Fast and Efficient Matching Algorithm with Deadline Instances
The online weighted matching problem is a fundamental problem in machine learning due to its numerous applications. Despite many efforts in this area, existing algorithms are either too slow or don’t take (the longest time a node can be matched) into account. In this paper, we introduce a market model with first. Next, we present our two optimized algorithms (FastGreedy and FastPostponedGreedy) and offer theoretical proof of the time complexity and correctness of our algorithms. In FastGreedy algorithm, we have already known if a node is a buyer or a seller. But in FastPostponedGreedy algorithm, the status of each node is unknown at first. Then, we generalize a sketching matrix to run the original and our algorithms on both real data sets and synthetic data sets. Let denote the relative error of the real weight of each edge. The competitive ratio of original Greedy and PostponedGreedy is and respectively. Based on these two original algorithms, we proposed FastGreedy and FastPostponedGreedy algorithms and the competitive ratio of them is and respectively. At the same time, our algorithms run faster than the original two algorithms. Given nodes in , we decrease the time complexity from to .
1 Introduction
The online weighted matching problem is a fundamental problem with numerous applications, e.g. matching jobs to new graduates [14], matching customers to commodities [2], matching users to ads [34]. Motivated by these applications, researchers have spent decades designing algorithms to solve this problem [25, 38, 30, 36, 37, 3, 12, 19, 48, 35]. Let denote the number of items that can be very large in real-world settings. For example, TikTok pushes billions of advertisements every day. Thus, it is necessary to find a method to solve this matching problem quickly. Finding the maximum weight is one of the processes of this method. Our goal is to provide faster algorithms to solve the online weighted matching problem with by optimizing the part of finding the maximum weight.
In a real-world setting, the weight of the edge between each pair of nodes can show the relationship between two nodes (for example, the higher the weight is, the more likely the buyer wants to buy the product). Each node may have multiple entries to describe its attribute, such as the times of searching for a specific kind of merchandise. And there might exist a time limit called to confine the longest time a node can be matched. For example, most meat and milk in Amazon need to be sold before it goes bad. This shows the significance of solving the online weighted matching problem with . Let be the original node dimension and denote . Sometimes the weight is already provided, but we offer a new method to calculate the weight of the edge. This helps accelerate the process of finding the maximum weight.
In this paper, we solve the online matching problem with and inner product weight matching. We introduce a sketching matrix to calculate the weight of the edge. By multiplying a vector with this matrix, we can hugely decrease the number of entries. Thus, it takes much less time to calculate the norm of the transformed vector. For nodes with entries each, we decrease the time complexity from to . In our experiment part, we also prove that the total matching value of our FastGreedy and FastPostponedGreedy is very close to Greedy and PostponedGreedy in practice, which means our approximated weight is very similar to the real weight.
1.1 Related Work
Online Weighted Bipartite Matching.
Online weighted bipartite matching is a fundamental problem studied by many researchers. [31] provided basic and classical algorithms to solve this problem. Many scientists provided the solution to this problem under various situations [30, 35, 9, 1, 10, 49, 23, 12]. Our work is different from theirs, because our model considered , and our algorithms are to times faster than the original algorithms. Moreover, we believe our optimized version is very valuable since it’s very fast and can be extended to other situations with a time limit.
Fast Algorithm via Data Structure.
Over the last few years, solving many optimization problems has boiled down to designing efficient data structures. For example, linear programming [11, 43, 6, 29, 45, 20], empirical risk minimization [32, 41], cutting plane method [27], computing John Ellipsoid [7, 46], exponential and softmax regression [33, 21, 15], integral minimization problem [28], matrix completion [22], discrepancy [17, 44, 50], training over-parameterized neural tangent kernel regression [5, 47, 50, 4, 24], matrix sensing [16, 40].
Roadmap.
In Section 2, we provide the definition and basic concepts of the model we use. We provide our two optimized algorithms and their proof of correctness in Section 3. We use experiments to justify the advantages and the correctness of our algorithms in Section 4. At last, we draw our conclusion in Section 5.
2 Preliminary
In this section, we first introduce the notations we use in this paper. Then, in Section 2.1, we give the formal definitions related to the bipartite graph. In Section 2.2, we present a useful lemma.
Notations.
We use to denote norm. For any function , we use to denote . For integer , we use to denote . For a set , we use to denote its cardinality.
2.1 Model
Now, given a bipartite graph , we start by defining matching.
Definition 2.1.
Let denote a bipartite graph with . We say is a matching if
-
•
-
•
For each vertex , there is exactly one edge in such that is one of the vertex in .
-
•
For each vertex , there is exactly one edge in such that is one of the vertex in .
Let denote a weight function. Let denote the weight of edge . We say is the weight of matching . Our goal is to make as large as possible.
