Flying Bird Object Detection Algorithm in Surveillance Video Based on Motion Information
Abstract
A Flying Bird Object Detection algorithm Based on Motion Information (FBOD-BMI) is proposed to solve the problem that the features of the object are not obvious in a single frame, and the size of the object is small (low Signal-to-Noise Ratio (SNR)) in surveillance video. Firstly, a ConvLSTM-PAN model structure is designed to capture suspicious flying bird objects, in which the Convolutional Long and Short Time Memory (ConvLSTM) network aggregated the Spatio-temporal features of the flying bird object on adjacent multi-frame before the input of the model and the Path Aggregation Network (PAN) located the suspicious flying bird objects. Then, an object tracking algorithm is used to track suspicious flying bird objects and calculate their Motion Range (MR). At the same time, the size of the MR of the suspicious flying bird object is adjusted adaptively according to its speed of movement (specifically, if the bird moves slowly, its MR will be expanded according to the speed of the bird to ensure the environmental information needed to detect the flying bird object). Adaptive Spatio-temporal Cubes (ASt-Cubes) of the flying bird objects are generated to ensure that the SNR of the flying bird objects is improved, and the necessary environmental information is retained adaptively. Finally, a LightWeight U-Shape Net (LW-USN) based on ASt-Cubes is designed to detect flying bird objects, which rejects the false detections of the suspicious flying bird objects and returns the position of the real flying bird objects. The monitoring video including the flying birds is collected in the unattended traction substation as the experimental dataset to verify the performance of the algorithm. The experimental results show that the flying bird object detection method based on motion information proposed in this paper can effectively detect the flying bird object in surveillance video.
Index Terms:
Flying Bird Detection; Video Object Detection; Feature Aggregation; Low Signal-to-Noise Ratio; St-Cubes; Motion RangeI Introduction
WE are working on the real-time detection of flying bird objects in surveillance videos. For this detection task, there are two main challenges(as shown in Fig. 1 left).
-
•
The features of the object in a single frame are not obvious. Flying birds generally have certain camouflage characteristics similar to the environment, and it is difficult to identify through a single frame.
-
•
The flying bird object is usually small. The monitoring area is generally a room or an outdoor area for general monitoring scenarios. When a bird intrudes into the monitoring area, the proportion of the number of pixels is usually small.
Although the features of the flying bird object in the single frame are not obvious, the flying bird object can still be found by observing the continuous multiple frames of images and using the motion information of the flying bird object (as shown in Fig. 1 on the right). This paper will explore how to use motion information to detect flying bird objects in surveillance videos.

