Formalizing and Evaluating Requirements of Perception Systems for Automated Vehicles using Spatio-Temporal Perception Logic
Abstract
Automated vehicles (AV) heavily depend on robust perception systems. Current methods for evaluating vision systems focus mainly on frame-by-frame performance. Such evaluation methods appear to be inadequate in assessing the performance of a perception subsystem when used within an AV. In this paper, we present a logic – referred to as Spatio-Temporal Perception Logic (STPL) – which utilizes both spatial and temporal modalities. STPL enables reasoning over perception data using spatial and temporal operators. One major advantage of STPL is that it facilitates basic sanity checks on the functional performance of the perception system, even without ground-truth data in some cases. We identify a fragment of STPL which is efficiently monitorable offline in polynomial time. Finally, we present a range of specifications for AV perception systems to highlight the types of requirements that can be expressed and analyzed through offline monitoring with STPL.
Index Terms:
Formal Methods, Perception System, Temporal Logic, Autonomous Driving Systems.I Introduction
The safe operation of automated vehicles (AV), advanced driver assist systems (ADAS), and mobile robots in general, fundamentally depends on the correctness and robustness of the perception system (see discussion in Sec. 3 by Schwarting et al. (2018)). Faulty perception systems and, consequently, inaccurate situational awareness can lead to dangerous situations (Lee (2018); Templeton (2020)). For example, in the accident in Tempe in 2018 involving an Uber vehicle (Lee (2018)), different sensors had detected the pedestrian, but the perception system was not robust enough to assign a single consistent object class to the pedestrian. Hence, the AV was not able to predict the future path of the pedestrian. This accident highlights the importance of identifying the right questions to ask when evaluating perception systems.





In this paper, we argue that in order to improve AV/ADAS safety, we need to be able to formally express what should be the assumptions, performance, and guarantees provided by a perception system. For instance, the aforementioned accident highlights the need for predicting the right object class quickly and robustly. An informal requirement (in natural language) expressing such a perception system performance expectation could be:
Req. 1
Whenever a new object is detected, then it is assigned a class within 1 sec, after which the object does not change class until it disappears.
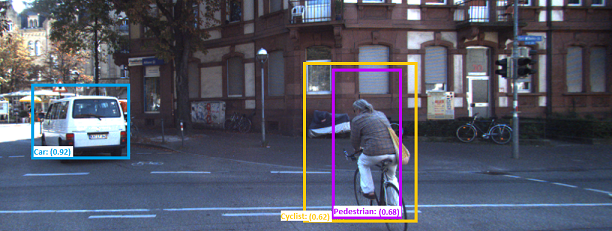
Such requirements are not only needed for deployed safety critical systems, but also for existing training and evaluation data sets. For example, a sequence of six image frames from the KITTI dataset is shown in Figure 1. All detected objects with bounding boxes are labeled with class names such as Car, Pedestrian, and Cyclist in those frames. Nonetheless, in Fig. 1(a), a cyclist that was detected in frame and existed in frame changed its class to pedestrian in frame , which is a violation of Req. 1. If such a requirement is too strict for the perception system, then it could be relaxed by requiring that the object is properly classified in at least 4 out of 5 frames (or any other desired frequency). The first challenge for an automated testing & verification framework is to be able to formally (i.e., mathematically) represent such high-level requirements.
Formalizing the expectations on the performance of the perception system has several benefits. First and foremost, such formal requirements can help us evaluate AV/ADAS perception systems beyond what existing metrics used in vision and object tracking can achieve (Yurtsever et al. (2020); Richter et al. (2017)). In particular, evaluation metrics used for image classification algorithms are typically operating on a frame-by-frame basis ignoring cross-frame relations and dependencies. Although tracking algorithms can detect misclassifications, they cannot assess the frequency and severity of them, or more complex spatio-temporal failure conditions.
Second, formal specifications enable automated search-based testing (e.g., see Abbas et al. (2017); Tuncali et al. (2020); Dreossi et al. (2019b, a); Corso et al. (2020); Gladisch et al. (2019); DeCastro et al. (2020)) and monitoring (e.g., see Rizaldi et al. (2017); Hekmatnejad et al. (2019)) for AV/ADAS. Requirements are necessary in testing in order to express the conditions (assumptions) under which system level violations are meaningful. Similarly, logical requirements are necessary in monitoring since without formal requirements, it is very hard to concisely capture the rules of the road. We envision that a formal specification language which specifically targets perception systems will enable similar innovations in testing and monitoring AV/ADAS.
Third, formal specifications on the perception system can also function as a requirements language between original equipment manufacturers (OEM) and suppliers. As a simple example for the need of a requirements language consider the most basic question: should the image classifier correctly classify all objects within the sensing range of the lidar, or all objects of at least pixels in diameter? Again, without requirements, any system behavior is acceptable and, most importantly, not testable/verifiable!
Finally, using a formal specification language, we can search offline perception datasets (see Kim et al. (2022); Anderson et al. (2023); Yadav and Curry (2019)) to find scenarios that violate the requirements in order to reproduce them in simulation, e.g., Bashetty et al. (2020), or to assess the real-to-sim gap in testing, e.g., Fremont et al. (2020).
Even though there is a large body of literature on the application of formal languages and methods to AV/ADAS (see the survey by Mehdipour et al. (2023)), the prior works have certain limitations when perception systems are specifically targeted. Works like Tuncali et al. (2020) and Dreossi et al. (2019a) demonstrated the importance of testing system level requirements for an AV when the AV contains machine learning enabled perception components. Both works use Signal Temporal Logic (STL) (Maler and Nickovic (2004)) for expressing requirements on the performance of the AV/ADAS. However, STL cannot directly express requirements on the performance of the perception system itself.
This limitation was identified by Dokhanchi et al. (2018a) who developed a new logic – Timed Quality Temporal Logic (TQTL) – which can directly express requirements for image classification algorithms like SqueezeDet by Wu et al. (2017). Namely, TQTL was designed to enable reasoning over objects classified in video frames and their attributes. For example, TQTL can formalize Req. 1 that an object should not change classes. However, TQTL does not support spatial or topological reasoning over the objects or regions in a scene. This is a major limitation since TQTL cannot express requirements such as occlusion, overlap, and other spatial relations for basic sanity checks, e.g., that objects do not “teleport” from frame to frame, or that “every 3D bounding box contains at least 1 lidar point”.
In this paper, we introduce the Spatio-Temporal Perception Logic (STPL) to address the aforementioned limitations. We combine TQTL with the spatial logic 111For a historical introduction to see van Benthem and Bezhanishvili (2007) and Kontchakov et al. (2007). to produce a more expressive logic specifically focused on perception systems. STPL supports quantification among objects or regions in an image, and time variables for referring to specific points in time. It also enables both 2D and 3D spatial reasoning by expressing relations between objects across time. For example with STPL, we can express requirements on the rate that bounding boxes should overlap:
Req. 2
The frames per second of the camera is high enough so that for all detected cars, their bounding boxes self-overlap for at least 3 frames and for at least 10% of the area.
which is satisfiable for the image frames in Fig. 1.
Beyond expressing requirements on the functional performance of perception systems, STPL can be used to compare different machine learning algorithms on the same perception data. For example, STPL could assess how rain removal algorithms (see the work by Sun et al. (2019)) improve the performance of the object detection algorithms over video streams. Along these lines, Mallick et al. (2023) proposed to use TQTL for differential testing between two different models for pedestrian detection in extreme weather conditions. As another example, STPL could evaluate the impact of a point cloud clustering algorithm on a prediction algorithm (see the works by Campbell et al. (2016) and Qin et al. (2016)).
Since STPL is a very expressive formal language (TQTL+), it is not a surprise that both the offline and online monitoring problems can be computationally expensive. The main challenge in designing a requirements language for perception systems is to find the right balance between expressivity and computability.
STPL borrows time variables and freeze time quantifiers from the Timed Propositional Temporal Logic (TPTL) by Alur and Henzinger (1994). Unfortunately, the time complexity of monitoring TPTL requirements is PSPACE-hard (see Markey and Raskin (2006)). Even though the syntax and semantics of STPL that we introduce in Section IV allow arbitrary use of time variables in the formulas, in practice, in our implementation, we focus on TPTL fragments which are computable in polynomial time (see Dokhanchi et al. (2016); Elgyutt et al. (2018); Ghorbel and Prabhu (2022)).
Another source of computational complexity in STPL is the use of object/region quantification and set operations, i.e., intersection, complementation, and union. Even our limited use of quantifiers (, ) over finite sets (i.e., objects in a frame) introduces a combinatorial component to our monitoring algorithms. This is a well known problem in first-order temporal logics that deal with data (e.g., see Basin et al. (2015) and Havelund et al. (2020)). In addition, the computational complexity of checking whether sets, which correspond to objects/regions, satisfy an arbitrary formula depends on the set representation and the dimensionality of the space (e.g., polytopes Baotic (2009), orthogonal polyhedra Bournez et al. (1999), quadtrees or octrees Aluru (2018), etc).
In this paper, we introduce an offline monitoring algorithm for STPL in Section VI, and We study its computational complexity in Section VI-E. In Section VI-F, we identify a fragment which can remain efficiently computable. Irrespective of the computational complexity of the full logic, in practice, our experimental results in Section VII indicate that we can monitor many complex specifications within practically relevant times.
All in all, to the best of our knowledge, this is the first time that a formal language is specifically designed to address the problem of functional correctness of perception systems within the context of autonomous/automated mobile systems. Our goal is to design a logic that can express functional correctness requirements on perception systems while understanding what is the computational complexity of monitoring such requirements in practice. As a bi-product, we develop a logical framework that can be used to compare different perception algorithms beyond the standard metrics.
In summary, the contributions of this paper are:
-
1.
We introduce a new logic – Spatio-Temporal Perception Logic (STPL) – that combines quantification and functions over perception data, reasoning over timing of events, and set based operations for spatial reasoning (Section IV).
- 2.
- 3.
-
4.
We study the time complexity of the offline monitoring problem for STPL formulas, and we propose fragments for which the monitoring problem is computable in polynomial time (Section VI-E).
-
5.
We experimentally study offline monitoring runtimes for a range of specifications and present the trade offs in using the different STPL operators (Section VII).
-
6.
We have released a publicly available open-source toolbox (STPL (2023)) for offline monitoring of STPL specifications over perception datasets. The toolbox allows for easy integration of new user-defined functions over time and object variables, and new data structures for set representation.
One common challenge with any formal language is its accessibility to users with limited experience in formal requirements. In order to remove such barriers, Anderson et al. (2022) developed PyFoReL which is a domain specific language (DSL) for STPL inspired by Python and integrated with Visual Studio Code. In addition, our publicly available toolbox contains all the examples and case studies presented in this paper which can be used as a tutorial by users without prior experience in formal languages. One can further envision integration with Large Language Models for direct use of natural language for requirement elicitation similar to the work by Pan et al. (2023); Fuggitti and Chakraborti (2023); Cosler et al. (2023) for signal or linear temporal logic.
Finally, even though the examples in the paper focus on perception datasets from AV/ADAS applications (i.e., Motional (2019); Geiger et al. (2013b)), STPL can be useful in other applications as well. One such example could be in robot manipulation problems where mission requirements are already described in temporal logic (e.g., see He et al. (2018) and He et al. (2015)).
II Preliminaries
We start by introducing definitions that are used throughout the paper for representing classified data generated by perception subsystems. In the following, an ego car (or the Vehicle Under Test – VUT) is a vehicle equipped with perception systems and other automated decision making software components, but not necessarily a fully automated vehicle (e.g., SAE automation level 4 or 5).
II-A Data-object Stream
A data-object stream is a sequence of data-objects representing objects in the ego vehicle’s environment. Such data objects could be the output of the perception system, or ground truth data, or even a combination of these. The ground truth can be useful to analyze the precision of the output of a perception system. That is, given both the output of the perception system and the ground truth, it is possible to write requirements on how much, how frequently, and under what conditions the perception system is allowed to deviate from the ground truth. In all the examples and case studies that follow, we assume that we are either given the output of the perception system, or the ground truth – but not both. In fact, we treat ground truth data as the output of a perception system in order to demonstrate our framework. Interestingly, in this way, we also discover inconsistencies in the labels of training data sets for AV/ADAS (see Fig. 4).
We refer to each dataset in the sequence as a frame. In each frame, objects are classified and stored in a data-object. Data-objects are abstract because in the absence of a standard classification format, the output of different perception systems are not necessarily compatible with each other. To simplify the presentation, we will also refer to the order of each frame in the data stream as a frame number. For each frame , is the set of data-objects for frame , where is the order of the frame in the data-object stream . We assume that a data stream is provided by a perception system, in which a function retrieves data-attributes for an identified object. A data-attribute is a property of an object such as class, probability, geometric characteristics, etc. Some examples could be:
-
•
by , we refer to the class of an object identified by in the ’th frame,
-
•
by , we refer to the probability that an object identified by in the ’th frame is correctly classified,
-
•
by , we refer to the point clouds associated with an object identified by in the ’th frame.
The function returns the set of identifiers for a given set of data-objects. By , we refer to all the identifiers that are assigned to the data-objects in the ’th frame. Another important attribute of each frame is its time stamp, i.e., when this frame was captured in physical time. We represent this attribute for the frame by .
Example II.1
Assume that data-object stream is represented in Figure 1, then the below equalities hold:
-
•
-
•
-
•
-
•
Finally, we remark that in offline monitoring, which is the application that we consider in this paper, the data stream is finite. We use the notation to indicate the total number of frames in the data stream.
II-B Topological Spaces
Throughout the paper, we will be using to refer to the set of natural numbers and to real numbers. In the following, for completeness, we present some definitions and notation related to topological spaces and the logic which are adopted from Gabelaia et al. (2005) and Kontchakov et al. (2007). Later, we build our definition on this notation.
Definition II.1 (Topological Space)
A topological space is a pair in which is the universe of the space, and is the interior operator on . The universe is a nonempty set, and satisfies the standard Kuratowski axioms where :
We denote (closure) as the dual operator to , such that for every . Below we list some remarks related to the above definitions:
-
•
is the interior of a set ,
-
•
is the closure of a set ,
-
•
is called open if ,
-
•
is called closed if ,
-
•
If is an open set then its complement is a closed set and vice versa,
-
•
For any set , its boundary is defined as ( and its complement have the same boundary),
II-C Image Space Notation and Definitions
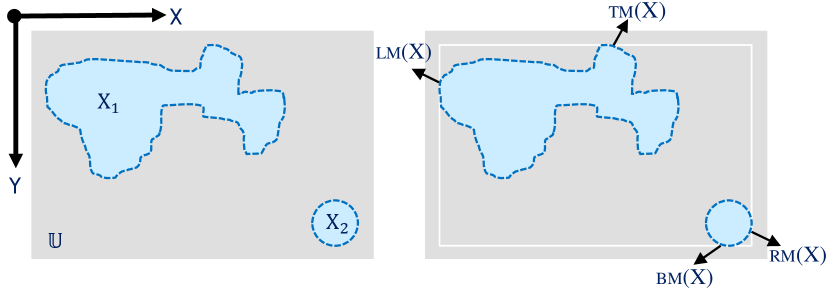
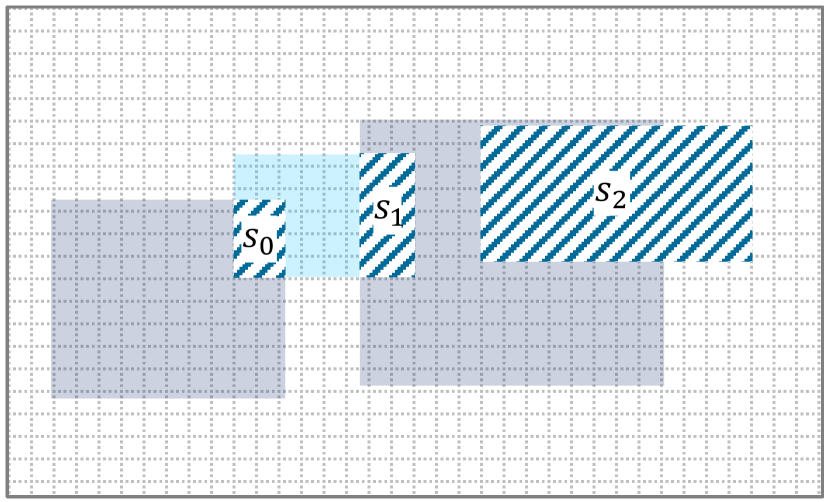
Even though our work is general and applies to arbitrary finite dimensional spaces, our main focus is on 2D and 3D spaces as encountered in perception systems in robotics. In the following, the discussion focuses on 2D image spaces with the usual pixel coordinate systems. In Figure 2 left, a closed set is illustrated as the light blue region, while its boundary is a dashed-line in darker blue.
