FedEdge AI-TC: A Semi-supervised Traffic Classification Method based on Trusted Federated Deep Learning for Mobile Edge Computing
Abstract
As a typical entity of MEC (Mobile Edge Computing), 5G CPE (Customer Premise Equipment) has proven to be a promising alternative to traditional HGU (Home Gateway Unit). Network TC (Traffic Classification) is a vital service quality assurance and security management method for communication networks, which has become a crucial functional entity in 5G CPE/HGU. In recent years, many researchers have applied Machine Learning (ML) or Deep Learning (DL) to TC, namely AI-TC, to improve its performance. However, AI-TC methods face significant challenges, including high data dependency, exhaustively costly traffic labeling, and network subscribers’ privacy. Besides, as the AI-TC carrier, 5G CPE/HGU’s limited computing resources often become the bottleneck of models for efficient classification. Furthermore, the long-standing problem of the ”black box” for AI-TC models has always perplexed network operators regarding the model’s transparency and credibility, i.e., AI model interpretability. Therefore, how to achieve an efficient and trusted classification carried on the ”weak computing power” network entity while protecting user privacy has become the key to ensuring the service quality and security of the home network. This paper presents the FedEdge AI-TC framework, a novel AI-TC approach for implementing trusted Federated Learning (FL) based efficient Network TC in 5G CPE/HGU. First, FedEdge AI-TC effectively protects the data privacy of network subscribers by proposing an FL based framework of local training, model parameters iterating, and centralized training. Second, a semi-supervised TC algorithm based on Variational Auto-Encoder (VAE) and convolutional neural network (CNN) is designed to reduce data dependence while keeping the TC accuracy. Finally, XAI-Pruning, an AI model compression method, combined with the DL model interpretability, is proposed to condense the model and interpret it globally and locally to achieve light-weighted AI-TC model deployment while building the trust in their decision of network operators. To demonstrate the efficiency of the proposed method, we conducted some experimental evaluations on commonly used public benchmark datasets and real network datasets. The results show that FedEdge AI-TC can outperform the benchmarking methods regarding the accuracy and achieve excellent TC performance of model inference on 5G CPE/HGU with limited computing resources, which effectively protects the users’ privacy and improve the model’s credibility.
Index Terms:
traffic classification, edge computing, federated learning, variational auto-encoder, semi-supervised, model interpretability.I Introduction
As a distinct entity of MEC, 5G CPE has gradually become an alternative to HGU. Network traffic classification has played a crucial role in ensuring service quality and managing security for home networks. It is a critical functional element within 5G CPE. It finds extensive applications in QoS (Quality of Service) / QoE (Quality of Experience) management, network resource optimization, congestion control, and intrusion detection. With the popularity of smart homes, many applications such as video surveillance, fire and smoke detection, smart appliances, VR/AR, and others have emerged alongside traditional internet services like high-definition videos and online gaming. These applications impose demanding requirements on the network’s QoS, including fast and flexible customization of services, real-time responsiveness, and high reliability. Thus, home networks exhibit four significant trends: ”Terminals Heterogeneity, Applications Diversity, High Privacy, and Rapid Evolution.” Traffic classification in home networks, as an important prerequisite for fine-grained network resource management, has become one of the crucial security measures for smart homes. As shown in Fig. 1, the 5G CPE/Edge Gateway serves as the ”connection point” between the smart home and the wide area network. It is crucial for the reliable forwarding of household application traffic. The AI-TC based on 5G CPE/Edge Gateway is the key to achieving fine-grained network resource management, QoE assurance, and intrusion detection in home networks.

The development of Network TC has generally gone through three stages. In the first phase, TC methods were mainly based on port matching or DPI (Deep Packet Inspection). However, this type of technology quickly became ineffective with the increasing use of techniques like tunneling, encryption, random ports, and concerns about security issues such as user privacy breaches. The second stage primarily leveraged machine learning techniques to extract underlying patterns of different services/applications/attacks traffic features and achieved TC by discriminating various applications in the data space. However, such methods require the extraction of high-quality traffic features as the training inputs for ML. The extraction and selection of these features heavily rely on the domain expertise of network specialists and are time-consuming and labor-intensive. In the third stage, with the rapid development of cloud computing, big data, especially deep learning, and high-performance computing technology, feature learning of massive traffic data has become feasible, bringing new imagination space for improving the TC’s performance. DL has three excellent features: automatic feature extraction, exploration of deep nonlinear features, and many classical models in computer vision/image/text/speech that can be reused. These advantages are all lacking in ML-based TC methods. Several DL-based TC technologies have been proposed recently, including CNN/AE/MLP/LSTM/GAN-based methods, which have achieved better classification performance than ML-TC[1, 2, 3, 4, 5].
However, applying DL technology to smart home network traffic classification faces three major challenges. Firstly, DL models heavily rely on a large volume of online behavior data from home users, which raises concerns about highly sensitive user privacy. Additionally, the collection and labeling of traffic samples are time-consuming and labor-intensive. Secondly, the 5G CPE/edge gateway’s limited computing resources often become the bottleneck of the AI-TC models for efficient classification. Thirdly, the ”black box” problem of the DL classification model has always perplexed the trustworthiness of home users/network operators. Therefore, efficiently achieving trusted classification of home network traffic on a ”weak computing power” gateway device while protecting user privacy is crucial in ensuring service quality and security.
Federated Learning is a distributed machine learning technology providing privacy protection, presenting a novel application paradigm that balances data privacy protection and sharing computing[6]. FL constructs a global model based on virtual fusion data through distributed model training among multiple data sources with local data, without exchanging local data but model parameters or intermediate results. In recent years, FL has been widely used in industries with high sensitivity to data privacy, such as finance and medical care, and has made significant progress[7]. Inspired by this, this paper proposes FedEdge AI-TC, an AI traffic classification method based on federated learning of 5G CPE/edge gateway. This method uses the FL framework to train the traffic classification model of the home network without uploading home network data to a centralized server but executing local distributed model training on a 5G CPE/edge gateway. The global traffic classification model is constructed by exchanging model parameters with the centralized server while protecting the privacy of home users. In addition, considering that traffic sample collection and labeling are time-consuming and labor-intensive, we design a semi-supervised traffic classification algorithm based on VAE and CNN to reduce dependency on traffic sample data. Finally, XAI-Pruning, an AI model compression method, combined with the DL model interpretability, is proposed to condense the model and interpret it globally and locally to achieve light-weighted AI-TC model deployment while building the trust in their decision of network operators. To demonstrate the efficiency of the proposed method, we conducted some experimental evaluations on commonly used public benchmark datasets and real network datasets. The results show that FedEdge AI-TC can outperform the benchmarking methods regarding the accuracy and achieve excellent TC performance of model inference on 5G CPE/HGU with limited computing resources, which effectively protects the users’ privacy and improve the model’s credibility. The contributions of this paper are as follows:
-
1.