Thanks to the development of deep learning, object detection performance [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] have been significantly improved. These methods mainly detect objects in still images and rely on the appearance features of the objects. However, the appearance characteristics of flying bird objects are not particularly obvious in surveillance videos, so the object detection method based on still images is ineffective when applied to our task.
In recent years, many methods for video object detection have been proposed. Video has rich temporal information, which we can exploit to enhance the performance of video object detection. It can overcome the problem of the degradation of the detection effect when the video object appears to motion blur, occlusion, and appearance change.
Some video object detection methods take advantage of the fact that the same object may appear in multiple frames within a certain period to improve the robustness of the whole detection. These methods first detect video frames as independent images and then use post-processing methods (such as frame sequence NMS [11], tracking [12], or other temporal consistency methods [13, 14]) to enhance the confidence of weak detections in the video. This method requires the algorithm to produce some strong predictions; however, in our task, some flying bird objects are difficult to identify from appearance to disappearance, so we cannot utilize this kind of video object detection method to solve our problem.
Another type of video object detection method uses the idea of feature aggregation [15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27] to improve the overall detection effect. These methods enhance the feature information of the current frame by aggregating the Spatio-temporal information of different frames to improve the detection performance of degraded frames (when the video object has motion blur, occlusion, and appearance change, the detection effect is degraded). However, their main purpose is still to solve the effect degradation problem in video object detection. When applying their idea to our task, it will have some effect (we also need to aggregate the Spatio-temporal information of adjacent frames to enhance the features of the flying bird object in the current frame, thus overcoming the problem of missing object features caused by small or blurred objects in a single frame), but there will still be a lot of false detections and missed detections. We further analyze that their method first extracts the intermediate features of a single frame image and then aggregates the extracted intermediate features to aggregate spatio-temporal information. Since the objects in their experimental data are clear and have large sizes on most images, problems such as short blur, occlusion, and appearance change can be solved after aggregation. However, in our task, the features of most flying bird objects are not obvious on any image, and the size is small. In the feature extraction process of single frame images, the features of the flying bird objects are easily lost, which leads to the failure of spatio-temporal information aggregation. Secondly, due to the object’s small size, the problem of low signal-to-noise ratio (unbalanced positive and negative samples) is not easy to eliminate in the training process.
We found that some works detect video objects by generating Spatio-temporal Cubes (St-Cubes) [28] or tubelets [29]. These methods can improve the SNR of video objects, especially small objects; however, since they do not consider that when the object moves too slowly, the object in the pipeline will lack the surrounding environmental information, which is also crucial for our task.
Based on the above analysis, we propose a Flying Bird Object Detection algorithm Based on Motion Information (FBOD-BMI) to solve the above problems. Firstly, a ConvLSTM-PAN model structure is designed to capture suspicious flying bird objects, in which the Convolutional Long and Short Time Memory (ConvLSTM) network aggregated the Spatio-temporal features of the flying bird object on adjacent multi-frame before the input of the model and the Path Aggregation Network (PAN) located the suspicious flying bird objects. Then, an object tracking algorithm is used to track suspicious flying bird objects and calculate their Motion Range (MR). At the same time, the size of the MR of the suspicious flying bird object is adjusted adaptively according to its speed of movement (specifically, if the bird moves slowly, its MR wil be expanded according to the speed of the bird to ensure the environmental information needed to detect the flying bird object). Adaptive Spatio-temporal Cubes (ASt-Cubes) of the flying bird objects are generated to ensure that the SNR of the flying bird objects is improved, and the necessary environmental information is retained adaptively. Finally, a LightWeight U-Shape Net (LW-USN) based on ASt-Cubes is designed to detect flying bird objects, which rejects the false detections of the suspicious flying bird objects and returns the position of the real flying bird objects.
There is an interesting work to detect flying birds, Glances and Stare Detection(GSD)[30], which simulates the characteristics of human observation of moving small objects by first taking a Glance at the whole image and then taking a closer look at the places that may contain the object. Formally, the region proposal sequence obtained by localization is first used to construct the candidate region sequence, and then the classification method is used to classify the candidate region sequence, and the classification results are fed back to localization to guide the generation of new region proposals. The region proposal is continuously narrowed by alternating localization and classification until the object is locked. The essence of GSD can be seen as solving the problem of low SNR of flying birds. Since the characteristics of the birds in the experimental data set are obvious on a single frame image, this work does not consider the problem that the characteristics of the object are not obvious on a single frame image (the input of the localization stage is the current frame). In this paper, the problem of missing features of the flying bird object on a single frame image and low SNR of the flying bird object is solved simply.
The main contributions of this paper are as follows.
-
•
This paper provides an idea to solve the problem that the features of flying bird objects are not obvious in a single frame image, which is to use ConvLSTM to aggregate the spatio-temporal features of flying bird objects on consecutive frames of images before the input of the model, rather than at the intermediate feature layer.
-
•
The ConvLSTM-PAN model structure is designed to capture the suspected flying bird objects. ConvLSTM aggregates the Spatio-temporal features of flying bird objects on consecutive frames, and PAN locates suspicious flying bird objects.
-
•
This paper provides a method to improve the SNR while retaining enough context information for the flying bird objects. Specifically, an adaptive St-Cube extraction method based on the motion information of flying bird objects is proposed in this paper. By using object tracking technology and the motion information of flying bird objects, the St-Cube of the flying bird object in consecutive frames is adaptively adjusted and extracted, so the signal-to-noise ratio of flying bird objects improved, and the necessary environmental information remained.
-
•
A lightweight U-shaped network (LW-USN) model structure was designed to realize the accurate classification and localization of flying bird objects using the St-Cube of suspected flying bird objects.
The remainder of this paper is structured as follows: Section II presents work related to this paper. Section III describes the flying bird object detection algorithm based on motion information in detail. In Section IV, the comparison and ablation experiments of the proposed algorithm are carried out. Section V concludes our work.
II Related Work
II-A Object Detection in Still Images
Traditional object detection methods detect objects by manually designed features related to the object to be detected [31, 32, 33]. For example, [32] proposed the Oriented Gradients (HOG) feature descriptor for feature extraction of object detection.
Based on the deep learning method, the CNN features related to the object to be detected are automatically extracted by learning to realize the location and classification of the object. For example, the two-stage object detector [1, 2, 3] first generates region proposals and then uses the CNN features of the region proposals to realize object classification and localization. One-stage object detector [4, 5, 6, 7, 8, 10], which directly uses an advanced feature extraction network to extract the CNN features of the object for classification and localization. However, they all rely on the appearance feature of the object in the still image, and their detection performance drops sharply when the appearance feature is not obvious.
II-B Video Object Detection
Compared to still images, video has an additional temporal dimension, which makes it possible for the same object to appear in consecutive video frames. Therefore, the video object possesses redundant and complementary information. Using this redundant and complementary information can improve the performance of video object detection. According to how to use the redundant and complementary information of video objects, video object detection methods can be roughly divided into video object detection methods based on post-processing and video object detection methods based on feature aggregation.
II-B1 Video Object Detection with Post-processing
These methods first use an image object detector to detect video frames as independent images. Then, the unique Spatio-temporal information of video data is used to improve the accuracy of detection results [11, 12, 13, 14]. For example, Seq-NMS [11] uses Intersection over Union (IOU) to find the same object in adjacent frames and then re-scores the object with low confidence to improve the detection score of the object in the video. Literature [12] proposed a complete framework for video object detection based on static image object detection and general object tracking. Firstly, object detection and object tracking techniques are used to generate tubelets object proposal frames. Then, the strong detection boxes in the tubelets are used to enhance the weak detection boxes. Finally, a temporal convolutional network is used to re-score the tubelets. [13] extends the popular still image detection framework to solve the generic object detection problem in videos by fusing temporal and contextual information from tubelets. this method effectively incorporates temporal information into the proposed detection framework by locally propagating detection results between adjacent frames and globally modifying detection confidence along the tubelets generated by the tracking algorithm. Literature [14] generates tubelets by matching Bboxes across time and then takes a similar idea as Literature [13] to correct false and missed detections in the tubelets.
These methods generally require that the detector has better detection performance in some frames or that the object to be detected has rich features in some frames. When the features of the object to be detected are not obvious in any frame, the algorithm will not achieve satisfactory results.
II-B2 Video Object Detection Based on Feature Aggregation
When the features of the object to be detected are not obvious in some frames, in the feature extraction stage, the feature information of other adjacent frames can be aggregated to enhance the features of the object in these frames. Literature [15] proposed a method of using optical flow propagation features, then used the features for video object detection, which improved the speed of video object detection. Literature [16, 17, 18] use optical flow to propagate features and then aggregates the features of the current frame and the propagated features to enhance the expression ability of the current frame to improve the detection accuracy of video objects. Literature [19, 20] use the characteristics of LSTM to realize the aggregation or association of feature information of different frames to realize the detection of video objects. Literature [21] models the semantic and spatio-temporal relationships between candidates within the same frame and between adjacent frames to aggregate and enhance the features of each candidate box. In Literature [22], the Sequence-level Semantic Aggregation (SELSA) method was proposed, which randomly sampled some frames from the whole video and aggregated the object candidates of the current frame with the weight of the distance between the object candidates to enhance the characteristics of the object candidates of the current frame. Literature [23] aggregated the ROI features of the current frame and the most similar ROI features of other frames to obtain the Temporal ROI feature so that the Temporal ROI feature contained the temporal domain information of the object to be detected in the whole video. Literature [24] combined class-aware pixel-level feature fusion and class-aware instance-level feature fusion to improve the detection accuracy of video objects. Literature [25] introduces a multi-level Spatio-temporal feature aggregation framework, which fully uses frame-level, proposition-level, and instance-level information under a unified framework, to improve the accuracy of video object detection. Literature [26, 27] designs a unique external memory to store the features of other frames and then fuses the features of the current frame to complete feature aggregation.
However, the feature aggregation operation of this kind of method is carried out in the intermediate feature layer. First, the feature extraction of each frame image is performed separately, and then the extracted features are aggregated, which has a good effect on the ImageNet dataset [34]. However, in our scene, most of the flying birds, the appearance features on any single frame are not particularly rich, the bird size is small, and the bird features are easily lost when extracting the features of a certain frame image alone. At the same time, looking at consecutive frames makes it more obvious where there are birds, which indicates that the flying bird has complementary feature information on multiple consecutive frames. Therefore, we use ConvLSTM to aggregate the features of the flying bird object on consecutive frames before the input of the model (instead of aggregating at the intermediate feature layer) and use the aggregated features to locate the flying bird object.
Due to the small proportion of pixels and low SNR of flying birds in the monitoring image, there are still many false and missed detections only using the previous detection method. Therefore, based on the above detection, we use the method of object tracking to obtain the MR of the flying bird object and generate the St-Cubes of the flying bird object to improve the SNR. This St-Cube is then used to classify and localize flying bird objects.
After processing the above methods, the detection effect still does not substantially improve. We further analyzed and found that there was a subset of flying birds with slow movements in our data. At this time, if the St-Cube of the flying bird object is still obtained by the above method, the slow moving flying bird object will lack the surrounding environment information, which will lead to the degradation of the flying bird object detection performance in this part. Therefore, the flying bird object’s motion information (motion speed) is considered in this paper. When the motion amount of the flying bird object is lower than a certain threshold, its motion range is expanded, and the environmental information of the flying bird object is increased to improve the identification of the flying bird object.
III The Proposed FBOD-BMI
Fig. 2 shows the overview diagram of the proposed FBOD-BMI, which contains three parts. Firstly, ConvLSTM is used to aggregate the features of flying bird objects on consecutive frames before the input of the model, and the aggregated features are used to capture suspicious flying bird objects. Secondly, the adaptive space-time cubes (ASt-Cubes) of suspicious flying bird objects were generated using the method of object tracking and the motion amount of suspicious flying bird objects, which improved the SNR of suspicious flying bird objects while retaining their necessary environmental information. Finally, the ASt-Cubes of the suspicious flying bird object were used to confirm and accurately locate the flying bird object by using a lightweight object detection method. Section III-A describes the suspicious flying bird object detection method based on the ConvLSTM feature aggregation technique. Section III-B introduces the adaptive Spatio-temporal cube extraction method of suspicious flying bird objects based on object tracking technology and amount of motion. Section III-C describes the flying bird object detection method based on ASt-Cubes.

