Federated Natural Language Generation for Personalized Dialogue System
Abstract
Neural conversational models have long suffered from the problem of inconsistency and lacking coherent personality. To address the issue, persona-based models capturing individual characteristics have been proposed, but they still face the dilemma of model adaption and data privacy. To break this dilemma, we propose a novel Federated Natural Language Generation (FedNLG) framework, which learns personalized representations from various dataset on distributed devices, and thus implements the personalized dialogue system efficiently and safely. FedNLG first pre-trains parameters of standard neural conversational model over a large dialogue corpus, and then fine-tune the model parameters and persona embeddings on specific datasets, in a federated manner. Thus, the model could simultaneously learn the persona embeddings in local clients and learn shared model parameters by federated aggregation, which achieves accuracy-privacy balance. By conducting extensive experiments, we demonstrate the effectiveness of our model by pre-training model over Cornell Movie-Dialogs Corpus and fine-tuning the model over two TV series dataset.
Introduction
As the widely application of conversational agents in digital world, such as house-hold robot, speech assistant, intelligent customer services, there has been growing research interest in training naturalistic conversation systems from large volumes of human-to-human interactions. In addition, there is an increasing need for personalized service, as personalization enables clients feel incorporated as an integral part of user experience.
Existing methods to generate dialogue responses are mainly based on neural machines. However, such corpus-driven methods argue for very large corpora and corpus evidence are not fully exploited, as discussed in (Xiao 2009). Besides, such methods utilize data itself as the sole source of hypotheses (Hinkka 2018), resulting in conversational models with low perplexity. We illustrate the issue of producing responses with consistency and humanity in Figure 1. Although recent work like (Li et al. 2016a) addresses the challenge of inconsistency by successfully endowing data-driven systems with the coherent “persona” to model human-like behavior, neural machine based models still face a data privacy issue. As shown in Figure 2, current persona-based models directly uses all conversational data from users during the training process, which results in a data privacy issue.


In this paper, we propose a framework, Federated Natural Language Generation (FedNLG), to address the challenge of consistency with humanity and accuracy-privacy balance at the same time. To tackle the challenge of consistency with humanity, we first embed user personal profile information (e.g., age, gender, location, education), and historical user behaviors (e.g., dialogue history, application using time duration) into profile embedding and behavior embedding, respectively. Then, we concatenate both of the embeddings into one single persona-based embedding. To tackle the challenge of data privacy, Federated Learning (FL) is a solution, which is a technique where machine learning models are trained in a decentralized manner. In particular, instead of explicitly exchanging client data, FL exchanges model parameters to avoid the data privacy issue. Thus, we learn the general embedding and persona embedding among clients by FL, which is designed for privacy-preserving natural language generation. As in Figure 3, the FedNLG framework perfectly combines the persona-based dialogue system with federated learning.
Specifically, in this work, we first pre-train a general conversational agent within a sequence-to-sequence (SEQ2SEQ) framework over Cornell Movie-Dialogs Corpus dataset. Then we finetune and incorporate persona embeddings over The Big Bang Theory and Friends movie scripts. During fine-tuning, we adopt our proposed FedNLG framework, which represents each persona as a local client, and each client upload the local parameters to the central server, and download the globally aggregated parameters from the central server to update the local model. The aggregation is adapt to existing commonly used federated techniques, such as FedAvg, which takes the local model parameters from each client as input, and output the averaged model parameters to each client for update without personal data shared.

In this paper, our contributions are as follows:
-
•
We propose FedNLG, a privacy-preserving persona-based framework that enables safe personalized services in the domain of natural language generation.
-
•
We empirically show that the FedNLG framework significantly improves the performance of models in the federated personalized setting and conclude that FedProx is more appropriate in federated personalized natural language generation.
-
•
Ablation study show that our proposed FedNLG is flexible and could be applied to exisiting widely used federated algorithms, including FedAvg and FedProx, etc.
