Flexible Two-point Selection Approach for Characteristic Function-based Parameter Estimation of Stable Laws
Abstract
Stable distribution is one of the attractive models that well describes fat-tail behaviors and scaling phenomena in various scientific fields. The approach based upon the method of moments yields a simple procedure for estimating stable law parameters with the requirement of using momental points for the characteristic function, but the selection of points is only poorly explained and has not been elaborated. We propose a new characteristic function-based approach by introducing a technique of selecting plausible points, which could bring the method of moments available for practical use. Our method outperforms other state-of-art methods that exhibit a closed-form expression of all four parameters of stable laws. Finally, the applicability of the method is illustrated by using several data of financial assets. Numerical results reveal that our approach is advantageous when modeling empirical data with stable distributions.
I Introduction
A fundamental theory of stochastic processes in various scientific fields is the generalized central limit theorem (GCLT), which points out that the sum of independent and identically distributed random variables converges only to the family of stable distribution Gnedenko1954 . There are some challenges to overcome the analytic difficulties of stable distributions since the probability density function (PDF) is not always expressed in a closed form. Numerically approximated expressions are known in symmetric cases () based on hypergeometric functions, but those in unrestricted asymmetric cases are often too complex for estimating the parameters of the stable distribution Crisanto2018 . More practically, the estimation of all parameters is the most basic and necessary process for any application, but it remains to be one of the most controversial issues when attempting to detect stable laws. Numerous approaches have been studied for the parameter estimation. The primary approaches include the approximate maximum likelihood estimation DuMouchel1973 ; BrorsenYang1990 ; Mittnik1999 ; Nolan2001 , the bayesian based method Koblents2016 , the quantile method (QM) FamaRoll1971 ; McCulloch1986 , the fractional lower order moment (FLOM) method Ma1995 ; Kuruoglu2001 , the method of log-cumulant (MLOC) Nicolas2002 ; Pastor2016 , the characteristic function-based (CF-based) method Koutrouvelis1980 ; Press1972 ; Bibalan2017 ; Krutto2016 ; Krutto2018 , and their hybrid combinations. Many of them tend to have different kinds of drawbacks, such as restrictions of parameter ranges, complex estimation algorithms, high computational costs, requirements of larger datasets, and low accuracy. To the best of our knowledge, the FLOM, MOLC, and QM and some class of the CF-based methods Press1972 ; Bibalan2017 ; Krutto2016 ; Krutto2018 provide closed-form estimators of stable laws.
The CF-based method is perhaps the largest classification group, including a variety of methods and approaches developed under different techniques. In particluar, Press (1972) Press1972 presents the method of moments, which offers a simple approach to estimate all four parameters of stable distribution using the characteristic function (CF) evaluated at four arbitrary points. The biggest advantage of this method is that it is likely to have less drawbacks compared to other primary methods, but it carries a fundamental problem. Without appropriate points given, the performance is poor, and unfortunately Press leaves unsolved the crucial idea about the choice of points at which the CF should be evaluated. The selection of the points has long been an open question, although several studies have made an effort to improve the method of moments by reducing the use of points from four to two and discussing their choice. Krutto (2016, 2018) provides some guidance on how the two positive points should be chosen through empirical searches relying on the cumulant function Krutto2016 ; Krutto2018 . Bibalan et al. (2017) focus on the absolute value of the CF and suggest an algorithmic approach where a positive point is fixed for each scaling parameter Bibalan2017 . They show accurate estimates within certain parameter ranges, but their method fails to support a wider range of parameter spaces. Thus, these approaches are not comprehensive, so that the method of detecting more appropriate points related to the CF is required for practical uses.
In this paper, we propose an effective and practical method for estimating stable laws. We greatly improve the method of moments by introducing a new technique for the selection of two positive points at which the CF is evaluated. The technique is developed over the extension of both algorithmic and empirical search approaches. The idea of empirical search plays a role in determining the scaling related estimates, which take crucial responsibility for indicating statistical values derived in the estimation process, whereas the concept of the algorithmic approach yields various ideas of inferences based on the absolute value of the CF. Our approach realizes the possibility of choosing different values of points depending on the index parameter , which is a new perspective. We assess and compare the performance of our method to those of other methods in terms of the Mean Squared Error (MSE) criterion and the Kolmogorov-Smirnov (KS) distance. Our proposed method generally outperforms all the other state-of-art methods that exhibit closed-form expressions for all four parameters of stable laws. It is practically straightforward and assures that there is no restriction of parameter ranges, except for due to the discontinuous form of the one-parameterization CF. Finally, we apply our method to price fluctuation behaviors of several financial assets to examine the appropriateness for practical uses.
This paper is organized as follows. Section 2 shows preliminaries on stable distribution and its basic properties. We follow in the next section to describe the existing methods for estimating the parameters of stable laws. In section 4 we propose a new technique of the CF-based parameter estimation method. The arguments for the selection of points at which the CF should be evaluated are discussed. In section 5 we report the performance with the comparison to other representative methods and present that our method provides accurate estimates of stable distribution. The last section shows application to financial data and confirms that our method is applicable for empirical studies.
II Stable Distribution
In this section, we summarize the basis and properties of the stable distribution. We explain the definition of the stable distribution and its properties.
II.1 Basis of stable distribution
Stable distribution, also known as -stable distribution, or Lévy’s stable distribution, was first introduced by Paul Lévy (1937) PaulLevy1937 , which is a family of parametric distribution with tails that are expressed as power-functions. In the far tails the PDF can be written as SamoTaqqu1994a ,
and the cumulative distribution function (CDF) written as,
where is a constant value . Stable distribution is represented by four parameters; the tail index parameter representing the fatness of the tail, the skewness parameter , the scaling parameter , and the location parameter . Especially the parameters and determine the shape of distribution, including various forms of widely-known distributions such as the Gaussian and Cauchy distribution. Smaller value of indicates fatter tails and hence it is well known that the variance diverges for , and also the mean cannot be defined for . Note that if , the distribution is symmetric, if , right-tailed, and if , left-tailed.
