Focus the Discrepancy: Intra- and Inter-Correlation Learning for Image Anomaly Detection
Abstract
Humans recognize anomalies through two aspects: larger patch-wise representation discrepancies and weaker patch-to-normal-patch correlations. However, the previous AD methods didn’t sufficiently combine the two complementary aspects to design AD models. To this end, we find that Transformer can ideally satisfy the two aspects as its great power in the unified modeling of patch-wise representations and patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can simultaneously spot the patch-wise, intra- and inter-discrepancies of anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to Intra-Inter-Correlation (I2Correlation). The I2Correlation contains a two-branch structure to first explicitly establish intra- and inter-image correlations, and then fuses the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning. Besides, we introduce an entropy constraint strategy to solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability. Extensive experiments on three unsupervised real-world AD benchmarks show the superior performance of our approach. Code will be available at https://github.com/xcyao00/FOD.
1 Introduction
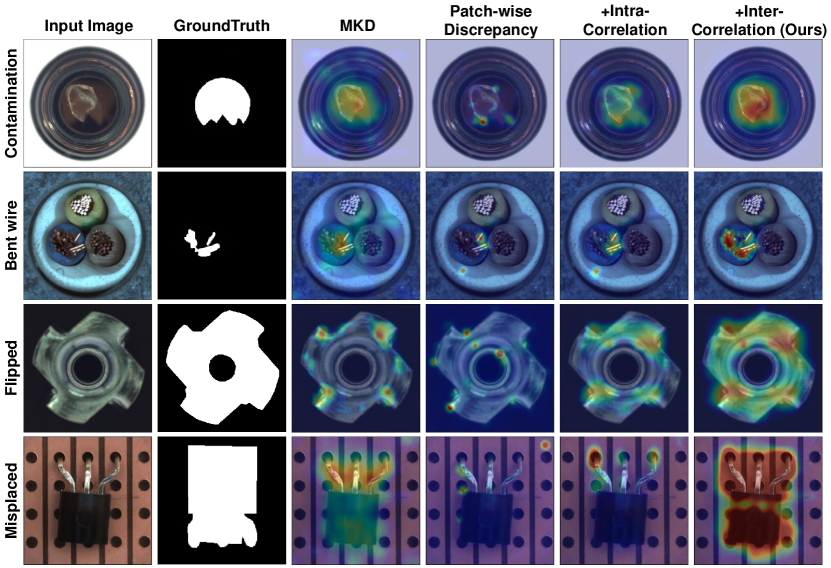
The goal of anomaly detection (AD) is to distinguish an instance containing anomalous patterns from those normal samples and further localize those anomalous regions. Anomalies are defined as opposite to normal samples and are usually rare, which means that we need to tackle AD tasks under the unsupervised setting with only normal samples accessible. The core idea of most unsupervised AD methods is to compare with normal samples to distinguish anomalies [46, 35, 60, 11, 28, 58]. Even for humans, we also recognize anomalies in this way, specifically through three discrepancies, i.e., 1. patch patterns that differentiate from the normal visuals; 2. image regions that destroy textures or structures; 3. novel appearances that deviate from our accumulated knowledge of normality. Namely, anomalous patches usually have three characteristics: their patch-wise representations are different from the normal visuals; they are different from most patches within one image; they deviate from our accumulated knowledge of normality. These views intrinsically reveal that humans’ recognition of anomalies depends on two aspects: patch-wise representations (1) and intra- and inter-image correlations (2, 3).
Previous methods mainly follow the former aspect to learn distinguishable representations or reconstructions, such as reconstruct-based methods [6, 57, 1] and knowledge distillation AD models [4, 41]. The goal of these methods is to generate reconstructed samples or feature representations, and larger patch-wise representation discrepancies can appear in the abnormal patches. However, only the patch-wise representation discrepancies are insufficient for detecting more complex anomalies (e.g., rows 3 and 4 in Figure 1), since the patch-wise errors can’t provide comprehensive descriptions of the spatial context. Other mainstream AD methods, such as embedding-based [11, 35] and one-class-classification-based (OCC) [39, 60] methods, are much similar to the latter aspect. These methods achieve anomaly detection by measuring the distances between the features of test samples and normal features. Compared with the non-learnable feature distances, the explicit intra- and inter-image correlations in our method are more effective to detect diverse anomalies (see Table 1, 2, 3). Moreover, patch-wise representation discrepancies and intra- and inter-correlation discrepancies are complementary, and can be combined to develop more powerful AD models.
Recently, with the self-attention mechanism and long-range modeling ability, transformers [50] have significantly renovated many computer vision tasks [14, 24, 7, 67, 56] and recently popular language-vision multimodal tasks [30, 22]. Transformers have shown great power in the unified modeling of patch-wise representations and patch-to-patch correlations. Transformers are quite suitable for AD tasks as their modeling ability can satisfy the two aspects of anomaly recognition quite well. Some works [26, 18, 8, 62] also attempt to employ transformers to construct AD models. However, these methods only use transformers to extract vision features, which didn’t sufficiently adapt transformers’ long-range correlation modeling capability to AD tasks. Different from these works, we explicitly exploit transformers’ self-attention maps to establish the intra- and inter-image correlations. The correlation distribution of each patch can provide more informative descriptions of the spatial context, which can reveal more intricate and semantic anomaly patterns.
In this paper, motivated by humans’ anomaly recognition process, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can exploit transformers’ unified modeling ability to simultaneously spot the patch-wise, intra- and inter-discrepancies. Our key designs are composed of three recognition branches: the patch-wise discrepancy branch is to reconstruct the input patch features for distinguishing simple anomalies; the intra-correlation branch is to explicitly model patch-to-patch correlations in one image for distinguishing hard global anomalies (e.g., row 1 in Figure 1); the inter-correlation branch is to explicitly learn inter-image correlations with known normal patterns from the whole normal training set. To implement the intra- and inter-correlation branches, we adapt Transformer and renovate the self-attention mechanism to the I2Correlation, which contains a two-branch structure to first separately model the intra- and inter-correlation distribution of each image patch, and then fuse the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning, the RBF kernel is used to present the neighborhood continuity of each image patch. Besides, an entropy constraint strategy is applied in the two branches, which can solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability.
In summary, we make the following main contributions:
1. We propose a novel AD framework: FOD, which can effectively detect anomalies by simultaneously spotting the patch-wise, intra- and inter-discrepancies.
2. We renovate the self-attention mechanism to the I2Correlation, which can explicitly establish intra- and inter-correlations in a self-supervised way with the target-correlations. An entropy constraint strategy is proposed to further amplify the normal-abnormal distinguishability.
3. Our method can achieve SOTA results on three real-world AD datasets, this shows our method can more effectively determine anomalies from complementary views.
2 Related Work
Anomaly Detection. In this paper, we divide the mainstream AD methods into five categories: reconstruction-based, embedding-based, OCC-based methods, knowledge distillation and normalizing flow AD models. The reconstruction-based methods are the most popular AD methods and also widely studied, where the assumption is that models trained by normal samples only can reconstruct normal regions but fail in abnormal regions. Many previous works attempt to train AutoEncoders [6, 28, 57, 8, 17, 64], Variational AutoEncoders [23] and GANs [42, 1, 29, 40] to reconstruct the input images. Overfitting to the input images is the most serious issue of these methods, which means that the anomalies are also well reconstructed [62].
Recently, some embedding-based methods [2, 33, 9, 11, 35] show better AD performance by using ImageNet pre-trained networks as feature extractors. In [33], the authors fit a multivariate Gaussian to model the image-level features for further Mahalanobis distance measurement. PaDiM [11] extends the above method to localize pixel-level anomalies. PatchCore [35] extends on this line by utilizing locally aggregated, mid-level features and introducing greedy coreset subsampling to form nominal feature banks. However, these methods directly utilize pre-trained networks without any adaptation to the target dataset. Some works [31, 10, 32] attempt to adapt pre-trained features to the target data distribution. There are also some other methods for using pre-trained networks by freezing them and only optimizing a sub-network, e.g., via knowledge distillation [4, 41, 12, 38], or normalizing flows [36, 15, 37, 63].