We propose a 5G CPE traffic classification method FedEdge AI-TC based on federated learning, which effectively protects the privacy of home user data by constructing the FL framework of local training, parameter updating, and centralized training;
-
2.
A semi-supervised traffic classification algorithm based on VAE and CNN is designed to reduce the dependence on traffic sample data;
-
3.
A pruning method based on DL model interpretability (XAI-Pruning) is proposed for model compression, and the model is globally and locally explained to increase model transparency and credibility;
-
4.
Experiments on public and self-built datasets show this method can achieve high traffic classification accuracy under limited computing resources.
The chapter organization of this paper is as follows: Section I is an overall introduction; Section II is related research works; Section III presents the framework for the proposed approach; Section IV describes the FedEdge AI-TC method; Section V evaluates the proposed method through experiments and provides a comprehensive discussion of the results.; Section VI concludes the contributions and outlines potential directions for future research. Table I below is the list of abbreviations in alphabetical order.
| Acronym | Explanation |
|---|---|
| AE | Auto Encoders |
| CPE | Customer Premise Equipment |
| CNN | Convolutional Neural Networks |
| DL | Deep Learning |
| DPI | Deep Packet Inspection |
| FL | Federated Learning |
| FAM | Flow Attribute Matrix |
| GAN | Generative Adversarial Network |
| HGU | Home Gateway Unit |
| LSTM | Long Short Term Memory |
| MSE | Mean Square Error |
| MLP | Multilayer Perceptron |
| QoE | Quality of Experience |
| QoS | Quality of Service |
| SSL | Semi-Supervised Learning |
| TC | Traffic Classification |
| VAE | Variational Auto Encoder |
| XAI | Model Explanation/Interpretability |
| ML | Machine Learning |
| GNN | Graph Neural Network |
II Related works
II-A Deep Learning based Traffic Classification
Deep learning, also referred to as deep structured learning or hierarchical learning, is achieved by acquiring the representation of data. In contrast to traditional machine learning algorithms, deep learning can automatically extract features without human intervention, rendering it an ideal approach for traffic classification. The application of deep learning techniques to Network TC[8, 9, 10, 11, 12] involves three steps: firstly, characterizing the input data by defining and designing the model input using data packets, PCAP files, or traffic statistics vectors as features; secondly, selecting suitable models and algorithms based on classifier objectives and model characteristics; finally extracting traffic features automatically through training a DL-based classifier and associating input data with corresponding category labels.
Recent research has demonstrated deep learning methods’ superiority in traffic classification. For example, CNNs[13, 14] are widely used in traffic classification. They can automatically extract features from raw network traffic data and have end-to-end learning capabilities during training. In addition, RNNs and LSTMs[15, 16] are used to process traffic sequence data and can capture the temporal dependencies in the data. These types of networks are often used in traffic classification to identify persistent attacks such as DDoS (Distributed Denial of Service) attacks. GNN has proven to be a novel information representation method for DL, which has been applied in TC or IDS[17].
II-B Semi-supervised Learning based Traffic Classification
Semi-supervised traffic classification[18, 19, 20, 21] is an approach that utilizes a small set of labeled data along with a substantial amount of unlabeled data to distinguish various network traffic types. There are four primary methods for semi-supervised traffic classification: cluster-based methods, generative models, GANs (Generative Adversarial Networks), and discriminative models. Cluster-based methods[22, 23] have low computational complexity but can be influenced by data distribution and may exhibit instability in practical usage. Generative model-based methods[24] are effective for unknown or dynamically changing network applications; however, they require prior knowledge to select appropriate statistical features and clustering parameters which might limit the generalization of classification results. GAN-based methods[25, 26] can enhance dataset diversity and quality, thereby improving the model’s generalization performance. Nevertheless, GAN models have complex structures and numerous parameters that pose challenges in training and render them impractical for deployment on edge devices. Therefore, this study primarily adopts a discriminative model-based approach by directly learning the mapping function from feature space to class space. Model parameters are optimized by minimizing the classification error of labeled data while incorporating a regularization term for unlabeled data. Subsequently, the unlabeled data is classified based on predicted results.

II-C FL and its applications in Traffic Classification
Federated Learning (FL) is a distributed ML/DL framework that focuses on decentralized training data, aiming to obtain ML/DL models by distributing the data across numerous nodes while ensuring privacy and security. FL allows local clients to retain their data, sharing only the model parameters with a central server, thereby reducing communication overhead and preserving client data privacy[7, 27]. Recently, two main approaches have emerged for traffic classification tasks by combining federated learning with deep learning techniques. The first approach[28, 29, 30, 31] empowers child nodes to annotate the data through various means. The second approach[32, 33, 34, 35, 36] involves transforming the model structure and training objectives so that sub-nodes can train the model using unlabeled data; subsequently, fine-tuning is performed by the server using labeled data to achieve semi-supervised traffic classification. We propose a semi-supervised traffic classification model based on VAE-CNN that incorporates a federated learning paradigm enabling edge devices’ semi-supervised training of the model.
III The Overall Framework
III-A The Workflow of FedEdge AI-TC
Smart home networks face four major challenges: terminal heterogeneity, application diversity, high privacy, and rapid evolution. A network TC system must continuously learn through long-term iterative optimization to overcome these challenges. The process follows the full life cycle of federated learning, as shown in Fig. 2. The edge-side AI-TC classification system workflow based on federated learning includes initialization, broadcast, training, parameter uploading, model aggregation and evaluation, edge deployment, and model monitoring. Here are the steps for implementing an AI-powered network traffic classification system:
-
1.
Initialization: Provide the client node with an initialization model for efficient local/global model training.
-
2.
Broadcast: The centralized server broadcasts the initialization model to all the client nodes like 5G CPE/HGU.
-
3.
Local Training: The client node performs feature engineering, model construction, and local training.
-
(a)
Feature Engineering: Extract, select, represent, and compress network traffic features to build an optimal feature subset for the AI-TC classification system.
-
(b)
Model Construction and Local Training: This step involves selecting what kind of learning methods (supervised/semi-supervised/unsupervised/weakly supervised), training methods (centralized/distributed training, federated learning), whether to pre-train, whether to use classical models for transfer learning, to form a local model (Local Model) on the local client node.
-
(a)
-
4.
Parameters Uploading: Upload encrypted parameter information obtained from local training to the centralized server.
-
5.
Aggregation: The centralized server performs ’secure aggregation’ on the parameter information uploaded by each client node (such as using the FedAvg algorithm) and performs global training.
