FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
Abstract
Ensuring safe, comfortable, and efficient navigation is fundamental to the development and reliability of autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving situations, they often struggle with rare, long-tail events. Recent advancements in large language models (LLMs) bring improved reasoning capabilities, yet their high computational demands complicate real-time decision-making and precise planning for autonomous vehicles. In this paper, we introduce FASIONAD, an innovative dual-system framework inspired by the cognitive model ”Thinking, Fast and Slow.” The fast system efficiently manages routine navigation tasks through rapid, data-driven path planning, while the slow system addresses complex reasoning and decision-making in unfamiliar or challenging scenarios. A dynamic switching mechanism, guided by score distribution and feedback, allows seamless transitions between fast and slow systems. Visual prompts from the fast system facilitate human-like reasoning in the slow system, which, in turn, supplies high-quality feedback to enhance the fast system’s decision-making. To evaluate our approach, we introduce a new benchmark derived from the nuScenes dataset, designed to distinguish between fast and slow scenarios. FASIONAD sets a new standard on this benchmark, pioneering a framework that differentiates fast and slow cognitive processes in autonomous driving. This dual-system approach offers a promising direction for creating more adaptive and human-like autonomous driving systems.
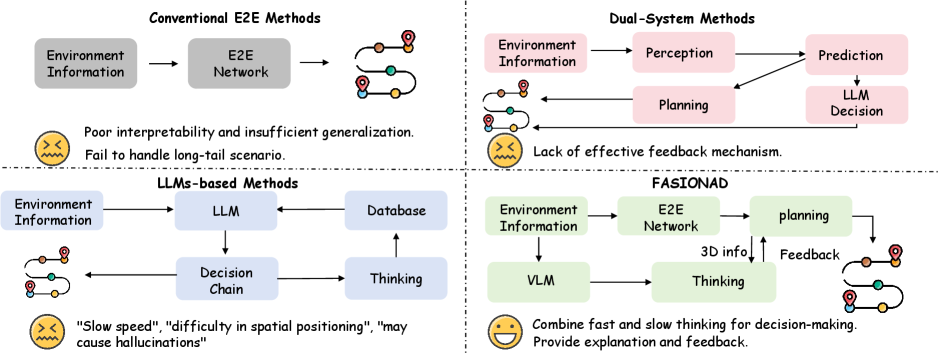
1 Introduction
Autonomous driving has the potential to transform transportation by enhancing efficiency, reducing human workload, and minimizing accidents [26]. Traditional autonomous driving systems typically adopt a modular design, with separate modules for perception, prediction, planning [26], and control. However, these systems struggle with adaptability in dynamic and complex environments, and face challenges in addressing long-tail problems and redundancy [63, 46], which limits their scalability and applicability.
To address these limitations, End-to-End (E2E) learning methods, such as Imitation Learning (IL) [39, 23, 24, 9, 57] and Reinforcement Learning (RL) [27, 8], have been widely explored. However, IL methods are prone to covariate shift, leading to a lack of robustness in critical scenarios [42, 32], even with improvements like Learning from Mistakes (LfM) [2]. RL methods, while effective in simulations, face significant safety issues and encounter challenges in real-world applications, particularly due to difficulties in reward design and sim-to-real transfer [11]. Recent works such as DriveCoT [55] and DriveInsight [28] aim to improve interpretability but are often time-consuming to generalize effectively across different scenarios.
With the recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs), researchers have begun to explore their applications in autonomous driving, including manipulation tasks [50], spatial grounding [48], and skill learning [49]. However, despite these advancements [47, 56, 45, 58], LLMs and VLMs still face challenges in spatial grounding and real-time decision-making [60]. Balancing safety and performance remains a critical issue [54], which restricts their broader application in complex, real-world autonomous driving environments.
Inspired by the dual-process theory from psychology, particularly the concepts outlined in Thinking, Fast and Slow [4], we introduce FASIONAD, an innovative adaptive feedback framework that seamlessly integrates fast and slow thinking methodologies. he framework employs fast thinking for routine driving tasks and leverages VLMs to handle the diverse complexities inherent in autonomous driving.
Within FASIONAD, we design a sophisticated switching mechanism that evaluates the complexity of each driving situation to determine whether to rely on the Fast Pathway or to engage the Slow Pathway. This mechanism is crucial for enabling adaptive, context-aware decision-making. By dynamically shifting between fast and slow pathways, FASIONAD ensures high responsiveness while maintaining safety in constantly changing environments.
We evaluate FASIONAD on challenging benchmarks, including nuScenes and CARLA. Experimental results demonstrate that FASIONAD outperforms state-of-the-art methods in both navigation success and safety. By enabling deeper situational understanding, intent analysis, and adaptive responses, FASIONAD marks a significant advancement in autonomous navigation. The main contributions of this work are as follows:
-
•
We propose FASIONAD, an adaptive feedback framework for autonomous driving that combines fast and slow thinking to address the adaptability limitations of traditional systems in dynamic environments.
-
•
We introduce a novel approach that simulates human decision-making, combining rapid strategy generation with VLM-based feedback evaluation to achieve optimal performance and flexibility in dynamic environments, addressing the limitations of pure end-to-end methods.
-
•
Through extensive experiments on nuScenes and CARLA, we demonstrate that FASIONAD significantly enhances navigation success and safety, outperforming state-of-the-art methods by leveraging the principles of fast and slow thinking.
2 Related Work
2.1 Learning-based Planning
Navigating dynamic and complex environments remains a central challenge in autonomous driving. Traditional methods often rely on modular pipelines that separate perception, planning, and control [53, 5], enabling targeted optimizations at each stage. However, these approaches can struggle with efficient information flow across modules, particularly in handling novel or unpredictable situations [19]. More recent advances have leaned towards end-to-end learning approaches, mapping raw sensor inputs directly to control commands [3, 12]. This trend is exemplified by GenAD [62] and VAD [24], which integrate Bird’s Eye View (BEV) representations with predictive models to navigate complex urban scenarios. Despite these advances, end-to-end methods often face challenges in interpretability and robustness when handling out-of-distribution samples [7, 16]. Hybrid approaches that combine learning-based perception with classical rule-based planning have been explored to address these gaps. Furthermore, models like InterFuser and other transformer-based methods [44] have shown promise in leveraging multi-modal inputs for more refined decision-making. Recently, RL-GPT [33] introduced a hierarchical framework that integrates reinforcement learning with task-specific code policies, achieving efficient decision-making in complex environments.