Related Works
Neural Conversational Modeling
Conversational modeling is a challenging research topic as it requires complex mapping between queries and responses. Previous works are restricted to specific domains and need feature engineering. Inspired by recent works (Kalchbrenner and Blunsom 2013; Sutskever, Vinyals, and Le 2014; Bahdanau, Cho, and Bengio 2015) which map sequences to sequences with neural networks, (Vinyals and Le 2015) proposed a neural conversational model based on SEQ2SEQ framework, which are capable of generating fluent and accurate replies in conversation in an end-to-end manner.
A common problem is that the produced responses often lack persona and consistency. Personalized responses are essential for providing an informative and human-like conversation. Thus modeling of users (Wahlster and Sonderforschungsbereich 1986; Kobsa 2005; Gur et al. 2018) has been extensively studied within standard dialog modeling framework. To tackle the difficulty of generating meaningful responses in an open-domain conversation scenario, many existing models (Walker, Lin, and Sawyer 2012) implement dialog-based user modeling by generalizing character style on the basis of qualitative statistical analysis.
In contrast, (Li et al. 2016a) proposed to train persona vectors directly from conversational data and relevant side-information in a SEQ2SEQ framework, and incorporate these directly into the LSTM. While sufficient amount of dialogs with speaker labels are required for these persona-based models (Li et al. 2016a; Zhang et al. 2018), they cannot be directly aggregated since personal dialog contains privacy-sensitive information.

Federated Learning
Federated learning (Konečný et al. 2016; Konecný et al. 2016) was first proposed by Google as a decentralized machine learning theory that allows distributed training on a large scale of data in edge-devices such as smartphones, sensors, robots, etc. Recent success of federated learning technique in the application of recent increased focus on privacy has earned a remarkable reputation in many pragmatic fields. There are many proposed federated learning framework that extremely boost the development of the these pragmatic fields, such as (Liu et al. 2020a) for vision-and-language grounding problems, (Kim et al. 2021) for face recognition, (Zhang et al. 2020a) for device failures detection in IIoT and (Brisimi et al. 2018; Kaissis et al. 2020) for sensitive records analysis. Accordingly, the aggregation algorithm such as Federated Averaging (McMahan et al. 2017) has been widely adopted in practical applications. FedProx (Sahu et al. 2018) was proposed to tackle heterogeneity in federated networks.
Federated learning has also been applied to some natural language processing tasks to exploit the corpus from different sources in a privacy-preserving way (Jiang et al. 2019; Huang, Liu, and Zou 2020; Hard et al. 2018; Chen et al. 2019; Liu et al. 2020b; Stremmel and Singh 2020). However, the application to neural conversational modeling is under explored. Our framework is devised to first incorporate persona-based neural conversational modeling with federated learning techniques, successfully satisfying the laws and regulations without losing user personalized experience.
Methodology
In this section, we first formulate our problem as persona-based natural language generation. Then we focus on the basic modules of our proposed federated architecture.
Problem Formulation
For the general response generation task, given input word sequence , the model aims at predicting the response sequence . and is the length of the message and the response respectively, and and denotes a word token that is associated with a dimensional distinct word embedding . In the task of persona-aware conversational generation, the character label would be added to input to generate speaker embedding , encodes speaker-specific information such as age, gender, location, education and personal preferences, which is shared across all conversations that involve speaker . Then, the input word sequence for speaker could be represented as
