[2]\fnmChenglong \surBao
[2]\fnmZuoqiang \surShi
1]\orgdivDepartment of Mathematical Sciences, \orgnameTsinghua University, \orgaddress\streetHaidian District, \cityBeijing, \postcode100084, \stateBeijing, \countryChina
[2]\orgdivYau Mathematical Sciences Center, \orgnameTsinghua University, \orgaddress\streetHaidian District, \cityBeijing, \postcode100084, \stateBeijing, \countryChina
3]\orgdivBeijing Institute of Mathematical Sciences and Applications, \orgaddress\streetHuairou District, \cityBeijing, \postcode101408, \stateBeijing, \countryChina
Fast and Scalable Semi-Supervised Learning for Multi-View Subspace Clustering
Abstract
In this paper, we introduce a Fast and Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel solution to the high computational complexity commonly found in existing approaches. FSSMSC features linear computational and space complexity relative to the size of the data. The method generates a consensus anchor graph across all views, representing each data point as a sparse linear combination of chosen landmarks. Unlike traditional methods that manage the anchor graph construction and the label propagation process separately, this paper proposes a unified optimization model that facilitates simultaneous learning of both. An effective alternating update algorithm with convergence guarantees is proposed to solve the unified optimization model. Additionally, the method employs the obtained anchor graph and landmarks’ low-dimensional representations to deduce low-dimensional representations for raw data. Following this, a straightforward clustering approach is conducted on these low-dimensional representations to achieve the final clustering results. The effectiveness and efficiency of FSSMSC are validated through extensive experiments on multiple benchmark datasets of varying scales.
keywords:
Large-scale clustering, Multi-view subspace clustering, Semi-supervised clustering, Nonconvex optimization, Anchor graph learning1 Introduction
Real-world datasets commonly encompass multi-view features that depict objects from different perspectives. For instance, materials conveying similar meanings might be expressed in different languages. The field of machine learning has seen the emergence of a significant topic known as multi-view clustering. This approach seeks to partition data by exploring consensus across multiple views. A prominent branch within this context is multi-view subspace clustering, which has garnered substantial attention during the last decade due to its promising performance [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]. These methodologies focus on acquiring self-representative affinity matrices by expressing each data point as a linear combination of all other data points in either the feature space or the latent space.
Despite the achievements of multi-view subspace clustering methods in various application domains, their application to large-scale datasets is hindered by significant time and memory overhead. These methods involve two primary phases: graph construction and spectral clustering. In the graph construction phase, the computational complexity of creating the self-representative affinity matrix for unstructured data is , where denotes the data size. The subsequent spectral clustering phase incurs a computational complexity of at least due to the use of Singular Value Decomposition (SVD). Furthermore, the overall space complexity is estimated at . In recent years, several landmark-based methods, as illustrated by [16, 17, 18], have emerged to enhance the efficiency of multi-view subspace clustering. These methods adopt an anchor graph strategy, generating a small number of landmarks (or anchors) and constructing anchor graphs to establish connections between the raw data and the landmarks. This anchor graph strategy significantly reduces computational and memory requirements, resulting in a linear complexity of , where denotes the data size.
In many applications, a small amount of supervisory information is often available despite the resource-intensive nature of data annotation. And several landmark-based semi-supervised learning methods like [19, 20, 21] have emerged to harness the available supervisory information. These methods encompass two core phases: anchor graph construction and label propagation. During anchor graph construction, an anchor graph is crafted by assessing similarities between raw data and landmarks. Subsequently, in label propagation, a graph structure is devised for landmarks with the previously derived anchor graph, confining the exploration of supervisory information to a much smaller graph and bypassing the complete graph construction for raw data. However, these methods handle anchor graph construction and label propagation in isolation. Consequently, the anchor graph’s formation occurs independently of supervisory information, potentially yielding a sub-optimal anchor graph that impairs label propagation. Moreover, their applicability is restricted to single-view datasets, precluding the utilization of multi-view features.
To address the above limitations of existing landmark-based semi-supervised learning methods, we introduce a novel method termed Fast Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC). This method formulates a unified optimization model aimed at concurrently facilitating the processes of anchor graph construction and label propagation. Notably, FSSMSC extends the landmark-based multi-view subspace clustering methods to harness supervisory information. Furthermore, the proposed FSSMSC offers a computational and space complexity of linear order with respect to the data size, rendering it applicable to large-scale datasets with multi-view features.
An efficient alternating update scheme is implemented to solve the proposed optimization model, cyclicly refreshing both the anchor graph and the landmarks’ low-dimensional representations. This iterative procedure facilitates simultaneous advancement in both the anchor graph and the low-dimensional representations of the landmarks. Significantly, within this iterative procedure, the consensus anchor graph undergoes updates utilizing both the data features and the landmarks’ representations, which contrasts with existing scalable semi-supervised learning methods such as [19, 20, 21] that solely construct the anchor graph based on data features. The landmarks’ representations act as pseudo supervision, facilitating the learning of the consensus anchor graph. While unsupervised clustering methods like [18] optimize anchor graph and landmarks simultaneously, they derive low-dimensional representations for clustering by employing Singular Value Decomposition (SVD) on the learned anchor graph, thereby handling anchor graph learning and low-dimensional representation learning separately. In contrast, our proposed semi-supervised learning method manages anchor graph construction and low-dimensional representation learning concurrently.
Our contributions can be summarized as follows:
-
•
We introduce a method termed Fast Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC), which extends the existing landmark-based multi-view subspace clustering methods to harness supervisory information. Moreover, the proposed FSSMSC offers linear computational and space complexity, making it well-suited for large-scale datasets with multi-view features.
-
•
Distinct from traditional methods that manage the anchor graph construction and the label propagation process separately, we formulate a unified optimization model that facilitates simultaneous learning of both.
-
•
An efficient alternating update scheme with convergence guarantees is introduced to solve the proposed optimization model, cyclicly updating both the anchor graph and the landmarks’ low-dimensional representations. Extensive experiments on multiple benchmark multi-view datasets of varying scales verify the efficiency and effectiveness of the proposed FSSMSC.
Notations. We denote matrices by boldface uppercase letters, e.g., , vectors by boldface lowercase letters, e.g., , and scalars by lowercase letters, e.g., . We denote or as the -th element of . We use Tr() to denote the trace of any square matrix . is the matrix consisting of the absolute value of each element in . We denote as a vector of diagonal elements in and as a diagonal matrix with being the diagonal elements. is the transpose of . We set as the identity matrix and as a matrix or vector of all zeros. We give the notations of some norms, e.g., -norm and Frobenius norm (or -norm of a vector) .
2 Related Work
2.1 Subspace Clustering
Subspace clustering assumes that the data points are drawn from a union of multiple low-dimensional subspaces, with each group corresponding to one subspace. This clustering paradigm finds applications in diverse domains, including motion segmentation [22], face clustering [23], and image processing [24]. Within subspace clustering, self-representative subspace clustering achieves state-of-the-art performance by representing each data point as a linear combination of other data points within the same subspace. Such a representation is not unique, and sparse subspace clustering (SSC) [22] pursues a sparse representation by solving the following problem
| (1) |
where is a self-representative matrix for data points , and reflects the affinity between data point and data point . Then the affinity matrix is induced by as , which is further used for spectral clustering (SC) [25] to obtain the final clustering results.