OCC is another classical AD paradigm, the earliest works are mainly to extend the OCC models such as OC-SVM [44] or SVDD [47, 39] for anomaly detection. Recently, in [60], a patch-based SVDD that contains multiple cores rather than a single core in [39] is proposed to enable anomaly localization. In [25], a Fully Convolutional Data Description combined with receptive field upsampling is proposed to generate anomaly maps. In [48], the authors further extend the PatchSVDD [60] model by the proposed multi-scale patch-based representation learning method.
Transformer-based Anomaly Detection Methods. Recently, transformers [50] have shown great power in modeling long-range dependencies. For image anomaly detection, some works [26, 18, 62, 8, 59] also attempt to exploit transformers to design AD models. However, most of these methods only use transformers as backbones to extract vision features, and don’t effectively adapt the long-range modeling capacity of transformers to AD tasks. Unlike the previous usage of transformers, we explicitly exploit the self-attention maps of transformers to establish intra- and inter-correlations. Our work shares some similarities with a recent work [20]. But we point out that our work has some significant differences from [20]: 1) Different Insight: [20] aims to unify the pointwise representation and pairwise association for time series AD, whereas our work aims to more sufficiently detect image anomalies through three complementary recognition views. 2) Novel Method: we propose entropy constraint, inter-correlation branch, and I2Correlation by effectively combining intra- and inter-correlation branches. 3) Different Task: [20] focuses on time-series AD, whereas we focus on image AD.
3 Approach
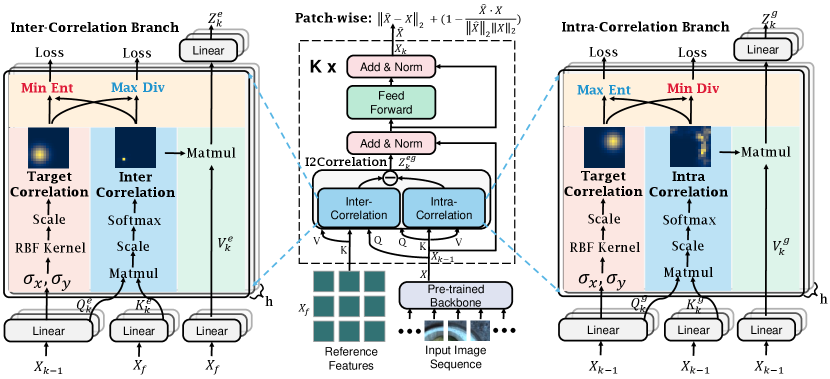
3.1 Model Overview
Figure 2 overviews our proposed approach. The model consists of three branches: patch-wise discrepancy branch, intra-correlation branch, and inter-correlation branch. The input 2D image is first sent into a pre-trained backbone to extract multi-scale feature maps. At each feature level, we construct a subsequent transformer network to explicitly model the intra- and inter-image correlations for spotting the intra- and inter-discrepancies. Each network is implemented by stacking the I2Correlation blocks and feed-forward layers alternately. Suppose each network contains layers with length- input features , the output of th layer is calculated as follows:
| (1) | |||
| (2) |
where is the reference features used by the inter-correlation branch, means LayerNorm, and is the th layer’s hidden features. The final output features are calculated by linear projection: , where is the output projection matrix.
3.2 Patch-Wise Reconstruction Discrepancy
Adopted from previous reconstruction-based AD methods, we employ feature reconstruction as our patch-wise recognition view for simplicity. In our approach, we construct a transformer network to reconstruct the input features. With the long-range dependency modeling ability, the features reconstructed by Transformer can have larger effective receptive fields [13], which are more conducive to detect hard global anomalies and logical anomalies. Moreover, with the further introduced inter-correlation branch (sec.3.4), the features can even perceive normal regions of images from the whole normal training set. Therefore, the reconstructed features generated by our model have better global perception and more discriminative semantic representation capability, which are more suitable for anomaly detection by patch-wise representation discrepancies.
Learning Objective. We can utilize classical reconstruction losses as the learning objective. We combine the distance and cosine distance to measure the feature distances between the reconstructed features and the input features . The loss function is defined as follows:
| (3) |
3.3 Intra-Correlation Learning
The intra-correlation learning branch aims to learn informative patch-to-patch correlations from the input patch sequence adaptively. As shown in the right part of Figure 2, we explicitly take advantage of the self-attention maps of transformers as intra-correlation matrices. Formally, the intra-correlation matrix of the th layer is calculated by:
| (4) |
where represent the query, key, and value of the th layer. represent the learnable projection matrices for , respectively. denotes the learned intra-image patch-to-patch correlations. Since can convert the values in the similarity map into range along the horizontal axis, each row of can represent a discrete correlation distribution for each corresponding image patch. But different from the vanilla transformers, we further introduce target correlation matrices as the learning objective to explicitly optimize the intra-image correlations.
Target Correlation. Inspired by the contrastive learning method BarlowTwins [66], we can construct a target correlation matrix as the learning target. The objective function of BarlowTwins measures the correlation matrix between the embeddings of two identical networks fed with distorted versions of a batch of samples, and tries to make this matrix close to the identity. In our work, the role of the target correlation is to introduce a prior correlation of patches as a pretext learning target, where each patch can be highly correlated to itself and also correlated to its neighborhood patches and the correlation decreases with the increase of distance. This allows us to optimize the intra- and inter-correlations in a self-supervised way. To this end, we use the radial basis function (RBF) to construct the target correlation matrix. We further adopt two learnable kernel variances and for horizontal and vertical axes to make the target correlation of each patch can adapt to the specific pattern of itself. The target correlation matrix of the th layer is defined as:
| (5) |
where means the Square Euclidean distance between point and , and means vertical and horizontal coordinates, respectively.
Next, we need to measure the distance between target- and intra-correlation distributions. This can usually be achieved by calculating the KL divergence. We can obtain a KL divergence value from each level of the network. Thus, we average all KL divergence values to combine the patch-to-patch correlations from multi-layer features into a more informative measure as follows:
| (6) |
where and its each element means the KL divergence between two discrete distributions corresponding to each row of and .
Due to the rarity of anomalies and the dominance of normal patterns, the normal patches should build strong correlations with most patches in the whole image, while the weights of abnormal correlation distributions are harder to distribute to most patches and are more likely to concentrate on the adjacent image patches due to the neighborhood continuity. Since normal and abnormal patches have different correlation distributions, this is a distinguishable criterion for anomaly detection. Note that the intra-correlation branch explicitly exploits the spatial dependencies of each image patch, which are more informative than the patch-wise representations for anomaly detection.
Entropy constraint. Since the normal image patterns are usually diverse, the learned correlation distributions of the normal patches may also easily concentrate on the adjacent patches, which can cause the distinguishability between normal and abnormal to be downscaled. To address this, we further introduce an entropy constraint item for making normal patches establish strong associations with most normal patches in the whole image as much as possible. The entropy constraint item is defined as:
| (7) |
We will maximize the entropy constraint item. The loss function for the intra-correlation branch is defined as:
| (8) |
where and are used to trade off the loss items. The optimization of intra-correlation is actually an alternating process with the guidance of target correlation (see App. A.1), ultimately resulting that each normal patch can establish strong correlations with most normal patches.
3.4 Inter-Correlation Learning
Through the intra-correlation branch, we can establish patch-to-patch correlations within a single image. However, an image usually doesn’t contain all possible normal patterns, which may cause it difficult to distinguish some ambiguous abnormal patches (see rows 2, 3, 4 in Figure 1) only through the intra-correlations. To address this, we should effectively take advantage of the known normal patterns from the normal training set, which are more likely to contain more informative normal patterns. Specifically, we further propose an inter-correlation learning branch to explicitly model pairwise correlations with the whole normal training set. In this branch, the features of each patch establish a discrete inter-correlation distribution with the reference features extracted from all normal samples (see Figure 2). The inter-correlation matrix of the th layer is similar to the corresponding intra-correlation, and is defined as:
| (9) |
where represents the external reference features, is the length of the reference features and is the feature dimension. and are learnable matrices for . denotes the learned inter-image correlations.
