Federated Learning for Channel Estimation in Conventional and RIS-Assisted Massive MIMO
Abstract
Machine learning (ML) has attracted a great research interest for physical layer design problems, such as channel estimation, thanks to its low complexity and robustness. Channel estimation via ML requires model training on a dataset, which usually includes the received pilot signals as input and channel data as output. In previous works, model training is mostly done via centralized learning (CL), where the whole training dataset is collected from the users at the base station (BS). This approach introduces huge communication overhead for data collection. In this paper, to address this challenge, we propose a federated learning (FL) framework for channel estimation. We design a convolutional neural network (CNN) trained on the local datasets of the users without sending them to the BS. We develop FL-based channel estimation schemes for both conventional and RIS (intelligent reflecting surface) assisted massive MIMO (multiple-input multiple-output) systems, where a single CNN is trained for two different datasets for both scenarios. We evaluate the performance for noisy and quantized model transmission and show that the proposed approach provides approximately 16 times lower overhead than CL, while maintaining satisfactory performance close to CL. Furthermore, the proposed architecture exhibits lower estimation error than the state-of-the-art ML-based schemes.
Index Terms:
Channel estimation, Federated learning, Machine learning, Centralized learning, Massive MIMO.I Introduction
Compared to the cellular communication systems in lower frequency bands, millimeter wave (mm-Wave) signals, with the frequency range - GHz, encounter a more complex propagation environment that is characterized by higher scattering, severe penetration losses, and higher path loss for fixed transmitter and receiver gains [1, 2, 3]. These losses are compensated by providing beamforming power gain through massive number of antennas at both transmitter and receiver with multiple-input-multiple-output (MIMO) architecture. However, such a large antenna array requires a dedicated radio-frequency (RF) chain for each antenna, resulting in an expensive system architecture and high power consumption. In order to address this issue and reduce the number of digital RF components, hybrid analog and baseband beamforming architectures have been introduced, wherein a small number of phase-only analog beamformers are employed [4]. As a result, the combination of high-dimensional analog and low-dimensional baseband beamformers significantly reduces the number of RF chains while maintaining sufficient beamforming gain [4].
Even with the reduced number of RF chains, the hybrid beamforming architecture combined with mm-Wave transmission comes with the expensive cost of energy consumption and hardware complexity [5]. In order to address these issues and provide a more green and suitable solution to enhance the wireless network performance, reconfigurable intelligent surfaces (RISs) (also known as intelligent reflecting surfaces) are envisaged as a promising solution with low cost and complexity [6, 7, 5, 8, 9]. An RIS is an electromagnetic 2-D surface that is composed of large number of passive reconfigurable meta-material elements, which reflect the incoming signal by introducing a pre-determined phase shift. This phase shift can be controlled via external signals by the base station (BS) through a backhaul control link. As a result, the incoming signal from the BS can be manipulated in real-time, thereby, reflecting the received signal towards the users. Hence, the usage of RIS improves the received signal energy at the distant users as well as expanding the coverage of the BS.
In both conventional and RIS-assisted massive MIMO scenarios, the performance of the system architecture strongly relies on the accuracy of the instantaneous channel state information (CSI), given the highly dynamic nature of the mm-Wave channel [10]. Thus, the channel estimation accuracy plays an important role in the design of the analog and digital beamformers in conventional massive MIMO [11, 12], and the design of reflecting beamformer phase shifts of the RIS elements in the RIS-assisted scenario [13, 8]. Furthermore, RIS-assisted massive MIMO involves signal reception through multiple channels (e.g., BS-RIS, RIS-user and BS-user), which makes the channel estimation task more challenging and interesting. As a result, several channel estimation schemes are proposed for massive MIMO and RIS-assisted scenarios, based on compressed sensing [13], angle-domain processing [14] and coordinated pilot-assignment [15]. The performance of these analytical approaches strongly depends on the perfection of the antenna array output so that reliable channel estimation accuracy can be obtained. In order to provide robustness against the imperfections/corruptions in the array data, data-driven techniques, such as machine learning (ML) based approaches, have been proposed to uncover the non-linear relationships in data/signals with lower computational complexity and achieve better performance for parameter inference and be tolerant against the imperfections in the data. As listed below, ML is more efficient than model-based techniques that largely rely on mathematical models:
-
•
A learning model constructs a non-linear mapping between the raw input data and the desired output to approximate a problem from a model-free perspective. Thus, its prediction performance is robust against the corruptions/imperfections in the wireless channel data.
-
•
ML learns the feature patterns, which are easily updated for the new data and adapted to environmental changes. In the long run, this results in a lower computational complexity than the model-based optimization.
-
•
ML-based solutions have significantly reduced run-times because of parallel processing capabilities. On the other hand, it is not straightforward to achieve parallel implementations of conventional optimization and signal processing algorithms.
In massive MIMO and RIS-assisted systems, ML has been proven to have higher spectral efficiency and lower computational complexity for the problems such as channel estimation [16, 17, 18], hybrid beamforming [19, 20, 21] and angle-of-arrival (AoA) estimation [22, 23].
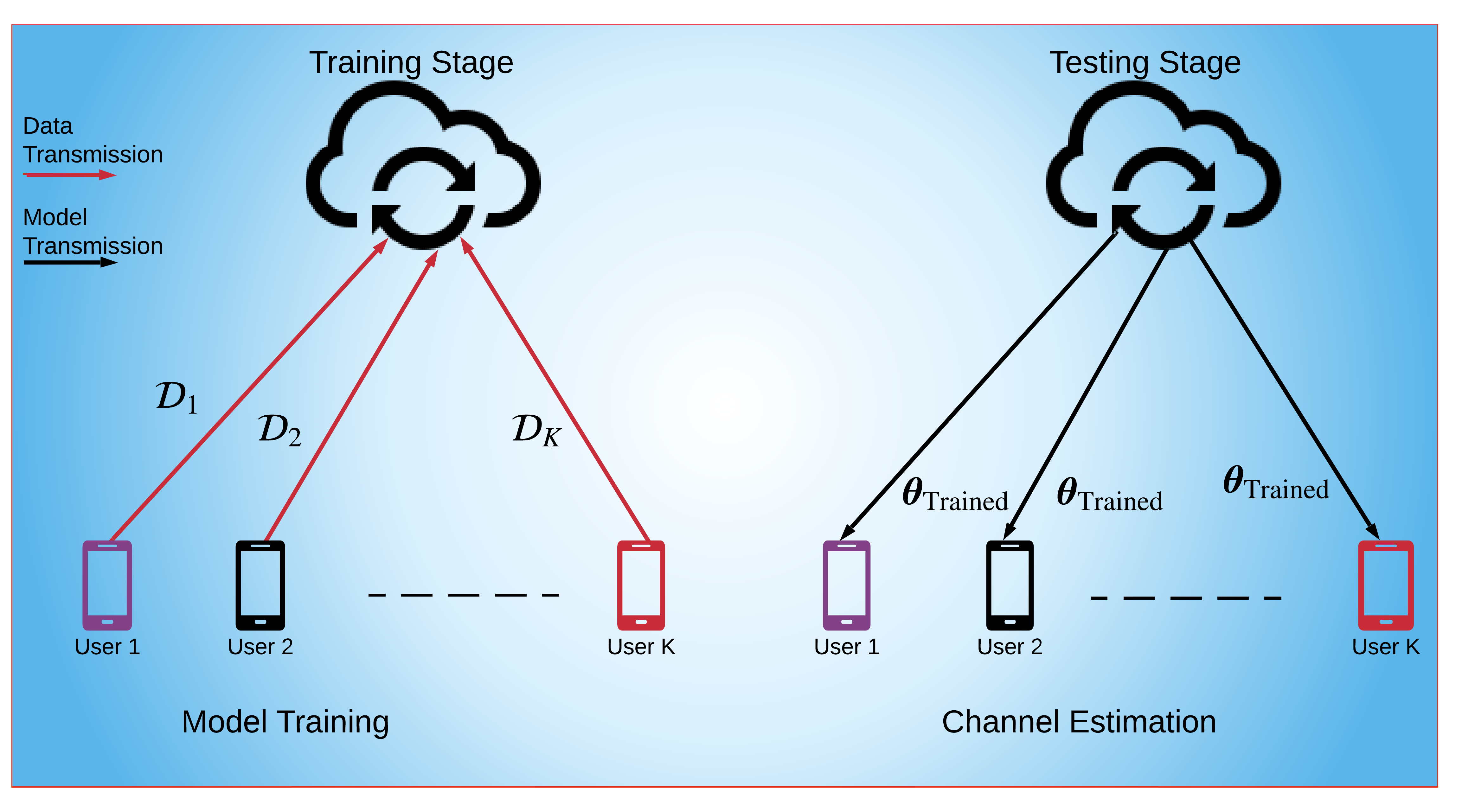
In ML context, channel estimation problem is solved by training a model, e.g., a neural network (NN), on the local datasets collected by the users [16, 17, 18]. The trained model provides a non-linear mapping between the input data, which can be usually selected as the received pilot signals, and the output data, i.e., the channel data. Previous works mostly consider centralized learning (CL) schemes where the whole dataset, i.e., input-output data pairs, is transmitted to the BS (via RIS in the RIS-assisted scenario) for model training, as illustrated in Fig. 1a. Once the model is trained at the BS, then the model parameters are sent to the users, which can perform channel estimation task by feeding the model with the received pilot data. However, this approach involves huge communication overhead, i.e., transmitting the whole dataset from users to the BS. For example, in LTE (long term evolution), a single frame of MHz bandwidth and ms duration can carry only complex symbols [24], whereas the size of the whole dataset can be on the order hundreds of thousands symbols [21, 20, 16, 17]. As a result, CL-based techniques demand huge bandwidth requirements.
