FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models
Abstract
Large Language Models (LLMs), such as ChatGPT, LLaMA, GLM, and PaLM, have exhibited remarkable performances across various tasks in recent years. However, LLMs face two main challenges in real-world applications. One challenge is that training LLMs consumes vast computing resources, preventing LLMs from being adopted by small and medium-sized enterprises with limited computing resources. Another is that training LLM requires a large amount of high-quality data, which are often scattered among enterprises.
To address these challenges, we propose FATE-LLM, an industrial-grade federated learning framework for large language models. FATE-LLM (1) facilitates federated learning for large language models (coined FedLLM); (2) promotes efficient training of FedLLM using parameter-efficient fine-tuning methods; (3) protects the intellectual property of LLMs; (4) preserves data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to facilitate the research of FedLLM and enable a broad range of industrial applications.
1 Introduction
In recent few years, the advent of large language models (LLMs) Yang et al. (2023b); Zhou et al. (2023) has been reshaping the field of artificial intelligence. In particular, the most advanced LLMs, such as ChatGPT OpenAI (2022), GPT-4 OpenAI (2023), and PaLM Chowdhery et al. (2022) that boast billions of parameters have gained considerable attention due to their remarkable performance in a variety of natural language generation tasks. Many open-sourced LLMs with high performance have been released, and the public’s enthusiasm for research and application of LLMs has been stimulated.

However, grounding LLMs in real-world applications faces many challenges. The two main challenges are (i) training LLMs consumes vast computing resources, which prevents LLMs from being adopted by small and medium-sized companies with limited computing resources; (ii) training LLMs requires a large amount of public data, which may run out soon Villalobos et al. (2022).
Federated learning (FL) McMahan et al. (2017) Yang et al. (2019), a privacy-preserving collaborative machine learning paradigm, is a promising approach to deal with these two challenges. For one thing, FL enables many companies with different computing resources to collaboratively train powerful machine learning models such that the computational burden of training large models can be alleviated. For another, massive high-quality data are scattered among companies that are typically isolated from each other, and FL can exploit these data silos in a privacy-preserving way.
In this work, we propose FATE-LLM, built upon FATE (Federated AI Technology Enabler) Liu et al. (2021b), to facilitate federated learning for large language models. More specifically, FATE-LLM (1) enables federated learning for both homogeneous and heterogeneous large language models (FedLLM); (2) promotes efficient training of FedLLM through parameter-efficient fine-tuning methods, such as LoRA Hu et al. (2021) and P-Tuning-v2 Liu et al. (2021a); (3) protects the intellectual property of LLMs using federated intellectual property protection approach Li et al. (2022); (4) protects data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to promote the research of FedLLM and enable a broad range of industrial applications.
2 Related Work
In this section, we briefly review related work regarding large language models and federated learning.
2.1 Large Language Models
The advancements in large language models(LLMs) have led to significant advances in a variety of NLP tasks. A great example of LLMs application is ChatGPTOpenAI (2022). ChatGPT is fine-tuned from the generative pretrained transformer GPT-3.5, which was trained on a blend of text and code. ChatGPT applies reinforcement learning from human feedback (RLHF), which has become a promising way to align LLMs with a human’s intent. LLMs are generally divided into two categories: encoder-decoder or encoder-only large language models and decoder-only large language models Yang et al. (2023b). Bert Devlin et al. (2018) is the representative of encoder-only large language models. GPTs Radford et al. (2018) is the representative of decoder-only large language models. At the early stage of LLMs development, decoder-only LLMs were not as popular as encoder-only and encoder-decoder LLMs. However, after 2021, with the introduction of GPT-3 Brown et al. (2020), decoder-only LLMs experienced a significant boom. At the same time, after the initial explosion brought about by BERT Devlin et al. (2018), encoder-only LLMs gradually began to fade away. Recently, many decoder-only LLMs have been released, such as LLaMA Touvron et al. (2023), OPT Zhang et al. (2022a), PaLM Chowdhery et al. (2022), and BLOOM Scao et al. (2022). These LLMs demonstrated reasonable few-/zero-shot performance via prompting and in-context learning.