The definition of stable distribution is that the linear combination of independent random variables that follow a stable distribution with tail index invariably becomes again a stable distribution with the same tail index . More particularly, when variables are i.i.d. copies of a random variable and are positive constant numbers, is said to be stable and follows a stable distribution if there is a positive constant number and a real number that satisfies
also known for stability property. When a variable follows a stable distribution, the notation is often used, where denotes equality in distribution SamoTaqqu1994 . Variable can be standardized according to the following property:
| (1) |
Another important property of stable distribution is the GCLT, which implies that the only possible limit distributions for sums of i.i.d random variables is a family of stable distribution. When , that is, when i.i.d. random variables have finite variance, the limit distribution then becomes a Gaussian according to the well-known classical Central Limit Theorem (CLT).
II.2 Characteristic function
The PDF of stable distribution cannot be written in a closed form except for some cases; Cauchy distribution (), Lévy distribution (), and Gaussian distribution (). Alternatively, the features are expressed by the characteristic function (CF), , which is the Fourier transform of the PDF. By taking the inverse Fourier transform of the CF, the PDF can be obtained as
When variable follows a stable distribution with , the CF is shown as
| (2) |
which corresponds to the one-parameterization form of in Nolan (2003) Nolan2018 . This is the most popular parameterization among many other forms of the stable distribution owing to the simplicity of the form. Figure 1 shows the standardized stable distributions with the one-parameterization form for different parameters of and , as an example.


One-parameterization is preferred when one is interested in the basic properties of the distribution, but the CF takes a discontinuous form at . Nolan suggests the use of the zero-parameterization form with different shown as
| (3) |
giving a more complex form, but provides a continuous form. The only difference between the parameterization is the location parameter, which they are related by
| (6) | |||
| (9) |
In this paper, we employ the simple one-parameterization, as we are interested in estimating the four parameters through the CF, and many existing estimation methods comply with that form. However, since this CF does not have a continuous form at , arguments with different parameterizations may be more appropriate for discussing distributions when we already know that is 1, for instance, the case of Cauchy distribution ().
III Parameter Estimation of Stable Laws
This section gives an overview of the methods for the parameter estimation of the stable distribution. We review two major methods, both of which are considered as an analytical approach that provides a closed-form expression of the estimates— the quantile method and the characteristic function-based method (CF-based method). Several different approaches are explained for the CF-based method.
III.1 Quantile method
McCulloch (1986) proposes the use of five sample quantiles , and as an informative measure for estimating the four parameters of stable laws, known as the quantile method (QM) McCulloch1986 . He improves the former method of Fama & Roll (1971) by eliminating bias in estimates and relaxing estimation restrictions FamaRoll1971 . The idea is to calculate the functions , where the relationships between the function values and the parameters are already studied and known beforehand. The method first sets out to estimate and by using the functions and independent of both and defined as
| (10) | ||||
| (11) |
Equation (10) refers to the measure of fat-tail behaviors with the focus on estimating , and equation (11) is a measure of skewness effects with the focus on estimating . With empirical values of sample quantiles and employing linear interpolation with tabular look-ups, the estimates are inversely obtained. To avoid being larger than 2, outside the parameter range, can be no larger than the upper range 2.439, which corresponds to the case of (note that is not identified in this case).
Next, the scale and location parameter and can be estimated using the functions defined as
| (12) | ||||
| (13) |
The function indicates the standardized form of sample sizes for the middle part of distribution. Since it does not depend on nor , the value can be informed by tabular look-ups based on and , which the relations are studied and known beforehand. After calculating in equation (12), the location parameter can be estimated from equation (13) using the values and . The relations of the parameter values and the function value are again, studied and known beforehand. In the case of , diverges and we cannot obtain the estimates for . McCulloch therefore suggests a complicated approach to overcome the discontinuity of the stable CF. The method improves other issues and provides accurate estimates, however, it has parameter restrictions and can be applied only when .
III.2 Characteristic function-based method
The CF-based method relies on the use of a consistent estimator of the CF for any fixed . The advantage of this method essentially lies in the fact that the stable CF can be expressed explicitly, making discussions straightforward compared to methods based on other distribution forms. Under the assumption that given data are ergodic ArnoldAvez , the CF is obtained empirically by the following equation,
| (14) |
There are several approaches for estimating parameters of stable laws that take advantage of the explicit form of CF. Koutrouvelis (1980) Koutrouvelis1980 proposed a regression-type approach, which employs the iteration of two regression runs. Moreover, the regression of the method requires different values of initial points depending on initial estimates of the parameters and sample sizes. The number of points necessary for the regression also varies over initial conditions. Although the accuracy of is unsatisfactory in some cases, the method generally shows accurate estimates of , and hence it is often suggested as a practical method for empirical analysis Wang2015 ; Kateregga2017 . However, some studies compare the method to McCulloch’s quantile method and report that the regression-type method does not significantly improve the classical quantile method Akgiray1989 ; Rene2011 , especially for smaller than 1. Other studies simplified the method by eliminating the iteration process and fixing the initial points to some extent, but still leaves behind the issues of estimating when is small Kogon1998 ; Borak2005 . We do not consider the regression-type approach in this paper as the method generally relies on iteration and the estimates cannot be written analytically.
