Fast Reinforcement Learning with Incremental Gaussian Mixture Models
Abstract
This work presents a novel algorithm that integrates a data-efficient function approximator with reinforcement learning in continuous state spaces. An online and incremental algorithm capable of learning from a single pass through data, called Incremental Gaussian Mixture Network (IGMN), was employed as a sample-efficient function approximator for the joint state and Q-values space, all in a single model, resulting in a concise and data-efficient algorithm, i.e., a reinforcement learning algorithm that learns from very few interactions with the environment. Results are analyzed to explain the properties of the obtained algorithm, and it is observed that the use of the IGMN function approximator brings some important advantages to reinforcement learning in relation to conventional neural networks trained by gradient descent methods.
1 Introduction
Reinforcement learning is at the center of many recent accomplishments in artificial intelligence, such as playing Atari games [21] and playing go at the grandmaster level [30]. However, most common approaches suffer from low data efficiency, which means that a high number of training episodes are necessary for the agent to acquire the desired level of competence on diverse tasks. The Deep Q-Learning Network (DQN) [20] and its variants [32, 15] as well as A3C [19] and other model-free actor-critic or policy gradient methods [29] require millions of agent-environment interactions due to very inefficient learning. This is not acceptable for some classes of tasks, such as robotics, where failure and damage must be minimized. A robot cannot afford to fall from stairs a thousand times before learning to avoid them. More data-efficient algorithms are necessary.
Some model-based solutions to such a problem were proposed, such as [10, 17], but results are still far from ideal, possibly due to its reliance on non-data-efficient function approximators like neural networks trained by gradient descent. While other works focus on the reinforcement learning side itself for data efficiency (by improving on exploration policies [3], for instance), the function approximation side is often neglected.
This research proposes a new solution to this problem, by integrating a sample-efficient function approximator, namely the Incremental Gaussian Mixture Network (IGMN) [12, 13, 14], with reinforcement learning techniques, reducing the number of required interactions with the real environment. It has been observed before that decoupling representation learning from behavior learning can be beneficial to reinforcement learning with function approximation [16, 27], since representations can be learned much faster than behavior, which relies on sparse reward signal, while some argue that behavior can be learned faster due to slow gradient descent on representation learning [5]. IGMN can learn both representations very fast and make locally linear predictions of Q-values based on those representations, while mostly avoiding catastrophic forgetting in the process.
This work is structured as follows: section 2 presents related works, while section 3 presents the latest iteration of the IGMN algorithm. Section 4 presents the proposed algorithm by combining IGMN and reinforcement learning. Section 5 shows experimental results, and section 6 finishes this work with discussions and future works.
2 Related Works
In [2], the authors use online EM to learn a single Gaussian mixture model (GMM) of the joint state-action-Q-value space. The algorithm is incremental, but it starts with some randomly placed Gaussian components instead of an empty model like the IGMN. Its component creation rule is based on an inference error threshold, as well as a Mahalanobis distance criterion. Continuous action selection is done approximately by computing the Q-value of a few random actions and selecting the one with the largest value. Matrix inverses are computed at each step, something that is avoided in the present work by using the fast variant of the IGMN algorithm (FIGMN) [25, 23]. An important contribution from the authors is the use of Q-value estimation variance provided by the GMM to drive exploration, resulting in something reminiscent of Q-value sampling in Bayesian Q-learning [8]. Another important insight is the need to forget old values, as Q-values are non-stationary and learned through bootstrapping, meaning that old values are mostly wrong.
In [11], the IGMN was applied to a traffic simulator with continuous action selection. The algorithm is fed with the current state and the maximum stored Q-value and outputs the greedy action. Moreover, IGMN outputs the action variance too, allowing for exploration by Gaussian noise around the greedy action, with the interesting feature that this variance is also adaptive, meaning that the exploration rate adapts to each state region. IGMN can linearly generalize inside each component, making the predictions smoother. The present work is targeted at discrete action environments instead of continuous actions, and thus uses a different architecture with one Q-value per action and some additions to the learning algorithm.
Recent works on episodic memory for reinforcement learning, such as Model-Free Episodic Control (MFEC) [5] and Neural Episodic Control (NEC) [26], have introduced a framework for stable, long-term, and immediately accessible memories to be stored and used analogously to Q-tables. Those models allow for generalization through k-Nearest Neighbors (kNN) search or by the use of a Radial Basis Function (RBF) layer and a linear output layer. An issue with both methods is the rapid filling of the memory, which is dealt with by removing the least recently used entries. In [1], authors propose to cluster the least recently used entry with its nearest entry, avoiding the removal of rare but important memories. That shows some resemblance to the inner workings of the IGMN algorithm, as it also stores memories as they arrive, available for immediate contribution to inference. Three main differences are: a) IGMN clusters memories continuously: there is no wait for the buffer to fill up (we observed better models constructed in this way; this feature was also added to MFEC in [22]); b) IGMN memory grows and shrinks as necessary; c) memories are complete Gaussian distributions of the joint input-output space, allowing for feature selection and linear regression inside each memory unit (this avoids the step-wise behavior observed in function approximators like kNN and RBF neural networks and requires fewer memory units). A downside of IGMN is the time complexity on the number of dimensions.
