FilterPrompt: A Simple yet Efficient Approach to Guide Image Appearance Transfer in Diffusion Models
Abstract
In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data to achieve representations accurately. Previous works have concentrated predominantly on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This allows the operation that we design and use in pixel space to achieve the desired control effect on the specific representation in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the effect of controllable generation. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the effect of controllable generation, as shown in Figure 1.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/800aeaf8-1238-4cbd-ab1d-0f819893f96b/x1.png)
1 Introduction
In controllable image generation, achieving flexible control over the appearance attributes of objects in the generated images, such as texture and material, remains a research focus [5]. Some researchers concentrate on refining the data, aiming to acquire the low-dimensional feature representations of input images [39, 31, 53]. Concurrently, another faction of researchers is interested in improving the model architecture. They employ deep learning techniques such as autoencoders (AE), variational autoencoders (VAE), and generative adversarial networks (GAN) to fine-tune feature extraction and processing methods, thereby enhancing the capacity of models to handle complex data autonomously [18, 27, 2, 14].
Specifically, controllable generation typically follows two ways: First, disentangling the characteristics of an input image in the feature space and obtaining feature representations relevant to the control objective. Subsequently, the network regulates the degree to which these feature representations are expressed in the generated image, employing a diverse array of meticulously designed loss metrics [8, 4, 57, 31, 51, 17]. Second, involving incorporating a conditioning mechanism into the architecture of the model. These works improve the capacity of the model to integrate control conditions while learning the target domain’s data distribution [37, 23, 33, 48]. Then, the generated images exhibit an artistic effect similar to the appearance of the training data set and consistent with the input image structure.
However, the above controllable generation ideas have their limitations. On the one hand, mapping different data domains to the same feature space will incur high computational costs. Information loss in this process cannot be avoided while there is also the problem of attribute entanglement between the representations obtained in the feature space [54, 6]. On the other hand, using machine learning algorithms to train style mappings may not have the same level of interpretability as traditional mathematical modeling approaches, and the training of such models often requires expensive data collection [7, 50].
Hence, unlike previous endeavors that focused on refining algorithms and models within the feature space, we redirect our focus toward the pixel space. Intuitively, certain semantic features, often indistinguishable in models, exhibit discernible distribution discrepancies visible to the naked eye in the pixel space. Following experimental comparisons of various mainstream generative models, we observe that the diffusion model possesses properties of input sensitivity and dynamic evolution which are very suitable for image processing operations in the pixel space. This integration enables image processing operations performed in the pixel space for a specific feature distribution of the input image and can achieve the desired control effect in the generated results. Therefore, we name this approach FilterPrompt as shown in Figure 2.
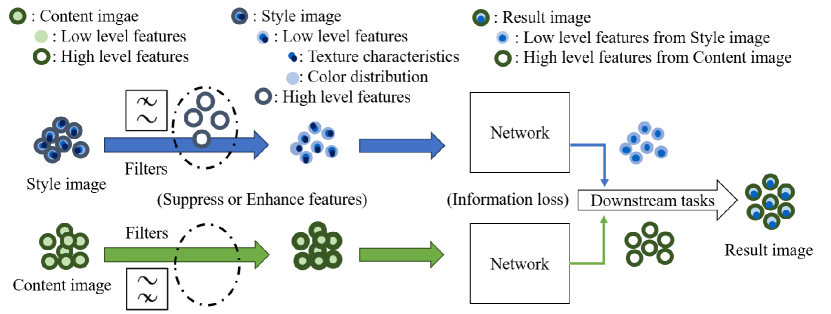
To validate the aforementioned statement, we build a framework for experimental testing based on the existing pre-trained model and use it to demonstrate the impact of FilterPrompt on the control effect of appearance features and structure features of the generated image. Then, we conduct quantitative analyses of the generated results. These analyses demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model’s control capability. At the same time, our approach can be easily generalized to more complex combinations without requiring additional training and is highly interpretable.
