Fractal Landscapes in Policy Optimization
Abstract
Policy gradient lies at the core of reinforcement learning (RL) in continuous spaces. Although it has achieved much success, it is often observed in practice that RL training with policy gradient can fail for a variety of reasons, even for standard control problems that can be solved with other methods. We propose a framework for understanding one inherent limitation of the policy gradient approach: the optimization landscape in the policy space can be extremely non-smooth or fractal, so that there may not be gradients to estimate in the first place. We draw on chaos theory and non-smooth analysis, and analyze the Maximum Lyapunov Exponents and Hölder Exponents of the policy optimization objectives. Moreover, we develop a practical method that statistically estimates Hölder exponents, to identify when the training process has encountered fractal landscapes. Our experiments illustrate how some failure cases of policy optimization in continuous control environments can be explained by our theory.
1 Introduction
Deep reinforcement learning has achieved much success in various applications atari; alphago; video, but they also often fail, especially in continuous spaces, on control problems that other methods can readily solve. The understanding of such failure cases is still very limited. Among the failures, two main issues arise: first, the training process of reinforcement learning is unstable in the way that the loss curve can fluctuate violently during training; second, the probability of obtaining a satisfactory solution can be surprisingly low, or even close to zero in certain tasks such as acrobot. Currently, they are attributed to the function approximation error Tsitsiklis; wang, the data error and inefficiency thomas, and making large moves in policy space schulman17. Nevertheless, all of these explanations solely focus on the training process, and there remains a lack of systematic study regarding the underlying causes of these failures from the perspective of the MDP itself.
Given that even a small update in policy space can significantly change the performance metric, it is natural to question the smoothness of the landscape of the objective function. Motivated by chaos theory, we adopt the concept of maximum Lyapunov exponent kantz to describe the exponential rate of trajectory divergence in the MDP under a given policy. It is related to the smoothness of the objective function in the following way: suppose that the discount factor in the MDP is , and the maximum Lyapunov exponent at certain policy parameter is which is inherent to the MDP. Then, we show that the objective function can be non-differentiable at when . Intuitively speaking, the objective function is non-differentiable when the rate of trajectory divergence is faster than the decay rate of discount factor. Furthermore, it demonstrates that the fluctuation in the loss curve is not a result of any numerical error but rather a reflection of the intrinsic properties associated with the corresponding MDP.
In this paper, we first analyze deterministic policies in Section 4. It is not just because the deterministic policies can be regarded as the limit of stochastic policies when the variance . More importantly, the ground truth we try to highlight is that: non-smoothness in objective functions is not a result of randomness but rather an inherent feature of the MDP itself. As shown in Section 6, the loss curve is still fractal even when all things in the MDP are deterministic. After that, we will briefly discuss the case of stochastic policies, and show why it is even more likely to have non-smoothness through an example. Although the fact that having positive MLEs can explain the non-smoothness of objective functions, we do not really need to compute it in practice even though it is possible as in kantz. Instead, we propose a statistical method is proposed in Section 5 that can directly estimate the Hölder exponent as a whole to determine whether is differentiable at a specific . It can also indicate if the training has run into fractal areas and hence should stop.
2 Related work
Policy gradient methods.
While the optimal policy is usually approximated by minimizing (or maximizing) the objective function, the most common way of performing optimization is via policy gradient methods that were originated from sutton99; william. After being reformulated as an optimization problem in parameter space, more and more efficient algorithms such as natural policy gradient kakade, deterministic policy gradient silver, deep deterministic policy gradient lillicrap, trust region policy optimization schulman15 and proximal policy optimization schulman17, were proposed. As all of these algorithms seek to estimate the gradient of the objective function for descent direction, they become fundamentally ill-posed when the true objective is non-differentiable since there does not exist any gradient to estimate at all, which is exactly the point we try to make in this paper. Consequently, it is not surprising to have a low probability of obtaining a good solution using these methods.
Chaos in machine learning.
