First–order integer–valued autoregressive processes with Generalized Katz innovations
Abstract
A new integer–valued autoregressive process (INAR) with Generalised Lagrangian Katz (GLK) innovations is defined. This process family provides a flexible modelling framework for count data, allowing for under and over–dispersion, asymmetry, and excess of kurtosis and includes standard INAR models such as Generalized Poisson and Negative Binomial as special cases. We show that the GLK–INAR process is discrete semi–self–decomposable, infinite divisible, stable by aggregation and provides stationarity conditions. Some extensions are discussed, such as the Markov–Switching and the zero–inflated GLK–INARs. A Bayesian inference framework and an efficient posterior approximation procedure are introduced. The proposed models are applied to 130 time series from Google Trend, which proxy the worldwide public concern about climate change. New evidence is found of heterogeneity across time, countries and keywords in the persistence, uncertainty, and long–run public awareness level.
keywords:
Bayesian inference , Big data , Counts time series , Climate Risk , Generalized Lagrangian Katz distribution , MCMC1 Introduction
In the recent years there has been a large interest in discrete–time integer–valued models, also due to increased availability of count data in very diverse fields including finance [Liesenfeld et al., 2006, Aknouche et al., 2021], economics [Freeland & McCabe, 2004, Berry & West, 2020], social sciences [Pedeli & Karlis, 2011], sports [Shahtahmassebi & Moyeed, 2016], image processing [Afrifa-Yamoah & Mueller, 2022] and oceanography [Cunha et al., 2018]. Among the modelling approaches, integer–valued autoregressive processes (INAR), introduced independently by Al-Osh & Alzaid [1987] and McKenzie [1985], become very popular. The stochastic construction of the INAR relies on the binomial thinning operator and the properties of the model on the discrete self–decomposability of the stationary distribution of the process [Steutel & van Harn, 1979]. See Scotto et al. [2015] for a review.
The original INAR model has been studied further in Al-Osh & Alzaid [1987] and extended in different directions. [McKenzie, 1986] introduced an INAR model with negative–Binomial and geometric marginal distributions, Jin-Guan & Yuan [1991] extended the INAR(1) model of Al-Osh & Alzaid [1987] to the higher order INAR. Al-Osh & Aly [1992] introduced a negative–binomial INAR with a new iterated thinning operator. Other extensions of the INAR process have been made to include a seasonal structure in the model [e.g., see Bourguignon et al., 2016]. INAR models with values in the set of signed integers have been propose firstly by Kim & Park [2008] and generalised by Alzaid & Omair [2014] and Andersson & Karlis [2014]. Freeland [2010] proposed a true integer–valued autoregressive model (TINAR(1)). More flexible INAR models have been introduced by assuming more flexible distributions for the innovations terms. Alzaid & Al-Osh [1993] propose integer–valued ARMA process with Generalized Poisson marginals and Kim & Lee [2017] introduced INAR with Katz innovations.
This paper introduces a general class of INARs with Generalized Lagrangian Katz innovations. The Lagrangian Katz family is a flexible distribution and naturally arises as first crossing probabilities, which is a common problem in actuarial mathematics, e.g. claim number distribution in cascading processes or ruin probability in discrete–time risk models [e.g., see Consul & Famoye, 2006, ch. 12]. It has been extended further by Janardan [1998] and Janardan [1999], which introduced the four–parameter generalized Pólya–Eggenberger (GPED) distributions of the first and second kind. Janardan [1998] showed that both families contain the Lagrangian Katz distribution as a special case. We consider the four-parameters GPED of the first kind, also known as Generalized Lagrangian Katz (GLK). The resulting process family provides a flexible modelling framework for count data, allowing for under and over–dispersion, asymmetry, and excess of kurtosis and includes standard INAR models such as Generalized Poisson and Negative Binomial as special cases. Further extensions are provided, such as the Markov–Switching and the zero–inflated GLK–INARs, to account for different sources of model instability and excess of zeros.
Various approaches to inference have traditionally been presented for count data models, such as the conditional likelihood approach, generalized method of moments and Yule–Walker approach. See Weiß & Kim [2013] for a review. Despite the popularity gained in recent years by Bayesian methods, the applications to count data models are still limited [e.g., see McCabe & Martin, 2005, Neal & Subba Rao, 2007, Drovandi et al., 2016, Shang & Zhang, 2018, Garay et al., 2020b]. Thus, we provide a Bayesian inference procedure for our model and illustrate the procedure’s efficiency on a synthetic dataset. The Bayesian approach to inference entirely considers parameter uncertainty in the prior knowledge about a random process. It allows for imposing parameter restrictions by specifying the prior distribution [Chen & Lee, 2016]. The posterior distribution of the parameters quantifies uncertainty in the estimation [Chen & Lee, 2017], which can be included in the prediction. The inference from the Bayesian perspective may result in richer inferences in the case of small samples [Garay et al., 2020a] and extra–sample information and in robust inference in the presence of outliers [Fried et al., 2015]. Finally, model selection for both nested and non–nested models can be easily carried out.
We illustrate the model’s flexibility with an application to an original Google Trend dataset of 130 time–series measuring the public concern about climate change in different countries. The contrasting features of the series, such as excess of zeros, outliers, and regimes, are common in count data and provide a challenging and diversified ground for illustrating the robustness and flexibility of the GLK–INAR model. Assessing public awareness and knowledge of a specific topic and understanding the dynamics of social consciousness allows for designing more effective public policies. For this reason, researchers measured and studied the level of awareness about the effects of climate change in different sectors of society such as households [Frondel et al., 2017], winegrowers [Battaglini et al., 2009], farmers [Fahad & Wang, 2018], mountain peoples [Ullah et al., 2018]. Most of these studies rely on surveys conducted in a specific geographical area and sector of society, with a few exceptions. For example, Ziegler [2017] proposed a cross–country analysis of climate change beliefs and attitudes. Lineman et al. [2015] provided a broader and global perspective by exploiting the potentiality of big data provided by Google Trend. This extended climate change perception literature along two lines. First, we consider a multi–country dataset, including country–specific measures to capture worldwide heterogeneity in public awareness. Moreover, we offer a model–based approach and an inference procedure to analyze these measures.
The paper is organized as follows. Section 2 introduces the GLK family and INAR process with some extensions such as the Markov–Switching GLK–INAR. Section 3 proposes a Bayesian inference procedure and provides some simulation results. Section 4 provides some illustrations on a multi–country Google Trend dataset related to climate change. Section 5 concludes.
2 INAR(1) with generalized Katz innovations
2.1 Generalized Lagrangian Katz family
The probability mass function (pmf), , of the Generalized Lagrangian Katz (GLK) is
| (1) |
, where is the rising factorial with the convention that , and , , and are the parameters [Consul & Famoye, 2006]. We denote the distribution with . We notice that for some additional constraints on the parameters are needed to have all the . See the discussion at the beginning of Subsection 3.1 and Appendix B in the Supplementary. GLK distributions have probability generating function (pgf)
which satisfies:
| (2) |
or alternatively
| (3) |
see Janardan [1998].
Remark 1.
Building on the Lagrangian expansion, Janardan [1998] introduced the Generalized Polya Eggenberger distribution. [Consul & Famoye, 2006] argued that since the distribution is unrelated to the Polya, it should be named Generalized Lagrangian Katz distribution. As shown in Appendix B in the Supplementary Material, it is possible to derive the Generalized Polya Eggenberger / Generalized Lagrangian Katz as a particular ”generalized Lagrangian distribution”.
The GLK distribution family is very general and includes some well–known distributions and new distributions that have yet to be used in count data modelling.
-
•
The Lagrangian Katz distribution is obtained by replacing with (which is called Generalized Katz in [Consul & Famoye, 2006]).
-
•
The Katz distribution is obtained for and by replacing with , [Katz, 1965].
-
•
The Polya–Eggenberger distribution is obtained for , [Janardan, 1998]. Note that the Katz distribution in Consul & Famoye [2006], Tab. 2.1, is not the Katz distribution of Katz [1965], it corresponds instead to the Generalized Polya Eggenberger of the first type (GPED1–I) of Janardan [1998] and can be obtain as the limit of the zero–truncated GLK for .
-
•
The Generalized Negative Binomial distribution is obtained for , , and .
-
•
The Negative Binomial distribution is obtained for and .
-
•
The Binomial distribution is obtained for , , and
- •
-
•
The Poisson distribution for , s.t. .
 |
 |
 |
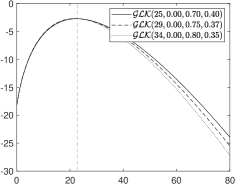 |
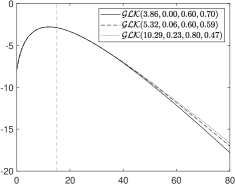
The probability mass function of the GLK for different parameter settings is given in Fig. 1. In the top–left plot, we compare , and with the same mean. The top–right plot illustrates the sensitivity of the pmf with respect to the different parameters. All distributions have the same mean (vertical dashed line). The bottom plots illustrate the effects of the parameters on the tails (log–scale) for a with over–dispersion (left) and under–dispersion (right).
We provide in Appendix A in the Supplementary Material some useful moments of the GLK distributions, which can be used to derive the following measures of dispersion. The standard deviation to the mean ratio returns the coefficient of variation. From the results in Appendix A in the Supplementary Material it follows that the coefficient of variation is where and , assuming . The Fisher index is given by the variance–to–mean ratio which does not depend on the parameter . For a given , following the values of ( and ), the distribution allows for various degrees of dispersion: not dispersed (), under–dispersed (), equally dispersed () and over–dispersed ().
We conclude this section with another important property.
Proposition 1.
A random variable is infinite divisible, in particular where .
Proof.
From the pgf of a GLK given in Eq. 3
| (4) |
which is the pgf of the sum of independent GLKs with distribution where according to the definition of GLK. ∎
2.2 A INAR(1) process
The Generalized Katz INAR(1) process (GLK–INAR(1)) is defined using the binomial thinning operator, . The binomial thinning for a non–negative discrete random variable is defined as
where are iid Bernoulli r.v.s with success probability .
Definition 1 (GLK–INAR process).
For , the GLK–INAR(1) process is defined by
where are iid random variables with Generalized Lagrangian Katz distribution , independent of , .
