FederatedNILM: A Distributed and Privacy-preserving Framework for Non-intrusive Load Monitoring based on Federated Deep Learning
Abstract
Non-intrusive load monitoring (NILM), which usually utilizes machine learning methods and is effective in disaggregating smart meter readings from the household-level into appliance-level consumptions, can help to analyze electricity consumption behaviours of users and enable practical smart energy and smart grid applications. However, smart meters are privately owned and distributed, which make real-world applications of NILM challenging. To this end, this paper develops a distributed and privacy-preserving federated deep learning framework for NILM (FederatedNILM), which combines federated learning with a state-of-the-art deep learning architecture to conduct NILM for the classification of typical states of household appliances. Through extensive comparative experiments, the effectiveness of the proposed FederatedNILM framework is demonstrated.
keywords:
non-intrusive load monitoring, federated learning, deep neural network, distributed machine learning, privacy-preserving.1 Introduction
With the development of smart grids, smart meters have been increasingly installed, which provides enormous opportunities for various smart energy applications such as smart homes and demand response [1]. Smart meters can record high-resolution energy consumption data and therefore have great potential to provide useful insights into the energy use patterns from the individual household level to the grid level. Non-intrusive load monitoring (NILM) [2], which usually utilizes machine learning in disaggregating smart meter readings from the household-level into appliance-level, is particularly useful for analyzing detailed energy consumption behaviours and enabling practical smart energy applications especially at the low-voltage level such as energy demand management and local energy trading.
Existing studies on NILM can be broadly categorized into supervised learning and unsupervised learning approaches. For the former, deep learning based models, which provide new opportunities for the electrical utility industry [3], are the most representative structures applied to NILM. The commonly adopted deep learning models include convolutional neural network (CNN) [4] and recurrent neural network (RNN) [5]. For unsupervised learning, combinatorial optimization (CO) [4], factorial Hidden Markov Model (FHMM) [6] [7] and clustering analysis [8] are commonly used for NILM. [4] compared unsupervised learning (CO, FHMM) with supervised learning (CNN) for NILM where results showed that the CNN-based model performed better than unsupervised models. Although deep learning models usually perform well on NILM, such models still face several challenges:
-
1.
The number of the labelled data generated by a single household is limited, and the size of the training set has a great impact on the effectiveness of the deep learning model. Therefore, it is necessary to collect the labelled data from multiple data sources on the premise of ensuring data security.
-
2.
Different users have different lifestyles and thus have different electricity usage patterns (i.e. data distribution), which put forward higher requirements for the generalization ability of the NILM model.
-
3.
Given the increasing public attention to data privacy and security preservation, it is necessary to satisfy the needs of training models with not only high precision but also reasonable communication efficiency under the premise of ensuring individual data privacy.
To overcome the above challenges, federated learning [9] was proposed where private data of individual users do not need to be uploaded to a central server for centralized training. Instead, under the coordination of the central cloud server, each participant can carry out the model training locally and only exchange typical parameters of their local model such as updated gradients [10]. Compared with other privacy-preserving technologies that need to encrypt the original data set, federated learning does not need to collect the original data centrally, therefore model training in this framework does not involve data transmission and public sharing, and can thus help to achieve individual data privacy protection. On the other hand, the wide penetration of the Internet of Things (IoT) in various areas [11] has sparked new opportunities for federated learning by providing massive amounts of distributed user-generated data on intelligent IoT devices and applications, which is poised to make substantial contributions in all aspects of our modern life, such as smart healthcare and smart grid system [12].
Although federated learning, as a newly proposed distributed and privacy-preserving framework, has been studied in various areas, limited attention has been paid to smart grid applications especially for NILM. Since NILM is one of the key technologies to unlock the full potential of local and distributed energy resources, a distributed and privacy-preserving framework is urgently needed to enable its practical applications. To this end, this paper develops a distributed and privacy-preserving federated deep learning framework for NILM (FederatedNILM). The main contributions of this paper are summarised as follows.
-
1.
We develop the FederatedNILM, a distributed and privacy-preserving framework for NILM based on federated deep learning. To the best of our knowledge, this is the first work to study the distributed and privacy-preserving NILM based on federated deep learning.
-
2.
We combine an advanced deep neural network architecture with federated learning, which could benefit the whole FederatedNILM framework by providing more accurate state inference for multiple appliances on the household level.
-
3.
Through comparative experiments, we verify the effectiveness of the proposed FederatedNILM by investigating key practical characteristics including communication costs and model accuracy.
The remainder of this paper is organized as follows. In Section II, existing studies on NILM with privacy-preserving methods and federated learning applications are reviewed. Preliminaries of NILM and federated deep learning are given in Section III. Section IV details the proposed FederatedNILM framework, followed by the performance evaluation in Section V. The conclusion and future work are given in Section VI.