3 Incremental Gaussian Mixture Model
In the next subsections we describe the current version of the IGMN algorithm.
3.1 Learning
The algorithm starts with no components, which are created as necessary (see subsection 3.2). Given vector x (a single instantaneous data point), which includes both input and output concatenated, the IGMN algorithm processing step is as follows. First, the squared Mahalanobis distance for each component is computed:
| (1) |
where is the component mean and its full precision matrix (the inverse of the covariance matrix) . If any is smaller than than (the percentile of a chi-squared distribution with degrees-of-freedom, where is the input dimensionality and is a user defined meta-parameter, e.g., ), an update will occur, and posterior probabilities are calculated for each component as follows:
| (2) |
| (3) |
where is the component’s prior probability (equation 13) and is the number of components.
After that, according to [25, 23], parameters are updated as follows. Note that rank one updates are applied directly to the precision matrices () and matrix inversions are avoided.
| (4) |
| (5) |
| (6) |
| (7) |
| (8) |
| (9) |
| (10) |
| (11) |
| (12) |
| (13) |
where and are the posteriors accumulator (a probabilistic version of a counter) and the age of component (used for prunning), respectively, and is its prior probability. Detailed learning steps are shown in algorithms 1 and 2.
where represents the initial size of Gaussian components (the variance on each feature). It could be set as a fraction of the variances or sensor ranges for each dimension, if available.
3.2 Creating New Components
If the update condition in algorithm 1 is not met, then a new component is created and initialized as show in algorithm 3.
3.3 Inference
In IGMN, any element can be predicted by any other element. This is done by reconstructing data from the target elements (, a slice of the entire input vector x) by estimating the posterior probabilities using only the given elements (, also a slice of the entire input vector x), as follows:
| (14) |
It is similar to equation 3, except that it uses a modified input vector with the target elements removed from calculations. After that, can be reconstructed using the conditional mean:
| (15) |
where is the submatrix of the th component’s precision matrix associating the known () and unknown () parts of the data, is the submatrix corresponding to the unknown () part only, is the th’s component mean’s known part () and its unknown part (). This procedure can be seen in algorithm 4, while the covariance matrix block decomposition is shown in equation 16.
| (16) |
Note that it requires a matrix inversion of , which is used in two different places but can be reused in order to avoid two inversions. Also, since in most applications the number of outputs is much smaller than the number of inputs, this does not impose any huge penalty in complexity. Also note that the original FIGMN paper was missing the first two formulas, but they were derived and presented in [7].
3.4 Removing Spurious Components
A component is removed whenever and , where and are manually chosen (e.g., 5.0 and 3.0, respectively). In that case, also, must be adjusted for all , , using (13). In other words, each component is given some time to show its importance to the model in the form of an accumulation of its posterior probabilities . We do not use component pruning in this work, since it produced deleterious results when combined with reinforcement learning (rare but still important experiences may be forgotten, such as reaching the goal in the Mountain Car problem). New removal procedures that protect high reward memories must be investigated.
4 Reinforcement Learning with IGMN
Here we develop a data-efficient (and here we define it empirically) reinforcement learning algorithm for continuous state spaces and discrete action spaces. We argue that other algorithms’ inefficiencies come partially from the slow function approximators they use, i.e., neural networks trained by gradient descent. Hence, a data-efficient function approximator should be used instead. The algorithm chosen here is the IGMN, due to its speed and versatility. IGMN can be combined with reinforcement learning in various ways [11], but here we focus on the most successful one, called Unified FIGMN-Q in [24]. For the sake of simplicity, it is called Q-IGMN from now on.
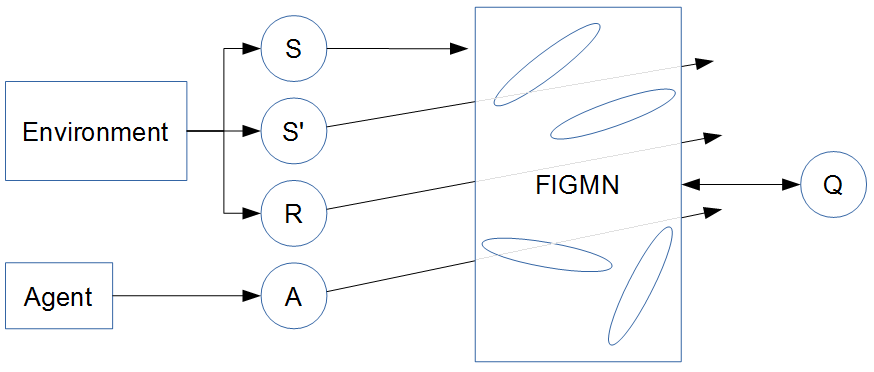
Q-IGMN is achieved by modeling the joint space of states and Q-values (one Q-value for each possible action), as this is IGMN’s standard way of doing supervised learning. This architecture is shown in figure 1. It allows only discrete actions, but, on the other hand, allows for fast action selection (just input the current state and select the action corresponding to the largest Q-value). Algorithm 5 describes the behavior of this architecture.