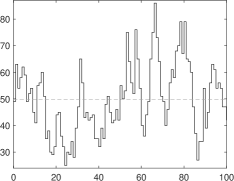
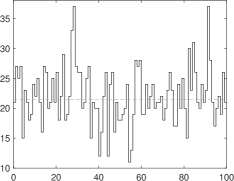
Figure 2 provides some trajectories of points each, simulated from a GLK–INAR(1) with innovation distributions given by the solid lines in the bottom plots of Fig. 1, that are , , , (overdispersion) and , , , (underdispersion). The trajectories correspond to the two parameter settings we find the empirical application to climate change discussed in Section 4, that are: (i) high persistence setting (, left); (ii) low persistence setting (, right). In all plots, the empirical mean of the observations is reported (dashed line) as a reference to illustrate the different levels of persistence in the trajectories.
Thanks to the general parametric family assumed, by setting , and , our GLK–INAR(1) nests the INARKF(1) of Kim & Lee [2017] as special case. The GLK–INAR(1) naturally nests the Poisson INAR(1) of Al-Osh & Alzaid [1987], the Negative Binomial INAR(1) of Al-Osh & Aly [1992] (NBINAR(1)), and the Generalized Poisson INAR(1) of Alzaid & Al-Osh [1993].
| (a) Over–dispersed innovations | |
 |
 |
| (a) Under-dispersed innovations | |
 |
 |
As for any INAR process, the GLK–INAR(1) has the following representation
and its conditional pgf can be written as
where is defined in Eq. 2 or in Eq. 3. Starting from the general results on INAR processes given in Alzaid & Al-Osh [1988], one easily obtains explicit expressions for the conditional mean and variance of the GLK–INAR(1):
| (5) | |||
| (6) |
where and .
Remark 2.
Setting , and the results in Kim & Lee [2017] Th. 2.2 are obtained.
Remark 3.
Since , and .
The process is a Markov Chain on and the transition probability satisfies
where is the pmf given in Eq. 1.
In the next Proposition, we summarize some of the asymptotic properties of a GLK–INAR(1). These properties follow from general results in Alzaid & Al-Osh [1988] and Schweer & Weiß [2014].
Proposition 2.
Assume that is a GLK–INAR(1).
-
(i)
The process is an irreducible, aperiodic and positive recurrent Markov chain. Hence there is a unique stationary distribution for the process .
-
(ii)
The marginal distribution of the stationary process is infinitely divisible.
Proof.
By Proposition 1, the distribution of the innovations is infinitely divisible, and hence, it is a compound Poisson distribution, see, e.g. Lemma 2.1 in Steutel & van Harn [1979]. Hence, both (i) and (ii) follow from Theorem 3.2.1 in Schweer & Weiß [2014]. In point of fact, (i) is true for any INAR process, see Al-Osh & Alzaid [1987]. An alternative derivation of (ii) is as follows. Since at stationarity the process satisfies , where , and the innovation terms are infinite divisible by Proposition 1, the stationary distribution satisfies the definition of discrete semi–self–decomposability given in Bouzar [2008]. Theorem 2 in Bouzar [2008] yields that it is also infinitely divisible. ∎
Since the GLK distribution satisfies the convolution property [see Janardan, 1998, Th. 8], then the GLK–INAR(1) is stable by aggregation as stated in the following
Proposition 3.
Let with be a sequence of independent GLK–INAR(1) which satisfy:
The process is GLK–INAR(1) which satisfies:
Below, we state explicit closed-form expressions for unconditional moments of the process.
Proposition 4.
Let , and the mean, second order non-central moment and variance given in Prop. 5 for a . For a GLK–INAR(1) process, the following unconditional moments can be derived:
-
(i)
-
(ii)
-
(iii)
-
(iv)
Higher-order non-central moments can be derived using the formula:
where and denote the Stirling’s numbers of the I and II kind, respectively.
Proof.
First- and second-order moments are known from Al-Osh & Alzaid [1987] for general INAR. Specifying the GLK innovations gives (i)–(iii). High-order moments can be computed similarly. See e.g. Weiß [2013]. For the sake of completeness, details are given in Appendix B.3 in the Supplementary Material. ∎
From the previous proposition, under the assumption one obtains the unconditional variance of the process and the dispersion index of the process
where is the innovation index of dispersion. It follows that there is under– or over–dispersion in the marginal distribution, and , if and only if there is under- or over–dispersion in the innovation, or respectively.
2.3 A Markov–switching GLK–INAR(1) process
The GLK–INAR(1) process can be extended to account for various sources of model instability such as structural breaks, regimes and outliers by introducing a time–varying parameter setting [see for example Malyshkina et al., 2009]. A parsimonious approach is to assume a finite set of regimes corresponding to different parameter configurations, i.e.
| (7) |
with , where the thinning coefficient and the parameters of the error term are time–varying , where . The for denotes a hidden Markov–chain process with transition probabilities for . From now on, this extension is denoted with MS–GLK–INAR(1).
A special case, which is relevant for a common issue in count data series, is the large proportion of zeros [e.g., Maiti et al., 2015]. The excess of zero, which leads to over–dispersion, can be handled by assuming a zero–inflated GLK–INAR(1). This can be defined by assuming that in one of the regimes, e.g. , there is complete thinning , and the error distribution is a Dirac centred at zero. Some alternatives where the GLK collapses to a Dirac include the (Negative) Binomial distribution with parameters , (), and .
The transition probabilities provide information on the persistence of these events. If the probability is independent on past information, i.e. for all , then the zero–inflated regime is transitory. If the zero–inflated regime is persistent, then the duration of the regime is captured by a large . Other regimes () with low mean and/or large variance can also generate zeroes. This is convenient in some applications, such as in epidemiology where zeroes from can be interpreted as under–reported cases of a particular disease [e.g., Douwes-Schultz & Schmidt, 2022].
2.4 Possible extensions of the GLK–INAR
The GLK–INAR can be extended to include more general auto–correlation structures and to the multivariate setting. The process can be modified to allow for multiple lags building on the specification strategy used in Neal & Subba Rao [2007]. In particular, a GLK integer–valued ARMA of order and , i.e. GLK–INARMA can be specified using independent thinning operators.
Definition 2 (GLK–INARMA process).
Let for and for , the GLK–INARMA(p,q) process is defined as
where are iid random variables with Generalized Lagrangian Katz distribution and and .
Compared to GLK–INAR(1), in the GLK–INARMA, a further restriction on the autoregressive parameters is required for stationarity, although a weaker condition can be used. For alternatives specification strategies such as combined INAR (CINAR) see for example McKenzie [2003], Weiß [2008].
For the case of random integer vectors, a multivariate GLK–INAR(1) (GLK–MINAR(1)) can be used by introducing a thinning matrix operator.
Definition 3 (GLK–MINAR(1) process).
Let be a random integer vector and , where , the GLK–MINAR(1) process can be defined by
where is iid Generalized Lagrangian Katz distributions, and is the thinning matrix operator, such that for each ,
and refers to the binomial thinning operator.
The independence between the innovation terms of the different equations allows us to estimate them separately. This assumption can be relaxed by adding common GLK errors to the equations, or under some special cases of the GLK, a joint distribution can be introduced, such as the bivariate Katz’s or Poisson distribution [Pedeli & Karlis, 2011, Diafouka et al., 2022].
3 Bayesian inference
3.1 Prior distribution
With the construction in Eq. 1, the constraint is guaranteed by the condition . Nevertheless, some constraints on the parameters are needed to have all the . Three different cases are discussed below (details are given in Appendix B in the Supplementary Material.).
-
•
For parameter values the pmf are positive. Moreover, for the extended binomial coefficient coincides with the standard binomial coefficient [Consul & Famoye, 2006, p. 8].
-
•
For , and , the pmf are positive for , while for .
-
•
If but the additional constraints of the previous point are not satisfied, the terms appearing in the product change sign, and there is no guarantee that the result is positive. Indeed, for all the such that one has and and hence there is an integer such that for and for . Hence
which is negative whenever is odd. For example take , and , for one has , which shows that which clearly is impossible.
Remark 4.
It should be noted that alternative definitions for can be considered. For example one can set to 0 the , i.e. when . In this case re-scaling the is necessary to get . The resulting pmf is not a generalized Lagrangian distribution (due to the truncation and rescaling), and the normalizing constant is not in closed form. See, for example, McCabe & Skeels [2020] for a discussion on the parameter values for the Katz distributions.
In a Bayesian framework, the parameter constraints can be easily included in the inference process through a suitable choice of the prior distributions. We assume:
where is the beta distribution with shape parameters and and the gamma distribution with shape and scale parameters and , respectively. In the empirical applications we assume a non-informative hyper-parameter setting for and , that is and an informative prior for and with , and .
In the case of Markov–switching specification of the GLK–INAR(1), the same prior is assumed for the regime–specific parameters for . For the transition probabilities of the allocation variable, we assume a symmetric Dirichlet prior for each row of the transition matrix, i.e. with concentration parameter , where for .
3.2 Posterior distribution
Let be a sequence of observations for the GLK–INAR(1) process, then the joint posterior distribution is given by
where is the parameter vector the joint prior and
where .
Following the discussion above in this section, if the parameter constraint is not imposed, the coefficients of the Lagrangian expansion can be negative. In this case, a truncated GLK can be used, similarly to what is proposed in McCabe & Skeels [2020] for the Katz distribution, and the inference procedure can be easily extended to include this type of distribution. The truncation can be imposed by using the following recursion for the transition probability:
where , and
The probability becomes null for if at .
Since the joint posterior is not tractable, we follow a Markov Chain Monte Carlo (MCMC) framework for posterior approximation. See Robert & Casella [2013] for an introduction to MCMC methods. We overcome the difficulties in tuning the parameters of the MCMC procedure by applying the Adaptive MCMC sampler (AMCMC) proposed in Andrieu & Thoms [2008]. Following a standard procedure, the following reparametrization is considered to impose constraints on the parameters of the GLK–INAR(1). Let be the 5-dimensional parameter vector obtained by the transformation with , , , , and and let be the posterior of , with the Jacobian of the transformation given above. Given the adaptation parameters and , at the -th iterations, the AMCMC consists of the following three steps. First, a candidate is generated from the random walk proposal: . Second, the candidate is accepted with probability , where
and third, the adaptive parameters are updated as follows:
where is the target acceptance probability and , is the adaptive scale [Andrieu & Thoms, 2008, , Algorithm 4]. Following the suggestions in Roberts et al. [1997] we set .
The latent allocation variables in the Markov–switching specification of the GLK–INAR(1) are sampled the Forward–Filtering Backward sampling procedure (FFBS). The prediction and filtering probabilities are given by
where , for . Notice that the conditioning on the parameters is included only in the likelihood but not in the probabilities to simplify the notation. The filtered probabilities can be smoothed by considering all the information available, i.e.
where and . The allocation variables are sampled directly from these smoothed probabilities.