Another approach is based on the method of moment Press1972 , which was later remodeled and simplified with the use of two given points of the CF Krutto2016 ; Bibalan2017 ; Krutto2018 . Starting off with the CF with the points and , taking the absolute value cancels out the effect of parameters and , and we obtain
| (15) |
Taking the cumulant function, which is the natural logarithm of the CF, leads to the same discussion neutralizing the effect of parameters and . The equation implies that the real part of the cumulant function corresponds to the natural logarithm of the absolute value of CF, shown as
| (16) |
for any value of . We consider only the positive values for convenience, since the CF is a symmetric function. By solving the above equations simultaneously, parameters and can be estimated shown as
| (17) | ||||
| (18) |
Since the one-parameterization form in equation (II.2) is discontinuous at , the estimation of the remaining parameters and is divided into two cases. When , the cumulant function of stable distributions with the points are
| (19) |
As we need the information of the parameters and , we take the imaginary part. Then the parameters and are estimated by solving the above equations simultaneously and using the estimates and :
| (20) | ||||
| (21) |
In the case of , the CF takes a discontinuous form and the cumulant functions are written as
| (22) |
Then the parameters are estimated by solving the above equations simultaneously as well:
| (23) | ||||
| (24) |
For simplicity, we express the estimates as a function of given points and as follows:
| (25) | ||||
| (26) | ||||
| (27) | ||||
| (28) |
where and additionally needs the information of the estimates and . Sometimes, the estimates can possibly outrange the parameter spaces , and , especially when the true parameters are close to the borders. In such cases, the parameters are set to the closet border, except for and , the estimates are set no lower than 0.01. Applications with other parameterizations use slightly different forms of CF, but the stable parameters are estimated essentially by the same procedure as explained above. For the zero-parameterization, which is another common parameterization form, the CF is replaced to its corresponding form shown in equations (3) and (6) for equations (15) and (19) (or (22)). For parameterization with a different definition of the scaling parameter written as Nikias1995 ; Bibalan2017 ; Liu2018 , Bibalan et al. (2017) Bibalan2017 presents an alternative procedure for the estimation. They first directly obtain the scaling parameter from taking the absolute value of the empirical CF, or the real part of the cumulant function as
| (29) |
Next is estimated as shown in equation (17). Then, the scale parameter in our criterion, , is obtained as,
| (30) |
The remaining parameters and are then estimated straightforwardly as similar to the case of the one-parameterization form. By replacing to in equations (20) and (21) (or equations (23) and (24)), and using the points and give the estimates.
IV Proposed Approach for the Characteristic Function-based Method
In this section, we make an improvement of the CF-based method by discussing how the points related to the CF should be chosen. We propose a technique that provides a flexible selection of the points. We also clarify the difference of how the points are selected between our proposal and the procedures in other existing CF-based methods.
IV.1 Argument for the inference of point
Two positive points of the CF, and , are ought to be selected to identify all four parameter estimates. As mentioned before in this paper, the absolute value of the CF in equation (15) is independent of the skew and location parameters for any , and provides information of and . When is satisfied, the absolute value of the CF takes a constant value
| (31) |
The advantage of setting as one of the candidate points is to reduce any estimation bias influenced by certain parameter values since we expect to get a constant estimate which is independent of all four parameters. When , however, empirically obtained values can cause significant estimation errors for the scale parameter in equation (31) Krutto2018 ; Paulson1975 . Therefore, we first consider a temporary estimate of the scaling parameter, , just in case the data exhibits scale far from the standardized form ().
Take the natural logarithm of equation (31). The temporary estimate can be obtained by approximately solving the equation that numerically satisfies
| (32) |
using a simple one-dimensional search function Brent2013 , or any other optimization procedure. Our rough estimate is then used for standardizing, or pre-standardizing, the candidate points. Specifically, point is set to , where empirically takes .
As explained above, pre-standardization is preferred especially when we suspect that datasets have too large or small scales. Whenever a new set of points is required for the parameter estimation process, we conduct pre-standardization. Point is replaced to , where is the latest scaling parameter estimate available at that time.
IV.2 Argument for the inference of point
For the argument of selecting point , which is perhaps the most important proposal in our study. We focus on the absolute value of the CF. Bibalan et al. (2017) proposed to calculate the distance between two absolute values of CFs with different index parameters , the Gaussian case () and the Cauchy case () Bibalan2017 . They set to the point which corresponds to the maximum distance and the other point to . Although the absolute CF changes depending on the index parameter , their approach considers a fixed distance and essentially chooses an identical point for any value of . In addition, the distance they consider does not account for the case of .
Our approach is an extension of Bibalan et al. (2017), and provides a more generalized technique of selecting the points. We deal with the problem that the distance between two absolute values of CFs can vary depending on the parameters. The basic idea is to find the point where the absolute CF, , presents the maximum sensitivity with respect to . In other words, we discuss the point where the distance between the absolute CF of index parameter , , and the absolute CF of , , shows the largest distance. Such a point is considered as in our study.
To make our discussion more simple, we consider the absolute CF as a function of variable :
where is a newly introduced variable which depends on and . The distance can be expressed as . The candidate point for , where the maximum distance is achieved, can be calculated by
| (33) |
Solving this equation for yields two solutions, and . For both points, the absolute value of CF shows the largest ratio of change in a local sense. The smaller point is employed, because the distance at the smaller point tends to have larger values than that at the larger point , which enables us to estimate and in a more desirable and informative manner. Another reason is that smaller is preferred rather than larger . As , the asymptotic variance of the empirical cumulant function decreases Krutto2018 . With empirical CF obtained by i.i.d. distributed datasets, the relation
| (34) |
holds Kakinaka2020 , which implies that as becomes larger, the empirical absolute CF is likely to be subject to sample errors. Thus, the smaller should be considered in this study.