Loss. The loss function for the inter-correlation branch has the opposite optimization direction to . Because the external reference features contain more comprehensive normal patterns, normal patches can establish stronger correlations with the closest reference normal patterns, instead of establishing strong correlations with most reference patterns. By contrast, it shall be harder for anomalous patches to establish strong correlations with any of the reference patterns. So the inter-correlation distributions of anomalies are more dispersed, while the normal inter-correction distributions are more likely to be concentrated. To this end, we maximize the KL divergence and minimize the entropy item in the training process. The practical optimization strategy is also opposite to the intra-correlation branch (see App. A.1 for details). The loss function is defined as:
| (10) |
External Reference Features. External reference features are used for providing accumulated knowledge of normality for the inter-correlation learning branch. Thus, these features should represent all possible normal patterns of all normal samples from the whole normal training set. To this end, we can employ many methods to generate the reference features, such as sampling key features by coreset subsampling algorithm [35], generating prototype features by memory module [28], or learning codebook features through vector quantization [65] or sparse coding techniques [55]. However, because the RBF-kernel in is position-sensitive, our reference features are better to preserve the positional information. The ablation results in App.B.2 show that the methods that can’t preserve the position information perform worse. From comprehensive ablation studies, we find that using patch-wise averaged features as the external reference features is a simple but effective way. We think that features extracted by deep neural networks are highly redundant [16, 52], and different normal patterns generally correspond to larger activation values at different channels in the feature vector [61]. So feature averaging will not eliminate some rare normal patterns [11], these patterns may be preserved at specific channels. And averaging can greatly reduce the feature redundancy, making the obtained reference features more representative. Formally, for position , we first extract the set of patch features at , from the normal training images. Then, the reference features at position is computed as . The final external reference features are composed of averaged features at all locations and then flattened into 1D: .
3.5 I2Correlation
We further combine the intra-correlation and inter-correlation branches to form the I2Correlation block. The output features of the intra- and inter-correlation branches are defined as: and , respectively. Then, we use the residual feature as the output of the I2Correlation block. The feature is generated from the external reference features, which can contain rich normal patterns. Thus, by subtracting from the feature , it is conducive to spotlight the abnormal patterns in the . This is beneficial for anomaly detection.
The total loss function consists of the there branch loss functions, and is combined as follows:
| (11) |
3.6 Anomaly Scoring
We utilize reconstruction errors as the baseline anomaly criterion and incorporate the normalized correlation distribution distances into the reconstruction criterion. The final anomaly score of the th patch in the input patch sequence is shown as follows:
| (12) | ||||
where is the element-wise multiplication.
4 Experiments
4.1 Experimental Setup
Datasets. We extensively evaluate our approach on two widely used industrial AD datasets: the MVTecAD [3] and BTAD [26], and one recent challenging dataset: the MVTecAD-3D [5]. MVTecAD is established as a standard benchmark for evaluating unsupervised image anomaly detection methods. This dataset contains 5354 high-resolution images from 15 real-world categories. 5 classes consist of textures and the other 10 classes contain objects. A total of 73 different anomaly types are presented. BTAD is another popular benchmark for unsupervised image anomaly detection, which contains 2540 RGB images of three industrial products. All classes in this dataset belong to textures. MVTecAD-3D is recently proposed, which contains 4147 2D RGB images paired with high-resolution 3D point cloud scans from 10 real-world categories. Even though this dataset is mainly designed for 3D anomaly detection, most anomalies can also be detected only through RGB images without 3D point clouds. Since we focus on image anomaly detection, we only use RGB images of the MVTecAD-3D dataset. We refer to this subset as MVTec3D-RGB.
Evaluation Metrics. The standard metric in anomaly detection, AUROC, is used to evaluate the performance of AD methods. Image-level AUROC is used for anomaly detection and a pixel-based AUROC for evaluating anomaly localization [3, 4, 11, 64].
Implementation Details. We use EfficientNet-b6 [45] to extract two levels of feature maps with downsampling ratios, the pre-trained networks are from the timm library [53]. Then, we construct a subsequent transformer network (see Figure 2) at each feature level to reconstruct patch features and learn patch-to-patch correlations. The parameters of the feature extractor are frozen in the training process, only the parameters of the subsequent transformer networks are learnable. All the subsequent transformer networks in our model contain 3 layers. We set the hidden dimension as and the number of heads as . The hyperparameters and are set as and to trade off two parts of the and loss functions (see App. B.2 for hyperparameter sensitivity analysis). We use the Adam [19] optimizer with an initial learning rate of . The total training epochs are set as 100 and the batch size is 1 by default. All the training and test images are resized and cropped to resolution from the original resolution.
| Discrepancy Type | Method | Venue | Image-level AUROC | Pixel-level AUROC |
| Patch-wise Representation Discrepancy | STAD [4] | CVPR 2020 | 0.877 | 0.939 |
| PaDiM [11] | ICPR 2020 | 0.955 | 0.975 | |
| DFR [57] | Neurocomputing 2021 | / | 0.950 | |
| FCDD [25] | ICLR 2021 | / | 0.920 | |
| MKD [41] | CVPR 2021 | 0.877 | 0.907 | |
| Hou et al. [17] | ICCV 2021 | 0.895 | / | |
| Metaformer [54] | ICCV 2021 | 0.958 | / | |
| DRAEM [64] | ICCV 2021 | 0.980 | 0.973 | |
| RDAD [12] | CVPR 2022 | 0.985 | 0.978 | |
| SSPCAB [34] | CVPR 2022 | 0.989 | 0.972 | |
| DSR [65] | ECCV 2022 | 0.982 | / | |
| NSA [43] | ECCV 2022 | 0.972 | 0.963 | |
| UniAD [62] | NIPS 2022 | 0.966 | 0.966 | |
| UTRAD [8] | Neural Networks 2022 | 0.960 | 0.967 | |
| Patch-to-patch Feature Distance | PatchSVDD [60] | ACCV 2020 | 0.921 | 0.957 |
| DifferNet [36] | WACV 2020 | 0.949 | / | |
| CFLOW [15] | WACV 2022 | 0.983 | 0.986 | |
| CS-FLOW [37] | WACV 2022 | 0.987 | / | |
| Tsai et al. [15] | WACV 2022 | 0.981 | 0.981 | |
| PatchCore [35] | CVPR 2022 | 0.991 | 0.980 | |
| Others | CutPaste [21] | CVPR 2021 | 0.952 | 0.960 |
| Wang et al. [51] | CVPR 2021 | / | 0.91 | |
| SPD [68] | ECCV 2022 | 0.946 | 0.946 | |
| Patch-wise&Intra&Inter | FOD (Ours) | - | 0.992 | 0.983 |
| Category | Image-level Anomaly Detection | |||||
| DRAEM [64] | PatchSVDD [60] | MKD [41] | PatchCore [35] | CFLOW [15] | FOD (Ours) | |
| Carpet | 0.978 | 0.963 | 1.000 | 1.000 | 0.987 | 1.000 |
| Grid | 1.000 | 0.892 | 0.975 | 0.992 | 0.996 | 1.000 |
| Leather | 1.000 | 0.953 | 0.956 | 1.000 | 1.000 | 1.000 |
| Tile | 0.998 | 0.969 | 0.999 | 1.000 | 0.999 | 1.000 |
| Wood | 0.991 | 0.989 | 0.989 | 0.985 | 0.991 | 0.991 |
| Bottle | 0.993 | 0.976 | 0.989 | 1.000 | 1.000 | 1.000 |
| Cable | 0.929 | 0.899 | 0.972 | 0.992 | 0.976 | 0.995 |
| Capsule | 0.984 | 0.763 | 0.979 | 0.984 | 0.977 | 1.000 |
| Hazelnut | 1.000 | 0.912 | 0.997 | 1.000 | 1.000 | 1.000 |
| Metal nut | 0.989 | 0.941 | 0.972 | 1.000 | 0.993 | 1.000 |
| Pill | 0.981 | 0.791 | 0.971 | 0.954 | 0.968 | 0.984 |
| Screw | 0.939 | 0.825 | 0.870 | 0.953 | 0.919 | 0.967 |
| Toothbrush | 1.000 | 0.992 | 0.886 | 0.906 | 0.997 | 0.944 |
| Transistor | 0.914 | 0.874 | 0.956 | 0.995 | 0.952 | 1.000 |
| Zipper | 1.000 | 0.982 | 0.981 | 0.989 | 0.985 | 0.997 |
| Mean | 0.980 | 0.915 | 0.966 | 0.983 | 0.983 | 0.992 |
4.2 Main Results
SOTA Methods. We extensively compare our method with those published SOTA methods in the past three years. The comparison results on MVTecAD are shown in Table 1. Then, we select five reproducible methods to report the detailed results on MVTecAD, these methods are representative and SOTA AD methods in the mainstream categories of image anomaly detection as we discuss in Related Work, including: DRAEM [64], PatchSVDD[60], PatchCore [35], MKD[41], CFLOW[15]. For a fair comparison, we reproduce all these methods with the same backbone as in our model. Thus, despite using the unmodified code from the official repositories, we are not able to exactly reproduce the original results, but our numbers are very close. The detailed image-level AUROC results are shown in Table 2, and detailed pixel-level AUROC results are in the App. Table 6. Most of the methods in Table 1 don’t report results on the BTAD and MVTec3D-RGB datasets, so we reproduce the five representative methods on the two datasets for comparison. The image-level and pixel-level AUROC results on BTAD and MVTec3D-RGB are shown in Table 3. Additional detailed results are in the App. Table 7, 8.