The conditional posterior distribution of the transition probabilities of the Markov chain is conditionally conjugate and can be sampled directly from where for .
For the possible extensions of the GLK–INAR, such as the GLK–INRMA(p,q) and the GLK–MINAR(1), data augmentation techniques can be used to improve the efficiency of the MCMC [Neal & Subba Rao, 2007, Marques et al., 2022]. For instance, in the case of the GLK–INRMA(p,q), conditional conjugacy of the thinning parameters can be obtained by assuming each autoregressive (moving average) component is a latent variable following a binomial distribution. In the case of GLK–MINAR(1), a similar strategy can be followed, see for instance Soyer & Zhang [2022].
3.3 Simulation results
We illustrate the Bayesian procedure’s effectiveness in recovering the parameters’ true value and the MCMC procedure’s efficiency through some simulation experiments. We test the algorithm’s efficiency in two different settings, commonly found in the data: low persistence and high persistence (see trajectories in Fig. 2). The true values of the parameters are: , , , , in the low persistence setting, and , ,, , in the high persistence setting. For each setting, we run the Gibbs sampler for 50,000 iterations on each dataset, discard the first 10,000 draws to remove dependence on initial conditions, and apply a thinning procedure with a factor of 10 to reduce the dependence between consecutive draws.
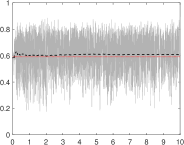
For illustrative purposes, in Figure C.1 in the Supplementary Material we show the MCMC posterior approximation for the parameter (first row), the unconditional mean of the process (second row), and the marginal likelihood (last row), in one of our experiments for the high- and low-persistence settings. Each plot represents the true value (solid black line) and the Bayesian estimates. Posterior estimated are approximated by using 4,000 MCMC samples after thinning and burn-in removal (dashed red line). Figures C.2-C.3 and C.4-C.5 in the Supplementary Material exhibit 10,000 MCMC posterior draws and the MCMC approximation of the posterior distribution for all the parameters, in the high- and low-persistence settings.
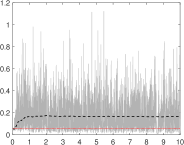
In our experiments, the acceptance rate is in the range of 40%-53% for both parameter settings (see Figure C.6 in the Supplementary Material). Table C.1 in the Supplementary Material shows, for all the parameters the autocorrelation function (ACF), effective sample size (ESS), inefficiency factor (INEFF) and Geweke’s convergence diagnostic (CD) before (BT subscript) and after thinning (AT subscript). The numerical standard errors are evaluated using the nse package [Geyer, 1992, Ardia & Bluteau, 2017, Ardia et al., 2018].
The thinning procedure is effective in reducing the autocorrelation levels and in increasing the ESS. The p-values of the CD statistics indicate that the null hypothesis that two sub-samples of the MCMC draws have the same distribution is always accepted. The efficiency of the MCMC after the thinning procedure is generally improved. After thinning, on average, the inefficiency measures (5.83), the p-values of the CD statistics (0.36) and the NSE (0.02) achieved the values recommended in the literature [e.g., see Roberts et al., 1997].
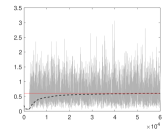
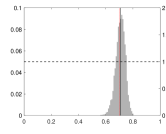
It is important to underline that the persistence parameter estimation and the forecast are highly sensitive to the innovation distributional assumption. An illustration is presented in the left plot of Figure 3, where the data generating process corresponds to a GLK–INAR(1) with large overdispersion (VRM=8.6). The standard model for count data is the Poisson INAR(1) model (PINAR(1)), which cannot capture overdispersion. This misspecified model entails an underestimation of the persistence parameter (medium gray histogram). The NBINAR(1) captures the overdispersion and provides reliable persistence estimates (light gray) comparable with the one of GLK–INAR (dark gray). Nevertheless, in the case of underdispersion (VRM=0.4, right plot of Figure 3), both NBINAR(1) and PINAR(1) return an estimation bias in the persistence parameter, while the INAR–GLK gives a good approximation of the true persistence. In summary, the INAR–GLK(1) model nests standard models, such as Generalized Poisson and Negative Binomial INARs, and allows for different degrees of underdispersion and overdispersion. Hence, it can be used without preliminary testing of the dispersion features of the series.
 |
 |
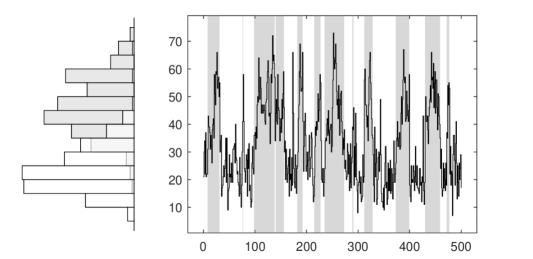
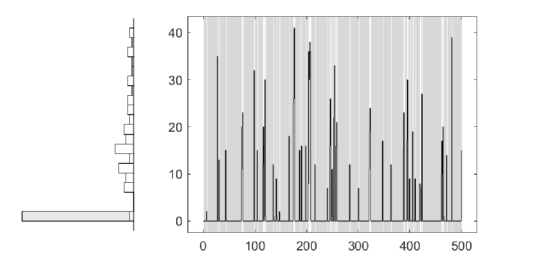
Similarly, to exemplify the effectiveness and efficiency of the estimation procedure in different scenarios we considered: i) high and low persistence regimes with the same parameter configuration of the settings presented before and ii) a large mean regime and an zero–inflated regime where , , , , . The simulated trajectories are shown in Figure C.7 (C.8) in the Supplementary Material together with the estimated allocations of the regimes, represented by the shaded areas, with an accuracy of 97% (100%) for the two regimes (zero–inflated) scenario. Moreover, the parameters are successfully retrieved, see in Figures C, C and C in the Supplementary Material. Notice that the zero–inflated parameters are not estimated but set by default to approximate the Dirac distribution.
In conclusion, the Gibbs sampler is computationally efficient and can retrieve the true parameter values of the MS–GLK–INAR in different settings, including the single–regime and the zero–inflated specifications. The MCMC for the GLK–INAR takes 0.5 minutes for a sample size of observations and for 30,000 MCMC iterations. This is comparable with the Negative Binomial INAR (0.4 minutes). The method is scalable and can be applied to datasets with thousands of observations. For larger-size datasets, the theoretical moment of the process can be used to devise alternative estimation procedures, such as the method of moments. The moments of the distribution are provided in closed form in Proposition 5 in the Supplementary Material.
4 Application to climate change
4.1 Data description
We used Google Trends data to measure the changes in public concern about climate change. Google Trend represents a source of big data [Choi & Varian, 2012, Scott & Varian, 2014] which have been used in many studies, for example, Anderberg et al. [2021] studied domestic violence during covid-19, Yang et al. [2021] studied influenza trends, Schiavoni et al. [2021] and Yi et al. [2021] presented applications to unemployment and Yu et al. [2019] studied oil consumption. In this study, we follow Lineman et al. [2015] and use Google search volumes as a proxy for public concern about “Climate Change” (CC) and “Global Warming” (GW). The search volume is the traffic for the specific combination of keywords relative to all queries submitted in Google Search in the world or a given region over a defined period. The indicator ranges from 0 to 100, with 100 corresponding to the largest relative search volume during the period of interest. The search volume is sampled weekly from 4th December 2016 until 21st November 2021. We analysed the dynamics at the global and country level. Countries with an excess of zeros above 95% in the search volume series have been excluded. The final dataset includes 65 countries of the about 200 countries provided by Google Trends. For illustration purposes, we report in the top plots of Fig. 4 the series of the world volume. The CC global volume exhibits overdispersion with , skewness and kurtosis and , respectively. The GW global volume has over–dispersion , skewness and kurtosis (see also the histograms in the bottom plots). The country-specific indexes exhibit different levels of persistence and over–dispersion.
 |
 |
 |
 |
| (a) Google search dataset “Climate Change” | |
 |
 |
| (b) Google search dataset “Global Warming” | |
 |
 |
| (a) Google search dataset “Climate Change” | ||
 |
 |
 |
| (b) Google search dataset “Global Warming” | ||
 |
 |
 |
4.2 Estimation results
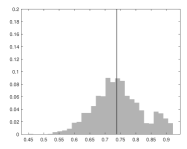
The posterior distribution of the autoregressive coefficient is given in Fig. 5. The coefficient estimate and posterior credible interval (in parenthesis) are and for the GW and the CC dataset, respectively (see also the approximation to the posterior distribution of the parameters in Figures D.1 and D.2 in the Supplementary Material). This result indicates that the public concern about climate risk is persistent over time worldwide at an aggregate level. The estimated parameter of the innovation process and their 0.95% credible intervals (in parenthesis) are , , and for the GW dataset and , , and for the CC one.
4.3 Model comparison
The results indicate a deviation from the Negative Binomial model. Thus we apply the DIC criterion to compare GLK–INAR(1) and NB–INAR(1). The is computed following [Spiegelhalter et al., 2002]:
| (8) |
where is the likelihood of the model, the MCMC draws after thinning and burn-in sample removal, and is the parameter estimate. The DICs for the GLK (NB) INARs fitted on the aggregate CC and GW series are and , respectively.
Given the high kurtosis levels and the multi–modality in the empirical distribution of both series (see Figure 4), the Markov Switching INAR is used to deal with outliers and parameter instability. We use DIC and RMSE to select the number of regimes and the model (see Table D.3 in the Supplementary Material). We find that GLK–INAR with two or three regimes present the best fit in–sample and out–sample for both the CC and GW datasets. The results with three–regimes are presented in Figure 6. The three regimes identify different persistence levels: high (right plot), medium (middle) and low (left). Some of the regimes also have different unconditional mean levels (see Figure 7 left plots). In terms of one–step–ahead forecasting, in both datasets, the model can reproduce the upward trend at the end of the sample and effectively cover the true values within their 90% credible intervals (see Figure 7 right plots).
 |
 |
 |
 |
4.4 Disaggregate analysis
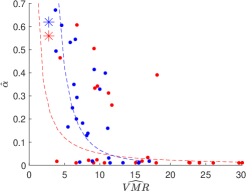
We run the analysis at a disaggregate level. The results are given in Figures 8-9 and Tables D.1-D.2 in the Supplementary Material. Figure 8 provides evidence of an inverse relationship between estimated persistence and dispersion cross countries (reference lines in the left plot). There is evidence of this inverse relationship in both the CC (blue dots) and GW (red dots) datasets. The plot on the right indicates an inverse (direct) relationship between the estimated unconditional mean and the dispersion index for the GW (CC). In the same picture, we indicate the parameter estimates for the world volume of searches (stars).
 |
 |
 |
 |
The terms “Climate Change” and “Global Warming” are used interchangeably. Nevertheless, they describe different phenomena and can be used to determine the public’s level of understanding about these two parallel concepts Lineman et al. [2015]. We investigate the relationships in the search volumes through the lens of our GLK–INAR(1) model. The left plot in Fig. 9 shows the unconditional mean of the search volumes for the two concepts in all countries (dots). In public attention, the two concepts are connected in the long run. We find a positive association for both countries with large (percentage of zeros 21%) and low search volumes (percentage of zeros 21%). There is an asymmetric effect in the overdispersion (right plot), and in all countries, the GW search volume has a larger VMR than the CC volume. This can be explained by the larger variability induced by the changes in the use of the GW term in official communications.