The above discussion implies that should be set close to zero (but not at zero because then the CF takes a constant value and no information of the parameters will be provided). But at the same time, the employed smaller point is standapart from zero to some extent, so that the empirical CF will be more or less exposed by sample errors. Therefore, the choice of points derived from equation (33) is unsatisfactory, and hence the distance should be modified. To reduce the effect of sample errors, we introduce a weight function that decreases monotonically as becomes larger (note that the introduced variable has a linear relationship with ).
Using the weight function , we now introduce a weighted distance for . For convenience, we employ , where , since the CF exhibits an exponential form. This choice leads to the association of the weighted distance with a statistical measure used for goodness-of-fit tests, developed by Matsui and Takemura (2008) Matsui2008 . They propose the following test statistic based on empirical CFs,
| (35) |
where is a monotonically decreasing weight function. denotes the weighted -distance between the empirical CF and the symmetric standardized stable CF . This weighted -distance can be associated with the weighted distance we are considering now.
Taking the absolute value of a CF yields again a standardized form of a CF with and :
Thus, the absolute values of CF with index parameter and are equivalent to the symmetric standardized stable CFs, and , respectively. The weighted -distance between these CFs essentially coincides , when the weight function satisfies
for . In this case, the difference between the CFs can be evaluated more accurately with the background of a meaningful measurement. Following Matsui and Takemura (2008), the asymptotic distribution of is numerically evaluated and the critical values of the test statistics are approximately obtained Matsui2008 . Through computational simulation, they provide evidence that the test is most powerful when (), especially for heavy tailed distributions. Thus, our choice of the weight function is , since . Other weight functions such as and Paulson1975 ; Heathcote1977 can be employed, but lacks a conclusive evidence for the use of these alternatives.
With the weight function, the candidate points are calculated by solving the following equation:
| (36) |
where . Then we have
| (37) |
For convenience, is set to for all cases in this study. Equation indicates the relationship between the index parameter and point that exhibits the maximum rate of a change, or the maximum sensitivity, of the absolute CF with respect to .
There could exist some relationship between and since they are interrelated due to . When some estimate is given, the corresponding point is obtained by computing that satisfies , and vice versa (the corresponding parameter of a given point can be calculated by computing the equation ). As we have discussed previously in this subsection, we focus on the point closer (smaller) to zero out of the two candidates of the calculated points from equation (36). Figure 2 ascertains whether our approach of equation (36) correctly estimates the parameters of stable distribution. The model clearly characterizes the distinctive relationship between and , which are empirically verified via simulation using synthetic data generated from random stable variables Weron1996 . This indicates that our selection of points is valid for identifying desired points in the estimation process.
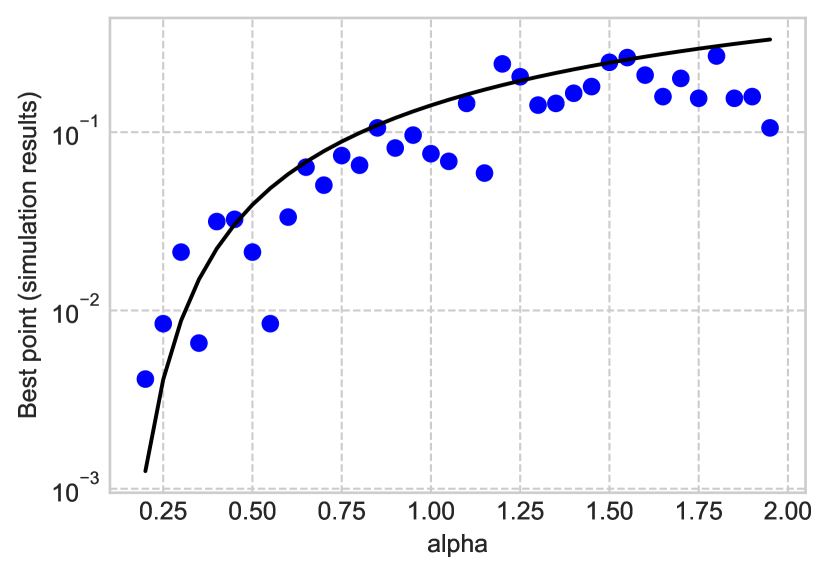
In practice, is unknown. Hence the selection of point is undecidable, so that the parameters for the stable law cannot be estimated directly. To cope with this problem, we first aim to get a rough estimate of calculated by using the temporary scale estimate . The rough estimate is considered poor as the estimation method, but it plays a role in starting off the estimation process with reasonable initial values. The accuracy of both points ( and ) and the parameters () can be improved by alternating searches of and from our relation model several times to get sophisticated estimates. With estimates and , the four parameters are ultimately calculated.
IV.3 Estimation procedures
Here we present our proposed algorithm for the estimation of all four parameters of stable laws by utilizing the relationship between and . Regarding the fact that empirically obtained estimates occur substantial errors induced by , we conduct a pre-standardization with replaced to . Using the expressions of the estimates in equations (25) (26) (27) (28), our algorithm is written as follows:
-
Step 1:
Compute a temporary estimate from sample data that satisfies the equation,
-
Step 2:
Set
where is any initial value of .
- Step 3:
-
Step 4:
Compute that satisfies , where is given in equation (IV.2).
