First-Order Bilevel Topology Optimization for Fast Mechanical Design
Abstract
Topology Optimization (TO), which maximizes structural robustness under material weight constraints, is becoming an essential step for the automatic design of mechanical parts. However, existing TO algorithms use the Finite Element Analysis (FEA) that requires massive computational resources. We present a novel TO algorithm that incurs a much lower iterative cost. Unlike conventional methods that require exact inversions of large FEA system matrices at every iteration, we reformulate the problem as a bilevel optimization that can be solved using a first-order algorithm and only inverts the system matrix approximately. As a result, our method incurs a low iterative cost, and users can preview the TO results interactively for fast design updates. Theoretical convergence analysis and numerical experiments are conducted to verify our effectiveness. We further discuss extensions to use high-performance preconditioners and fine-grained parallelism on the Graphics Processing Unit (GPU).
Index Terms:
Topology Optimization, Bilevel Optimization, Low-Cost Robotics, Mechanisms and DesignI Introduction
Several emerging techniques over the past decade are contributing to the new trend of lightweight, low-cost mechanical designs. Commodity-level additive manufacturing has been made possible using 3D printers and user-friendly modeling software, allowing a novice to prototype devices, consumer products, and low-end robots. While the appearance of a mechanical part is intuitive to perceive and modify, other essential properties, such as structural robustness, fragility, vibration frequencies, and manufacturing cost, are relatively hard to either visualize or manage. These properties are highly related to the ultimate performance criteria, including flexibility, robotic maneuverability, and safety. For example, the mass and inertia of a collaborative robot should be carefully controlled to avoid harm to the human when they collide. For manipulators on spaceships, the length of each part should be optimized to maximize the end-effector reachability under strict weight limits. Therefore, many mechanical designers rely on TO methods to search for the optimal structure of mechanical parts by tuning their center-of-mass [1], inertia [2], infill pattern [3], or material distribution [4].

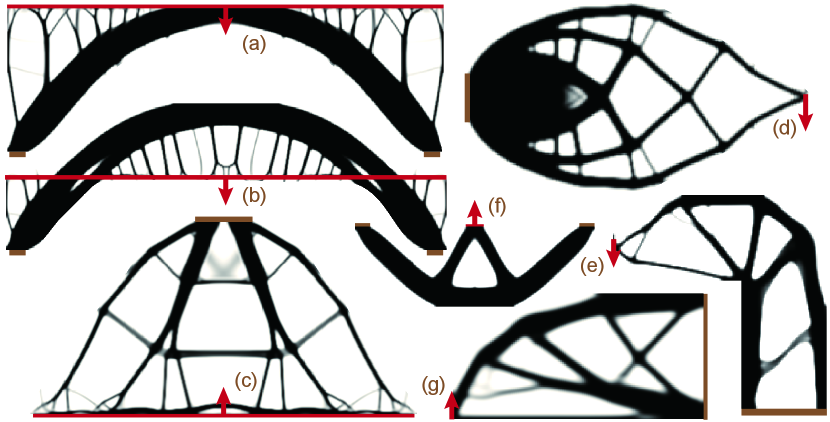
Unfortunately, the current TO algorithms [6] pose a major computational bottleneck. Indeed, TO algorithms rely on FEA to predict the relationship between the extrinsic (boundary loads) and intrinsic status (stress, strain, and energy densities) of a mechanical part. Such predictions are made by solving systems of (non-)linear equations during each iteration of TO. The design space and resulting system size are often gigantic when designing fine-grained material shapes. For example, an design space illustrated in Figure 1 incurs decision variables. Prior works make full use of high-end GPU [7] or many-core CPU [8, 9] to solve such problems. Even after such aggressive optimization, the total time spent on FEA is typically at the level of hours. As a result, mechanical engineers cannot modify or preview their designs without waiting for tens of minutes or even hours, which significantly slow down the loops of design refinement.
Main Results: We propose a low-cost algorithm that solves a large subclass of TO problems known as Solid Isotropic Material with Penalization (SIMP) [10]. The SIMP model is widely used to search for fine-grained geometric shapes by optimizing the infill levels. Our main observation is that, in conventional TO solvers, the computation resources are predominated by solving the system of equations to the machine precision. We argue that pursuing such precision for intermediary TO iterations is unnecessary as one only expects the system to be exactly solved on final convergence. Therefore, we propose to maintain an approximate solution that is refined over iterations. We show that such a TO solver corresponds to a bilevel reformulation of the SIMP problems (Section III). We further propose a first-order algorithm to solve these bilevel problems with guaranteed convergence to a first-order critical point (Section IV) of moderate accuracy. Compared with conventional TO algorithms [6], our method incurs a much lower iterative cost of ( is the number of decision variables), allowing the mechanical designers to interactively preview the TO results and accelerate the loops of design refinement. We then discuss several useful extensions including different preconditioning schemes for refining the approximate solutions (Section IV-A) and a GPU-based implementation that achieves an asymptotic iterative cost of (Section IV-C). We highlight the effectiveness of our method through a row of 2D benchmark problems from [11, 12, 13] (Section V), where our iterative cost can be as low as ms when handling a resolution of up to k grid cells.
II Related Work
We review representative TO formulations, numerical solvers for TO problems, and bilevel optimizations.
TO Formulations & Applications: Generally speaking, TO involves all mathematical programming problems that use geometric shapes as decision variables. A TO problem has three essential component: geometric representations, governing system of equations, and design objectives/constraints. The SIMP model [10] uses density-based representation where the geometric shape is discretized using FEA and decision variables are the infill levels of discrete elements. There are other popular representations. For example, truss optimization [14] uses the decision variables to model the discrete beam existence. Infill pattern optimization [3] searches for the local arrangements of shape interiors. Compared with the SIMP model, these formulations typically induce much fewer decision variables due to simplicity of shapes or locality.
In terms of governing system of equations, the SIMP model assumes linearized elastic models, which means that the extrinsic and intrinsic properties of a mechanical part are linearly related. Linear models make fairly accurate predictions under the small-deformation assumption, which is the case with most mechanical design problems with rigid parts. For large deformations, there are extensions to the SIMP model that use nonlinear elastic models [15, 16] or even elastoplastic models [17]. However, the use of these nonlinear, non-convex models induces optimization problems of a more complex class than the SIMP model [18], for which our analysis does not apply. In a similar fashion as SIMP, truss optimization [19] has small- and large-deformation variants. We speculate that similar ideas and analysis apply for truss optimization problems under small-deformations.