5 Experiments and Results
OpenAI Gym [6] has been used as the primary platform for testing the proposed algorithm and comparing it to other popular alternatives. This open-source platform provides ready-to-use reinforcement learning environments and is used to provide a leaderboard-like page111This feature has since been removed from the platform, but experiment result files are still accessible comparing the performance of algorithms from different users, including the most common algorithms like Q-learning. The performance is measured by two factors: episodes to solve (data efficiency) and mean reward. Each environment has some goal accumulated reward to reach. More precisely, the agent must obtain an average accumulated reward equal or higher than the goal for 100 consecutive episodes, making it a very robust experiment. Time to solve is defined as the first episode of the successful 100 episode window.
More demanding tasks like the Atari games [4] were avoided due to hardware restrictions, but are planned for future experiments. All experiments were executed on an Intel i7 laptop without access to GPU.
Since the OpenAI Gym platform currently only supports the Python language, this was the language of choice for implementing the final experiments. An existing open-source implementation 222https://github.com/renatopp/liac/blob/master/liac/models/igmn.py of the IGMN algorithm in this language was used as a basis for the more scalable FIGMN algorithm implementation.
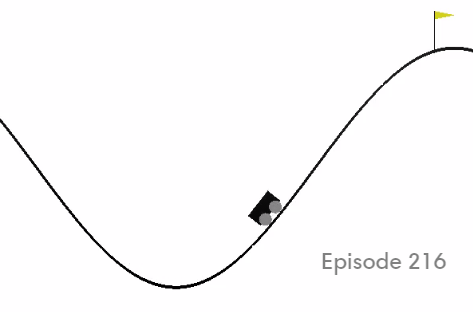
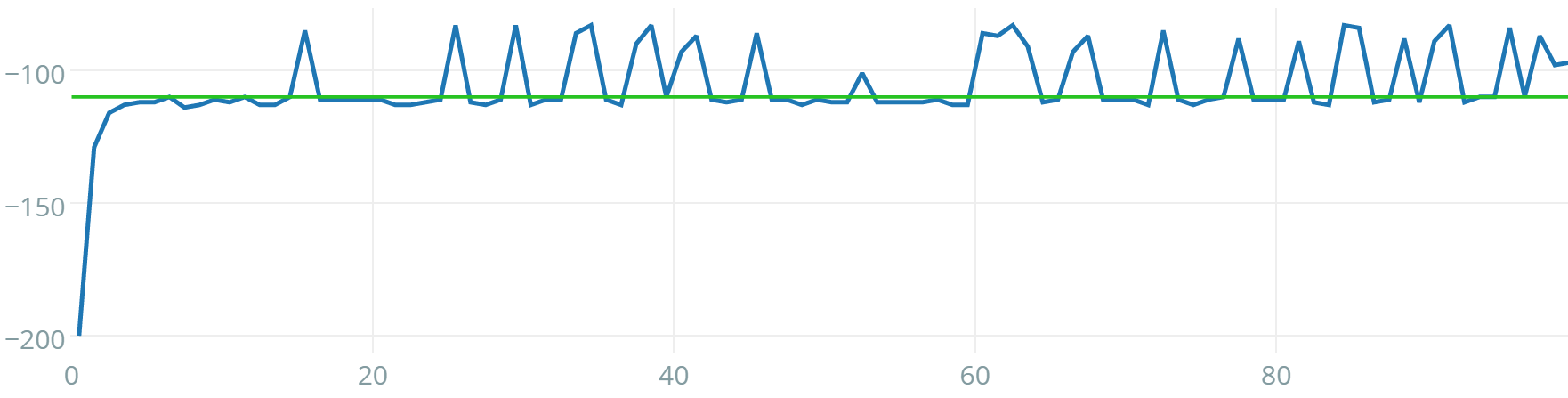
The mountain car task consists of controlling an underpowered car to reach the top of a hill. It must go up the opposite slope to gain momentum first. The agent has three actions at its disposal, accelerating it leftwards, rightwards, or no acceleration at all. The agent’s state is made up of two features: current position and speed. Only 200 steps are available for the agent to explore during each episode. This task is considered solved after 100 consecutive episodes with an average of 110 steps or less to reach the top of the hill. A screenshot of this environment can be seen in figure 2.
