Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Abstract
In federated learning, all networked clients contribute to the model training cooperatively. However, with model sizes increasing, even sharing the trained partial models often leads to severe communication bottlenecks in underlying networks, especially when communicated iteratively. In this paper, we introduce a federated learning framework FedD3 requiring only one-shot communication by integrating dataset distillation instances. Instead of sharing model updates in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (e.g. a few unrecognizable images) from networks for model training. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on CIFAR-10 with 10 clients under non-independent and identically distributed (Non-IID) setting, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, compared to other one-shot federated learning approaches.
I Introduction

Federated learning has become an emerging paradigm for collaborative learning in large-scale distributed systems with a massive number of networked clients, such as smartphones, connected vehicles or edge devices. Due to the limited bandwidth between clients [1], previous research [2, 3, 4, 5, 6, 7, 8] attempts to speed up convergence and improve communication efficiency. However, for modern neural networks with over hundreds of million parameters, this kind of cooperative optimization still leads to extreme communication volumes, which require substantial network bandwidth (up to the Gbps level [9]) in order to work reliably and efficiently. This drawback hinders any large-scale deployment of federated learning models in commercial wireless mobile networks, e.g., vehicular communication networks [10] or industrial sensor networks [11].
Motivated by this communication bottleneck, prior federated learning algorithms attempt to reduce the number of communication rounds and with that the communication volume, to reach a good learning performance. Guha et al. [12] introduce a one-shot federated learning approach aimed at reducing communication overhead during the training process of a support vector machine (SVM). By exchanging information in a single communication round, it offers significant efficiency improvements. Kasturi et al. [13] provide a fusion federated learning method that uploads both model and data distribution to the server, but characterizing a distribution of a real dataset can be difficult. The one-shot federated learning based on knowledge transfer from Li et al. [14] is general, but it requires additional communication overhead to transmit multiple student models to the server.
Inspired by the one-shot scheme [12], we introduce a federated learning training scheme with one-shot communication via dataset distillation [15, 16, 17, 18]. Intuitively, dramatically smaller but more informative datasets, which include dense features, are synthesized and transmitted. This way, more informative training data is transmitted across the limited bandwidth without any privacy violation.
Specifically, we introduce a novel federated learning framework incorporating dataset distillation, FedD3, which is shown in Fig. 1. It enables efficient federated learning via transmitting the locally distilled dataset to the server in a one-shot manner, which can be applied as a pre-trained model and used for personalized [19, 20] and fairness-aware [21] learning. Note that dataset distillation can keep the advantage of privacy in federated learning[22, 23, 24, 25, 26, 27, 28, 29, 30]. It anonymously maps distilled datasets from the original client data without any exposure, which is analogous to the shared model parameters in previous federated learning methods, but substantially more efficient and effective.
We perform an extensive analysis of our method in various scenarios to showcase the effectiveness of our method in massively distributed systems and on Non-IID (non-independent and identically distributed) datasets. Specifically, our experiments highlight the trade-off between accuracy and communication cost. To handle this trade-off, we propose a new evaluation metric, the -accuracy gain. By tuning the importance of accuracy gain to the communication cost, the communication efficiency in federated learning is scored accordingly. We also investigate the effects of specific external parameters, including Non-IID datasets, number of clients and local contributions, and demonstrate a great potential for our framework in networks with constrained communication budgets in federated learning. We experimentally show that FedD3 has the following advantages: (i) Compared to conventional multi-shot federated learning, FedD3 significantly reduces the amount of bits that needs to be communicated, making our approach practically feasible even in low-bandwidth environments; (ii) Compared to other approaches for one-shot federated learning, FedD3 achieves a much better performance even with less communication volume, where the accuracy in a distributed system with 500 clients is enhanced by over 2.3 (from 42.08% to 94.74%) on Non-IID MNIST and 3.6 (from 10.74% to 38.27%) on Non-IID CIFAR-10 compared to FedAvg in one single round; (iii) Compared to centralized dataset distillation, FedD3 achieves much better results due to the broader data resource via federated learning.
Contributions To summarize, our contributions are as fourfold:
-
•
We introduce a decentralized dataset distillation scheme in federated learning systems, where distilled data instead of models are uploaded to the server;
-
•
We formulate and propose a novel framework, FedD3, for efficient federated learning in a one-shot manner, and demonstrate FedD3 with two different dataset distillation instances in clients;
-
•
We propose a novel evaluation metric -accuracy gain, which can be used to tune the importance of accuracy and analyze communication efficiency;
-
•
We conduct an extensive analysis of the proposed framework. The experiments showcase the great potentials of our framework in networks with constrained communication budget in federated learning, especially considering the trade-off between accuracy and communication costs. The software implementation of FedD3 is publicly available as open source at GitHub111https://github.com/rruisong/FedD3.git.
