FDM-Bench: A Comprehensive Benchmark for Evaluating Large Language Models in Additive Manufacturing Tasks
Abstract
Fused Deposition Modeling (FDM) is a widely used additive manufacturing (AM) technique valued for its flexibility and cost-efficiency, with applications in a variety of industries including healthcare and aerospace. Recent technological developments have made affordable FDM machines accessible and encouraged adoption among diverse users. However, the design, planning, and production process in FDM require specialized interdisciplinary knowledge. Managing the complex parameters and resolving print defects in FDM remain challenging. These technical complexities form the most critical barrier preventing individuals without technical backgrounds and even professional engineers without training in other domains from participating in AM design and manufacturing. Large Language Models (LLMs), with their advanced capabilities in text and code processing, offer the potential for addressing these challenges in FDM. However, existing research on LLM applications in this field is limited, typically focusing on specific use cases without providing comprehensive evaluations across multiple models and tasks. To this end, we introduce FDM-Bench, a benchmark dataset designed to evaluate LLMs on FDM-specific tasks. FDM-Bench enables a thorough assessment by including user queries across various experience levels and G-code samples that represent a range of anomalies. We evaluate two closed-source models (GPT-4o and Claude 3.5 Sonnet) and two open-source models (Llama-3.1-70B and Llama-3.1-405B) on FDM-Bench. A panel of FDM experts assess the models’ responses to user queries in detail. Results indicate that closed-source models generally outperform open-source models in G-code anomaly detection, whereas Llama-3.1-405B demonstrates a slight advantage over other models in responding to user queries. These findings underscore FDM-Bench’s potential as a foundational tool for advancing research on LLM capabilities in FDM.
keywords:
Large language model; Fused deposition modeling; Additive manufacturing; Benchmark dataset; Anomaly detection; G-code analysis; User queries1 Introduction
Fused Deposition Modeling (FDM) is a widely adopted additive manufacturing (AM) technique valued for its versatility and cost-effectiveness [1]. Its ability to reduce lead times and accelerate prototyping cycles makes FDM particularly attractive to industries that prioritize rapid iteration [2, 3]. Therefore, this method is extensively used across industries, including manufacturing [2, 4], healthcare [5, 6], aerospace [7], and consumer goods [8, 9, 10], for producing complex geometries and customized components. The accessibility of FDM has extended its reach beyond industrial applications, making it available to small businesses [11], research labs [12], and individuals.
Despite its broad applications, FDM is susceptible to quality issues such as low dimensional accuracy [13] and poor surface quality [14]. Various process parameters, such as layer height, bed temperature, print speed, and fill angle, affect the quality of FDM-printed parts [15, 16, 17, 18]. These parameters interact in complex ways [19], and their optimal configuration depends on numerous factors, such as machine type, filament materials, and nozzle dimensions [20, 21]. Additionally, a wide range of print defects in FDM can stem from root causes related to both hardware and material properties [22]. Mitigating these defects requires careful diagnosis by knowledgeable operators [23]. Consequently, the challenges of parameter tuning, defect diagnosis, and defect mitigation create a steep learning curve that prevents the general public from designing their personalized parts and fabricating with FDM [23]. This highlights the need for robust solutions and standardized practices to plan and optimize production as well as streamline troubleshooting within FDM [24].
Large Language Models (LLMs) are advanced transformer-based models trained on extensive datasets. These models demonstrate promising capabilities across various natural language processing tasks, including interpreting and generating text and code [25]. Beyond these core functions, LLMs exhibit reasoning abilities that enable them to draw conclusions and address complex problems in novel domains [26, 27]. This adaptability has led to their increasing application across diverse fields, from customer support to data-driven problem-solving. These successful applications suggest the potential of LLMs for addressing challenges specific to FDM.
A few preliminary studies have explored the potential of LLMs in the FDM domain, particularly for answering questions and conducting G-code-related analyses. For example, Sriwastwa et al. [28] investigated whether ChatGPT, an LLM developed by OpenAI, can effectively respond to FDM-related questions posed by biomedical students. However, this study lacks quantitative evaluations and focuses solely on biomedical users. In G-code-related research, Badini et al. [29] assessed ChatGPT’s capability to optimize FDM printing parameters based on inputted G-code. Although ChatGPT was reported to be effective in optimizing parameters, this study did not observe concrete, measurable improvements in print quality.
Another limitation of these studies is that they focus exclusively on ChatGPT, which represents only one of the state-of-the-art LLMs. To address this, Jignasu et al. [30] examined the capabilities of multiple open-source and closed-source models in manipulating G-codes for tasks such as part rotation and translation. However, this study also lacks a quantitative comparison between models. Despite some advancements in using LLMs for G-code interaction, a critical gap remains in applying these models for G-code-based anomaly detection. Accurately identifying defects requires that LLMs understand the syntax of G-code and can extract relevant printing parameters. Additionally, the models need to understand the relationships between these parameters and potential errors to provide effective detections.