In this paper, we represent each data point using selected landmarks to facilitate linear computational and space complexity relative to the data size .
2.2 Semi-Supervised Multi-View Learning
Owing to the prevalence of extensive real-world datasets with diverse features, numerous semi-supervised learning approaches have been developed specifically for multi-view data [26, 27, 28, 29, 30, 31, 32, 33]. The multiple graphs learning framework (AMGL) in [34] automatically learned the optimal weights for view-specific graphs. Additionally, the work [29] presented a multi-view learning with adaptive neighbors (MLAN) framework, concurrently performing label propagation and graph structure learning. [31] proposed a semi-supervised multi-view clustering method (GPSNMF) that constructs an affinity graph to preserve geometric information. An anti-block-diagonal indicator matrix was introduced in [32] to enforce the block-diagonal structure of the shared affinity matrix. [35] introduced a constrained tensor representation learning model to utilize prior weakly supervision for multi-view semi-supervised subspace clustering task. The work [33] proposed a novel semi-supervised multi-view clustering approach (CONMF) based on orthogonal non-negative matrix factorization. Despite their success in semi-supervised learning, these methods typically entail affinity matrix construction and exhibit at least computational complexity, where denotes the data size. Notably, a semi-supervised learning approach based on adaptive regression (MVAR) was introduced in [30], offering linear scalability with and quadratic scalability with feature dimension.
This paper introduces FSSMSC, a fast and scalable semi-supervised multi-view learning method to address the prevalent high computational complexity in existing approaches. FSSMSC exhibits linear computational and space complexity relative to data size and feature dimension.
3 Methodology
| Notations | Descriptions |
|---|---|
| Number of data points within the whole dataset | |
| Number of selected landmarks | |
| Number of clusters (categories) | |
| Number of chosen labeled samples | |
| Data matrix for the -th view | |
| Data matrix of the selected landmarks for the -th view | |
| Matrices of pairwise constraints | |
| Laplacian matrices of and | |
| Consensus anchor graph | |
| Low-dimensional representations of the selected landmarks |
This section introduces the proposed Fast Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) approach. We present the main notations of this paper in Table 1.
3.1 The Unified Optimization Model
For multi-view data, let denote the number of views, and represent the data matrix for data points in the -th view, where and stand for the dimension of the -th view and the data size, respectively. We perform -means clustering on the concatenated features of all views to establish consistent landmarks across all views. The resulting clustering centers are then partitioned into distinct views, denoted as , . Assuming the first data points are provided with labels, while the remaining data points remain unlabeled. The label assigned to is denoted as , , where is the number of data categories. We formulate a more flexible form of supervisory information for the labeled data points, i.e., pairwise constraints and , where and denote the sets of data pairs subject to must-link and cannot-link constraints, respectively.
Scalable semi-supervised learning methods like [19, 20, 21] compute the soft label vectors for data points by a linear combination of the soft label vectors of chosen landmarks (anchors), where is notably smaller than . Similarly, we compute low-dimensional representations for data points through a linear combination of low-dimensional representations of landmarks
| (2) |
where is the -th column of , is the -th column of . Here, signifies the dimension of the low-dimensional space, consistently set as the number of data categories throughout this paper. Additionally, is a consensus anchor graph capturing the relationships (similarities) between data points and selected landmarks.
However, these previous methods in [19, 20, 21] treat anchor graph learning and the learning of landmarks’ soft label vectors as disjoint sub-problems. In contrast, we formulate a unified optimization model facilitating concurrent advancement in both the anchor graph and the low-dimensional representations of the landmarks. Specifically, the proposed unified optimization model of the anchor graph and low-dimensional representations is based on the following observations.
Firstly, each entry within the anchor graph should capture the affinity between the -th data point and the -th landmark. To fulfill this requirement, we extend the optimization model in (1) to a landmark-based multi-view clustering scenario. As discussed in Section 2.1, the optimization model (1) proposed in [22] represents each data point as a sparse linear combination of other data points within the same subspace, and induces the affinity matrix using these linear combination coefficients. Denote , where represents the feature vector of the -th data point in the -th view. In this paper, we depict each as a linear combination of the landmarks and assume that the combination coefficients are shared across views. Therefore, we explore the relationship among views by assuming that the anchor graph is shared across views to capture their consensus. Furthermore, we enforce coefficient sparsity by utilizing the -norm on , leading to the following optimization problem:
| (3) |
where we impose non-negativity constraints on the elements in . The parameter governs the sparsity level in .
Secondly, the low-dimensional representations for the data points, denoted as following (2), need to conform to the provided pairwise constraints. Specifically, data points with must-link (cannot-link) constraints should exhibit similar (distinct) low-dimensional representations. To fulfill this requirement, we encode the pairwise constraints into two matrices, and , with elements defined as:
| (4) |
where () is the total number of must-link (cannot-link) constraints in (). The matrix represents prior pairwise similarity constraints among data points. The element functions as a reward factor, with a positive value indicating a constraint that data points and should be grouped into the same cluster. In contrast, the matrix denotes prior pairwise dissimilarity constraints. The element acts as a penalty factor, where positive values suggest that data points and should be assigned to different clusters. To balance the influence of must-link and cannot-link constraints, we normalize the non-zero entries in and by and , respectively. Subsequently, we utilize and to measure intra-class and inter-class distances for labeled data points, respectively, in the low-dimensional space. Specifically, we ensure that data pairs in share similar low-dimensional representations through the minimization of
| (5) | ||||
where is the first columns of and is any -th column of , , where is a diagonal degree matrix with the -diagonal element being . Similarly, we ensure that data pairs in exhibit distinct low-dimensional representations through the maximization of
| (6) | ||||
where and is a diagonal degree matrix with the -diagonal element being .
Thirdly, the representations of landmarks should exhibit smoothness on the graph structure of landmarks, signifying that landmarks with higher similarity ought to possess spatially close representations. This objective is commonly achieved through the application of manifold smoothing regularization. Specifically, for a symmetric similarity matrix of chosen landmarks, the manifold smoothing regularization is given by
| (7) |
where is the diagonal degree matrix with . Minimizing this objective ensures that landmarks and with high similarity value have their scaled low-dimensional representations and close to each other.
Given that signifies the similarity between landmark and data point , we define the graph structure for landmarks as , consistent with the definition in prior literature [20, 21]. We subsequently derive the normalized Laplacian matrix using . Then, we introduce the manifold smoothing regularization as follows:
| (8) |
where and .
By consolidating the aforementioned optimization requirements, we establish a unified optimization problem for the simultaneous learning of and as follows:
| (9) | ||||
where are penalty parameters.
We introduce auxiliary variable subject to the constraint . Subsequently, we replace with in , denoted as . To facilitate numerical stability and convergence analysis, we impose an upper bound on the elements in and enforce upper bound and lower bound on the elements in . Additionally, a positive constant is added to the denominator in (9). Consequently, the optimization problem is formulated as follows:
| (10) | ||||
where is the penalized term for the constraint and is a penalized parameter.
3.2 Numerical Algorithm
We employ the Alternating Direction Method of Multipliers (ADMM) approach to solve the optimization problem (10).