2.2 Vision-Language Models for Reasoning
VLMs have recently gained traction for enhancing perception in autonomous driving systems, providing a richer semantic understanding of complex scenes [40, 1]. These models align visual inputs with textual data, enabling more comprehensive scene interpretations, as seen in CLIP [40] and Flamingo [1]. Applications of VLMs in autonomous driving have focused on providing detailed scene descriptions and inferring intent [29, 31]. For instance, Video-LLaVA [31] and DrivingCLIP [29] enhance situational awareness through multi-turn dialogue capabilities and semantic scene understanding. The integration of VLMs into autonomous driving extends beyond perception, facilitating reasoning processes in dynamic environments. By interpreting interactions among traffic agents and extracting high-level semantic features, VLMs have been shown to improve decision-making in complex traffic scenarios [17]. The FASIONAD framework advances these efforts by leveraging VLMs within its Thinking Module, using them not only for perception but also for reasoning during forward and backward planning.
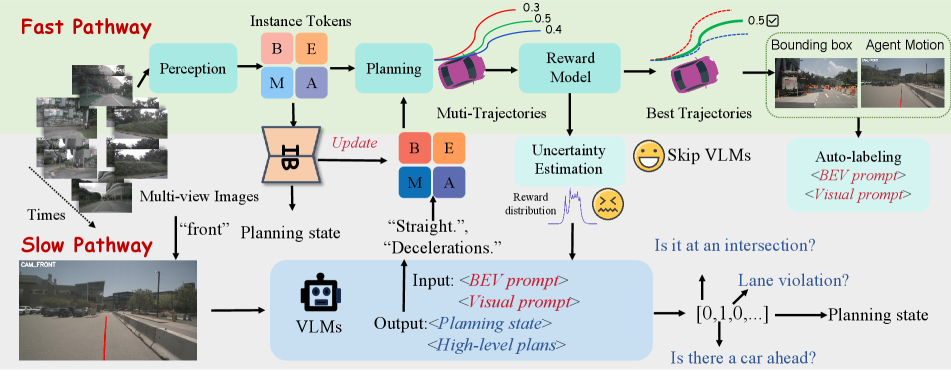
3 Methodology
3.1 Overview
As depicted in Fig. 2, the FASIONAD framework employs a dual-pathway architecture: a Fast Pathway for rapid, real-time responses, and a Slow Pathway for comprehensive analysis and complex decision-making in uncertain or challenging driving scenarios. In the Fast Pathway, given a set of multi-view images and high-level navigation commands , the model generates a sequence of waypoints , where each waypoint represents the predicted Bird’s Eye View (BEV) position of the ego vehicle at time . This pathway can be formulated as:
| (1) |
In contrast, the Slow Pathway processes only the multi-view images to generate a planning state and high-level meta-actions , providing a more detailed assessment and strategic guidance for decision-making in complex scenarios. This pathway complements the Fast Pathway by enabling deeper analysis in uncertain or challenging conditions. The Slow Pathway is represented as:
| (2) |
To coordinate Fast and Slow Pathways, we introduce uncertainty-based waypoints prediction and trajectory rewards. This mechanism optimizes responsiveness versus accuracy by dynamically activating either pathway based on environmental context and complexity, enabling both immediate reactions and thorough analysis when needed. Details of the Switch Mechanism are provided in Section 3.4.
3.2 Fast Pathway
3.2.1 Waypoints Prediction and Reward Evaluation
Trajectory Generator. The trajectory generator outputs waypoint predictions , with each waypoint representing a spatial position in BEV coordinates. To capture interactions among traffic participants, we adopt a generative framework inspired by GenAD [61], modeling trajectory prediction as a future trajectory generation problem.
Reward Model. The model generates candidate trajectories , where each trajectory represents a sequence of waypoints over a time horizon . Here, is the number of navigation commands, and represents the top- sampled multi-modal trajectories. Each trajectory is assigned a reward by the reward model , which integrates factors such as safety, comfort, efficiency, and economic considerations:
| (3) |
where are weights determining the relative importance of each factor.
3.3 Slow Pathway
In complex scenarios, accurate interpretation of environmental factors is vital for safe decision-making. The Slow Pathway emulates human-like reasoning to infer context and predict future actions, similar to human drivers.This section discusses how VLMs can support such reasoning, with a focus on Question-Answering (QA) design in Section 3.3.1 and data generation in Section 3.3.2.
3.3.1 Planning-Oriented QA
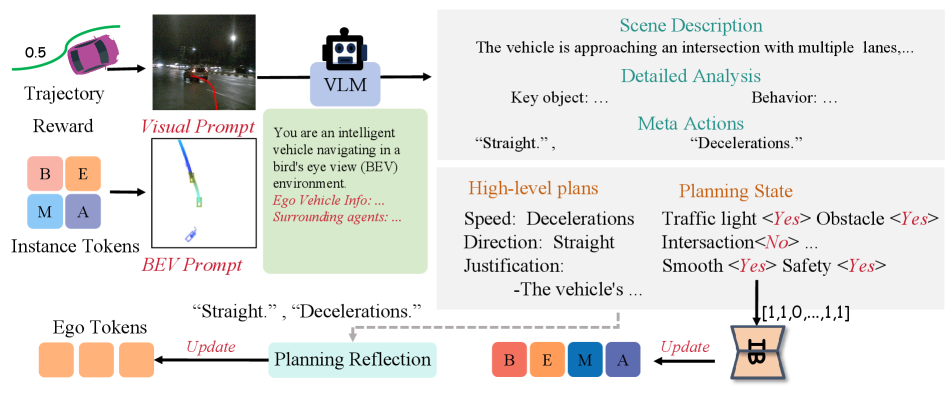
We propose a series of decision-oriented Question-Answering (QA) tasks to facilitate human-like reasoning in autonomous driving systems. Fig. 3 illustrates the types of QA questions.
