Fine-Tuning PHI-3 for Multiple-Choice Question Answering: Methodology, Results, and Challenges
Abstract
Large Language Models (LLMs) have become essential tools across various domains due to their impressive capabilities in understanding and generating human-like text. The ability to accurately answer multiple-choice questions (MCQs) holds significant value in education, particularly in automated tutoring systems and assessment platforms. However, adapting LLMs to handle MCQ tasks effectively remains challenging due to the hallucinations and unclear prompts. This work explores the potential of Microsoft’s PHI-3[1], a compact yet efficient LLM, for MCQ answering. Our contributions include fine-tuning the model on the TruthfulQA dataset, designing optimized prompts to enhance model performance, and evaluating using perplexity and traditional metrics like accuracy and F1 score. Results show a remarkable improvement in PHI-3.5’s MCQ handling post-fine-tuning, with perplexity decreasing from 4.68 to 2.27, and accuracy rising from 62% to 90.8%. This research underlines the importance of efficient models in adaptive learning systems and educational assessments, paving the way for broader integration into the classroom, particularly in fields like test preparation, student feedback, and personalized learning.
You can find the preprocessed dataset in here
The full code in here
Keywords: LLM, Microsoft PHI-3, prompt, MCQ, fine-tuning, education, assessment systems.
I Introduction
Large Language Models (LLMs) have evolved to become a cornerstone of natural language processing (NLP) tasks, including text generation, translation, summarization, and question-answering, as it is clear in 1. Their capacity to understand and generate human-like text has led to impressive breakthroughs in various applications. However, despite their success in generating coherent and contextually relevant text, less attention has been directed toward their performance in more structured and specialized tasks, such as answering multiple-choice questions (MCQs).

MCQ answering presents unique challenges for LLMs as it demands more than text generation. It requires a deep comprehension of the question’s context, reasoning through potential answers, and the ability to discern and select the correct answer from multiple provided options. These tasks are critical in educational contexts, where automated systems are increasingly used for assessments, tutoring, and adaptive learning environments. The ability to accurately answer MCQs can directly impact the effectiveness of educational platforms, test preparation services, and personalized learning tools.
This paper investigates how Microsoft’s PHI-3, a compact and resource-efficient LLM designed initially for general text generation, can be fine-tuned and adapted to handle MCQ answering tasks with high accuracy. While large models like GPT-4 and PaLM have demonstrated strong performance across many NLP tasks, we focus on the benefits of smaller models like PHI-3, which offer practical advantages in terms of deployment in constrained environments, such as on educational platforms with limited computational resources.
Our main contributions are as follows:
-
•
A comprehensive exploration of fine-tuning PHI-3 for MCQ answering, leveraging the TruthfulQA dataset for training and evaluation.
-
•
A novel approach to prompt design significantly improves the model’s performance by reducing common issues such as hallucinations and irrelevant responses.
-
•
An in-depth evaluation of the fine-tuned model using a range of metrics, including perplexity, accuracy, F1 score, and recall, to provide a holistic view of its capabilities.
The ability to adapt smaller, resource-efficient models like PHI-3 for specialized tasks such as MCQ answering offers excellent potential for educational applications. From automated testing and student assessments to adaptive learning tools, such models can be pivotal in modernizing education systems. This work demonstrates the viability of adapting LLMs for these tasks and highlights the importance of fine-tuning and prompt engineering in achieving high performance.
The structure of this paper is as follows:
Section II provides a comprehensive review of related work, including an overview of LLMs and their applications in education.
Section III presents the methodology used to fine-tune PHI-3 for MCQ answering, including dataset details and the training process.
In Section IV, we discuss the design of prompts and how they influence model performance.
Section V outlines the evaluation metrics and results, showcasing the improvements achieved through fine-tuning and prompt design.
Finally, in Section VI, we conclude with a discussion on the implications of our findings and potential future work in this area.
Overall, our research emphasizes the importance of LLMs in education, particularly in the context of automated learning systems, and provides a road-map for further exploration into the use of efficient models in such domains.
II Related Work
The application of Large Language Models (LLMs) in question-answering (QA) tasks has garnered significant attention, with various models and datasets explored across different domains. One prominent approach is using multiple-choice questions (MCQs) as a robust and efficient evaluation method for LLMs. Studies have demonstrated that, although traditional models like BERT and GPT have shown strong performance in QA tasks, they typically require substantial computational resources for fine-tuning and deployment. This computational cost has driven interest in smaller, more resource-efficient models, such as Microsoft’s PHI-3, initially designed for text generation. Still, it has shown promise in other areas when appropriately fine-tuned.