III-A To Capture the Suspicious Flying Bird Object
In this paper, we perform two steps to capture suspicious flying bird objects (coarse detection of flying bird objects) in consecutive video images. Firstly, the features of flying bird objects on consecutive frames are aggregated. Then, the aggregated features are used to locate the suspicious flying bird object by object detection. This subsection will introduce the acquisition of aggregated features of flying bird objects (Section III-A1) and localization of suspicious flying bird objects (Section III-A2), respectively.
III-A1 Acquisition of Aggregated Features for Flying Bird objects
It has been introduced before that the characteristics of the most flying bird objects are not obvious in a single frame, but they have complementary characteristics in multiple consecutive frames. Therefore, we need to aggregate the features of flying bird objects over multiple consecutive frames.
The recurrent neural network ConvLSTM(structure shown in Fig. 3) contains three gates, namely the input gate, output gate, and forget gate, which is used to control the input and output and what information needs to be forgotten and discarded. At the same time, the input gate and output gate can also be understood as controlling the writing and reading of the memory cell. So ConvLSTM can retain useful information and discard redundant or unimportant information.

The coarse-detection phase captures the suspicious flying bird object, and the input is the whole video image, which has the characteristics of many background interference and redundant information (different frames have many identical backgrounds). According to the characteristics of ConvLSTM structure, it can remove redundant or unimportant information while aggregating the features of the flying bird object on consecutive frames. So, in the coarse-detection stage, we use ConvLSTM to extract and aggregate the features of the flying bird object on consecutive frames. Specifically, given the input consecutive frames of images (Where H and W are the height and width of the input image, and is an odd number), using ConvLSTM network to extract and aggregate the features of flying bird object on the consecutive frames, to get spatial-temporal aggregation features (Where C is the number of channels) of the flying bird object,
| (1) |
where, when , . is the learnable parameter of the ConvLSTM network. The Spatio-temporal aggregation features of consecutive frames of images are input into the subsequent classification and positioning module to determine the category and spatial location information of the suspicious flying bird object.
III-A2 Localization of Suspicious flying bird Objects
In convolutional neural networks, deeper layers generally have smaller sizes, better global semantic information, and can predict larger objects. The shallower depth layers generally have a larger size, have more delicate spatial information, and can predict smaller objects. However, the large feature layer often does not have a relatively high degree of semantic information, and the small feature layer does not have sufficient spatial positioning information. Therefore, relevant researchers have proposed the structure of FPN [35] to combine the strong semantic information of the small feature layer and the strong spatial positioning information of the large feature layer. However, the researchers of PANet(Path Aggregation Network) [36] found that when FPN transmitted information, there was information loss due to the transfer distance when the information was transmitted to the low-level feature layer. Therefore, path-enhanced FPN, namely PANet structure (see Fig. 4), was proposed. The PANet structure opens up a green channel for low-level information transmission and avoids low-level information loss to a certain extent. In this paper, the PANet structure is used to classify and locate flying bird objects.

