Fast Beam Training for IRS-Assisted
Multiuser Communications
Abstract
In this letter, we consider an intelligent reflecting surface (IRS)-assisted multiuser communication system, where an IRS is deployed to provide virtual line-of-sight (LoS) links between an access point (AP) and multiple users. We consider the practical codebook-based IRS passive beamforming and study efficient design for IRS reflect beam training, which is challenging due to the large number of IRS reflecting elements. In contrast to the conventional single-beam training, we propose a new multi-beam training method by dividing the IRS reflecting elements into multiple sub-arrays and designing their simultaneous multi-beam steering over time. By simply comparing the received signal power over time, each user can detect its optimal IRS beam direction with a high probability, even without searching over all possible beam directions as the single-beam training. Simulation results show that our proposed multi-beam training significantly reduces the training time of conventional single-beam training and yet achieves comparable IRS passive beamforming performance for data transmission.
Index Terms:
Intelligent reflecting surface (IRS), multi-beam training, passive beamforming.I Introduction
Intelligent reflecting surface (IRS) has emerged as a promising cost-effective technology for enhancing the spectral and energy efficiency of future wireless networks [1]. In particular, by smartly controlling signal reflection via a massive number of low-cost passive reflecting elements, IRS is able to dynamically program the radio propagation environment for achieving signal enhancement and/or interference suppression. Compared to traditional active relay, IRS incurs much lower hardware cost and energy consumption due to its passive reflection. These appealing advantages have spurred intensive enthusiasm recently in deploying IRS to enhance the communication performance of various wireless systems [2, 3, 4, 5, 6].
Particularly, for millimeter-wave (mmWave) communications at high operation frequencies where the direct channels between an access point (AP) and its served users are susceptible to severe blockage and propagation loss, IRS can be properly deployed to provide virtual line-of-sight (LoS) AP-IRS-user links, and hence significantly enhance their communication performance [6]. To reap the large passive beamforming gain of IRS, it is indispensable for the IRS to conduct passive/reflect beam training in coordination with the AP’s transmit beam training for establishing high signal-to-noise ratio (SNR) links with IRS-assisted users before implementing efficient channel estimation and data transmission. This, however, is practically challenging due to the massive number of IRS reflecting elements that generate pencil-like sharp beams and thus require a large number of beam directions in the training codebook to cover the space of interest. The conventional single-beam training needs to search over all possible beam directions and inevitably incurs prohibitively high training overhead.
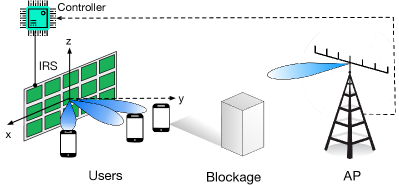
This thus motivates this letter to study a more efficient beam training design for an IRS-assisted multiuser communication system as shown in Fig. 1, where an IRS is deployed to establish LoS links with both a multi-antenna AP and a group of single-antenna users that are assumed to be located near the helping IRS (e.g., in a hot spot scenario). As the AP and IRS are at fixed locations, we assume for simplicity that the AP’s transmit beamforming is fixed and thereby focus on designing the reflect beam training for IRS. To reduce the training time of conventional single-beam training, we propose a new multi-beam training method. Specifically, we divide the IRS reflecting elements into multiple sub-arrays and design their multi-beam codebook to steer different beam directions simultaneously over time. Then, each user can detect its optimal IRS beam direction with a high probability via simple received signal power/SNR comparisons over time, without the need of searching over all possible beam directions as the single-beam training. Simulation results show significant training time reduction by our proposed multi-beam training as compared to conventional single-beam training, yet without compromising much the IRS passive beamforming performance for data transmission. It is worth noting that multi-beam training design has also been proposed in [7]; however, it relies on random hashing (RH), which incurs a random number of training symbols for achieving unique beam identification. In contrast, our proposed multi-beam training applies with any given number of training symbols and is numerically shown to outperform that in [7] in terms of passive beamforming gain given the same training time.
II System Model
As shown in Fig. 1, we consider the downlink beam training in an IRS-assisted multiuser communication system, where an IRS is deployed to assist the communications between an AP equipped with an -antenna uniform linear array (ULA) and single-antenna users, denoted by the set . The IRS is composed of reflecting elements placed in the - plane, and is attached with a smart controller for tuning signal reflection at each reflecting element as well as exchanging information with the AP via a separate reliable link. The users are distributed in the same horizontal - plane with the IRS located in the center.
