2022
[1]\fnmAshok \surVeeraraghavan
[1]\orgdivDept. of ECE, \orgnameRice University, \orgaddress\cityHouston, \postcode77005, \stateTX, \countryUSA
2]\orgdivDept. of ECE, \orgnameUniversity of Washington, \orgaddress\citySeattle, \postcode98195, \stateWA, \countryUSA
3]\orgdivDept. of Physics, \orgnameUniversity of Washington, \orgaddress\citySeattle, \postcode98195, \stateWA, \countryUSA
4]\orgdivInstitute for Nano-Engineered Systems, \orgnameUniversity of Washington, \orgaddress\citySeattle, \postcode98195, \stateWA, \countryUSA
Foveated Thermal Computational Imaging
in the Wild Using All-Silicon Meta-Optics
Abstract
Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution, and is critical in long wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the “foveal" element is a metalens that focuses s-polarized light at a distance of without affecting the p-polarized light; the second element which we call the “perifoveal" element is another metalens that focuses p-polarized light at a distance of without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image and video capture in the wild.
keywords:
computational imaging, thermal, LWIR, meta-optics, foveation, silicon, polarization1 Introduction
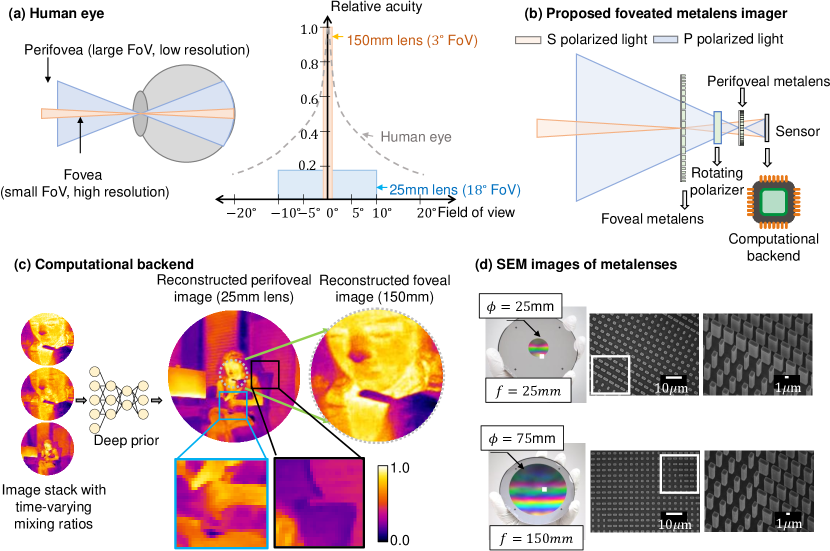
Nature has optimized the mammalian eye to have a large field of view (FoV) for situational awareness and high resolution in the central area for target detection with high precision. In the human eye, the fovea (small central region covering a FoV) carries half as much information as the perifovea (large outer region covering more than FoV), thereby dedicating precious bandwidth to the central region (see Fig. 1 (a)). Such foveation has long been desired in artificial vision systems as well, since high resolution in the central area is desirable for target detection, while large FoV is essential for contextual awareness. This is particularly true at long wave infrared (LWIR) wavelengths where detectors tend to be low-resolution making the simultaneous capture of high resolution target and large FoV context especially challenging.
Existing solutions for foveated imaging such as foveated sensors [1, 2] and foveating dynamic optics [3] do not work for thermal imaging because of the unique challenges at those wavelengths. Foveated sensor designs [2] are only practical when sensor pixel sizes are small. Unfortunately, thermal sensors have large pixel sizes due to their noise characteristics, making foveated sensor designs impractical. Foveated dynamic optics such as [3] have never been demonstrated in the thermal regime, primarily because of the challenges in dynamic control of optical properties in materials such as germanium and zinc selenide (materials used typically used to fabricate LWIR lenses). In this paper, we leverage recent advances in two rapidly emerging fields – meta-optics and computational imaging – to demonstrate first-of-its-kind, real-time, thermal, foveated image and video capture in the wild.
Meta-optics with sub-wavelength feature sizes for arbitrary phase control [4, 5] have rapidly grown as alternatives to traditional optics [6, 7, 8, 9, 10, 11, 12], over a wide range of wavelengths and novel applications, including reflectors [13, 14, 15], vortex beam generators [16, 17, 18, 19], holographic masks [20, 21, 22], gratings [23, 24], optical convolutional neural networks [25], and polarization optics [26, 27]. Meta-optics have two distinct advantages over traditional optics: (a) multiplexing (combining multiple phase functions in a single surface) and (b) polarization control (meta-optics can be manufactured with different phase functions for orthogonal states of polarization), and these properties have been used previously for polarimetry [28], depth sensing [29], and tunable focus [30, 31].
Here, we leverage the polarization sensitivity of meta-optics to design a three-element optic that achieves large-aperture foveated imaging at the LWIR wavelengths. The first element which we call the “foveal" element is a metalens that encodes a phase function for a convex lens of focal length for s-polarization, whereas the p-polarized light is transmitted without any change (or a lens with focal length ). The second element which we call the “perifoveal" elment is another metalens encodes a phase function for a convex lens of focal length for P-polarization, whereas the S-polarization that was modulated by the previous surface is left unaltered. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. This results in a linear expansion of the FoV by by the foveal lens, which we call the foveal expansion. The schematic of the proposed optical system is shown in Fig. 1(b). S and P polarized light independently focused by these two elements multiplexes on the image sensor, resulting in a video sequence that is not human-interpretable, but can be leveraged to reconstruct the two images with computational approaches.
Over the last decade, computational imaging has emerged as a powerful tool, where signal processing [32, 33, 34, 35, 36, 37, 38, 39, 40, 41] and machine learning [42, 43, 44, 45, 46] algorithms co-designed with such multiplexed imaging systems can undo the effects of multiplexing and reconstruct images and videos. The freely rotating linear polarizer better-conditions the inverse problem by dynamically changes the fraction of S-polarized and P-polarized image that is multiplexed on the image sensor, meaning each frame in the captured video has a different weighted combination of the two images (one with foveal element and another with perifoveal element). The two images are then recovered by a computational backend that takes the sequence of images as input, and simultaneously estimates the time-varying mixing ratios, as well as the low-resolution, large FoV and high-resolution, narrow FoV images. Most conventional deep learning based reconstruction algorithms require large amounts of in-domain training data to be successful, something that is challenging when using LWIR meta-optics due to poor signal to noise ratio (SNR) of LWIR sensors, as well as a paucity of training data. Our reconstruction algorithm consists of a deep generative prior [47] that has the distinct advantage of not requiring any training data, while producing high quality results. The pipeline for our computational backened as well as a simulated example is shown in Fig. 1 (c).
We validated our approach by designing and fabricating the metalenses (optimized for m wavelength) in an all-silicon platform using direct laser writing![7]. The foveal element was designed with a diameter of 75mm for a focal length of 150mm. The perifoveal element was designed with a diameter of 25mm for a focal length of 25mm. This resulted in a foveal expansion of . Images of the metalenses, as well as their scanning electron microscopic (SEM) images are shown in Fig. 1 (d). Our three-element optic demonstrates first-of-its-kind videos in the wild at real time ( frames per second) enabling high resolution thermal videos of buildings, moving cars, and dynamic humans.
2 Results
System overview. Figure 1 shows an overview of the proposed foveated computational metaoptical system optimized for imaging at wavelength. The phase functions of the two metalenses are
| (3) | |||
| (6) |
where is the design wavelength. The foveal lens has a focal length of mm and a diameter of 75mm, while the perifoveal lens has a focal length of mm and a diameter of 25mm. The lenses are placed at a distance of and , respectively, from the sensor. The linear polarizer rotating freely at 2Hz and is placed between the lens assembly and the sensor to capture measurements with varying intensity of the image from each metalenses. Additionally, we placed a 10m spectral filter between the perifoveal metalens and the sensor for some of the experiments to reduce chromatic blur. The sensor captures images 12 frames per second.