Our study addresses five key aspects essential for enhancing the robustness of autonomous driving systems by improving the system’s understanding and replication of human-like driving behaviors:
Scene Analysis. This involves evaluating environmental factors such as weather conditions (e.g., sunny, rainy, snowy), time of day (morning, afternoon, evening, night), traffic density (light or heavy), and road conditions (wet, dry, icy). A thorough analysis of these factors enables the system to interpret the broader context, influencing critical decisions such as speed and maneuver selection.
Traffic Sign Recognition. This task focuses on recognizing and interpreting various traffic signs, including traffic lights, stop signs, yield signs, and speed limits. Accurate sign recognition is crucial for regulatory compliance and safety, forming a fundamental component of human-like driving behavior.
Key Object Recognition and Behavior Analysis. This involves identifying and analyzing key objects in the environment, such as vehicles, pedestrians, cyclists, and animals, and predicting their future behavior based on past movements. Accurate recognition and behavior prediction are vital for anticipating hazards and enabling proactive decision-making to avoid collisions.
Planning State. Planning-related states are represented as -dimensional binary vectors that describe the current environmental context relevant to decision-making. This structured representation supports high-level planning by allowing the system to prioritize actions, optimize routing, and improve decision-making. Detailed state representations are provided in the supplementary materials.
High-Level Planning and Justification. This aspect involves formulating high-level plans for actions such as route selection, lane changes, and merging maneuvers, while considering long-term goals and constraints. By justifying these decisions, the system ensures that its actions are both safe and efficient, aligning with overarching driving objectives. This component is critical for replicating human-like decision-making in autonomous systems.
3.3.2 Data Collection and Auto-labeling
To generate these Question-Answering (QA) tasks, we utilize outputs from the Fast Pathway, including 3D object detection boxes and tracking trajectories, for automatic annotation. Additionally, we leverage Large Vision-Language Models (LVLMs), such as Qwen, to produce descriptive QAs that closely align with the observed scene and its elements. Inspired by the cognitive demands of driving decisions, we introduce two types of prompts to enhance QA generation: a visual prompt, which aids in interpreting visual cues and scene elements similarly to human perception, and a BEV prompt, which provides a top-down view of the environment to improve the understanding of spatial relationships and agent interactions.
To address the variability in VLMs outputs, which may contain extraneous or irrelevant information, we employ a regularization strategy inspired by few-shot learning in natural language processing (NLP). However, unlike general NLP applications, autonomous driving requires high reliability and consistency. Therefore, we refine the VLM outputs through a simplification process, ensuring that feedback to the Fast Pathway planner remains concise and effective, ultimately supporting the generation of new, accurate trajectories.
The slow pathway pipeline can be formulated as follows:
| (5) |
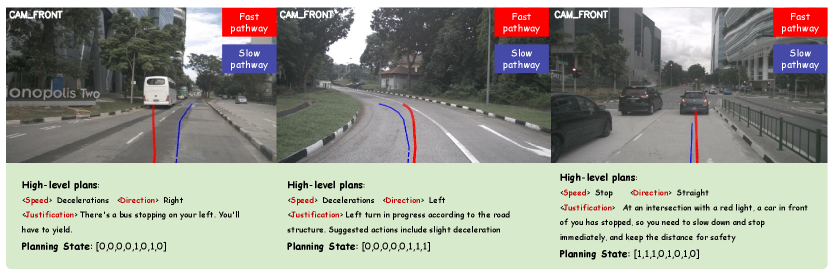
Visual Prompt. In typical autonomous driving systems, waypoints generated by high-level planners are numerical outputs [23, 24, 9]. However, VLMs are not inherently designed to process numerical data in this context. Human decision-making in complex driving scenarios relies more on intuitive reasoning and visual cues than on direct numerical computation. To bridge this gap, we integrate trajectory visual prompts into our slow-path planning. Specifically, we project the waypoints generated by the fast-path planner onto the front-view camera, creating a visual representation of the trajectory. This visual approximation of the planned path facilitates human-like reasoning processes, enabling more intuitive evaluation and modification of decisions, which leads to more reliable and effective high-level plans.
BEV Prompt. To further enhance the system’s spatial understanding, particularly in 3D space and relative positioning, we introduce a BEV prompt. Based on the vehicle’s BEV coordinate system, this prompt provides a clear depiction of spatial relationships and dynamic interactions between the ego vehicle and surrounding agents, represented as .
Planning State and High-Level Plans. Planning states are represented as binary vectors and are determined through a Yes/No decision pipeline. Additionally, we propose a high-level plans encoder, denoted as , which transforms high-level decisions from the VLM into meta-action features . Since high-level plans can be decomposed into structured sets of meta-actions, the encoder performs a one-to-one mapping from these meta-actions to their corresponding meta-action features using a set of learnable embeddings , where represents the number of meta-actions. Finally, the planning state and meta-action features are input into the Fast Pathway to regenerate the trajectory, providing feedback that mimics human-like decision-making.
Reward-Guided VLM Tuning. Traditional approaches with LLMs rely primarily on auto-regressive learning. In contrast, our approach combines auto-regressive learning with Maximum Likelihood Estimation (MLE) loss to tune the VLM. To improve prediction accuracy in complex scenarios, we introduce a reward-guided regression loss. Unlike InstructGPT [37], which depends on human feedback for reinforcement learning fine-tuning, our system utilizes automatically generated guidance. The objective is to replicate the planning state and high-level plans, which are directly accessible in our task setting. Thus, we define the ground truth as .
Since the GPT-based model typically applies supervision at the token level, whereas the entire sequence is meaningful for regression, we incorporate Proximal Policy Optimization (PPO) [43] with masking to apply supervision more effectively. The tuning loss, denoted as , is computed as a reward within the policy gradient framework:
| (6) |
where represents the predicted token at time step , and is the reward function for waypoint prediction in the Fast Pathway. The final training loss combines the standard language loss and the reward-guided loss:
| (7) |
3.4 FAst and Slow Fusion Autonomous Driving
3.4.1 Uncertainty Estimation and Decision Mechanism
To effectively navigate dynamic and unpredictable environments, estimating uncertainty in waypoint predictions is essential, as it allows the system to adapt its decision-making based on prediction reliability. To handle outliers and model uncertainty in waypoint predictions, we employ a Laplace distribution:
| (8) |
where denotes the predicted reward at time , is the scale parameter, and represents the model parameters. This distribution’s heavy tails make it robust to outliers, which is advantageous in dynamic driving environments.