In summary, our contributions are as follows: 1. We introduce a new approach, FilterPrompt, aimed at optimizing model control effects. Our approach can be customized for various input data based on specific task requirements and combined with the diffusion model to achieve the expected control effect. 2. We analyze how FilterPrompt facilitates the desired control effect within the diffusion model framework. Additionally, we have designed experiments to provide explanations to demonstrate the feasibility of our approach. 3. Our experiments encompass a range of tasks for the local, object-centered, and full-graph appearance transfer. We present the application of FilterPrompt in these tasks and compare its performance with various other models. Through experimentation, we substantiate the efficacy of our approach in image transfer.
2 Related Work
2.1 Controllable Generation in Diffusion Modeling
The research on the controllable image generation task in the diffusion model can be broadly divided into three stages.
The first stage is mainly based on the iterative denoising process and achieves controllable generation effects by rationally using the input image to generate a deterministic guided generation paradigm [9, 36, 34]. This stage of the work controls the semantic similarity between the generated image and the input image by influencing the proportion of information mixing in the denoising network of U-Net. The second stage is based on the image generation strategy guided by the display classifier. Optimization is performed by adding gradient information from the classifier to the loss function. This idea first originated from classifier guidance[46] and further advanced in[11, 42]. Since then, numerous studies have broadened the scope of classifiers, extending the classification guidance of the diffusion model to encompass diverse modalities such as text, images, and other multi-modal data [3, 24, 52, 17, 32]. The third stage marks the era of large models based on implicit classifiers. To address the issue of declining diversity in classifier guidance, classifier-free guidance strategy [19] emerges later. This approach involves decomposing the gradient guidance from the explicit classifier into two components. One component is an unconditionally generated gradient prediction model, akin to the conventional DDPM [20]. The other is a gradient prediction model based on conditional generation, conceptualized as a U-Net network with an overlay of a cross-attention mechanism. The success of this approach has catalyzed the evolution of a variety of subsequent image editing technologies. These technologies utilize the diffusion model as a foundational framework and integrate the attention mechanism, resulting in notable progress in the application of the diffusion model across diverse fields. Notable projects in this domain include DALLE-2 [40], DreamFusion [38], Stable Diffusion Model (SDM) [41], and more.
Here, our primary focus lies on Grounded Generation and Layout-driven Generation within the context of the controllable generation problem. Representative works in this area include GLIGEN [29], ControlNet [58], and IP-Adapter [56]. We aim to investigate the generative capabilities of diffusion models in addressing semantic-level conditional guidance, particularly in scenarios with limited sample sizes. For example, appearance transfer task [47]. It needs to preserve the structure of the target image while applying the desired appearance attributes.
2.2 Explicit Decomposition
Explicit decomposition is aimed at breaking down the representation of data or a model into simpler, more independent components or factors. Specifically, this process involves splitting a high-dimensional representation space into multiple low-dimensional subspaces, each responsible for encoding a specific aspect or attribute of the data. Through explicit decomposition, neural networks can more easily understand various aspects of the data, such as geometry, color distribution, texture, etc., in the image [21].
Traditionally, filtering algorithms have been considered the explicit decomposition approach as they can break down input data into components at different frequencies or spatial scales. Examples of common filters include the Gaussian filter, Sobel filter [45], Adaptive filter [22], and Gabor filter [12, 43]. These filters can weigh data at different frequencies or scales to suppress or enhance specific features. Therefore, performing preprocessing operations may help neural networks better understand the structure and features of data in order to acquire more refined representations.
3 Prerequisite

3.1 Prompt Impact on Diffusion Models
The forward diffusion defines a known Gaussian translation process. Then the image intermediate quantity at each moment of the forward process can establish a unique relationship with the input image as:
| (1) |
The reverse denoising process of the diffusion model can be seen as a migration process to the target data distribution. During this process, the model will continuously try to reduce noise and be guided by the condition to restore the structure or characteristics of the specified data. Every migration process can be expressed as:
| (2) |
The focus of this process is the network’s prediction of noise distribution: . This prediction is affected by the current moment and condition , and condition comes from the external reference image mapping result. Therefore, if we perform filters on either side of the input like making become , it will affect the prediction results of the noise distribution , and even affect the migration direction of the generated distribution at that time node as illustrated in Figure 4. The impact caused by conditions or the input structure image would be reiterated at each sampling instance, and the minor changes introduced by filters would be involved in the entire generation process.
