Follow-the-Regularized-Leader Routes to Chaos in Routing Games
Abstract.
We study the emergence of chaotic behavior of Follow-the-Regularized Leader (FoReL) dynamics in games. We focus on the effects of increasing the population size or the scale of costs in congestion games, and generalize recent results on unstable, chaotic behaviors in the Multiplicative Weights Update dynamics [42, 10, 11] to a much larger class of FoReL dynamics. We establish that, even in simple linear non-atomic congestion games with two parallel links and any fixed learning rate, unless the game is fully symmetric, increasing the population size or the scale of costs causes learning dynamics to become unstable and eventually chaotic, in the sense of Li-Yorke and positive topological entropy. Furthermore, we show the existence of novel non-standard phenomena such as the coexistence of stable Nash equilibria and chaos in the same game. We also observe the simultaneous creation of a chaotic attractor as another chaotic attractor gets destroyed. Lastly, although FoReL dynamics can be strange and non-equilibrating, we prove that the time average still converges to an exact equilibrium for any choice of learning rate and any scale of costs.
BIELAWSKI, CHOTIBUT, FALNIOWSKI, KOSIOROWSKI, MISIUREWICZ, PILIOURAS
1. Introduction
We study the dynamics of online learning in a non-atomic repeated congestion game. Namely, every iteration of the game presents a population (i.e., a continuum of players) with a choice between two strategies, and imposes on them a cost which increases with the fraction of population adopting the same strategy. In each iteration, the players update their strategy accommodating for the outcomes of previous iterations. The structure of cost function here concerns that of the congestion games, which are introduced by Rosenthal [45] and are amongst the most studied classes of games. A seminal result of [40] shows that congestion games are isomorphic to potential games; as such, numerous learning dynamics are known to converge to Nash equilibria [14, 16, 15, 28, 29, 35, 5].
A prototypical class of online learning dynamics is Follow the Regularized Leader (FoReL) [48, 22]. FoReL algorithm includes as special cases ubiquitous meta-algorithms, such as the Multiplicative Weights Update (MWU) algorithm [2]. Under FoReL, the strategy in each iteration is chosen by minimizing the weighted (by the learning rate) sum of the total cost of all actions chosen by the players and the regularization term. FoReL dynamics are known to achieve optimal regret guarantees (i.e., be competitive with the best fixed action with hindsight), as long as they are executed with a highly optimized learning rate; i.e., one that is decreasing with the steepness of the online costs (inverse to the Lipschitz constant of the online cost functions) as well as decreasing with time at a rate [48].
Although precise parameter tuning is perfectly reasonable from the perspective of algorithmic design, it seems implausible from the perspective of behavioral game theory and modeling. For example, experimental and econometric studies based on a behavioral game theoretic learning model known as Experienced Weighted Attraction (EWA), which includes MWU as a special case, have shown that agents can use much larger learning rates than those required for the standard regret bounds to be meaningfully applicable [24, 23, 25, 9]. In some sense, such a tension is to be expected because small and optimized learning rates are designed with system stability and asymptotic optimality in mind, whereas selfish agents care more about short-term rewards which result in larger learning rates and more aggressive behavioral adaptation. Interestingly, recent work on learning in games study exactly such settings of FoReL dynamics with large, fixed step-sizes, showing that vanishing and even constant regret is possible in some game settings [4, 3].
For congestion games, it is reasonable to expect that increased demands and thus larger daily costs should result in steeper behavioral responses, as agents become increasingly agitated at the mounting delays. However, to capture this behavior we need to move away from the standard assumption of effective scaling down of the learning rate. Then, the costs increase and allow more general models that can incorporate non-vanishing regret. Thus, in this regime, FoReL dynamics in congestion games cannot be reduced to standard regret based analysis [7], or even Lyapunov function arguments (e.g., [43]), and more refined and tailored arguments will be needed.
In a series of work [42, 10, 11], the special case of MWU was analyzed under arbitrary population, demands. In a nutshell, for any fixed learning rate, MWU becomes unstable/chaotic even in small congestion games with just two strategies/paths as long as the total demand exceeds some critical threshold, whereas for small population sizes it is always convergent. Can we extend our understanding from MWU to more general FoReL dynamics? Moreover, are the results qualitatively similar showing that the dynamic is either convergent for all initial conditions or non-convergent for almost all initial conditions, or can there be more complicated behaviors depending on the choice of the regularizer of FoReL dynamics?