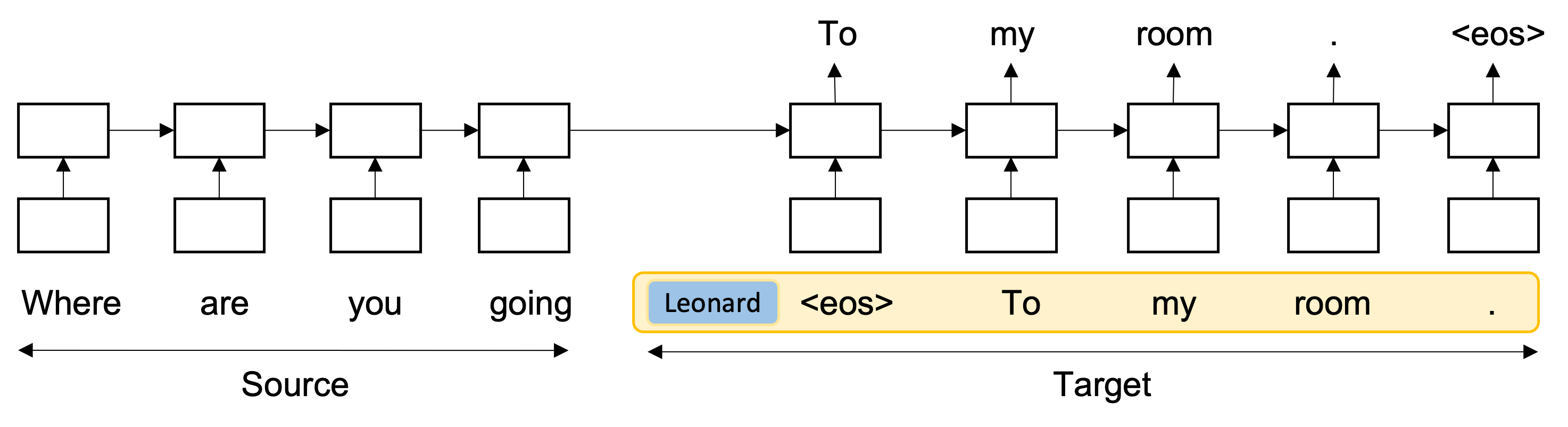
Persona-embedded Model
Encoding
The model represents each individual speaker as a user-level representation vector , which encodes speaker-specific information (e.g., age, gender, location, education, personal preferences) based on their personal information and dialogue history. The embedding would further shape the style of the responses.
As in standard sequence-to-sequence (SEQ2SEQ) models, we first encode message into a vector representation using the Recurrent Neural Network (). Then for each step in the target side, hidden units are obtained by combining the representation produced by the target LSTM at the previous time step, the word representations at the current time step, and the speaker embedding :
Particularly, we use LSTM cell as the basic unit to model dialogue corpus. Each LSTM unit at time consists of a memory cell , an input gate , a forget gate , and an output gate . These gates are computed from previous hidden state and the current input , for standard sequence-to-sequence model:
| (1) |
where and denotes the sigmoid function. In this way, the model ignore speaker information and thus predicts general responses throughout the generation process. As for persona-based model:
| (2) |
where and denotes the sigmoid function.. In this way, speaker information is encoded and injected into the hidden layer at each tie step and thus helps predict personalized responses throughout the generation process. The Speaker embedding is shared across all conversations that involve speaker . are learned by back propagating word prediction errors to each neural component during training. The memory cell is updated by partially forgetting the existing memory and adding a new memory content :
| (3) |
Once the memory content of the LSTM unit is updated, the hidden state at time step is given by:
| (4) |
At time step , the new states of the user can be inferred as:
| (5) |
where denote hidden states for the speaker .
Note that LSTM can be replaced by other options, such as the third version of generative pre-train transformer (GPT-3) proposed in (Radford and Narasimhan 2018) and a state-of-the-art large-scale pre-trained dialogue response generation model (DialoGPT) proposed in (Zhang et al. 2020b), etc. In this paper, we focus on exploiting federated learning into natural language generation (NLG) task. For simplicity, we select LSTM to evaluate the effectiveness of our federated framework to address two major challenges, consistency with humanity and privacy-accuracy balance.
Decoding
For decoding, we adopt the log-likelihood of target response given source question as our objective function for FedNLG as follows:
| (6) |
We conduct beam search over the above objective with beam size and a maximum length of the generated candidates to generate the -best lists.
Reranking
We follow (Li et al. 2016b) by adopting a scoring function for reranking the generated -best list. The scoring function linearly combines a length penalty and the log likelihood of the source question given the target response as follows:
| (7) |
where denotes the probability of generating response given the source question and the respondent’s speaker identification . denotes the length of the target response and denotes the associated penalty weight. We optimize and using Minimum Error Rate Training (Och 2003) by optimizing BLEU. An inverse standard SEQ2SEQ model with no speaker information was trained to compute .
