Finding emergence in data by maximizing effective information
Abstract
Quantifying emergence and modeling emergent dynamics in a data-driven manner for complex dynamical systems is challenging due to the lack of direct observations at the micro-level. Thus, it’s crucial to develop a framework to identify emergent phenomena and capture emergent dynamics at the macro-level using available data. Inspired by the theory of causal emergence (CE), this paper introduces a machine learning framework to learn macro-dynamics in an emergent latent space and quantify the degree of CE. The framework maximizes effective information, resulting in a macro-dynamics model with enhanced causal effects. Experimental results on simulated and real data demonstrate the effectiveness of the proposed framework. It quantifies degrees of CE effectively under various conditions and reveals distinct influences of different noise types. It can learn a one-dimensional coarse-grained macro-state from fMRI data, to represent complex neural activities during movie clip viewing. Furthermore, improved generalization to different test environments is observed across all simulation data.
Keywords:causal emergence; dynamics learning; effective information; coarse-graining; invertible neural network
1. Introduction
The climate system, ecosystems, bird flocks, ant colonies, cells, brains, and many other complex systems are composed of numerous interacting elements and exhibit a wide range of nonlinear dynamical behaviors [1, 2]. In the past few decades, the research topic of data-driven modeling complex systems has gained significant attention, driven by the increasing availability and accumulation of data from real dynamical systems [3, 4, 5, 6]. However, complex systems always exhibit emergent behaviors [7, 1]. That means some interesting emergent patterns or dynamical behaviors such as waves [8], periodic oscillations [9] and solitons [10] can hardly be directly observed and identified from the micro-level behavioral data. Therefore, the identification and measure of emergence and the capture of emergent dynamical patterns solely from observational raw data have become crucial challenges in complex systems research [11, 12, 13, 14]. But in order to address these problems, it is necessary to first develop a quantitative understanding of emergence.
Emergence, as a distinctive feature of complex systems [7], has historically been challenging to quantify and describe in quantitative terms [15, 16, 17, 18]. Most conventional measures or methods either rely on predefined macro-variables (e.g., [19, 20, 21]) or are tailored to specific scenarios in engineered systems (e.g. [17, 22, 23, 24]). However, there is a need for a unified method to quantify emergence across different contexts. The theory of causal emergence (CE), introduced by Erik Hoel in 2013, offers a framework to tackle this challenge [25, 26]. Hoel’s theory aims to understand emergence through the lens of causality. The connection between emergence and causality is implied in the descriptive definition of emergence, as stated in the work by J. Fromm[27]. According to this definition, a macro-level property, such as patterns or dynamical behaviors, is considered emergent if it cannot be explained or directly attributed to the individuals in the system. The theory of causal emergence formalizes this concept within the framework of discrete Markov dynamical systems. As shown in Figure 1(a), Hoel et al’s theory states that if a system exhibits stronger causal effects after a specific coarse-graining transformation compared to the original system, then CE has occurred. In Hoel’s framework, the degree of causal effect in a dynamical system is quantified using effective information (EI) [28]. EI can be understood as an intervention-based version of mutual information between two successive states in a dynamical system over time. It is a measure that solely depends on the system’s dynamics. If a dynamical system is more deterministic and non-degenerate, meaning that the temporal adjacent states can be inferred from each other in both directions of the time arrow, then it will have a larger EI [25]. This measure has been shown to be compatible with other well-known measures of causal effect [29]. Figure 1(b) gives an example of CE for simple Markov chain.

While the causal emergence theory has successfully quantified emergence using EI and has found applications in various fields [30, 31, 32], there are some drawbacks. Firstly, the markov transition matrix of the micro-dynamics should be given rather than constructed from data. Secondly, a predefined coarse-graining strategy must be provided or optimized through maximizing EI, but this optimization process is computationally complex[33, 30]. Although Rosas et al.[11] proposed a new framework for CE based on partial information decomposition theory [34], which does not require a predefined coarse-graining strategy, it still involves iterating through all variable combinations on the information lattice to compare synergistic information, resulting in significant computational complexity. Rosas et al. also proposed an approximate method to mitigate the complexity [11], but it requires a pre-defined macro-variable.
Therefore, the challenge of finding emergence in data, which involves determining whether CE has occurred within a system and to what extent based solely on observational data of its behavior, remains unresolved. The most daunting task is that all the elements, including the markov dynamics at both the micro- and macro-levels, as well as the coarse-graining strategy to obtain macro-variables, need to be learned from raw data and cannot be predefined in advance [12]. Once the learning process is completed, we can compare the strength of causal effects (measured by EI) in dynamics at different scales to identify CE from the data. Therefore, the problem of finding CE within Hoel’s theoretical framework is essentially equivalent to the challenge of data-driven modeling within a coarse-grained space for complex systems [12]. Building models for complex systems at multiple coarse-grained levels within learned emergent spaces is of utmost importance for both identifying CE and conducting data-driven modeling in complex systems.
Recently, several machine learning frameworks have emerged for learning and simulating the dynamics of complex systems within coarse-grained latent or hidden spaces [35, 14, 36, 37, 38]. By learning the dynamics in a hidden space, these frameworks enable the removal of noise and irrelevant factors from raw data, enhancing prediction capabilities and adaptability to diverse environments. While these learning systems can capture emergent dynamics, they may not directly address the fundamental nature of CE, which entails stronger causality. According to Judea Pearl’s hierarchy of causality, prediction-based learning is situated at the level of association and cannot address the challenges related to intervention and counterfactuals [39]. Empirically, dynamics learned solely based on predictions may be influenced by the distributions of the input data, which can be limited by data diversity and the problem of over fitting models [40]. However, what we truly desire is an invariant causal mechanism or dynamics that are independent of the input data. This allows the learned mechanism or dynamics to be adaptable to broader domains, generalizable to areas beyond the distribution of training data, and capable of accommodating diverse interventions [41, 42, 43]. Unfortunately, few studies have explored the integration of causality and latent space dynamics to address the challenges of data-driven modeling in complex systems [44].
Inspired by the theory of causal emergence, this paper aims to address the challenge of learning causal mechanisms within a learned coarse-grained macro-level(latent) space. The approach involves maximizing the EI of the emergent macro-level dynamics, which is equivalent to maximizing the degree of causal effect in the learned coarse-grained dynamics [29]. By artificial intervening the distributions of input data as uniform distribution, this maximization process helps separating the invariant causal mechanisms from the variant data distribution as much as possible. To achieve this, a novel machine learning framework called Neural Information Squeezer Plus (NIS+) is proposed. NIS+ extends the previous framework (NIS) to solve the problem of maximizing EI under coarse-grained representations. As shown in Figure 2, NIS+ not only learns emergent macro-dynamics and coarse-grained strategies but also quantifies the degree of CE from time series data and captures emergent patterns. Mathematical theorems ensure the flexibility of our framework in different application scenarios, such as cellular automata and multi-agent systems. Numerical experiments demonstrate the effectiveness of NIS+ in capturing emergent behaviors and finding CE in various simulations, including SIR dynamics[45], bird flocking (Boids model)[46], and the Game of Life[47]. Additionally, NIS+ is applied to find emergent features in real brain data from 830 subjects while watching the same movie. Experiments also demonstrate that the learned dynamical model exhibits improved performance in generalization compared to other models.

2. Finding causal emergence in data
Finding CE in time series data involves two sub-problems: emergent dynamics learning and causal emergence quantification. In the first problem, both the dynamics in micro- and macro-level and the coarse-graining strategy should be learned from data. After that, we can measure the degree of CE and judge if emergence occurs in data according to the learned micro- and macro-dynamics.
2.1. Problem definition
Suppose the behavioral data of a complex dynamical system is a time series with time steps and dimension , they form observable micro-states. And we assume that there are no unobserved variables. The problem of emergent dynamics learning is to find three functions according to the data: a coarse-graining strategy , where is the dimension of macro-states which is given as a hyper-parameter, a corresponding anti-coarsening strategy , and a macro-level markov dynamics , such that the EI of macro-dynamics is maximized under the constraint that the predicted by , , and is closed to the real data of :
| (1) | ||||
Where, is the appropriate version of EI to be maximized. For continuous dynamical systems that mainly considered in this paper, is the dimension averaged effective information (dEI)[12](see method section 2) , is a given small constant.
The objective of maximizing EI in Equation LABEL:old_optimization is to enhance the causal effect of the macro-dynamics . However, the direct maximization of EI, as depicted in Figure 1, can result in trivial solutions, as highlighted by Zhang et al. [12]. Additionally, it can lead to issues of ambiguity and violations of commutativity, as pointed out by Eberhardt, F and Lee, L.L. [48]. To address these issues, constraints are introduced to prevent such problems. The constraints in Equation LABEL:old_optimization ensure that the macro-dynamics can simulate the micro-dynamics in the data as accurately as possible, with the prediction error being less than a given threshold .
This is achieved by mapping the micro-state to the macro-state at each time step. The macro-dynamics then makes a one-step prediction to obtain . Subsequently, an anti-coarsening strategy is employed to decode back into the micro-state, resulting in the reconstructed micro-state . The entire computational process can be visualized by referring to the upper part(NIS) in Figure 2b.
In practice, we obtain the value of by setting the normalized MAE (mean absolute error divided by the standard deviation of ) on the training data. The choice of normalized MAE ensures a consistent standard across different experiments, accounting for the varying numerical ranges.
By changing we can obtain macro-dynamics in various dimensions. If , then becomes the learnt micro-dynamics. Then we can compare and for any . The problem of causal emergence quantification can be defined as the calculation of the following difference,
| (2) |
where is defined as the degree of causal emergence. The micro-dynamics is also obtained by solving Equation LABEL:old_optimization with dimension . If , then we say CE occurs within the data.
2.2. Solution
While, solving the optimization problem defined in Equation LABEL:old_optimization directly is difficult because the objective function is the mutual information after intervention which deserved special process.
To tackle this problem, we convert the problem defined in Equation LABEL:old_optimization into a new optimization problem without constraints, that is:
| (3) |
where . and are the macro-states. is a new function that we introduce to simulate the inverse macro-dynamics on the macro-state space, that is to map each macro-state at time step back to the macro-state at time step. is a Lagrangian multiplier which will be taken as a hyper-parameter in experiments. is the inverse probability weights which is defined as:
| (4) |
where is the new distribution of macro-states after intervention for , and is the natural distribution of the data. In practice, is estimated through kernel density estimation (KDE)[49](see method section 4). The approximated distribution, , is assumed to be a uniform distribution, which is characterized by a constant value. Consequently, the weight is computed as the ratio of these two distributions. Mathematical theorems mentioned in method section 5.1.2 and proved in support information section 10.1 guarantee this new optimization problem (Equation 9) is equivalent to the original one (Equation LABEL:old_optimization).
3. Results
We will validate the effectiveness of the NIS+ framework through numerical experiments where data is generated by different artificial models (dynamical systems, multi-agent systems, and cellular automata). Additionally, we will apply NIS+ to real fMRI data from human subjects to uncover interesting macro-level variables and dynamics. In these experiments, we will evaluate the models’ prediction and generalization abilities. We will also assess their capability to identify CE and compare it with Rosas’ indicator proposed in [11], an alternative measure for quantifying CE approximately. For the experiments, a threshold of normalized MAE of 0.3 was selected based on the observation that exceeding this value leads to a significant change in the relationship between normalized MAE and noise (see below).
3.1. SIR
The first experiment revolves around the SIR (Susceptible, Infected, and Recovered or Died) model, a simple dynamical system. In this experiment, the SIR dynamics serve as the ground truth for the macro-level dynamics, while the micro-level variables are generated by introducing noise to the macro-variables. The primary objective is to evaluate our model’s ability to effectively remove noise, uncover meaningful macroscopic dynamics, identify CE, and demonstrate generalization beyond the distribution of the training dataset.
Formally, the macro-dynamics can be described as:
| (5) |
where represents the proportions of healthy, infected and recovered or died individuals in a population, and are parameters for infection and recovery rates, respectively. Figure 3(a) shows the phase space of the SIR dynamics. Because the model has only two degrees of freedom, as , , and satisfy , all macro-states are distributed on a triangular plane in three dimensions, and only and are used to form the macro-state variable , and is removed.
We then expand into a four-dimensional vector and introduce Gaussian noises to form a microscopic state:
| (6) |
Among which, are two-dimensional Gaussian noises and independent each other, and is the correlation matrix. In this way, we obtain a micro-states sequence as the training samples in the experiment. We randomly select initial conditions by sampling points within the triangular region depicted in Figure 3(a) and generate time series data using the aforementioned process. These generated data are then utilized to train the models.