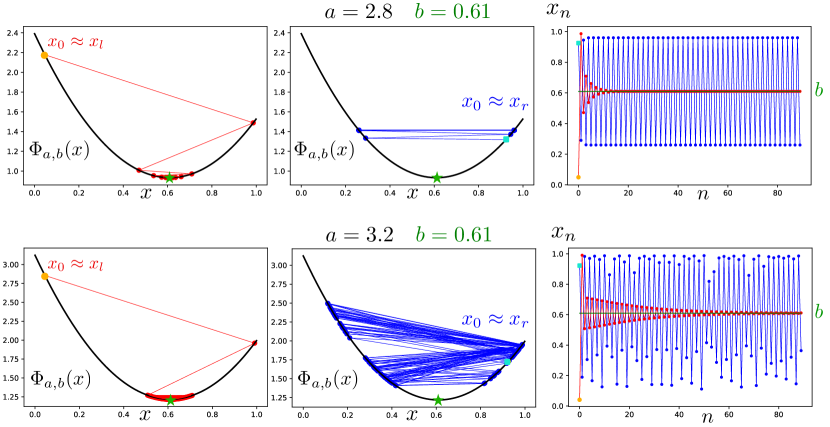
Our model & results. We analyze FoReL-based dynamics with steep regularizers111Steepness of the regularizer guarantees that the dynamics will be well-defined as a function of the current state of the congestion game. For details, see Section 2. in non-atomic linear congestion games with two strategies. This seemingly simple setting will suffice for the emergence of highly elaborate and unpredictable behavioral patterns. For any such game and an arbitrarily small but fixed learning rate , we show that there exists a system capacity such that the system is unstable when the total demand exceeds this threshold. In such case, we observe complex non-equilibrating dynamics: periodic orbits of any period and chaotic behavior of trajectories (Section 7). A core technical result is that almost all such congestion games (i.e. unless they are fully symmetric), given sufficiently large demand, will exhibit Li-Yorke chaos and positive topological entropy (Section 7.1). In the case of games with asymmetric equilibrium flow, the bifurcation diagram is very complex (see Section 8). Li-Yorke chaos implies that there exists an uncountable set of initial conditions that gets scrambled by the dynamics. Formally, given any two initial conditions in this set, while , meaning trajectories come arbitrarily close together infinitely often but also then move away again. In the special case where the two edges have symmetric costs (equilibrium flow is the split), the system will still become unstable given large enough demand, but chaos is not possible. Instead, in the unstable regime, all but a measure zero set of initial conditions gets attracted by periodic orbits of period two which are symmetric around the equilibrium. Furthermore, we construct formal criteria for when the Nash equilibrium flow is globally attracting. For such systems we can prove their equilibration and thus social optimality even when standard regret bounds are not applicable (Section 6.1). Also, remarkably, whether the system is equilibrating or chaotic, we prove that the time-average flows of FoReL dynamics exhibit regularity and always converge exactly to the Nash equilibrium (Section 4).
In Section 8, for the first time, to our knowledge, we report strange dynamics arising from FoReL in congestion games. Firstly, we numerically show that for FoReL dynamics a locally attracting Nash equilibrium and chaos can coexist, see Figure 2. This is also formally proven in Section 6.2. Given the prominence of local stability analysis to equilibria for numerous game theoretic settings which are widely used in Artificial Intelligence, such as Generative Adversarial Networks (GANs), e.g., [18, 37, 33, 41, 53], we believe that this result is rather important as it reveals that local stability analysis is not sufficient to guard against chaotic behaviors even in a trivial game with one (locally stable) Nash equilibrium! Secondly, Figure 4 reveals that chaotic attractors can be non-robust. Specifically, we show that mild perturbations in the parameter can lead to the destruction of one complex attractor while another totally distinct complex attractor is born! To the best of our knowledge, these phenomena have never been reported, and thus expanding our understanding of the range of possible behaviors in game dynamics. Several more examples of complex phenomena are provided in Section 8. Finally, further calculations for entropic regularizers can be found in Appendix A.
Our findings suggest that the chaotic behavior of players using Multiplicative Weights Update algorithm in congestion games (see results from [42, 10, 11]) is not an exception but the rule. Chaos is robust and can be seen for a vast subclass of online learning algorithms. In particular, our results apply to an important subclass of regularizers, of generalized entropies, which are widely used concepts in information theory, complexity theory, and statistical mechanics [13, 51, 50]. Steep functions [36, 34, 35] and generalized entropies are also often used as regularizers in game-theoretic setting [12, 35, 8]. In particular, Havrda-Charvát-Tsallis entropy-based dynamics was studied, for instance, in [20, 26]. Lastly, the emergence of chaos is clearly a hardness type of result. Such results only increase in strength the simpler the class of examples is. Complicated games are harder to learn and it is harder for players to coordinate on an equilibrium. Thus, in more complicated games one should expect even more complicated, unpredictable behaviors.
2. Model
We consider a two-strategy congestion game (see [45]) with a continuum of players (agents), where all of the players apply the Follow the Regularized Leader (FoReL) algorithm to update their strategies [48]. Each of the players controls an infinitesimally small fraction of the flow. We assume that the total flow of all the players is equal to . We denote the fraction of the players adopting the first strategy at time as . The second strategy is then chosen by fraction of the players. This model encapsulates how a large population of commuters selects between the two alternative paths that connect the initial point to the end point. When a large fraction of the players adopt the same strategy, congestion arises, and the cost of choosing the same strategy increases.
Linear congestion games: We focus on linear cost functions. Specifically, the cost of each path (link, route, or strategy) is proportional to the load. By denoting the cost of selecting the strategy (when relative fraction of the agents choose the first strategy),
| (1) |
where are the coefficients of proportionality. Without loss of generality we will assume throughout the paper that . Therefore, the values of and indicate how different the path costs are from each other.
A quantity of interest is the value of the equilibrium split; i.e., the relative fraction of players using the first strategy at equilibrium. The first benefit of this formulation is that the fraction of agents using each strategy at equilibrium is independent of the flow . The second benefit is that, independent of , and , playing Nash equilibrium results in the optimal social cost, which is the point of contact with the Price of Anarchy research [30, 11].
2.1. Learning in congestion games with FoReL algorithms
We assume that the players at time know the cost of the strategies at time (equivalently, the realized flow (split) ) and update their choices according to the Follow the Regularized Leader (FoReL) algorithm. Namely, in the period the players choose the first strategy with probability such that:
| (2) | ||||
where is a total cost that is inflicted on the population of agents playing against the mix in period , while is a regularizer which represents a “risk penalty”: namely, that term would penalize abrupt changes of strategy based on a small amount of data from previous iterations of the game. The existence of a regularizer rules out strategies that focus too much on optimizing with respect to the history of our game. A weight coefficient of our choosing is used to balance these two terms and may be perceived as a propensity to learn and try new strategies based on new information: the larger is, the faster the players learn and the more eager they are to update their strategies. Commonly adopted as a standard assumption, the learning rate can be regarded as a small, fixed constant in the following analysis but its exact value is not of particular interest. Our analysis/results holds for any fixed choice of .