We observe that after applying filtering operations to a specific feature distribution in pixel space, the degree of expression for that distribution aligns with expectations. Moreover, the filtering operations targeting a specific feature distribution do not affect the expression of other features. This indicates that the influence of filters is independent in the feature space from the encoding of other representations. Therefore, prompts in pixel space offer a lightweight and convenient way to optimize the entanglement between feature representations in the diffusion model.
Based on the framework of combining ControlNet [58] and IP-Adapter [56], we examine the impact of filters at various stages of the sampling inference process and elucidate that the filter plays a guiding role in guiding the Gaussian distribution of the current data toward the target distribution during the migration and diffusion process.
We perform a detailed analysis of the sampling inference stage for the task of converting a bronze sketch to a photo, as shown in Figure 3. The sampled results vividly illustrate that detailed representations of arc patterns initially present in the early stages are weakened by the Gaussian filter, manifesting as point-like distributions. Besides, the Gaussian filter disrupts the continuous semantic expression of patterns. Concurrently, subsequent texture generation doesn’t emerge the negative impact of full-graph blurring, so it illustrates the property that the filtering operation is only effective for specific feature distributions.
The third row of the evolution sequence in Figure 3 illustrates the impact of applying the Gaussian filter only in the first 12 steps, where we observe the absence of redundant pattern features in the final generation result. A set of comparisons in lines 4 and 5 also showcase the effectiveness. In the first 6 steps, only ControlNet is utilized to regulate the structural layout. Introducing IP-adapter in the 7th step guides appearance features. The final results reveal that, even if the Gaussian filter does not initially suppress redundant features, it remains effective in later stages during the generation of detailed textures. The above findings highlight that the impact of filtering on the diffusion process is intuitive, controllable, and predictable.
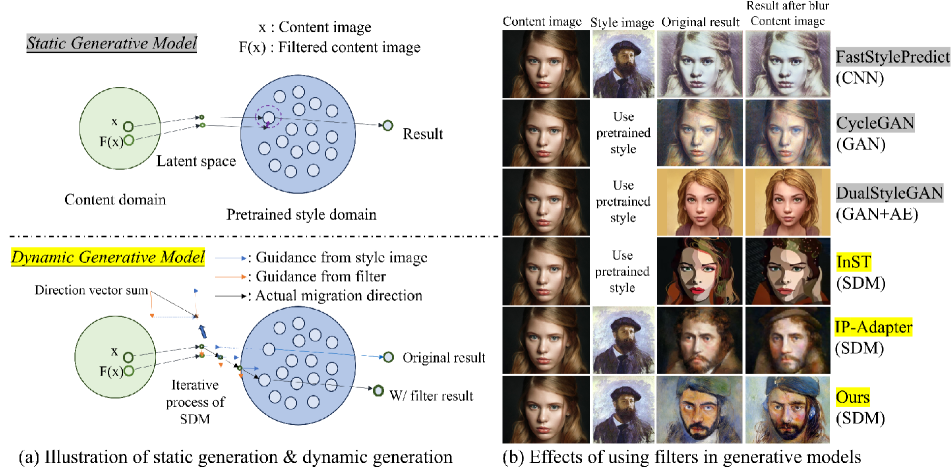
3.2 Static Generation vs. Dynamic Generation
We pay attention to the fact that in the sampling inference stage, the diffusion model has different dynamic evolution properties from the traditional generative model. In the basic theory of the diffusion model, the process of generating an image starts from a simple noise image [20], and through multiple iterations, the noise in the image is gradually removed until a final clear image is generated. From this perspective, the diffusion model generation process is continuous in time, and the image is generated through a gradually changing process. Therefore, we believe that the gradual evolution of the diffusion model makes it a dynamic generative model.