We introduce auxiliary variables , leading to the augmented Lagrangian expression as follows:
| (11) | ||||
where is the Lagrange multiplier. The trade-off parameters , , and are utilized to harmonize various components. We define , and , with their respective indicator functions denoted as , and . Throughout our experiments, we fix and as , as , as , and and as .
In each iteration, we alternatingly minimize over , , , B and then take gradient ascent steps on the Lagrange multiplier. The minimizations over hold the other variables fixed and use the most recent value of each variable.
Update of . The sub-problem on optimizing can be written as an equivalent form
| (12) |
where and . The trace ratio optimization problem (12) can be effectively addressed using ALGORITHM 4.1 presented in [36].
Update of . The sub-problem on optimizing can be written as follows:
| (13) |
We employ a one-step projected gradient descent strategy to update . By deriving the gradient of with respect to , we can obtain:
| (14) | ||||
where , , and . Then we update by
| (15) |
where is the step size, consistently set as in this paper.
Update of . The sub-problem on optimizing can be written as follows:
| (16) |
By deriving the gradient of with respect to , we can obtain:
| (17) | ||||
Then we update by
| (18) |
where is the step size, consistently set as in this paper.
Update of . The sub-problem on optimizing is
| (19) |
The solution to the above least-square problem is
| (20) |
Since , , the computational complexity of solving the least-square problem amounts to .
3.3 Clustering Label Inference
Upon obtaining the anchor graph and landmarks’ low-dimensional representations from Algorithm 1, the low-dimensional representations for the data points are computed as . Subsequently, the cluster label for each data point , is inferred using
| (22) |
3.4 Complexity Analysis
We begin by conducting a computational complexity analysis of the proposed FSSMSC. For updating , the complexity is . The update of involves a complexity of . The complexity of updating is , while updating requires , where stands for the total dimension of all features. The updates for incur a complexity of . Therefore, the overall computational complexity of FSSMSC amounts to . Moving on to the space complexity evaluation, considering matrices such as , for , , , and , the aggregate space complexity totals .
In summary, the proposed method demonstrates linear complexity, both in computation and space, with respect to the data size .
3.5 Convergence Analysis
We denote as the variables generated by Algorithm 1 at iteration , and establish convergence guarantees for Algorithm 1.
Lemma 1.
Theorem 1.
If , , and , the following properties hold:
(1) in (11) is lower bounded;
(2) There exists a constant such that
| (23) |
(3) When , we have
| (24) |
The proofs for the aforementioned lemma and theorem are available in the appendix.
| Dataset | Samples | Views | Categories |
|---|---|---|---|
| Caltech7 | 1,474 | 6 | 7 |
| HW | 2,000 | 6 | 10 |
| Caltech20 | 2,386 | 6 | 20 |
| Reuters | 18,758 | 5 | 6 |
| NUS | 30,000 | 5 | 31 |
| Caltech101 | 9,144 | 6 | 102 |
| YoutubeFacesel | 101,499 | 5 | 31 |
4 Experiments
| Dataset | FPMVS | LMVSC | MVAR | MLAN | AMGL | GPSNMF | CONMF | FSSMSC |
|---|---|---|---|---|---|---|---|---|
| ACC() | ||||||||
| Caltech7 | 57.1 | 70.6 | 91.7 1.7 | 91.6 2.4 | 85.3 1.6 | 93.1 1.5 | 92.7 1.6 | 93.7 1.9 |
| HW | 82.3 | 89.4 | 95.6 2.0 | 97.3 0.2 | 86.1 2.3 | 97.1 0.8 | 97.0 0.5 | 97.1 0.5 |
| Caltech20 | 66.4 | 48.8 | 78.9 1.8 | 78.1 2.2 | 68.4 3.4 | 80.8 1.4 | 80.0 1.2 | 82.4 1.8 |
| Reuters | 57.5 | 49.6 | OM | OM | 63.1 1.7 | 73.1 1.3 | 75.0 1.0 | 75.8 2.4 |
| NUS | 19.4 | 14.9 | 25.5 1.8 | OM | 19.1 1.3 | 28.3 1.0 | 24.8 1.0 | 29.2 1.6 |
| Caltech101 | 28.8 | 25.6 | 44.3 0.8 | 45.2 0.6 | 39.6 1.0 | 43.1 0.8 | 47.3 0.8 | 47.1 0.8 |
| Youtube111Youtube is an abbreviation of the dataset YoutubeFacesel. | 24.1 | 24.8 | OM | OM | OM | 39.9 2.0 | OM | 42.3 0.6 |
| NMI () | ||||||||
| Caltech7 | 55.6 | 48.1 | 78.3 3.8 | 79.7 3.5 | 66.4 2.7 | 82.6 3.5 | 81.2 2.1 | 84.3 4.2 |
| HW | 79.2 | 83.7 | 91.7 1.1 | 94.2 0.5 | 86.0 2.6 | 93.7 1.2 | 93.3 0.8 | 93.4 1.0 |
| Caltech20 | 63.9 | 59.5 | 67.4 2.6 | 68.6 2.6 | 56.5 3.7 | 72.6 1.7 | 69.9 1.6 | 74.6 1.5 |
| Reuters | 35.9 | 35.6 | OM | OM | 36.3 2.4 | 47.0 2.0 | 49.7 0.9 | 50.9 2.7 |
| NUS | 13.5 | 12.5 | 12.2 1.0 | OM | 6.7 1.1 | 14.4 0.6 | 13.0 0.2 | 17.7 1.0 |
| Caltech101 | 41.8 | 48.5 | 41.5 0.8 | 46.1 0.8 | 38.1 0.8 | 44.0 0.7 | 50.9 0.5 | 50.9 0.6 |
| Youtube | 24.5 | 22.2 | OM | OM | OM | 26.8 1.6 | OM | 27.6 0.6 |
| ARI () | ||||||||
| Caltech7 | 41.3 | 43.0 | 87.6 4.1 | 85.4 6.0 | 65.4 4.1 | 92.6 3.0 | 92.4 2.1 | 93.6 4.1 |
| HW | 72.7 | 80.0 | 91.1 2.2 | 94.1 0.5 | 78.6 4.0 | 93.7 1.5 | 93.5 1.1 | 93.6 1.1 |
| Caltech20 | 63.6 | 33.3 | 80.6 3.7 | 65.8 6.5 | 39.0 7.6 | 84.6 2.2 | 81.0 2.9 | 88.8 1.5 |
| Reuters | 33.2 | 22.1 | OM | OM | 33.1 4.2 | 48.4 2.1 | 51.9 1.7 | 55.1 3.9 |
| NUS | 6.5 | 4.9 | 6.7 1.8 | OM | 2.8 1.6 | 10.8 0.7 | 10.7 0.5 | 13.8 2.2 |
| Caltech101 | 17.4 | 19.1 | 41.5 2.4 | 35.7 3.5 | 20.6 3.3 | 39.2 1.9 | 63.5 1.8 | 63.8 1.2 |
| Youtube | 6.0 | 4.6 | OM | OM | OM | 7.8 2.1 | OM | 13.6 0.6 |
| Running Time () | ||||||||
| Caltech7 | 23.2 | 251.7 | 4.6 | 10.9 | 0.9 | 8.4 | 12.9 | 2.8 |
| HW | 25.5 | 8.6 | 3.9 | 11.6 | 1.5 | 7.7 | 6.9 | 4.8 |
| Caltech20 | 26.4 | 28.8 | 18.7 | 23.4 | 2.5 | 14.2 | 24.5 | 6.3 |
| Reuters | 1342.1 | 317.7 | OM | OM | 326.3 | 1206.3 | 5096.6 | 109.5 |
| NUS | 1113.2 | 1879.4 | 763.9 | OM | 990.4 | 145.4 | 1431.4 | 40.7 |
| Caltech101 | 684.9 | 2558.1 | 137.1 | 412.8 | 47.6 | 54.3 | 199.8 | 20.5 |
| Youtube | 3187.1 | 1152.7 | OM | OM | OM | 1128.4 | OM | 209.8 |
In this section, we conduct extensive experiments on seven benchmark multi-view datasets to evaluate the effectiveness and efficiency of the proposed method.