Let be the images formed by the foveal and perifoveal metalenses respectively. Assuming the two images are static between and , the resultant image on the sensor is
| (7) |
where is the mixing ratio depending on the position at time of the linear polarizer at . We then estimate the images and , and the mixing ratio by solving the regularized linear inverse problem
| (8) |
where is a regularization term that ensures spatial smoothness of individual images and encourages the two recovered images to be dissimilar. Further details about the optimization procedure are provided in Section 4.
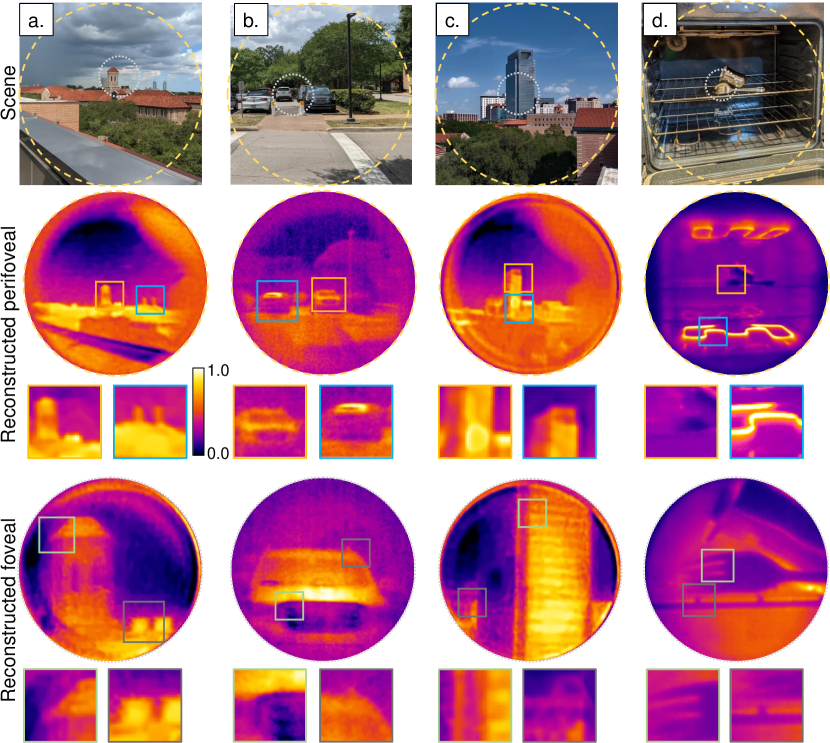
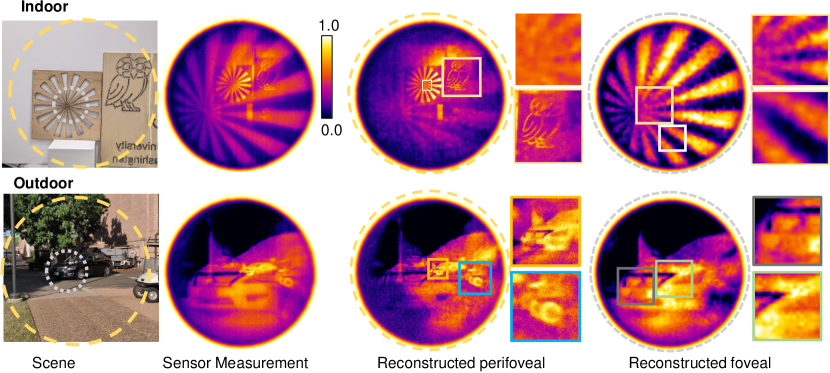
Image reconstruction of still life in the wild. Our optical setup produces high resolution foveated images in diverse indoor and outdoor settings. The powerful computational backend is capable of reconstructing images from raw measurements in diverse settings. Figure 2 shows reconstruction of several outdoor (a, b, c) and indoors (d) scenes with a wide range of temperature variations. In each case, 8 seconds of video data was captured with the polarizer rotating freely. We removed the spectral filter for Fig. 2 (a, c) to increase measurement SNR. We note that, while our metalens is designed only for 10-micron, we can still capture images under broadband light as demonstrated recently [7]. The images are shown in the “iron” color map as is customary in thermal image visualization. The advantages of dual focal length are evident – the perifoveal image provides a context of the surroundings, while the foveal image provides high quality details of the central region. In particular, note the clear grating-like structure in Fig. 2 (c) due to window frames, as well as the parallel prongs of the fork in Fig. 2 (d).
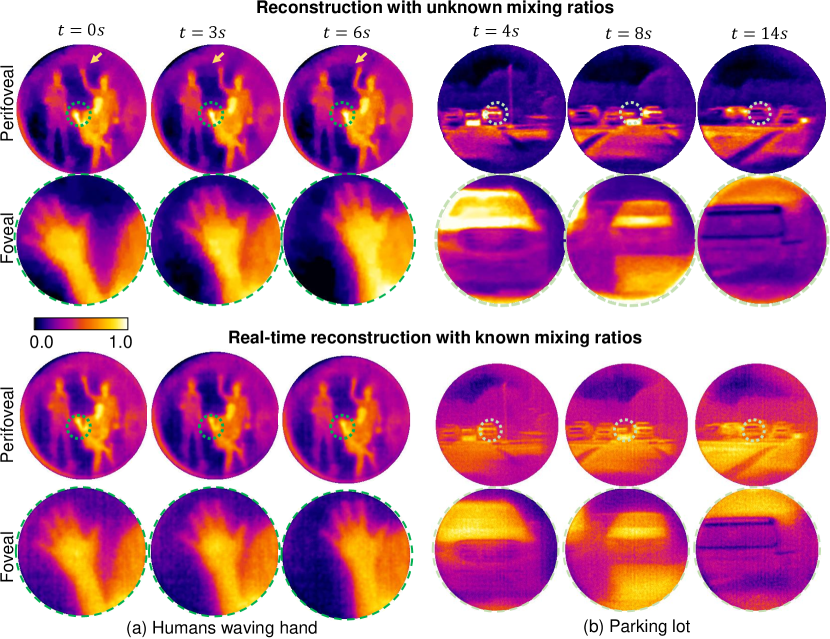
Video reconstruction of dynamic scenes at 12 fps. Our optical setup is capable of capturing dynamic scenes at high spatial and temporal resolutions, a result previously unreported in the metalens literature. To demonstrate this, we imaged three people exhibiting different forms of motion, as shown in Fig. 3 (a). The person on the left was rocking left to right, the person in the middle was sitting on a chair and waving his hand with small range of motion, and the person on the right was waving his hand with a large range. We reconstructed a video sequence in a sliding window manner, where a continuous sequence of 8 measured images was used to recover a pair of perifoveal and foveal video frames. Note the perifoveal image clearly showing waving of the right person’s hand, but nearly no motion of the person sitting in the center. The foveal however clearly shows the waving motion, along with all fingers separately. Fig. 3 (b) shows a parking lot with several cars. The perifoveal images capture the complete scene with all three cars, while the foveal images show details of each car in each snapshot. If the mixing ratios are known apriori, such as in the case when the polarizer rotates synchronously with the sensor exposure duration, then we can leverage a least squares-based reconstruction (details in section B) without any deep prior. This enables a real-time reconstruction, visualized in the second row in Fig. 3. The computational time per frame was less than 20ms of CPU time per each frame. This computation can be performed asynchronously while the camera is capturing images, thereby enabling a real-time reconstruction at 12 fps. Thanks to the low computational complexity of OpenCV [48] functions, the computational backend can be implemented on a low-power computational platform such as a Raspberry-Pi, creating a compact imaging system.