Chaotic behaviors due to in the learning dynamics have been reported in other learning problems camuto; pascanu. For instance, when training recurrent neural networks for a long period, the outcome will behave like a random walk due to the vanishing and the exploding gradient problems bengio. In parmas, the authors point out that the chaotic behavior in finite-horizon model-based reinforcement learning problems may be caused by long chains of non-linear computations. However, there is a significant difference compared to our theory: the true objective function is provably differentiable when time horizon is finite, and our theory focuses on more general infinite-horizon MDPs. Actually, all of these work fundamentally differ from our theory in the following sense: they attribute the chaos to the randomness during training such as noise and errors from computation or sampling, without recognizing the fact that it can be an intrinsic feature of the model.
Loss landscape of policy optimization.
There are many works in the study of the landscape of objective functions. In particular, it has been shown that the objective functions in finite state-space MDPs are smooth agarwal; xiao, which allows people to perform further optimization algorithm such as gradient descent and direct policy search without worrying about the well-posedness of those methods. It also explains why the classical RL algorithms in sutton98 are provably efficient in finite space settings. Also, such smoothness results can be extended to continuous state-space MDPs having "very nice properties". For instance, the objective function in Linear Quadratic Regulator (LQR) problems is almost smooth fazel as long as the cost is finite, along with a similar result obtained for the problem zhang. For the robust control problem, despite the objective function not being smooth, it is indeed locally Lipschitz continuous, which implies differentiability almost everywhere and further leads to global convergence of direct policy search guo. Due to the lack of analytical tools, however, there is still a vacancy in the theoretical study of loss landscapes of policy optimization for nonlinear and complex MDPs. Our paper partially addresses this gap by pointint out the possibility that the loss landscape can be highly non-smooth and even fractal, which is far more complex than all aforementioned types.
3 Preliminaries
3.1 Continuous state-space MDPs
Let us consider the deterministic continuous MDP given as dynamical system:
| (1) |
where is the state at time , is the initial state and is the action taken at time based on a stochastic policy parameterized by . The sample space is compact. Also, we define the value function of policy and the objective function to be minimized as
| (2) |
where is the discount factor and is the cost function. The following assumptions are made throughout this paper:
-
•
(A.1) is Lipschitz continuous over any compact domains (i.e., locally Lipschitz continuous);
-
•
(A.2) The cost function is non-negative and locally Lipschitz continuous everywhere;
-
•
(A.3) The state space is closed under transitons, i.e., for any , the next state .
3.2 Policy gradient methods
Generally, policy gradient methods provide an estimator of the gradient of true objective function with respect to policy parameters. One of the most commonly used forms is
| (3) |
where is a stochastic policy parameterized by and is the Q-value function of , and is the advantage function, often used for variance reduction. The theoretical guarantee of the convergence of policy gradient methods is essentially established upon the argument that the tail term as in satisfies sutton99
| (4) |
for any . Usually, two additional assumptions are made for (4):
-
•
exists and continuous for all ;
-
•
is uniformly bounded over .
Apparently, the second assumption is automatically satisfied if the first assumption holds in the case that is either finite or compact. However, as we will see in Section 4 and 6, the existence of may fail in many continuous MDPs even if is compact, which poses challenges to the fundamental well-posedness of all policy gradient methods.
3.3 Maximal Lyapunov exponents
Notice that the most important property of chaotic systems is their “sensitive dependence on initial conditions.” To make it precise, consider the following dynamical system
| (5) |
and suppose that a small perturbation is made to the initial state , and the divergence resulted at time , say , can be estimated by where is called the Lyapunov exponent. For chaotic systems, positive Lyapunov exponents are usually observed, which implies an exponential divergence rate of the separation of nearby trajectories lorenz. Since the Lyapunov exponent at a given point may depend on the direction of the perturbation , and we are often interested in identifying the largest divergence rate, the concept of the maximal Lyapunov exponent (MLE) in this paper is defined as follows:
Definition 3.1.
(Maximal Lyapunov exponent) For the dynamical system (5), the maximal Lyapunov exponent at is defined as the largest value such that
| (6) |
Just as shown in (6), not only chaotic systems but also systems with unstable equilibrium can have a positive MLE at corresponding states. Therefore, the framework built in this paper is not limited to chaotic MDPs, but is applicable to a broad class of continuous state-space MDPs having any one of these characteristics.
4 Non-smooth objective functions
Now we begin to consider the landscape of objective functions. In this section, we will show that the true objective function given in (2) can be non-differentiable at some where the system (1) has a positive MLE. Before showing how this argument is made, we first introduce the notion of -Hölder continuity to extend the concept of Lipschitz continuity:
Definition 4.1.
