2021
[1]\fnmCuong \surPham
1]\orgdivFaculty of Information Technology, \orgnamePosts and Telecommunications Institute of Technology, \orgaddress\streetNguyen Trai, Ha Dong, \cityHanoi, \postcode12100, \countryVietnam
2]\orgdivFaculty of Information Technology, \orgnameThuyloi University, \orgaddress\streetDong Da, \cityHanoi, \postcode116830, \countryVietnam
3]\orgnameVinAI Research, \orgaddress\streetTechnopark building, \cityHanoi, \postcode12100, \countryVietnam
Federated Few-shot Learning for Cough Classification with Edge Devices
Abstract
Automatically classifying cough sounds is one of the most critical tasks for the diagnosis and treatment of respiratory diseases. However, collecting a huge amount of labeled cough dataset is challenging mainly due to high laborious expenses, data scarcity, and privacy concerns. In this work, our aim is to develop a framework that can effectively perform cough classification even in situations when enormous cough data is not available, while also addressing privacy concerns. Specifically, we formulate a new problem to tackle these challenges and adopt few-shot learning and federated learning to design a novel framework, termed F2LCough, for solving the newly formulated problem. We illustrate the superiority of our method compared with other approaches on COVID-19 Thermal Face & Cough dataset, in which F2LCough achieves an average F1-Score of 86%. Our results show the feasibility of few-shot learning combined with federated learning to build a classification model of cough sounds. This new methodology is able to classify cough sounds in data-scarce situations and maintain privacy properties. The outcomes of this work can be a fundamental framework for building support systems for the detection and diagnosis of cough-related diseases.
keywords:
Attention mechanism, cough classification, deep neural network, federated learning, few-shot learning.1 Introduction
1.1 Background and Motivation
Respiratory illnesses are highly prevalent, wherein cough serves as a typical and initial manifestation of both asthma and chronic obstructive pulmonary disease (COPD) corrao1979chronic , smith2006cough . Recently, the world has revealed the outbreak of Coronavirus disease (Covid-19) which is announced as a global pandemic by the World Health Organization (WHO).111Source: https://www.who.int/health-topics/coronavirus#tab=tab_1, accessed: April 29, 2022. Covid-19 has lead to 509,531,232 confirmed cases and 6,230,357 deaths.222Source: https://covid19.who.int/, accessed: April 29, 2022. A persistent cough is a common symptom among patients diagnosed with COVID-19 as well as those with respiratory illnesses. Prompt and accurate diagnosis of respiratory diseases through coughing symptoms is critical for healthcare professionals in providing appropriate treatment to patients. Consequently, there has been a significant increase in research aimed at utilizing cough sounds to diagnose respiratory diseases, including cough counting, sound classification, and detection. The current study delves into the challenge of classifying cough sounds in the presence of limited labeled cough data, while ensuring the protection of patients’ confidential information.
In recent decades, machine learning algorithms have demonstrated their efficacy in supporting healthcare systems as evidenced by various studies liao2021recognizing . There has been a proliferation of research that leverages machine learning models for the detection of coughs, with many studies focusing on analyzing cough sounds to develop cough recognition and classification systems. With the advancements in deep learning, methods based on deep neural networks for the detection and diagnosis of respiratory diseases from lung and cough sounds have been proposed and have shown promising results lella2022automatic ; pham2021cnn .
However, deep learning models require a significant amount of labeled data for training. This presents a challenge in the case of cough classification, as the collection of labeled cough data is both expensive and risks the disclosure of sensitive information. The former challenge is due to the fact that deep learning algorithms typically require a large amount of data to perform optimally, while the latter challenge arises from the scarcity of correctly labeled cough data. Pathological cough data is only available from patients with the disease and requires expert labeling, making the collection of such data a major challenge in the healthcare field. This is attributed to the need for assistance from trained medical professionals, the protection of privacy, and obtaining consent from patients suffering from diseases ijaz2022towards .
Furthermore, the collection of medical data presents two practical challenges. The first challenge is the scarcity of data available in the early stages of novel diseases, as evidenced by the lack of medical data on COVID-19 prior to its outbreak. The second challenge pertains to the importance of security and privacy in the collection of medical data. Data protection laws are implemented to prevent the unauthorized collection of private information, and the use of public devices to record cough sounds is discouraged due to the potential for sensitive patient information to be leaked during data collection. As a result, privacy-preserving data collection has become a topic of significant interest among researchers.
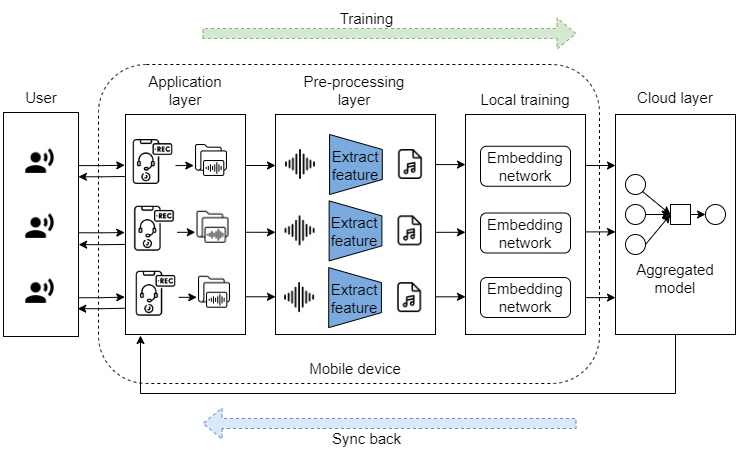
The two aforementioned problems inspire us to give birth to an edge-computing framework that supports the classification of novel cough sounds without collecting a large number of data while still ensuring the security of user data. As illustrated in Fig.1, client data is processed at the periphery of the network, consisting of mobile devices including mobile phones and laptops. To tackle the data scarcity problem, we base on few-shot learning (FSL), which has been receiving a lot of attention wang2022semantic ; bi2022critical recently. FSL allows us to train a model from an available large dataset, so-called the base set. Then, this model is used to classify novel classes that have not been seen in training while requiring only a few samples of each of novel classes. To address the data security problem, we investigate federated learning, which enables training of models using data located on different local devices owned by local medical centers while effectively protecting medical and health data privacy through parameter exchange. To the best of our knowledge, there has been no prior study of both few-shot and federated learning on cough sounds yet.
