Fast MATLAB evaluation of nonlinear energies
using FEM in 2D and 3D: Nodal elements
Abstract
Nonlinear energy functionals appearing in the calculus of variations can be discretized by the finite element (FE) method and formulated as a sum of energy contributions from local elements. A fast evaluation of energy functionals containing the first order gradient terms is a central part of this contribution. We describe a vectorized implementation using the simplest linear nodal (P1) elements in which all energy contributions are evaluated all at once without the loop over triangular or tetrahedral elements. Furthermore, in connection to the first-order optimization methods, the discrete gradient of energy functional is assembled in a way that the gradient components are evaluated over all degrees of freedom all at once. The key ingredient is the vectorization of exact or approximate energy gradients over nodal patches. It leads to a time-efficient implementation at higher memory-cost. Provided codes in MATLAB related to 2D/3D hyperelasticity and 2D p-Laplacian problem are available for download and structured in a way it can be easily extended to other types of vector or scalar forms of energies.
1 Introduction
Given a domain , where is the space-dimension, we consider a minimization problem
| (1) |
where is a space of trial functions and represents an energy functional in the form
| (2) |
where denotes its first-gradient part and its linear part. Examples of such minimization problems are numerous and their study is a general subject of the Calculus of variations. There are models with higher order derivatives (such as plate problems with the second derivative in their formulation) available but not considered in this contribution.
As the main example we recall a class of vector nonlinear elasticity problems represented by minimizations of energies of hyperelastic materials [10, 12]. The trial space is chosen as
i.e., the (vector) Sobolev space of integrable functions with the first weak derivative being also integrable and satisfying (in the sense of traces) Dirichlet boundary conditions at the domain boundary for a prescribed function . A primal variable is the deformation mapping describing the relocation of any point during the deformation process. Then the gradient deformation tensor is defined as
| (3) |
The first-gradient and the linear parts of the energy functional (2) read
where defines a strain-energy density function and a loading functional. We assume the compressible Neo-Hookean density
| (4) |
where uses the Frobenius norm , and is the matrix determinant operator. An extension to other gradient densities as the St. Venant Kirchhoff is possible.
As the second example we recall a scalar p-Laplacian problem [7] with the energy functional defined as
| (5) |
where . The functional is then known to be strictly convex in for and it has therefore a unique minimizer .
The main motivation of this contribution is to describe how nonlinear energy functionals can be efficiently and automatically evaluated by the finite element method (FE). We provide vectorization concepts and MATLAB implementation for
-
•
evaluations of the value ,
-
•
evaluations of the gradient vector
expressed for a trial function . These two objects can be passed to an external optimization method of the first order to find a minima of the energy and the corresponding minimal energy value . We utilize the trust-region optimization method [4] available in the MATLAB Optimization Toolbox for benchmarking. Our implementation is built on the top of our own vectorized codes [3, 6, 15] developed primarily for assemblies of finite element matrices. There are no explicit loops over mesh elements in evaluations of and , all necessary data such as gradients of basis functions and energy densities are computed all at once. It leads to a significant computational speedup, but also it is memory intensive. Practically, the user specifies the form of the energy and the corresponding gradient vector is evaluated approximately by a central difference scheme. Alternatively, if the user is willing to apply some differential calculus to a particular form of the energy, then the exact gradient can be assembled. This exact gradient approach is not versatile, but leads to the further performance speedup in our tests. We set up a set of six benchmarks as a base for future tests and improvements:
-
•
The mesh and the nodal patches data are preprocessed in Benchmark 1.
-
•
Evaluations of and for a given are provided in Benchmarks 2 and 3.
-
•
The full minimizations of 2D/3D hyperelasticity and 2D p-Laplacian energies are shown in Benchmarks 4, 5 and 6.
Authors are not aware of any similar MATLAB implementation. This is also our first attempt in this direction apart from our own contribution [13] focusing on p-Laplacian energy minimization. There is a growing number of MATLAB vectorized implementations of the second order linear partial differential equations eg. [9, 17] or particular nonlinear partial differential equations [6, 16].
The paper is structured in the following way: Section 2 summarizes useful notation and Section 3 basics of FEM. Section 4 includes implementation of two structures: mesh and (nodal) patches. Section 5 is focused on implementation of energy evaluation and Section 6 on implementation of the gradient of energy. The final Section 7 reports on the solutions of particular minimization problems.
2 Notation
Index mappings in the construction of FEM:
-
- (local to global) mapping which for a local basis function on an element returns the index of the corresponding global basis function
-
- (degree to node) mapping which for the -th degree of freedom returns the index of the corresponding node, see (22)
Domain triangulations are described by the following parameters:
-
- a set of elements, a set of nodes
-
- a set of (at least partially) free nodes
-
- the -th nodal patch, the -th nodal patch
-
- the sizes of sets
Both scalar and vector problems are treated together as a vector problem with components, where for scalar problems, for vector problems and is the space dimension. The following indices are frequently used:
-
- the index of a node (, also or )
-
- the index of a vector component ()
-
- the index of an element (), also () or ()
-
- the index of a local basis function ()
-
- the index of a spatial component ()
-
- the index of a global degree of freedom () or an active degree of freedom ()
-
- the index of a global patches matrix row ()
Nodal basis functions are used in several ways:
-
- a scalar global nodal basis function, a vector global nodal basis function
-
- the th local basis function on the th element
A trial vector function is addressed in several ways:
-
- a trial vector function and its -th component
-
V - a matrix of the coefficients of in the nodal finite element basis
-
- the -th row of V, the -th column of V, the (i,j) element of V
-
v - a vector reshaped from V
-
- the restriction of v to free nodes
Given matrices the following operators are used:
-
- the trace of matrix (for )
-
- the determinant of matrix (for )
-
- the elementwise (Hadamard) product defined as a matrix , where
-
- the scalar product defined as
3 Finite element discretization
The finite element method [5] is applied for the discretization of (1). We assume a trial function and a trial space of the form
and approximate in the finite-dimensional subspace
where and the scalar basis space is generated from the scalar basis functions
where denotes their number. Hence, any component of is given by a linear combination
| (6) |
The coefficients from (6) are assembled in a matrix given as
| (7) |
and latter two equivalent forms assume a row vector , and a column vector . Using a row vector basis function
one can rewrite (6) in a compact way for all components as
| (8) |
where the symbol represents an elementwise (or Hadamard) multiplication (here multiplication of components with the same index ). Formula (8) is the key tool for a vectorized implementation, since MATLAB provides the elementwise multiplication.