Anomaly Detection. On MVTecAD, we set the SOTA performance on the mean detection AUROC, which is slightly higher than the best competitor, PatchCore [35]. Note that the results in Table 2 show that our method can achieve much better results than PatchCore when using the same backbone. What’s more, in addition to the pill, screw and toothbrush classes, our method achieves more than 99% AUROC in all other classes, while other methods only achieve more than 99% AUROC in most nine classes. This shows that our method is more stable and effective in real-world applications. In the classes (e.g. metal nut, screw, and transistor) with more global and logical anomalies, our method can achieve significantly better results than those methods depending on patch-wise discrepancy (e.g. DRAEM [64] and MKD [41]), and can also achieve better results compared with other methods. This verifies that the three discrepancies are complementary factors and our model can simultaneously spot these discrepancies to recognize harder global and logical anomalies. On BTAD, our FOD can achieve 96.0% mean detection AUROC, which can outperform the best competitor CFLOW [15] by a margin of 1.2%. On MVTec3D-RGB, we can outperform all previous SOTA methods by a margin of 3.3%. Note that this dataset is much more challenging than the MVTecAD dataset when comparing the best results (99.2% for MVTecAD vs. 88.4% AUROC for MVTec3D-RGB). This demonstrates the robustness of our method.
| Method | DRAEM [64] | PatchSVDD [60] | MKD [41] | PatchCore [35] | CFLOW [15] | FOD (Ours) |
| BTAD Dataset | ||||||
| Image-level AUROC | 0.922 | 0.924 | 0.935 | 0.934 | 0.948 | 0.960 |
| Pixel-level AUROC | 0.942 | 0.964 | 0.965 | 0.976 | 0.978 | 0.975 |
| MVTec3D-RGB Dataset | ||||||
| Image-level AUROC | 0.757 | 0.743 | 0.688 | 0.839 | 0.851 | 0.884 |
| Pixel-level AUROC | 0.974 | 0.852 | 0.970 | 0.977 | 0.974 | 0.976 |
Anomaly Localization. Our method can achieve comparable results with the best competitors on all three datasets. Our method is slightly lower than CFLOW [15] and PatchCore [35] on the three datasets, but we observe that our model that considers the intra- and inter-correlations outperforms the vanilla reconstruction AD models (e.g. DRAEM [64] and MKD [41]) on all three datasets, which verifies the effectiveness of correlation modeling. Compared with patch-wise reconstruction methods, our method is more effective and robust to detect hard global and logical anomalies (see Figure 3).
4.3 Ablation Study and Model Analysis
Ablation Study. To explain how our model works effectively, we further investigate the effect of the three key designs in our model: recognition views, entropy constraint and reference features. The quantitative results are shown in Table 4, more results can be found in App. Table 9. The entropy constraint is quite effective and necessary in the intra-correlation branch. Specifically, it brings a remarkable 7.7% averaged absolute AUROC promotion, which demonstrates that the entropy constraint strategy is really conducive to increase the distinguishability between abnormal and normal. Only utilizing pure reconstruction criterion or pure KL divergence can’t get the most superior detection results, the combined criterion can outperform each single criterion consistently by a margin of 1.0% and 9.8%. Thus the reconstruction errors and the intra- and inter-correlations can collaborate to improve detection performance. For the external reference features, we compare the simple mean features with more elaborate coreset features [35] (see App. Table 15 for more comparison methods). The results show that the simple mean features are more effective than the coreset features (0.923 vs. 0.836), which means that mean features are effective enough to represent all possible normal patterns and preserve the positional information. Finally, our proposed FOD surpasses the pure reconstruction Transformer by 4.0% absolute improvement. These verify that our proposed explicit correlation learning approach is effective.
| Recognition Views | Entropy Constraint | Reference Features | Anomaly Scoring | MVTecAD | BTAD | MVTec3D-RGB | Avg |
| Patch-wise | / | / | Rec | 0.972 | 0.954 | 0.790 | 0.905 |
| Intra | w/o | / | Div | 0.700 | 0.811 | 0.708 | 0.740 |
| w/ | / | Div | 0.911 | 0.822 | 0.717 | 0.817 | |
| w/ | / | Rec&Div | 0.974 | 0.952 | 0.818 | 0.915 | |
| Inter | w/ | Mean | Rec&Div | 0.980 | 0.958 | 0.832 | 0.923 |
| w/ | Coreset | Rec&Div | 0.925 | 0.884 | 0.700 | 0.836 | |
| Intra+Inter | w/ | Mean | Div | 0.896 | 0.922 | 0.814 | 0.877 |
| Patch-wise+Intra +Inter (Ours) | w/ | Mean | Rec&Div | 0.992 | 0.960 | 0.884 | 0.945 |
Effect for Different Anomalies. To illustrate the effectiveness of our model intuitively, we explore the anomaly localization quality under different types of anomalies (see Figure 3). E.g., simple local anomalies (Column 1) are obviously different from normal visuals; hard global anomalies (Columns 2,3) have less obvious visual appearances, which usually need to be effectively compared with normal regions to detect; logical anomalies (Columns 4,5) may be locally normal and can be detected correctly through the overall semantic understanding. We can find that our FOD is more distinguishable in general. For simple local anomalies, patch-wise reconstruction methods can also achieve good results. While for hard global anomalies, these methods cannot detect or only detect partial anomalies. However, for logical anomalies, these methods cannot detect them at all. In contrast, our method is conducive to detect diverse anomalies because of its complementary recognition views. This verifies that our method can make more precise detection and reduce the false-negative rate compared with the pure patch-wise reconstruction methods.