We conduct comparative analysis between NIS+ and other alternative models, including NIS (without EI maximization compared to NIS+), feed-forward neural network (NN), and variational autoencoder (VAE). To make a fair comparison, we ensure that all benchmark models have a roughly equal number of parameters. Moreover, we employ the same techniques of probability reweighting and inverse dynamics learning on the feed-forward neural network (NN+) and variational autoencoder (VAE+) as utilized in NIS+. We evaluate the performances of all candidate models by requiring them to predict future states for multiple time steps (10 steps) on a separate test dataset. The results show that NIS+(green bars) outperforms other competitors on multi-step prediction as shown in Figure 3(d) no matter if they use the techniques like probability reweighting to maximize EI, this manifests that an invertible neural network as an encoder and decoder is necessary (the details can be referred to method section 6).
Further, to assess the model’s generalization ability beyond the region of the training dataset, in addition to the regular training and testing, we also conduct experiments where the model was trained on a subset of the data and tested on the complete dataset. The training samples in this experiment are shown in the dotted area in Figure 3(a)(the area with is missing), and the test samples are also in the blue triangle. As shown by the red bars in Figure 3(d), the performances of out-of-distribution generalization of NIS+ are better than other benchmarks although the test region is beyond the trained region. And the differences among different models are larger on partial dataset.
To further test whether the models successfully learn the ground-truth macro-dynamics, we conduct a comparison between the vector fields of the real SIR dynamics, represented by , and the learned emergent dynamics . This comparison is illustrated in Figure 3(c) for NIS+ and (f) for NIS. In both sub-figures, the learned vectors align with the ground-truth (real) dynamics and match the theoretical predictions based on the Jacobian of the encoder (for more details, please refer to support information section 11.3). However, it is evident that NIS+ outperforms NIS in accurately capturing the underlying dynamics, especially in peripheral areas with limited training samples.
Next, we test NIS+ and other comparison models on EI maximization and CE quantification, the results are shown in Figure 3(b) and (e). First, to ensure that EI is maximized by NIS+, Figure 3(b) illustrates the evolution of EI (dimension averaged) over training epochs. It is evident that the curves of NIS+ (red solid), NIS (black dashed), and VAE+(green solid) exhibit upward trends, but NIS+ demonstrates a faster rate of increase. This indicates that NIS+ can efficiently maximize to a greater extent than other models. Notably, NIS also exhibits a natural increase in EI as it strives to minimize prediction errors.
Second, to examine NIS+’s ability to detect and quantify CE, we compute s and compare them with Rosas’ indicators as the noise level in micro-states increased (see support information section 11.2 for details). We utilize the learned macro-states from NIS+ as the prerequisite variable to implement Rosas’ method [11]. The results are depicted by the black and yellow solid lines in Figure 3(e).
Both indicators exhibit a slight increase with and always holds when it is less than 0.01, but Rosas’ after . Therefore, NIS+ indicates that CE consistently occurs at low noise levels, whereas Rosas’ method does not. NIS+’s result is more reasonable since it can extract macro-dynamics similar to the ground-truth from noisy data, and this deterministic dynamics should have a larger EI than the noisy micro-dynamics. We also plot the curves (red dashed line) and (green dashed line) for macro- and micro-dynamics, respectively. These curves decrease as increase, but decreases at a faster rate, leading to the observed occurrence of CE. However, when Rosas’ , we cannot make a definitive judgment as can only provide a sufficient condition for CE. Both indicators reach their peak at , which corresponds to the magnitude of the time step () used in our simulations and reflects the level of change in micro-states.
On the other hand, if the noise becomes too large, the limited observational data makes it challenging for NIS+ to accurately identify the correct macro-dynamics from the data. Consequently, the degree of CE decreases to zero. Although NIS+ determines that there is no CE when , this result is not reliable since the normalized prediction errors have exceeded the selected threshold 0.3 after (the vertical dashed and dotted line).
Therefore, these experiments manifest that by maximizing EI and learning an independent causal mechanism, NIS+ can effectively disregard noise within the data and accurately learn the ground truth macro-dynamics, and generalization to unseen data. Additionally, NIS+ demonstrates superior performance in quantifying CE. More details about experimental settings are shown in support information section 11.
3.2. Boids
The second experiment is on Boids model which is a famous multi-agent model to simulate the collective behaviors of birds [50, 51]. In this experiment, we test the ability of NIS+ on capturing emergent collective behaviors and CE quantification on different environments with intrinsic and extrinsic noises. To increase the explainability of the trained coarse-graining strategy, we also try to give an explicit correspondence between the learned macro-states and the micro-states.
We conducted simulations following the methodology of [50] with boids on a canvas to generate training data. The detailed dynamical rules of the Boids model can be found in support information section 12. In order to assess the ability of NIS+ to discover meaningful macro-states, we separate all boids into two groups, and artificially modified the Boids model by introducing distinct constant turning forces for each group. This modification ensured that the two groups exhibited separate trajectories with different turning angles, as depicted in Figure 4a. The micro-states of each boid at each time step consisted of their horizontal and vertical positions, as well as their two-dimensional velocities. The micro-states of all boids formed a dimensional vector of real numbers, which was used as input for training NIS+.
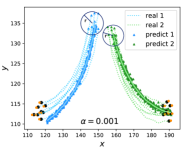
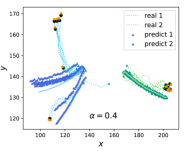
As depicted by the triangles in Figure 4a, the predicted emergent collective flying behaviors for 50 steps closely follow the ground-truth trajectories of the two groups, particularly at the initial stages. These predicted trajectories are generated by decoding the predicted macro-states into the corresponding micro-states, and the two solid lines represent their averages. The hyperparameter is chosen for this experiment based on the observation that the CE consistently reaches its highest value when , as indicated in Figure 4c.
To enhance the interpretability of the learned macro-states and coarse-graining function in NIS+, we utilize the Integrated Gradient (IG) method[52](see method section 7) to identify the most significant micro-states for each learned emergent macro-state dimension. We normalized the calculated IG and enhanced the maximum gradient of the micro-state in each macro-state and disregard the velocity dimensions of each boid due to their lower correlations with macro-states. The normalized IG is drawn into a matrix diagram(Figure 4d). As depicted by Figure 4d, the 1st, 2nd, 5th, and 6th dimensions in macro-states correspond to the boids in the first group (with ID<8), while the 3rd, 4th, 7th, and 8th dimensions correspond to the second group (with ID>=8). Thus, the learned coarse-graining strategy uses two positional coordinates to represent all other information to form one dimension of macro-state.
To compare the learning and prediction effects of NIS+ and NIS, we assess their generalization abilities by testing their performances on initial conditions that differed from the training dataset. During the simulation for generating training data, the positions of all boids are constrained within a circle with a radius of , as depicted in Figure 4a. However, we assess the prediction abilities of both models when the initial positions are located on the larger circles. Figure 4b shows the MAEs of NIS+ and NIS, which increase with the radius , where smaller prediction errors indicate better generalization. The results clearly demonstrate NIS+’s superior generalization across all tested radii compared to NIS.
Furthermore, to examine the impact of intrinsic and observational perturbations on CE, two types of noises are introduced. Intrinsic noise is incorporated into the rule by adding random turning angles to each boid at each time step. These angles are uniformly distributed within the interval , where is a parameter controlling the magnitude of the intrinsic noise. On the other hand, extrinsic noise is assumed to affect the observational micro-states. In this case, we assume that the micro-states of each boid cannot be directly observed, but instead, noisy data is obtained. The extrinsic or observational noise is added to the micro-states, and is the parameter determining the level of this noise.
The results are shown in Figure 4f and 4g, where the normalized MAE increases in both cases, indicating more challenging prediction tasks with increasing intrinsic and extrinsic noises. However, the differences between these two types of noises can be observed by examining the degrees of CE (). Figure 4f demonstrates that increases with the level of extrinsic noise (), suggesting that coarse-graining can mitigate noise within a certain range and enhance causal effects. When , the normalized MAE is smaller than (black dashed horizontal line), satisfying the constraint in Equation LABEL:old_optimization. In this case, the degree of CE increases with . However, when the threshold of 0.3 is exceeded, and even though decreases, we cannot draw any meaningful conclusion because the violation of the constraint in Equation LABEL:old_optimization undermines the reliability of the results.
On the other hand, Figure 4g demonstrates that decreases as the level of intrinsic noise () increases. This can be attributed to the fact that the macro-level dynamics learner attempts to capture the flocking behaviors of each group during this stage. However, as the intrinsic noise increases, the flocking behaviors gradually diminish, leading to a decrease in CE. We have not included cases where because the normalized MAE exceeds the threshold of 0.3, the constraints in Equation LABEL:old_optimization is violated. Figure 4e illustrates real trajectories and predictions for random deflection angle noise with . It can be observed that in the early stage, the straight-line trend can be predicted, but as the noise-induced deviation gradually increases, the error also grows, which intuitively reflects the reduction in CE. To compare, we also test the same curves for Rosas’ , the results are shown in support information section 12 because all the values are negative with large magnitudes.
Therefore, we conclude that NIS+ learns the optimal macro-dynamics and coarse-graining strategy by maximizing EI. This maximization enhances its generalization ability for cases beyond the training data range. The learned macro-states effectively capture average group behavior and can be attributed to individual positions using the IG method. Additionally, the degree of CE increases with extrinsic noise but decreases with intrinsic noise. This observation suggests that extrinsic noise can be eliminated through coarse-graining, while intrinsic noise cannot. More details about the experiments of Boids can be referred to support information section 12.





