FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow
Abstract
Dynamic environments are challenging for visual SLAM since the moving objects occlude the static environment features and lead to wrong camera motion estimation. In this paper, we present a novel dense RGB-D SLAM solution that simultaneously accomplishes the dynamic/static segmentation and camera ego-motion estimation as well as the static background reconstructions. Our novelty is using optical flow residuals to highlight the dynamic semantics in the RGB-D point clouds and provide more accurate and efficient dynamic/static segmentation for camera tracking and background reconstruction. The dense reconstruction results on public datasets and real dynamic scenes indicate that the proposed approach achieved accurate and efficient performances in both dynamic and static environments compared to state-of-the-art approaches.
I Introduction
Simultaneous Localization and Mapping (SLAM) method for a robot is to acquire the information from the unknown environment, build up the map and locate the robot itself on that map. Dynamic environment is a big problem for the real scene implementation of SLAM in both robotics and computer vision research fields. The reason is that most of the existed SLAM approaches and Visual Odometry(VO) solutions guarantee their robustness and efficiencies based on the static environment assumption. When the dynamic obstacles occur or the observed environment changes, these methods cannot extract enough reliable static visual features, so as to insufficient feature associations, which lead to the motion estimation failures between different camera poses.
To deal with the dynamic environments, one straightforward idea for visual SLAM is to extract the dynamic components from the input data and filter them as exceptions to apply the existed robust static SLAM frameworks. Recently, the fast development of deep learning-based image segmentation and object detection methods have gained greatly in both efficiency and accuracy. Many researchers try to handle the dynamic environments via involving semantic labeling or object detection pre-processing to remove the potential dynamic objects. These methods have shown very effective results in particular scenes dealing with particular dynamic objects. However, their robustness may drop down when unknown dynamic objects turn up. Considering more generalized dynamic features, flow approaches are explored to describe all kinds of dynamic objects, e.g., the scene flow in 3D point clouds and the optical flow in 2D images. The flow approaches are to estimate the pixel motions between the given image pair or point clouds data. These methods are sensitive to slight motions and have advantages when tracking the moving non-rigid surfaces. Nevertheless, flow methods need complex penalty setting and suffered from the unclear segmentation boundaries.
In this paper, to get rid of the pre-known dynamic object hypothesis, we deal with the dynamic SLAM problem via flow based dynamic/static segmentation. Different from the existed methods, we provide an novel optical flow residuals based dynamic segmentation and dense fusion RGB-D SLAM scheme. Through improving the dynamic factor influence, in our approach, the dynamic segments are efficiently extracted in current RGB-D frame, the static environments are then accurately reconstructed. Moreover, demonstrations on the real challenging humanoid robot SLAM scenes indicate that the proposed approach outperforms the other state-of-the-art dynamic SLAM solutions.
II Related Works
Saputra et al. summary the dynamic SLAM methods by the year of 2017 in [1]. Most of these approaches are dedicated to specialized scenes. For human living environments, benefit from the economic RGB-D sensors and the computational power improvement from economical graphics processing units(GPU), the dense RGB-D fusion based approaches, e.g., KinectFusion [2] and ElasticFusion(EF) [3], made real-time static indoor environments reconstruction come true with high robustness and accuracy. Many researchers tried to extend these frameworks to dynamic scenes:
The motion segmentation problem can be treated as a semantic labeling problem. For instance, R. Martin et al. proposed Co-Fusion(CF) in [4] and Xu et al. proposed Mid-Fusion in [5]. CF is a real-time object segmentation and tracking method which combined the hierarchical deep learning based segmentation method from [6] and the static dense reconstruction framework of EF.
Besides the semantic labeling solutions, some people insisted to find out the dynamic point clouds as outliers from the dense RGB-D fusion scheme. Such as J, Mariano et al. provided a joint motion segmentation and scene flow estimation method(JF) in [7], R. Scona et al. proposed a static backgrounds reconstruction approach in StaticFusion(SF) [8].
In addition, with the help of deep learning based object detection approaches, some works deal with the dynamic environment problem by involving object detection pre-processing and remove the potential dynamic objects, then reconstruct the environments via static SLAM frameworks. e.g., Zhang et al. proposed the human object detection and background reconstruction method PoseFusion(PF) [9]; C. Yu et al. in [10] applied SegNet [11] to detect and remove foreground humans and then estimate the camera motions with ORB-SLAM2 [12] framework.
More than that, some researchers tried to define the environment dynamic properties as a semantic concept and solve it with SLAM tools. The environment rigidity is firstly defined as a semantics instead of the particular object classification in [13]. In which, the environment rigidity refers to the static background point clouds set, which is stationary, as opposed to the moving objects. Then, in [14], Lv et al. proposed a deep learning based 3D scene flow estimation approach, which combines two deep learning networks: the optical flow approach from [15], and another net for static background rigidity learning.