1.2 Main Contributions
In this study, we aim to to develop a method that effectively learns from limited data while maintaining the privacy of patients who provide audio recordings. To achieve this, we employ a combination of few-shot and federated learning techniques. The study begins by preprocessing the cough audio using Mel Frequency Cepstral Coefficients (MFCCs). The resulting MFCC features are then fed into an embedding network based on ResNet-18 and augmented with an attention mechanism to create embedded vectors, with each class represented by a prototype. The classification task is performed by computing the distances to these prototype representations. Additionally, since the data is stored on multiple devices across various medical centers, the learning of the prototype embedding is conducted in a federated manner, where only the training weights are shared. Our contributions are summarized as follows:
-
•
We formulate a new problem to tackle the cough classification task in the case when data are not only scarce but also required to be protected;
-
•
We propose a novel framework, termed F2LCough, that combines FSL with federated learning techniques to solve the newly formulated problem;333The source code and data of our proposed framework are available online at https://github.com/ngandh/F2LCough.
-
•
We empirically evaluate the performance of our proposed framework and competitive baselines using real-world medical data;
-
•
We evaluate the proposed framework in a real-world scenario, in which the proposed model is deployed on devices with limited computational resources.
1.3 Organization
The outline of this paper is as follows. In Section 2, we review related works for respiratory diseases, coughs, and the ability of FSL combined with federated learning. In Section 3, we describe the definition of the main problem and present our proposed framework. The experimental details and results are presented in Section 4. Finally, the discussion and conclusion are included in Section 5.
2 Related Work
Cough-related problem. Detecting cough sounds is an important problem in supporting the diagnosis and treatment of respiratory diseases. A series of research focused on tackling cough classification and cough detection hoyos2018efficient ; Windmon2019TussisWatchAS . By analyzing unique features of cough sound, the authors in chatrzarrin2011feature proposed a method to classify dry and wet cough by utilizing the energy and cough frequency spectrum of cough sounds. However, this approach depends on limited features of sound and thus does not generalize diverse cough sounds in reality. Another method schroder2016classification adopted a Gaussian Mixture Model and a Hidden Markov Model (GMM-HMM) to classify dry cough, positive cough, and unknown (arbitrary sounds out of cough sounds). Since GMM faces a distribution problem of data, the proposed method is also not effective in the case of diversified cough sounds. For feature extraction, MFCCs have been used in discriminating between dry coughs and wet coughs swarnkar2013automatic as well as classifying tuberculosis coughs.
Owing to the development of deep learning, several works proved that Convolutional Neural Networks (CNNs) are well-fitted for tasks related to respiratory sounds. Authors in shuvo2020lightweight extracted the hybrid scalogram features utilizing the empirical mode decomposition (EMD) and continuous wavelet transform (CWT) of lung sounds, following by a lightweight convolutional neural network to classify respiratory diseases using ICBHI 2017 lung sound dataset rocha2017alpha . For cough identification, the authors in 9720192 proposed a method that used a triplet network architecture that maps Mel spectrograms of cough sounds to an embedding space via CNN. Another study on Covid-19 cough classification showed that ResNet-50 can discriminate between the COVID-19 positive and healthy coughs with an area under the ROC curve (AUC) of 0.98 pahar2021covid . Following up, there is a variety of studies yang20e_interspeech , lella2022automatic using CNN-based architecture for respiratory tasks effectively. Recently, a series of studies have proven that attention-based modules can enhance the abilities of neural networks on feature recognition ren2019attention , zhao2019exploring . Zijiang Yang et al. yang20e_interspeech proposed a method using ResNet-18 combined with attention blocks to classify adventitious respiratory, which utilized STFT Spectrogram as preprocessed input.
To be able to deal with deploying models on smart devices, Daniyal Liaqat et al. proposed a CNN-based architecture called CoughWatch which is integrated with smartwatches to detect coughs liaqat2021coughwatch . Additionally, a smart-phone based system named TussisWatch Windmon2019TussisWatchAS was designed to record and process cough sound for the identification of Chronic Obstructive Pulmonary Disease (COPD) and Congestive Heart Failure (CHF) using Random forests.
Few-shot learning. While deep learning-based methods require a large amount of data to be effective, collecting audio data of people is challenging. Recently, meta-learning and FSL have proven highly effective when labeled data is scarce. In garcia2018fewshot , FSL is based on a convolutional network to extract data features and a graph neural network to calculate the classification probability. Based on the theory that FSL is learning to compare samples with each other, a relevant network method was proposed sung2018learning . One of the most significant works is the prototypical network snell2017prototypical , which is based on the idea that there exists a space embedding in which points are clustered around a unique archetypal representation for each class.