We consider the propagation environment with limited scattering (which is typical for mmWave channels) and adopt the commonly-used geometric channel model [8]. Assume that the direct AP-user links are blocked due to obstacles (e.g., buildings), whereas by properly deploying the IRS, there exists a deterministic LoS path in both the AP-IRS and IRS-user links. Let denote the steering vector function, defined as
| (1) |
where is the ULA array size, denotes the constant phase difference between the observations at two adjacent antennas/elements, and denotes the imaginary unit. Since the AP and IRS are at fixed locations once deployed, the AP-IRS link typically has a much longer channel coherence time than the IRS-user link (due to user mobility) and thus can be considered as quasi-static. As such, we assume for simplicity that the AP has aligned its transmit beamforming with the AP-IRS LoS channel and thus can be treated as having an equivalent single antenna. Then, the effective channel from the AP to IRS, denoted by , can be modeled as . where denotes the complex-valued path gain of the AP-IRS link; and denote respectively the (physical) azimuth and elevation angles-of-arrival (AoAs) at the IRS. Moreover, represents the receive array response vector of IRS, which can be expressed as , where stands for the Kronecker product, and are referred to as the horizontal and vertical spatial directions, respectively, with and respectively denoting the signal wavelength and IRS’s reflecting element spacing. Note that there exists a one-to-one mapping between and . Moreover, due to the same altitude of the IRS center and users, the elevation angles-of-departure (AoD) from the IRS to different users are all and denoted by . Then, the IRS-user LoS path can be modeled as , where denotes the complex-valued path gain of the IRS-user link; denotes the azimuth AoD from the IRS to user ; and represents the transmit array response vector of IRS with and .
Let denote the diagonal IRS reflecting matrix, where for simplicity we assume that the reflection amplitude of each element is set to one (or its maximum value),111This assumption is valid for the ideal case of independent reflection amplitude-and-phase control; while for the practical case of phase-dependent amplitude control [9], we need to assume that the effective resistance of each reflecting element is sufficiently low so that its reflection amplitude variation over phase is negligible. and , denotes the reflection phase shift of element .222The proposed IRS beam-training method can be extended to the case with practical IRS discrete phase shifts by e.g., using the nearest-phase quantization for discretizing the continuous phase shifts as in [3]. Based on [3], the received signal at each user is given by
| (2) |
where denotes the symbol transmitted by the AP with power , is the received additive white Gaussian noise (AWGN) at user with power , , , and
| (3) |
where stands for the Hadamard product; ; and . Then, by leveraging the property that is a periodic function with period , we define as the effective cascaded IRS azimuth spatial direction for each user , and as the common IRS elevation spatial direction for all the users, such that , and , where denotes the modulo operation that returns the remainder after the division of by .
For the IRS reflect beam training, it can be easily observed from (2) that for each user , the optimal IRS beamforming vector is , i.e., both the azimuth and elevation directions are perfectly aligned. To reduce the computational complexity for the joint three-dimensional (3D) IRS beam training, we first write as a Hadamard product of two vectors, i.e., , where and are referred to as the horizontal and vertical IRS beam training vectors, respectively. As such, in (2) can be rewritten as
| (4) |
where the horizontal and vertical beam training vectors are decoupled. For simplicity, we assume that the IRS vertical beamforming has been aligned as it does not depend on users’ locations and thus focus on designing the IRS horizontal beam training for all the users. Specifically, given the fixed and using (4), the received signal at each user in (2) can be simplified as
| (5) |
where .
III Single-Beam Training
Similar to [10], given IRS horizontal reflecting elements, we divide the entire spatial domain into equal-size sectors for the horizontal beam training, represented by their central directions that are given by . As such, the single-beam training codebook can be constructed as , where denotes the codeword that steers reflecting beam towards direction , which can be set as [10] . Let denote the beam gain of along the spatial direction . It is well known that the beam pattern of (i.e., has a main-lobe with beam width centered at the direction , where it achieves the maximum beam gain of [10]. Moreover, as increases, the main-lobe becomes narrower and the side-lobe diminishes.
Given the sampled directions, we denote by the optimal IRS beam direction for each user , which is given by . With the codebook , a straightforward IRS beam-training method is as follows: The AP consecutively sends multiple training symbols while the IRS changes its reflecting direction in sequentially over different training symbols; then each user finds its best beam direction that achieves the maximum received signal power/SNR, which is given by . However, such an exhaustive-search based single-beam training requires at least training symbols, which can be practically prohibitive due to the massive number of IRS reflecting elements, thus incurring large training overhead/delay for establishing high-SNR links. As such, this training method is not suitable for delay-sensitive and/or short-packet transmissions.