Definition II.2 (Totally-ordered Topological Space)
A Totally-ordered (TO) topological space is a topological space that is equipped with a total ordering relation . That is, either or .
Definition II.3 (Total order in 2D spaces)
In a two-dimensional (2D) TO topological space , denotes its coordinates in the Cartesian coordinate system, where . For , the ordering relation is defined as:
Note that even though Def. II.3 considers the coordinates over the reals, i.e., , in practice, the image space is defined over the integers, i.e., (pixel coordinates). The topological space in Figure 2 consists of the universe which is all the pixels that belong to the whole 2D gray-rectangle and the closure operator that for any set of regions includes their edges. Assume that the left-upper corner of the image is the origin of the Cartesian coordinate system, and the and the are along the width and height of the image, respectively. This is the standard coordinate system in image spaces. Then, any pixel that belongs to the universe has an order with respect to the other pixels. For example, consider in Fig. 2, then all the pixels that belong to have higher orders than those in .
Definition II.4 (Spatial Ordering Functions)
Given a closed set from a 2D TO topological space , we define the top-most, bottom-most, left-most, right-most, and center-point functions by , respectively such that
is the center point of the rectangle defined by , , , and points.
In Def. II.4, the notation for a set denotes the set of all subsets of , i.e., the powerset of . In Figure 2, we have identified the left-most, right-most, bottom-most, and right-most elements of the set using the , , and function definitions. The right rectangle in Figure 2 is the tightest bounding box for the set , and it can be derived using only those four points.
II-D Spatio-Temporal Logic MTL
Next, we introduce the logic MTL over discrete-time semantics. MTL is a combination of Metric Temporal Logic (MTL) (Koymans (1990)) with the logic of topological spaces. From another perspective, it is an extension to the logic PTL (see Gabelaia et al. (2005)) by adding time/frame intervals into the spatio-temporal operators. Even though MTL is a new logic introduced in this paper, we present it in the preliminaries section in order to gradually introduce notation and concepts needed for STPL. In this paper, we use the Backus-Naur form (BNF) (see Perugini (2021)) which is standard for providing the grammar when we define the syntax of formal and programming languages.
In the following, we provide the formal definitions for MTL. Henceforth, the symbol refers to a spatial proposition, i.e., it represents a set in the topological space. In addition, the symbol represents spatial expressions that evaluate to subsets of the topological space. We refer to as a spatial term.
Definition II.5 (Syntax of MTL as a temporal logic of topological spaces)
Let be a finite set of spatial propositions over , then a formula of can be defined as follows:
where is a spatial proposition.
In the above definition, the grammar for MTL consists of two sets of production rules and . The spatial production rule in Def. II.5 contains a mix of spatial () and spatio-temporal () operators. Here, is the spatial complement of the spatial term , is the spatial intersection operator, and is the spatial interior operator. The and operators are the spatio-temporal until and the spatio-temporal next, respectively. Here, the subscript denotes a non-empty interval of and captures any timing constraints for the operators. When timing constraints are not needed, then we can set , or remove the subscript from the notation. Intuitively, the spatio-temporal until and next operators introduce spatial operations over time. For instance, the expression computes the union over all sets resulting by the intersection of each occurrence of set at some time in the interval with all the sets up to that time (see Def. II.6 for more details). We refer to the spatio-temporal operators and , as Spatio-Temporal Evolving (STE) operators. Also, we call a formula STE if it has STE operators in it. Similarly, we call a spatio-temporal formula Spatial Purely Evolving (SPE) if there is no STE operator in the formula. For more information refer to the (OC) and (PC) definitions by Gabelaia et al. (2005).
In the production rule in Def. II.5, the spatially exists checks if the spatial term following it evaluates to a non-empty set. That is, checks if there exist some points in the set represented by . In , except for the spatially exists , the other operators are the same as in MTL. That is , , and are the negation, conjunction, timed until, and next time operators, respectively (see the review by Bartocci et al. (2010)). As an example of a simple formula in MTL, the expression is true if the set represented by is nonempty at some point in time between and until then the set represented by is non-empty.
In the following, we define the bounded discrete-time semantics for MTL. The definition uses the spatial semantics of while extending the temporal fragment (PTL) with time constraints over finite traces as in MTL. The semantics are defined over a data-object stream . However, for consistency with PTL, we will assume the existence of a spatio-temporal valuation function that associates with every proposition and time frame a subset of the topological space. In the definition of STPL in Section IV, the sets will correspond to identified objects in the environment, i.e., bounding boxes, bounding rectangles, or even regions in semantic segmentation. In this section, the the sets are just arbitrary subsets of the universe.
Definition II.6 (Quantified Topological Temporal Model and Valuation)
A Quantified Topological Temporal Model (QTTM) is a tuple of the form , where is a TO topological space, is a spatio-temporal valuation function, is a data-object stream of size , maps frame numbers to their physical times, and is any non-empty interval of over time.
Given a model , the valuation function represents a subset of the topological space that is occupied by spatial proposition in the ’th frame (e.g., is the captured time). The valuation is inductively extended to any formulas that can be produced by the production rule in the Def. II.5 as follows:
where .
The valuation function definition is straightforward for the spatial operations, i.e., ; is just applying the corresponding set theoretic operations, i.e., . The more interesting cases are the spatio-temporal () operators. The spatial-next operator first checks if the next sample satisfies the timing constraints, i.e., , and if so, it returns the set that represents at time . The spatial until is a little bit more involved and it is better explained through derived operators. In the following, we define some of the commonly used derived operators:
-
•
The spatially for all operator checks if the spatial expression represents a set which is the same as the universe:
-
•
The spatial union operator:
-
•
The spatial closure operator:
-
•
The spatial eventually operator: ,
-
•
The spatial always operator: .
Notice that in the definition of the spatial eventually operator, we used the universe set as a terminal even though the syntax in Def. II.5 does not explicitly allow for that. The universe () and the empty set () can be defined as derived spatial expressions, i.e., and . Therefore, if we replace in the definition of for , we can observe that corresponds to the spatial union of the expression over the time interval .
Example II.2
A simple example is presented in Fig. 3 for a data-stream with 4 frames. The spatial expression corresponds to the union of all the sets represented by over time (gray set in Fig. 3) since there are no timing constraints. On the other hand, the spatial expression corresponds to the intersection of the sets of at frames since the last frame () with does not satisfy the timing constraints . The set is represented as a black box in Fig. 3.
Given the definition of the valuation function for QTTM, we can proceed to define the semantics of MTL. Recall that the valuation of spatial expressions returns sets from some topological space. On the other hand, MTL formulas are interpreted over Boolean values True () / False (), i.e., the formulas are satisfied or are not satisfied. To evaluate MTL formulas, we use a valuation function which takes as an input an MTL formula , a data stream , a sample , and a timestamp function , and returns True () or False ().
Definition II.7 (MTL semantics)
Given an MTL formula , a QTTM , and a frame , the semantics of are defined recursively as follows:
Notice that the definitions of the propositional and temporal operators closely match the definitions of the spatial and spatio-temporal operators where set operations (union and intersection) have been replaced by Boolean operations (disjunction and conjunction). Therefore, similar to the spatial expressions, we can define disjunction as ), eventually as , and always as . Finally, the constant true is defined as .
Remark II.8
In some specifications, it is easier to formalize a requirement using frame intervals and reason over frames rather than time intervals. To highlight this option, we add a tilde on top of the spatio-temporal operators with frame intervals, i.e., in , , , and the interval is over frame interval. When reasoning over frames, equals , i.e., is the identity function.
Example II.3
Revisiting Example II.2, we can now introduce and explain some MTL formulas. The formulas and evaluate to true since the sets and are not empty. On the other hand, the formula is false because the set that corresponds to is empty (in Fig. 3 there is no common subset for across all frames). Notice that the MTL formula is true since the set is not empty at every frame. Finally, considering time stamps versus frames, the set , which considers timing constraints, is the same as the set , which considers frame constraints.
III Problem Definition
Given a data stream as defined in II-A, the goal of this paper is to:
-
1.
formulate object properties in such a data stream, and
-
2.
monitor satisfiability of formulas over the stream.
III-A Assumptions
Given a data stream , we assume that a tracking perception algorithm uniquely assigns identifiers to classified objects for all the frames (see the work by Gordon et al. (2018)).
In order to relax this assumption, we need to enable probabilistic reasoning within the spatio-temporal framework, which is out of the scope of this work. However, our framework could do some basic sanity checks about the relative positioning of the objects during a series of frames to detect misidentified objects.
This assumption is only needed for some certain types of requirements and for the rest it can be lifted.
III-B Overall Solution
We define syntax and semantics of Spatio-Temporal Perception Logic (STPL) over sets of points in topological space, and quantifiers over objects. We build a monitoring algorithm over TPTL, MTL, and and show the practicality, expressivity and efficiency of the algorithm by presenting examples. This is a powerful language and monitoring algorithm with many applications for verification and testing of complex perception systems. Our proposed language and its monitoring algorithm are different than prior works as we discussed in the introduction (see also related works in Section VIII), and briefly summarized below. STPL
-
•
reasons over spatial and temporal properties of objects through functions and relations;
-
•
extends the reasoning of prior set-based logics by equipping them with efficient offline monitoring algorithm tools;
-
•
focuses on expressing functional requirements for perception systems; and
-
•
is supported by open source monitoring tools.
IV Spatio-Temporal Perception Logic
In this section, we present the syntax and semantics of the Spatio-Temporal Perception Logic (STPL). Our proposed logic evaluates the geometric relations of objects in a data stream and their evolution over time. Theoretically, any set-based topological space can be used in our logic. However, we focus on topological spaces and geometric operations relevant to applications related to perception.
Next, we are going to define and interpret STPL formulas over data-object streams. We define our topological space to be axis aligned rectangles in 2D images, or arbitrary polyhedral sets (potentially boxes) in 3D environments. An axis aligned rectangle can be represented by a set of two points that correspond to two non-adjacent corners of the rectangle with four sides each parallel to an axis. A polyhedral is a set formed by the intersection of a finite number of closed half spaces. We assume that this information is contained in the perception datastream as annotations or attributes for each object or region identified by the perception system. For instance, may store a rectangular axis-aligned convex-polygon that is associated with an object in the ’th frame. Alternatively, may store a convex-polyhedron. Without loss of generality, we will typically use definitions for 2D spaces (image spaces), and later in the case study, we will use bounding volumes (3D spaces).
IV-A STPL Syntax
The syntax of STPL is based on the syntax of TQTL (Dokhanchi et al. (2018a)) and (Gabelaia et al. (2005)).
In the context of STPL, the spatial propositions are the symbols that correspond to objects or regions in the perception dataset. We use the function symbol to map these objects to their corresponding sets. Hence, the syntax of spatial terms in STPL is the same as in MTL, but the function symbols replace the spatial propositions . In addition, we add grammar support under production rule for area computation for spatial terms. Area computation is needed in standard performance metrics for 2D vision algorithms, for example to compute union over intersection (UoI). In the same spirit, we can also support volume computation for spatial terms in 3D spaces.
For many requirements, we also need to access other attributes of the objects in the datastream, e.g., classes, probabilities, estimated velocities, or even compute some basic functions on object attributes, e.g., distances between bounding boxes. For usability, we define some basic functions to retrieve data and compute the desired properties. The functions which are currently supported are: object class (), class membership probability (), latitude () and longitude () coordinates of a point (), area of bounding box (), and distance () between two points (). We provide the syntax for using such functions under the production rule .
This set of functions is sufficient to demonstrate the generality of our logic. However, a more general approach would be to define arithmetic expressions over user definable functions which can retrieve any desired data from the datastream. Such functionality support is going to be among the goals of future software releases.
Definition IV.1 (STPL Syntax over Discrete-Time Signals)
Let and be sets of time variables and object variables, respectively.
Assume that is a time variable,
is an object variable,
is any non-empty interval of over time.
The syntax for Spatio-Temporal Perception Logic (STPL) formulas is provided by the following grammar starting from the production rule :
The syntax for spatial terms is:
The syntax for the functions that compute the area of a spatial term are:
The atomic propositions that represent coordinates for a bounding box are:
| CRT |
The syntax for spatio-temporal functions are:
The syntax for the STPL formula is:
where is the symbol for true, , and , and are constants. Here, is a function that maps object variables into spatial propositions.
The syntax of STPL is substantially different from the syntax of MTL. In the STPL syntax, stands for the freeze time quantifier. When this expression is evaluated, the corresponding frame is stored in the clock variable . The prefix in the rule or the rule is the Existential object quantifier. When the formula is evaluated, then it is satisfied (true) when there is an object at frame/time that makes true. The formula is also searching for an object that makes true, but in this case we do not need to refer to the time that the object was selected. Similarly, the Universal object quantifier is defined as or . The universal quantifier requires that all the objects in a frame satisfy the subformula . Notice that the syntax of STPL cannot enforce that all uses of time or object variables are bound, i.e., declared before use. In practice, such errors can be detected after the parse tree of the formula has been constructed through a simple tree traversal.
In contrast to MTL, the timing constraints in STPL are not annotating the temporal operators, but rather they are explicitly stated as arithmetic expressions in the formulas. For example, consider the specification “There must exist a car now which will have class membership probability greater than 90% within 1.5 sec”. With timing constraints annotating the temporal operators, the requirement would be:
Since STPL uses time variables and arithmetic expressions to express timing constraints, the same requirement may be written as:
The use of time variables enables the requirements engineer to define more complex timing requirements and to refer to objects at specific instances in time. The time, frame, and object constraints of STPL formulas are in the form of , , and , respectively. We denote and to refer to the elapsed time and frames, respectively. Note that we use the same variable to refer to the freeze time and frame, but distinguish their type based on how they are used in the constraints ( represents the current time, and represents the current frame number). The operator in the expression is used to specify periodic constraints. For reasoning over the past time, we added (previous) and (since) operators as duality for the and operators, respectively.
For STPL formulas , , we define , (False), ( Implies ), ( releases ), ( non-strictly releases ), (Eventually ), (Always ) using syntactic manipulation.
Remark IV.2
In principle, in STPL, it is easy to add multiple classes and classification probabilities for each object. We would simply need to replace in Def. IV.1 the rules
in with
where is now a function which returns a set of classes for the object. In order to write meaningful requirements over multiple classes, we would also need to introduce quantifiers over arbitrary sets. That is, we should be able to write a formula such as “there exists at least one class with probability greater than ”: . This is within the scope of First Order Temporal Logics (e.g., see Basin et al. (2015) and Havelund et al. (2020)) and we plan to consider such additions in the future.
In general, the monitoring problem for STPL formulas is PSPACE-hard (since STPL subsumes Timed Proposition Temporal Logic (TPTL); see Markey and Raskin (2006)). However, there exists a fragment of STPL which is efficiently monitorable (in polynomial time).