There have been several studies on FSL for audio classification. In wang2021few , the authors proposed a few-shot model by combining ConvNet along with a prototypical network snell2017prototypical . In parnami2022few , a temporally dilated CNN architecture was designed to combine a novel embedding function with prototypical network snell2017prototypical to solve the keyword spotting problem using only limited samples on the speech dataset. Another approach that used a contrastive loss function to learn a latent space from MFCCs to detect COVID-19 cough was proposed in bhosale2021contrastive . Recently, few-shot learning has been used in the healthcare field and achieved significant results wang2022semantic .
Federated learning. Google AI researchers proposed federated learning for the first time since 2016 to alleviate data privacy issues. Federated learning has been well-allied to many different domains ek2022evaluation ; zeng2023fedprols . Fed-Affect shome2021fedaffect , a few-shot meta-learning method based on the Federated learning framework that can learn from a few labeled images was proposed in recognizing human facial expressions. In fan2021federated , authors designed the first federated few-shot learning framework (F2L) by adopting adversarial learning strategy to create a consistent feature space over the clients and optimize the client models to yield a better representation for unseen data samples. Federated learning has been using in the several medical fields to solve privacy and security issues 9774951 ; 9855868 .
Discussion. Despite the significant results of previous works in cough classification, these methods need a large dataset to achieve good results. Additionally, no prior study in classifying cough has tackled data scarcity and data security simultaneously.
3 Methodology
Our paper focuses on the human cough classification task. To tackle data scarcity and information security problems, we proposed a new F2L approach designed specifically for the cough classification problem, where input sound data is classified with corresponding cough labels. In this section, we define the interest problem, present the data processing progress, and describe our proposed framework to address the problem.
3.1 Problem Definition
3.1.1 Notations and Basic Assumptions
The notations that are used in this paper are summarized in Table 1. These notations are formally defined in the following sections that describe our method and technical details.
| Notation | Description |
| The number of the local devices | |
| The numerical order of the local device | |
| An episode in which a few-shot task is performed by utilizing a sampled mini-batch | |
| The support set of the -th local device | |
| The query set of the -th local device | |
| representation vector (Prototype) for class in | |
| The base set of the -th local device | |
| The novel set of the -th local device | |
| Weights of embedding network | |
| Weights of embedding network after aggregating weights | |
| Embedding model with weights of the -th local device | |
| Global embedding model with weights | |
| Euclidean distance of vector and vector . |
In this study, we tackle the case in which a new type of disease appears suddenly and medical systems have no records related to the disease data before. We can take COVID-19 as a particular example. The data can only be collected from patients suffering from these diseases. Moreover, we deal with the situation where we have multiple local medical centers, each can collect a few samples of a patient’s cough data. However, these centers do not want to leak their data to protect patient information. Our goal is to classify and detect a novel type of cough without the need for a huge unified dataset.
To this end, we first assume that each local medical center has a sufficient amount of data on several types of traditional cough related to diseases that have been discovered and treated in the past. The available data, the so-called base set, have been labeled and are denoted as = , where and denote the -th cough audio representation and the corresponding cough type on the -th local device, respectively, includes types of cough that have been gathered during the past years. The base set acts as the prior knowledge, which can be exploited to learn the novel classes of cough through only a few samples. We also assume that there are local devices holding cough data belonging to new types of cough that have not been found before and are not included in . The new dataset including only a few labeled data on the -th device is denoted as where denotes the data point belonging to the novel type of cough on the -th local device, is -th audio records of cough, is the corresponding label of , and includes types of novel cough sounds.
We follow the idea of FSL that utilizes the base set to train a classifier to classify a novel set . In our work, the FSL procedure follows the episodic learning mechanism snell2017prototypical , where an episode , including of a support set and a query set, is formed to perform a few-shot task. Intuitively, the two support and query sets are created to mimic the circumstances encountered during real evaluation. In our cough classification context, the support set is the set that has information about the long-established cough sounds and the corresponding labels, which is the prior knowledge that helps to train the model to predict novel labels of data samples in the query set. This idea is based on human learning, for example, a child can utilize knowledge learned from a few sample images of a drawing animal (the support set) to recognize real-world animals (query set).
In the training procedure, we undertake a specific approach wherein we randomly select classes from the base set on each device . Within this selection, we further employ random sampling to draw support data samples and query data samples per class, thereby composing an episode denoted as . Consequently, within each episode , every class in the selected classes is represented by two distinct sets: the support set and the query set, both of which consist of sampled images. The support set is denoted as , including different audio data samples from classes , and . Based on the support set, the classifier predicts a query set. The query set consists of data samples belonging to labels in the support set and is denoted as . consists of different data points from classes , and . As the result, the episodes can be characterized by three key variables: the quantity of classes denoted by (also referred to as the ”ways”), the number of samples per class in the support set denoted by (termed as the ”shots”), and the number of samples per class in the query set denoted by .
After the training process is completed, we evaluate the classifier by using the test set which is the novel set . The support set and the query set are taken from the test set as the way performed in the training process. In the testing process, the support set includes . And the query set consists of . In fact, the query set consists of unlabeled data. We only know that the labels of the data in the query set exist in the support set. We have to use an FSL model to predict the labels of data samples in the query set. In our evaluation process, the support set is provided by hospitals, and the query set can be obtained from the patients.
As medical centers have records of cough-related diseases but do not want to leak them out to protect patient information, we adopt federated learning to ensure the privacy of data as well as the satisfaction of patients. To this end, all local devices are supplied with models that have the same architecture. Each device trains the model with its own data. After that, local devices exchange the weight of models together to produce a global model without sharing data. Specifically, each device learns a local model following the prototypical network method. After a fixed period, we aggregate local model from local devices to generate global model , which is called a communication round. After that, the global model is synced back to local devices to continue learning. Finally, we stop the training when we get a good global model that meets our expectations. In this work, we assume a communication round which is performed after all the local devices complete one training round.