IV Multi-Beam Training
To reduce the training time of conventional single-beam training, we propose a new multi-beam training method for IRS-assisted multiuser communications in this section.
First, we divide the (horizontal) IRS reflecting elements into sub-arrays, each consisting of (assumed to be an integer) adjacent reflecting elements. For each sub-array , we equip it with an individual codebook, , which comprises codewords that cover the same sampled directions as the single-beam codebook, i.e., . As such, we have where , represents the codeword of sub-array that steers reflecting beam in direction using reflecting elements only. Based on the single-beam codeword , we construct as
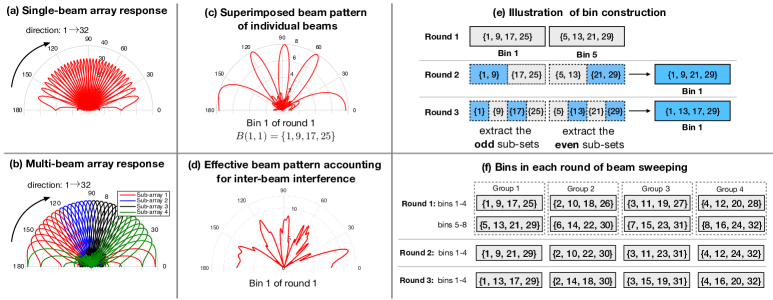
such that when all the sub-arrays steer reflecting beams in the same direction , the composite multi-beam codeword is equivalent to the single-beam counterpart . Compared to the full-array codeword , each sub-array codeword has a wider beam width (i.e., versus ) as well as a smaller beam gain (i.e., versus ), as illustrated in Figs. 2(a) and 2(b), respectively.
Next, for the proposed multi-beam training, let the IRS steer sub-array beams towards multiple different directions simultaneously which generally change over training symbol durations according to the multi-beam codebook . By properly designing the beam directions of IRS sub-arrays over different training symbols, each user’s optimal beam direction can be found via simple received signal power/SNR comparisons over time with a high probability. For ease of exposition, we consider a typical case where with , is an even number, and . Our proposed fast beam-training method consists of two phases, namely, IRS beam sweeping and IRS beam identification, which are elaborated as follows.
IV-1 IRS Beam Sweeping
This phase consists of rounds of beam sweeping, where in each round, the AP sends multiple training symbols that are reflected by different sets of IRS sub-array reflecting beam directions. For each round , we denote by the bin that collects the sub-array beam directions (arranged in an ascending order) during the -th training symbol. For any beam-direction set , we define its intra-set distance as . As such, a larger intra-set distance indicates that the beams indexed by are farther separated in the spatial domain (see Fig. 2(b)). For , we map the directions into bins, each comprising directions. To separate the beam directions in each bin as far as possible for minimizing the inter-beam interference, we set the bins as . It can be shown that such a direction-bin mapping maximizes the minimum intra-bin distance among all the bins with . As illustrated in Figs. 2(c) and 2(d), for the case with and , the individual beam patterns of sub-array beams in (corresponding to the codeword ) are well separated in the spatial domain (see Fig. 2(c)), such that the effective beam pattern even after accounting for the inter-beam interference still features strong beam directionality to the directions (see Fig. 2(d)).
In the subsequent -rounds of beam sweeping, we exploit different combinations of IRS beam directions to help each user identify its best beam direction in the next beam identification phase. Specifically, in round , for each initial bin with , we partition its directions into equal-size sub-sets as and , each consisting of adjacent directions. To determine which sub-set contains the best beam direction, instead of individually beam-searching the sub-sets and comparing their beam power, we propose to test only one of them (with half number of sub-arrays) for reducing the training time, by exploiting the fact that the searched sub-set is likely to contain the best beam direction if it yields a large received power above a certain threshold (as specified later in the next subsection), and vice versa. Moreover, to further reduce the training time, we make full use of the sub-arrays to allow simultaneous search of two sub-sets from two different initial bins, which, however, introduces the interference between different beam sub-sets. To address this issue, we first pair the initial bins into groups as , such that the beam directions in the two bins for all groups are separated as far as possible with the identical (maximum) intra-group distance given by . Then, for each group , we extract the odd sub-set of and the even sub-set of to construct a new bin (as illustrated in Fig. 2(e)). As such, bins are constructed for , which are set as It can be verified that by using the above bin grouping-and-extracting, the second-round of beam sweeping achieves the same max-min intra-bin distance as the first round (i.e., both are ). Similarly, for round , as illustrated in Fig. 2(e), we further partition each of the sub-sets in round into equal-size smaller sub-sets and select one of them for beam searching; the new bins are constructed by following a similar procedure in round . To summarize, for , each round of beam sweeping consists of bins, which are set as
where . Moreover, for each round of beam sweeping, the identical (maximum) intra-bin distance for different bins can be numerically deduced as
For illustration, we provide in Fig. 2(f) an example of all the designed bins in the beam-sweeping phase for the case with and .
