Fine-Tuning Language Models
with Advantage-Induced Policy Alignment
Abstract
Reinforcement learning from human feedback (RLHF) has emerged as a reliable approach to aligning large language models (LLMs) to human preferences. Among the plethora of RLHF techniques, proximal policy optimization (PPO) is of the most widely used methods. Despite its popularity, however, PPO may suffer from mode collapse, instability, and poor sample efficiency. We show that these issues can be alleviated by a novel algorithm that we refer to as Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function based on the estimated advantages. We demonstrate empirically that APA consistently outperforms PPO in language tasks by a large margin, when a separate reward model is employed as the evaluator. In addition, compared with PPO, APA offers a more stable form of control over the deviation from the model’s initial policy, ensuring that the model improves its performance without collapsing to deterministic output. In addition to empirical results, we also provide a theoretical justification supporting the design of our loss function.
1 Introduction
Reinforcement learning from human feedback (RLHF, or preference-based reinforcement learning) (Knox and Stone, 2008, Wirth et al., 2017) has delivered significant empirical successes in several fields, including games (Christiano et al., 2017), robotics (Sadigh et al., 2017, Kupcsik et al., 2018), recommendation systems (Maghakian et al., 2022). Recently, RLHF has also exhibited striking potential for integrating human knowledge with large language models (Ziegler et al., 2019, Ouyang et al., 2022, OpenAI, 2023, Beeching et al., 2023, Zhu et al., 2023, Bai et al., 2022b). To employ RLHF in the training pipeline of language models, a common protocol is as follows.
- •
-
•
Supervised fine-tuning (SFT): training the model on a smaller amount of curated data to improve the performance and accuracy of the model on specific tasks;
- •
Both PT and SFT rely on the use of distributional loss functions, such as cross entropy, to minimize the distance between the text distributions in the training dataset and in the model output (Vaswani et al., 2017, Devlin et al., 2018, Brown et al., 2020). Such a simple strategy is not viable, however, for the RLHF stage. As the ultimate target is to make the language model output conform to human linguistic norms, which are difficult to define or quantify, researchers usually resort to a reward model that is trained separately from the language model on a meticulously collected, human-labeled dataset (Ouyang et al., 2022). Such a reward model produces a scalar score for each generated response, and is, therefore, able to provide the language model with online feedback. This accessibility to online feedback allows the language model to be trained via reinforcement learning (RL), giving rise to the RLHF stage.
Among the RL techniques that are applied to language models, one of the most prominent algorithms is proximal policy optimization (PPO) (Schulman et al., 2017). Despite the acclaimed effectiveness of PPO (Ouyang et al., 2022, Stiennon et al., 2020, Nakano et al., 2021), it suffers from instability and poor sample efficiency. The family of policy gradient algorithms suffers from slow convergence and can yield poor ultimate policies (Yuan et al., 2022, Dong et al., 2022).
To address such issues, we introduce a novel algorithm, Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function that directly aligns the output policy of the language model with a target policy in each training epoch. The target policy combines the initial language model policy before the RLHF stage and a correction term based on the advantage function estimated from online samples.
We compare APA with PPO and advantage weighted regression (AWR) both theoretically and empirically. At a high level, the two existing algorithms (PPO and AWR) solve a KL-constrained policy optimization problem, relying on the estimated importance ratio between consecutive policies to compute the policy gradient. On the other hand, APA uses squared error to regularize the deviation of model policy and no longer requires estimating the importance ratio. We show that such differences bring huge benefits in terms of sample efficiency.
To demonstrate the efficacy of APA empirically, we apply APA, PPO and AWR to fine-tuning up to 7B language models, using the human-labeled Anthropic Helpfulness and Harmlessness dataset (Ganguli et al., 2022) and the StackExchange Beeching et al. (2023) dataset. We first evaluate using the reward model, trained on the same dataset to produce a scalar reward for each prompt-response pair. We also evaluate the human preferences of the resulting language model using GPT-4 to demonstrate the effectiveness of the algorithm. Our empirical results highlight three major advantages of APA over PPO:
-
(i)
APA is more sample-efficient. Fine-tuned on the same number of samples, the language model obtained via APA scores consistently higher on the evaluation set than the one obtained with PPO.
-
(ii)
APA affords steadier control over the deviation from the language model’s initial policy. Measured by KL divergence, the deviation of the ultimate policy generated by APA is comparable with that of PPO, yet APA is less prone to sudden performance degradation during training, which is occasionally observed in PPO. Note that previous study has shown that the control over deviations from the initial policy is critical in preventing over-optimization on reward models (Gao et al., 2022).