The domain is then approximated by its triangulation into closed elements in the sense of Ciarlet [5]. The simplest possible elements are considered, i.e., triangles for and tetrahedra for . The elements are geometrically specified by their nodes (or vertices) belonging to the set of nodes . The nodes are also clustered into elements edges (for ) and faces (for ). The numbers of elements and nodes are denoted as and .
Given a node , we define a nodal patch by
and the number of its elements by . The nodal patch consists of elements denoted as , which are adjacent to the node . The same nodal patch can be alternatively denoted by , where and is the index of one of the corresponding degrees of freedom.
We consider only the case where is the space of nodal, elementwise linear and globally continuous scalar basis functions. Then the number of basis functions is equal to the number of nodes
but some coefficients of the trial function are known due to the Dirichlet boundary conditions.
Example 1
One regular triangulation of an L-shape domain is shown in Fig. 1. The triangulation is specified by and . The graph of the global scalar basis function is displayed. The function has a hexagonal pyramid shape and the support on the nodal patch
The restrictions of to its six supporting triangles in are given as linear functions with values 1 at the node and values 0 at the two remaining nodes.
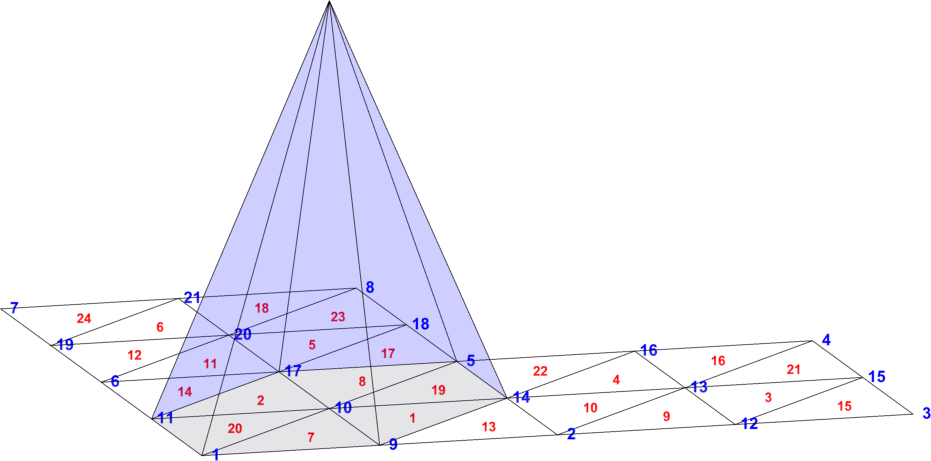
Additionally, for the scalar case () the node has only one corresponding degree of freedom with index and, therefore, as long as . For the vector case () the same node has two corresponding degrees of freedom with indices , hence, as long as . This alternative notation is essential in Section 6.
3.1 The first-gradient energy term
Since the first gradient of any scalar basis function , is a piecewise constant function on each element, the gradient part of the discrete energy can be written as a sum over the elements
| (9) |
and denotes the size of the element (equal to its length in 1D, its area in 2D or its volume in 3D). In order to evaluate (9), we need to assemble the gradient on every element. To do it, we define a (local-global) mapping which for the -th element and its -th node returns the global index of this node. Then a local basis function is given as
| (10) |
for . Hence, any partial derivative of with respect to reads
| (11) |
where represents the values of v in the -th node of the -th element.
3.2 The linear energy term
Furthermore, if , then the linear term of the energy (2) rewrites as
| (12) |
All integral terms in the formula above can be assembled in a sparse and symmetric mass matrix with entries
| (13) |
Then we can define vectors where and it is easy to check the exact formula
| (14) |
which allows us to represent the linear part of the discrete energy as a linear function.
4 Implementation: Mesh and nodal patches
We describe the typical properties of meshes and nodal patches needed in our computational techniques. Considered finite element meshes consist of triangles (in 2D) and tetrahedra (in 3D), however detailed explanations of Sections 4, 5, 6 address 3D version only.

4.1 The ’mesh’ structure
The topology and important attributes of the computational domain are stored in the structure-type data object ’mesh’. For the example of a tetrahedral mesh displayed in Fig. 2, a vector energy model and full Dirichlet boundary conditions (specified in all three directions and indicated by the nodes in red circles) it provides the following information:
mesh = struct with fields: dim: 3 level: 1 nn: 729 ne: 1920 elems2nodes: [1920×4 double] nodes2coord: [729×3 double] volumes: [1920×1 double] dphi: {[1920×4 double] [1920×4 double] [1920×4 double]} nodesDirichlet: [18×1 double] nodesMinim: [711×1 double] dofsDirichlet: [54×1 double] dofsMinim: [2133×1 double] Parameter dim represents the domain dimension (here ) of the problem and level the level of a uniform refinement. Higher levels of refinement lead to finer uniformly refined meshes with more elements. The numbers of mesh nodes and elements are provided in nn and ne. Mesh nodes belonging to each tetrahedron are collected in a matrix ’elems2nodes’ and the Cartesian coordinates of mesh nodes in a matrix ’nodes2coord’.