TO formulations deviate from each other mostly due to their design objectives and constraints. The SIMP model minimizes the total potential energy under a single external load and a total-volume constraint. Standard SIMP model does not have constraints to limit deformations, but there are extensions to include strain/stress constraints [20]. Unfortunately, stress-constrained formulations also induce a more complex problem class, where our analysis does not apply. Yet another extension to the SIMP model [21, 22, 23] is to consider multiple or uncertain external loads. Such extension is favorable because a mechanical system can undergo a variety of unknown extrinsic situations. We speculate it is possible to adapt our method to these cases by sampling the uncertain situations and use our method as underlying solvers for each sampled scenario.
Numerical TO Solvers: Three categories of numerical approaches have been extensively used: truncated gradient method, general-purpose method, and hierarchical method. The reference implementation [10] of the SIMP solver uses the heuristic, truncated gradient method [24]. This method first computes the exact gradient and then updates the design along the negative gradient direction using heuristic step sizes. Although the convergence of these heuristic schemes is hard to analyze, they perform reasonably well in practice and are thus widely used, e.g. in [12]. General-purpose methods are off-the-shelf optimization algorithms (e.g., sequential quadratic programming (SQP)/interior point method [25], and augmented Lagrangian method (ALM) [26]). The generality of these solvers makes it easier to experiment with different TO formulations. Without problem-specific optimization, however, they typically scale poorly to the high-dimensional decision space of practical problems. In particular, the (Globally Convergent) Method of Moving Asymptotes (GCMMA) [27] is a special form of SQP that can handle a large set of box constraints, making it particularly suitable for SIMP-type problems. Finally, solving problem in a hierarchical approach is an attempting way to tackle high-dimensional problems. [28] [28] used a quadtree to focus computational resources on the material boundaries. The multigrid method [12, 29] constructs a hierarchy of grids to accelerate FEA system solves.
Bilevel Optimization [18]: When a constraint of an optimization problem (high-level problem) involves another optimization (low-level problem), the problem is considered bilevel. In our formulation, the high-level problem optimizes the material infill levels, while the low-level problem performs the FEA analysis. Bilevel problems frequently arise in robotics for time optimality [30], trajectory search [31], and task-and-motion planning [32]. As a special case considered in our method, if the low-level problem is strictly convex, then its solution is unique and the low-level problem can be replaced by a well-defined solution mapping function. This treatment essentially reduces the bilevel to a single-level optimization. Otherwise, low-level problem can be non-convex and the solution map is multi-valued, where additional mechanism is needed to compare and select low-level solutions (e.g., a maximum- or minimum-value function can be used and the associated problem is NP-hard [33]). It is noteworthy that oftentimes an arbitrary solution of the low-level problem suffice, in which case penalty method [34] can be used to approximate one of the solutions on the low-level. Bilevel formulation has been used in TO community for years, but prior works resort to off-the-shelf solvers [35] or machine learning [36] to (approximately) solve the underlying optimization problem, while we utilize the special structure of the SIMP model to design our efficient, first-order method.
III Problem Formulation
In this section we introduce the SIMP model using notations in [12]. (see Table II in our appendix for a list of symbols) This model uses FEA to discretize a mechanical part governed by the linear elastic constitutive law. If the material is undergoing an internal displacement where is the material domain, then the internal potential energy is accumulated according to the constitutive law as follows:
where is the potential energy functional, is the spatially varying stiffness tensor parameterized by infinite-dimensional decision variable that determines the infill levels. FEA discretizes the material domain into a set of elements each spanning the sub-domain . The elements are connected by a set of nodes. By restricting to a certain finite-dimensional functional space (the shape space), the potential energy can be written as the following sum over elements:
Here is the stiffness matrix of the th element, is the stiffness matrix assembled from . With a slight abuse of notation, we denote as a finite-dimensional potential energy function, without bracket as a vector of 2D nodal displacements ( in 3D), and without bracket as a vector of elementwise infill levels. The SIMP model is compatible with all kinds of FEA discretization scheme and the case with regular grid is illustrated in Figure 2.

Suppose an external force is exerted on the mechanical part, then the total (internal+external) potential energy is:
SIMP model works with arbitrary force setup, but external forces are only applied to the boundary in practice. For example, if only the th boundary node is under a force , then we have with being the unit vector. The equilibrium state is derived by minimizing with respect to , giving (Figure 2a). As the name suggests the two variables are linearly related under the linear elastic constitutive law. The goal of TO is to minimize the induced internal potential energy due to :
| (1) |
where is a compact, convex set bounding away from potentially singular configurations. Several widely used stiffness matrix parameterization of includes the linear law or the power law where is some constant. In both cases, we need to choose such that the spectrum of is bounded from both sides:
| (2) |
for any , where is the eigenvalues of a matrix. A typical choice of to this end is:
where is the infill level of the th element, is the minimal elementwise infill level, is the total infill level, and are the all-one and all-zero vectors, respectively. In this work, we use the following more general assumption on the stiffness matrix parameterization and the shape of :
Assumption III.1.
is a compact polytopic subset of , on which Equation 2 holds and is smooth.
Remark III.2.
The compactness of is obvious. is also polytopic because we only have linear constraints, which is essential when we measure optimality using relative projection error (see Section IV for details). Assumption III.1 is more general than the standard SIMP model. Indeed, can be parameterized using any smooth activation function for the th element as , which obviously satisfies Assumption III.1 as long as is bounded from both above and below on , away from zero. Our assumption also allows a variety of topology modifications and constraints, some of which are illustrated here: Symmetry-Constraint: We can plug in a left-right symmetric mapping matrix and define where is the infill levels for the left-half of the material block. Component-Cost-Constraint: A mechanical part can be divided into different sub-components and the amount of material can be assigned for each component as follows:
where is the number of sub-components, is the sub-vector of consisting of decision variables for the th component, and is the total allowed amount of material for that sub-component. Material-Filtering: [37] [37] proposed to control the thickness of materials by filtering the infill levels using some convolutional kernel denoted as . As long as the convolution operator is smooth, Assumption III.1 holds by plugging in .