3.3. Real fMRI time series data for brains
We test our models on real fMRI time series data of brains for 830 subjects, called AOMIC ID1000[53]. The fMRI scanning data is collected when the subjects watch the same clip of movie. Thus, similar experiences of subjects under similar natural stimulus is expected, which corresponds to time series of the same dynamics with different initial conditions. We pre-process the raw data through Schaefer atlas method [54] to reduce the dimensionality of time series for each subject from roughly 140,000 (it varies among subjects.) to 100 such that NIS+ can operate and obtain more clear results. Then, the first 800 time series data are selected for training and the remaining 30 time series are for test. We also compare our results with another fMRI dataset AOMIC PIOP2 [53] for 50 subjects in resting state. Further description about the dataset can be referred to the method section.
To demonstrate the predictive capability of NIS+ for micro-states, Figure 5(a) illustrates the changes in normlized MAE with the prediction steps of the micro-dynamics on test data for different hyperparameters . It is evident that NIS+ performs better in predictions when and . Specifically, the curve for exhibits a slower rate of increase compared to the curve for as the prediction steps increase. This suggests that selecting the hyperparameter as 27 may be more suitable than 1.
However, Figure 5(b) suggests a different outcome. When comparing the degree of CE () for different hyperparameters (the green bars), the highest is observed when . Conversely, a negative value is obtained when . This indicates that the improved prediction results may be attributed to overfitting when . Thus, outperforms other values of in terms of . This finding is supported by the NIS framework (the red bars), despite observing a larger standard deviation in when . Furthermore, we also compare the results of CE with resting data and observe that peaks are reached at , which is just the number of subsystems in Schaefer atalas, for both NIS (deep blue bars) and NIS+ (yellow bars). Therefore, we can conclude that when subjects watch movies, the activities in different brain areas can be represented by a single real number at each time step. More analysis for the resting data can be referred to the support information section 14.1.
To investigate how NIS+ coarse-grains the input data into a single-dimensional macro-state, we also utilize the IG method to identify the most significant dimensions of the micro-state [52]. The results are depicted in Figure 5(c) and (d). We observe that the visual (VIS) sub-networks exhibit the highest attribution (Figure 5(c)). These visual sub-networks represent the functional system that subjects utilize while watching movie clips. Furthermore, we can visualize the active areas in finer detail on the brain map (Figure 5(d)), where darker colors indicate greater attribution to the single macro-state. Therefore, the regions exhibiting similar darkest colors identified by NIS+, which correspond to the deep visual processing brain region, could potentially represent the “synergistic core” [55] when the brain is actively engaged in watching movies. The numeric neurons in these areas may collaborate and function collectively. However, this conclusion should be further confirmed and quantified by decomposing the mutual information between micro-states and macro-states into synergistic, redundant, and unique information [34, 11].
In conclusion, NIS+ demonstrates its capability to learn and coarse-grain the intricate fMRI signals from the brain, allowing for the simulation of complex dynamics using a single macro-state. This discovery reveals that the complex neural activities during movie watching can be encoded by a one-dimensional macro-state, with a primary focus on the regions within the visual (VIS) sub-network. The robustness of our findings is further supported by comparable results obtained through alternative methods for data pre-processing, as demonstrated in the support information section 14.

4. Concluding Remarks
Inspired by the theory of causal emergence, this paper introduces a novel machine learning framework called Neural Information Squeezer Plus (NIS+) to learn emergent macro-dynamics, and suitable coarse-graining methods directly from data. Additionally, it aims to quantify the degree of CE under various conditions.
The distinguishing feature of our framework, compared to other machine learning frameworks, is its focus on maximizing the effective information (EI) of the learned macro-dynamics while maintaining effectiveness constraints. This enables the learned emergent macro-dynamics to capture the invariant causal mechanism that is as independent as possible from the distribution of input data. This feature not only enables NIS+ to identify CE in data across different environments but also enhances its ability for generalization on the environments which are distinct from training data. By introducing the error constraint in Equation LABEL:old_optimization, we can address the issues raised in [48] and enhance the robustness of the maximization of EI framework. As a result, NIS+ extends Hoel’s theory of CE to be applicable to both discrete and continuous dynamical systems, as well as real data.
Three experiments were conducted to evaluate the capabilities of NIS+ in learning and generalization, and quantifying CE directly from data. Furthermore, we applied this framework to the domain of the Game of Life (refer to the support information section 13). These experiments encompassed three simulation scenarios and one real fMRI dataset for 830 human subjects while watching same movie clips.
The experiments indicate that by maximizing EI, NIS+ outperforms other machine learning models in tasks such as multi-step predictions and pattern capturing, even in environments that were not encountered during the training process. Consequently, NIS+ enables the acquisition of a more robust macro-dynamics in the latent space.
Furthermore, the experiments show that NIS+ can quantify CE in a more reasonable way than Rosas’ indicator. With this framework, we can distinguish different scenarios in the data and identify which settings contain more regular patterns, as demonstrated in the experiment conducted on the Game of Life. The experiment on the Boid model also provides insights into how two types of noise can impact the degrees of CE. The conclusion is that extrinsic noise may increase CE, while intrinsic noise may decrease it. This indicates that extrinsic noise, arising from observational uncertainty, can be mitigated by the learned coarse-graining strategy. On the other hand, intrinsic noise, stemming from inherent uncertainty in the dynamical rules, cannot be eliminated.
The process of coarse-graining a complex system can be effectively learned by NIS+ and illustrated using the Integrated Gradients (IG) method, as demonstrated in the experiments involving the Boid model and the brain dataset. Through this method, the relationship between macro-states and micro-states can be visualized, allowing for the identification of the most significant variables within the micro-states. In the brain experiment, it was observed that the most crucial information stored in the unique macro-state exhibited a strong correlation with the micro-variables of the visual subnetwork. This finding highlights the ability of NIS+ to identify an appropriate coarse-graining strategy that aligns with meaningful biological interpretations.
NIS+ holds potential for various applications in data-driven modeling of real complex systems, such as climate systems, collective behaviors, fluid dynamics, brain activities, and traffic flows. By learning more robust macro-dynamics, the predictive capabilities of these systems can be enhanced. For instance, El Niño, which arises from the intricate interplay of oceanic and atmospheric conditions, exemplifies the emergence of a major climatic pattern from underlying factors. Understanding these emergent macro-dynamics can be instrumental in modeling and predicting El Niño events. By leveraging NIS+ to capture and quantify the CE in such complex systems, we can gain valuable insights and improve our ability to forecast their behavior.
Further extensions of the EI maximization method to other problem domains, such as image classification and natural language understanding, in addition to dynamics learning, warrant attention. Specifically, applying this principle to reinforcement learning agents equipped with world models has the potential to enhance performance across various environments. By incorporating the EI maximization approach into these domains, we can potentially improve the ability of models to understand and interpret complex visual and textual information. This can lead to advancements in tasks such as image recognition, object detection, language understanding, and machine translation.
The relationship between causal emergence and causal representation learning (CRL)[41] deserves further exploration. The NIS+ framework can be seen as a form of CRL, where the macro-dynamics serve as the causal mechanism and the coarse-graining strategy acts as the representation. As such, techniques employed in CRL can be applied to find CE in data. Conversely, the concept of CE and coarse-graining can be leveraged in CRL to enhance the interpretability of the model. By integrating the principles and methodologies from both CE and CRL, we can potentially develop more powerful and interpretable models. This synergy can lead to a deeper understanding of the causal relationships within complex systems and enable the extraction of meaningful representations that capture the emergent patterns and causal mechanisms present in the data. Further research in this direction can contribute to advancements in both CE and causal representation learning.
Another interesting merit of NIS+ is its potential contribution to emergence theory by reconciling the debate on whether emergence is an objective concept or an epistemic notion dependent on the observer. By designing a machine to maximize EI, we can extract objective emergent features and dynamics. The machine serves as an observer, but an objective one. Therefore, if the machine observer detects interesting patterns in the data, emergence occurs.
However, there are several limitations in this paper that should be addressed in future studies. Firstly, the requirement of a large amount of training data for NIS+ to learn the macro-dynamics and coarse-graining strategy may not be feasible in many real-world cases. If the training is insufficient, it may lead to incorrect identification of CE. Therefore, it is necessary to incorporate other numeric method, such as Rosas’ ID [11], to make accurate judgments. One advantage of NIS+ is its ability to identify coarse-grained macro-states, which can then be used as input for Rosas’ method. Secondly, the interpretability of neural networks, particularly for the macro-dynamics learner, remains a challenge. Enhancing the interpretability of the learned models can provide valuable insights into the underlying mechanisms and improve the trustworthiness of the results. Additionally, the learned macro-dynamics in this work are homogeneous, resulting in the same EI value across different locations in the macro-state space. However, in real-world applications, this may not always hold true. Therefore, it is necessary to develop local measures for CE, especially for systems with heterogeneous dynamics. This would facilitate the identification of local emergent patterns, making the analysis more nuanced and insightful. Lastly, the current framework is primarily designed for Markov dynamics, while many real complex systems exhibit long-term memory or involve unobservable variables. Extending the framework to accommodate non-Markov dynamics is an important area for future research. Addressing these limitations and exploring these avenues for improvement will contribute to the advancement of the field and enable the application of NIS+ to a wider range of complex systems.
5. Methods and Data
In order to provide a comprehensive understanding of the article, we will first dedicate a certain amount of space to introduce Erik Hoel’s theory of causal emergence, and we introduce the details of the NIS and NIS+ frameworks and other used techniques. After that, the details of the fMRI time series data is introduced.
5.1. Machine Learning Frameworks
We will introduce the details of the two frameworks NIS and NIS+ in this section.
5.1.1. Neural Information Squeezer (NIS)
NIS use neural networks to parameterize all the functions to be optimized in Equation LABEL:old_optimization, in which the coarse-graining and anti-coarsening function and are called encoder and decoder, respectively, and the macro-dynamics is called dynamics-learner. Second, considering the symmetric position between and , invertible neural network(with RealNVP framework[56], details can be referred to the following sub-section) is used to reduce the model complexity and to make mathematical analysis being possible[12].
Concretely,
| (7) |
where is an invertible neural network with parameters , and represents the projection operation with the first dimensions reserved to form the macro-state , and the last dimensional variable are dropped. Empirically, can be approximately treated as a Gaussian noise and independent with or we can force to be independent Gaussian by training the neural network. Similarly, in a symmetric way, can be approximated in the following way: for any input ,
| (8) |
where is a standard Gaussian random vector with dimensions, and represents the vector concatenation operation.
Last, the macro-dynamics can be parameterized by a common feed-forward neural network with weight parameters . Its number of input and output layer neurons equal to the dimensionality of the macro state . It has two hidden layers, each with 64 neurons, and the output is transformed using LeakyReLU. The detailed architectures and parameter settings of and can be referred to the supporting information (support information section 15). To compute EI, this feed-forward neural network is regarded as a Gaussian distribution, which models the conditional probability .
Previous work [12] has been proved that this framework merits many mathematical properties such as the macro-dynamics forms an information bottleneck, and the mutual information between and approximates the mutual information between and when the neural networks are convergent such that the constraint in Equation LABEL:old_optimization is required.
5.1.2. Neural Information Squeezer Plus (NIS+)
To maximize EI defined in Equation LABEL:old_optimization, we extend the framework of NIS to form NIS+. In NIS+, we first use the formula of mutual information and variational inequality to convert the maximization problem of mutual information into a machine learning problem, and secondly, we introduce a neural network to learn the inverse macro-dynamics that is to use to predict such that mutual information maximization can be guaranteed. Third, the probability re-weighting technique is employed to address the challenge of computing intervention for a uniform distribution, thereby optimizing the EI. All of these techniques compose neural information squeezer plus (NIS+).
Formally, the maximization problem under the constraint of inequality defined by Equation LABEL:old_optimization can be converted as a minimization of loss function problem without constraints, that is:
| (9) |
where are the parameters of neural networks of , , and , respectively. and are the macro-states. is a Lagrangian multiplier which will be taken as a hyper-parameter in experiments. is the inverse probability weights which is defined as:
| (10) |
where is the new distribution of macro-states after intervention for , and is the natural distribution of the data. In practice, is estimated through kernel density estimation (KDE)[49](Please refer method section 4). The approximated distribution, , is assumed to be a uniform distribution, which is characterized by a constant value. Consequently, the weight is computed as the ratio of these two distributions.
We can prove a mathematical theorem to guarantee such problem transformation as mentioned below:
Theorem 5.1 (Problem Transformation Theorem).
For a given value of , assuming that , and are the optimal solutions to the unconstrained objective optimization problem defined by equation (9). Then , and , where are the optimal solution to the constrained objective optimization problem Eq.(LABEL:old_optimization).
The details of proof can be seen in support information section 10.1.