Comparing the coefficients across the rows of Tables D.1-D.2 in the Supplementary Material, we find evidence of two types of series, one with high persistence and the other with low persistence. Moreover, for each country, the level of persistence is similar across the two datasets (compare columns of Tables D.1-D.2 in the Supplementary Material).
Tables D.1-D.2 in the Supplementary Material report the marginal likelihood of the GLK–INAR(1) and Lagrangian Katz INAR(1) in columns GLK and LK, respectively. We find evidence of a better fitting of the GLK–INAR(1) for some countries and variables, e.g. CC searches in India and CC and GW searches in South Africa. To get further insights into the results, we study the relationship between the dynamic and dispersion properties of the series and the actual level of climate risk of the countries. We consider the Global Climate Risk Index (CRI), which ranks countries and regions following the impacts of extreme weather events (such as storms, hurricanes, floods, heatwaves, etc.). The lower the index value, the larger the climate risk is. Following the values of the CRI for 2021, based on the events recorded from 2000 to 2019, our dataset includes some of the countries most exposed to climate risk, such as Japan, Philippines, Germany, South Africa, India, Sri Lanka and Canada [Eckstein et al., 2021, see].
The left plot in Fig. 10 shows the unconditional mean against the CRI. There is evidence of a positive relationship between the public interest in climate-related topics and the actual level of climatic risk. The lower the CRI level, the larger the Google search volumes are (see dashed lines). For example, India has a high risk (CRI equal to 7) and a very high long-run level of public attention.
The right plot reports the coefficient of variation against the CRI for all countries in the “Climate Change” (blue) and “Global Warming” (red) datasets. The dashed lines represent linear regressions estimated on the data. There is evidence of a negative relationship between the dispersion of public concern and climatic risk; in countries with more significant risk levels, the Google search volumes are less over–dispersed.
 |
 |
To deal with the excess of zeros, which are very frequent in more than 62% of the series, we apply the MS–GLK–INAR(1) with two states, where the first state represents a prolonged absence of searches on Google and the second a persistent search activity. The MS–GLK–INAR(1) performs better than MS–NBINAR(1) in 119 out of the 130 CC and GW time series following the DIC (see Table D.5 and D.4 in the Supplementary Material). Accounting for the excess of zeros allows for improving the estimation of the persistence and provides an estimate of the probability to stay in an inactive search regime. The findings on the persistence parameter discussed in this section for the GLK–INAR(1) are confirmed by the MS–GLK–INAR. Furthermore, there is evidence of a positive relationship between the probability and the CRI, consistent with the results on the Google search persistence.
5 Conclusion
A novel integer–valued autoregressive process is proposed with Generalized Lagrangian Katz innovations (GLK–INAR). Theoretical properties of the model, such as stationarity, moments, and semi–self–decomposability, are provided. To deal with parameter instability and excess of zeroes, we also propose a Markov–Switching GLK–INAR. A Bayesian approach to inference and an efficient Gibbs sampling procedure have been proposed, which naturally account for uncertainty when forecasting. The modelling framework is applied to a Google Trend dataset measuring the public concern about climate change in 65 countries. The greater flexibility of the GLK–INAR allows for a superior fitting compared to the standard INAR models and a better comprehension of the heterogeneity in public perception. More specifically, new evidence is provided about the long-run level of public attention, its persistence and dispersion in countries with low and high levels of climate risk. The Markov-switching GLK-INAR identified regimes with the absence of searches and changes in the dynamic features of the series.
Acknowledgment
The authors acknowledge support from: the MUR– PRIN project ‘Discrete random structures for Bayesian learning and prediction’ under g.a. n. 2022CLTYP4 and the Next Generation EU – ‘GRINS– Growing Resilient, INclusive and Sustainable’ project (PE0000018), National Recovery and Resilience Plan (NRRP)– PE9 – Mission 4, C2, Intervention 1.3. The views and opinions expressed are only those of the authors and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the European Commission can be held responsible for them.
References
- Afrifa-Yamoah & Mueller [2022] Afrifa-Yamoah, E., & Mueller, U. (2022). Modeling digital camera monitoring count data with intermittent zeros for short-term prediction. Heliyon, 8, e08774.
- Aknouche et al. [2021] Aknouche, A., Almohaimeed, B. S., & Dimitrakopoulos, S. (2021). Forecasting transaction counts with integer-valued garch models. Studies in Nonlinear Dynamics & Econometrics, 26, 529–539.
- Al-Osh & Alzaid [1987] Al-Osh, M., & Alzaid, A. A. (1987). First-order integer-valued autoregressive (INAR (1)) process. Journal of Time Series Analysis, 8, 261–275.
- Al-Osh & Aly [1992] Al-Osh, M. A., & Aly, E.-E. A. (1992). First order autoregressive time series with negative binomial and geometric marginals. Communications in Statistics - Theory and Methods, 21, 2483–2492.
- Alzaid & Al-Osh [1988] Alzaid, A., & Al-Osh, M. (1988). First-order integer-valued autoregressive (INAR ) process: distributional and regression properties. Statist. Neerlandica, 42, 53–61.
- Alzaid & Al-Osh [1993] Alzaid, A., & Al-Osh, M. (1993). Generalized Poisson ARMA processes. Annals of the Institute of Statistical Mathematics, 45, 223–232.
- Alzaid & Omair [2014] Alzaid, A. A., & Omair, M. A. (2014). Poisson difference integer valued autoregressive model of order one. Bulletin of the Malaysian Mathematical Sciences Society, 37, 465–485.
- Anderberg et al. [2021] Anderberg, D., Rainer, H., & Siuda, F. (2021). Quantifying domestic violence in times of crisis: An internet search activity-based measure for the covid-19 pandemic. Journal of the Royal Statistical Society: Series A (Statistics in Society), .
- Andersson & Karlis [2014] Andersson, J., & Karlis, D. (2014). A parametric time series model with covariates for integers in Z. Statistical Modelling, 14, 135–156.
- Andrieu & Thoms [2008] Andrieu, C., & Thoms, J. (2008). A tutorial on adaptive MCMC. Statistics and computing, 18, 343–373.
- Ardia & Bluteau [2017] Ardia, D., & Bluteau, K. (2017). nse: Computation of numerical standard errors in r. Journal of Open Source Software, 2, 172.
- Ardia et al. [2018] Ardia, D., Bluteau, K., & Hoogerheide, L. F. (2018). Methods for computing numerical standard errors: Review and application to value-at-risk estimation. Journal of Time Series Econometrics, 10.
- Battaglini et al. [2009] Battaglini, A., Barbeau, G., Bindi, M., & Badeck, F.-W. (2009). European winegrowers’ perceptions of climate change impact and options for adaptation. Regional Environmental Change, 9, 61–73.
- Berry & West [2020] Berry, L. R., & West, M. (2020). Bayesian forecasting of many count-valued time series. Journal of Business & Economic Statistics, 38, 872–887.
- Bourguignon et al. [2016] Bourguignon, M., Vasconcellos, K. L., Reisen, V. A., & Ispány, M. (2016). A Poisson INAR(1) process with a seasonal structure. Journal of Statistical Computation and Simulation, 86, 373–387.
- Bouzar [2008] Bouzar, N. (2008). Semi-self-decomposable distributions on . Annals of the Institute of Statistical Mathematics, 60, 901–917.
- Chen & Lee [2016] Chen, C. W., & Lee, S. (2016). Generalized Poisson autoregressive models for time series of counts. Computational Statistics & Data Analysis, 99, 51–67.
- Chen & Lee [2017] Chen, C. W., & Lee, S. (2017). Bayesian causality test for integer-valued time series models with applications to climate and crime data. Journal of the Royal Statistical Society: Series C (Applied Statistics), 66, 797–814.
- Choi & Varian [2012] Choi, H., & Varian, H. (2012). Predicting the present with Google Trends. Economic Record, 88, 2–9.
- Consul & Famoye [2006] Consul, P. C., & Famoye, F. (2006). Lagrangian probability distributions. Springer.
- Cunha et al. [2018] Cunha, E. T. d., Vasconcellos, K. L., & Bourguignon, M. (2018). A skew integer-valued time-series process with generalized Poisson difference marginal distribution. Journal of Statistical Theory and Practice, 12, 718–743.
- Diafouka et al. [2022] Diafouka, M. K., Louzayadio, C. G., Malouata, R. O., Ngabassaka, N. R., & Bidounga, R. (2022). On a bivariate katz’s distribution. Advances in Mathematics: Scientific Journal, 11, 955–968.
- Douwes-Schultz & Schmidt [2022] Douwes-Schultz, D., & Schmidt, A. M. (2022). Zero-state coupled markov switching count models for spatio-temporal infectious disease spread. Journal of the Royal Statistical Society Series C: Applied Statistics, 71, 589–612.
- Drovandi et al. [2016] Drovandi, C. C., Pettitt, A. N., & McCutchan, R. A. (2016). Exact and Approximate Bayesian Inference for Low Integer-Valued Time Series Models with Intractable Likelihoods. Bayesian Analysis, 11, 325 – 352.
- Eckstein et al. [2021] Eckstein, D., Künzel, V., & Schäfer, L. (2021). Global climate risk index 2021. Who suffers most from extreme weather events? Weather-related loss events in 2019 and 2000-2019. Bonn: Germanwatch, 2021.
- Fahad & Wang [2018] Fahad, S., & Wang, J. (2018). Farmers’ risk perception, vulnerability, and adaptation to climate change in rural pakistan. Land Use Policy, 79, 301–309.
- Freeland & McCabe [2004] Freeland, R., & McCabe, B. P. (2004). Analysis of low count time series data by Poisson autoregression. Journal of Time Series Analysis, 25, 701–722.