II Background and Related Work
Federated learning Federated learning was first introduced by McMahan et al. [1], where models can be learned collaboratively from decentralized data through model exchange between clients and a central server without violating privacy. The proposed federated learning scheme FedAvg [1] aggregates the received models and updates global model by averaging their parameters.
Compared to other distributed optimization approaches, federated optimization addresses more practical challenges, e.g., communication efficiency [2], data heterogeneity [31], privacy protection [32], system design [33], which enables a large-scale deployment in real-world application scenarios [34, 35, 36, 37, 38, 39, 40, 41, 42, 43].
In a federated learning scenario, given a set of clients indexed by , machine learning models with weights are trained individually on local client datasets , where is one data point with its label in client and is the number of the local data points. The goal of local training in client is to minimize
| (1) |
where is the loss function on one data point with the label . Finally, the goal is to minimize aggregated local goals in (1):
| (2) |
i.e. . Note that the datasets across clients can be Non-IID in federated learning.
However, most federated optimization methods exchange models or gradients for learning updates, which can still lead to excessive communication volumes when a model has numerous parameters. This is even more problematic in wireless networks common in many mobile applications, as frequently exchanging data leads to higher error likelihood when connections are unstable, which can cause federated learning to fail.
One-shot Federated Learning Federated learning with one-shot communication has been studied in several projects [12, 13, 14]. Guha et al. [12] introduce an algorithm for training a support vector machine in one-shot fashion. The framework proposed by Kasturi et al. [13] uploads models and additionally the local dataset distribution, which hard to do when training on real datasets. Li et al. [14] utilize knowledge transfer to distill models in each client, which can change the original model structure and may cause much communication cost for sharing student models.
Instead of distilling models, our framework distills input data into smaller synthetic datasets in clients, which can be used for training a more general model by only relying on one-shot communication.
Dataset Distillation Dataset distillation [15] has become an attractive paradigm. It attempts to synthesize a significantly smaller dataset from a large dataset, aiming to maintain the same training performance in terms of test accuracy. Dataset distillation was proposed by Wang et al. [15]. Methods like matching outputs or gradients [44, 17, 45, 16] have been achieving outstanding results. Beside updating synthetic datasets with forward and backward propagation, Nguyen et al. [18] perform Kernel Inducing Points (KIP) and Label Solve (LS) for the optimal solution. Relating back to our work, dataset distillation has been successfully applied in centralized training in limited fashion.
Dataset Distillation in Federated Learning Though some previous works in dataset distillation, e.g. [44], have mentioned the dataset distillation might be beneficial for federated learning, they have not provided detailed analysis and experimental evaluation on it. Only little research has explored the dataset distillation approaches in federated learning: Zhou et al. [46] and Goetz et al. [47] have attempted to employ the approaches proposed by Wang et al. [15] ,and Sucholutsky and Schonlau [48] in federated learning, respectively. However, more advanced methods, e.g. [18] [16] with more stable performance have been developed, and further studies on decentralized dataset distillation in federated settings are needed. Furthermore, both of them have not pointed out the dataset distillation can improve the training on heterogeneous data, which is one of the biggest challenges in federated learning.
In fact, the computation abilities in distributed edge devices are normally limited, while most dataset distillation methods require high computation power. For instance, the approach from [16] can lead to computation overhead, though it can generate satisfactory distilled dataset. Therefore, in this work, we consider the coreset-based and KIP-based [49, 18] methods for decentralized dataset distillation in our federated learning framework, and focus on improving the communication efficiency while training on federated datasets.
III FedD3: Federated Learning from Decentralized Distilled Datasets
To explore the dataset distillation in federated settings, we introduce FedD3, a federated learning framework from decentralized distilled datasets in this section. Specifically, we consider a joint learning task with clients, where the client owns local dataset . If we distill a synthetic dataset (), in the client from its local dataset (), the goal of the dataset distillation instance is to minimize , where the represents the matrix of stacked distilled data points in the client , , contains the corresponding labels, and indicates a set of parameters in the instance models. Note that can vary, depending on the instance used in the client .
III-A Coreset-based Methods
We start from coreset-based methods to distill the decentralized datasets. We assume that there exists a synthetic dataset , which can approximate the statistical distribution of the original dataset . Through minimizing the error in a small subset of , we can generate the coreset using a specific instance, e.g. Kernel Herding [50]. More generally, we consider a clustering-based methods to generate a coreset in the client for one of classes ( is the set of local classes), then the goal is to minimize a clustering loss, for instance generating coreset using a Gaussian mixture model (GMM) [51] for each class in all clients.