Federated Framework
In order to guarantee the model performance, data-privacy, and preserve personalization, we empirically found that simply applying Federated Averaging or any other federated algorithms in neural conversational model would achieve poor performance in persona learning. We suspect it is due to the global aggregation of persona parameters which lead persona to general representation and fail to fully exploit local personal data. Thus, to enable models to learn personal representation, we first separate our learning parameters in the framework into tow parts, federated part and private part. For the word embeddings and neural model parameters, we categorize them into the part, while for the persona embeddings , we regard them as part.
Our framework FedNLG include two phases: 1) open-domain dialog pre-training; and 2) persona-based fine-tuning under federated frameworks. Federated fine-tuning phase is composed of local training and federated aggregation.
Pre-training To obtain a general dialog model, we pre-train a standard SEQ2SEQ model by optimizing scores on publicly available dataset. In our expeirments, we utilize Cornell Movie-Dialogs Corpus.
Local Training Each client’s conversation utterances will be trained by separated models. Each model locally fine-tunes based on its assigned character’s private conversation history. Neither do central server have assess to local clients’ data nor do local clients have access to any other characters’ data. At the start of local fine-tuning, the model of character uniformly initializes persona parameters as and load other parameters from pre-trained model as . represents a local parameter that will change during local training, denotes persona parameters of user stored locally on user ’s device. In each iteration , local model optimize with gradient descent on the model of user , which updates its federated parameters and personal parameters .
Federated Aggregation When local fine-tuning reaches certain number of epochs, federated aggregation begins. In particular, locally updated federated parameters are sent to the server for global aggregation while personal parameters are still kept in local model.
As discussed in (Bui et al. 2019), parameters splitting is valid for any FL algorithms that satisfy Equation 8 for federated parameters update and Equation 9 for private parameters update.
| (8) |
| (9) |
where the function represents federated aggregation function, while the function is the identity function. represents summary information about data of character .
Our proposed FedNLG satisfies such constraint by assigning persona-related parameters as private parameters and other parameters as federated parameters. Specifically, we train our neural conversational model to predict responses given questions and adopt configuration of commonly used federated aggregation algorithms, such as Federated Averaging (McMahan et al. 2017) and Federated Proximal (Sahu et al. 2018). For FedAvg Variant, the update of federated parameters, including word embeddings and neural model parameters is as follows:
| (10) |
As persona parameters are kept in local client, the update equation is as follows:
| (11) |
where denotes the training samples for character , denotes model delta of parameters of character, and denotes the total number of characters. For , is set to to guarantee that no clients persona parameters are distributed to any other clients or central server.
Experiments
In this section, we first introduce the data used in experiments, and evaluation metrics. Then, we introduce the methods to compare, and conduct extensive experiments to demonstrate the effectiveness of the proposed framework.
| The Big Bang Theory | Friends | ||||
| # | Model | BLEU Score | Perplexity | BLEU Score | Perplexity |
| 0 | SEQ2SEQ | 0.108 | 65.0 | 0.116 | 34.7 |
| 1 | FL | ||||
| 2 | Persona | ||||
| 3 | FedNLG (FedProx) | ||||
| 4 | FedNLG (FedDrop) | ||||
| 5 | FedNLG (FedAvg) | ||||
Data
-
•
Cornell Movie-Dialogs (Danescu-Niculescu-Mizil and Lee 2011) contains conversational messages between pairs of movie characters, which involves characters from movies. We ignore the character meta-data information and use this corpus as general movie dataset to pre-train our open-domain dialogue model.
-
•
The Big Bang Theory: To compare with prior persona models, we use dialogues in American TV series The Big Bang Theory to fine-tune our pre-trained model. It contains characters and total utterances. We collect main characters from this series. We randomly split the corpus into training, development and testing set with ratio , and respectively.
-
•
Friends: To compare with prior persona models, we use dialogues in American TV series Friends to fine-tune our pre-trained model. It contains characters and total utterances. We collect main characters from this series. We randomly split the corpus into training (70% of utterances), development (10%) and testing set (10%), respectively.