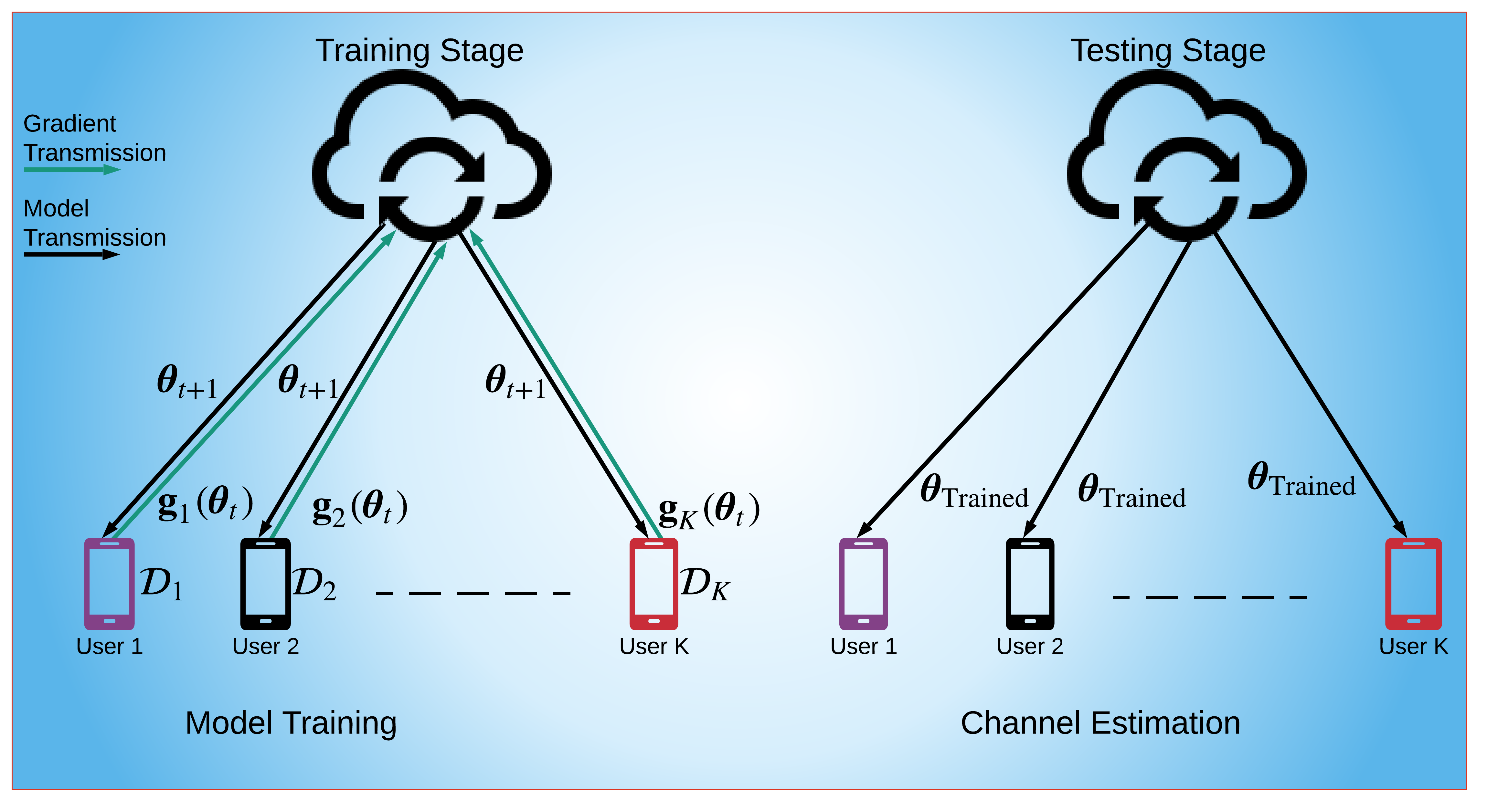
In order to deal with high communication overhead of CL schemes, recently federated learning (FL) schemes have been proposed [25, 26]. In FL, instead of sending the whole dataset, only the model updates, i.e., gradients of the model parameters, are transmitted, as illustrated in Fig. 1b. As a result, the communication overhead is reduced. In the literature, FL has been considered for the scheduling and power allocation in wireless sensor networks [27], the trajectory planning of UAV (unmanned aerial vehicle) networks [28], task fetching and offloading in vehicular networks [29, 26], image classification in [24, 30], and massive MIMO hybrid beamforming design [31]. All of these studies accommodate multiple edge devices exchanging model updates with the parameter server to train a global model. In the aforementioned works, FL has been mostly used for image classification/object detection problems in different networking schemes by the assumption that the perfect CSI is available. Motivated by the fact that the acquisition of CSI is very critical in massive MIMO systems and FL has not been considered directly for the channel estimation problem, in this work, we leverage FL for the channel estimation problem, which has been studied previously in the context of CL-based training [16, 17, 18, 32]. Compared to CL, FL is more applicable in case of distributed devices, such as mobile phones. Furthermore, training the same model with FL, rather than CL, reduces the communication overhead significantly during training while maintaining satisfactory channel estimation performance close CL. To the best of our knowledge, this is the first work for the use of FL in channel estimation.
In this paper, we propose an FL-based model training approach for channel estimation problem in both conventional and RIS-assisted massive MIMO systems. We design a convolutional neural network (CNN), which is located at the BS and trained on the local datasets. For these datasets, where the input is received pilot signal and the output is the channel matrix, the usage of the CNN is more convenient than the recurrent NNs (RNNs), which are designed to predict the future CSI by using the previous channels based on the sequential data [33]. The proposed approach has three stages, namely, data collection, training and prediction. In the first stage, each user collects its training datasets and stores them for model training, which is not explicitly discussed in the previous ML-based works [16, 17, 18, 34]. In the second stage, each user uses its own local dataset, and computes the model updates and sends them to the BS111The model parameters computed at the users are transmitted to the BS via the RIS in RIS-assisted scenario., where the model updates are aggregated to train a global model. The main advantage of the proposed FL approach is the reduction in the communication overhead. This overhead is proportional to the dimensionality of the channel matrix, which can be higher in RIS-assisted systems than the conventional MIMO due to the large number of RIS elements. Apart from that, the proposed approach reduces the computation time as well as increasing the robustness against data corruptions. One of the main challenges in FL-based channel estimation is due to the non-i.i.d. (independent identical distribution) structure of the training data. FL is known to converge faster if the local datasets are i.i.d. [35]. Since the channel estimation dataset is non-i.i.d. because of the distribution of the user locations, FL is expected to converge slower. In order to improve the performance in non-i.i.d. scenario, using deeper and wider learning models help to provide better feature extraction and representation performance [31]. Thus, we perform a hyper-parameter optimization to achieve a satisfactory performance.
The main contributions of this paper can be summarized as follows:
-
1.
We propose an FL-based channel estimation approach for both conventional and RIS-assisted massive MIMO systems. Different from the conventional centralized model learning techniques, the proposed FL framework provides decentralized learning, which significantly reduces the communication overhead compared to the CL-based techniques while maintaining satisfactory channel estimation performance close to CL.
-
2.
In order to estimate both direct (BS-user) and cascaded (BS-RIS-user) channels in RIS-assisted scenario, input and output data are combined together for each communication link, hence a single CNN architecture is designed, instead of using different NNs for each task.
-
3.
We prove the convergence of FL and demonstrate its superior performance over CL in terms of communication overhead and channel estimation accuracy via extensive numerical simulations for different number of users while considering the quantization and corruption of the gradient and model data as well as the loss of a portion of the model data during transmission.
Throughout the paper, the identity matrix of size is denoted by . and denote transpose and conjugate transpose operations, respectively. For a matrix and a vector , and denote the th element of matrix and the th element of vector , respectively. The function provides the statistical expectation of its argument and measures the angle of complex quantity. and denote the Frobenius and -norm, respectively. is the Hadamard element-wise multiplication and represents the gradient with respect to . A convolutional layer with 2-D kernel is represented by @ .
II System Model
We consider a multi-user MIMO-OFDM (orthogonal frequency division multiplexing) system with subcarriers, where the BS has antennas to communicate with users, each of which has antennas. In the downlink, the BS first precodes data symbols at each subcarrier () by applying the subcarrier-dependent baseband precoders . Then, the signal is transformed to the time-domain via -point inverse discrete Fourier transform (IDFT). After adding cyclic prefix (CP), the BS employs subcarrier-independent analog precoder to form the transmitted signal. Given that consists of analog phase shifters, we assume that the RF precoder has constant unit-modulus constraints, i.e., . Additionally, we have the power constraint that is enforced by the normalization of the baseband precoder . Thus, the transmitted signal becomes
II-A Channel Model
Before reception at the users, the transmitted signal is passed through the mm-Wave channel, which can be represented by a geometric model with limited scattering [11]. Let us define as the mm-Wave channel matrix between the BS and the th user. Then, includes the contributions of paths, each of which has the time delay with relative AoA (), angle-of-departure (AoD) , and the complex path gain for the th user and th path. Let denote a pulse shaping function for -spaced signaling evaluated at seconds. Then, the mm-Wave delay- MIMO channel matrix in time domain is given by
| (1) |
where and are the , and steering vectors representing the array responses of the antenna arrays at the users and the BS, respectively. Let be the wavelength for the subcarrier at frequency . Since the operating frequency is relatively higher than the bandwidth in mm-Wave systems and the subcarrier frequencies are close to each other (i.e., , ), we use a single operating wavelength , where is speed of light and is the central carrier frequency [11, 12]. This approximation also allows for a single frequency-independent analog beamformer for each subcarrier. Then, for a uniform linear array (ULA), the array response of the antenna array at the BS is
| (2) |
where is the antenna spacing. The th element of can be defined in a similar way as for as , . After performing -point DFT of the delay- channel model in (1), the channel matrix of the th user at subcarrier becomes
| (3) |
where is the CP length. The frequency domain channel in (3) is used in MIMO-OFDM systems, where the orthogonality of each subcarrier is held such that for and .