Based on the above beam-sweeping design, the total number of training symbols of our proposed multi-beam training method is given by
| (6) |
which monotonically decreases with an increasing (i.e., IRS reflecting elements are divided into more sub-arrays), and is smaller than that of the single-beam training with for .
IV-2 IRS Beam Identification
After the beam-sweeping phase, each user can identify its best IRS reflecting beam direction independently based on their own received powers/SNRs in the first phase. Consider an arbitrary user . Let denote its received power from the -th bin of the -th round of beam sweeping and represent the set of candidate directions for its best beam direction after the -th round of beam sweeping. For , is set as the best bin that has the largest received power, i.e., with . While for each of the subsequent rounds , the user only needs to inspect one bin that has common directions with as only it may potentially contain the best beam direction, which is denoted by with . For this bin, as the expected received power from the corresponding multiple beams that cover/do not cover the best direction is approximately (ignoring the receiver noise and any inter-beam interference) and , respectively, we set the binary-decision threshold on the received power as for determining whether contains the best beam direction or not. As such, for each , combining the binary decision with , the new candidate directions for round are determined as follows.
It can be verified that the size of is logarithmically decreasing as . An illustrative example is provided as follows to demonstrate the detailed procedures for identifying a unique beam direction for an arbitrary user.
Example 1.
Consider the case with and ; the designed bins are shown in Fig. 2(f). For , assuming that user receives the largest power from bin , we set . As such, for , the user only needs to examine bin , since only it has common directions with bin . Supposing , we decide that does not contain the best beam direction of user and thus obtain . Last, for , user only needs to inspect bin . Assuming , we finally identify the best beam direction for user as .
Note that for each user , the identified best beam direction, , may not be the actual optimal beam direction, , or that obtained by the single-beam training, , due to the receiver noise, interference due to channel non-LoS (NLoS) components, and inter-beam interference in practice. Although increasing can help reduce the training time of the proposed multi-beam training method (see (6)), it will decrease the sub-array beam gains as well as cause more severe inter-beam interference, thus resulting in degraded beam identification accuracy, as will be shown in the next section by simulations. Hence, there exists a fundamental trade-off between training time and resultant passive beamforming performance in the proposed multi-beam training method by adjusting .
V Simulation Results
This section provides simulation results to numerically validate our proposed design. We consider a mmWave system operating at a carrier frequency of GHz. For simplicity, we consider an IRS array placed horizontally and centered at meter (m), which is composed of reflecting elements with . There are users randomly distributed on a semi-circle around the IRS with distance of m. The AP centered at m is equipped with antennas with half-wavelength antenna spacing. For the large-scale path loss, the reference channel power gain at a distance of m is set as dB, and the path loss exponents of the AP-IRS and IRS-user links are set as and , respectively. The small-scale fading is modeled by the Rician fading, with the AP-IRS and IRS-user Rician factors set as dB and dB, respectively. We define the average SNR of the IRS-assisted mmWave system as
| (7) |
where and denote respectively the AP-IRS and IRS-user distances, and the noise power is set as dBm. To characterize the beam identification accuracy, we define as its success rate, where stands for the indicator function. Moreover, to show the passive beamforming gain for data transmission in the identified single-beam direction, , we define the average achievable rate of all users as , where , , and dB denotes the SNR gap due to the practical modulation and coding. Note that we ignore the loss of achievable rate due to training overhead for ease of comparison. The simulation results are averaged over Rician fading channel realizations.
.