The Spatio-temporal aggregation features of consecutive frames are input into the PANet structure to extract high-level abstract features of flying bird objects ,
| (2) |
where, is the learnable parameter of the PANet network. The high-level abstract features of flying bird objects can be directly used for classification and localization of flying bird objects.
When the distance between the flying bird object and the surveillance camera is different, the size of the flying bird object is also different, so the flying bird object to be detected has a multi-scale property. According to the multi-scale property of the flying bird object, this paper uses the MultiScale Detection Head (MS-D Head) to detect the suspicious flying bird object.
The objects in the middle frame of consecutive frames have symmetric contextual information, which can get more accurate results in prediction. Therefore, this paper predicts the suspicious flying bird object in the middle frame of consecutive frames as the detection result of the Coarse-detection stage. Specifically, the high-level abstract feature of the flying bird object is input into the MS-D Head to obtain the output of the model,
| (3) |
where, is the learnable parameter of the MS-D Head. Then post-processing operations such as Boxes Decoding and non-maximum suppression were performed on the output of the model to obtain the location of the suspicious flying bird object in the middle frame of consecutive frames,
| (4) |
where, means the locations of the flying bird objects in frames. indicates the predicted position of the object with IDk (the object with IDk is taken as an example unless otherwise specified). denotes the post-processing method.
III-B To Obtain the ASt-Cubes of flying bird objects
In this paper, we extract the St-Cubes of the suspicious flying bird objects on consecutive frames to improve the SNR of the flying bird objects. At the same time, to ensure the necessary environmental information of the suspicious flying bird objects, the size of the MR is adaptively adjusted according to the motion amount of the suspicious flying bird so that the subsequent detection results are more accurate. Specifically, we will divide it into two steps to obtain the ASt-Cubes of suspicious flying bird objects. Respectively, the original MR of the suspicious flying bird object is extracted using the object tracking technology (Section III-B1), and the MR is adaptively adjusted using the motion amount of the suspicious flying bird object to obtain the ASt-Cubes (Section III-B2).
III-B1 Acquisition of the Original MR of the Suspicious flying bird Object
From the frame, there are detection results of the suspicious flying bird object, and we start to track the suspicious flying bird object from the frame. In some cases, the appearance characteristics of flying bird objects are not obvious, so we only use their motion information when tracking them and use a relatively simple SORT [37] object tracking algorithm to track suspicious flying bird objects,
| (5) |
where, represents the position on consecutive image frames of a suspicious flying bird object with ID number k, and represents the SORT object tracking method. After obtaining the position of the suspicious flying bird object on consecutive image frames, we can find the Motion Range (MR) of the suspicious flying bird object on consecutive frames. Specifically, the minimum circumscribed rectangle at positions is calculated according to the position of the same object on consecutive frames of images,
| (6) | ||||
where, denotes the function to find the minimum circumscribed rectangle of rectangular boxes. For example, to find the minimum circumscribed rectangle (Using the horizontal and vertical coordinates of the top left and bottom right vertices of the rectangle) of , the specific calculation method is as follows,
| (7) | ||||
where, denotes the horizontal and vertical coordinates of the upper left and lower right vertices of in the image. The obtained minimum circumscribed rectangle is the MR of the flying bird object in consecutive frames. The diagram of the motion range of the flying bird object on five consecutive frames of images is shown in Fig. 5, which, after cropping, can be used as a St-Cubes for flying bird objects.

III-B2 Adaptively Adjust the MR to Obtain ASt-Cubes Based on the Amount of Motion
We crop the MR of the suspicious flying bird object in consecutive frames to generate the St-Cubes of the flying bird object. The St-Cube eliminates the interference of other background and negative samples, which can improve the SNR of the flying bird object. However, suppose the flying bird object moves too slowly. In that case, the resulting St-Cubes will lack the necessary environmental information (see Raw St-Cube in Fig. 6), which is not conducive to the detection of flying bird objects. To balance the contradiction between SNR and environmental information, this paper proposes an ASt-Cubes extraction method based on the amount of motion of the flying bird object, which adaptively adjusts the size of the MR of the flying bird object according to the speed of the object’s motion. There are two steps.