2 Related work
The existing studies on privacy-preserving methods for NILM as well as federated learning for various applications such as IoT are reviewed in this section.
2.1 NILM and its privacy-preserving methods
Existing research shows that the analysis of real-time data may expose user’s privacy information [13]. Many studies designed privacy protection schemes for NILM, which can be mainly divided into identity privacy and data privacy protection.
Identity privacy protection refers to implement user identity recognition while hiding the real ID of the users by special mechanisms such as blind signature [14]. For instance, [15] adopted blind signature to protect the identity privacy of smart meter users. In the proposed scheme, the power company has access to real-time electricity data but does not know the identity of owners so the privacies of users are protected.
Data privacy protection, on the other hand, is usually achieved by adding noises or encryptions to electricity consumption data. [16] suggested that the load signatures of appliances in individual households could be moderated by home electrical power routing. [17] studied the sensitive data in smart metering from an information-theoretic perspective. In the paper, the smart meter readings were diversified by the alternative energy source and the real consumption data were filtered by the storage units. [18] proposed a fog computing approach based on differential privacy against NILM, which adds noises to the behaviour parameter derived from the FHMM rather than the original consumption data. The proposed scheme achieved a satisfying trade-off between data utility and privacy. [19] compared four variants of differential privacy in blockchain-based smart metering, and the experiment showed that such mechanisms could provide an effective privacy-preserving scheme.
2.2 Federated learning applications
The emergence of federated learning on the one hand ensures the privacy of the distributed data such as those collected by IoT devices, and on the other hand, solves the problem of data isolation. [20] proposed an autonomous self-learning distributed system, which combined anomaly detection with federated learning to detect damaged IoT devices. [21] used federated learning for multi-task network anomaly detection, which improved the training efficiency compared with multiple single-task models as well as preserved the privacy of data. Later, [22] combined federated learning with the deep neural network to solve the same problem in [21]. Particularly, transfer learning was adopted to reconstruct the model to further improve the anomaly detection performance.
Although federated learning has been studied in different areas, limited attention has been paid to NILM. As aforementioned, NILM is one key technology to unlock the potential of smart local energy systems, and therefore developing a practical, distributed and privacy-aware framework for NILM is urgently needed. In this paper, we take the first attempt to address the problem by developing a distributed and privacy-preserving deep learning framework for NILM based on federated learning.
3 Preliminaries
In this section, we introduce essential concepts related to the proposed federated deep learning framework.
3.1 Non-intrusive load monitoring
Given the aggregated load at time :
| (1) |
the goal of non-intrusive load monitoring (NILM) is to recover the status of target electrical appliances. and denote the load consumption for the -th appliance and the residual/unmonitored load respectively at time . NILM can be formulated as either a classification task or a regression task depending on the status variables of individual electrical appliances we aim to recover.
For the regression task, the NILM model aims to find the approximation, denotes as , of the true relationship between the aggregated household-level consumption () and the appliance-level consumption.
| (2) |
where is the predicted load consumption sequence of target electrical appliances at time .
For the classification task, thresholds need to be set for the NILM model to determine the states (e.g. ON/OFF) of each target appliance. The threshold method we choose in this paper is the activation-time thresholding, which could avoid the negative effect of the abnormal spikes during the OFF state to better improve the inference accuracy [4]. For the sake of simplicity, we assume that there are two typical states (ON/OFF) for the target appliances, and the state for -th appliance at time is related to its threshold
| (3) |
where 0 represents the OFF state, and 1 denotes the ON state. Therefore the classification task for NILM can be defined as
| (4) |
where is a binary variable indicating the predicted ON/OFF state of -th electrical appliance at time .
3.2 Federated deep learning
When data owners intend to combine their local data to train a deep neural network model, the traditional way is to integrate their individual data into the central server and use the integrated data to train a standard centralized model. However, the data uploading and integration process often involves legal issues such as data privacy and security. Therefore federated learning was introduced to overcome the problem [23].
Federated learning is a machine learning strategy whose goal is to train a high-quality global model while the original training data are distributed in each local client without the need of transferring to the central server. The training process of the federated deep learning framework is shown in Figure 1.