III-B KIP-based Methods
We review and adopt KIP [49, 18] to federated fashion for its fast divide up gradient computation. Each client aims to distill the original local dataset (a.k.a. target dataset) to a synthetic dataset (a.k.a. support dataset) by minimizing the kernel ridge-regression (KRR) loss as follows:
| (3) |
where is the kernel used in the client and is the regularization constant deduced by ridge regression in KIP. is an identity matrix. We refer the readers to the work of Nguyen et al. [49] for further details regarding kernels.
III-C Aggregation and Learning
After decentralized dataset distillation, the distilled datasets in all connected clients are transmitted to the server and aggregated as . We consider a non-convex neural network objective in the server and train a machine learning model on instead of on original dataset , the objective is then minimizing:
| (4) |
where is the loss of the prediction on one distilled data point with its label and model weights . If the could be distilled from perfectly, the learning result of minimizing on should be similar to it on . The FedD3 pseudocode is given in Algorithm 1.
III-D Gamma Communication Efficiency
In federated learning, communication cost is even more expensive than computational cost [1]. It is worth studying how much communication cost is needed for achieving a dedicated gain of the model performance in terms of accuracy. To tackle the trade-off between model performance and required communication cost, we define the Gamma Communication Efficiency (GCE) using -accuracy gain per binary logarithmic bit as follows:
| (5) |
where is the total communication rounds and is the required communication volume in each round.
We use the binary logarithmic bit to describe the communication cost from communication round to . Then the gain per binary logarithmic bit can be defined by , where the 0 communication cost gives us infinitive high gain and infinitive high communication cost lead to 0 gain. is the prediction accuracy value. is an tunable parameter to represent the importance of the prediction accuracy. If , the accuracy and communication cost in logarithmic bit is near proportional. The higher is defined, the more test accuracy is weighted. A tiny test accuracy gain can be scored very well with an infinitely high . Through selecting an appropriate , we can evaluate the performance of federated learning approaches, considering both test accuracy and communication cost based on the application scenarios.
IV Experiment
IV-A Experimental Settings
We conduct experiments mainly on MNIST [52] and CIFAR-10 [53], as they are widely used for federated learning evaluation. For FedD3, we use GMM for coreset generation in coreset-based instance [51] and employ a four-layer fully connected neural network model with the width of 1024 as instance for KIP-based instance [18].

| FedAvg | FedProx | FedNova | SCAFFOLD |
| Dataset | Metric | MSFL1 | OSFL | FedD3 (Ours)2 | ||||||||
| FedAvg | FedProx | FedNova | SCAFFOLD | FedAvg | FedProx | FedNova | SCAFFOLD | Coreset | KIP | |||
| MNIST | IID | ACC % | 96.970.02 | 96.550.03 | 85.500.01 | 97.490.02 | 85.340.02 | 83.630.02 | 74.780.02 | 67.475.89 | 86.820.46 | 94.370.67 |
| 0.01-GCE % | 0.270.01 | 0.270.00 | 0.690.00 | 0.130.00 | 4.160.00 | 4.070.00 | 3.630.00 | 1.630.15 | 5.560.03 | 6.090.05 | ||
| 0.5-GCE % | 1.480.00 | 1.380.01 | 1.790.00 | 0.820.00 | 10.660.01 | 9.880.01 | 7.120.01 | 2.850.54 | 15.010.34 | 24.991.78 | ||
| Non-IID | ACC % | 71.290.02 | 67.540.04 | 71.330.08 | 88.690.12 | 42.080.03 | 49.250.01 | 63.610.75 | 36.920.03 | 77.292.58 | 94.740.64 | |
| 0.01-GCE % | 0.200.00 | 0.200.00 | 0.200.00 | 0.120.00 | 2.020.00 | 2.370.00 | 3.070.04 | 0.890.00 | 5.760.20 | 7.170.06 | ||
| 0.5-GCE % | 0.310.00 | 0.310.00 | 0.300.00 | 0.350.00 | 2.640.00 | 3.310.00 | 5.040.11 | 1.110.00 | 11.951.13 | 30.432.17 | ||
| CIFAR-10 | IID | ACC % | 48.120.38 | 47.890.27 | 47.690.80 | 41.890.11 | 36.230.60 | 36.260.63 | 36.590.27 | 24.330.01 | 46.180.08 | 48.970.83 |
| 0.1-GCE % | 0.600.76 | 0.330.00 | 0.420.06 | 0.140.00 | 1.470.03 | 1.470.03 | 1.490.01 | 0.490.00 | 2.740.01 | 2.920.05 | ||
| 2-GCE % | 1.601.35 | 1.140.02 | 1.340.21 | 0.400.00 | 3.460.12 | 3.470.13 | 3.540.06 | 0.830.00 | 8.910.04 | 10.500.53 | ||
| Non-IID | ACC % | 13.145.02 | 18.460.83 | 12.985.00 | 34.270.04 | 10.730.01 | 10.710.01 | 10.720.01 | 10.050.00 | 30.321.43 | 38.271.45 | |
| 0.1-GCE % | 0.350.04 | 0.190.04 | 0.390.00 | 0.120.00 | 0.420.00 | 0.420.00 | 0.420.00 | 0.200.00 | 2.020.10 | 2.580.10 | ||
| 2-GCE % | 0.440.04 | 0.240.05 | 0.480.00 | 0.260.00 | 0.520.00 | 0.520.00 | 0.520.00 | 0.240.00 | 4.010.36 | 6.450.56 | ||
-
1
We select the best result in the first 18 and 6 communication rounds for the training on MNIST and CIFAR-10, respectively.