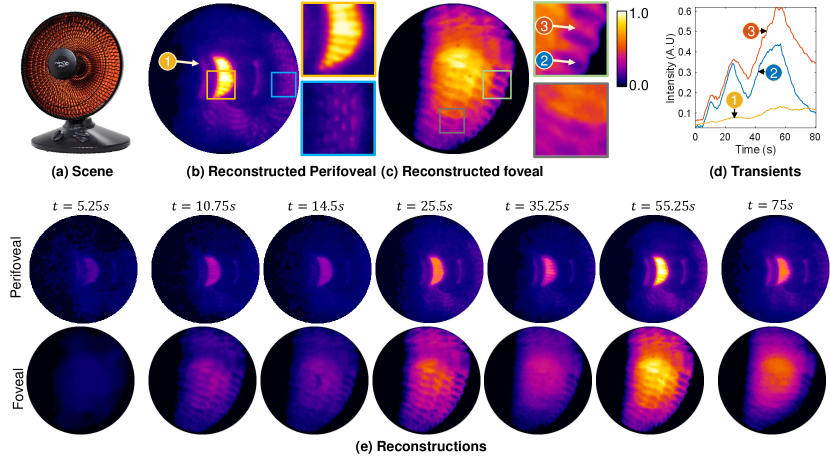
As with dynamic motion, our setup can also image thermodynamic phenomena at high resolution. Figure 4 (a) shows a portable heater going through three cycles of switching on and off (5s, 10s, and 20s), producing a distinct transient visualized in Fig. 4 (d). The effect of this heating cycle shows up in three forms. At the spatial point 1 that is indirectly heated, the rise and fall in relative intensity is small, and smooth. At point 2 that is also indirectly heated but close to the heating coil, the transients are stronger than at point 1. At point 3 on the coil, the transients are the strongest. Point 1 is easy to distinguish in the perifoveal image that provides an overall view of the heater, including the high frequency components of the parabolic reflector, but does not resolve the fine coil structure. In contrast, the foveal image clearly shows the coils and enables evaluation of transients at very fine-grained spatial resolutions.
Single image reconstruction. While polarization control enables high quality image separation, it may not always be feasible to add a polarizer in the optical system, such as imaging with very high frame rates. Our deep prior-based computational backend is sufficiently powerful to work in such scenarios, where we can only capture a single frame with a combination of images from both lenses. There, we leverage the similarity between the downsampled foveal image, and the central crop of the perifoveal image to regularize the inverse problem. Details about solving the inverse problem with a single measurement is provided in section B.
Figure 5 shows an indoor example with a wooden stencil and an outdoor example with a parked car. The indoor scene has a perifoveal image consisting of the sector star target, as well as an owl, while the foveal image zooms into the sector star. The foveal image clearly shows the sector at high resolution. The sensor measurement for the outdoor scene has distinct contributions from both perifoveal (small car, and golf cart) and foveal (enlarged car) images. The reconstructed images show the surroundings in the perifoveal image including the wheels of a golf cart, while the foveal image shows the features of the car. Note that there is some overlap in the reconstructions. The ill-posedness of the inverse problem produces artifacts in both perifoveal and foveal images. It is possible to remove such artifacts with more advanced computational approaches including a trained neural network [49], which we leave for future work.
3 Discussion
We have demonstrated a first-of-its-kind optical system based on polarization-sensitive metalenses that enables foveation. The optical setup along with a powerful computational backend is capable of imaging in the wild at real-time rates, opening up a wide range of possibilities in applications that require compact optical systems along with large field of view, and high spatial resolution.
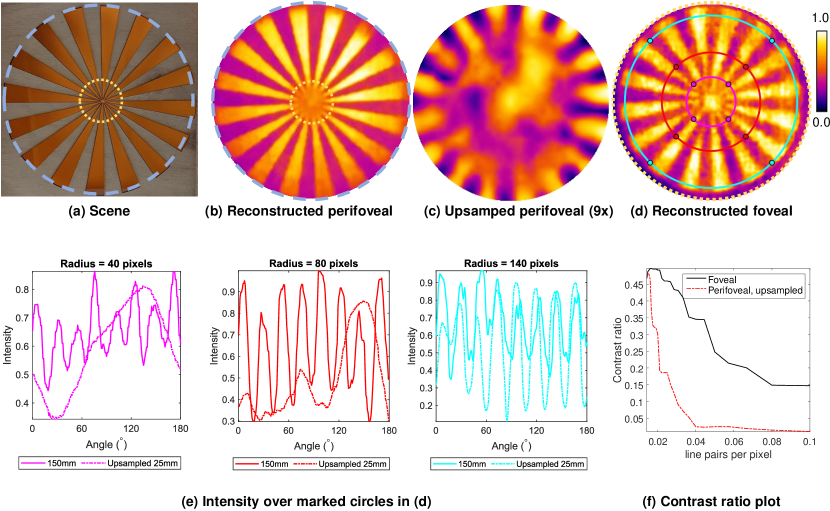
System analysis. To quantify the performance of our optical system, we imaged a wooden cutout of the Seimen’s sector target. The backside of the cutout consists of a thin chart paper heated by a portable heater to create temperature contrast. Figure 6 shows the reconstructions with the 25mm and 150mm image as well as intensity profiles over circles with increasing radii. For large radii (140 pixels), the intensity profiles of the upsampled perifoveal image and the foveal image match. As the radius decreases (40, 80 pixels), the intensity profile for the foveal image continues to have high contrast, while the upsampled perifoveal image lacks any contrast. Figure 6(f) shows the contrast ratio as a function of line pairs per pixel (LPP). At very low lpp, the perifoveal and foveal images have similar contrast ratio. At larger radii, the foveal image has significantly higher contrast ratio, while the contrast of the perifoveal image reduces to a very small value.
Limitations and future directions. Our metalens-based foveated imager currently produces sharp images only for a narrow range of wavelengths. This limitation is common across most metalenses [50]. However by co-optimizing the meta-optics and computational backend, the metalenses can be made to focus over a much broader range of wavelengths as shown in the visible [43]. Foveated imaging with broadband performance will constitute a promising future direction. Our metalenses have moderate transmission efficiency (approximately 60%), due to a lack of antireflection (AR) coating and absorption in the silicon substrate. This can be overcome with more advanced manufacturing procedures with AR coatings on the metalenses or using transparent materials in the LWIR range, such as As2S3 or GeSbSe thin-films on CaF2 substrate [51].
4 Materials and Methods
Metalens design. To implement the polarization-dependent phase response in the two meta-optics we designed a scatterer with a polarization-dependent response using a rectangular footprint of each nanopost. We first calculated the phase and amplitude response for pillars using rigorous coupled wave analysis (RCWA) [52], assuming a pillar height of 10 m, period of 4 m and varying rectangular footprint defined by the sidewidths, x and y. We then selected a scatterer that would have a phase response covering a range of 2 for S-polarization, while not altering the phase for light with P-polarization. We note that meta-optics for imaging in LWIR have been demonstrated in recent times with polarization insensitivity [53], broadband response [54], large aperture [55], and operation in ambient temperatures [7]. However, to the best of our knowledge, our system is the first to demonstrate results on polarization-sensitive metalenses at LWIR wavelengths. Further details about the optimization procedure are available in section A.
Metalens fabrication. Each metalens was fabricated on a 500m thick double-side polished silicon wafer, lightly doped with boron, giving a sheet resistivity of 10-20 -cm. We used direct-write lithography (Heidelberg DWL ) to define the location of the metalens aperture in a negative photoresist layer. A 240nm thick aluminum layer was deposited via electron beam evaporation (CHA solution) and lifted off to form the metal mask surrounding the designated aperture of the metalens, reducing the noise in the experiments. The metalens scatterer layout was aligned and patterned into the open circular aperture using direct-write lithography with a positive photoresist. We utilized deep reactive-ion etching (SPTS DRIE) to transfer the metalens pattern into the silicon layer with a scatterer depth of 10 m and highly vertical sidewalls.
Optimization approach. Let and be the vector representation of perifoveal and foveal images respectively.
To regularize the inverse problem in eq. (8), we rely on the inherent regularization offered by convolutional neural networks and solve the following modified optimization problem,
| (9) | ||||
| (10) | ||||
| , | (11) |
where and are untrained neural networks, are weights of the neural networks to be optimized, and and are inputs with each entry drawn in a uniformly random manner. This approach of optimizing for the weights of an untrained neural network instead of the image is similar in spirit to deep image prior [47]. Utilizing two separate networks promotes dissimilarity between the two images and , and hence results in high quality separation [56]. Further details about the network, as well as the regularization function , are available in section A.