Once the last two matrices are given, the codes of [15] generate the ’volumes’ of all tetrahedra together with the restrictions of the partial derivatives (gradients) of all P1-basis functions to tetrahedra stored in a cell ’dphi’ whose components are matrices corresponding to the partial derivates with respect to every .
The indices of Dirichlet boundary nodes are stored in a vector ’nodesDirichlet’ and the remaining free nodes in a vector ’nodesMinim’. Vectors ’dofsDirichlet’ and ’dofsMinim’ denote the indices of the degrees of freedom corresponding to Dirichlet and free nodes.
Remark 1
Vectors ’dofsDirichlet’ and ’dofsMinim’ are equal to vectors ’nodesDirichlet’ and ’nodesMinim’ in case of a scalar energy formulation.
4.2 The ’patches’ structure
This object is only relevant if the knowledge of gradient is required, e.g. as an input of the trust-region method of Section 7. Then, the additional structure-type data object ’patches’ is constructed for the evaluation of its gradient part given by (9).
Remark 2
Only the components of corresponding to free nodes are evaluated in our implementation, and the remaining components belonging to the full Dirichlet boundary conditions are omitted. Thus, the nodes with at least one free degree of freedom also belong to the set of free nodes and the gradient is evaluated in all of their components and finally restricted to free degrees of freedom.
We denote by a set of all free nodes and by their number. Then, the node index , goes exclusively through the free nodes. A nodal patch is implemented as a vector of elements indices ’elems_’, a vector of their volumes ’volumes_’, a matrix of the corresponding elements nodes stored as ’elems2nodes_’, values of the gradients of local basis functions stores as a cell ’dphi_’ with matrices components dphi_, , dphi_. All these matrices and vectors are of size and , respectively.
The data of all nodal patches are then collected in the corresponding long global matrices or vectors with the number of rows equal to
For we define the indices
| (15) |
and additionally . Then the submatrix or subvector extracted from rows of the global matrices or vector above corresponds to the -th nodal patch. It is shown schematically in Fig. 3.
Thus we obtain the global vectors ’elems’, ’volumes’ of size and the global matrices ’elems2nodes’, dphi, , dphi, of size .
Remark 3
For the gradient evaluation of Section 6 we will need to extend a set of , indices up to . Thus, we additionally define
| (16) |
In order to maintain the right ordering of the local basis functions within each nodal patch, an additional logical-type matrix of zeros and ones ’logical’ is provided. If the -th row corresponds to the -th patch, then logical means that elems2nodes. Therefore, in every row of ’logical’ matrix the value ’’ has exactly one single occurrence.
Below we provide an example of the ’patches’ structure along with the same ’mesh’ one introduced in Subsection 4.1 and corresponding to the domain in Fig. 2.
patches = struct with fields: lengths: [711×1 double] elems: [7584×1 double] volumes: [7584×1 double] elems2nodes: [7584×4 double] dphi: {[7584×4 double] [7584×4 double] [7584×4 double]} logical: [7584×4 logical] The first vector ’lengths’ is of size with entries . Here, its size is equal to , where is the number of mesh nodes and is the number of nodes with full Dirichlet boundary conditions.
Benchmark 1
The script benchmark1_start.m generates a sequence of the structures mesh and patches corresponding to each of the uniform mesh refinements. Table 1 provides the assembly times and the memory requirements of both objects.
| mesh level | number of nodes | number of elems. | number of free dofs | mesh setup time [s] | patches setup time [s] | mesh memory size [MB] | patches memory size [MB] |
|---|---|---|---|---|---|---|---|
| 1 | 729 | 1920 | 2133 | 0.01 | 0.01 | 0.30 | 1.13 |
| 2 | 4025 | 15360 | 11925 | 0.02 | 0.02 | 2.32 | 9.07 |
| 3 | 26001 | 122880 | 77517 | 0.06 | 0.13 | 18.17 | 72.73 |
| 4 | 185249 | 983040 | 554013 | 0.51 | 0.98 | 144.07 | 582.53 |
| 5 | 1395009 | 7864320 | 4178493 | 5.56 | 10.62 | 1147.67 | 4663.18 |
Note that the most memory consuming part of both structures is given by substructures ’dphi’ containing the values of the precomputed gradients of basis functions.
5 Implementation: energy evaluation
The following matrix-vector transformation is frequently used: matrices are stretched to the isomorphic vectors
| (17) |
where and . Here, symbol is the integer division operator and is the modulo operator. Put simply, for any the elements of v with indices corresponds to the values of the trial function in the -th node in the directions .
5.1 The linear energy term
The linear part of the energy (14) rewrites equivalently as
| (18) |
where denotes the scalar product of matrices.
5.2 The first-gradient energy term
The gradient part of the discrete energy (9) is given as a sum of the energy contributions from every element and its evaluation in MATLAB is performed effectively by using operations with vectors and matrices only. The energy evaluation for a trial vector is performed by the main function:
The structure ’mesh’ is described in Section 5 and the ’params’ contains material parameters apart from some other parameters (e.g. visualization parameters). The code above is vectorized and generates the objects:
-
A cell ’v_elems’ containing matrices v_elems, v_elems, v_elems of size providing the restrictions of nodal deformations to all elements.
-
A cell ’F_elems’ of size storing the deformation gradients (see (3)) in all elements. In particular, F_elems is then a vector of size evaluating the partial derivatives of the -th component of deformation with respect to the -th variable in all elements.
-
A vector ’densities.Gradient’ of size containing gradient densities in all elements.
The Neo-Hookean density function from (4) is implemented as
Benchmark 2
Assume a bar domain , where , specified by the material parameters (Young’s modulus) and (Poisson’s ratio) and deformed by the prescribed deformation given by
| (19) |
or, equivalently, using matrix operations
| (20) |
Here, means that the right Dirichlet wall is twisted once around the x-axes (Fig. 4).