With the aforementioned block-fading channel model [11], the received signal at the th user before analog processing at subcarrier is , i.e.,
| (4) |
where represents the average received power and is additive white Gaussian noise (AWGN) vector. At the th user, the received signal is first processed by the analog combiner . Then, the cyclic prefix is removed from the processed signal and -point DFTs are applied to yield the signal in frequency domain. Then, the received baseband signal becomes
| (5) |
where the analog combiner has the constraint , similar to the RF precoder. Once the received symbols, i.e., are obtained at the th user, they are demodulated according to its respective modulation scheme, and the information bits are recovered for each subcarrier. To accurately recover the data streams in (5), the channel matrix should be estimated. This is usually done by using pilot signals in the preamble stage [36, 16], wherein the beamformers , and are designed accordingly (See Section III-C).
II-B Problem Description
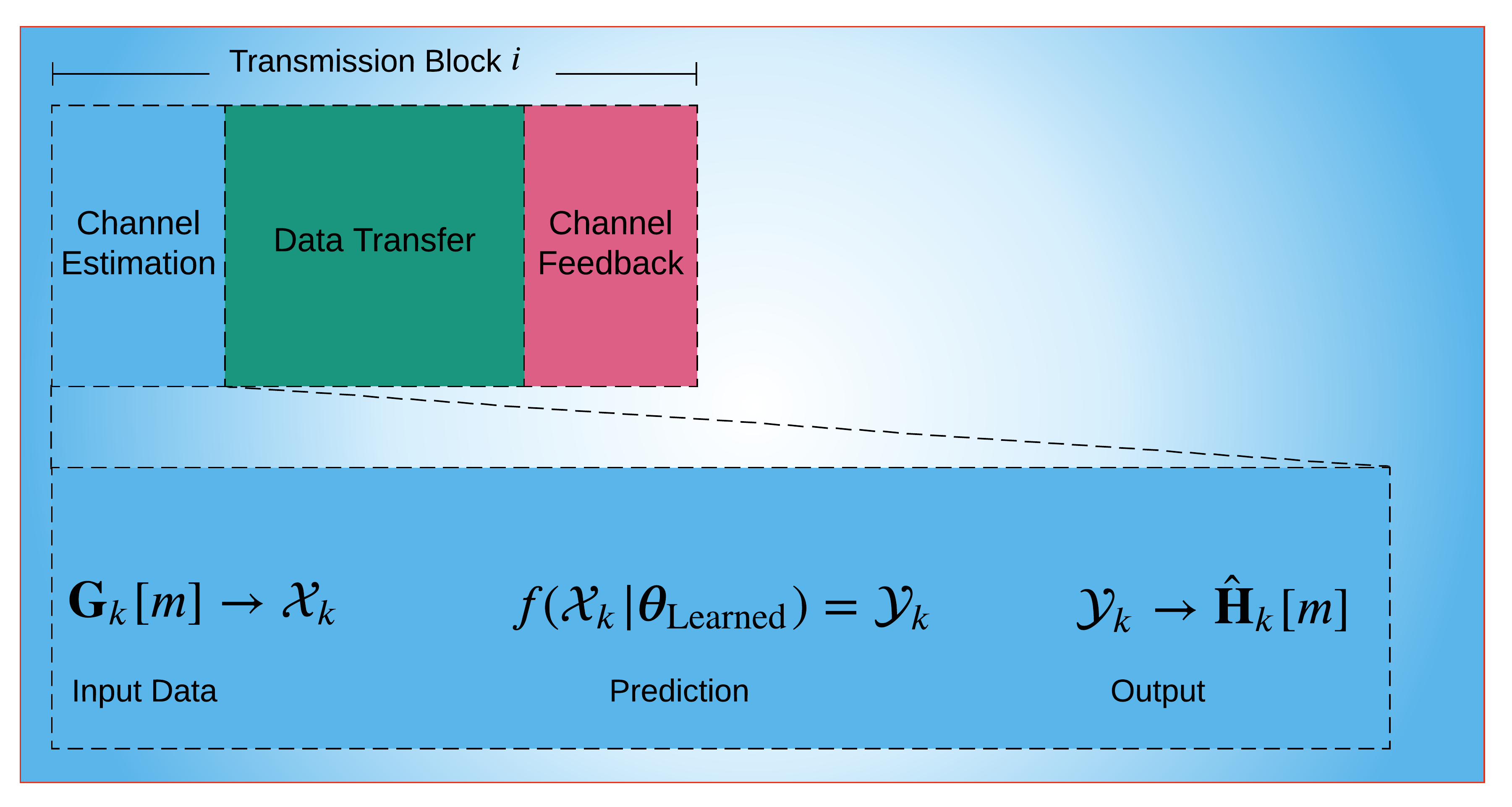
The aim in this work is to estimate the channel matrix via FL, as illustrated in Fig. 1b. To this end, the global NN for channel estimation (henceforth called ChannelNet) located at the BS is trained on the local datasets of the users. Let denote the local dataset at the th user, containing the input-output pairs 222The sizes of and depend on the size of the channel matrix, and they are explicitly given in Sec. III-C and Sec. III-D for conventional and RIS-assisted massive MIMO scenario, respectively., and is the size of the local dataset . Here, represents the th input data, i.e., the received pilot signals, denotes the th output/label data, i.e., the channel matrix, for , . Thus, for an input-output pair , ChannelNet constructs a non-linear relationship between the input and the output data as , where denotes the learnable parameters.
III Federated Learning for Channel Estimation
In this section, we present the proposed FL-based channel estimation scheme, which is comprised of three stages: training data collection, model training and prediction. First, we present the training data collection stage, in which each user collects its own training dataset from the received pilot signals. After providing the FL-based model training scheme, we discuss how the input and output label data are determined for both massive MIMO and RIS-assisted scenarios, respectively. Once the learning model is trained, then it can be used for channel estimation in the prediction stage.
III-A Training Data Collection
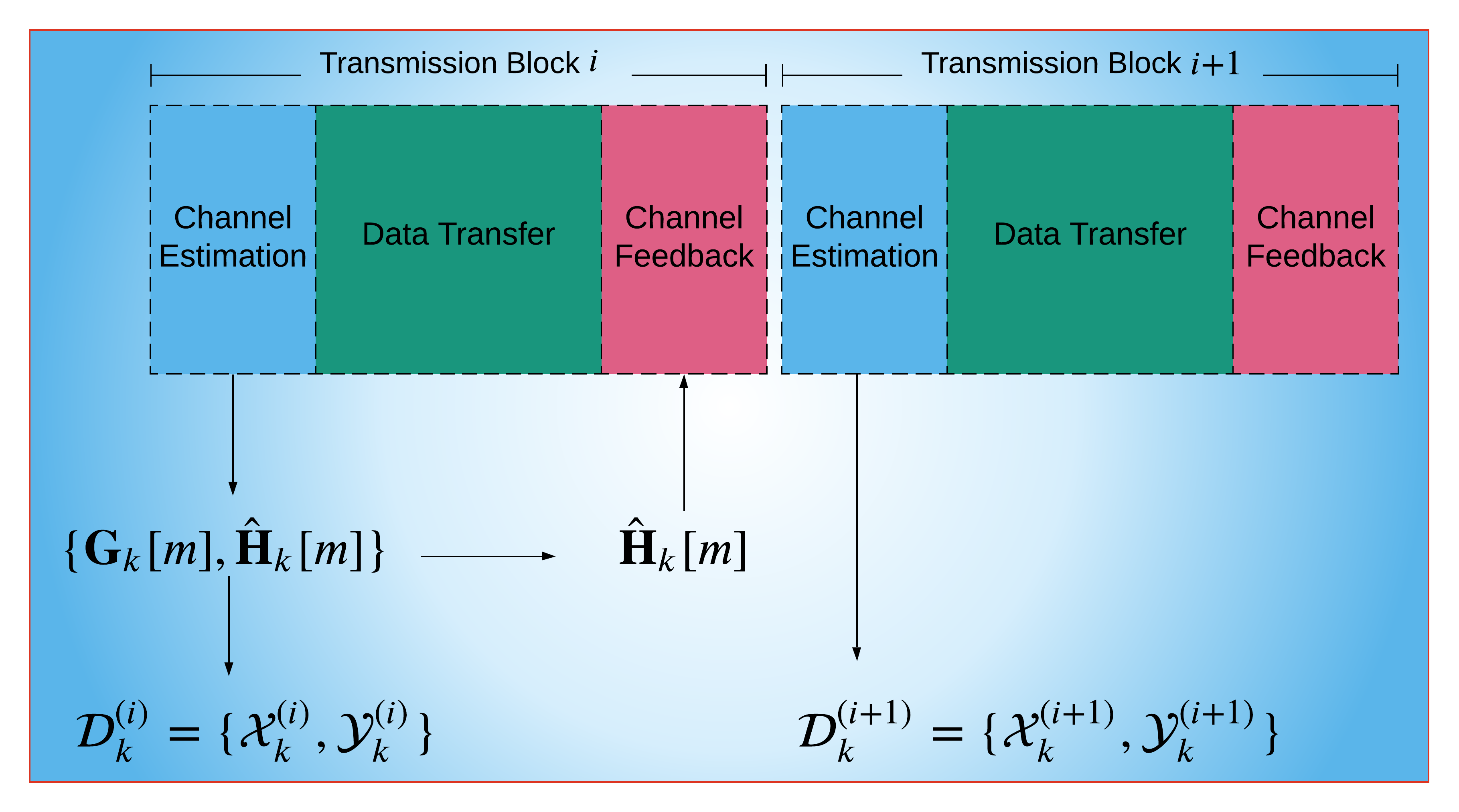
In Fig. 2, we present the communication interval at the user for two consecutive data transmission blocks. At the beginning of each transmission block, the received pilot signals are acquired and processed for channel estimation. This can be done by employing one of the analytical channel estimation techniques, which can be based on compressed sensing [37, 38], angle-domain processing [14] and coordinated pilot-assignment [15]. The analytical approach is only used in the training data collection stage, which is relatively smaller than the prediction stage [32]. Hence, the use of ML/FL in the prediction stage becomes more advantageous over the analytical techniques in the long term.
