Feasible Actor-Critic: Constrained Reinforcement Learning for Ensuring Statewise Safety
Abstract
The safety constraints commonly used by existing reinforcement learning (RL) methods are defined only on expectation of initial states, but allow each certain state to be unsafe, which is unsatisfying for real-world safety-critical tasks. In this paper, we introduce the feasible actor-critic (FAC) algorithm, which is the first model-free constrained RL method that considers statewise safety, that is safety for each initial state. We claim that some states are inherently unsafe no matter what policy we choose, while for other states there exist policies ensuring safety, where we say such states and policies are feasible. By adopting an additional neural network to first approximate the statewise Lagrange multiplier and then construct a novel statewise Lagrange function, we manage to obtain the optimal feasible policy which ensures safety for each feasible state, and the safest possible policy for infeasible states. Furthermore, the trained multiplier net can indicate whether a state is feasible or not. We provide theoretical guarantees that the constraint function and total rewards of FAC are upper and lower bounded by that of the expectation-based constrained RL methods, respectively. Experimental results on multiple tasks suggest that FAC has fewer constraint violations and higher average rewards than previous methods.
Keywords: Reinforcement Learning, Constrained Optimization, Lagrange Multiplier, Constraint Learning, AI Safety.
1 Introduction
Reinforcement learning (RL) has achieved superhuman performance in solving many complicated sequential decision-making problems like Go (Silver et al., 2016, 2017), Atari games (Mnih et al., 2013), and Starcraft (Vinyals et al., 2019). Such a huge potential attracts many real-world applications like autonomous driving (Guan et al., 2020; Ma et al., 2021), energy system management (Mason and Grijalva, 2019) and surgical robotics (Richter et al., 2019). However, most successful RL applications with these real-world applications are only with simulation platforms, for example, CARLA (Chen et al., 2021), TORCS (Wang et al., 2018) and SUMO (Ren et al., 2020) in autonomous driving. The lack of safety guarantee is one of the major limitations preventing these simulation achievements from being transferred to the real world, which becomes an urgent problem for widely benefiting from high-level artificial intelligence.
Current safety consideration of constrained or safe RL studies are usually defined on expectations of all possible initial states (Altman, 1999; Li, 2020; Achiam et al., 2017; Ray et al., 2019; Chow et al., 2017; Duan et al., 2019). However, there are several fatal flaws with this expectation-based safety constraint: (1) Each specific state is allowed to be unsafe as long as the expectation of states satisfies the constraint; (2) There is no way to know which states are safe and which are not, which means the safety for a specific state is almost random. Such properties are not acceptable for real-world safety-critical tasks. To avoid this problem, one might think about designing a constrained RL method to guarantee the whole state space to be safe. However, this is impossible in many realistic tasks (Mitchell et al., 2005; Duan et al., 2019; Li, 2020). For example, Figure 1 demonstrates an emergency braking task. Intuitively, if the vehicle is too close or too fast, the collision is inevitable. In this simple case, we can actually directly calculate which states are safe and which are not shown as the green region and red region in Figure 1(i), respectively. We claim such phenomenon is common in many real-world tasks that some states are inherently unsafe no matter what policy we choose, while for other states, there exist policies ensuring safety, where we say such states and policies are feasible. However, as shown in Figure 1(ii), the previous expectation-based method cannot approximate these regions well.

In this paper, we propose the feasible actor-critic (FAC) algorithm to guarantee safety of all feasible initial states and indicate which states are infeasible. By adopting an additional neural network to approximate the statewise Lagrange multiplier, we can handle infinite number of statewise safety constraints, thus considers safety for all possible states. The multiplier network stores additional information from the learning progress, and we can show that it can accurately indicate the feasibility of states through the statewise complementary slackness conditions and the gradient computation of multipliers. By training policy and multiplier networks with the primal-dual gradient ascent, we can obtain an optimal feasible policy that ensures safety for each feasible state, the safest possible policy for infeasible states, and a multiplier network indicating which states are infeasible. Furthermore, we provide theoretical guarantees that the constraint function and total rewards of FAC are upper and lower bounded by that of the expectation-based constrained RL methods.
Our main contributions are:
(1) We point out that commonly used expectation-based constraints fail to meet real-world safety requirements, and then introduce the novel definitions of statewise safety for more realistic safety criteria. We also clarify which states are possible to be safe by defining the feasible state and region.
(2) We propose FAC to obtain an optimal feasible policy that ensures safety for each feasible initial state. With an additional multiplier network, FAC can indicate the feasible property of a specific state. This feasibility indication has not been obtained by any other existing RL method.
(3) Experimental results on multiple tasks and safety constraints suggest that FAC has fewer constraint violations and higher average rewards than previous methods. The feasibility indicating ability is also verified.
2 Preliminaries
2.1 Constrained Markov Decision Process
The constrained Markov decision process (CMDP), , is to maximize the expected return of rewards while satisfying the constraint on the expected return of costs:
| (EP) |
where and are state and action space, is the policy in policy set , is the environment transition model, is the reward and cost, are their discounted factors, is the trajectory under policy starting from an initial state distribution (Sutton and Barto, 2018; Altman, 1999). The feasible policy set is defined as , but CMDP does not discuss which states are feasible. Notably, the percentile indicators rather than mean value are used to define worst-case safety constraints in some studies (Chow et al., 2017; Yang et al., 2021). Nevertheless, they are still wrapped by the trajectory expectation, so the problem that certain state is allowed to be unsafe still exists. Our motivation is to deal with the failure of safety guarantee caused by computing the expectation on initial state distribution, which is different from these worst-case studies.