Definition 2.2.
Let denote . Let denote the set of all the sellers. Let denote the set of all the buyers. Each set contains vertices indexed by . Each node arrives sequentially time . And for a seller , it can only be matched in time after it reaches the market.
Definition 2.3.
We create an undirected bipartite graph . We let denote the weight of edge between node and node .
Definition 2.4.
Let denote a matching function. For a seller , there is a buyer matched with seller if .
2.2 Useful Lemma
Here, we present a lemma from [26].
The following JL Lemma helps us to create a sketching matrix to accelerate the process of calculating the distance between two points.
Lemma 2.5 (JL Lemma, [26]).
For any of size , there exists an embedding where such that .
3 Algorithm
In this section, we present the important properties of the algorithms.
Lemma 3.1.
StandardGreedy in Algorithm 5 is a -competitive algorithm.
Proof.
We use to denote the current matching value of seller . Let denote the weight of the edge between the buyer node and -th seller node. Let be the increment of matching value when buyer arrives:
Let be the final matching value for a seller node . If we add all the increments of matching value that every buyer node brings, we will get the sum of every seller node’s matching value.
Let be the weight of the matching in StandardGreedy. Let . Let be the optimal matching weight of any matching that can be constructed. Let denote the arrival time of node . We need to do the following things to acquire the maximum of :
During the whole process, we update the value of only when . So . Since is the maximum of , we can conclude that . Therefore, and is a feasible solution.
We conclude
where the first step follows from , the second step follows from , and the last step follows from . ∎
Lemma 3.2.
Let denote the real weight of the edge between seller and buyer , and denote the approximated weight. Let denote the precision parameter. If there exists a -approximation algorithm for the online weighted matching problem, where for any seller node and buyer node , there exists a greedy algorithm with competitive ratio .
Proof.
Since and we have . Let and denote the matching weight and optimal weight of the original problem respectively. Then we define is the matching weight of another problem , and our algorithm gives the optimal weight .
Since for each edge and , we can know that Since for each edge and , we can know that Thus,
where the first step follows from , the second step follows from there exists a -approximation greedy algorithm, the third step follows from , and the last step follows from . Then we can draw our conclusion because we can replace with a new in the last step. ∎
Lemma 3.3.
If a node is determined to be a seller or a buyer with probability in StandardGreedy in Algorithm 5, then this new StandardPostponedGreedy algorithm is a -competitive algorithm.
Proof.
Let denote the weight constructed by FastPostponedGreedy algorithm. Let and denote the matching weight and optimal weight of original problem respectively.
Since the probability of a node being a seller is , we can know that
where the first step follows from the definition of , the second step follows from the probability of a node being a seller is , the third step follows from , and the last step follows from Lemma 3.1. ∎
Theorem 3.4.
For precision parameter , FastGreedy is a -competitive algorithm.
Proof.
According to Lemma 3.1, there exists a -competitive algorithm. According to Lemma 2.5, we create a sketching matrix , let and denote the real matching weight of the edge between seller node and buyer node , and denote the approximated weight of the edge between seller node and buyer node , then there will be for . Then according to Lemma 3.2, we can conclude that the competitive ratio of FastGreedy is . ∎
Theorem 3.5 (Informal version of Theorem A.1, Correctness of FastPostponedGreedy in Algorithm 3 and Algorithm 4).
FastPostponedGreedy is a -competitive algorithm.
Theorem 3.6.
Consider the online bipartite matching problem with the inner product weight, for any , , there exists a data structure FastGreedy that uses space. FastGreedy supports the following operations
-
•
Init. Given a series of offline points , a precision parameter and a failure tolerance as inputs, this data structure preprocesses in
-
•
Update. It takes an online buyer point as inputs and runs in time. Let denote the arrival time of any online point.
-
•
Query. Given a query point , the Query approximately estimates the Euclidean distances from to all the data points in time . For , it provides estimates estimates such that:
-
•
TotalWeight.It outputs the matching value between offline points and known online points in time. It has competitive ratio with probability at least .
We prove the data structure (see Algorithm 1 and Algorithm 2) satisfies the requirements of Theorem 3.6 by proving the following lemmas.
Proof.
is the dimension after transformation. Line 17 is assigning each element of the sketching matrix, and it takes time since it is a matrix. Line 23 is multiplying the sketching matrix and the vector made up of each coordinate of a node, and it will take . Since we have nodes to deal with, this whole process will take time.
After carefully analyzing the algorithm, it can be deduced that the overall running time complexity is ∎
Lemma 3.8.
Proof.
is the dimension after transformation. We call Update when a new node comes. If is a buyer node, line 9 is calling Query, which takes time. Line 10 is finding which makes maximum if that vertex can still be matched, which takes time. So, in total, the running time is
Then we will prove the second statement.