Constants are transformed according to the formulas where is the shear modulus and is the bulk modulus. The exact evaluation shows that the corresponding gradient energy using the Neo-Hookean density function (4) reads
The script benchmark2_start.m evaluates an approximation of on the sequence of the uniform mesh refinements defined in Benchmark 1. In order to provide higher accuracy of the evaluation times, the energies are recomputed 10 times. Table 2 provides evaluation times and values of the energy approximations (times for setting up the ’mesh’ structure are not included).
| mesh level | number of free dofs | evaluation (10x) of : time [s] | value of |
| 1 | 2133 | 0.01 | 12.6623 |
| 2 | 11925 | 0.02 | 7.9083 |
| 3 | 77517 | 0.08 | 6.7219 |
| 4 | 554013 | 0.76 | 6.4255 |
| 5 | 4178493 | 12.82 | 6.3514 |
6 Implementation: energy gradient evaluation
Evaluation of the full gradient where , requires in general computation of all partial derivatives , . Some minimization methods (e.g. trust-region mentioned applied in Section 7) require the knowledge of gradient, but only restricted to free degrees of freedom.
The gradient easily reads using (18)
| (21) |
where b is of size , given by (17) and its restriction to free degrees of freedom is then trivial.
The evaluation of is technically more involved. Firstly, it is evaluated with respect to Remark 2 for all degrees of freedom belonging to all (at least partially) free nodes. Secondly, it is restricted to free degrees of freedom only. In order to determine to which node the -th active degree of freedom belongs we define the index mapping
| (22) |
which for the -th active degree of freedom returns the corresponding -th free node (here is an integer division operator). By
we denote the set of elements adjacent to node belonging to the -th active degree of freedom and by their number. The gradient of the nonlinear part can be computed in two different ways:
-
1.
numerically, where the partial derivatives are computed approximately by using a difference scheme.
-
2.
exactly by taking the explicit partial derivatives.
Deriving the exact partial derivatives can be demanding and it depends on the particular problem. On the contrary, the numerical approach is more general and is feasible regardless of the complexity of the function representing the corresponding discrete energy. Hence, we first describe the numerical approach by using the central difference scheme and then explain the gradient evaluation by deriving the explicit form of the partial derivatives.
6.1 Numerical approach to evaluate
By using the central difference scheme, one can write
| (23) |
where is the -th canonical vector in and is a small positive number. Both summands in the numerator above can be directly evaluated by taking the energy evaluation procedure introduced in the previous subsection as
However, this approach is ineffective as long as the step of the central difference scheme occurs only in a few summands of the sums representing and given by (9), while the remaining summands are the same and therefore vanish. Hence, we can further simplify
| (24) |
By using the substitutions
| (25) |
one can rewrite (24)
| (26) |
and evaluate the whole via the simple for-loop over its components.
Remark 4
The energy evaluation procedure has to be called in every loop over the vector components and it turned out to cause multiple self built-in times that slowed down performance. To avoid that, the original energy evaluation procedure is modified so that the multiple input vectors can be processed simultaneously and the energy evaluation procedure be called only once.
The outer gradient evaluation procedure is simple:
Here ’es_minsplus’ is a matrix of size with the components given by (25):
es_minsplus , es_minsplus .
The gradient vector g is then assembled by using the central difference scheme (23) with a constant central difference step size for all . Obviously, a generalization of the above code to higher accuracy difference schemes is possible.
We recall a cell ’v_elems’ containing matrices
v_elems, v_elems, v_elems of size
is assembled in the energy evaluation procedure energy from Subsection 5.2. For the evaluation of (23) by using (26) we need to assemble a cell-structure ’v_patches’ containing matrices
v_patches, v_patches, v_patches of size
that provide the restrictions of nodal deformations to all patches. In fact, the structure ’v_patches’ copies parts of ’v_elems’ to the particular positions.
The extended procedure energies evaluates all -perturbed values of energies: {listing}
The cells ’v_elems’ and ’F_elems’ are the same as in the first-gradient energy evaluation procedure from Subsection 5.2. The cell ’v_patches_eps’ contains matrices
v_patches_eps, v_patches_eps, v_patches_eps of size
that provide the restrictions of nodal deformations to all patches, but here these deformations are perturbed by the value of the central difference step . This cell is used for the construction of the key cell ’GG’ of size containing vectors
GG of length
storing the partial derivatives of deformations of the -th component with respect to the -th variable. The structure of ’GG’ is in details displayed in Fig. 5.
All three layers of vector indices have the same size of entries and the following meaning:
-
-
the 1st layer corresponds to the -perturbation of the component ,
-
-
the 2nd layer corresponds to the -perturbation of the component ,
-
-
the 3rd layer corresponds to the -perturbation of the component .
The cell ’G’ has the same size as ’F’, but contains deformation gradient matrices corresponding to the deformations perturbed by .
The most important feature is using the values of the precomputed input cell ’F’ for the efficient construction of the ’GG’ cell. Note that if the numeric difference step is added or subtracted from the first component of displacements, the deformation gradients of the rest two components remain the same and their values are already stored in the ’F’ cell.
A vector ’csep’ of length contains the cumulative sums of ’e_patches’ with elements
An output matrix e of size contains all energy contributions and for any
| (27) |
Note that vector ’e_patches’ changes its value inside the loop over the components . Therefore, the whole vector e is evaluated at once using the Matlab difference function diff with the input vector ’indx’ of length , where indx, with defined in (15) and additionally in (16).