-
Step 5:
Recalculate the points associated with ,
-
Step 6:
Estimate and as
-
Step 7:
Compute that satisfies
-
Step 8:
Recalculate the points associated with ,
-
Step 9:
Finally, we estimate the parameters and as
- Step 10:
V Numerical Assessments
In this section, we show numerical assessments for the estimation of stable laws. We compare the performances of our proposal approach to other state-of-art approaches using the MSE and the KS-distance. The comparison is studied for three approaches. We focus on the approaches of characteristic function-based methods presented by Bibalan et al. (2017) Bibalan2017 and Krutto (2018) Krutto2018 . We also compare with the traditional QM method McCulloch1986 ; FamaRoll1971 explained in subsection 3.1, to provide a benchmark with a well-known criterion. Note that all three approaches above exhibit closed-form expressions for all four estimates of stable parameters.
Bibalan et al. (2017) have shown that their approach generally outperforms other methods that yield a closed-form expression, such as the FLOM, the QM, and the MOLC Bibalan2017 . Krutto (2018) also compares the performances with several well-known methods and concludes that the method gives accurate estimates Krutto2018 . Since both of them belong to the family of the CF-based method, the selection of the points and plays an important role. In Bibalan et al. (2017), is set to 1. Point is always set to where the point shows the maximum distance between the absolute Gaussian CF and the absolute Cauchy CF, by using the estimates of which they are calculated beforehand. It should be mentioned that the CF in this case poses a alternative definition of the scaling parameter, so we eventually obtain in the last procedure in equation (30). On the other hand, Krutto (2018) suggests to employ two points that satisfies
under empirical searches Krutto2018 . We examine the performance for each parameter of stable distribution in addition to the fit with the entire estimated stable distribution. We also refer to the effects of sample sizes for each estimation method. For all the simulations in this paper, we generate synthetic data of i.i.d. random stable samples. Synthetic random data sequences following a stable distribution can be generated by algorithms constructed by Chambers et al. (1976) Chambers1976 , Weron (1996) Weron1996 , and Umeno (1998) Umeno1998 . Umeno (1998) generates random stable variables based on the superposition of chaotic processes. The classical method of Chambers et al. (1976) is widely known as the pioneer of all the methods, which the algorithm was reorganized and corrected later by Weron (1996). Weron’s algorithm is our choice of method, which is simple and is the fastest in calculation.
V.1 Performance of parameter estimates
The performance of the estimated parameters are examined by the MSE criterion:
where and is the parameter of stable laws and the number of times the simulation is implemented, respectively. We calculate the MSE of all four parameters and evaluate each parameter individually.
Table 1 shows the simulation results of the MSE associated with the estimate bias for each parameter. We consider the cases of parameters with and , all with a standardized form of and . Our proposed approach generally provides the most accurate estimation with the smallest MSE. Especially for the index parameter and , our approach significantly improves the accuracy of the estimates. Note that for the QM, the method has parameter restrictions of and hence the cases with smaller than 0.6 can not be implemented. More detailed simulation results for different cases of parameters are shown in Figures 5, 6, 7 in Appendix A. In particular, we show the cases of and , with parameter values varying within the parameter ranges. The results imply that for whatever parameter combination, our method generally outperforms the others with the highest accuracy. Although we find that other methods sometimes show higher accuracy on either the parameter or in cases of in in Figure 5 and for in Figure 6, our method appears to be powerful for estimating all four stable parameters.
| 0.5 | 1.5 | 1.8 | ||||||
| () | 0 | 0.5 | 0 | 0.5 | 0 | 0.5 | ||
| proposed | MSE | 0.859 | 0.767 | 3.353 | 2.881 | 2.128 | 2.100 | |
| bias | (1.047) | (5.376) | (9.776) | (4.193) | (1.567) | (2.140) | ||
| Bibalan et al. | 5.252 | 4.803 | 4.015 | 3.757 | 2.346 | 2.234 | ||
| (8.435) | (4.880) | (2.793) | (16.51) | (2.994) | (1.710) | |||
| Krutto | 1.387 | 1.429 | 4.958 | 4.604 | 2.816 | 2.728 | ||
| (13.48) | (2.535) | (18.95) | (4.333) | (0.231) | (3.642) | |||
| QM | — | — | 3.915 | 5.306 | 9.282 | 8.857 | ||
| (—) | (—) | (4.732) | (16.75) | (16.63) | (16.97) | |||
| proposed | MSE | 6.867 | 7.522 | 11.54 | 11.55 | 40.68 | 48.78 | |
| bias | (13.78) | (3.230) | (0.629) | (12.33) | (24.90) | (16.48) | ||
| Bibalan et al. | 20.95 | 20.64 | 15.09 | 16.61 | 47.62 | 56.67 | ||
| (19.32) | (5.274) | (17.51) | (4.882) | (36.72) | (19.40) | |||
| Krutto | 11.66 | 12.64 | 15.71 | 15.18 | 37.05 | 42.97 | ||
| (0.736) | (3.166) | (9.488) | (3.711) | (7.387) | (29.83) | |||
| QM | — | — | 11.59 | 13.01 | 61.39 | 162.3 | ||
| (—) | (—) | (6.575) | (64.02) | (3.764) | (373.2) | |||
| proposed | MSE | 15.95 | 13.20 | 1.444 | 1.396 | 0.842 | 0.857 | |
| bias | (14.74) | (20.28) | (5.552) | (3.004) | (0.748) | (9.113) | ||
| Bibalan et al. | 13.66 | 13.29 | 1.450 | 1.386 | 0.845 | 0.854 | ||
| (24.70) | (44.02) | (5.306) | (3.741) | (0.984) | (9.016) | |||
| Krutto | 31.33 | 32.42 | 1.910 | 1.841 | 0.895 | 0.938 | ||
| (48.27) | (25.64) | (13.73) | (4.923) | (1.007) | (9.917) | |||
| QM | — | — | 1.613 | 1.989 | 1.483 | 1.518 | ||
| (—) | (—) | (11.55) | (27.58) | (9.162) | (20.74) | |||
| proposed | MSE | 10.80 | 14.25 | 8.401 | 10.27 | 3.147 | 3.428 | |
| bias | (11.90) | (33.02) | (10.70) | (1.020) | (0.243) | (2.800) | ||
| Bibalan et al. | 30.86 | 35.41 | 10.72 | 13.43 | 3.497 | 3.965 | ||
| (15.92) | (20.27) | (26.94) | (8.638) | (3.954) | (3.118) | |||
| Krutto | 61.87 | 88.23 | 9.796 | 12.00 | 3.151 | 3.275 | ||
| (23.49) | (56.67) | (4.332) | (10.58) | (2.116) | (4.712) | |||
| QM | — | — | 9.394 | 11.68 | 3.710 | 3.815 | ||
| (—) | (—) | (14.87) | (46.61) | (1.920) | (32.97) | |||
V.2 Performance of the estimated distribution
Next, we examine the performance of estimating stable laws from a different perspective; evaluation of the entire distribution. We use the KS distance expressed as
which represents the maximum distance between two distributions in terms of the CDF. Here and denotes the empirically obtained CDF, and the theoretical estimated CDF, respectively. The standard density and distribution functions of stable distributions are numerically derived approximately by implementing the Fourier integral formulas Zolotarev1986 ; Nolan1997 , which are available in package libstable that provides good approximation values Roy2017 . KS distance is one of the most major standards for numerical assessments when discussing stable laws. We set aside any issues related to numerical approximations of stable distributions, so that we can focus on the performance between the methods. The root mean square (RMS) of the KS distance is used for the numerical assessment to make the small differences of the comparison results more apparent.