We suppose the total matching value maintains a -approximate matching before calling Update. From Lemma 3.9, we can know that after we call Query, we can get and for with probability at least. According to Lemma 3.1 and Lemma 3.2, the competitive ratio of FastGreedy is still after running Query. Therefore, the total matching value still maintains a -approximate matching with probability at least . ∎
Lemma 3.9.
Proof.
Line 17 is multiplying the sketching matrix with the vector made up of each coordinate of the new buyer node , which takes time. Line 19 is calculating the weight of edge between the new buyer node and the seller node still in the market, which takes time. Since we need to calculate for times at most, the whole process will take time. After carefully analyzing the algorithm, it can be deduced that the overall running time complexity is
According to Lemma 2.5, we create a sketching matrix , let and denote the real matching weight of the edge between seller node and buyer node , and denote the approximated weight of the edge between seller node and buyer node , then there will be for . Since the failure parameter is , for it will provide
with probability at least . ∎
Lemma 3.10 (Informal version of Lemma A.2).
Lemma 3.11 (Informal version of Lemma A.3, Space storage for FastGreedy in Algorithm 1 and Algorithm 2).
Theorem 3.12.
Consider the online bipartite matching problem with the inner product weight, for any , there exists a data structure FastPostponedGreedy that uses space. Assuming there are no offline points at first, each of the online points will be determined if it is a buyer node or a seller node when it needs to leave the market. FastPostponedGreedy supports the following operations
-
•
Init. Given a precision parameter and a failure tolerance as inputs, this data structure preprocesses in time.
-
•
Update. It takes an online point as inputs and runs in time. Let denote the arrival time of any online point. Query approximately estimates the Euclidean distances from to all the data points in time . For , it provides estimates estimates such that:
-
•
TotalWeight. It outputs the matching value between offline points and known online points in time. It has competitive ratio with probability at least .
To establish the validity of the data structure utilized in Algorithm 3 and its adherence to the conditions specified in Theorem 3.12, we provide a series of lemmas for verification. These lemmas serve as intermediate steps in the overall proof.
Proof.
is the dimension after transformation. Line 17 is assigning each element of the sketching matrix, and it takes time since it is a matrix. After carefully analyzing the algorithm, it can be deduced that the overall running time complexity is ∎
Lemma 3.14 (Informal version of Lemma A.4).
Lemma 3.15 (Informal version of Lemma A.5).
Lemma 3.16 (Informal version of Lemma A.6).
4 Experiments
After presenting these theoretical analyses, we now move on to the experiments.
















| Dataset Names | ||||
|---|---|---|---|---|
| GECRS | ||||
| Arcene | ||||
| ARBT | ||||
| REJAFADA |
Purpose. This section furnishes a systematic evaluation of our optimized algorithms’ performance using real-world data sets. We employ a sketching matrix to curtail the vector entries, thus expediting the resolution of online weighted bipartite problems amidst substantial data quantities. Detailed accounts of the synthetic data set experimentation are provided in the appendix. Here, we encapsulate the results obtained from real-world data sets:
-
•
For small enough , our algorithms demonstrate superior speed compared to their original counterparts.
-
•
All four algorithms exhibit linear escalation in running time with an increase in .
-
•
For our algorithms, the running time escalates linearly with , an effect absent in the original algorithms.
-
•
The original algorithms exhibit a linear increase in running time with , and our algorithms follow suit when and are substantially smaller compared to .
-
•
Denoting the parameter as , it is observed that the running time of all four algorithms intensifies with .
Configuration. Our computations utilize an apparatus with an AMD Ryzen 7 4800H CPU and an RTX 2060 GPU, implemented on a laptop. The device operates on the Windows 11 Pro system, with Python serving as the programming language. We represent the distance weights as . The symbol signifies the count of vectors in both partitions of the bipartite graph, thereby implying an equal quantity of buyers and sellers.
Real data sets. In this part, we run all four algorithms on real data sets from the UCI library [13] to observe if our algorithms are better than the original ones in a real-world setting.
-
•
Gene expression cancer RNA-Seq Data Set [8]: This data set is structured with samples stored in a row-wise manner. Each sample’s attributes are its RNA-Seq gene expression levels, measured via the Illumina HiSeq platform.
-
•
Arcene Data Set [18]: The Arcene data set is derived from three merged mass-spectrometry data sets, ensuring a sufficient quantity of training and testing data for a benchmark. The original features represent the abundance of proteins within human sera corresponding to a given mass value. These features are used to distinguish cancer patients from healthy individuals. Many distractor features, referred to as ’probes’ and devoid of predictive power, have been included. Both features and patterns have been randomized.