2.2 Related Works
Constrained RL with expectation-based safety constraint. We focus on recent practical constrained RL algorithms for continuous state space. One branch of recent studies is to compute a constraint-satisfying policy gradient, for example, using Rosen projection (Uchibe and Doya, 2007) or the local approximate second-order solver similar to natural policy gradient (PG) (Achiam et al., 2017; Yang et al., 2020; Zhang et al., 2020). These local solvers have the recovery issue, which means that the recovery mechanism must be manually designed in case that there exists no constraint-satisfying policy gradient at a specific step. Furthermore, the approximation error and recovery mechanism makes these constrained RL methods hard to implement and also harms their performance. Another branch is the Lagrangian-based constrained RL, which is to
optimize the linear combination of expected returns and costs with a scalar multiplier. Lagrangian-based modification is applied with vanilla PG, actor-critic (AC), trust-region policy optimization (TRPO), and proximal policy optimization (PPO) (Chow et al., 2017; Schulman et al., 2015, 2017; Ray et al., 2019). Lagrangian-based approach is simple to implement and outperforms the constrained gradient methods in some complex tasks (Ray et al., 2019; Stooke et al., 2020). However, the oscillation issue seriously affects the performance of Lagrangian approach. Stooke et al. (2020); Peng et al. (2021) use the over-integral in the control theory to explain this phenomenon, and propose the PID-Lagrangian method to handle the oscillation problem.
Shielding RL or RL with controllers.
Some studies in the control theory have similar motivations of statewise safety, like safety barrier certificate or reachability theory (Mitchell et al., 2005; Ames et al., 2019; Ma et al., 2021). With these control-based approaches to compute a safe action set at a specific state, some RL studies project the action into the safe set to achieve safety of the current state (Cheng et al., 2019; Dalal et al., 2018; Pham et al., 2018). These methods is simple to implement, but have difficulties in handling stochastic policy and guaranteeing the policy optimality. The major limitation of shields or controllers is that they require a prior model and can only predict at a specific state, while FAC is a model-free constrained RL algorithm with a feasibility indicator of the whole state space. We do not consider these methods in the baselines since prior models are not available for the empirical environments.
3 Statewise Safety and Feasibility Analysis
In this section, we introduce the complete definition about statewise safety constraint, and the feasible partition of state space. How to interpreter the feasibility of a given state by the Lagrange multiplier is also explained.
3.1 Definitions of Statewise Safety
Definition 1 (Feasible state under )
Given a policy , we define that a state is feasible, or safe if its expected return of cost satisfies the inequality:
where denotes that the expected value of trajectory generated by policy starting from a given initial state . is named as safety critic, or cost value function. If the constraint is violated under policy at state , the state is defined to be unsafe.
Before defining safety constraints, we first define the feasible partition of state space:
Definition 2 (Infeasible region)
States those are unsafe no matter what policy we choose are defined as the infeasible state. The infeasible region is defined as the set of all infeasible states:
Definition 3 (Feasible region)
The feasible region is defined as the complementary set of the infeasible region
Note that the feasible and infeasible regions are irrelevant with policy . However, the policy may be not good enough to guarantee that all possibly feasible states to be feasible, so we define feasible region under policy :
It is obvious that . Denote as the set of all possible initial states. Ideally, if , we can guarantee all initial states to be feasible, or safe. However, in practice, may include infeasible states, and we can not find an appropriate policy for these infeasible states. To define a meaningful feasible property of policy, we consider the intersection of and :
Definition 4 (Statewise safety constraint)
Define the feasible initial state set as . The statewise safety constraint is defined to guarantee every state in the feasible initial state set to be safe:
| (3.1) |
We define a policy to be feasible if it satisfies the statewise safety constraint. For those infeasible initial states , consistently optimizing them will damage the performance. We can actually identify them by our method in the following.
The feasible policy set under statewise safety constraint is . Equivalently, . Finally, without changing the RL maximization objective, we formulate the optimization problem with statewise safety constraint:
| (SP) |
3.2 Multipliers: Statewise Feasibility Indicators
We use the Lagrangian-based approach to solve problem (SP). As each state in has a constraint, there exists the corresponding Lagrange multiplier at each state, and we denote the statewise multiplier as . The resulting Lagrange function is named as original statewise Lagrangian, which is shown as:
| (O-SL) |
The multipliers have the physical meaning of solution feasibility. We explain the relation between multipliers and feasibility first by the statewise complementary slackness condition:
Proposition 5 (Statewise complementary slackness condition)
For the problem (SP), at state the optimal multiplier and optimal safety critic are , the following conditions hold:111We assume the strong duality holds here for simplicity, and the following experimental results depict that the feasibility indicator still works in complex environments where the strong duality assumption may fail.
| (3.2) |
The proposition comes from the Karush-Kuhn-Tucker (KKT) necessary condition for the problem (SP). If , we say that the constraint at state is active. An active constraint represents that the constraint is preventing the objective function to be further optimized, otherwise the state steps into the infeasible region. A state whose safety constraint is not active must lie inside the feasible region. In this way, the optimal multiplier can indicate whether the constraint of a feasible state is active or not. However, in practical, it is not helpful for the identification of those infeasible states . Thanks to the following Corollary, we can further distinguish the infeasible states by the multipliers, pick out them and find the approximate optimal feasible solution.