-
6.
Model Evaluation: Evaluate the global model obtained from the centralized server’s global training. If the training process converges, it will enter the model deployment step; otherwise, it will inform the client node to continue training and iterative optimization. In addition, the model evaluation also needs to consider its computational complexity, time complexity, and the computing resources and time required for training/inference.
-
7.
Edge deployment: Deploy the model on the edge or terminal side using the pull/push/subscribe model deploy method and update strategy. Model compression and interpretation are two important tasks in this step.
-
(a)
Model Compression: Compress the inference/classification model small enough to meet the fast classification under limited computing power.
-
(b)
XAI(Model Interpretation/Explanation): Solve the ”black box” problem of the AI-TC model to make the classification model users trust the model.
-
(a)
-
8.
Model Monitoring: Monitor the status of the classification system, including model, and real-time network flow, to report some key issues such as classification system failures and model degradation.
-
9.
Continuous Learning: Initiate iterative optimizations and continuous learning from initialization to maintain high adaptability, robustness, and reliability of the classification system.
The following sections of this article will focus on initialization, model training, compression, and explanation.
III-B The Architecture of FedEdge AI-TC

The overall architecture of FedEdge AI-TC is illustrated in Fig. 3, which is divided into the client node and central server/central aggregator based on our previous work[37]. HGU, functioning as the client node, performs local training and inference classification tasks[38]. On the other hand, the central aggregator acts as a centralized server responsible for aggregated training, model evaluation, compression, interpretation, and deployment of inference models. The workflow can be summarized as follows: Initially, the central aggregator broadcasts the initial classification model to HGU. Subsequently, HGU collects real-time packets and performs redundant/invalid packet filtering, network flow attribute calculation, and normalization to formulate a FAM (Flow Attribute Matrix), depicted in Fig.4. This matrix is then utilized for training an initialization model locally. Afterward, encrypted gradient information, loss, and other parameter details are uploaded to the central aggregator for aggregate training. Since each HGU exhibits similar flow characteristics, Horizontal Federated Learning (HFL) is employed for aggregate training by standard secure aggregation algorithms like FedAvg. Then the model performance metrics will be evaluated, including accuracy, precision, recall, and F1-Score for assessing model convergence. If convergence occurs successfully, the aggregated global model undergoes compression to meet computing resource constraints of HGU (including CPU/memory/Flash). Once an available inference model is obtained, XAI-based methods are applied to provide both global and local explanations of the model. Finally, the resulting inference model will be distributed across all HGUs. Otherwise, if convergence fails, the global model will be issued to each HGU, initiating a new epoch of iterative training and optimization until it converges.
IV The Methodology of FedEdge AI-TC
IV-A Initial Model
The initial model plays a crucial role in determining the convergence speed and performance of federated aggregation training, which serves as the initial stage of federated learning. While randomly initialized models can be used within the FL framework, it is essential to construct an initial model that enhances local/global model training efficiency. Unlike traditional AI domains like images and text, network traffic classification lacks pre-trained models, necessitating the development of the initial model by ourselves. In this study, we utilize three benchmarking datasets including (ISCIX[39], UNSW-NB15[40], and MIRAGE[41]) as baseline datasets for constructing our initial model. We adopt CNN as the supervised training algorithm, and further details about the initial model can be found in our previous work[37].
IV-B Federated Semi-Supervised Learning Traffic Classification Method using VAE+CNN
IV-B1 The Introduction of FSSL
There are two types of network traffic data in the FedEdge AI-TC system. The first type, labeled data, is stored in the central aggregator. The second type, unlabeled data, is located in the local HGU, i.e., real-time traffic data. From the perspective of FL, it belongs to the disjoint scenario. This alignment with the home network scenario arises due to the absence of labels for real-time traffic forwarded by the HGU, making it impractical to annotate such data. Conversely, the central aggregator possesses powerful computing resources and can effectively accomplish this work. Semi-supervised Learning (SSL) aims at leveraging unlabeled data to enhance model training by learning classification boundaries within these unlabeled samples and evaluating their proximity to labeled ones. Consequently, this approach strengthens both the robustness and generalization ability of models. The advantages of SSL primarily are in two aspects: (1) enhancing the robustness of TC classification models; (2) mitigating loss in model generalization caused by domain differences—for instance, traffic forwarded by different HGU devices may exhibit non-independent and identically distributed (non-IID) characteristics. In the subsequent section, we will propose an SSL-based method for traffic classification using FSSL.
IV-B2 Problem Formulation
-
a)
Basic definitions: ; refers to the network traffic dataset, which consists of a labeled dataset and an unlabeled dataset , ; and represent the total number of records in labeled and unlabeled datasets, respectively; , refers to the dataset of the traffic classification label, where , and is the total number of application types; , is a collection of flow feature vectors; , refers to the set of labeled flow feature vectors; , refers to the set of unlabeled flow feature vectors; , labeled/unlabeled flow feature vectors are denoted by and , , .
-
b)
Definitions related to network traffic:
-
•
flow: A flow is identified by a five-tuple consisting of the source address, destination address, source port, destination port, and TCP/UDP protocol. , represents a set of flows.
-
•
flow feature: It includes packet-level features, flow-level features, and statistical features, formally defined as . is the flow feature vector, composed of a total of 78 feature sub-items [13], which consist of the following three types of features:
-
–
Packet-level features: The temporal and spatial features with packets as the granularity, including packet payload characteristics, packet length-related features, and time-related features. For example, packet length, inter-arrival time between packets, etc.
-
–
Flow-level features: The temporal and spatial features of flows, with flows as the granularity, including flow length, flow duration, number of packets in a flow, and so on.
-
–
Statistical features: The expectation, variance, maximum value, and minimum value of the relevant feature.
-
–
Table II presents an example collection of traffic features for FedEdge AI-TC. From the example, it can be observed that specific feature entries involve a high level of user privacy.
TABLE II: A typical example (partial) of a network traffic feature set Flow Attributes Definition Catogory Description Domain Name DNS/SNI in TLS Payload related domain.com, which is applicable to applications such as HTTP/HTTPS. TCP slide_win TCP Slide Window Packet related TCP flow control parameters TLS_handshake TLS handshake packet information Payload related Handshake types, cipher suites, content types, key length, etc. Total Fwd Pkts Packet length sequence Packet related The sequence of packet lengths in the flow. Pkt IAT Min Packet arrival time Packet related The sequence of arrival times of packets in the flow. Flow Len Flow length correlation Flow related The total number of bytes in the flow per unit of time. Flow Duration Flow duration Flow related The duration of the TCP flow. 