III Optical Flow based Joint Dynamic Segmentation and Dense Fusion
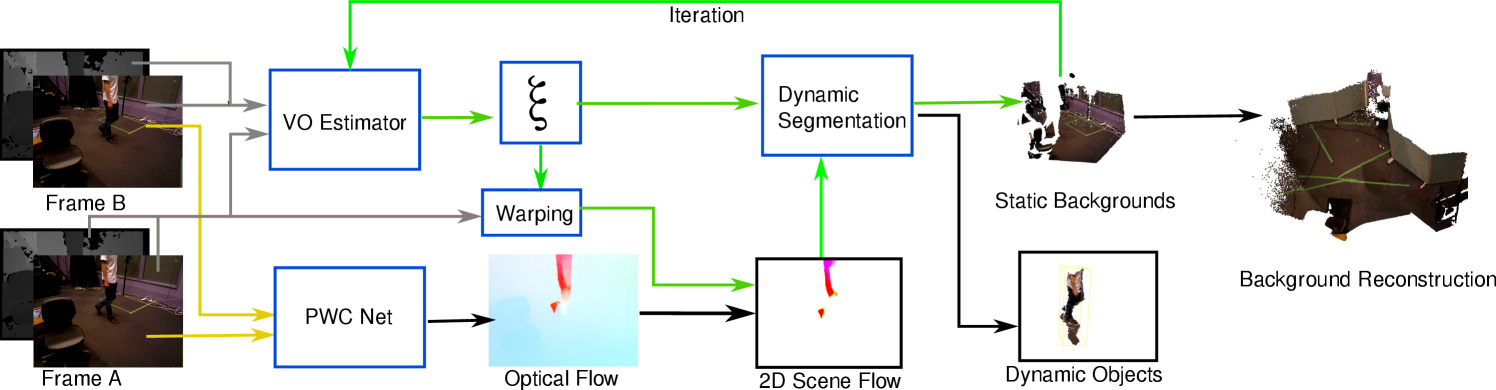
This Section describes how does the proposed VO keep its robustness in dynamic environments. The flowchart of the proposed approach is shown in Fig.1. Our approach takes two RGB-D Frames A and B as input, the RGB images are fed into PWC to estimate the optical flow(yellow arrows). Meanwhile, the intensity and depth pairs of A and B are fed to the robust camera ego-motion estimator to estimate an initial camera motion (introduced in Section III-A). We then warp frame A to A’ with and obtain the projected 2D scene flow(in Section III-B) for dynamic segmentation. After several iterations(Section III-C, the green arrows), the static backgrounds are achieved for the following environment reconstruction. As the proposed method applied optical flow residuals for dynamic segmentation, we name it as FlowFusion (FF).
III-A Visual Odometry in Dense RGB-D Fusion
Following the RGB-D fusion frameworks [3] and [7], our VO front-end is formulated as an optimizing problem of the color(photometric) and depth(geometric) alignment errors. Given RGB-D camera frames and , If we denote intensity image as , depth image as , and are the intensity and depth images on the 2D image plane of camera frame . The 3D Point Clouds Data(PCD) can be generated from () via pinhole camera model. We first over segment the PCD of into clusters according to supervoxel clustering [16] and obtain the adjacency graph (similar to JF and SF, for efficiency, we use intensity distance instead of RGB distance for clustering). As each cluster is composed of similar point clouds, we treat each cluster as a rigid body. Then, we define as the initial rigid motion guess of the that frame. Assume that the robot starts to move in a static environment, can be solved from the formulated energy function considering photometric and depth residuals:
| (1) |
in which, is a scale factor to make the intensity item be comparable to the depth term. The and pre-weight the depth and intensity terms according to their measurement noise. The photometric residuals can be computed as:
| (2) |
and the geometric residuals are obtained from the Depth measurements.
| (3) |
the transformation is denoted as , which is the transformation of , it is composed by the camera rotation and translation between the and frames. In addition, the stands for an image warping operation:
| (4) |
in which, the stands for the pixel coordinates on the 2D image of . indicates the depth value on the depth image. We denote as the projecting from a world coordinate point to camera plane, and we denote the extrinsic parameters as .
| (5) |
the function of is depending on the sensors types (such as pinhole camera, stereo camera, and laser scanners). In this paper, we deal with RGB-D PCD, thus it is a pinhole camera model here.
Finally, the function of is a robust penalty to balance the optimization computation’s robustness and convergence. For RGB-D visual odometry, refers to [7, 8], the Cauchy robust penalty is usually adopted since it’s more robust than norms:
| (6) |
in which, the is the inflection point of , which can be tuned according to the residual levels. Equation 1 is high nonlinear, we solve it via coarse-to-fine scheme using the iterative re-weighted least-square solver provided by [17]. This VO estimator works well in static environments but loses its robustness in dynamic cases. The reason is that, in Eq.1, the depth and intensity residuals contribute to the VO estimator based on the environment’s rigid motion hypothesis. To deal with the dynamic objects, we define the optical flow residuals which directly indicates the non-rigid environment motions.
III-B Optical Flow Residual Estimated by Projecting the Scene Flow

(a) Dynamic Scene

(b) Optical flow

(c) 2D scene flow

(d) Iteration 7
Theoretically, we can distinguish a cluster is dynamic or static via . As () are warped using then we compute the average residuals of each cluster, the real backgrounds do not move, their pixel clusters move along with the camera motion , thus their residuals are low. The dynamic clusters which move along with the dynamic objects should contain high residuals since their motions don’t coincide with the camera motion . Therefore, the dynamic clusters can be extracted by setting the thresholds for high and low residuals. However, in the real cases, the intensity and depth residuals are not good metrics, the reasons are:
-
•
The depth and intensity images are obtained from different lens, they cannot be registered perfectly since the time delay.
-
•
The depth measurement is discrete on the boundary regions, which results in wrong alignment.
-
•
The depth measurement errors grow along with the range.