-
2
Each client contributes 1 distilled image per class (Img/Cls = 1) from its local dataset.
| Dataset | Metric | MSFL | OSFL | FedD3 | |
| Fashion-MNIST | IID | Acc % | 79.400.00 | 69.690.07 | 74.800.75 |
| 0.01-GCE % | 0.950.00 | 2.480.00 | 4.650.05 | ||
| 0.5-GCE % | 2.050.00 | 4.450.01 | 9.130.23 | ||
| Non-IID | Acc % | 40.690.01 | 27.920.00 | 76.780.98 | |
| 0.01-GCE % | 0.480.00 | 0.990.00 | 5.560.07 | ||
| 0.5-GCE % | 0.620.00 | 1.160.00 | 11.390.39 | ||
| SVHN | IID | Acc % | 80.990.00 | 25.000.49 | 80.420.63 |
| 0.01-GCE % | 0.160.00 | 0.440.01 | 3.850.03 | ||
| 0.5-GCE % | 0.360.00 | 0.510.01 | 8.560.21 | ||
| Non-IID | Acc % | 46.320.06 | 19.960.05 | 69.100.98 | |
| 0.01-GCE % | 0.100.01 | 0.350.00 | 3.690.05 | ||
| 0.5-GCE % | 0.130.02 | 0.390.01 | 6.560.02 | ||
| CIFAR-100 | IID | Acc % | 41.150.03 | 20.210.06 | 47.890.42 |
| 0.1-GCE % | 0.150.01 | 0.360.00 | 2.410.02 | ||
| 2-GCE % | 0.050.00 | 0.550.00 | 8.310.21 | ||
| Non-IID1 | Acc % | 29.790.03 | 10.270.00 | 38.050.49 | |
| 0.1-GCE % | 0.040.00 | 0.180.00 | 1.970.03 | ||
| 2-GCE % | 0.070.00 | 0.220.00 | 4.900.14 | ||
-
1
Each client holds data with 50 classes ().


We compare FedD3 with eight other baselines, where four federated learning methods are evaluated in both multi-shot federated learning (MSFL) and one-shot federated learning (OSFL). The federated learning methods are: FedAvg [1], FedProx [54], FedNova [55] and SCAFFOLD [31]. The required binary logarithmic bit for communication is shown in Tab. I. We train an LeNet [56] and an AlexNet [57] on MNIST and CIFAR-10, respectively.
Considering properties in federated learning [1], we demonstrate our methods and baselines on IID and Non-IID datasets in distributed systems with a different number of clients. We vary the number of classes in each client to design Non-IID datasets [58]. Guided by federated learning benchmark datasets made by Caldas et al. [59], we use Non-IID to denote (pathological Non-IID [19]), unless specified otherwise.
IV-B Robust Training on Heterogeneous Data
First, we focus on the performance of FedD3 on data heterogeneity and consider FedAvg as the baseline here. The accuracy changing with increasing total communication volume required in each method is observed in Fig, 2. In experiment with IID decentralized datasets, though FedAvg with unlimited communication cost has higher accuracy than FedD3, FedD3 outperforms FedAvg at the same communication volume. The best performance of one-shot FedAvg can be reached by using FedD3 with only around half of the communication volume. Note that we consider the communication volume only for uploading. In fact, MSFL methods still require further cost for downloading the global models.
Additionally, as shown in Fig. 2, the performance of FedD3 is obviously more robust than FedAvg, when the data heterogeneity across clients increases from left to right. With decreasing number of classes in local datasets, the prediction accuracy FedAvg reduces notably, however, the results of FedD3 are not much affected. In the scenario with extreme data heterogeneity, i.e. , the standard federated learning can even not easily converged and one-shot federated learning performances very badly, while FedD3 can achieve the similar accuracy as in IID scenarios. We believe the reason is that aggregating distilled datasets allows server to train a model on a similar distribution of original datasets.