Corollary 6
If lies in infeasible region, then with the primal-dual ascent.
The main idea is that if the feasible solution do not exists, the gradient of will always be positive for state . Detailed proof is provided in Appendix A.1. As suggested by the Proposition 5 and Corollary 6, the approximate relation between multipliers and feasibility can be established, as shown in Table 1.
[h] Multiplier scale Feasibility situation of Zero Inactive (inside feasible region) Finite Active (on the boundary of feasible region) Infinite Infeasible region
-
A heuristic threshold is set to indicate infinity practically.
4 Feasible Actor-Critic
In this section, we provide details about the feasible actor-critic algorithm. Firstly, we introduce the difficulties of handling the original Lagrangian (O-SL), which is also the reason why this type of safety constraint is not considered by existing studies. Then we provides theoretical performance analysis and implementation instructions.
4.1 Statewise Lagrangian for Practical Implementation
For practical implementation with RL, the sum term in (O-SL) is intractable since we have no access to the feasible region but only a state distribution . Besides, the summation over infinite state set is impractical in continuous domain. This is the reason why the existing constrained RL methods do not consider this type of safety constraint. We try to adapt the original statewise Lagrangian (O-SL) to fit the paradigm of sample-based learning. For this, we first formulate the statewise Lagrangian as:
| (SL) |
Then, we propose a theorem for the equivalence of (O-SL) and (SL).
Theorem 7 (Equivalence of (O-SL) and (SL))
If the optimal policy and Lagrange multiplier mapping and exist for problem , then is the optimal policy of problem (SP).
The main idea of this proof is to scale the safety constraints by the probabilistic density, that is, . As and for , , the scaled constraint is equivalent to the statewise safety constraint (3.1). For those infeasible initial states , the multiplier still goes to infinity. See Appendix A.2 for detailed proof.
4.2 Performance Comparison with Expected Lagrangian Methods
In this section, we provide theoretical analysis on performance of FAC. Two theorems are proposed to discuss the upper bound of constraint satisfaction and the lower bound of total rewards, which are exactly those with the expectation-based safety constraint, respectively.
Theorem 8
If all possible initial states are feasible or , a feasible policy under statewise constraints must be feasible under expectation-based constraints, that is, for the same constraint threshold , .
See Appendix A.3 for its proof. The theorem indicates that a feasible policy under the criterion of expectation-based constraints may become "unsafe" in certain states, suggesting the necessities of the statewise constraints in safety-critical tasks.
The performance comparison is under the concave-convex assumption both on policy and state space. The Lagrange function of the optimization problem with expectation constraint is:
| (EL) |
We name the Lagrange function (EL) as the expected Lagrangian. The optimal Lagrangian and total rewards of (EL) and (SL) are denoted by and .
Theorem 9
Assume that are both nonempty convex set. is concave on and , and is convex on and . The optimal expected Lagrangian (EL) is the upper bound of the optimal statewise Lagrangian (SL), that is, . If the Slater’s condition holds on for each , then , {stw, exp}. We further obtain the total rewards lower bound of statewise Lagrangian (SL) as
| (4.1) |
See Appendix A.4 for its proof. The main idea of proof is that the statewise multipliers find the optimal solution of the dual problem on each feasible initial state, while the expected Lagrangian optimizes the dual problem with only a single dual variable or multiplier. Assumptions made in this theorem may be a little strong. Nevertheless, the thought of optimizing the dual problems in a statewise manner does introduce more flexibility to obtain better Lagrangian, and further better policies practically.
4.3 Practical Algorithm
We optimize the statewise Lagrangian (SL) based on the off-policy maximum entropy RL framework. A notable difference is that we incorporate a neural network to approximate Lagrange multiplier with parameters , that is, . We need to train the value function , cost value function , policy , and the multipliers listed in Table 2.
| Function name | Function type | Notions | Weights |
|---|---|---|---|
| Value function | soft Q-function | ||
| Cost value function | Q-function | ||
| Policy | stochastic policy with bijector | ||
| Multipliers | multiplier function |
We use the primal-dual gradient ascent to alternatively update policy and multiplier networks. The pseudocode is shown in Algorithm 1. represent the losses of values (two values and one cost value), policy, temperature and multiplier updates. is their learning rates. The loss and gradient of soft Q-function, or the reward value function is exactly the same as those in the study by Haarnoja et al. (2018). The update of cost Q-function is:
The stochastic gradient to optimize cost Q-function is
According to Theorem 7, we expand the with the soft Q-function and Q-function, respectively, to formulate the policy loss:
| (4.2) |
The policy gradient with the reparameterized policy can be approximated by:
where the threshold is neglected since it is irrelevant with . The loss function for updating multiplier net is the same as (4.2), which is simplified by
where the entropy and reward value function term are neglected since they are irrelevant with the multipliers. The stochastic gradient is
| (4.3) |
Additionally, we introduce some tricks used in practical implementations. The primal-dual gradient ascent has poor convergence performance practically. Inspired by exiting studies about learning with adversarial objective function and delayed policy update tricks (Goodfellow et al., 2014; Fujimoto et al., 2018), we set a different interval schedule for policy delay steps and ascent delay steps to improve stability. The oscillation issue is also an inherent problem for primal-dual ascent. Rather than adopting the PID controller to enforce stability (for example, Peng et al., 2021; Stooke et al., 2020), We start training the multiplier net until the cost value function gets close to the constraint threshold. These tricks significantly improve the stability of the training process.