For the snapshot case, given the perifoveal image and the foveal image , we have
| (12) |
where is the cropping operator, and is the downsampling operator. We then solve the modified optimization problem,
| (13) |
where is the weight of penalty for similarity between the cropped perifoveal image and the downsampled foveal image. Further details about the regularizer are available in section B.
Experimental setup. Our setup consists of two, four inch metalenses mounted on optomechanical systems (Thorlabs LMR4) on a rail system. A linear polarizer (Thorlabs WP25M-IRC) was mounted on a fast rotation stage (Thorlabs ELL14) and asynchronously rotated at 2Hz. Images in Fig. 2(a), (c), Fig. 3, Fig. 4, and Fig. 6 were captured with an Infratec VarioCAM HD 1800 camera, while the images in Fig. 2(b), (d), and Fig. 5 were captured with a FLIR A655sc camera. The Infratec VarioCAM HD 1800 camera was fitted with a relay lens, and the FLIR A655sc was fitted with a relay lens. The relay system was required to overcome the mechanical constraints of the camera, which prevented us from placing the 25mm lens at the appropriate distance from the sensor. We found that the relay had no effect on the final quality of the acquired images, except for a magnification. Further details are available in section B.
Acknowledgments The work is supported by NSF grants NSF-2127235, CCF-1911094, IIS-1838177, IIS-1730574, IIS-1652633, and IIS-2107313; ONR grants N00014-18-12571, N00014-20-1-2534, and MURI N00014-20-1-2787; AFOSR grant FA9550-22-1-0060; and a Vannevar Bush Faculty Fellowship, ONR grant N00014-18-1-2047. Part of this work was conducted at the Washington Nanofabrication Facility / Molecular Analysis Facility, a National Nanotechnology Coordinated Infrastructure (NNCI) site at the University of Washington with partial support from the National Science Foundation via awards NNCI-1542101 and NNCI-2025489.
Appendix A Computational Reconstruction
A.1 Network details
The optimization function used for recovering the foveal and perifoveal images is given by
| (14) | ||||
| (15) | ||||
| . | (16) |
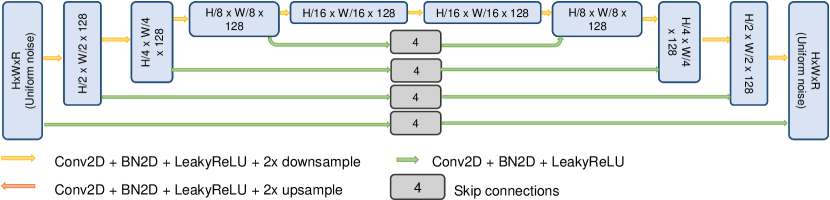
Inspired by the deep image prior (DIP) work, we chose both the networks to be UNet [57] with skip connections. The specific network structure produces outputs that resemble images, and hence is robust to noise. Figure 7 shows the network architecture for each image. Prior work by Gandelsman et. al. [56] has shown that utilizing two separate networks to produce a “double DIP” representation encourages dissimilar images.
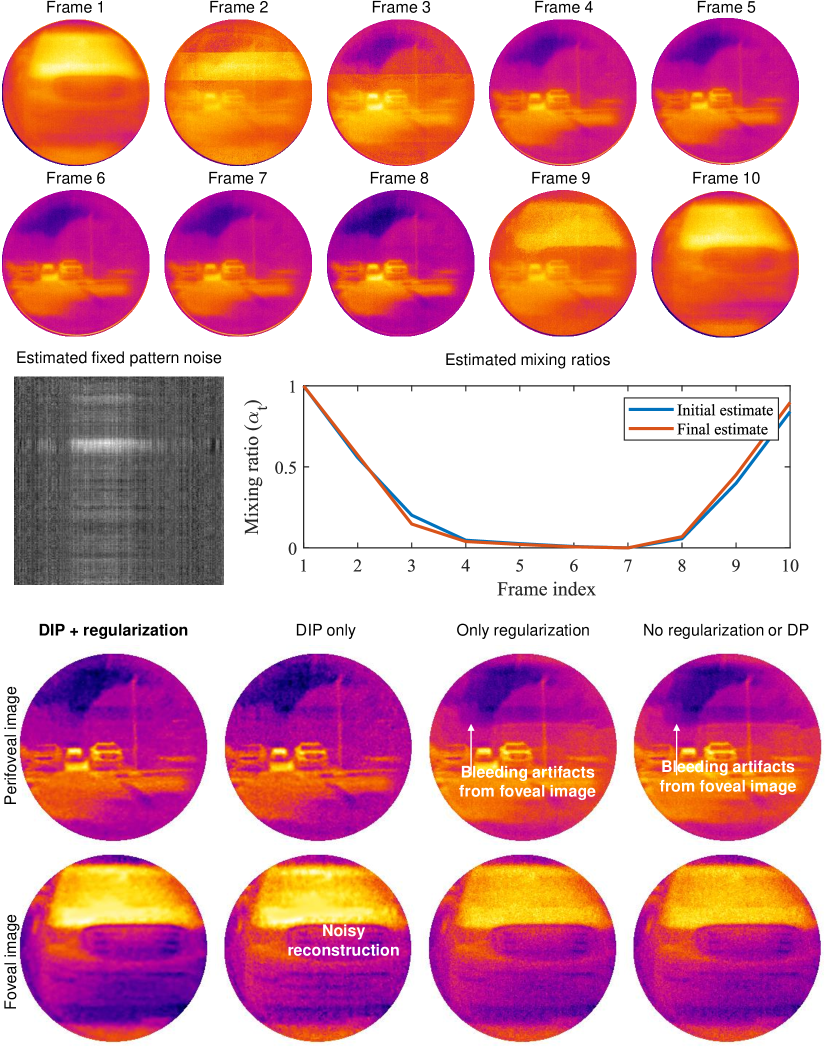
A.2 Fixed pattern noise
Microbolometer cameras suffer from slowly varying fixed pattern noise and non-uniformities due to manufacturing defects and internal thermodynamics. Recent works [58] identified that such non-uniformities tend to be low rank. The works by [59] have shown that these non-uniformities do not change over a short duration of time and hence can be modeled as constants. Inspired by this work, we introduce non-uniformity as another variable to be optimized, giving us,
| (17) | ||||
| (18) | ||||
| (19) | ||||
| , | (20) |
where is the non-uniform noise to be corrected. We chose the rank to be 20 for all our experiments. Further, we constrained the entries of to lie between and . Some of the recovered noise images are visualized in the upcoming experiments section.
A.3 Regularization
The regularization function is,
| (21) |
where is the total variation (TV) loss, and is the gradient exclusion loss [49] that encourages and to be different. The penalty terms was set to , and was set to .
A.4 Effect of initial mixing ratios
Since the reconstruction problem is highly non-convex, the initialization of each variable plays an important role in recover. We found that initializing the weights with mean intensity of each video frame lead to a faster convergence and accurate estimate of true mixing ratios. Figure 8 shows an example on simulated images with and without regularization. The addition of a double DIP, as well as the gradient exclusion loss considerably improve the quality of reconstruction.
A.5 Effect of focal ratio
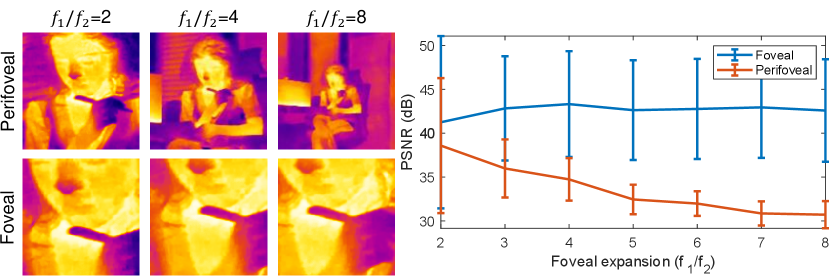
We showed results with a foveal focal length of 150mm and perifoveal focal length of 25mm, leading to a foveal expansion of , which was largely inspired by relative acuity of human eye. It is however possible to build systems with arbitrary focal ratios. To evaluate the accuracy of estimate with various foveal expansions, we simulated reconstruction with foveal expansions from 2 to 8 in steps of 1. For each case, we simulated a capture of 10 images with varying mixing ratios. Figure 9 shows images with each foveal expansion, as well as accuracy (PSNR) across configurations averaged over 3 simulated examples for a fixed foveal focal length. The reconstruction accuracy stays nearly the same for foveal image, since the focal length was kept fixed. In contrast, the PSNR for perifoveal image reduces with increasing focal ratio, primarily due to increasing texture. More importantly, our approach can be gracefully extended to nearly any foveal expansion as required by the end application.