The procedure for the construction of ’GG’ is listed below:
6.2 Exact approach to evaluate
Evaluation of the exact requires an explicit deriving of every . The gradient of the linear part is trivial and is given by (18). Using (9) one can write
| (28) |
Note that the only elements whose energy contributions depend on are those belonging to the -th patch, where . Therefore, we can simplify the equation above as
| (29) |
By using the chain rule one can write
| (30) |
where assuming the Neo-Hookean density from (4)
| (31) |
Using the row or the column expansion rule for calculating the determinant of a matrix, one can express
| (32) |
where is the submatrix of F given by dropping the -th row and the -th column of F. Futhermore, can be also simplified by
| (33) |
From Subsection 6.1 we already know how to assemble and . Here, in addition, we need to express and .
Similarly to the numeric gradient evaluation, the exact gradient evaluation procedure uses the same precomputed structures ’v_cell’, ’v_elems’ and ’F_elems’.
The main procedure for the exact gradient evaluation is provided below:
Here, ’D_densities_patches’ is a vector of size containing all for every given by (30). Note that the function density_D_GradientVector_3D uses the input cell structure ’D_F_patches’, where D_F_patches.
Benchmark 3
The script benchmark3.m evaluates approximations of on the sequence of the uniform mesh refinements defined in Benchmark 2. In order to provide higher accuracy of
evaluation times, the energies are recomputed 10 times. Table 3 provide evaluation times of the gradient approximations both in the exact and numerical case (the times for setting up ’mesh’ and ’patches’ structures are not included).
| mesh level | number of free dofs | evaluation (10x) of exact : time [s] | evaluation (10x) of num. : time [s] |
| 1 | 2133 | 0.12 | 0.08 |
| 2 | 11925 | 0.14 | 0.15 |
| 3 | 77517 | 1.18 | 1.51 |
| 4 | 554013 | 12.47 | 15.64 |
| 5 | 4178493 | 487.34 | 533.24 |
7 Application to practical energy minimizations
For a practical energy minimization, the trust-region method [4] available in the MATLAB Optimization Toolbox is utilized. Standard stopping criteria (the first-order optimality, tolerance on the argument and tolerance on the function) equal to are considered in all benchmarks. The method also allows to specify the sparsity pattern of the Hessian matrix in free degrees of freedom, i.e., only positions (indices) of nonzero entries. The sparsity pattern is directly given by a finite element discretization.
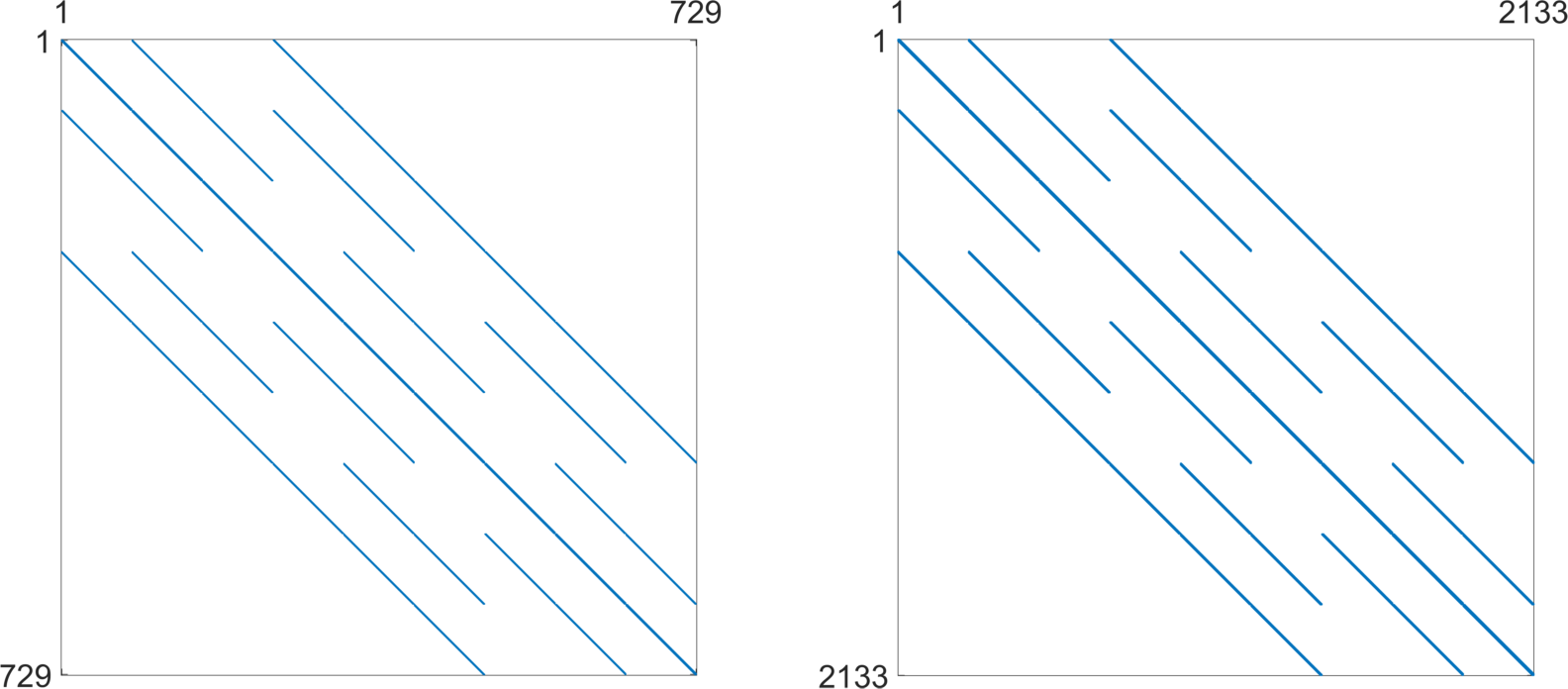
Example 2
The sparsity pattern related to the 3D bar domain of Fig. 2 is displayed in Fig. 6 (left). It corresponds to the FEM mesh not taking the Dirichlet boundary conditions into account. Therefore, it is of size . In practical computations, it is first extended from a scalar to a vector problem and then restricted to the ’mesh.dofsMinim’ indices (right). Since there are 18 Dirichlet nodes fixed in all three directions, the corresponding number of rows and columns of the right hessian sparsity pattern is .