To deal with these problems, we want to find a concept that directly indicate the pixel or point clouds’ dynamic level. The Scene flow method is to estimate the moving 3D points, but it cannot be obtained directly (e.g., in JF, the scene flows were obtained after several VO estimation iterations). On the other hand, optical flows which can be easily obtained from image pairs are often applied to describe the moving objects captured by static cameras. Therefore, to get rid of the camera ego-motions, inspired by [14], we involve the concept of optical flow residual, which is defined as projected 2D scene flow, to highlight the pixel’s dynamic property.
Specifically, to estimate the optical flow between time and :
| (7) |
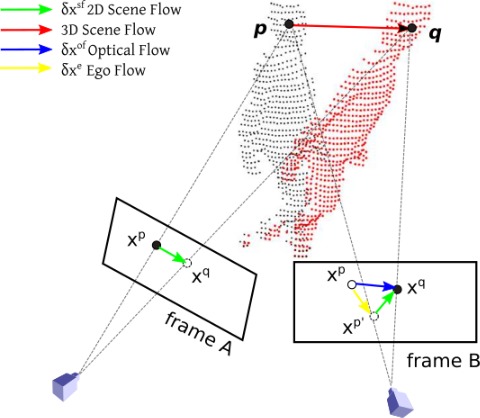
See Figure 2, is an pixel of an object point in frame A and is the same object point seen in frame B. The red arrow indicates the scene flow, which is a 3D motion in world space. The blue arrows are the optical flows , the green arrows are the projected 2D scene flows on image planes, the yellow vectors are the camera ego-motion flows .
The optical flows are defined as the pixel motions on the image coordinates, as shown in Figure 3 (b), in which, the colors indicate flow direction and the intensity indicate the pixel displacement. In the real scene of (a), the robot was moving leftwards and the human was moving rightwards. Thus the blue flows were resulted from camera ego-motion. We define such kind of flow as the camera ego flow , which means the observed optical flow was purely resulted from camera motion (without moving objects). If we subtract the ego flows from the optical flows, the scene flow components on the image plane can be obtained, as shown in (c) and (d).
For one 2D pixel of frame , given the camera motion , the camera ego-motion flow can be computed as:
| (8) |
The projected scene flow on the image plane can be computed as:
| (9) |
For the static pixels, Equation 9 is close to zero, since its optical flow comes from the camera motions. For the dynamic pixels, the 2D scene flows are non-zero, and their absolute values grow along with the moving speed. Therefore, we define the flow residual as its corresponding . As the dense optical flow computation is time-consuming, instead of using Equation 7, we apply a GPU speed-up dense optical flow estimation method PWC-net [15].
III-C Dynamic Clusters Segmentation
By now, we have projected the frame using the VO , we have defined three residuals, and , relative to the intensity, depth and optical flow, respectively. We proposed to distinguish a cluster is static or not according to its average residuals. This will be done in two procedures. Firstly, we compute a metric to combine these three residuals, secondly, we compose a minimizing function to qualify the dynamic level of clusters.
To combine the residuals, an average residual of the cluster is defined as:
| (10) |
in which is cluster size, is the cluster’s average depth, and control the flow and intensity weights. For each cluster, we compute its dynamic level means cluster is definitely belong to static segments.
Then we formulate the energy function of clusters b:
| (11) |
in which, stands for the relationship between and the threshold. Let’s set top and bottom average residuals as , then,
| (12) |
respect to the assignment function:
| (13) |
To increase the contribution of high residual parts, the weight is defined as:
| (14) |
Refer to SF [8], to enhance the connectivity of adjacent clusters and push the similar clusters to the same dynamic/static segments, we form :
| (15) |
with the supervoxel adjacency graph: . if , otherwise .
As is convex, since it is designed with all squared items. Thus the Equation 11 could be solved respect to b. Once obtaining b, we then modify the Equation 1 to considering the dynamic-static segmentation:
| (16) |
in which, is the dynamic score of cluster which contains the pixel . is the size of static pixels. We can solve this Equation 16 with the solved b using the iteratively re-weighted least-square solver provided by [18, 17].

| TUM | 0.022 | |
| TUM | 0.9 | |
| TUM | Max Iteration | 8 |
| HRPSlam | 0.018 | |
| HRPSlam | 0.88 | |
| HRPSlam | Max Iteration | 8 |
IV Dynamic SLAM Experiments and Evaluations

To evaluate the proposed FlowFusion dynamic segmentation and dense reconstruction approach, we compare the VO and mapping results of FF to state-of-the-art dynamic SLAM methods SF, JF and PF in the public TUM [19] and HRPSlam [20] datasets. The former provides widely accepted SLAM evaluation metrics: Absolute Trajectory Error (ATE) and Relative Pose Error (RPE).