-
•
A study of Asian Religious and Biblical Texts Data Set [42]: This data set encompasses instances, each with attributes. The majority of the sacred texts in the data set were sourced from Project Gutenberg.
-
•
REJAFADA Data Set [39]: The REJAFADA (Retrieval of Jar Files Applied to Dynamic Analysis) is a data set designed for the classification of Jar files as either benign or malware. It consists of malware Jar files and an equal number of benign Jar files.
Results for Real Data Set. We run Greedy, FastGreedy, PostponedGreedy (PGreedy for shorthand in Figure 1, 2, 3, 4.) and FastPostponedGreedy (Fast PGreedy for shorthand in Figure 1, 2, 3, 4.) algorithms on GECRS, Arcene, ARBT, and REJAFADA data sets respectively. Specifically, Fig. 1a and Fig. 1b illustrate the relationship between the running time of the four algorithms and the parameters and on the GECRS data set, respectively. Similarly, Fig. 2a and Fig. 2b showcase the running time characteristics of the algorithms with respect to the parameters and on the Arcene data set. Analogously, Fig. 3a and Fig. 3b represent the relationship between the running time and parameters and on the ARBT data set. Lastly, Fig. 4a and Fig. 4b exhibit the running time variations concerning the parameters and on the REJAFADA data set. The results consistently indicate that our proposed FastGreedy and FastPostponedGreedy algorithms exhibit significantly faster performance compared to the original Greedy and PostponedGreedy algorithms when applied to real data sets. These findings highlight the superiority of our proposed algorithms in terms of efficiency when dealing with real-world data scenarios.
5 Conclusion
In this paper, we study the online matching problem with and solve it with a sketching matrix. We provided a new way to compute the weight of the edge between two nodes in a bipartite. Compared with original algorithms, our algorithms optimize the time complexity from to
Furthermore, the total weight of our algorithms is very close to that of the original algorithms respectively, which means the error caused by the sketching matrix is very small. Our algorithms can also be used in areas like recommending short videos to users. For matching nodes with many entries, the experiment result shows that our algorithms only take us a little time if parameter is small enough. We think generalizing our techniques to other variations of the matching problem could be an interesting future direction. We remark that implementing our algorithm would have carbon release to the environment.
Impact Statement
This paper aims to study the fundamental machine learning problem, namely the online weighted matching problem. There might be some social impacts resulting from this work, but we do not believe it is necessary to highlight them in this paper.
References
- ABD+ [18] Itai Ashlagi, Maximilien Burq, Chinmoy Dutta, Patrick Jaillet, Amin Saberi, and Chris Sholley. Maximum weight online matching with deadlines. CoRR, abs/1808.03526, 2018.
- ABMW [18] Ivo Adan, Ana Bušić, Jean Mairesse, and Gideon Weiss. Reversibility and further properties of fcfs infinite bipartite matching. Mathematics of Operations Research, 43(2):598–621, 2018.
- ACMP [14] Gagan Aggarwal, Yang Cai, Aranyak Mehta, and George Pierrakos. Biobjective online bipartite matching. In International Conference on Web and Internet Economics, pages 218–231. Springer, 2014.
- ALS+ [22] Josh Alman, Jiehao Liang, Zhao Song, Ruizhe Zhang, and Danyang Zhuo. Bypass exponential time preprocessing: Fast neural network training via weight-data correlation preprocessing. arXiv preprint arXiv:2211.14227, 2022.
- BPSW [21] Jan van den Brand, Binghui Peng, Zhao Song, and Omri Weinstein. Training (overparametrized) neural networks in near-linear time. In ITCS, 2021.
- Bra [20] Jan van den Brand. A deterministic linear program solver in current matrix multiplication time. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 259–278. SIAM, 2020.
- CCLY [19] Michael B Cohen, Ben Cousins, Yin Tat Lee, and Xin Yang. A near-optimal algorithm for approximating the john ellipsoid. In Conference on Learning Theory, pages 849–873. PMLR, 2019.
- CGARN+ [13] JN Cancer Genome Atlas Research Network et al. The cancer genome atlas pan-cancer analysis project. Nature genetics, 45(10):1113–1120, 2013.
- CHN [14] Moses Charikar, Monika Henzinger, and Huy L Nguyen. Online bipartite matching with decomposable weights. In European Symposium on Algorithms, pages 260–271. Springer, 2014.
- CI [21] Justin Y Chen and Piotr Indyk. Online bipartite matching with predicted degrees. arXiv preprint arXiv:2110.11439, 2021.
- CLS [19] Michael B Cohen, Yin Tat Lee, and Zhao Song. Solving linear programs in the current matrix multiplication time. In STOC, 2019.