2.2 Federated Learning
Federated learning (FL) McMahan et al. (2017) Yang et al. (2019); Liu et al. (2022) is a distributed machine learning paradigm that enables clients (devices or organizations) to train a machine learning model collaboratively without exposing clients’ data. Unlike traditional centralized machine learning techniques, data are fixed locally rather than being gathered in a central server, which exists many of the systemic privacy risks and costs Kairouz et al. (2021). Hence, FL is a promising approach to deal with this data isolation challenge. To enhance data privacy, federated learning uses a variety of secure computing protocols. The most popular protocols are Homomorphic Encryption (HE) Paillier (1999), Multi-Party Computation(MPC) Shamir (1979) Damgård et al. (2012), and Differential Privacy (DP) Dwork et al. (2014). In recent years, the literature has presented various algorithms in the FL setting. Hardy et al. (2017) proposed vertical logistic regression (VLR) using homomorphic encryption (HE) to protect data privacy. Chen et al. (2021) further enhanced the privacy-preserving capability of VLR by employing a hybrid strategy combining HE and secret sharing (SS). Cheng et al. (2021) proposed the SecureBoost, a VFL version of XGBoost, that leverages HE to protect the parameters exchanged among parties. Kang et al. (2022) applied a semi-supervised learning method to estimate missing features and labels for further training. McMahan et al. (2017) proposed Secure Aggregation to enhance data protection.
3 FATE-LLM System Design
We introduce the FATE-LLM system, including its components, architecture, and roadmap.
3.1 Overview of FATE-LLM system
FATE-LLM222FATE-LLM was open-sourced in April 2023 in the FATE Community and is running on the infrastructure of FATE. was open-sourced as a submodule of FATE, and it contains three components: Communication-Efficient Hub, FedLLM Model Hub, and FedLLM Privacy Hub. Figure 2 overviews the FATE-LLM system.

The Communication-Efficient Hub integrates a variety of communication-efficient methods into FedLLM to reduce the communication cost for training LLMs, including parameter-efficiency fine-tuning (PEFT) Zhang et al. (2022b) methods (e.g., Adapter Tuning Cai et al. (2022) and Prompt Tuning Zhao et al. (2022), Knowledge Distillation(KD) Wu et al. (2022), and Model Quantization Zhang et al. (2018). More specifically, Zhang et al. (2022b) proposed PETuning methods that can reduce the communication overhead by orders of magnitude under the FL setting compared with full fine-tuning. They also found that PETuning methods can bring down local model adaptation costs for clients in FL systems. These results imply that FL clients (e.g., devices) with limited storage capacity can benefit from PETuning methods since these methods enable sharing an LLM across different tasks and maintaining a few parameters for each task, reducing the storage requirement.



The FedLLM Model Hub integrates a variety of mainstream LLMs, including BERT Devlin et al. (2018), GPTs Radford et al. (2018), ChatGLM-6B Du et al. (2022), LLaMA Touvron et al. (2023), BLOOM Scao et al. (2022), and Baichuan Yang et al. (2023a). These LLMs have different architectures and sizes and can be applied in different scenarios.
The FedLLM Trainer Hub offers a variety of training methods for different federated LLMs learning scenarios, including FedHomoLLM, FedHeteroLLM, FedCoLLM, and FedOST.
In FL, clients may have sufficient computing resources to train LLMs of the same size. However, in many heterogeneous scenarios, clients are likely to have quite different computing or data resources so that they can afford to train LLMs of quite different sizes. FATE-LLM offers Federated Homogeneous LLMs (FedHomoLLM) and Federated Heterogeneous LLMs (FedHeteroLLM) to support both scenarios. FedHomoLLM leverages PEFT techniques to train clients’ LLMs with the same architecture and size (illustrated in Figure 3(a)). FedHeteroLLM leverages knowledge distillation (KD) Shen et al. (2020) and PEFT techniques to deal with the FL scenario where FL clients own LLMs of different sizes (illustrated in Figure 3(b)). Specifically, each client in FedHeteroLLM leverages KD to learn a mentee model from its local pre-trained LLM. Then, all clients send adaptor or prompt parameters to the server for secure aggregation. Next, the server dispatches the aggregated model to all clients for the next round of training.