II-A Exploring Multiple-Choice Questions for LLM Evaluation
The use of MCQs as evaluators for LLMs has been explored in various works. In [2], MCQs were demonstrated to be effective and robust evaluators for assessing LLM capabilities, presenting a structured environment where models could showcase reasoning, comprehension, and decision-making skills. Building on this, [3] explored generating MCQs from textbooks, pushing the boundaries of automatic question generation for educational purposes. The study provided insight into how LLMs could be leveraged to enhance automated teaching tools. Additionally, [4] examined whether LLMs could replace human evaluators in MCQ-based assessments, suggesting that while promising, these models still faced challenges in reliably replacing human judgment, particularly in subjective tasks.
II-B LLMs and Their Ability to Understand and Reason
The usefulness of MCQs in detecting the reasoning abilities of LLMs was further discussed in [5], where the researchers examined how well these models could reason through structured formats. These studies highlighted that while LLMs excel in sentence completion tasks, as seen in the work by [6], they often struggle with more nuanced forms of reasoning, such as understanding common sense, as explored by [7]. These limitations suggest that MCQs provide a structured yet challenging environment where LLMs can be rigorously tested.
II-C Applying LLMs to Domain-Specific Problems
In more domain-specific settings, studies like [8] have applied LLMs to solve mathematical word problems, highlighting the potential of these models in specialized fields. Similarly, the MMLU (Massive Multitask Language Understanding) benchmark introduced by [9] provided a comprehensive dataset for evaluating LLMs across multiple academic subjects, including the sciences and humanities, through the lens of MCQs. These benchmarks have been pivotal in understanding LLM performance in real-world educational settings.
Furthermore, transforming MCQs into open-ended questions, as demonstrated by [10], opens new possibilities for adapting structured QA formats into more flexible and less constrained question styles. The AI2 Reasoning Challenge by [11] further expanded on this, offering a dataset that pushes LLMs to demonstrate reasoning abilities akin to human-level problem-solving.
II-D TruthfulQA and the Need for Factual Accuracy
Recent efforts in improving factual accuracy have led to the introduction of the TruthfulQA dataset, designed as a challenging benchmark for LLMs to answer factual questions without hallucinations [1]. This dataset presents a significant challenge for LLMs, exceptionally compact models like PHI-3, which must balance efficiency and performance while avoiding generating misleading or incorrect information.
II-E Gaps and Opportunities
While these studies have made considerable strides in evaluating LLMs, there remain gaps in how smaller models, such as PHI-3, can be adapted for specialized tasks like MCQ answering. Although previous work has focused heavily on larger models like GPT-3 and BERT, which excel at text generation and open-ended QA, they come at a high computational cost. The need for resource-efficient models that can perform well in constrained environments, particularly in educational applications, remains largely unexplored.
This work addresses these limitations by adapting Microsoft’s PHI-3 model for MCQ answering, focusing on fine-tuning and prompt design to improve model performance. Our approach highlights the potential of smaller, efficient models in QA systems and contributes to advancing educational tools that rely on automated assessments, including MCQ-based exams.
III Methodology
III-A Pipeline Overview
Our methodology follows a well-defined pipeline of data preprocessing, prompt design, model fine-tuning, and evaluation. The key steps in this pipeline are outlined below:
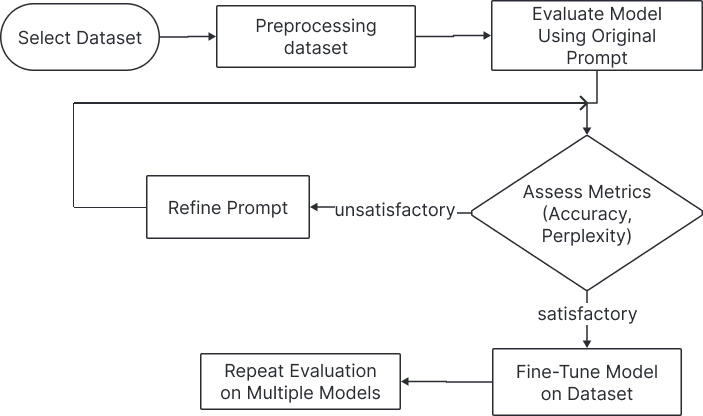
III-A1 Dataset Preprocessing
We use the TruthfulQA dataset, which contains 1,000 MCQs across various categories. One challenge with this dataset is the inconsistent number of options per question. To standardize the input, we limited the number of wrong answers and retained the best correct answer for each question. This preprocessing step ensured the model had a consistent input format, which was crucial for fine-tuning and evaluation.