5 Empirical Analysis
We choose two different sets of experiments to evaluate the safety enhancement of FAC under different constraint formulations: (1) MuJuCo robots walking with speed limits; (2) Safety Gym agents exploring safely while avoiding multiple obstacles. The speed constraint is a rather easy one, while the constraint of safe exploration is more realistic and challenging. All environments are implemented with Gym API and MuJoCo physical simulator (Brockman et al., 2016; Ray et al., 2019; Todorov et al., 2012).
We compare our algorithm against commonly used constrained RL baseline algorithms (Achiam et al., 2017; Ray et al., 2019; Stooke et al., 2020), including Constrained Policy Optimization (CPO), TRPO-Lagrangian (TRPO-L) and PPO-Lagrangian (PPO-L). They are all with the expectation-based constraint. TRPO-L and PPO-L use the primal-dual gradient ascent to compute the saddle point of expected Lagrangian (EL) with a scalar multiplier, and the objective function is the surrogate formulations in TRPO or PPO. The metrics include both constraint satisfaction and total rewards, and a good policy is to get as high returns as possible while satisfying constraints. Details about baselines and the hyperparameters are provided in Appendix B.
5.1 Controlling Robots with Speed Limit



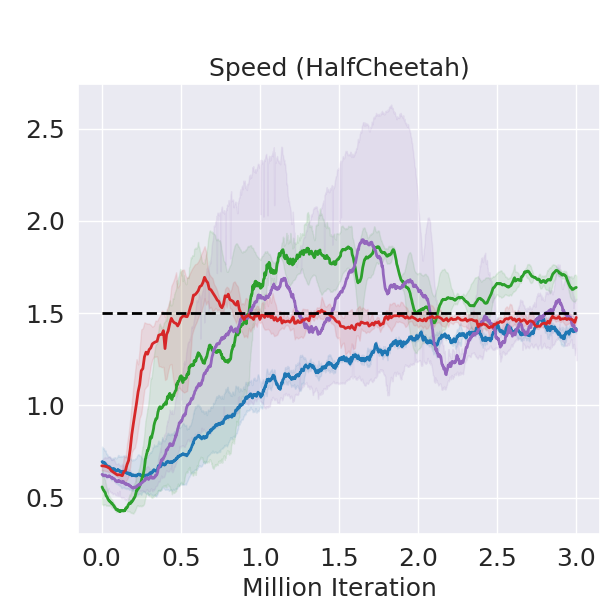
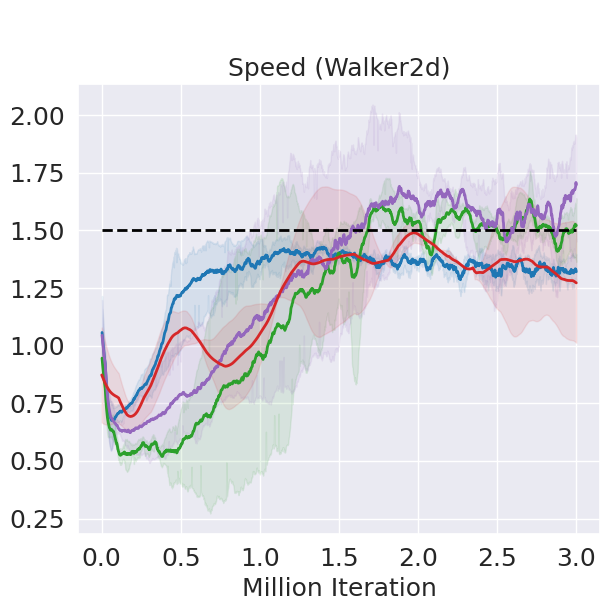


We choose three MuJoCo environments where we attempt to train a robotic agent to walk with speed limit. Figure 2 shows that FAC outperforms other baselines in terms of reward on all three tasks while enforcing the speed constraint. As for the expectation-based Lagrangian methods, TRPO-L and PPO-L outperform CPO in some environments, which is consistent with the results of Ray et al. (2019); Stooke et al. (2020). However, they suffer from the oscillation issues, and the constraints are violated in some environments while FAC consistently enforces the constraint satisfaction of not only the mean value, but also most of the error bar. FAC is robust in all environments, while baseline methods might perform not well in some environments. Especially in the rather challenging task of Walker2d, PPO-L fails to learn a meaningful policy.