All the conventional methods such as the (GC)MMA [38, 27], SQP [5, 25], and [12] for solving Equation 1 involve computing the exact gradient via sensitivity analysis (Figure 2b):
where we have used the derivatives of the matrix inverse. The major bottleneck lies in the computation of that involves exact matrix inversion. Here we assume that is a third-order tensor of size and its left- or right-multiplication means contraction along the first and second dimension. Note that the convergence of GCMMA and SQP solvers rely on the line-search scheme that involves the computation of objective function values, which in turn requires matrix inversion. Practical methods [12] and [10] avoid the line-search schemes using heuristic step sizes. Although working well in practice, the theoretical convergence of these heuristic rules is difficult to establish.
IV Bilevel Topology Optimization
In this section, we first propose our core framework to solve SIMP problems that allows inexact matrix inversions. We then discuss extensions to accelerate convergence via preconditioning (Section IV-A) and fast projection operators (Section IV-B). Finally, we briefly discuss parallel algorithm implementations (Section IV-C). Inspired by the recent advent of first-order bilevel optimization algorithms [39, 40, 41], we propose to reformulation Equation 1 as the following bilevel optimization:
| (3) | ||||
| s.t. |
The low-level part of Equation 3 is a least-square problem in and, since is always positive definite when , the low-level solution is unique. Plugging the low-level solution into the high-level objective function and Equation 1 is recovered. The first-order bilevel optimization solves Equation 3 by time-integrating the discrete dynamics system as described in Algorithm 1 and we denote this algorithm as First-Order Bilevel Topology Optimization (FBTO). The first line of Algorithm 1 is a single damped Jacobi iteration for refining the low-level solution using an adaptive step size of . But instead of performing multiple Jacobi iterations until convergence, we go ahead to use the inexact result after one iteration for sensitivity analysis. Finally, we use a projected gradient descend to update the infill levels with an adaptive step size of .
Here is the projection onto the convex set under Euclidean distance. This scheme has linear iterative cost of as compared with conventional method that has superlinear iterative cost due to sparse matrix inversions (some operations of Algorithm 1 have a complexity of but we know that ).
Remark IV.1.
The succinct form of our approximate gradient ( in Line 3) makes use of the special structure of the SIMP model, which is not possible for more general bilevel problems. If a general-purpose first-order bilevel solver is used, e.g. [39] and follow-up works, one would first compute/store and then approximate via sampling. Although the stochastic approximation scheme does not require exact matrix inversion, they induce an increasing number of samples with a larger number of iterations. Instead, we make use of the cancellation between in the high-level objective and in the low-level objective to avoid matrix inversion or its approximations, which allows our algorithm to scale to high dimensions without increasing sample complexity.
As our main result, we show that Algorithm 1 is convergent under the following choices of parameters.
Assumption IV.2.
We choose constant and some constant satisfying the following condition:
| (4) |
Assumption IV.3.
Define and suppose , we choose the following uniformly bounded sequence with constant :
where is the finite upper bound of on .
Assumption IV.4.
We choose as follows:
for positive constants , where is the L-constant of and is the upper bound of the Frobenius norm of when .
Assumption IV.5.
We choose positive constants satisfying the following condition:
Theorem IV.6.
We prove Theorem IV.6 in Section VIII where we further show that the high-level optimality error scales as , so that should be as small as possible for the best convergence rate. Direct calculation leads to the constraint of from the first two conditions of Assumption IV.5, so the convergence rate can be arbitrarily close to as measured by the following relative projection error [42]:
Although our analysis of convergence uses a similar technique as that for the two-timescale method [40], our result is only single-timescale. Indeed, the low-level step size can be constant and users only need to tune a decaying step size for . We will further show that certain versions of our algorithm allow a large choice of (see Section IX-E). In addition, our formula for choosing does not rely on the maximal number of iterations of the algorithm.
IV-A Preconditioning
Our Algorithm 1 uses steepest gradient descend to solve the linear system in the low-level problem, which is known to have a slow convergence rate of [43] with being the condition number of the linear system matrix. A well-developed technique to boost the convergence rate is preconditioning [44], i.e., pre-multiplying a symmetric positive-definite matrix that approximates whose inverse can be computed at a low-cost. Preconditioning is a widely used technique in the TO community [12, 45] to accelerate the convergence of iterative linear solvers in solving . In this section, we show that FBTO can be extended to this setting by pre-multiplying in the low-level problem and we name Algorithm 2 as Pre-conditioned FBTO or PFBTO. Algorithm 2 is solving the following different bilevel program from Equation 3:
| (5) | ||||
| s.t. |
where the only different is the low-level system matrix being squared to . Since is non-singular, the two problems have the same solution set. Equation 5 allows us to multiply twice in Algorithm 2 to get the symmetric form of . To show the convergence of Algorithm 2, we only need the additional assumption on the uniform boundedness of the spectrum of :
Assumption IV.7.
For any , we have:
Assumption IV.7 holds for all the symmetric-definite preconditioners. The convergence can then be proved following the same reasoning as Theorem IV.6 with a minor modification summarized in Section VIII-E. Our analysis sheds light on the convergent behavior of prior works using highly efficient preconditioners such as geometric multigrid [12, 45] and conjugate gradient method [46]. We further extend these prior works by enabling convergent algorithms using lightweight preconditioners such as Jacobi/Gauss-Seidel iterations and approximate inverse schemes, to name just a few. The practical performance of Algorithm 2 would highly depend on the design and implementation of specific preconditioners.
On the down side of Algorithm 2, the system matrix in the low-level problem of Equation 5 is squared and so is the condition number. Since the convergence speed of low-level problem is , squaring the system matrix can significantly slow down the convergence, counteracting the acceleration brought by preconditioning. This is because we need to derive a symmetric operator of form . As an important special case, however, only a single application of suffice if commutes with , leading to the Commutable PFBTO or CPFBTO Algorithm 3. A useful commuting preconditioner is the Arnoldi process used by the GMRES solver [47], which is defined as:
| (6) | ||||
where is the size of Krylov subspace. By sharing the same eigenvectors, is clearly commuting with . This is a standard technique used as the inner loop of the GMRES solver, where the least square problem Equation LABEL:eq:LSP is solved via the Arnoldi iteration. The Arnoldi process can be efficiently updated through iterations if is fixed, which is not the case with our problem. Therefore, we choose the more numerically stable Householder QR factorization to solve the least square problem, and we name Equation LABEL:eq:LSP as Krylov-preconditioner.