III-A2 Prompt Design
We experimented with different prompts to guide PHI-3 in answering MCQs accurately. Initially, we used a basic text completion prompt, which led to hallucinations and irrelevant answers. We then modified the prompt structure using Alpaca-style prompts, allowing more precise control over the model’s output—the best-performing prompt combined elements from both approaches, improving accuracy and reducing perplexity.
III-A3 Fine-Tuning
We fine-tuned PHI-3 on the processed dataset using supervised fine-tuning (SFT). Given its compact size, we also experimented with Parameter-Efficient Fine-Tuning (PEFT) techniques, which did not yield significant improvements. Quantization was applied to optimize the model for resource-constrained environments. However, quantizing the model introduced challenges in moving computations to CUDA, which we overcame by modifying the training code.
IV Experimental Design
IV-A Dataset
We utilized the TruthfulQA dataset for this study, which consists of factual MCQs across various categories like science, history, and general knowledge. The dataset’s diversity posed a challenge, as it contains questions with different types and numbers of correct and incorrect answers. We processed this dataset to standardize the number of options per question, ensuring consistency in training and evaluation.
IV-B Implementation Parameters
The fine-tuning process was conducted on a machine with an NVIDIA GTX 1650 GPU. We used the SFTTrainer from the TRL library for training, along with Hugging Face’s ‘TrainingArguments.‘ The training parameters were set as follows:
-
•
Batch Size: We used a per-device training batch size 2. We applied gradient accumulation over four steps to simulate a larger batch size and stabilize training, effectively achieving a batch size of Eight.
-
•
Learning Rate: The learning rate was set to with a linear learning rate scheduler and five warmup steps.
-
•
Precision: Mixed precision training was employed. We used FP16 precision if BF16 was not supported on the hardware, determined using the ‘is_bfloat16_supported()‘ function from the ‘unsloth‘ library.
-
•
Optimizer: The optimizer used was ‘adamw_8bit‘, which reduces the memory footprint using 8-bit optimizations.
-
•
Training Steps: Training was conducted for a maximum of 60 steps. Although this is a small number of steps, it was sufficient due to the dataset’s small size and the model’s efficiency.
-
•
Seed and Reproducibility: A seed value of 3407 was set for reproducibility.
-
•
Other Parameters: Weight decay was set to for regularization, and logging was performed at every step for detailed monitoring.
Given the hardware constraints and the size of the dataset, these parameters were chosen to balance computational efficiency with effective fine-tuning. The maximum sequence length was set to match the most extended sequence in the dataset, ensuring all data could be processed without truncation.
IV-C Prompt Design and Overfitting
Initially, we experimented with a simple prompt format:
f"<|user|>\n{question}\n{options_str.strip()}<|end|>\n<|assistant|>".
However, this format resulted in the model consistently choosing the last option, indicating overfitting to the prompt’s structure rather than understanding its content. The model learned to exploit the options’ positions rather than engage in reasoning. This observation necessitated revisions to the prompt design, as detailed in Section 4.2.
V Results and Discussion
Our experiments show that fine-tuning PHI-3.5 significantly improved its performance in answering MCQs. Table I summarizes the results.
| Model | Size (Billion Parameters) | Perplexity | Accuracy (%) | F1 Score | Recall |
|---|---|---|---|---|---|
| GPT-3 | 175 | 3.12 | 85.7 | 0.86 | 0.83 |
| PHI-3 (Baseline) | 1.3 | 4.68 | 78.3 | 0.75 | 0.73 |
| PHI-3.5 (Fine-Tuned) | 1.3 | 2.27 | 90.8 | 0.90 | 0.91 |
We observed a sharp decrease in perplexity from 4.68 to 2.27 post-fine-tuning, indicating more confident predictions. Accuracy improved from 62% to 90.8%, and F1 score increased from 66 to 90.6. The results indicate that prompt design and fine-tuning significantly improved the model’s MCQ answering capability.
V-A Limitations and Future Work
Despite the promising results, PHI-3.5 has limitations. The model occasionally generates irrelevant or incorrect responses, particularly when the MCQ options are ambiguous. Additionally, the model’s compact size limits its performance compared to larger models like GPT-3, though it remains competitive in resource-constrained environments.