It is also worth to mention that the training data can be obtained via offline datasets which are prepared by collecting the data from the field measurements. In [39], authors present a channel estimation dataset, which is obtained by electromagnetic simulations tools. While this approach can also be followed, the offline collected data may not always reflect the channel characteristics and the imperfections in the mm-Wave channel. In this work, we evaluate the performance of the proposed approach on the datasets whose labels are selected as both true and estimated channel data. For the estimated channel, we assume that the training data are collected, as described in Fig. 2, by employing angle-domain channel estimation (ADCE) technique [14], which has close to minimum mean-square-error (MMSE) performance.
After channel estimation, the training data can be collected by storing the received pilot data and the estimated channel data in the internal memory of the user. (We discuss how is determined in Sec. III-C.) Then, the user feedbacks the estimated channel data to the BS via uplink transmission. As a result, the local dataset can be collected at the th user after transmission blocks. This approach allows us to collect training data for different channel coherence times, which can be very short due to dynamic nature of the mm-Wave channel, such as indoor and vehicular communications [10].
The above process is the first stage of the proposed FL-based channel estimation framework. Once the training data is collected, the global model is trained (see, e.g., Fig. 1b). After training, each user can estimate its own channel via the trained NN by simply feeding the NN with and obtains , as illustrated in Fig. 2b.
III-B FL-based Model Training
We begin by introducing the training concept in conventional CL, then develop FL-based model training.
In CL-based model training for channel estimation [16, 17, 32, 18, 34], the training of the global NN is performed by collecting the local datasets from the users, as illustrated in Fig. 1a. Once the BS has collected the whole dataset , the training is performed by solving the following problem
| (6) |
where is the number of training samples and denotes the loss function defined as
| (7) |
which is the MSE between the label data and the prediction of the NN, .
On the other hand, in FL, the local datasets are preserved at the users and not transmitted to the BS. Hence, FL-based model training is performed at the user side as
| (8) |
where . Notice that the FL-based model training in (III-B) is solved at the user while the CL problem in (III-B) is handled at the BS. To efficiently solve (III-B) and (III-B), gradient descent (GD) is employed and the problems are solved iteratively. In CL, the gradient is computed over the whole dataset as and the parameter update is performed as
| (9) |
where is the learning rate.
In FL, each user computes the gradients individually as to solve (III-B), then sends them to the BS, where the model parameters are updated as
| (10) |
The transmission of gradients to the BS provides more energy-efficiency than directly transmitting the model parameters as in the FedAvg algorithm [35]. The main reason is that gradients include only the model updates obtained from the GD algorithm, whereas model transmission includes already known data from the previous iteration. Hence, model transmission wastes a significant amount of transmit power from all the users [31, 30, 40].
The gradients are sent to the BS via wireless channel, which causes corruptions during transmission. Therefore, the corrupted model parameters and gradients at the th iteration are given as [24, 41]
| (11) | ||||
| (12) | ||||
| (13) |
where represents the noisy model parameters captured at the users, is the gradient vector computed at the user based on and denotes the noisy gradient vector received at the BS. , and represent the noise terms added onto , and , respectively. Then, the model update rule can be given by
| (14) |
which can be rewritten as
| (15) |
where corresponds to the overall noise term added onto . Now, let us consider the statistics of . Without loss of generality, the noise terms due to wireless transmission in (11) and (13), i.e., and , can be modeled as AWGN with variances and , respectively [42, 41]. Furthermore, we define in (12) as AWGN with variance due to the linearity of gradient and the NN layers333Many of the NN layers, such as convolutional, fully connected, normalization and dropout layers, perform linear operations, whereas pooling and ReLU layers are non-linear [43, 41, 42].. Hence, the overall noise term can be viewed as an AWGN with variance .
In order to solve (III-B) effectively in the presence of noisy model parameters, we define a regularized loss function as
| (16) |
which is widely used in stochastic optimization [44]. (16) can be obtained via first order Taylor expansion of the expectation-based loss , which can be approximately written as
| (17) |
where the first term corresponds to the minimization of the loss function with perfect estimation and the second term is the additional cost due to noise [44, 41]. Using (16), the regularized version of FL-based training problem in (III-B) is given by
| (18) |
which can be effectively solved via GD in the presence of noisy model updates as
| (19) |
where and .
Due to the effect of noisy gradient transmission, converges slower than . In the following theorem, we prove the convergence of . While the convergence of the regularized loss function was studied in different FL works [42, 41], they consider model transmission, whereas in this work we investigate the gradient transmission approach. The convergence analysis is also different from the previous gradient transmission-based works, e.g., [30, 24], which are based on the sparsity assumption of the gradient vector, which may not be always satisfied.
Theorem 1: Let and be the initial and optimal model parameters, respectively. Then, the FL-based model training converges with the convergence rate as
| (20) |
with the learning rate for some .
Proof: See Appendix A.∎
In practice, the convergence of the learning model is subject to the wireless factors, such as the SNR of the transmitted/received model updates. In particular, the convergence becomes slower due to the packet errors during training [45]. Furthermore, the channel statistics change in each communication round, which entails CSI acquisition for each round. While some of the recent works assume that a single communication round between the server and the clients takes a single channel coherence time [31, 30, 24], in [46] FL-based training is completed in a single long-coherence time, which is approximately composed of 40 small-scale fading channel coherence intervals [46].
III-C FL for Channel Estimation in Massive MIMO
Here, we discuss how the input and output of ChannelNet are determined for massive MIMO scenario.
The input of ChannelNet is the set of received pilot signals at the preamble stage. Consider the downlink received signal model in (5) and assume that the BS activates only a single RF chain, one at a time. Let be the resulting beamformer vector and pilot signals are , where and . At the receiver side, each user activates the RF chain for times and applies the beamformer vector , to process the received pilots [16]. Hence, the total channel use in the channel acquisition process is . Therefore, the received pilot signal at the th user becomes
| (21) |
where and are and beamformer matrices, respectively. denotes pilot signals and is the effective noise matrix, where . Without loss of generality, we assume that and and . Then, the received signal (21) becomes
| (22) |
Using , we define the input of ChannelNet as
| (23) |
where and Here, and clear the effect of unitary matrices and in (22), respectively. Since ChannelNet accepts real-valued data, we construct the final form of the input as three “channel” tensors. Thus, the first and second “channel” of are the real and imaginary parts of , i.e., and , respectively. Finally, the third “channel” is given by . We note here that the use of three “channel” input (e.g., real, imaginary and angle information of ) provides better feature representation [19, 18, 36]. As a result, the size of the input data is .
The output of ChannelNet is given by a real-valued vector as
| (24) |
As a result, ChannelNet maps the received pilot signals to the channel matrix .
III-D FL for Channel Estimation in RIS-Assisted Massive MIMO
In this part, we examine the channel estimation problem in RIS-assisted massive MIMO, which is shown in Fig. 3. First, we present the received signal model including both direct (BS-user) and cascaded (BS-RIS-user) channels444Channel estimation is required to design the passive beamformer weights. Although the BS-user, BS-RIS and RIS-user channels can be estimated separately [47], the estimation of the direct and the cascaded channels is sufficient for beamformer design [48, 49].. Then, we show how input-output pairs of ChannelNet are obtained for RIS-assisted scenario.