Definition IV.3 (Almost Arbitrarily Nested Formula)
An Almost Arbitrarily Nested (AAN) formula is an STPL formula in which no time or object variables are used in the scope of another freeze time operator.
For example,
are AAN formulas. In formula , the time variable is not used in the scope of the freeze time operator. In formula , there is no nested quantifier/freeze time operators. Therefore, they are both ANN STPL formulas. On the other hand,
are not AAN formulas. That is because in , the variable is used in the scope of the nested quantifier operator “”. In , the is used in the scope of the second nested quantifier operator “”.
The authors in Dokhanchi et al. (2016) presented an efficient monitoring algorithm for TPTL formulas with an arbitrary number of independent time variables. Our definition of AAN formulas is adopted from their definition of encapsulated TPTL formulas that are TPTL formulas with only independent time variables in them.
Remark IV.4
Our definition of AAN formulas is syntactical. However, there can be syntactically AAN formulas that can be rewritten as semantically equivalent non-AAN formulas. There are other ways to define formulas that are not syntactically ANN but semantically equivalent to AAN formulas. The precise mathematical definitions of these formulas is beyond the scope of this paper. In the following, we will show examples of AAN formulas and some other formulas that are equivalent to AAN formulas. For example,
which is not an AAN formula can be rewritten as AAN
On the other hand, although
is not an AAN formula, our monitoring tool supports it since the clock variables are not used. That is, it can be written as:
IV-B STPL Semantics
Before getting into the semantics of the STPL, we represent spatio-temporal function definitions that are used in production rules and . The definitions of these functions are independent of the semantics of the STPL language, and therefore, we can extend them to increase the expressivity of the language.
IV-B1 Spatio-Temporal Functions
We define functions as follows:
-
•
Class of an object:
returns the as the class of the object in the ’th frame, where if is specified, and otherwise. -
•
Probability of a classified object:
returns the as the probability of the object in the ’th frame, where if is specified, and otherwise. -
•
Distance between two points from two different objects:
computes and returns the Euclidean Distance between the point of the object and point of the object in the ’th and ’th frames, respectively; and we have if is specified, and otherwise, and if is specified, and otherwise. -
•
Lateral distance of a point that belongs to an object in a coordinate system (for image space, see section II-C):
computes and returns the Lateral Distance of the CRT point of the object in the ’th frame from the Longitudinal axis, where if is specified, and otherwise. -
•
Longitudinal distance of a point that belongs to an object in a coordinate system (for image space, see section II-C):
computes and returns the Longitudinal Distance of the CRT point of the object in the ’th frame from the Lateral axis, where if is specified, and otherwise. -
•
Area of a region:
computes and returns the area of an spatial term if is specified, otherwise it returns unspecified.
In the above functions, we use identifier variables to refer to objects in a data stream. Some parameters are point specifiers to choose a single point from all the points that belong to an object. The only function with a spatial term as an argument is the area function that calculates the area of a 2D bounding box. Similar reasoning for a 3D geometric shape (polyhedra in general) using a volume function is possible. This is supported by our open-source software STPL (2023), but we don’t provide formal definitions here for the brevity of the presentation.
All the functions have , , and as arguments. Functions need the data stream to access and retrieve perception data, the frame number to access a specific frame in time (“current” frame), a data structure (typically referred to as “environment”) to store and retrieve the values assigned to variables (both for time and objects), and, finally, a data structure to acquire the time/frame at which an object was selected through quantification. The data structure is used to distinguish whether the time that an object was selected is needed or not (see semantics for in Section IV-B2). For example, if we would like to store in the object variable , the value as the identifier of an object in a frame, and store in the frame variable x, the value as the frozen frame, then we would write
and
respectively. Similarly, we write
to denote that we store the frame number when the object variable was set. The initial data structures (environments) and are empty. That is, no information is stored about any object identifier of the clock variable. The environment is needed for the comparison of objects, probabilities, etc over different points in time, and environment is needed for the comparison of time/frame constraints and quantification of the object variables.
Note that the above functions are application dependent, and we can add to this list based on future needs. In the next section, when we introduce an example of 3D space reasoning, we present a new spatio-temporal function.
Definition IV.5 (Semantics of STPL)
Consider , as a topological temporal model in which is a topological space, is a spatial valuation function, is a data-object stream, is an object evaluating function, and is a frame-evaluating function. Here, is the index of current frame, is a mapping function from frame numbers to their physical times, (i.e., formulas belong to the language of the grammar of STPL), is a set of time variables, and is a set of object variables. The quality value of formula with respect to at frame i with evaluations and is recursively assigned as follows:
IV-B2 Semantics of Temporal Operators
IV-B3 Semantics of Past-Time Operators
Many applications require requirements that refer to past time. Past time operators are particularly relevant to online monitoring algorithms.
IV-B4 Semantics of Spatio-Temporal Operators
Now we define the operators and functions that are needed for capturing the requirements that reason over different properties of data objects in a data stream. Note that in some of the following definitions, we used to avoid rewriting the semantics we built up upon the syntax and semantics as part of logic. The semantics of STPL will be based on the valuation function of with the change that will now also accept the environments and , and we extend the definition of over the spatial term . That is, we replace in the semantics of the the valuation of spatial propositions with:
where if is specified, and otherwise. The semantics for the rest of the spatial operators are:
where , and “otherwise∗” has a higher priority to become true in the if statements if .
Note that we omit the semantics for some of the spatio-temporal operators in the production rule except the ones stated above due to their similarity to the semantics of the presented operators.
Definition IV.6 (STPL Satisfiability)
We say that the data stream satisfies the STPL formula under the current environment iff , which is equivalent to denote .
Note that by and , we reset all the variables to be empty. This enables the use of the presented proof system of TPTL by Dokhanchi et al. (2016).
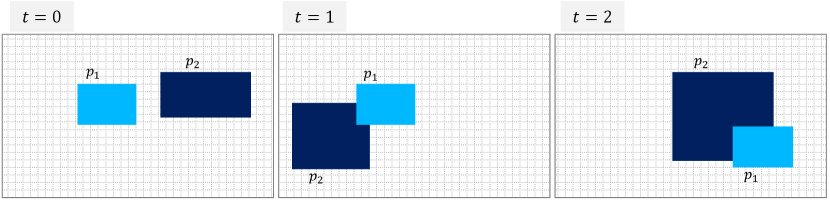
Example IV.1 (Evaluating a simple spatio-temporal STPL formula)
A sample data stream of three frames time stamped at times , , and is illustrated in Figure 4. We labeled rectangular geometric shapes in each frame by and , and will refer to them by and , respectively. Object does not change its geometric shape in all the frames, but evolves in each frame. The location of the is the same in the first two frames, but in the third frame, it moves to the bottom-right corner of the frame. The location of the changes constantly in each frame, that is, it first horizontally expands and moves to the bottom-left of the frame, and then expands horizontally and vertically and moves to the right-center of the frame. We are going to compute and evaluate the formula
according to the semantics in Def. II.6 and Def. IV.5. An English statement equivalent to the above formula is:
“There exist two objects and in the first frame such that, is non-empty in the first frame; or, for the next two frames, its intersection with in the previous frames is non-empty (given that does not change)”.
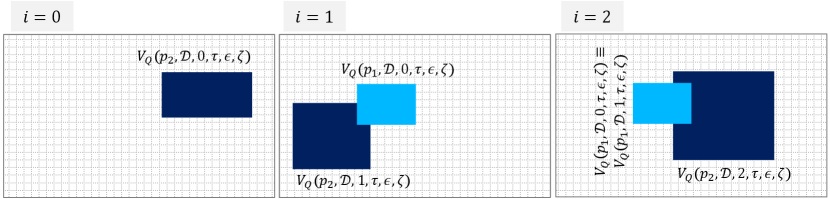
In Figure 5, we demonstrate the result of evaluating the subformula for to , where we assign to and from the four possible assignments. We used and to refer to and in each frame, respectively. That is, at is equivalent to . The evaluation of STPL formula starts with the following equation
where, and .
The evaluating of the until subformula is computed as below
where and .. The above formula is equal to the below disjunctive normal formula as shown in Fig. 5
The final evaluation of the above formula is depicted as hashed regions , and in Fig. 6. The union of the regions is a non-empty set, hence, the spatial existential operator returns true.
IV-C MTL/STL Equivalences in STPL
Below, we represent some rewriting rules to translate time interval based formulas in MTL/STL to their equivalent STPL formulas.
In the next section, we use specific examples of perception systems to explain each aspect of the logic individually gradually and later combined.
V Case Study
In this section, we are going to gradually demonstrate the expressivity of the STPL language using a sample perception data stream corresponding to the image frames in Figure 1. There are six frames in this case-study that are taken from the KITTI222http://www.cvlibs.net/datasets/kitti/ databases (Geiger et al. (2013a)). We adopt a perception system based on SqueezeDet by which some desirable classes of objects in image frames are recognized. The perception classifies an object as one class from three desirable classes Car, Cyclist, and Pedestrian. It also assigns to each detected object a confidence level (normalized between 0 and 1), and a bounding box that surrounds the object. We also manually associate a unique object identifier to the detected objects of each frame. The data is available to the object data stream function as represented in Table II, and visualized in the frames in Fig. 1.
In the following sections, we focus on STPL specifications that use quantifiers, and spatial and temporal operators. We present the formalization of 15 requirements in total. A highlight is the STPL formula (16) that formalizes Req. 15 and its utilization on the KITTI dataset in our monitoring tool. Our monitoring tool was able to detect some mismatches in the labeled data. All of the STPL formulas and their monitoring result except the last two are distributed with our monitoring framework (STPL (2023)).
Note that in the rest of the sections, when we translate a requirement into STPL, we will refer to the following assumptions. These assumptions enable us to write smaller formulas. They can be relaxed at the expense of more complex requirements.
Assumption V.1
There are different perception modules to detect, track and classify the objects. That is, the object detector detects objects, and the object tracker assigns unique identifiers to the detected objects, and the classifier assigns classes to the detected objects.
Assumption V.2
Object detector always detects objects.
Assumption V.3
Each detected and tracked object has a unique id.
The tracker can check the detected objects through the sequence of frames but it does not imply that the classifier will assign the same class to them in all the frames. If we cannot assume the existence of unique IDs on the same object, then we can still write requirements in a more complicated form to achieve more conservative results. For example, in the requirements that follow (Req 3-18), whenever we check for the presence of the same ID, e.g.,
then this precondition can be replaced with one where we quantify over all objects that intersect with the original object in the previous frame, e.g.,
Notice the increase in complexity between the two formulas. In , we just need to store the ID of the object in and just check if in the future there is another object () with the same ID. In , we need to store the time that we observed the object , so that we can retrieve its bounded box and check for intersection with future objects along with checking the agreement of classes. Clearly, and are not syntactically or semantically equivalent. Nevertheless, under the assumption of sufficient sampling rate, then the objects that satisfy will also satisfy . There exist other possible formulas under which we can relax the requirement for persistent unique IDs. However, in the following presentation, we will always be using the assumptions that result in the simplest STPL formulas.
For the requirements that are formalized into STPL in the rest of this section, we used our STPL monitoring tool to apply the data stream in Table II to each STPL formula, and presented the result in Table I.
* We used the dataset “0018” from KITTI tracking benchmark for evaluating formula in Eq.(16).
V-A Object Quantifier Examples
First, we present a requirement that enables search through a data stream to find a frame in which there are at least two unique objects from the same class.
Req. 3
There is at least one frame in which at least two unique objects are from the same class.
STPL (using all the assumptions):
| (1) |
In the above formula, the object variable constraint requires a unique assignment of object identifiers to the variables and . Additionally, the equivalence proposition is valid only if the classes of a unique pair of objects are equal. Also, the existential quantifier requires one assignment of objects to the object variables that satisfy its following subformula. Lastly, the eventually operator requires one frame in which its following subformula is satisfiable.
Checking the Formula on Real Data:
From the data stream in Table II, and as depicted in the frames in Fig. 1, the frame numbers 0, 2 and 3 have two pedestrians, and frame number 3 has two cars in them. Therefore, the formula is satisfiable for the given object data stream and we can denote it as . Note that we can push the operator after the existential quantifier (i.e., ) and still expect the same result.
V-B Examples with Time Constraints
Next, we formalize a requirement in which we should use nested quantifiers and time/frame constraints in our formalization.
Req. 4
Always, for all objects in each frame, their class probability must not decrease with a factor greater than 0.1 in the next two seconds, unless Frame Per Second (FPS) drops below 10 during the first second.
Notice that the function “” is not directly allowed by the syntax of STPL (Def. IV.1). However, the arithmetic expression uses a single freeze time variable and, hence, its evaluation is no more computationally expensive than of the individual expressions “” and “”. We remark that the function Ratio introduces the possibility of division by zero. In the formula , the issue is avoided in the specification by using the next time operator (). However, an implementation of the function Ratio should handle the possibility of division by zero. The subformula searches for a vehicle for which within 2 sec in the future, i.e., (), its classification probability drops below the desired threshold. Notice that with the expression , we compare probabilities for the same object across different points in time. The subformula checks whether within 1 sec in the future the FPS drops below 10. The implication enforces that if there is a vehicle for which the classification probability drops, then at the same time the FPS should be low.
Checking the Formula on Real Data:
Except for the object with in the first frame in Table II, the rest of the objects satisfy the requirement. Therefore, the whole requirement is not satisfiable, that is . Formula (2) is too strict. That is, it checks the maximum allowed drop in probabilities for a classified object in all the frames rather than for the newly classified objects. For example, assume a sample data stream of size three with only one object classified as a car with the probabilities , , during the first, second, and third frames, respectively. Formula (2) without the always operator is not satisfiable starting from the second frame (more than probability decrement), but satisfiable for the first and the last frame.
We can relax Formula (2) by adding a precondition to the antecedent of the implication to only consider the newly detected objects. The relaxed requirement is possible by using the weak previous operator . The weak previous operator does not become unsatisfiable in the first frame on a data stream where there is no previous frame. Similarly, by , we denote the weak next operator. It is similar to the next operator, but it does not become unsatisfiable in the last frame on a finite data stream. For more information about weak temporal operators and past LTL see the works by Eisner and Fisman (2006) and Cimatti et al. (2004), respectively.
The following formula is a revised version of Formula (2):
In formula , the antecedent subformula checks if an object did not exist in the previous frame. Therefore, the consequent is only checked for new objects that appear in the frame for the first time.
Req. 5
Always, each object in a frame must exist in the next 2 frames during 1 second.
Similar to the previous example, the equalities that need to hold are in the consequent of the second implication, but its antecedent is a conjunction of time and frame constraints. In this formula, there is a freeze time variable after the first quantifier operator, which is followed by an always operator. Thus, the constraints apply to the elapsed time and frames between the freeze time operator and the second always operator. Therefore, for any three consecutive frames, if the last two frames are within 1 second of the first frame, then all the objects in the first frame have to reappear in the second and third frames.
Running Formula in Real Data Stream:
The same result as in the previous example holds here for the data stream in Table II that is .
Below, we translate the requirement previously presented as in Req. 1.
Req. 6
Whenever a new object is detected, then it is assigned a class within 1 sec, after which the object does not change class until it disappears.
STPL (using Assumptions V.1-V.3):
| (5) |
where the subformulas are defined as:
In the above formula, we evaluate the two implication-form subformulas for any objects in all the frames. If there is an object that is not classified (i.e., ), then we check the consequence of the corresponding subformula. The subformula corresponding to the subformula requires that when an unclassified object was observed, then eventually in less than a second afterward, the object always has a class being assigned to it. If there is an object that is already classified, then the second predicate has to be evaluated. The subformula equivalent to the requires that when a classified object was observed, then afterward the same object only can take the same class.