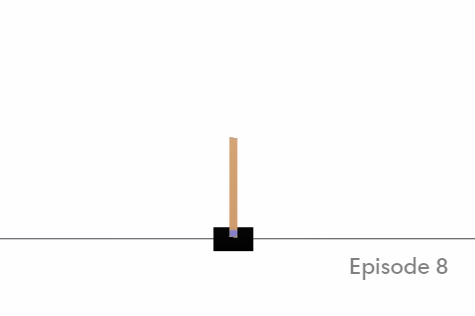
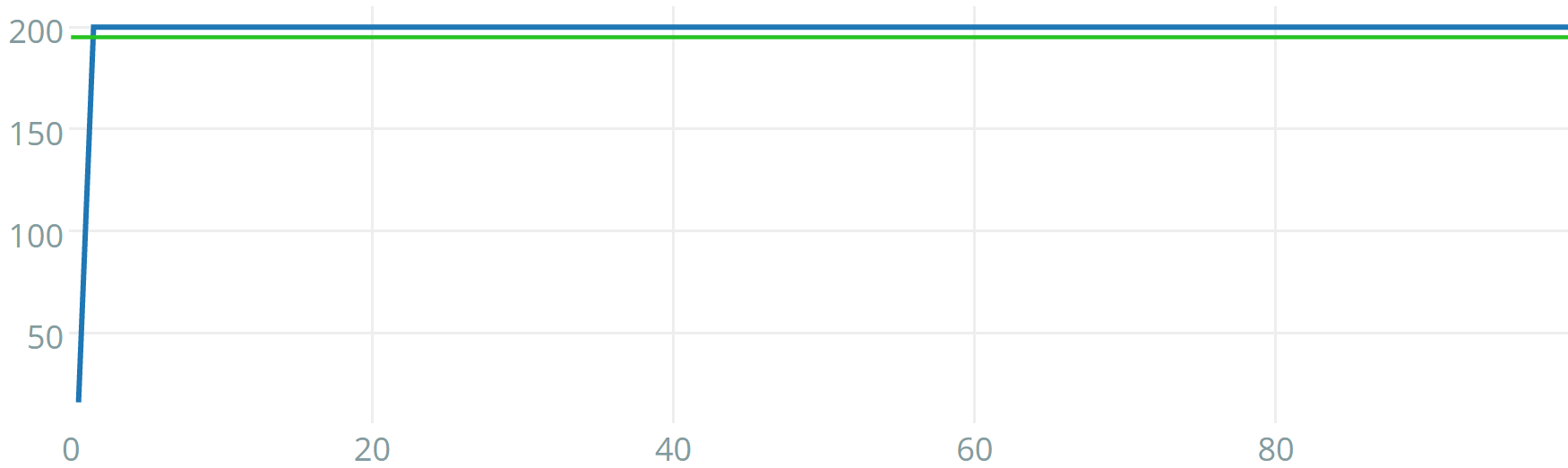
The cart-pole task consists of balancing a pole above a small car that can move left or right at each time step. Four variables are available as observations: current position and speed of the cart and current angle and angular velocity of the pole. Version 0 requires the pole to be balanced for 200 steps, while version 1 requires 500 steps. This task is considered solved after 100 consecutive episodes with an average of 195 steps for version 0 and 475 steps for version 1 without dropping the pole. A screenshot of this environment can be seen in figure 3
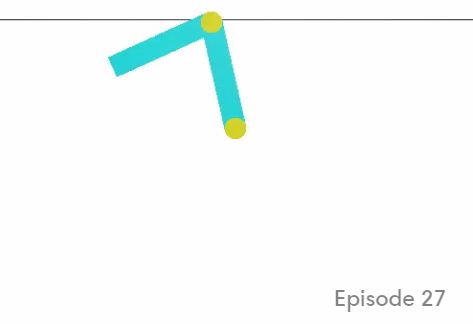
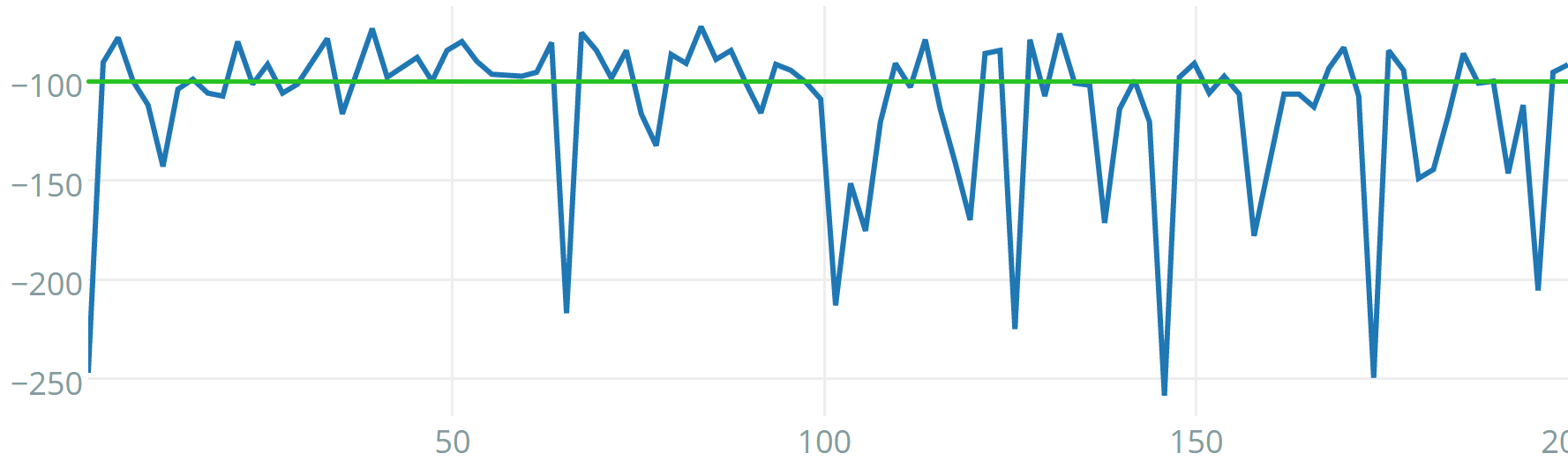
Finally, the acrobot task requires a 2-joint robot to reach a certain height with the tip of its ”arm”. Torque in two directions can be exerted on the 2 joints, resulting in 4 possible actions. The current angle and angular velocity of each joint are provided as observations. There are 200 steps per episode available for exploration. This task is considered solved after 100 consecutive episodes with an average of 100 or fewer steps to reach the target height. A screenshot of this environment can be seen in figure 4
The Q-IGMN algorithm was compared to other 3 algorithms with high scores on OpenAI Gym: Sarsa() with Tile Coding, Trust Region Policy Optimization [28] and Dueling Double DQN [32]. These algorithms were chosen according to the OpenAI Gym rank at the time of writing. Table 1 shows the number of episodes required for each algorithm to reach the required reward threshold for the 3 tasks 333The OpenAI Gym platform computes results based only on successful runs. Results were extracted on June-2016 and January-2017.
| Environment | Q-IGMN 444https://gym.openai.com/algorithms/alg_gt0l11Rf6hkwUXjVsRcw | Sarsa() 555https://gym.openai.com/algorithms/alg_hJcbHruxTLOa1zAuPkkAYw | TRPO 666https://gym.openai.com/algorithms/alg_yO8abVs8Spm21Icr60SB8g | Duel DDQN 777https://gym.openai.com/algorithms/alg_zy3YHp0RTVOq6VXpocB20g |
|---|---|---|---|---|
| Cart-Pole V0 | 0.5 0.56 | 557 | 2103.50 3542.86 | 51.00 7.24 |
| Mountain Car V0 | 0.0 | 1872.50 6.04 | 4064.00 246.25 | - |
| Acrobot V0* | 0.0 | 742 | 2930.67 1627.26 | 31 |
| * This task is not available on the OpenAI Gym server anymore, so the result can be verified only locally. | ||||
Albeit being very difficult to tune, Q-IGMN proved to be the most data-efficient reinforcement learning algorithm in this set of experiments. It was able to solve each of the tasks in a few episodes. Typical learning curves for this algorithm in all tasks are shown in figures 5, 6 and 7. Note that, when this experiment was performed, acrobot v0 was not available anymore at the Gym server, so experiments were kept locally. The acrobot learning curve shown is for v1, where physics where improved, there are 500 available time steps per episode instead of 200 and there is no reward threshold, so it is not trivial to compare algorithms regarding data-efficiency (hence why we use v0 in the comparison table). Its learning curve is still informative, nevertheless. Another interesting result is that Q-IGMN solved most of the tasks with a single Gaussian component, implying that their Q-value function is (at least approximately) linear. The mountain car task, on the other hand, required 8 Gaussian components (its Q-value function has a spiral surface).