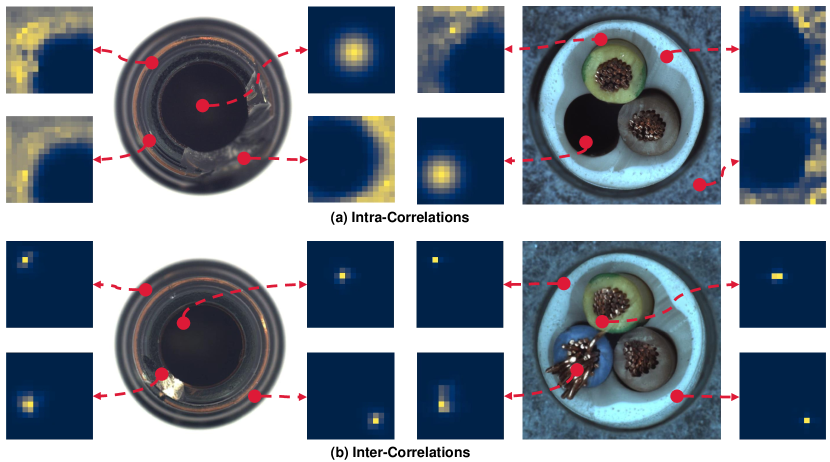
Correlations Visualization. To explain what our model has learned intuitively, we visualize some learned correlations in Figure 4 with the MVTecAD dataset. For the intra-correlation branch, the normal patches learn to build strong correlations with most patches in the whole image, while the correlation distributions of anomalies usually concentrate in the adjacent image patches. It can be found that the normal correlations are much spread and the abnormal correlations are more concentrated in the adjacent regions. For the inter-correlation branch, most normal correlations only concentrate in one point and the abnormal correlations are more spread, which exactly means that each normal patch can build strong correlations with one special normal pattern and abnormal patches are harder to establish correlations with normal patterns.
5 Conclusion
Humans recognize anomalies through two aspects: patch-wise representation discrepancies and weak patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy, to simultaneously spot the patch-wise, intra- and inter-discrepancies. The patch-wise discrepancies and intra- and inter-correlations are complementary factors, and can be combined to detect more complex and diverse anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to I2Correlation to explicitly establish intra- and inter-image correlations for AD modeling. The combination of explicit correlation learning and transformer architecture can match the core idea of anomaly detection quite well.
Acknowledgements
This work was supported in part by the National Natural Science Fund of China (61971281), the Shanghai Municipal Science and Technology Major Project (2021SHZDZX0102), and the Science and Technology Commission of Shanghai Municipality (22DZ2229005).
References
- [1] Samet Akcay, Amir Atapour-Abarghouei, and Toby P. Breckon. Ganomaly: Semi-supervised anomaly detection via adversarial training. In ACCV, pages 622–637, 2018.
- [2] Liron Bergman, Niv Cohen, and Yedid Hoshen. Deep nearest neighbor anomaly detection. arXiv preprint arXiv: 2002.10445, 2020.
- [3] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad - a comprehensive real-world dataset for unsupervised anomaly detection. In CVPR, 2019.
- [4] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In CVPR, 2020.
- [5] Paul Bergmann, Xin Jin, David Sattlegger, and Carsten Steger. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. arXiv preprint arXiv:2112.09045, 2021.
- [6] Paul Bergmann, Sindy Löwe, Michael Fauser, and David Sattlegger. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. In ICCVTA, 2019.
- [7] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- [8] Liyang Chen, Zhiyuan You, Nian Zhang, Juntong Xi, and Xinyi Le. Utrad: Anomaly detection and localization with u-transformer. In Neural Networks, 2022.
- [9] Niv Cohen and Yedid Hoshen. Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv: 2005.02357v3, 2020.
- [10] Lucas Deecke, Lukas Ruff, Robert A. Vandermeulen, and Hakan Bilen. Transfer-based semantic anomaly detection. In ICML, 2021.
- [11] Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: a patch distribution modeling framework for anomaly detection and localization. In The 1st International Workshop on Industrial Machine Learning, pages 475–489, 2021.
- [12] Hanqiu Deng and Xingyu Li. Anomaly detection via reverse distillation from one-class embedding. In CVPR, 2022.
- [13] Xiaohan Ding, Xiangyu Zhang, Yizhuang Zhou, Jungong Han, Guiguang Ding, and Jian Sun. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In CVPR, 2022.
- [14] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
- [15] Denis Gudovskiy, Shun Ishizaka, and Kazuki Kozuka. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In WACV, 2022.
- [16] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. In CVPR, 2020.
- [17] Jinlei Hou, Yingying Zhang, Qiaoyong Zhong, Di Xie, Shiliang Pu, and Hong Zhou. Divide-and-assemble: Learning block-wise memory for unsupervised anomaly detection. In ICCV, 2021.
- [18] Keng Chaia Jonathan Pirnaya. Inpainting transformer for anomaly detection. arXiv preprint arXiv:2104.13897, 2021.
- [19] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [20] Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. Anomaly transformer: Time series anomaly detection with association discrepancy. In ICLR, 2022.
- [21] Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. In CVPR, 2021.
- [22] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In CVPR, 2022.
- [23] Wenqian Liu, Runze Li, Meng Zheng, Srikrishna Karanam, Ziyan Wu, Bir Bhanu, Richard J. Radke, and Octavia Camps. Towards visually explaining variational autoencoders. In CVPR, 2020.
- [24] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shiftedwindows. In ICCV, 2021.
- [25] Philipp Liznerski, Lukas Ruff, Robert A. Vandermeulen, Billy Joe Franks, Marius Kloft, and Klaus-Robert M¨uller. Expalinable deep one-class classification. In ICLR, 2021.
- [26] Pankaj Mishra, Riccardo Verk, Daniele Fornasier, Claudio Piciarelli, and Gian Luca Foresti. Vt-adl: Avision transformer network for image anomaly detection and localization. arXiv preprint arXiv:2104.10036, 2021.
- [27] Radford M. Neal. Pattern recognition and machine learning. Technometrics, 2007.
- [28] Hyunjong Park, Jongyoun Noh, and Bumsub Ham. Learning memory-guided normality for anomaly detection. In CVPR, 2020.
- [29] Stanislav Pidhorsky, Ranya Almohsen, Domald A.Adjeroh, and Gianfraneo Doretto. Generative probabilities novelty detection with adversarial autoencoders. In NeurIPS, 2018.
- [30] Alec Radford, JongWook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [31] Tal Reiss, Niv Cohen, Liron Bergman, and Yedid Hoshen. Panda: Adapting pretrained features for anomaly detection and segmentation. In CVPR, 2021.
- [32] Tal Reiss and Yedid Hoshen. Mean-shifted contrastive loss for anomaly detection. arXiv preprint arXiv:2106.03844, 2021.
- [33] Oliver Rippel, Patrick Mertens, and Dorit Merhof. Modeling the distribution of normal data in pre-trained deep features for anomaly detection. arXiv preprint arXiv: 2005.14140, 2020.
- [34] Nicolae-Catalin Ristea, Neelu Madan, Radu Tudor Ionescu, Kamal Nasrollahi, Fahad Shahbaz Khan, Thomas B. Moeslund, and Mubarak Shah. Self-supervised predictive convolutional attentive block for anomaly detection. In CVPR, 2022.
- [35] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Scholkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. In CVPR, 2022.
- [36] Marco Rudolph, Bastian Wandt, and Bodo Rosenhahn. Same same but differnet: Semi-supervised defect detection with normalizing flows. In WACV, 2021.
- [37] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and BastianWandt. Fully convolutional cross-scale-flows for image based defect detection. In WACV, 2022.
- [38] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Asymmetric student-teacher networks for industrial anomaly detection. In WACV, 2023.
- [39] Lukas Ruff, Nico Görnitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Robert Vandermeulen, Alexander Binder, Emmanuel Müller, and Marius Kloft. Deep one-class classification. In ICML, pages 4390–4399, 2018.
- [40] Mohammad Sabokrou, Mohammad Khaloori, Mahmood Fathy, and Ehsan Adeli. Adversarially learned one-class classifier for novelty detection. In CVPR, 2018.
- [41] Mohammadreza Salehi, Niousha Sadjadi, Soroos Hossein Rohban, and Hamid R.Rabiee. Multiresolution knowledge distillation for anomaly detection. In CVPR, 2021.