3.1.2 Problem formulation
Definition 1 (The few-shot task of cough classification on the -th local device).
Given labeled data set called a support set , few-shot task predicts the labels of data points on a query set .
| (1) |
where is a few-shot task of the support set and the query set . The output of the few-shot task is which is the predicted label set of .
Definition 1 formulates the problem that each local medical center can perform few-shot tasks, in which a different embedding space is learned in each local device. Specifically, on each device, the objective is to minimize the distance , ) at each training step, where is the Euclidean distance function, is the label of , and is a representation vector called prototype. Each device uses and to train . First, from of classes, a few-shot model calculates for each class. Second, the model chooses that has the smallest distance , ) as the label of query .
To train a single few-shot task, the objective of each local device is expressed as:
| (2) |
where is the negative log-likelihood of the true label of each query sample (, ) that the model of the -th local device needs to minimize in a few-shot task .
The average of objectives of few-shot tasks on a device is formulated as:
| (3) |
where is the average of the objective functions of few-shot tasks per local device. is the total number of few-shot tasks per the -th local device.
To allow information to be exchanged between local devices, we assume that all devices can join communication rounds periodically to generate , aggregated from learned models of local devices. A communication round starts when each local device uploads its embedding network to the server and ends when all local devices download the global model. To be able to get , we minimize the average of the objectives of all devices
| (4) |
where is the total number of few-shot tasks on all devices and is the number of local devices.
Definition 2 (Cough classification).
Given the cough data of patient , we aim to predict the cough type of , which is a member of .
To complete the aim, from (4), our method has learned a transformation function to create an embedding space where cough data points are clustered closely around the class centroid, which is computed as the center point of all having the same value of , denoted as . Therefore, we train a classifier to choose label as the cough type of by comparing the smallest distance from the embedded vector of to , i.e., we find satisfying the following condition:
| (5) |
3.2 F2LCough Framework
3.2.1 Overall Procedure
To solve the formulated problem in (5), we propose a framework that consists of two main components: FSL to classify cough sounds and a federated learning paradigm, illustrated in Fig. 2.
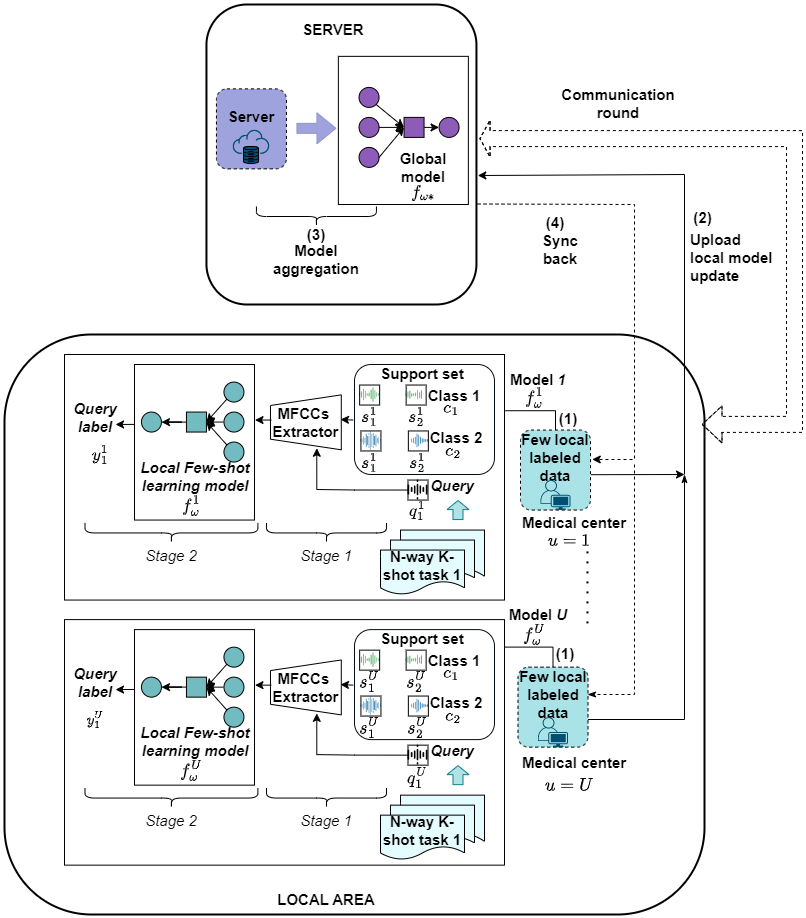
First, we describe the architecture of FSL, where each local device exploits its data to train the embedding model by performing few-shot tasks. To achieve this, we design a training procedure consisting of two stages, as shown in Step (1) in Fig. 2. The first stage involves extracting Mel Frequency Cepstral Coefficients (MFCCs) from cough sounds in both and . The second stage is dedicated to classifying the query labels, wherein the MFCCs are fed into the embedding network to map the data into the embedding space. This stage utilizes prototypical networks snell2017prototypical to create an embedding space for audio records. In this space, classification is performed by calculating the distance to prototype representations of classes.
In Step (2), all local devices upload their weights to a server. In Step (3), the global model is aggregated from the uploaded weights. Finally, in Step (4), local devices download and sync the global model to complete a communication round. All four steps are iteratively performed until is converged.
3.2.2 Implementation Details
Feature Extraction
Mel Frequency Cepstral Coefficients (MFCCs) are extracted from both support and query data. Empirically, we extract 40-dimensional features of MFCCs and design sliding windows to extract MFCCs in which the length of each window is 128ms with a 64ms hop length. After that, these features are inputted into an embedding network to map data into the embedding space.