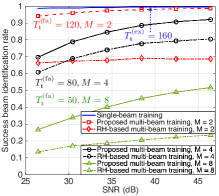
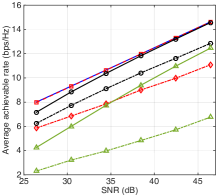
Figs. 3(a) and 3(b) show the effects of the number of IRS sub-arrays () and SNR on the training overhead, success beam identification rate, and average achievable rate. The proposed multi-beam training is compared with the conventional single-beam training as well as the RH based multi-beam training proposed in [7] that conducts the max-min intra-bin distance direction-bin mapping followed by multiple rounds of RH for beam sweeping, and applies a voting mechanism for beam identification. For fair comparison, we enforce the same training time for the RH based multi-beam training as our proposed one by limiting its number of direction-bin mappings, so as to compare their beam identification accuracy and passive beamforming gain with the same training overhead. Several interesting observations are made as follows. First, with a small number of sub-arrays (i.e., ), the proposed multi-beam training not only reduces of the training overhead of the single-beam training (i.e., versus ), but also achieves a very close success beam identification rate and average achievable rate. Second, by slightly increasing the number of sub-arrays to , the proposed multi-beam training achieves training time reduction with respect to the single-beam training (i.e., versus ), while it still attains a high success beam identification rate at high SNR (e.g., for SNR = dB) as well as close rate performance to the single-beam training (see Fig. 3(b)). However, the proposed multi-beam training with is observed to suffer a substantial loss in the beam identification accuracy even in the high-SNR regime (see Fig. 3(a)) and thus degraded passive beamforming gain (see Fig. 3(b)), due to more severe inter-beam interference. Moreover, it is observed that the proposed multi-beam training significantly outperforms the RH based benchmark for all values of in terms of both the beam identification accuracy and passive beamforming gain, owing to its more efficient beam sweeping and identification designs. In particular, the beam identification accuracy of the RH based multi-beam training with is almost invariant with the increase of SNR, since its RH round in beam training only randomly covers half of the total beam directions, thus inevitably missing some directions and greatly limiting the voting-based beam identification performance.
VI Conclusions
In this letter, we proposed a fast IRS reflect beam-training method for an IRS-assisted multiuser communication system. It was shown that by dividing IRS elements into multiple sub-arrays and properly designing sub-array beam directions over different training symbols with users’ independent beam identification based on received power/SNR comparisons, our proposed multi-beam training can significantly reduce the training overhead of conventional single-beam training, yet achieving comparable passive beamforming performance for data transmission. Moreover, it is worth noting that the proposed multi-beam training method is general and can also be applied to IRS’s vertical beam training as well as AP’s transmit beam training to multiple users without IRS or with fixed IRS (horizontal) reflection.
References
- [1] Q. Wu and R. Zhang, “Towards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network,” IEEE Commun. Mag., vol. 58, no. 1, pp. 106–112, Jan. 2020.
- [2] B. Zheng, C. You, and R. Zhang, “Intelligent reflecting surface assisted multi-user OFDMA: Channel estimation and training design,” Available: http://arxiv.org/abs/2003.00648.
- [3] C. You, B. Zheng, and R. Zhang, “Channel estimation and passive beamforming for intelligent reflecting surface: Discrete phase shift and progressive refinement,” to appear in IEEE J. Sel. Areas Commun.
- [4] M.-M. Zhao, Q. Wu, M.-J. Zhao, and R. Zhang, “Intelligent reflecting surface enhanced wireless network: Two-timescale beamforming optimization,” Available: http://arxiv.org/abs/1912.01818.
- [5] B. Ning, Z. Chen, W. Chen, and Y. Du, “Channel estimation and transmission for intelligent reflecting surface assisted THz communications,” in Proc. IEEE Intl. Conf. Commun. (ICC), Dublin, Ireland, Jun. 2020.
- [6] X. Tan, Z. Sun, D. Koutsonikolas, and J. M. Jornet, “Enabling indoor mobile millimeter-wave networks based on smart reflect-arrays,” in Proc. IEEE Conf. Comput. Commun. (INFOCOM), Honolulu, HI, USA, Apr. 2018, pp. 270–278.
- [7] H. Hassanieh, O. Abari, M. Rodriguez, M. Abdelghany, D. Katabi, and P. Indyk, “Fast millimeter wave beam alignment,” in Proc. ACM Conf. Spec. Interest Group Data Commun., Budapest, Hungary, Aug. 2018, pp. 432–445.
- [8] O. El Ayach, S. Rajagopal, S. Abu-Surra, Z. Pi, and R. W. Heath, “Spatially sparse precoding in millimeter wave MIMO systems,” IEEE Trans. Wireless Commun., vol. 13, no. 3, pp. 1499–1513, Mar. 2014.
- [9] S. Abeywickrama, R. Zhang, Q. Wu, and C. Yuen, “Intelligent reflecting surface: Practical phase shift model and beamforming optimization,” IEEE Trans. Commun., DoI: 10.1109/TCOMM.2020.3001125.
- [10] Z. Xiao, T. He, P. Xia, and X.-G. Xia, “Hierarchical codebook design for beamforming training in millimeter-wave communication,” IEEE Trans. Wireless Commun., vol. 15, no. 5, pp. 3380–3392, May 2016.