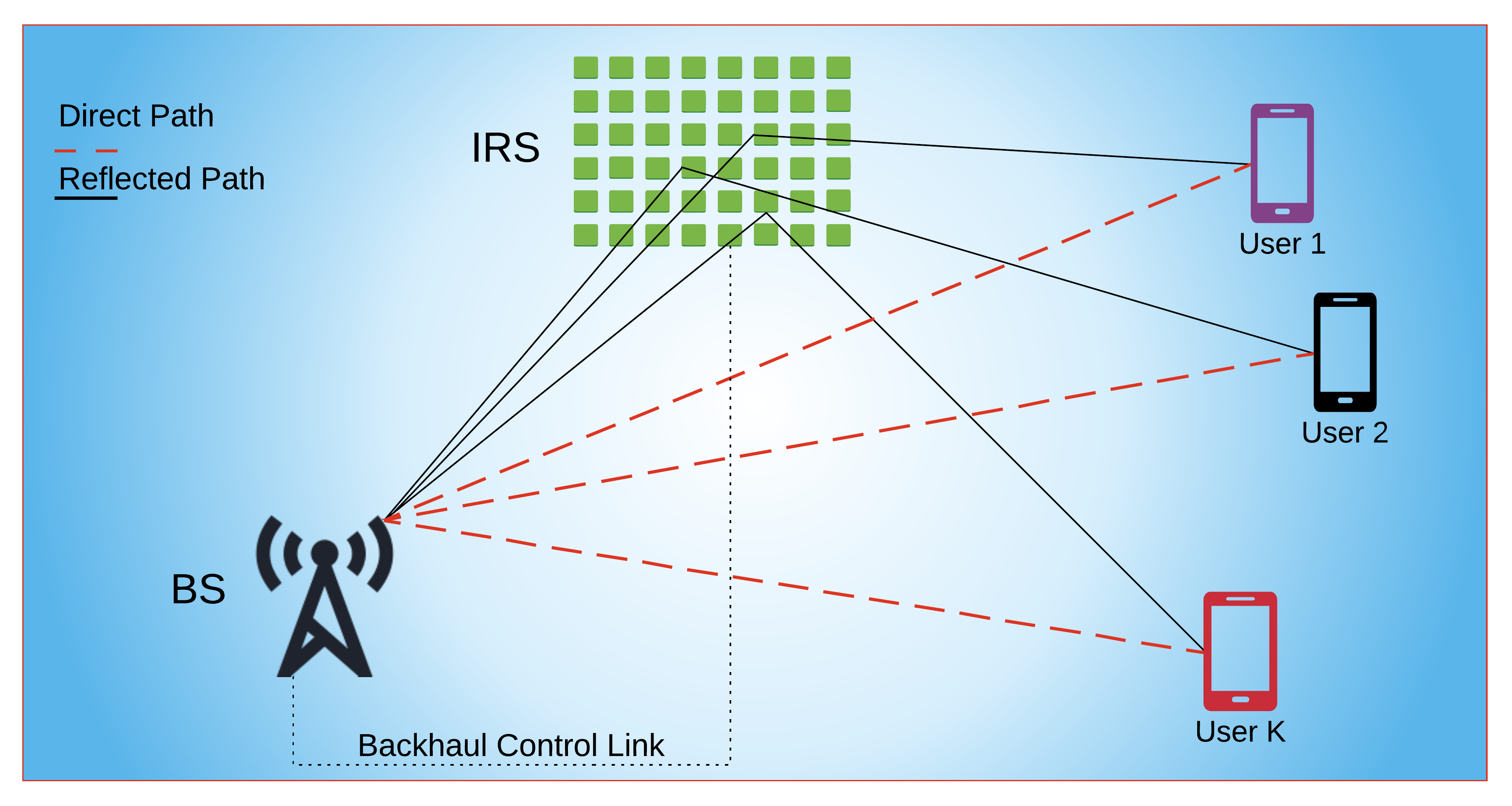
We consider the downlink channel estimation, where the BS has antennas to serve single-antenna users with the assistance of RIS, which is composed of reflective elements, as shown in Fig. 3. The incoming signal from the BS is reflected from the RIS, where each RIS element introduces a phase shift , for . This phase shift can be adjusted through the PIN (positive-intrinsic-negative) diodes, which are controlled by the RIS-controller connected to the BS over the backhaul link. As a result, RIS allows the users receive the signal transmitted from the BS when they are distant from the BS or there is a blockage among them. Let , be the pilot signals transmitted from the BS, then the received signal at the th user becomes
| (25) |
where and are row vectors and represents the channel for the communication link between the BS and the th user. is the reflecting beamformer vector, whose th entry is , where denotes the on/off stage of the th element of the RIS and is the phase shift introduced by the RIS. In practice, the RIS elements cannot be perfectly turned on/off, hence, they can be modeled as for small , which represent the insertion loss of the reflecting elements [18]. In (25), denotes the cascaded channel for the BS-RIS-user link and it can be defined in terms of the channel between BS-RIS and RIS-user as
| (26) |
where is the channel between the BS and the RIS and it can be defined similar to (1) as
| (27) |
where and are the number of received paths and the complex gain respectively. and are the steering vectors corresponding to the BS and RIS with the AoA and AoD angles of , respectively. In (26), and represents the channel between the RIS and the th user. and have similar structure and they can be defined as follows
| (28) | ||||
| (29) |
where , and (, , ) are the number of paths, complex gain and the steering vector for the BS-user (RIS-user) communication link, respectively.
In order to estimate the direct channel , we assume that all the RIS elements are turned off, i.e., for . Then, the received signal at the th user becomes
| (30) |
Then, the direct channel between BS-user can be estimated from the received pilot signal via LS and MMSE estimators as and where [16].
Next, we consider the cascaded channel estimation. We assume that each RIS element is turned on one by one while all the other elements are turned off. This is done by the BS requesting the RIS via a micro-controller device in the backhaul link so that a single RIS element is turned on at a time. Then, the reflecting beamformer vector at the th frame becomes , where and the received signal is given by
| (31) |
where is the th column of , i.e., , where . Using the estimate of from (30), (31) can be solved for , , and the cascaded channel can be estimated. Then, the received data for can be given by as . In order to train ChannelNet for RIS-assisted massive MIMO scenario, we select the input-output data pair as and for direct and cascaded channels respectively. To jointly learn both channels, a single input is constructed to train a single NN as . Following the same strategy in the previous scenario, the three “channel” of the input data can be constructed as and , , respectively. We can define the output data as , hence, the output label can be given by a real-valued vector as
| (32) |
Consequently, we have the sizes of and are and respectively.
III-E Neural Network Architecture and Training
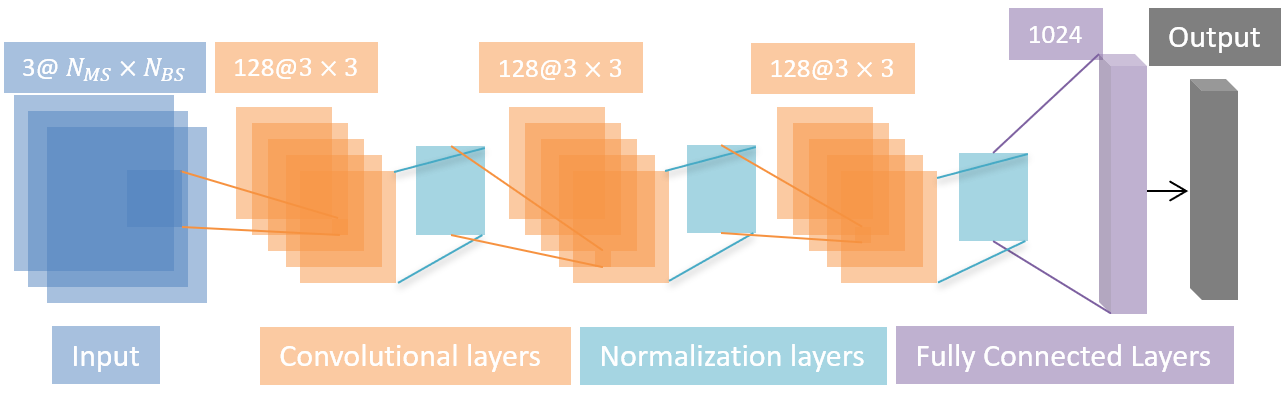
We design a single CNN, i.e., ChannelNet trained on two different datasets for both conventional and RIS-assisted massive MIMO applications. The proposed network architecture is a CNN with layers. The first layer is the input layer, which accepts the input data of size and for conventional and RIS-assisted massive MIMO scenario respectively. The th layers are the convolutional layers with filters, each of which employs a kernel for 2-D spatial feature extraction. The th layers are the normalization layers. The eighth layer is a fully connected layer with units, whose main purpose is to provide feature mapping. The ninth layer is a dropout layer with probability. The dropout layer applies an mask on the weights of the fully connected layer, whose elements are uniform randomly selected from . As a result, at each iteration of FL training, randomly selected different set of weights in the fully connected layer is updated. Thus, the use of dropout layer reduces the size of and , thereby, reducing model transmission overhead. Finally, the last layer is output regression layer, yielding the output channel estimate of size and for conventional and RIS-assisted massive MIMO applications respectively.
During FL-based training, the collected datasets at the users are used to compute the model updates as in Section III-B and transmitted to the BS. The collected model parameters at the BS are then aggregated as in (10) and broadcast to the users for the next iteration. This process is conducted for communication rounds until convergence.
IV Communication Overhead and Complexity
IV-A Communication Overhead
Communication overhead can be defined as the size of the transmitted data during model training. Let and denote the communication overhead of FL and CL, respectively. Then, we can define for both conventional and RIS-assisted scenario as
| (35) |
which includes the number of symbols in the uplink transmission of the training dataset from the users to the BS. In contrast, the communication overhead of FL includes the transmission of and in uplink and downlink communication for , respectively. Hence, is given by
| (38) |
We can see that the dominant terms in (35) and (38) are D and , which are the number of training data pairs and the number of NN parameters respectively. While D can be adjusted according to the amount of available data at the users, is usually unchanged during model training. Here, is computed as where is the number of convolutional layers and is the number of spatial “channels”. are the 2-D kernel sizes. As a result, we have . Since the number of samples in the training dataset is usually larger than the number of model parameters, it is expected to have [35, 30, 31] (see Fig. 11).
| 2 | 3 | 3 | 3 | 128 | ||
| 4 | 3 | 3 | 128 | 128 | ||
| 6 | 3 | 3 | 128 | 128 |
IV-B Computational Complexity
We further examine the computational complexity of the proposed CNN architecture. The time complexity of the convolutional layers can be written as [16, 36]
| (39) |
where are the column and row sizes of each output feature map, are the 2-D filter size of the -th layer. and denote the number of input and output feature maps of the -th layer respectively. Table I lists the parameters of each convolutional layer for an input. Thus, the complexity of three convolutional layers with @ spatial filters approximately becomes
| (40) |
The time complexity of the fully connected layer similarly is
| (41) |
where is the number of units with dropout. and are the 2-D input size of the fully connected layer respectively. Then, the time complexity of the fully connected layer approximately is
| (42) |
Hence the total time complexity of ChannelNet is , which approximately is
| (43) |
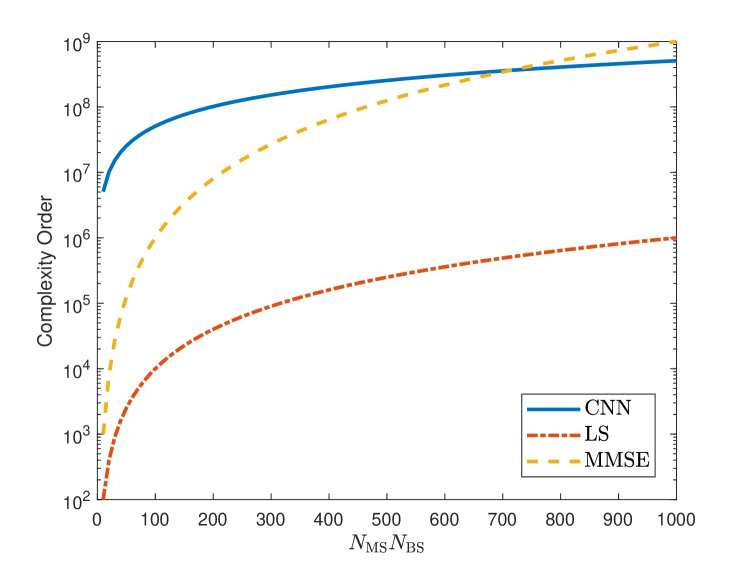
which is further simplified as . Since the computation of the pseudo-inverse of the received pilot data is required in the testing stage, the complexity order of LS and MMSE estimation are and , respectively [16, 50].