Note that FoReL can also be regarded as an instance of an exploration-exploitation dynamics under the multi-armed bandits framework in online learning [54]. In the limit such that (2) is well approximated by the minimization of the cumulative expected cost
the minimization yields
Namely, the strategy that incurs the least cumulative cost in the past time horizon is selected with probability 1. This term thus represents exploitation dynamics in reinforcement learning and multi-armed bandits framework. In the opposite limit when , (2) is well approximated by the minimization of the regularizer For the Shannon entropy regularizer that results in the Multiplicative Weight Update algorithm (see the details in Appendix A and Sec. 3), its minimization yields
The entropic regularization term tends to explore every strategy with equal probabilities, neglecting the information of the past cumulative cost. Thus, this regularization term corresponds to exploration dynamics. Therefore, adjusts the tradeoff between exploration and exploitation. The continuous time variant of (2) with the Shannon entropy regularizer has been studied as models of collective adaption [47, 46], also known as Boltzmann learning [27], in which the exploitation term is interpreted as behavioral adaptation whereas the exploration term represents memory loss. More recent continuous-time variants study generalized entropies as regularizers, leading to a larger class of dynamics called Escort Replicator Dynamics [20] which was analyzed extensively in [34, 35].
Motivated by the continuous-time dynamics with generalized entropies, we extend FoReL discrete-time dynamics (2) to a larger class of regularizers. For a given regularizer , we define an auxiliary function:
| (3) |
We restrict the analysis to a FoReL class of regularizers for which the dynamics implied by the algorithm is well-defined. Henceforth, we assume that is a steep symmetric convex regularizer, namely , where:
These conditions on regularizers are not overly restrictive: the assumptions for convexity and symmetry of the regularizer are natural, and if is finite, then the dynamics of from (2) will not be well-defined.
Many well-known and widely used regularizers like (negative) Arimoto entropies (Shannon entropy, Havrda-Charvát-Tsallis (HCT) entropies and log-barrier being most famous ones) and (negative) Rényi entropies, under mild assumptions, belong to (see Appendix A). A standard non-example is the square of the Euclidean norm .
3. The dynamics introduced by FoReL
Let . Assume that up to the iteration the trajectory was established by (2). Then
First order condition yields
We know that is convex, therefore the sufficient and necessary condition for to satisfy (2) takes form:
| (4) | ||||
We define . Table 1 depicts functions for different entropic regularizers222By substituting the negative Shannon entropy as in (4), that is , we obtain the Multiplicative Weights Update algorithm.. Before proceeding any further, we need to establish crucial properties of the function .
| regularizer | ||
|---|---|---|
| Shannon | ||
| Havrda-Charvát-Tsallis, | ||
| Rényi, | ||
| log-barrier |
Proposition 3.1.
Let be a function derived from a regularizer from . Then
-
i)
for .
-
ii)
is a homeomorphism, , and .
Proof.
After substituting
| (5) |
we obtain from (4) a general formula for the dynamics
| (6) |
where . Thus, we introduce as
| (7) |
By the properties of , is continuous, and (7) defines a discrete dynamical system emerging from the FoReL algorithm for the pair of parameters .
Lemma 3.2.
The following properties hold:
-
i)
if and only if and if and only if .
-
ii)
If is given by , then
-
iii)
Under the dynamics defined by (7), there exists a closed invariant and globally attracting interval .
Proof.
We obtain (i) directly from (7) and the fact that is decreasing.
is a homeomorphism, thus if for some , then
Hence,
Now let . Then
and (ii) follows.
By (i), for and for . Therefore, there exists such that for . There exists also such that . Set . Then, the interval is invariant.
To complete the proof of (iii) we need to show that is attracting. Assume that is such that its -trajectory never enters . Since , the distance between and (that is, , where for and for ) is decreasing and . Sequence is decreasing and bounded from below by , so it is convergent to some . Therefore, the -set of the trajectory of is a non-empty subset of . However, no non-empty subset of can be invariant (and thus, can be an -set of a trajectory), because and thus , and . By this contradiction, such does not exist, thus is globally attracting.
∎
4. Average behavior — Nash equilibrium is Cesáro attracting
We start by studying asymptotic behavior by looking on the average behavior of orbits. We will show that the orbits of our dynamics exhibit regular average behavior known as Cesáro attraction to the Nash equilibrium .
Definition 4.1.
For an interval map a point is Cesáro attracting if there is a neighborhood of such that for every the averages converge to .
Theorem 4.2 (Cesáro attracting).
For every , and we have
| (8) |
Proof.
Fix and let .
From (7) we get by induction that
| (9) |
By Lemma 3.2.iii there is such that there exists a closed, globally absorbing and invariant interval . Thus, for sufficiently large
is decreasing, thus
Corollary 4.3.
The center of mass of any periodic orbit of in , namely , is equal to .
Applying the Birkhoff Ergodic Theorem, we obtain:
Corollary 4.4.
For every probability measure , invariant for and such that , we have
In the following sections, we will show that, despite the regularity of the average trajectories which converge to the Nash equilibrium , the trajectories themselves typically exhibit complex and diverse behaviors.