Given these gaps, this study aims to evaluate the effectiveness of LLMs on a range of FDM-specific tasks by establishing a comprehensive benchmark dataset, referred to as FDM-Bench. FDM-Bench addresses two critical areas: user query response and G-code anomaly detection, both of which are essential for improving print quality and providing effective support for FDM users. To ensure a thorough evaluation, FDM-Bench includes queries representing a broad spectrum of user expertise, from beginners to advanced researchers in FDM technology. Additionally, we generate G-codes with various types of anomalies and create multiple samples for each type by adjusting different parameters. This approach enables a comprehensive assessment of the models’ capabilities in accurately detecting these defects.
In this study, we evaluate the performance of four state-of-the-art LLMs on FDM-Bench, including two closed-source models (GPT-4o [31] and Claude 3.5 Sonnet [32]) and two open-source models (Llama-3.1-70B and Llama-3.1-405B [33]). To assess each model’s effectiveness, a panel of FDM experts evaluate responses in the user query section, focusing on accuracy, precision, and relevance. Additionally, we include multiple-choice questions (MCQs) to facilitate future evaluations by non-experts. Our results show that Llama-3.1-70B generally performs the lowest across both tasks, likely due to its smaller model size. In G-code-related tasks, closed-source models consistently outperform open-source models, while in user queries, Llama-3.1-405B achieves results comparable to the closed-source models. Our main contributions are summarized as follows:
-
1.
We introduce FDM-Bench, the first benchmark dataset for evaluating LLMs on FDM-specific tasks. FDM-Bench includes user queries across different expertise levels and G-code samples with diverse anomalies, providing a solid foundation for assessing model performance in FDM applications.
-
2.
We evaluate four state-of-the-art LLMs on FDM-Bench, including closed-source models (GPT-4o, Claude 3.5 Sonnet) and open-source models (Llama-3.1-70B, Llama-3.1-405B). Our results indicate that closed-source models generally perform better in G-code anomaly detection, while Llama-3.1-405B achieves comparable results to the closed-source models in responding to user queries.
-
3.
To support evaluations by both expert and non-expert users, FDM-Bench includes MCQs and open-ended queries. The MCQs enable efficient automated scoring, while open-ended queries allow for an in-depth assessment of model performance in supporting FDM users.
The remainder of this paper is organized as follows. Section 2 provides a detailed overview of tasks included in FDM-Bench. Section 3 describes the dataset created for this study, and Section 4 introduces the evaluation metrics used for each task. Section 5 presents a comprehensive evaluation of the LLMs on FDM-Bench. Finally, Section 6 concludes the paper.
2 Task Definition
2.1 G-code based anomaly detection
This task focuses on analyzing G-code to predict anomalies before the printing process begins. FDM printing is prone to defects like spaghetti (SP), under-extrusion (UE), and over-extrusion (OE), which can compromise both the quality and functionality of printed parts. These issues often arise from configuration settings or parameter values specified within the G-code. For example, UE may result from an insufficient flow rate or low nozzle temperature, whereas OE is commonly due to an excessive extrusion multiplier. Detecting and addressing these issues in the G-code before printing can help save time, materials, and costs associated with failed prints.
In this task, LLMs receive G-code from both successful and defective prints, along with information about the printer model and slicer software. The models are then asked to predict which specific anomaly is most likely to occur or if the part will print without issues.
2.2 User queries
This task assesses the LLMs’ ability to provide accurate responses to FDM-related questions across various user experience levels. Additionally, we evaluate whether the models can identify and adapt to the user’s level of experience. To ensure both a comprehensive evaluation and efficient automatic assessment, we review the models’ answers to two types of questions.
2.2.1 Free-form questions
In this format, LLMs respond to questions in a free-form style. The FDM-related questions span a wide range of topics, requiring answers that are both technically and theoretically accurate. Each response must also be appropriate for the user’s experience level. Human experts and detailed qualitative metrics are essential for evaluating this type of question. This assessment allows for a thorough examination of the depth, breadth, and relevance of the LLMs’ answers.
2.2.2 Multiple-choice questions
MCQs with a single correct answer, or “ground truth,” are needed to enable fast and scalable evaluation of LLMs. This format allows for automatic scoring, eliminating the need for human evaluators and providing a quick assessment of how accurately each model addresses various FDM-related questions. While this setup effectively measures factual accuracy, it lacks the flexibility of free-form responses, which are essential for evaluating reasoning, relevance to user experience levels, and the exclusion of irrelevant information.
3 Dataset Description
In this section, we introduce a dataset containing G-codes, questions, and prompts to enable a comprehensive evaluation of LLMs on the tasks outlined in the previous section. The code and dataset developed in this study are publicly available at https://github.com/AhmadrezaNia/FDM-Bench.
3.1 G-codes

In this section, we describe the process of generating a G-code dataset by printing a sample bridge geometry on a Prusa 3D printer using PLA filament. By adjusting various printing parameters in Prusa Slicer software, we systematically introduce specific anomalies into the printed samples. The key parameters that are modified include bed temperature, nozzle temperature, print speed, layer height, fill angle, and flow rate (controlled through the extrusion multiplier setting). Figure 1 illustrates the four categories of printed parts in our dataset. These categories include:
-
1.
Non-defective (ND) prints are created using standard, recommended parameter ranges. For example, with PLA filament, a bed temperature of 60°C and a nozzle temperature of 210°C, combined with standard flow rate settings (extrusion multiplier set to 1), yielded stable prints at typical print speeds and layer heights.