FSL
The embedding network employed in our study is based on ResNet-18 he2016deep architecture, augmented with both channel attention block and spatial attention block. To integrate these components into our embedding network, we follow the approach outlined in woo2018cbam . A visual representation of our embedding network is presented in Fig. 3.

In the embedding space, we follow the implementation of prototypical networks snell2017prototypical . For every episode, a prototype is computed by averaging the embedded support examples per class:
| (6) |
where f is embedding function, is the number of support examples belonging to class c in episode e. We apply a softmax function to the negative distance to choose the label of the query sample.
Federated learning
We adopt the Federated averaging (FedAvg) algorithm mcmahan2017communication to complete the aggregation step, whose objective function is given in (4).
System design
To evaluate the proposed framework in a real-world application, edge devices are utilized as in Fig. 1. Specifically, a user has a mobile phone which helps the user to record audio to predict. When training, mobile phones save their data and send it to laptops for training. In the Pre-processing layer, extracting MFCCs of audio data is performed on the laptop in the local training layer. Then, laptops use these MFCCs data to train an embedding network. Each embedding network trained completely in one communication round will be pushed to the cloud layer treated as a server to aggregated weights. Finally, a global model is sent back to the mobile phone to serve users.
4 Experimental Results
4.1 Dataset
COVID-19 Thermal Face & Cough Dataset: COVID-19 Thermal Face & Cough Dataset ward2021flunet includes the thermal face dataset and the cough dataset. We utilize the cough dataset for our experiments. Each audio file lasts 1 second at the sample rate of 44,100 Hz. The cough dataset consists of 53,471 seconds of “not cough” samples consisting of background noise, office, music, airport, coffee shop, harbor, nightclub, simulated turbulence sounds, and 1,557 seconds of cough sounds. Additionally, 40,856 seconds of cough sounds are augmented with random background noise at a random volume ratio. In our experiments, we only use eight types of cough: Barking cough, Chesty and wet cough, Coughing up crap again, Dry afternoon cough, Gaggy wet cough, Spring allergy coughing, Heavy cold, and sore throat coughing, Night wet cough.
4.2 Baselines
We compare our proposed method with three state-of-the-art approaches:
-
•
Momentum Contrast (MoCo) he2020momentum is known as a state-of-the-art method of unsupervised learning, it is able to learn a meaningful representation of data for downstream tasks.
-
•
Relational network sung2018learning is a framework for FSL with an end-to-end approach from scratch.
-
•
TC-ResNet: This model has great results in Keyword Spotting problems choi19_interspeech . We utilize a modified version called TD-ResNet7 parnami2022few as an embedding network to compare with our designed embedding network.
4.3 Experimental Setup
To create a simulation for federated learning, we separate the audio dataset into = 5 portions, which correspond to 5 local datasets stored in 5 local devices. In each device, we divide the local dataset into two sets: the training set and the test set . In our experiment, we adopt a cross-validation approach wherein we construct novel sets by selecting two out of the eight types of cough, while the remaining six types are utilized as the base set. Specifically, the novel sets consist of the following pairs: (Heavy cold and sore throat coughing, Night wet cough), (Dry afternoon cough, Gaggy wet cough), (Spring allergy coughing, Coughing up crap again), and (Chesty and wet cough, Barking cough). Additionally, in-depth assessments in this study focus on the novel set containing (Heavy cold and sore throat coughing, Night wet cough) due to their closeness to our domain knowledge.
We note that for experiments without federated learning, we solely utilize the data from one user. This approach enables us to evaluate the outcomes when a reduced amount of data is employed.
In the training process, we train our F2LCough with the learning rate set to 0.001 and the number of epochs is 200.
We utilize the F1-Score as the evaluation metric, which is a widely adopted measure in classification tasks. The results are presented in Mean Standard deviation format and are expressed as percentages.
4.4 Experimental Results
Our empirical study in this subsection is designed to answer the following three key research questions.
-
•
Q1. How effective is our proposed embedding architecture?
-
•
Q2. How much can F2LCough boost the security and accuracy of the classifier?
-
•
Q3. How does F2L Cough operate in practical applications using low-capacity devices?
4.4.1 Comparison between ResNet-18 - Attention and TC-ResNet (Q1)
Since our proposed embedding network architecture is similar to TC-ResNet, we perform an ablation study that replaces our embedding network, in which ResNet-18 combined with attention mechanisms is employed, with an implementation of TC-ResNet (termed TD-ResNet7) in parnami2022few . In this experiment, we only consider the performance comparison in a few-shot setting without federated learning. More specifically, all the few-shot settings are listed as follows: 2-way 2-shot, 2-way 8-shot, and 5-way 8-shot. Table 2 illustrates the performance comparison between TD-ResNet7 and our proposed ResNet-Attention architectures. From the table, we discuss the following interesting observations:
-
•
We observe that the performance of TD-ResNet7 is slightly superior to our ResNet-Attention in the case of the 2-way 2-shot task.
-
•
However, except for the 2-way 2-shot task, the F1-Scores obtained by using TD-ResNet7 are significantly lower than those from ResNet-Attention in the remaining tasks.
