yang Chen, Shouhong Ding, and Ran Yi. Exploiting fine-grained face forgery clues via progressive enhancement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 735–743, 2022.
- [20] Junyi Cao, Chao Ma, Taiping Yao, Shen Chen, Shouhong Ding, and Xiaokang Yang. End-to-end reconstruction-classification learning for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4113–4122, 2022.
- [21] Yuting Xu, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. Tall: Thumbnail layout for deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22658–22668, 2023.
- [22] Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8984–8994, 2024.
- [23] Jongwook Choi, Taehoon Kim, Yonghyun Jeong, Seungryul Baek, and Jongwon Choi. Exploiting style latent flows for generalizing deepfake video detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1133–1143, 2024.
- [24] Han Chen, Yuezun Li, Dongdong Lin, Bin Li, and Junqiang Wu. Watching the big artifacts: Exposing deepfake videos via bi-granularity artifacts. Pattern Recognition (PR), 135:109179, 2023.
- [25] Shuai Jia, Chao Ma, Taiping Yao, Bangjie Yin, Shouhong Ding, and Xiaokang Yang. Exploring frequency adversarial attacks for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4103–4112, 2022.
- [26] Ricard Durall, Margret Keuper, and Janis Keuper. Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 7890–7899, 2020.
- [27] Davis King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research (JMLR), Dec 2009.
- [28] Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In European conference on computer vision (ECCV), pages 86–103. Springer, 2020.
- [29] Ricard Durall, Margret Keuper, Franz-Josef Pfreundt, and Janis Keuper. Unmasking deepfakes with simple features. arXiv preprint arXiv:1911.00686, 2019.
- [30] Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pages 1874–1883, 2016.
- [31] Andrew G Howard. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [32] Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Cotsia, and Stefanos P Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), page 1–1, Jan 2021.
- [33] Jiahao Liang, Huafeng Shi, and Weihong Deng. Exploring disentangled content information for face forgery detection. In European Conference on Computer Vision (ECCV), pages 128–145. Springer, 2022.
- [34] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016.
- [35] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- [36] Mingxing Tan and Quoc Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning (ICML), volume 97 of Proceedings of Machine Learning Research, pages 6105–6114. PMLR, 09–15 Jun 2019.
- [37] Iacopo Masi, Aditya Killekar, Royston Marian Mascarenhas, Shenoy Pratik Gurudatt, and Wael AbdAlmageed. Two-branch recurrent network for isolating deepfakes in videos. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pages 667–684. Springer, 2020.
- [38] Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. Exploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF international conference on computer vision (ICCV), pages 15044–15054, 2021.
- [39] Shen Chen, Taiping Yao, Yang Chen, Shouhong Ding, Jilin Li, and Rongrong Ji. Local relation learning for face forgery detection. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 1081–1088, 2021.
- [40] Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 16317–16326, 2021.
- [41] Ke Sun, Taiping Yao, Shen Chen, Shouhong Ding, Jilin Li, and Rongrong Ji. Dual contrastive learning for general face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 2316–2324, 2022.
- [42] Li Lin, Xinan He, Yan Ju, Xin Wang, Feng Ding, and Shu Hu. Preserving fairness generalization in deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16815–16825, 2024.
- [43] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [44] François Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pages 1251–1258, 2017.
- [45] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- [46] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. International Journal of Computer Vision (IJCV), page 336–359, Feb 2020.
- [47] Ziqi Huang, Kelvin C.K. Chan, Yuming Jiang, and Ziwei Liu. Collaborative diffusion for multi-modal face generation and editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- [48] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 4401–4410, 2019.
- [49] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 8110–8119, 2020.
- [50] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In International Conference on Machine Learning (ICML), 2015.
- [51] Jiakai Wang. Adversarial examples in physical world. In IJCAI, pages 4925–4926, 2021.
- [52] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations (ICLR), 2018.
- [53] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In IEEE symposium on security and privacy (SP), pages 39–57. IEEE, 2017.
Appendix A Appendix / supplemental material
Various Loss Weights . These weights are empirically selected based on experimental results. As shown in Table 7, we evaluate the performance across various set of . The results exhibit that our method is not particularly sensitive to the settings of loss weights, with performance variations within approximately . For our main experiments, we select the set of as it yields the best performance.
| CDF | FF++ | FFIW | DFDCP | Avg | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 93.16 | 96.30 | 87.82 | 85.32 | 90.65 |
| 0.1 | 1 | 0.1 | 0.5 | 93.59 | 95.60 | 84.78 | 86.60 | 90.14 |
| 0.1 | 1 | 0.01 | 0.5 | 94.27 | 96.11 | 85.54 | 87.81 | 90.93 |
| 0.01 | 1 | 0.0001 | 0.1 | 93.60 | 96.00 | 85.85 | 87.38 | 90.71 |
| 1/12 | 1 | 0.001 | 1/4 | 94.59 | 96.13 | 86.14 | 87.56 | 91.11 |
More Details of Complementary to Spatial-blending Methods. Table 8 shows the detailed results of every manipulation in the FF++ dataset. It can be seen that our method improves the performance of all manipulation methods, averaging for DSP-FWA, for I2G, and for Face X-ray. This improvement further demonstrates the effectiveness of our method.