Figure 4: The Example of L_FAM. -
•
-
c)
Flow Features Matrix(FAM): FAM comprises flow feature vectors and application category labels, formally defined as . refers to the labeled flow feature matrix, . refers to the unlabeled flow feature matrix, . Fig. 4 represents an example of .
IV-B3 VAE
As we all know, an Autoencoder (AE) is specifically designed to acquire a low-dimensional latent representation of samples by constructing an encoder and a decoder. It is commonly employed for tasks such as data compression or generation. However, due to its sole focus on learning the encoding of the sample itself, AE-based models usually show weak generalization. Therefore, AE’s capacity to capture the underlying data distribution needs to be improved. In addition, network traffic consistently exhibits characteristics such as large scale, dynamic, and heterogeneity. A conventional AE model usually fails to fully reconstruct comprehensive network traffic even when provided with extensive datasets. Consequently, accurate classification becomes imperative when encountering traffic samples beyond the dataset.

Variational Autoencoder (VAE) is an extension of Autoencoder (AE). More precisely, it is a generative model widely employed for unsupervised pre-training of unlabeled data. Its excellent ability to learn the latent distribution enables the model to acquire strong generalization capabilities during subsequent fine-tuning. As depicted in Fig. 5, the core concept behind VAE lies in learning the implicit representation of actual samples and the implicit distribution from these samples to generated samples . This approach enhances the robustness of the model in learning implicit feature representations. It estimates the overall data distribution by constructing a generative model based on data samples. However, commonly used methods for estimating data distributions rely on maximum likelihood estimation through parameter estimation techniques. Assuming that the distribution of data samples follows a Gaussian distribution , this transforms the statistical problem of generating models into a parameter estimation problem. The remaining challenge lies in fitting the distributions of encoder and decoder . While autoencoders (AE) typically learn data distributions by minimizing reconstruction loss like Mean Square Error (MSE), this type of fitting primarily occurs at a sample level within datasets. It fails to capture underlying data distributions effectively. In contrast, VAE employs KL divergence as a measure for quantifying differences between two distributions, also known as relative entropy. Therefore, we can define our loss function as Eq. 1.
| (1) |
The loss function consists of two components: the first component is the reconstruction loss, and the second component is the KL divergence between the proper distribution and the distribution we have chosen. VAE aims to minimize this relative entropy, as expressed in Eq. 2.
| (2) | ||||
is called the Variational Lower Bound. We aim to optimize this lower bound, as the closer it is to , the smaller the KL divergence. In this case, can estimate more accurately.
The VAE further decomposes the sampling of into two parts: one consists of fixed values such as the standard deviation and the mean , and the other is a random Gaussian noise . After applying the reparameterization trick, we can rewrite as Eq. 3:
| (3) |
The optimization of the variational lower bound of implies that, while ensuring that the values generated by the encoder conform to a prior Gaussian distribution, the decoder can maximize the possibility of reconstructing the original .
IV-B4 VAE based Unsupervised Learning Algorithm for Network TC
As shown in Alg.1, the entire algorithm mainly consists of the following three steps:
-
a)
Define the hyperparameters: Input dimension is ; Hidden layer dimensions are for , where is the number of hidden layers; Dependent variable dimension is ; Batch size is ; Number of epochs for training is .
-
b)
Dataset: , is equivalent to a with .
-
c)
Model construction and training:
-
•
Define the exact architectures of Encoder and Decoder. This includes determining the number of layers, , , , and the loss function. The Encoder maps into the latent space , while the Decoder maps the randomly sampled from into the data space . The ultimate goal is to make and as close as possible.
-
•
The feed-forward propagation process from Encoder to Decoder.
-
–
In this context, the input data , referred to as , is fed into the Encoder. After sequential computations, the mean and variance of the posterior distribution in the latent space are obtained.
-
–
The technique of reparameterization is used to sample a latent variable from , i.e., , where , and it is then fed into the Decoder.
-
–
The decoder performs layer-by-layer computations to obtain the reconstructed output of the input data , which can be expressed as .
-
–
Calculate the reconstruction error and KL divergence based on Eq. 1 to obtain.
-
–
-
•
Backpropagation and Optimization. By iterating through and utilizing the optimizer defined, the VAE model is trained in a loop to optimize the model parameters with the goal of minimizing .
-
•

The structure of the unsupervised model for network traffic based on VAE is shown in Fig. 6, and detailed parameters are provided in Table III.
| Parameter name | Parameter value | Parameter Interpretation |
|---|---|---|
| input_dim | 78 | Model input dimension |
| Layers of Encoder/Decoder | 3 | Number of layers in the encoder and decoder |
| , , | 78,64,32 | Dimension of each layer |
| loss function for Encoder | ReLU | Loss function |
| loss function for Decoder | ReLU | Loss function |
| loss function for Decoder’s output | Sigmoid | Loss function |
| batch_size | 128 | Batch size |
| learning rate | 0.01 | Learning rate |
IV-B5 VAE+CNN based Semi-supervised Learning Algorithm for Network TC

As illustrated in Fig.7, there are three parts in the semi-supervised based network traffic classifier: the encoder of VAE model, CNN, and softmax classifier. The labeled data, i.e., L_FAM is fed into the Encoder of the VAE model obtained from Section.IV-B4, then the output of the VAE encoder is subsequently fed into a three layers CNN model with a softmax classifier, which is concatenated with the VAE encoder. Finally, the decision results will be outputted for classification. The overall process is commonly referred to as Fine-Tuning. Due to the limited space of this paper, we do not provide the detail of the CNN classifier, which can be found in our previous work[37].
IV-C The Model Compression Method Based on Interpretation
IV-C1 Model Interpretation
We propose to implement an interpretable framework for deep learning traffic classification models based on SHAP values, which are mainly used to quantify the contribution of each feature to the model prediction. The basic design idea is to calculate the marginal contribution SHAP value when features are added to the model so that the importance of the features can be interpreted according to the SHAP value, which is calculated as Eq. 4 in this paper. Suppose the i-th sample of sample set M is , the j-th feature of sample is , is the shapely value of .
| (4) |
where , is the set of all possible input features excluding , is the number of features of the sample, and is the prediction result of the feature subset .
The architecture of Model Interpretation is shown in Fig. 8. The left part is the traditional structure of the traffic classification model, and the process shown on the right allows for the interpretability of the traffic classification model and the optimization of the structure and parameters of the traffic classification model. This framework is divided into a local interpretation and a global interpretation.
Local interpretation means that for each data instance, the contribution of each feature to its predicted outcome is calculated and presented visually. The formula for calculating the local interpretation is as follows:
| (5) |
where is the predicted value of the model for sample , is the mean of all sample evaluated values.