-
2.
OE occurs when excess filament is extruded, leading to overlapping print patterns and dimensional inaccuracies. To create over-extruded samples, we increase the extrusion multiplier above the standard setting, with values ranging from 1.3 to 1.6. While the flow rate is the primary parameter influencing OE, we also slightly adjust the bed temperature, nozzle temperature, and layer height to replicate realistic variations observed in over-extruded prints.
-
3.
UE occurs when insufficient filament is extruded, leading to visible gaps and weak bonding between layers. Under-extruded samples are produced by setting the extrusion multiplier below the standard value, specifically within the range of 0.6 to 0.9. As with OE, we also adjust bed temperature, nozzle temperature, and layer height.
-
4.
SP is a printing anomaly where the filament extrudes into the air rather than onto the print bed, creating a chaotic, spaghetti-like pattern. This error typically arises from two scenarios: (1) poor bed adhesion causes the print to detach and shift freely on the bed, or (2) excessive edge deformation leads to collisions between the print and the nozzle, displacing the print. In our dataset, SP is commonly induced by using low bed temperatures (35-40°C), a 90-degree fill angle (placing filament parallel to the bridge’s long axis), and high print speeds (110 mm/s).
3.2 Questions
In this section, we include questions relevant to a wide range of FDM users. We define three experience levels to better evaluate the LLMs’ performance in answering questions that require varying degrees of technical and theoretical knowledge:
-
1.
Beginner user ranges from absolute beginners with no prior experience in 3D printing to early learners who are starting to understand fundamental terms and processes. This group typically requires straightforward, non-technical guidance as they become familiar with basic terminology (e.g., nozzle, filament) and settings. Their focus is primarily on understanding the essentials and troubleshooting initial challenges.
-
2.
Experienced user ranges from regular operators who have been using FDM printers for several months and are familiar with standard terms, materials, and maintenance practices, to advanced operators or technicians who work with FDM printers professionally. While skilled at troubleshooting and optimizing print settings and maintenance practices, users at this level generally do not engage in research aimed at advancing the underlying FDM technology.
-
3.
Theoretical user includes individuals who engage in research or theoretical work related to FDM technology. This level ranges from students and research assistants studying the FDM process to professors and faculty members conducting or supervising research. Users at this level often explore complex topics such as inter-layer bonding and material properties to advance FDM technology.
We define both free-form questions and MCQs for these three experience levels as follows:
3.2.1 Free-form questions
The free-form questions include topics such as error diagnosis, theoretical analysis, and knowledge of slicing, hardware, and printing parameters. These questions are developed using a variety of sources, including standard references on 3D printing, textbooks, slicer software guidelines, and insights from field experts.
3.2.2 Multiple-choice questions
The MCQs are concise and targeted, with each question offering five answer choices. Only one choice is correct, while the remaining four serve as distractors, designed to assess comprehension and address common misconceptions. These questions are developed using the same topics and sources as the free-form questions in Section 3.2.1.
3.3 Prompts
To evaluate the LLMs’ performance, we craft prompts tailored to the specific requirements of each task, emphasizing reasoning and factual accuracy over creative output. Accordingly, we set the temperature parameter to zero across all models. The temperature parameter, which ranges from 0 to 1, controls the randomness in a model’s responses. Lower values produce more consistent outputs, while higher values introduce variability for creative responses.
In addition, we retain each model’s default settings without hyperparameter tuning. This approach ensures a fair comparison, as all models operate under identical conditions, allowing performance differences to reflect each model’s inherent capabilities rather than adjustments in parameter configurations.
To ensure clarity and consistency across tasks, prompts are structured as follows:
-
1.
Role: The LLM is assigned a role relevant to the task.
-
2.
Context: A brief context is provided to ground the task requirements.
-
3.
Task: The LLM receives a clear, action-oriented task.
-
4.
Output: The expected output format is specified, indicating whether the response should be a single-choice answer, a free-form answer, or identify specific anomalies in the G-code.
4 Evaluation Metrics
This section describes the metrics used to evaluate model performance for each FDM-specific task.
4.1 G-code anomaly detection
We use two evaluation approaches to assess model performance in detecting anomalies from G-code.
In the first approach, models are instructed to select a deterministic label that best represents the type of anomaly present in the G-code. The labels include specific anomaly types, such as SP, OE, UE, or an ND label when no anomalies are detected. For this evaluation, we measure model performance using accuracy, reflecting how often the model correctly identifies the ground truth label for each G-code instance.
In the second approach, LLMs analyze the G-code and assign a probability to each possible label, expressed as a percentage. Here, we focus on the probability assigned to the actual ground truth label as the primary performance measure. This approach offers insights into the model’s confidence in its predictions and its capability to differentiate accurately among various potential anomalies.
4.2 User queries
4.2.1 Free-form questions
A panel of FDM experts with relevant research expertise evaluates LLM responses to free-form questions. To assess response quality, each evaluator scores them on a scale of 1 to 5 for each of the following three criteria, with 5 indicating the highest performance and 1 the lowest:
-
1.