- [42] Thomas Schlegl, Philipp Seebock, Sebastian M. Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In ICIPMI, pages 146–157, 2017.
- [43] Hannah M. Schluter, Jeremy Tan1, Benjamin Hou, and Bernhard Kainz. Natural synthetic anomalies for self-supervised anomaly detection and localization. In ECCV, 2022.
- [44] Bernhard Schölkopf, John C Platt, John Shawe-Taylor, Alex J Smola, and Robert C Williamson. Estimating the support of a high-dimensional distribution. In Neural Computation 13, 7 (2001), pages 1443–1471, 2001.
- [45] Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In ICML, 2019.
- [46] Xian Tao, Xinyi Gong, Xin Zhang, Shaohua Yan, and Chandranath Adak. Deep learning for unsupervised anomaly localization in industrial images: A survey. In IEEE Transactions on Instrumentation and Measurement, 2022.
- [47] David Martinus Johannes Tax and Robert P W Duin. Support vector data description. In Machine Learning 54, 1 (2004), pages 45–66, 2004.
- [48] Chin-Chia Tsai, Tsung-Hsuan Wu, and Shang-Hong Lai. Multi-scale patch-based representation learning for image anomaly detection and segmentation. In WACV, 2022.
- [49] Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In NIPS, 2018.
- [50] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
- [51] Shenzhi Wang, Liwei Wu, Lei Cui, and Yujun Shen. Glancing at the patch: Anomaly localization with global and local feature comparison. In CVPR, 2021.
- [52] Xudong Wang and Stella X. Yu. Tied block convolution: Leaner and better cnns with shared thinner filters. In AAAI, 2021.
- [53] Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019.
- [54] Jhih-Ciang Wu, Ding-Jie Chen, Chiou-Shann Fuh, and Tyng-Luh Liu. Learning unsupervised metaformer for anomaly detection. In ICCV, 2021.
- [55] Jhih-Ciang Wu, He-Yen Hsieh, Ding-Jie Chen, Chiou-Shann Fuh, and Tyng-Luh Liu. Self-supervised sparse representation for video anomaly detection. In ECCV, 2022.
- [56] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. In NIPS, 2021.
- [57] Jie Yang, Yong Shi, and Zhiquan Qi. Dfr: Deep feature reconstruction for unsupervised anomaly segmentation. arXiv preprint arXiv: 2012.07122, 2020.
- [58] Xincheng Yao, Ruoqi Li, Jing Zhang, Jun Sun, and Chongyang Zhang. Explicit boundary guided semi-push-pull contrastive learning for supervised anomaly detection. In CVPR, 2023.
- [59] Xincheng Yao, Chongyang Zhang, Ruoqi Li, Jun Sun, and Zhenyu Liu. One-for-all: Proposal masked cross-class anomaly detection. In AAAI, 2023.
- [60] Jihun Yi and Sungroh Yoon. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In ACCV, 2020.
- [61] Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization. arXiv preprint arXiv:1506.06579, 2015.
- [62] Zhiyuan You, Lei Cui, Yujun Shen, Kai Yang, Xin Lu, Yu Zheng, and Xinyi Le. A unified model for multi-class anomaly detection. In NIPS, 2022.
- [63] Jiawei Yu, Ye Zheng, Xiang Wang, Wei Li, Yushuang Wu, Rui Zhao, and Liwei Wu. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv preprint arXiv:2111.07677, 2021.
- [64] Vitjan Zavrtanik, Matej Kristan, and Danijel Skocaj. Draem: A discriminatively trained reconstruction embedding for surface anomaly detection. In ICCV, 2021.
- [65] Vitjan Zavrtanik, Matej Kristan, and Danijel Skocaj. Dsr – a dual subspace re-projection network for surface anomaly detection. In ECCV, 2022.
- [66] Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stephane Deny. Barlow twins: Self-supervised learning via redundancy reduction. In ICML, 2021.
- [67] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip H.S. Torr, and Li Zhang. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In CVPR, 2021.
- [68] Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer. Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. In ECCV, 2022.
Appendix
Appendix A Implementation Details
A.1 Two-Phase Optimization Strategy
Note that directly optimizing the (E.q.8) will not make normal patches build strong correlations with most patches in the whole image. Instead, as both and have learnable parameters, it’s easier to generate trivial solutions [27], where different patches have not learned position-adaptive , and of normal and abnormal patches also collapse to a similar discrete distribution. Similarly, directly optimizing the (E.q.10) also can not make each normal patch establish a stronger correlation with a specific external normal pattern, the collapse issue may also exist. To better optimize the intra- and inter-correlation branches, we follow the minimax strategy in [20] to propose a two-phase optimization strategy. Specifically, in the first phase, we minimize the item to make the target correlations adapt to various image patterns of different patches. In the second phase, we maximize the item to force the intra-correlations to pay more attention to the non-adjacent patches with the maximum entropy constraint. Through the two-phase optimization strategy, we can gradually distribute the weights in the intra-correlations to the non-adjacent patches, instead of all image patches forming similar intra-image patch-to-patch correlations, which can effectively reduce the risk of over-fitting. For the inter-correlation branch, the optimization goal is to make each normal patch establish a stronger correlation with a specific external normal pattern, so we first maximize the item and then minimize the , which is opposite to the optimization process in the intra-correlation branch. When optimizing intra- and inter-correlations, we also need to add the entropy constraint items: maximizing for the intra-correlation branch and minimizing for the inter-correlation branch. Thus, combining the reconstruction loss , the loss functions of two phases are:
| (13) | ||||
where is the reconstruction loss defined in E.q.3, means to stop gradient backpropagation, and are used to trade off the loss items. With the two-phase optimization strategy, each normal patch can establish stronger correlations with most normal patches and a stronger correlation with a specific external normal pattern, this is much harder for anomalies to achieve these correlations, thereby beneficial to amplify the normal-abnormal distinguishability. We further conduct ablation experiments on the direct optimization of and and the two-phase optimization strategy, the results are shown in Table 10 of App. B.2.
When implementing the two-phase optimization strategy, we can first calculate the backpropagated gradients of loss and retain the gradient graph, and then calculate the backpropagated gradients of loss. The backpropagated gradients calculated in the second phase will be accumulated to the gradients in the first phase, and then we can call the optimizer to update the model parameters.
A.2 Computation Cost
We provide computation cost analysis of our model and other compared models. All the values are measured with one NVIDIA RTX 3090 GPU and AMD EPYC 7453 28-Core CPU on the MVTecAD dataset, the results are shown in Table 5. For all models, we input a image to calculate the FLOPs and set batch size to 4 to estimate the training time. Compared with other models, our model has the same order of magnitude of learnable parameters (PatchCore [35] has no learnable parameters) and fewer FLOPs, but our model can achieve better detection results.
Appendix B Additional Results
B.1 Detailed Results
The detailed pixel-level AUROC results of each category on the MVTecAD dataset are shown in Table 6. The detailed results of each category for anomaly detection and localization performance on the BTAD and MVTec3D-RGB datasets are shown in Table 7 and 8.
Table 7 shows the AUROCs of our method and the SOTA methods for detecting anomalies on the three classes of BTAD. Our FOD can achieve 96.0% mean detection AUROC, which can outperform the best competitor CFLOW [15] by a margin of 1.2%.