-
(iii)
APA has fewer hyperparameters. The loss function in APA involves only one major tunable parameter for KL control, whereas in PPO one has to carefully calibrate the combination of various extra hyperparameters, such as the clipping ranges for importance ratio and value estimates, and the coefficients of the KL controller.
More broadly, this work is related to the line of literature on leveraging ideas from RL to improve the performance of language models. A few notable examples in this literature include Paulus et al. (2017), who propose a loss function based on the policy gradient objective to tackle the abstractive summarization task, using ROUGE scores as reward; and Snell et al. (2022), who present the implicit language -learning (ILQL) algorithm to facilitate learning from offline human-labeled samples without a reward model. A thorough comparison between different RL algorithms is also made in Ramamurthy et al. (2022) on GRUE benchmarks. There have been some alternative frameworks of RLHF that replaces PPO with SFT on best generated sample (Yuan et al., 2023), or a direct preference-based offline learning (Rafailov et al., 2023).
The remainder of this paper is organized as follows. In Section 2, we introduce our notation. In Section 3, we formally specify the algorithm APA, and discuss the intuitions behind the algorithmic elements. Experimental results are presented in Section 4. Section 5 concludes by summarizing and discussing the experimental results.
2 Preliminaries
In this section, we overview the standard RL setting in Section 2.1, and discuss how language model training fits into this setting in Section 2.2. We use the following notation. For a positive integer , we will use the bracket notation to refer to the set of integers ; for a finite set , we denote by the set of probability distributions on , and the cardinality of . We use to denote the unit ball in -dimensional space.
2.1 Reinforcement Learning
Reinforcement learning (RL) captures the interaction between an agent and an environment via the formalism of a Markov decision process (MDP). We consider a finite-horizon MDP represented by a tuple , where is a finite state space, is a finite action space, is the horizon, is a probability transition matrix, is a reward function, and is the initial state distribution. When the agent takes action in state at step , it receives a scalar reward , and transitions to a state , where is drawn from distribution . Each episode consists of consecutive steps. At the end of an episode, the agent is reset to a state drawn from , and a new episode begins.
A policy is a function that maps a state to a distribution over actions. The value function of policy is defined as the expected sum of discounted rewards when the agent starts from initial state and follows policy throughout the episode. Let be the discount factor. For any , we have
Given a policy , the state-action value function, also known as the -function, can be defined analogously. For state and , we have
We also define the important notion of an advantage function. For a policy , state and action , the advantage, defined as
quantifies the extra value that is obtained by replacing the immediate action prescribed by with the action , when the agent is in state at step .
We also define the occupancy measures and as
where signifies that all actions are drawn from . To avoid clutter, we overload the notation such that refers to , and refers to .
2.2 Language Model as Reinforcement Learning Agent
In its simplest form, a language model receives as input a sequence of tokens , and generates a distribution over the next token . All tokens lie in a finite set . Whenever the agent selects a token that represents the completion of a response (e.g., the end-of-sequence token), or the total number of tokens reaches a specific limit, the entire sequence is scored by a reward model, which produces a scalar reward .
Comparing with the RL formulation in Section 2.1, a language model can be viewed as an agent that operates in an environment with state space and action space , where is the maximum number of tokens. The transitions are always deterministic, with the next state equal to the concatenation of all the previous tokens and the current token . Traditionally, each episode involves the generation of one complete sequence, and a reward is delivered only when an episode terminates. In this context, fine-tuning is equivalent to improving the agent policy . The field of RL offers a formidable arsenal for this task. In this work, we will focus on policy-based RL algorithms, which parameterize the set of agent policies by a set of parameters and optimize in the parameter space. In what follows, we will omit the step index , as its information is already encoded in each state.
We note that most transformer-based language models map a state (context) and an action (next token) to a logit , and the next token is sampled according to the distribution induced by the logits . This naturally gives rise to the following parameterization of language model policy:
3 Fine-Tuning Based on Reinforcement Learning
As is mentioned in Section 1, the RLHF stage is usually composed of two steps. First, a reward model is trained from a human-labeled dataset. An RL algorithm is then applied to improve the language model policy, using the rewards generated by the reward model. Here we focus mainly on the second step with a given reward function.
We summarize a typical policy-based RL algorithm in Algorithm 1. In practice, the parameter update in Equation (1) usually involves several gradient steps rather than a full minimization.
| (1) |
In the remainder of this section, we discuss several potential choices for , each targeting the goal of maximizing regularized advantages. We also introduce the new algorithm APA, and discuss the intuitions behind it.
As a first step, for each fixed state , we consider the following -regularized optimization problem as a target of policy improvement:
| (2) |
Here refers to the initial policy of the language model before the RLHF stage, is an arbitrary policy that we hope to improve upon. The first term in the objective function is an expected advantage, and to maximize the expected advantage, the agent is encouraged to move toward the optimal action in state . The second term in , a regularizer, controls the deviation of from . Such regularization is essential, as language models are prone to over-optimization when rewards are generated by an imperfect reward model, a phenomenon observed in Gao et al. (2022). Combined, the single-state optimization problem in (2) aims at improving upon policy in state within the proximity of .