Firstly, the amount of motion of the flying bird object over consecutive frames is calculated. If an object of the same size moves fast on consecutive frames, its MR is large; otherwise, its MR is small. Therefore, we use the ratio of the area of the MR of the flying bird object on consecutive frames to the area of the single frame image occupied by the flying bird object to define its motion amount on consecutive frames,
| (8) |
where, is the motion amount, represents the function to calculate the area, and represents the object with ID number k. The area of MR is then the area of the minimum circumscribed rectangle . Since the area occupied by a flying bird object in a single image frame may vary due to its shape changes, and it is not easy to calculate accurately, we use the rectangular area of its bounding box to approximately represent its area in this paper.
Then, according to the amount of motion of the flying bird object, the MR of the flying bird object is adaptively adjusted as the Adaptive MR of the flying bird object. Specifically, a motion hyperparameter is introduced. When the amount of motion of the flying bird object is less than , the MR of the flying bird object is expanded to make the amount of motion of the flying bird object reach . Therefore, the Adaptive MR of the flying bird object can be expressed as follows,
| (9) |
The is used to crop the corresponding consecutive frames of video image respectively, and the frame screenshots obtained are the Adaptive St-Cubes (ASt-Cubes) () of the flying bird object,
| (10) | ||||
| (11) |
III-C flying bird Object Detection Based on St-Cube
After the previous processing, we improve the SNR of the flying bird object, retain its necessary environmental information, and obtain the ASt-Cubes of the flying bird object. In the fine-detection stage, we can use the ASt-Cubes of the flying bird object to classify and locate the flying bird object. Specifically, the fine-detection phase includes feature aggregation of flying bird objects (III-C1) and flying bird objects’ classification and localization (III-C2).
III-C1 feature aggregation of flying bird objects
The input of the fine-detection model is the ASt-Cubes of the flying bird object extracted earlier. The coarse-detection model may detect multiple suspicious flying bird objects at one time, so there will be multiple ASt-Cubes, and the fine-detection model will detect each ASt-Cubes separately. So it is possible to run a coarse-detection model once and a fine-detection model many times. Therefore, to balance the accuracy and speed, the way of aggregating the Spatio-temporal features of the flying bird object in the fine-inspection stage is used to merge the input of multiple consecutive frames. At the same time, to reduce data redundancy, except for the middle frame, the rest of the frames are input in the form of a grayscale image single channel. Specifically, firstly, grayscale the screenshots of the ASt-Cubes of the flying bird object except for the middle screenshot,
| (12) |
where, is a function that finds the grayscale of a color image. Then, the processed screenshots of the ASt-Cubes are Concatenate in the channel dimension as the input of the fine-detection stage,
| (13) |
where, the second argument of the function indicates that the concatenation operation is performed in the third input dimension (height, width, channel). The length and width of are equal to the length and width of rectangle , and the number of channels is , which contains the flying bird object’s features in the ASt-Cubes. It is input into the fine-detection model to classify and locate the flying bird object accurately.
III-C2 Classification and Localization of flying bird objects
In order to further improve the speed of the whole flying bird object detection process, this paper uses a lightweight U-Shaped Network (USN) (in the experiment, we use MobilenetV2 [38]as the backbone network of the USN) as the feature extraction network of the flying bird object in the fine-detection stage, as shown in Fig. 7.
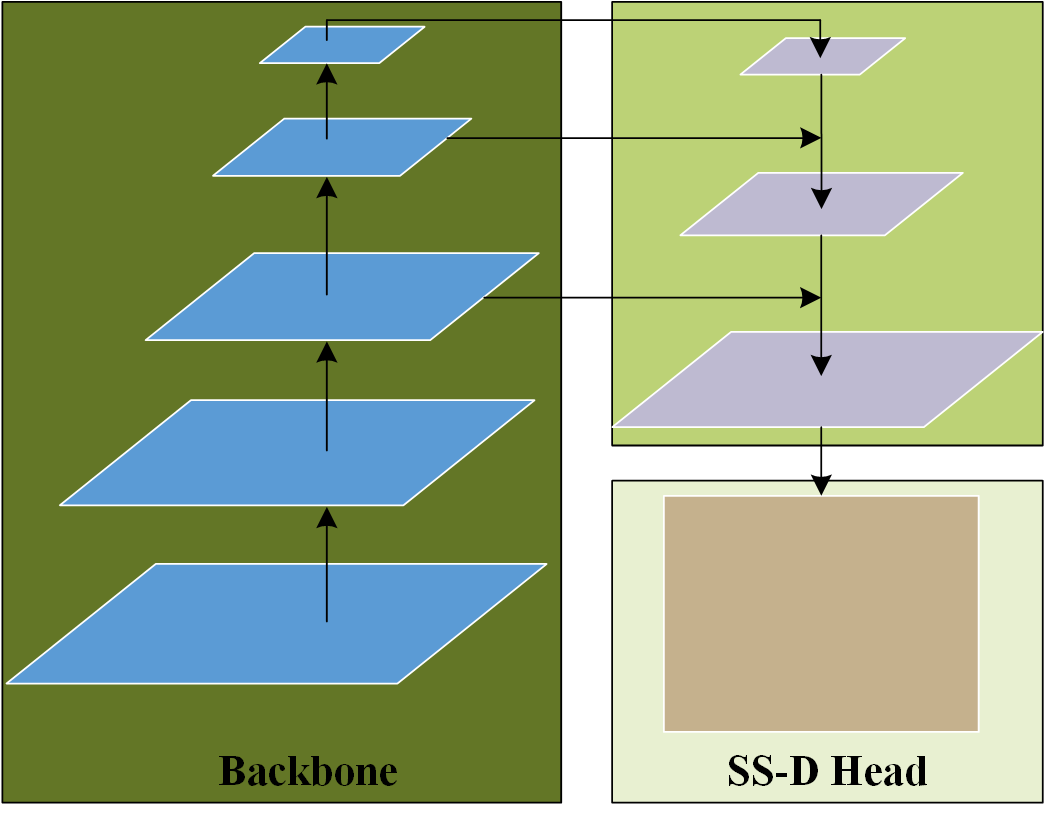
We feed , which aggregates the ASt-Cubes of the flying bird object, into the LW-USN feature extraction network to obtain the aggregated ASt-Cubes feature of the flying bird Object,
| (14) |
where, is the learnable parameter of the LW-USN.
The ASt-Cube of a flying bird object may contain more than one object. Moreover, due to the interference of background and negative samples, the detection accuracy of the coarse-detection model is not satisfactory; there will be false and missed detection. So, the ASt-Cube may contain no object, one object, or multiple objects. Therefore, the detection model in the fine-detection stage should still have the ability of multi-object detection. However, since the ASt-Cubes of flying bird objects are only a small area (relative to the input image) and cannot contain many flying bird objects, the output of the fine-detection model need not be designed with a complex structure. In summary, the paper uses a relatively simple Single Scale Detection Head (SS-D Head) structure as the output structure of the fine-detection model (see Fig. 7). Specifically, is fed into the SS-D Head to obtain the output of the fine-detection model,
| (15) |
where, is the learnable parameter of the SS-D Head. Then, post-processing operations such as Boxes Decoding and non-maximum suppression are performed on the output to obtain the final detection result of the flying bird object,
| (16) |
where, represents the category of the object in the ASt-Cube of the flying bird object, and (in this paper, the position of the object in the middle frame of consecutive frames is taken as the detection result) is the bounding box of the corresponding object in this region.
Finally, the bounding box of the flying bird object in the ASt-Cubes is mapped to the original video image. That is, the final detection result of the flying bird object is obtained.
IV Experiment
In this section, A series of experiments are conducted to quantitatively and qualitatively evaluate the proposed FBOD-BMI. Next, we will introduce datasets (IV-A), evaluation metrics (IV-B), experimental platforms (IV-C), implementation details (IV-D), and parameter analysis experiment (IV-E), comparative analysis experiment (IV-F).
IV-A Datasets
We collected and annotated 115 videos containing flying birds (the size of video images is 1280 720) in an unattended traction substation. We end up with 28156 images, of which 7634 contain flying birds, with 8589 flying bird objects. From the 115 videos, we randomly selected 18 videos for testing and the remaining 97 videos for training. The training set includes 24771 images, and the test set includes 3385 images.
From Fig. 8, we can see that the size of flying birds is mainly distributed between 0 0 and 80 80 pixels, and more than 60% are below 40 40 pixels.