- DFNS [22] Steven Delong, Alireza Farhadi, Rad Niazadeh, and Balasubramanian Sivan. Online bipartite matching with reusable resources. In Proceedings of the 23rd ACM Conference on Economics and Computation, pages 962–963, 2022.
- DG [17] Dheeru Dua and Casey Graff. UCI machine learning repository, 2017.
- DK [21] Christoph Dürr and Shahin Kamali. Randomized two-valued bounded delay online buffer management. Operations Research Letters, 49(2):246–249, 2021.
- [15] Yichuan Deng, Zhihang Li, and Zhao Song. Attention scheme inspired softmax regression. arXiv preprint arXiv:2304.10411, 2023.
- [16] Yichuan Deng, Zhihang Li, and Zhao Song. An improved sample complexity for rank-1 matrix sensing. arXiv preprint arXiv:2303.06895, 2023.
- DSW [22] Yichuan Deng, Zhao Song, and Omri Weinstein. Discrepancy minimization in input-sparsity time. arXiv preprint arXiv:2210.12468, 2022.
- GGBHD [04] Isabelle Guyon, Steve Gunn, Asa Ben-Hur, and Gideon Dror. Result analysis of the nips 2003 feature selection challenge. Advances in neural information processing systems, 17, 2004.
- GKS [19] Buddhima Gamlath, Sagar Kale, and Ola Svensson. Beating greedy for stochastic bipartite matching. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2841–2854. SIAM, 2019.
- GS [22] Yuzhou Gu and Zhao Song. A faster small treewidth sdp solver. arXiv preprint arXiv:2211.06033, 2022.
- GSY [23] Yeqi Gao, Zhao Song, and Junze Yin. An iterative algorithm for rescaled hyperbolic functions regression. arXiv preprint arXiv:2305.00660, 2023.
- GSYZ [23] Yuzhou Gu, Zhao Song, Junze Yin, and Lichen Zhang. Low rank matrix completion via robust alternating minimization in nearly linear time. arXiv preprint arXiv:2302.11068, 2023.
- HST+ [22] Hang Hu, Zhao Song, Runzhou Tao, Zhaozhuo Xu, and Danyang Zhuo. Sublinear time algorithm for online weighted bipartite matching. arXiv preprint arXiv:2208.03367, 2022.
- HSWZ [22] Hang Hu, Zhao Song, Omri Weinstein, and Danyang Zhuo. Training overparametrized neural networks in sublinear time. arXiv preprint arXiv:2208.04508, 2022.
- HTWZ [19] Zhiyi Huang, Zhihao Gavin Tang, Xiaowei Wu, and Yuhao Zhang. Online vertex-weighted bipartite matching: Beating 1-1/e with random arrivals. ACM Transactions on Algorithms (TALG), 15(3):1–15, 2019.
- JL [84] William B Johnson and Joram Lindenstrauss. Extensions of lipschitz mappings into a hilbert space. Contemporary mathematics, 26(189-206):1, 1984.
- JLSW [20] Haotian Jiang, Yin Tat Lee, Zhao Song, and Sam Chiu-wai Wong. An improved cutting plane method for convex optimization, convex-concave games and its applications. In STOC, 2020.
- JLSZ [23] Haotian Jiang, Yin Tat Lee, Zhao Song, and Lichen Zhang. Convex minimization with integer minima in time. arXiv preprint arXiv:2304.03426, 2023.
- JSWZ [21] Shunhua Jiang, Zhao Song, Omri Weinstein, and Hengjie Zhang. Faster dynamic matrix inverse for faster lps. In STOC, 2021.
- KMT [11] Chinmay Karande, Aranyak Mehta, and Pushkar Tripathi. Online bipartite matching with unknown distributions. In Proceedings of the forty-third annual ACM symposium on Theory of computing, pages 587–596, 2011.
- KVV [90] Richard M Karp, Umesh V Vazirani, and Vijay V Vazirani. An optimal algorithm for on-line bipartite matching. In Proceedings of the twenty-second annual ACM symposium on Theory of computing, pages 352–358, 1990.
- LSZ [19] Yin Tat Lee, Zhao Song, and Qiuyi Zhang. Solving empirical risk minimization in the current matrix multiplication time. In Conference on Learning Theory (COLT), pages 2140–2157. PMLR, 2019.
- LSZ [23] Zhihang Li, Zhao Song, and Tianyi Zhou. Solving regularized exp, cosh and sinh regression problems. arXiv preprint, 2303.15725, 2023.
- M+ [13] Aranyak Mehta et al. Online matching and ad allocation. Foundations and Trends® in Theoretical Computer Science, 8(4):265–368, 2013.