In the early days, the fast style transfer algorithm [15, 28, 16] is based on CNN, AE, and GAN [10, 61, 55], and their fitting effect on the target data distribution depends on the design of the training process. During the training process, the model attempts to capture the statistical characteristics of the entire data distribution and obtain the maximum likelihood representation of the data distribution. When training is completed, the generated samples exist statically in the latent space. Therefore, we consider this type of model to be the static generative model.
We noticed that prompts in pixel space may exhibit certain limitations in previous static generation models, but it can be well combined with dynamic generation models. As shown in Figure 4, we applied the same level of blur interference to the input data of various generative models. The results indicate that the impact of blur prompt on static generative models is relatively weak, while the outcomes of diffusion models show significant changes. We believe that for static generation models, using prompt on input data during the sampling inference stage will only have a slight impact on the mapping position of this input in the static distribution. And this position is close to the mapping result of the original image . Therefore, prompts in pixel space will not significantly affect the generation results of static generation models. However, for diffusion models, as indicated by Equation 1, there is a predefined long-term dependency between the current time node image and the input image , in the forward process. Therefore, the impact of using prompts on the input structure image will be executed again at each sampling, and the minor changes caused by prompts will participate in the entire generation process, thereby exerting a more significant influence on the generation results.
4 Our Approach
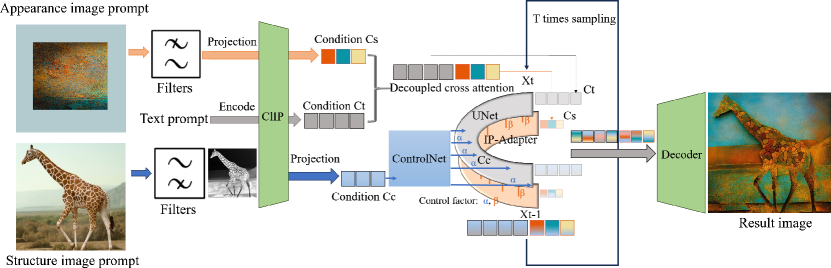
We propose the adoption of pixel-space methodology, FilterPrompt, to directly manipulate the frequency or distribution characteristics of specific image attributes, thereby influencing the subsequent expression levels of the representation. Our approach offers an intuitive and straightforward approach, and significantly saves computational overhead.
4.1 FilterPrompt
We leverage IP-Adapter[56] to obtain conditional encoding , which controls rendering attributes in the generated image from the appearance reference . Concurrently, we employ ControlNet[58] to obtain the conditional encoding , responsible for regulating the geometric attributes from the structure reference image . These encodings, and , represent features from their respective reference images:
| (3) | |||
However, since and features are not fully disentangled, using them directly in latent space may cause structural conflicts. Drawing upon the successful performance of prompts demonstrated in the dynamic generation model above, we try to alleviate these conflicts by leveraging FilterPrompt, which adjusts feature frequencies or distributions. For instance, a color-removing prompt removes color features , modifying the encodings as follows:
| (4) | |||
The pixel range affected by is intuitive and convenient, so we can estimate the impact of it on the migration of Gaussian distribution in Equation 2 and change the iterative process into:
| (5) |
In conclusion, we advocate for the adoption of our innovative approach, FilterPrompt, which directly manipulates the frequency or distribution characteristics of specific image attributes, thereby influencing the subsequent expression levels of the representation.
4.2 Architecture Details
Our framework are built based on combined filtering operations, ControlNet [58] and IP-Adapter [56], as shown in Figure 5. Subsequently, we map the low-level features in the appearance image to a global embedding and concatenate it with the default text prompt embedding of SDM. This process can be described as . These two parts in hidden state are processed separately at each denoising generation. A portion of is delegated to ControlNet, which projects the latent distribution into a fused distribution controlled by high-level features . The global embedding of another part in utilizes the IP-Adapter for decoding, unfolding, and guiding the generation of low-level features. We use to represent the hidden state predicted at the next moment in Equation 2. The intermediate hidden states obtained from both processes are weighted and summed according to Equation 6, achieving the effect of unifying representations related to Structure and Appearance into the latent space of SDM as shown in Equation 6.
| (6) |
where , are weight control factors and is scale control factor.