Discriminate from Figure 6(a), a new computational graph for NIS+ which is depicted in Figure 6(b) is implied by the optimization problem defined in Equation 9. For given pair of data: , two dynamics, namely the forward dynamics and the reverse dynamics are trained by optimizing two objective functions and , simultaneously. In the training process, the encoder, and the decoder, are shared.
This novel computational framework of NIS+ can realize the maximization of EI under the coarse-grained emergent space. Therefore, it can optimize an independent causal mechanism() represented by on the emergent space. It can also be used to quantify CE in raw data once the macro-dynamics is obtained for different .
5.1.3. Extensions for Practical Computations
When we apply NIS+ to the data generated by various complex systems such as cellular automata and multi-agent systems, the architecture of encoder(decoder) should be extended for stacked and parallel structures. Fortunately, NIS+ is very flexible to different real scenarios which means the important properties such as Theorem 5.1 can be retained.

Firstly, it is important to consider that when dealing with high-dimensional complex systems, discarding multiple dimensions at once can pose challenges for training neural networks. Therefore, we replace the encoder in NIS+ with a Stacked Encoder. As shown in Figure 7(a), this improvement involves stacking a series of basic encoders together and gradually discard dimensions, thereby reducing the training difficulty.
In addition, complex systems like cellular automota are always comprise with multiple components with similar dynamical rules. Therefore, we introduce the Parallel Encoder to represent each component or groups of these components and combine the results together. Concretely, as shown in Figure 7(b), inputs may be grouped based on their physical relationships(e.g. adjacent neighborhood), and each group is encoded using a basic encoder. By sharing parameters among the encoders, neural networks can capture homogeneous coarse-graining rules efficiently and accurately. Finally, the macro variables obtained from all the encoders are concatenated into a vector to derive the overall macro variables. Furthermore, we can combine this parallel structures with other well-known architectures like convolutional neural networks.
To enhance the efficiency of searching for the optimal scale, we leverage the multiple scales of hidden space obtained through the stacked encoder by training multiple dynamics learners in different scales simultaneously. This forms the framework of Multistory NIS+ as shown in Figure 7(c). This approach is equivalent to searching macro-dynamics for different and thereby avoiding to retrain the encoders.
Theorem 5.2 guarantees that the important properties such as Theorem 5.1 can be retained for the extensions of stacked and parallel encoders. And a new universal approximation theorem (Theorem 5.3) can be proved such that multiple stacked encoders can approximate any coarse-graining function (any map defined on ).
Theorem 5.2 (Problem Transformation in Extensions of NIS+ Theorem).
When the encoder of NIS+ is replaced with an arbitrary combination of stacked encoders and parallel encoders, the conclusion of Theorem 2.1 still holds true.
Theorem 5.3 (Universal Approximating Theorem of Stacked Encoder).
For any continuous function which is defined on , where is a compact set, and , there exists an integer and an extended stacked encoder with hidden size and an expansion operator such that:
| (11) |
Thereafter, an extended stacked encoder with expansion operators is of universal approximation property which means that it can approximate and simulate any coarse-graining function defined on .
The extended stacked encoder refers to stacking two basic encoders together and gradually reducing dimensions, encoding the input from dimensions to dimensions, with an intermediate dimension of . Besides basic operations such as invertible mapping and projection, a new operation, vector expansion(, e.g., ), should be introduced, and locate in between the two encoders. All the proves of these theorems are referred to support information section 10.2 and 10.3.
5.1.4. Training NIS+
In practice, two stages are separated during training process for NIS+ and all extensions. The first stage only trains the forward neural networks (the upper information channel as shown in Figure 2) such that the loss is small enough. Then, the second stage which only trains the neural networks for the reverse dynamics (the lower information channel as shown in Figure 2) is conducted. Because the trained inverse dynamics is never used, the second stage is for training in essence.
6. Acknowledgement
The authors would like to acknowledge all the members who participated in the "Causal Emergence Reading Group" organized by the Swarma Research and the "Swarma - Kaifeng" Workshop. We are especially grateful to Professors Yizhuang You, Peng Cui, Jing He, Dr.Chaochao Lu, and Dr. Yanbo Zhang for their invaluable contributions and insightful discussions throughout the research process. We also thank the large language model ChatGPT for its assistance in refining our paper writing.
Support Information
1. A Brief Introduction of Causal Emergence Theory
The basic idea of Hoel’s theory is that we have two different views (micro and macro) of a same Markov dynamical system, and CE occurs if the macro-dynamics has stronger causal effect than the micro-dynamics. As shown in Figure 1, for example, the micro-scale system is composed by many colliding balls. The macro-scale system is a coarse-grained description of the colliding balls with colorful boxes where each box represents the number of balls within the box. In Figure 1, the vertical axis represents the scale(micro- and macro-), and the horizontal axis represents time, which depicts the evolution of the system’s dynamics in both scales. All the dynamical systems considered are Markovian, therefore two temporal successive snapshots are necessary. The dynamics in both micro- and macro-scales are represented by transitional probability matrix(TPM): for micro-dynamics and for macro-dynamics.
We can measure the strength of its causal effects for each dynamics(TPM) by effective information (EI). EI can be understood as an intervention-based version of mutual information between two successive states in a dynamical system over time. For any TPM , EI can be calculated by:
| (1) |
where, is the random variable to represent the state of the system at time , represents the do-operator [39] that intervene the state of the system at time to force that follows a uniform distribution on the value space of . is the probability at the th row and the th column. is the total number of states and is also the number of rows or columns. represents the logarithmic operation with a base of 2. Equation 1 can be further decomposed into two terms: determinism and non-degeneracy which characterize that how the future state can be determined by the past state and vice versa, respectively[25].
With EI, we can compare two TPMs. If is larger than , we say CE occurs in this dynamical system. In practice, we calculate another value called causal emergence to judge if CE takes place, that is:
| (2) |
Therefore, if , then CE occurs. can be treated as the quantitative measure of emergence for Markov dynamics. An example of CE on Markov chain is shown in Figure 1(b).
2. Measures and calculations of EI and causal emergence for neural networks
The measure of EI of discrete Markov chains can be calculated by Equation 1, however, it is not suitable for neural networks because a neural network is a deterministic function. Therefore, we need to extend the definition of EI for general neural networks. We continue to use the method defined in [12]. The basic idea is to understand a neural network as a Gaussian distribution conditional on the input vector with the mean as the deterministic function of the input values, and the standard deviations as the mean square errors of this neural network on the training or test datasets.
In general, if the input of a neural network is , which means is defined on a hyper-cube with size , where is a very large integer. The output is , and . Here is the deterministic mapping implemented by the neural network: , and its Jacobian matrix at is . If the neural network can be regarded as a Gaussian distribution conditional on given , then the effective information (EI) of the neural network can be calculated in the following way:
| (3) | ||||
where, is the co-variance matrix, and is the standard deviation of the output which can be estimated by the mean square error of under given . is the uniform distribution on , and is absolute value, and is determinant. If for all , then we set .
However, Equation 3 can not be applied in real cases directly because it will increase as the dimension of input or output increases[12]. Therefore, larger EI is always expected for the models with higher dimension. The way to solve this problem is by dividing the input dimension to define dimension averaged effective information(dEI) and is denoted as :
| (4) |
When the numbers of input and output are identical (, this condition is always hold for all the results reported in the main text), Equation 3 becomes:
| (5) |
We always use this measure to quantify EI for neural networks in the main text. However, this measure is also not perfect because it is dependent on a free parameter , the range of the domain for the input data. Our solution is to calculate the dimension averaged CE to eliminate the influence of . For macro-dynamics with dimension and micro-dynamics with dimension , we define dimension averaged CE as:
| (6) |
If and are parameterized by neural networks of with dimension and with dimension , then
| (7) | ||||
where and are the standard deviations for and on the th dimension, respectively. At this point, the influences of the input or output dimensions and the parameter has been completely eliminated, making it a more reliable indicator. Therefore, the comparisons between the learned macro-dynamics reported in the main text are reliable because the measure of dimension averaged CE is used.
In practice, the first step is to select a sufficiently large value for to ensure that all macro-states are encompassed within the region . Subsequently, the determinant of Jacobian matrices can be estimated using Monte Carlo integration, which involves sampling data points within this region. The standard deviations can be estimated using a test dataset, and the probability reweighting technique is employed to account for interventions and ensure a uniform distribution.
3. Invertible neural network in encoder(decoder)
In NIS, both the encoder() and the decoder() use the invertible neural network module RealNVP[56].