Running Formula in Real Data Stream:
In the frame in Table II, the object with changes its class from cyclist to pedestrian. Therefore, the data stream does not satisfy the requirement .
| Frame | ID | Class | Prob | |||||
| 0 | 0 | 1 | car | 0.88 | 58 | 151 | 220 | 287 |
| 0 | 0 | 2 | cyclist | 0.75 | 479 | 124 | 690 | 382 |
| 0 | 0 | 3 | pedestrian | 0.63 | 522 | 130 | 632 | 377 |
| 0 | 0 | 4 | pedestrian | 0.64 | 861 | 133 | 954 | 329 |
| 1 | 0.04 | 1 | car | 0.88 | 61 | 152 | 217 | 283 |
| 1 | 0.04 | 2 | cyclist | 0.57 | 493 | 111 | 699 | 383 |
| 1 | 0.04 | 3 | pedestrian | 0.64 | 877 | 136 | 972 | 330 |
| 2 | 0.08 | 1 | car | 0.89 | 58 | 143 | 220 | 271 |
| 2 | 0.08 | 2 | pedestrian | 0.65 | 511 | 107 | 724 | 367 |
| 2 | 0.08 | 3 | pedestrian | 0.64 | 911 | 115 | 1001 | 340 |
| 3 | 0.12 | 1 | car | 0.92 | 56 | 139 | 216 | 266 |
| 3 | 0.12 | 2 | cyclist | 0.59 | 493 | 111 | 705 | 380 |
| 3 | 0.12 | 3 | pedestrian | 0.72 | 541 | 125 | 649 | 351 |
| 3 | 0.12 | 4 | car | 0.58 | 926 | 107 | 1004 | 302 |
| 3 | 0.12 | 5 | pedestrian | 0.76 | 938 | 118 | 998 | 332 |
| 4 | 0.16 | 1 | car | 0.91 | 53 | 139 | 217 | 265 |
| 4 | 0.16 | 2 | pedestrian | 0.80 | 551 | 126 | 658 | 356 |
| 5 | 0.2 | 1 | car | 0.92 | 52 | 140 | 216 | 264 |
| 5 | 0.2 | 2 | cyclist | 0.62 | 506 | 104 | 695 | 368 |
| 5 | 0.2 | 3 | pedestrian | 0.68 | 552 | 115 | 669 | 362 |
V-C Examples of Space and Time Requirements with 2-D Images
In the following examples, we want to demonstrate the expressivity and usability of the STPL language to capture requirements related to the detected objects and their spatial and temporal properties.
V-C1 Basic Spatial Examples without Quantifiers.
Let us assume that we have a spatial proposition as in Fig. 3.
Example V.1
One way to formalize that the sampling rate is sufficient is to check if the bounding box of an object overlaps with itself across consecutive frames. The following requirement can be used as a template in more complex requirements.
Req. 7
The intersection of a spatial predicate with itself across all frames must not be empty.
STPL:
| (6) |
The above requirement is clearly too strict. In order to make the requirement more realistic, we introduce frame intervals (see Rem. II.8) and also use quantification over objects. If we change the above requirement to: “All the objects in all the frames must intersect with themselves in the next three frames”, then we can modify Eq. (6) to the following:
| (7) |
Example V.2
It is interesting to check the occupancy of an object across a series of frames. This can be used for identifying regions of interest.
Req. 8
The union of a spatial proposition with itself in all the frames is not equal to the universe.
STPL:
| (8) |
The result of applying the formula on a sequence of three frames is shown in Fig. 3. The resulting set is not equal to the universe; hence; the formula evaluates to true.
V-C2 Basic Spatial Examples with Quantifiers.
In the following examples, the spatial requirements cannot be formalized without the use of quantifiers.
Example V.3
We can check if some properties hold for all the objects across all the frames.
Req. 9
Always, all the objects must remain in the bounding box .
STPL (using Assumption V.2):
| (9) |
Running Formula in Real Data Stream:
The result of evaluating the above formula depends on the size and position of the bounding box. For example, if the bounding box is the same as the image frame in the data stream in Table II, then we have .
Example V.4
The combination of eventually/globally operators and a quantifier operator is very useful for specifying properties of an object across time.
Req. 10
Eventually, there must exist an object that at the next frame shifts to the right.
STPL (using Assumptions V.2-V.3):
| (10) |
Note that in the above formula, the is quantified in a freeze time quantifier to get access to the data-object values in the frozen time. If we change the first existential quantifier to the universal quantifier, then the formula represents the following requirement: “Eventually, there must exist a frame in which all the objects shift to the right in the next frame”.
Running Formula in Real Data Stream:
The data stream as in Table II satisfies the above formula . For example, the pedestrian with moved to the right in the frame . Note that the pedestrian and the recording camera both moved to the left, while the camera’s movement was faster.
Example V.5
The requirement below checks the robustness of the tracking algorithms in a perception system using time and spacial constraints.
Req. 11
If an object disappears from the right of the image in the next frame, then during the next 1 seconds, it can only reappear from the right.
STPL (using Assumptions V.2-V.3):
| (11) |
where
Note that in the above formula, the and are quantified in a nested freeze time quantifier structure, and hence, it is not an AAN formula. There, is a constant denoting the width of the image in pixels. This formalization will check the reappearance of an object even if it happened more than once. In order to force the formula to only check once for the reappearance of an object, one should use the release operator.
Checking the Formula on Real Data:
In Table II, in the third frame, the pedestrian with has disappeared in the fourth frame and reappeared in the last frame. However, the preconditions captured in subformula for that object do not hold assuming that for the data stream. That is the least position of the bounding box for the object with is in frame , and then it changes to in frame which violates the condition for shifting toward right before disappearing (the condition in the subformula ). Note that, from the second frame afterward, the tracking algorithm mixes the ID association to the objects, and as a result, the geometrical positions of the objects are not consistent. The inconsistent object tracking makes the subformula not hold for viable cases. Therefore, for the data stream in Table II, we have .






For the examples in the rest of this section, we focus on the real-time requirements that concern detected objects in perception systems.
Example V.6
The requirement below checks the robustness of the classification of the pedestrians in a perception system using time and spatial constraints.
Req. 12
If a pedestrian is detected with probability higher than in the current frame, then for the next second, the probability associated with the pedestrian should not fall below , and the bounding box associated with the pedestrian in the future should not overlap with another detected bounding box.
Running Formula in Real Data Stream:
In Table II, there is no pedestrian associated with probability higher than , therefore the data stream satisfies the above formula .
Example V.7
The requirement below represents a situation in which all the adversarial cars in the frames from the current time forward are moving at least as fast as the ego car and in the same direction.
Req. 13
Always all the bounding boxes of the cars in the image frames do not expand.
Running Formula in Real Data Stream:
In Table II, the bounding box of the car with has expanded in the frame . Therefore, the data stream does not satisfy the above formula .
To ease the presentation in the formalization of the requirements in the following examples, we introduce some derived spatial operators:
-
•
Subset:
-
•
Set equality:
Example V.8
We want to formalize a requirement specification that applies restrictions on the positions and movements of the adversarial and the ego car in all the image frames. The following requirement can be thought of as a template to be used within other requirements.
Req. 14
The relative position and velocity of all the cars are fixed with respect to the ego car.
STPL (using Assumptions V.2-V.3):
Notice that we quantify over all objects in the first frame (), and then we require that for all future times there is an object () with the same ID and bounding box. If in addition, we would like to impose the requirement on any new objects that we observe, then the formalization of the requirement would be:
| (14) |
Another formalization for the last requirements is
| (15) |
Running Formula in Real Data Stream:
All of the objects in Table II have different bounding boxes in different frames. Thus, the data stream does not satisfy the above formulas .
Example V.9
In this example, we represent a sample requirement for detecting occluded objects. The example is about a high confidence OBJECT which suddenly disappears without getting close to the borders. The requirement checks if such an object existed before and next disappeared, then it has to be occluded by a previously close proximity object.
Req. 15
If there exists a high confidence OBJECT, and in the next frame, it suddenly disappears without being close to the borders, then it must be occluded by another object.
STPL (using Assumptions V.2-V.3):
| (16) |
and the predicates are defined as:
In the above formulas, the subformula checks if the object identified by is close to the borders of the image frame at the current time, where , , , and are some integers. The subformula is to check if an object disappeared. In the subformula , the refers to the object which disappears in the next frame, and the refers to the object that occludes the other object. The spatial subformulas check if the bounding box of the two objects intersect each other in the current frame, or one bounding box in the current frame intersects with the other bounding box in the next frame. Similarly, we can formalize the occlusion without using STE operators by rewriting as below
| (17) |
Note that the second formalization is less realistic because it puts a threshold on the Euclidean distance (i.e., is a positive real number) between two objects to infer their overlap.
Running Formula in Real Data Stream:
All the objects in Table II are close to the borders of the images, and the data stream does not satisfy the subformula . Therefore, the data stream satisfies the the above formula .
In the following, we used the above formula to partially validate the correctness of a training data stream that is used for object tracking.
Running Formula in Real Data Stream:
We used the formula in Eq. (16) to verify the correctness of the labeled objects as “largely occluded” in the KITTI tracking benchmark. From the 21 datasets, except for 4 of them (i.e., datasets “0013”, “0016”, “0017”, and “0018”), we detected inconsistencies in labeling objects as “largely occluded”. For example, in the dataset “0008” (to refer to as data stream ), we identified 3 frames in each a car was labeled as “largely occluded”, while they were inconsistent with the rest of the occluded labels. That is, we have . Our STPL monitoring tool detected the wrong labels by applying the STPL formula in Eq. (16) on the data stream in less than 2 seconds. The result of this experiment is shown in the Figure 4. We provide all the datasets as part of our monitoring tool.
Below, we translate the requirement previously presented as in Req. 2.
Req. 16
The frames per second of the camera is high enough so that for all detected cars, their bounding boxes self-overlap for at least 3 frames and for at least 10% of the area.
We interpret the above requirement to require an overlap check over a batch of three frames rather than three consecutive frames.
STPL (using Assumptions V.2-V.3):
| (18) |
In the above formula, the spatial subformula is in the form of a non-equality ratio function. Its first parameter represents an occupied area for the intersection of the bounding boxes of any two objects and referred to by and , respectively. The second parameter denotes the area for . For the non-equality to be satisfiable, first, there must be a non-empty intersection between the two objects. Second, the ratio of the intersected area to the area of the second object must be at least .
Running Formula in Real Data Stream:
The data stream in Table II satisfies the above formula .
V-D Examples of Space and Time Requirements with 3D environment
V-D1 Missed classification scenario

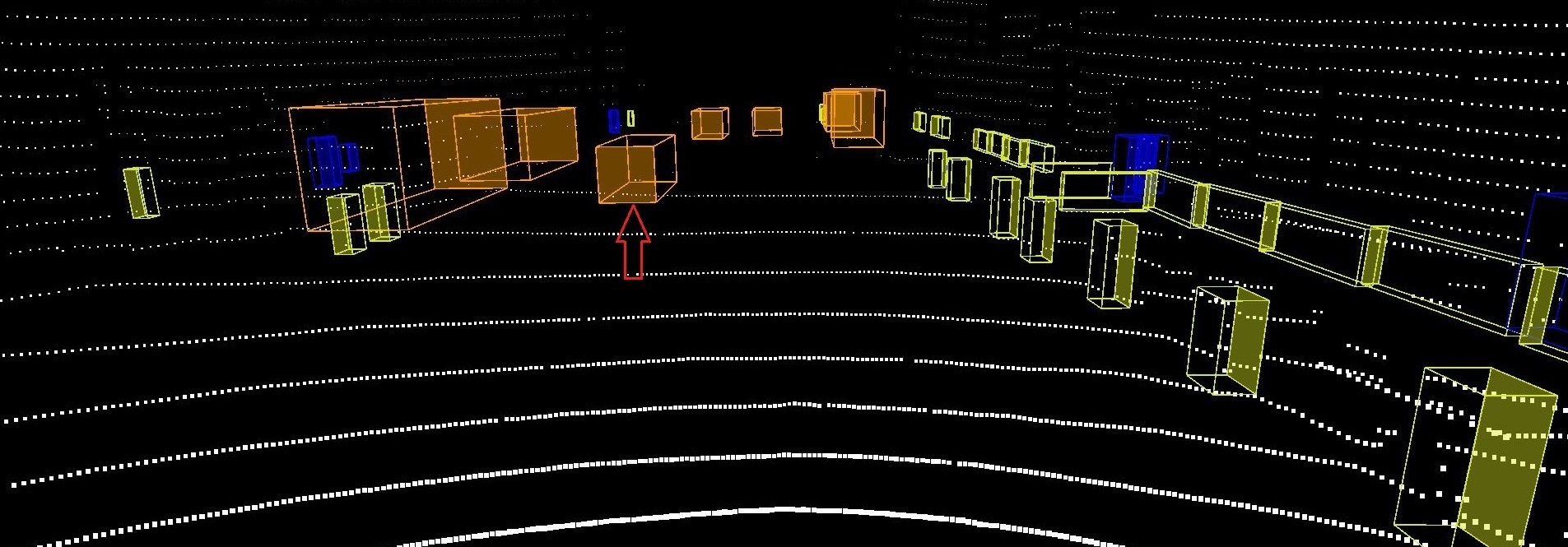




Here, we are going to show by example how 3D reasoning is possible using STPL. Specifically, we are going to show by example if the perception system misses some important objects. The six images in Figure 8 illustrates annotated information of two consecutive frames that are taken from nuScenes-lidarseg555https://www.nuscenes.org/nuscenes?sceneId=scene-0274&frame=0&view=lidar dataset (Caesar et al. (2020)). For each detected class of objects, they adopt color coding to represent the object class in the images. The color orange represents cars, and the color cyan represents drivable regions. The color-coded chart of the classes, along with their frequency in the whole dataset can be found online (Motional (2019)). In the first frame, at time , the LiDAR annotated image is shown in Fig. 8(a). The corresponding camera image for the LiDAR scene is shown in Fig. 8(c). There is a car in this image that we pointed to in a red arrow. As one can check, there is no point cloud data associated with the identified car in the LiDAR image, and as a result, it is not detected/recognized as a car. In the next images illustrated in Fig. 8(b,d), the undetected car at is identified and annotated as a car at time . Unlike before, there are some point cloud data associated with the car by which it was detected. The semantic segmentation of the corresponding images is shown in Fig. 8(e-f). First, we will discuss how to decide if there is a missed object in the datasets, similar to what we presented here. Second, we represent a requirement specification in STPL that can formalize such missed-detection scenarios.
Example V.10
For this and the next example scenarios, we have 3D coordinates of bounding volumes and 3D point clouds representing each detected object in the frames. However, the height of those points and cubes are not helpful in these cases, and therefore, we mapped them to the x-y plane by ignoring the z-axis of sensor positions (i.e., see Motional (2019)).
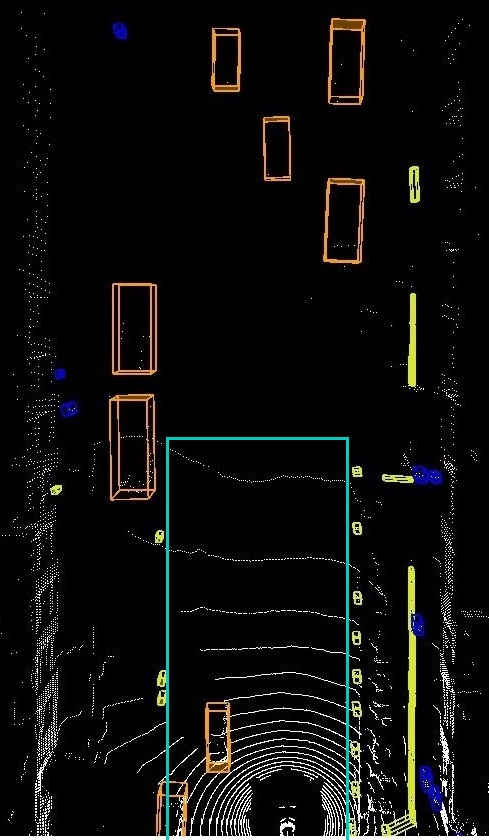
Let assume that the origin of the coordinate system is the center of the ego vehicle, and the y-axis is positive for all the points in front of the ego car, and the x-axis is positive for all the points to the right of the ego. That is, we have 2D bounding boxes of classified objects that are mapped to a flat ground-level environment as shown in Fig. 9. Therefore, we do not need to define new spatial functions for 3D reasoning.