However, a single trick was essential to guarantee this data-efficiency: we employed a kind of experience replay buffer. But instead of sampling it randomly and repeatedly at each time step (as commonly done in most works with neural networks), it was sampled from the most recent observation to the oldest one (randomly sampling the experience replay buffer also works here, but performance degrades), in a single pass (which means that we still perform only one update per step, they are just shifted and accumulated), and learning only happens when the buffer is full; after that, it is emptied again. Interestingly, time-correlated data does not impair IGMN’s performance as it does with neural networks. It is shown in the original Incremental Gaussian Mixture Model paper [9] that data should vary slowly (i.e., it should not be independent and identically distributed (i.i.d.), exactly the opposite condition for neural networks). From another point-of-view, this could be seen as mini-batch learning. This technique drastically improved the algorithm, and there seem to be 2 effects taking place to explain this:
-
•
First, it is common knowledge that conventional Q-learning with function approximation diverges due to the non-stationary nature of the Q-values [31]. The Q-learning update rule uses the function approximator itself to provide a target, which changes immediately, while action selection is also done using the same ever-changing approximator. By doing updates in mini-batches, this issue is minimized, as action selection is performed over a stable function approximator. Then, it is updated all at once, and after that, actions can be selected from a stable approximator again. This bears resemblance to Double Q-Learning, where 2 estimators are used to select actions from a stable approximator which is updated once in a while from the second estimator (which updates constantly), except we use a single estimator with sporadic updates instead;
-
•
The second effect produced by this mini-batch approach is similar to trace decays: while conventional Q-learning updates a single state-action per step, trace decays allow us to update a large portion of the state-action history at once. So, when a goal is reached, its value is rapidly propagated backward. The mini-batch approach results in something very much like it: since the most recently visited states are updated first, older states will receive updated values immediately, eliminating the need to visit those states again to ”see” the new values. A key difference is that trace decays perform all these updates at every time step, resulting in high computational demands.