Evaluation Metrics
To compare the performance of different models, we use the following 2 metrics:
-
•
BLEU: We use BLEU scores to fine-tune and evaluate models. It is an accuracy measure quantifying the precision of the generated response. -
•
Perplexity: We use perplexity to evaluate the capability of models, which describe the degree of surprise of a model. The perplexity is inversely correlated to the precision of the probability that model predicts of responses.
Experimental Configuration
We pre-train four-layer SEQ2SEQ base model on Cornell Movie-Dialogs Corpus without access to their character metadata. Then we fine-tine on the Friends and The Big Bang Theory dataset. Details are as follows:
-
•
Vocabulary size is limited to . Each sentence length is limited under .
-
•
The LSTM is layer with hidden cells for each layer. The dimension of persona embedding is set to .
-
•
Batch size is set to . Learning rate is set to . Dropout rate is set to . Gradients are clipped to avoid gradient explosion with a threshold of .
-
•
Parameters are initialized with Xavier uniform initializer when pre-training. During fine-tuning, the persona embedding layer is initialized to normal distribution, while other parameters are loaded from pre-trained model.
-
•
We use 60 epochs on the pre-training and 90 epochs for the federated phase.
| The Big Bang Theory | Friends | |||
|---|---|---|---|---|
| Person | Sheldon | Leonard | Rachel | Ross |
| Question | Well, this calls for an expression of gratitude. | What if i smack my head on the concrete? | ||
| SEQ2SEQ | No, I have a little more. | Well, I just wanted to talk to you. | ||
| Persona | So, what do you say? | So, how’d it go? | Hey, you guys, you’re not gonna be able. | What are you doing? |
| FedNLG | He’s not gonna get married. | He’s not a little worried about you. | You’re not gonna be a girl and Monica? | You’re not gonna be a genius? |
| Question | Your love confuses me. | Come on, what, you never think about our future? | ||
| SEQ2SEQ | Yeah. I mean, like the same thing. | Oh , I’m sorry. | ||
| Persona | That’s a good idea. | Do you know what I do? | I’m sorry, I’m sorry. | I’m sorry. |
| FedNLG | So, I don’t know. | Why? | Oh, okay… What?! | Oh, okay… And Monica, I’m sorry, I’m sorry. |
Quantitative Comparison to the State-of-the-Art Methods
To validate the effectiveness of our proposed FedNLG framework, we compare the proposed framework with the following 3 methods on two publicly available TV series datasets, The Big Bang Theory and Friends:
-
•
SEQ2SEQ: This work (Vinyals and Le 2015) proposed a neural conversational model, which makes use of the sequence-to-sequence framework, which is based on a recurrent neural network. -
•
Persona-based Model: (Li et al. 2016a) present persona-based model to address the challenge of producing responses with consistency and persona in conversational model. They explore to embed persona into an LSTM to produce personalized responses. This model is implemented with full access to character metadata and thus face the risk of private data leakage. -
•
SEQ2SEQ with Federated Learning: We also implement the standard SEQ2SEQ model in federated framework as a base model without access to character metadata, thus no personalization.
We report performance our proposed FedNLG on The Big Bang Theory and Friends dataset over metric of BLEU scores and Perplexity are reported in Table 1. Experimental results for Standard SEQ2SEQ, SEQ2SEQ(+FL) and SEQ2SEQ (+Persona) are reported for reference.
As can be seen in Table 1, for The Big Bang Theory and Friends TV series dataset, FedNLG (FedProx) improve significant relative performance than standard SEQ2SEQ model up to and in BLEU scores, and in perplexity, respectively. The improvement indicates effectiveness of our proposed FedNLG to incorporate personalized natural language generation with federated learning techniques. FedNLG achieves similar results over BLEU scores and perplexity as Persona model. The major difference between these two models is that Persona is implemented with full access to global data which also lead to data privacy issue, while FedNLG only access local client data. Thus the small drop in metrics compared to global Persona is expected and tolerable, which is also discussed in (McMahan et al. 2017). This comparison result indicates effectiveness of our proposed model to tackle the challenge of balancing between model accuracy and data privacy. Similarly, we observe small decrease in BLEU scores for the SEQ2SEQ (+FL) compared to the standard SEQ2SEQ. Besides, we observe small decrease in the perplexity, which is not uniform with BLEU performance. We suspect it is due to that the model fluctuates with predictions to similar options, as no persona is utilized for SEQ2SEQ (+FL), while still gets more confident in cases of obvious difference. This observation is also consistent with research work (Rikters 2016).