The optimization (2) is usually broken down into multiple iterations. In each iteration, we maximize , where is the policy that the agent arrives at in the previous iteration. This technique, referred to as Conservative Policy Iteration (CPI), was first presented in Kakade and Langford (2002). The optimization was subsequently generalized to KL-constrained and regularized methods referred to as Trust Region Policy Optimization (TRPO) (Schulman et al., 2015a) and Proximal Policy Optimization (PPO) (Schulman et al., 2017), respectively. In addition to these core methods, there have been several other policy optimization methods inspired by (2), with one notable example being the Advantage-Weighted Regression (AWR) method (Peng et al., 2019, Nair et al., 2020).
In the following subsection, we will discuss how is connected with the loss function in various algorithms, and propose a new proximal optimization problem whose solution approximates that of (2). The loss function in APA will be based on this new proximal optimization problem.
3.1 Proximal policy optimization
PPO leverages importance sampling to circumvent sampling from , arriving at
where the expectation on the right-hand side can be estimated in an unbiased manner from finite samples.
PPO also involves the following innovation: Instead of penalizing the expected advantage with the estimated KL-divergence as in (2), PPO directly subtracts the KL penalty term from the reward received by the agent. And one may also adaptively adjust the penalty weight based on the deviation of from (Schulman et al., 2017, Dhariwal et al., 2017, Ziegler et al., 2019). The KL-penalized reward is then used to estimate a new advantage function . To avoid ill-conditioned gradients caused by large values or importance ratio estimates, PPO applies clipping to the objective function. The final loss function is thus
Note that the loss function relies on extra tunable hyperparameters. The clipping also makes the estimator biased.
3.2 Advantage weighted regression
If the parameterized policy space contained all possible policies including the ground truth policy, the maximizer of (2) would induce a policy that satisfies
| (3) |
where is a normalizing factor. In the case that does not contain all policies, a natural way to maximize is to project to with respect to KL-divergence. From (3),
| (4) |
where is a constant that does not depend on .
To facilitate online update, AWR makes three changes from Equation (4):
-
•
AWR replaces the first-round policy with the previous-round policy . This ensures that one can utilize the new roll-out samples from previous-round policy to approximate (4).
-
•
The KL-divergence in (4) only accounts for one state . AWR minimizes a distribution of states .
-
•
AWR approximates . We also provide a related discussion in Appendix A on why such an approximation is warranted.
These changes lead to the loss function introduced in AWR:
| (5) |
Given a finite dataset sampled from , the corresponding empirical loss can be written as
| (6) |
For the well-specified case where the parameterized family contains the minimizing policy, the minimizer of the population loss is as follows:
| (7) |
3.3 Advantage-Induced Policy Alignment
To project the optimal policy in (3) onto the parameterized policy space, we consider another distance instead of -divergence. In APA, we employ the squared error between log probabilities in place of the -divergence:
Similar to the approximation in AWR, we also apply , and minimize the expected loss under a state distribution in each round, giving rise to the following population loss:
| (8) |
The empirical loss on a finite dataset sampled from is thus
| (9) |
Assuming that the parameter space is and that the parameterized policy space is well-specified such that , where is defined in Equation (3), we can establish theoretically that the empirical loss is a reasonable surrogate for the population loss.
Theorem 1.
Let be a minimizer of the population loss. Then
Furthermore, let be an empirical loss minimizer. Assume that and for any , and that is -Lipschitz with respect to under -norm for any . Then for all , with probability at least , for some universal constant ,
The proof is deferred to Appendix E. From the theorem, we see that the minimizer of the population APA loss is exactly the target policy if the policy is supported on all state-action pairs. In contrast, as we discussed earlier, convergence properties of the PPO and AWR algorithms have not yet been established.
We also provide alternative interpretations of the proposed loss in terms of -divergence and soft-Q learning in Appendix B.
4 Experimental Results
In our implementation of all of the algorithms that we test, including APA, we define the advantage function to be , which is estimated from data. We use the same generalized advantage estimation approach to estimate the advantage as discussed in earlier work Mnih et al. (2016), Schulman et al. (2015b). In particular, for the rollout , the generalized advantage estimator is
Here the value function is another standalone network that we fit throughout the training process with a squared loss, . Thus the overall loss function is
For the implementation of PPO, we use the PPO2 version from Dhariwal et al. (2017), with the adaptive KL controller from Ziegler et al. (2019). We implement PPO with the same hyperparameters as the implementation in trlX111https://github.com/CarperAI/trlx, which also follows default hyperparameters suggested by Schulman et al. (2017). The main difference between our version of PPO and that in trlX is that we create a completely separate value network rather than creating a value head on top of the language model. In APA, we take to impose a weaker constraint on the KL coefficient. For AWR, we find that setting leads to an explosion of the loss; thus we take to stabilize training.