The results for individual classes of MVTec3D-RGB are given in Table 8. We are able to outperform all previous SOTA methods regarding the average of all classes by a margin of 3.3%. Note that this dataset is more challenging than the MVTecAD dataset when comparing the best results (99.2% for MVTecAD vs. 88.4% AUROC for MVTec3D-RGB). Nevertheless, we detect defects in 6 out of 10 categories at an AUROC of more than 90%, while other methods only achieve moth than 90% AUROC in most four categories. This demonstrates the robustness of our method.
| Category | Pixel-level Anomaly Localization | |||||
| DRAEM [64] | PatchSVDD [60] | MKD [41] | PatchCore [35] | CFLOW [15] | FOD (Ours) | |
| Carpet | 0.955 | 0.953 | 0.990 | 0.991 | 0.994 | 0.990 |
| Grid | 0.997 | 0.961 | 0.986 | 0.988 | 0.993 | 0.989 |
| Leather | 0.986 | 0.978 | 0.978 | 0.994 | 0.997 | 0.995 |
| Tile | 0.992 | 0.911 | 0.952 | 0.948 | 0.969 | 0.948 |
| Wood | 0.964 | 0.916 | 0.953 | 0.954 | 0.969 | 0.954 |
| Bottle | 0.991 | 0.978 | 0.985 | 0.989 | 0.988 | 0.987 |
| Cable | 0.947 | 0.964 | 0.972 | 0.985 | 0.975 | 0.986 |
| Capsule | 0.943 | 0.958 | 0.979 | 0.992 | 0.989 | 0.990 |
| Hazelnut | 0.997 | 0.978 | 0.982 | 0.986 | 0.984 | 0.989 |
| Metal nut | 0.995 | 0.980 | 0.972 | 0.980 | 0.971 | 0.985 |
| Pill | 0.976 | 0.963 | 0.971 | 0.963 | 0.976 | 0.986 |
| Screw | 0.976 | 0.957 | 0.983 | 0.994 | 0.988 | 0.992 |
| Toothbrush | 0.981 | 0.983 | 0.986 | 0.988 | 0.983 | 0.987 |
| Transistor | 0.909 | 0.970 | 0.886 | 0.968 | 0.923 | 0.989 |
| Zipper | 0.988 | 0.961 | 0.981 | 0.981 | 0.986 | 0.977 |
| Mean | 0.973 | 0.961 | 0.970 | 0.980 | 0.979 | 0.983 |
| Image-level Anomaly Detection | ||||||
| Category | DRAEM [64] | PatchSVDD [60] | MKD [41] | PatchCore [35] | CFLOW [15] | FOD (ours) |
| Product01 | 0.995 | 0.984 | 0.938 | 0.984 | 1.000 | 0.995 |
| Product02 | 0.774 | 0.836 | 0.882 | 0.818 | 0.857 | 0.864 |
| Product03 | 0.998 | 0.951 | 0.985 | 1.000 | 0.987 | 1.000 |
| Mean | 0.922 | 0.924 | 0.935 | 0.934 | 0.948 | 0.960 |
| Pixel-level Anomaly Localization | ||||||
| Product01 | 0.927 | 0.948 | 0.949 | 0.973 | 0.971 | 0.971 |
| Product02 | 0.936 | 0.954 | 0.963 | 0.961 | 0.967 | 0.957 |
| Product03 | 0.964 | 0.990 | 0.983 | 0.993 | 0.996 | 0.996 |
| Mean | 0.942 | 0.964 | 0.965 | 0.976 | 0.978 | 0.975 |
| Image-level Anomaly Detection | |||||||||||
| Method | Bagel | Cable | Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean |
| DRAEM [64] | 0.988 | 0.445 | 0.819 | 0.635 | 0.759 | 0.862 | 0.849 | 0.506 | 0.986 | 0.724 | 0.757 |
| PatchSVDD [60] | 0.892 | 0.831 | 0.570 | 0.695 | 0.722 | 0.626 | 0.618 | 0.653 | 0.999 | 0.827 | 0.743 |
| MKD [41] | 0.940 | 0.616 | 0.782 | 0.275 | 0.656 | 0.736 | 0.684 | 0.703 | 0.910 | 0.575 | 0.688 |
| PatchCore [35] | 0.887 | 0.939 | 0.903 | 0.703 | 0.972 | 0.809 | 0.750 | 0.581 | 0.959 | 0.884 | 0.839 |
| CFLOW [15] | 0.973 | 0.887 | 0.871 | 0.789 | 0.989 | 0.735 | 0.810 | 0.692 | 0.983 | 0.786 | 0.851 |
| FOD (Ours) | 0.940 | 0.952 | 0.911 | 0.844 | 0.987 | 0.844 | 0.843 | 0.662 | 0.992 | 0.864 | 0.884 |
| Pixel-level Anomaly Localization | |||||||||||
| DRAEM [64] | 0.977 | 0.972 | 0.985 | 0.930 | 0.982 | 0.959 | 0.981 | 0.984 | 0.984 | 0.983 | 0.976 |
| PatchSVDD [60] | 0.953 | 0.923 | 0.817 | 0.857 | 0.870 | 0.897 | 0.907 | 0.792 | 0.709 | 0.790 | 0.852 |
| MKD [41] | 0.991 | 0.974 | 0.989 | 0.957 | 0.977 | 0.896 | 0.975 | 0.977 | 0.986 | 0.977 | 0.970 |
| PatchCore [35] | 0.959 | 0.979 | 0.982 | 0.967 | 0.968 | 0.988 | 0.977 | 0.979 | 0.987 | 0.985 | 0.977 |
| CFLOW [15] | 0.984 | 0.982 | 0.984 | 0.974 | 0.987 | 0.900 | 0.982 | 0.983 | 0.980 | 0.981 | 0.974 |
| FOD (Ours) | 0.988 | 0.992 | 0.992 | 0.979 | 0.995 | 0.862 | 0.989 | 0.987 | 0.992 | 0.982 | 0.976 |
B.2 Ablation Results
Ablation results in pixel-level AUROC are shown in Table 9. The pixel-level AUROC results demonstrate the same conclusion as in Table 4: the three key designs in our model: recognition views, entropy constraint, and reference features are all effective. These results also verify that our proposed explicit correlation learning approach is effective and the intra- and inter-image correlations are complementary factors to the patch-wise representation discrepancies.
| Recognition Views | Entropy Constraint | Reference Features | Anomaly Scoring | MVTecAD | BTAD | MVTec3D-RGB |
| Patch-wise | / | / | Rec | 0.974 | 0.975 | 0.964 |
| Intra | w/o | / | Div | 0.717 | 0.602 | 0.778 |
| w/ | / | Div | 0.804 | 0.620 | 0.863 | |
| w/ | / | Rec&Div | 0.972 | 0.970 | 0.961 | |
| Inter | w/ | Mean | Rec&Div | 0.978 | 0.976 | 0.964 |
| w/ | Coreset | Rec&Div | 0.948 | 0.897 | 0.928 | |
| Intra+Inter | w/ | Mean | Div | 0.846 | 0.831 | 0.965 |
| Patch-wise+Intra +Inter (Ours) | w/ | Mean | Rec&Div | 0.983 | 0.975 | 0.976 |
Optimization Strategy. Ablation results in optimization strategy are shown in Table 10. Directly optimizing the and cannot make the intra-correlations pay more attention to the non-adjacent areas and will force the inter-correlations to pay more attention to diverse normal patterns. Moreover, direct optimization will cause the optimization problem of RBF kernel [27], thus cannot strongly amplify the difference between normal and abnormal patches as expected. The two-phase optimization strategy first optimizes the target-correlations to provide better guidance to the intra- and inter-correlations. Thus, the two-phase optimization strategy obtains more distinguishable correlation distributions than direct optimization and thereby performs better.
| Dataset | MVTecAD | BTAD | MVTec3D-RGB | |||
| Strategy | Direct | Two-phase | Direct | Two-phase | Direct | Two-phase |
| Image-level AUROC | 0.986 | 0.991 | 0.959 | 0.960 | 0.828 | 0.884 |
| Pixel-level AUROC | 0.957 | 0.982 | 0.956 | 0.975 | 0.952 | 0.976 |
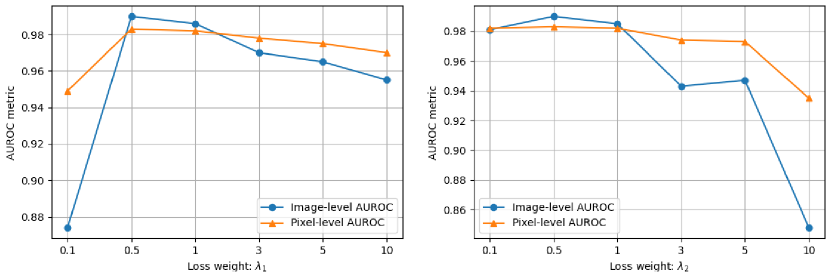
Hyper-parameter Sensitivity. We adopt the loss weights and to trade off the reconstruction loss, the correlation part and the entropy constraint part. The loss weight hyper-parameters and are set to and by default in the main text through comprehensive ablation experiments. To illustrate the sensitivity of our model, we further provide the model performance under different choices of the loss weights. Note that to avoid too many experiments, we only conduct experiments on the MVTecAD dataset, and fix to to change and then fix to the best value to change . The ablation results are shown in Figure 5 and Table 11. It can be found that and are stable and easy to tune in the range of to . The results verify that our model is not very sensitive to the loss weight hyper-parameters, which is essential for applications.