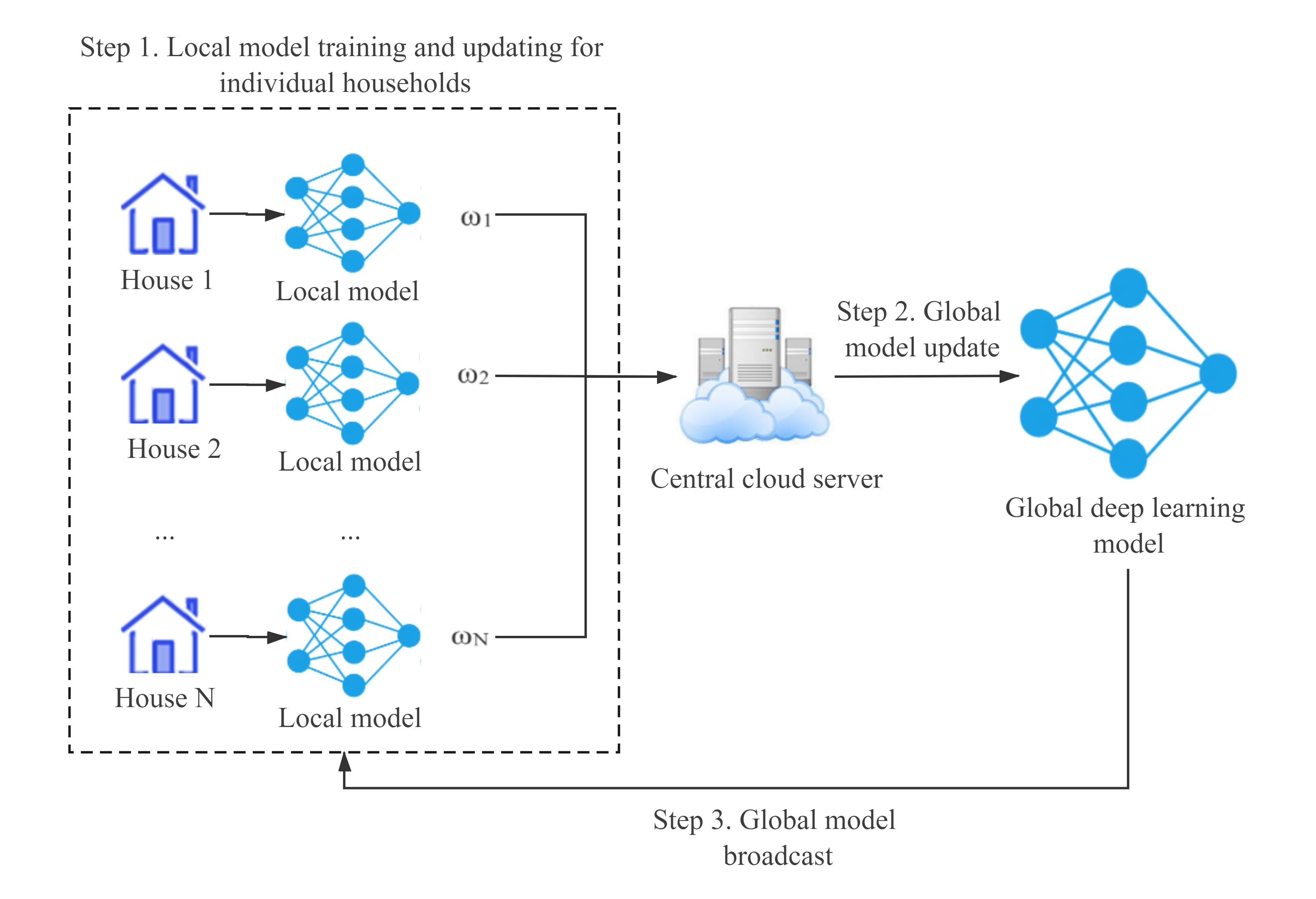
As described in the figure, at step 1, each client (i.e. each household) uses its local private data to train the local model and update its local parameters during each training round. Then, each client passes the updated parameters to a central cloud server. At step 2, the global model aggregates the updated parameters from all local clients and updates its own parameters accordingly in the central cloud server. Subsequently, the updated global model parameters are broadcast to each local client at step 3. The process is iterated for multiple rounds until convergence.
Compared to traditional centralized methods, federated learning only requires the transfer of model parameters rather than original data between clients and the central server, which avoids the need of transferring distributed data and therefore is particularly useful for distributed data privacy protection.
4 Federated deep learning NILM (FederatedNILM) framework
In this section, we will first describe the workflow of the proposed FederatedNILM framework, and then detail the architecture of the deep learning network model used in both local clients and the global model.
4.1 The workflow of the proposed FederatedNILM framework
The goal of the FederatedNILM framework is to accurately infer the ON/OFF states of multiple appliances in individual households in a distributed and privacy-preserving way. The whole workflow of the FederatedNILM can be described in three stages (see Algorithm 1).
4.1.1 Initialisation
The parameters of global deep learning model , global sharing batch , along with parameters of model training including learning rate , momentum and loss function need to be initialised first. Then set the global and local communication round index to 1, initialise the moment estimate variable to 0, and begin the first round of training.
4.1.2 Local households model updating, training, and uploading
The local households will train their own local deep learning model based on the local data after receiving the broadcast parameters from the global deep learning model. As described in , in each local epoch, the local deep learning models aim to find the best approximation (Equation (4)). The local training returns the updated parameters from all the local models, which are then uploaded to the global cloud server.