Concretely, if the input of the module is with dimension and the output is with the same dimension, then the RealNVP module can perform the following computation steps:
| (8) |
where, is an integer in between 1 and .
| (9) |
where, is element-wised time, and are feed-forward neural networks with arbitrary architectures, while their input-output dimensions must match with the data. For the experiments in this article, they each have two intermediate hidden layers. The input and output layers have the same number of neurons as the dimensions of the micro-state samples. Each hidden layer has 64 neurons, and the output of each hidden layer is transformed by the non-linear activation function LeakyReLU. In practice, or always do an exponential operation on the output of the feed-forward neural network to facilitate the inverse computation.
Finally,
| (10) |
It is not difficult to verify that all three steps are invertible. Equation 9 is invertible because the same form but with negative signs can be obtained by solving the expressions of and with and from Equation 9.
To simulate more complex invertible functions, we always duplex the basic RealNVP modules by stacking them together. In the main text, we use duplex the basic RealNVP module by three times.
Due to the reversibility of RealNVP, if its output is used as input in a subsequent iteration, the new output will be the same as the original input. Therefore, the neural networks used in the encoder-decoder can share parameters. The process of encoding to obtain the macro-state involves projecting the forward output and retaining only the first few dimensions. On the other hand, the process of decoding to obtain the micro-state involves concatenating the macro-state with a normal distribution noise, expanding it to match the micro-state dimensions, and then feeding it back into the entire invertible neural network.
4. KDE for probability reweighting
In order to use inverse probability weighting technique, we need to estimate the probability distribution of the samples. KDE(Kernel Density Estimation) is a commonly used estimation method that can effectively eliminate the influence of outliers on the overall probability distribution estimation. In this experiment, we estimate the probability distribution of macro-states . Below is an introduction to the operation details of KDE. For a sample , we have the following kernel density estimation:
| (11) |
represents the number of samples, the hyperparameter denotes the bandwidth, which is determined based on the rough range of the data and typically set to 0.05 in this article. is the kernel, specifically the standard normal density function. After obtaining the estimation function, each sample point is evaluated individually, resulting in the corresponding probability value for each sample point. By dividing the probability of the target distribution (uniform distribution) by our estimated probability value, we obtained the inverse probability weights corresponding to each sample point. To cover all sample points, the range of the uniform distribution needs to be limited by a parameter , which ensures that a square with side length can encompass all the sample points in all dimensions.
Another thing to note is that the weights obtained at this point are related to the sample size, so they need to be normalized. However, this will result in very small weight values corresponding to the samples. Therefore, it is necessary to multiply them by the sample quantity to amplify the weight values back to their normal scale. Then, multiply this weight value by the training loss of each sample to enhance the training of sparse regions, achieving the purpose of inverse probability weighting. Since the encoder parameters change with each iteration, causing the distribution of to change, we will re-estimate the probability distribution of the entire sample using KDE every 1000 epochs (a total of at least 30000 epochs of iteration, the number of iterations may vary in different experiments).
5. Calculation method of Rosas’
We present here the computing method for Rosas’ , a measurable indicator of CE proposed by Rosas [11]. Its definition is as follows:
| (12) |
where represents the given macrostate, and represent the macrostates at two consecutive time points, and represents the -th dimension of the microstate at time . According to Rosas’ theory, Rosas’ being greater than 0 is a sufficient but not necessary condition for emergence to occur. In this paper, we employ the method proposed by Lu et al. [57] to compute the continuous variable mutual information in the experimental configuration.
6. Comparison models in the SIR experiment
To compare the advantages of the NIS+ framework itself, we constructed a regular fully connected neural network (NN) with 33,668 parameters and a Variational Autoencoder (VAE) with 34,956 parameters in the SIR experiment (the NIS+ model consists of a total of 37,404 parameters, which includes the inverse dynamics component). NN consists of an input layer, an output layer, and four hidden layers with 4, 64, 128, 128, 64, 4 neurons respectively. NN+ refers to the NN that combines inverse probability weighting technique, with the same parameter framework. For each data point , we estimate the KDE probability distribution and calculate the inverse probability weighting. Finally, the weights are multiplied with the loss to give different training weights to samples with different densities.
VAE is a generative model that maps micro-level data to a normal distribution in latent space. During each prediction, it samples from the normal distribution and then decodes it [58]. It consists of an encoder and a decoder, both of which have 4 hidden layers, each layer containing 64 neurons. The input and predicted output are both four-dimensional variables, and the latent space also has four dimensions, with two dimensions for mean and two dimensions for variance. The macro-dynamic learner fits the dynamical changes of the two-dimensional mean variables. During the training process, the loss function consists of two parts: reconstruction error, which is the MAE error between the predicted output and the true label, and the KL divergence between the normal distribution of the latent space samples and the standard normal distribution. These two parts are combined with a 2:1 ratio and used for gradient backpropagation. VAE+ combines inverse probability weighting and bidirectional dynamic learning in the training of VAE, and adopts the same training method as NIS+. We keep the variance variables obtained from encoding unchanged, and use inverse probability weighting to obtain weight factors for the mean variables. Additionally, a reverse dynamic learner is constructed to predict given .
Because NN+ does not have a multi-scale framework for encoding and decoding, it directly estimates and calculates inverse probability weights at the micro-scale data level, and cannot improve the forward dynamics EI through training reverse dynamics. In VAE+, we focus on the dynamics trained in the latent space, aiming to estimate and calculate inverse probability weights in the latent space, and can optimize the encoder by training the reverse dynamics in the latent space to improve EI.The comparison results are shown in Figure 3(b) and (d).
7. Integrated Gradients for attribution
Here we introduce a method called Integrated Gradients[59] that is used to explain the connection between macro-states and micro-states. To formally describe this technique, let us consider a function that represents a deep network. Specifically, let denote the input under consideration, and denote the baseline input. In both the fMRI and Boids experiments, the baseline is set to 0.
We compute the gradients at each point along a straight-line path (in ) from the baseline to the input . By accumulating these gradients to obtain the final measure of integrated gradients(IG). More precisely, integrated gradients are defined as the path integral of the gradients along the straight-line path from the baseline to the input .
The integrated gradient along the i-th dimension for an input x and baseline is defined as follows. Here, represents the gradient of along the -th dimension. The Integrated Gradients(IG) that we have computed are shown in Equation 13.
| (13) |
8. fMRI time series data description in detail
AOMIC is an fMRI collection which composes AOMIC PIOP1, AOMIC PIOP2 and AOMIC ID1000[53].
The AOMIC PIOP2 collects subjects’ data for mutiple tasks such as emotion-matching, working-memory and so on. Here, we just use 50 subjects’ resting fMRI data since some time steps of other subject’s have been thrown outby removing the effects of artificial motion, global signal, and white matter signal and cerebrospinal fluid signal using fMRIPrep results[60, 61], which means a difficulty in time alignment.
The AOMIC ID 1000 collected when 881 subjects are watching movies. It contains both raw data and preprocsessed data(See more experimental and preprocsessing details in [53]). Here, we should notice that the movie is edited in a way for no clear semantic meanings but just some concatenated images from the movie. Therefore, it is expected that subjects’ brain activation patterns shouldn’t respond to some higher-order functions such as semantic understandings.
When working with fMRI data, the high dimensionality of the data (over 140,000 dimensions) poses computational challenges. To address this, dimension reduction techniques through brain atlas are employed to make the calculations feasible. We first preprocessed the data by removing the effects of artificial motion, global signal, and white matter signal and cerebrospinal fluid signal using fmriPrep results contained in AOMIC ID1000 [60, 61]. Simultaneously, we detrend and normalize the data during this process. By doing the whole preprocessing process, we also throw out 51 subjects’ data since some time steps of these subject’s have been removed. Furthermore, to facilitate the investigation of the correlation between the required brain function for watching movie clips and the emergent macro dynamics, we employed the Schaefer atlas to divide the brain into 100 functional areas. Also, we have committed the philosophy of anatomical Atlas, which seems to suggest the converging evidence(See support information section 14.2). All of these preprocessing steps were performed using Nilearn[62, 63]. During the training process, the only difference is the use of PCA in dimension reduction to handle the KDE approximation required for reweighting if .
9. Preceding instructions
Before we prove the theorem, let us first introduce the symbols that will be used in the following paragraphs. We will use capital letters to represent the corresponding random variables. For example, represents the random variable of the micro-state at time , and represents the random variable corresponding to the macro-state . For any random variable , represents the same random variable after intervention. means the prediction for given by neural networks.
Second, to understand how the intervention on can affect other variables, a causal graph derived from the framework of NIS and NIS+ and depicts the causal relations among variables is very useful, this is shown in Figure 2. In which, and denote the input random variable and predicted output random variable of the NIS+ on a micro scale, while and represent the input and output of on a macro scale. After intervening on , , represent different micro or macro variables under the intervention , corresponding to ,, and , respectively.

10. Mathematical Proves
In this sub-section, we will show the mathematical proves of the theorems mentioned in the main text.
10.1. Proof of Theorem 5.1
To prove this theorem, we utilize a combination of the inverse macro-dynamic and probability re-weighting technique, along with information theory and properties of neural networks. In this proof, we need three lemmas, stated as follows:
Lemma 10.1 (Bijection mapping does not affect mutual information).
For any given continuous random variables and , if there is a bijection (one to one) mapping and another random variable such that for any there is a , and vice versa, where denotes the domain of the variable , then the mutual information between and is equal to the information between and , that is:
| (14) |
Lemma 10.2 (Mutual information will not be affected by concatenating independent variables).
If and form a Markov chain , and is a random variable which is independent on both and , then:
| (15) |
Lemma 10.3 (variational upper bound of a conditional entropy).
Given a conditional entropy , where , there exists a variational upper bound on this conditional entropy:
| (16) |
where is any distribution.
Proof.
First, we unfold the conditional entropy
| (17) |
Due to the property of KL divergence[64], for any distribution ,
| (18) |
On the other words,
| (19) |
So,
| (20) | ||||
∎
To prove the theorem, we also use an assumption:
Assumption: The composition of the inverse dynamics and the encoder can be regarded as a conditional probability , and this probability can be approximated as a Gaussian distribution , where , and is the MSE loss of the th dimension of output . Further, suppose is bounded, thus for any , where and are the minimum and maximum values of MSEs.
This assumption is supported by the reference [65].
Next, we restate the theorem that needs to be proved:
Theorem 5.1(Problem Transformation Theorem): For a given value of , assuming that , and are the optimal solutions to the unconstrained objective optimization problem defined by equation (9). Then , and , where are the optimal solution to the constrained objective optimization problem Eq.(LABEL:old_optimization).
Proof.
The original constrained goal optimization framework is as follows:
| (21) | ||||
We know that , where is a reversible mapping that doesn’t affect the mutual information according to Lemma 14. Therefore, based on Lemma 10.2, we have the capability to apply a transformation to the mutual information :
| (22) |
Here, represents mutual information. By utilizing the property of mutual information, we can derive the following equation:
| (23) |
Now, , where is a uniform distribution on a macro space. Therefore, we have:
| (24) |
The optimization of the objective function can be reformulated as the optimization of the conditional entropy , since is a constant. The variational upper bound on is obtained by Lemma10.3.
| (25) |
where represents the probability distribution function of random variables in case of being intervened.
We will use a neural network to fit the distribution . Based on the assumption, we can consider it as a normal distribution. According to Lemma10.3, since the conditional probability can be any distribution, we can assume it to be a normal distribution for simplicity. Predicting with as input can be divided into two steps. First, is encoded by the encoder into the macro latent space. Then, the reverse macro dynamics are approximated using . As a result, the expectation of can be obtained using the following equation:
| (26) |
Therefore, we have , where is a constant diagonal matrix and . In order to utilize the properties of intervention on , we need to separate . Following Equation 25, we can further transform :
| (27) |
Assuming that the training is sufficient, we can have
| (28) |
So,
| (29) |
According to Equation26, we obtain the logarithm probability density function of
:
| (30) | ||||
Because , so
| (31) | ||||
where . Here, . Thus, we obtain , where represents the target distribution and represents the natural distribution obtained from the data. We can define the inverse probability weights as follows:
| (32) |
Let . Therefore, we can express Equation 31 as follows:
| (33) |
Because we train neural networks using discrete samples , we can use the sample mean as an approximate estimate of the expectation in Equation33. Therefore, the variational upper bound of can be written as:
| (34) |
Substituting the equation into Equation 24, we obtain the variational lower bound of the original objective function:
| (35) |
Therefore, the optimization problem(Equation LABEL:old_optimization) is transformed into
| (36) | |||
| (37) |
where , , respectively represent the parameters of the three neural networks , , in the NIS+ framework.
Then we construct Lagrange function,
| (38) |
Therefore, the optimization goal is transformed into
| (39) |
∎
10.2. Proof of Theorem 5.2
We will first use two separate lemmas to prove the scalability of stacked encoder and parallel encoder, thereby demonstrating that their arbitrary combination can keep the conclusion of Theorem 5.1 unchanged.
Lemma 10.4 (Mutual information will not be affected by stacked encoder).
If and form a Markov chain , and and represent the L-layer stacked encoder and decoder, respectively, then:
| (40) |
Proof.
According to Figure7(a), we can obtain
| (41) |
is a basic decoder as shown in Equation 8. represents the composition of functions. Therefore, according to Lemma 10.2 and the fact that reversible mappings do not change mutual information, we obtain
| (42) |
Let , we can further obtain , and so on, leading to the final result
| (43) |
∎
Lemma 10.5 (Mutual information will not be affected by parallel encoder).
If and form a Markov chain , and and represent parallel encoder and decoder composed of T ordinary encoders or decoders, respectively, then:
| (44) |
Proof.
the decoding process can be divided into two steps:
| (45) |
can be decomposed as , and all the introduced noise , even if the order of their concatenation changes, it will not affect the mutual information between the overall variable and other variables. Let , where is a partition of , and are all invertible functions. Therefore, is also an invertible function, meaning that this function transformation does not change the mutual information. According to Lemma 10.2, we have
| (46) |
Finally proven,
| (47) |
∎
Next, we provide the proof of Theorem 5.2.
Theorem 5.2(Problem Transformation in Extensions of NIS+ Theorem) When the encoder of NIS+ is replaced with an arbitrary combination of stacked encodes and parallel encoders, the conclusion of Theorem 2.1 still holds true.
Proof.
To demonstrate that Theorem 5.1 remains applicable to the extended NIS+ framework, we only need to prove that Equation 22 still holds true, as the only difference between the extended NIS+ and the previous framework lies in the encoder. First, we restate Equation 22 as follows:
| (48) |
According to Lemma 10.4 and Lemma 10.5, Equation 22 holds true when the encoder of NIS+ is replaced with either a stacked encoder or a parallel encoder. And any combination of these two encoders is nothing more than an alternating nesting of stacking and parallelization, so the conclusion still holds. ∎
10.3. Proof of Theorem 5.3
To prove the universality theorem, we need to extend the definition of the basic encoder by introducing a new operation , which represents the self-replication of the original variables.
| (49) |
The vector is composed of dimensions, where each dimension is a duplicate of a specific dimension in . For example, if , then .
The basic idea to prove theorem 5.3 is to use the famous universal approximation theorems of common feed-forward neural networks mentioned in [66, 67] and of invertible neural networks mentioned in [68, 69] as the bridges, and then try to prove that any feed-forward neural network can be simulated by a serious of bijective mapping(), projection() and vector expansion () procedures. The basic encoder after the extension for vector expansion can be expressed by the following equation:
| (50) |
The functions and represent two reversible mappings. The final dimensionality that is retained may be larger than the initial dimensionality . In the context of coarse-graining microscopic states to obtain macroscopic states, for the sake of convenience, we usually consider as a dimension reduction operator.
First, we need to prove a lemma.
Lemma 10.6.
For any vector and matrix , where , there exists an integer and two basic units of encoder: and such that:
| (51) |
where, represents approximate or simulate.
Proof.
For any , we can SVD decomposes it as:
| (52) |
where are all orthogonal matrices, is a diagonal matrix composed by nonzero eigenvalues of : , and zeros, where is the rank of the matrix . Because all matrices can be regarded as functions, therefore:
| (53) |
where, . That is, the functional mapping process of can be decomposed into four steps: matrix multiplication by , projection (projecting a dimensional vector to an dimensional vector), vector expansion (expanding the dimensional vector to an dimensional one), and matrix multiplication by . Notice that the first and the last steps are invertible because the corresponding matrices are invertible. Therefore, according to [68, 69], there are invertible neural networks and that can simulate orthogonal matrix and the invertible matrix , respectively. Thus, , and . Then we have:
| (54) |
That is can be approximated by an extended stacked encoder. ∎
Theorem 5.3(Universal Approximating Theorem of Stacked Encoder): For any continuous function which is defined on , where is a compact set, and , there exists an integer and an extended stacked encoder with hidden size and an expansion operator such that:
| (55) |
Thereafter, an extended stacked encoder is of universal approximation property which means that it can approximate(simulate) any coarse-graining function defined on .
Proof.
According to universal approximation theorem in [66, 67], for any function defined on , where is a compact set, and , and small number , there exists an integer and such that:
| (56) |
where, is the sigmoid function on vectors.
According to Lemma 10.6 and and are all invertible operators, therefore, there exists invertible neural networks , and two integers which are ranks of matrices and , respectively, such that:
| (57) |
where, approximates(simulates) the function and approximates(simulates) the function .
Therefore, if we let , then ∎
In real applications, although the basic encoder and the extended versions do not include expansion operator, we always expand input vector before it is input for the encoder. Therefore, it is reasonable to believe that Theorem 5.3 still holds for stacked encoders.
11. SIR Model
In this section, we will introduce various parameters and specific methods in the SIR experiment.
11.1. Data generation
In Equation6, are two-dimensional Gaussian noises and independent each other, and . For this covariance matrix, we can easily deduce that and are both two-dimensional normal distributions with a correlation coefficient of . The parameter controls the overall magnitude of the noise, which is set to in the experiments conducted in this paper. For macroscopic state data, we discretize the original continuous model with and run 7 time steps for each starting point. After sampling with different starting points, we concatenate equal amounts of and to obtain four-dimensional microscopic data.
In the SIR model experiment conducted in this article, we generated two datasets: the complete dataset and the partial dataset. For the complete dataset, we uniformly sampled 9000 initial points from the entire range of possible values for and (), resulting in a total of 63000 data points. For the partial dataset, we uniformly sampled 6000 initial points from the region where . Additionally, to satisfy the requirements of KDE estimation for the support set, we randomly sampled 10 initial points from the region where . In total, the partial dataset consists of 42070 sample points. The training and testing results of the NIS+ neural network on these two different sample sets are presented in Figure 3.
11.2. Training and testing details
For NIS+, two stages are separated at the 3000th epoch(see method section 5.1.4). In the second stage (after 3000 epochs), NIS+ incorporates inverse probability weighting and bidirectional dynamic learning, distinguishing it from the NIS model.
In Figure 3(d), the test involves selecting 20 starting points within an area where the training samples are missing, evolving them for 10 steps using the learned macro-dynamics, and then decoding the results back into micro-states. The mean of the multi-step prediction errors for these 20 starting points is displayed. In Figure 3(e), considering the significant differences in the range of experimental data, the threshold measures the magnitude of relative error, which is obtained by dividing the absolute error by the standard deviation of the data itself. We set , which means that the machine training is considered sufficient when the relative error is less than or equal to 0.3.
11.3. Methods for the vector field results
The following step-by-step explanation outlines how to average the vector field results of emergent dynamics, as demonstrated in Figure 3. The aim of this process is to compute the vector field through extensive sampling and averaging. Initially, we generate grid points on the phase space with a step size of 0.007, as shown in Figure 3(a). This step serves to obtain a significant number of samples for further analysis. To achieve this, we introduce noise to these grid points and their subsequent time steps, extending them to four-dimensional data. Next, we employ the well-trained NIS+ model to encode these extended data points, resulting in samples in the latent space. These samples are then divided into different grids on the latent space with a step size of 0.015, enabling a comprehensive analysis of the emergent dynamics. The subsequent calculation involves determining the average motion vector for each grid using the methodology outlined in Figure 3(d). It is important to note that the primary objective of this step is to compute the average vector field by aggregating the motion vectors across the grids. For comparison, we also generate sparser grid points on the phase space with a step size of 0.07. By applying the same noise and encoding techniques, we establish a one-to-one correspondence between the motion vectors of the grids and the new grid points. This correspondence allows us to depict the vector field of the macro latent space of NIS+ as shown in Figure 3(c). Similarly, by replacing the encoder of NIS+ with the encoder of NIS, we can obtain the latent space vector field of NIS, as illustrated in Figure 3(f). This approach, based on extensive sampling and averaging, provides valuable insights into the macro features of emergent dynamics.