Accuracy assesses the factual accuracy of the response, focusing on alignment with the essential content required to answer the question. Higher scores indicate that the response comprehensively includes all essential correct information while avoiding any incorrect information.
-
2.
Precision measures the focus of the response by evaluating how free it is from unnecessary or extraneous content. Higher precision scores indicate concise responses that contain only the information directly relevant to the question.
-
3.
Relevance to experience level evaluates how effectively the response aligns with the specified user expertise level. Responses that provide appropriately detailed information for the intended user’s level receive higher scores, while responses that are too simplistic or overly complex for the specified skill level are rated lower.
4.2.2 Multiple-choice questions
We automatically evaluate the LLMs’ accuracy in selecting correct answers to each MCQ. Accuracy is determined as the percentage of questions answered correctly by comparing responses with the ground truth. This metric directly measures the LLM’s effectiveness in retrieving FDM-related information.
5 Results and Discussions
5.1 Models
In this study, we evaluate the performance of four state-of-the-art LLMs on FDM-specific tasks. The selected models include both closed-source and open-source options, allowing for comparative analysis across architectures, model sizes, and accessibility. Each model undergoes identical tasks to assess its capabilities in FDM anomaly detection and responding to user queries.
The closed-source LLMs include:
-
1.
GPT-4o: Developed by OpenAI, GPT-4o is an advanced iteration of the Generative Pre-trained Transformer series, released in May 2024. While the exact parameter count remains undisclosed, GPT-4o supports a maximum input context window of 128,000 tokens and can generate up to 16,384 tokens in a single response.
-
2.
Claude 3.5 Sonnet: Anthropic’s Claude 3.5 Sonnet, released in June 2024, is designed to excel in natural language understanding and generation. While the exact parameter count is undisclosed, it supports a maximum input context window of 200,000 tokens and can produce up to 4,096 tokens in length. Hereafter, any reference to Claude refers specifically to this model.
The open-source LLMs include:
-
1.
Llama-3.1-70B: Released by Meta in July 2024, this model comprises 70 billion parameters and supports an input context window of 128,000 tokens, allowing for the effective processing of extensive textual data.
-
2.
Llama-3.1-405B: Introduced by Meta in July 2024, this larger model includes 405 billion parameters. Designed for handling complex tasks with high accuracy, it also supports an input context window of 128,000 tokens.
5.2 Performance comparison in anomaly detection
This section compares the anomaly detection performance of four LLM models through both deterministic labeling and the probabilistic scoring method.
5.2.1 Deterministic labeling
Figure 2 presents the confusion matrices for each LLM evaluated using the deterministic approach. Each model is evaluated with four data samples per class across the four categories: SP, UE, OE, and ND. GPT-4o achieves the highest accuracy, correctly identifying the ground truth anomaly label in 62% of cases. Llama 405B and Claude followed, each achieving an accuracy of 44%. Llama 70B demonstrated the lowest accuracy at 31%, slightly above random guessing (25%). These results suggest that all models, including Llama 70B, have some capacity for interpreting G-codes.

The confusion matrices reveal specific misclassification patterns, with each model showing a tendency to favor certain labels. For instance, Claude and Llama 405B primarily assigned the ND and UE labels, respectively. The other two models show a similar, though less pronounced, trend. Notably, Llama 70B and Llama 405B exhibit similar preferences in label assignment, potentially due to both models being developed by Meta AI [33] and likely trained on similar datasets.
Additionally, both open-source Llama models demonstrate a more cautious approach to anomaly detection and rarely label parts as ND. In contrast, the closed-source models (GPT-4o and Claude) are less conservative and tend to label more parts as ND than they actually are. This difference in labeling tendencies might reflect different approaches to anomaly detection across these models.
5.2.2 Probabilistic scoring
In the probabilistic scoring approach, we utilize the same set of G-codes used in the deterministic method. However, instead of requesting a single label, we instruct each LLM to assign a likelihood to each label in percentage terms, with probabilities summing to 100% for each G-code sample.
Each LLM produces four probability values per sample, corresponding to the likelihood of each class. Figure 3 presents the models’ performance by showing the average probability assigned to the correct label for each class. We compute the average probability for the correct label across the four samples per class, with the standard deviation reflecting the consistency of each model’s performance across these samples.
Additionally, to account for potential biases seen in the deterministic approach, where certain models favored specific labels, we calculate the average probability assigned to each label across all samples for each model. These average probabilities are marked with crosses in Figure 3. Comparing the average correct label probability with overall label preferences provides insights into whether each model effectively differentiates among distinct G-code patterns or only favors certain labels regardless of input.
As shown in Figure 3, the probabilistic scoring results show that GPT-4o, Claude, and Llama 405B tend to assign higher probabilities to the correct labels (indicated by circles) compared to their average probability assignment across all labels (indicated by crosses). This pattern suggests that these models effectively analyze G-codes, extract relevant information, and detect anomalies accurately. In contrast, Llama 70B does not show a clear distinction between correct and incorrect labels, indicating a limited ability to identify anomalies accurately. This weaker performance may be due to the smaller size of Llama 70B compared to the other three models. Additionally, this task involves a near-maximum input token size, potentially limiting Llama 70B’s capacity to fully interpret the G-code data.