IV-C Scalable Communication Efficiency
Then, we compare the results from 2 variants of FedD3 with 8 baselines on both IID and Non-IID, MNIST and CIFAR10 distributed in 500 clients. As shown in Tab. II, on IID datasets, FedD3 can achieve a comparable test accuracy to other federated learning, while the GCE is significantly higher. On Non-IID datasets, FedD3 is outperforms others for both test accuracy and GCE. We consider various to indicate the evaluation based on different importance of accuracy. We assign for CIFAR-10 with greater values than for MNIST, as a high accuracy for training model on CIFAR-10 is harder to achieve and should deserve to spend more communication cost for it.
We conduct further experiments for training a ResNet-18 [60] on Fashion-MNIST [61] and SVHN [62], and training a CNN consisting of 5 convolutional and 3 fully connected layers on CIFAR-100 [62], using MSFL and OSFL with FedAvg, and FedD3 with KIP-instances. As shown in Tab. III, we observe consistent results.
To perform the scalablity of communication efficiency, we meanwhile evaluate FedD3 with increasing number of images per class in each client. Fig. 3 shows the test accuracy raises and thereby GCE with higher increases, when each client contributes more distilled images to the server. However, GCE with reduces, because much communication cost is required for only a small accuracy gain. FedD3 provides the opportunity to optimize the GCE by adjusting the Img/Cls in decentralized dataset distallation, considering different importance of accuracy and constraint communication budget in practical applications.
IV-D Evaluation with System Parameters
Finally, we explore the performance of FedD3 affected by federated system parameters, including the number of clients and distilled images. In Fig. 4, we run FedD3 in federated systems containing various number of clients with IID and Non-IID decentralized datasets. We hold the total number of distilled images constant by varying the number of distilled images in each client. Fig. 4 shows that the prediction accuracy decreases at a larger number of clients. This can be led by the following reason: When increasing the client number, both the local data volume and distilled image per client reduce in our experimental setup. This results in lower granularity and thereby decreases prediction accuracy.
In fact, federated learning considers massively distributed systems in practical applications. Thus, even if each client provides a small number of distilled images, a promising training performance can be achieved, when the number of clients is large. As we can observe in Fig. 4, when each client provides the same number of distilled images, a better model can be trained with more clients, due to more distilled images received in the server. Moreover, additional clients in real applications can enrich the training dataset, and hence reach a better prediction accuracy, which is consistent with the motivation of deploying federated learning.
V Discussion
Distilled Datasets in Multi-round Due to the robustness on data heterogeneity, we further explore the potential benefits of distilled datasets in federated learning. We believe that sharing such synthetic data might bridge the information silos. For that, we extend FedD3 to multiple shots and consider a hybrid federated learning method by adding a spoon of distilled datasets from other clients via D2N (Device to Networks) or D2D (Device to Device) networks, before the first round in standard federated learning.
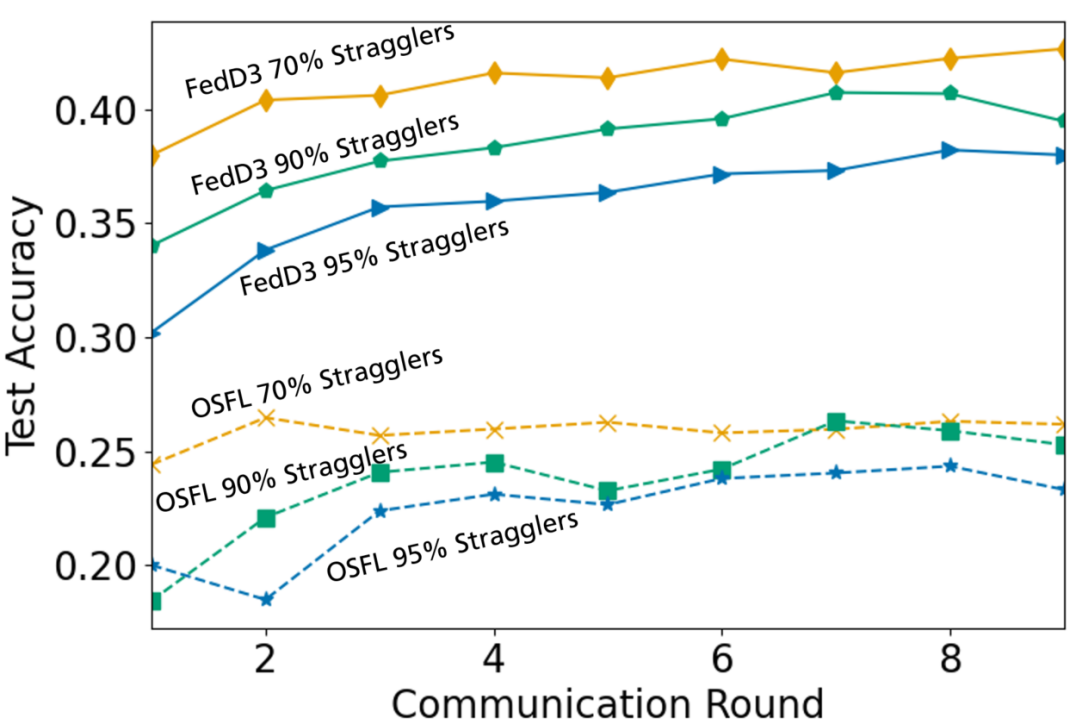
Network Assumption Compared to multi-shot schemes, a one-shot scheme is less affected by network heterogeneity. Despite, to evaluate the impact of network heterogeneity and address the network assumption in federated learning application scenarios, we consider the Quality of Service (QoS) of at most once for the one-shot scheme and compare the performance of FedD3 and OSFL with different ratios of stragglers. As shown in Fig 5, FedD3 outperforms OSFL.