4.1.3 Global deep learning model aggregation, training, and broadcasting
The global deep learning model receives the local updated parameters from the global sharing batch , and adopts federated averaging (FedAvg) to the parameter sets [9]. Then, the global deep learning model will be updated based on the FedAvg results. After this, the updated global parameters will be broadcast to the local models of each house. After running all the global communication rounds between the local households and the central cloud server, a final global deep learning model will be generated.
4.2 The deep learning model for NILM
The deep learning architecture utilized to enhance the overall inferring performance is inspired from [24], which was originally used for image semantic segmentation. The selection of the above particular architecture is motivated by its potentially promising performance on NILM after appropriate adjustments as demonstrated in [25]. The complete layout of our chosen deep learning model for NILM is shown in Figure. 2

Specifically, the architecture of the deep learning model for NILM is composed of three modules: the encoder, the temporal pooling module, and the decoder.
4.2.1 Encoder
The input of the encoder is the household aggregated load consumption of the target appliances over a 12.6 minutes interval (the length of the input window of consumption datasets is 126). The encoder increases the output features from a single aggregation value to 256, while paying the price of decreasing the time signal resolution by 10 times.
4.2.2 Temporal pooling
The temporal pooling module consists of four average pooling modules. The filters in this module are reduced from the whole size of the input signal to one-sixth of it, which is the same case with the stride. After going through a convolutional layer, the feature dimension of the input is reduced to a quarter of its original size, and the acquired feature maps were upsampled to increase their size to the size of the input time signals. Then the upsampled feature maps (shallow features) are concatenated with the original input signal (deep features) from the temporal pooling to get the final feature maps. The fusion of the deep and shallow features of the temporal pool could enable this block to get contextual information fed into the decoder.
4.2.3 Decoder
The decoder receives the output from the temporal pooling block and passes it to a convolutional layer to recover the temporal resolution. Then the output is fed into the final convolutional layer to produce the final output.
is utilized to classify the states of multiple targeted appliances. After this, the binary cross-entropy is chosen as the loss function, which is given by:
| (5) |
where is the number of the training samples, is the length of the output from classifier, is the true state of -th appliance, and denotes the predicted probability that -th appliance is in the activation state. Also, stochastic gradient descent (SGD) is selected as the optimizer to facilitate the convergence of the binary cross entropy.
5 Performance evaluation
This section gives numerical experiments to evaluate the proposed FederatedNILM framework. Firstly, experimental settings including the environment setup, data preprocessing, training and testing split, and the evaluation metrics are introduced. Secondly, we compare our proposed FederatedNILM with the centralized counterpart in terms of model performance and training time efficiency. Finally, we compare adopted deep learning architecture (used in the FederatedNILM and the centralized counterpart) with several existing advanced NILM models to evaluate the performance of the proposed FederatedNILM framework.
5.1 Experimental settings
5.1.1 Environmental setup
The FederatedNILM model is implemented on Pytorch and conducted on a Windows 10 platform using an NVIDA GeForce RTX 2080 Ti GPU with 64GB of RAM and CUDA v10.2.
5.1.2 Dataset and preprocessing
In this paper, we consider the UK-DALE dataset [26], which is a public and commonly used dataset and recorded both the aggregated load (high frequency and low frequency) and the individual appliances (low frequency) consumption from 5 different households (see Table 1).
| House No. | 1 | 2 | 3 | 4 | 5 |
| Total days | 1631 | 237 | 42 | 208 | 139 |
| Appliances | 52 | 19 | 4 | 11 | 24 |
| Fridge | - | ||||
| Dishwasher | - | - | |||
| Washing machine | - |
To demonstrate the effectiveness of the proposed FederatedNILM model and the utilized deep neural network architecture, we deploy a simplified experimental setup following [4] for comparison purpose. We consider common appliances possessed by most houses, i.e. fridge, dishwasher, and washing machine, which narrowed the dataset to houses 1, 2 and 5. The date range selected from the three houses is from 12/04/2013 to 01/07/2015 for house 1, 22/05/2013 to 03/10/2013 for house 2, and 29/06/2014 to 01/09/2014 for house 5.
Following the same data preprocessing procedure in [4], abnormal load consumption records were firstly filtered out by the max power threshold provided in Table 2 followed by a down-sampling of the aggregated load from 1s to 6s to align with the submetered data. The resampled data were normalized by subtracting the mean and then dividing a constant value 2000 W. Finally, the state series of each target appliance were derived from the activation-time thresholding as the input of the proposed FederatedNILM model where relevant thresholds are provided in Table 2.
| Fridge | Dishwasher | Washing Machine | |
| Max power (W) | 300 | 2500 | 2500 |
| Power threshold (W) | 50 | 20 | 20 |
| Min. ON duration (s) | 1 | 60 | 60 |
| Min. OFF duration (s) | 0 | 60 | 5 |
5.1.3 Training and testing
Both the seen house case and the unseen house case are considered to verify the effectiveness of FederatedNILM.