| Sequence | JF | SF | FF | PF |
| fr1/xyz | 0.051 | 0.017 | 0.020 | 0.020 |
| fr1/desk2 | 0.15 | 0.051 | 0.034 | 0.023 |
| fr3/walk_xyz | 0.51 | 0.21 | 0.12 | 0.041 |
| fr3/walking_static | 0.35 | 0.037 | 0.028 | 0.072 |
| HRPSlam2.1 | 0.51 | 0.25 | 0.23 | 0.21 |
| HRPSlam2.4 | 0.32 | 0.44 | 0.49 | 0.47 |
| HRPSlam2.6 | 0.21 | 0.18 | 0.11 | 0.15 |
| Sequence | JF | SF | FF | PF |
| fr1/xyz | 0.021 | 0.012 | 0.023 | 0.019 |
| fr1/desk2 | 0.084 | 0.041 | 0.038 | 0.031 |
| fr3/walk_xyz | 0.68 | 0.29 | 0.21 | 0.13 |
| fr3/walking_static | 0.18 | 0.097 | 0.030 | 0.072 |
| HRPSlam2.1 | 0.35 | 0.32 | 0.28 | 0.31 |
| HRPSlam2.4 | 0.31 | 0.63 | 0.59 | 0.41 |
| HRPSlam2.6 | 0.12 | 0.11 | 0.060 | 0.10 |
To compute the ATE of one trajectory, firstly align it to the ground truth using the least-square method, and then directly compares the distances between the estimated positions and the ground truth at the same timestamps. The RPE is the relative pose error at timestamp over a time interval. Our experiments are implemented on a desktop that has Intel Xeon(R) CPU