A.6 Comparison against other foveated systems
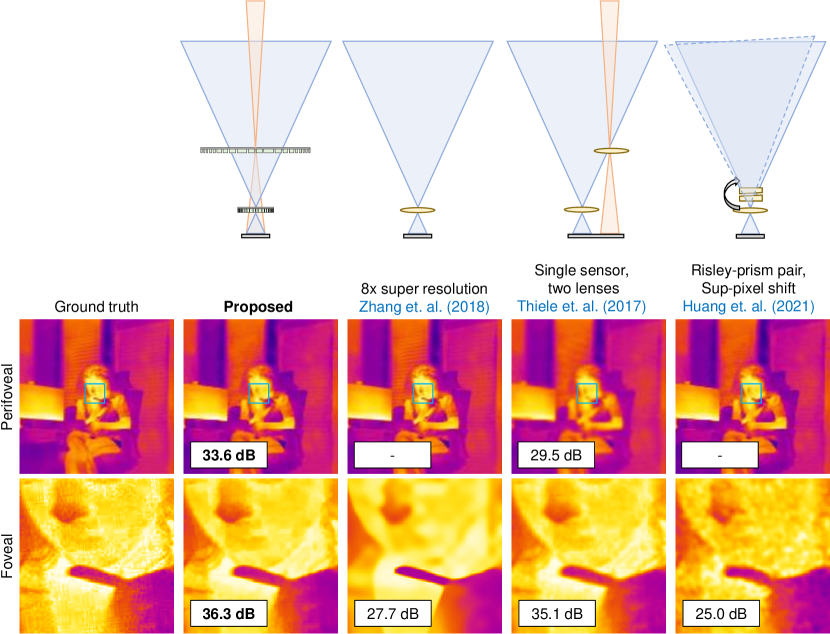
Though there are some works that utilize polarization for foveated displays [60, 61], there are very few imaging systems that enable double focal length foveation with a single sensor. Ude et al. [62] showed that foveation is useful for robotic manipulation but used two sensors with two different focal lengths. Carles et al. [2] leveraged sub-pixel shifts in the central area of the sensor to obtain super resolution, but used a large array of camera sensors. To the best of our knowledge, two works are close to the proposed approach in the paper. Thiele et al. [1] utilized two smaller lenses on top of a CMOS sensor to obtain foveation. Huang et al. [63] utilized a rotating risley prism pair to obtain several measurements with sub-pixel shifts. We compare our approach against these two approaches, as well as a pure algorithm-only super resolution using channel attention-based neural networks [64]. Figure 10 compares various approaches visually and quantitatively in terms of PSNR and SSIM for an example image. Across the board, we observe that our polarization multiplexed approach achieves superior performance both visually and quantitatively.
A.7 Single image recovery
For snapshot case, we have a single measurement of the form,
| (22) |
By design, the downsampled version of is (approximately) equal to the center crop of (assuming ). This gives us,
| (23) |
where is a downsampling operator by times, and is the cropping operator.
The specific optimization objective for recovering the two images,
| (24) | ||||
| (25) | ||||
| (26) |
Prior work including [47] and [56] modeled as uniform random variables. However, we found that the following initialization was critical to a successful recovery of the two images,
| (27) | ||||
| (28) |
The key idea is that an upsampled version of the observation resembles the high resolution image , and hence is a good initial estimate.

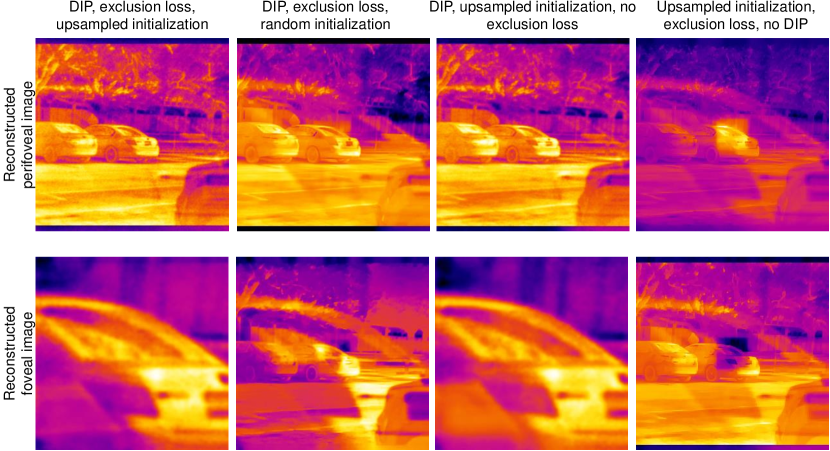
Figure 11 demonstrates reconstruction with our approach on a simulated image, and Fig. 12 evaluates the effect of each component in the recovery algorithm on the final separation. As with multi-frame recovery, we observe that the initialization, deep prior, and the exclusion loss work in tandem to produce a high quality reconstruction.
Appendix B Experimental Details

B.1 Lab prototype
Figure 13 shows our lab prototype consisting of two metalenses, a freely rotating polarizer, a narrowband filter, and relay lens. We used a FLIR A655sc longwave infrared (LWIR) camera to capture raw images. Additionally, we placed black shutter (Acktar Black metal velvet) in front of the 150mm metalens to account for stray light and internal reflections (narcissus effect). We captured images from the camera using the Spinnaker Python software development kit (SDK) from FLIR. The polarizer and the flip mount were controlled with python software as well.
B.2 Metalens design
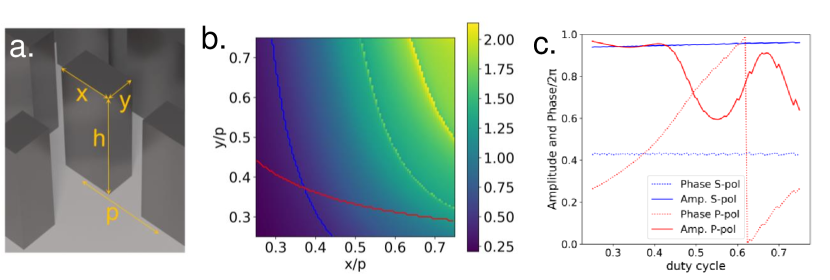
To implement the polarization dependent phase response in the two meta-optics, we designed scatterer with a polarization dependent response using a rectangular footprint of each nanopost. We first calculated the phase and amplitude response for pillars using rigorous coupled wave analysis (RCWA) [52], assuming a pillar height of 10 m, period of 4 m and varying rectangular footprint defined by the side widths, x and y. A map of the phase response for light with S-polarization in dependence of the respective duty cycles (x/p and y/p) is shown in (Figure 14b). We then selected scatterer that would have a phase response covering a range of 2 for S-polarization (red curve), while not altering the phase for light with P-polarization (blue curve). The extracted phase response is plotted in (Figure 14c).