A closer examination of Claude’s performance reveals that although it detects ND, UE, and OE G-codes with fairly high accuracy, it consistently assigns low probabilities to the SP anomaly, indicating a potential blind spot for this specific defect. This limitation may reflect a gap in Claude’s training data or an inherent model bias. Additionally, the high variability in Claude’s results, reflected by a larger standard deviation, suggests inconsistent predictions across different samples. This inconsistency could impact Claude’s reliability in real-world applications, where stable performance is essential.
An analysis of GPT-4o’s results indicates that its labeling variation remains within a reasonable range and assigns consistently higher probabilities to correct labels than the average probability for each label. This consistency aligns with the deterministic labeling results, where GPT-4o outperforms the other models, highlighting its potential as a more robust choice for G-code anomaly detection tasks.
5.3 Performance comparison in answering free-form questions
This section investigates the performance of LLMs in answering free-form user queries across beginner, experienced, and theoretical FDM users. Fourteen evaluators score these responses across three key metrics: accuracy, precision, and relevance to user experience level, on a scale from 1 to 5. Figure 4 presents each model’s average performance on these metrics, with standard deviation bars indicating the variability across different expertise levels.

As shown in Figure 4, GPT-4o achieves the highest accuracy among the models, with minimal variation, suggesting consistent performance in accurately addressing questions across all user levels. Following GPT-4o, Llama 405B ranks second in accuracy, with a small margin difference, indicating strong performance. In terms of relevance and precision, Llama 405B outperforms the other models, highlighting its ability to provide responses that are concise and appropriately tailored to each user’s expertise level. In contrast, Llama 70B demonstrates the lowest performance across all three metrics. Notably, Claude exhibits the largest variability in its scores, indicating less consistent responses across different user levels.
These findings suggest that while GPT-4o excels in delivering accurate answers, Llama 405B is more effective in ensuring relevance and precision, albeit with a slight trade-off in accuracy.
5.4 Performance comparison in answering multiple-choice questions
This section compares the performance of the LLMs in answering MCQs across three user expertise levels: beginner, experienced, and theoretical. Figure 5 shows the accuracy of each model across these categories.
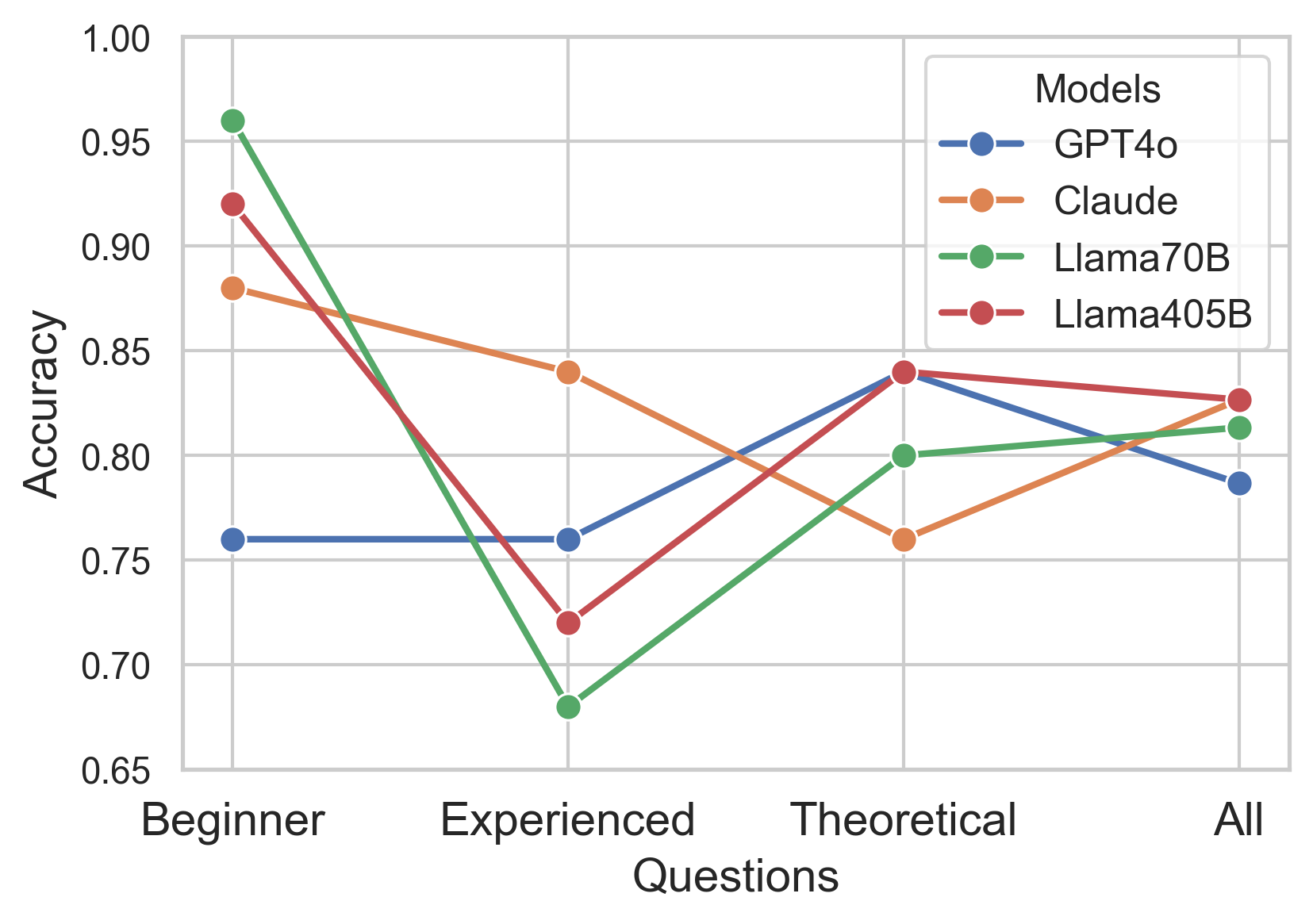
Overall accuracy, calculated as the average across all question levels, shows that the models perform similarly, with Claude and Llama 405B achieving slightly higher accuracy than the others. However, examining accuracy across user levels reveals clearer differences among the models. Notably, the top-performing model varies by user level. For instance, Llama 70B achieves the highest accuracy for beginner-level questions, while Claude performs best at the experienced level. However, neither ranks highest for theoretical questions.