The Laplace distribution’s heavy tails and sharp peak make it robust to outliers and effective for uncertainty estimation in dynamic driving environments. Based on the reward ( R ) and estimated uncertainty, the system chooses between the Fast Pathway for immediate navigation (when ( R ) exceeds a threshold and uncertainty is low) or the Slow Pathway for detailed analysis.
3.4.2 Feedback with Information Bottleneck
Driving environments often contain significant irrelevant or noisy information that does not contribute to planning. To address this, we apply the information bottleneck principle [18] to distill only the information relevant to decision-making. This approach ensures that the model prioritizes critical features for navigation, effectively minimizing the influence of extraneous data.
To align instance-aware features with , we employ an MLP that maps to a one-dimensional vector . The knowledge distillation process minimizes the following objective:
| (9) |
where is the probability distribution over the VLM-derived vector given , and encodes instance-aware features from the current state. Here, is a prior distribution on , and is a regularization parameter.
3.4.3 Feedback Fusion Mechanism
The Slow Pathway, activated by reward signals and uncertainty, enables selective deep analysis of essential VLM-derived features. Integration occurs through cross-attention between learnable embeddings and the ego token , where queries as key-value pairs. This captures contextual dependencies, and the resulting fused state feeds into the Fast Pathway for trajectory planning, mimicking human decision-making in complex driving scenarios.
4 Experiments
In this section, we evaluate the performance of our proposed FASIONAD framework on standard autonomous driving benchmarks. Specifically, we assess the system’s ability to navigate complex, dynamic environments while adhering to strict safety constraints. We focus on two widely used datasets: CARLA [15] and nuScenes [6], which provide realistic driving scenarios and varying environmental conditions.
4.1 Experimental Setup
Our evaluation for FASIONAD encompasses both open-loop and closed-loop performance metrics. For open-loop assessment, we utilize the nuScenes dataset, which provides comprehensive annotated data from urban driving scenarios. This evaluation focuses on measuring the policy’s similarity to expert demonstrations through L2 distance and collision rate metrics. We prioritize these open-loop measurements in our ablation studies due to their computational efficiency and consistency in results. The closed-loop evaluation employs the CARLA Closed-loop Town05 Short Benchmark, which features challenging scenarios including narrow streets, dense traffic, and frequent intersections. The primary performance indicators are the Driving Score (DS)—calculated as the product of Route Completion (RC) and Infraction Score—and Route Completion itself. To ensure fair comparison with existing methods, we implement a rule-based wrapper around the learning-based policy, following standard practice in benchmark evaluations. This wrapper helps minimize infractions during testing.
| Method | Input | L2 (m) | Collision Rate (%) | FPS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1s | 2s | 3s | Avg | 1s | 2s | 3s | Avg | |||
| IL[41] | LiDAR | 0.44 | 1.15 | 2.47 | 1.35 | 0.08 | 0.27 | 1.95 | 0.77 | - |
| NMP[59] | LiDAR | 0.53 | 1.25 | 2.67 | 1.48 | 0.04 | 0.12 | 0.87 | 0.34 | - |
| FF[21] | LiDAR | 0.55 | 1.20 | 2.54 | 1.43 | 0.06 | 0.17 | 1.07 | 0.43 | - |
| EO[25] | LiDAR | 0.67 | 1.36 | 2.78 | 1.60 | 0.04 | 0.09 | 0.88 | 0.33 | - |
| ST-P3 [22] | Camera | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 | 1.6 |
| UniAD [23] | Camera | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 | 0.31 | 1.8 |
| OccNet [52] | Camera | 1.29 | 2.13 | 2.99 | 2.14 | 0.21 | 0.59 | 1.37 | 0.72 | 2.6 |
| VAD-Tiny [24] | Camera | 0.60 | 1.23 | 2.06 | 1.30 | 0.31 | 0.53 | 1.33 | 0.72 | 6.9† |
| VAD-Base [24] | Camera | 0.54 | 1.15 | 1.98 | 1.22 | 0.04 | 0.39 | 1.17 | 0.53 | 3.6† |
| GenAD [61] | Camera | 0.36 | 0.83 | 1.55 | 0.91 | 0.06 | 0.23 | 1.00 | 0.43 | 6.7† |
| DriveVLM* [51] | Camera | 0.15 | 0.29 | 0.48 | 0.31 | 0.05 | 0.08 | 0.17 | 0.10 | 6.7† |
| FASIONAD *(Ours) | Camera | 0.13 | 0.26 | 0.45 | 0.28 | 0.05 | 0.08 | 0.15 | 0.09 | 6.9† |
| Agent-Driver[38] | Camera | 0.22 | 0.65 | 1.34 | 0.74 | 0.02 | 0.13 | 0.48 | 0.21 | None† |
| FASIONAD (Ours) | Camera | 0.19 | 0.62 | 1.25 | 0.69 | 0.02 | 0.09 | 0.44 | 0.18 | 6.9† |
4.2 Results and Analysis
| Methods | Modality | DS (%) | RC (%) |
|---|---|---|---|
| CILRS [13] | C | 7.47 | 13.40 |
| LBC [14] | C | 30.97 | 55.01 |
| Transfuser [10] | C+L | 54.52 | 78.41 |
| ST-P3 [22] | C | 55.14 | 86.74 |
| VAD [24] | C | 64.29 | 87.26 |
| Agent-Driver [38] | C | 64.31 | 87.31 |
| FASIONAD (Ours) | C | 64.83 | 89.04 |
We compare FASIONAD’s performance against several baseline models, including ST-P3 [22], an end-to-end vision-based framework integrating spatial-temporal learning for improved real-time driving accuracy and safety; VAD [24], a vectorized scene representation framework enabling efficient perception, prediction, and planning for faster decision-making without deep reinforcement learning; UniAD [23], a unified framework that prioritizes perception, prediction, and planning tasks, demonstrating superior performance on the nuScenes benchmark; CILRS [13], a behavior cloning framework that addresses dataset bias and generalization issues in unseen environments; and Transfuser [10], which uses a transformer-based fusion mechanism to integrate image and LiDAR data for enhanced perception in dense, dynamic scenarios. Additionally, we assess forward-planning-only systems, which generate plans without backward safety evaluations. We also conduct ablation studies to evaluate FASIONAD’s performance without the slow strategy to measure the impact of safety evaluations and without LLM-based intent inference by substituting a rule-based system to quantify the LLM’s contribution to understanding high-level driving intent.