B.3 Real Experiments
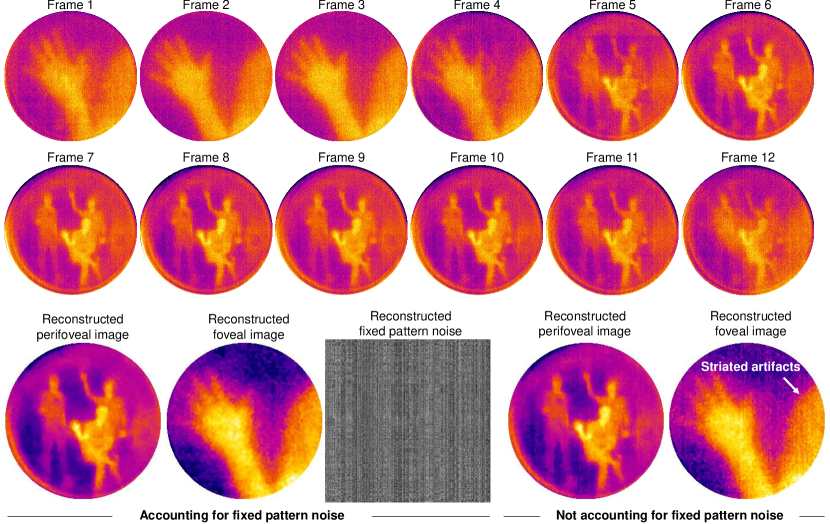
B.3.1 Effect of including fixed pattern noise
To demonstrate the advantages of accounting for the fixed pattern noise, we compared the reconstructions with and without the fixed pattern noise. Figure 15 shows a side-by-side comparison of the reconstructions for a noisy measurement. Not including the fixed pattern noise produces strong column artifacts that correlate with the noise pattern. In contrast, recovery that accounts for the fixed pattern noisy is considerably sharper and devoid of any such artifacts.
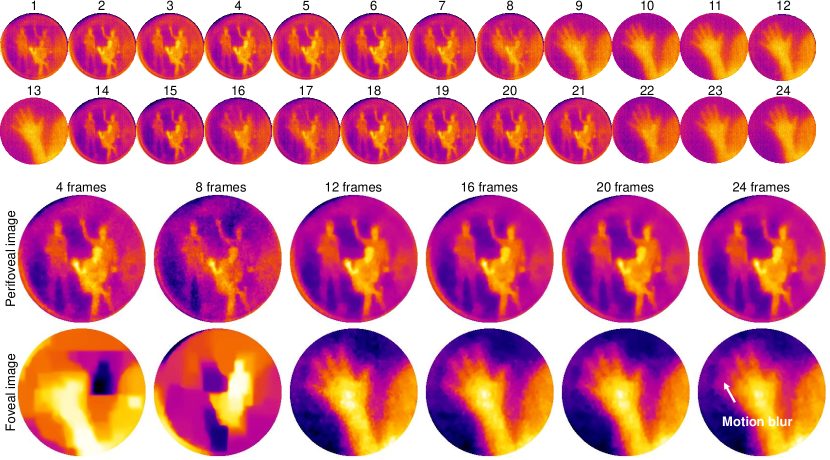
B.3.2 Optimal number of images for video reconstruction
The optimal number of images for reconstructing each frame of a video depends on the speed of polarizer, and the motion in the scene. To empirically verify the effect of number of images, we varied the number of inputs for the hand waving scene from 4 to 24 in steps of 4. Figure 16 shows a comparison for varying number of images. For fewer than 12 images, the reconstruction had significant overlap between the 150mm image and the 25mm image. In contrast, if the images were more than 20, the reconstructions had strong motion blurring. We found the optimal number of images to be between 8 and 12, as it corresponded to a full period of the polarizer rotating at 2Hz, while frames were captured at 12Hz. We do note that a rapidly changing scene would cause motion artifacts. This can be readily remedied with faster polarizers, or with sensors that are equipped with an array of linear polarizers.
B.3.3 Real-time reconstruction
The video results in the main paper were reconstructed with a deep image prior to obtain high quality results. However, the optimization procedure takes up to thousand gradient descent steps, precluding real-time reconstruction. It is however possible to obtain real-time reconstruction at the cost of noisy reconstructions. To do so, we need to know the mixing ratios apriori. This is very much possible, as the rotating polarizer can be fully synchronized with the camera exposure duration. In such conditions, estimating the foveal and perifoveal image involves solving a simple and computationally inexpensive least squares problem,
| (29) |
The solution to the above least squares has a simple closed form given by,
| (30) | ||||
| (31) | ||||
| (32) | ||||
| (33) |
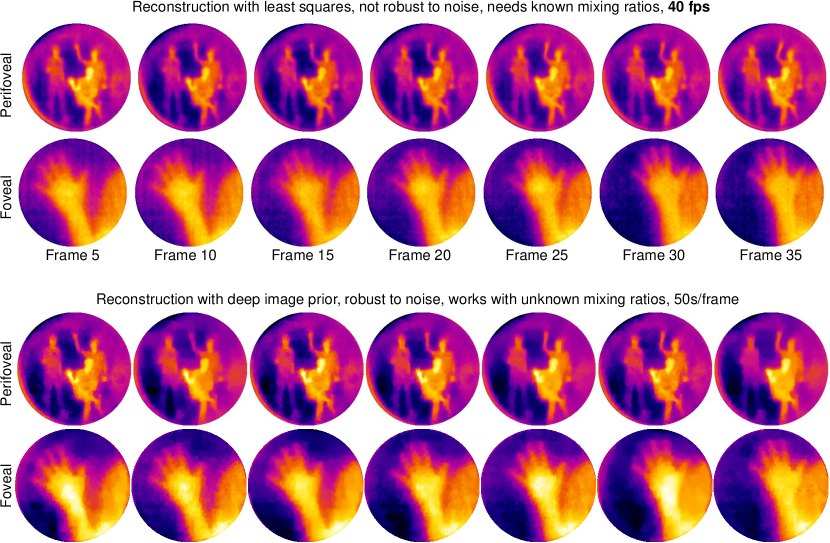
To test this, we reconstructed the hand waving scene in the main paper with known mixing ratios. Figure 17 shows a comparison of reconstruction with deep prior (robust but not real-time) with unknown mixing ratios, and least squares (real-time but not robust) with known mixing ratios. We performed an additional bilateral filtering to reduce the noise in least squares-based reconstruction. We notice that the least squares solution is noisier compared to deep prior results, but we can obtain results at 40 fps for sized image. Future work will focus on training neural networks that can robustly separate the two images in real time with efficient GPU-based implementations.
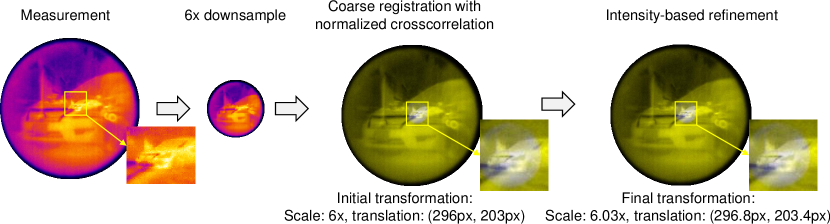
B.3.4 Calibration for snapshot recovery
Recovery from a single image (without polarizer) requires knowledge of the downsampling operator and cropping operator . We assume that the 150mm image and the 25mm image are related by a simple rigid transformation consisting of scaling and translation. It is possible to perform a one-time calibration of the system using standard geometric targets such as a checker board, however, since the lenses were not fixed in place, each capture had a unique set of transformation parameters. To estimate the parameters for each scene, we relied on a two stage approach. First, we assumed the scale to be fixed and equal to the ratio of the focal lengths. We then estimated the translation using normalized cross correlation between the captured combination image, and its downsampled version. We then refined the scale and translation with an intensity-based registration approach. Figure 18 visualizes the calibration procedure using our two stage approach.
References
- Thiele et al. [2017] Simon Thiele, Kathrin Arzenbacher, Timo Gissibl, Harald Giessen, and Alois M Herkommer. 3d-printed eagle eye: Compound microlens system for foveated imaging. Science Adv., 3(2):e1602655, 2017.
- Carles et al. [2016] Guillem Carles, Shouqian Chen, Nicholas Bustin, James Downing, Duncan McCall, Andrew Wood, and Andrew R Harvey. Multi-aperture foveated imaging. Optics Letters, 41(8):1869–1872, 2016.
- Tremblay et al. [2013] Eric J Tremblay, Igor Stamenov, R Dirk Beer, Ashkan Arianpour, and Joseph E Ford. Switchable telescopic contact lens. Optics Express, 21(13):15980–15986, 2013.