4.1 Experimental Settings
4.1.1 Datasets
We perform experiments on seven datasets widely employed for multi-view clustering: Handwritten (HW) [37], Caltech101 [38], Caltech7, Caltech20, Reuters [39], NUS-WIDE-Object (NUS) [40], and YoutubeFacesel [41, 18]. Specifically, HW comprises 2,000 handwritten digits from 0 to 9. Caltech101 is an object recognition dataset including 9,144 data points. Caltech7 and Caltech20 are two widely-used subsets of Caltech101. Reuters includes documents in five languages and their translations; we use the English-written subset and its translations, which consists of 18,758 data points in 6 categories. NUS is also a dataset for object recognition, comprising 30,000 data points in 31 categories. YoutubeFacesel is a video dataset containing 101,499 samples. The key dataset statistics are presented in Table 2.
4.1.2 Compared Methods
4.1.3 Evaluation Metrics
We evaluate the clustering performance with clustering accuracy (ACC) [42], Normalized Mutual Information (NMI) [42], Adjusted Rand Index (ARI) [43], and running time in seconds. Since the proposed approach and the compared methods in the paper are implemented in MATLAB, we use the ”tic” and ”toc” functions to measure the elapsed time for each algorithm, with ”tic” marking the start and ”toc” marking the end of the execution of the algorithm. This elapsed time is reported as the algorithm’s running time.
4.1.4 Implementation Details
To ensure an equitable comparison, we acquired the released codes of the comparative methods and fine-tuned the parameters according to the corresponding papers to achieve optimal outcomes. In our approach, we consistently fix and as , as , as , and as , and and as . Moreover, we select from , from , and from . The number of clusters is set as the number of data categories . For LMVSC and FPMVS, the landmark number is explored from , with the best clustering performance reported. For the proposed FSSMSC, is employed for most datasets, except for Caltech7 and Reuters, where is selected. For AMGL, MLAN, MVAR, GPSNMF, CONMF, and FSSMSC, labeled samples constitute of the total samples for HW, Caltech7, Caltech20, and Caltech101, and for the larger datasets, Reuters, NUS and YoutubeFacesel. Each experiment is repeated 20 times independently, and the average values and standard deviations are reported. All experiments are implemented in Matlab R2021a and run on a platform with a 2.10GHz Intel Xeon CPU and 128GB RAM.
4.2 Experimental Results and Discussion
Table 3 presents the clustering performance of different methods on the seven datasets. Based on the results depicted in Table 3, the following observations can be made:
-
•
Compared to the scalable multi-view subspace clustering methods, FPMVS and LMVSC, the proposed approach demonstrates a significant enhancement in clustering performance while utilizing a limited amount of supervisory information. For instance, FSSMSC exhibits improvements of , , and over datasets Reuters, NUS, and YoutubeFacesel, respectively, for the ACC metric. Furthermore, FSSMSC notably outperforms FPMVS and LMVSC regarding running time.
-
•
In comparison to the semi-supervised multi-view learning methods (MVAR, MLAN, AMGL, GPSNMF, and CONMF), the proposed FSSMSC demonstrates comparable or superior performance with remarkably enhanced computational efficiency, particularly on large datasets such as YoutubeFacesel, NUS, and Reuters. Specifically, FSSMSC demonstrates improvements of , , and in ARI metric on datasets YoutubeFacesel, Reuters, and NUS, respectively, when contrasted with the five semi-supervised methods. Furthermore, FSSMSC exhibits computational efficiency advantages, running nearly 25 times faster than AMGL on NUS, 15 times faster than MVAR on NUS, 10 times faster than GPSNMF on Reuters, 20 times faster than MLAN on Caltech101, and 45 times faster than CONMF on Reuters.
-
•
When conducting experiments on the largest dataset, YoutubeFacesel, the semi-supervised methods MVAR, MLAN, AMGL, and CONMF faced out-of-memory issues. The proposed FSSMSC demonstrates improvements of and over GPSNMF in terms of the ACC and ARI metrics, respectively, achieving this enhancement with significantly reduced running time.
These experiments verify the scalability, effectiveness, and efficiency of the proposed method.


4.3 Sensitivity and Convergence Analysis
In Fig. 1 and Fig. 2, we conduct a sensitivity analysis for the three key parameters in FSSMSC, namely , , and , on six datasets. The following observations can be made from Fig. 1 and Fig. 2: (1) The parameter , governing the sparsity level of , significantly influences the clustering performance. Notably, the clustering accuracy exhibits more stable changes when the value of is relatively small; (2) Among the three relatively large datasets (Caltech101, NUS, and YoutubeFacesel), higher values of such as and smaller values of such as and are advantageous.
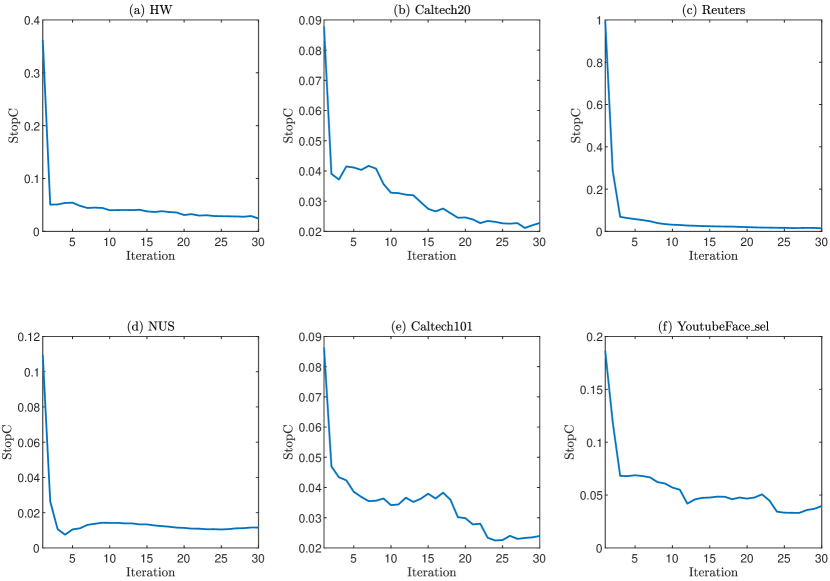
Additionally, numerical convergence curves for six datasets are presented in Fig. 3. It can be observed that the stopping criterion decreases rapidly in the initial five iterations and continues to decrease throughout the iterations. In our experiments, we set the maximum iteration number to 30.