4.3 Effects of Various FilterPrompts
We define structure as the geometric features in the structure image and appearance as the rendering features from the reference image’s color and texture. We then assess baseline performance on these features before and after applying FilterPrompt (see Figure 6).
Firstly, we apply our approach on the ControlNet path for controlling structural details. The comparison of results among existing image preprocessing approaches and FilterPrompt indicates that our approach retains more details in the generated results and brings the colors closer to the target appearance. The combination of operations (including the ITV-R 601-2 luma transform method for decolorization, inversion, and contrast enhancement of the grayscale image) is succinctly referred to as . As illustrated in Figure 6-FilterPrompt(4), best preserves structural information by enhancing brightness for clearer outlines, demonstrating FilterPrompt’s clarity and interpretability.
We then analyze the IP-adapter path, responsible for appearance, before and after applying FilterPrompt. Figure 6 shows that applying noise-processing filters to the appearance image affects the generated stroke details, aligning with the filter’s effects—e.g., Sharpen enhances fine strokes, while Gaussian blurs them. This verifies FilterPrompt’s capacity to control appearance.
Taking a step further, we explore the control effect of FilterPrompt on both paths in the baseline. In appearance task as shown in Figure 7), we aim is to transfer a bronze sketch to a photo with a specified appearance image without altering geometric features from the structure image. For structure control, in the ControlNet path was used, but initial results showed redundant patterns. Applying a Gaussian filter in the IP-Adapter path suppressed high-frequency noise. When the Gaussian kernel increased to 4, redundant features diminished significantly.
5 Experimental Results
| Structure Preservation | Shape and Edge | Feature Distribution | Texture | Quality | Color Correlation | |
|---|---|---|---|---|---|---|
| SP↑ | CD↓ | FID↓ | GLCM↓ | PSNR↑ | CHC↑ | |
| Cross-Image | 0.7791 | 5.4133 | 245.0973 | 0.1376 | 9.4278 | 0.9357 |
| IP-Adapter | 0.8313 | 4.0967 | 210.2189 | 0.1619 | 9.5546 | 0.8004 |
| Baseline | 0.8547 | 3.3027 | 222.8576 | 0.1618 | 10.5011 | 0.9364 |
| Ours | 0.8799 | 2.8092 | 215.8267 | 0.1072 | 10.5594 | 0.9405 |


5.1 Quantitative analysis
Our quantitative analysis covers six specific appearance transfer: cat to cat, cat to dog, cat to wild, bird to bird, airplane to bird, and car to car. Following previous works [44, 30, 13, 1], we selected six metrics for our experiment. To evaluate the retention of geometric and semantic features from structure images in the generated images, we use three primary indicators: Structure Preservation (SP), Chamfer Distance (CD), and Fréchet Inception Distance (FID). Additionally, to assess the fidelity of low-level features between appearance images and generated images, we employ three specific metrics: Gray-Level Co-occurrence Matrix (GLCM), Peak Signal-to-Noise Ratio (PSNR), and Color Histogram Correlation (CHC).
-
•
Structure Preservation (SP): we utilize the marquee interaction mode of SAM [25] for selecting areas to obtain binary masks corresponding to structure images and their respective output images. Then, we compute their Intersection over Union (IoU) results as a measure of Structure Preservation.
-
•
Chamfer Distance (CD): we first extract the line drawings of the structure and generated images, and then filter out redundant details using the Canny operator. The high and low thresholds used by the Canny operator are set to 150 and 50, respectively. Finally, we calculate the chamfer distance between the line drawings as a measure of the gap between the sets of edge points in the two images. A smaller value indicates a higher degree of match between the shape or edge features in the structure and generated images.
-
•
Fréchet Inception Distance (FID): we calculate the FID score between the structure image and the generated image to quantify the extent to which the two images align in terms of their structural features.