Fig. 5 shows the time complexity comparison of CNN, MMSE and LS with respect to . We see that ChannelNet has higher complexity than LS. As the number of antennas, i.e., increases, the complexity of MMSE becomes closer to that of ChannelNet, it becomes larger after approximately . While the complexity of ChannelNet seems comparable with the conventional techniques, it is able to run more efficiently by using parallel processor, e.g., GPUs, which can significantly reduce the computation time [16, 50, 32]. However, the implementation with GPUs is not straightforward for the other algorithms, and it requires algorithm-dependent processor configuration.
V Numerical Simulations
The goal of the simulations is to compare the performance of the proposed FL-based channel estimation approach to the channel estimation performance of the state-of-the-art ML-based channel estimation techniques SF-CNN [16] and MLP [17], and the MMSE and LS estimation in terms of normalized MSE (NMSE), defined by where number of Monte Carlo trials. We also present the validation RMSE of the training process, defined by where and respectively denote the input-output pairs in the validation dataset , which includes of the whole dataset , hence, we have .
The local dataset of each user includes different channel realizations for users. The number of antennas in the massive MIMO scenario at the BS and users are and , respectively, and we select and . For the RIS-assisted scenario, . Hence, we have the same number of input elements for both scenario, i.e, . In both scenarios, location of each user is selected as and , where and are the equally-divided subregions of the angular domain , i.e., , respectively. The pilot data are generated as and for and . We selected and as the first columns of an DFT matrix and the first columns of an DFT matrix, respectively [16]. During training, we have added AWGN on the input data for three SNR levels, i.e., SNR dB, for and realizations in order to provide robust performance against noisy input [19, 18] in both scenarios. As a result, both training datasets have the same number of input-output pairs as and , respectively. The proposed ChannelNet model is realized and trained in MATLAB on a PC with a -core GPU. For CL, we use the SGD algorithm with momentum of and the mini-batch size , and update the network parameters with learning rate . For FL, we train ChannelNet for iterations/rounds. Once the training is completed, the labels of the validation data (i.e., of the whole dataset) are used in prediction stage. During the prediction stage, each user estimates its own channel by feeding ChannelNet with () and obtains ( and ) at the output for massive MIMO (RIS) scenario, respectively555The source codes of the FL-based channel estimation scheme can be found at https://sites.google.com/view/elbir/publications..
V-A Channel Estimation in Massive MIMO
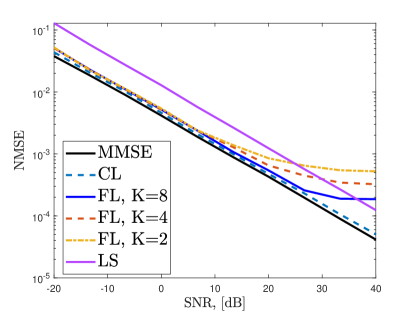
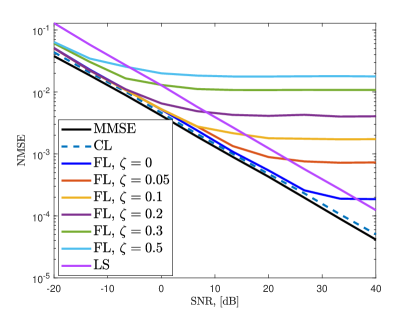
In Fig. 6, we present the training performance (Fig. 6a) and the channel estimation NMSE (Fig. 6b) of the proposed FL approach for channel estimation for different number of users. In this scenario, we fix the total dataset size D by selecting . As increases, the training performance is observed to improve and gets closer to the performance of CL since the model updates superposed at the BS become more robust against the noise. As decreases, the corruptions in the model aggregation increase due to the diversity in the training dataset.
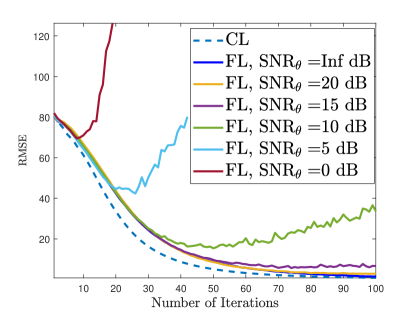
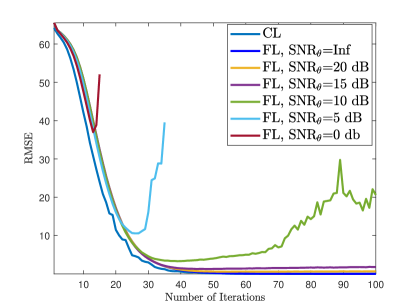
Fig. 7 shows the training and channel estimation performance for different noise levels added to the transmitted gradient and model data when . Here, we add AWGN onto both and with respect to , where . We observe in Fig. 7a that the training diverges for low (e.g., SNR dB) due to the corruptions in the model parameters. The corresponding channel estimation performance is presented in Fig. 7b when the ChannelNet converges and at least SNR dB is required to obtain reasonable channel estimation performance, e.g., .
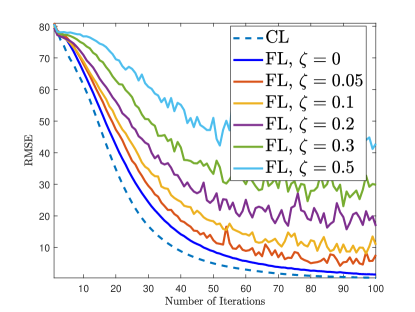
Fig. 8 shows the training and channel estimation performance in case of an impulsive noise causing the loss of gradient and model data. In this experiment, we multiply and with as and , where the elements of are and the remaining terms are . This allows us to simulate the case when a portion of the gradient/model data are completely lost during transmission. We observe that the loss of model data significantly affects both training and channel estimation accuracy. Therefore, reliable channel estimation demands at most parameter loss during transmission.
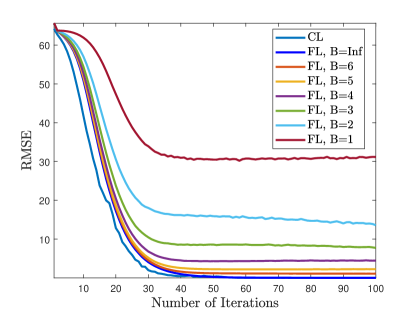
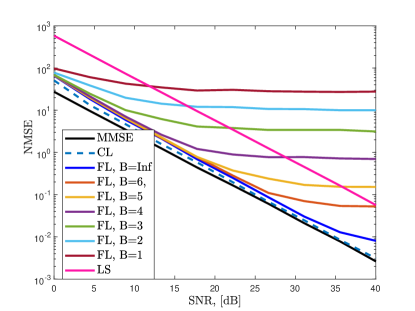
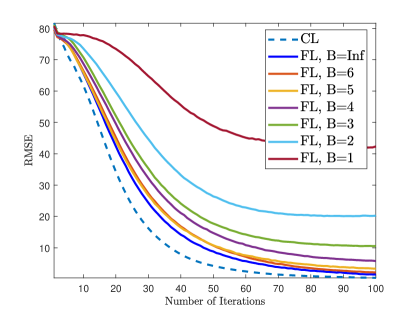
Fig. 9 shows the training and channel estimation performance when the transmitted data (i.e., and ) are quantized with bits. As expected, the performance improves as increases and at least bits are required to obtain a reasonable channel estimation performance. Compared to the results in Fig. 7, quantization has more influence on the accuracy than .
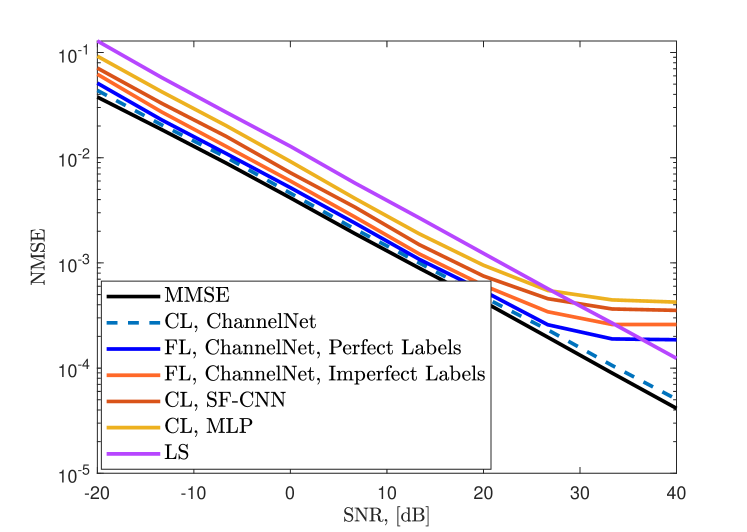
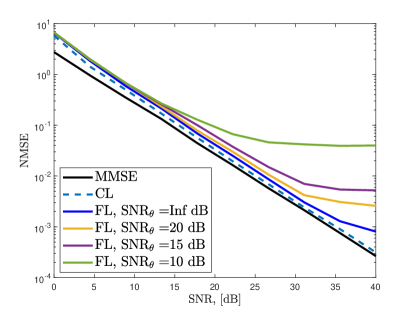
In Fig. 10, we present the channel estimation NMSE for different algorithms when . We train ChannelNet with both CL and FL frameworks and observe that CL follows the MMSE performance closely. CL provides better performance than that of FL since it has access the whole dataset at once. Nevertheless, FL has satisfactory channel estimation performance despite decentralized training. Specifically, FL and CL have similar NMSE for SNR dB and the performance of FL maxes out in high SNR regime. This is because the learning model loses precision due to FL training and cannot perform better. This is a common problem in ML-based techniques [16, 18]. In order to improve the performance, over-training can be employed so that more precision can be obtained. However, this introduces overfitting, i.e., the model memorizes the data, hence, it cannot perform well for different inputs. In Fig. 10, the comparison between the training with perfect (true channel data) and imperfect (estimated channel via ADCE) labels is also presented. The use of imperfect labels causes a slight performance degradation, while still providing less NMSE than SF-CNN and MLP. The other algorithms also exhibit similar behavior but perform worse than ChannelNet. This is because SF-CNN and MLP have convolutional-only and fully-connected-only layers, respectively. In contrast, ChannelNet includes both structures, hence, exhibiting better feature extraction and data mapping performance.