Additionally, individual model performance shifts significantly across expertise levels. For example, while Llama 70B performs best on beginner questions, it shows the lowest accuracy at the experienced level, highlighting differences in model adaptability across expertise levels. As expected, most models perform best on beginner questions, likely due to their simpler content. Interestingly, overall accuracy is higher for theoretical questions than for experienced questions, possibly reflecting the nature of the training data used for these models.
These findings suggest that LLM effectiveness varies significantly with question complexity and technical demands. This indicates that some models may be better suited to specific user expertise levels.
6 Conclusion and Future Work
In this study, we introduce FDM-Bench, the first comprehensive benchmark designed to evaluate LLMs on tasks specific to FDM. Two closed-source models (GPT-4 and Claude 3.5 Sonnet) and two open-source models (Llama-3.1-70B and Llama-3.1-405B) are evaluated on user queries and G-code samples. Our findings highlight the unique strengths each model offers for different FDM-related tasks. Although closed-source models generally achieve higher accuracy in G-code anomaly detection, Llama-3.1-405B also demonstrates promising results, particularly in its cautious approach to defect identification. Unlike the closed-source models, which more confidently label some anomalous G-codes as ND, Llama-3.1-405B shows a more conservative and potentially advantageous strategy in quality control contexts. Additionally, Llama-3.1-405B slightly outperforms the closed-source models in responding to user queries, demonstrating that open-source models can achieve performance comparable to state-of-the-art closed-source options.
These findings underscore the potential for further enhancement of open-source models through fine-tuning [34] or retrieval-augmented methods [35] to achieve better performance in FDM-specific tasks. By establishing a standardized evaluation framework, FDM-Bench supports consistent benchmarking of these improved LLMs, thus contributing to more effective LLM applications in AM.
Future expansions of FDM-Bench can focus on broadening its applicability across a wider range of AM tasks. This will include evaluations of additional AM technologies such as selective laser sintering, stereolithography, and metal AM [36]. Another promising direction is the inclusion of image-based tasks that utilize large vision-language models (LVLMs) [37, 38, 39] to improve visual defect detection and enable the prediction of anomalies arising from external causes, rather than those solely related to printing parameters and settings [40]. Together, these expansions are expected to establish a more comprehensive framework for evaluating LVLM performance across a broad spectrum of AM applications and settings.
Additionally, given the sensitivity of these models to prompt structure [41, 42], incorporating advanced prompting techniques, such as few-shot prompting [43], chain-of-thought [44], and tree-of-thought [45] prompting, may offer deeper insights into their reasoning processes. These techniques could enhance model accuracy and consistency in both reasoning and calculations within AM contexts.
Acknowledgements
This work was supported by the National Science Foundation (NSF) under grants 2126246, 2434383, and 2434385, and the U.S. Department of Agriculture (USDA) under grant AG Sub UCDavisA21-0845-S003 S.
References
- Zisopol et al. [2023] Zisopol, D.G., Tănase, M. and Portoacă, A.I., 2023. Innovative strategies for technical-economical optimization of FDM production. Polymers, 15(18), p.3787.
- Sing et al. [2020] Sing, S.L., Tey, C.F., Tan, J.H.K., Huang, S. and Yeong, W.Y., 2020. 3D printing of metals in rapid prototyping of biomaterials: Techniques in additive manufacturing. In Rapid prototyping of biomaterials (pp. 17-40). Woodhead Publishing.
- Aabith et al. [2022] Aabith, S., Caulfield, R., Akhlaghi, O., Papadopoulou, A., Homer-Vanniasinkam, S. and Tiwari, M.K., 2022. 3D direct-write printing of water soluble micromoulds for high-resolution rapid prototyping. Additive Manufacturing, 58, p.103019.
- Cleeman et al. [2022] Cleeman, J., Bogut, A., Mangrolia, B., Ripberger, A., Maghouli, A., Kate, K. and Malhotra, R., 2022, June. Multiplexed 3D Printing of Thermoplastics. In International Manufacturing Science and Engineering Conference (Vol. 85802, p. V001T01A004). American Society of Mechanical Engineers.