- Freeland [2010] Freeland, R. K. (2010). True integer value time series. AStA Advances in Statistical Analysis, 94, 217–229.
- Fried et al. [2015] Fried, R., Agueusop, I., Bornkamp, B., Fokianos, K., Fruth, J., & Ickstadt, K. (2015). Retrospective Bayesian outlier detection in INGARCH series. Statistics and Computing, 25, 365–374.
- Frondel et al. [2017] Frondel, M., Simora, M., & Sommer, S. (2017). Risk perception of climate change: Empirical evidence for Germany. Ecological Economics, 137, 173–183.
- Garay et al. [2020a] Garay, A. M., Medina, F. L., Cabral, C. R., & Lin, T.-I. (2020a). Bayesian analysis of the p-order integer-valued ar process with zero-inflated poisson innovations. Journal of Statistical Computation and Simulation, 90, 1943–1964.
- Garay et al. [2020b] Garay, A. M., Medina, F. L., Cabral, C. R. B., & Lin, T.-I. (2020b). Bayesian analysis of the p-order integer-valued ar process with zero-inflated poisson innovations. Journal of Statistical Computation and Simulation, 90, 1943–1964.
- Geyer [1992] Geyer, C. J. (1992). Practical Markov chain Monte Carlo. Statistical Science, (pp. 473–483).
- Janardan [1998] Janardan, K. (1998). Generalized Polya Eggenberger family of distributions and its relation to Lagrangian Katz family. Communications in Statistics-Theory and Methods, 27, 2423–2442.
- Janardan [1999] Janardan, K. (1999). Estimation of parameters of the GPED. Communications in Statistics-Theory and Methods, 28, 2167–2179.
- Jin-Guan & Yuan [1991] Jin-Guan, D., & Yuan, L. (1991). The integer-valued autoregressive (INAR (p)) model. Journal of Time Series Analysis, 12, 129–142.
- Katz [1965] Katz, L. (1965). Unified treatment of a broad class of discrete probability distributions. Classical and contagious discrete distributions, 1, 175–182.
- Kim & Lee [2017] Kim, H., & Lee, S. (2017). On first-order integer-valued autoregressive process with Katz family innovations. Journal of Statistical Computation and Simulation, 87, 546–562.
- Kim & Park [2008] Kim, H.-Y., & Park, Y. (2008). A non-stationary integer-valued autoregressive model. Statistical Papers, 49, 485.
- Liesenfeld et al. [2006] Liesenfeld, R., Nolte, I., & Pohlmeier, W. (2006). Modelling financial transaction price movements: A dynamic integer count data model. Empirical Economics, 30, 795–825.
- Lineman et al. [2015] Lineman, M., Do, Y., Kim, J. Y., & Joo, G.-J. (2015). Talking about climate change and global warming. PloS one, 10, e0138996.
- Maiti et al. [2015] Maiti, R., Biswas, A., & Das, S. (2015). Time series of zero-inflated counts and their coherent forecasting. Journal of Forecasting, 34, 694–707.
- Malyshkina et al. [2009] Malyshkina, N. V., Mannering, F. L., & Tarko, A. P. (2009). Markov switching negative binomial models: an application to vehicle accident frequencies. Accident Analysis & Prevention, 41, 217–226.
- Marques et al. [2022] Marques, P., Graziadei, H., & Lopes, H. F. (2022). Bayesian generalizations of the integer-valued autoregressive model. Journal of Applied Statistics, 49, 336–356.
- McCabe & Martin [2005] McCabe, B., & Martin, G. (2005). Bayesian predictions of low count time series. International Journal of Forecasting, 21, 315–330.
- McCabe & Skeels [2020] McCabe, B. P., & Skeels, C. L. (2020). Distributions you can count on… But what’s the point? Econometrics, 8, 9.
- McKenzie [1985] McKenzie, E. (1985). Some simple models for discrete variate time series. Water Resources Bulletin, 21, 645–650.
- McKenzie [1986] McKenzie, E. (1986). Autoregressive moving-average processes with negative-binomial and geometric marginal distributions. Advances in Applied Probability, 18, 679?705.
- McKenzie [2003] McKenzie, E. (2003). Discrete variate time series. In D. N. Shanbhag, & C. R. Rao (Eds.), Stochastic Processes: Modelling and Simulation (pp. 573–606). Elsevier.
- Neal & Subba Rao [2007] Neal, P., & Subba Rao, T. (2007). MCMC for integer-valued ARMA processes. Journal of Time Series Analysis, 28, 92–110.
- Pedeli & Karlis [2011] Pedeli, X., & Karlis, D. (2011). A bivariate INAR(1) process with application. Statistical Modelling, 11, 325–349.
- Robert & Casella [2013] Robert, C., & Casella, G. (2013). Monte Carlo statistical methods. Springer Science & Business Media.
- Roberts et al. [1997] Roberts, G. O., Gelman, A., Gilks, W. R. et al. (1997). Weak convergence and optimal scaling of random walk metropolis algorithms. The Annals of Applied Probability, 7, 110–120.
- Schiavoni et al. [2021] Schiavoni, C., Palm, F., Smeekes, S., & van den Brakel, J. (2021). A dynamic factor model approach to incorporate big data in state space models for official statistics. Journal of the Royal Statistical Society: Series A (Statistics in Society), 184, 324–353.
- Schweer & Weiß [2014] Schweer, S., & Weiß, C. H. (2014). Compound Poisson INAR(1) processes: stochastic properties and testing for overdispersion. Comput. Statist. Data Anal., 77, 267–284.
- Scott & Varian [2014] Scott, S. L., & Varian, H. R. (2014). Predicting the present with Bayesian structural time series. International Journal of Mathematical Modelling and Numerical Optimisation, 5, 4–23.
- Scotto et al. [2015] Scotto, M. G., Weiß, C. H., & Gouveia, S. (2015). Thinning-based models in the analysis of integer-valued time series: A review. Statistical Modelling, 15, 590–618.
- Shahtahmassebi & Moyeed [2016] Shahtahmassebi, G., & Moyeed, R. (2016). An application of the generalized Poisson difference distribution to the Bayesian modelling of football scores. Statistica Neerlandica, 70, 260–273.
- Shang & Zhang [2018] Shang, H., & Zhang, B. (2018). Outliers detection in INAR (1) time series. Journal of Physics: Conference Series, 1053, 012094.
- Soyer & Zhang [2022] Soyer, R., & Zhang, D. (2022). Bayesian modeling of multivariate time series of counts. Wiley Interdisciplinary Reviews: Computational Statistics, 14, e1559.
- Spiegelhalter et al. [2002] Spiegelhalter, D. J., Best, N. G., Carlin, B. P., & Van Der Linde, A. (2002). Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64, 583–639.
- Steutel & van Harn [1979] Steutel, F. W., & van Harn, K. (1979). Discrete analogues of self-decomposability and stability. The Annals of Probability, (pp. 893–899).
- Ullah et al. [2018] Ullah, H., Rashid, A., Liu, G., & Hussain, M. (2018). Perceptions of mountainous people on climate change, livelihood practices and climatic shocks: A case study of Swat District, Pakistan. Urban Climate, 26, 244–257.
- Weiß [2008] Weiß, C. H. (2008). The combined INAR (p) models for time series of counts. Statistics & probability letters, 78, 1817–1822.
- Weiß [2013] Weiß, C. H. (2013). Integer-valued autoregressive models for counts showing underdispersion. J. Appl. Stat., 40, 1931–1948.
- Weiß & Kim [2013] Weiß, C. H., & Kim, H.-Y. (2013). Parameter estimation for binomial AR(1) models with applications in finance and industry. Statistical Papers, 54, 563–590.
- Yang et al. [2021] Yang, S., Ning, S., & Kou, S. C. (2021). Use internet search data to accurately track state level influenza epidemics. Scientific Reports, 11, 4023.
- Yi et al. [2021] Yi, D., Ning, S., Chang, C.-J., & Kou, S. C. (2021). Forecasting unemployment using internet search data via prism. Journal of the American Statistical Association, 116, 1662–1673.
- Yu et al. [2019] Yu, L., Zhao, Y., Tang, L., & Yang, Z. (2019). Online big data-driven oil consumption forecasting with Google trends. International Journal of Forecasting, 35, 213–223.
- Ziegler [2017] Ziegler, A. (2017). Political orientation, environmental values, and climate change beliefs and attitudes: An empirical cross country analysis. Energy Economics, 63, 144–153.
First–order integer–valued autoregressive processes with Generalized Katz innovations
Supplement
This supplement consists of four Appendices. Appendix A provides some properties of the GLK distributions. Appendix B provides proof of the paper’s results. Appendix C contains the simulation results, while Appendix D includes more details on the empirical application.
Appendix A Properties of the GLK distributions
Studying the moments allows for a better understanding of the flexibility of the GLK distribution. The following are four moments relevant to our analysis.
Proposition 5.
Let , define and then
where and .
For a proof, see Janardan [1998] Theorems 1–3.
| (a) Mean () | (b) Index of Dispersion () |
 |
 |
| (c) Skewness () | (d) Kurtosis () |
 |
 |
The skewness and the kurtosis of the distribution are
respectively. For a given value of , there is negative skewness if with and positive otherwise.
Figure A.1 illustrates the effect of the parameter values on the mean, dispersion index, skewness and kurtosis. Increasing the value of (horizontal axis) the distribution allows for different types of dispersion (panel b), for both negative and positive skewness (panel c) and various degrees of excess of kurtosis (panel d).
Appendix B Details of some statements of Section 2
B.1 Connection with generalized Lagrangian distributions
As stated in Remark 1 it is possible to derive the Generalized Lagrangian Katz distribution as a ”generalized Lagrangian distribution”. Let and be two analytic functions of , which are infinitely differentiable in with . Following [Consul & Famoye, 2006, p. 10-11] the general Lagrangian expansion of is
| (B.1) |
where satisfies . The definition of Lagrangian distribution given in Janardan [1998] uses a slightly different expansion, which is obtained from the one given above by replacing with . By applying iteratively the derivative to the product of functions, we obtain the coefficient in the -th term of the expansion
where we set to get the result and the following equivalent Lagrangian expansion used in Janardan [1998]
| (B.2) | |||
| (B.3) |
In particular, if , the function defines the pgf of the ”generalized Lagrangian distribution” provided that for . Assuming and , the expressions in (2) and (1) follows after some algebra as detailed in the following. The expansion coefficients become
Hence
while, for , the -th coefficient of the Lagrangian expansion in Eq. B.2 is
where and is the rising factorial.
We now discuss conditions for which for all .
-
•
If one has for every .