In general, larger buffer sizes improved the results. For small episodic tasks like the ones presented here, it is enough to set the maximum buffer size as the maximum number of steps per episode for each task, resulting in episodic batch updates (note, however, that IGMN updates are always incremental, i.e., each experience is presented to the algorithm and then discarded). The resulting buffer sizes are vastly smaller than conventional experience replay buffers for deep learning.
Additionally, in the mountain car task, it was necessary to apply other techniques to ensure stability and convergence:
-
•
The first one was to set an independent learning rate (with its own annealing schedule) for the Q-value variables in the Q-IGMN. It means that equation 7 (reproduced below) should only apply to the state variables when updating the mean and also the precision matrix.
(17) When updating the means and precision matrices for variables corresponding to the Q-values, the following equation should be used instead:
(18) This effectively decouples representation learning speed from behavior learning speed, and is necessary in some cases, since the default IGMN learning rate given by the original equation decreases very fast, which may not be appropriate for a given task. Also, the original equation results in the component mean converging to the true mean of all input data, which is expected when dealing with stationary data, but not with non-stationary data as is the case of the Q-values. The same problem was found by [2] and solved in a way that was appropriate for the used algorithm, but it would be analogous to applying a decay rate to in Q-IGMN, thus making decrease slower. It is not the same as the independent learning rate, as it affects all variables and not only the Q-values. In our experiments, the independent learning rate for Q-values was able to find a solution, while decay was not.
-
•
The second one was a technique akin to early stopping, which is used in neural networks to avoid overfitting. Here, a reward threshold (in this case ) was set in order to stop learning. When this threshold is reached, the exploration parameter, the learning rate, and the component creation threshold are all set to , effectively stopping any learning. This is necessary to avoid new components being created in overlapping positions with old ones, producing catastrophic forgetting. An alternative, which is explored in [7], is to improve the stability of IGMN itself by avoiding overlaps automatically.
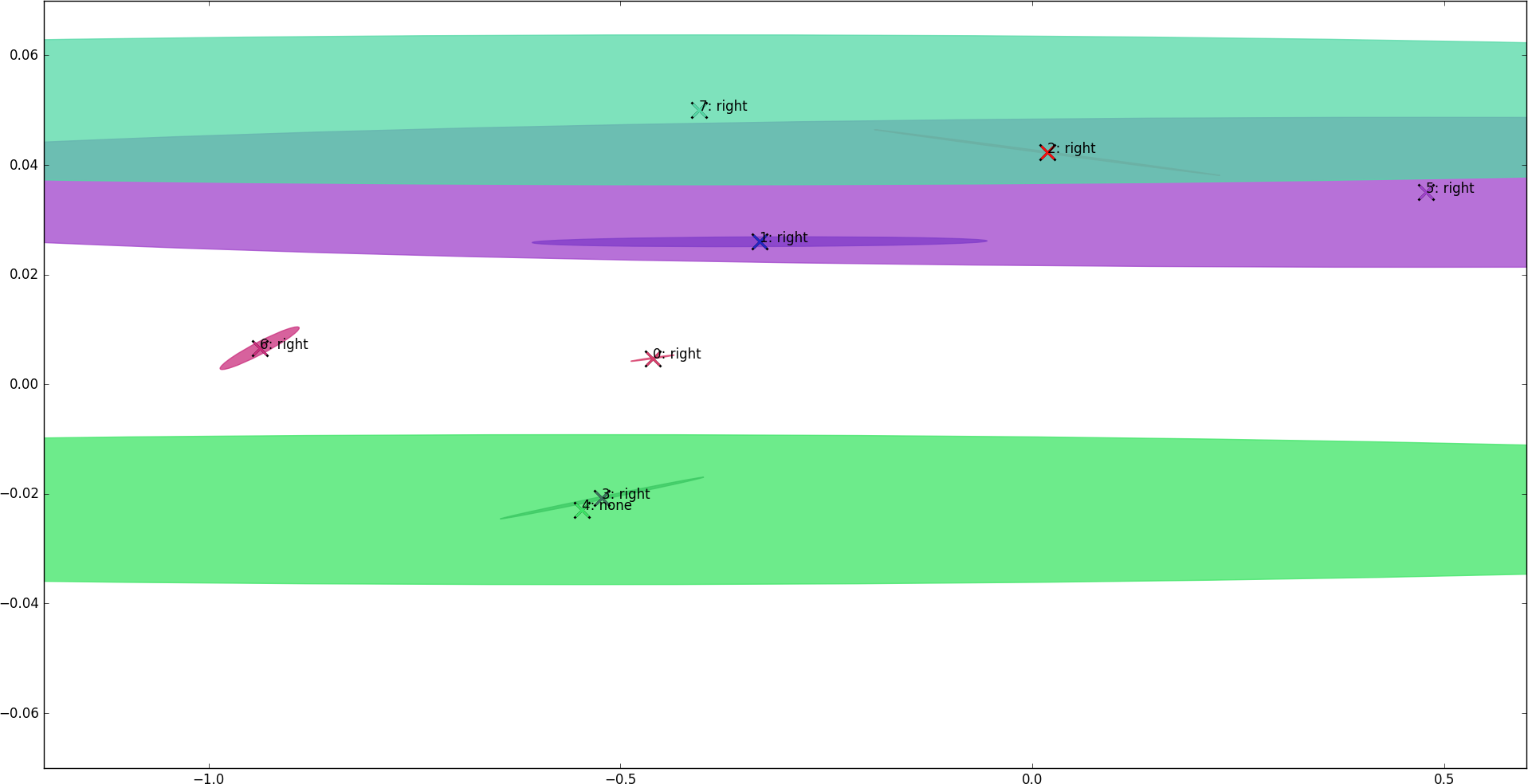
The learned policy is shown in figure 8. Actions are shown according to the largest Q-value in the Gaussian means. It is possible to verify that most components suggest the ”right” action, having a single ”none” action on the lower half of the graph. It is expected, as the optimal policy involves applying torque in the same direction as the car’s current speed. Upon analyzing the covariance matrices of components #3 and #6, negative covariances were found between the state variables and the ”left” action, meaning that when the car is moving left (negative speed), the Q-value for the ”left” action increases, which matches the expected policy. This is something impossible to achieve with local feature representations like RBF or tile coding, since components only generalize the state space and Q-values do not vary inside a single unit. This explains why Q-IGMN can solve problems with very few Gaussian components (often 1), which also, in turn, makes it very fast.
6 Conclusion