| Environment |
|
FAC | CPO | TRPO-L | PPO-L | ||
|---|---|---|---|---|---|---|---|
| HalfCheetah-v3 | Return | 131826.3 | 1303120 | 96755.9 | 1180432 | ||
| Speed | 1.460.013 | 1.410.011 | 1.430.125 | 1.630.065 | |||
| Walker2d-v3 | Return | 1651314 | 979400 | 1483384 | 46068.8 | ||
| Speed | 1.300.230 | 1.320.051 | 1.670.197 | 1.500.088 | |||
| Ant-v3 | Return | 212168.4 | 1898111 | 2017119 | 1646117 | ||
| Speed | 1.480.052 | 1.44 0.053 | 1.520.150 | 1.430.032 |
5.2 Safe Exploration Tasks
We choose two Safety Gym environments with different agents and tasks, called Point-Button (PB) and Car-Goal (CG). In both environments, we control the agent to collect as many as bonuses distributed among a 2D arena while avoiding collisions with static or moving obstacles as best as we can. Especially, the cost signal is encoded by a binary variable, which provides once any unsafe action is taken, otherwise . The safety constraints are the dangerous action rate . It is transformed to the safety critic constraint . Details of the transformation is provided in Appendix C.2. Besides, we call an episode is dangerous when the dangerous action rate constraint is violated. We count the cost value distribution, the episodic dangerous action rate and the number of dangerous episodes as the metrics to evaluate the constraint satisfaction performance.



To better understand the constraint satisfaction property with statewise safety constraints, we visualize the cost value distribution over a batch of state during training in Figure 3. Results show that most states in the distribution with FAC satisfy the safety constraint. Inevitably, there exist some infeasible states in the batch in practical implementation, so not all states satisfy the safety constraint after training. With TRPO-L, the peak of distribution lies on the constraint threshold approximately. The distribution is approximately symmetric, so the fact that the peak lies on the constraint threshold corresponds to that the expectation satisfies the safety constraint. Obviously with the expectation constraint satisfied, half of the batch states are still violating the safety constraint. The constraint-violating states are even more for CPO since CPO does not obey the expectation-based constraint.




| Env |
|
FAC | CPO | TRPO-L | PPO-L | |||
|---|---|---|---|---|---|---|---|---|
| PB | Return | 17.083.55 | 25.671.96 | 18.761.42 | 20.480.63 | |||
| (%) | 6.3721.764 | 13.190.688 | 10.475.357 | 11.080.855 | ||||
|
3 | 73 | 52 | 66 | ||||
| CG | Return | 7.510.56 | 18.623.25 | 12.491.31 | 10.992.25 | |||
| (%) | 6.0862.508 | 16.711.874 | 12.291.636 | 9.8151.064 | ||||
|
8 | 77 | 69 | 47 |
Table 4 shows the numerical summaries of safe exploration tasks, and training curves can be found in Figure 4. Results demonstrate that FAC not only confines the average episodic dangerous action rate to satisfy the constraint, but most of the error range to satisfy the constraint, which means almost all test episodes are enforced to be safe. The remarkable lowest numbers of dangerous test episodes verify the effectiveness of our method. As for baseline algorithms, CPO fails to satisfy the expectation-based constraints in all safe exploration tasks, which is consistent with observation made by Ray et al. (2019). For TRPO-L or PPO-L, although they yield a constraint-satisfying result for their expectation-based constraints, there are still half of the dangerous episodes. It suggests that expectation-based safety constraints are not enough to guarantee the safety of a trajectory, while FAC improves this in a large margin. The trade-off between the reward and cost returns in safe exploration environments is consistent with results of Ray et al. (2019), so the performance sacrifice of FAC is reasonable.
5.3 Feasibility Indicator by Multiplier Network






We select one episode from each safe exploration task to demonstrate the ability to indicate feasibility with the multiplier network. One of them demonstrates how the agent restores from the infeasible region, and the other demonstrates how the agent keeps itself away from the infeasible region by staying on the boundary. Figure 5 shows three representative frames in each episode. The heuristic threshold of infinity is , which is determined by the scale of value function and cost value function. Details about determining this threshold are analyzed in Appendix C.3.
In Figure 5(a), the multiplier exceeds the infinite threshold and the multiplier is rather large, which indicates that the agent lies in the infeasible region. The agent chooses to turn around and wait for the moving blocks (the purple cube) to go away, which is the safest policy for standing still. Thanks to the moving block giving way, the multiplier decreases quickly, suggesting that state in (b) changes to a feasible state lying on the boundary of feasible region. The agent bypasses the static obstacles since going straight will leave the feasible region. Finally, when the agent approaches the destination in (c), the multiplier becomes zero. Obviously, the agent lies in the feasible region without active safety constraints. The similar progress with (b)-(c) happens in (d)-(f). The agent chooses to bypass the static obstacles by firstly heading to the upper zone where the obstacles are sparse, then turning around to the destination. Notably, the cost value function can also indicate the activeness of the constraints. However, this judgement requires highly accurate value estimation, which is hard for RL value estimations. As shown in Figure 5 (b) and (d), the constraints are active with finite multipliers, but cost values are not strictly equal to the threshold. Furthermore, if constraint violation happens like Figure 5(a) and (d), only the cost value function can not distinguish whether the state lies in infeasible region. These cases are critical since we must avoid infeasible region like (a), but can improve policy to make (d) feasible.