To show the convergence of Algorithm 3, we use a slightly different analysis summarized in the following theorem:
Assumption IV.8.
We choose constant and some constant satisfying the following condition:
| (7) |
Assumption IV.9.
Define and suppose , we choose the following uniformly bounded sequence with constant :
where is the finite upper bound of on .
Assumption IV.10.
We choose as follows:
for some positive constants , where is the L-coefficient of ’s Frobenius norm on .
Theorem IV.11.
IV-B Efficient Implementation
We present some practical strategies to further accelerate the computational efficacy of all three Algorithm 1,2,3 that are compatible with our theoretical analysis. First, the total volume constraint is almost always active as noted in [38]. Therefore, it is useful to maintain the total volume constraint when computing the approximate gradient. If we define the approximate gradient as and consider the total volume constraint , then a projected gradient can be computed by solving:
with the analytic solution being . In our experiments, using in place of in the last line of FBTO algorithms can boost the convergence rate at an early stage of optimization.
Second, the implementation of the projection operator can be costly in high-dimensional cases. However, our convex set typically takes a special form that consists of mostly bound constraints with only one summation constraint . Such a special convex set is known as a simplex and a special algorithm exists for implementing the as proposed in [48]. Although the original algorithm [48] only considers the equality constraint and single-sided bounds , a similar technique can be adopted to handle our two-sided bounds and inequality summation constraint and we provide its derivation for completeness. We begin by checking whether the equality constraint is active. We can immediately return if . Otherwise, the projection operator amounts to solving the following quadratic program:
whose Lagrangian and first-order optimality conditions are:
where are Lagrange multipliers. We can conclude that and the following equality holds due to the constraint being active:
| (8) |
which is a piecewise linear equation having at most pieces. There are left-nodes in the form of and right-nodes in the form of , separating different linear pieces. The piecewise linear equation can be solved for and thus by first sorting the nodes at the cost of and then looking at each piece for the solution. We summarize this process in Algorithm 4 where we maintain the sorted end points of the line segments via running sums.
IV-C Fine-Grained Parallelism

Prior work [12] proposes to accelerate TO solver on GPU, but they require a complex GPU multgrid implementation which is also costly to compute per iteration. In comparison, our Algorithm 1,2,3 can make full use of many-core hardwares with slight modifications. In this section, we discuss necessary modifications for a GPU implementation assuming the availability of basic parallel scan, reduction, inner-product, and radix sort operations [49]. A bottleneck in Algorithm 1,2,3 is matrix-vector production , of which the implementation depends on the type of FEA discretization. If the discretization uses a regular pattern, such as a regular grid in Figure 2, then the element-to-node mapping is known and can be hard coded, so the computation for each node is independent and costs if thread blocks are available. For irregular discretizations, we have to store the sparse matrix explicitly and suggest using a parallel sparse matrix-vector product routine [50]. To implement the Krylov-preconditioner, we perform in-place QR factorization to solve for . The in-place QR factorization involves computing the inner-product for times and then solving the upper-triangular system. Altogether, the least square solve in Equation LABEL:eq:LSP costs when threads are available. Here we use a serial implementation of the upper-triangular solve, which is not a performance penalty when . Finally, Algorithm 4 involves one radix sort that costs and three for loops, the first and last for loops do not have data dependency and cost . The second for loop accumulates two variables () that can be accomplished by a parallel scan taking . In summary, the cost of each iteration of Algorithm 1,2,3 can be reduced to when threads are available. We profile the parallel acceleration rate in Figure 4.

|

|



V Experiments
In this section, we compare our most efficient Algorithm 3 with other methods that can provide convergence guarantee. We implement our method using native C++ on a laptop machine with a 2.5G 6-core Intel i7 CPU and a 1.48G Nvidia GTX 1060 mobile GPU having 1280 cores. Our implementation makes full use of the cores on CPU via OpenMP and GPU via Cuda and we implement the regular grid FEA discretization. In all the examples, we apply a separable Gaussian kernel as our material filter (see Remark III.2), which can be implemented efficiently on GPU as a product of multiple linear kernels. We found that a kernel achieves the best balance between material thickness and boundary sharpness. Unless otherwise stated, we choose Algorithm 3 with for our Krylov-preconditioner in all the experiments where varies across different experiments. We justify these parameter choices in Section IX-E. For the three algorithms in Section IV, we terminate when the relative change to infill levels over two iterations () is smaller than and the absolute error of the linear system solve () is smaller than , which can be efficiently checked on GPU by using a reduction operator that costs . The two conditions are measuring the optimality of the high- and low-level problems, respectively. The later is otherwise known as the tracking error, which measures how closely the low-level solution follows its optima as the high-level solution changes. We choose 7 benchmark problems from [11, 12, 13] to profile our method as illustrated in Figure 3 and summarized in Table I. Our iterative cost is at most ms when handling a grid resolution of , which allows mechanical designers to quickly preview the results.
| Benchmark | Res. | Frac. | #Iter. |
|
|
Mem. | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Figure 1 | ||||||||||
| Figure 3a | ||||||||||
| Figure 3b | ||||||||||
| Figure 3c | ||||||||||
| Figure 3d | ||||||||||
| Figure 3e | ||||||||||
| Figure 3f | ||||||||||
| Figure 3g |
Convergence Analysis
We highlight the benefit of using approximate matrix inversions by comparing our method with Projected Gradient Descent (PGD). Using a single-level formulation, PGD differs from Algorithm 3 by using exact matrix inversions, i.e., replacing Line 2 with . We profile the empirical convergence rate of the two formulations in Figure 5 for solving the benchmark problem in Figure 1. The comparisons on other benchmark problems are given in Section VII. Since exact, sparse matrix factorization prevents PGD from being implemented on GPU efficiently, our method allows fine-grained parallelism and is much more GPU-friendly. For comparison, we implement other steps of PGD on GPU while revert to CPU for sparse matrix factorization. As shown in Figure 5a, the high- and low-level error in our method suffers from some local fluctuation but they are both converging overall. We further plot the evolution of exact energy value . After about s of computation, our method converges to a better optima, while PGD is still faraway from convergence as shown in Figure 5b. We further notice that our method would significantly increase the objective function value at an early stage of optimization. This is because first-order methods rely on adding proximal regularization terms to the objective function to form a Lyapunov function (see e.g. [51]). Although our analysis is not based on Lyapunov candidates, we speculate a similar argument to [51] applies.