4.1 Results on the StackExchange dataset
In this section, we present our experimental results with StackExchange dataset. This dataset includes questions and their corresponding answers from the StackExchange platform (including StackOverflow for code and many other topics). The answers are then voted by the users on the platform and an accepted answer is labeled. Following Beeching et al. (2023), Askell et al. (2021), we assign a score to each answer depending on the number of upvotes:

We used the pre-processed dataset provided in Beeching et al. (2023) for all SFT, reward modeling and RL training purposes, available in the HuggingFace Datasets as lvwerra/stack-exchange-paired222https://huggingface.co/datasets/lvwerra/stack-exchange-paired . We use LLaMA-7B Touvron et al. (2023) models for this experiment. We use Low-Rank Adaptation (LoRA) method Hu et al. (2021) to reduce the memory consumption while training. We used 8xA100 GPUs for our experiments. The hyper-parameters for this experiment are listed in the Appendix C.4. Fig. 2 shows the reward on the left and KL divergence from the initial policy for the three algorithms, PPO, APA and AWR. We adjust the hyper-parameters to achieve similar KL divergence values, allowing us to compare the rewards for various algorithms. In the case of AWR, each hyper-parameter set displayed some level of instability. Clearly, APA quickly converges to a higher reward than PPO and AWR.


GPT-4 Evaluation:
We conduct a GPT-4 evaluation to evaluate the models trained by different RL methods on StackExchange dataset. GPT-4 compares the outputs produced by two models, using a reference (chosen) response as a basis for comparison. Fig. 1 shows the win-rates for comparing SFT vs PPO, SFT vs APA and PPO vs APA models. APA consistently outperforms the other two models.
4.2 Results on the HH dataset
In this section, we compare PPO, AWR and APA on the human-labeled Helpfulness and Harmlessnes (HH) dataset from Bai et al. (2022a).333https://huggingface.co/datasets/Dahoas/static-hh. We fine tune three models, including Dahoas/pythia-125M-static-sft,444https://huggingface.co/Dahoas/pythia-125M-static-sft Dahoas/pythia-1B-static-sft,555https://huggingface.co/Dahoas/pythia-1B-static-sft and Dahoas/pythia-6B-static-sft.666https://huggingface.co/Dahoas/pythia-6B-static-sft All the models have gone through supervised fine-tuning with labeled prompt-response pairs, similar to the protocol in Ouyang et al. (2022) and Ramamurthy et al. (2022). We present the performance of the RL algorithms for pythia-125M and pythia-1B in Fig. 3. It shows that after some steps, PPO’s performance begins to deteriorate while APA and AWR are stable. APA achieves the higher reward while maintaining KL divergence from the initial policy smaller. The details about hyper-parameters used for training and additional results for larger models are discussed in Appendix C.1.




5 Conclusions
In this paper, we study the problem of online policy optimization in RLHF. We benchmark the performance of existing algorithms PPO and AWR, and introduce a new method, APA, which has a theoretical convergence guarantee and affords several advantages over existing algorithms. The key takeaways from our study can be summarized as follows.
Stability.
As we discussed in Section 1, one of the challenges in RLHF is instability. It is crucial in RL algorithms to impose control on the divergence between new policies and the initial policy after SFT. However, the clipping of the objective function and the adaptive KL controller can make the behavior of PPO unstable; for AWR, the update in (7), which reweighs the previous policy by a multiplicative factor in each iteration, also has unknown ramifications. APA, on the other hand, provably converges to when the advantage function is fixed, which is close to the initial policy in KL divergence. From the experimental results, we see that APA is able to provide better and easy-to-adjust KL control by explicitly tuning the hyperparameter . Our experiments reveal different levels of instability for PPO and AWR. Specifically, PPO suffers from occasional performance degradation whenever the model policy diverges too much from the initial policy , and such effect is more pronounced for smaller models. We attribute this to the KL controller in PPO. In Appendix D, we demonstrate that PPO can achieve a similar sample efficiency as APA without the KL penalty, albeit at the cost of weaker KL efficiency.
Sample efficiency.
With the same level of control over KL-divergence, APA shows higher sample efficiency than PPO and AWR. One possible explanation is that in both PPO and AWR, policy improvement critically depends on using finite samples to reconstruct the sampling policy , whereas in APA, minimizing the population loss (8) hinges less on the reconstruction of . In fact, the APA population loss (8) can be effectively minimized as long as the dataset has a decent coverage over state-action pairs that are frequently visited by . For more discussions on sample efficiency, please refer to Appendix B.