In Figure 3(c) and (f), we provide a theoretic vector field. It is obtained by the folowing steps. First,
| (58) |
where is the Jacobian matrix of the encoder. Therefore, we could obtain the vector by representing the relationship between the true dynamics and the latent space dynamics. We notice that according to Equation 6:
| (59) |
Because and the noises are independent of time and have zero mean, we can replace in the experiment. Finally, we obtain:
| (60) |
where, and . Therefore, after multiplying the ground truth vector field with the Jacobian matrix , we obtain the theoretic prediction of the vector field in the graph. The difference between this theoretic vector field and the true dynamics is due to the errors of the encoder .
In order to achieve a better dynamic vector field, we specifically conducted multi-step prediction training when drawing Figure 3(c) and (f). Specifically, given the input of microstate at a certain moment, we make multi-step predictions for the next 10 microstates respectively and combine them with certain weights to form a loss for gradient backpropagation. The weights decay at a rate of as the prediction steps increase. For reverse prediction, we take the target corresponding to the last step as the input and perform multi-step prediction training in the same way. In addition, we adopt the approach of interval sampling, taking every 100 sample points as a step, so that NIS+ can make long-term predictions on the SIR model.
12. Boids Model
In 1986, Craig Reynolds created a simulation of the collective behavior of birds, known as the Boids model [50]. This model only used three simple rules to control the interactions between individuals, resulting in flock-like behavior.
12.1. Method of Simulating the Trajectory of Boids

In Boids model, the micro-state of each individual boid is a four dimensional vector , where is the positional vector, and is the velocity vector. Thus, the complete micro-state for all boids is a dimensional vector. The micro-states follow the dynamical update equations:
| (61) |
Where, is the external force exerted on by its neighbors, and it is composed with three components which called cohesion, alignment, and separation, respectively, according to the dynamical rules of Boids model. is a force on turning direction exerted on each boid at each time step, where is a fixed value or random number.
The motion vector of bird at time can be expressed as where and represent the position coordinates, and represent the projection of velocity on two coordinate axes. With boids, . The motion vector can be decomposed into position vector and velocity vector and . The distance between two boids and can be expressed as . Although the Boids model belongs to a continuous system, in order to facilitate the simulation process and subsequent experiments, we uniformly set . For a single boid in the model, the acceleration can be divided into four parts: separation, parallelism, cohesion, and random deflection angle noise. We stipulate that the velocity magnitude of a boid during the flight remains stable, so the impact of acceleration mainly changes the direction of Boids’ flight. After knowing the motion state vector of each boid in the flock at time , the motion state at time can be generated. Specify , , as the variation of separation, parallelism, and cohesion velocities, respectively. In which
| (62) |
We stipulate that the maximum and minimum detection distances for Boids are and . The sets of Boids within the minimum and maximum detection range are specified as and . So the centers of gravity of and are represented as and , which are the mean values of the boids’ position coordinates within two sets. With equation
| (63) |
we can obtain Equation 61 in Section 3.2. The relationship between the above variables is shown in Fig.4. By modifying the starting vector or and , the aggregation of bird flocks will change. And we can adjust the trajectory and randomness of Boids by modifying the mean and variance of the deflection angle in Equation 61.
12.2. Methods for Collecting Experimental Data and Training
We record the velocity vector and position vector of each bird at each time during its flight as data. For each time step , we need to record the data at that time and the data at the next time step . We merge the data into dimensional vectors at each time step as
| (64) |
This vector corresponds to our micro-state data , . We can repeat the preparation and recording stages multiple times until the data volume meets our expectations. The ID of birds is , evenly divided into two sets, and . The model we generated contains two sets of birds randomly generated near the center of the canvas.
We generate observation data in two phases: preparation and recording. In the preparation phase, one group of birds is randomly generated within a circle with as the center and 5 as the radius and the other group of birds is randomly generated within a circle with as the center and 5 as the radius. Then by modifying the or the mean and variance of the deflection angle two groups of birds can fly different trajectories in Fig.4a and 4e. The norm of the velocity vector is always 1, that is We set and so that the birds within the same group will interact with each other, while the effects between birds in different groups can be ignored. Subsequently, we allowed two groups of birds to fly for 20 steps without affecting each other, resulting in two groups of birds with distance and relatively stable internal stability. Then the positions and velocities of all birds serve as the starting point for us to record data.
In the recording phase, we have the birds continue to run 50 steps on the basis of the preparation phase, recording the velocity and position vectors of each bird separately. We randomly sort the generated data and input them into our NIS+ model for training, using the multistory structure of the NIS+ in Fig.7 during the training process. We sample the data for 4 batches. After inputting , the microstate , and predicted value can be output, and training can begin. The encoders and decoders are stacked, and the dynamics learners in different layers, , operate in parallel. This design facilitates simultaneous training for different dynamics learners with distinct dimensions and enables parallel searching for the optimal dimension, which is . Due to the previous experiments showing that the model performs better when than other scales, and having too many layers can also slow down learning efficiency, we can discard layers with in the later experiments. All the boids are separated into two groups by forcing their as two distinct values for boids with , and for boids . Therefore, the two groups will have separating trajectories with different turning angles as shown in Figure 4a.
After training with 800,000 epochs by NIS, reaches its maximum value when . We continue to optimize the existing model using NIS+ training 400,000 epochs, the results are shown in Fig.4c. Then we can obtain multi-step prediction data as shown in Figure 4a. It can be seen that the multi-step predicted trajectory matches the flight trajectory of the real bird flock. However, if the variance of is large, the training effect of the model will deteriorate, and the multi-step prediction distance will become shorter as shown in 4e. Causal emergence occurs for all tested dimensions() (see Figure 4c). With up to dimensional macro-state vectors, NIS+ can best capture the emergent collective flying behaviors of the two groups by tracing their centers of the trajectories. This can be visualized by decoding the predicted macro-states into the predicted micro-states as shown in Figure 4a by the two solid lines. With the method of generating data, we can observe the impact of noise. For different observation noises, in cases where the noise is not too significant, we can use the same method to train the model with NIS first, then optimize it with NIS+ to obtain Fig.4f. For different deflection angle noises, after training from random initial parameter values, in order to unify the control variables, we optimized them in the dimension of and obtained Fig.4g.
We test the degree of Rosas’ using the same learned macro-state variable of NIS+. The results, shown in Figure 5, display results of Rosas’ for different extrinsic noises. For Rosas’ , all cases yield values are far less than 0. One possible reason to explain this is that much redundant information is ignored by the approximation by . Another possible reason is that the Boids’ coordinate data has a large order of magnitude, which can result in a significant increase in the value of lost information. Thus, unreasonable results are produced which makes Rosas’ impossible to determine whether CE occurs. Therefore, the proposed in this paper is a superior method for identifying CE.