4.2.1 Baseline Driving Performance Comparison
Open-loop evaluation: The nuScenes dataset was used to evaluate open-loop autonomous driving systems, covering diverse real-world scenarios like varying weather, traffic density, and urban complexity. We compared multiple methods based on L2 error and collision rate in Table 1, revealing their strengths and limitations under different conditions and highlighting their potential real-world applicability. In the open-loop planning evaluation on the nuScenes validation dataset, FASIONAD achieved the best overall performance compared to state-of-the-art methods. It recorded the lowest average L2 distance of 0.80 meters and the lowest average collision rate of 0.32%, demonstrating superior motion planning accuracy and safety.
FASIONAD outperformed strong baselines such as GenAD, which had an average L2 distance of 0.91 meters and a collision rate of 0.43%, and VAD-Base, with an L2 distance of 1.22 meters and a collision rate of 0.53%. FASIONAD also maintained competitive inference speed with 6.5 FPS, making it highly effective for real-time applications.
Closed-loop evaluation: We used the CARLA Closed-loop Town05 Short Benchmark to assess driving in tight, complex environments with short routes, multiple intersections, and dense traffic. The evaluation focuses on Driving Score (DS) and Route Completion (RC) to measure performance in fast-paced, dynamic scenarios. In the closed-loop evaluation of autonomous driving methods on the Town05 Short benchmark, FASIONAD demonstrated the best overall performance. Known for its challenging road conditions, this benchmark tested the planning and driving capabilities of each method.
FASIONAD achieved a Driving Score (DS) of 64.83% and a Rate of Completion (RC) of 89.04%, outperforming all other methods. Notably, it surpassed VAD, which recorded a DS of 64.29% and an RC of 87.26%, and ST-P3, with a DS of 55.14% and an RC of 86.74%. These results highlight FASIONAD’s superior ability to handle complex driving environments and complete routes effectively.
4.2.2 Ablation Study
Information Bottleneck and High-Level Action Performance. Our ablation study demonstrates the complementary benefits of the Information Bottleneck (IB) and High-Level Action (HA) components(Table 3). The full model incorporating both components achieved the best performance (L2: 0.69m, collision rate: 0.18%). Using either component alone led to decreased performance - IB-only (L2: 0.74m, collision rate: 0.21%) and HA-only (L2: 0.77m, collision rate: 0.19%) - highlighting their synergistic relationship in improving prediction accuracy through effective information filtering and high-level planning.
| Setting | L2 (m) | Collision Rate (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| IB | HA | 1s | 2s | 3s | Avg. | 1s | 2s | 3s | Avg. |
| ✓ | ✗ | 0.23 | 0.66 | 1.34 | 0.74 | 0.03 | 0.12 | 0.47 | 0.21 |
| ✗ | ✓ | 0.24 | 0.68 | 1.37 | 0.77 | 0.02 | 0.10 | 0.45 | 0.19 |
| ✓ | ✓ | 0.19 | 0.62 | 1.25 | 0.69 | 0.02 | 0.09 | 0.44 | 0.18 |
VLM Prompt Strategy Performance. Our ablation study on VLM prompt strategies revealed the significant impact of prompt design (Table 4). The Full.P configuration, featuring comprehensive prompt instructions, achieved the best results with an L2 distance of 0.69 meters and 0.18% collision rate. Performance gradually declined with simpler prompting approaches: Visual.P (0.74m, 0.20%), BEV.P (0.79m, 0.24%), and Simple.P (0.80m, 0.32%). These results demonstrate that detailed, well-structured prompts are crucial for maximizing VLM’s predictive capabilities.
| Setting | L2 (m) | Collision Rate (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| 1s | 2s | 3s | Avg. | 1s | 2s | 3s | Avg. | |
| Simple.P | 0.31 | 0.71 | 1.38 | 0.80 | 0.05 | 0.16 | 0.74 | 0.32 |
| BEV.P | 0.29 | 0.70 | 1.36 | 0.79 | 0.04 | 0.14 | 0.65 | 0.24 |
| Visual.P | 0.24 | 0.67 | 1.30 | 0.74 | 0.02 | 0.11 | 0.48 | 0.20 |
| Full.P | 0.19 | 0.62 | 1.25 | 0.69 | 0.02 | 0.09 | 0.44 | 0.18 |
5 Conclusion and Future Work
In summary, FASIONAD establishes a robust foundation for autonomous navigation, effectively integrating fast-response capabilities and safety-focused assessments within a modular, scalable framework. Achieving a 10-15% reduction in collision metrics compared to state-of-the-art baselines and reaching a Driving Score (DS) of 64.83% and Route Completion (RC) of 89.04% on the CARLA Town05 Short Benchmark, FASIONAD demonstrates superior performance across standard benchmarks. Its dual-pathway design enhances adaptability and supports integration with multi-sensor navigation systems, positioning it for real-time deployment in both single-agent and fleet-based scenarios. Future work will focus on expanding FASIONAD’s robustness in rural and unstructured environments and integrating additional sensor modalities such as LiDAR and radar. Furthermore, ongoing research into reinforcement learning from human feedback (RLHF) and fleet coordination will explore avenues for optimizing performance in complex, multi-agent contexts. FASIONAD is poised to meet the operational demands of diverse, real-world driving environments, representing a significant advancement in autonomous navigation.
References
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeffrey Donahue, Pauline Luc, Antoine Miech, Ivan Barr, Yazhe Li, Christian Puhrsch, Joe Spurling, Alex Cain, P. Musharaf, Tim Stone, Yana Hasson, Simon Kornblith, Kevin Duh, Krzysztof J. Geras, Michael Andriluka, James Keim, Daniel Rubino, Pablo Sprechmann, H. Kuwajima, and Mohammad Norouzi. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- Arasteh et al. [2024] Fazel Arasteh, Mohammed Elmahgiubi, Behzad Khamidehi, Hamidreza Mirkhani, Weize Zhang, Cao Tongtong, and Kasra Rezaee. Validity learning on failures: Mitigating the distribution shift in autonomous vehicle planning, 2024.