As for Global interpretation, firstly, a matrix of feature SHAP values is calculated, with one instance per row and one feature per column. Secondly, in the traditional global interpretation, the feature j’s contribution is obtained by summing the shapely mean of feature j for all samples with Eq. 6. And then, SHAP values are sorted in descending order to obtain the importance of the model features.
| (6) |
IV-C2 Model Pruning
To address the issue of how to compress models to make them suitable for training and inference on resource-limited devices, in particular, we will focus on pruning, an easier-to-implement model compression technique. Model pruning is based on an underlying assumption: ’weight contribution,’ which means that not every weight contributes equally to the output prediction.

Therefore, the basic design idea of model pruning in this paper is to rank the feature importance by global interpretation, after which the importance ranking of the convolutional kernels is calculated using the causal evaluation mechanism. The convolutional kernels with importance below a threshold are filtered out and pruned.
V Experimental Evaluation and Discussion
V-A Evaluation Settings and Chosen Datasets
We conducted the experimental evaluation on two datasets. One is a benchmarking public dataset, ISCX-VPN2016. The other is a private dataset built by ourselves. The latter comprises six popular applications and background traffic from terminals collected in the campus network scenario, including Bilibili, QQ music, Honor of Kings, Teamfight Tactics, and Game for peace. These apps cover the five popular app categories of video, music, Moba games, First Person Shooting (FPS) and Role-playing game (RPG). To collect the data, we used a semi-automatic web traffic generation tool. We leveraged an automated traffic generator to collect traffic from Bilibili and QQ music, with 13,314 flows from Bilibili and 20703 flows from QQ music. For the other interactive games, we chose to collect them manually. We used PCAPDroid to mark the network traffic as it occurred at the endpoint and also at the router, where the two were compared and filtered. The network flow features were calculated by CICFlowMeter for each application’s PCAP files. In addition, this experiment also provides the statistics of the background traffic information, which contains information about network location services, security components, and syslog services. Table IV shows the exact number of flows.
| Applications Name | Type | Number |
|---|---|---|
| bilibili | Video | 13314 |
| QQ music | Music | 20703 |
| Honor of Kings | Moba | 9475 |
| Teamfight Tactics | RPG | 14005 |
| Game for peace | FPS | 7763 |
| Background | Log | 13017 |
The experimental environment is AMD Ryzen 3600, 16GB RAM, NVIDIA GTX 1660, CUDA 7.5, CDNN10.5. In this paper, Python3 is the primary programming language. The following is a description of the evaluation metrics: Precision, Recall, F1, Accuracy, and AUC.
Time-complexity-related metrics about training like training time are not included in this paper because we think those are highly dependent on the hardware resources.
V-B Performance Evaluation
The training process of the VAE part in the VAE+CNN (E-CNN) model is divided into two parts. Firstly, the labels were removed from the datasets, which can be acted as the unlabeled flows for the unsupervised learning training. After training, one can save the trained encoder in the VAE model for further semi-supervised learning. The training process for the CNN part mainly aim to convert the labeled data into digital encoding for fine-tuning.
In the single CNN model, we process the dataset and divide it into training and testing sets according to ratio, which is then trained and evaluated in the CNN.
For the E-CNN and single CNN models, we obtained the following two diagrams by adjusting the ratio of the dataset to the training and testing sets. The horizontal axis in the diagram represents the partitioning ratio. For example, 0.2 means that 80 of the entire dataset is allocated to the training set, and the remaining 20 is allocated to the testing set. The vertical axis represents the accuracy of the model training results under this partition. Fig. 9 displays the model results of E-CNN and single CNN in real-life scenarios, while Fig. 10 shows the results in the public dataset.


According to the figures, as the partition ratio increases, meaning that the training set data decreases, the accuracy of both models tends to decrease and becomes similar, both at around 0.7. Within the partition ratio interval [0.2, 0.8], E-CNN achieves good results with higher accuracy than a single CNN.
We have set the partition ratio to 0.45. After training and testing, we obtained the respective Confusion Matrix and Classification Report for E-CNN and single CNN using this ratio. The Confusion matrix is shown in Fig. 11 and Fig. 12. In the figures, the x-axis represents the prediction labels, the y-axis represents the actual labels, and the color intensity indicates the count of correct and incorrect predictions. According to the figure, under the partition with this ratio, E-CNN shows relatively accurate predictions for ’QQmusic,’ ’Teamfight Tactics,’ and ’Bilibili.’ On the other hand, compared to CNN, E-CNN’s predictions for ’QQmusic,’ ’IQiyi,’ and ’Teamfight Tactics’ are relatively accurate, but there are also several errors.