Req. 17
If there is a car driving toward the ego car in the current frame, it must exist in the previous frame.
| (19) |
and the predicates are defined as:
Note that in the above 2D spatial functions, we used BM and TM in contrast to their original semantics in the previous examples due to the change of origin of the universe. Also, we assume that the perception system uses an accurate object tracker that assigns unique IDs to objects during consecutive frames. We used , , and to refer to a car in the current frame, a car in the previous frame, and the drivable region. Note that we needed to use the previous frame operator to check if an existing car was absent in the previous frame. That is, in , we check if the car identified by matches with the same car in the previous frame. The antecedent of the formula as in Eq. (19) holds in the current frame, but the consequent of it fails because the car that exists in the current frame did not exist in the previous frame. Thus, the data stream shown as image frames in Fig. 9 falsifies the formula.
It is more realistic to formulate the same requirement using lane-based coordinate systems, if the perception system detects different lanes. Consequently, we can simplify the subformula to encode if the cars drive in the same lane.
V-D2 3D occlusion scenario




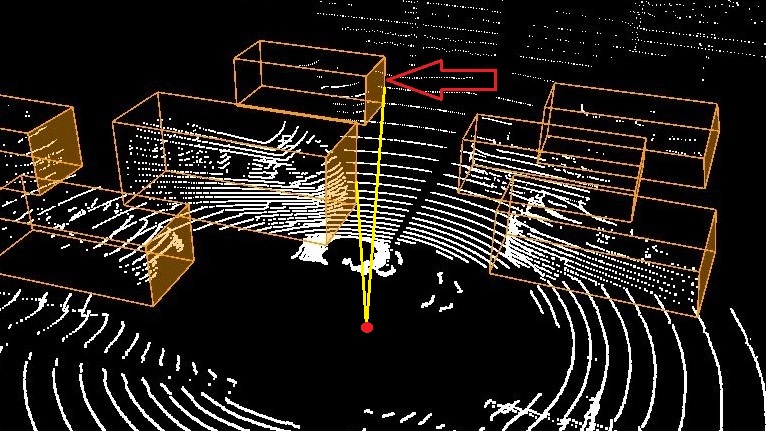
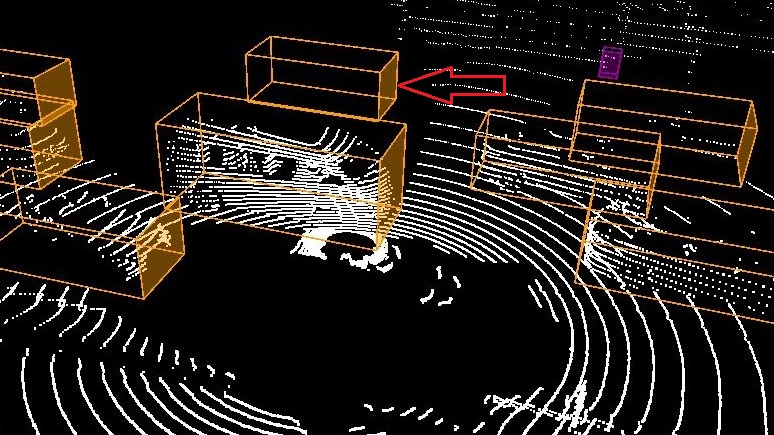
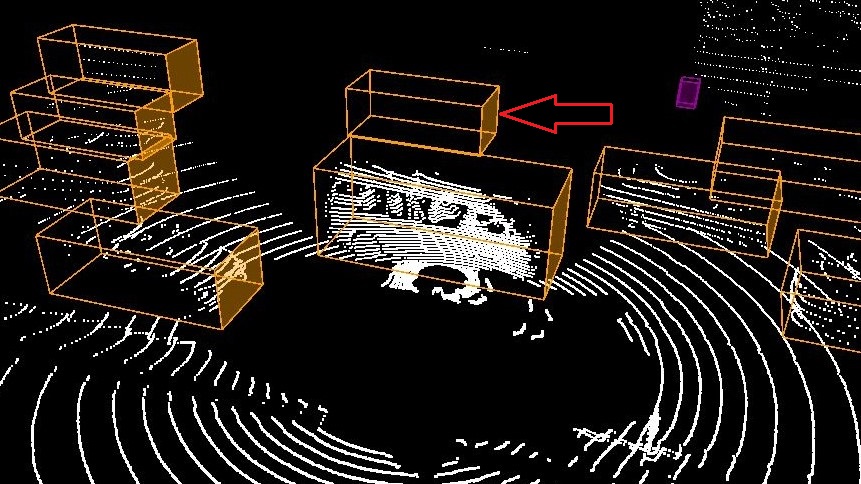
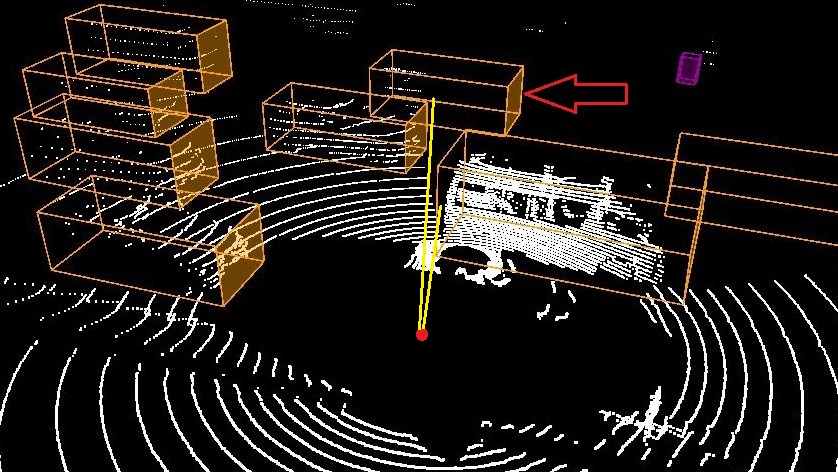
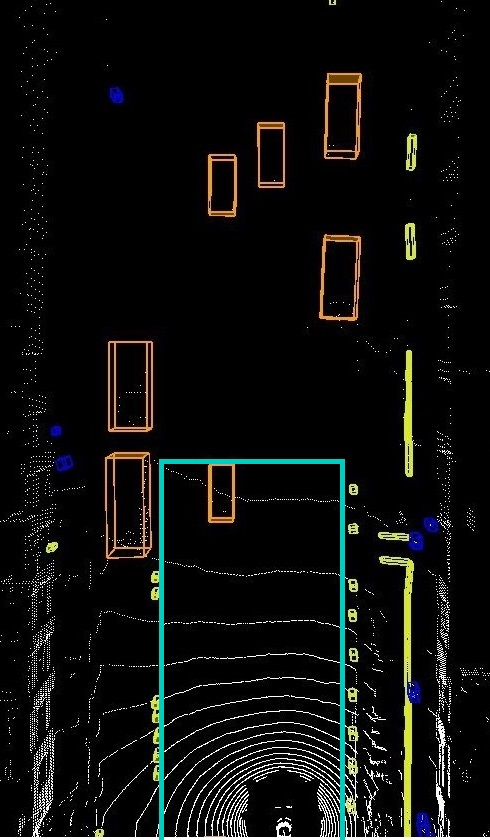
In Figure 10, there are four frames captured at to . In the second and third frames, an occluded car (pointed to a red arrow) is detected. The perception system detected a car for which there is no information from the sensors (the cubes in frames 2 and 3 are empty, and the cameras cannot see the occluded vehicle). Although this can be the desired behavior for a perception system that does object tracking, here we are going to formalize a requirement that detects similar cases as wrong classifications.
For this example, we need to define a new 3D spatial function Visible by which we can check if given two cars are visible from the view of a third car. Additionally, we need to add a data attribute Empty to the data-object stream that determines if a bounding volume of an object is empty (e.g., checks if there is no point could data associated with an object identified by ) or not. For instance, by we check if an object identified by in the ’th frame is empty. We use function as a new syntax that serves as above.
returns true if the and objects are visible from the view point CRT of in the ’th frame, where if is specified, and otherwise. If one or both are invisible from the viewpoint of object , then the function returns false.
Example V.11
The below requirement checks the robustness of the object detection in a perception system using spatial constraints and functions on point cloud data.
Req. 18
Any detected car (using the LiDAR data) driving the same direction on the left side of the ego car must include some point cloud data in its bounding volume unless it is occluded.
STPL (using Assumptions V.1-V.3):
| (20) |
In the above formula, we keep track of two cars using and that are to the left of the ego car (their distance has to be limited between 1 to 6 meters from the left side of the ego car). We assume that the perception system returns the moving direction of each classified object, and we use function to retrieve the direction for a given object identifier. Note that this function can be replaced by a spatial formula that uses the coordinates of an object in different frames to calculate its moving direction. The subformula requires a visible angle between the two cars from the point of view of the ego car (i.e., the center point of the ) to return true. We draw a sample visible angle in the first and fourth frames in yellow. For the two cars that we could find a visible angle for them in the first frame, there is none in frames 2 and 3. Additionally, there is no point cloud in the occluded car’s bounding volume in frames 2 and 3 that satisfies the whole formula until the implies operator. The consequence of the implication is a release formula to be satisfiable from the next time/frame. In the release formula, the right-hand side requires the occluded object to be empty, and only when it becomes visible again, it can be non-empty. The whole formula is satisfiable for the pair of cars we discussed here. The data stream shown as image frames in Fig. 10 satisfies the formula in Eq. (20).
VI Monitoring Algorithm
The offline monitoring algorithm for STPL is one of the main contributions of this work. We use a dynamic programming (DP) approach similar to Dokhanchi et al. (2016); Fainekos et al. (2012) since we are operating over data streams (timed state sequences). To keep the presentation as succinct as possible, we focus the presentation only to the future fragment of STPL. We divide our monitoring algorithm into four algorithms that work in a modular way. We present the pseudocode of the algorithms to analyze the worst case complexity of our STPL monitoring framework. In the following, we are going to use the formula
to explain some of the aspects of the future fragment of our monitoring algorithm.
VI-A Algorithm-1
This algorithm represents the main dynamic programming body of the monitoring algorithm. It receives an STPL formula , a data stream , and dynamic programming tables and . The formula is divided into subformulas as in the example in Fig. 11. That is, the formula is divided into subformulas based on the presence of freeze time operators () and spatial quantifiers (). It is important to note that the nested subformulas have lower index, e.g., is nested in as in Fig. 11. Notice that when we have subindexes, i.e., , we refer to the formula in the scope of ’th freeze variable and the ’th index from the root in the depth-first-search order.
The main loop of Algorithm 1 has 4 nested loops (lines 4-20). Further nested loops exist in (Algorithm 3). These nested loops are also the source of the computational complexity in our monitoring algorithm. The loops in lines 4 and 5 are responsible for exploring all possible assignments to the freeze time variables starting from the inner nested freeze time operators. Line 6 explores the data stream backward in time to resolve the future fragment of Linear Temporal Logic (LTL) and the terms. Lines 10-14 identify whether the subformula is a spatio-temporal operator and calls the respective function.
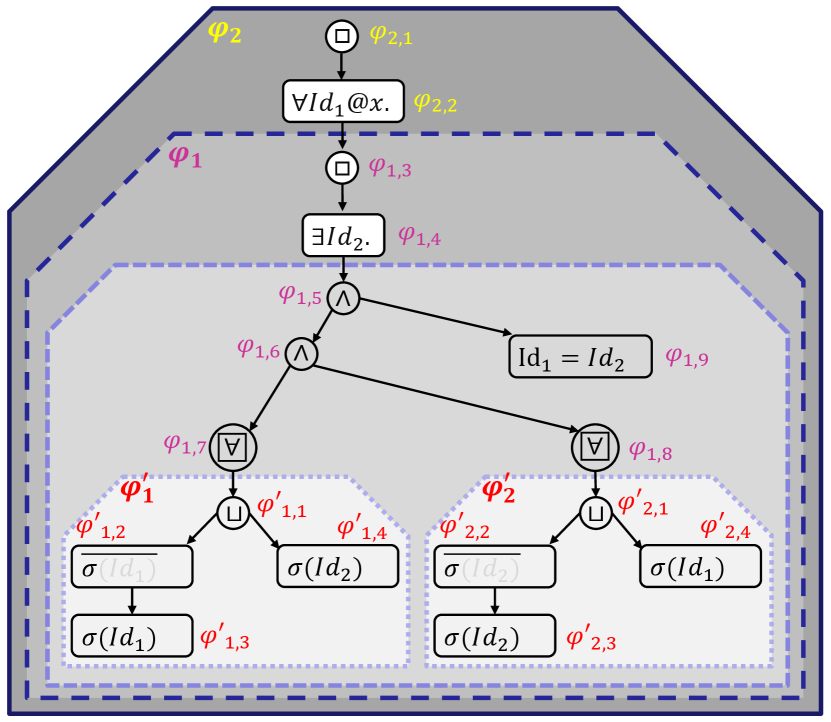
VI-B Algorithm-2
This algorithm computes the values of the DP table as defined in the temporal semantics of the STPL logic in Def. IV-B2. For a given subformula, first, it determines the operator and then fills the current columns of the DP tables accordingly. Most of the lines of the algorithm are straightforward where there is no DP table in the assignments. The idea of using the separate DP table for the freeze subformulas is to store the result of their evaluation at each frozen time, and then update the DP table accordingly. Table has two columns for each subformula, one for the current time and another for the next time. We use and to refer to the current column (current frame) for updating and the next column (next frame) for reading, respectively. Therefore, we need to toggle the value of these variables (between 0 and 1) to change the read column to write column and vice versa. Table has two rows for each frame, one for the current time and the other for the next time. We use and to refer to the current row for updating and the next row for reading, respectively. Therefore, we need to toggle the value of these variables (between 0 and 1) to change the read row to write row and vice versa. The data-member of the DP table keeps the current evaluating result of the ’th subformula at the current frame. The other data-members are used to update min/max values for the quantifier operators. The data-member is a table of size , where is the maximum number of objects in all input frames, and is the set of the variables in the scope of the evaluating subformula . In Alg. 2, the only computationally expensive part is the update of the table in line 24. In practice, the table update is not an issue since the number of variables is not high (at most 4-5 object variables in the examples in this paper) and the table update can be parallelized.
Input: , ; Global variables: , ; Output: .
Comments:
is a table used to store the evaluation of spatial subformulas. For all the tables, the out-of-index accesses are handled case by case (i.e., or is a default value)
Procedure STPL-Monitor(, )
end procedure
VI-C Algorithm-3
This algorithm computes the identifier table values of the DP table . Here, we compute spatial functions and quantifier operators. For a given spatial function , if it has nested function operators, then this algorithm recursively computes the final values. The table stores the values for any functional expression based on the combinatorial assignments of objects to the object variables. In line 10, if the combination of object identifiers does not satisfy the correct range of existing objects in the current frame or a frozen frame, then it assigns (false). Otherwise, if any parameter is a spatial formula, then it runs algorithm 4. The size of the table is the maximum number of combinations for objects with respect to the object variables. For example, if there are a maximum of five objects per frame in an object stream, and a formula has a maximum of three nested object variables, then the size of is . We choose the size of the table based on the worst case scenario, but for efficient computation, we only compute as many as needed combinations for each quantifier subformula based on its scope. Therefore, we mark the remaining cells of the table with NaN for extended computation that merges these tables for different subformulas in Algorithm 2 by calling function at line 24.