Computation Costs Most dataset distillation methods can result in high computation loads. In our experiment setup, we take into account computation limitations in KIP and scale the number of distilled images on each client. In our FedD3 setup, we use FC-4 kernel without pooling and convolutional kernels for dataset distillation. In each client, we only distill a small number of images, i.e. 1 Img/Cls. In Federated Learning, local training can result in a linear increase in computational cost with the number of epochs. We also disregard the computational cost caused by a large number of epochs and aim to achieve better results in the baselines for a fair comparison only for communication efficiency. Additionally, we measure the required time on a compact NVIDIA Quadro RTX 4000 GPU for training an AlexNet on CIFAR-10: On average 73.69s are needed for FedD3 with 800 distillation steps for 1 Img/Cls, and 89.96s for one-shot FedAvg with 10 epochs.
Beyond Kernel: Individual DD-instances Because of stable performance, we mainly employ KIP methods as dataset distillation instances in FedD3. In fact, according to the actual local datasets, we can also consider individual instances to generate the synthetic dataset for uploading. Self-selecting instances in each client should be encouraged, which can be advantageous to the quality of distilled data, as the server and other clients should be not aware of the distribution of local data. Additionally, we believe the autonomy of local dataset distillation can enhance privacy.
Lessons Learned for Orchestration In FedD3, all local datasets should meet the requirement of the used dataset distillation method. Here we can think about two example scenarios: (i) If there is only one data point in one of the clients, and are the same at the first epoch in ClientDatasetDistillation in Algorithm 1; (ii) If there is only one data point with its label for a specific class , the distilled dataset can be always the same as , especially when only the loss is backpropagated on . Both situations can break the privacy, as it will upload at least one raw data point to the server. To tackle this issue, we believe a good orchestration for dataset and client selection is recommended.
VI Conclusion
In this work, we introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in particular in network constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multi-way communication. Our conducted experimental evaluation shows that FedD3 can well balance the trade-off between prediction accuracy and communication cost for federated learning. Compared to other federated learning, it provides a more robust training performance, especially on Non-IID data silos.
References
- [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” in International Conference on Artificial Intelligence and Statistics (AISTATS), vol. 54, 2017, pp. 1273–1282.
- [2] R. Pathak and M. J. Wainwright, “Fedsplit: An algorithmic framework for fast federated optimization,” Advances in Neural Information Processing Systems, vol. 33, pp. 7057–7066, 2020.
- [3] H. Yuan and T. Ma, “Federated accelerated stochastic gradient descent,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 5332–5344. [Online]. Available: https://proceedings.neurips.cc/paper/2020/file/39d0a8908fbe6c18039ea8227f827023-Paper.pdf
- [4] G. Malinovskiy, D. Kovalev, E. Gasanov, L. Condat, and P. Richtárik, “From local sgd to local fixed-point methods for federated learning,” in ICML, 2020, pp. 6692–6701. [Online]. Available: http://proceedings.mlr.press/v119/malinovskiy20a.html
- [5] D. Rothchild, A. Panda, E. Ullah, N. Ivkin, I. Stoica, V. Braverman, J. Gonzalez, and R. Arora, “Fetchsgd: Communication-efficient federated learning with sketching,” in ICML, 2020, pp. 8253–8265. [Online]. Available: http://proceedings.mlr.press/v119/rothchild20a.html
- [6] J. Hamer, M. Mohri, and A. T. Suresh, “FedBoost: A communication-efficient algorithm for federated learning,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 3973–3983. [Online]. Available: https://proceedings.mlr.press/v119/hamer20a.html
- [7] R. Song, L. Zhou, L. Lyu, A. Festag, and A. Knoll, “Resfed: Communication efficient federated learning by transmitting deep compressed residuals,” arXiv preprint arXiv:2212.05602, 2022.
- [8] H. Gao, A. Xu, and H. Huang, “On the convergence of communication-efficient local sgd for federated learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2021, pp. 7510–7518.