IV-B Evaluation Metrics
In this paper, the widely used measures in object detection, average precision (AP), is adopted to evaluate the proposed FBOD-BMI. More specifically, (The subscript 50 means that the detection result is regarded as the True Positive when the IOU between the detection result and the ground truth is greater than or equal to 50%. That is, the IOU threshold is set 50% ), (The subscript 75 has a similar meaning with the subscript 50), and AP (Average Precision averaged over multiple thresholds, IOU threshold is set from 50% to 95%, in intervals of 5%) are adopted.
IV-C Experimental Platforms
All the experiments are implemented on a desktop computer with an Intel Core i7-9700 CPU, 32 GB of memory, and a single NVIDIA GeForce RTX 3090 with 24 GB GPU memory.
IV-D Implementation Details
We implemented the proposed method based on YOLOV4 [8] with modifications.
Specifically, for the coarse-detection model, we directly place the ConvLSTM module before the input of the CSPDarkNet53, the backbone network of the YOLOV4 model (i.e., the input of CSPDarkNet53 was originally an image, but now the input is the output of ConvLSTM aggregating the features of consecutive frames). As shown in Fig. 9b. For the input size of the coarse-detection model, we set it to 640 384 to ensure the ratio of effective input pixels as much as possible and, at the same time, ensure the running speed. During training, the input is consecutive frames of images, the label is the object’s position on the intermediate frame, and the loss function of the YOLOV4 algorithm is reused.
For the fine-detection model, the lightweight MobilenetV2 is used as the backbone of the U-shaped network. For the input size of the fine-detection model, we set it to 160 160. For the training data, we used the coarse-detection model and the object tracking SORT algorithm to collect the Motion Region (MR) containing the flying bird object as the positive and negative samples without the object. During training, the input is the screenshot of the MR of consecutive frames, the label is the object’s position on the intermediate screenshot, and the loss function of YOLOV4 is reused.
In this paper, all experiments are implemented under the Pytorch framework. All network models are trained on an NVIDIA GeForce RTX 3090 with 24G video memory. The batch size setting is set to 4 when training the coarse-detection model designed in this paper and other comparable models, and it is set to 8 when training the fine-detection model. All the experimental models were trained from scratch, and no pre-trained models were used. The trainable parameters of the network were randomly initialized using a normal distribution with a mean of 0 and a variance of 0.01. Adam was chosen as the optimizer for the model in this paper. The initial learning rate is set to 0.001. For each iteration, the learning rate is multiplied by 0.95, and the model is trained for 100 iterations. In the training phase, we used simple data augmentation, including random horizontal flipping, random Gaussian noise, etc., to enhance the robustness of the model.
IV-E Parameter Analysis Experiments
IV-E1 Effect of feature aggregation at different locations on the accuracy of the algorithm
To prove that, for the characteristics of flying birds in our task (most flying birds do not have obvious features on a single frame image), it is necessary to perform feature aggregation on continuous video images before input to the model, and we set up a set of comparison experiments. Specifically, we set 3 modes for aggregating features of flying birds. In the first (aggregation mode I), we directly place the ConvLSTM module before the input of the CSPDarkNet53, the backbone network of the YOLOV4 model (i.e., the input of CSPDarkNet53 was originally an image, but now the input is the output of ConvLSTM aggregations of the features of five consecutive frames of images. As shown in Fig. 9b); In the second (aggregation mode II), the ConvLSTM module is embedded between the first CrossStage module and the second CrossStage module of CSPDarkNet53, the backbone network of YOLOV4 model (that is, for each image frame, Need to run to the first CrossStage module of CSPDarkNet53 to perform feature aggregation, as shown in Fig. 9c); In the third (aggregation mode III), the ConvLSTM module is embedded between the second CrossStage module and the third CrossStage module of CSPDarkNet53, the backbone network of YOLOV4 model (that is, for each image frame, Need to run to the second CrossStage module of CSPDarkNet53 to aggregate the features, as shown in Fig. 9d).




Because the bird’s features are not obvious and its size is small in our detection task, the feature is easy to disappear in the process of feature extraction of a single frame image, and the deeper the layer is, the more obvious the feature disappears. Experimental results are shown in TABLE I. Without Fine-Detection, the of the aggregation mode I is 2.71% higher than aggregation mode II and 28.38% higher than aggregation mode III. The experimental results prove the above point of view, that is, for the flying bird object with unobvious features, the feature aggregation should be performed before the feature extraction as much as possible. At the same time, we can see that without Fine-Detection, the of aggregation mode III is even 1.83% lower than that of the still image based detection method YOLOV4. This indicates that feature aggregation, when the features of the flying bird object gradually disappear, will affect the feature expression of the flying bird object instead. Therefore, our algorithm adopts the aggregation mode I to aggregate the features of flying bird objects. In addition, for the same aggregation mode, the detection accuracy will be greatly improved after adding the Fine-Detection stage.
| Aggregation mode | AP | Run time(s) | ||
|---|---|---|---|---|
| Mode I w/o FD | 0.6664 | 0.0493 | 0.2085 | 0.0075 |
| Mode I | 0.7089 | 0.2011 | 0.3137 | 0.060 |
| Mode II w/o FD | 0.6393 | 0.0488 | 0.2011 | 0.0094 |
| Mode II | 0.6830 | 0.1221 | 0.2734 | 0.085 |
| Mode III w/o FD | 0.3826 | 0.0060 | 0.0094 | 0.014 |
| Mode III | 0.5778 | 0.1617 | 0.2489 | 0.090 |
| Method | AP | Run time(s) | ||
| YOLOV4 | 0.4009 | 0.0719 | 0.1527 | 0.006 |
IV-E2 Effect of Different Number of Consecutive Input Frames on the Performance of the Algorithm.
We design test experiments with different numbers of consecutive frame inputs to evaluate the impact on the detection accuracy and efficiency of the proposed method. Specifically, there are three consecutive frames of input, five consecutive frames of input, seven consecutive frames of input, etc. Theoretically, with the increase in the number of consecutive frames, the motion information of the flying bird object will be gradually enriched. However, the motion range of the flying bird object will also increase, and the difficulty of feature aggregation will also increase. Therefore, as the number of consecutive frames increases, the detection accuracy of the algorithm should be a process of first rising and then falling. Meanwhile, as the number of consecutive frames increases, the algorithm’s running time will increase accordingly. The algorithm’s detection performance test results are shown in TABLE II (the motion amount parameter is set to 4.0). The experimental results show that the algorithm has the fastest running speed but the lowest detection accuracy when input is input for three consecutive frames. The detection accuracy and running time are better when the input is for five consecutive frames. Therefore, five consecutive frames of input are used in our algorithm.
| Frame num | AP | Run Time(s) | ||
|---|---|---|---|---|
| 3 w/o FD | 0.6409 | 0.0277 | 0.1971 | 0.007 |
| 3 | 0.6723 | 0.0821 | 0.2588 | 0.04 |
| 5 w/o FD | 0.6664 | 0.0493 | 0.2085 | 0.0075 |
| 5 | 0.7089 | 0.2011 | 0.3137 | 0.060 |
| 7 w/o FD | 0.6451 | 0.0564 | 0.2170 | 0.0079 |
| 7 | 0.7069 | 0.1359 | 0.2918 | 0.08 |
IV-E3 Influence of Different Amount of Motion Parameter on the Accuracy of the Algorithm
We obtain the ASt-Cubes of different sizes of the flying bird object by setting different motion amount parameter . If the MR is small, the context background information is less; if the MR is large, the SNR is large. Therefore, different sizes of MRs of the same flying bird object have different effects on the algorithm’s performance. Fig. 10 shows the influence of different motion amount parameter on the algorithm’s accuracy.