- Kamali et al. [2018] Seyedeh Mahsa Kamali, Ehsan Arbabi, Amir Arbabi, and Andrei Faraon. A review of dielectric optical metasurfaces for wavefront control. Nanophotonics, 7(6):1041–1068, 2018.
- Zhan et al. [2017] Alan Zhan, Shane Colburn, Christopher M Dodson, and Arka Majumdar. Metasurface freeform nanophotonics. Nature Scientific Reports, 7(1):1–9, 2017.
- Han et al. [2022] Zheyi Han, Shane Colburn, Arka Majumdar, and Karl F Böhringer. Millimeter-scale focal length tuning with mems-integrated meta-optics employing high-throughput fabrication. Nature Scientific Reports, 12(1):1–10, 2022.
- Huang et al. [2021a] Luocheng Huang, Zachary Coppens, Kent Hallman, Zheyi Han, Karl F Böhringer, Neset Akozbek, Ashok Raman, and Arka Majumdar. Long wavelength infrared imaging under ambient thermal radiation via an all-silicon metalens. Optical Materials Express, 11(9):2907–2914, 2021a.
- Arbabi et al. [2018] Ehsan Arbabi, Amir Arbabi, Seyedeh Mahsa Kamali, Yu Horie, MohammadSadegh Faraji-Dana, and Andrei Faraon. Mems-tunable dielectric metasurface lens. Nature Communications, 9(1):1–9, 2018.
- Vo et al. [2014] Sonny Vo, David Fattal, Wayne V Sorin, Zhen Peng, Tho Tran, Marco Fiorentino, and Raymond G Beausoleil. Sub-wavelength grating lenses with a twist. IEEE Photonics Technology Letters, 26(13):1375–1378, 2014.
- West et al. [2014] Paul R West, James L Stewart, Alexander V Kildishev, Vladimir M Shalaev, Vladimir V Shkunov, Friedrich Strohkendl, Yuri A Zakharenkov, Robert K Dodds, and Robert Byren. All-dielectric subwavelength metasurface focusing lens. Optics Express, 22(21):26212–26221, 2014.
- Lin et al. [2014] Dianmin Lin, Pengyu Fan, Erez Hasman, and Mark L Brongersma. Dielectric gradient metasurface optical elements. Science, 345(6194):298–302, 2014.
- Lu et al. [2010] Fanglu Lu, Forrest G Sedgwick, Vadim Karagodsky, Christopher Chase, and Connie J Chang-Hasnain. Planar high-numerical-aperture low-loss focusing reflectors and lenses using subwavelength high contrast gratings. Optics Express, 18(12):12606–12614, 2010.
- Arbabi et al. [2017] Amir Arbabi, Ehsan Arbabi, Yu Horie, Seyedeh Mahsa Kamali, and Andrei Faraon. Planar metasurface retroreflector. Nature Photonics, 11(7):415–420, 2017.
- Fan et al. [2017] Qingbin Fan, Pengcheng Huo, Daopeng Wang, Yuzhang Liang, Feng Yan, and Ting Xu. Visible light focusing flat lenses based on hybrid dielectric-metal metasurface reflector-arrays. Nature Scientific Reports, 7(1):1–9, 2017.
- Fattal et al. [2010] David Fattal, Jingjing Li, Zhen Peng, Marco Fiorentino, and Raymond G Beausoleil. Flat dielectric grating reflectors with focusing abilities. Nature Photonics, 4(7):466–470, 2010.
- Ran et al. [2018] Yuzhou Ran, Jiangang Liang, Tong Cai, and Haipeng Li. High-performance broadband vortex beam generator using reflective pancharatnam–berry metasurface. Optics Communications, 427:101–106, 2018.
- Yue et al. [2016] Fuyong Yue, Dandan Wen, Jingtao Xin, Brian D Gerardot, Jensen Li, and Xianzhong Chen. Vector vortex beam generation with a single plasmonic metasurface. ACS Photonics, 3(9):1558–1563, 2016.
- Ma et al. [2015] Xiaoliang Ma, Mingbo Pu, Xiong Li, Cheng Huang, Yanqin Wang, Wenbo Pan, Bo Zhao, Jianhua Cui, Changtao Wang, ZeYu Zhao, et al. A planar chiral meta-surface for optical vortex generation and focusing. Nature Scientific Reports, 5(1):1–7, 2015.
- Yang et al. [2014] Yuanmu Yang, Wenyi Wang, Parikshit Moitra, Ivan I Kravchenko, Dayrl P Briggs, and Jason Valentine. Dielectric meta-reflectarray for broadband linear polarization conversion and optical vortex generation. ACS Nano Letters, 14(3):1394–1399, 2014.
- Ren et al. [2020] Haoran Ren, Xinyuan Fang, Jaehyuck Jang, Johannes Bürger, Junsuk Rho, and Stefan A Maier. Complex-amplitude metasurface-based orbital angular momentum holography in momentum space. Nature Nanotechnology, 15(11):948–955, 2020.
- Hu et al. [2019] Yueqiang Hu, Ling Li, Yujie Wang, Min Meng, Lei Jin, Xuhao Luo, Yiqin Chen, Xin Li, Shumin Xiao, Hanbin Wang, et al. Trichromatic and tripolarization-channel holography with noninterleaved dielectric metasurface. ACS Nano Letters, 20(2):994–1002, 2019.
- Zheng et al. [2015] Guoxing Zheng, Holger Mühlenbernd, Mitchell Kenney, Guixin Li, Thomas Zentgraf, and Shuang Zhang. Metasurface holograms reaching 80% efficiency. Nature Nanotechnology, 10(4):308–312, 2015.
- Arbabi et al. [2020] Amir Arbabi, Ehsan Arbabi, Mahdad Mansouree, Seunghoon Han, Seyedeh Mahsa Kamali, Yu Horie, and Andrei Faraon. Increasing efficiency of high numerical aperture metasurfaces using the grating averaging technique. Nature Scientific Reports, 10(1):1–10, 2020.
- Lalanne et al. [1998] Philippe Lalanne, Simion Astilean, Pierre Chavel, Edmond Cambril, and Huguette Launois. Blazed binary subwavelength gratings with efficiencies larger than those of conventional échelette gratings. Optics Letters, 23(14):1081–1083, 1998.
- Burgos et al. [2021] Carlos Mauricio Villegas Burgos, Tianqi Yang, Yuhao Zhu, and A Nickolas Vamivakas. Design framework for metasurface optics-based convolutional neural networks. Applied Optics, 60(15):4356–4365, 2021.
- Dorrah et al. [2021] Ahmed H Dorrah, Noah A Rubin, Aun Zaidi, Michele Tamagnone, and Federico Capasso. Metasurface optics for on-demand polarization transformations along the optical path. Nature Photonics, 15(4):287–296, 2021.
- Arbabi et al. [2015] Amir Arbabi, Yu Horie, Mahmood Bagheri, and Andrei Faraon. Dielectric metasurfaces for complete control of phase and polarization with subwavelength spatial resolution and high transmission. Nature Nanotechnology, 10(11):937–943, 2015.
- Rubin et al. [2019] Noah A Rubin, Gabriele D’Aversa, Paul Chevalier, Zhujun Shi, Wei Ting Chen, and Federico Capasso. Matrix fourier optics enables a compact full-stokes polarization camera. Science, 365(6448):eaax1839, 2019.
- Guo et al. [2019] Qi Guo, Zhujun Shi, Yao-Wei Huang, Emma Alexander, Cheng-Wei Qiu, Federico Capasso, and Todd Zickler. Compact single-shot metalens depth sensors inspired by eyes of jumping spiders. Proc. National Academy of Sciences, 116(46):22959–22965, 2019.
- Tian et al. [2019] Shengnan Tian, Hanming Guo, Jinbing Hu, and Songlin Zhuang. Dielectric longitudinal bifocal metalens with adjustable intensity and high focusing efficiency. Optics Express, 27(2):680–688, 2019.
- Yao and Chen [2021] Zan Yao and Yuhang Chen. Focusing and imaging of a polarization-controlled bifocal metalens. Optics Express, 29(3):3904–3914, 2021.