5. Two definitions of chaos
In this section we introduce two notions of chaotic behavior: Li-Yorke chaos and (positive) topological entropy. Most definitions of chaos focus on complex behavior of trajectories, such as Li-Yorke chaos or fast growth of the number of distinguishable orbits of length , detected by positivity of the topological entropy.
Definition 5.1 (Li-Yorke chaos).
Let be a dynamical system and . We say that is a Li-Yorke pair if
A dynamical system is Li-Yorke chaotic if there is an uncountable set (called scrambled set) such that every pair with and is a Li-Yorke pair.
Intuitively orbits of two points from the scrambled set have to gather themselves arbitrarily close and spring aside infinitely many times but (if is compact) it cannot happen simultaneously for each pair of points. Obviously the existence of a large scrambled set implies that orbits of points behave in unpredictable, complex way.
A crucial feature of the chaotic behavior of a dynamical system is also exponential growth of the number of distinguishable orbits. This happens if and only if the topological entropy of the system is positive. In fact positivity of topological entropy turned out to be an essential criterion of chaos [17]. This choice comes from the fact that the future of a deterministic (zero entropy) dynamical system can be predicted if its past is known (see [52, Chapter 7]) and positive entropy is related to randomness and chaos. For every dynamical system over a compact phase space, we can define a number called the topological entropy of transformation . This quantity was first introduced by Adler, Konheim and McAndrew [1] as the topological counterpart of a metric (and Shannon) entropy. In general, computing topological entropy is not an easy task. However, in the context of piecewise monotone interval maps, topological entropy is equal to the exponential growth rate of the minimal number of monotone subintervals for .
Theorem 5.2 ([39]).
Let be a piecewise monotone interval map and, for all , let be the minimal cardinality of a monotone partition for . Then
6. Asymptotic stability of Nash equilibria
6.1. Asymptotic stability of Nash equilibria
The dynamics induced by (7) admits three fixed points: , and . By Lemma 3.2.iii we know that all orbits starting from eventually fall into a globally attracting interval . Thus, the points and are repelling. When does the Nash equilibrium attract all point from ? First, we look when is an attracting and when it is a repelling fixed point. With this aim, we study the derivative of :
Then,
| (10) |
The fixed point is attracting if and only if , which is equivalent to the condition:
| (11) |
Thus, the fixed point is attracting if and only if and repelling otherwise. We will answer when is globally attracting on . First we will show the following auxiliary lemma.
Lemma 6.1.
Let a function be such that . Then
for every .
Proof.
Without loss of generality we can assume that . Then
where the inequality follows from the fact that is smaller in the latter region while the integration is over the set of the same size. Therefore,
which completes the proof of lemma. ∎
The following theorem answers, whether is globally attracting on .
Theorem 6.2.
Let be a homeomorphism derived from a regularizer from . Suppose that is an attracting fixed point of . If , then trajectories of all points from converge to .
Proof.
In order to prove this theorem it is sufficient to show that doesn’t have periodic orbits of period 2.
Suppose that is a periodic orbit of of period 2.
We have that , and therefore,
Thus, or equivalently
| (12) |
By Lemma 6.1
| (13) |
but the point is attracting if and only if , which contradicts the inequality (13). Therefore, has no periodic point of period 2.
Now, by [6], Chapter VI, Proposition 1, every trajectory of converges to a fixed point.
∎
Corollary 6.3.
Let . Then the Nash equilibrium attracts all points from the open interval if and only if .
Functions derived from Shannon entropy, HCT entropy or log-barrier satisfy the inequality . Nevertheless, this additional condition is needed, because for an arbitrary derived from attracting orbits of any period may exist together with the attracting Nash equilibrium . In the next section we will discuss thoroughly an example of such behavior. This shows that even for the well-known class of FoReL algorithms knowledge of local behavior (even attraction) of the Nash equilibrium may not be enough to properly describe behavior of agents.


6.2. Coexistence of attracting Nash equilibrium and chaos
In this section we will describe an example of the regularizer from , which introduces game dynamics in which attracting Nash equilibrium coexist with chaos, see example in Figure 2. This phenomenon is observed by replacing the Shannon entropic regularizer by the log-barrier regularizer. Namely, we take
We will show that there exist , such that has an attracting fixed point (which is the Nash equilibrium) yet the map can be chaotic!
Proposition 6.4.
There exist , such that has an attracting fixed point (Nash equilibirum), positive topological entropy and is Li-Yorke chaotic.
Proof.
Let us take and (see the graph of in Figure 3).

Set
Since , the fixed point is attracting.
To show that is chaotic, we will prove that has a periodic point of period 6. With this aim, we will show that for any . We start by showing that is monotone on . Formula for the derivative of is
Set . Then if and only if , where
We have
and the discriminant of this quadratic polynomial is negative. Therefore, has only one zero (approximately ), so has only two zeros, symmetric with respect to 0.5. Thus, as
there is no zero of between these two points. Moreover, those computations give us an approximation to both zeros of : and .
Now we look at the first six images of :
\tabto51pt
\tabto51pt
\tabto51pt
\tabto51pt
\tabto48pt
\tabto48pt
\tabto48pt
\tabto48pt
\tabto47pt
\tabto47pt
\tabto47pt
\tabto47pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt
\tabto44pt .
We have , so . Write for or . If and is monotone on , then . Thus, the computations show that
and
Therefore, for any we have
so by theorem from [31], has a periodic point of period 3 and has a periodic point of period 6. Thus, because has a periodic point of period that is not a power of 2, the topological entropy is positive (see [38]) and it is Li-Yorke chaotic. ∎
Corollary 6.5.