7.1 Benchmark 4: time-dependent hyperelasticity in 3D
We consider the elastic bar specified in Benchmark 2 with a time-dependent nonhomogeneous Dirichlet boundary conditions on the right wall (). The torsion of the right wall is described by the formula (19) for , where the rotation angle is assumed to be a time dependent function for a sequence of integer discrete times . Here we assume the final time and the maximal angle of rotation ensuring four full rotations of the right Dirichlet wall around the x-axis. Altogether we solve a sequence of minimization problems (1) with the Neo-Hook energy density (4) and no loading ().
The trust-region method accepts an initial deformation approximation. For the first discrete time we run iterations from the identity and for the next discrete time the minimizer of the previous discrete time problem serves as its initial approximation. We output the found energy minimizer for each minimization problem with some minimizers shown in form of the deformed meshes in Fig. 7. Additionally, we also provide the minimization time, the number of the trust-region iterations and the value of the corresponding minimal energy.
The overall performance is explained in Table 4 for separate computations on tetrahedral meshes of levels 1, 2, 3 applying the numerical gradient evaluation of Subsection 6.1 only with the choice . We notice that the minimizations of finer meshes require only slightly higher number of iterations, which is acceptable. Comparison of the values in each line of Table 4 indicates convergence in space of the energy minimizers.
| level 1, 2133 free dofs | level 2, 11925 free dofs | level 3, 77517 free dofs | |||||||
| step | time [s] | iters | time [s] | iters | time [s] | iters | |||
| t=3 | 6.65 | 40 | 3.1177 | 66.23 | 47 | 1.8244 | 2148.62 | 93 | 1.4631 |
| t=6 | 10.42 | 60 | 12.4423 | 117.74 | 76 | 7.2962 | 1404.68 | 68 | 5.8533 |