We can see from Fig. 10 that with the increase of parameter , the detection precision of the proposed method has a first rise after the fall of a trend. As previously analyzed, when the MR is too small, it lacks contextual information, and when the MR is too large, it is easy to introduce more noise (in an extreme case, when the MR is already consistent with the original input image, the previous processing will be meaningless, because the input of the fine-detection stage is directly the original image. At the same time, because the fine-detection model is relatively simple and the input size is small (160 160), the detection effect is bound to be poor), so whether the MR is too small or too large will affect the accuracy of the algorithm. Through experiments, we find that when the motion amount parameter is 4.0, the detection performance of the algorithm is the best.
Through parameter analysis experiments, we conclude that when the number of consecutive input frames is 5, the algorithm can get a good balance between accuracy and speed. When the motion parameter is 4.0, the algorithm’s accuracy reaches the highest. So we suggest the following parameter setting scheme. The number of consecutive input frames is set to 5, and the motion amount parameter is set to 4.0.
IV-F Comparative Analysis Experiments
In order to verify the advancement of the proposed flying bird object detection algorithm. We design a series of comparative experiments to compare the accuracy of different methods in detecting flying bird objects. Specifically, we compare the static image object detection methods represented by YOLOV4 [8] and YOLOV5 [9] and the video object detection methods represented by FGFA [16], SELSA [22], and Temporal RoI Align [23]. These methods use the relevant open-source code, among which FGFA [16], SELSA [22], and Temporal RoI Align [23] use the MMTracking [39] open-source framework. Note that all methods are trained from scratch without pre-trained models.
By the way, the parameters of the proposed method are designed as follows. The input size is set to 640 384, the number of consecutive input frames is set to 5 frames,and the motion amount parameter is set to 4.0.
The results of quantitative comparison experiments are shown in TABLE III. The experimental results show that for flying birds in surveillance videos, except for the method proposed in this paper, the YOLOV5 [9] series achieves good results. Compared with YOLOV5l [9], the of the proposed method is improved by 21.25%, which proves once again that for flying bird objects with unobvious features and small size in a single frame image, their features are easy to disappear in the process of feature extraction, so it is necessary to perform feature aggregation for flying bird objects. Secondly, the detection accuracy of the video-based object detection method is not better than that of the static image-based detection method, and it is even lower than that of the advanced static image-based detection method (YOLOV5 [9] series). Therefore, in the process of feature disappearance, feature aggregation will affect the feature expression of flying bird objects. Therefore, for flying bird objects with unobvious features and small sizes in a single frame image, their features should be aggregated before input into the model for feature extraction. In addition, the of the proposed method is generally lower than that of the other methods, which indicates that the proposed method is less accurate than the other methods in detecting boxes.
| Method | backbnoe | AP | ||
|---|---|---|---|---|
| YOLOV4 [8] | CSPDarkNet53 | 0.4009 | 0.0719 | 0.1527 |
| YOLOV5s [9] | CSPResNet50 | 0.4663 | - | 0.2492 |
| YOLOV5m [9] | CSPResNet50 | 0.4950 | - | 0.2697 |
| YOLOV5l [9] | CSPResNet50 | 0.4964 | - | 0.2867 |
| FGFA [16] | ResNet101 | 0.2729 | 0.1878 | 0.1586 |
| SELSA [22] | ResNet101 | 0.4530 | 0.2688 | 0.2595 |
| Temporal RoI Align [23] | ResNet101 | 0.4424 | 0.2418 | 0.2331 |
| FBOD-BMI w/o FD | CSPDarkNet53 | 0.6664 | 0.0493 | 0.2085 |
| FBOD-BMI(ours) | CSPDarkNet53 | 0.7089 | 0.2011 | 0.3137 |
In the qualitative comparison experiment, YOLOV5l [9] and SELSA [22] with higher detection accuracy are selected to compare with the proposed method. By comparing the experimental results shown in Fig. 11, it can be seen that when the appearance characteristics of the flying bird object are relatively obvious, all the methods can detect the object (see Fig. 11a and Fig. 11b). However, YOLOV5l [9] and SELSA [22] will miss detection when the appearance features of a single frame image of a flying bird object are not obvious. However, the proposed method can achieve good results regardless of whether the appearance features of the single frame image of the flying bird object are obvious or not (see Fig. 11c and Fig. 11d). At the same time, we find that the detection box of the proposed method is not as compact as YOLOV5l [9] and SELSA [22], which verifies the experimental results in the table, that is, with the increase of IOU threshold, the detection accuracy of the proposed method decreases faster than that of YOLOV5 [9] and SELSA [22]. However, this does not affect the effectiveness of the proposed method because for our task, detection is more important than detection accuracy, and since the object is small, such a difference can be ignored.