There exist FoReL dynamics such that when applied to symmetric linear congestion games with only two strategies/paths the resulting dynamics have
-
•
a set of positive measure of initial conditions that converge to the unique and socially optimum Nash equilibrium and
-
•
an uncountable scrambled set for which trajectories exhibit Li-Yorke chaos,
-
•
periodic orbits of all possible even periods.
Thus, the (long-term) social cost depends critically on the initial condition.
FoReL dynamics induced by this regularizer manifests drastically different behaviors that depend on the initial condition.
7. Behavior for sufficiently large
7.1. Non-convergence for sufficiently large
In this subsection, we study what happens as we fix and let be arbitrarily large333By (5) it reflects the case when we fix cost functions (and learning rate ) and increase the total demand .. First, we study the asymmetric case, namely . We show chaotic behavior of our dynamical system for sufficiently large, that is we will show that if is sufficiently large then is Li-Yorke chaotic, has periodic orbits of all periods and positive topological entropy.
The crucial ingredient of our analysis is the existence of periodic orbit of period 3.
Theorem 7.1.
If , then there exists such that if then has a periodic point of period 3.
Proof.
By Lemma 3.2.ii, without loss of generality, we may assume . We will show that there exists such that .
Fix and . We set , then formula (9) holds. Hence if and only if and, because is decreasing, is equivalent to .
From the fact that we have that . So we can take such that . Then . Moreover
Thus, since , there exists such that if , then , so . Hence, if , then .
Now we conclude that has a periodic point of period 3 for , from theorem from [31], which implies that if for some odd , then has a periodic point of period .
∎
By the Sharkovsky Theorem ([49]), existence of a periodic orbit of period 3 implies existence of periodic orbits of all periods, and by the result of [32], period 3 implies Li-Yorke chaos. Moreover, because has a periodic point of period that is not a power of 2, the topological entropy is positive (see [38]). Thus:
Corollary 7.2.
If , then there exists such that if then has periodic orbits of all periods, has positive topological entropy and is Li-Yorke chaotic.
This result has an implication in non-atomic routing games. Recall that the parameter expresses the normalized total demand. Thus, Corollary 7.2 implies that when the costs (cost functions) of paths are different, then increasing the total demand of the system will inevitably lead to chaotic behavior.
Now we consider the symmetric case, when , which corresponds to equal coefficients of the cost functions, . To simplify the notation we denote .
Theorem 7.3.
If the parameter is small enough, then all trajectories of starting from converge to the attracting fixed point . There exists such that if , then all points from (except countably many points, whose trajectories eventually fall into the repelling point ) are attracted by periodic attracting orbits of the form , where . Moreover, if there exists such that is convex on , then there exists a unique attracting orbit , which attracts trajectories of all points from , except countably many points, whose trajectories eventually fall into the repelling fixed point .
Proof.
By Lemma 3.2.ii the maps and commute. Set . Since is an involution, we have . We show that the dynamics of is simple, no matter how large is.
We aim to find fixed points and points of period 2 of and . Clearly,
By (9) we have
so the fixed points of are , and the solutions to , that is, to . Thus, the fixed points of (which, as we noticed, is equal to ) are the fixed points of and and .
We can choose the invariant interval symmetric, so that . Let us look at . All fixed points of are also fixed points of , so has no periodic points of period 2. By the Sharkovsky Theorem, has no periodic points other than fixed points. For such maps it is known (see, e.g., [6]) that the -limit set of every trajectory is a singleton of a fixed point, that is, every trajectory converges to a fixed point. If , then the -trajectory of after a finite time enters , so -trajectories of all points of converge to a fixed point of in . Observe that a fixed point of can be a fixed point of (other that 0, 1) or a periodic point of of period 2. Thus, the -trajectory of every point of converges to a fixed point or a periodic orbit of period of , other than and .
Observe now that is a fixed point of both and . The fixed points of in are the solutions of the equation , which is equivalent to , further to
and finally, by Proposition 3.1.i, to
Define . We look for such that
| (14) |
We know that and . As ( is strictly decreasing) there is no solution of (14) in for sufficiently small . Then, is the only fixed point of in . Thus, will attract all points from .
If , then there exists such that . Because and and both functions are continuous, there exists such that . Finally, if and only if .
Lastly, if is convex on some neighborhood of zero, that is , then we can choose (sufficiently large) such that all solutions of (14) in lay in . From the fact that is convex on this interval and is an affine function we obtain uniqueness of . ∎
Theorem 7.3 has a remarkable implication in non-atomic routing games. It implies that if cost of both paths is the same, then there is a threshold such that if the total demand will cross this threshold, then starting from almost any initial condition the system will oscillate, converging to the symmetric periodic orbit of period 2, never converging to the Nash equilibrium.
8. Experimental results


In this section we report complex behaviors in bifurcation diagrams of FoReL dynamics. We investigate the structures of the attracting periodic orbits and chaotic attractors associated with the interval map defined by (7). In the asymmetric case, that is when differs from , the standard equilibrium analysis applies when the fixed point is stable, which is when , or equivalently when . Therefore, as we argued in the previous section, in this case the dynamics will converge toward the fixed point whenever . However, when there is no attracting fixed point. Moreover, a chaotic behavior of trajectories emerges when is sufficiently large, as the period-doubling bifurcations route to chaos is guaranteed to arise.