| t=9 | 10.33 | 60 | 27.8993 | 125.76 | 85 | 16.4079 | 1441.84 | 73 | 13.1735 |
| t=12 | 18.43 | 104 | 49.5506 | 102.11 | 68 | 29.1664 | 1277.04 | 65 | 23.4286 |
| t=15 | 15.51 | 81 | 77.3859 | 127.17 | 87 | 45.5677 | 1130.02 | 58 | 36.6236 |
| t=18 | 18.31 | 97 | 111.3369 | 110.65 | 75 | 65.5470 | 1540.90 | 76 | 52.7641 |
| t=21 | 15.74 | 82 | 151.4946 | 74.47 | 51 | 89.1672 | 5523.64 | 290 | 71.7883 |
| t=24 | 16.37 | 91 | 197.7577 | 91.79 | 63 | 116.3261 | 2660.44 | 131 | 93.7238 |








7.2 Benchmarks 5 and 6: hyperelasticity and p-Laplacian in 2D
Although our exposition is mainly focused on implementation details in 3D, a reduction to 2D () is straightforward.
As the first example we consider a square domain with lengths perforated by a hole with radius (Fig. 9 left) and whose center is located at the center of the square, subjected to zero Dirichlet boundary condition on the bottom and left edges, a constant loading and the elastic parameters specified in Benchmark 2. We assume the choice in the evaluation of the numerical gradient. The resulting deformation and the deformation gradient densities are depicted in Fig. 9 (right).

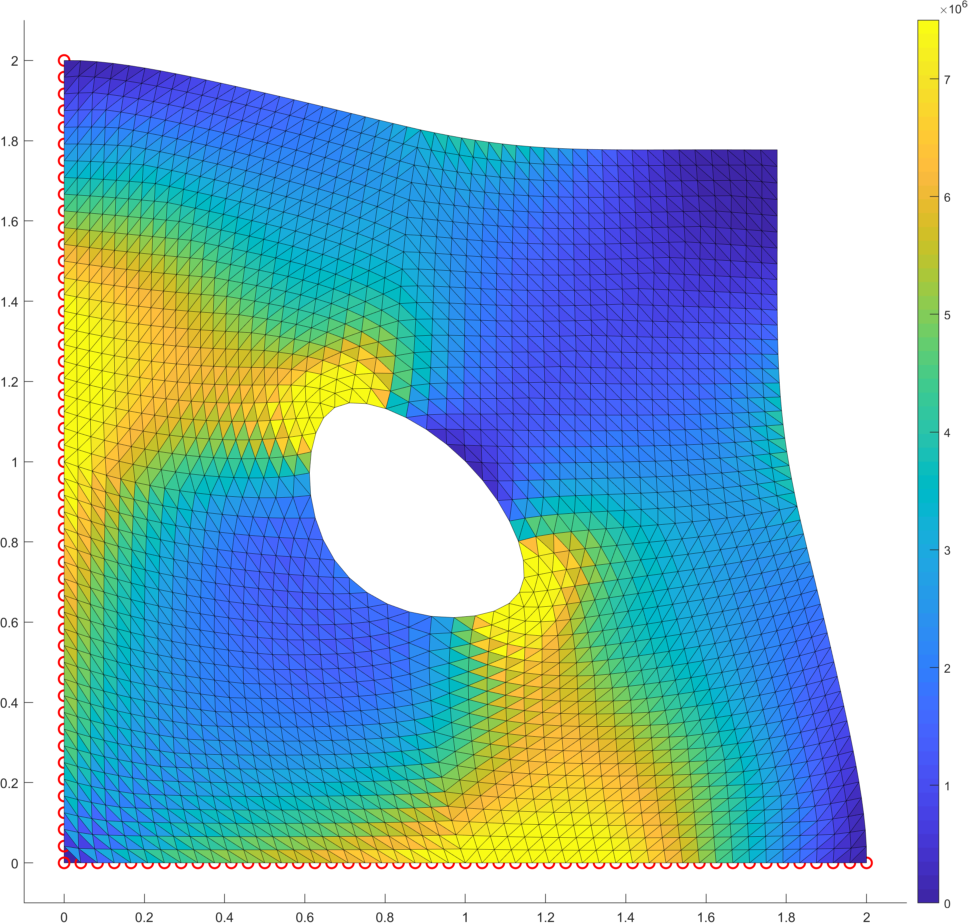
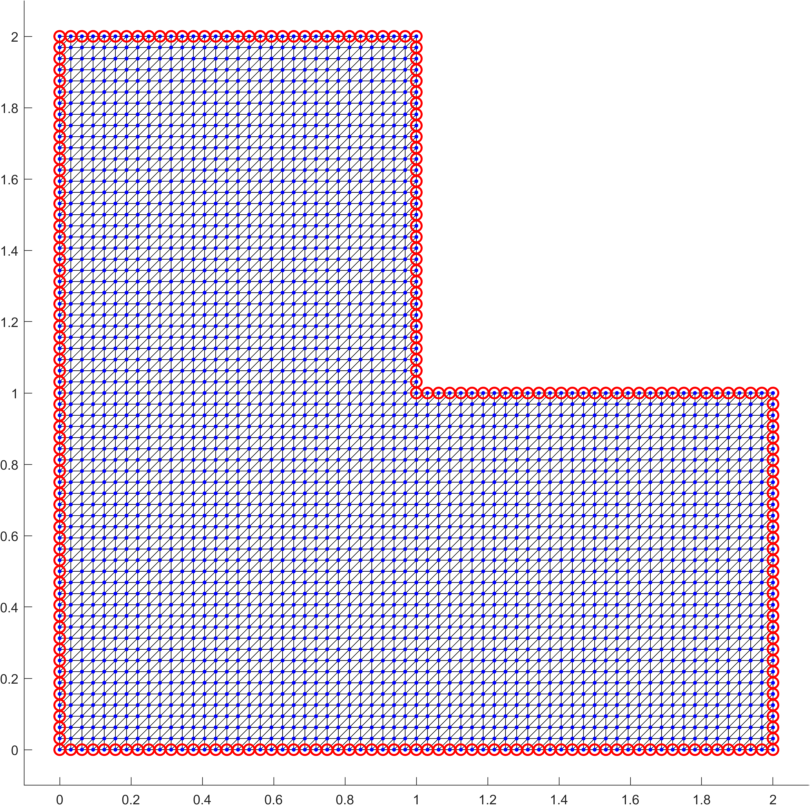
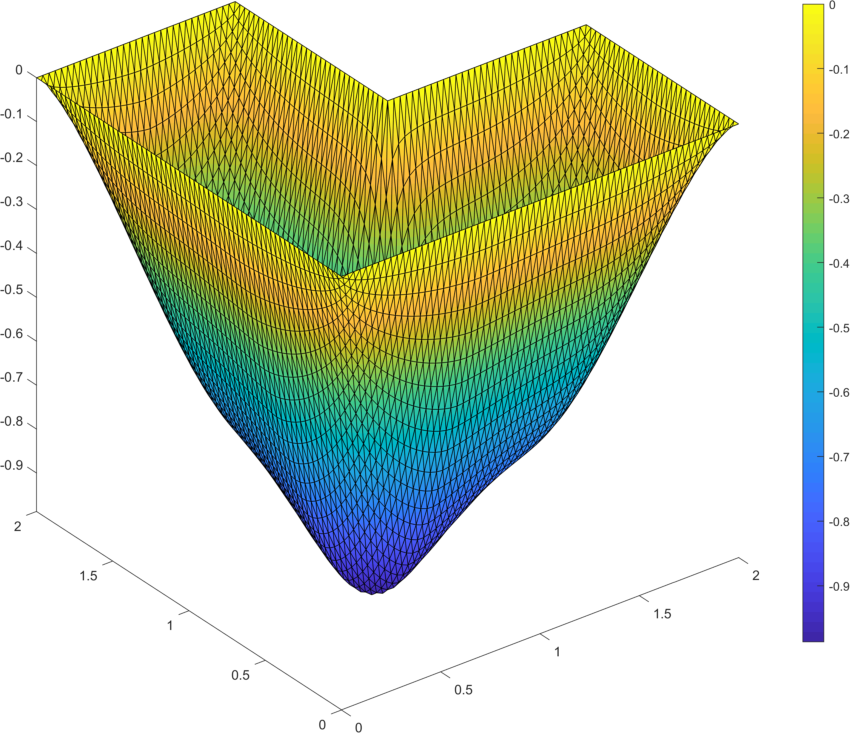
As the second example we minimize the p-Laplacian energy functional (5) over the L-shape domain (Fig. 9 left). The constant loading is assumed together with zero Dirichlet boundary conditions on the full domain boundary. For the numerical gradient we assume . The solution is displayed in Fig. 9 (right). Table 6 depicts performance of all options for the power and confirms faster evaluation times in comparison to our former contribution [13]. This is mainly due to the improved vectorization concepts here, due to the faster CPU and finally due to updates of the trust-region in-built implementation in the latest version of Matlab.