4.4 Comparison of Semi-Supervised Methods under Different Labeled Ratios
We conduct experiments to assess the performance of our proposed method under different ratios of labeled samples. The results are presented in Fig. 4, Fig. 5, Fig. 6, and Fig. 7. The results are not included when an out-of-memory issue occurs. These results show that our proposed FSSMSC performs comparably to or better than semi-supervised competitors (MVAR, MLAN, AMGL, GPSNMF, and CONMF) across different labeled sample ratios. Additionally, as presented in Table 3, FSSMSC demonstrates notably reduced running times on the large datasets—NUS, Reuters, and YoutubeFacesel. These results further validate the effectiveness of our approach.




4.5 Ablation Study
We conduct an ablation study for each component of our optimization model (9). The results are presented in Table 4. These ablation experiments include:
-
•
W/O : Omitting the norm of in , resulting in . Since is a necessary component to utilize the data features , we preserve this part in .
-
•
W/O : Excluding the component .
-
•
W/O : Omitting the component .
-
•
W/O : Excluding the component .
The results in Table 4 demonstrate that the full FSSMSC model consistently achieves superior clustering performance in most cases compared to versions with individual components removed. This confirms the importance and effectiveness of each component in our proposed model.
| Dataset | Reuters | NUS | YoutubeFacesel | Caltech101 | Caltech20 | HW |
|---|---|---|---|---|---|---|
| ACC() | ||||||
| W/O | 68.1 2.3 | 29.2 1.2 | 34.5 0.6 | 38.5 0.6 | 75.8 1.5 | 89.5 1.9 |
| W/O | 64.4 2.4 | 20.8 0.9 | 35.9 0.8 | 43.4 0.6 | 80.5 1.5 | 96.9 0.6 |
| W/O | 69.5 1.9 | 17.1 1.3 | 24.7 0.9 | 44.8 0.7 | 82.2 1.7 | 97.1 0.5 |
| W/O | 58.0 12.7 | 21.9 4.5 | 30.2 1.5 | 42.9 1.2 | 80.5 4.2 | 86.8 6.3 |
| FSSMSC | 75.8 2.4 | 29.2 1.6 | 42.3 0.6 | 47.1 0.8 | 82.4 1.8 | 97.1 0.5 |
| NMI() | ||||||
| W/O | 41.3 2.4 | 17.2 1.0 | 21.2 0.7 | 42.8 0.6 | 64.7 1.4 | 82.5 1.5 |
| W/O | 37.0 2.6 | 11.0 0.5 | 21.1 0.6 | 47.3 0.5 | 72.3 1.4 | 93.2 1.2 |
| W/O | 44.2 2.0 | 7.6 0.9 | 9.7 0.5 | 47.8 0.7 | 75.1 1.3 | 93.6 0.9 |
| W/O | 28.1 15.0 | 13.6 4.5 | 16.9 1.3 | 46.8 1.3 | 70.6 6.4 | 77.8 7.8 |
| FSSMSC | 50.9 2.7 | 17.7 1.0 | 27.6 0.6 | 50.9 0.6 | 74.6 1.5 | 93.4 1.0 |
Moreover, we perform an ablation study on the parameter . FSSMSC∗ indicates the case where is fixed at 0 in Algorithm 1, while FSSMSC denotes the usage of a tuned non-zero . The principal distinction between FSSMSC∗ and FSSMSC lies in the update. In FSSMSC∗, is updated without utilizing the landmarks’ representations . Conversely, in FSSMSC, is updated using both data features and landmarks’ representations. Therefore, anchor graph learning in FSSMSC∗ is decoupled from the label propagation process. The results of applying FSSMSC and FSSMSC∗ to different datasets are presented in Table 5. The outcomes depicted in Table 5 illustrate that FSSMSC outperforms FSSMSC∗ in terms of ACC and NMI metrics. This observation verifies the efficacy of the simultaneous learning of the anchor graph and label propagation.
| Dataset | Reuters | NUS | YoutubeFacesel | Caltech101 | HW |
|---|---|---|---|---|---|
| ACC() | |||||
| FSSMSC∗ | 75.2 2.5 | 26.1 1.1 | 41.0 0.6 | 46.9 0.7 | 97.0 0.6 |
| FSSMSC | 75.8 2.4 | 29.2 1.6 | 42.3 0.6 | 47.1 0.8 | 97.1 0.5 |
| NMI() | |||||
| FSSMSC∗ | 49.9 2.8 | 14.7 0.6 | 26.1 0.5 | 50.4 0.6 | 93.3 1.0 |
| FSSMSC | 50.9 2.7 | 17.7 1.0 | 27.6 0.6 | 50.9 0.6 | 93.4 1.0 |
4.6 Relationship Between Computational Complexity and Running Time
In this section, we illustrate the relationship between the computational complexity and the growth speed of running time. For instance, the compared semi-supervised algorithms MLAN, AMGL, GPSNMF, and CONMF require constructing similarity matrices for all samples across all views. The computational complexity for constructing these similarity matrices is , where is the total feature dimension of all views and is the number of samples. This complexity scales quadratically with , whereas our algorithm’s overall complexity scales linearly with . Therefore, as increases, the running time required to construct these similarity matrices grows significantly faster for these methods compared to our approach.
We provide empirical evidence for this by reporting the total running time of the semi-supervised methods, as well as the running time required to construct similarity matrices before the iterative update procedure, across four datasets, as detailed in Table 6. In Table 6, values in parentheses denote the running time for similarity matrix construction, while those outside parentheses represent the total running time. It can be observed that as increases, the running time required to construct the similarity matrices (values in parentheses) grows significantly faster compared to our FSSMSC. For example, the data size of the YoutubeFacesel dataset is nearly 3.4 times that of the NUS dataset, yet the running time for constructing similarity matrices for GPSNMF on the YoutubeFacesel dataset (646.0 seconds) is nearly 15.3 times that of the NUS dataset (42.3 seconds). In contrast, the total running time of our algorithm on the YoutubeFacesel dataset (209.8 seconds) is approximately 5.2 times that of the NUS dataset (40.7 seconds).