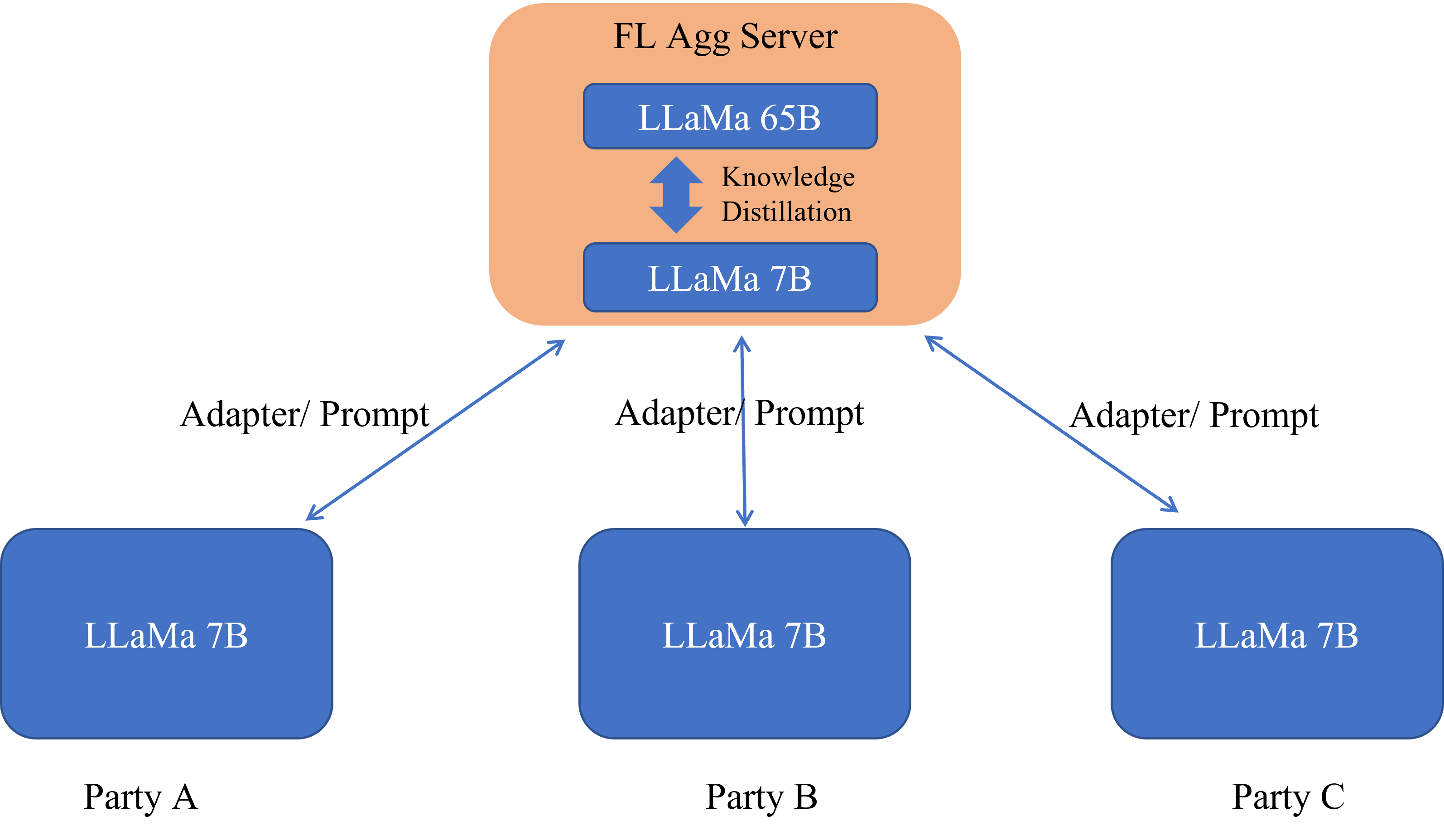
Initializing clients with an LLM distilled from a larger one hosted by the server enables federated LLMs to obtain a better global model more efficiently than starting clients’ models from random initialization Wang et al. (2023). On the other hand, the domain knowledge captured by clients’ local LLMs allows the server’s larger LLM to continue to evolve. FATE offers the FedCoLLM (Federated Co-tuning LLM) framework to co-evolve the LLMs of the server and clients. Figure 3(c) illustrates the FedCoLLM. Specifically, in FedCoLLM, each client having a LLaMa-7B model conducts federated learning applying PEFT techniques. On the server side, the server distills the knowledge between its LLaMa-65B model and the aggregated LLaMa-7B mode to co-evolve models on both sides.
Xiao et al. (2023) proposed Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt an LLM to downstream tasks without access to the LLM’s full weights. More specifically, in Offsite-Tuning, the server sends two adaptors and an emulator of its LLM to a client, which in turn finetunes adaptors with the help of the frozen emulator using its domain-specific data. Next, the client sends adaptors back to the server, which then plugs them into its LLM to form an adapted LLM for the client. The Offsite-Tuning has the potential to protect the client’s data privacy and the server’s model property.