| exact gradient | numerical gradient | ||||||
|---|---|---|---|---|---|---|---|
| level | free dofs | time [s] | iters | time [s] | iters | ||
| 1 | 278 | 0.36 | 4 | 24.5745 | 0.13 | 4 | 24.5745 |
| 2 | 1102 | 0.15 | 4 | 24.3558 | 0.16 | 4 | 24.3558 |
| 3 | 4382 | 0.54 | 4 | 24.2957 | 0.54 | 4 | 24.2957 |
| 4 | 17470 | 2.35 | 5 | 24.2799 | 2.65 | 5 | 24.2799 |
| 5 | 69758 | 11.27 | 5 | 24.2758 | 12.39 | 5 | 24.2758 |
| 6 | 278782 | 83.27 | 6 | 24.2748 | 88.74 | 6 | 24.2748 |
| exact gradient | numerical gradient | ||||||
|---|---|---|---|---|---|---|---|
| level | free dofs | time [s] | iters | time [s] | iters | ||
| 1 | 33 | 0.02 | 8 | -7.5353 | 0.03 | 8 | -7.5353 |
| 2 | 161 | 0.05 | 11 | -7.9729 | 0.12 | 15 | -7.9729 |
| 3 | 705 | 0.11 | 11 | -8.1039 | 0.19 | 11 | -8.1039 |
| 4 | 2945 | 0.30 | 11 | -8.1445 | 0.56 | 12 | -8.1445 |
| 5 | 12033 | 1.50 | 11 | -8.1578 | 2.08 | 12 | -8.1578 |
| 6 | 48641 | 6.30 | 12 | -8.1625 | 9.48 | 12 | -8.1625 |
| 7 | 195585 | 48.61 | 13 | -8.1642 | 60.62 | 12 | -8.1642 |
| 8 | 784385 | 617.92 | 22 | -8.1649 | 672.04 | 16 | -8.1649 |
7.3 Implementation remarks and outlooks
Assembly times in all benchmarks were obtained on a MacBook Air (M1 processor, 2020) with 16 GB memory running MATLAB R2021a. Our implementation is available at
https://www.mathworks.com/matlabcentral/fileexchange/97889
for download and testing. It is based on own codes of [3, 6, 15] used primarily for assemblies of finite element matrices. It also utilizes the function mcolon from the reservoir simulator [11]. The names of mesh attributes were initially motivated by codes of [1] and further modified.
The 3D cuboid mesh is generated by the code of [6] and 2D meshes (the square with the hole and the L-shape) by our own code. Vectorized evaluations of gradients of basis functions are taken from [3, 15]. The general structure of the code was initially taken from [13] and extended to the implementation of hyperelasticity in 2D and 3D. Many parts of this code (mainly related to the gradient evaluation) have been significantly improved since then.
Acknowledgement
A. Moskovka was supported by the Strategy 21 of the CAS, program 23: City as a Laboratory of Change; Historical Heritage and Place for Safe and Quality Life and by the RD project 8J21AT001 Model Reduction and Optimal Control in Thermomechanics. J. Valdman announces the support of the Czech Science Foundation (GACR) through the grant GF19-29646L Large Strain Challenges in Materials Science.
References
- [1] J. Alberty, C. Carstensen, S. Funken: Remarks around 50 lines of Matlab: short finite element implementation, Numerical Algorithms 20, 1999, 117-137.
- [2] S. Almi, U. Stefanelli: Topology Optimization for Incremental Elastoplasticity: A Phase-Field Approach, SIAM Journal on Control and Optimization, 2021, Vol. 59, No. 1 : pp. 339-364.
- [3] I. Anjam, J. Valdman: Fast MATLAB assembly of FEM matrices in 2D and 3D: edge elements, Applied Mathematics and Computation, 2015, 267, 252–263.
- [4] A.R. Conn, N.I.M. Gould, P.L. Toint: Trust-Region Methods. SIAM, Philadelphia, 2000.
- [5] P.G. Ciarlet: The Finite Element Method for Elliptic Problems, SIAM, Philadelphia, 2002.
- [6] M. Čermák, S. Sysala, J. Valdman: Efficient and flexible MATLAB implementation of 2D and 3D elastoplastic problems, Applied Mathematics and Computation, 2019, 355, 595-614.
- [7] P. Drábek, J. Milota: Methods of Nonlinear Analysis: Applications to Differential Equations (second edition), Birkhauser, 2013.
- [8] M. Frost, B. Benešová, P. Sedlák: A microscopically motivated constitutive model for shape memory alloys: formulation, analysis and computations, Math. Mech. Solids, 21(3): 358–382, 2016.
- [9] J. Koko: Fast MATLAB assembly of FEM matrices in 2D and 3D using cell-array approach, International Journal of Modeling, Simulation, and Scientific Computing Vol. 7, No. 3 (2016).
- [10] M. Kružík, T. Roubíček: Mathematical Methods in Continuum Mechanics of Solids, Springer, 2019.
- [11] K. A. Lie: An introduction to reservoir simulation using MATLAB: User guide for the Matlab Reservoir Simulation Toolbox (MRST), Technical report, SINTEF ICT, December 2016. (http://www.sintef.no/projectweb/mrst/).
- [12] J. E. Marsden, T. J.R. Hughes: Mathematical foundations of elasticity, Dover Publications, 1994.
- [13] C. Matonoha, A. Moskovka, J. Valdman: Minimization of p-Laplacian via the Finite Element Method in MATLAB, I. Lirkov and S. Margenov (eds): LSSC 2021, LNCS 13127, pp. 496–503 (2022).
- [14] MATLAB documentation to Minimization with Gradient and Hessian Sparsity Pattern, https://www.mathworks.com/help/optim/ug/minimization-with-gradient-and-hessian-sparsity-pattern.html.
- [15] T. Rahman, J. Valdman: Fast MATLAB assembly of FEM matrices in 2D and 3D: nodal elements, Applied Mathematics and Computation, 2013, 219, 7151-7158.
- [16] G. K. Rose: Computational Methods for Nonlinear Systems Analysis With Applications in Mathematics and Engineering (2017), Doctor of Philosophy (PhD), Dissertation, Mechanical Aerospace Engineering, Old Dominion University.
- [17] T. Weinberg, B. Sousedík: Fast implementation of mixed RT0 finite elements in MATLAB, SIAM Undergraduate Research Online, volume 12, 2018.