In particular, we study the attractors of the map generated by the log-barrier regularizer (see Example A.2 with ) and by the Havrda-Charvát-Tsallis regularizer for (see Example A.3). Note that for both of these regularizers, we have that . Note also that the functions for these regularizers can be found in Table 1.
We first focus on the log-barrier regularizer444From the regularity of the map (see Appendix B), we know that every limit cycle of the dynamics generated by can be found by studying the behavior of the critical points of . Therefore, all attractors of this dynamics can be revealed by following the trajectories of these two critical points (as in Figure 4).. Figure 4 reveals an unusual bifurcation phenomenon, which, to our knowledge, is not known in other natural interval maps. We observe simultaneous evolution of two attractors in the opposite directions: one attractor, generated by the trajectory of the left critical point, is shrinking, while the other one, generated by the trajectory of the right critical point, is growing. Figure 5 shows another unusual bifurcation phenomenon: a chaotic attractor arises via period-doubling bifurcations and then collapses. After that, the trajectories of the critical points, one after the other, jump, and then they together follow a period-doubling route to chaos once more.
Finally we study the bifurcation diagrams generated from Havrda-Charvát-Tsallis regularizer with . In Figure 8 we observe a finite number of period-doubling (and period-halving) bifurcations, a behavior that does not lead to chaos. Nevertheless, as increases from 39.915 to 39.93, the trajectory of the right critical point leaves the attractor which it shared with the trajectory of the left critical point, and builds a separate chaotic attractor. When chaos arises, however, we observe that the induced dynamics of the log-barrier regularizer and of the Havrda-Charvát-Tsallis regularizer with both exhibit period-doubling routes to chaos though the regularizers are starkly different, see Figure 6 and Figure 7 respectively.








9. Conclusion
We study FoReL dynamics in non-atomic congestion games with arbitrarily small but fixed step-sizes, rather than with decreasing and regret-optimizing step-sizes. Our model allows for agents that can learn over time (e.g., by tracking the cumulative performance of all actions to inform about their future decisions), while being driven by opportunities for short-term rewards, rather than only by long-term asymptotic guarantees. As a result, we can study the effects of increasing system demand and delays on agents’ responses, which can become steeper as they are increasingly agitated by the increasing costs. Such assumptions are well justified from a behavioral game theory perspective [24, 9]; however, FoReL dynamics are pushed outside of the standard parameter regime in which classic black-box regret bounds do not apply meaningfully. Using tools from dynamical systems, we show that, under sufficiently large demand, dynamics will unavoidably become chaotic and unpredictable. Thus, our work vastly generalizes previous results that hold in the special case of Multiplicative Weights Update [42, 10, 11]. We also report a variety of undocumented complex behaviors such as the co-existence of a locally attracting Nash equilibrium and of chaos in the same game. Despite this behavioral complexity of the day-to-day behavior, the time-average system behavior is always perfectly regular, converging to an exact equilibrium. Our analysis showcases that local stability in congestion games should not be considered as a foregone conclusion and paves the way toward further investigations at the intersection of optimization theory, (behavioral) game theory, and dynamical systems.
Acknowledgements
Georgios Piliouras acknowledge AcRF Tier 2 grant 2016-T2-1-170, grant PIE-SGP-AI-2018-01, NRF2019-NRF- ANR095 ALIAS grant and NRF 2018 Fellowship NRF-NRFF2018-07. Fryderyk Falniowski acknowledges the support of the National Science Centre, Poland, grant 2016/21/D/HS4/01798 and COST Action CA16228 “European Network for Game Theory”. Research of Michał Misiurewicz was partially supported by grant number 426602 from the Simons Foundation. Jakub Bielawski and Grzegorz Kosiorowski acknowledge support from a subsidy granted to Cracow University of Economics. Thiparat Chotibut acknowledges a fruitful discussion with Tanapat Deesuwan, and was partially supported by grants for development of new faculty staff, Ratchadaphiseksomphot endownment fund, and Sci-Super VI fund, Chulalongkorn University.
References
- [1] R. L. Adler, A. G. Konheim, and M. H. McAndrew. Topological entropy. Transactions of American Mathematical Society, 114:309–319, 1965.
- [2] S. Arora, E. Hazan, and S. Kale. The multiplicative weights update method: a meta-algorithm and applications. Theory of Computing, 8(1):121–164, 2012.
- [3] J. P. Bailey, G. Gidel, and G. Piliouras. Finite regret and cycles with fixed step-size via alternating gradient descent-ascent. CoRR, abs/1907.04392, 2019.
- [4] J. P. Bailey and G. Piliouras. Fast and furious learning in zero-sum games: Vanishing regret with non-vanishing step sizes. In Advances in Neural Information Processing Systems, volume 32, pages 12977–12987, 2019.
- [5] P. Berenbrink, M. Hoefer, and T. Sauerwald. Distributed selfish load balancing on networks. In ACM Transactions on Algorithms (TALG), 2014.
- [6] L. Block and W. A. Coppel. Dynamics in one dimension, volume 513 of Lecture Notes in Mathematics. Springer, Berlin New York, 2006.
- [7] A. Blum, E. Even-Dar, and K. Ligett. Routing without regret: On convergence to nash equilibria of regret-minimizing algorithms in routing games. In Proceedings of the twenty-fifth annual ACM symposium on Principles of distributed computing, pages 45–52. ACM, 2006.
- [8] I. M. Bomze, P. Mertikopoulos, W. Schachinger, and M. Staudigl. Hessian barrier algorithms for linearly constrained optimization problems. SIAM Journal on Optimization, 29(3):2100–2127, 2019.