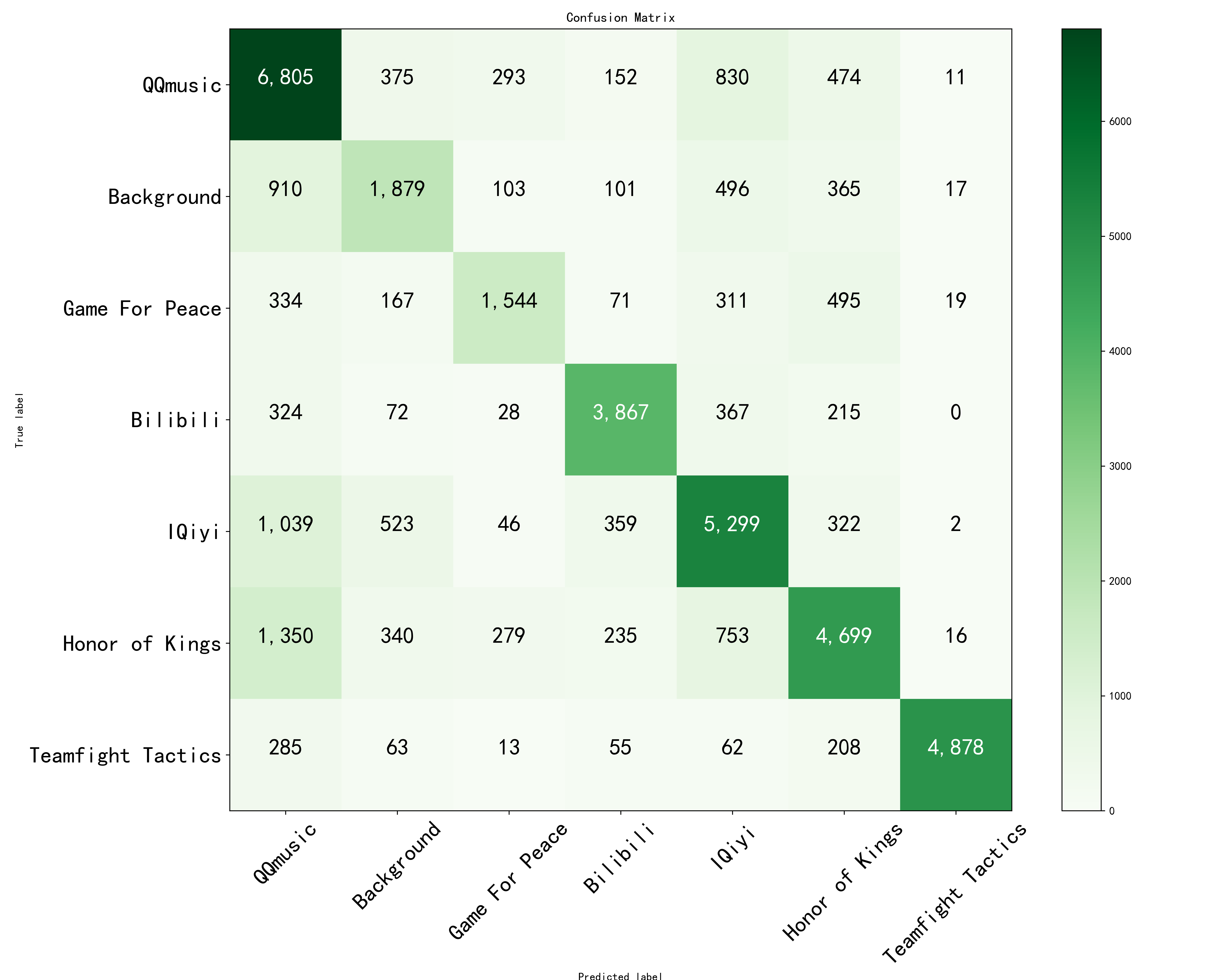
The classification report is presented in Table V and Table VI. It is evident from the tables that, under this partition ratio, E-CNN demonstrates relatively accurate predictions for ’Teamfight Tactics’ and ’Bilibili,’ with prediction accuracy rates above 0.9. The prediction accuracy for other applications is also around 0.7, resulting in a total classification accuracy of 0.7422. In contrast, CNN’s performance is notably inferior to that of E-CNN. The lowest prediction accuracy is approximately 0.5, and the highest prediction accuracy is only around 0.8. Its overall classification accuracy is merely 0.6989.
| Precision | Recall | F1-score | Support | |
|---|---|---|---|---|
| QQmusic | 0.7736 | 0.7485 | 0.7609 | 9270 |
| Background | 0.5163 | 0.6754 | 0.5852 | 5853 |
| Game For Peace | 0.6214 | 0.6598 | 0.6401 | 3513 |
| Bilibili | 0.9097 | 0.9000 | 0.9048 | 6020 |
| IQiyi | 0.7056 | 0.6644 | 0.6843 | 6272 |
| Honor of Kings | 0.6915 | 0.4897 | 0.5734 | 4243 |
| Teamfight Tactics | 0.9457 | 0.9379 | 0.9418 | 6280 |
| accuracy | 0.7422 | 41451 | ||
| macro avg | 0.7377 | 0.7251 | 0.7272 | 41451 |
| weighted avg | 0.7515 | 0.7422 | 0.7434 | 41451 |
| Precision | Recall | F1-score | Support | |
|---|---|---|---|---|
| QQmusic | 0.6160 | 0.7612 | 0.6809 | 8940 |
| Background | 0.5496 | 0.4854 | 0.5155 | 3871 |
| Game For Peace | 0.6696 | 0.5250 | 0.5885 | 2941 |
| Bilibili | 0.7990 | 0.7936 | 0.7963 | 4873 |
| IQiyi | 0.6527 | 0.6982 | 0.6747 | 7590 |
| Honor of Kings | 0.6933 | 0.6125 | 0.6504 | 7672 |
| Teamfight Tactics | 0.9869 | 0.8767 | 0.9285 | 5564 |
| accuracy | 0.6989 | 41451 | ||
| macro avg | 0.7096 | 0.6789 | 0.6907 | 41451 |
| weighted avg | 0.7059 | 0.6989 | 0.6989 | 41451 |
Based on the experimental results presented above, we can conclude that when the ratio of labeled data to total data falls within the range of [0.2, 0.8], the VAE+CNN method proposed in this paper can be employed for classifying and recognizing network application traffic. At this range, the recognition outcomes outperform those achieved by solely training with CNN, and the classification accuracy is commendable.
Fig. 13 visualizes the importance of ten features for the classification results. These ten features are the most significant ones contributing to the classification outcomes. For instance, in the case of the applications Bilibili and IQiyi, the most crucial feature for the classification result is s_idleMax, representing the maximum idle time of any neighboring packet in a stream. Notably, video streams exhibit distinct characteristics on this feature due to their continuous packet sending and shorter inter-packet idle time, which differentiates them from game streams.

| Baseline model | XAI-Pruning model | |
|---|---|---|
| Size of zipped file | 634163 bytes | 207292 bytes |
| Accuracy of prediction | 0.75 | 0.69 |
| Inference Time | 2.78s | 1.12s |
The XAI-Pruning model effectively filters out unimportant weights and parameters, substantially reducing the number of parameters and the overall model size. As a result, the model becomes more compact, enabling significantly faster inference and quicker predictions. On the other hand, the baseline model, which includes all weights and parameters, generally exhibits higher prediction accuracy due to its capacity to capture more intricate model details and complexity.
As depicted in Table VII, the baseline model size is approximately three times larger than the XAI-Pruning model, and the inference time is doubled. However, despite these changes, both models still exhibit comparable prediction accuracy without significant differences. Consequently, the pruning method proposed in this paper effectively reduces the model’s compression size and inference time to some extent while having a relatively minor impact on prediction accuracy.
VI Conclusion and Future work
This paper presents the FedEdge AI-TC approach for trusted Federated Learning (FL) based efficient Network TC in 5G CPE/HGU. Firstly, FedEdge AI-TC effectively protects the data privacy of network subscribers by proposing an FL-based framework of local training, model parameters iterating, and centralized training. Secondly, a semi-supervised TC algorithm based on Variational Auto-Encoder (VAE) and convolutional neural network (CNN) is designed to reduce data dependence while keeping the TC accuracy. Finally, XAI-Pruning, an AI model compression method, combined with the DL model interpretability, is proposed to condense the model and interpret it globally and locally to achieve light-weighted AI-TC model deployment while building the trust in their decision of network operators. To demonstrate the efficiency of the proposed method, we conducted some experimental evaluations on commonly used public benchmark datasets and real network datasets. The results show that FedEdge AI-TC can outperform the benchmarking methods regarding the accuracy and achieve excellent TC performance of model inference on 5G CPE/HGU with limited computing resources, which effectively protects the users’ privacy and improve the model’s credibility.