Parameter Sensitivity
When setting up the SIMP problem, the user needs to figure out the material model and external load profile . We use linear elastic material relying on Young’s modulus and Poisson’s ratio. We always set Young’s modulus to and normalize the external force , since these two parameters only scale the objective function without changing the solutions. When solving the SIMP problem, our algorithm relies on two critical parameters: initial high-level step size and Krylov subspace size for preconditioning. We profile the sensitivity with respect to in Figure 6 for benchmark problem in Figure 3e. We find our method convergent over a wide range of , although an overly large could lead to excessive initial fluctuation. In practice, matrix-vector product is the costliest step and takes up of the computational time, so the iterative cost is almost linear in . As illustrated in Figure 7, Algorithm 1 would require an extremely small and more iterations to converge, while Algorithm 3 even with a small can effectively reduce the low-level error and allow a wide range of choices for , leading to a faster overall convergence speed. We profiled the sensitivity to subspace size in Figure 8, and we observe convergent behaviors for all when , so we choose in all examples and only leave to be tuned by users.

Comparison with SQP
SQP is an off-the-shelf algorithm that pertains global convergence guarantee [5] and have been used for topology optimization. We conduct comparisons with SQP on the benchmark problem in Figure 3c. We use the commercial SQP solver [52] where we avoid computing the exact Hessian matrix of via L-BFGS approximation and we avoid factorizing the approximate Hessian matrix using a small number of conjugate gradient iterations. The comparisons are conducted at a resolution of , which is one third that of Figure 3c. Using an exact Hessian factorization or a larger resolution in SQP would use up the memory of our desktop machine. As shown in Figure 9, our method converges to an approximate solution much quicker than SQP, allowing users to preview the results interactively. Such performance of our method is consistent with many other first-order methods, e.g., the Alternating Method Direction of Multiplier (ADMM), which is faster in large-scale problems and converges to a solution of moderate accuracy, while SQP takes longer to converge to a more accurate solution.
Comparison with ALM
ALM formulates both as decision variables and treat FEA as additional hard constraints:
By turning the hard constraints into soft penalty functions via the augmented Lagrangian penalty term, ALM stands out as another solver for TO that allows inexact matrix inversions. Although we are unaware of ALM being used for TO problems, it has been proposed to solve general bilevel programs in [34]. We compare our method with the widely used ALM solver [53]. As the major drawback, ALM needs to square the FEA system matrix , which essentially squares its condition number and slows down the convergence. We have observed this phenomenon in Figure 10, where we run ALM at a resolution of which is one-sixth that of Figure 3c. Even at such a coarse resolution, ALM cannot present meaningful results until after s (hr) that is much longer than either FBTO or SQP. Our Algorithm 2 suffers from the same problem of squaring the system matrix. Therefore, we suggest using Algorithm 2 only when one has a highly efficient, non-commuting preconditioner such as a geometric multigrid.
VI Conclusion & Limitation
We present a novel approach to solve a large subclass of TO problems known as the SIMP model. Unlike classical optimization solvers that perform the exact sensitivity analysis during each iteration, we propose to use inexact sensitivity analysis that is refined over iterations. We show that this method corresponds to the first-order algorithm for a bilevel reformulation of TO problems. Inspired by the recent analytical result [39], we show that this approach has guaranteed convergence to a first-order critical point of the original problem. Our new approach leads to low-iterative cost and allows interactive result preview for mechanical designers. We finally discuss extensions to use preconditioners and fine-grained GPU parallelism. Experiments on several 2D benchmarks from [11, 12, 13] highlight the computational advantage of our method.
An inherent limitation of our method is the requirement to estimate step size parameters . We have shown that is fixed and our results are not sensitive to , but users still need to give a rough estimation of that can affect practical convergence speed. Further, our first-order solver is based on plain gradient descendent steps, for which several acceleration schemes are available, e.g. Nesterov [54] and Anderson [55] accelerations. The analysis of these techniques are left as future works. Finally, when additional constraints are incorporated into the polytopic set or non-polytopic constraints are considered, our analysis needs to be adjusted and the efficacy of Algorithm 4 might be lost.
References
- [1] Jun Wu, Lou Kramer and Rüdiger Westermann “Shape interior modeling and mass property optimization using ray-reps” In Computers & Graphics 58 Elsevier, 2016, pp. 66–72
- [2] Moritz Bächer, Emily Whiting, Bernd Bickel and Olga Sorkine-Hornung “Spin-It: Optimizing Moment of Inertia for Spinnable Objects” In ACM Trans. Graph. 33.4 New York, NY, USA: Association for Computing Machinery, 2014 DOI: 10.1145/2601097.2601157
- [3] Jun Wu, Anders Clausen and Ole Sigmund “Minimum compliance topology optimization of shell–infill composites for additive manufacturing” In Computer Methods in Applied Mechanics and Engineering 326, 2017, pp. 358–375 DOI: https://doi.org/10.1016/j.cma.2017.08.018
- [4] Thanh T. Banh and Dongkyu Lee “Topology Optimization of Multi-Directional Variable Thickness Thin Plate with Multiple Materials” In Struct. Multidiscip. Optim. 59.5 Berlin, Heidelberg: Springer-Verlag, 2019, pp. 1503–1520 DOI: 10.1007/s00158-018-2143-8
- [5] Susana Rojas-Labanda and Mathias Stolpe “An efficient second-order SQP method for structural topology optimization” In Structural and Multidisciplinary Optimization 53.6 Springer, 2016, pp. 1315–1333
- [6] Ole Sigmund and Kurt Maute “Topology optimization approaches” In Structural and Multidisciplinary Optimization 48.6 Springer, 2013, pp. 1031–1055