-
•
Gray-Level Co-occurrence Matrix (GLCM): it is used to calculate the loss value of texture features between the appearance image and the generated image.
-
•
Peak Signal-to-Noise Ratio (PSNR): it is used to measure how well the generated image preserves the low-level features of appearance.
-
•
Color Histogram Correlation (CHC): it is used to calculate the color similarity between the generated image and the appearance image. Among them, we use mask to cover the background of the image.
Test Datasets: AFHQ [10], CUB-200-2011 [49], FGVC-Airaft [35], Stanford-Cars [26]. Among them, the three domain data of cat, dog, and wild are all from the AFHQ test set. We followed the setting of AFHQ’s test set, with 500 images for each category, and randomly selected 500 images from three other datasets as appearance images. For every types of appearance transfer tasks there are 2000 pairs, Therefore, the data in Table 5 is based on the evaluation results of 12000 Structure-Appearance image pairs. We show examples of the comparison results in Figure 8.
5.2 Qualitative analysis
The qualitative analysis experiments include a total of five domains (cat, dog, wild, bird, bronze). In addition to the datasets used in the quantitative analysis experiments as shown in Figure 9, additional data is: Bronze Dings [60]. In this task, the appearance reference and the structure image do not have semantic correspondence, and their relationships belong to different domains. So the focus in this task is to obtain the low-level texture features from the appearance image without semantic correspondence and then render it to the structure image.
5.3 User Study
We conducted a user study with 18 questions evaluating generated results in structure preservation, rendering feature transfer effectiveness, and overall quality. Each participant was paid 0.5$. To address the common issue of low-quality feedback caused by participants’ lack of understanding of task, we had eight facilitators provide detailed background information to participants on campus. Participants were then asked to select the most fitting options from anonymous choices based on their preferences. Finally, we received 215 valid survey submissions, with ours garnering a support rate of 51. 89% (cross-image 24. 00%, IP-Adapter 14. 98%, ControlNet + IP-Adapter 9. 13%).
6 Limitation and Conclusion
We constructed an experimental framework based on IP-Adapter to explore image generation techniques. However, we found that the identity consistency of the generated results is not always satisfactory when the input image prompt contains rich semantic information. This limitation is partly because IP-Adapter may not fully balance these properties when processing different image attributes, thus affecting the consistency of the final output, which may be attempted by using mask technology to optimize identity consistency and image quality. Beyond the baseline framework utilized in this study, the integration of other advanced diffusion models may potentially lead to even superior results if they are implemented to replace certain components in the baseline framework. We will explore this further in future work.
In conclusion, we propose a pixel-space processing, FilterPrompt, to guide image appearance transfer, by focusing on the input sensitivity and dynamic evolution of diffusion models. We find that the models adapt to input feature distributions, enabling targeted operations for precise control in final generated images. Experimental results show that our approach helps refine structural control and reduce redundant textures in transfer tasks. Although FilterPrompt requires manual setup, it provides a simple yet efficient way to enhance customization and control in diffusion models.
References
- Alaluf et al. [2023] Yuval Alaluf, Daniel Garibi, Or Patashnik, Hadar Averbuch-Elor, and Daniel Cohen-Or. Cross-image attention for zero-shot appearance transfer. arXiv preprint arXiv:2311.03335, 2023.
- Arjovsky et al. [2017] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- Avrahami et al. [2022] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- Bass et al. [2020] Cher Bass, Mariana da Silva, Carole Sudre, Petru-Daniel Tudosiu, Stephen Smith, and Emma Robinson. Icam: interpretable classification via disentangled representations and feature attribution mapping. Advances in Neural Information Processing Systems, 33:7697–7709, 2020.
- Bengio et al. [2013] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
- Brehmer et al. [2022] Johann Brehmer, Pim De Haan, Phillip Lippe, and Taco S Cohen. Weakly supervised causal representation learning. Advances in Neural Information Processing Systems, 35:38319–38331, 2022.
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023.