This work presented the combination of incremental Gaussian mixture models with reinforcement learning. IGMN was employed as a function approximator for Q-values of three classic continuous reinforcement learning tasks. Results show that it presents astounding data-efficiency, learning the three tasks within a few episodes. This can be attributed to the algorithm’s similarity to double Q-Learning, delayed Q-Learning, and trace decays, all of which are known to improve data-efficiency, combined with a data-efficient function approximator itself. However, due to time and hardware constraints, the algorithm could only be tested on relatively simple environments, where this performance is not that impressive. New experiments in more complex environments (e.g., Atari) should be conducted in future works to assess the generality and scalability of this solution.
An interesting discovery found while using experience replay is that some drawbacks of conventional neural networks that require some workarounds are not present in IGMN, allowing it to take full advantage of the procedure. For instance, the IGMN does not require i.i.d. data, so experience replay does not need to be sampled randomly. Also, due to its high data-efficiency, only a single scan through the experience replay buffer is necessary. By only updating the model sporadically, simultaneous use of the Q-function estimate for action selection and updating is avoided, improving convergence, which draws parallels with double Q-learning. Thus, one of the main contributions of this research is to show how non-mainstream algorithms can be successfully combined with reinforcement learning, suggesting that neural networks (in their current forms) trained by gradient descent are not the only possibility and possibly not the best.
The main obstacles found reside in the non-stationary nature of the Q-value function, which is not appropriate for the learning rate annealing schedule of IGMN. IGMN finds means of input data, while the Q-value updates require an emphasis on more recent data, in some cases even totally overwriting previous inaccurate values (due to bootstrapping). We fixed this issue by providing a separate learning rate for the Q-values, as well as implementing a tighter control over its variance to avoid singularities.
Another obstacle found during the experiments was IGMN’s high sensitivity to its hyper-parameters ( and ). A very small change in these parameters is enough to make the algorithm create more or less Gaussian components, which has a huge impact on the final model, like a butterfly effect. Moreover, the excessive creation of components can cause overfitting, as well as catastrophic forgetting. New components can have large overlapping regions with old components, interfering with what has been previously learned. Thus, we propose that, in future works, this issue must be addressed with a certain urgency, as this can deter practical use of the IGMN (the same issue was also found by [18] and explored by [7]).
References
- Agostinelli et al. [2019] Agostinelli, A., Arulkumaran, K., Sarrico, M., Richemond, P., and Bharath, A. A. (2019). Memory-efficient episodic control reinforcement learning with dynamic online k-means.
- Agostini and Celaya [2010] Agostini, A. and Celaya, E. (2010). Reinforcement learning with a gaussian mixture model. In Neural Networks (IJCNN), The 2010 International Joint Conference on, pages 1–8. IEEE.
- Aubret et al. [2019] Aubret, A., Matignon, L., and Hassas, S. (2019). A survey on intrinsic motivation in reinforcement learning. arXiv preprint arXiv:1908.06976.
- Bellemare et al. [2013] Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. (2013). The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research (JAIR), 47:253–279.
- Blundell et al. [2016] Blundell, C., Uria, B., Pritzel, A., Li, Y., Ruderman, A., Leibo, J. Z., Rae, J., Wierstra, D., and Hassabis, D. (2016). Model-free episodic control. arXiv preprint arXiv:1606.04460.