- MCF [13] Reshef Meir, Yiling Chen, and Michal Feldman. Efficient parking allocation as online bipartite matching with posted prices. In AAMAS, pages 303–310, 2013.
- MJ [13] Andrew Mastin and Patrick Jaillet. Greedy online bipartite matching on random graphs. arXiv preprint arXiv:1307.2536, 2013.
- MNP [06] Adam Meyerson, Akash Nanavati, and Laura Poplawski. Randomized online algorithms for minimum metric bipartite matching. In Proceedings of the seventeenth annual ACM-SIAM symposium on Discrete algorithm, pages 954–959, 2006.
- NR [17] Krati Nayyar and Sharath Raghvendra. An input sensitive online algorithm for the metric bipartite matching problem. In 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS), pages 505–515. IEEE, 2017.
- PLF+ [19] Ricardo Pinheiro, Sidney Lima, Sérgio Fernandes, Edison Albuquerque, Sergio Medeiros, Danilo Souza, Thyago Monteiro, Petrônio Lopes, Rafael Lima, Jemerson Oliveira, et al. Next generation antivirus applied to jar malware detection based on runtime behaviors using neural networks. In 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design (CSCWD), pages 28–32. IEEE, 2019.
- QSZ [23] Lianke Qin, Zhao Song, and Ruizhe Zhang. A general algorithm for solving rank-one matrix sensing. arXiv preprint arXiv:2303.12298, 2023.
- QSZZ [23] Lianke Qin, Zhao Song, Lichen Zhang, and Danyang Zhuo. An online and unified algorithm for projection matrix vector multiplication with application to empirical risk minimization. In AISTATS, 2023.
- SF [19] Preeti Sah and Ernest Fokoué. What do asian religions have in common? an unsupervised text analytics exploration, 2019.
- Son [19] Zhao Song. Matrix theory: optimization, concentration, and algorithms. The University of Texas at Austin, 2019.
- SXZ [22] Zhao Song, Zhaozhuo Xu, and Lichen Zhang. Speeding up sparsification using inner product search data structures. arXiv preprint arXiv:2204.03209, 2022.
- SY [21] Zhao Song and Zheng Yu. Oblivious sketching-based central path method for linear programming. In International Conference on Machine Learning, pages 9835–9847. PMLR, 2021.
- SYYZ [22] Zhao Song, Xin Yang, Yuanyuan Yang, and Tianyi Zhou. Faster algorithm for structured john ellipsoid computation. arXiv preprint arXiv:2211.14407, 2022.
- SZZ [21] Zhao Song, Lichen Zhang, and Ruizhe Zhang. Training multi-layer over-parametrized neural network in subquadratic time. arXiv preprint arXiv:2112.07628, 2021.
- WW [15] Yajun Wang and Sam Chiu-wai Wong. Two-sided online bipartite matching and vertex cover: Beating the greedy algorithm. In International Colloquium on Automata, Languages, and Programming, pages 1070–1081. Springer, 2015.
- XZD [22] Gaofei Xiao, Jiaqi Zheng, and Haipeng Dai. A unified model for bi-objective online stochastic bipartite matching with two-sided limited patience. In IEEE INFOCOM 2022-IEEE Conference on Computer Communications, pages 1079–1088. IEEE, 2022.
- Zha [22] Lichen Zhang. Speeding up optimizations via data structures: Faster search, sample and maintenance. Master’s thesis, Carnegie Mellon University, 2022.
Appendix
Roadmap.
In Section A, we also provide more proof, such as Theorem 3.5, Lemma 3.11 and Lemma 3.17 which prove the correctness of FastPostponedGreedy, the space storage of FastGreedy, and the space storage of FastPostponedGreedy respectively.
In Section B, to illustrate the impact of various parameters, namely , , , and , we present additional experimental results. The parameters are defined as follows: is the node count, is the original node dimension, is the dimension after transformation, and is the maximum matching time per node (referred to as the deadline).
Appendix A Missing Proofs
In Section A.1, we provide the proof for Theorem 3.5. In Section A.2, we provide the proof for Lemma 3.10. In Section A.3, we provide the proof for Lemma 3.11. In Section A.4, we provide the proof for Lemma 3.14. In Section A.5, we provide the proof for Lemma 3.15. In Section A.6, we provide the proof for Lemma 3.16. In Section A.7, we provide the proof for Lemma 3.17.
A.1 Proof of Theorem 3.5
Theorem A.1 (Formal version of Theorem 3.5, Correctness of FastPostponedGreedy in Algorithm 3 and Algorithm 4).
FastPostponedGreedy is a -competitive algorithm.
Proof.