Input: ;
procedure ComputeLTL()
end procedure
VI-D Algorithm-4
This algorithm computes the values of the DP table . It evaluates spatial-temporal formulas similar to the temporal formulas of Algorithm 2 with the modification that now set operations are used as opposed to Boolean operations. The data structures for the set representation and the corresponding set operations can affect the computational complexity of 4. Depending on the application, e.g., 2D vs 3D, a number of solutions are possible ranging from a linked list of pairs of 2D points (i.e., union of rectangles) to quadtrees or octrees (see next section).
Input: ;
procedure ComputeFnExpr()
end procedure
Input: ;
procedure ComputeSpatioTemporal()
end procedure
VI-E Correctness and Complexity Analysis
Let be an input signal of size , be an AAN STPL formula of size (note that size of a formula is the summation of the number of spatial, temporal and spatio-temporal subformulas), be the size of freeze time variables (or 1 if there is none), be the maximum number of used object variables in the scope of a quantifier operator, and be the maximum number of objects in a single frame in . If is a TPTL formula, then it is known from Dokhanchi et al. (2016) that the upper bound time complexity for the variable-bounded TPTL monitoring algorithm is , which is polynomial. Additionally, the upper bound space complexity of the presented algorithm by Dokhanchi et al. (2016) is . Our STPL monitoring algorithm is founded based on the TPTL monitoring algorithm, but there are two major additions to the TPTL syntax and semantics. The first addition to the STPL grammar presented in Def. IV.1 is the existential/universal quantifiers that precedes the freeze time operator. The second addition is the production rule . We call this extension of the TPTL language the Quantifiable TPTL (QTPTL). Next is the production rule that produces purely spatio-temporal formulas ( and quantify the spatio-temporal in a constant time). The last addition to the QTPTL results in the STPL language. Therefore, we only analyze the time and space complexity of our algorithm for parts that concern the two aforementioned additions.
Our proposed monitoring algorithm is based on the Dynamic Programming (DP) algorithm by Dokhanchi et al. (2016) and, therefore, to consider the first addition, we need to evaluate each object variable related subformula at most times. This also requires extra space to build the DP tables. Therefore, the upper bound time and space complexity of the QTPTL algorithms increases to and , respectively.
Finally, we consider spatial and spatio-temporal subformulas denoted as in addition to temporal ones denoted as to do complexity analysis of the STPL algorithm. It is easy to see that the production rule has the same grammar as MTL/STL, except that the logical operators are replaced with spatial ones. Therefore, the time/space complexity of monitoring these formulas follows the same complexity as in MTL/STL monitoring algorithms except for the spatial operations. In MTL/STL, all the logical operations compute in constant time. However, for spatial operations, depending on the used data structure for representing the spatial terms, this might not hold. In Appendix: Complexity Analysis of STE formulas, we calculate exponential lower bound for some spatio-temporal formulas where the linked-list was used to represent the spatial terms. That is, if we do not exploit the geometrical properties of the spatial terms while storing them, then we get exponential complexity for the spatial operations. Whereas, if we use some geometry-sensitive data structures such as region Quadtrees and region Octrees for storing and computing 2D and 3D spatial terms (e.g., see Aluru (2018); Shneier (1981)), respectively, then, we get a polynomial time and space complexity, e.g., Bournez et al. (1999). Assume that we can decompose our d-dimensional topological space (dimension is fixed to be 2D or 3D) into cells, where is the constant resolution along each axis. Construction of an image Quadtree/Octree is linear in the size of the image (see Shneier (1981)). The union and intersection algorithm for Quadtrees, in the worst case, requires visiting all the nodes in the trees, which can be done in times. For computing a spatio-temporal formula , at each time-step, in the worst case, it requires as many spatial operations as linear to the size of the formula.
Therefore, the time complexity of computing the formula against an input signal is as follows:
-
•
, if there is no time/frame intervals in the formula and no frozen object variable is used in the formula. Note that is a big constant (i.e., is a function of the dimension and the resolution of the space) and we did not omit it to emphasize its impact on the computation.
-
•
, if there are time/frame intervals in the formula and no frozen object variable is used in the formula. Here, is defined as
where contains all the timing constraints which are either attached on the temporal operators in formula , or are timing constraints of the form or in the scope of a temporal operator in . For example, if , then , or if , then . Intuitively, the function returns all the samples that satisfy a constraint from the set starting from a sample . Formally,
with . Note that when considering constraints on the number of frames, i.e., , then the timestamp mapping is the identity function. For a discussion on for STL/MTL with discrete time semantics see Fainekos et al. (2012).
-
•
, if there is no time/frame intervals in the formula, but there are frozen object variables used in the formula.
-
•
, if there are time/frame intervals in the formula, and there are frozen object variables used in the formula.
Overall, the upper bound time and space complexity of the STPL algorithm are and , respectively.
In our implementation of the monitoring algorithms (discussed in Monitoring Algorithm), we focus on the future fragment of the STPL logic to avoid complexity (e.g, by excluding past-time operators as presented in Appendix: STPL Future Syntax). That is, we improved the space complexity of STPL formulas without spatial terms by decoupling the DP tables into two separate tables: one dedicated to the values of subformulas at the current time step, and the other for their frozen values along the time horizon. Therefore, we reduced the space complexity to for non-spatial STPL formulas and spatial formulas without time/frame intervals in them. For improving the exponential complexity of the spatial STPL formulas, we merge the fragmented subsets after spatial operations. Additionally, if there is no frozen object variable used in a spatial formula, we only evaluate it once. Some optimizations can be done based on the content of the formulas, for example, if a temporal formula does not have globally, eventually, until and release operators in it, then we deduce the needed horizon length of the input signal accordingly (i.e., next time operator only requires the evaluation of the first two frames). Also, we interpret the time/frame constraints in a formula to possibly ignore the evaluation of the affected subformulas accordingly.
The correctness of the algorithm with respect to the presented syntax and semantics of STPL can be proven by using the correctness proofs that are presented for the TPTL and MTL monitoring algorithms by Dokhanchi et al. (2016) and Fainekos et al. (2012).
We have released an open-source version of the code for both Linux and Windows OS in a public repository in GitLab (see STPL (2023)). Our tool can be run in standalone mode or as part of Matlab. Additionally, there are data stream files and input configuration files that cover most of the examples in the previous sections, as well as the sensitivity analysis result in the following section.
VI-F A Polynomial Time/Space Fragment
In this section, we identify STPL specification templates for which the monitoring problem becomes polynomial time in the worst case. In the template below, we assume that the size of the spatial formula is bounded.
VI-F1 Example
The complexities of evaluating an arbitrary SPE formula (the formula is in conjunctive form) on a data stream is
-
•
for time and space, if there is no complement operator in the formula, where , and we have: . For instance, .
-
•
for time and space, if there are complement operators in the NNF formula. For instance, .
VI-F2 Example
An arbitrary -level nested spatial globally formula , with a spatial term as its right-most subformula, is of time and space complexity.
VI-F3 Example
An arbitrary -level nested spatial eventually formula , with a spatial term as its right-most subformula, is of time and space complexity.
VI-F4 Example
An arbitrary -level nested spatial eventually subformula followed by an arbitrary -level nested spatial globally subformula , with a spatial term as its right-most subformula, is of time and space complexity.
VI-F5 Example
A right-hand-side -level nested spatial until formula , where the left-hand-side of all the until operators are a single spatial term, is of .
VI-F6 Example
A left-hand-side -level nested spatial release formula , where the right-hand-side of all the until operators are a single spatial term, is of .
VII Experiments and Results
| m-time | e-time | ||||||
| quantifier-formed STPL Formula (9) without spatial operators | |||||||
| 25 | 9 | 0 | 0 | 20 | 1 | 0 | 0.002 |
| 50 | 9 | 0 | 0 | 20 | 1 | 0 | 0.001 |
| 100 | 9 | 0 | 0 | 23 | 1 | 0 | 0.005 |
| 200 | 9 | 0 | 0 | 24 | 1 | 0 | 0.008 |
| mix-formed STPL Formula (10) without spatial operators | |||||||
| 25 | 7 | 0 | 1 | 20 | 2 | 0 | 0.132 |
| 50 | 7 | 0 | 1 | 20 | 2 | 0 | 0.519 |
| 100 | 7 | 0 | 1 | 23 | 2 | 0 | 2.76 |
| 200 | 7 | 0 | 1 | 24 | 2 | 0 | 11.31 |
| mix-formed STPL Formula (14) with SPE operators | |||||||
| 25 | 9 | 8 | 1 | 20 | 2 | 0.004 | 1.25 |
| 50 | 9 | 8 | 1 | 20 | 2 | 0.003 | 4.13 |
| 100 | 9 | 8 | 1 | 23 | 2 | 0.005 | 16.32 |
| 200 | 9 | 8 | 1 | 24 | 2 | 0.005 | 63.52 |
| quantifier-formed STPL Formula (15) with STE operators | |||||||
| 25 | 3 | 4 | 0 | 20 | 1 | 0 | 0.006 |
| 50 | 3 | 4 | 0 | 20 | 1 | 0 | 0.029 |
| 100 | 3 | 4 | 0 | 23 | 1 | 0 | 0.119 |
| 200 | 3 | 4 | 0 | 24 | 1 | 0 | 0.176 |
| mix-formed STPL Formula (16) with spatial terms | |||||||
| 25 | 29 | 6 | 1 | 20 | 3 | 0.023 | 2.23 |
| 50 | 29 | 6 | 1 | 20 | 3 | 0.023 | 4.97 |
| 100 | 29 | 6 | 1 | 23 | 3 | 0.037 | 16.07 |
| 200 | 29 | 6 | 1 | 24 | 3 | 0.043 | 46.88 |
| mix-formed STPL Formula (17) without spatial terms | |||||||
| 25 | 29 | 0 | 1 | 20 | 3 | 0 | 1.16 |
| 50 | 29 | 0 | 1 | 20 | 3 | 0 | 2.73 |
| 100 | 29 | 0 | 1 | 23 | 3 | 0 | 10.41 |
| 200 | 29 | 0 | 1 | 24 | 3 | 0 | 33.69 |
We selected some of the presented example formulas to cover different possible combinations for the operators and quantifiers, and to demonstrate how the computation time scales concerning the size of the data stream and the formulas. For this experimental analysis, we used the DeepDrive dataset 666https://bdd-data.berkeley.edu/ (Yu et al. (2020)). As indicated in the last column of Table III, the performance of the STPL monitoring algorithm for hundreds of monitoring frames (including thousands of objects) is feasible for offline monitoring. Some statistics about the experiments are summarized in Table III. We used a Windows 10 machine with Intel Core i7 CPU U GHZ, GB RAM, and Matlab R2020a. The STPL monitoring algorithm is implemented in language and compiled for Matlab.
The formulas in Table III were selected based on the types of operators and their computational complexity. The maximum number of nested quantifiers is a source of exponential complexity (i.e., ) in our monitoring algorithm. The highest number of nested quantification operators was 3 in Formulas (16) and (17). Another source of complexity is the number of spatial operators in the formula. For instance, the worst execution time is observed for the Formula (14) due to its higher number of spatial operators. These results are not surprising and are in agreement with our theoretical analysis in Section VI-E.
In order to study the impact of the number of objects in each frame on the monitoring algorithm, we manipulated the BDD dataset to create artificial datasets with specific number of objects. The result is presented in Table IV. In the first row, the maximum number of objects in all the frames is 5. For all the following rows, this number is doubled. Based on the , the e-time of rows should increase with the ratio of . To remedy the exponential complexity of the nested quantified formulas, we can use parallel computation to efficiently evaluate quantified subformulas. More specifically, Algorithm 3 can be parallelized.
Since the theoretical time complexity of offline STPL monitoring is the same as the time complexity of online past-time STPL monitoring (see Balakrishnan et al. (2021) for a toolbox), the problem of online monitoring of bounded time short duration STPL properties is practically feasible and relevant. However, the offline STPL monitoring problem over extremely large perception datasets may not be feasible without further optimizations or expressivity restrictions. One promising direction is to prefilter very large perception datasets and extract subsequences that are interesting for STPL specifications. One such possibility for filtering is the perception query language SpRE (Anderson et al. (2023)) – see Section VIII for a brief discussion. We plan to pursue such a direction in the future.
| m-time | e-time | ||||||
| 25 | 29 | 6 | 1 | 5 | 3 | 0.001 | 0.060 |
| 25 | 29 | 6 | 1 | 10 | 3 | 0.005 | 0.441 |
| 25 | 29 | 6 | 1 | 20 | 3 | 0.043 | 2.419 |
| 25 | 29 | 6 | 1 | 40 | 3 | 0.312 | 20.027 |
VIII Related Works
| Language | Temporal Foundation | (data) | (spatial) | Spatial Foundation | Domain in practice | Applications |
| STPL | AAN-TPTL | Sets in Euclidean spaces | Perception systems | |||
| TQTL | AAN-TPTL | Predicates | Perception data | Vision based (2D) perception | ||
| SpRE | FSM | Sets in Euclidean spaces | Perception systems | |||
| STSL | STL | Distances in Euclidean spaces | System level requirements for CPS | |||
| SpaTel | STL | TSSL | Quadrants | Pattern recognition | ||
| SSTL | STL | Graph-based modeling | Distances in Euclidean spaces | Pattern recognition | ||
| GSTL | STL | Mereotopology | Cubics | Knowledge representation |
In this section, we provide a detailed overview of related works. We primarily focus on comparing STPL with other spatio-temporal logics. In Table V, we provide a summary comparison of the most relevant logics for easy reference. We conclude the section with some references on promising directions on the analysis of perception systems which are not directly related to spatio-temporal logics.
Region Connection Calculus by Cohn et al. (1997), Shape Calculus by Bartocci et al. (2010), and Situation Calculus by Bhatt and Loke (2008) are just some examples of the vast literature on logics about topology and space. Comprehensive surveys and comparisons of reasoning methods about topology and time are provided by Dylla et al. (2017); Aiello et al. (2007). Spatio-temporal logics and calculi are also frequently used in robotics for human-robot communication (Kress-Gazit and Pappas (2010); Summers-Stay et al. (2014)) and for specifying and verifying properties of AV (Linker and Hilscher (2013); Loos et al. (2011)). All the aforementioned works that deal with topology and time primarily focus on deductive reasoning, theorem proving, knowledge representation, axiomatization, and – in some cases – planning. In contrast, STPL requires computationally efficient tools for spatio-temporal reasoning in order to monitor data streams from perception systems.
Even though there exist spatio-temporal logics that can process spatio-temporal data (offline or online) such as SpaTeL (Haghighi et al. (2015)), SSTL (Nenzi et al. (2015)), or SaSTL (Ma et al. (2020)) (for a short survey see Bartocci et al. (2018)), or even images, e.g., SLCS (Buonamici et al. (2019)), all these logics are application dependent and cannot support the topological reasoning needed for perception data in AV. To highlight the fundamental differences between the aforementioned logics and STPL, we provide a detailed comparison with SpaTeL and SSTL. The differences with the other listed logics and conceptually similar in scope. The two spatio-temporal languages (SSTL and SpaTeL) are explicitly developed for describing high-level spatial patterns that evolve. Both languages are founded based on a graph-based representation of discrete models of space. For the SSTL, undirected weighted graphs are used to model space, and in SpaTeL, a networked system whose states encapsulate an image are represented as quad transition systems.