- [9] C. F. Camerer. Behavioral game theory: Experiments in strategic interaction. Princeton University Press, 2011.
- [10] T. Chotibut, F. Falniowski, M. Misiurewicz, and G. Piliouras. Family of chaotic maps from game theory. Dynamical Systems, 2020. https://doi.org/10.1080/14689367.2020.1795624.
- [11] T. Chotibut, F. Falniowski, M. Misiurewicz, and G. Piliouras. The route to chaos in routing games: When is price of anarchy too optimistic? Advances in Neural Information Processing Systems, 33, 2020.
- [12] P. Coucheney, B. Gaujal, and P. Mertikopoulos. Penalty-regulated dynamics and robust learning procedures in games. Mathematics of Operations Research, 40(3):611–633, 2015.
- [13] I. Csiszár. Axiomatic characterizations of information measures. Entropy, 10(3):261–273, 2008.
- [14] E. Even-Dar and Y. Mansour. Fast convergence of selfish rerouting. In Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’05, pages 772–781, Philadelphia, PA, USA, 2005. Society for Industrial and Applied Mathematics.
- [15] S. Fischer, H. Räcke, and B. Vöcking. Fast convergence to wardrop equilibria by adaptive sampling methods. In Proceedings of the Thirty-eighth Annual ACM Symposium on Theory of Computing, STOC ’06, pages 653–662, New York, NY, USA, 2006. ACM.
- [16] D. Fotakis, A. C. Kaporis, and P. G. Spirakis. Atomic congestion games: Fast, myopic and concurrent. In B. Monien and U.-P. Schroeder, editors, Algorithmic Game Theory, volume 4997 of Lecture Notes in Computer Science, pages 121–132. Springer Berlin Heidelberg, 2008.
- [17] E. Glasner and B. Weiss. Sensitive dependence on initial conditions. Nonlinearity, 6(6):1067–1085, 1993.
- [18] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [19] P. D. Grünwald and A. P. Dawid. Game theory, maximum entropy, minimum discrepancy and robust bayesian decision theory. The Annals of Statistics, 32(4):1367–1433, 2004.
- [20] M. Harper. Escort evolutionary game theory. Physica D: Nonlinear Phenomena, 240(18):1411–1415, 2011.
- [21] J. Havrda and F. Charvát. Quantification method of classification processes. concept of structural -entropy. Kybernetika, 3(1):30–35, 1967.
- [22] E. Hazan et al. Introduction to online convex optimization. Foundations and Trends® in Optimization, 2(3-4):157–325, 2016.
- [23] T.-H. Ho and C. Camerer. Experience-weighted attraction learning in coordination games: Probability rules, heterogeneity, and time-variation. Journal of Mathematical Psychology, 42:305–326, 1998.
- [24] T.-H. Ho and C. Camerer. Experience-weighted attraction learning in normal form games. Econometrica, 67:827–874, 1999.
- [25] T.-H. Ho, C. F. Camerer, and J.-K. Chong. Self-tuning experience weighted attraction learning in games. Journal of Economic Theory, 133:177–198, 2007.
- [26] G. P. Karev and E. V. Koonin. Parabolic replicator dynamics and the principle of minimum Tsallis information gain. Biology Direct, 8:19 – 19, 2013.
- [27] A. Kianercy and A. Galstyan. Dynamics of Boltzmann learning in two-player two-action games. Phys. Rev. E, 85:041145, Apr 2012.
- [28] R. Kleinberg, G. Piliouras, and É. Tardos. Multiplicative updates outperform generic no-regret learning in congestion games. In ACM Symposium on Theory of Computing (STOC), 2009.
- [29] R. Kleinberg, G. Piliouras, and É. Tardos. Load balancing without regret in the bulletin board model. Distributed Computing, 24(1):21–29, 2011.
- [30] E. Koutsoupias and C. Papadimitriou. Worst-case equilibria. In C. Meinel and S. Tison, editors, STACS 99, pages 404–413, Berlin, Heidelberg, 1999. Springer Berlin Heidelberg.
- [31] T. Y. Li, M. Misiurewicz, G. Pianigiani, and J. A. Yorke. Odd chaos. Physics Letters A, 87(6):271–273, 1982.
- [32] T. Y. Li and J. A. Yorke. Period three implies chaos. The American Mathematical Monthly, 82:985–992, 1975.
- [33] T. Liang and J. Stokes. Interaction matters: A note on non-asymptotic local convergence of generative adversarial networks. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 907–915. PMLR, 2019.
- [34] P. Mertikopoulos and W. H. Sandholm. Learning in games via reinforcement and regularization. Mathematics of Operations Research, 41(4):1297–1324, 2016.
- [35] P. Mertikopoulos and W. H. Sandholm. Riemannian game dynamics. Journal of Economic Theory, 177:315–364, 2018.
- [36] P. Mertikopoulos and Z. Zhou. Learning in games with continuous action sets and unknown payoff functions. Mathematical Programming, 173(1-2):465–507, 2019.
- [37] L. Mescheder, A. Geiger, and S. Nowozin. Which training methods for gans do actually converge? arXiv preprint arXiv:1801.04406, 2018.
- [38] M. Misiurewicz. Horseshoes for mapping of the interval. Bull. Acad. Polon. Sci. Sér. Sci., 27:167–169, 1979.
- [39] M. Misiurewicz and W. Szlenk. Entropy of piecewise monotone mappings. Studia Mathematica, 67(1):45–63, 1980.
- [40] D. Monderer and L. S. Shapley. Fictitious play property for games with identical interests. Journal of Economic Theory, 68(1):258–265, 1996.