Intuitively, although both TD-ResNet7 and our proposed architecture are built upon ResNet-18, the difference in implementation details causes the performance gap between the two architectures. Specifically, TD-ResNet7 sets the kernel sizes to and instead of the square kernels in ResNet-18. Besides, TD-ResNet7 applies dilated convolutional layers instead of normal convolutional layers. This architecture of TD-ResNet7 performs effectively on normal sequential data such as speech. However, the cough has a cycle that is not as same as other sequential data; therefore, TD-ResNet7 is unable to capture meaningful features of cough sound while our proposed architecture can do better.
| Label | Model | 2-way 2-shot | 2-way 8-shot | 5-way 8-shot |
| Heavy cold, and sore throat coughing | TC-ResNet | 0.79 0.04 | 0.74 0.03 | 0.79 0.04 |
| ResNet-Attention | 0.76 0.04 | 0.85 0.02 | 0.81 0.03 | |
| Night wet cough | TC-ResNet | 0.77 0.04 | 0.74 0.03 | 0.77 0.03 |
| ResNet-Attention | 0.75 0.02 | 0.83 0.02 | 0.85 0.02 |
4.4.2 Comparative study among F2LCough and other approaches (Q2)
Table 3 shows the performance comparison between our proposed F2LCough and all competitive schemes following the cross-validation approach, including MoCo, Relational network, TC-ResNet (few-shot learning only), ResNet-Attention, TC-ResNet-F (few-shot learning combined with federated learning), and F2LCough under the 2-way 2-shot setting.444In our experiments, other FSL settings show similar trends. We summary observations as follows:
-
•
Overall, F2LCough demonstrates effectiveness across most types of cough with superior performance than those of other methods, with the exception of Dry afternoon cough and Gaggy wet cough.
-
•
The two types of cough, including Dry afternoon cough and Gaggy wet cough, pose challenges due to their susceptibility to confusion with other types. For the Dry afternoon cough case, models trained on multiple devices, such as TC-ResNet-F and F2LCough, exhibit slow or unstable convergence, leading to inferior performance compared to ResNet-Attention and TC-ResNet.
-
•
The MoCo approach is the least effective for classifying coughs with all F1-Scores under 0.5. The reason for immensely low performance is that MoCo utilizes a contrastive learning method that requires a significant amount of training data to acquire a good result.
-
•
When using a Relational Network the F1-Scores fluctuate between the range of 0.43 and 0.57. One can see that the family of methods following the prototypical approach such as TC-ResNet outweighs the relational network both in the prediction of Heavy cold, and sore throat coughing and Night wet cough. Via our empirical experiments, we believe that the coughing data tend to form geometric clusters, thus the distance metric employed in the prototypical approach is more appropriate than the relational metric used in the Relational network for the cough classification task.
-
•
The F1-scores obtained from methods utilizing the F2L setting are significantly higher than those without federated learning. According to the experimental results, leveraging federated learning in cough classification is one of the most suitable manners, which is capable of exploiting as much user data as possible to preserve user privacy and acquire high performance. Consequently, the federated learning scheme is well-suited for applications, which require preserving user privacy and highly accurate precision like health care applications.
It is worth noting that since federated learning is employed for F2LCough, we only synchronize weights of models of local devices without sharing data in each communication round. As a result, our framework can protect the sensitive data of each user.
| Label | MOCO | Relational network | TC-ResNet | ResNet-Attention | TC-ResNet-F | F2LCough |
| Heavy cold, and sore throat coughing | 0 | 0.52 | 0.79 0.04 | 0.73 0.04 | 0.84 0.04 | 0.87 0.02 |
| Night wet cough | 0.22 | 0.57 | 0.77 0.04 | 0.75 0.02 | 0.82 0.04 | 0.85 0.02 |
| Dry afternoon cough | 0.16 | 0.5 | 0.61 0.05 | 0.62 0.03 | 0.63 0.03 | 0.57 0.04 |
| Gaggy wet cough | 0.26 | 0.51 | 0.72 0.03 | 0.75 0.02 | 0.66 0.04 | 0.67 0.03 |
| Spring allergy coughing | 0.47 | 0.53 | 0.71 0.02 | 0.66 0.03 | 0.72 0.05 | 0.95 0.01 |
| Coughing up crap again | 0.16 | 0.52 | 0.67 0.03 | 0.48 0.04 | 0.68 0.06 | 0.95 0.01 |
| Chesty and wet cough | 0.27 | 0.43 | 0.65 0.04 | 0.53 0.1 | 0.78 0.04 | 0.85 0.02 |
| Barking cough | 0.18 | 0.49 | 0.59 0.05 | 0.62 0.05 | 0.78 0.04 | 0.87 0.02 |
4.4.3 Evaluation on real-world scenarios using low-capacity devices (Q3)
In a practical scenario, we aim to use the trained model to predict a newly outbreak decease of patients. Thus, the medical centers should be able to deploy the learned model into lightweight devices for field operations. Therefore, to demonstrate the capability of implementing F2LCough in a real-world situation, we experiment on a setup where users record their cough data and save the trained model using an application installed on Android phones while the medical center utilize laptops as mobile devices for training. The interface of the application is shown in Fig. 4.

We measure the prediction time of the model integrated on the laptop, shown in Table 4. Note that the following laptop specification is used in this experiment:
-
•
Laptop (using CPU to train the model): Ram 8GB, Processor 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
| Type | Running time (ms) |
| Average weights | 184.68 |
| Update weights | 375.33 |
Furthermore, we assess the running time on users’ Android devices by implementing the F2LCough model using TensorFlow Lite. This implementation is designed to classify various cough sounds, as well as non-cough sounds. The application exhibits a highly efficient inference time, with an average of approximately 2.5 milliseconds.
To validate the application, we conducted a study with 55 volunteers who tested the application and provided their opinions. The volunteer group consisted of individuals aged 21 to 30, including 5 individuals who work in medical fields. Feedback was collected through a Google form, which included a user satisfaction score ranging from 1 to 5, with 5 representing exceptional satisfaction and 1 indicating a poor experience.