E5-1620 v4 @ 3.50 GHz 8, 64 GiB System memory and dual GeForce GTX 1080 Ti GPUs. The experimental setting of FF is given in Tab.I. We set the image pyramid levels as 4, each level at max 2 iterations, thus, the total iteration times limitation is 8. For the comparison experiments, we adopt their default parameters.
We first evaluate the proposed dynamic segmentation method on TUM RGB-D dynamic sequence fr3/walking_xyz, which contains 827 RGB-D images, including two moving humans and slightly object motions (e.g., the chairs are slightly moved by the people). See Figure 4, which indicates the dynamic segmentation performances of JF, SF, PF and FF. The first row is input RGB frames, the other rows are the dynamic/static segments of each method, the last column shows the background reconstruction results(except JF, since their open source version didn’t provide reconstruction function). See Tab.II and Tab.III for the comparison results. In which, in the static sequences and , the VO performances of these four methods are similar, because SF, PF and FF are all basing on EF framework. EF is dedicated to static(or slightly dynamic) local areas reconstruction, thus in static sequences, these three methods are all converge to EF’s performance.
In the highly dynamic sequences, these four methods show different pros and cons. Our previous work PF achieves very small errors in the scenes which only contain human objects. Depending on the deep learning based detection method, PF detect both dynamic and static human objects with clear segment boundaries(see the fourth row in Fig.4). However, the drawback is that PF always tends to segments the PCDs attached to the humans into foreground segments, see the wrong segmentation on table and chairs areas close to the humans objects. Furthermore, as PF’s object detection front-end OpenPose [21] doesn’t work well if the input image has no head, PF dropped its performances in HRPSlam sequences(Because in HRPSlam datasets, the camera was mounted on a 151 cm high humanoid robot, who cannot smooth inspect human faces). JF and SF detect the moving objects by jointly minimize the