6 Concluding Remarks
We introduced the concept of statewise safety, which requires that the safety constraints starting from arbitrary feasible initial states should be satisfied. We proposed the feasible actor-critic (FAC) algorithm to guarantee statewise safety with a multiplier network as the feasibility indicator. FAC is easy to implement and shows effective guarantee of statewise safety in several simulated robotics tasks. The multiplier network can provide accurate feasible region indication. We also provided theoretical guarantees that the constraint function and total rewards of FAC are upper and lower bounded by that of the expectation-based constrained RL methods. Safety issues are supremely critical to applying RL in real-world tasks. We believe that a meaningful safety threshold should be the statewise formulation starting from each initial state, rather than from the initial distributions. Therefore, the statewise safety constraint must be taken into consideration, and we suggest safe RL researchers to focus on the statewise safety. Moreover, the multiplier net actually learns and stores the information not explored by any other previous RL algorithms. Further exploiting the multiplier network may inspire new paradigms when considering safety in the RL society. FAC still suffers from inherent problems of primal-dual ascent, like oscillations and sensitivity to the update of the multiplier network, which will be addressed in the future works. A more accurate judgement from the multiplier to the feasibility is also considered. There are some promising directions related to the feasibility information provided by the multiplier net. For example, it can be used to design safe exploration rules.
Acknowledgments
This study is supported by National Key R&D Program of China with 2020YFB1600200. This study is also supported by Tsinghua University Toyota Joint Research Center for AI Technology of Automated Vehicle.
A Proof of Theorems
A.1 Proof of Corollary 6
There always not exists feasible solution means that at state , the inequality always holds:
According to the gradient of multiplier network (4.3), is always greater than 0, which drives the multiplier to infinity.
A.2 Proof of Theorem 7
Considering only the feasible region since we can not find a policy to enforce infeasible states to be safe, and the alternative Lagrangian in equation (SL) with a parameterized policy is:
Construct an alternative constrained optimization problem here, whose formulation is exactly corresponding to the optimization problem (SP):
| (A-SP) | ||||
| s.t. |
We focus on the constraint formulation of problem (A-SP). The visiting probability has the property of:
The initial feasible state set has the property
According to the definition of possible initial state set, for those with , . For those with , that is, the constraints in problem (A-SP) is equivalent to . Therefore, the constraint can be reformulated to
which is exactly the definition of feasible policy.
A.3 Proof of Theorem 8
The expectation-based constraints can be reformulated as
According to the Definition 4, for a policy and , . Therefore, the expectation on the initial state distribution
A.4 Proof of Theorem 9
We regard the state as a random variable in optimizing problem (SP). Then for each state, we can construct a Lagrange function as
| (A.1) |
The Lagrange dual problem is
| (A.2) |
We denote as the dual problem:
| (A.3) |
The expected Lagrangian optimize the expected solution of .
Lemma 10 (Convex condition for infimum operation (Bertsekas, 1997))
If is a convex nonempty set, the function is convex in , then the infimum on
| (A.4) |
is concave.
Proposition 11
The dual problem of :
| (A.5) |
is concave on .
Proof According to the concave-convex assumption and the linear of convexity, for each ,
| (A.6) |
is convex on . Therefore, according to Lemma 10, for each , is concave on .
Lemma 12 (Lower bound on deterministic equivalent (Shapiro et al., 2014))
For a stochastic programming problem with the optimization variable and random variable , if is convex in for each , then
| (A.7) |
We use to denote the optimal solution of dual problems of (EL). Then we get
| (A.8) | ||||
The inequality holds because the Jensen inequality under the concave-convex assumption.
Lemma 13 (Infinite fitting power of policy and multipliers (Li, 2020))
If the policy has infinite fitting power, then
According to the definition of the statewise Lagrangian (SL), we get
| (A.9) | ||||
The equality between swapping the expectation and infimum is because if the policy has infinite fitting ability. The inequality about expectation and max is analyzed by Thrun and Schwartz (1993).222If the multiplier net also has infinite fitting power here, the inequality is replaced by the equality. We do not need the infinite fitting ability of multiplier approximation here.
Proposition 14
The optimal solution of dual problem (A.5) is concave on .
Proof
According to the property of dual problem, the domain of dual problem (A.5) is convex, and dual problem is concave on (Bertsekas, 1997). As we already give the convavity of on , we can use Lemma 10 again and get the concavity of .
According to Lemma A.7 and combining (A.8) and (A.9), we get:
Then we get:
Additionally, if the Slater’s condition holds on for each , then the strong duality holds (Bertsekas, 1997). The total rewards lower bound can be further obtained:
B Baseline Algorithms and Implementations
B.1 Implementations
Implementation of FAC are based on the Parallel Asynchronous Buffer-Actor-Learner (PABAL) architecture proposed by Guan et al. (2021). All experiments are implemented on Intel Xeon Gold 6248 processors with 12 parallel actors, including 4 workers to sample, 4 buffers to store data and 4 learners to compute gradients.333Our open-source implementation of FAC can be found at https://github.com/mahaitongdae/Feasible-Actor-Critic. The original implementation of PABAL can be found at https://github.com/idthanm/mpg. The baseline implementation is modified from https://github.com/openai/safety-starter-agents and https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail.