- [7] Jesús Martínez-Frutos, Pedro J. Martínez-Castejón and David Herrero-Pérez “Efficient topology optimization using GPU computing with multilevel granularity” In Advances in Engineering Software 106, 2017, pp. 47–62 DOI: https://doi.org/10.1016/j.advengsoft.2017.01.009
- [8] A Mahdavi, R Balaji, M Frecker and Eric M Mockensturm “Topology optimization of 2D continua for minimum compliance using parallel computing” In Structural and Multidisciplinary Optimization 32.2 Springer, 2006, pp. 121–132
- [9] Niels Aage, Erik Andreassen and Boyan Stefanov Lazarov “Topology optimization using PETSc: An easy-to-use, fully parallel, open source topology optimization framework” In Structural and Multidisciplinary Optimization 51.3 Springer, 2015, pp. 565–572
- [10] Ole Sigmund “A 99 line topology optimization code written in Matlab” In Structural and multidisciplinary optimization 21.2 Springer, 2001, pp. 120–127
- [11] S Ivvan Valdez et al. “Topology optimization benchmarks in 2D: Results for minimum compliance and minimum volume in planar stress problems” In Archives of Computational Methods in Engineering 24.4 Springer, 2017, pp. 803–839
- [12] Jun Wu, Christian Dick and Rüdiger Westermann “A System for High-Resolution Topology Optimization” In IEEE Transactions on Visualization and Computer Graphics 22.3, 2016, pp. 1195–1208 DOI: 10.1109/TVCG.2015.2502588
- [13] Sandilya Kambampati, Carolina Jauregui, Ken Museth and H Alicia Kim “Large-scale level set topology optimization for elasticity and heat conduction” In Structural and Multidisciplinary Optimization 61.1 Springer, 2020, pp. 19–38
- [14] Herbert Martins Gomes “Truss optimization with dynamic constraints using a particle swarm algorithm” In Expert Systems with Applications 38.1 Elsevier, 2011, pp. 957–968
- [15] Thomas Buhl, Claus BW Pedersen and Ole Sigmund “Stiffness design of geometrically nonlinear structures using topology optimization” In Structural and Multidisciplinary Optimization 19.2 Springer, 2000, pp. 93–104
- [16] Tyler E Bruns and Daniel A Tortorelli “Topology optimization of non-linear elastic structures and compliant mechanisms” In Computer methods in applied mechanics and engineering 190.26-27 Elsevier, 2001, pp. 3443–3459
- [17] Kurt Maute, Stefan Schwarz and Ekkehard Ramm “Adaptive topology optimization of elastoplastic structures” In Structural optimization 15.2 Springer, 1998, pp. 81–91
- [18] Benoît Colson, Patrice Marcotte and Gilles Savard “Bilevel programming: A survey” In 4or 3.2 Springer, 2005, pp. 87–107
- [19] Krister Svanberg “Optimization of geometry in truss design” In Computer Methods in Applied Mechanics and Engineering 28.1, 1981, pp. 63–80 DOI: https://doi.org/10.1016/0045-7825(81)90027-X
- [20] Erik Holmberg, Bo Torstenfelt and Anders Klarbring “Stress constrained topology optimization” In Structural and Multidisciplinary Optimization 48.1 Springer, 2013, pp. 33–47
- [21] Abderrahmane Habbal, Joakim Petersson and Mikael Thellner “Multidisciplinary topology optimization solved as a Nash game” In International Journal for Numerical Methods in Engineering 61.7 Wiley Online Library, 2004, pp. 949–963
- [22] Erik Holmberg, Carl-Johan Thore and Anders Klarbring “Game theory approach to robust topology optimization with uncertain loading” In Structural and Multidisciplinary Optimization 55.4 Springer, 2017, pp. 1383–1397
- [23] Peter D Dunning, H Alicia Kim and Glen Mullineux “Introducing loading uncertainty in topology optimization” In AIAA journal 49.4, 2011, pp. 760–768
- [24] Martin P Bendsøe and Ole Sigmund “Optimization of structural topology, shape, and material” Springer, 1995
- [25] Susana Rojas-Labanda and Mathias Stolpe “Benchmarking optimization solvers for structural topology optimization” In Structural and Multidisciplinary Optimization 52.3 Springer, 2015, pp. 527–547
- [26] Gustavo Assis Silva and André Teófilo Beck “Reliability-based topology optimization of continuum structures subject to local stress constraints” In Structural and Multidisciplinary Optimization 57.6 Springer, 2018, pp. 2339–2355
- [27] Krister Svanberg “The method of moving asymptotes—a new method for structural optimization” In International Journal for Numerical Methods in Engineering 24.2, 1987, pp. 359–373 DOI: https://doi.org/10.1002/nme.1620240207
- [28] H Nguyen-Xuan “A polytree-based adaptive polygonal finite element method for topology optimization” In International Journal for Numerical Methods in Engineering 110.10 Wiley Online Library, 2017, pp. 972–1000
- [29] Oded Amir, Niels Aage and Boyan S Lazarov “On multigrid-CG for efficient topology optimization” In Structural and Multidisciplinary Optimization 49.5 Springer, 2014, pp. 815–829
- [30] Gao Tang, Weidong Sun and Kris Hauser “Enhancing bilevel optimization for uav time-optimal trajectory using a duality gap approach” In 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 2515–2521 IEEE
- [31] Benoit Landry, Zachary Manchester and Marco Pavone “A Differentiable Augmented Lagrangian Method for Bilevel Nonlinear Optimization” In Proceedings of Robotics: Science and Systems, 2019 DOI: 10.15607/RSS.2019.XV.012
- [32] Marc Toussaint “Logic-geometric programming: An optimization-based approach to combined task and motion planning” In Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015
- [33] Jonathan F Bard “Some properties of the bilevel programming problem” In Journal of optimization theory and applications 68.2 Springer, 1991, pp. 371–378
- [34] Akshay Mehra and Jihun Hamm “Penalty method for inversion-free deep bilevel optimization” In Asian Conference on Machine Learning, 2021, pp. 347–362 PMLR
- [35] Michal Kočvara “Topology optimization with displacement constraints: a bilevel programming approach” In Structural optimization 14.4 Springer, 1997, pp. 256–263
- [36] Jonas Zehnder, Yue Li, Stelian Coros and Bernhard Thomaszewski “NTopo: Mesh-free Topology Optimization using Implicit Neural Representations” In Advances in Neural Information Processing Systems 34 Curran Associates, Inc., 2021
- [37] James K Guest, Jean H Prévost and Ted Belytschko “Achieving minimum length scale in topology optimization using nodal design variables and projection functions” In International journal for numerical methods in engineering 61.2 Wiley Online Library, 2004, pp. 238–254
- [38] Krister Svanberg “MMA and GCMMA, versions September 2007” In Optimization and Systems Theory 104 KTH Stockholm, Sweden, 2007