- [41] V. Nagarajan and J. Z. Kolter. Gradient descent gan optimization is locally stable. In Advances in neural information processing systems, pages 5585–5595, 2017.
- [42] G. Palaiopanos, I. Panageas, and G. Piliouras. Multiplicative weights update with constant step-size in congestion games: Convergence, limit cycles and chaos. In Advances in Neural Information Processing Systems, pages 5872–5882, 2017.
- [43] I. Panageas, G. Piliouras, and X. Wang. Multiplicative weights updates as a distributed constrained optimization algorithm: Convergence to second-order stationary points almost always. In International Conference on Machine Learning, pages 4961–4969. PMLR, 2019.
- [44] A. Rényi. On measures of entropy and information. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, 1961.
- [45] R. Rosenthal. A class of games possessing pure-strategy Nash equilibria. International Journal of Game Theory, 2(1):65–67, 1973.
- [46] Y. Sato, E. Akiyama, and J. P. Crutchfield. Stability and diversity in collective adaptation. Physica D: Nonlinear Phenomena, 210(1):21 – 57, 2005.
- [47] Y. Sato and J. P. Crutchfield. Coupled replicator equations for the dynamics of learning in multiagent systems. Phys. Rev. E, 67:015206, Jan 2003.
- [48] S. Shalev-Shwartz. Online learning and online covex optimization. Foundations and Trends in Machine Learning, 4(2):107–194, 2012.
- [49] A. N. Sharkovsky. Coexistence of the cycles of a continuous mapping of the line into itself. Ukrain. Math. Zh., 16:61–71, 1964.
- [50] W. Słomczyński, J. Kwapień, and K. Życzkowski. Entropy computing via integration over fractal measures. Chaos: An Interdisciplinary Journal of Nonlinear Science, 10(1):180–188, 2000.
- [51] C. Tsallis. Possible generalization of Boltzmann-Gibbs statistics. Journal of Statistical Physics, 52(1-2):479–487, 1988.
- [52] B. Weiss. Single orbit dynamics, volume 95 of CBMS Regional Conference Series in Mathematics. American Mathematical Society, Providence, RI, 2000.
- [53] Y. Yaz, C.-S. Foo, S. Winkler, K.-H. Yap, G. Piliouras, V. Chandrasekhar, et al. The unusual effectiveness of averaging in gan training. In International Conference on Learning Representations, 2018.
- [54] Q. Zhao. Multi-Armed Bandits: Theory and Applications to Online Learning in Networks. Morgan and Claypool Publishers, 2019.
Appendices
Appendix A Generalized entropies as regularizers
We present information measures which are often used as regularizers.
Example A.1 (Shannon entropy).
Let , where
Then is the Shannon entropy of a probability distribution and
From
we observe that .555By substituting the (negative) Shannon Entropy as into (4) we obtain the Multiplicative Weights Update algorithm.
Example A.2 (Arimoto entropies).
We consider the class of Arimoto entropies [13], that is functions defined as
where is a concave function.666In the decision theory Arimoto entropies correspond to separable Bregman scores [19].
We define
Then, by its definition, and . Moreover,
Thus, is convex and the limit is finite. Therefore, the condition for is steepness of at zero:
| (15) |
Hence, if and only if satisfies (15).
Several well-known regularizers are given by (negative) Arimoto entropies satisfying (15). For instance, the Shannon entropy from Example A.1 is an Arimoto entropy for , as well as log-barrier regularizer obtained from . Another widely used (especially in statistical physics) example of Arimoto entropy is the Havrda-Charvát-Tsallis entropy.777This entropy (called also entropy of degree ) was first introduced by Havrda and Charvát [21] and used to bound probability of error for testing multiple hypotheses. In statistical physics it is known as Tsallis entropy, referring to [51].
Example A.3 (Havrda-Charvát-Tsallis entropies).
The Havrda-Charvát-Tsallis entropy for is defined as
| (16) |
is an Arimoto entropy for , satisfying (15) for . If then
and for .
Evidently there exist functions which are not Arimoto entropies but also generate regularizers that belong to , one of them being the Rényi entropy of order .
Example A.4 (Rényi entropies).
The Shannon entropy represents an expected mean of individual informations of the form . Rényi [44] introduced alternative information measures, namely generalized means , where is a continuous, strictly monotone function.Then, the Rényi entropy of order correspond to , namely:
As the variables and are not separable, this is not an Arimoto entropy. However, for , and . Moreover,
and
Thus, for we know that on and . Because we infer that for .
Appendix B Regularity of log-barrier dynamics
To understand better the phenomenon discussed in Section 8, let us investigate regularity of . Nice properties of interval maps are guaranteed by the negative Schwarzian derivative. Let us recall that the Schwarzian derivative of is given by the formula
A “metatheorem” states that almost all natural noninvertible interval maps have negative Schwarzian derivative. Note that, by Lemma 3.2.ii, if then is a homeomorphism, so we should not expect negative Schwarzian derivative for that case. For maps with negative Schwarzian derivative each attracting or neutral periodic orbit has a critical point in its immediate basin of attraction. Thus, if we show that the Schwarzian derivative is negative, then we will know that all periodic orbits can be find by studying behavior of critical points of . Therefore, we want to show that for sufficiently large for determined by log-barrier regularizer.
In general, computation of Schwarzian derivative may be very complicated. However, there is a useful formula
| (17) |
Direct computations yield
and
Observe that for all . Thus , and
| (19) |
Therefore, for . Moreover,
Thus,