intensity and depth energy function, but these energy functions lack of items with dynamic property, which leads to wrong dynamic/static segmentation in the 2nd and 3rd rows of Fig.4. As the proposed FF involved the optical flow residuals which greatly indicate the pixel’s moving status, FF achieved dynamic object extraction in frame 4 and 606 and reduced the wrong static background segmentation as shown in frame 184, 506 and 606.
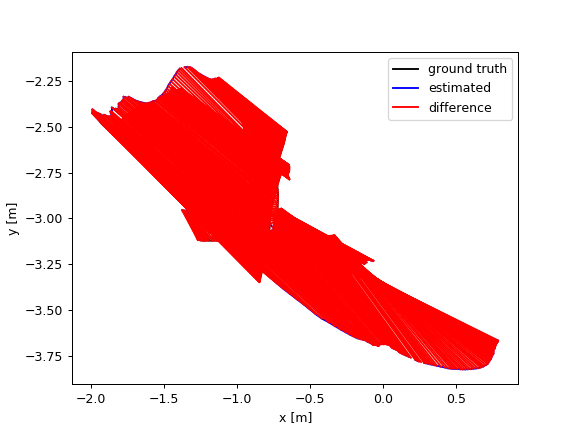
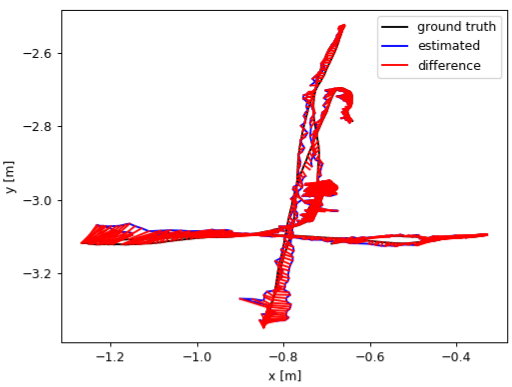
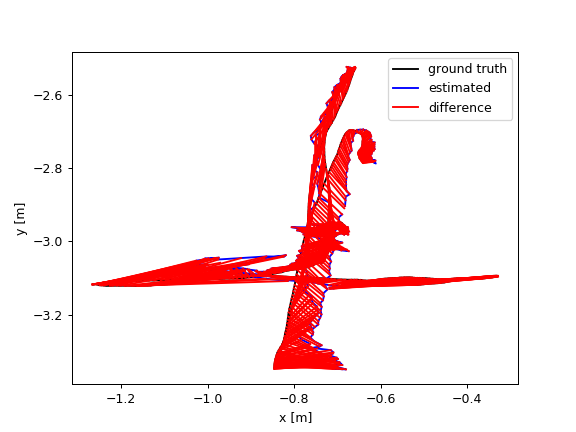
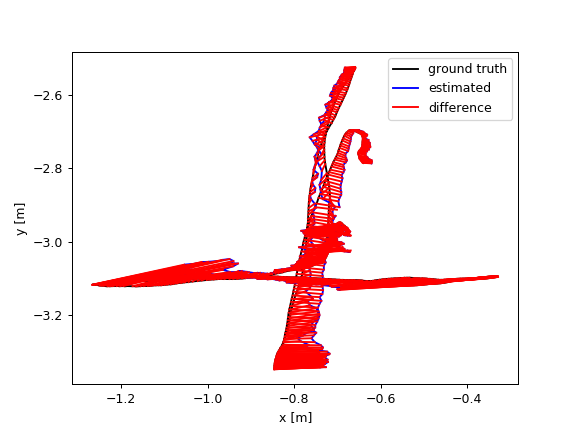
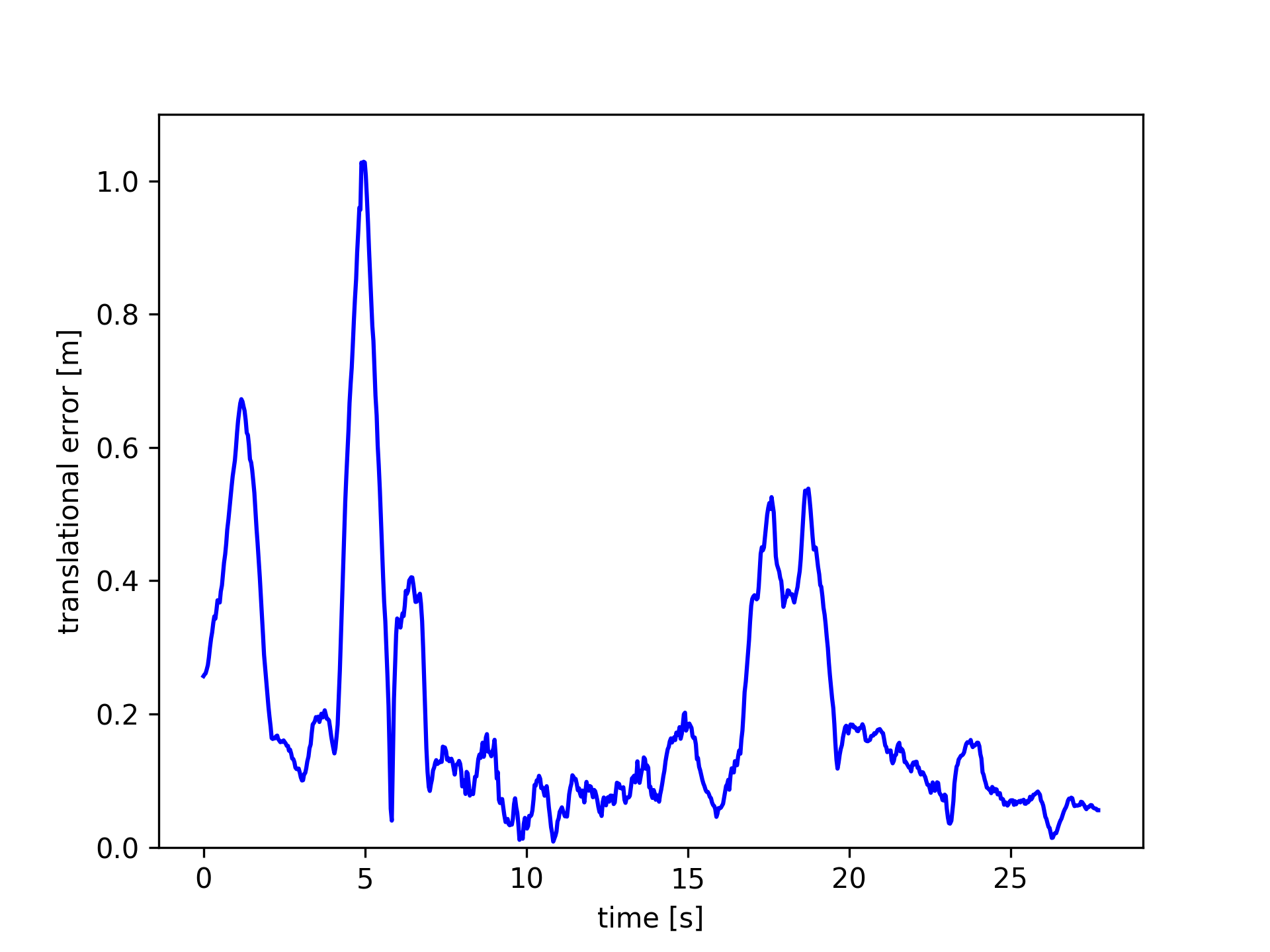
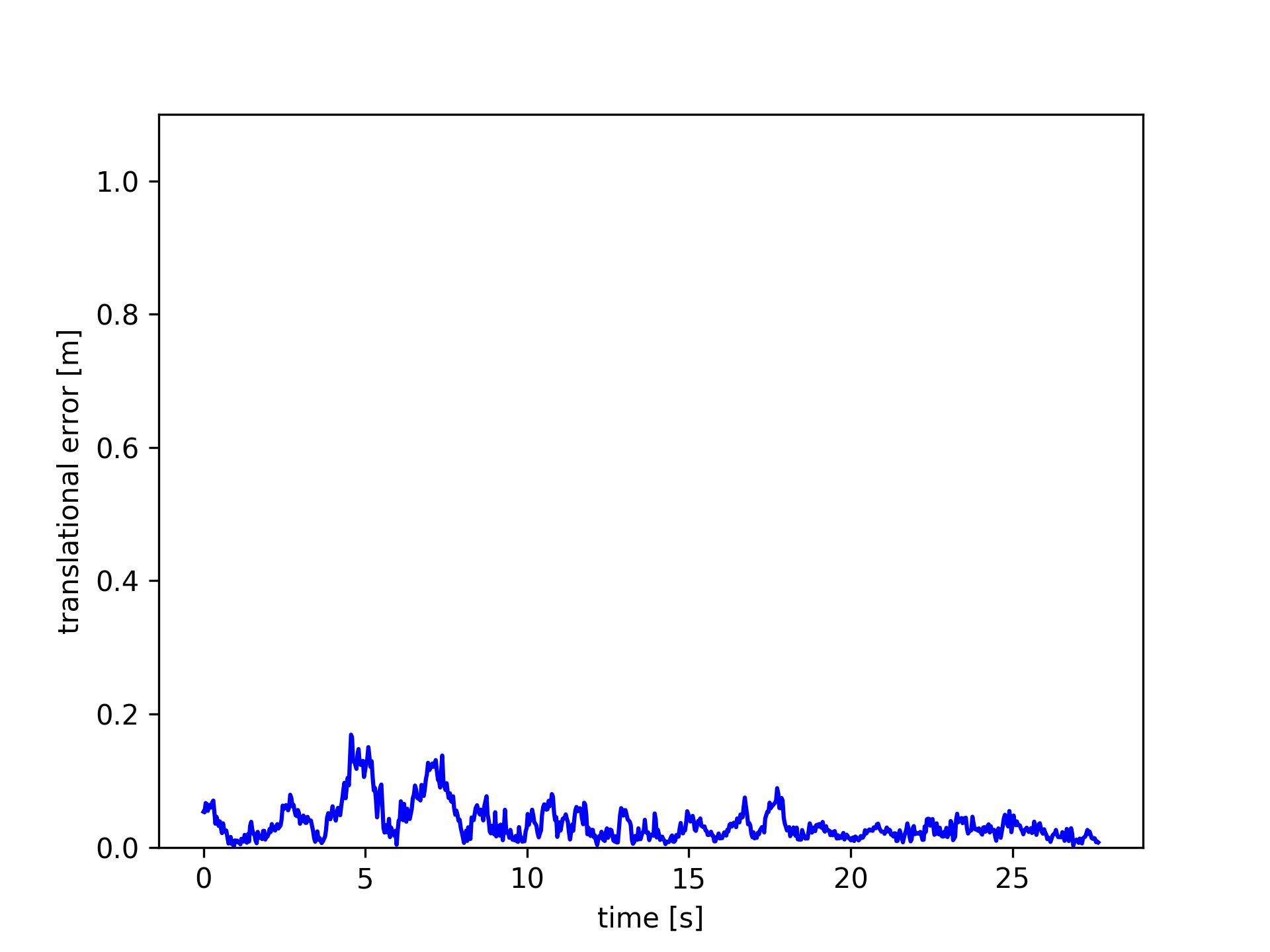
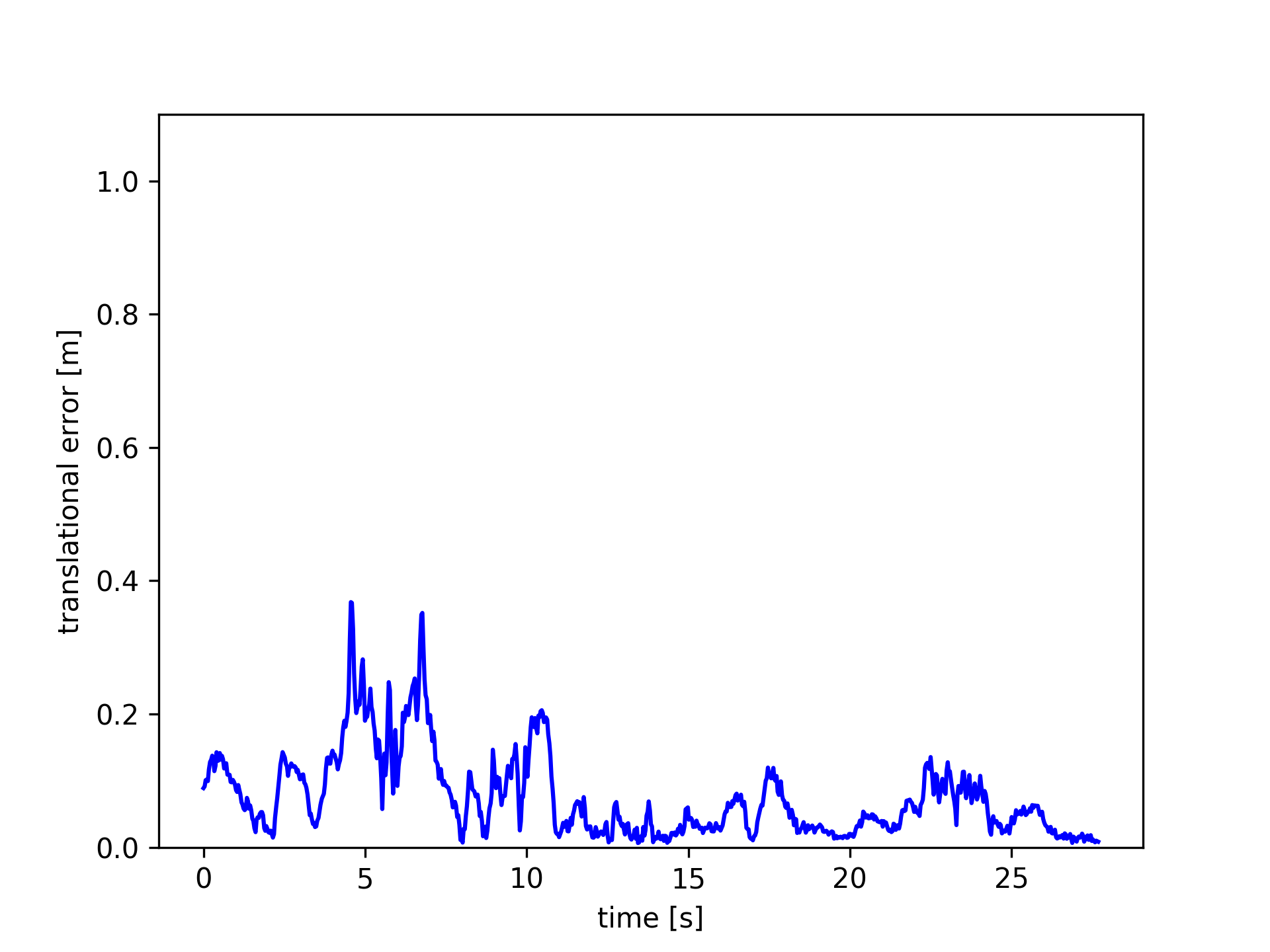
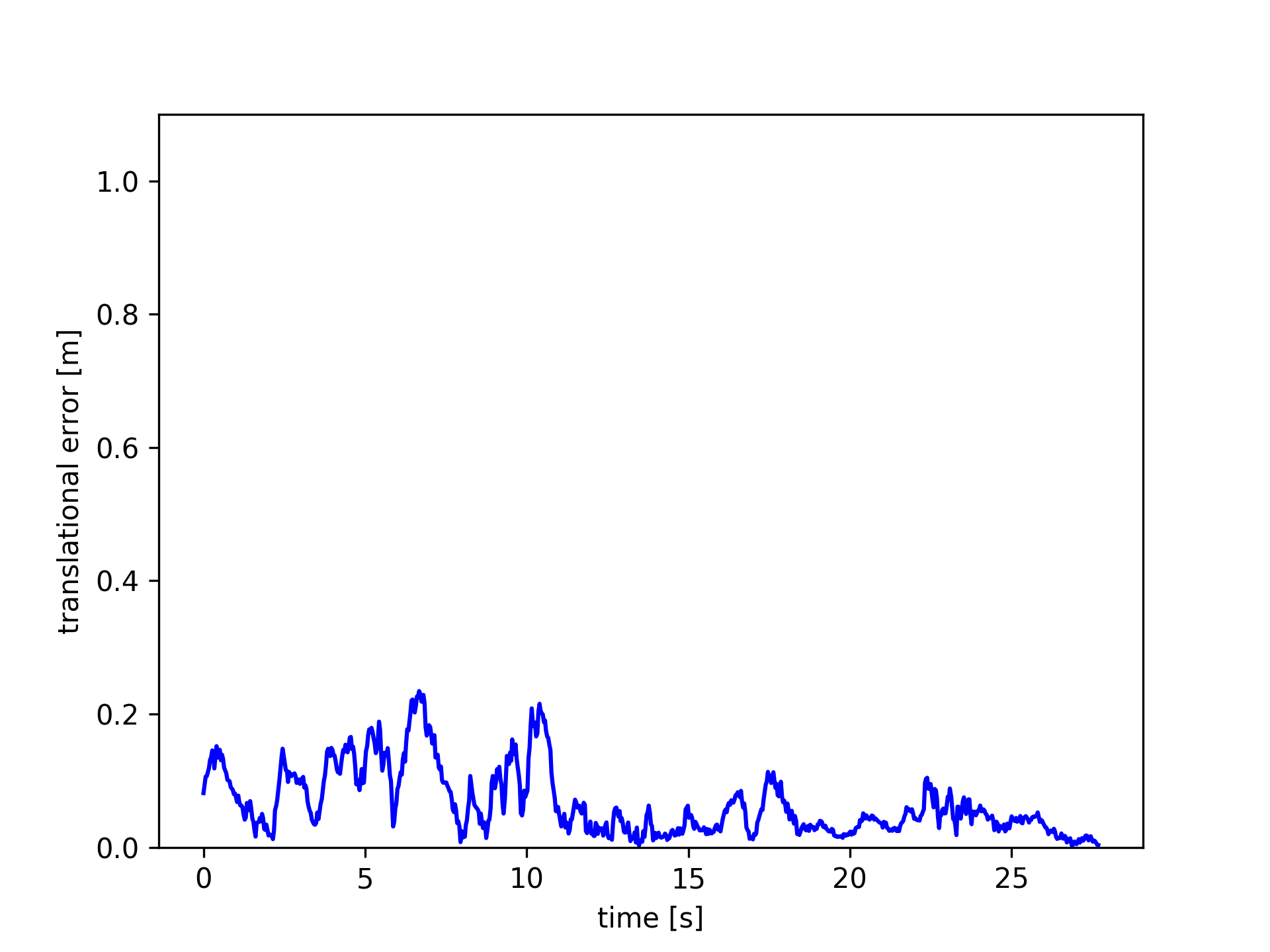
Images in Fig.5 plot the ATE and RPE of the fr3/walking_xyz sequence. In which, PF achieved the smallest trajectory errors. Amongst the module-free dynamic SLAM methods, the proposed FF outperforms the others. PF achieved very small trajectory errors, root-mean-square-error (rmse) 4.1 cm, while FF gets 12 cm.