B.2 Hyperparameters
The hyperparameters of FAC and baseline algorithms are listed in Table 5.
| Algorithm | Value |
|---|---|
| FAC | |
| Optimizer | Adam () |
| Approximation function | Multi-layer Perceptron |
| Number of hidden layers | 2 |
| Number of hidden units per layer | 256 |
| Nonlinearity of hidden layer | ELU |
| Nonlinearity of output layer | linear |
| Actor learning rate | Linear annealing |
| Critic learning rate | Linear annealing |
| Learning rate of multiplier net | Linear annealing |
| Learning rate of | Linear annealing |
| Reward discount factor () | 0.99 |
| Cost discount factor () | 0.99 |
| Policy update interval () (speed limit tasks) | 2 |
| Policy update interval () (safe exploration tasks) | 4 |
| Multiplier ascent interval () (speed limit tasks) | 6 |
| Multiplier ascent interval () (safe exploration tasks) | 12 |
| Target smoothing coefficient () | 0.005 |
| Max episode length () | 1000 |
| Expected entropy () | Action Dimentions |
| Replay buffer size | |
| Reward scale factor (speed limit tasks) | 0.2 |
| Reward scale factor (safe exploration tasks) | 1 |
| Replay batch size | 256 |
| CPO, TRPO-Lagrangian | |
| Max KL divergence | |
| Damping coefficient | |
| Backtrack coefficient | |
| Backtrack iterations | |
| Iteration for training values | |
| Init | |
| GAE parameters | |
| Batch size | |
| Max conjugate gradient iterations | |
| PPO-Lagrangian | |
| Clip ratio | |
| KL margin | |
| Mini Bactch Size |
C Additional Experiment Details
C.1 Details about Emergency Braking Task
The emergency braking tasks includes a static obstacles, and a vehicle. The reward is to decelerate as less as possible:
| (C.1) |
As we want the safety constraint holds for each time , we use a finite horizon design for finite constraint in one initial state: the safety constriant: , where represents the prediction steps. The initial state distribution is a uniform distribution on the theoretical feasible region . We use the vanilla PG method (Sutton et al., 2000) added with a expectation-based Lagrangian to solve this problems. The resulting region in Figure 1(ii) is estimated by sampling approximation. We sample the initial state every 0.1 m or m/s in the state space, which adds up to samples. Then for each initial states, we use the trained policy to drive the car, and see if it will collide with the obstacles.
C.2 Safety Critic Constraint Transformation
A real-world safety-oriented constraint is usually the limited frequency of dangerous action frequency in the continuous tasks, or the limited number of cost signal in a -step episode (Ray et al., 2019). We use the binary formulation of cost function , where if the action is dangerous otherwise . We further assume the cost signal occurs uniformly in the sampling. We use the to denote the frequency threshold (the limited number in a -step episode is correspondingly), then a real-world safety-oriented dangerous action frequency constraint can be transferred to a discounted value safety constraint with discounted factor :
| (C.2) |
In practice, and is a large integer in the episodic task case or infinite in the continuous task case, so can be neglected, and the relation can be simplified as . In our safe exploration tasks, .
C.3 Boundary of Infinite Multipliers
We use the following equation of estimate the boundary between finite and infinite multipliers. For the optimal Lagrange multiplier at state of (SL), the following equation holds:
| (C.3) |
Therefore, the scale of can be a heuristic threshold for the multipliers. A simplest choice is the ratio of average gradient norm of objective and constraint function, as the threshold, which is what we use in the safe exploration tasks. More dedicated design will be considered in the future works.
References
- Achiam et al. (2017) Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In International Conference on Machine Learning, pages 22–31, Sydney, Australia, 2017. PMLR.
- Altman (1999) Eitan Altman. Constrained Markov decision processes, volume 7. CRC Press, 1999.
- Ames et al. (2019) Aaron D Ames, Samuel Coogan, Magnus Egerstedt, Gennaro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications. In 2019 18th European Control Conference (ECC), pages 3420–3431, Bochum, Germany, 2019. IEEE.
- Bertsekas (1997) Dimitri P Bertsekas. Nonlinear programming. Journal of the Operational Research Society, 48(3):334–334, 1997.
- Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Chen et al. (2021) Jianyu Chen, Shengbo Eben Li, and Masayoshi Tomizuka. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems, 2021.
- Cheng et al. (2019) Richard Cheng, Gábor Orosz, Richard M Murray, and Joel W Burdick. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 3387–3395, 2019.
- Chow et al. (2017) Yinlam Chow, Mohammad Ghavamzadeh, Lucas Janson, and Marco Pavone. Risk-constrained reinforcement learning with percentile risk criteria. The Journal of Machine Learning Research, 18(1):6070–6120, 2017.
- Dalal et al. (2018) Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces. arXiv preprint arXiv:1801.08757, 2018.