(-Hölder continuity) Suppose that some scalar . A function is -Hölder continuous at if there exist and such that
for any , where denotes the open ball of radius centered at .
In the remaining part of section, we will mainly investigate the Hölder continuity of and respectively in the case of deterministic policy. After that, a discussion about why it is even more likely to have non-smoothness in the stochastic case is provided.
4.1 Hölder Exponent of at
For simplicity, we denote the deterministic policy by throughout this section as it directly gives the action instead of a probability distribution. Consider a given parameter such that the MLE of (1), say , is greater than . Let be another initial state that is close to , i.e., is small enough. According to the assumption (A.3), we can find a constant such that both and for all . Additionally, it is natural to make the following assumptions:
-
•
(A.4) There exists such that for all and .
-
•
(A.5) The policy is locally Lipschitz continuous;
First, we present the following theorem to provide a lower bound for the Hölder exponent of and the detailed proof can be found in the Appendix:
Theorem 4.1.
(Non-smoothness of ) Assume (A.1)-(A.5) and the parameterized policy is deterministic. Let denote the MLE of (1) at . Suppose that , then is -Hölder continuous at .
Although the counterexample given in Example 4.1 shows that it is theoretically impossible to prove -Hölder continuity for for any , we believe that providing an illustrative demonstration can help to gain a better understanding how large MLEs lead to non-smootheness.
To show that the strongest continuity result one can prove is -Hölder continuous where , suppose that is some constant for which we would like to prove that -Hölder continuous at , and let us see why the largest value for is :
According to Definition 4.1, it suffices to find some such that when . A usual way is to work on a relaxed form
| (7) |
While handling the entire series is tricky, we instead split this analysis into three parts as shown in Figure 1: the sum of first terms, the sum from to , and the sum from to infinity. First, applying (A.4) to the sum of the first terms yields
| (8) |
where is a Lipschitz constant obtained by (A.2) and (A.5). Therefore, if we wish to bound the right-hand side of (8) by some term of order when , the length should have
| (9) |
where is some constant independent of and .

Next, for the sum of the tail terms in starting from , it is naturally bounded by
| (10) |
where is the maximum of continuous function over the compact domain (and hence exists). Therefore, letting the right-hand side of (10) be of order yields
| (11) |
for some independent constant . Since the sum of (8) and (10) provides a good estimate of only if the slope of , say should be no less than that of , or there would be infinitely many terms in the middle part as and hence cannot be controlled by any terms. In this case, the slopes satisfy the inequality by solving which we finally obtain the desired .
Specifically, the following counterexample shows that Theorem 4.1 has already provided the strongest guaranteed continuity result for at :
Example 4.1.
Suppose that the one-dimensional MDP where
is defined over the state space and the cost function . Also, the policy is linear. It is easy to verify that all assumptions (A.1)-(A.5) are satisfied. Now let and , then applying (6) directly yields
On the other hand, let be sufficiently small, then
where and is the flooring function. Therefore, we have
Thus, is the largest Hölder exponent of that can be proved in the worst case.
4.2 Hölder Exponent of at
The following lemma establishes a direct connection between and through :
Lemma 4.1.
Suppose that , then
where is the trajectory generated by the policy .
The proof can be found in the Appendix. Notice that indeed we have and , substituting with these two terms in the previous lemma and applying some additional calculations yield the main theorem as follows:
Theorem 4.2.
(Non-smoothness of ) Assume (A.1)-(A.5) and the parameterized policy is deterministic. Let denote the MLE of (1) at . Suppose that , then is -Hölder continuous at .
The detailed proof of Theorem 4.2 is put in the Appendix. Actually, the most important implication of this theorem is that is not guaranteed (and is very unlikely) to be Lipschitz continuous when , similar counterexample can be constructed as in Example 4.1. Finally, let us see how the loss landscape of the objective function becomes non-smooth when is large through the following example:
Example 4.2.
(Logistic model) Consider the following MDP:
| (12) |
where the policy is given by deterministic linear function . The objective function is defined as where is user-defined. It is well-known that (12) begins to exhibit chaotic behavior with positive MLEs (as shown in Figure 2(a)) when jordan, so we plot the graphs of for different discount factors over the interval . From Figure 2(b) to 2(d), the non-smoothness becomes more and more significant as grows. In particular, Figure 2(e) shows that the value of fluctuates violently even within a very small interval of , suggesting a high degree of non-differentiability in this region.