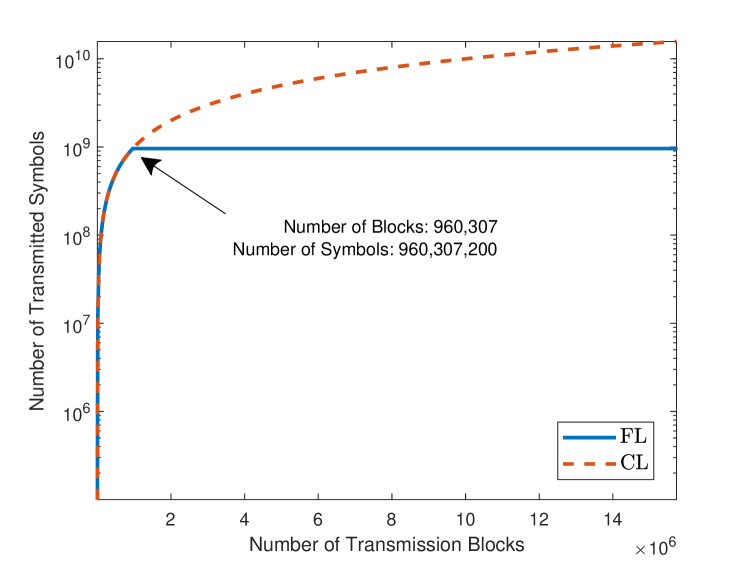
According to the analysis in Sec. IV-A, the communication overhead of FL and CL are and , respectively. This clearly shows the effectiveness of FL over CL. We also present the number of transmitted symbols during training with respect to data transmission blocks in Fig. 11, where we assume that data symbols are transmitted at each transmission block. We can see that, it takes about data blocks to complete the gradient/model transmission in FL (see, e.g., Fig. 1b) whereas CL-based training demands approximately data blocks to complete the task for training dataset transmission (see, e.g., Fig. 1a). Therefore, the communication overhead of FL is approximately times lower than that of CL.
V-B Channel Estimation in RIS-assisted Massive MIMO
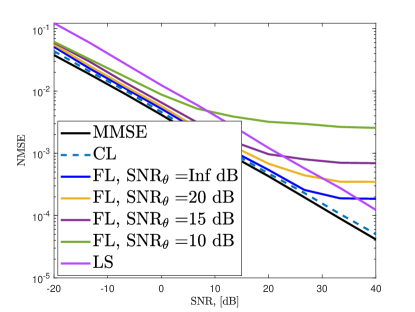
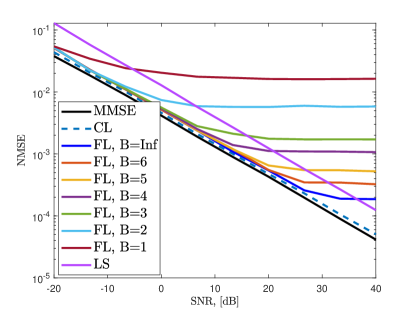
In Fig. 12, we present the validation RMSE and the channel estimation NMSE. We compute the NMSE of both direct channel and the cascaded channel together and present the results in a single plot. Similar results are obtained for model training, which diverges when dB and channel estimation NMSE becomes relatively small if dB.
Fig. 13 shows the validation RMSE and channel estimation NMSE for different quantization levels. The small number of bits causes the loss of precision in channel estimation NMSE. Similar to the massive MIMO scenario, at least bits are required to obtain satisfactory channel estimate performance at large SNRs, i.e., dB.
VI Conclusions
In this paper, we propose a FL framework for channel estimation in conventional and RIS-assisted massive MIMO systems. We evaluate the performance of the proposed approach via several numerical simulations for different number of users and when the gradient/model parameters are quantized and corrupted by noise. We show that at least bit quantization and dB SNR on the model parameters are required for reliable channel estimation performance, i.e, . We further analyze the scenario when a portion of the gradient/model parameters are completely lost and observe that FL exhibits satisfactory performance under at most information loss. We also examine the channel estimation performance of the proposed CNN architecture with both perfect and imperfect labels. A slight performance degradation is observed in case of imperfect labels as compared to the perfect CSI case. Nevertheless, the performance of imperfect label scenario strongly depends on the accuracy of the channel estimation algorithm employed during training dataset collection. Furthermore, the proposed CNN architecture provides lower NMSE than the state-of-the-art NN architectures. Apart from the channel estimation performance, FL-based approach enjoys approximately times lower transmission overhead as compared to the CL-based training. As a future work, we plan to develop compression-based techniques for both training data and the model parameters to further reduce the communication overhead.
Appendix A Proof of Theorem 1
We first make the following assumptions needed to ensure the convergence, which are typical for the -norm regularized linear regression, logistic regression, and softmax classifiers [42, 41, 35].
Assumption 1: The loss function is convex, i.e., for and arbitrary and .
Assumption 2: is L-Lipschitz, i.e., for arbitrary and .
Assumption 3: is -Smooth, i.e., for arbitrary and .
In order to prove Theorem 1, we first investigate the -Smoothness of in the following lemma.
Lemma 1: is a -Smooth function with , where .
Using (45), Assumption 2 and Assumption 3 imply that is second order differentiable as . Using this fact, performing a quadratic expression around yields
| (46) |
Substituting the GD update in (A), we get
| (47) |
which bounds the GD update with . Now, let us bound with the optimal objective value . Using Assumption 1, we have
| (48) |
Furthermore, using , we have . Thus, (47) becomes
| (49) |
By plugging (A) into (49), we get
| (50) |
which can be rewritten as
| (51) |
By adding into the right hand side of (51), we get
| (52) |
which is obtained after incorporating the expansion of . Substituting the GD update into (52), we have
| (53) |
Now, replacing by and summing over yield
| (54) |
where the summation on the right hand side disappears since the consecutive terms cancel each other. Since is a decreasing function, we have
| (55) |
Inserting (54) into (55), we finally have
| (56) |
∎
References
- [1] R. W. Heath, N. González-Prelcic, S. Rangan, W. Roh, and A. M. Sayeed, “An overview of signal processing techniques for millimeter wave MIMO systems,” IEEE J. Sel. Topics Signal Process., vol. 10, no. 3, pp. 436–453, 2016.
- [2] F. Rusek, D. Persson, B. K. Lau, E. G. Larsson, T. L. Marzetta, O. Edfors, and F. Tufvesson, “Scaling up MIMO: Opportunities and challenges with very large arrays,” IEEE Signal Process. Mag., vol. 30, no. 1, pp. 40–60, 2013.
- [3] J. G. Andrews, S. Buzzi, W. Choi, S. V. Hanly, A. Lozano, A. C. K. Soong, and J. C. Zhang, “What will 5G be?” IEEE J. Sel. Areas Commun., vol. 32, no. 6, pp. 1065–1082, 2014.
- [4] O. E. Ayach, S. Rajagopal, S. Abu-Surra, Z. Pi, and R. W. Heath, “Spatially sparse precoding in millimeter wave MIMO systems,” IEEE Trans. Wireless Commun., vol. 13, no. 3, pp. 1499–1513, 2014.
- [5] Q. Wu and R. Zhang, “Towards Smart and Reconfigurable Environment: Intelligent Reflecting Surface Aided Wireless Network,” IEEE Commun. Mag., vol. 58, no. 1, pp. 106–112, January 2020.
- [6] A. M. Elbir and K. V. Mishra, “A Survey of Deep Learning Architectures for Intelligent Reflecting Surfaces,” arXiv, Sep 2020. [Online]. Available: https://arxiv.org/abs/2009.02540v3
- [7] C. Huang, S. Hu, G. C. Alexandropoulos, A. Zappone, C. Yuen, R. Zhang, M. Di Renzo, and M. Debbah, “Holographic MIMO Surfaces for 6G Wireless Networks: Opportunities, Challenges, and Trends,” IEEE Wireless Commun., vol. 27, no. 5, pp. 118–125, Jul 2020.
- [8] C. Huang, A. Zappone, G. C. Alexandropoulos, M. Debbah, and C. Yuen, “Reconfigurable Intelligent Surfaces for Energy Efficiency in Wireless Communication,” IEEE Trans. Wireless Commun., vol. 18, no. 8, pp. 4157–4170, Jun 2019.
- [9] C. Huang, R. Mo, and C. Yuen, “Reconfigurable Intelligent Surface Assisted Multiuser MISO Systems Exploiting Deep Reinforcement Learning,” IEEE J. Sel. Areas Commun., vol. 38, no. 8, pp. 1839–1850, Jun 2020.