For the seen house case, the split of the three houses datasets is listed in Table 3. The first 80% series from each household were selected as the training set, followed by a 10% for validation, and 10% for testing. In this case, the disaggregation ability of the model is evaluated when signatures of specific appliances are learned.
| Train | Validation | Test | |
| House 1 | 80% | 10% | 10% |
| House 2 | 80% | 10% | 10% |
| House 5 | 80% | 10% | 10% |
For the unseen house case, the chosen of three houses allows us to train using two houses and test on another. The unseen house case aims to verify the generalization ability of the model, and the generic signature characteristics of the same type of appliances need to be distinguished. As detailed in Table 4, we split two houses data into training and validation sets, and use the other unseen house as the test set. Then, we average results of all three different combination cases of the training and testing for comparative analysis.
| House Number | Case 1 | Case 2 | Case 3 | ||||||
| Training | Validation | Testing | Training | Validation | Testing | Training | Validation | Testing | |
| 1 | 90% | 10% | - | 90% | 10% | - | - | - | 100% |
| 2 | 90% | 10% | - | - | - | 100% | 90% | 10% | - |
| 5 | - | - | 100% | 90% | 10% | - | 90% | 10% | - |
The parameters used in the FederatedNILM model training are listed in Table 5. Different global rounds [2, 4, 6, 8, 10] are selected to conduct comparative experiments. We repeat the experiment five times for all the cases and report the average performance for each model.
| Item | Explanation | Value |
| Global sharing batch size | 32 | |
| Global communication rounds | [2, 4, 6, 8, 10] | |
| Local batch size | 32 | |
| Local epochs | 10 | |
| Learning rate | 1e-4 | |
| Activation function | - | ReLU |
| Dropout probability | - | 0.1 |
| Momentum | 0.5 | |
| Optimizer | - | SGD |
5.1.4 Evaluation criteria
Four evaluation metrics are used to assess the performance of the proposed framework.
By denoting true positive as TP, true negative as TN, false positive as FP, and false negative as FN, the evaluation metrics are defined as follows:
| (6) |
| (7) |
| (8) |
| (9) |
where precision represents the proportion of TPs to all the data sequences classified to the ON state. Recall denotes the ratio of TPs to all data sequences that are actually in the ON state. Accuracy reflects the ratio of all correctly identified samples to all the data sequences. is defined as a weight average representation for precision and recall within the range of . An close to 1 indicates that the classification results for the target appliance are better.
5.2 Comparative studies
We consider FederatedNILM model and the centralized counterpart (termed as Centralized-NILM) for both the seen house case and unseen house case.
For Centralized-NILM, each household needs to upload their original data directly to the trusted central server, in which the data are trained in a centralized way by the deep learning model described in Section 4.2. This scenario could not provide any data privacy guarantee to participants.
FederatedNILM, on the other hand, does not require access to the original data. In this scenario, households only need to share the training outcomes (parameter sets) of the local deep learning model with the central server.
5.2.1 Performance comparison with centralized model based on seen house case
In this section, we conduct comparative studies between the proposed FederatedNILM and Centralized-NILM for the seen house case. We run 10 global rounds with 10 local epochs for FederatedNILM training, and 100 epochs for Centralized-NILM training.
Figure 3 shows the disaggregation performance in the seen house case.



From the results, we can see that for each appliance, both Centralized-NILM and FederatedNILM achieve satisfactory results on the dishwasher and washing machine, and reasonable results on the fridge. It is worth pointing out that the fridge consumes relatively low power compared with other appliances and is likely to be learned with less evident signature during model training since its consumption can easily be omitted as unidentified load noise. This might explain why testing results of the fridge show relatively low scores compared with other appliances.
It should be highlighted that the FederatedNILM achieves very similar performance to Centralized-NILM on all appliances. Therefore, it is reasonable to infer that our proposed FederatedNILM framework works well in a distributed and privacy-preserving manner for the seen house case and can achieve a good trade-off between data privacy and data utility.
5.2.2 Performance comparison with centralized model based on unseen house case
In this section, we apply our proposed models for the unseen house case to evaluate the generalization ability of FederatedNILM.
Figure 4 shows the disaggregation scores on a house not seen during training for the three target appliances.



Compared with the seen house case, both models produce satisfying results for fridge and dishwasher but perform less well for washing machine. One possible reason is that the washing machine, as a multi-state appliance, has more complex signature characteristics [27], which is likely to be more difficult to distinguish the generic signature characteristics.