FATE-LLM offers the FedOST (Federated OffSite-Tuning) that extends the Offsite-Tuning framework to the federated learning setting (see Figure 3(d)). In FedOST, multiple clients collaboratively train two global adaptors that adapt the LLM to all clients. FedOST brings two additional benefits than Offsite-Tuning: (1) FedOST enhances data privacy by adopting secure aggregation, and (2) it adapts an LLM to clients that did not even participate in the FL because of the generalization of the FL global model.
The FedLLM Privacy Hub integrates various privacy and security protection technologies, including federated intellectual property protection (FedIPR) Li et al. (2022), secure aggregation (SecureAgg) McMahan et al. (2017), Differential Privacy (DP) and Multi-Party Computation (MPC) to protect data privacy and model security. Specifically, FedIPR Li et al. (2022) proposed a federated deep neural network ownership verification scheme that enables private watermarks to be embedded into private DNN models during FL training (see Figure 4) such that each client can independently verify the existence of embedded watermarks and claim its ownership of the federated model without disclosing private training data and watermark information. FedIPR can be applied to FedLLM to verify the IP ownership of the federated LLMs. SecureAgg, DP, and MPC can be applied to FedLLM during training and fine-tuning to protect clients’ data privacy.

| Metrics | LoRA Federated | LoRA Centralized | LoRA Client-1 | LoRA Client-2 |
|---|---|---|---|---|
| Rouge-1 | 32.331 | 32.384 | 31.824 | 31.764 |
| Rouge-2 | 7.740 | 8.150 | 7.849 | 7.765 |
| Rouge- | 25.600 | 25.830 | 25.408 | 25.404 |
| BLEU-4 | 8.344 | 8.730 | 8.340 | 8.366 |
| Metrics | P-Tuning-v2 Federated | P-Tuning-v2 Centralized | P-Tuning-v2 Client-1 | P-Tuning-v2 Client-2 |
|---|---|---|---|---|
| Rouge-1 | 32.227 | 32.184 | 31.362 | 31.18 |
| Rouge-2 | 7.644 | 8.048 | 7.472 | 7.478 |
| Rouge- | 25.853 | 26.010 | 25.454 | 25.227 |
| BLEU-4 | 8.490 | 8.851 | 8.329 | 8.221 |
3.2 Architecture of FATE-LLM
FATE-LLM is running on the infrastructure of FATE, which consists of FATE-Flow, Eggroll, and OSX as the main components. FATE-Flow is a task scheduling engine for the multi-party federated learning end-to-end pipeline, Eggroll is the distributed computing engine, and OSX (open site exchange) is the multi-party federated communication engine. FATE-LLM Algorithm Hub and LLM Optim Lib Hub are tailored to perform FedLLM. FATE-LLM Algorithm Hub includes Communication-Efficient Hub, FedLLM Model Hub, and FedLLM Privacy Hub (see Figure 2). LLM Optim Lib Hub includes DeepSpeed and Megatron-LM. As of June 2023, FATE has integrated DeepSpeed into Eggroll, which can manage the GPUs cluster well and dispatch DeepSpeed LLMs tasks. Figure 5 shows the architecture of FATE-LLM.

3.3 RoadMap of FATE-LLM
We present the roadmap of FATE-LLM in Figure 6. As of June 2023, three versions of FTE-LLM have been released: FATE-LLM 1.0, FATE-LLM 1.1, and FATE-LLM 1.2. The three versions integrate Bert, GPT-2, ChatGLM-6B, and LLaMA, consecutively, and adopt FedIPR and privacy-preserving techniques to protect data privacy and model ownership.

4 Experiments
We conduct experiments on the scenario in which each client owns a ChatGLM-6B Du et al. (2022) model, and all clients want to fine-tune their models collaboratively through federated learning. Since fine-tuning all parameters of ChatGLM-6B involves huge computational and communication costs, all clients leverage a PETuning method to only fine-tune a small portion of the ChatGLM-6B parameters through federated learning.
We leverage our FedLLM modules to conduct these experiments using both LoRA Hu et al. (2021) and P-Tuning-v2 Liu et al. (2021a). Figure 7 illustrates this scenario we conduct our experiments on.