Comparison to Different Federated Learning Algorithms
As the proposed framework is ubiquitous for various federated learning algorithms, we further analyze the performance of using different federated technique under our proposed model and report the experimental results in Table 1. We consider the following federated learning algorithms in the following experiments:
-
•
FedAvg(McMahan et al. 2017) : We adopt Federated Averaging to implement a federated module variant. This variant could learn parameters based on iterative model averaging between global server and clients. -
•
FedDrop(Ji et al. 2020): We add some modification to original FedAvg by different client drop out strategy in each aggregation round for communication-efficiant federated variant. - •
As shown in Row 1 in Table 1, we empirically find that simply applying federated techniques to neural conversational models not only fails to learn persona representation, but also results in poor performance and producing less diversified responses. Motivated by some research work established in (Bui et al. 2019), we devise our framework to be able to adaptively separate parameters into persona part to learn persona embedding locally, and federated part, which could be aggregated globally to train neural network. Furthermore, we establish several variants of our federated modules to investigate the effectiveness of different federated configurations. Performance of different configurations of our framework, including FedDrop, FedAvg ,and FedProx are reported in Table 1. Not surprisingly, FedNLG (FedDrop) achieves poor performance due to it uses less information from clients. FedNLG (FedAvg) achieves relatively good performance in both TV series dataset, which is consistent with it’s claimed to cope with imbalanced data and not independent and identically distributed (non-iid) data. It is worth noting that FedNLG (FedAvg) achieves relatively bad performance on The Big Bang Theory compared to Friends. This result is intuitive as The Big Bang Theory is more heterogeneous than Friends, with more variance in characters lines and more diversified conversational context with differed distribution for different characters.
FedNLG (FedProx) achieves best performance over both BLEU and perplexity on The Big Bang Theory and Friends under our framework. It also achieve better performance than FedNLG (FedAvg). We suspect this is primarily due to that our dataset is not independent and identically distributed (non-iid), thus FedNLG (FedProx) has some advantage over FedNLG (FedAvg) as expected, which is also consistent with previous research work (Sahu et al. 2018). In addition, personalized federated learning seeks to reduce heterogeneity and maintain high-quality client contributions to central server as discussed in (Zhou et al. 2021), which is successfully by our FedProx configuration. Thus we demonstrate that FedProx with separated parameters techniques is a state-of-the-art configuration in our proposed framework, and probably in the scenario of federated personalized natural language generation. These results also demonstrate the flexibility of our framework to incorporate existing widely used federated algorithms.
Qualitative Comparison to the State-of-the-Art Methods
To further illustrate the effectiveness of personalized conversational response generation, we report random selected cases in Table 2. The SEQ2SEQ represent the standard sequence-to-sequence model, Persona represent the persona-based Speaker Model proposed in (Li et al. 2016a), and FedNLG represent personalized conversational model with federated learning technique. As can be seen, the standard SEQ2SEQ produces the same response to the given question for different characters, which is intuitive that no persona was learned in this model. In contrast, we observe that Persona model and our proposed FedNLG are both sensitive to the identity of the character, generating diversified responses which contains persona and humanity. For example, the model produces ”You’re not gonna be a genius?” in response to ”What if i smack my head on the concrete?”, which could be recognized as ”Ross” style. Both Persona and FedNLG predicts diversified responses with persona in two movie datasets, Friends and The Big Bang Theory. We also test our model on consistency by generating some similar questions, empirically our persona-based models successfully produce consistent responses compared to standard SEQ2SEQ model, which is consistent with results in (Li et al. 2016a).