- Buj-Corral et al. [2021] Buj-Corral, I., Tejo-Otero, A. and Fenollosa-Artés, F., 2021. Use of FDM technology in healthcare applications: recent advances. Fused Deposition Modeling Based 3D Printing, pp.277-297.
- Cailleaux et al. [2021] Cailleaux, S., Sanchez-Ballester, N.M., Gueche, Y.A., Bataille, B. and Soulairol, I., 2021. Fused Deposition Modeling (FDM), the new asset for the production of tailored medicines. Journal of controlled release, 330, pp.821-841.
- Kalender et al. [2019] Kalender, M., Kılıç, S.E., Ersoy, S., Bozkurt, Y. and Salman, S., 2019, June. Additive manufacturing and 3D printer technology in aerospace industry. In 2019 9th International Conference on Recent Advances in Space Technologies (RAST) (pp. 689-694). IEEE.
- Jeong et al. [2021] Jeong, J., Park, H., Lee, Y., Kang, J. and Chun, J., 2021. Developing parametric design fashion products using 3D printing technology. Fashion and Textiles, 8, pp.1-25.
- Tsegay et al. [2023] Tsegay, F., Ghannam, R., Daniel, N. and Butt, H., 2023. 3D printing smart eyeglass frames: a review. ACS Applied Engineering Materials, 1(4), pp.1142-1163.
- Jahangir et al. [2022] Jahangir, M.N., Cleeman, J., Pan, C., Chang, C.H. and Malhotra, R., 2022. Flash light assisted additive manufacturing of 3D structural electronics (FLAME). Journal of Manufacturing Processes, 82, pp.319-335.
- Laplume et al. [2016] Laplume, A., Anzalone, G.C. and Pearce, J.M., 2016. Open-source, self-replicating 3-D printer factory for small-business manufacturing. The International Journal of Advanced Manufacturing Technology, 85, pp.633-642.
- Pearce [2012] Pearce, J.M., 2012. Building research equipment with free, open-source hardware. Science, 337(6100), pp.1303-1304.
- Haghshenas Gorgani et al. [2021] Haghshenas Gorgani, H., Korani, H., Jahedan, R. and Shabani, S., 2021. A nonlinear error compensator for FDM 3D printed part dimensions using a hybrid algorithm based on GMDH neural network. Journal of Computational Applied Mechanics, 52(3), pp.451-477.
- Dey and Yodo [2019] Dey, A. and Yodo, N., 2019. A systematic survey of FDM process parameter optimization and their influence on part characteristics. Journal of Manufacturing and Materials Processing, 3(3), p.64.
- Cleeman and Malhotra [2023] Cleeman, J. and Malhotra, R., 2023, June. Highly Parsimonious Multi-Fidelity Learning of Process Parameter-Performance Relationships: A Case Study With Fused Filament Fabrication. In International Manufacturing Science and Engineering Conference (Vol. 87240, p. V002T06A031). American Society of Mechanical Engineers.
- Solomon et al. [2021] Solomon, I.J., Sevvel, P. and Gunasekaran, J.J.M.T.P., 2021. A review on the various processing parameters in FDM. Materials Today: Proceedings, 37, pp.509-514.
- Zharylkassyn et al. [2021] Zharylkassyn, B., Perveen, A. and Talamona, D., 2021. Effect of process parameters and materials on the dimensional accuracy of FDM parts. Materials Today: Proceedings, 44, pp.1307-1311.
- Maurya et al. [2021] Maurya, N.K., Maurya, M., Dwivedi, S.P., Srivastava, A.K., Saxena, A., Chahuan, S., Tiwari, A. and Mishra, A., 2021. Investigation of effect of process variable on dimensional accuracy of FDM component using response surface methodology. World Journal of Engineering, 18(5), pp.710-719.
- Ajjarapu et al. [2024] Ajjarapu, K.P.K., Mishra, R., Malhotra, R. and Kate, K.H., 2024. Mapping 3D printed part density and filament flow characteristics in the material extrusion (MEX) process for filled and unfilled polymers. Virtual and Physical Prototyping, 19(1), p.e2331206.
- Hıra et al. [2022] Hıra, O., Yücedağ, S., Samankan, S., Çiçek, Ö.Y. and Altınkaynak, A., 2022. Numerical and experimental analysis of optimal nozzle dimensions for FDM printers. Progress in Additive Manufacturing, pp.1-16.
- Lei et al. [2022] Lei, M., Wei, Q., Li, M., Zhang, J., Yang, R. and Wang, Y., 2022. Numerical simulation and experimental study of the effects of process parameters on filament morphology and mechanical properties of FDM 3D printed PLA/GNPs nanocomposite. Polymers, 14(15), p.3081.
- Baechle-Clayton et al. [2022] Baechle-Clayton, M., Loos, E., Taheri, M. and Taheri, H., 2022. Failures and flaws in fused deposition modeling (FDM) additively manufactured polymers and composites. Journal of Composites Science, 6(7), p.202.