- Bojarski et al. [2016] Mariusz Bojarski, Davide Del Testa, and et al. End to end learning for self-driving cars. In Proceedings of the Neural Information Processing Systems (NeurIPS), pages 1–9, 2016.
- Booch et al. [2021] Grady Booch, Francesco Fabiano, Lior Horesh, Kiran Kate, Jonathan Lenchner, Nick Linck, Andreas Loreggia, Keerthiram Murgesan, Nicholas Mattei, Francesca Rossi, et al. Thinking fast and slow in ai. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 15042–15046, 2021.
- Buehler et al. [2009] Chris Buehler, Tim Beck, and et al. Darpa urban challenge: Autonomous vehicles in city traffic. Journal of Field Robotics, 26(9):646–659, 2009.
- Caesar et al. [2020] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020.
- Chen et al. [2020] Dian Chen, Bolei Zhou, Vladlen Koltun, and Philipp Krahenbuhl. Learning by cheating. In Conference on Robot Learning, pages 66–75. PMLR, 2020.
- Chen et al. [2024a] Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–20, 2024a.
- Chen et al. [2024b] Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243, 2024b.
- Chitta et al. [2022] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. arXiv preprint arXiv:2205.15997v1, 2022.
- Chung et al. [2022] Seung-Hwan Chung, Seung-Hyun Kong, Sangjae Cho, and I Made Aswin Nahrendra. Segmented encoding for sim2real of rl-based end-to-end autonomous driving. In 2022 IEEE Intelligent Vehicles Symposium (IV), pages 1290–1296, 2022.
- Codevilla et al. [2018] Fernando Codevilla, Antonio M. Lopez, and et al. End-to-end driving via conditional imitation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–10, 2018.
- Codevilla et al. [2019] Felipe Codevilla, Eder Santana, Antonio M Lopez, and Adrien Gaidon. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- Cui et al. [2021] Alexander Cui, Sergio Casas, Abbas Sadat, Renjie Liao, and Raquel Urtasun. Lookout: Diverse multi-future prediction and planning for self-driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Dosovitskiy et al. [2017a] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. In Conference on Robot Learning, pages 1–16. PMLR, 2017a.
- Dosovitskiy et al. [2017b] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. In Proceedings of the Conference on Robot Learning (CoRL), 2017b.
- Fang et al. [2023] Hui Fang, Jingyi Wang, and Wei Liu. Video-based autonomous driving with vision-language models. arXiv preprint arXiv:2307.12345, 2023.
- Feng et al. [2024] Kaituo Feng, Changsheng Li, Dongchun Ren, Ye Yuan, and Guoren Wang. On the road to portability: Compressing end-to-end motion planner for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15099–15108, 2024.
- Geiger et al. [2012] Andreas Geiger, Philip Lenz, and Raquel Urtasun. We are different: Unsupervised learning for urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–8, 2012.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
- Hu et al. [2021] Peiyun Hu, Aaron Huang, John Dolan, David Held, and Deva Ramanan. Safe local motion planning with self-supervised freespace forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12732–12741, 2021.
- Hu et al. [2022] Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.
- Hu et al. [2023] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Jiang et al. [2023] Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8340–8350, 2023.
- Khurana et al. [2022] Tarasha Khurana, Peiyun Hu, Achal Dave, Jason Ziglar, David Held, and Deva Ramanan. Differentiable raycasting for self-supervised occupancy forecasting. In European Conference on Computer Vision, pages 353–369. Springer, 2022.
- Kiran et al. [2021] B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A Al Sallab, Senthil Yogamani, and Patrick Pérez. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2021.
- Kiran et al. [2022] B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A. Al Sallab, Senthil Yogamani, and Patrick Pérez. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2022.
- Li et al. [2024] Jiankun Li, Hao Li, Jiangjiang Liu, Zhikang Zou, Xiaoqing Ye, Fan Wang, Jizhou Huang, Hua Wu, and Haifeng Wang. Exploring the causality of end-to-end autonomous driving, 2024.
- Li et al. [2023] Yifei Li, Yuchen Zhang, and Xintong Wang. Drivingclip: Learning driving policies from the clip model. arXiv preprint arXiv:2303.16828, 2023.
- Li et al. [2022] Zhiqi Li, Wenhai Wang, Hongsheng Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In European Conference on Computer Vision (ECCV), pages 1–18. Springer, 2022.
- Lin et al. [2023] Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122v2, 2023.
- Liu and Feng [2024] Henry X Liu and Shuo Feng. Curse of rarity for autonomous vehicles. nature communications, 15(1):4808, 2024.
- Liu et al. [2024] Shaoteng Liu, Haoqi Yuan, Minda Hu, Yanwei Li, Yukang Chen, Shu Liu, Zongqing Lu, and Jiaya Jia. Rl-gpt: Integrating reinforcement learning and code-as-policy. arXiv preprint arXiv:2402.19299, 2024.
- Loshchilov and Hutter [2016] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations (ICLR), 2019. Published: 21 Dec 2018, Last Modified: 19 May 2023.
- Maas et al. [2013] Andrew L Maas, Awni Y Hannun, Andrew Y Ng, et al. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml, page 3. Atlanta, GA, 2013.
- Mao et al. [2023] Jiageng Mao, Yuxi Qian, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
- Mao et al. [2024] Jiageng Mao, Junjie Ye, Yuxi Qian, Marco Pavone, and Yue Wang. A language agent for autonomous driving. arXiv preprint arXiv:2311.10813, 2024.
- Pomerleau [1991] Dean A. Pomerleau. Efficient training of artificial neural networks for autonomous navigation. Neural Computation, 3(1):88–97, 1991.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Ratliff et al. [2006] Nathan D Ratliff, J Andrew Bagnell, and Martin A Zinkevich. Maximum margin planning. In Proceedings of the 23rd international conference on Machine learning, pages 729–736, 2006.
- Ross et al. [2011] Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shao et al. [2023] Hao Shao, Letian Wang, Ruobing Chen, Hongsheng Li, and Yu Liu. Safety-enhanced autonomous driving using interpretable sensor fusion transformer. arXiv preprint arXiv:2207.14024, 2023.