- [9] Y. Lin, S. Han, H. Mao, Y. Wang, and W. J. Dally, “Deep gradient compression: Reducing the communication bandwidth for distributed training,” arXiv preprint arXiv:1712.01887, 2017.
- [10] A. Festag, “Standards for vehicular communication - from ieee 802.11p to 5g,” e & i Elektrotechnik und Informationstechnik, Springer Verlag, vol. 132, no. 7, pp. 409–416, 2015. [Online]. Available: https://link.springer.com/article/10.1007/s00502-015-0343-0
- [11] R. Karlstetter, A. Raoofy, M. Radev, C. Trinitis, J. Hermann, and M. Schulz, “Living on the edge: Efficient handling of large scale sensor data,” in 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2021, pp. 1–10.
- [12] N. Guha, A. Talwalkar, and V. Smith, “One-shot federated learning,” arXiv preprint arXiv:1902.11175, 2019.
- [13] A. Kasturi, A. R. Ellore, and C. Hota, “Fusion learning: A one shot federated learning,” in International Conference on Computational Science. Springer, 2020, pp. 424–436.
- [14] Q. Li, B. He, and D. Song, “Practical one-shot federated learning for cross-silo setting,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2021, pp. 1484–1490, main Track. [Online]. Available: https://doi.org/10.24963/ijcai.2021/205
- [15] T. Wang, J.-Y. Zhu, A. Torralba, and A. A. Efros, “Dataset distillation,” arXiv preprint arXiv:1811.10959, 2018.
- [16] G. Cazenavette, T. Wang, A. Torralba, A. A. Efros, and J.-Y. Zhu, “Dataset distillation by matching training trajectories,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- [17] B. Zhao, K. R. Mopuri, and H. Bilen, “Dataset condensation with gradient matching,” in International Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=mSAKhLYLSsl
- [18] T. Nguyen, R. Novak, L. Xiao, and J. Lee, “Dataset distillation with infinitely wide convolutional networks,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [19] Y. Huang, L. Chu, Z. Zhou, L. Wang, J. Liu, J. Pei, and Y. Zhang, “Personalized cross-silo federated learning on non-iid data.” in AAAI, 2021, pp. 7865–7873.
- [20] R. Song, R. Xu, A. Festag, J. Ma, and A. Knoll, “Fedbevt: Federated learning bird’s eye view perception transformer in road traffic systems,” arXiv preprint arXiv:2304.01534, 2023.
- [21] H. Yu, Z. Liu, Y. Liu, T. Chen, M. Cong, X. Weng, D. Niyato, and Q. Yang, “A fairness-aware incentive scheme for federated learning,” in Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 2020, pp. 393–399.
- [22] T. Dong, B. Zhao, and L. Lyu, “Privacy for free: How does dataset condensation help privacy?” in Proceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 17–23 Jul 2022, pp. 5378–5396. [Online]. Available: https://proceedings.mlr.press/v162/dong22c.html
- [23] I. Sucholutsky and M. Schonlau, “Secdd: Efficient and secure method for remotely training neural networks (student abstract),” in Proceedings of the AAAI Conference on Artificial Intelligence, 2021, pp. 15 897–15 898.
- [24] G. Li, R. Togo, T. Ogawa, and M. Haseyama, “Soft-label anonymous gastric x-ray image distillation,” in 2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2020, pp. 305–309.
- [25] Y. Han and X. Zhang, “Robust federated learning via collaborative machine teaching,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 4075–4082.
- [26] Y. Wang, Y. Tong, and D. Shi, “Federated latent dirichlet allocation: A local differential privacy based framework,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 6283–6290.
- [27] Y. Zhou, X. Ma, D. Wu, and X. Li, “Communication-efficient and attack-resistant federated edge learning with dataset distillation,” IEEE Transactions on Cloud Computing, 2022.
- [28] Y. Xiong, R. Wang, M. Cheng, F. Yu, and C.-J. Hsieh, “FedDM: Iterative distribution matching for communication-efficient federated learning,” in Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022. [Online]. Available: https://openreview.net/forum?id=erV2t8ZLk2o
- [29] G. Li, R. Togo, T. Ogawa, and M. Haseyama, “Dataset distillation for medical dataset sharing,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Workshop, 2023, pp. 1–6.
- [30] ——, “Compressed gastric image generation based on soft-label dataset distillation for medical data sharing,” Computer Methods and Programs in Biomedicine, vol. 227, p. 107189, 2022.
- [31] S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 5132–5143. [Online]. Available: https://proceedings.mlr.press/v119/karimireddy20a.html
- [32] A. Reisizadeh, F. Farnia, R. Pedarsani, and A. Jadbabaie, “Robust federated learning: The case of affine distribution shifts,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 554–21 565, 2020.