4.3 Non-smoothness in the case of stochastic policies
The original MDP (1) becomes stochastic when a stochastic policy is employed. In fact, it makes the objective less likely to be smooth and we will demonstrate this point now. First, let us instead consider the slightly modified version of MLE:
| (13) |
where is a small pertubation made to the initial state and is the difference in the sample path at time and . Since this definition is consistent with that in (6) when taking the variance to , we use the same notation to denote the MLE at given and again assume .
Recall that in the deterministic case, the Hölder continuity result was proved under the assumption that the policy is locally Lipschitz continuous. When it comes to the stochastic case, however, we cannot make any similar assumption for . The reason is that while the deterministic policy directly gives the action, the stochastic policy is instead a probability density function from which the action is sampled, and hence cannot be locally Lipschitz continuous in . For instance, consider the one-dimensional Gaussian distribution where denotes the parameters. Apparently, becomes more and more concentrated at as approaches , and eventually converges to the Dirac delta function , which means that cannot be Lipschitz continuous within a neighborhood of any even though its deterministic limit is indeed Lipschitz continuous.
Therefore, there is a trade-off: if we want the probability density function to cover its deterministic limit, then it cannot be locally Lipschitz continuous. Conversely, it is not allowed to cover the deterministic limit if it is assumed to be locally Lipschitz continuous. Since the former case is widely accepted in practice, we present the following example to show that in this case the Hölder exponent of the objective function can be arbitrarily smaller than :
Example 4.3.
Suppose that the one-dimensional MDP where
is defined over the state space and action space . The cost function is . Also, the parameter space is and the policy is a uniform distribution where is constant. It is easy to verify that all required assumptions are satisfied. Let the initial state and , then applying (13) directly yields similarly to Example 4.1. Now suppose that is small and , then for any , the sampled trajectory generated by has
when . Thus, we have for all and , which further leads to
using the fact that . Plugging into the above inequality yields
| (14) |
Since is arbitrary, the Hölder exponent can be arbitrarily close to .
In particular, (14) prohibits us from achieving the -Hölder continuity result for when , which further implies that the loss landscape of can become even more fractal and non-smooth in the case of stochastic policies. As a consequence, it is not surprising that policy gradient methods perform poorly in such problems. Some discussion from the perspective of fractal theory can be found in the Appendix and also in barnsley; falconer; hardy; hirsch; mcdonald; preiss.
5 Estimating Hölder Exponents from Samples
In the previous sections, we have seen that the true objective function can be highly non-smooth. Thus, any gradient-based method are no longer guaranteed to work well in the policy parameter space. The question is: how can we determine whether the objective function is differentiable at some or not in high-dimensional settings? To answer this question, we propose a statistical method to estimate the Hölder exponent: Consider the objective function and the Gaussian distribution where is the identity matrix. The diagonal form of the covariance matrix is assumed for simplicity. In the general case, let be -Hölder continuous over , then its variance matrix can be expressed as
where is obtained from applying the intermediate value theorem to and hence not a constant. If the -Hölder continuity is tight, say when , then it has the following approximation
| (15) |
when . Therefore, (15) provides a way to directly estimate the Hölder exponent of around any given , especially when the dimension is large. In particular, taking the logarithm on both sides of (15) yields
| (16) |
for some constant where the subscript in indicates its dependence on the standard deviation of . Thus, the log-log plot of versus is expected to be close to a straight line with slope where is the Hölder exponent of around . Therefore, one can estimate the Hölder exponent by sampling around with different variance and estimating the slope using linear regression. Usually, is Lipschitz continuous at when the slope is close to or greater than . Some examples will be presented in Section 6.