13. Game of Life
Conway’s Game of Life is a famous two dimensional cellular automota model on which various interesting dynamical patterns like glider, square, flower, signal light, honeycomb, traffic light emerge. Different from SIR model and Boids model, the micro-states of Game of Life at each time step are discrete(0 or 1) on a large regular grid as shown in Figure 6. Further, the micro-dynamics can not be represented by differential or difference equations but by rule tables (details can be referred to section 13.1).
We train NIS+ using data generated by the Game of Life simulation with random initial conditions and extract the time series of states from the 100th step to the 120th step. Figures 6(a),(b) and (c) show the dynamical patterns that are generated by the ground truth simulations(the first row) and the predictions by NIS+(the third row), as well as the emergent macro-states that can make those predictions(the second row). We input two images with successive time steps into NIS+, and obtain another image pair with next two successive time steps. Compare the upper picture and lower ones, the patterns are similar. However, the learned and predicted patterns in the third column, specifically the “glider” pattern, appear vague due to the limited occurrence of training samples with this pattern in random initial conditions. To enhance the quality of predictions, we can generate a new set of training samples that include initial conditions with two “gliders”. As a result, the predictions become clearer, as depicted in Figure 6(d), even though the number of gliders in this test environment is three. That means, NIS+ can capture the patterns including moving, static, and oscillating structures.
Furthermore, we evaluate the generalization ability of the models in test environments that differ from the training environments. We compare the multi-step prediction performance of NIS and NIS+ across eight different pattern types, which are distinct from the initial random patterns. The results are depicted in Figure 6(f) showing that NIS+ consistently achieves a higher AUC (area under the curve) than NIS for all the pattern types. Where, in the tick labels of the x-coordinate, we adopt the format of “pattern name (quantity)” to represent various initial conditions. For instance, “glider(2)” signifies an initial configuration comprising two gliders. Thus, we have provided the evidence that the enhanced NIS+ method possesses superior generalization ability in capturing these patterns.
We further test the degree of CE () and compare it with Rosas’ using the same learned macro-state variable of NIS+. We use the same patterns as initial conditions to test for the comparison. The results, shown in Figure 6(g), display results of CE, in which each bar representing a combination of and Rosas’ for one initial pattern. Regarding , except for the “random” case, all eight cases demonstrate the occurrence of CE. The case with “glider” patterns exhibit the lowest degree of CE due to poor prediction (see Figure 6(c)). The remaining seven patterns show similar values. These results indicate that provides a more reasonable indication of the occurrence of CE, aligning with our intuition. However, for Rosas’ , all cases yield values less than or equal to 0. One possible reason to explain this is that much redundant information is ignored by the approximation by . Thus, unreasonable results are produced which makes Rosas’ impossible to determine whether CE occurs. Therefore, the proposed in this paper is a superior method for identifying CE.
Additionally, this example highlights the versatility of NIS+. In order to conduct the aforementioned experiments, we needed to coarse-grain the micro-states of the cellular automata in both spatial and temporal dimensions. To address this challenge, we incorporated the concept of spatiotemporal convolution. The architecture used in this experiment is illustrated in Figure 6(e). The entire coarse-graining process can be divided into two steps: first, aggregating information within a fixed-size window (a 3x3 window in this paper) to obtain spatial coarse-grained results; and second, aggregating these results over multiple successive time steps to form a spatiotemporal coarse macro-state. All of these processes are implemented through parallel encoders in NIS+.

13.1. Data generation
In this paper, we use Conway’s Game of Life as the experimental object, in which each cell has two states for two-dimensional state input: alive (1) or dead (0), and each cell is affected by its eight neighbors. The evolution of the Game of Life is only affected by the input state and its update rules, in which the Game of Life has four evolutionary rules, respectively corresponding to cell reproduction and death, and so on. The update rules for the Game of Life are shown in the following table:
| 0 | 1 (there are three living cells around) |
| 1 | 0 (less than two surviving cells around the cell (excluding two)) |
| 1 (there are two or three living cells around) | |
| 0 (there are more than three living cells around) |
The training sample generation process of the Game of Life is as follows: firstly, a state is initialized. When considering a temporal coarse-grained of two steps, the subsequent three steps of states , , and are then generated based on the update rule and are input to the machine learning model. The two input states are and , with the micro-dynamics output being and . Due to the utilization of spatiotemporal coarse-graining, the macro-dynamics will output a macro-state which will be decoded into the micro-states and . This process is repeated multiple times (50,000 samples) and generate the data for training in Figure 6d. While in the other experiments, we generate 500,000 samples.
13.2. The model predictive ability on glider pattern
We then test the capability of capturing dynamical patterns on glider pattern, where the model was trained based on two glider patterns. The model depicts a good prediction effect and the results are shown in Figure 7.
In addition, please refer to Table 2 for more detailed information on the other model parameters.

14. Brain Results
14.1. resting state
We also apply integrated gradient to see what seven macro dimensions mean for micro brain areas. Different from results from visual fMRI,we can see some distinct patterns. Unfortunately, we can’t see that some one-to-one relationship between these seven dimensions and seven systems defined by Schaefer atlas(See Figure 8)

14.2. AAL Results
We repeat what we have done in sections 3.3 and 8 expect that we have utilized AAL3 atlas and made to be 0.5 for layer 1 training of NIS+ since will lead to a trivial solution where macro predictions for all areas will remain the same, which make the prediction can’t be meaningful. We can see a converging evidence that NIS+ framework will lead to an improvement of (see Figure 9(b) and a stronger correlation with those areas which responds to the visual areas(See Figure 9(a) and (c)).