We can also find that the FederatedNILM has very similar performance compared with Centralized-NILM on all appliances for the unseen house case, which aligns well with our conclusion on the proposed FederatedNILM framework in terms of data privacy and data utility in Section 5.2.1 for the seen house case.
5.2.3 Global round, local epochs, and training time efficiency
In this section, different global rounds and their corresponding training costs and testing results are given to explore the relationship between training efficiency and model performance.
The epochs for the Centralized-NILM are set to 20, 40, 60, 80, and 100 respectively corresponding to the global rounds 2, 4, 6, 8, 10 with 10 local epochs of the FederatedNILM model. Tables 6 to 8 listed the testing results of both models using different global rounds in the unseen house case for fridge, dishwasher, washing machine respectively, and the best results of each model are marked in bold. Figure. 5 shows the training time of the two models with the increasing of epochs/global rounds.
| Global rounds | FederatedNILM | Baseline epochs | Centralized-NILM | ||||||
| Acc. | Pre. | Rec. | Acc. | Pre. | Rec. | ||||
| 2 | 0.80 | 0.80 | 0.77 | 0.70 | 20 | 0.80 | 0.76 | 0.73 | 0.75 |
| 4 | 0.82 | 0.69 | 0.76 | 0.74 | 40 | 0.81 | 0.78 | 0.73 | 0.75 |
| 6 | 0.83 | 0.72 | 0.86 | 0.78 | 60 | 0.83 | 0.79 | 0.74 | 0.75 |
| 8 | 0.84 | 0.70 | 0.82 | 0.73 | 80 | 0.83 | 0.80 | 0.73 | 0.79 |
| 10 | 0.85 | 0.83 | 0.79 | 0.78 | 100 | 0.85 | 0.82 | 0.77 | 0.79 |
| Global rounds | FederatedNILM | Baseline epochs | Centralized-NILM | ||||||
| Acc. | Pre. | Rec. | Acc. | Pre. | Rec. | ||||
| 2 | 0.79 | 0.55 | 0.54 | 0.45 | 20 | 0.97 | 0.70 | 0.74 | 0.74 |
| 4 | 0.81 | 0.58 | 0.57 | 0.68 | 40 | 0.97 | 0.74 | 0.81 | 0.73 |
| 6 | 0.98 | 0.73 | 0.69 | 0.69 | 60 | 0.98 | 0.74 | 0.84 | 0.77 |
| 8 | 0.89 | 0.75 | 0.77 | 0.69 | 80 | 0.98 | 0.76 | 0.91 | 0.77 |
| 10 | 0.98 | 0.77 | 0.82 | 0.78 | 100 | 0.98 | 0.76 | 0.90 | 0.79 |
| Global rounds | FederatedNILM | Baseline epochs | Centralized-NILM | ||||||
| Acc. | Pre. | Rec. | Acc. | Pre. | Rec. | ||||
| 2 | 0.96 | 0.52 | 0.53 | 0.41 | 20 | 0.97 | 0.53 | 0.49 | 0.44 |
| 4 | 0.95 | 0.53 | 0.57 | 0.45 | 40 | 0.98 | 0.50 | 0.52 | 0.47 |
| 6 | 0.95 | 0.54 | 0.58 | 0.50 | 60 | 0.98 | 0.55 | 0.57 | 0.49 |
| 8 | 0.94 | 0.55 | 0.58 | 0.54 | 80 | 0.98 | 0.59 | 0.55 | 0.53 |
| 10 | 0.96 | 0.56 | 0.59 | 0.53 | 100 | 0.98 | 0.61 | 0.60 | 0.54 |

The overall performance of the FederatedNILM model and the Centralized-NILM generally improves with the increase of the epochs.
With the increase of the global rounds, the time consumption cost also increases. The training time consumption of the FederatedNILM model is slightly higher but still within the acceptable range compared with the Centralized-NILM. Besides, given similar classification scores, the proposed FederatedNILM model has similar training time efficiency compared with the Centralized-NILM. For instance, the proposed model obtained an accuracy, precision, recall, of 0.98, 0.77, 0.82, 0.78 respectively for the dishwasher when global rounds reach 10 whereas similar scores (0.98, 0.76, 0.90, 0.79 for accuracy, precision, recall, , respectively) were achieved in the Centralized-NILM with 100 epochs. Therefore, we can also reasonably infer that the training cost of FederatedNILM is within an acceptable range compared with the Centralized-NILM under similar accuracy requirements. The above analysis can further confirm the proposed model could achieve a satisfactory trade-off between the computational costs and the model performance.
5.2.4 Performance comparison with state-of-the-arts
In the previous subsections, we compare the proposed FederatedNILM with Centralized-NILM to examine its feasibility from the perspective of communication cost and model accuracy (i.e. distributed vs centralized). In the following, we compare our adopted deep learning architecture (used in both FederatedNILM and Centralized-NILM) with state-of-the-arts considered in [4] on model generalization performance for NILM task.