6 Experiments
In this section, we will validate the theory established in this paper through some of the most common tasks in RL. All environments are adopted from The OpenAI Gym Documentation brockman with continuous control input. The experiments are conducted in two steps: first, we randomly sample a parameter from a Gaussian distribution and estimate the gradient from (3); second, we evaluate at for each small . Based on the previous theoretical results, the loss curve is expected to become smoother as decreases, since smaller makes the Hölder exponent larger. In the meantime, the policy gradient method (3) should give a better descent direction while the true objective function becoming smoother. Notice that a single sample path can always be non-smooth when the policy is stochastic and therefore interfere the desired observation, we use stochastic policies to estimate the gradient in (3), and apply their deterministic version (by setting variance equal to 0) when evaluating . Regarding the infinite series, we use the sum of first 1000 terms to approximate . The stochastic policy is given by where the mean is represented by the 2-layer neural network where and are weight matrices. Let denote the vectorized policy parameter. For the width of the hidden layer, we use for the inverted pendulum and acrobot task, and for the hopper task.





Inverted pendulum.
The inverted pendulum task is a standard test case for RL algorithms, and here we use it as an example of non-chaotic system. The initial state is always taken as ( is the upright position), and quadratic cost function , where is a diagonal matrix, and . The initial parameter is given by . In Figure 4(a) and 4(c), we see that the loss curve is close to a straight line within a very small interval, which indicates the local smoothness of . It is validated by the estimate of the Hölder exponent of at which is based on (15) by sampling many parameters around with different variances. In Figure 3(e), the slope is very closed to so Lipschitz continuity (and hence differentiability) is verified at . As a comparison, the loss curve of single sample path is totally non-smooth as shown in Figure 3(b) and 3(e).




Acrobot.
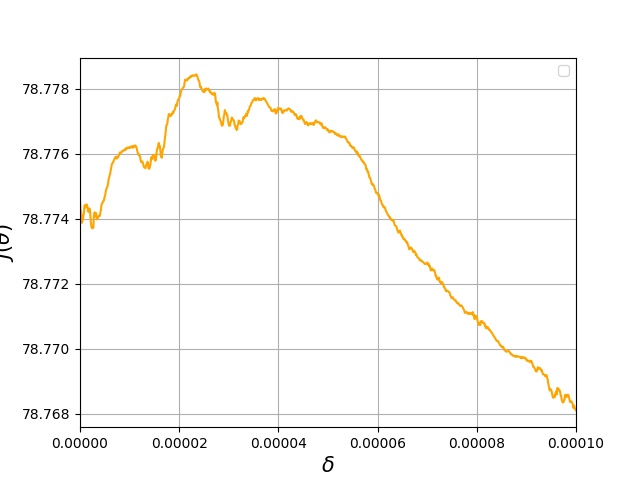
The acrobot system is well-known for its chaotic behavior and hence we use it as the main test case. Here we use the cost function , where , and . The initial state is . The initial parameter is again sampled from . From Figure 4(a)-4(c), the non-smoothness grows as increases and finally becomes completely non-differentiable when which is the most common value used for discount factor. It may partially explain why the acrobot task is difficult and almost unsolvable by policy gradient methods. In Figure 4(e), the Hölder exponent of at is estimated as , which further indicates non-differentiability around .




Hopper.
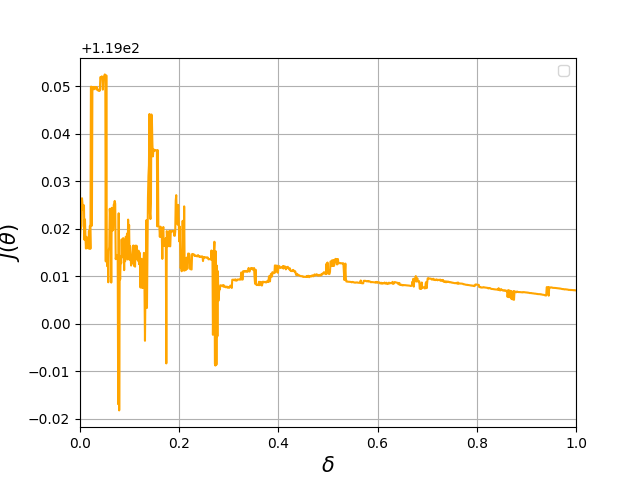
Now we consider the Hopper task in which the cost function is defined , where is the first coordinate in which indicates the height of hopper. Because the number of parameters involved in the neural network is larger, the initial parameter is instead sampled from . As we see that in Figure 5(a), the loss curve is almost a straight line when , and it begins to show non-smoothness when and becomes totally non-differentiable when . A supporting evidence by the Hölder exponent estimation as in Figure 5(e) where the slope is far less than .