- Chen et al. [2016] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29, 2016.
- Choi et al. [2021] Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Conditioning method for denoising diffusion probabilistic models. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 14347–14356. IEEE Computer Society, 2021.
- Choi et al. [2020] Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8188–8197, 2020.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems, pages 8780–8794. Curran Associates, Inc., 2021.
- Gabor [1946] D Gabor. Electrical engineers-part iii: Radio and communication engineering. Journal of the Institution of, 93(429):39, 1946.
- Gao et al. [2022] Chenjian Gao, Qian Yu, Lu Sheng, Yi-Zhe Song, and Dong Xu. Sketchsampler: Sketch-based 3d reconstruction via view-dependent depth sampling. In European Conference on Computer Vision, pages 464–479. Springer, 2022.
- Gao et al. [2018] Fei Gao, Yue Yang, Jun Wang, Jinping Sun, Erfu Yang, and Huiyu Zhou. A deep convolutional generative adversarial networks (dcgans)-based semi-supervised method for object recognition in synthetic aperture radar (sar) images. Remote Sensing, 10(6):846, 2018.
- Gatys et al. [2016] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2414–2423, 2016.
- Ghiasi et al. [2017] Golnaz Ghiasi, Honglak Lee, Manjunath Kudlur, Vincent Dumoulin, and Jonathon Shlens. Exploring the structure of a real-time, arbitrary neural artistic stylization network. In Procedings of the British Machine Vision Conference 2017. British Machine Vision Association, 2017.
- Goel et al. [2023] Vidit Goel, Elia Peruzzo, Yifan Jiang, Dejia Xu, Nicu Sebe, Trevor Darrell, Zhangyang Wang, and Humphrey Shi. Pair-diffusion: Object-level image editing with structure-and-appearance paired diffusion models. arXiv preprint arXiv:2303.17546, 2023.
- Higgins et al. [2016] Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In International conference on learning representations, 2016.
- Ho and Salimans [2022] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 6840–6851, 2020.
- Huang et al. [2023] Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: creative and controllable image synthesis with composable conditions. In Proceedings of the 40th International Conference on Machine Learning, pages 13753–13773, 2023.
- Hwang and Haddad [1995] Humor Hwang and Richard A Haddad. Adaptive median filters: new algorithms and results. IEEE Transactions on image processing, 4(4):499–502, 1995.
- Hwang et al. [2020] HyeongJoo Hwang, Geon-Hyeong Kim, Seunghoon Hong, and Kee-Eung Kim. Variational interaction information maximization for cross-domain disentanglement. Advances in Neural Information Processing Systems, 33:22479–22491, 2020.
- Kim et al. [2022] Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2426–2435, 2022.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023.
- Krause et al. [2013] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In Proceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013.
- Larsen et al. [2016] Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, and Ole Winther. Autoencoding beyond pixels using a learned similarity metric. In International conference on machine learning, pages 1558–1566. PMLR, 2016.
- Li and Wand [2016] Chuan Li and Michael Wand. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2479–2486, 2016.
- Li et al. [2023] Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511–22521, 2023.
- Liu et al. [2020] Runtao Liu, Qian Yu, and Stella X Yu. Unsupervised sketch to photo synthesis. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 36–52. Springer, 2020.
- Liu et al. [2022] Xiyao Liu, Ziping Ma, Junxing Ma, Jian Zhang, Gerald Schaefer, and Hui Fang. Image disentanglement autoencoder for steganography without embedding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2303–2312, 2022.
- Liu et al. [2023] Xihui Liu, Dong Huk Park, Samaneh Azadi, Gong Zhang, Arman Chopikyan, Yuxiao Hu, Humphrey Shi, Anna Rohrbach, and Trevor Darrell. More control for free! image synthesis with semantic diffusion guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 289–299, 2023.
- Lu et al. [2023] Haoming Lu, Hazarapet Tunanyan, Kai Wang, Shant Navasardyan, Zhangyang Wang, and Humphrey Shi. Specialist diffusion: Plug-and-play sample-efficient fine-tuning of text-to-image diffusion models to learn any unseen style. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14267–14276, 2023.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11461–11471, 2022.