Ground Truth




YOLOV5l




SELSA




FBOD-BMI w/o FD




FBOD-BMI



Through the qualitative and quantitative analysis of the experimental results, the flying bird object detection method proposed in this paper is advanced and effective.
V Conclusion
This paper proposes a flying bird Object Detection algorithm Based on Motion Information (FBOD-BMI) to solve the problem that the features of the object are not obvious in a single frame and the object’s size is small (low SNR in surveillance video). Firstly, the ConvLSTM-PANet model was used to coarse detect the whole frame of continuous video frames to capture suspicious flying bird objects. Then, the object tracking method tracks the suspicious flying bird object, and the MR Of the suspicious flying bird object on consecutive frames of images is determined. At the same time, according to the movement speed of the suspicious flying bird object, the size of its MR is adaptively adjusted (specifically, if the object is moving slowly, its MR is expanded according to its speed to ensure the context environment information), and its adaptive St-Cubes (ASt-Cubes) are generated to ensure that the SNR of the flying bird object is improved while the necessary environmental information is retained adaptively. Then, the ASt-Cubes of suspicious flying bird objects are accurately classified and located by the LW-USN model. Finally, qualitative and quantitative experiments verify the effectiveness of the proposed flying bird object detection algorithm based on motion information. At the same time, we proved through ablation experiments that for the problem that the features of single frame images of flying bird objects in videos are not obvious, it is necessary to perform feature fusion before feature extraction as much as possible.
References
- [1] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 580–587.
- [2] R. Girshick, “Fast r-cnn,” in 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [3] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2017.
- [4] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788.
- [5] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in 2016 European Conference on Computer Vision (ECCV), 2016.
- [6] J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6517–6525.
- [7] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv e-prints, 2018.
- [8] A. Bochkovskiy, C. Y. Wang, and H. Liao, “Yolov4: Optimal speed and accuracy of object detection,” 2020.
- [9] Y. Contributors, “You only look once version 5,” https://github.com/ultralytics/yolov5, 2021.
- [10] Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “YOLOX: exceeding YOLO series in 2021,” CoRR, vol. abs/2107.08430, 2021. [Online]. Available: https://arxiv.org/abs/2107.08430
- [11] W. Han, P. Khorrami, T. L. Paine, P. Ramachandran, M. Babaeizadeh, H. Shi, J. Li, S. Yan, and T. S. Huang, “Seq-nms for video object detection,” CoRR, vol. abs/1602.08465, 2016. [Online]. Available: http://arxiv.org/abs/1602.08465
- [12] K. Kang, W. Ouyang, H. Li, and X. Wang, “Object detection from video tubelets with convolutional neural networks,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 817–825.
- [13] K. Kang, H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Wang, R. Wang, X. Wang, and W. Ouyang, “T-cnn: Tubelets with convolutional neural networks for object detection from videos,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 2896–2907, 2018.
- [14] H. Belhassen, H. Zhang, V. Fresse, and E.-B. Bourennane, “Improving video object detection by seq-bbox matching,” vol. 5, Prague, Czech republic, 2019, pp. 226 – 233. [Online]. Available: http://dx.doi.org/10.5220/0007260002260233
- [15] X. Zhu, Y. Xiong, J. Dai, L. Yuan, and Y. Wei, “Deep feature flow for video recognition,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4141–4150.
- [16] X. Zhu, Y. Wang, J. Dai, L. Yuan, and Y. Wei, “Flow-guided feature aggregation for video object detection,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 408–417.
- [17] C. Hetang, H. Qin, S. Liu, and J. Yan, “Impression network for video object detection,” arXiv, 2017.
- [18] X. Zhu, J. Dai, L. Yuan, and Y. Wei, “Towards high performance video object detection,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7210–7218.
- [19] Y. Lu, C. Lu, and C.-K. Tang, “Online video object detection using association lstm,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2363–2371.
- [20] M. Zhu and M. Liu, “Mobile video object detection with temporally-aware feature maps,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 5686–5695.
- [21] H. Luo, L. Huang, H. Shen, Y. Li, C. Huang, and X. Wang, “Object detection in video with spatial-temporal context aggregation,” CoRR, vol. abs/1907.04988, 2019. [Online]. Available: http://arxiv.org/abs/1907.04988
- [22] H. Wu, Y. Chen, N. Wang, and Z.-X. Zhang, “Sequence level semantics aggregation for video object detection,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 9216–9224.
- [23] T. Gong, K. Chen, X. Wang, Q. Chu, F. Zhu, D. Lin, N. Yu, and H. Feng, “Temporal roi align for video object recognition,” in The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), 2021, pp. 1442–1450.
- [24] L. Han, P. Wang, Z. Yin, F. Wang, and H. Li, “Class-aware feature aggregation network for video object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 12, pp. 8165–8178, 2022.
- [25] C. Xu, J. Zhang, M. Wang, G. Tian, and Y. Liu, “Multilevel spatial-temporal feature aggregation for video object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 11, pp. 7809–7820, 2022.
- [26] H. Deng, Y. Hua, T. Song, Z. Zhang, Z. Xue, R. Ma, N. Robertson, and H. Guan, “Object guided external memory network for video object detection,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6677–6686.
- [27] M. Fujitake and A. Sugimoto, “Temporal feature enhancement network with external memory for live-stream video object detection,” Pattern Recognition, vol. 131, p. 108847, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0031320322003284
- [28] A. Rozantsev, V. Lepetit, and P. Fua, “Detecting flying objects using a single moving camera,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 5, pp. 879–892, 2017.
- [29] P. Tang, C. Wang, X. Wang, W. Liu, W. Zeng, and J. Wang, “Object detection in videos by high quality object linking,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 5, pp. 1272–1278, 2020.
- [30] S. Tian, X. Cao, Y. Li, X. Zhen, and B. Zhang, “Glance and stare: Trapping flying birds in aerial videos by adaptive deep spatio-temporal features,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 9, pp. 2748–2759, 2019.
- [31] P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, vol. 1, 2001, pp. I–I.
- [32] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1, 2005, pp. 886–893 vol. 1.
- [33] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained part-based models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1627–1645, 2010.
- [34] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, and M. Bernstein, “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
- [35] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 936–944.
- [36] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 8759–8768.
- [37] A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in 2016 IEEE International Conference on Image Processing (ICIP), 2016, pp. 3464–3468.
- [38] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
- [39] M. Contributors, “MMTracking: OpenMMLab video perception toolbox and benchmark,” https://github.com/open-mmlab/mmtracking, 2020.