The results of the study are depicted in Fig. 5, which displays the user satisfaction statistics. As illustrated, the majority of users rated the application at a score of 4, accounting for 67.3% of the total responses. Additionally, 18.2% of users rated the results at a score of 5, while 14.5% rated the results at a score of 3.

5 Conclusion
In this study, we proposed a framework called F2LCough, which is a combination of FSL with federated learning to classify cough sounds. Specifically, we built F2LCough upon ResNet-18 architecture with an attention mechanism and designed a federated learning procedure to learn F2LCough. F2LCough was empirically proved to be an effective method in data scarcity situations and also was able to classify novel data not seen in the training process while still preserving data privacy. Specifically, we obtained 0.87 0.02 and 0.85 0.02 average F1-Score for Heavy cold, and sore throat coughing and Night wet cough, which act as the novel cough types not seen in the training process. Additionally, we also evaluated F2LCough on edge devices such as mobile phones and laptops and found that it exhibited a fast inference time, demonstrating the feasibility of our proposed method.
6 Acknowledgement
This work has been supported by the research project coded DT. 17/23, funded by the Ministry of Information and Communication, 2023.
Declarations
This section presents declarations related to this study.
-
•
Funding: This work has been supported by the research project coded DT. 17/23, funded by the Ministry of Information and Communication, 2023.
-
•
Conflict of interest/Competing interests: Not applicable
-
•
Ethics approval: Consent was obtained from all participants prior to their involvement in the study, and they were informed of their right to withdraw at any time without consequence.
-
•
Consent to participate: All authors agreed to participate in the construction and development of this research topic.
-
•
Consent for publication: All authors agreed to make this study public
-
•
Availability of data and materials: The paper uses public data obtained from ward2021flunet . The use of data in this study follows the guidelines given by the dataset’s authors.
-
•
Code availability: Reference sources for building experiments have been mentioned in this paper. We have also included our code repository for research and reference. The source code of our proposed framework is available online at .
-
•
Authors’ contributions: All authors contributed to the study’s conception and design. Cuong Pham and Cong Tran had the idea for the article. Material preparation, data collection, and analysis were performed by Ngan Dao. Experiments were conducted by Ngan Dao and Dat Tran. The first draft of the manuscript was written by Ngan Dao and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
References
- \bibcommenthead
- (1) Corrao, W.M., Braman, S.S., Irwin, R.S.: Chronic cough as the sole presenting manifestation of bronchial asthma. New England Journal of Medicine 300(12), 633–637 (1979)
- (2) Smith, J., Woodcock, A.: Cough and its importance in copd. International journal of chronic obstructive pulmonary disease 1(3), 305 (2006)
- (3) Liao, J., Liu, D., Su, G., Liu, L.: Recognizing diseases with multivariate physiological signals by a deepcnn-lstm network. Applied Intelligence, 1–13 (2021)
- (4) Lella, K.K., Pja, A.: Automatic diagnosis of covid-19 disease using deep convolutional neural network with multi-feature channel from respiratory sound data: cough, voice, and breath. Alexandria Engineering Journal 61(2), 1319–1334 (2022)
- (5) Pham, L., Phan, H., Palaniappan, R., Mertins, A., McLoughlin, I.: Cnn-moe based framework for classification of respiratory anomalies and lung disease detection. IEEE journal of biomedical and health informatics 25(8), 2938–2947 (2021)
- (6) Ijaz, A., Nabeel, M., Masood, U., Mahmood, T., Hashmi, M.S., Posokhova, I., Rizwan, A., Imran, A.: Towards using cough for respiratory disease diagnosis by leveraging artificial intelligence: A survey. Informatics in Medicine Unlocked, 100832 (2022)
- (7) Wang, Y., Jiang, C., Wu, Y., Lv, T., Sun, H., Liu, Y., Li, L., Pan, X.: Semantic-powered explainable model-free few-shot learning scheme of diagnosing covid-19 on chest x-ray. IEEE Journal of Biomedical and Health Informatics (2022)
- (8) Bi, S., Wang, Y., Li, X., Dong, M., Zhu, J.: Critical direction projection networks for few-shot learning. Applied Intelligence 52(5), 5400–5413 (2022)
- (9) Hoyos-Barceló, C., Monge-Álvarez, J., Pervez, Z., San-José-Revuelta, L.M., Casaseca-de-la-Higuera, P.: Efficient computation of image moments for robust cough detection using smartphones. Computers in biology and medicine 100, 176–185 (2018)
- (10) Windmon, A., Minakshi, M., Bharti, P., Chellappan, S., Johansson, M., Jenkins, B.A., Athilingam, P.R.: Tussiswatch: A smart-phone system to identify cough episodes as early symptoms of chronic obstructive pulmonary disease and congestive heart failure. IEEE Journal of Biomedical and Health Informatics 23, 1566–1573 (2019)
- (11) Chatrzarrin, H., Arcelus, A., Goubran, R., Knoefel, F.: Feature extraction for the differentiation of dry and wet cough sounds. In: 2011 IEEE International Symposium on Medical Measurements and Applications, pp. 162–166 (2011). IEEE
- (12) Schröder, J., Anemuller, J., Goetze, S.: Classification of human cough signals using spectro-temporal gabor filterbank features. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6455–6459 (2016). IEEE