7 Conclusion
In this paper, we initiate the study of chaotic behavior in reinforcement learning, especially focusing on how it is reflected on the non-smoothness of objective functions. A method to statistically estimate the Hölder exponent at some given parameter is proposed, so that one can figure out if the training has run into chaos and hence determine whether to stop or not. We believe that the theory established in this paper can help to explain many existing results in reinforcement learning, such as the unsolvability of acrobot task and the fluctuating behavior of training curve. It also poses a serious question to the well-posedness of policy gradient methods given the fact that no gradient exists in many continuous state-space RL problems. Finally, We conjecture that, the chaotic behavior may be able to explain the limits of a much wider range of deep learning problems beyond the scope of reinforcement learning.
Checklist
The checklist follows the references. Please read the checklist guidelines carefully for information on how to answer these questions. For each question, change the default [TODO] to [Yes] , [No] , or [N/A] . You are strongly encouraged to include a justification to your answer, either by referencing the appropriate section of your paper or providing a brief inline description. For example:
-
•
Did you include the license to the code and datasets? [Yes] See Section LABEL:gen_inst.
-
•
Did you include the license to the code and datasets? [No] The code and the data are proprietary.
-
•
Did you include the license to the code and datasets? [N/A]
Please do not modify the questions and only use the provided macros for your answers. Note that the Checklist section does not count towards the page limit. In your paper, please delete this instructions block and only keep the Checklist section heading above along with the questions/answers below.
-
1.
For all authors…
-
(a)
Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes]
-
(b)
Did you describe the limitations of your work? [Yes]
-
(c)
Did you discuss any potential negative societal impacts of your work? [N/A]
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes]
-
(a)
-
2.
If you are including theoretical results…
-
(a)
Did you state the full set of assumptions of all theoretical results? [Yes]
-
(b)
Did you include complete proofs of all theoretical results? [Yes]
-
(a)
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes]
-
(b)
Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes]
-
(c)
Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [N/A]
-
(d)
Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [N/A]
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
-
(a)
If your work uses existing assets, did you cite the creators? [N/A]
-
(b)
Did you mention the license of the assets? [N/A]
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [N/A]
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
(a)
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)
Appendix A Brief introduction to chaos theory
As mentioned in the Introduction, chaos exists in many systems in the real world. Although no universal definition of chaos can be made, there are, indeed, three features that a chaotic system usually exhibits [hirsch]:
-
•
Dense periodic points;
-
•
Topologically transitive;
-
•
Sensitive dependence on initial conditions;
In some cases, some of these properties imply the others. It is important to note that, despite the appearance of chaos is always accompanied by high unpredictability, it should be emphasized that chaotic behavior is entirely deterministic and is not a consequence of randomness. Another interesting fact is that trajectories in a chaotic system are usually bounded, which force us to think about the convergence of policy gradient methods beyond the boundedness property.


Actually, it can be summarized from the results in this paper that for a given MDP, it has to possess the following three features to exhibit chaotic behavior:
-
•
Infinite time horizon (allows );
-
•
Continuous state space (allows );
-
•
Exponential divergence (allows );
Since these features are not necessarily binded to certain types of continuous state-space MDPs, it would be exciting for future studies to investigate other types of MDPs using the framework developed in the paper.
Appendix B Proofs omitted in Section 4
B.1 Proof of Theorem 4.1
Proof.
Suppose that is another initial state close to . Let be the smallest integer that satisfies
| (17) |
then applying the Lipschitz condition of yields
where is the Lipschitz constant of over compact set .
On the other hand, the tail terms in is bounded by
using that where is the maximum of the continuous function over .
Combining the above two inequalities yields
and we complete the proof. ∎
B.2 Proof of Lemma 4.1
Proof.
For the ease of notation, let and .
Using the fact that as from the boundedness assumption yields
and the proof is completed using . ∎
B.3 Proof of Theorem 4.2
Proof.
First, we will show that is -Hölder Lipschitz with respect to . Note that for any ,
for some using the locally Lipschitz continuity of and .
Note that , combining it with Lemma 4.1 yields
using the fact that is Lipschitz continuous in a neighborhood of for some constant and we complete the proof. ∎
Appendix C From the perspective of fractal theory
We will go through some basic concepts in fractal theory that are related to the study of non-smooth functions.