- Brockman et al. [2016] Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., and Zaremba, W. (2016). Openai gym. arXiv preprint arXiv:1606.01540.
- Chamby-Diaz et al. [2018] Chamby-Diaz, J. C., Recamonde-Mendoza, M., Bazzan, A. L., and Grunitzki, R. (2018). Adaptive incremental gaussian mixture network for non-stationary data stream classification. In 2018 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE.
- Dearden et al. [1998] Dearden, R., Friedman, N., and Russell, S. (1998). Bayesian q-learning. In AAAI/IAAI, pages 761–768.
- Engel and Heinen [2010] Engel, P. and Heinen, M. (2010). Concept Formation Using Incremental Gaussian Mixture Models. Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, pages 128–135.
- Gu et al. [2016] Gu, S., Lillicrap, T., Sutskever, I., and Levine, S. (2016). Continuous deep q-learning with model-based acceleration. arXiv preprint arXiv:1603.00748.
- [11] Heinen, M., Bazzan, A., and Engel, P. (2011a). Dealing with continuous-state reinforcement learning for intelligent control of traffic signals. In Intelligent Transportation Systems (ITSC), 2011 14th International IEEE Conference on, pages 890–895. IEEE.
- [12] Heinen, M., Engel, P., and Pinto, R. (2011b). IGMN: An Incremental Gaussian Mixture Network that Learns Instantaneously from Data Flows. In Proceedings of the IX ENIA - Brazilian Meeting on Artificial Intelligence, Natal (RN).
- [13] Heinen, M. R., Engel, P. M., and Pinto, R. C. (2011c). Applying the incremental gaussian neural network to concept formation and robotic tasks. Proc. 10th Brazilian Congr. Computational Intelligence (CBIC). Fortaleza, CE, Brazil (Nov 2011).
- Heinen et al. [2012] Heinen, M. R., Engel, P. M., and Pinto, R. C. (2012). Using a gaussian mixture neural network for incremental learning and robotics. In Neural Networks (IJCNN), The 2012 International Joint Conference on, pages 1–8. IEEE.
- Hessel et al. [2018] Hessel, M., Modayil, J., Van Hasselt, H., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., and Silver, D. (2018). Rainbow: Combining improvements in deep reinforcement learning. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Higgins et al. [2017] Higgins, I., Pal, A., Rusu, A., Matthey, L., Burgess, C., Pritzel, A., Botvinick, M., Blundell, C., and Lerchner, A. (2017). Darla: Improving zero-shot transfer in reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1480–1490. JMLR. org.
- Kaiser et al. [2019] Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R. H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., et al. (2019). Model-based reinforcement learning for atari. arXiv preprint arXiv:1903.00374.
- Koert et al. [2018] Koert, D., Trick, S., Ewerton, M., Lutter, M., and Peters, J. (2018). Online learning of an open-ended skill library for collaborative tasks. In 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), pages 1–9. IEEE.
- Mnih et al. [2016] Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pages 1928–1937.
- Mnih et al. [2013] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
- Mnih et al. [2015] Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540):529–533.
- Pinto [2020] Pinto, R. (2020). Model-free episodic control with state aggregation. arXiv preprint arXiv:2008.09685.
- Pinto and Engel [2017] Pinto, R. and Engel, P. (2017). Scalable and incremental learning of gaussian mixture models. arXiv preprint arXiv:1701.03940.
- Pinto [2017] Pinto, R. C. (2017). Continuous reinforcement learning with incremental Gaussian mixture models. PhD dissertation, Universidade Federal do Rio Grande do Sul.
- Pinto and Engel [2015] Pinto, R. C. and Engel, P. M. (2015). A fast incremental gaussian mixture model. PloS one, 10(10):e0139931.
- Pritzel et al. [2017] Pritzel, A., Uria, B., Srinivasan, S., Badia, A. P., Vinyals, O., Hassabis, D., Wierstra, D., and Blundell, C. (2017). Neural episodic control. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2827–2836. JMLR. org.
- Raffin et al. [2019] Raffin, A., Hill, A., Traoré, K. R., Lesort, T., Díaz-Rodríguez, N., and Filliat, D. (2019). Decoupling feature extraction from policy learning: assessing benefits of state representation learning in goal based robotics. arXiv preprint arXiv:1901.08651.
- Schulman et al. [2015] Schulman, J., Levine, S., Moritz, P., Jordan, M. I., and Abbeel, P. (2015). Trust region policy optimization. arXiv preprint arXiv:1502.05477.
- Schulman et al. [2017] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Silver et al. [2016] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Driessche, G. V. D., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489.
- Sutton and Barto [1998] Sutton, R. and Barto, A. (1998). Reinforcement learning: An introduction, volume 1. Cambridge Univ Press.
- Wang et al. [2015] Wang, Z., de Freitas, N., and Lanctot, M. (2015). Dueling network architectures for deep reinforcement learning. arXiv preprint arXiv:1511.06581.