Conclusion
We introduce a framework, Federated Natural Language Generation (FedNLG), to tackle two major challenges in personalized natural language generation, producing consistent responses with humanity and achieving accuracy-privacy balance. FedNLG is a novel flexible framework that could learn the personalized representations from various dataset on distributed devices, and thus implement the personalized neural conversational model efficiently and safely. As both quantitative and qualitative results show, FedNLG significantly improves performance over non-personalized standard SEQ2SEQ model and achieve similar performance to global trained Persona model with superiority of accuracy-privacy balance. Investigation on different federated variants also indicates our proposed framework is flexible enough to incorporate with existing popular federated techniques.
References
- Bahdanau, Cho, and Bengio (2015) Bahdanau, D.; Cho, K.; and Bengio, Y. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. CoRR, abs/1409.0473.
- Brisimi et al. (2018) Brisimi, T. S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.; and Shi, W. 2018. Federated learning of predictive models from federated Electronic Health Records. International journal of medical informatics, 112: 59–67.
- Bui et al. (2019) Bui, D.; Malik, K.; Goetz, J.; Liu, H.; Moon, S.; Kumar, A.; and Shin, K. G. 2019. Federated User Representation Learning. CoRR, abs/1909.12535.
- Chen et al. (2019) Chen, M.; Suresh, A. T.; Mathews, R.; Wong, A.; Allauzen, C.; Beaufays, F.; and Riley, M. 2019. Federated Learning of N-gram Language Models. CoRR, abs/1910.03432.
- Danescu-Niculescu-Mizil and Lee (2011) Danescu-Niculescu-Mizil, C.; and Lee, L. 2011. Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs. In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, ACL 2011.
- Gur et al. (2018) Gur, I.; Hakkani-Tür, D.; Tür, G.; and Shah, P. 2018. User Modeling for Task Oriented Dialogues. CoRR, abs/1811.04369.
- Hard et al. (2018) Hard, A.; Rao, K.; Mathews, R.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; and Ramage, D. 2018. Federated Learning for Mobile Keyboard Prediction. CoRR, abs/1811.03604.
- Hinkka (2018) Hinkka, A. 2018. Data-driven Language Typology.
- Huang, Liu, and Zou (2020) Huang, Z.; Liu, F.; and Zou, Y. 2020. Federated Learning for Spoken Language Understanding. In Proceedings of the 28th International Conference on Computational Linguistics, 3467–3478. Barcelona, Spain (Online): International Committee on Computational Linguistics.
- Ji et al. (2020) Ji, S.; Jiang, W.; Walid, A.; and Li, X. 2020. Dynamic Sampling and Selective Masking for Communication-Efficient Federated Learning. ArXiv, abs/2003.09603.
- Jiang et al. (2019) Jiang, D.; Song, Y.; Tong, Y.; Wu, X.; Zhao, W.; Xu, Q.; and Yang, Q. 2019. Federated Topic Modeling. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM ’19, 1071–1080. New York, NY, USA: Association for Computing Machinery. ISBN 9781450369763.
- Kaissis et al. (2020) Kaissis, G.; Makowski, M.; Rückert, D.; and Braren, R. 2020. Secure, privacy-preserving and federated machine learning in medical imaging. Nature Machine Intelligence, 2: 305–311.
- Kalchbrenner and Blunsom (2013) Kalchbrenner, N.; and Blunsom, P. 2013. Recurrent Continuous Translation Models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1700–1709. Seattle, Washington, USA: Association for Computational Linguistics.
- Kim et al. (2021) Kim, J.; Park, T.; Kim, H.; and Kim, S. 2021. Federated Learning for Face Recognition. 2021 IEEE International Conference on Consumer Electronics (ICCE), 1–2.
- Kobsa (2005) Kobsa, A. 2005. User modeling in dialog systems: Potentials and hazards. AI & SOCIETY, 4: 214–231.
- Konecný et al. (2016) Konecný, J.; McMahan, H. B.; Yu, F.; Richtárik, P.; Suresh, A. T.; and Bacon, D. 2016. Federated Learning: Strategies for Improving Communication Efficiency. ArXiv, abs/1610.05492.