-
•
If , and , then for one has
and hence also
proving that . For one has that is an integer with and hence the product since for one has . This shows that for every .
B.2 Generalized Poisson as limit
One obtains a Lagrangian Katz distribution by replacing by . The LK is one of the few distributions which admit more pgfs. Let us consider the following definition of pgf for a
| (B.4) |
given in [Consul & Famoye, 2006, p. 241]. Defining and the limiting pgf becomes
| (B.5) |
with
| (B.6) |
which is the pgf of the Generalized Poisson given in [Consul & Famoye, 2006, pp. 166].
B.3 Proof of the results in Theorem 4
(i) Under stationarity assumption one has for all , thus which implies .
(ii) Let for all , then . By the law of iterated expectation
and hence
(iii) One has
(iv) Let us denote with the falling factorial and with the -order falling factorial moment of a random variable . The following two results will be used. The relationships between non-central moments and falling factorial moments are
| (B.7) | |||||
| (B.8) |
where and are the Stirling numbers of the I and II kind, respectively [e.g., see Consul & Famoye, 2006, p. 18]. Let and be two random variables then
| (B.9) |
which can be proved by induction. Let a binomial thinning with a discrete random variable, then
| (B.10) |
where . Using the results given above and stationarity (i.e. one obtains
| (B.11) | |||
| (B.12) | |||
| (B.13) |
which implies the -order falling factorial moment of a INAR(1) is
| (B.14) | |||
| (B.15) |
and the -order moment is
| (B.16) |
Appendix C Further simulation results
 |
 |
 |
 |
 |
 |
| Low persistence | High persistence | |||||||||
| , , , , | , , , , | |||||||||
| 0.93 | 0.92 | 0.93 | 0.92 | 0.94 | 0.94 | 0.92 | 0.93 | 0.92 | 0.94 | |
| 0.71 | 0.68 | 0.72 | 0.66 | 0.74 | 0.72 | 0.68 | 0.73 | 0.65 | 0.74 | |
| 0.52 | 0.47 | 0.54 | 0.45 | 0.56 | 0.53 | 0.48 | 0.55 | 0.44 | 0.55 | |
| 0.54 | 0.47 | 0.55 | 0.44 | 0.58 | 0.53 | 0.48 | 0.56 | 0.45 | 0.57 | |
| 0.08 | 0.06 | 0.13 | 0.08 | 0.16 | 0.06 | 0.05 | 0.11 | 0.02 | 0.08 | |
| -0.01 | 0.02 | 0.02 | 0.04 | 0.06 | 0.01 | -0.003 | -0.004 | 0.06 | 0.03 | |
| 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | |
| 0.17 | 0.18 | 0.15 | 0.18 | 0.14 | 0.19 | 0.20 | 0.15 | 0.20 | 0.16 | |
| 17.05 | 16.43 | 17.20 | 16.12 | 17.61 | 17.30 | 16.51 | 17.46 | 16.00 | 17.57 | |
| 5.84 | 5.51 | 6.45 | 5.54 | 6.97 | 5.35 | 5.07 | 6.58 | 4.87 | 6.09 | |
| 0.002 | 0.05 | 0.002 | 0.006 | 0.002 | 0.001 | 0.06 | 0.004 | 0.01 | 0.004 | |
| 0.002 | 0.09 | 0.003 | 0.01 | 0.004 | 0.002 | 0.09 | 0.003 | 0.01 | 0.004 | |
| 1.12 | -2.08 | -0.42 | 0.31 | 1.72 | -0.48 | -0.92 | -0.13 | -1.48 | -0.83 | |
| (0.26) | (0.04) | (0.68) | (0.76) | (0.09) | (0.63) | (0.36) | (0.89) | (0.14) | (0.41) | |
| -1.047 | 0.57 | -1.32 | 0.68 | 1.12 | -1.05 | 0.57 | -1.32 | 0.68 | 1.12 | |
| (0.30) | (0.57) | (0.19) | (0.50) | (0.26) | (0.30) | (0.57) | (0.19) | (0.50) | (0.26) | |
| High-persistence setting | |
 |
 |
 |
 |
 |
 |
| High–persistence setting | |
 |
 |
 |
 |
 |
 |
| Low–persistence setting | |
 |
 |
 |
 |
 |
 |
| Low-persistence setting | |
 |
 |
 |
 |
 |
 |
| High–persistence setting | |
 |
 |
| Low–persistence setting | |
 |
 |
| a) Low persistence regime | b) High persistence regime | |
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
| a) Low persistence regime | b) High persistence regime | |
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
Appendix D Further real data results
| Google search dataset “Climate Change” | |
 |
 |
 |
 |
 |
 |
| Google search dataset “Global Warming” | |
 |
 |
 |
 |
 |
 |
| Climate Change dataset | Climate Warming dataset | |||||||
| Country | GLK | NB | GLK | NB | ||||
| Australia | 0.547 | (0.501,0.589) | -882.43∗ | -885.87 | 0.343 | (0.287,0.397) | -1125.99 | -1120.90∗ |
| Bangladesh | 0.018 | (0.002,0.053) | -1118.68 | -1111.99∗ | 0.001 | (0.001,0.005) | -1166.74 | -1162.50∗ |
| Brazil | 0.011 | (0.001,0.029) | -1187.96 | -1165.17∗ | 0.001 | (0.001,0.002) | -1027.29 | -1024.77∗ |
| Canada | 0.672 | (0.615,0.714) | -711.55∗ | -716.70 | 0.512 | (0.468,0.554) | -1003.35 | -1000.60∗ |
| Emirates | 0.010 | (0.001,0.029) | -1200.72 | -1182.74∗ | 0.005 | (0.001,0.020) | -1158.09 | -1149.59∗ |
| France | 0.184 | (0.127,0.248) | -1069.66 | -1068.36∗ | 0.006 | (0.001,0.019) | -1140.59 | -1130.91∗ |
| Germany | 0.298 | (0.209,0.373) | -1023.87 | -1022.87∗ | 0.021 | (0.001,0.060) | -1099.04 | -1094.57∗ |
| India | 0.499 | (0.420,0.562) | -922.74∗ | -923.57 | 0.482 | (0.417,0.541) | -1019.07 | -1018.57∗ |
| Indonesia | 0.021 | (0.003,0.064) | -1123.06 | -1108.15∗ | 0.253 | (0.193,0.311) | -1195.34 | -1172.30∗ |
| Ireland | 0.333 | (0.279,0.388) | -953.35 | -952.64∗ | 0.001 | (0.001,0.002) | -1093.97 | -1094.39∗ |
| Italy | 0.169 | (0.090,0.241) | -983.83 | -982.26∗ | 0.001 | (0.001,0.004) | -1036.21 | -1034.28∗ |
| Malaysia | 0.002 | (0.001,0.008) | -1171.22 | -1167.40∗ | 0.006 | (0.001,0.031) | -1135.02 | -1129.73∗ |
| Mexico | 0.009 | (0.001,0.031) | -1160.49 | -1148.85∗ | 0.001 | (0.001,0.001) | -1098.96 | -1097.73∗ |
| Netherlands | 0.148 | (0.075,0.218) | -1064.29 | -1061.30∗ | 0.001 | (0.001,0.005) | -1066.26 | -1059.54∗ |
| NewZealand | 0.353 | (0.283,0.412) | -894.23∗ | -895.29 | 0.013 | (0.001,0.044) | -1151.01 | -1136.31∗ |
| Nigeria | 0.129 | (0.068,0.191) | -1043.77 | -1041.80∗ | 0.017 | (0.001,0.062) | -974.18 | -966.83∗ |
| Pakistan | 0.212 | (0.148,0.272) | -1131.60∗ | -1124.74 | 0.023 | (0.001,0.064) | -1135.66 | -1128.55∗ |
| Philippine | 0.409 | (0.354,0.460) | -1069.39 | -1066.66∗ | 0.383 | (0.327,0.432) | -1150.86 | -1138.26∗ |
| Singapore | 0.159 | (0.095,0.222) | -1099.02 | -1094.02∗ | 0.006 | (0.001,0.023) | -1132.94 | -1122.04∗ |
| SouthAfrica | 0.413 | (0.353,0.467) | -923.33∗ | -925.21 | 0.334 | (0.274,0.391) | -865.23∗ | -868.48 |
| Spain | 0.253 | (0.193,0.320) | -883.65∗ | -886.68 | 0.001 | (0.001,0.002) | -1049.48 | -1041.62∗ |
| Thailand | 0.008 | (0.001,0.035) | -1082.74 | -1078.49∗ | 0.004 | (0.001,0.012) | -1218.44 | -1193.67∗ |
| UK | 0.535 | (0.486,0.587) | -932.80∗ | -937.25 | 0.319 | (0.246,0.388) | -1084.84 | -1081.81∗ |
| US | 0.601 | (0.549,0.649) | -867.57∗ | -871.12 | 0.606 | (0.558,0.649) | -941.39∗ | -942.22 |
| Vietnam | 0.003 | (0.001,0.012) | -1189.79 | -1178.82∗ | 0.001 | (0.001,0.001) | -987.59 | -986.21∗ |
| Climate Change dataset | Climate Warming dataset | |||||||
| Country | GLK | NB | GLK | NB | ||||
| Argentina | 0.001 | (0.001,0.001) | -1022.22∗ | -1044.08 | 0.001 | (0.001,0.001) | -803.30∗ | -850.10 |