Notably, MVAR does not involve similarity matrix construction, and its computational complexity scales linearly with while quadratically with . Variations in running times for similarity matrix construction on the same dataset among MLAN, AMGL, GPSNMF, and CONMF are due to differences in their respective construction methods.
| Dataset | data size | MVAR | MLAN | AMGL | GPSNMF | CONMF | FSSMSC |
|---|---|---|---|---|---|---|---|
| Caltech20 | 2,386 | 18.7 | 23.4(1.4) | 2.5(1.7) | 14.2(0.6) | 24.5(2.3) | 6.3 |
| Caltech101 | 9,144 | 137.1 | 412.8(20.8) | 47.6(27.1) | 54.3(4.1) | 199.8(8.6) | 20.5 |
| NUS | 30,000 | 763.9 | OM | 990.4(440.2) | 145.4(42.3) | 1431.4(105.5) | 40.7 |
| Youtube | 101,499 | OM | OM | OM | 1128.4(646.0) | OM | 209.8 |
4.7 The Floating Point Operations Evaluation
The proposed approach and the compared methods in the paper are implemented in MATLAB. However, MATLAB does not have an official function or program to report exact Floating Point Operations (FLOPs). We use a publicly available MATLAB program [44] to estimate the FLOPs on the four large datasets, as shown in Table 7. From Table 7, we can observe that our proposed FSSMSC achieves significantly fewer FLOPs compared to other semi-supervised competitors.
| Dataset | MVAR | MLAN | AMGL | GPSNMF | CONMF | FSSMSC |
|---|---|---|---|---|---|---|
| Caltech101 | ||||||
| Reuters | OM | OM | ||||
| NUS | OM | |||||
| YoutubeFacesel | OM | OM | OM | OM |
It should be noted that while GPSNMF typically has more FLOPs than CONMF, it takes less running time. This discrepancy arises from the FLOPs calculation rules in the used program [44]. The program calculates the FLOPs of multiplying an matrix by a matrix as , regardless of whether the matrix is represented as sparse or not. However, in the released codes of GPSNMF, the similarity matrix and its sub-matrix are represented in sparse format (encoding the row and column indexes for the nonzero elements). Therefore, the actual FLOPs of matrix multiplication with these matrices may be overestimated. This may explain why the running time of GPSNMF is less than that of CONMF.
Additionally, the semi-supervised competitors MLAN, AMGL, GPSNMF, and CONMF require constructing similarity matrices for all samples across all views before the iterative update procedure. The FLOPs for this process are estimated as , where is the total feature dimension of all views and is the number of samples. The FLOPs for this process on the Caltech101, NUS, and YoutubeFacesel datasets are shown in Table 8. On the YoutubeFacesel dataset, the FLOPs for constructing similarity matrices () is nearly 3.4 times of the FLOPs of our proposed FSSMSC (). Moreover, the FLOPs for constructing these similarity matrices scale quadratically with , whereas our approach scales linearly with . This means that the FLOPs of constructing similarity matrices for these methods grows significantly faster compared to our approach.
| Dataset | Caltech101 | NUS | YoutubeFacesel |
|---|---|---|---|
| data size | 9,144 | 30,000 | 101,499 |
| total dimension | 3,766 | 639 | 2,125 |
4.8 Experimental Validation of Linear Space Complexity
We conduct experiments to confirm the linear property of our algorithm’s space complexity. As illustrated in Table 9, we evaluate the space complexity by examining the memory usage of the variables in the MATLAB implementation of our algorithm. The Reuters dataset is not included due to its extremely high feature dimension compared to the other six datasets. The results show that the values of bytes/n for our approach are comparable across different datasets, indicating that the space complexity empirically scales linearly with the data size . Additionally, the observed fluctuations in the values of bytes/n are due to variations in feature dimensions and the number of selected landmarks across datasets.
| Dataset | HW | Caltech7 | Caltech20 | Caltech101 | NUS | YoutubeFacesel |
|---|---|---|---|---|---|---|
| data size | 2,000 | 1,474 | 2,386 | 9,144 | 30,000 | 101,499 |
| total dimension | 649 | 3,766 | 3,766 | 3,766 | 639 | 2,125 |
| bytes | ||||||
| bytes/n |
For comparison, since each element of the matrix consumes 8 bytes, the similarity matrices for all five views of the YoutubeFacesel dataset takes bytes of , which is significantly large than the bytes required by our approach. Furthermore, the memory usage for a full similarity matrix grows quadratically with the data size , whereas the memory usage for our approach grows linearly with .
5 Conclusion
This paper introduces the Fast Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel approach addressing the prevalent high computational complexity in existing approaches. Importantly, FSSMSC offers linear computational and space complexity, rendering it suitable for large-scale multi-view datasets. Unlike conventional methods that manage anchor graph construction and label propagation independently, we propose a unified optimization model for simultaneously learning both components. Extensive experiments on seven multi-view datasets demonstrate the efficiency and effectiveness of the proposed method.
Acknowledgements
We appreciate the support by the National Natural Science Foundation of China (No.12271291, No.12071244, and No.92370125) and the National Key RD Program of China (No.2021YFA1001300).
Appendix A Proofs of Lemma 1 and Theorem 1
We begin by presenting essential notations and definitions, followed by the proofs for Lemma 1 and Theorem 1 in the paper, denoted as Lemma 2 and Theorem 2 in this appendix.
Let , , and , along with their indicator functions denoted as , , and .
Let and define the functions and as follows:
| (25) | ||||
Additionally, let
Then, we can rewrite the objective as
| (26) |
where
| (27) |
Then, the augmented Lagrangian is defined as:
| (28) |
where is the Lagrangian multiplier.
In the paper, we denote as the variables generated by Algorithm 1 at iteration .
The objective for the sub-problem of updating is defined as:
where
| (29) |
The objective for the sub-problem of updating is defined as:
where
| (30) |
Definition 1 ([45]).
Let be a proper lower semi-continuous function which is lower bounded, and a positive parameter. The proximal correspondence , is defined through the formula
Definition 2.
For any nonempty closed subset of , the projection on is the following point-to-set mapping:
Recall that for any closed subset of , its indicator function is defined by
where .
Then, for any nonempty closed subset of and any positive , we have the equality
Consequently, our alternating iteration algorithm (Algorithm 1) at the -th iteration is as follows:
| (31) | ||||
Definition 3 (Lipschitz Continuity).
A function is Lipschitz continuous on the set , if there exists a constant such that
is called the Lipschitz constant.
Lemma 2.
Proof.
Applying Lemma 8, we directly obtain that is Lipschitz continuous with a Lipschitz constant .
As for the Lipschitz continuity of , according to the updating rules for and in (A), we have and . Then, according to Lemma 6, we have is Lipschitz continuous on with a Lipschitz constant . In addition, using the fact that , we can directly obtain that is Lipschitz continuous with a Lipschitz constant . Therefore, , where is defined in (30), is Lipschitz continuous on with a Lipschitz constant , where .
As for the Lipschitz continuity of , according to the updating rule for in (A), we have and . According to Lemma 4, we have is Lipschitz continuous with respect to on with a Lipschitz constant . According to Lemma 5, we have is Lipschitz continuous with respect to on with a Lipschitz constant . Consequently, applying the definition of in (29), we directly obtain is Lipschitz continuous with respect to on with a Lipschitz constant , where .
Therefore, we complete the proof. ∎
Theorem 2.
If , , and , the following properties hold:
(1) The augmented Lagrangian in (28) is lower bounded;
(2) There exists a constant such that
| (32) |
(3) When , we have
| (33) |
Proof.
Firstly, we provide the proof of part (1). Note that and is a bounded set, implying the existence of constant such that . Considering the definition of and , we have .
Let . Moreover, since and are two given positive semi-definite matrices, we have . Let , , and . Then, we derive that
where . Since is a positive semi-definite matrix, we have . Additionally, since is a diagonal matrix, we can obtain . Then, we can derive
Consequently, we obtain the first inequality. The second inequality relies on the positive semi-definite property of the Laplacian matrix . Consequently, we obtain
| (34) |
Consequently, we obtain the lower bound of defined in (27) as follows
According to the definition of , we have . Hence, we obtain
where the first equality relies on Lemma 9(a): and the first inequality utilizes Lemma 2 and Lemma 7:
Therefore, we complete the proof of part (1).