In more detail, in SSTL, the syntax of the language adds two spatial operators and into Signal Temporal Logic (STL) (Maler and Nickovic (2004)), which are named bounded somewhere and bounded surround, respectively. The first operator requires to hold in a location that can be reached from the current location with a cost between and . The cost is usually the distance between the two locations. For the second operator, the notation of external boundary of a set is required. An external boundary of a given set of nodes is defined as the set of nodes that are directly connected to the elements of the given set but are not members of it. The semantics of the second operator requires that for the current location and a given trace , belongs to a set of locations that all satisfy the formula , and for all the locations in the external boundary of , they satisfy the formula . An SSTL formula can be arbitrarily nested.
In SpaTeL, a combination of Tree Spatial Superposition Logic (TSSL) (Gol et al. (2014)) and STL is proposed to reason on spatial patterns. TSSL uses quad-trees to represent the space by partitioning the space recursively into quadrants. The TSSL logic is similar to the classic Computation Tree Logic (CTL) (e.g., see Huth and Ryan (2004)), with the main difference that the next and until operators are not temporal, but spatial. That is, evolution happens by a change of resolution (or zoom in). All the spatial operators are augmented by a set that selects the spatial directions (i.e., NW, NE, SW, and SE) in which the operators are allowed to work. Additionally, similar to temporal operators, there is a parameter that limits the operator’s evaluation range on a finite sequence of states. For example, means that there exists a set of directions in by which the -th label of a path satisfies the formula and all the other labels on the path until satisfy the formula . A difference between the former and the latter is that in the former one, the TSSL fragment of a formula does not include temporal subformulas.
In summary, the key differences of these logics with our proposed STPL logic are:
-
•
Modeling: SSTL and SpaTeL are not designed to model physical objects in 2D or 3D spaces. On the other hand, our logic is explicitly designed to handle physical objects.
-
•
Expressivity: SpaTeL is inherently less expressive than SSTL due to its modeling and traversing approach on quad-trees and the decoupled syntax for spatial and temporal formulas. Therefore, we are going to compare STPL with SSTL. There are two significant differences. The first one is the presence of time freeze operator and time variables and, hence, STPL is more expressive. The second one is the presence of the quantifiers and set operations over spatial terms/locations. As an example, SSTL cannot reason on whether the same object over two different frames overlaps or not with itself.
-
•
Application: SSTL and SpaTeL are mostly helpful for pattern recognition purposes, while STPL is a more general-purpose language. Quantitative semantics: there is quantitative and qualitative semantics for SSTL and SpaTeL, but currently, we only presented qualitative semantics for STPL. The graph-based modeling of the spatial environment and the fixed metric properties such as distance makes it more straightforward to define quantitative semantics for their underlying logic.
In another line of work, a graph-based spatio-temporal logic – GSTL by Liu et al. (2020) – is presented for knowledge representation and reasoning. GSTL deals with spatial elements as regions, and uses mereotopology (combination of mereology and topology to support parthood and connectivity, respectively) to represent relations between spatial elements. It exploits rectangle/cubic algebra to represent spatial objects. GSTL combines STL temporal logic with mereotopology-based spatial operators enriched with interval algebra. The satisfiability problem for GSTL is decidable by restricting the evolution of spatial elements. GSTL was primarily designed for model checking which restricts its expressivity for decidability reasons.
The works closest to ours stem from combining temporal logics with spatial logics (for a historical overview and a discussion on see Kontchakov et al. (2007)). Gabelaia et al. (2005) combine Linear Temporal Logic (LTL) (Manna and Pnueli (1992)) with to define the logic . They further define several fragments of and they study the decidability of the satisfiability problem. However, the problem of offline monitoring is not investigated in this line of work.
More recently, STSL was proposed by Li et al. (2021) where STL is combined with . Even though the monitoring problem is studied for STSL, STSL falls short of the goals of STPL in multiple directions. First and foremost, STSL does not support generic data and quantification over such data. That is, it is not possible to express a property such as Req. 2 where we need to quantify over the bounding boxes of all the cars in a frame. Second, STPL is based on TPTL which is a strictly more expressive logic than STL used in STSL. Third, a theoretical or experimental computational complexity analysis is not presented for STSL to identify what fragments are computationally important while still being practically relevant. Finally, and most importantly, the applications presented for STSL are restricted to properties over numerical trajectories produced by Cyber-Physical Systems, and it is clear that with the metric space chosen for STSL, the corresponding formal specifications can be expressed in STL. That is, in practice, there is no gain in expressive power in STSL over STL.
Another line of research relevant to our work is formal languages for analysis of perception systems. Timed Quality Temporal Logic (TQTL) by Dokhanchi et al. (2018a) was designed to reason over streams of perception data. TQTL is built upon the AAN fragment of Timed Propositional Temporal Logic (AAN-TPTL) (Dokhanchi et al. (2016)) by introducing quantification (, ) over the objects in each frame, and by introducing functions that retrieve data relevant to each object, e.g., class, probabilities, bounding box coordinates, etc. The AAN fragment of TPTL was chosen due to its polynomial time complexity while still being strictly more expressive then STL. Note that further algorithmic improvements on AAN-TPTL are possible, e.g., see Elgyutt et al. (2018); Ghorbel and Prabhu (2022). Nevertheless, TQTL cannot reason directly about properties of bounding boxes. For example, TQTL cannot reason about self-overlap of bounding boxes across time, i.e., TQTL cannot express Req. 2. More generally, TQTL cannot reason about 3D scenes (e.g, bird-eye view of the world) since this requires a mechanism to relate spatially different objects in the environment. STPL resolves these shortcomings of TQTL to enable a versatile framework to reason about perception systems in both 2D and 3D (along with other state variables included in the perception data).
Spatial Regular Expressions (SpREs) were recently introduced by Anderson et al. (2023) to find patterns in streaming data. That is, given a SpRE, the goal is to find all the sequences of frames that match the pattern specified by SpRE. SpREs were designed to closely resemble regular expressions, and, hence, the underlying model of computation for processing streaming perception data is automata (Sipser (2006)). The current version of SpRE does not support quantification over data in order to enable online real-time processing. However, SpRE supports operators on per frame basis. Clearly, SpRE is less expressive than STPL, but we envision an interplay between the two languages. SpRE can potentially find very quickly the subsequences of streaming data over which we need to run the more expressive STPL requirements.
The PerSyS monitoring system by Antonante et al. (2021) presents a mathematical model for fault detection in perception systems. The base of their work is Perfect Minicomputer Corporation (PMC) model in multiprocessor systems, which is generalized to account for models with heterogeneous outputs (i.e., perception systems), and equipped with temporal dimensions to support interaction among PMC models. Their system supports consistency checking among different sensory outputs of a perception system with some formal guarantees on the maximum number of inconsistencies. In PerSyS, it is possible to design models that identify faults, but, similar to any other graph-based modeling technique, it is highly reliant on a correct model to begin with, and then adding formalized requirements as a set of constraints on the models (i.e., constraints on the edges of the PMC graphs). STPL monitoring goals are orthogonal to PerSyS. STPL is a specification language that formalizes assumptions and guarantees on the functional performance of the perception system. As such a language, it is more expressive than the constraints used in PerSyS. As a byproduct, STPL can also function as a comparison framework between different perception stacks.
Finally, the language Scenic by Fremont et al. (2018) has been developed for creating single scene images for testing object detection and classification algorithms. However, our work is complementary to languages that generate static scenes.
IX Conclusions
In this paper, we presented Spatio-Temporal Perception Logic (STPL), which is a logic which is specifically designed for reasoning over data streams of perception systems. STPL merges and extends other practical logics such as TPTL (Alur and Henzinger (1994)) and (Aiello et al. (2007)) with data (object) quantification, functions and relations that enable topological reasoning over time. Our new logic can be used for specifying correctness requirements on perception systems, as well as to compare different machine learning stacks on their performance beyond the standard metrics (e.g., see Mallick et al. (2023)). We have identified fragments of STPL which are efficiently monitorable for perception applications, and we have demonstrated that practically relevant requirements which do not fall within these fragments can still be efficiently monitorable in practice. An open source publicly available toolbox has been developed STPL (2023) which can be used for offline perception system analysis. An online monitor for the past fragment of STPL is also available (Balakrishnan et al. (2021)). Using STPL, we have been able to discover inconsistencies in publicly available training datasets for AV/ADAS.
Since STPL formulas are rather complex even for experts, we have have been working toward developing a Domain Specific Language (DSL) called PyFoReL (Anderson et al. (2022)) for easier elicitation and maintenance of STPL requirements. PyFoReL provides a Pythonic language to compose requirements in a modular way while enforcing that they are valid STPL formulas. The next step would be to interface PyFoReL and/or the STPL syntax with Large Language Models (LLM). Similar work has been done in the past for LTL and STL with practically relevant success (e.g., see Pan et al. (2023); Fuggitti and Chakraborti (2023)). In addition, verification and debugging tools for STPL formulas will be needed since LLMs cannot be trusted to always produce correct translations. In the past, we have done similar work for STL/MTL specifications in Dokhanchi et al. (2018b). We expect to achieve further computational improvements on our monitoring algorithms by parallelization and by filtering relevant sequences of data through our new query language SpRE (Anderson et al. (2023)) before the STPL tools are used. Finally, it would also be interesting to see if meaningful robust semantics (Bartocci et al. (2018)) could be defined in order to support test case generation or even self-supervised training of neural networks.
Acknowledgment
This work was partially supported by NSF under grants CNS-2039087, CNS-2038666, IIP-1361926, and the NSF I/UCRC Center for Embedded Systems.
References
- Abbas et al. (2017) Abbas H, O’Kelly ME, Rodionova A and Mangharam R (2017) A driver’s license test for driverless vehicles. Mechanical Engineering 139: S13–S16.
- Aiello et al. (2007) Aiello M, Pratt-Hartmann IE and van Benthem JF (2007) Handbook of spatial logics. Springer.
- Alur and Henzinger (1994) Alur R and Henzinger TA (1994) A really temporal logic. J. ACM 41: 181–203.
- Aluru (2018) Aluru S (2018) Quadtrees and octrees. In: Handbook of Data Structures and Applications. Chapman and Hall/CRC, pp. 309–326.
- Anderson et al. (2023) Anderson J, Fainekos G, Hoxha B, Okamoto H and Prokhorov D (2023) Pattern matching for perception streams. In: 23rd International Conference on Runtime Verification (RV).
- Anderson et al. (2022) Anderson J, Hekmatnejad M and Fainekos G (2022) PyFoReL: A domain-specific language for formal requirements in temporal logic. In: IEEE 30th International Requirements Engineering Conference (RE).
- Antonante et al. (2021) Antonante P, Spivak DI and Carlone L (2021) Monitoring and diagnosability of perception systems. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, pp. 168–175.
- Balakrishnan et al. (2021) Balakrishnan A, Deshmukh J, Hoxha B, Yamaguchi T and Fainekos G (2021) Percemon: Online monitoring for perception systems. In: International Conference on Runtime Verification (RV), LNCS, volume 12974.
- Baotic (2009) Baotic M (2009) Polytopic computations in constrained optimal control 50: 119–134.
- Bartocci et al. (2010) Bartocci E, Corradini F, Berardini MRD, Merelli E and Tesei L (2010) Shape calculus. a spatial mobile calculus for 3d shapes. Scientific Annals of Computer Science 20: 1–31.
- Bartocci et al. (2018) Bartocci E, Deshmukh J, Donzé A, Fainekos G, Maler O, Nickovic D and Sankaranarayanan S (2018) Specification-based monitoring of cyber-physical systems: A survey on theory, tools and applications. In: Lectures on Runtime Verification - Introductory and Advanced Topics, LNCS, volume 10457. Springer, pp. 128–168.
- Bashetty et al. (2020) Bashetty SK, Amor HB and Fainekos G (2020) DeepCrashTest: turning dashcam videos into virtual crash tests for automated driving systems. In: International Conference on Robotics and Automation (ICRA).
- Basin et al. (2015) Basin D, Klaedtke F, Müller S and Zălinescu E (2015) Monitoring metric first-order temporal properties 62(2).
- Bhatt and Loke (2008) Bhatt M and Loke S (2008) Modelling dynamic spatial systems in the situation calculus. Spatial Cognition & Computation 8: 86–130.
- Bournez et al. (1999) Bournez O, Maler O and Pnueli A (1999) Orthogonal polyhedra: Representation and computation. In: International Workshop on Hybrid Systems: Computation and Control. Springer, pp. 46–60.
- Buonamici et al. (2019) Buonamici FB, Belmonte G, Ciancia V, Latella D and Massink M (2019) Spatial logics and model checking for medical imaging. International Journal on Software Tools for Technology Transfer : 1–23.
- Caesar et al. (2020) Caesar H, Bankiti V, Lang AH, Vora S, Liong VE, Xu Q, Krishnan A, Pan Y, Baldan G and Beijbom O (2020) nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11621–11631.
- Campbell et al. (2016) Campbell J, Amor HB, Ang MH and Fainekos G (2016) Traffic light status detection using movement patterns of vehicles. In: 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC). IEEE, pp. 283–288.
- Cimatti et al. (2004) Cimatti A, Roveri M and Sheridan D (2004) Bounded verification of past ltl. In: International Conference on Formal Methods in Computer-Aided Design. Springer, pp. 245–259.
- Cohn et al. (1997) Cohn AG, Bennett B, Gooday J and Gotts NM (1997) Qualitative spatial representation and reasoning with the region connection calculus. GeoInformatica 1(3): 275–316.
- Corso et al. (2020) Corso A, Moss RJ, Koren M, Lee R and Kochenderfer MJ (2020) A survey of algorithms for black-box safety validation. arXiv preprint arXiv:2005.02979 .
- Cosler et al. (2023) Cosler M, Hahn C, Mendoza D, Schmitt F and Trippel C (2023) nl2spec: Interactively translating unstructured natural language to temporal logics with large language models. In: Computer Aided Verification, LNCS, volume 13965. Springer, pp. 383–396.
- DeCastro et al. (2020) DeCastro J, Leung K, Aréchiga N and Pavone M (2020) Interpretable policies from formally-specified temporal properties. In: 2020 IEEE 23rd International Conference on Intelligent Transportation Systems Conference (ITSC).
- Dokhanchi et al. (2018a) Dokhanchi A, Amor HB, Deshmukh JV and Fainekos G (2018a) Evaluating perception systems for autonomous vehicles using quality temporal logic. In: International Conference on Runtime Verification. Springer, pp. 409–416.
- Dokhanchi et al. (2018b) Dokhanchi A, Hoxha B and Fainekos G (2018b) Formal requirement debugging for testing and verification of cyber-physical systems. ACM Transactions on Embedded Computing Systems 17. DOI:10.1145/3147451.
- Dokhanchi et al. (2016) Dokhanchi A, Hoxha B, Tuncali CE and Fainekos G (2016) An efficient algorithm for monitoring practical tptl specifications. In: 2016 ACM/IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE). IEEE, pp. 184–193.
- Dreossi et al. (2019a) Dreossi T, Donzé A and Seshia SA (2019a) Compositional falsification of cyber-physical systems with machine learning components. Journal of Automated Reasoning 63: 1031–1053.
- Dreossi et al. (2019b) Dreossi T, Fremont DJ, Ghosh S, Kim E, Ravanbakhsh H, Vazquez-Chanlatte M and Seshia SA (2019b) Verifai: A toolkit for the formal design and analysis of artificial intelligence-based systems. In: International Conference on Computer Aided Verification. Springer, pp. 432–442.
- Dylla et al. (2017) Dylla F, Lee JH, Mossakowski T, Schneider T, Delden AV, Ven JVD and Wolter D (2017) A survey of qualitative spatial and temporal calculi: Algebraic and computational properties. ACM Computing Surveys 50.
- Eisner and Fisman (2006) Eisner C and Fisman D (2006) Weak vs. strong temporal operators. A Practical Introduction to PSL : 27–34.