| Austria | 0.001 | (0.001,0.001) | -1085.17 | -1082.50∗ | 0.001 | (0.001,0.001) | -717.08∗ | -754.18 |
| Belgium | 0.002 | (0.001,0.012) | -1141.59 | -1136.92∗ | 0.001 | (0.001,0.001) | -879.09∗ | -944.73 |
| Colombia | 0.001 | (0.001,0.002) | -1040.35∗ | -1053.91 | 0.001 | (0.001,0.001) | -848.15∗ | -882.50 |
| Denmark | 0.008 | (0.001,0.023) | -1123.97 | -1101.34∗ | 0.002 | (0.001,0.005) | -973.88 | -950.20∗ |
| Egypt | 0.001 | (0.001,0.002) | -1103.36∗ | -1114.87 | 0.001 | (0.001,0.002) | -855.84∗ | -867.85 |
| Ethiopia | 0.002 | (0.001,0.011) | -1089.74 | -1081.68∗ | 0.001 | (0.001,0.001) | -876.11∗ | -914.27 |
| Finland | 0.027 | (0.001,0.084) | -987.30 | -983.16∗ | 0.001 | (0.001,0.001) | -670.46∗ | -679.12 |
| Ghana | 0.003 | (0.001,0.012) | -992.09 | -980.8∗3 | 0.001 | (0.001,0.001) | -854.44∗ | -922.58 |
| Jamaica | 0.001 | (0.001,0.005) | -995.13 | -994.24∗ | 0.001 | (0.001,0.001) | -900.84∗ | -947.66 |
| Greece | 0.001 | (0.001,0.001) | -1070.08∗ | -1095.69 | 0.001 | (0.001,0.001) | -620.97∗ | -687.79 |
| HongKong | 0.005 | (0.001,0.040) | -1116.20 | -1104.70∗ | 0.001 | (0.001,0.001) | -1070.33∗ | -1076.02 |
| Iran | 0.001 | (0.001,0.002) | -1046.05∗ | -1107.53 | 0.001 | (0.001,0.002) | -945.79∗ | -992.93 |
| Israel | 0.001 | (0.001,0.001) | -914.20∗ | -959.02 | 0.001 | (0.001,0.001) | -726.50∗ | -797.23 |
| Japan | 0.008 | (0.001,0.026) | -1209.16 | -1193.53∗ | 0.002 | (0.001,0.004) | -1099.15∗ | -1109.15 |
| Kenya | 0.104 | (0.049,0.170) | -1100.01 | -1092.16∗ | 0.001 | (0.001,0.001) | -1073.55∗ | -1096.71 |
| Lebanon | 0.001 | (0.001,0.001) | -761.11∗ | -776.44 | 0.001 | (0.001,0.001) | -800.14∗ | -850.50 |
| Morocco | 0.001 | (0.001,0.001) | -755.97∗ | -839.02 | 0.001 | (0.001,0.002) | -471.85∗ | -534.09 |
| Mauritius | 0.001 | (0.001,0.002) | -887.72∗ | -926.89 | 0.001 | (0.001,0.001) | -601.12∗ | -655.86 |
| Myanmar | 0.001 | (0.001,0.001) | -917.99∗ | -979.43 | 0.001 | (0.001,0.002) | -602.14∗ | -665.81 |
| Nepal | 0.001 | (0.001,0.001) | -1148.05 | -1145.39∗ | 0.001 | (0.001,0.001) | -1027.36∗ | -1060.00 |
| Norway | 0.016 | (0.003,0.051) | -1121.71 | -1105.17∗ | 0.001 | (0.001,0.001) | -1002.83∗ | -1004.64 |
| Peru | 0.001 | (0.001,0.001) | -915.67∗ | -950.87 | 0.001 | (0.001,0.001) | -666.93∗ | -712.80 |
| Polish | 0.001 | (0.001,0.001) | -1078.86∗ | -1090.00 | 0.001 | (0.001,0.001) | -1000.76∗ | -1063.99 |
| Portugal | 0.002 | (0.001,0.010) | -1035.62 | -1030.57∗ | 0.001 | (0.001,0.001) | -800.35∗ | -851.13 |
| Qatar | 0.001 | (0.001,0.001) | -879.41∗ | -917.09 | 0.001 | (0.001,0.001) | -674.32∗ | -701.04 |
| Romania | 0.001 | (0.001,0.001) | -880.49∗ | -901.20 | 0.001 | (0.001,0.001) | -819.31∗ | -896.17 |
| Russia | 0.001 | (0.001,0.003) | -1038.70∗ | -1050.47 | 0.001 | (0.001,0.001) | -984.09∗ | -1023.75 |
| StHelena | 0.001 | (0.001,0.001) | -873.70∗ | -914.40 | 0.001 | (0.001,0.002) | -374.81∗ | -394.04 |
| SouthKorea | 0.004 | (0.001,0.019) | -1149.02∗ | -1142.78 | 0.001 | (0.001,0.003) | -1051.25∗ | -1057.01 |
| SriLanka | 0.001 | (0.001,0.001) | -1086.31∗ | -1109.74 | 0.001 | (0.001,0.003) | -842.37∗ | -863.17 |
| Sweden | 0.136 | (0.067,0.205) | -1031.72 | -1026.82∗ | 0.001 | (0.001,0.001) | -1078.30∗ | -1089.70 |
| Swiss | 0.028 | (0.005,0.063) | -1055.02 | -1046.17∗ | 0.001 | (0.001,0.001) | -835.78∗ | -878.17 |
| Taiwan | 0.001 | (0.001,0.001) | -1074.92∗ | -1085.60 | 0.001 | (0.001,0.001) | -794.34∗ | -815.63 |
| TrinidadTobago | 0.001 | (0.001,0.001) | -920.81∗ | -955.62 | 0.001 | (0.001,0.001) | -809.94∗ | -858.50 |
| Turkey | 0.004 | (0.001,0.019) | -1095.99 | -1091.08∗ | 0.001 | (0.001,0.001) | -1085.46∗ | -1091.38 |
| Ukraine | 0.001 | (0.001,0.001) | -902.24∗ | -949.78 | 0.001 | (0.001,0.002) | -709.80∗ | -745.82 |
| Hungary | 0.001 | (0.001,0.001) | -935.84 | -953.58∗ | 0.001 | (0.001,0.001) | -642.03∗ | -717.52 |
| Zambia | 0.001 | (0.001,0.003) | -1075.30 | -1053.65∗ | 0.001 | (0.001,0.001) | -746.07∗ | -789.78 |
| Zimbabwe | 0.001 | (0.001,0.002) | -1130.16 | -1128.73∗ | 0.001 | (0.001,0.002) | -658.24∗ | -690.68 |
| Data | Distr. | K | In–sample | Out–of–sample | |||
| DIC | RMSE | CIcov | CIwidth | ||||
| Climate Change | GLK | 2 | 1400.81 | 2.65 | 1 | 14.00 | |
| 3 | 1365.68 | 2.68 | 1 | 14.50 | |||
| NB | 2 | 1399.19 | 2.68 | 1 | 13.10 | ||
| 3 | 1379.05 | 2.68 | 1 | 13.80 | |||
| P | 2 | 1661.23 | 4.36 | 1 | 16.80 | ||
| 3 | 1454.00 | 2.65 | 1 | 12.70 | |||
| Global Warming | GLK | 2 | 1644.95 | 4.86 | 1 | 22.80 | |
| 3 | 1377.39 | 4.67 | 1 | 21.70 | |||
| NB | 2 | 1647.50 | 4.80 | 1 | 21.40 | ||
| 3 | 1590.23 | 4.69 | 1 | 20.60 | |||
| P | 2 | 1653.30 | 5.35 | 1 | 16.80 | ||
| 3 | 1633.60 | 4.98 | 1 | 16.90 | |||
| Country | Climate Change dataset | Global Warming dataset | |||||||||||||
| GLK | NB | GLK | NB | ||||||||||||
| DIC | DIC | DIC | DIC | ||||||||||||
| Argentina | 0.089 | 0.345 | 1619.585∗ | 0.099 | 0.345 | 1780.791 | 0.039 | 0.607 | 1119.311∗ | 0.037 | 0.607 | 1396.970 | |||
| Australia | 0.598 | 0.509 | 1596.879∗ | 0.600 | 0.466 | 1602.322 | 0.352 | 0.170 | 2078.651 | 0.371 | 0.093 | 2070.579∗ | |||
| Austria | 0.090 | 0.108 | 1872.957∗ | 0.100 | 0.099 | 1933.522 | 0.122 | 0.626 | 1074.436∗ | 0.127 | 0.627 | 1363.791 | |||
| Bangladesh | 0.036 | 0.070 | 2045.797∗ | 0.043 | 0.071 | 2055.200 | 0.074 | 0.097 | 1965.099∗ | 0.086 | 0.095 | 2033.827 | |||
| Belgium | 0.148 | 0.169 | 2007.494∗ | 0.170 | 0.160 | 2039.671 | 0.070 | 0.550 | 1294.334∗ | 0.072 | 0.550 | 1544.908 | |||
| Brazil | 0.093 | 0.223 | 2053.698∗ | 0.105 | 0.220 | 2079.390 | 0.074 | 0.193 | 1731.327∗ | 0.079 | 0.188 | 1826.657 | |||
| Canada | 0.672 | 0.508 | 1327.845∗ | 0.664 | 0.495 | 1340.503 | 0.522 | 0.499 | 1879.075 | 0.524 | 0.472 | 1876.222∗ | |||
| Colombia | 0.090 | 0.398 | 1667.121∗ | 0.000 | 0.397 | 1803.969 | 0.192 | 0.553 | 1259.727∗ | 0.198 | 0.552 | 1498.598 | |||
| Denmark | 0.107 | 0.255 | 1898.035∗ | 0.116 | 0.249 | 1948.963 | 0.109 | 0.519 | 1462.477∗ | 0.111 | 0.518 | 1659.000 | |||
| Egypt | 0.066 | 0.244 | 1780.555∗ | 0.071 | 0.241 | 1891.883 | 0.137 | 0.414 | 1347.583∗ | 0.138 | 0.413 | 1563.709 | |||
| Emirates | 0.160 | 0.071 | 2074.214∗ | 0.173 | 0.063 | 2105.633 | 0.135 | 0.256 | 1996.096∗ | 0.143 | 0.248 | 2039.387 | |||
| Ethiopia | 0.104 | 0.153 | 1867.472∗ | 0.106 | 0.150 | 1924.091 | 0.095 | 0.476 | 1337.687∗ | 0.092 | 0.475 | 1572.360 | |||
| Finland | 0.187 | 0.314 | 1724.529∗ | 0.204 | 0.291 | 1784.135 | 0.057 | 0.645 | 1069.114∗ | 0.055 | 0.646 | 1340.069 | |||
| France | 0.168 | 0.496 | 1935.826 | 0.179 | 0.491 | 1933.377∗ | 0.114 | 0.244 | 1951.947∗ | 0.127 | 0.239 | 2007.952 | |||