We also show hyper-parameter sensitivity for the number of heads and layers in Table 12 and 13, respectively. It can be found that when setting the number of heads to and the number of layers to can achieve the best result. Thus, we use and as the default values in the main text.
| 0.1 | 0.5 | 1 | 3 | 5 | 10 | |
| Image-level AUROC | 0.874 | 0.990 | 0.986 | 0.970 | 0.965 | 0.955 |
| Pixel-level AUROC | 0.949 | 0.983 | 0.982 | 0.978 | 0.975 | 0.970 |
| 0.1 | 0.5 | 1 | 3 | 5 | 10 | |
| Image-level AUROC | 0.981 | 0.990 | 0.985 | 0.943 | 0.947 | 0.848 |
| Pixel-level AUROC | 0.982 | 0.983 | 0.982 | 0.974 | 0.973 | 0.935 |
| Number of heads | 2 | 4 | 8 |
| Image-level AUROC | 0.987 | 0.990 | 0.992 |
| Pixel-level AUROC | 0.982 | 0.983 | 0.983 |
| Number of layers | 2 | 3 | 4 | 5 | 6 |
| Image-level AUROC | 0.986 | 0.990 | 0.983 | 0.979 | 0.957 |
| Pixel-level AUROC | 0.982 | 0.983 | 0.978 | 0.978 | 0.969 |
Feature Levels. Besides, we also explore the impact of different network layers on model performance and show the results in Table 14. For single-layer features, one-layer yields the best result as it trades off both semantic representation capability and fine-granularity of the features. Multi-scale feature fusion helps to improve the detection performance as it’s conducive to cover more types and scales of anomalies. Note that using the three-layer features doesn’t gain significant performance improvement compared with two-layer features, but it instead increases the computational cost. Therefore, we use two-layer features by default throughout the main text.
| Feature Level | & | && | |||
| Image-level AUROC | 0.885 | 0.981 | 0.975 | 0.990 | 0.988 |
| Pixel-level AUROC | 0.932 | 0.981 | 0.970 | 0.983 | 0.983 |
B.3 External Reference Features
External reference features are used for providing accumulated knowledge of normality for the inter-correlation learning branch. Thus, these features should represent all possible normal patterns of all normal samples. To this end, we can employ many methods to generate the external reference features, such as mean features, nearest features, sampling key features by coreset subsampling algorithm [35], generating prototype features by memory module [28], and learning codebook features through vector quantization [65] or sparse coding techniques [55]. However, because the RBF-kernel in is position-sensitive, the reference features are better to preserve the positional information. In the following, we will introduce how to generate reference features in detail.
Mean Features. Using patch-wise averaged features as the external reference features is really simple but effective. Formally, for position , we first extract the set of patch features at , from the normal training images. Then, the reference features at position is computed as . The final external reference features are composed of averaged features at all locations and then flattened into 1D: .
Nearest Features. To represent all possible normal patterns and also preserve the positional information, another simple way is to retain all normal features and then select the nearest features as the reference features. Specifically, we first extract the features of all images from the normal training set, which are denoted as . Then, for each position , we select its nearest normal feature in the neighborhood as the reference feature . The neighborhood is defined as follows:
| (14) |
The reference feature is calculated as follows:
| (15) |
where is the neighborhood features for position , is the input feature at position .
Coreset Features. Following [35], we can employ a coreset subsampling algorithm to sample key features as the reference features. The normal features are also first extracted by a pre-trained network. Then, we can establish a coreset feature pool by the coreset subsampling mechanism. Conceptually, coreset feature pool aims to most closely and especially more quickly approximate the original features in the feature space. Therefore, it can effectively preserve the key normal patterns in normal features. The minimax facility location coreset selection algorithm is utilized, the procedure to generate can be defined as follows:
| (16) |
The exact computation of is NP-Hard. We follow [35] to use the iterative greedy approximation strategy to sample each coreset feature. The th coreset feature in the coreset feature pool is sampled as follows:
| (17) |
Then the coreset feature pool is updated by . We can repeat the sampling process (E.q.17) until the pre-defined coreset size.
Prototype Features. In MemoryAE [28], the authors propose to use a memory module to generate prototype features of normal data for lessening the powerful reconstruction capability of CNNs to abnormal video frames. The memory module contains prototypes recording various prototypical patterns of normal data. However, the prototype features used in our method are slightly different, we need to learn prototype features at each location to preserve the position information. We denote prototype features at position by . We then perform the memory writing operation to update the prototype features.
To update each prototype feature at position , we first need to select all input features declaring that the is the nearest one. Thus, we compute the cosine similarity between each input feature and all prototypes . The matching weights are as follows:
| (18) |
Note that multiple input features can be assigned to a single prototype in the memory. We denote by the set of indices for the corresponding input features for the th item in the memory. We update the th prototype using the input features indexed by the set as follows:
| (19) |
where means the normalization. By using a weighted average of the input features, we can concentrate more on the input features close to the prototype. To this end, we can compute matching weights similar to E.q.18:
| (20) |
and renormalize it as follows:
| (21) |
Codebook Features. Besides, we can also employ vector quantization (VQ) [49] to learn codebook features as the reference features. Codebook features are highly semantic as VQ is based on quantizing the input features with features from a codebook which has been trained for optimal decoding of spatial configurations of quantized features into high-fidelity images. For each input feature at position , we can obtain a quantized feature representation by replacing the feature vector with its nearest neighbor in :
| (22) |
After quantizing the input features to the codebook features, we feed the quantized features to a decoder. The decoder output feature at position aims at reconstructing the input feature . During learning the codebook features, we maximize the cosine similarity between the decoder output and the input . Note that the quantization process (E.q.22) is non-differentiable, but we could approximate the gradient similar to the straight-through estimator and directly copy gradients from decoder input to input feature [49]. The learning objective is defined as:
| (23) |
With the codebook features, we can use the quantized feature as the reference feature as position .
| Reference Features | Dataset | ||
| MVTecAD | BTAD | MVTec3D-RGB | |
| Mean Features | 0.990/0.983 | 0.960/0.975 | 0.884/0.976 |
| Nearest Features | 0.973/0.969 | 0.947/0.973 | 0.842/0.970 |
| Coreset Features [35] | 0.925/0.948 | 0.884/0.897 | 0.700/0.928 |
| Prototype Features [28] | 0.987/0.978 | 0.958/0.975 | 0.898/0.982 |
| Codebook Features [65] | 0.970/0.970 | 0.955/0.970 | 0.797/0.956 |
Results. Ablation results in external reference features are shown in Table 15. As we mentioned, the reference features are better to preserve the positional information, the results also show that the methods (e.g., Coreset Features and Codebook Features) that can’t preserve the position information performs worse. Prototype features can achieve comparable performance with mean features, but it’s more intricate to generate prototype features by memory module [28]. The ablation results demonstrate that although the mean features are simple, they are quite effective and can achieve better results than these more intricate reference feature generation methods.
Appendix C Qualitative Results
We present in Figure 6 additional anomaly localization results of categories with different anomalies in the MVTecAD dataset.