Secondly, we provide the proof of part (2). Given , , and , we have in Lemma 11, in Lemma 12, and in Lemma 13. Consequently, part (2) is a direct result of combining Lemma 10, Lemma 11, Lemma 12, and Lemma 13. Therefore, we complete the proof of part (2).
Thirdly, we provide the proof of part (3). Note that is lower bounded (part (1)). Summing over for the inequality in part (2), we deduce that the series converges. Consequently, we have when . Moreover, according to Lemma 9(b), we have . Finally, based on the update rule for in (A), we obtain
Thus, we have . Therefore, we complete the proof of part (3).
The proof is completed. ∎
Lemma 3.
If the gradient of , namely , is Lipschitz continuous on with a Lipschitz constant , we have the following inequality:
Moreover, there exists such that
Proof.
According to the update rule of in (A) and Definition 1, we have the following inequality:
Eliminating the same terms in both sides of this inequality, we get:
| (35) |
Hence, we have:
where the first inequality relies on the Lipschitz continuity of and Lemma 7, and the second inequality relies on (35). The first part is thereby proven.
According to the update rule of in (A), Definition 1, and the first-order optimal conditions of , it is known that there exists such that
Let , then
The latter part is thereby proven. ∎
Lemma 4.
Fixing any and any , is Lipschitz continuous with respect to on with a Lipschitz constant .
Proof.
Note that and are bounded sets, implying the existence of constants and such that and . Considering the definition of , we have . Additionally, let since and are given matrices.
Define
and
Then, we obtain
since is a given positive semi-definite matrix, we have . Deriving the gradients with respect to , we obtain
This leads to the Lipschitz continuity of :
and the Lipschitz continuity of
where and .
Similarly, from the boundedness of , , and , we have:
| (36) |
As , the gradient is given by:
| (37) |
We now derive the Lipschitz continuity of the first component in (37) as follows:
| (38) |
where the third inequality relies on the Mean Value Theorem and .
Subsequently, we derive the Lipschitz continuity of the second component in (37). First, using the triangle inequality, Lipschitz continuity of , and the inequalities in (A), we obtain
| (39) |
and
| (40) |
Consequently, combining (A) and (A), we obtain Lipschitz continuity of the second component in (37) as follows:
| (41) |
Combine (A) and (A), we obtain the Lipschitz continuity of :
which completes the proof. ∎
Lemma 5.
For any , is Lipschitz continuous with respect to on with a Lipschitz constant .
Proof.
Since , we can obtain the gradient of with respect to as follows:
Note that is a bounded set, implying the existence of constant such that . Considering the definition of , we have . Then, using the triangle inequality and the boundedness of and , we obtain the following two inequalities for any :
and
Combining the above two inequalities, we obtain
Define as , and we complete the proof. ∎
Lemma 6.
Fixing any and any , is Lipschitz continuous with respect to on with a Lipschitz constant .
Proof.
Note that and are bounded sets, implying the existence of constants and such that and . Considering the definition of , we have . Additionally, let since and are given matrices.
Let . since is a given positive semi-definite matrix, we have . Then, the gradient with respect to is given by:
Using the triangle inequality and the boundedness of , , and , we have
| (42) | ||||
In the above derivation, the first inequality utilizes the triangle inequality, while the second inequality employs the relations , , and . Additionally, due to , we have
| (43) |
Let and denote the -th elements of vectors and , respectively. Then,
Thus,
| (44) |
Similarly, we have
Hence,
| (45) |
Combining (A), (43), (44), and (45), we obtain
which completes the proof. ∎
Lemma 7.
Given a function , if the gradient of , namely , is Lipschitz continuous on the convex set with a Lipschitz constant , the inequality below is satisfied for any :
Proof.
Using the Lipschitz continuity assumption of , we obtain
This completes the proof. ∎
Lemma 8.
is Lipschitz continuous with a Lipschitz constant .
Proof.
Using the fact that and the definition of Lipschitz continuity, we obtain the Lipschitz continuity of . ∎
Lemma 9.
For all , it holds that
(a)
(b)
Proof.
Lemma 10 (descent of during update).
When updating in (A), we have
Proof.
The inequality could be directly obtained using the definition of in (A). ∎
Lemma 11 (descent of during and update).
When updating and in (A), we have
Proof.
Lemma 12 (sufficient descent of during update).
When updating in (A), we obtain
Proof.
Lemma 13 (sufficient descent of during update).
When updating in (A), we have
References
- \bibcommenthead
- Cao et al. [2015] Cao, X., Zhang, C., Fu, H., Liu, S., Zhang, H.: Diversity-induced multi-view subspace clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 586–594 (2015)
- Gao et al. [2015] Gao, H., Nie, F., Li, X., Huang, H.: Multi-view subspace clustering. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4238–4246 (2015)
- Wang et al. [2017] Wang, X., Guo, X., Lei, Z., Zhang, C., Li, S.Z.: Exclusivity-consistency regularized multi-view subspace clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 923–931 (2017)
- Brbić and Kopriva [2018] Brbić, M., Kopriva, I.: Multi-view low-rank sparse subspace clustering. Pattern Recognit. 73, 247–258 (2018)
- Luo et al. [2018] Luo, S., Zhang, C., Zhang, W., Cao, X.: Consistent and specific multi-view subspace clustering. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 3730–3737 (2018)
- Zhang et al. [2018] Zhang, C., Fu, H., Hu, Q., Cao, X., Xie, Y., Tao, D., Xu, D.: Generalized latent multi-view subspace clustering. IEEE Trans. Pattern Anal. Mach. Intell. 42(1), 86–99 (2018)
- Li et al. [2019a] Li, R., Zhang, C., Fu, H., Peng, X., Zhou, T., Hu, Q.: Reciprocal multi-layer subspace learning for multi-view clustering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8172–8180 (2019)
- Li et al. [2019b] Li, R., Zhang, C., Hu, Q., Zhu, P., Wang, Z.: Flexible multi-view representation learning for subspace clustering. In: IJCAI, pp. 2916–2922 (2019)
- Gao et al. [2020] Gao, Q., Xia, W., Wan, Z., Xie, D., Zhang, P.: Tensor-svd based graph learning for multi-view subspace clustering. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 3930–3937 (2020)
- Zhang et al. [2020] Zhang, C., Fu, H., Wang, J., Li, W., Cao, X., Hu, Q.: Tensorized multi-view subspace representation learning. Int. J. Comput. Vis. 128(8), 2344–2361 (2020)