- Konečný et al. (2016) Konečný, J.; McMahan, H. B.; Yu, F. X.; Richtárik, P.; Suresh, A. T.; and Bacon, D. 2016. Federated Learning: Strategies for Improving Communication Efficiency. CoRR, abs/1610.05492.
- Li et al. (2016a) Li, J.; Galley, M.; Brockett, C.; Gao, J.; and Dolan, B. 2016a. A Persona-Based Neural Conversation Model. CoRR, abs/1603.06155.
- Li et al. (2016b) Li, J.; Galley, M.; Brockett, C.; Gao, J.; and Dolan, W. 2016b. A Diversity-Promoting Objective Function for Neural Conversation Models. In NAACL.
- Liu et al. (2020a) Liu, F.; Wu, X.; Ge, S.; Fan, W.; and Zou, Y. 2020a. Federated Learning for Vision-and-Language Grounding Problems. In AAAI.
- Liu et al. (2020b) Liu, F.; Wu, X.; Ge, S.; Fan, W.; and Zou, Y. 2020b. Federated Learning for Vision-and-Language Grounding Problems. In AAAI.
- McMahan et al. (2017) McMahan, H. B.; Moore, E.; Ramage, D.; Hampson, S.; and Arcas, B. A. Y. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. In AISTATS.
- Och (2003) Och, F. 2003. Minimum Error Rate Training in Statistical Machine Translation. In ACL.
- Radford and Narasimhan (2018) Radford, A.; and Narasimhan, K. 2018. Improving Language Understanding by Generative Pre-Training.
- Rikters (2016) Rikters, M. 2016. Neural Network Language Models for Candidate Scoring in Hybrid Multi-System Machine Translation. In Proceedings of the Sixth Workshop on Hybrid Approaches to Translation (HyTra6), 8–15. Osaka, Japan: The COLING 2016 Organizing Committee.
- Sahu et al. (2018) Sahu, A. K.; Li, T.; Sanjabi, M.; Zaheer, M.; Talwalkar, A.; and Smith, V. 2018. On the Convergence of Federated Optimization in Heterogeneous Networks. CoRR, abs/1812.06127.
- Stremmel and Singh (2020) Stremmel, J.; and Singh, A. 2020. Pretraining Federated Text Models for Next Word Prediction. arXiv:2005.04828.
- Sutskever, Vinyals, and Le (2014) Sutskever, I.; Vinyals, O.; and Le, Q. V. 2014. Sequence to Sequence Learning with Neural Networks. In NIPS.
- Vinyals and Le (2015) Vinyals, O.; and Le, Q. 2015. A Neural Conversational Model.
- Wahlster and Sonderforschungsbereich (1986) Wahlster, W.; and Sonderforschungsbereich, A. 1986. Dialog-Based User Models.
- Walker, Lin, and Sawyer (2012) Walker, M.; Lin, G. I.; and Sawyer, J. 2012. An Annotated Corpus of Film Dialogue for Learning and Characterizing Character Style. In LREC.
- Xiao (2009) Xiao, R. 2009. 46. Theory-driven corpus research: Using corpora to inform aspect theory:, 987–1008. De Gruyter Mouton.
- Zhang et al. (2018) Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; and Weston, J. 2018. Personalizing Dialogue Agents: I have a dog, do you have pets too? CoRR, abs/1801.07243.
- Zhang et al. (2020a) Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S. K.; Chen, S.; Xu, X.; and Zhu, L. 2020a. Blockchain-based Federated Learning for Failure Detection in Industrial IoT. ArXiv, abs/2009.02643.
- Zhang et al. (2020b) Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.-C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; and Dolan, W. 2020b. DIALOGPT : Large-Scale Generative Pre-training for Conversational Response Generation. In ACL.
- Zhou et al. (2021) Zhou, J.; Zhang, S.; Lu, Q.; Dai, W.; Chen, M.; Liu, X.; Pirttikangas, S.; Shi, Y.; Zhang, W.; and Herrera-Viedma, E. 2021. A Survey on Federated Learning and its Applications for Accelerating Industrial Internet of Things. CoRR, abs/2104.10501.