| Mean | SD | Skew | Kurt | Min | Max | N | |
|---|---|---|---|---|---|---|---|
| USDJPY | 1.027 | 0.0062 | -0.0531 | 4.7880 | -0.0384 | 0.0550 | 4190 |
| WTI | -7.312 | 0.0041 | 0.5900 | 23.945 | -0.0576 | 0.1068 | 54356 |
Figure 3 shows the simulation results of the KS distance for several cases of stable distributions; , , , and . The RMS of the KS distance is calculated for each case with various values of parameters ranging within parameter ranges. We find in Figure 3 (c) that the estimation for the scaling parameter poses significant estimation errors. This is caused by the effect of sample errors induced by the scaling parameter far from the standardized form, as shown in equation (31). On the other hand, our proposed method achieves the smallest value of KS distances for all cases of parameter combinations. This proves that we are also successful in improving the estimation of the entire stable distribution.
V.3 Effect of sample size
Needless to say, the accuracy of the estimation method strongly depends on the number of samples. Larger sample sizes give more information of the dataset whereas smaller sample sizes have only little information making it challenging to detect the true values. We examine the effect of sample size by comparing the performance among the estimation methods. Figure 4 displays the MSE of each parameter of stable distribution as the sample size changes from 300 to 10000. The study is examined for the case of . The MSE simulated by means of our method decreases with the order while the MSE simulated by means of other representative methods also exhibited similar behaviors of order. Our proposed approach offers the best performance except for the location parameter , where the QM method sometimes give more accurate estimates for large datasets.
VI Application to Financial Empirical Data
This section shows application of the proposed estimation method to real financial data. We provide several empirical studies to present that our proposed approach is appliable for a wide range of empirical analysis in finance.
| method | KS | ||||
|---|---|---|---|---|---|
| proposed | 1.708 | -0.121 | 0.0035 | -0.00004 | 0.0214 |
| Bibalan et al. | 1.884 | -0.261 | 0.0039 | -0.00002 | 0.0396 |
| Krutto | 1.767 | -0.138 | 0.0036 | -0.00004 | 0.0279 |
| QM | 1.584 | -0.064 | 0.0034 | -0.00012 | 0.0216 |
| method | KS | ||||
|---|---|---|---|---|---|
| proposed | 1.357 | -0.045 | 0.0015 | -0.00007 | 0.018 |
| Bibalan et al. | 1.846 | -0.012 | 0.0024 | -0.00002 | 0.088 |
| Krutto | 1.487 | -0.071 | 0.0017 | -0.00007 | 0.036 |
| QM | 1.260 | -0.031 | 0.0015 | -0.00009 | 0.019 |
Asset price returns in various financial markets tend to show interesting properties of stable laws ever since Mandelbrot (1963) first revealed that stable distribution fits cotton price returns better than the classical Gaussian distribution Mandelbrot1963 . This argument have attracted attention to identifying price behaviors in many financial fields such as equities Fama1965 ; MantegnaStanley1995 ; Xu2011 , price consumer index inflation Chronis2016 , metal markets Krezolek2012 , oil markets Yuan2014 , and Cryptocurrency markets Kakinaka2020 . We investigate return distributions of the Japanese Yen currency exchange rate in terms of the US dollar (USDJPY) and the West Texas Intermediate (WTI) crude oil futures market, both of which are potent indices in finance. The basic statistics of the indices are provided in Table 2. We explore both cases of common daily analysis and high-frequency data analysis. In particular, we use daily and one-hour return time series for the USDJPY and the WTI market, respectively. Since the scale of returns for both cases are too small for the method based on Bibalan et al. (2017) to give plausible estimates, we do a pre-standardization process beforehand. We multiply returns by 100 and after the estimation the parameters and are adjusted by dividing them by 100. Table 3 presents the estimates of the fitted stable distribution associated with the KS-distance between the empirical distribution and the estimated stable distribution for USDJPY, calculated based on four controversial estimation methods. Our primary focus is on the KS-distance value. The results show that the estimated distribution based on our proposed method presents the smallest value among other estimation methods. The smallest KS-distance implies that our method exhibits stable laws that best describes the observed data. Parameter estimates and the distance measure for the WTI market are shown in Table 4. The result indicates that the outstanding performance of our method also holds for high-frequency data with the lowest KS-distance. What makes the development of the estimation method a crucial matter is that the parameter estimates can differ so much among the methods when applied to empirically observed data, even for large datasets. We find in Table 4 that the estimate of marks a low 1.260 based on the QM method whereas Bibalan et al.’s method presents 1.846, which the value differs quite a lot between the methods in spite of the large sample size of dataset with . A method that accomplishes the inference of the closest distribution or set of parameters provides a more reliable model. Hence, our proposed estimation approach play a significant role as a tool for modeling with stable laws.