- Kang et al. [2020] Kang, Z., Zhao, X., Peng, C., Zhu, H., Zhou, J.T., Peng, X., Chen, W., Xu, Z.: Partition level multiview subspace clustering. Neural Netw. 122, 279–288 (2020)
- Zhang et al. [2020] Zhang, P., Liu, X., Xiong, J., Zhou, S., Zhao, W., Zhu, E., Cai, Z.: Consensus one-step multi-view subspace clustering. IEEE Trans. Knowl. Data Eng. 34(10), 4676–4689 (2020)
- Sun et al. [2021] Sun, M., Wang, S., Zhang, P., Liu, X., Guo, X., Zhou, S., Zhu, E.: Projective multiple kernel subspace clustering. IEEE Trans. Multimedia 24, 2567–2579 (2021)
- Si et al. [2022] Si, X., Yin, Q., Zhao, X., Yao, L.: Consistent and diverse multi-view subspace clustering with structure constraint. Pattern Recognit. 121, 108196 (2022)
- Cai et al. [2023] Cai, X., Huang, D., Zhang, G.-Y., Wang, C.-D.: Seeking commonness and inconsistencies: A jointly smoothed approach to multi-view subspace clustering. Inf. Fusion 91, 364–375 (2023)
- Kang et al. [2020] Kang, Z., Zhou, W., Zhao, Z., Shao, J., Han, M., Xu, Z.: Large-scale multi-view subspace clustering in linear time. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4412–4419 (2020)
- Sun et al. [2021] Sun, M., Zhang, P., Wang, S., Zhou, S., Tu, W., Liu, X., Zhu, E., Wang, C.: Scalable multi-view subspace clustering with unified anchors. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 3528–3536 (2021)
- Wang et al. [2021] Wang, S., Liu, X., Zhu, X., Zhang, P., Zhang, Y., Gao, F., Zhu, E.: Fast parameter-free multi-view subspace clustering with consensus anchor guidance. IEEE Trans. Image Process. 31, 556–568 (2021)
- Liu et al. [2010] Liu, W., He, J., Chang, S.-F.: Large graph construction for scalable semi-supervised learning. In: Proceedings of the 27th International Conference on Machine Learning, pp. 679–686 (2010)
- Wang et al. [2016] Wang, M., Fu, W., Hao, S., Tao, D., Wu, X.: Scalable semi-supervised learning by efficient anchor graph regularization. IEEE Trans. Knowl. Data Eng. 28(7), 1864–1877 (2016)
- Zhang et al. [2022] Zhang, Y., Ji, S., Zou, C., Zhao, X., Ying, S., Gao, Y.: Graph learning on millions of data in seconds: Label propagation acceleration on graph using data distribution. IEEE Trans. Pattern Anal. Mach. Intell. 45(2), 1835–1847 (2022)
- Elhamifar and Vidal [2013] Elhamifar, E., Vidal, R.: Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 35(11), 2765–2781 (2013)
- Zhang et al. [2019] Zhang, J., Li, C.-G., You, C., Qi, X., Zhang, H., Guo, J., Lin, Z.: Self-supervised convolutional subspace clustering network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5473–5482 (2019)
- Yang et al. [2016] Yang, Y., Feng, J., Jojic, N., Yang, J., Huang, T.S.: -sparse subspace clustering. In: European Conference on Computer Vision, pp. 731–747 (2016)
- Ng et al. [2002] Ng, A.Y., Jordan, M.I., Weiss, Y.: On spectral clustering: Analysis and an algorithm. In: Proceedings of the International Conference on Neural Information Processing Systems, pp. 849–856 (2002)
- Wang et al. [2009] Wang, M., Hua, X.-S., Hong, R., Tang, J., Qi, G.-J., Song, Y.: Unified video annotation via multigraph learning. IEEE Trans. Circuits Syst. Video Technol. 19(5), 733–746 (2009)
- Cai et al. [2013] Cai, X., Nie, F., Cai, W., Huang, H.: Heterogeneous image features integration via multi-modal semi-supervised learning model. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1737–1744 (2013)
- Karasuyama and Mamitsuka [2013] Karasuyama, M., Mamitsuka, H.: Multiple graph label propagation by sparse integration. IEEE Trans. Neural Netw. Learn. Syst. 24(12), 1999–2012 (2013)
- Nie et al. [2017] Nie, F., Cai, G., Li, J., Li, X.: Auto-weighted multi-view learning for image clustering and semi-supervised classification. IEEE Trans. Image Process. 27(3), 1501–1511 (2017)
- Tao et al. [2017] Tao, H., Hou, C., Nie, F., Zhu, J., Yi, D.: Scalable multi-view semi-supervised classification via adaptive regression. IEEE Trans. Image Process. 26(9), 4283–4296 (2017)
- Liang et al. [2020] Liang, N., Yang, Z., Li, Z., Xie, S., Su, C.-Y.: Semi-supervised multi-view clustering with graph-regularized partially shared non-negative matrix factorization. Knowl.-Based Syst. 190, 105185 (2020)
- Qin et al. [2021] Qin, Y., Wu, H., Zhang, X., Feng, G.: Semi-supervised structured subspace learning for multi-view clustering. IEEE Trans. Image Process. 31, 1–14 (2021)
- Liang et al. [2022] Liang, N., Yang, Z., Li, Z., Xie, S.: Co-consensus semi-supervised multi-view learning with orthogonal non-negative matrix factorization. Inf. Process. Manag. 59(5), 103054 (2022)
- Nie et al. [2016] Nie, F., Li, J., Li, X., et al.: Parameter-free auto-weighted multiple graph learning: a framework for multiview clustering and semi-supervised classification. In: IJCAI, pp. 1881–1887 (2016)
- Tang et al. [2021] Tang, Y., Xie, Y., Zhang, C., Zhang, W.: Constrained tensor representation learning for multi-view semi-supervised subspace clustering. IEEE Trans. Multimedia 24, 3920–3933 (2021)
- Ngo et al. [2012] Ngo, T.T., Bellalij, M., Saad, Y.: The trace ratio optimization problem. SIAM Rev. 54(3), 545–569 (2012)
- [37] Duin, R.: Multiple Features. UCI Machine Learning Repository. https://doi.org/10.24432/C5HC70. Accessed 7 Sept 2022.
- [38] Li, F.-F., Andreeto, M., Ranzato, M., Perona, P.: Caltech 101. CaltechDATA. https://doi.org/10.22002/D1.20086. Accessed 15 Nov 2022.
- Amini et al. [2009] Amini, M.R., Usunier, N., Goutte, C.: Learning from multiple partially observed views-an application to multilingual text categorization. In: Proceedings of the 22nd International Conference on Neural Information Processing Systems, pp. 28–36 (2009)
- Chua et al. [2009] Chua, T.-S., Tang, J., Hong, R., Li, H., Luo, Z., Zheng, Y.: Nus-wide: a real-world web image database from national university of singapore. In: Proceedings of the ACM International Conference on Image and Video Retrieval, pp. 1–9 (2009)
- Wolf et al. [2011] Wolf, L., Hassner, T., Maoz, I.: Face recognition in unconstrained videos with matched background similarity. In: CVPR, pp. 529–534 (2011)
- Li et al. [2017] Li, Z., Tang, J., He, X.: Robust structured nonnegative matrix factorization for image representation. IEEE Trans. Neural Netw. Learn. Syst. 29(5), 1947–1960 (2017)
- Hubert and Arabie [1985] Hubert, L., Arabie, P.: Comparing partitions. J. Classif. 2(1), 193–218 (1985)
- [44] Qian, H.: Counting the Floating Point Operations (FLOPS). MATLAB Central File Exchange. https://www.mathworks.com/matlabcentral/fileexchange/50608-counting-the-floating-point-operations-flops. Accessed 15 Jul 2024.
- Attouch et al. [2013] Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward–backward splitting, and regularized gauss–seidel methods. Math. Program. 137(1-2), 91–129 (2013)