4.1 Experimental Setup
We detail the experimental setup, including the dataset, FL setting, and baselines.
Dataset and setting. We conduct experiments on AdvertiseGen Shao et al. (2019), a dataset for advertising text generation. We simulate the FL setting with 2 clients and randomly split the AdvertiseGen dataset such that each client has 57K samples. Each client is assigned 8 NVIDIA V100 and trained on DeepSpeed. We set the FL training epoch to 5 and run the experiments in the LAN network environment.
Baselines. We adopt two types of baselines. One is centralized, in which data of all clients are centralized to conduct fine-tuning (either LoRA or P-Tuning-v2) on a ChatGLM-6B model. The another is that each client uses local data to fine-tune its local ChatGLM-6B model.
4.2 Experiment Results
4.2.1 Model Performance
The experimental results for FedLLM using LoRA and P-Tuning-v2 are reported in Table 1 and Table 2, respectively, which show that LoRA Federated and P-Tuning-v2 Federated generally outperform their individual client counterparts across all performance metrics, demonstrating that federated learning help enhance the fine-tuning performance for each client. From Table 1 and Table 2, we also observe that the performance of LoRA and P-Tuning-v2 federated fine-tuning are generally worse than their centralized counterparts across all performance metrics, indicating that there has room to improve federated fine-tuning methods.
4.2.2 Communication Cost
We investigate the communication cost for FedLLM using LoRA and P-Tuning-v2 in terms of the size of parameters to be fine-tuned. Table 3 reports the results, and it shows that FedLLM using LoRA consumes 0.058% communication cost of FedLLM fine-tuning all parameters, while FedLLM using P-Tuning-v2 accounts for 0.475% communication cost of FedLLM fine-tuning all parameters.
| Methods | Model Size (MB) | Param Percent (%) |
|---|---|---|
| LoRA | 3.6 | 0.058 |
| P-Tuning-v2 | 29.3 | 0.475 |
| Fine-tune All | 6173 | 100 |
5 Conclusions and Future Work
We proposed FATE-LLM, an industrial-grade federated learning framework for large language models(FedLLM). As an open-sourced software, FATE-LLM encourages collaboration among the research and industry communities and expects to receive increasing feedback on its use.
In the future, we may consider research directions: (1) reconcile LLMs of different model architectures during FL fine-tuning; (2) fine-tune private LLMs of one party using private data of another party without compromising the data privacy and model ownership; (3) protect the privacy of user prompts efficiently in the inference stage; (4) apply FedLLM to vertical federated learning Liu et al. (2022).
References
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cai et al. [2022] Dongqi Cai, Yaozong Wu, Shangguang Wang, Felix Xiaozhu Lin, and Mengwei Xu. Autofednlp: An efficient fednlp framework. arXiv preprint arXiv:2205.10162, 2022.
- Chen et al. [2021] Chaochao Chen, Jun Zhou, Li Wang, Xibin Wu, Wenjing Fang, Jin Tan, Lei Wang, Alex X Liu, Hao Wang, and Cheng Hong. When homomorphic encryption marries secret sharing: Secure large-scale sparse logistic regression and applications in risk control. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 2652–2662, 2021.
- Cheng et al. [2021] Kewei Cheng, Tao Fan, Yilun Jin, Yang Liu, Tianjian Chen, Dimitrios Papadopoulos, and Qiang Yang. Secureboost: A lossless federated learning framework. IEEE Intelligent Systems, 36(6):87–98, 2021.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Damgård et al. [2012] Ivan Damgård, Valerio Pastro, Nigel Smart, and Sarah Zakarias. Multiparty computation from somewhat homomorphic encryption. In Annual Cryptology Conference, pages 643–662. Springer, 2012.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Du et al. [2022] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, 2022.
- Dwork et al. [2014] Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407, 2014.
- Hardy et al. [2017] Stephen Hardy, Wilko Henecka, Hamish Ivey-Law, Richard Nock, Giorgio Patrini, Guillaume Smith, and Brian Thorne. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv preprint arXiv:1711.10677, 2017.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Kairouz et al. [2021] Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- Kang et al. [2022] Yan Kang, Yuanqin He, Jiahuan Luo, Tao Fan, Yang Liu, and Qiang Yang. Privacy-preserving federated adversarial domain adaptation over feature groups for interpretability. IEEE Transactions on Big Data, 2022.