| Method | FF++ | ||||
|---|---|---|---|---|---|
| DF | F2F | FS | NT | Avg | |
| DSP-FWA [10] | 55.48 | 43.79 | 49.26 | 44.05 | 48.14 |
| DSP-FWA [10] + Ours | 56.20 | 45.93 | 53.96 | 41.74 | 49.46 |
| I2G [15] | 47.83 | 82.13 | 60.82 | 47.47 | 59.56 |
| I2G [15] + Ours | 56.90 | 81.26 | 61.66 | 55.52 | 63.84 |
| Face X-ray [14] | 89.38 | 85.02 | 83.45 | 71.17 | 82.26 |
| Face X-ray [14] + Ours | 93.21 | 85.41 | 82.70 | 74.79 | 84.03 |
Probability in FreqBlender. As shown in Table 9, we evaluate the effect of using various probability . Note that denotes the probability of generating a synthetic face whether using spatial-blending or using FreqBlender after spatial-blending. denotes only using FreqBlender, while means only using spatial-blending. It can be observed that solely using our method can not perform well, as no color space knowledge is involved, hindering the overall effectiveness of pseudo-fake faces. In contrast, solely using spatial-blending operations can reach a favorable performance. However, when inserting pseudo-fake faces generated by FreqBlender, the generalization performance is further enhanced, as our method can compensate for the loss of frequency knowledge. The optimal effect on CDF evaluation is achieved when is set to 0.2. This experiment demonstrates the complementary effect of our method to existing spatial-blending methods. More generalization experiments on more datasets have been conducted in the main paper, demonstrating the effectiveness of our method.
| FF++ | CDF | |||||
|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | Avg | ||
| 1 | 63.18 | 59.85 | 65.79 | 54.61 | 60.86 | 56.34 |
| 0.8 | 98.58 | 94.80 | 97.69 | 89.83 | 95.23 | 90.27 |
| 0.5 | 99.03 | 96.99 | 97.81 | 91.68 | 96.38 | 91.83 |
| 0.3 | 99.12 | 97.15 | 97.93 | 90.91 | 96.28 | 93.76 |
| 0.2 | 99.18 | 96.76 | 97.68 | 90.88 | 96.13 | 94.59 |
| 0.1 | 99.11 | 97.11 | 97.93 | 90.91 | 96.26 | 93.76 |
| 0 | 99.17 | 97.63 | 97.77 | 91.35 | 96.50 | 93.58 |

Visual Demonstration of FreqBlender. The goal of our method is to create pseudo-fake faces that resemble the frequency distribution of wild fake faces. To verify this, we conduct a visual experiment on the FF++ dataset. Specifically, we randomly select images from each manipulation method (Deepfakes, FaceSwap, Face2Face, NeuralTextures) and calculate the average frequency map for each manipulation method respectively. Then we create the same number of pseudo-fake faces using our method and calculate their average frequency map. Finally, we visualize the frequency difference between our method and wild fake faces. The results are illustrated in Fig. 7. It is important to note that represents the probability of applying FreqBlender. Hence, means all pseudo-fake faces are created using our method, while denotes our method is degraded to SBI. From this figure, we can see that the difference is minimal when . As decreases, the difference becomes larger as the pseudo-fake faces are more likely created by SBI. This demonstrates that our method effectively simulates the frequency distribution of wild fake faces.
Performance on FF++ Low-quality (LQ). To investigate the performance of our method on low-quality videos, we conduct experiments on the FF++ Low-quality (LQ) set. The results in Table 11 show that while all methods experience substantial performance drops on the LQ set, our method consistently achieves the highest performance, demonstrating better generalization capability on low-quality videos compared to other methods.
Tentative Validation on Various Synthesized Faces. In addition to validation on the standard datasets, we investigate a new scenario: Diffusion-based face-swap deepfake detection. In this scenario, we employ a recent diffusion model (Collaborative Diffusion [47]) to synthesize faces, which are then blended into original videos. We create 200 fake faces and evaluate our method in Table 11. It can be seen that our method is effective in detecting such forged faces.
Moreover, although our method is designed for face-swapping techniques, we also test it on face images generated by StyleGAN [48] and StyleGAN2 [49]. The results, also shown in Table 11, reveal a notable performance drop across all methods. However, our method still outperforms the others.
Performance against Evasion Attacks. We employ a widely recognized library TorchAttacks with four well-known attack methods: FGSM [50], BIM [51], PGD [52] and CW [53]. The attack experiment is conducted on the CDF dataset with six models and the attack configuration is set by default. The results are shown in Table 12. It can be seen without any defense strategies, all models can be easily attacked in the white-box attacking mode, which exactly aligns with our expectations and the discoveries in the papers of FGSM, BIM, etc.