- Levin et al. [2007] Anat Levin, Rob Fergus, Frédo Durand, and William T Freeman. Image and depth from a conventional camera with a coded aperture. ACM Trans. Graphics, 26(3):70–80, 2007.
- Raskar et al. [2006] Ramesh Raskar, Amit Agrawal, and Jack Tumblin. Coded exposure photography: Motion deblurring using fluttered shutter. ACM SIGGRAPH, 2006.
- Duarte et al. [2008] Marco F Duarte, Mark A Davenport, Dharmpal Takhar, Jason N Laska, Ting Sun, Kevin F Kelly, and Richard G Baraniuk. Single-pixel imaging via compressive sampling. IEEE Signal Proc. Magazine, 25(2):83–91, 2008.
- Sankaranarayanan et al. [2012] Aswin C Sankaranarayanan, Christoph Studer, and Richard G Baraniuk. Cs-muvi: Video compressive sensing for spatial-multiplexing cameras. IEEE Intl. Conf. Computational Photography (ICCP), 2012.
- Hitomi et al. [2011] Yasunobu Hitomi, Jinwei Gu, Mohit Gupta, Tomoo Mitsunaga, and Shree K Nayar. Video from a single coded exposure photograph using a learned over-complete dictionary. IEEE Comp. Vision and Pattern Recognition Conf. (CVPR), 2011.
- Veeraraghavan et al. [2007] Ashok Veeraraghavan, Ramesh Raskar, Amit Agrawal, Ankit Mohan, and Jack Tumblin. Dappled photography: Mask enhanced cameras for heterodyned light fields and coded aperture refocusing. ACM Trans. Graphics, 26(3):69, 2007.
- Zheng et al. [2013] Guoan Zheng, Roarke Horstmeyer, and Changhuei Yang. Wide-field, high-resolution fourier ptychographic microscopy. Nature Photonics, 7(9):739–745, 2013.
- Wagadarikar et al. [2008] Ashwin Wagadarikar, Renu John, Rebecca Willett, and David Brady. Single disperser design for coded aperture snapshot spectral imaging. Applied Optics, 47(10):B44–B51, 2008.
- Saunders et al. [2019] Charles Saunders, John Murray-Bruce, and Vivek K Goyal. Computational periscopy with an ordinary digital camera. Nature, 565(7740):472–475, 2019.
- Shin et al. [2016] Dongeek Shin, Feihu Xu, Dheera Venkatraman, Rudi Lussana, Federica Villa, Franco Zappa, Vivek K Goyal, Franco NC Wong, and Jeffrey H Shapiro. Photon-efficient imaging with a single-photon camera. Nature Communications, 7(1):1–8, 2016.
- Baek et al. [2021] Seung-Hwan Baek, Hayato Ikoma, Daniel S Jeon, Yuqi Li, Wolfgang Heidrich, Gordon Wetzstein, and Min H Kim. Single-shot hyperspectral-depth imaging with learned diffractive optics. IEEE Intl. Conf. Computer Vision (ICCV), 2021.
- Tseng et al. [2021] Ethan Tseng, Shane Colburn, James Whitehead, Luocheng Huang, Seung-Hwan Baek, Arka Majumdar, and Felix Heide. Neural nano-optics for high-quality thin lens imaging. Nature Communications, 12(1):1–7, 2021.
- Li et al. [2020] Yuqi Li, Miao Qi, Rahul Gulve, Mian Wei, Roman Genov, Kiriakos N Kutulakos, and Wolfgang Heidrich. End-to-end video compressive sensing using anderson-accelerated unrolled networks. IEEE Intl. Conf. Computational Photography (ICCP), 2020.
- Sitzmann et al. [2018] Vincent Sitzmann, Steven Diamond, Yifan Peng, Xiong Dun, Stephen Boyd, Wolfgang Heidrich, Felix Heide, and Gordon Wetzstein. End-to-end optimization of optics and image processing for achromatic extended depth of field and super-resolution imaging. ACM Trans. Graphics, 37(4):1–13, 2018.
- Chakrabarti et al. [2014] Ayan Chakrabarti, William T Freeman, and Todd Zickler. Rethinking color cameras. IEEE Intl. Conf. Computational Photography (ICCP), 2014.
- Ulyanov et al. [2018] Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. IEEE Comp. Vision and Pattern Recognition Conf. (CVPR), 2018.
- Bradski [2000] G. Bradski. The OpenCV Library. Dr. Dobb’s J. Software Tools, 2000.
- Zhang et al. [2018a] Xuaner Zhang, Ren Ng, and Qifeng Chen. Single image reflection separation with perceptual losses. IEEE Comp. Vision and Pattern Recognition Conf. (CVPR), 2018a.
- Presutti and Monticone [2020] Federico Presutti and Francesco Monticone. Focusing on bandwidth: achromatic metalens limits. Optica, 7(6):624–631, 2020.
- Eggleton et al. [2011] Benjamin J Eggleton, Barry Luther-Davies, and Kathleen Richardson. Chalcogenide photonics. Nature Photonics, 5(3):141–148, 2011.
- Liu and Fan [2012] Victor Liu and Shanhui Fan. S4: A free electromagnetic solver for layered periodic structures. Computer Physics Communications, 183(10):2233–2244, 2012.
- Fan et al. [2018] Qingbin Fan, Mingze Liu, Cheng Yang, Le Yu, Feng Yan, and Ting Xu. A high numerical aperture, polarization-insensitive metalens for long-wavelength infrared imaging. Applied Physics Letters, 113(20):201104, 2018.
- Meem et al. [2019] Monjurul Meem, Sourangsu Banerji, Apratim Majumder, Fernando Guevara Vasquez, Berardi Sensale-Rodriguez, and Rajesh Menon. Broadband lightweight flat lenses for long-wave infrared imaging. Proc. National Academy of Sciences, 116(43):21375–21378, 2019.
- Li et al. [2022] Junwei Li, Yilin Wang, Shengjie Liu, Ting Xu, Kai Wei, Yudong Zhang, and Hao Cui. Largest aperture metalens of high numerical aperture and polarization independence for long-wavelength infrared imaging. Optics Express, 30(16):28882–28891, 2022.
- Gandelsman et al. [2019] Yosef Gandelsman, Assaf Shocher, and Michal Irani. Double-dip: Unsupervised image decomposition via coupled deep-image-priors. IEEE Comp. Vision and Pattern Recognition Conf. (CVPR), 2019.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- He et al. [2018] Zewei He, Yanpeng Cao, Yafei Dong, Jiangxin Yang, Yanlong Cao, and Christel-Löic Tisse. Single-image-based nonuniformity correction of uncooled long-wave infrared detectors: A deep-learning approach. Applied optics, 57(18):D155–D164, 2018.
- Saragadam et al. [2021] Vishwanath Saragadam, Akshat Dave, Ashok Veeraraghavan, and Richard G Baraniuk. Thermal image processing via physics-inspired deep networks. In IEEE Intl. Conf. Computer Vision (ICCV) Workshop on Learning for Computational Imaging, 2021.
- Yin et al. [2022] Kun Yin, Ziqian He, Yannanqi Li, and Shin-Tson Wu. Foveated imaging by polarization multiplexing for compact near-eye displays. Journal of the Society for Information Display, 30(5):381–386, 2022.
- Yoo et al. [2020] Chanhyung Yoo, Jianghao Xiong, Seokil Moon, Dongheon Yoo, Chang-Kun Lee, Shin-Tson Wu, and Byoungho Lee. Foveated display system based on a doublet geometric phase lens. Optics Express, 28(16):23690–23702, 2020.
- Ude et al. [2006] Ales Ude, Chris Gaskett, and Gordon Cheng. Foveated vision systems with two cameras per eye. In IEEE Intl. Conf. Robotics and Automation, 2006.
- Huang et al. [2021b] Feng Huang, He Ren, Xianyu Wu, and Pengfei Wang. Flexible foveated imaging using a single risley-prism imaging system. Optics Express, 29(24):40072–40090, 2021b.
- Zhang et al. [2018b] Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In IEEE European Conf. Computer Vision (ECCV), 2018b.