15. The Structure and parameters of neural networks.
Next, we list the neural network parameters used in our experimental study, as shown in Table 2. The parameter in the table is derived from Equation 9 and serves as the weight coefficient for the forward prediction error. is an assumption about the range of data distribution, which represents the length of a hypercube with side length that is used to calculate the probability value for a uniform distribution. It is not difficult to see that different types of neural networks have been used to handle different types of complex systems. Both the Boids and fMRI experiments employ the Multistory NIS+ framework, which traverses different macroscopic scales and eventually selects an optimal scale (the dimension of input or output in the Inverse Dynamics Learner table).
| Experiment | Module | Parameter |
| SIR | Encoder(Decoder) | Three RealNVP modules Input(Onput) dimensions: 4 Macro-state dimensions: 2 |
| Dynamics Learner | Input(Onput) dimensions: 2 Hidden Layers: 2 Hidden Units: 64 Activation Function: LeakyReLu Total Epochs:30000 Batch Size:700 L: 1 | |
| Inverse Dynamics Learner | : 0.33 Input(Onput) dimensions: 2 Hidden Layers: 2 Hidden Units: 64 Activation Function: LeakyReLu Stage II Epochs:27000 | |
| Boids | Encoder(Decoder) | Three RealNVP modules Input(Onput) dimensions: 64 Macro-state dimensions: 32,16,8 |
| Dynamics Learner | Input(Onput) dimensions: 64,32,16,8 Hidden Layers: 2 Hidden Units: 32 Activation Function: LeakyReLu Total Epochs:800,000 Batch Size:4 L: 100 | |
| Inverse Dynamics Learner | : 1 Input(Onput) dimensions: 8 Hidden Layers: 2 Hidden Units: 32 Activation Function: LeakyReLu Stage II Epochs:400,000 | |
| Game of life | Encoder(Decoder) | Three RealNVP modules Input(Onput) dimensions: Macro-state dimensions: |
| Dynamics Learner | Input(Onput) dimensions: 36 Hidden Layers: 2 Hidden Units: 64 Activation Function: LeakyReLu Total Epochs: 300,000 Batch Size: 50 L: 100 | |
| Inverse Dynamics Learner | : 1 Input(Onput) dimensions: Hidden Layers: 2 Hidden Units: 64 Activation Function: LeakyReLu Stage II Epochs: 200,000 | |
| fMRI | Encoder(Decoder) | Six RealNVP modules Input(Onput) dimensions: 100 Macro-state dimensions: 52,27,14,7,3,1 |
| Dynamics Learner | Input(Onput) dimensions: 100,52,27,14,7,3,1 Hidden Layers: 5 Hidden Units: 256 Activation Function: LeakyReLu and a final tanh Total Epochs: 60000 Batch Size: 100 L: 1 | |
| Inverse Dynamics Learner | : 1 Input(Onput) dimensions: 1 Hidden Layers: 5 Hidden Units: 256 Activation Function: LeakyReLu Stage II Epochs: 10000 |
References
- [1] H. Sayama, Introduction to the modeling and analysis of complex systems. Open SUNY Textbooks, 2015.
- [2] J. Odell, “Agents and complex systems,” Journal of Object Technology, vol. 1, no. 2, pp. 35–45, 2002.
- [3] W.-X. Wang, Y.-C. Lai, and C. Grebogi, “Data based identification and prediction of nonlinear and complex dynamical systems,” Physics Reports, p. 1–76, Jul 2016. [Online]. Available: http://dx.doi.org/10.1016/j.physrep.2016.06.004
- [4] T. Kipf, E. Fetaya, K.-C. Wang, M. Welling, and R. Zemel, “Neural relational inference for interacting systems,” in International conference on machine learning. PMLR, 2018, pp. 2688–2697.
- [5] J. Casadiego, M. Nitzan, S. Hallerberg, and M. Timme, “Model-free inference of direct network interactions from nonlinear collective dynamics,” Nature Communications, vol. 8, no. 1, Dec 2017. [Online]. Available: http://dx.doi.org/10.1038/s41467-017-02288-4
- [6] Y. Zhang, Y. Guo, Z. Zhang, M. Chen, S. Wang, and J. Zhang, “Universal framework for reconstructing complex networks and node dynamics from discrete or continuous dynamics data,” Physical Review E, vol. 106, no. 3, p. 034315, 2022.
- [7] J. H. Holland, Emergence: From chaos to order. OUP Oxford, 2000.
- [8] S. Ben Tahar, J. J. Muñoz, S. J. Shefelbine, and E. Comellas, “Turing pattern prediction in three-dimensional domains: the role of initial conditions and growth,” bioRxiv, pp. 2023–03, 2023.
- [9] P. C. Matthews and S. H. Strogatz, “Phase diagram for the collective behavior of limit-cycle oscillators.” Physical Review Letters, vol. 65, no. 14, p. 1701–1704, Jul 2002. [Online]. Available: http://dx.doi.org/10.1103/physrevlett.65.1701
- [10] Y. Du, Z. He, Q. Gao, H. Zhang, C. Zeng, D. Mao, and J. Zhao, “Emergent phenomena of vector solitons induced by the linear coupling,” Laser & Photonics Reviews, p. 2300076, 2023.
- [11] F. E. Rosas, P. A. M. Mediano, H. J. Jensen, A. K. Seth, A. B. Barrett, R. L. Carhart-Harris, and D. Bor, “Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data,” PLOS Computational Biology, vol. 16, no. 12, p. e1008289, Dec 2020. [Online]. Available: http://dx.doi.org/10.1371/journal.pcbi.1008289
- [12] J. Zhang and K. Liu, “Neural information squeezer for causal emergence,” Entropy, vol. 25, no. 1, p. 26, 2022.
- [13] E. O’toole, V. Nallur, and S. Clarke, “Decentralised detection of emergence in complex adaptive systems,” ACM Transactions on Autonomous and Adaptive Systems, vol. 12, no. 1, p. 1–31, Mar 2017. [Online]. Available: http://dx.doi.org/10.1145/3019597
- [14] F. P. Kemeth, T. Bertalan, T. Thiem, F. Dietrich, S. J. Moon, C. R. Laing, and I. G. Kevrekidis, “Learning emergent partial differential equations in a learned emergent space,” Nature communications, vol. 13, no. 1, p. 3318, 2022.
- [15] F. Keijzer, “Artificial life xi: Proceedings of the eleventh international conference on the simulation and synthesis of living systems,” MIT Press eBooks, Jan 2008.
- [16] C. Shalizi and C. Moore, “What is a macrostate? subjective observations and objective dynamics,” arXiv: Statistical Mechanics, Mar 2003.
- [17] A. K. Seth, “Measuring emergence via nonlinear granger causality.” in alife, vol. 2008, 2008, pp. 545–552.
- [18] R. A. Haugen, N.-O. Skeie, G. Muller, and E. Syverud, “Detecting emergence in engineered systems: A literature review and synthesis approach,” Systems Engineering, 2023.
- [19] D. Fisch, M. Jänicke, B. Sick, and C. Müller-Schloer, “Quantitative emergence–a refined approach based on divergence measures,” in 2010 Fourth IEEE International Conference on Self-Adaptive and Self-Organizing Systems. IEEE Computer Society, 2010, pp. 94–103.
- [20] M. Mnif and C. Müller-Schloer, “Quantitative emergence,” Organic Computing—A Paradigm Shift for Complex Systems, pp. 39–52, 2011.
- [21] D. Fisch, M. Jänicke, C. Müller-Schloer, and B. Sick, “Divergence measures as a generalised approach to quantitative emergence,” Organic Computing—A Paradigm Shift for Complex Systems, pp. 53–66, 2011.
- [22] J. S. Osmundson, T. V. Huynh, and G. O. Langford, “Kr14 emergent behavior in systems of systems,” in INCOSE International Symposium, vol. 18, no. 1. Wiley Online Library, 2008, pp. 1557–1568.
- [23] R. Raman and A. Murugesan, “Framework for complex sos emergent behavior evolution using deep reinforcement learning,” in INCOSE International Symposium, vol. 32, no. 1. Wiley Online Library, 2022, pp. 809–823.
- [24] Y. M. Teo, B. L. Luong, and C. Szabo, “Formalization of emergence in multi-agent systems,” in Proceedings of the 1st ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, 2013, pp. 231–240.
- [25] E. P. Hoel, L. Albantakis, and G. Tononi, “Quantifying causal emergence shows that macro can beat micro,” Proceedings of the National Academy of Sciences, vol. 110, no. 49, pp. 19 790–19 795, 2013.
- [26] E. P. Hoel, “When the map is better than the territory,” Entropy, vol. 19, no. 5, p. 188, 2017.
- [27] J. Fromm, “Types and forms of emergence,” arXiv: Adaptation and Self-Organizing Systems, Jun 2005.
- [28] G. Tononi and O. Sporns, “Measuring information integration,” BMC neuroscience, vol. 4, pp. 1–20, 2003.
- [29] R. Comolatti and E. Hoel, “Causal emergence is widespread across measures of causation,” arXiv preprint arXiv:2202.01854, 2022.
- [30] R. Griebenow, B. Klein, and E. Hoel, “Finding the right scale of a network: Efficient identification of causal emergence through spectral clustering,” arXiv: Social and Information Networks, Aug 2019.
- [31] E. Hoel and M. Levin, “Emergence of informative higher scales in biological systems: a computational toolkit for optimal prediction and control,” Communicative & Integrative Biology, vol. 13, no. 1, p. 108–118, Jan 2020. [Online]. Available: http://dx.doi.org/10.1080/19420889.2020.1802914
- [32] S. Marrow, E. J. Michaud, and E. Hoel, “Examining the causal structures of deep neural networks using information theory,” Entropy, p. 1429, Dec 2020. [Online]. Available: http://dx.doi.org/10.3390/e22121429
- [33] B. Klein and E. Hoel, “The emergence of informative higher scales in complex networks,” Complexity, vol. 2020, pp. 1–12, 2020.
- [34] P. L. Williams and R. D. Beer, “Nonnegative decomposition of multivariate information,” arXiv preprint arXiv:1004.2515, 2010.
- [35] P. R. Vlachas, G. Arampatzis, C. Uhler, and P. Koumoutsakos, “Multiscale simulations of complex systems by learning their effective dynamics,” Nature Machine Intelligence, vol. 4, no. 4, pp. 359–366, 2022.
- [36] D. Floryan and M. D. Graham, “Data-driven discovery of intrinsic dynamics,” Nature Machine Intelligence, vol. 4, no. 12, pp. 1113–1120, 2022.
- [37] L. Cai and S. Ji, “A multi-scale approach for graph link prediction,” Proceedings of the AAAI Conference on Artificial Intelligence, p. 3308–3315, Jun 2020. [Online]. Available: http://dx.doi.org/10.1609/aaai.v34i04.5731
- [38] Z. Chen, S. Li, B. Yang, Q. Li, and H. Liu, “Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition,” Proceedings of the AAAI Conference on Artificial Intelligence, p. 1113–1122, Sep 2022. [Online]. Available: http://dx.doi.org/10.1609/aaai.v35i2.16197
- [39] L. R. Goldberg, “The book of why: The new science of cause and effect,” Notices of the American Mathematical Society, p. 1, Aug 2019. [Online]. Available: http://dx.doi.org/10.1090/noti1912
- [40] Z. Shen, J. Liu, Y. He, X. Zhang, R. Xu, H. Yu, and P. Cui, “Towards out-of-distribution generalization: A survey,” Cornell University - arXiv,Cornell University - arXiv, Aug 2021.
- [41] B. Schölkopf and J. von Kügelgen, “From statistical to causal learning,” arXiv preprint arXiv:2204.00607, 2022.
- [42] D. Janzing, J. Peters, E. Sgouritsa, K. Zhang, J. Mooij, and B. lkopf, “On causal and anticausal learning,” International Conference on Machine Learning, Jun 2012.
- [43] J. Peters, P. Bühlmann, and N. Meinshausen, “Causal inference by using invariant prediction: identification and confidence intervals,” Journal of the Royal Statistical Society Series B: Statistical Methodology, vol. 78, no. 5, pp. 947–1012, 2016.
- [44] A. Zhang, C. Lyle, S. Sodhani, A. Filos, M. Kwiatkowska, J. Pineau, Y. Gal, and D. Precup, “Invariant causal prediction for block mdps,” in International Conference on Machine Learning. PMLR, 2020, pp. 11 214–11 224.
- [45] W. O. Kermack and A. G. McKendrick, “A contribution to the mathematical theory of epidemics,” Proceedings of the royal society of london. Series A, Containing papers of a mathematical and physical character, vol. 115, no. 772, pp. 700–721, 1927.
- [46] A. Attanasi, A. Cavagna, L. Del Castello, I. Giardina, T. S. Grigera, A. Jelić, S. Melillo, L. Parisi, O. Pohl, E. Shen et al., “Information transfer and behavioural inertia in starling flocks,” Nature physics, vol. 10, no. 9, pp. 691–696, 2014.
- [47] M. Gardner, “The fantastic combinations of jhon conway’s new solitaire game’life,” Sc. Am., vol. 223, pp. 20–123, 1970.
- [48] F. Eberhardt and L. L. Lee, “Causal emergence: When distortions in a map obscure the territory,” Philosophies, vol. 7, no. 2, p. 30, 2022.
- [49] M. Rosenblatt, “Remarks on some nonparametric estimates of a density function,” The annals of mathematical statistics, pp. 832–837, 1956.
- [50] C. W. Reynolds, “Flocks, herds and schools: A distributed behavioral model,” in Proceedings of the 14th annual conference on Computer graphics and interactive techniques, 1987, pp. 25–34.
- [51] C. W. Reynolds et al., “Steering behaviors for autonomous characters,” in Game developers conference, vol. 1999. Citeseer, 1999, pp. 763–782.
- [52] M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” CoRR, vol. abs/1703.01365, 2017. [Online]. Available: http://arxiv.org/abs/1703.01365
- [53] L. Snoek, M. van der Miesen, T. Beemsterboer, A. Leij, A. Eigenhuis, and H. Scholte, “The amsterdam open mri collection, a set of multimodal mri datasets for individual difference analyses,” Scientific Data, vol. 8, 03 2021.
- [54] A. Schaefer, R. Kong, E. M. Gordon, T. O. Laumann, X.-N. Zuo, A. J. Holmes, S. B. Eickhoff, and B. T. T. Yeo, “Local-Global Parcellation of the Human Cerebral Cortex from Intrinsic Functional Connectivity MRI,” Cerebral Cortex, vol. 28, no. 9, pp. 3095–3114, 07 2017. [Online]. Available: https://doi.org/10.1093/cercor/bhx179
- [55] A. Luppi, P. Mediano, F. Rosas, N. Holland, T. Fryer, J. O’Brien, J. Rowe, D. Menon, D. Bor, and E. Stamatakis, “A synergistic core for human brain evolution and cognition,” Nature Neuroscience, vol. 25, pp. 1–12, 06 2022.
- [56] L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real nvp,” International Conference on Learning Representations,International Conference on Learning Representations, May 2016.
- [57] C. Lu and J. Peltonen, “Enhancing nearest neighbor based entropy estimator for high dimensional distributions via bootstrapping local ellipsoid,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 5013–5020.
- [58] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [59] M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” Cornell University - arXiv,Cornell University - arXiv, Mar 2017.
- [60] O. Esteban, C. Markiewicz, R. Blair, C. Moodie, A. Isik, A. Erramuzpe, J. Kent, M. Goncalves, E. DuPre, M. Snyder, H. Oya, S. Ghosh, J. Wright, J. Durnez, R. Poldrack, and K. Gorgolewski, “fmriprep: a robust preprocessing pipeline for functional mri,” Nature Methods, vol. 16, 01 2019.
- [61] O. Esteban, R. Ciric, K. Finc, R. Blair, C. Markiewicz, C. Moodie, J. Kent, M. Goncalves, E. DuPre, D. Gomez, Z. Ye, T. Salo, R. Valabregue, I. Amlien, F. Liem, N. Jacoby, H. Stojić, M. Cieslak, S. Urchs, and K. Gorgolewski, “Analysis of task-based functional mri data preprocessed with fmriprep,” Nature Protocols, vol. 15, 06 2020.
- [62] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
- [63] A. Abraham, F. Pedregosa, M. Eickenberg, P. Gervais, A. Mueller, J. Kossaifi, A. Gramfort, B. Thirion, and G. Varoquaux, “Machine learning for neuroimaging with scikit-learn,” Frontiers in neuroinformatics, vol. 8, p. 14, 02 2014.
- [64] S. Fang and Q. Zhu, “Independent gaussian distributions minimize the kullback-leibler (kl) divergence from independent gaussian distributions.” Cornell University - arXiv, Nov 2020.
- [65] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, “Weight uncertainty in neural networks,” arXiv: Machine Learning, May 2015.
- [66] K. Hornik, “Approximation capabilities of multilayer feedforward networks,” Neural Networks, vol. 4, no. 2, pp. 251–257, 1991.
- [67] S. Haykin, Neural Networks: A Comprehensive Foundation, Volume 2. Prentice Hall, 1998.
- [68] T. Teshima, I. Ishikawa, K. Tojo, K. Oono, M. Ikeda, and M. Sugiyama, “Coupling-based invertible neural networks are universal diffeomorphism approximators,” in Advances in Neural Information Processing Systems, vol. 33, 2020, p. 3362–3373.
- [69] T. Teshima, K. Tojo, M. Ikeda, I. Ishikawa, and K. Oono, “Universal approximation property of neural ordinary differential equations,” arXiv preprint arXiv:2012.02414, 2017.