- Kantaros and Piromalis [2021] Kantaros, A. and Piromalis, D., 2021. Employing a low-cost desktop 3D printer: Challenges, and how to overcome them by tuning key process parameters. International Journal of Mechanics and Applications, 10(1), pp.11-19.
- Hsiang Loh et al. [2020] Hsiang Loh, G., Pei, E., Gonzalez-Gutierrez, J. and Monzón, M., 2020. An overview of material extrusion troubleshooting. Applied Sciences, 10(14), p.4776.
- Ni et al. [2024] Ni, A., Yin, P., Zhao, Y., Riddell, M., Feng, T., Shen, R., Yin, S., Liu, Y., Yavuz, S., Xiong, C., Joty, S., Zhou, Y., Radev, D. and Cohan, A., 2024. L2CEval: Evaluating language-to-code generation capabilities of large language models. Transactions of the Association for Computational Linguistics, 12, pp.1311-1329.
- Devunuri et al. [2024] Devunuri, S., Qiam, S. and Lehe, L.J., 2024. ChatGPT for GTFS: Benchmarking LLMs on GTFS Semantics and Retrieval. *Public Transport*, pp.1-25.
- Kevian et al. [2024] Kevian, D., Syed, U., Guo, X., Havens, A., Dullerud, G., Seiler, P., Qin, L. and Hu, B., 2024. Capabilities of large language models in control engineering: A benchmark study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra. *arXiv preprint arXiv:2404.03647*.
- Sriwastwa et al. [2023] Sriwastwa, A., Ravi, P., Emmert, A., Chokshi, S., Kondor, S., Dhal, K., Patel, P., Chepelev, L.L., Rybicki, F.J. and Gupta, R., 2023. Generative AI for medical 3D printing: a comparison of ChatGPT outputs to reference standard education. 3D Printing in Medicine, 9(1), p.21.
- Badini et al. [2023] Badini, S., Regondi, S., Frontoni, E. and Pugliese, R., 2023. Assessing the capabilities of ChatGPT to improve additive manufacturing troubleshooting. Advanced Industrial and Engineering Polymer Research, 6(3), pp.278-287.
- Jignasu et al. [2023] Jignasu, A., Marshall, K., Ganapathysubramanian, B., Balu, A., Hegde, C. and Krishnamurthy, A., 2023. Towards foundational AI models for additive manufacturing: Language models for G-code debugging, manipulation, and comprehension. arXiv preprint arXiv:2309.02465.
- OpenAI [2024] OpenAI, 2024. GPT-4o. Available at: https://platform.openai.com/docs/models/gpt-4
- Anthropic [2024] Anthropic, 2024. Claude 3.5 Sonnet. Available at: https://www.anthropic.com/claude/sonnet
- Meta AI [2024] Meta AI, 2024. Llama 3.1: Open Foundation and Fine-Tuned Chat Models. Available at: https://ai.facebook.com/blog/llama-3-1/
- Hu et al. [2021] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L. and Chen, W., 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
- Lewis et al. [2020] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.T., Rocktäschel, T. and Riedel, S., 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, pp.9459-9474.
- Chandrasekhar et al. [2024] Chandrasekhar, A., Chan, J., Ogoke, F., Ajenifujah, O. and Farimani, A.B., 2024. AMGPT: a Large Language Model for Contextual Querying in Additive Manufacturing. *arXiv preprint arXiv:2406.00031*.
- Li et al. [2023] Li, J., Li, D., Savarese, S. and Hoi, S., 2023. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In *Proceedings of the 40th International Conference on Machine Learning* (Vol. 202, pp. 19730-19742). PMLR.
- Liu et al. [2024] Liu, H., Li, C., Wu, Q. and Lee, Y.J., 2024. Visual instruction tuning. In *Advances in Neural Information Processing Systems* (Vol. 36).
- Zhu et al. [2023] Zhu, D., Chen, J., Shen, X., Li, X. and Elhoseiny, M., 2023. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. *arXiv preprint arXiv:2304.10592*.
- Jadhav et al. [2024] Jadhav, Y., Pak, P. and Farimani, A.B., 2024. LLM-3D Print: Large Language Models To Monitor and Control 3D Printing. *arXiv preprint arXiv:2408.14307*.
- Arora et al. [2022] Arora, S., Narayan, A., Chen, M.F., Orr, L., Guha, N., Bhatia, K., Chami, I., Sala, F. and Ré, C., 2022. Ask me anything: A simple strategy for prompting language models. *arXiv preprint arXiv:2210.02441*.
- Bhargava et al. [2023] Bhargava, A., Witkowski, C., Looi, S.Z. and Thomson, M., 2023. What’s the Magic Word? A Control Theory of LLM Prompting. *arXiv preprint arXiv:2310.04444*.
- Brown et al. [2020] Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I. and Amodei, D., 2020. Language models are few-shot learners. *arXiv preprint arXiv:2005.14165*.
- Wei et al. [2022] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V. and Zhou, D., 2022. Chain-of-thought prompting elicits reasoning in large language models. *Advances in Neural Information Processing Systems*, 35, pp.24824-24837.
- Yao et al. [2024] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y. and Narasimhan, K., 2024. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. *Advances in Neural Information Processing Systems*, 36.