- [10] E. Björnson, L. Van der Perre, S. Buzzi, and E. G. Larsson, “Massive MIMO in sub-6 GHz and mmWave: Physical, practical, and use-case differences,” IEEE Wireless Commun., vol. 26, no. 2, pp. 100–108, 2019.
- [11] A. Alkhateeb and R. W. Heath, “Frequency selective hybrid precoding for limited feedback millimeter wave systems,” IEEE Trans. Commun., vol. 64, no. 5, pp. 1801–1818, 2016.
- [12] F. Sohrabi and W. Yu, “Hybrid analog and digital beamforming for mmWave OFDM large-scale antenna arrays,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 7, pp. 1432–1443, 2017.
- [13] A. Taha, M. Alrabeiah, and A. Alkhateeb, “Enabling large intelligent surfaces with compressive sensing and deep learning,” arXiv preprint arXiv:1904.10136, 2019.
- [14] D. Fan, F. Gao, Y. Liu, Y. Deng, G. Wang, Z. Zhong, and A. Nallanathan, “Angle Domain Channel Estimation in Hybrid Millimeter Wave Massive MIMO Systems,” IEEE Trans. Wireless Commun., vol. 17, no. 12, pp. 8165–8179, Dec 2018.
- [15] H. Yin, D. Gesbert, M. Filippou, and Y. Liu, “A Coordinated Approach to Channel Estimation in Large-Scale Multiple-Antenna Systems,” IEEE J. Sel. Areas Commun., vol. 31, no. 2, pp. 264–273, February 2013.
- [16] P. Dong, H. Zhang, G. Y. Li, I. S. Gaspar, and N. NaderiAlizadeh, “Deep CNN-Based Channel Estimation for mmWave Massive MIMO Systems,” IEEE J. Sel. Topics Signal Process., vol. 13, no. 5, pp. 989–1000, Sep. 2019.
- [17] H. Huang, J. Yang, H. Huang, Y. Song, and G. Gui, “Deep learning for super-resolution channel estimation and doa estimation based massive mimo system,” IEEE Trans. Veh. Technol., vol. 67, no. 9, pp. 8549–8560, Sept 2018.
- [18] A. M. Elbir, A. Papazafeiropoulos, P. Kourtessis, and S. Chatzinotas, “Deep Channel Learning for Large Intelligent Surfaces Aided mm-Wave Massive MIMO Systems,” IEEE Wireless Commun. Lett., vol. 9, no. 9, pp. 1447–1451, 2020.
- [19] A. M. Elbir, “CNN-based precoder and combiner design in mmWave MIMO systems,” IEEE Commun. Lett., vol. 23, no. 7, pp. 1240–1243, 2019.
- [20] A. M. Elbir and K. V. Mishra, “Joint antenna selection and hybrid beamformer design using unquantized and quantized deep learning networks,” IEEE Trans. Wireless Commun., vol. 19, no. 3, pp. 1677–1688, March 2020.
- [21] A. M. Elbir and A. Papazafeiropoulos, “Hybrid Precoding for Multi-User Millimeter Wave Massive MIMO Systems: A Deep Learning Approach,” IEEE Trans. Veh. Technol., vol. 69, no. 1, p. 552–563, 2020.
- [22] A. M. Elbir, K. V. Mishra, and Y. C. Eldar, “Cognitive radar antenna selection via deep learning,” IET Radar, Sonar & Navigation, vol. 13, pp. 871–880, 2019.
- [23] A. M. Elbir, “DeepMUSIC: Multiple Signal Classification via Deep Learning,” IEEE Sensors Letters, vol. 4, no. 4, pp. 1–4, 2020.
- [24] M. M. Amiri and D. Gündüz, “Federated Learning Over Wireless Fading Channels,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3546–3557, 2020.
- [25] T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated Learning: Challenges, Methods, and Future Directions,” IEEE Signal Process. Mag., vol. 37, no. 3, pp. 50–60, 2020.
- [26] A. M. Elbir and S. Coleri, “Federated Learning for Vehicular Networks,” arXiv preprint arXiv:2006.01412, 2020.
- [27] M. M. Wadu, S. Samarakoon, and M. Bennis, “Federated learning under channel uncertainty: Joint client scheduling and resource allocation,” arXiv preprint arXiv:2002.00802, 2020.
- [28] T. Zeng, O. Semiari, M. Mozaffari, M. Chen, W. Saad, and M. Bennis, “Federated Learning in the Sky: Joint Power Allocation and Scheduling with UAV Swarms,” arXiv preprint arXiv:2002.08196, 2020.
- [29] S. Batewela, C. Liu, M. Bennis, H. A. Suraweera, and C. S. Hong, “Risk-sensitive task fetching and offloading for vehicular edge computing,” IEEE Commun. Lett., vol. 24, no. 3, pp. 617–621, 2020.
- [30] M. Mohammadi Amiri and D. Gündüz, “Machine learning at the wireless edge: Distributed stochastic gradient descent over-the-air,” IEEE Trans. Signal Process., vol. 68, pp. 2155–2169, 2020.
- [31] A. M. Elbir and S. Coleri, “Federated Learning for Hybrid Beamforming in mm-Wave Massive MIMO,” IEEE Commun. Lett., pp. 1–1, 2020.
- [32] A. M. Elbir, K. V. Mishra, M. R. B. Shankar, and B. Ottersten, “Online and Offline Deep Learning Strategies For Channel Estimation and Hybrid Beamforming in Multi-Carrier mm-Wave Massive MIMO Systems,” arXiv preprint arXiv:1912.10036, 2019.
- [33] J. Yuan, H. Q. Ngo, and M. Matthaiou, “Machine Learning-Based Channel Prediction in Massive MIMO With Channel Aging,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 2960–2973, Feb 2020.
- [34] H. Ye, G. Y. Li, and B. Juang, “Power of deep learning for channel estimation and signal detection in OFDM systems,” IEEE Commun. Lett., vol. 7, no. 1, pp. 114–117, 2018.
- [35] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” arXiv, Feb 2016. [Online]. Available: https://arxiv.org/abs/1602.05629v3
- [36] A. M. Elbir, “A Deep Learning Framework for Hybrid Beamforming Without Instantaneous CSI Feedback,” IEEE Trans. Veh. Technol., pp. 1–1, 2020.
- [37] W. U. Bajwa, J. Haupt, G. Raz, and R. Nowak, “Compressed channel sensing,” in Annual Conference on Information Sciences and Systems, March 2008, pp. 5–10.
- [38] Z. Marzi, D. Ramasamy, and U. Madhow, “Compressive Channel Estimation and Tracking for Large Arrays in mm-Wave Picocells,” IEEE J. Sel. Topics Signal Process., vol. 10, no. 3, pp. 514–527, April 2016.
- [39] A. Klautau, P. Batista, N. González-Prelcic, Y. Wang, and R. W. Heath, “5G MIMO Data for Machine Learning: Application to Beam-Selection Using Deep Learning,” in 2018 Information Theory and Applications Workshop (ITA), 2018, pp. 1–9.
- [40] D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. Vojnovic, “QSGD: Communication-efficient SGD via gradient quantization and encoding,” in Advances in Neural Information Processing Systems, 2017, pp. 1709–1720.
- [41] F. Ang, L. Chen, N. Zhao, Y. Chen, W. Wang, and F. R. Yu, “Robust Federated Learning With Noisy Communication,” IEEE Trans. Commun., vol. 68, no. 6, pp. 3452–3464, Mar 2020.
- [42] X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the Convergence of FedAvg on Non-IID Data,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=HJxNAnVtDS
- [43] Y. Lecun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015.
- [44] C. M. Bishop, “Training with Noise is Equivalent to Tikhonov Regularization,” Neural Comput., vol. 7, no. 1, pp. 108–116, Jan 1995.
- [45] M. Chen, Z. Yang, W. Saad, C. Yin, H. V. Poor, and S. Cui, “A Joint Learning and Communications Framework for Federated Learning over Wireless Networks,” IEEE Trans. Wireless Commun., p. 1, Oct 2020.
- [46] T. T. Vu, D. T. Ngo, N. H. Tran, H. Q. Ngo, M. N. Dao, and R. H. Middleton, “Cell-Free Massive MIMO for Wireless Federated Learning,” IEEE Trans. Wireless Commun., vol. 19, no. 10, pp. 6377–6392, Jun 2020.
- [47] L. Wei, H. Chongwen, A. G. C., C. Yuen, and M. Zhang, Zhaoyangand Debbah, “Channel Estimation for RIS-Empowered Multi-User MISO Wireless Communications,” arXiv, Aug 2020. [Online]. Available: https://arxiv.org/abs/2008.01459v1
- [48] S. Lin, B. Zheng, G. C. Alexandropoulos, M. Wen, M. Di Renzo, and F. Chen, “Reconfigurable Intelligent Surfaces with Reflection Pattern Modulation: Beamforming Design and Performance Analysis,” IEEE Trans. Wireless Commun., p. 1, Oct 2020.
- [49] D. Mishra and H. Johansson, “Channel Estimation and Low-complexity Beamforming Design for Passive Intelligent Surface Assisted MISO Wireless Energy Transfer,” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4659–4663, Dec 2017.
- [50] A. M. Elbir and K. V. Mishra, “Sparse array selection across arbitrary sensor geometries with deep transfer learning,” IEEE Trans. on Cogn. Commun. Netw., pp. 1–1, 2020.
| Ahmet M. Elbir (IEEE Senior Member) received the Ph.D. degree from Middle East Technical University in 2016 He is a Senior Researcher at Duzce University, Duzce, Turkey, and Research Fellow at the University of Hertfordshire, Hatfield, UK. |
| Sinem Coleri (IEEE Senior Member) received the Ph.D. degree from the University of California at Berkeley in 2005. She is a Faculty Member with the Department of Electrical and Electronics Engineering, Koc University, Turkey. |