- [39] Saeed Ghadimi and Mengdi Wang “Approximation methods for bilevel programming” In arXiv preprint arXiv:1802.02246, 2018
- [40] Mingyi Hong, Hoi-To Wai, Zhaoran Wang and Zhuoran Yang “A two-timescale framework for bilevel optimization: Complexity analysis and application to actor-critic” In arXiv preprint arXiv:2007.05170, 2020
- [41] Prashant Khanduri et al. “A Near-Optimal Algorithm for Stochastic Bilevel Optimization via Double-Momentum” In Advances in neural information processing systems 34, 2021
- [42] Paul H Calamai and Jorge J Moré “Projected gradient methods for linearly constrained problems” In Mathematical programming 39.1 Springer, 1987, pp. 93–116
- [43] David G Luenberger and Yinyu Ye “Linear and nonlinear programming” Springer, 1984
- [44] Michele Benzi “Preconditioning techniques for large linear systems: a survey” In Journal of computational Physics 182.2 Elsevier, 2002, pp. 418–477
- [45] Haixiang Liu et al. “Narrow-Band Topology Optimization on a Sparsely Populated Grid” In ACM Trans. Graph. 37.6 New York, NY, USA: Association for Computing Machinery, 2018 DOI: 10.1145/3272127.3275012
- [46] Thomas Borrvall and Joakim Petersson “Large-scale topology optimization in 3D using parallel computing” In Computer methods in applied mechanics and engineering 190.46-47 Elsevier, 2001, pp. 6201–6229
- [47] Youcef Saad and Martin H Schultz “GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems” In SIAM Journal on scientific and statistical computing 7.3 SIAM, 1986, pp. 856–869
- [48] Laurent Condat “Fast projection onto the simplex and the l1-ball” In Mathematical Programming 158.1 Springer, 2016, pp. 575–585
- [49] Jason Sanders and Edward Kandrot “CUDA by example: an introduction to general-purpose GPU programming” Addison-Wesley Professional, 2010
- [50] Nathan Bell and Michael Garland “Efficient sparse matrix-vector multiplication on CUDA”, 2008
- [51] Tianyi Chen, Yuejiao Sun and Wotao Yin “Closing the Gap: Tighter Analysis of Alternating Stochastic Gradient Methods for Bilevel Problems” In Advances in Neural Information Processing Systems 34, 2021
- [52] Richard A Waltz and Jorge Nocedal “KNITRO 2.0 User’s Manual” In Ziena Optimization, Inc.[en ligne] disponible sur http://www. ziena. com (September, 2010) 7, 2004, pp. 33–34
- [53] Robert J Vanderbei “LOQO user’s manual—version 3.10” In Optimization methods and software 11.1-4 Taylor & Francis, 1999, pp. 485–514
- [54] Amir Beck and Marc Teboulle “A fast iterative shrinkage-thresholding algorithm for linear inverse problems” In SIAM journal on imaging sciences 2.1 SIAM, 2009, pp. 183–202
- [55] Junzi Zhang, Brendan O’Donoghue and Stephen Boyd “Globally convergent type-I Anderson acceleration for nonsmooth fixed-point iterations” In SIAM Journal on Optimization 30.4 SIAM, 2020, pp. 3170–3197
| Variable | Definition |
|---|---|
| a point in material domain | |
| displacement field | |
| internal potential energy | |
| stiffness tensor field | |
| infill level, infill level of th element | |
| solutions at th iteration | |
| infill level bounds | |
| sub-domain of th element | |
| number of elements, nodes | |
| stiffness matrix, stiffness of th element | |
| external force field | |
| total energy | |
| unit vector at th element | |
| displacement caused by force | |
| induced internal potential energy | |
| power law coefficient | |
| eigenvalue function | |
| eigenvalue bounds | |
| all-one, all-zero vectors | |
| activation function of th element | |
| symmetry mapping matrix | |
| infill levels of the left-half material block | |
| number of sub-components | |
| total infill level of th component | |
| material filter operator | |
| high-level, low-level step size | |
| low-level, high-level error metrics | |
| low-level error metric used to analyze Algorithm 3 | |
| upper bound of | |
| coefficients of low-level error | |
| upper bounds of | |
| algorithmic constants | |
| L-constants of | |
| coefficients of reduction rate of | |
| tangent cone of | |
| feasible direction in and step size | |
| lower bound of | |
| uniform upper bound of | |
| projected gradient into normal cone | |
| error tolerance of gradient norm | |
| projection operator onto | |
| condition number | |
| preconditioner | |
| eigenvalue bounds of preconditioner | |
| coefficients of Krylov vectors | |
| dimension of Krylov subspace | |
| approximate gradient | |
| mean-projected approximate gradient | |
| Lagrangian multiplier for projection problem |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x12.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x13.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x14.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x15.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x16.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x17.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/dad015ed-e1bc-43cb-80fa-428e8ac20efa/x18.png)
|
Figure 11: We summarize the comparative convergence history of PGD and FBTO for all the benchmarks (Figure 3a-g). PGD and FBTO are implemented on GPU with matrix factorization of PGD on CPU. All other parameters are the same. | |
VII Additional Experiments
We compare the performance of FBTO and PGD for all the benchmarks in Figure 3 and the results are summarized in Figure 11. Note that PGD uses an exact low-level solver so it requires less iterations then FBTO, while FBTO uses more iterations with a much lower iterative cost. For fairness we compare them based on computational time. PGD outperforms or performs similarly to FBTO on two of the problems (Figure 11df), where PGD converges rapidly in iterations while FBTO requires thousands of iterations. In all other cases, FBTO converges faster to an approximate solution.
VIII Convergence Analysis of Algorithm 1
We provide proof of Theorem IV.6. We start from some immediate observations on the low- and high-level objective functions. Then, we prove the rule of error propagation for the low-level optimality, i.e., the low-level different between and its optimal solution . Next, we choose parameters to let the difference diminish as the number of iterations increase. Finally, we focus on the high-level objective function and show that the difference between and a local optima of would also diminish. Our analysis resembles the recent analysis on two-timescale bilevel optimization, but we use problem-specific treatment to handle our novel gradient estimation for the high-level problem without matrix inversion.