Online vs. offline learning.
Our experiments primarily examine the online case, where new data can be generated during the training process. The offline setting, where a fixed dataset is given and new samples are not available, may yield qualitatively different results. In particular, suppose that the offline dataset consists of rollouts from a policy . In this case, if it were trained with infinitely many samples, AWR would converge to the policy specified in (3). However, the performance of APA may suffer from distribution shift because it can only learn from state-action pairs covered by , and there is no guarantee that the learned policy performs well on the state-action pairs visited by the current policy. Such distribution mismatch can lead to a significant performance drop for APA, as we observe in Appendix D.3. We also observe that AWR typically outperforms ILQL for offline learning, although both perform poorly with larger models.
References
- Askell et al. (2021) A. Askell, Y. Bai, A. Chen, D. Drain, D. Ganguli, T. Henighan, A. Jones, N. Joseph, B. Mann, N. DasSarma, N. Elhage, Z. Hatfield-Dodds, D. Hernandez, J. Kernion, K. Ndousse, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, and J. Kaplan. A general language assistant as a laboratory for alignment, 2021.
- Bai et al. (2022a) Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022a.
- Bai et al. (2022b) Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, et al. Constitutional AI: Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073, 2022b.
- Beeching et al. (2023) E. Beeching, Y. Belkada, K. Rasul, L. Tunstall, L. von Werra, N. Rajani, and N. Lambert. StackLLaMA: An RL fine-tuned LLaMA model for Stack Exchange question and answering, 2023. URL https://huggingface.co/blog/stackllama.
- Brown et al. (2020) T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Christiano et al. (2017) P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, pages 4299–4307, 2017.
- Devlin et al. (2018) J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dhariwal et al. (2017) P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford, J. Schulman, S. Sidor, Y. Wu, and P. Zhokhov. OpenAI baselines. https://github.com/openai/baselines, 2017.
- Dong et al. (2022) S. Dong, B. Van Roy, and Z. Zhou. Simple agent, complex environment: Efficient reinforcement learning with agent states. Journal of Machine Learning Research, 23(255):1–54, 2022.
- Ganguli et al. (2022) D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y. Bai, S. Kadavath, B. Mann, E. Perez, N. Schiefer, K. Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858, 2022.
- Gao et al. (2022) L. Gao, J. Schulman, and J. Hilton. Scaling laws for reward model overoptimization. arXiv preprint arXiv:2210.10760, 2022.
- Hu et al. (2021) E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models, 2021.
- Kakade and Langford (2002) S. Kakade and J. Langford. Approximately optimal approximate reinforcement learning. In Proceedings of the Nineteenth International Conference on Machine Learning, pages 267–274, 2002.
- Knox and Stone (2008) W. B. Knox and P. Stone. TAMER: Training an agent manually via evaluative reinforcement. In 7th IEEE International Conference on Development and Learning, pages 292–297. IEEE, 2008.
- Kupcsik et al. (2018) A. Kupcsik, D. Hsu, and W. S. Lee. Learning dynamic robot-to-human object handover from human feedback. In Robotics research, pages 161–176. Springer, 2018.
- Maghakian et al. (2022) J. Maghakian, P. Mineiro, K. Panaganti, M. Rucker, A. Saran, and C. Tan. Personalized reward learning with interaction-grounded learning (IGL). arXiv preprint arXiv:2211.15823, 2022.
- Mnih et al. (2016) V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning, pages 1928–1937. PMLR, 2016.
- Nair et al. (2020) A. Nair, A. Gupta, M. Dalal, and S. Levine. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020.
- Nakano et al. (2021) R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- OpenAI (2023) OpenAI. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
- Paulus et al. (2017) R. Paulus, C. Xiong, and R. Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
- Peng et al. (2019) X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019.
- Rafailov et al. (2023) R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Ramamurthy et al. (2022) R. Ramamurthy, P. Ammanabrolu, K. Brantley, J. Hessel, R. Sifa, C. Bauckhage, H. Hajishirzi, and Y. Choi. Is reinforcement learning (not) for natural language processing? benchmarks, baselines, and building blocks for natural language policy optimization. arXiv preprint arXiv:2210.01241, 2022.
- Sadigh et al. (2017) D. Sadigh, A. D. Dragan, S. Sastry, and S. A. Seshia. Active preference-based learning of reward functions. In Robotics: Science and Systems, 2017.
- Schulman et al. (2015a) J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust region policy optimization. In International Conference on Machine Learning, pages 1889–1897. PMLR, 2015a.