According to Lemma 3.3, there exists a -competitive algorithm. According to Lemma 2.5, we create a sketching matrix , let and denote the real matching weight of the edge between seller node and buyer node , and denote the approximated weight of the edge between seller node and buyer node , then there will be for . Based on the implications of Lemma 3.2, we can confidently assert that the competitive ratio of FastPostponedGreedy is . ∎
A.2 Proof of Lemma 3.10
Lemma A.2 (Formal version of Lemma 3.10).
Proof.
Line 25 is returning the total matching value which has already been calculated after calling Update, which requires time.
The analysis demonstrates that the overall running time complexity is constant, denoted as .
According to Lemma 3.8, we can know that the total weight maintains a -approximate matching after calling Update. So when we call TotalWeight, it will output a -approximate matching if it succeeds.
The probability of successful running of Update is at least , so the probability of success is at least. ∎
A.3 Proof of Lemma 3.11
Lemma A.3 (Formal version of Lemma 3.11, Space storage for FastGreedy in Algorithm 1 and Algorithm 2 ).
Proof.
is the dimension after transformation. In FastGreedy, we need to store a sketching matrix, multiple arrays with elements, two point sets containing nodes with dimensions, and a point set containing nodes with dimensions. The total storage is
∎
A.4 Proof of Lemma 3.14
Lemma A.4 (Formal version of Lemma 3.14).
Proof.
is the dimension after transformation. We call Update when a new node comes. Line 3 is multiplying the sketching matrix and the vector made up of each coordinate of a node, and it will take time. Line 25 is calling Query, which requires time. Line 26 is finding which makes maximum if that vertex can still be matched, which requires time.
So, in total, the running time is
Then we will prove the second statement.
We suppose the total matching value maintains a -approximate matching before calling Update. From Lemma 3.15, we can know that after we call Query, we can get and for with probability at least. According to Lemma 3.3 and Lemma 3.2, the competitive ratio of FastPostponedGreedy is still after running Query. Therefore, the total matching value still maintains a -approximate matching with probability at least . ∎
A.5 Proof of Lemma 3.15
Lemma A.5 (Formal version of Lemma 3.15).
Proof.
Line 33 is calculating the weight of the edge between the buyer node copy and the seller node still in the market, which requires time. Since we need to calculate for times at most, the whole process will take time.
So, in total, the running time is
According to Lemma 2.5, we create a sketching matrix , let and denote the real matching value of seller node when buyer node comes, and denote the approximated matching value of seller node when buyer node comes, then there will be for .
Since the failure parameter is , for it will provide
with probability at least . ∎
A.6 Proof of Lemma 3.16
Lemma A.6 (Formal version of Lemma 3.16).
Proof.
Line 39 is returning the total matching value which has already been calculated after calling Update, which requires time.
The analysis demonstrates that the overall running time complexity is constant, denoted as .
According to Lemma 3.14, we can know that the total weight maintains a -approximate matching after calling Update. So when we call TotalWeight, it will output a -approximate matching if it succeeds.
The probability of successful running of Update is at least , so the probability of success is at least. ∎
A.7 Proof of Lemma 3.17
Lemma A.7 (Formal version of Lemma 3.17, Space storage for FastPostponedGreedy in Algorithm 3 and Algorithm 4).
The space storage for FastPostponedGreedy is .
Proof.
is the dimension after transformation. In FastPostponedGreedy, we need to store a sketching matrix, multiple arrays with elements, a point set containing nodes with dimensions, and two point sets containing nodes with dimensions. The total storage is
∎
Appendix B More Experiments
Data Generation. At the beginning, we generate random vectors of for seller set and for buyer set. Each vector follows the subsequent procedure:
-
•
Each coordinate of the vector is selected uniformly from the interval .
-
•
Normalization is applied to each vector such that its norm becomes .
Given that the vectors are randomly generated, the order of their arrival does not affect the experimental results. We define that -th vector of a set in each set comes at time .
In the previous algorithm, for -th vector of the seller set and -th vector of the buyer set, we define the weights between the two nodes to be , which requires time.
In the new algorithm, we choose a sketching matrix whose entry is sampled from . We have already known at the beginning, and we precompute for . In each iteration, when a buyer comes, we compute and use to estimate the weight. This takes time. After we calculate the weight, we need to find the seller to make the weight between it and the current buyer maximum.
Parameter Configuration. In our experimental setup, we select the following parameter values: , , and as primary conditions.












Results for Synthetic Data Set. To assess the performance of our algorithms, we conducted experiments comparing their running time with that of the original algorithms. We decide that the -th node of a set comes at -th iteration during our test. Fig. 5a and Fig. 5b illustrate that our algorithms consistently outperformed the original algorithms in terms of running time at each iteration. Specifically, our algorithms exhibited running times equivalent to only and of the original algorithms, respectively.