- Shao et al. [2024] Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15120–15130, 2024.
- Shi et al. [2019] Tianyu Shi, Pin Wang, Xuxin Cheng, Ching-Yao Chan, and Ding Huang. Driving decision and control for automated lane change behavior based on deep reinforcement learning. In 2019 IEEE intelligent transportation systems conference (ITSC), pages 2895–2900. IEEE, 2019.
- Sima et al. [2023] Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. arXiv preprint arXiv:2312.14150, 2023.
- Song et al. [2023] Chan Hee Song, Brian M. Sadler, Jiaman Wu, Wei-Lun Chao, Clayton Washington, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2986–2997, 2023.
- Sun et al. [2024] Jingkai Sun, Qiang Zhang, Yiqun Duan, Xiaoyang Jiang, Chong Cheng, and Renjing Xu. Prompt, plan, perform: Llm-based humanoid control via quantized imitation learning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16236–16242, 2024.
- Tan et al. [2024] Runjia Tan, Shanhe Lou, Yanxin Zhou, and Chen Lv. Multi-modal llm-enabled long-horizon skill learning for robotic manipulation. In 2024 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE International Conference on Robotics, Automation and Mechatronics (RAM), pages 14–19, 2024.
- Tian et al. [2024] Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. In Conference on Robot Learning (CoRL), 2024. * Equal contribution. Listing order is random. † Corresponding author.
- Tong et al. [2023] Wenwen Tong, Chonghao Sima, Tai Wang, Li Chen, Silei Wu, Hanming Deng, Yi Gu, Lewei Lu, Ping Luo, Dahua Lin, et al. Scene as occupancy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8406–8415, 2023.
- Urmson et al. [2008] Chris Urmson, Joshua Anhalt, Drew Bagnell, Christopher Baker, Robert Bittner, MN Clark, John Dolan, Dave Duggins, Tugrul Galatali, Chris Geyer, et al. Autonomous driving in urban environments: Boss and the urban challenge. Journal of field Robotics, 25(8):425–466, 2008.
- Wang et al. [2024a] Jun Wang, Guocheng He, and Yiannis Kantaros. Safe task planning for language-instructed multi-robot systems using conformal prediction. arXiv preprint arXiv:2402.15368, 2024a.
- Wang et al. [2024b] Tianqi Wang, Enze Xie, Ruihang Chu, Zhenguo Li, and Ping Luo. Drivecot: Integrating chain-of-thought reasoning with end-to-end driving. arXiv preprint arXiv:2403.16996, 2024b.
- Wang et al. [2023] Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving. arXiv preprint arXiv:2312.09245, 2023.
- Weng et al. [2024] Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024.
- Xu et al. [2024] Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024.
- Zeng et al. [2019] Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8660–8669, 2019.
- Zhang et al. [2024] Ruijun Zhang, Xianda Guo, Wenzhao Zheng, Chenming Zhang, Kurt Keutzer, and Long Chen. Instruct large language models to drive like humans. arXiv preprint arXiv:2406.07296, 2024.
- Zheng et al. [2024a] Wenzhao Zheng, Ruiqi Song, Xianda Guo, and Long Chen. Genad: Generative end-to-end autonomous driving. arXiv preprint arXiv:2402.11502, 2024a.
- Zheng et al. [2024b] Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end autonomous driving. arXiv preprint arXiv:2402.11502, 2024b.
- Zhou et al. [2022] Weitao Zhou, Zhong Cao, Nanshan Deng, Xiaoyu Liu, Kun Jiang, and Diange Yang. Dynamically conservative self-driving planner for long-tail cases. IEEE Transactions on Intelligent Transportation Systems, 24(3):3476–3488, 2022.
Appendix A More Details about Model Design
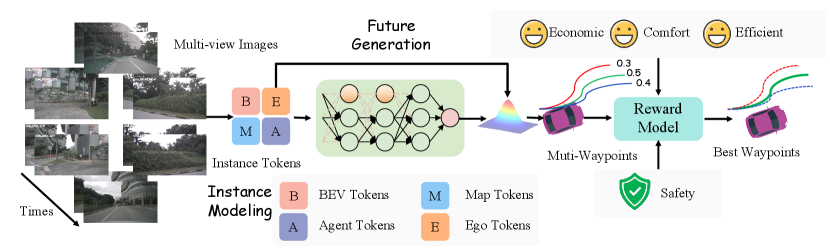
A.1 Instance Modeling
The first step in the Fast Pathway is to process sensor inputs to obtain high-level descriptions of the surrounding environment. Inspired by the decision-making processes of human drivers, we categorize the information needed for decision-making into two levels: low-level perception information (what do we observe?) and high-level perception information (understanding the interactions among observed elements). Low-level perception information includes details about traffic participants and map features, while high-level perception information captures the interactions between these elements, as shown in Fig.5.
BEV Encoder. Following this framework, we adopt a vision-centric perception pipeline, initially extracting Bird’s Eye View (BEV) features, which serve as a foundation for refining both low-level and high-level perception information. We adopt the BEVFormer approach [30] to extract BEV features, denoted as ( where represents the batch size and the feature dimension), which encapsulate the environmental topology. This process can be formulated as:
| (10) |
Instance-centric Token Modeling.
Since semantic map elements are typically sparse in the BEV space, we represent low-level perception information using sparse map tokens and agent tokens. These tokens are updated through attention mechanisms with BEV tokens, following the approach in [24]. Specifically, the updated Agent Tokens, now incorporating motion information, are concatenated with the Ego Token. Self-attention is then applied to capture high-order interactions among different traffic participants. Additionally, Map Tokens engage in cross-attention with tokens that encapsulate interactions between traffic participants. This final cross-attention step enriches the tokens with semantic map information, resulting in an instance-centric scene representation that captures both agent interactions and contextual map features. This representation provides a comprehensive and compact description of the autonomous driving scenario. The modeling process is represented as follows:
| (11) |
| (12) |
where denote instance tokens, agent tokens, and map tokens, respectively. CA denotes the cross attention mechanism.
Cross-Attention Mechanism.