- Schulman et al. (2015b) J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015b.
- Schulman et al. (2017) J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Snell et al. (2022) C. Snell, I. Kostrikov, Y. Su, M. Yang, and S. Levine. Offline RL for natural language generation with implicit language Q-learning. arXiv preprint arXiv:2206.11871, 2022.
- Stiennon et al. (2020) N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Touvron et al. (2023) H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. RoziÚre, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models, 2023.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- Wirth et al. (2017) C. Wirth, R. Akrour, G. Neumann, and J. Fürnkranz. A survey of preference-based reinforcement learning methods. The Journal of Machine Learning Research, 18(1):4945–4990, 2017.
- Yuan et al. (2022) R. Yuan, R. M. Gower, and A. Lazaric. A general sample complexity analysis of vanilla policy gradient. Proceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS), 2022.
- Yuan et al. (2023) Z. Yuan, H. Yuan, C. Tan, W. Wang, S. Huang, and F. Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
- Zhu et al. (2023) B. Zhu, J. Jiao, and M. I. Jordan. Principled reinforcement learning with human feedback from pairwise or -wise comparisons. International Conference on Machine Learning, 2023.
- Ziegler et al. (2019) D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Appendix A Argument for
Note that in both advantage-weighted regression and advantage-based squared loss, we approximate with . Here we justify why this does not hurt the performance.
Consider an infinitesimal scenario where . In the scenario of language model, this is usually true since is supported on approximately distinct tokens and can be very close to zero, while can be adjusted to small numbers by adjusting .
In this case, we have
This advantage is usually estimated as , which can be close to . And we have
Thus we know that
In practice, we observe that the squared loss decreases very slowly due to a small learning rate (). This suggests that the policy changes very slowly, which is another reason why the normalizing factor is not important.
Appendix B Alternative Interpretation of APA
Recall that APA can be written as
where . In the case when is close to , minimizing the squared loss in APAis equivalent to minimizing the following distance between and :
This can be viewed as a new -divergence with . We can show by Cauchy-Schwarz that this is always a upper bound for the KL divergence:
Appendix C Additional Experiments
C.1 Results on the HH dataset
In this dataset, each item is comprised of a prompt, a chosen response and a rejected response labeled by human to evaluate the helpfulness and harmlessness of the responses. For the reward model, we use the proxy reward model Dahoas/gptj-rm-static777https://huggingface.co/Dahoas/gptj-rm-static with 6B parameters trained from the same dataset based on EleutherAI/gpt-j-6b.888https://huggingface.co/EleutherAI/gpt-j-6b For all three algorithms, we run two epochs of update after generating 64 responses from randomly sampled prompts. For the 125M model, we use batch size and learning rate . For the 1B model, we use batch size and learning rate . For the 6B and larger models, we use batch size and learning rate . We use a 32GB Nvidia V100 GPU for fine-tuning 125M and 1B models, and a 64GB AMD Mi200 GPU for fine-tuning the 6B and larger models. The maximum response length is set to be 128 tokens, and the maximum total sequence length is set to be 1024 tokens. We unfreeze the last two layers during fine-tuning. For each experiment, we run 20k steps in total. The results are plotted as below.


In the left of Figure 4, we compare the three methods on the HH dataset. For all three models, we repeat the experiments with three random seeds , and plot their min, mean and max. We see that with the same amount of data, APA is able to achieve the highest reward in all three cases. We also observe that PPO becomes more stable with large models, potentially due to smaller batch size, or the ability of getting higher reward with a smaller deviation in KL divergence.
On the right of Figure 4, we show how the KL divergence between the current policy and the initial policy changes as a function of the training process for the three seeds. We can see that for all three models, APA provides similar or better KL control than PPO and AWR, although we note that for the 6B model the KL control for PPO is slightly better than APA. Combined with the left part of the figure, we can see that APA is more KL-efficient than PPO and AWR; i.e., it attains a better performance on the reward model under the same KL divergence.
We include more experiment results in Appendix C, where we fine tune databricks/dolly-v2-7b999https://huggingface.co/databricks/dolly-v2-7b on the same HH dataset, and 2.7B and 6B models on the TLDR dataset101010https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons for the summarization task.
We also conduct ablation studies on the effect of the adaptive KL controller on PPO and the effect of different choices of for AWR; see Appendix D. We show in Appendix D.2 that without KL control, PPO can be as sample efficient as APA, but less KL-efficient. We also observe instability even without the KL controller. On the other hand, we observe that changing provides a straightforward tradeoff between KL control and performance in APA.