However, besides reliability, robustness, and generalization are still two important topics when handling network traffic classification, especially using ML/DL. In the future, we will continuously focus on how to leverage ML/DL algorithms like generative models or large language models to enhance the reliability, robustness, and generalization of network traffic classification models.
Acknowledgment
The paper is supported by National Natural Science Fundation (General Program) of China under Grant 61972211
Reference
- [1] S. Rezaei and X. Liu, “Deep learning for encrypted traffic classification: An overview,” IEEE communications magazine, vol. 57, no. 5, pp. 76–81, 2019.
- [2] X. Zhou, Y. Hu, J. Wu, W. Liang, J. Ma, and Q. Jin, “Distribution bias aware collaborative generative adversarial network for imbalanced deep learning in industrial iot,” IEEE Transactions on Industrial Informatics, vol. 19, no. 1, pp. 570–580, 2023.
- [3] G. Aceto, D. Ciuonzo, A. Montieri, and A. Pescapé, “Mobile encrypted traffic classification using deep learning,” in 2018 Network traffic measurement and analysis conference (TMA). IEEE, 2018, pp. 1–8.
- [4] P. Wang, F. Ye, X. Chen, and Y. Qian, “Datanet: Deep learning based encrypted network traffic classification in sdn home gateway,” IEEE ACCESS, vol. 6, pp. 55 380–55 391, 2018.
- [5] G. Aceto, D. Ciuonzo, A. Montieri, and A. Pescapé, “Mobile encrypted traffic classification using deep learning: Experimental evaluation, lessons learned, and challenges,” IEEE Transactions on Network and Service Management, vol. 16, no. 2, pp. 445–458, 2019.
- [6] S. Niknam, H. S. Dhillon, and J. H. Reed, “Federated learning for wireless communications: Motivation, opportunities, and challenges,” IEEE Communications Magazine, vol. 58, no. 6, pp. 46–51, 2020.
- [7] X. Zhou, X. Ye, K. I.-K. Wang, W. Liang, N. K. C. Nair, S. Shimizu, Z. Yan, and Q. Jin, “Hierarchical federated learning with social context clustering-based participant selection for internet of medical things applications,” IEEE Transactions on Computational Social Systems, pp. 1–10, 2023.
- [8] P. Wang, X. Chen, F. Ye, and Z. Sun, “A survey of techniques for mobile service encrypted traffic classification using deep learning,” IEEE Access, vol. 7, pp. 54 024–54 033, 2019.
- [9] N. Bayat, W. Jackson, and D. Liu, “Deep learning for network traffic classification,” arXiv preprint arXiv:2106.12693, 2021.
- [10] B. Pang, Y. Fu, S. Ren, Y. Wang, Q. Liao, and Y. Jia, “Cgnn: traffic classification with graph neural network,” arXiv preprint arXiv:2110.09726, 2021.
- [11] L. Yang, A. Finamore, F. Jun, and D. Rossi, “Deep learning and zero-day traffic classification: Lessons learned from a commercial-grade dataset,” IEEE Transactions on Network and Service Management, vol. 18, no. 4, pp. 4103–4118, 2021.
- [12] P. Wang, S. Li, F. Ye, Z. Wang, and M. Zhang, “Packetcgan: Exploratory study of class imbalance for encrypted traffic classification using cgan,” in ICC 2020-2020 IEEE International Conference on Communications (ICC). IEEE, 2020, pp. 1–7.
- [13] X. Kong, C. Wang, Y. Li, J. Hou, T. Jiang, and Z. Liu, “Traffic classification based on cnn-lstm hybrid network,” in International Forum on Digital TV and Wireless Multimedia Communications. Springer, 2021, pp. 401–411.
- [14] H. Zhou, Y. Wang, and M. Ye, “A method of cnn traffic classification based on sppnet,” in 2018 14th international conference on computational intelligence and security (CIS). IEEE, 2018, pp. 390–394.
- [15] K. N. K. Thapa and N. Duraipandian, “Malicious traffic classification using long short-term memory (lstm) model,” Wireless Personal Communications, vol. 119, pp. 2707–2724, 2021.
- [16] H.-K. Lim, J.-B. Kim, K. Kim, Y.-G. Hong, and Y.-H. Han, “Payload-based traffic classification using multi-layer lstm in software defined networks,” Applied Sciences, vol. 9, no. 12, p. 2550, 2019.
- [17] X. Zhou, W. Liang, W. Li, K. Yan, S. Shimizu, and K. I.-K. Wang, “Hierarchical adversarial attacks against graph-neural-network-based iot network intrusion detection system,” IEEE Internet of Things Journal, vol. 9, no. 12, pp. 9310–9319, 2022.
- [18] S. Rezaei and X. Liu, “How to achieve high classification accuracy with just a few labels: A semi-supervised approach using sampled packets,” arXiv preprint arXiv:1812.09761, 2018.
- [19] Y. Liu, Z. Zhu, and P. Zhong, “A classification method for network traffic based on semi-supervised approach,” in Journal of Physics: Conference Series, vol. 2010, no. 1. IOP Publishing, 2021, p. 012014.
- [20] J. Ning, Y. Wang, J. Yang, H. Gacanin, and S. Ci, “A novel malware traffic classification method using semi-supervised learning,” in 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall). IEEE, 2021, pp. 1–5.
- [21] R. Zhao, X. Deng, Z. Yan, J. Ma, Z. Xue, and Y. Wang, “Mt-flowformer: A semi-supervised flow transformer for encrypted traffic classification,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 2576–2584.
- [22] A. Almalawi and A. Fahad, “An efficient network classification based on various-widths clustering and semi-supervised stacking,” IEEE Access, vol. 9, pp. 151 681–151 696, 2021.
- [23] Z. Jin, Z. Liang, M. He, Y. Peng, H. Xue, and Y. Wang, “A federated semi-supervised learning approach for network traffic classification,” International Journal of Network Management, vol. 33, no. 3, p. e2222, 2023.
- [24] T. Li, S. Chen, Z. Yao, X. Chen, and J. Yang, “Semi-supervised network traffic classification using deep generative models,” in 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). IEEE, 2018, pp. 1282–1288.
- [25] C. Xu, R. Xia, Y. Xiao, Y. Li, G. Shi, and K.-C. Chen, “Federated traffic synthesizing and classification using generative adversarial networks,” in ICC 2021-IEEE International Conference on Communications. IEEE, 2021, pp. 1–6.
- [26] P. Wang, Z. Wang, F. Ye, and X. Chen, “Bytesgan: A semi-supervised generative adversarial network for encrypted traffic classification in sdn edge gateway,” Computer Networks, vol. 200, p. 108535, 2021.