VIII-A Low-Level Error Propagation
If Assumption III.1 holds, then the low-level objective function is -strongly convex and Lipschitz-continuous in for any with being the L-constant, so that:
| (9) |
Similarly, we can immediately estimate the approximation error of the low-level problem due to an update on :
Lemma VIII.1.
Under Assumption III.1, the following relationship holds for all :
Proof.
The following result holds by the triangle inequality and the bounded spectrum of (Equation 2):
| (10) |
The optimal solution to the low-level problem is , which is a smooth function defined on a compact domain, so any derivatives of is bounded L-continuous and we have the following estimate of the change to due to an update on :
| (11) |
where we have used Young’s inequality and the contractive property of the operator. Here we denote as the L-constant of . By triangular inequality, we further have:
| (12) |
The result of Lemma VIII.1 is a recurrent relationship on the low-level optimality error , which will be used to prove low-level convergence via recursive expansion.
VIII-B Low-Level Convergence
We use the following shorthand notation for the result in Lemma VIII.1:
| (13) |
By taking Assumption IV.2 and direct calculation, we can ensure that (i.e., the first term is contractive). To bound the growth of the second term above, we show by induction that both and can be uniformly bounded for all via a sufficiently small, constant .
Lemma VIII.2.
Proof.
First, since and is compact, we have . Next, we prove by induction. We already have . Now suppose , then Equation 13 and our assumption on immediately leads to:
Finally, we have: and our lemma follows. ∎
The shrinking coefficient and the uniform boundedness of allows us to establish low-level convergence with the appropriate choice of with .
Proof.
Theorem VIII.3 is pivotal by allowing us to choose and tune the convergence speed of the low-level problem, which is used to establish the convergence of high-level problem.
VIII-C High-Level Error Propagation
The high-level error propagation is similar to the low-level analysis, which is due to the L-continuity of any derivatives of in the compact domain . The following result reveals the rule of error propagation over a single iteration:
Lemma VIII.4.
VIII-D High-Level Convergence
We first show that is diminishing via the follow lemma:
Lemma VIII.5.
Proof.
By choosing for some constant and summing up the recursive rule of Lemma VIII.4, we have the following result:
| (16) |
Equation 16 can immediately lead to the convergence of . However, the update from to is using the approximate gradient. To show the convergence of , we need to consider an update using the exact gradient. This can be achieved by combining Equation 16 and the gradient error estimation in Equation 15:
| (17) |
We can prove our lemma by combining Lemma VIII.4, Equation 16, Equation 17. ∎
The last three terms on the righthand side of Lemma VIII.5 are power series, the summand of which scales at the speed of , respectively. Therefore, for the three summation to be upper bounded for arbitrary , we need the first condition in Assumption IV.5. The following corollary is immediate:
Corollary VIII.6.
Proof.
Our remaining argument is similar to the standard convergence proof of PGD [42], with minor modification to account for our approximate gradient:
Proof of Theorem IV.6.
We denote by :
Note that is derived from using the true gradient, while is derived using our approximate gradient. Due to the polytopic shape of in Assumption III.1, for , we can always choose a feasible direction from with such that:
We further have the follow inequality holds for any due to the obtuse angle criterion and the convexity of :
Applying Corollary VIII.6 and we can choose sufficiently large such that:
Here the first inequality holds by choosing sufficiently small -dependent such that and using the fact that . The third inequality holds by choosing sufficently large and Corollary VIII.6. The last equality holds by the contractive property of projection operator, Theorem VIII.3, and Lemma VIII.4. ∎
VIII-E Convergence Analysis of Algorithm 2
IX Convergence Analysis of Algorithm 3
The main difference in the analysis of Algorithm 3 lies in the use of a different low-level error metric defined as . Unlike which requires exact matrix inversion, can be computed at a rather low cost. We will further show that using for analysis would lead to a much larger, constant choice of low-level step size . To prove Theorem IV.11, we follow the similar steps as Theorem IV.6 and only list necessary changes in this section.
IX-A Low-Level Error Propagation
Lemma IX.1.
Assuming commutes with and III.1, the following relationship holds for all :
where we define: for any .
Proof.
The following result holds by the triangle inequality and the bounded spectrum of (Equation 2):
| (18) |
Next, we estimate an update due to via the Young’s inequality:
Putting the above two equations together, we have:
| (19) |
which is a recursive relationship to be used for proving the low-level convergence. ∎
IX-B Low-Level Convergence
We use the following shorthand notation for the result in Lemma IX.1:
| (20) |
By taking Assumption IV.2 and direct calculation, we can ensure that (i.e., the first term is contractive). To bound the growth of the second term above, we show by induction that both and can be uniformly bounded for all via a sufficiently small, constant .
Lemma IX.2.
Proof.
First, since and is compact, we have . Next, we prove by induction. We already have . Now suppose , then Equation 20 and our assumption on immediately leads to:
Finally, we have: and our lemma follows. ∎
The shrinking coefficient and the uniform boundedness of allows us to establish low-level convergence.
Proof.
Theorem IX.3 allows us to choose and tune the convergence speed of the low-level problem, which is used to establish the convergence of high-level problem.
IX-C High-Level Error Propagation
We first establish the high-level rule of error propagation over a single iteration:
Lemma IX.4.
IX-D High-Level Convergence
We first show that is diminishing via the follow lemma:
Lemma IX.5.
Proof.
The following corollary can be proved by the same argument as Corollary VIII.6:
Corollary IX.6.
Finally, we list necessary changes to prove Theorem IV.11:
IX-E Parameter Choices
We argue that is a valid choice in Algorithm 3 if a Krylov-preconditioner is used. Note that choosing is generally incompatible with Assumption IV.8, which is because we make minimal assumption on the preconditioner , only requiring it to be commuting with and positive definite with bounded spectrum. However, many practical preconditioners can provide much stronger guarantee leading to being a valid choice. To see this, we observe that the purpose of choosing according to Assumption IV.8 is to establish the following contractive property in Equation 18:
| (24) |
Any preconditioner can be used if they pertain such property with . The following result shows that Krylov-preconditioner pertains the property:
Lemma IX.7.
Proof.
We define and, by the definition of , we have:
where the first inequality holds by the definition of . ∎
Unfortunately, it is very difficult to theoretically establish this property for other practical preconditioners, such as incomplete LU and multigrid, although it is almost always observed in practice.