By considering the experiment environment setup in this paper and in [4] and to allow for a direct comparison, the appliances and corresponding house numbers listed in Table 9 are considered.
| Train | Testing | |
| Dishwasher | [1, 2] | 5 |
| Washing machine | [1, 5] | 2 |
Table 10 gives the comparative results of FederatedNILM and Centralized-NILM with state-of-the-arts for dishwasher and washing machine respectively. The models considered for the comparative study are combinatorial optimization(CO), factorial hidden Markov models (Neural-NILM FHMM), and deep neural network (Autoencoder, Rectangles, Neural-NILM LSTM, centralized-NILM, and FederatedNILM).
| State-of-the-art models | Dishwasher | Washing machine | ||||||||
| Acc. | Pre. | Rec. | Acc. | Pre. | Rec. | |||||
| CO [4] | 0.64 | 0.06 | 0.67 | 0.11 | 0.88 | 0.06 | 0.48 | 0.10 | ||
|
0.33 | 0.03 | 0.49 | 0.05 | 0.79 | 0.04 | 0.64 | 0.08 | ||
| Autoencoder [4] | 0.92 | 0.29 | 0.99 | 0.44 | 0.82 | 0.07 | 1.00 | 0.13 | ||
| Rectangles [4] | 0.99 | 0.89 | 0.64 | 0.74 | 0.98 | 0.29 | 0.24 | 0.27 | ||
|
0.30 | 0.04 | 0.87 | 0.08 | 0.23 | 0.01 | 0.73 | 0.03 | ||
|
0.99 | 0.79 | 0.99 | 0.83 | 1.00 | 0.85 | 0.96 | 0.90 | ||
|
0.98 | 0.84 | 0.69 | 0.78 | 1.00 | 0.77 | 0.67 | 0.92 | ||
In general, the deep neural network-based models for NILM have relatively better performance than other models. It is also worth pointing out that both the Centralized-NILM and FederatedNILM achieved better testing results on the unseen house 2 (see Tables 9 and 10) than the average testing results of all three cases in Table 4 for the washing machine. One possible reason is that house 1 provides the largest dataset, and when this house is considered as an unseen house as in Table 4, the training size of the model becomes much smaller, which could impact the model performance. Among all the methods, the Centralized-NILM model achieved the highest accuracy score for both appliances, which proves that the deep learning architecture we utilized in this paper could enhance the local training performance and thus improve the overall state inference accuracy in our framework. As already discussed in previous subsections, the above results also demonstrated that our proposed FederatedNILM with the same deep learning architecture as in Centralized-NILM could achieve promising generalization performance. Considering FederatedNILM works in a distributed and privacy-preserving manner, which is fundamentally different from the other considered methods (i.e. centralized based methods), our proposed framework could achieve a good trade-off between data privacy protection and data utility.
6 Conclusion
In this paper, we proposed a distributed and privacy-preserving framework based on federated learning for NILM (FederatedNILM) to classify the typical states of appliances on the household level. The proposed FederatedNILM combines federated learning with a novel deep neural network model, which could benefit from labelled data of multiple distributed user data sources for NILM. More importantly, compared with the standard centralized model, the framework only requires model parameters uploading instead of data transmitting, which has good capability for data privacy protection. Comparative experiments on a real-world dataset demonstrate the feasibility and good performance of the proposed distributed and privacy-preserving framework as well as the superior model performance of the adopted deep learning architecture for NILM.
Although our proposed FederatedNILM achieved satisfactory results for most of the cases, its average disaggregation performance on the washing machine for the unseen house case still needs to be improved. The same situation has been found in [4]. Therefore, in our future work, we will explore to further improve the NILM generalization model performance for particular appliances with more complicated characteristics. In addition, how to further optimize our FederatedNILM framework to enhance its privacy-preserving level with minimal reduction of data utility is another future research direction that is worth exploring.
Acknowledgement
This work was supported by the PhD Studentship at University of Essex under the project “A distributed and real-time learning framework for smart meter big data” (2019-2022).
References
- [1] L. C. De Silva, C. Morikawa, I. M. Petra, State of the art of smart homes, Engineering Applications of Artificial Intelligence 25 (7) (2012) 1313–1321.
- [2] C. Klemenjak, P. Goldsborough, Non-intrusive load monitoring: A review and outlook, arXiv preprint arXiv:1610.01191.
- [3] M. Mishra, J. Nayak, B. Naik, A. Abraham, Deep learning in electrical utility industry: A comprehensive review of a decade of research, Engineering Applications of Artificial Intelligence 96 (2020) 104000.
- [4] J. Kelly, W. Knottenbelt, Neural nilm: Deep neural networks applied to energy disaggregation, in: Proceedings of the 2nd ACM international conference on embedded systems for energy-efficient built environments, 2015, pp. 55–64.