- Li et al. [2022] Bowen Li, Lixin Fan, Hanlin Gu, Jie Li, and Qiang Yang. Fedipr: Ownership verification for federated deep neural network models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- Lin [2004] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- Liu et al. [2021a] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021.
- Liu et al. [2021b] Yang Liu, Tao Fan, Tianjian Chen, Qian Xu, and Qiang Yang. Fate: An industrial grade platform for collaborative learning with data protection. J. Mach. Learn. Res., 22(226):1–6, 2021.
- Liu et al. [2022] Yang Liu, Yan Kang, Tianyuan Zou, Yanhong Pu, Yuanqin He, Xiaozhou Ye, Ye Ouyang, Ya-Qin Zhang, and Qiang Yang. Vertical federated learning. arXiv preprint arXiv:2211.12814, 2022.
- McMahan et al. [2017] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017.
- OpenAI [2022] OpenAI. Chatgpt. 2022.
- OpenAI [2023] OpenAI. Gpt-4. 2023.
- Paillier [1999] Pascal Paillier. Public-key cryptosystems based on composite degree residuosity classes. In International conference on the theory and applications of cryptographic techniques, pages 223–238. Springer, 1999.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- Scao et al. [2022] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Shamir [1979] Adi Shamir. How to share a secret. Communications of the ACM, 22(11):612–613, 1979.
- Shao et al. [2019] Zhihong Shao, Minlie Huang, Jiangtao Wen, Wenfei Xu, and Xiaoyan Zhu. Long and diverse text generation with planning-based hierarchical variational model. arXiv preprint arXiv:1908.06605, 2019.
- Shen et al. [2020] Tao Shen, Jie Zhang, Xinkang Jia, Fengda Zhang, Gang Huang, Pan Zhou, Kun Kuang, Fei Wu, and Chao Wu. Federated mutual learning. arXiv preprint arXiv:2006.16765, 2020.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Villalobos et al. [2022] Pablo Villalobos, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. Will we run out of data? an analysis of the limits of scaling datasets in machine learning. arXiv preprint arXiv:2211.04325, 2022.
- Wang et al. [2023] Boxin Wang, Yibo Jacky Zhang, Yuan Cao, Bo Li, H Brendan McMahan, Sewoong Oh, Zheng Xu, and Manzil Zaheer. Can public large language models help private cross-device federated learning? Workshop on Challenges in Deployable Generative AI at International Conference on Machine Learning (ICML), 2023.
- Wu et al. [2022] Chuhan Wu, Fangzhao Wu, Lingjuan Lyu, Yongfeng Huang, and Xing Xie. Communication-efficient federated learning via knowledge distillation. Nature communications, 13(1):2032, 2022.
- Xiao et al. [2023] Guangxuan Xiao, Ji Lin, and Song Han. Offsite-tuning: Transfer learning without full model. arXiv preprint arXiv:2302.04870, 2023.
- Yang et al. [2019] Qiang Yang, Yang Liu, Yong Cheng, Yan Kang, Tianjian Chen, and Han Yu. Federated learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 13(3):1–207, 2019.
- Yang et al. [2023a] Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, Fan Yang, et al. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305, 2023.
- Yang et al. [2023b] Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv preprint arXiv:2304.13712, 2023.
- Zhang et al. [2018] Dongqing Zhang, Jiaolong Yang, Dongqiangzi Ye, and Gang Hua. Lq-nets: Learned quantization for highly accurate and compact deep neural networks. In Proceedings of the European conference on computer vision (ECCV), pages 365–382, 2018.
- Zhang et al. [2022a] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Zhang et al. [2022b] Zhuo Zhang, Yuanhang Yang, Yong Dai, Lizhen Qu, and Zenglin Xu. When federated learning meets pre-trained language models’ parameter-efficient tuning methods. arXiv preprint arXiv:2212.10025, 2022.
- Zhao et al. [2022] Haodong Zhao, Wei Du, Fangqi Li, Peixuan Li, and Gongshen Liu. Reduce communication costs and preserve privacy: Prompt tuning method in federated learning. arXiv preprint arXiv:2208.12268, 2022.
- Zhou et al. [2023] Ce Zhou, Qian Li, Chen Li, Jun Yu, Yixin Liu, Guangjing Wang, Kai Zhang, Cheng Ji, Qiben Yan, Lifang He, et al. A comprehensive survey on pretrained foundation models: A history from bert to chatgpt. arXiv preprint arXiv:2302.09419, 2023.