Additionally, we analyzed the running time of each algorithm per iteration. Fig. 5a and Fig. 5b depict the running time of each algorithm during per iteration. The results demonstrate that our algorithms consistently outperformed the original algorithms in terms of running time per iteration. the maximum matching time per node (referred to as the deadline). The is randomly chosen from . In this case, the of original algorithms is . The running time of per iteration increases as the number of iterations increases until it reaches . This is because all nodes are required to remain in the market for iterations and are not matched thereafter.
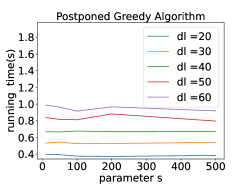
Furthermore, we investigated the influence of the parameter while keeping the other parameters constant. Fig. 6a and Fig. 6b illustrate that our algorithms consistently outperformed the original algorithms when . Additionally, the running time of each algorithm exhibited a linear increase with the growth of , which aligns with our initial expectations.
We also examined the impact of the parameter by varying its value while keeping the other parameters constant. Fig. 6a and Fig. 6b reveal that does not significantly affect the running time of the original algorithms but does impact the running time of our algorithms. Notably, our algorithms demonstrate faster performance when is smaller.
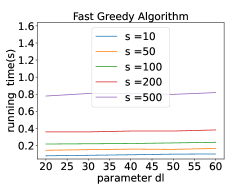
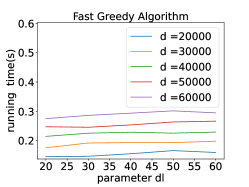
To evaluate the influence of the parameter , we varied its value while running all four algorithms. Throughout our tests, we observed that the impact of was considerably less pronounced compared to and . Consequently, we set to a sufficiently large value relative to and . As shown in Fig. 7a and Fig. 7b, indicate that does not significantly affect the running time of our algorithms, but it does have a considerable influence on the running time of the original algorithms.
We conducted experiments to assess the influence of the parameter while keeping the other parameters constant. was selected from the interval as choosing values outside this range would render the parameter irrelevant since all nodes would remain in the market throughout the entire process. Fig. 7a and Fig. 7b show that our algorithms are faster than original algorithms when .As the value of increased, the running time of all algorithms correspondingly increased. This observation highlights the impact of on the overall execution time of the algorithms.
| Algorithms | |||||
|---|---|---|---|---|---|
| Greedy | |||||
| FGreedy | |||||
| PGreedy | |||||
| FPGreedy |
Table 2 shows the total weight of each algorithm when changes. Since Greedy and PostponedGreedy don’t depend on , the total weight of them doesn’t change while changes. We can see that the total weight of each optimized algorithm is very close to that of each original algorithm respectively, which means the relative error of our algorithm is very small in practice. As increases, the difference between the total weight of each optimized algorithm and each original algorithm also becomes smaller. And the total weight of FastGreedy is times of that of FastPostponedGreedy. These empirical results match our theoretical analysis. Parameter can’t affect the total weight of each algorithm. The competitive ratio of FastGreedy and FastPostponedGreedy is and respectively.
Optimal Usage of Algorithms. The results presented above demonstrate that our algorithms exhibit significantly faster performance when the values of , , and are sufficiently large. Additionally, reducing the value of leads to a decrease in the running time of our algorithms. Our proposed algorithms outperform the original algorithms, particularly when the value of is extremely large. Consequently, our algorithms are well-suited for efficiently solving problems involving a large number of nodes with substantial data entries.
More Experiments. To assess the impact of parameter in the presence of other variables, we varied the values of the remaining parameters and executed all four algorithms. As illustrated in Fig. 8, Fig. 9, Fig. 10, and Fig. 11, it is evident that the running time consistently increases with an increase in , regardless of the values assigned to the other parameters.
To investigate the impact of parameter in the presence of other variables, we varied the values of the remaining parameters and executed all four algorithms.Fig. 12 and Fig. 13 demonstrate that the value of is independent of the original algorithms. Conversely, Fig. 14 and Fig. 15 indicate that the running time of our algorithms increases with an increase in , irrespective of the values assigned to the other parameters.
To examine the impact of parameter in the presence of other variables, we varied the values of the remaining parameters and executed all four algorithms. The results depicted in Fig. 16, Fig. 17, Fig. 18 and Fig. 19 reveal that the running time of both the original and our proposed algorithms increases with an increase in , regardless of the values assigned to the other parameters.
To assess the impact of parameter in the presence of other variables, we varied the values of the remaining parameters and executed all four algorithms. As evident from Fig. 20, Fig. 21, Fig. 22, and Fig. 23, the running time consistently increases with an increase in , regardless of the values assigned to the other parameters.