- [5] J.-G. Kim, B. Lee, Appliance classification by power signal analysis based on multi-feature combination multi-layer lstm, Energies 12 (14) (2019) 2804.
- [6] W. Kong, Z. Y. Dong, J. Ma, D. J. Hill, J. Zhao, F. Luo, An extensible approach for non-intrusive load disaggregation with smart meter data, IEEE Transactions on Smart Grid 9 (4) (2016) 3362–3372.
- [7] A. Lucas, L. Jansen, N. Andreadou, E. Kotsakis, M. Masera, Load flexibility forecast for dr using non-intrusive load monitoring in the residential sector, Energies 12 (14) (2019) 2725.
- [8] S. Desai, R. Alhadad, A. Mahmood, N. Chilamkurti, S. Rho, Multi-state energy classifier to evaluate the performance of the nilm algorithm, Sensors 19 (23) (2019) 5236.
- [9] B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in: Artificial Intelligence and Statistics, PMLR, 2017, pp. 1273–1282.
- [10] A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, D. Ramage, Federated learning for mobile keyboard prediction, arXiv preprint arXiv:1811.03604.
- [11] Veeramanikandan, S. Sankaranarayanan, J. J. Rodrigues, V. Sugumaran, S. Kozlov, Data flow and distributed deep neural network based low latency iot-edge computation model for big data environment, Engineering Applications of Artificial Intelligence 94 (2020) 103785.
- [12] L. Atzori, A. Iera, G. Morabito, The internet of things: A survey, Computer networks 54 (15) (2010) 2787–2805.
- [13] K. G. Boroojeni, M. H. Amini, S. S. Iyengar, Smart grids: security and privacy issues, Springer, 2017.
- [14] Z. Erkin, J. R. Troncoso-Pastoriza, R. L. Lagendijk, F. Pérez-González, Privacy-preserving data aggregation in smart metering systems: An overview, IEEE Signal Processing Magazine 30 (2) (2013) 75–86.
- [15] J. C. Cheung, T. W. Chim, S.-M. Yiu, V. O. Li, L. C. Hui, Credential-based privacy-preserving power request scheme for smart grid network, in: 2011 IEEE Global Telecommunications Conference-GLOBECOM 2011, IEEE, 2011, pp. 1–5.
- [16] G. Kalogridis, C. Efthymiou, S. Z. Denic, T. A. Lewis, R. Cepeda, Privacy for smart meters: Towards undetectable appliance load signatures, in: 2010 First IEEE International Conference on Smart Grid Communications, IEEE, 2010, pp. 232–237.
- [17] D. Gündüz, J. Gomez-Vilardebo, O. Tan, H. V. Poor, Information theoretic privacy for smart meters, in: 2013 information theory and applications workshop (ITA), IEEE, 2013, pp. 1–7.
- [18] H. Cao, S. Liu, L. Wu, Z. Guan, X. Du, Achieving differential privacy against non-intrusive load monitoring in smart grid: A fog computing approach, Concurrency and Computation: Practice and Experience 31 (22) (2019) e4528.
- [19] M. U. Hassan, M. H. Rehmani, J. Chen, Performance evaluation of differential privacy mechanisms in blockchain based smart metering, arXiv preprint arXiv:2007.09802.
- [20] T. D. Nguyen, S. Marchal, M. Miettinen, H. Fereidooni, N. Asokan, A.-R. Sadeghi, Dïot: A federated self-learning anomaly detection system for iot, in: 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), IEEE, 2019, pp. 756–767.
- [21] Y. Zhao, J. Chen, D. Wu, J. Teng, S. Yu, Multi-task network anomaly detection using federated learning, in: Proceedings of the tenth international symposium on information and communication technology, 2019, pp. 273–279.
- [22] Y. Zhao, J. Chen, Q. Guo, J. Teng, D. Wu, Network anomaly detection using federated learning and transfer learning, in: International Conference on Security and Privacy in Digital Economy, Springer, 2020, pp. 219–231.
- [23] Q. Li, Z. Wen, Z. Wu, S. Hu, N. Wang, Y. Li, X. Liu, B. He, A survey on federated learning systems: vision, hype and reality for data privacy and protection, arXiv preprint arXiv:1907.09693.
- [24] H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890.
- [25] D. Precioso, D. Gómez-Ullate, Nilm as a regression versus classification problem: the importance of thresholding, arXiv preprint arXiv:2010.16050.
- [26] J. Kelly, W. Knottenbelt, The uk-dale dataset, domestic appliance-level electricity demand and whole-house demand from five uk homes, Scientific data 2 (1) (2015) 1–14.
- [27] M. D’Incecco, S. Squartini, M. Zhong, Transfer learning for non-intrusive load monitoring, IEEE Transactions on Smart Grid 11 (2) (2019) 1419–1429.