These results indicate that the proposed optical flow residuals based static/dynamic semantic segmentation method achieved efficient dynamic foreground PCDs extraction performances in RGB-D benchmarks. Similar to PF, FF performs as similar as EF in the static scenes. The advantage of FF is not relying on object modules. FF can extract different kinds of moving objects, while PF can only detect human objects. The disadvantage of FF (same to the other model-free methods, e.g., SF, JF) is non-sensitive to slight motions, neither very fast motions, such as robot falling down. As shown in Figure 6, since very fast motions usually result in wrong optical flow estimations.
V Conclusions
In this paper, we provided a novel dense RGB-D SLAM algorithm that jointly figures out the dynamic segments and reconstructs the static environments. The newly provided dynamic segmentation and dense fusion formulation applied the advanced dense optical flow estimator, which enhanced the dynamic segmentation performance in both accuracy and efficiency. The demonstrations on both online datasets and real robotics application scenes showed competitive performances in both static and dynamic environments.
Acknowledgements
This work was supported by JSPS Grants-in-Aid for Scientific Research (A) 17H06291. We thank Dr. Raluca Scona for opening source the codes of StaticFusion. The discussion with her is very helpful.
References
- [1] M. R. U. Saputra, A. Markham, and N. Trigoni, “Visual slam and structure from motion in dynamic environments: A survey,” ACM Computing Surveys (CSUR), vol. 51, no. 2, p. 37, 2018.
- [2] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, and A. Fitzgibbon, “Kinectfusion: Real-time dense surface mapping and tracking,” in Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. IEEE, 2011, pp. 127–136.
- [3] T. Whelan, R. F. Salas-Moreno, B. Glocker, A. J. Davison, and S. Leutenegger, “Elasticfusion: Real-time dense slam and light source estimation,” The International Journal of Robotics Research, vol. 35, no. 14, pp. 1697–1716, 2016.
- [4] M. Rünz and L. Agapito, “Co-fusion: Real-time segmentation, tracking and fusion of multiple objects,” arXiv preprint arXiv:1706.06629, 2017.
- [5] B. Xu, W. Li, D. Tzoumanikas, M. Bloesch, A. Davison, and S. Leutenegger, “Mid-fusion: Octree-based object-level multi-instance dynamic slam,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 5231–5237.
- [6] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollár, “Learning to refine object segments,” in European Conference on Computer Vision. Springer, 2016, pp. 75–91.
- [7] M. Jaimez, C. Kerl, J. Gonzalez-Jimenez, and D. Cremers, “Fast odometry and scene flow from rgb-d cameras based on geometric clustering,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 3992–3999.
- [8] R. Scona, M. Jaimez, Y. R. Petillot, M. Fallon, and D. Cremers, “Staticfusion: Background reconstruction for dense rgb-d slam in dynamic environments,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 1–9.
- [9] T. Zhang and Y. Nakamura, “Posefusion: Dense rgb-d slam in dynamic human environments,” in Proceedings of the 2018 International Symposium on Experimental Robotics, J. Xiao, T. Kröger, and O. Khatib, Eds. Cham: Springer International Publishing, 2020, pp. 772–780.
- [10] C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, “Ds-slam: A semantic visual slam towards dynamic environments,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1168–1174.
- [11] V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481–2495, 2017.
- [12] R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017.
- [13] J. Wulff, L. Sevilla-Lara, and M. J. Black, “Optical flow in mostly rigid scenes,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, no. 3. IEEE, 2017, p. 7.
- [14] Z. Lv, K. Kim, A. Troccoli, D. Sun, J. M. Rehg, and J. Kautz, “Learning rigidity in dynamic scenes with a moving camera for 3d motion field estimation,” arXiv preprint arXiv:1804.04259, 2018.
- [15] D. Sun, X. Yang, M.-Y. Liu, and J. Kautz, “Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8934–8943.
- [16] J. Papon, A. Abramov, M. Schoeler, and F. Worgotter, “Voxel cloud connectivity segmentation-supervoxels for point clouds,” in Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on. IEEE, 2013, pp. 2027–2034.
- [17] C. Kerl, J. Sturm, and D. Cremers, “Robust odometry estimation for rgb-d cameras,” in Robotics and Automation (ICRA), 2013 IEEE International Conference on. IEEE, 2013, pp. 3748–3754.
- [18] M. Jaimez, M. Souiai, J. Gonzalez-Jimenez, and D. Cremers, “A primal-dual framework for real-time dense rgb-d scene flow,” in Robotics and Automation (ICRA), 2015 IEEE International Conference on. IEEE, 2015, pp. 98–104.
- [19] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ International Conference on. IEEE, 2012, pp. 573–580.
- [20] T. Zhang and Y. Nakamura, “Hrpslam: A benchmark for rgb-d dynamic slam and humanoid vision,” in 2019 Third IEEE International Conference on Robotic Computing (IRC). IEEE, 2019, pp. 110–116.
- [21] Z. Cao, T. Simon, S. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in CVPR. IEEE Computer Society, 2017, pp. 1302–1310.