| Germany | 0.293 | 0.514 | 1896.652 | 0.294 | 0.498 | 1895.353∗ | 0.048 | 0.098 | 2020.428∗ | 0.053 | 0.097 | 2025.436 | |||
| Ghana | 0.151 | 0.240 | 1631.274∗ | 0.163 | 0.221 | 1711.621 | 0.092 | 0.556 | 1253.993∗ | 0.091 | 0.556 | 1512.884 | |||
| Greece | 0.125 | 0.276 | 1692.857∗ | 0.143 | 0.273 | 1837.323 | 0.042 | 0.717 | 860.269∗ | 0.533 | 0.006 | 1225.069 | |||
| HongKong | 0.101 | 0.311 | 1901.765∗ | 0.114 | 0.307 | 1954.842 | 0.163 | 0.315 | 1781.510∗ | 0.183 | 0.307 | 1896.437 | |||
| Hungary | 0.128 | 0.405 | 1476.092∗ | 0.132 | 0.406 | 1663.531 | 0.033 | 0.663 | 931.925∗ | 0.018 | 0.665 | 1256.010 | |||
| India | 0.534 | 0.491 | 1714.041∗ | 0.531 | 0.508 | 1714.829 | 0.636 | 0.511 | 1835.222∗ | 0.635 | 0.505 | 1839.658 | |||
| Indonesia | 0.088 | 0.115 | 1977.859∗ | 0.099 | 0.108 | 1997.493 | 0.361 | 0.162 | 2108.212 | 0.359 | 0.424 | 2102.328∗ | |||
| Iran | 0.105 | 0.362 | 1619.937∗ | 0.111 | 0.361 | 1806.291 | 0.092 | 0.497 | 1391.738∗ | 0.092 | 0.495 | 1625.134 | |||
| Ireland | 0.395 | 0.114 | 1703.061 | 0.431 | 0.047 | 1702.772∗ | 0.162 | 0.218 | 1872.783∗ | 0.182 | 0.197 | 1947.321 | |||
| Israel | 0.059 | 0.499 | 1399.355∗ | 0.059 | 0.499 | 1623.913 | 0.045 | 0.620 | 1070.880∗ | 0.045 | 0.619 | 1364.546 | |||
| Italy | 0.186 | 0.069 | 1779.219∗ | 0.211 | 0.050 | 1780.901 | 0.149 | 0.252 | 1787.010∗ | 0.169 | 0.233 | 1864.037 | |||
| Jamaica | 0.105 | 0.413 | 1646.154∗ | 0.121 | 0.408 | 1765.751 | 0.068 | 0.573 | 1313.182∗ | 0.067 | 0.573 | 1557.623 | |||
| Japan | 0.094 | 0.016 | 2097.733∗ | 0.105 | 0.017 | 2120.688 | 0.071 | 0.264 | 1773.651∗ | 0.076 | 0.263 | 1887.743 | |||
| Kenya | 0.175 | 0.181 | 1929.977∗ | 0.183 | 0.178 | 1938.944 | 0.103 | 0.361 | 1655.868∗ | 0.106 | 0.362 | 1807.085 | |||
| Lebanon | 0.104 | 0.538 | 1165.567∗ | 0.109 | 0.538 | 1420.193 | 0.038 | 0.647 | 1187.075∗ | 0.036 | 0.649 | 1455.428 | |||
| Malaysia | 0.182 | 0.158 | 2070.368∗ | 0.187 | 0.155 | 2079.151 | 0.084 | 0.027 | 2027.732∗ | 0.095 | 0.029 | 2042.069 | |||
| Mauritius | 0.032 | 0.500 | 1326.807∗ | 0.029 | 0.500 | 1566.223 | 0.131 | 0.704 | 945.556∗ | 0.132 | 0.704 | 1272.587 | |||
| Mexico | 0.099 | 0.097 | 2041.225∗ | 0.107 | 0.096 | 2063.796 | 0.134 | 0.266 | 1873.485∗ | 0.142 | 0.263 | 1942.329 | |||
| Morocco | 0.036 | 0.671 | 1059.084∗ | 0.037 | 0.672 | 1363.009 | 0.114 | 0.832 | 625.621∗ | 0.127 | 0.832 | 1009.280 | |||
| Country | Climate Change dataset | Global Warming dataset | |||||||||||||
| GLK | NB | GLK | NB | ||||||||||||
| DIC | DIC | DIC | DIC | ||||||||||||
| Myanmar | 0.096 | 0.488 | 1371.038∗ | 0.093 | 0.487 | 1609.242 | 0.066 | 0.738 | 813.777∗ | 0.066 | 0.738 | 1166.376 | |||
| Nepal | 0.109 | 0.136 | 1965.494∗ | 0.116 | 0.132 | 2023.832 | 0.104 | 0.432 | 1593.188∗ | 0.115 | 0.430 | 1769.996 | |||
| Netherlands | 0.147 | 0.496 | 1972.367 | 0.152 | 0.488 | 1969.887∗ | 0.055 | 0.315 | 1792.008∗ | 0.000 | 0.314 | 1890.708 | |||
| NewZealand | 0.362 | 0.492 | 1659.492∗ | 0.370 | 0.356 | 1662.115 | 0.158 | 0.322 | 1980.746∗ | 0.167 | 0.320 | 2033.827 | |||
| Nigeria | 0.161 | 0.097 | 1932.834∗ | 0.170 | 0.084 | 1934.833 | 0.106 | 0.122 | 1719.025∗ | 0.120 | 0.085 | 1766.515 | |||
| Norway | 0.137 | 0.259 | 1890.741∗ | 0.151 | 0.255 | 1943.169 | 0.067 | 0.413 | 1639.325∗ | 0.073 | 0.412 | 1794.887 | |||
| Pakistan | 0.252 | 0.099 | 2043.832 | 0.259 | 0.093 | 2043.666∗ | 0.114 | 0.068 | 2047.780∗ | 0.116 | 0.064 | 2052.311 | |||
| Peru | 0.123 | 0.465 | 1387.617∗ | 0.115 | 0.463 | 1602.407 | 0.054 | 0.687 | 937.838∗ | 0.052 | 0.688 | 1255.208 | |||
| Philippine | 0.497 | 0.493 | 1921.648 | 0.498 | 0.494 | 1917.078∗ | 0.409 | 0.065 | 2064.834 | 0.411 | 0.060 | 2063.957∗ | |||
| Polish | 0.069 | 0.229 | 1767.794∗ | 0.077 | 0.229 | 1882.671 | 0.090 | 0.401 | 1560.757∗ | 0.096 | 0.400 | 1752.885 | |||
| Portugal | 0.041 | 0.277 | 1727.197∗ | 0.041 | 0.273 | 1827.148 | 0.031 | 0.587 | 1215.954∗ | 0.030 | 0.586 | 1478.256 | |||
| Qatar | 0.058 | 0.520 | 1291.855∗ | 0.064 | 0.521 | 1539.752 | 0.042 | 0.554 | 1006.056∗ | 0.041 | 0.551 | 1307.701 | |||
| Romania | 0.097 | 0.458 | 1351.055∗ | 0.098 | 0.457 | 1558.692 | 0.053 | 0.626 | 1211.659∗ | 0.052 | 0.625 | 1477.310 | |||
| Russia | 0.075 | 0.368 | 1553.053∗ | 0.075 | 0.370 | 1720.946 | 0.082 | 0.449 | 1524.936∗ | 0.081 | 0.448 | 1715.720 | |||
| Singapore | 0.199 | 0.165 | 2010.912 | 0.207 | 0.158 | 2009.881∗ | 0.072 | 0.073 | 2002.081∗ | 0.087 | 0.066 | 2035.269 | |||
| SouthAfrica | 0.522 | 0.388 | 1630.689∗ | 0.530 | 0.435 | 1632.432 | 0.418 | 0.120 | 1570.317∗ | 0.441 | 0.084 | 1571.766 | |||
| SouthKorea | 0.054 | 0.020 | 2025.651∗ | 0.061 | 0.021 | 2046.260 | 0.067 | 0.415 | 1599.901∗ | 0.071 | 0.415 | 1755.566 | |||
| Spain | 0.246 | 0.518 | 1651.155∗ | 0.253 | 0.414 | 1655.710 | 0.126 | 0.312 | 1759.649∗ | 0.133 | 0.306 | 1850.803 | |||
| SriLanka | 0.050 | 0.345 | 1670.538∗ | 0.050 | 0.341 | 1818.467 | 0.044 | 0.517 | 1268.525∗ | 0.042 | 0.516 | 1515.381 | |||
| StHelena | 0.132 | 0.484 | 1338.414∗ | 0.133 | 0.482 | 1572.449 | 0.080 | 0.817 | 594.577∗ | 0.583 | 0.007 | 860.226 | |||
| Sweden | 0.160 | 0.262 | 1883.905∗ | 0.169 | 0.257 | 1899.062 | 0.060 | 0.347 | 1829.726∗ | 0.066 | 0.345 | 1935.821 | |||
| Swiss | 0.083 | 0.087 | 1888.159∗ | 0.090 | 0.075 | 1913.949 | 0.098 | 0.551 | 1283.276∗ | 0.098 | 0.550 | 1529.698 | |||
| Taiwan | 0.116 | 0.324 | 1714.102∗ | 0.119 | 0.322 | 1839.746 | 0.126 | 0.460 | 1245.494∗ | 0.119 | 0.460 | 1483.356 | |||
| Thailand | 0.132 | 0.022 | 1928.947∗ | 0.143 | 0.023 | 1948.096 | 0.027 | 0.154 | 2014.468∗ | 0.029 | 0.152 | 2072.000 | |||
| TrinidadTobago | 0.077 | 0.447 | 1359.122∗ | 0.076 | 0.446 | 1587.225 | 0.114 | 0.585 | 1217.544∗ | 0.109 | 0.586 | 1477.778 | |||
| Turkey | 0.096 | 0.373 | 1854.282∗ | 0.106 | 0.370 | 1927.291 | 0.135 | 0.480 | 1793.179∗ | 0.148 | 0.478 | 1905.162 | |||
| UK | 0.571 | 0.510 | 1696.845∗ | 0.568 | 0.454 | 1701.288 | 0.322 | 0.507 | 2016.025 | 0.324 | 0.498 | 2012.407∗ | |||
| Ukraine | 0.111 | 0.457 | 1349.152∗ | 0.113 | 0.458 | 1578.258 | 0.049 | 0.597 | 1002.874∗ | 0.048 | 0.595 | 1311.657 | |||
| US | 0.632 | 0.520 | 1623.722∗ | 0.624 | 0.506 | 1634.120 | 0.636 | 0.509 | 1761.454∗ | 0.632 | 0.511 | 1765.975 | |||
| Vietnam | 0.100 | 0.149 | 2053.407∗ | 0.109 | 0.147 | 2091.799 | 0.212 | 0.180 | 1777.152∗ | 0.336 | 0.035 | 1804.133 | |||
| Zambia | 0.102 | 0.262 | 1736.355∗ | 0.111 | 0.254 | 1849.733 | 0.131 | 0.589 | 1111.358∗ | 0.123 | 0.588 | 1396.448 | |||
| Zimbabwe | 0.170 | 0.308 | 1808.413∗ | 0.192 | 0.303 | 1913.692 | 0.050 | 0.659 | 862.586∗ | 0.049 | 0.661 | 1197.766 | |||