C.2 Results on the TLDR Dataset
We fine-tune the EleutherAI/gpt-neo-2.7B111111https://huggingface.co/EleutherAI/gpt-neo-2.7B and 6B CarperAIopenai_summarize_tldr_sft121212https://huggingface.co/CarperAI/openai_summarize_tldr_sft models on the TLDR dataset131313https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons for the summarization task. For EleutherAI/gpt-neo-2.7B, we first fine-tune it with supervised fine-tuning on the labeled response in the same summarization dataset, and run RLHF on the supervised fine-tuned policy. The 6B model CarperAIopenai_summarize_tldr_sft has already gone through the supervised fine-tuning stage. The reward model is a pre-trained EleutherAI/gpt-j-6b141414https://huggingface.co/EleutherAI/gpt-j-6b reward model for summarization dataset CarperAI/openai_summarize_comparisons151515https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons.
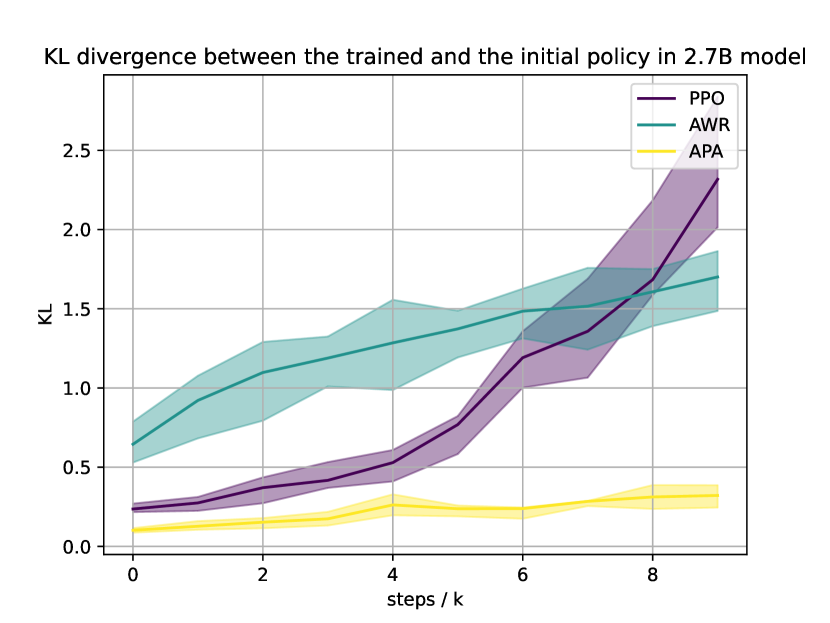
We follow the default setting in trlX with seed 0 and 100, and plot the results in Figure 5. One can see that APA is more sample efficient and provides better KL control than PPO in both 2.7B and 6B models.



C.3 Results on the Dolly Model
We fine-tune the databricks/ dolly-v2-7b161616https://huggingface.co/databricks/dolly-v2-7b model on the HH dataset. We follow the default setting in trlX with seed 0 and 100, and plot the results in Figure 6. We only include the results for APA and PPO since AWR drops directly. Different from all other experiments, here for APA we set rather than to stablize the training and impose stronger KL control. One can see that APA can still improve over the original dolly 7B model and provide better KL control, while PPO fails to bring further improvement.


C.4 StackExchange experiment details
| Parameter | Value |
| Max sequence length | 1024 |
| Max output length | 128 |
| Learning rate | 2e-5 |
| Batch size | 16 |
| Gradient Accumulation | 8 |
| SFT LoRA dimension | 16 |
| RM LoRA dimension | 8 |
| RL LoRA dimension | 16 |
| Adaptive KL initial KL coeff (PPO) | 0.1 |
| Adaptive KL target KL coeff (PPO) | 6 |
| (APA) | 0.1 |
Appendix D Ablation Studies
D.1 KL control in APA
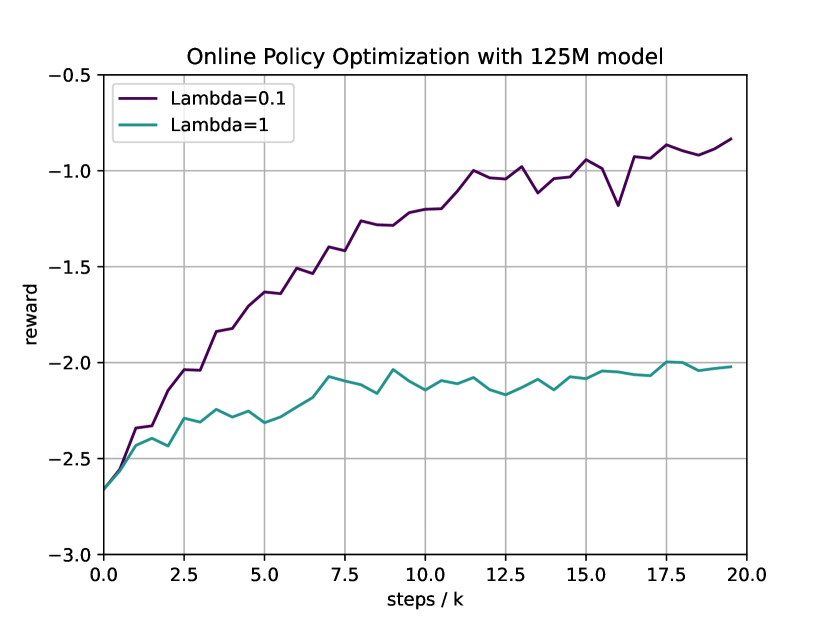
In this section, we show how the performance and KL divergence change with different values of . We set for the 125M model and plot their performances in Figure 7 with seed . One can see that the choice of directly determines the level of KL control, along with the convergent point APA reaches. This shows that provides a clear trade-off between KL control and model performance.