VII Conclusion
This paper has proposed a new approach for estimating stable laws and applied this approach to the exploration of price behaviors in financial markets. Our new technique is developed under the method of moments, which is one of the widely known CF-based methods that require the choice of appropriate momental points. The points necessary for the estimation process are flexibly chosen, as the estimation accuracy of stable laws depends heavily on their true parameter values. We have focused on the fact that the index parameter and the desired momental points exhibit a distinctive relationship, which is a new perspective in the literature. This relation is modelled as , based on the idea of employing points at which the weighted absolute values of the CF present the maximum sensitivity. To detect appropriate points, we have suggested a procedure relying on the combination of empirical searches and algorithmic approaches. The advantage of employing these points is that the parameters of stable laws can be estimated in a more precise manner while remaining straightforwardly the implementation of the method. The relative performance of the parameter estimates is benchmarked against other existing methods, specifically the QM and the methods of Bibalan et al. (2017) and Krutto (2018), through simulation studies in terms of the MSE and KS-distance criteria. The results have implied that our method is the most powerful with the best performance. Our approach assures that the estimates of all four parameters of stable laws present a closed-form expression without any restrictions on parameter ranges, making the method significantly practical. We have also explored the behaviors of price fluctuations in several financial markets to show that our method is applicable for empirical financial studies. For the USD-JPY exchange rate and the WTI crude oil future price, our method supports stable laws with the highest performance among all the other methods discussed in this paper. This would motivate us to further develop analytical methods for examining stable laws, as well as to further investigate various features of financial markets.
Appendix A Figures of simulation results
We show in this section some of the additional simulation results examined for checking the performance of the parameter estimates. Each of the four parameters of stable laws are studied for various cases of parameter combinations. The results imply that for most cases, our proposed approach based method leads to improve the accuracy of the estimates. We find that the state of performance is also consistent with all four parameters, outperforming the other existing methods.












References
- (1) Gnedenko, B. V., & Kolmogorov, A. N. (1954). Limit Distributions for Sums of Independent. Random Variables, Addison-Wesley.
- (2) Crisanto-Neto, J. C., da Luz, M. G. E., Raposo, E. P., & Viswanathan, G. M. (2018). An efficient series approximation for the Lévy α-stable symmetric distribution. Physics Letters A, 382(35), 2408-2413.
- (3) DuMouchel, W. H. (1973). On the asymptotic normality of the maximum-likelihood estimate when sampling from a stable distribution. The Annals of Statistics, 1(5), 948-957.
- (4) Wade Brorsen, B., & Yang, S. R. (1990). Maximum likelihood estimates of symmetric stable distribution parameters. Communications in Statistics-Simulation and Computation, 19(4), 1459-1464.
- (5) Mittnik, S., Doganoglu, T., & Chenyao, D. (1999). Maximum likelihood estimation of stable Paretian models. Mathematical and Computer Modelling, 29(10-12), 275-293.
- (6) Nolan, J. P. (2001). Maximum likelihood estimation and diagnostics for stable distributions. In Lévy processes (pp. 379-400). Birkhäuser, Boston, MA.
- (7) Koblents, E., Míguez, J., Rodríguez, M. A., & Schmidt, A. M. (2016). A nonlinear population Monte Carlo scheme for the Bayesian estimation of parameters of -stable distributions. Computational Statistics & Data Analysis, 95, 57-74.
- (8) Fama, E. F., & Roll, R. (1971). Parameter estimates for symmetric stable distributions. Journal of the American Statistical Association, 66(334), 331-338.
- (9) McCulloch, J. H. (1986). Simple consistent estimators of stable distribution parameters. Communications in Statistics-Simulation and Computation, 15(4), 1109-1136.
- (10) Ma, X., & Nikias, C. L. (1995). Parameter estimation and blind channel identification in impulsive signal environments. IEEE Transactions on Signal Processing, 43(12), 2884-2897.
- (11) Kuruoglu, E. E. (2001). Density parameter estimation of skewed -stable distributions. IEEE Transactions on signal processing, 49(10), 2192-2201.
- (12) Nicolas, J. M., & Anfinsen, S. N. (2002). Introduction to second kind statistics: Application of log-moments and log-cumulants to the analysis of radar image distributions. Trait. Signal, 19(3), 139-167.
- (13) Pastor, G., Mora-Jiménez, I., Caamaño, A. J., & Jäntti, R. (2016). Asymptotic expansions for heavy-tailed data. IEEE Signal Processing Letters, 23(4), 444-448.
- (14) Koutrouvelis, I. A. (1980). Regression-type estimation of the parameters of stable laws. Journal of the American Statistical Association, 75(372), 918-928.
- (15) Press, S. J. (1972). Estimation in univariate and multivariate stable distributions. Journal of the American Statistical Association, 67(340), 842-846.
- (16) Bibalan, M. H., Amindavar, H., & Amirmazlaghani, M. (2017). Characteristic function based parameter estimation of skewed alpha-stable distribution: An analytical approach. Signal Processing, 130, 323-336.