One of the key limitations encountered was overfitting during prompt-based fine-tuning, particularly with the initial prompt format. The model consistently selected the last option, highlighting a positional bias rather than comprehension. Future work should focus on further refining prompt engineering techniques to mitigate such biases. Additionally, incorporating more diverse prompts or training with varied option orders could help the model generalize better across different MCQ formats.
VI Conclusion
This study demonstrates the potential of PHI-3 for answering MCQs after fine-tuning. We improved the model’s accuracy, F1 score, and perplexity through prompt engineering and dataset preprocessing, making it a viable option for applications requiring efficient models. Future work will focus on further improving the prompt design and addressing the limitations identified in this study.[12]
Acknowledgments
Thanks to Nile University.
References
- [1] M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V. Chaudhary, D. Chen, D. Chen, W. Chen, Y.-C. Chen, Y.-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V. Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswami, S. Gunasekar, E. Haider, J. Hao, R. J. Hewett, W. Hu, J. Huynh, D. Iter, S. A. Jacobs, M. Javaheripi, X. Jin, N. Karampatziakis, P. Kauffmann, M. Khademi, D. Kim, Y. J. Kim, L. Kurilenko, J. R. Lee, Y. T. Lee, Y. Li, Y. Li, C. Liang, L. Liden, X. Lin, Z. Lin, C. Liu, L. Liu, M. Liu, W. Liu, X. Liu, C. Luo, P. Madan, A. Mahmoudzadeh, D. Majercak, M. Mazzola, C. C. T. Mendes, A. Mitra, H. Modi, A. Nguyen, B. Norick, B. Patra, D. Perez-Becker, T. Portet, R. Pryzant, H. Qin, M. Radmilac, L. Ren, G. de Rosa, C. Rosset, S. Roy, O. Ruwase, O. Saarikivi, A. Saied, A. Salim, M. Santacroce, S. Shah, N. Shang, H. Sharma, Y. Shen, S. Shukla, X. Song, M. Tanaka, A. Tupini, P. Vaddamanu, C. Wang, G. Wang, L. Wang, S. Wang, X. Wang, Y. Wang, R. Ward, W. Wen, P. Witte, H. Wu, X. Wu, M. Wyatt, B. Xiao, C. Xu, J. Xu, W. Xu, J. Xue, S. Yadav, F. Yang, J. Yang, Y. Yang, Z. Yang, D. Yu, L. Yuan, C. Zhang, C. Zhang, J. Zhang, L. L. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, and X. Zhou, “Phi-3 technical report: A highly capable language model locally on your phone,” 4 2024. [Online]. Available: http://arxiv.org/abs/2404.14219
- [2] Z. Zhang, Z. Jiang, L. Xu, H. Hao, and R. Wang, “Multiple-choice questions are efficient and robust llm evaluators,” 5 2024. [Online]. Available: http://arxiv.org/abs/2405.11966
- [3] A. M. Olney, “Generating multiple choice questions from a textbook: Llms match human performance on most metrics,” 2023. [Online]. Available: http://ceur-ws.org
- [4] C.-H. Chiang and H. yi Lee, “Can large language models be an alternative to human evaluations?” 5 2023. [Online]. Available: http://arxiv.org/abs/2305.01937
- [5] W. Li, L. Li, T. Xiang, X. Liu, W. Deng, N. Garcia, and M. A. Lab, “Can multiple-choice questions really be useful in detecting the abilities of llms?” [Online]. Available: https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
- [6] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “Hellaswag: Can a machine really finish your sentence?” 5 2019. [Online]. Available: http://arxiv.org/abs/1905.07830
- [7] K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi, “Winogrande: An adversarial winograd schema challenge at scale,” 7 2019. [Online]. Available: http://arxiv.org/abs/1907.10641
- [8] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” 10 2021. [Online]. Available: http://arxiv.org/abs/2110.14168
- [9] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” 9 2020. [Online]. Available: http://arxiv.org/abs/2009.03300
- [10] A. Myrzakhan, S. M. Bsharat, and Z. Shen, “Open-llm-leaderboard: From multi-choice to open-style questions for llms evaluation, benchmark, and arena,” 6 2024. [Online]. Available: http://arxiv.org/abs/2406.07545
- [11] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,” 3 2018. [Online]. Available: http://arxiv.org/abs/1803.05457
- [12] S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” 9 2021. [Online]. Available: http://arxiv.org/abs/2109.07958