- [33] K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konečnỳ, S. Mazzocchi, B. McMahan et al., “Towards federated learning at scale: System design,” Proceedings of Machine Learning and Systems, vol. 1, pp. 374–388, 2019.
- [34] R. Xu, X. Xia, J. Li, H. Li, S. Zhang, Z. Tu, Z. Meng, H. Xiang, X. Dong, R. Song, H. Yu, B. Zhou, and J. Ma, “V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception,” in The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023.
- [35] C. He, S. Li, J. So, X. Zeng, M. Zhang, H. Wang, X. Wang, P. Vepakomma, A. Singh, H. Qiu et al., “Fedml: A research library and benchmark for federated machine learning,” arXiv preprint arXiv:2007.13518, 2020.
- [36] L. U. Khan, W. Saad, Z. Han, E. Hossain, and C. S. Hong, “Federated learning for internet of things: Recent advances, taxonomy, and open challenges,” IEEE Communications Surveys & Tutorials, 2021.
- [37] R. Song, L. Zhou, V. Lakshminarasimhan, A. Festag, and A. Knoll, “Federated learning framework coping with hierarchical heterogeneity in cooperative its,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), 2022, pp. 3502–3508.
- [38] D. Z. Chen, A. X. Chang, and M. Nießner, “Scanrefer: 3d object localization in rgb-d scans using natural language,” in Computer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer International Publishing, 2020, pp. 202–221.
- [39] Z. Chen, A. Gholami, M. Niessner, and A. X. Chang, “Scan2cap: Context-aware dense captioning in rgb-d scans,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 3193–3203.
- [40] D. Z. Chen, Q. Wu, M. Nießner, and A. X. Chang, “D3net: A unified speaker-listener architecture for 3d dense captioning and visual grounding,” in Proceedings of European Conference on Computer Vision (ECCV), 2022.
- [41] R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2583–2589.
- [42] R. Xu, Y. Guo, X. Han, X. Xia, H. Xiang, and J. Ma, “Opencda: an open cooperative driving automation framework integrated with co-simulation,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021, pp. 1155–1162.
- [43] S. Banik, A. M. GarcÍa, and A. Knoll, “3d human pose regression using graph convolutional network,” in 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 924–928.
- [44] B. Zhao and H. Bilen, “Dataset condensation with differentiable siamese augmentation,” in Proceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 12 674–12 685. [Online]. Available: https://proceedings.mlr.press/v139/zhao21a.html
- [45] K. Wang, B. Zhao, X. Peng, Z. Zhu, S. Yang, S. Wang, G. Huang, H. Bilen, X. Wang, and Y. You, “Cafe: Learning to condense dataset by aligning features,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 12 196–12 205.
- [46] Y. Zhou, G. Pu, X. Ma, X. Li, and D. Wu, “Distilled one-shot federated learning,” arXiv preprint arXiv:2009.07999, 2020.
- [47] J. Goetz and A. Tewari, “Federated learning via synthetic data,” arXiv preprint arXiv:2008.04489, 2020.
- [48] I. Sucholutsky and M. Schonlau, “Soft-label dataset distillation and text dataset distillation,” in 2021 International Joint Conference on Neural Networks (IJCNN), 2021, pp. 1–8.
- [49] T. C. Nguyen, Z. Chen, and J. Lee, “Dataset meta-learning from kernel ridge-regression,” in ICLR 2021, 2021. [Online]. Available: https://openreview.net/forum?id=l-PrrQrK0QR
- [50] Y. Chen, M. Welling, and A. Smola, “Super-samples from kernel herding,” in Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence, ser. UAI’10. Arlington, Virginia, USA: AUAI Press, 2010, p. 109–116.
- [51] J.-P. Baudry, A. E. Raftery, G. Celeux, K. Lo, and R. Gottardo, “Combining mixture components for clustering,” Journal of computational and graphical statistics, vol. 19, no. 2, pp. 332–353, 2010.
- [52] Y. LeCun, C. Cortes, and C. Burges, “Mnist handwritten digit database,” ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, vol. 2, 2010.
- [53] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Technical report, 2009.
- [54] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” Proceedings of Machine Learning and Systems, vol. 2, pp. 429–450, 2020.
- [55] J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” Advances in neural information processing systems, vol. 33, pp. 7611–7623, 2020.
- [56] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998, doi:10.1109/5.726791.
- [57] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, Eds., vol. 25. Curran Associates, Inc., 2012. [Online]. Available: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- [58] Q. Li, Y. Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: An experimental study,” in IEEE International Conference on Data Engineering, 2022.
- [59] S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Konečnỳ, H. B. McMahan, V. Smith, and A. Talwalkar, “Leaf: A benchmark for federated settings,” arXiv preprint arXiv:1812.01097, 2018.
- [60] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [61] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [62] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” 2011.