- Duan et al. (2019) Jingliang Duan, Zhengyu Liu, Shengbo Eben Li, Qi Sun, Zhenzhong Jia, and Bo Cheng. Deep adaptive dynamic programming for nonaffine nonlinear optimal control problem with state constraints. arXiv preprint arXiv:1911.11397, 2019.
- Fujimoto et al. (2018) Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International Conference on Machine Learning, pages 1587–1596, Stockholm, Sweden, 2018. PMLR.
- Goodfellow et al. (2014) Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. arXiv preprint arXiv:1406.2661, 2014.
- Guan et al. (2020) Yang Guan, Yangang Ren, Shengbo Eben Li, Qi Sun, Laiquan Luo, and Keqiang Li. Centralized cooperation for connected and automated vehicles at intersections by proximal policy optimization. IEEE Transactions on Vehicular Technology, 69(11):12597–12608, 2020.
- Guan et al. (2021) Yang Guan, Jingliang Duan, Shengbo Eben Li, Jie Li, Jianyu Chen, and Bo Cheng. Mixed policy gradient. arXiv preprint arXiv:2102.11513, 2021.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pages 1861–1870, Stockholm, Sweden, 2018. PMLR.
- Li (2020) Shengbo Eben Li. Reinforcement Learning and Control. Tsinghua University Lecture Notes, 2020. URL http://www.idlab-tsinghua.com/thulab/labweb/publications.html.
- Ma et al. (2021) Haitong Ma, Jianyu Chen, Shengbo Eben Li, Ziyu Lin, and Sifa Zheng. Model-based constrained reinforcement learning using generalized control barrier function. arXiv preprint arXiv:2103.01556, 2021.
- Mason and Grijalva (2019) Karl Mason and Santiago Grijalva. A review of reinforcement learning for autonomous building energy management. Computers & Electrical Engineering, 78:300–312, 2019.
- Mitchell et al. (2005) Ian M Mitchell, Alexandre M Bayen, and Claire J Tomlin. A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games. IEEE Transactions on automatic control, 50(7):947–957, 2005.
- Mnih et al. (2013) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Peng et al. (2021) Baiyu Peng, Yao Mu, Jingliang Duan, Yang Guan, Shengbo Eben Li, and Jianyu Chen. Separated proportional-integral lagrangian for chance constrained reinforcement learning. arXiv preprint arXiv:2102.08539, 2021.
- Pham et al. (2018) Tu-Hoa Pham, Giovanni De Magistris, and Ryuki Tachibana. Optlayer-practical constrained optimization for deep reinforcement learning in the real world. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6236–6243, Brisbane, Australia, 2018. IEEE.
- Ray et al. (2019) Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep reinforcement learning. arXiv preprint arXiv:1910.01708, 2019.
- Ren et al. (2020) Yangang Ren, Jingliang Duan, Shengbo Eben Li, Yang Guan, and Qi Sun. Improving generalization of reinforcement learning with minimax distributional soft actor-critic. In 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), pages 1–6, Online, 2020. IEEE.
- Richter et al. (2019) Florian Richter, Ryan K Orosco, and Michael C Yip. Open-sourced reinforcement learning environments for surgical robotics. arXiv preprint arXiv:1903.02090, 2019.
- Schulman et al. (2015) John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International conference on machine learning, pages 1889–1897, Lille, France, 2015. PMLR.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shapiro et al. (2014) Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczyński. Lectures on stochastic programming: modeling and theory. SIAM, 2014.
- Silver et al. (2016) David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016.
- Silver et al. (2017) David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
- Stooke et al. (2020) Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by pid lagrangian methods. In International Conference on Machine Learning, pages 9133–9143, Online, 2020. PMLR.
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Sutton et al. (2000) Richard S Sutton, David A McAllester, Satinder P Singh, Yishay Mansour, et al. Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems, volume 12, pages 1057–1063, Denver, Colorado, 2000.
- Thrun and Schwartz (1993) Sebastian Thrun and Anton Schwartz. Issues in using function approximation for reinforcement learning. In Proceedings of the Fourth Connectionist Models Summer School, pages 255–263. Hillsdale, NJ, 1993.
- Todorov et al. (2012) Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033, Algarve, Portugal, 2012. IEEE.
- Uchibe and Doya (2007) Eiji Uchibe and Kenji Doya. Constrained reinforcement learning from intrinsic and extrinsic rewards. In 2007 IEEE 6th International Conference on Development and Learning, pages 163–168, Lugano, Switzerland, 2007. IEEE.
- Vinyals et al. (2019) Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Wang et al. (2018) Sen Wang, Daoyuan Jia, and Xinshuo Weng. Deep reinforcement learning for autonomous driving. arXiv preprint arXiv:1811.11329, 2018.
- Yang et al. (2021) Qisong Yang, Thiago D Simão, Simon H Tindemans, and Matthijs TJ Spaan. Wcsac: Worst-case soft actor critic for safety-constrained reinforcement learning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence., Online, 2021.
- Yang et al. (2020) Tsung-Yen Yang, Justinian Rosca, Karthik Narasimhan, and Peter J Ramadge. Projection-based constrained policy optimization. arXiv preprint arXiv:2010.03152, 2020.
- Zhang et al. (2020) Yiming Zhang, Quan Vuong, and Keith Ross. First order constrained optimization in policy space. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 15338–15349, Online, 2020.