- (17) Krutto, A. (2016). Parameter estimation in stable law. Risks, 4(4), 43.
- (18) Krutto, A. (2018). Empirical cumulant function based parameter estimation in stable laws. Acta et Commentationes Universitatis Tartuensis de Mathematica, 22(2), 311-338.
- (19) Lévy, P. (1937). Theéorie de l’addition des variables aléatoires. Paris: Gauthier-Villars.
- (20) Samorodnitsky, G., & Taqqu, M. (1994). Non-Gaussian Stable Processes: Stochastic Models with Infinite Variance. Chapman ft Hall, London.
- (21) Samorodnitsky, G., & Taqqu, M. S. (1994). Stable Non-Gaussian Random Processes: Stochastic Models with Infinite Variance Chapman & Hall: New York.
- (22) Nolan, J. (2003). Stable distributions - models for heavy-tailed data.
- (23) Arnol’d, V. I., & Avez, A. (1968). Ergodic Problems of Classical Mechanics (NewYork: Benjamin).
- (24) Wang, X., Li, K., Gao, P., & Meng, S. (2015). Research on parameter estimation methods for alpha stable noise in a laser gyroscope’s random error. Sensors, 15(8), 18550-18564.
- (25) Kateregga, M., Mataramvura, S., & Taylor, D. (2017). Parameter estimation for stable distributions with application to commodity futures log-returns. Cogent Economics & Finance, 5(1), 1318813.
- (26) Akgiray, V., & Lamoureux, C. G. (1989). Estimation of stable-law parameters: A comparative study. Journal of Business & Economic Statistics, 7(1), 85-93.
- (27) Garcia, R., Renault, E., & Veredas, D. (2011). Estimation of stable distributions by indirect inference. Journal of Econometrics, 161(2), 325-337.
- (28) Kogon, S. M., & Williams, D. B. (1998). Characteristic function based estimation of stable distribution parameters. A Practical Guide to Heavy Tails: Statistical Techniques and Applications, 311-338.
- (29) Borak, S., Härdle, W., & Weron, R. (2005). Stable distributions. In Statistical Tools for Finance and Insurance (pp. 21-44). Springer, Berlin, Heidelberg.
- (30) Nikias, C. L., & Shao, M. (1995). Signal Processing with Alpha-stable Distributions and Applications. Wiley-Interscience.
- (31) Liu, Y., Ye, Y., Wang, Q., & Liu, X. (2018). Stability Prediction Model of Roadway Surrounding Rock Based on Concept Lattice Reduction and a Symmetric Alpha Stable Distribution Probability Neural Network. Applied Sciences, 8(11), 2164.
- (32) Paulson, A. S., Holcomb, E. W., & Leitch, R. A. (1975). The estimation of the parameters of the stable laws. Biometrika, 62(1), 163-170.
- (33) Brent, R. P. (2013). Algorithms for Minimization without Derivatives. Courier Corporation.
- (34) Kakinaka, S., & Umeno, K. (2020). Characterizing Cryptocurrency Market with Lévy’s Stable Distributions. Journal of the Physical Society of Japan, 89(2), 024802.
- (35) Matsui, M., & Takemura, A. (2008). Goodness-of-fit tests for symmetric stable distributions—empirical characteristic function approach. Test, 17(3), 546-566.
- (36) Heathcote, C. R. (1977). The integrated squared error estimation of parameters. Biometrika, 64(2), 255-264.
- (37) Weron, R. (1996). On the Chambers-Mallows-Stuck method for simulating skewed stable random variables. Statistics & Probability Letters, 28(2), 165-171.
- (38) Chambers, J. M., Mallows, C. L., & Stuck, B. W. (1976). A method for simulating stable random variables. Journal of the American Statistical Association, 71(354), 340-344.
- (39) Umeno, K. (1998). Superposition of chaotic processes with convergence to Lévy’s stable law. Physical Review E, 58(2), 2644.
- (40) Zolotarev, V. M. (1986). One-dimensional stable distributions (Vol. 65). American Mathematical Soc.
- (41) Nolan, J. P. (1997). Numerical calculation of stable densities and distribution functions. Communications in Statistics. Stochastic Models, 13(4), 759-774.
- (42) Royuela-del-Val, J., Simmross-Wattenberg, F., & Alberola-López, C. (2017). Libstable: Fast, Parallel and High-Precision Computation of-Stable Distributions in C/C++ and MATLAB, Journal of Statistical Software, 78(1), 1-25.
- (43) Mandelbrot, B. (1963). The Variation of Certain Speculative Prices. The Journal of Business, 36(4), 394-419.
- (44) Fama, E. F. (1965). The behavior of stock-market prices. The Journal of Business, 38(1), 34-105.
- (45) Mantegna, R. N., & Stanley, H. E. (1995). Scaling behaviour in the dynamics of an economic index. Nature, 376(6535), 46-49.
- (46) Xu, W., Wu, C., Dong, Y., & Xiao, W. (2011). Modeling Chinese stock returns with stable distribution. Mathematical and Computer Modelling, 54(1-2), 610-617.
- (47) Chronis, G. A. (2016). Modelling the extreme variability of the US Consumer Price Index inflation with a stable non-symmetric distribution. Economic Modelling, 59, 271-277.
- (48) Krezolek, D. (2012). Non-classical measures of investment risk on the market of precious non-ferrous metals using the methodology of stable distributions. Dynamic Econometric Models, 12, 89-103.
- (49) Yuan, Y., Zhuang, X. T., Jin, X., & Huang, W. Q. (2014). Stable distribution and long-range correlation of Brent crude oil market. Physica A: Statistical Mechanics and its Applications, 413, 173-179.