- Maji et al. [2013] S. Maji, J. Kannala, E. Rahtu, M. Blaschko, and A. Vedaldi. Fine-grained visual classification of aircraft. Technical report, 2013.
- Meng et al. [2021] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2021.
- Mirza and Osindero [2014] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
- Poole et al. [2022] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations, 2022.
- Preechakul et al. [2022] Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. Diffusion autoencoders: Toward a meaningful and decodable representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10619–10629, 2022.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Rombach et al. [2022a] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022a.
- Rombach et al. [2022b] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022b.
- Roslan and Jamil [2012] Rosniza Roslan and Nursuriati Jamil. Texture feature extraction using 2-d gabor filters. In 2012 International Symposium on Computer Applications and Industrial Electronics (ISCAIE), pages 173–178. IEEE, 2012.
- Saito et al. [2020] Kuniaki Saito, Kate Saenko, and Ming-Yu Liu. Coco-funit: Few-shot unsupervised image translation with a content conditioned style encoder. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 382–398. Springer, 2020.
- Sobel et al. [1968] Irwin Sobel, Gary Feldman, et al. A 3x3 isotropic gradient operator for image processing. a talk at the Stanford Artificial Project in, pages 271–272, 1968.
- Song et al. [2020] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2020.
- Suri et al. [2024] Saksham Suri, Moustafa Meshry, Larry S Davis, and Abhinav Shrivastava. Grit: Gan residuals for paired image-to-image translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4965–4975, 2024.
- Voynov et al. [2023] Andrey Voynov, Kfir Aberman, and Daniel Cohen-Or. Sketch-guided text-to-image diffusion models. In ACM SIGGRAPH 2023 Conference Proceedings, pages 1–11, 2023.
- Wah et al. [2022] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. Cub-200-2011, 2022.
- Wang et al. [2022] Churan Wang, Jing Li, Xinwei Sun, Fandong Zhang, Yizhou Yu, and Yizhou Wang. Learning domain-agnostic representation for disease diagnosis. In The Eleventh International Conference on Learning Representations, 2022.
- Wang et al. [2023] Zhizhong Wang, Lei Zhao, and Wei Xing. Stylediffusion: Controllable disentangled style transfer via diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7677–7689, 2023.
- Wu et al. [2023a] Qiucheng Wu, Yujian Liu, Handong Zhao, Ajinkya Kale, Trung Bui, Tong Yu, Zhe Lin, Yang Zhang, and Shiyu Chang. Uncovering the disentanglement capability in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2023a.
- Wu et al. [2023b] Qiucheng Wu, Yujian Liu, Handong Zhao, Ajinkya Kale, Trung Bui, Tong Yu, Zhe Lin, Yang Zhang, and Shiyu Chang. Uncovering the disentanglement capability in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2023b.
- Yang et al. [2021] Mengyue Yang, Furui Liu, Zhitang Chen, Xinwei Shen, Jianye Hao, and Jun Wang. Causalvae: Disentangled representation learning via neural structural causal models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9593–9602, 2021.
- Yang et al. [2022] Shuai Yang, Liming Jiang, Ziwei Liu, and Chen Change Loy. Pastiche master: Exemplar-based high-resolution portrait style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7693–7702, 2022.
- Ye et al. [2023] Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721, 2023.
- Zhang et al. [2021] Jinsong Zhang, Kun Li, Yu-Kun Lai, and Jingyu Yang. Pise: Person image synthesis and editing with decoupled gan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7982–7990, 2021.
- Zhang et al. [2023a] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023a.
- Zhang et al. [2023b] Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10146–10156, 2023b.
- Zhou et al. [2023] Rixin Zhou, Jiafu Wei, Qian Zhang, Ruihua Qi, Xi Yang, and Chuntao Li. Multi-granularity archaeological dating of chinese bronze dings based on a knowledge-guided relation graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3103–3113, 2023.
- Zhu et al. [2017] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017.