D.2 KL control in PPO
We show how the performance and KL divergence change with or without adaptive KL control in PPO. We plot their performances in Figure 8 for 125M model with seed . For PPO with adaptive KL controller, the initial KL coefficient is set to be . One can see that without KL control, PPO converges to a higher reward compared to APA in Figure 7, at a cost of a significantly higher KL divergence. On the other hand, the reward of PPO with adaptive KL control begins to drop in the middle. This is due to the large deviation from the original policy, which leads to a much larger KL regularization term that dominates the reward. Compared with Figure 7, one can see that APA provides more stable and controllable KL regularization.


D.3 Experiments for Offline Learning
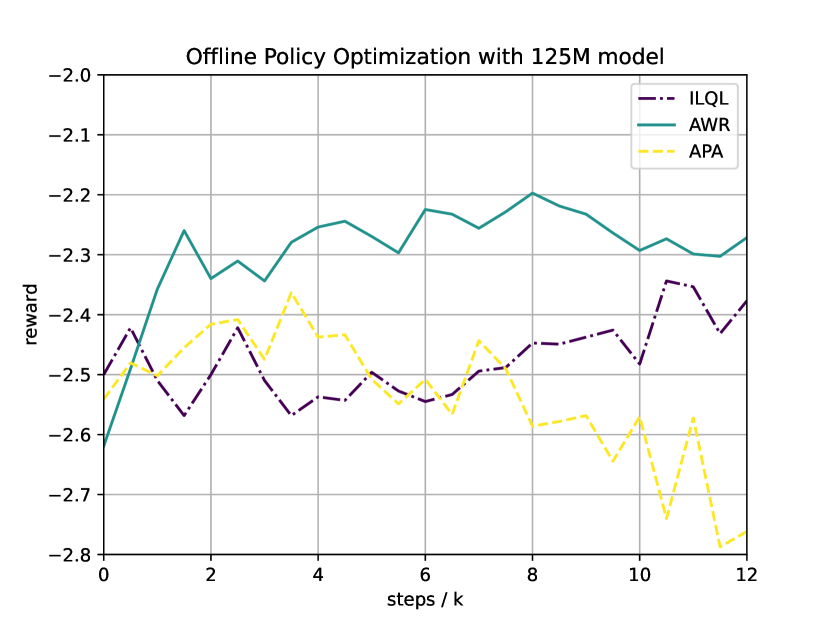
We conduct experiments for offline learning as well. The offline dataset is selected to be all the prompts and responses from the HH dataset, with reward labeled by the reward model. We use the trained GPT-J reward function to label the reward for all the offline data, and compare ILQL, AWR and APA on the same 125M and 1B model after supervised fine-tuning with seed . The result is given in Figure 9. From the results, one can see that AWR performs better than ILQL, and APA cannot be directly adapted to the offline case. Furthermore, offline learning cannot help too much after the supervised fine-tuning stage, potentially due to the large distribution shift between the offline data and the current policy.

Appendix E Proof of Theorem 1
Proof.
From the well-specified assumption , we know that there exists some such that . For the population loss, we know that
Thus for any , there must be , which is equivalent to
This means that for any on the support of , we have .
For the second part of the theorem, we know from Hoeffding’s inequality that for any fixed ,
Let the be -covering of under norm, i.e. for any , one can find some such that . We also have . By taking union bound, we know that for all , with probability at least ,
| (10) |
Let be the minimizer of . Then we know that there exists some such that . This further implies that
| (11) |
Similarly, we also have Overall, we have
For the first and third difference, from Equation (11) we know that they are both bounded by For the second difference, we know from Equation (10) that it is bounded by . Lastly, we know that since and . Thus overall, we have
Taking finishes the proof. ∎