- (13) Swarnkar, V., Abeyratne, U.R., Chang, A.B., Amrulloh, Y.A., Setyati, A., Triasih, R.: Automatic identification of wet and dry cough in pediatric patients with respiratory diseases. Annals of biomedical engineering 41(5), 1016–1028 (2013)
- (14) Shuvo, S.B., Ali, S.N., Swapnil, S.I., Hasan, T., Bhuiyan, M.I.H.: A lightweight cnn model for detecting respiratory diseases from lung auscultation sounds using emd-cwt-based hybrid scalogram. IEEE Journal of Biomedical and Health Informatics 25(7), 2595–2603 (2020)
- (15) Rocha, B., Filos, D., Mendes, L., Vogiatzis, I., Perantoni, E., Kaimakamis, E., Natsiavas, P., Oliveira, A., Jácome, C., Marques, A., et al.: A respiratory sound database for the development of automated classification. In: International Conference on Biomedical and Health Informatics, pp. 33–37 (2017). Springer
- (16) Jokić, S., Cleres, D., Rassouli, F., Steurer-Stey, C., Puhan, M.A., Brutsche, M., Fleisch, E., Barata, F.: Tripletcough: Cougher identification and verification from contact-free smartphone-based audio recordings using metric learning. IEEE Journal of Biomedical and Health Informatics 26(6), 2746–2757 (2022). https://doi.org/10.1109/JBHI.2022.3152944
- (17) Pahar, M., Klopper, M., Warren, R., Niesler, T.: Covid-19 cough classification using machine learning and global smartphone recordings. Computers in Biology and Medicine 135, 104572 (2021)
- (18) Yang, Z., Liu, S., Song, M., Parada-Cabaleiro, E., Schuller, B.W.: Adventitious Respiratory Classification Using Attentive Residual Neural Networks. In: Proc. Interspeech 2020, pp. 2912–2916 (2020). https://doi.org/10.21437/Interspeech.2020-2790
- (19) Ren, Z., Kong, Q., Han, J., Plumbley, M.D., Schuller, B.W.: Attention-based atrous convolutional neural networks: Visualisation and understanding perspectives of acoustic scenes. In: ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 56–60 (2019). IEEE
- (20) Zhao, Z., Bao, Z., Zhao, Y., Zhang, Z., Cummins, N., Ren, Z., Schuller, B.: Exploring deep spectrum representations via attention-based recurrent and convolutional neural networks for speech emotion recognition. IEEE Access 7, 97515–97525 (2019)
- (21) Liaqat, D., Liaqat, S., Chen, J.L., Sedaghat, T., Gabel, M., Rudzicz, F., de Lara, E.: Coughwatch: Real-world cough detection using smartwatches. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8333–8337 (2021). IEEE
- (22) Satorras, V.G., Estrach, J.B.: Few-shot learning with graph neural networks. In: International Conference on Learning Representations (2018). https://openreview.net/forum?id=BJj6qGbRW
- (23) Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P.H., Hospedales, T.M.: Learning to compare: Relation network for few-shot learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1199–1208 (2018)
- (24) Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. Advances in neural information processing systems 30 (2017)
- (25) Wang, Y., Bryan, N.J., Cartwright, M., Bello, J.P., Salamon, J.: Few-shot continual learning for audio classification. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 321–325 (2021). IEEE
- (26) Parnami, A., Lee, M.: Few-shot keyword spotting with prototypical networks. In: 2022 7th International Conference on Machine Learning Technologies (ICMLT), pp. 277–283 (2022)
- (27) Bhosale, S., Tiwari, U., Chakraborty, R., Kopparapu, S.K.: Contrastive learning of cough descriptors for automatic covid-19 preliminary diagnosis. In: Proc. Interspeech, vol. 2021, pp. 946–50 (2021)
- (28) Ek, S., Portet, F., Lalanda, P., Vega, G.: Evaluation and comparison of federated learning algorithms for human activity recognition on smartphones. Pervasive and Mobile Computing 87, 101714 (2022)
- (29) Zeng, Q., Lv, Z., Li, C., Shi, Y., Lin, Z., Liu, C., Song, G.: Fedprols: federated learning for iot perception data prediction. Applied Intelligence 53(3), 3563–3575 (2023)
- (30) Shome, D., Kar, T.: Fedaffect: Few-shot federated learning for facial expression recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4168–4175 (2021)
- (31) Fan, C., Huang, J.: Federated few-shot learning with adversarial learning. In: 2021 19th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), pp. 1–8 (2021). IEEE
- (32) Salim, M.M., Park, J.H.: Federated learning-based secure electronic health record sharing scheme in medical informatics. IEEE Journal of Biomedical and Health Informatics, 1–1 (2022). https://doi.org/10.1109/JBHI.2022.3174823
- (33) Wicaksana, J., Yan, Z., Yang, X., Liu, Y., Fan, L., Cheng, K.-T.: Customized federated learning for multi-source decentralized medical image classification. IEEE Journal of Biomedical and Health Informatics, 1–12 (2022). https://doi.org/10.1109/JBHI.2022.3198440
- (34) He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
- (35) Woo, S., Park, J., Lee, J.-Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
- (36) McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Artificial Intelligence and Statistics, pp. 1273–1282 (2017). PMLR
- (37) Ward, R.J., Jjunju, F.P.M., Kabenge, I., Wanyenze, R., Griffith, E.J., Banadda, N., Taylor, S., Marshall, A.: Flunet: An ai-enabled influenza-like warning system. IEEE Sensors Journal 21(21), 24740–24748 (2021)
- (38) He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2020)
- (39) Choi, S., Seo, S., Shin, B., Byun, H., Kersner, M., Kim, B., Kim, D., Ha, S.: Temporal Convolution for Real-Time Keyword Spotting on Mobile Devices. In: Proc. Interspeech 2019, pp. 3372–3376 (2019). https://doi.org/10.21437/Interspeech.2019-1363