- [27] H. H. Yang, Z. Zhongyuan, and T. Quek, “Enabling intelligence at network edge network edge: An overview of federated learning,” ZTE Commun., vol. 18, no. 2, pp. 2–10, 2020.
- [28] O. Aouedi, K. Piamrat, G. Muller, and K. Singh, “Fluids: Federated learning with semi-supervised approach for intrusion detection system,” in 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC). IEEE, 2022, pp. 523–524.
- [29] P. Zhou, “Federated deep payload classification for industrial internet with cloud-edge architecture,” in 2020 16th International Conference on Mobility, Sensing and Networking (MSN). IEEE, 2020, pp. 228–235.
- [30] O. Aouedi, K. Piamrat, G. Muller, and K. Singh, “Intrusion detection for softwarized networks with semi-supervised federated learning,” in ICC 2022-IEEE International Conference on Communications. IEEE, 2022, pp. 5244–5249.
- [31] X. Zhou, W. Liang, K. I.-K. Wang, and L. T. Yang, “Deep correlation mining based on hierarchical hybrid networks for heterogeneous big data recommendations,” IEEE Transactions on Computational Social Systems, vol. 8, no. 1, pp. 171–178, 2021.
- [32] Y. Zhao, J. Chen, D. Wu, J. Teng, and S. Yu, “Multi-task network anomaly detection using federated learning,” in Proceedings of the 10th international symposium on information and communication technology, 2019, pp. 273–279.
- [33] H. Mun and Y. Lee, “Internet traffic classification with federated learning,” Electronics, vol. 10, no. 1, p. 27, 2020.
- [34] U. Majeed, L. U. Khan, and C. S. Hong, “Cross-silo horizontal federated learning for flow-based time-related-features oriented traffic classification,” in 2020 21st Asia-Pacific Network Operations and Management Symposium (APNOMS). IEEE, 2020, pp. 389–392.
- [35] E. Bakopoulou, B. Tillman, and A. Markopoulou, “Fedpacket: A federated learning approach to mobile packet classification,” IEEE Transactions on Mobile Computing, vol. 21, no. 10, pp. 3609–3628, 2021.
- [36] X. Zhou, W. Liang, K. I.-K. Wang, Z. Yan, L. T. Yang, W. Wei, J. Ma, and Q. Jin, “Decentralized p2p federated learning for privacy-preserving and resilient mobile robotic systems,” IEEE Wireless Communications, vol. 30, no. 2, pp. 82–89, 2023.
- [37] Z. Wang, C. Miao, Y. Xu, Z. Li, Z. Sun, and P. Wang, “Trusted encrypted traffic intrusion detection method based on federated learning and autoencoder,” China Communications, vol. 0, no. 0, pp. 1–25, 2023. [Online]. Available: http://www.cic-chinacommunications.cn/EN/10.23919/JCC.ja.2022-0392#2
- [38] P. Wang, F. Ye, and X. Chen, “A smart home gateway platform for data collection and awareness,” IEEE Commun. Mag., vol. 56, no. 9, pp. 87–93, 2018. [Online]. Available: https://doi.org/10.1109/MCOM.2018.1701217
- [39] G. Draper-Gil, A. H. Lashkari, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of encrypted and vpn traffic using time-related,” in Proceedings of the 2nd international conference on information systems security and privacy (ICISSP), 2016, pp. 407–414.
- [40] N. Moustafa and J. Slay, “Unsw-nb15: a comprehensive data set for network intrusion detection systems (unsw-nb15 network data set),” in 2015 military communications and information systems conference (MilCIS). IEEE, 2015, pp. 1–6.
- [41] G. Aceto, D. Ciuonzo, A. Montieri, V. Persico, and A. Pescapé, “Mirage: Mobile-app traffic capture and ground-truth creation,” in 2019 4th International Conference on Computing, Communications and Security (ICCCS). IEEE, 2019, pp. 1–8.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/wp.png) |
Pan Wang (M’18) received the BS/MS/Ph.D. degree in Electrical & Computer Engineering from Nanjing University of Posts&Telecommunications, Nanjing, China, in 2001, 2004, and 2013, respectively. He is currently a Full Professor at Nanjing University of Posts & Telecommunications, Nanjing, China. His research interests include AI-powered networking and security in B5G/6G/IoT/Smart Grid/CFN, and AI-enabled big data analysis. From 2017 to 2018, he has been a visiting scholar at University of Dayton (UD) in the Department of Electrical and Computer Engineering, OH, USA. He served as a TPC member of IEEE CyberSciTech Congress. He is also a reviewer for several journals, including IEEE Transaction on Network and Service Management, IEEE Transaction on EMERGING TOPICS IN COMPUTATIONAL INTELLIGENCE, IEEE Internet of Things Journal, IEEE Journal on Selected Areas in Communications, IEEE ACCESS, Computer Networks, Computer&Security, Computer Communications, Engineering Applications of Artificial Intelligence, Big Data Research, etc. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/lzy.png) |
Zeyi Li is currently pursuing the Ph.D. degree in Cyberspace Security at Nanjing University of Posts and Telecommunications. He was born in Soochow, Jiangsu, China, in 1997. He received his bachelor’s degree in mathematics in 2019 and received M.S. degree in computer science in 2022. His research interests include network security, communication network security, anomaly detection and analysis, deep packet inspection, and graph neural networks. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/fmy.jpg) |
Mengyi Fu was born in Huaian, Jiangsu, China ,in 2000. She is currently pursuing the Ph.D degree at NanjingUniversity of Posts and Telecommunications. She received her B.Sc from Nanjing University of Posts and Telecommunications, NanjingChina, in 2022. Her research includes encrypted traffic identification, deep learning and traffic prediction. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/wzx.png) |
Zixuan Wang was born in Nanjing, Jiangsu, China ,in 1994 . He obtained a bachelor’s degree from Tongda College of Nanjing University of Posts and Telecommunications in 2017, He is currently pursuing a master’s degree in logistics engineering at Nanjing University of Posts and Telecommunications. His research interests include encrypted traffic identification and data balancing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/zz.jpg) |
Ze Zhang currently pursuing the Master’s degree in Information Network at Nanjing University of Postsand Telecommunications. He was born in Zhenjiang, Jiangsu, China, in 2000. He received his Bachelor’s degree in Network Engineering in 2022. His research interests include computer networks, network security, anomaly detection and analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db15b578-3910-4f62-8114-4dfd5bbb7b7b/lmy.jpg) |
Minyao Liu was born in Ganzou, Jiangxi, China, in 2000. She is currently pursuing her master’s degree at Nanjing Post and Telecommunications University. She received her bachelor’s degree in Management from NUPT in 2022. Her research areas include traffic identification, deep learning and anomaly detection. |