C.1 The Hausdorff dimension
The Hausdorff dimension is the most fundamental concept in fractal theory. First, let us define the concept of -cover and Hausdorff measure
Definition C.1.
(-cover) Let be a countable collection of sets of diameter at most (i.e. ) and , then is a -cover of if .
Definition C.2.
(Hausdorff measure) For any and , let
Then we call the limit the -dimensional Hausdorff measure of .
Definition C.3.
(Hausdorff dimension) Let be a subset, then its Hausdorff dimension
Indeed, the Hausdorff dimension is well-defined: First, it is clear that when , is non-increasing with respect to . Thus, is non-increasing as well.
Let such that , then for any and any -cover of , we have
which implies by taking infimum on both sides and letting .
Therefore, the set contains at most one point, which further implies .
More details regarding the well-posedness of Hausdorff dimension can be found in [barnsley, falconer]. In particular, one can easily verify that the Hausdorff dimension coincides with the standard dimension (i.e. ) when is a regular manifold. Typically, the Hausdorff dimension of a fractal is not an integer, and we will be exploiting this fact through the section. To see how it is associated with the non-smoothness of functions, the following claim makes a rigorous statement on the dimension of fractal loss surfaces:
Proposition C.1.
([falconer]) Let be a subset and suppose that is -Hölder continuous, then .
An immediate implication is that if the objective function is -Hölder for some , its loss landscape can be a fractal with Hausdorff dimension . A famous example is the Weierstrass function as shown in Figure 7. A comparison of Figure 2(e) and Figure 7(c) (they have the same scale) gives some sense about how non-smooth the objective function can be.



C.2 Non-existence of tangent plane
Actually, when is Lipschitz continuous on any compact subset of , by the Rademacher’s Theorem, we know that it is differentiable almost everywhere which implies the existence of tangent plane. As it comes to fractal landscapes, however, the tangent plane itself does not exist for almost every , which makes all policy gradient algorithms ill-posed. Although similar results were obtained for higher-dimensional cases as in [preiss], we restrict it to the two-dimensional case so that it provides clearer geometric intuition. First, we introduce the notion of -sets:
Definition C.4.
Let be a Borel set and , then is called an -set if .
The intuition is that: when the dimension of fractal is a fraction between 1 and 2, then there is no direction along which a significant part of concentrates within a small double sector with vertex as shown in Figure 7(a). To be precise, let denote the double sector and , then we say that has a tangent at if there exists a direction such that for every angle , it has
-
1.
;
-
2.
;
where the first condition means that the set behaves like a fractal around , and the second condition implies that the part of lies outside of any double sector is negligible when . Then, the main result is as follows:
Proposition C.2.
(Non-existence of tangent planes, [falconer]) If is an -set with , then at almost all points of , no tangent exists.
Therefore, "estimate the gradient" no longer makes sense since there does not exist a tangent line/plane at almost every point on the loss surface. This means that all policy gradient algorithms are ill-posed since there is no gradient for them to estimate at all.
C.3 Accumulated uncertainty
Another issue that may emerge during optimization process is the accumulation of uncertainty. To see how the uncertainty entered at each step accumulates and eventually blows up when generating a path along fractal boundaries, let us consider the following toy problem: Suppose that the distance between the initial point and the target is , and step size is adapted at the -th step, as shown in Figure 8(a). If there exists such that the projection for all which implies that the angle between the direction from to and the true direction does not exceed . In this case, a successful path that converges to should give
using as , which is equivalent to .


On the other hand, when walking on the loss surface, it is not guaranteed to follow the correct direction at each iteration. For any small step size , the uncertainty fraction involved in every single step can be estimated by the following result [mcdonald]:
Proposition C.3.
Let be the step size and where is the Hausdorff dimension of loss surface of , then the uncertainty when .
Therefore, we may assume that there exists another such that the uncertainty at the -th step has for all . Then, the accumulated uncertainty
is bounded when (i.e. boundary is smooth) using the earlier result . However, the convergence of no longer guarantees the convergence of when , and a counterexample is the following series:
for all , which means that the uncertainty accumulated over the course of iterations may blow up and eventually lead the sequence toward randomness.