- Elgyutt et al. (2018) Elgyutt A, Ferrere T and Henzinger TA (2018) Monitoring temporal logic with clock variables. In: Formal Modeling and Analysis of Timed Systems (FORMATS), LNCS, volume 11022. Springer.
- Fainekos et al. (2012) Fainekos GE, Sankaranarayanan S, Ueda K and Yazarel H (2012) Verification of automotive control applications using s-taliro. In: 2012 American Control Conference (ACC). IEEE, pp. 3567–3572.
- Fremont et al. (2020) Fremont DJ, Kim E, Pant YV, Seshia SA, Acharya A, Bruso X, Wells P, Lemke S, Lu Q and Mehta S (2020) Formal scenario-based testing of autonomous vehicles: From simulation to the real world. In: 23rd IEEE International Conference on Intelligent Transportation Systems (ITSC).
- Fremont et al. (2018) Fremont DJ, Yue X, Dreossi T, Ghosh S, Sangiovanni-Vincentelli AL and Seshia SA (2018) Scenic: Language-based scene generation. Technical report, arXiv:1809.09310.
- Fuggitti and Chakraborti (2023) Fuggitti F and Chakraborti T (2023) Nl2ltl – a python package for converting natural language (nl) instructions to linear temporal logic (ltl) formulas 37(13): 16428–16430.
- Gabelaia et al. (2005) Gabelaia D, Kontchakov R, Kurucz A, Wolter F and Zakharyaschev M (2005) Combining spatial and temporal logics: expressiveness vs. complexity. Journal of artificial intelligence research 23: 167–243.
- Geiger et al. (2013a) Geiger A, Lenz P, Stiller C and Urtasun R (2013a) Vision meets robotics: The kitti dataset. The International Journal of Robotics Research 32(11): 1231–1237.
- Geiger et al. (2013b) Geiger A, Lenz P, Stiller C and Urtasun R (2013b) Vision meets robotics: The KITTI dataset. International Journal of Robotics Research (IJRR) 32: 1231–1237.
- Ghorbel and Prabhu (2022) Ghorbel B and Prabhu V (2022) Linear time monitoring for one variable tptl. In: 25th ACM International Conference on Hybrid Systems: Computation and Control (HSCC).
- Gladisch et al. (2019) Gladisch C, Heinz T, Heinzemann C, Oehlerking J, von Vietinghoff A and Pfitzer T (2019) Experience paper: Search-based testing in automated driving control applications. In: 34th IEEE/ACM International Conference on Automated Software Engineering (ASE).
- Gol et al. (2014) Gol EA, Bartocci E and Belta C (2014) A formal methods approach to pattern synthesis in reaction diffusion systems. In: 53rd IEEE Conference on Decision and Control.
- Gordon et al. (2018) Gordon D, Farhadi A and Fox D (2018) Re3: Real-time recurrent regression networks for visual tracking of generic objects. IEEE Robotics and Automation Letters 3(2): 788–795.
- Haghighi et al. (2015) Haghighi I, Jones A, Kong Z, Bartocci E, Grosu R and Belta C (2015) Spatel: a novel spatial-temporal logic and its applications to networked systems. In: Proceedings of the 18th International Conference on Hybrid Systems: Computation and Control. pp. 189–198.
- Havelund et al. (2020) Havelund K, Peled D and Ulus3 D (2020) First-order temporal logic monitoring with bdds 56.
- He et al. (2015) He K, Lahijanian M, Kavraki LE and Vardi MY (2015) Towards manipulation planning with temporal logic specifications. In: 2015 IEEE international conference on robotics and automation (ICRA). IEEE, pp. 346–352.
- He et al. (2018) He K, Lahijanian M, Kavraki LE and Vardi MY (2018) Automated abstraction of manipulation domains for cost-based reactive synthesis. IEEE Robotics and Automation Letters 4(2): 285–292.
- Hekmatnejad et al. (2019) Hekmatnejad M, Yaghoubi S, Dokhanchi A, Amor HB, Shrivastava A, Karam L and Fainekos G (2019) Encoding and monitoring responsibility sensitive safety rules for automated vehicles in signal temporal logic. In: 17th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE).
- Huth and Ryan (2004) Huth M and Ryan M (2004) Logic in Computer Science: Modelling and reasoning about systems. Cambridge university press.
- Kim et al. (2022) Kim E, Shenoy J, Junges S, Fremont DJ, Sangiovanni-Vincentelli A and Seshia SA (2022) Querying labelled data with scenario programs for sim-to-real validation. In: ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS). pp. 34–45.
- Kontchakov et al. (2007) Kontchakov R, Kurucz A, Wolter F and Zakharyaschev M (2007) Handbook of spatial logics: Spatial logic + temporal logic = ? Springer, pp. 497–564.
- Koymans (1990) Koymans R (1990) Specifying real-time properties with metric temporal logic. Real-Time Systems 2(4): 255–299.
- Kress-Gazit and Pappas (2010) Kress-Gazit H and Pappas GJ (2010) Automatic synthesis of robot controllers for tasks with locative prepositions. In: IEEE International Conference on Robotics and Automation (ICRA). pp. 3215–3220.
- Lee (2018) Lee TB (2018) Report: Software bug led to death in uber’s self-driving crash. Ars Technica May 07.
- Li et al. (2021) Li T, Liu J, Sun H, Chen X, Yin L, Mao X and Sun J (2021) Runtime verification of spatio-temporal specification language 21(26): 2392–2406.
- Linker and Hilscher (2013) Linker S and Hilscher M (2013) Proof theory of a multi-lane spatial logic. In: International Conference on Theoretical Aspects of Computing (ICTAC), LNCS, volume 8049. Springer, pp. 231–248.
- Liu et al. (2020) Liu Z, Jiang M and Lin H (2020) A graph-based spatial temporal logic for knowledge representation and automated reasoning in cognitive robots. arXiv preprint arXiv:2001.07205 .
- Loos et al. (2011) Loos SM, Platzer A and Nistor L (2011) Adaptive cruise control: Hybrid, distributed, and now formally verified. In: Formal Methods, LNCS, volume 6664. Springer, pp. 42–56.
- Ma et al. (2020) Ma M, Bartocci E, Lifland E, Stankovic J and Feng L (2020) SaSTL: Spatial aggregation signal temporal logic for runtime monitoring in smart cities. In: ACM/IEEE 11th International Conference on Cyber-Physical Systems (ICCPS). pp. 51–62.
- Maler and Nickovic (2004) Maler O and Nickovic D (2004) Monitoring temporal properties of continuous signals. In: Proceedings of FORMATS-FTRTFT, LNCS, volume 3253. pp. 152–166.
- Mallick et al. (2023) Mallick S, Ghosal S, Balakrishnan A and Deshmukh J (2023) Safety monitoring for pedestrian detection in adverse conditions. In: 23rd International Conference on Runtime Verification (RV).
- Manna and Pnueli (1992) Manna Z and Pnueli A (1992) The Temporal Logic of Reactive and Concurrent Systems — Specification. Springer.
- Markey and Raskin (2006) Markey N and Raskin JF (2006) Model checking restricted sets of timed paths. Theoretical Computer Science 358: 273–292.
- Mehdipour et al. (2023) Mehdipour N, Althoff M, Tebbens RD and Belta C (2023) Formal methods to comply with rules of the road in autonomous driving: State of the art and grand challenges 152: 110692.
- Motional (2019) Motional (2019) nuScenes dataset. URL https://www.nuscenes.org/nuscenes. Accessed: 2020-11-14.
- Nenzi et al. (2015) Nenzi L, Bortolussi L, Ciancia V, Loreti M and Massink M (2015) Qualitative and quantitative monitoring of spatio-temporal properties. In: Runtime Verification. Springer, pp. 21–37.
- Pan et al. (2023) Pan J, Chou G and Berenson D (2023) Data-efficient learning of natural language to linear temporal logic translators for robot task specification. In: IEEE International Conference on Robotics and Automation (ICRA).
- Perugini (2021) Perugini S (2021) Programming languages: Concepts and implementation. Jones & Bartlett Learning.
- Qin et al. (2016) Qin B, Chong ZJ, Soh SH, Bandyopadhyay T, Ang MH, Frazzoli E and Rus D (2016) A spatial-temporal approach for moving object recognition with 2d lidar. In: Experimental Robotics. Springer, pp. 807–820.
- Richter et al. (2017) Richter SR, Hayder Z and Koltun V (2017) Playing for benchmarks. In: IEEE International Conference on Computer Vision, ICCV. pp. 2232–2241.
- Rizaldi et al. (2017) Rizaldi A, Keinholz J, Huber M, Feldle J, Immler F, Althoff M, Hilgendorf E and Nipkow T (2017) Formalising and monitoring traffic rules for autonomous vehicles in isabelle/hol. In: Integrated Formal Methods. Springer, pp. 50–66.
- Schwarting et al. (2018) Schwarting W, Alonso-Mora J and Rus D (2018) Planning and decision-making for autonomous vehicles. Annual Review of Control, Robotics, and Autonomous Systems 1: 187–210.
- Shneier (1981) Shneier M (1981) Calculations of geometric properties using quadtrees. Computer Graphics and Image Processing 16(3): 296–302.
- Sipser (2006) Sipser M (2006) Introduction to the theory of computation. 2nd edition. Course Technology.
- STPL (2023) STPL (2023) Spatio-Temporal Perception Logic (STPL) Offline Monitoring Tools. https://gitlab.com/vnv-tools/STPL.
- Summers-Stay et al. (2014) Summers-Stay D, Cassidy T and Voss C (2014) Joint navigation in commander/robot teams: Dialog & task performance when vision is bandwidth-limited. In: Third Workshop on Vision and Language.
- Sun et al. (2019) Sun H, Ang MH and Rus D (2019) A convolutional network for joint deraining and dehazing from a single image for autonomous driving in rain. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, pp. 962–969.
- Templeton (2020) Templeton B (2020) Tesla in taiwan crashes directly into overturned truck, ignores pedestrian, with autopilot on. Forbes June 2.
- Tuncali et al. (2020) Tuncali CE, Fainekos G, Prokhorov D, Ito H and Kapinski J (2020) Requirements-driven test generation for autonomous vehicles with machine learning components. IEEE Transactions on Intelligent Vehicles 5: 265–280. DOI:10.1109/TIV.2019.2955903.
- van Benthem and Bezhanishvili (2007) van Benthem J and Bezhanishvili G (2007) Modal logics of space. Handbook of Spatial Logics : 217–298.
- Wu et al. (2017) Wu B, Iandola F, Jin PH and Keutzer K (2017) Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 129–137.
- Yadav and Curry (2019) Yadav P and Curry E (2019) Vidcep: Complex event processing framework to detect spatiotemporal patterns in video streams. In: IEEE International conference on big data. pp. 2513–2522.
- Yu et al. (2020) Yu F, Chen H, Wang X, Xian W, Chen Y, Liu F, Madhavan V and Darrell T (2020) Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2636–2645.
- Yurtsever et al. (2020) Yurtsever E, Lambert J, Carballo A and Takeda K (2020) A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 8: 58443–58469.
Appendix A Appendix: STPL Future Syntax
The following definition introduces a future fragment of the introduced STPL syntax in Def. IV.1. Here, we restrict the grammar by including rules that enforce a formula to be an Almost Arbitrarily Nesting Formula as in Def. IV.3. Notice that in the following, the grammar rules force the expressions to be indexed to track the level of nesting in quantifier operators.
Definition A.1 (STPL AAN Syntax for Discrete-Time Signal)
Let and be sets of time variables and object variables, respectively. Let be a vector of time variables, i.e., , and be a vector of object variables, i.e., , and be any non-empty interval of over time. The syntax for Spatio-Temporal Perception Logic (STPL) formulas is provided by the following grammar:
| CRT |
where , and the grammar starts from .
The time and frame constraints of STPL are represented in the form of and , respectively. The freeze time quantifier assigns the current frame to time variable before processing the subformula . The Existential quantifier is denoted as , and the Universal quantifier is denoted as . The following syntactic equivalences hold for the STPL formulas and using syntactic manipulation. , , (False), ( Implies ), ( releases ), ( non-strictly releases ), (Eventually ), (Always ). All the other operators with on them are with frame intervals, that is in , , , , , and the interval is over frame interval.
For parsing a formula using the above grammar, there are two production rules and in which we can use the initial production rule after increasing the index (i.e., ). The index is to force scope for the use of freeze time variables. For example, if in the scope of a variant-quantifier operator we use , then the index will increases to to avoid use of in the scope of the next variant-quantifier operator. The index is used as a pointer to each quantifier operator to track the scope of object variables. For example, in the formula , we have and while parsing the subformula , whereas, in , we have and . Thus any function in with object variables in it will use the production rule . Thus, the allowed object variables in are and . However, while parsing the subformula , we use in which the only allowed object variable is .
Appendix B Appendix: Complexity Analysis of STE formulas
| 0 | 1 | 1 | 1 | 1 | 1 | |
| 1 | 1 | 1(1+1) = 2 | 1(1+ 1(1+1)) = 3 | 1(1+ 1(1+ 1(1+1))) = 4 | 1(1+ 1(1+ 1(1+ 1(1+1)))) = 5 | |
| 2 | 1 | 2(1+1) = 4, | 3(1+ 2(1+1)) = 15, | 4(1+ 3(1+ 2(1+1))) = 64, | 5(1+ 4(1+ 3(1+ 2(1+1)))) = 325, | |
| 3 | 1 | 2(1+1) (1+1) = 8 | 3(1+ 2(1+1)) (1+ 2(1+1) (1+1)) = 135 |
4(1+ 3(1+ 2(1+1))) (1+
3(1+ 2(1+1)) (1+ 2(1+1) (1+1))) = 8,704 |
5(1+ 4(1+ 3(1+ 2(1+1)))) (1+
4(1+ 3(1+ 2(1+1))) (1+ 3(1+ 2(1+1)) (1+ 2(1+1) (1+1)))) = 2,829,125 |
|
Here the assumption is that we use the linked-list data structure to represent a spatial term as a union of a finite number of unique subsets. We can compute recursively as . For each until formula in each row of Table VI (starting from the row ), for each time step , we use the recursive evaluation function to calculate the maximum number of bounding boxes as a result of computing the formula. The maximum number of bounding boxes that can be produced by is equal to the total number of boxes in the two spatial terms (i.e., ). Additionally, the maximum number of bounding boxes that can be produced by is equal to the product of number of boxes in the two spatial terms (i.e., ). Consequently, the maximum number of bounding boxes that can be produced at each time step for the above until formula is .
B-A Formulas with Exponential Time/Space Complexities
As it is stated in the first and second rows in Table VI, the number of needed operations grow as in arithmetic sequences. Thus, the time complexity which is the summation of numbers in the rows, are linear and polynomial functions of the number of the time steps for the first and second rows, respectively. Moreover, the space complexity for the first and the second rows are constant and linear functions of number of the time steps, respectively.
In the following, we calculate an upper bound and a lower bound for the maximum number of bounding boxes that can be produced for the third row (level 2) of the until operator. We use the function to denote the maximum number of bounding boxes that are produced at the time step for the until formula .
| (21) |
We repetitively use the inequality for to derive the following inequality from the above equation
| (22) |
where . Therefore, we have
| (23) |
Next, we calculate a lower bound for the maximum number of bounding boxes that can be produced for the level 2 of the until operator. We repetitively use the inequality for to derive the following inequality from Eq. (21)
| (24) |
where . Therefore, we have
| (25) |
This time inequality suggests that the time/space complexity for any formulas with more than one level of nesting can be exponential.
B-B Best Complexity for the Worst Formulas
We can repeat the above method to calculate a lower bound for each row of the table by using the inequality for in each summation of the elements of rows to derive the below inequality
where . Therefore, we have
| (26) |
This concludes the complexity of the algorithm to be .