To incorporate contextual information, cross-attention is applied between the BEV tokens and feature sets , , and , which represent agents, the ego vehicle, and map features, respectively:
| (13) | ||||
| (14) | ||||
| (15) |
where , , and for . Here, , , and are learnable projection matrices, and is a scaling factor.
Trajectory Generator.
The trajectory generator outputs waypoint predictions , with each waypoint representing a spatial position in BEV coordinates. To capture interactions among traffic participants, we adopt a generative framework inspired by GenAD [61], modeling trajectory prediction as a future trajectory generation problem.
| (16) |
where represents a Gaussian distribution parameterized by mean and variance . This learned distribution captures prior knowledge of the ground-truth motion field, enhancing the realism of motion predictions.
| (17) |
Reward Model.
| (18) |
where are weighting coefficients for each aspect.
Safety Component. considers collision risk, distance to obstacles, deviation from the desired path, and speed constraints:
| (19) |
where measures the exponential decay of collision risk with distance , and evaluates directional alignment with the desired path. The terms and penalize the deviation from ideal positioning and target speed, respectively, using VAD/GenAD for critical areas.
Comfort Component. evaluates smoothness and comfort in terms of lateral and longitudinal accelerations:
| (20) |
where and are the lateral and longitudinal acceleration terms, and accounts for centrifugal forces, promoting comfortable maneuvers.
Efficiency Component. focuses on maintaining optimal speed and minimizing travel time:
| (21) |
where penalizes deviations from the target speed , and incentivizes efficient travel times.
Economic Component. reduces fuel consumption or energy usage:
| (22) |
where and are coefficients for speed and acceleration, with constants and representing baseline energy consumption.
Once the rewards are computed for each candidate trajectory, the model selects the top-K trajectories based on the highest reward scores. If the rewards are uniformly low or the distribution indicates high uncertainty, a reward distribution check is performed to determine if VLMs are needed for further refinement. The VLM generates a Visual Prompt to assess collision risks, traffic rule violations, and environmental context, updating the semantic embedding based on this feedback. For example, the VLM may evaluate if the vehicle is positioned correctly to avoid violations like crossing road lines or exceeding speed limits, especially when overtaking or approaching intersections. The model then adjusts based on these checks, incorporating surrounding vehicle speed and contextual speed limits.
A.2 VLMs QA
The Slow Pathway in FASIONAD leverages Vision-Language Models (VLMs) to perform advanced reasoning in complex scenarios. This section details its inputs, the modeling process to derive intermediate tokens, and demonstrates its functionality with a specific example derived from the main paper and JSON data.
A.2.1 Inputs
The Slow Pathway processes raw visual inputs and generates intermediate representations. It also relies on spatial and semantic prompts derived from Fast Pathway outputs. Key inputs include:
-
•
Multi-view Images (): Front-view sensory data collected from cameras at time , providing raw visual information for scene understanding.
-
•
BEV and Visual Prompts: Derived from the Fast Pathway’s trajectory outputs and 3D bounding boxes (). These prompts provide spatial and dynamic context:
-
–
BEV Prompt: Encodes the spatial relationships and interactions between agents, such as vehicles and pedestrians.
-
–
Visual Prompt: Highlights projected trajectories and potential risks, overlaying them onto the camera view for enhanced interpretability.
-
–
A.2.2 Modeled Representations
Intermediate tokens and semantic features are generated during the modeling process to support decision-making:
-
•
Instance Tokens: Derived via self-attention and cross-attention mechanisms. These include:
-
–
Ego Tokens (): Encodes the ego vehicle’s state, including position, velocity, and orientation.
-
–
Agent Tokens (): Represent dynamic agents and their predicted trajectories.
-
–
Map Tokens (): Capture static environmental features like traffic signals, lanes, and intersections.
-
–
-
•
Planning State Vectors (): -dimensional binary vectors representing environmental conditions relevant to planning, e.g., pedestrian presence (), no obstacles (), red light ().
-
•
Meta-Actions (): High-level planning actions, such as lane changes or stopping, extracted via structured reasoning over instance and prompt data.
A.2.3 Decision Process
The Slow Pathway interprets environmental context to refine trajectory predictions and meta-actions. This includes:
-
•
Uncertainty Estimation: A threshold-based mechanism evaluates the uncertainty in waypoint predictions from the Fast Pathway. If uncertainty exceeds the threshold, the Slow Pathway is activated for detailed analysis.
-
•
QA Reasoning: Predefined Question-Answering tasks, such as ”What traffic rules apply?” and ”Are there potential conflicts?”, guide the generation of structured planning outputs.
A.2.4 Outputs
-
•
Planning State (): Binary vectors encoding key scene-specific conditions.
-
•
Meta-Actions (): High-level decisions directly guiding trajectory refinement.
-
•
Refined Trajectories (): Adjusted waypoints integrating feedback from VLMs.
-
•
Semantic Feedback: Descriptive language-based recommendations for future actions, e.g., ”Yield to pedestrian, then prepare to stop.”
A.2.5 Example: Complex Intersection Navigation
Scenario:
The vehicle approaches an intersection with pedestrians and other vehicles under rainy conditions.
Inputs:
-
•
Multi-view images (): Capturing reduced visibility, crosswalk activity, and adjacent vehicle signaling.
-
•
BEV Tokens (): Encodes pedestrian positions and traffic light states.
-
•
Prompts: Emphasizing risks (collision or rule violation) and spatial relationships.
Outputs:
-
•
Planning State:
(23) -
•
Meta-Actions:
(24) -
•
Refined Trajectory:
(25) -
•
Semantic Feedback:
”Stop at crosswalk. Wait for pedestrians to clear. Yield to adjacent vehicle turning left.”
A.3 Slow Pathway Feedback
Information Bottleneck.
To reduce noise and enhance feature alignment, we incorporate an information bottleneck objective, which seeks to learn a representation that minimizes the correlation between the representation and the input while maximizing the correlation between the representation and the class.This is achieved through the following optimization:
| (26) |
where measures the relevant mutual information between and , ensuring that the representation retains useful class-specific information, while captures the mutual information between and extraneous variables , which is minimized to avoid noise. The information bottleneck principle ensures that serves as a compact yet effective representation that focuses on class-relevant features, enhancing the alignment with .
In the information bottleneck, we configure both the encoder and decoder of the information bottleneck by using a 3-layer MLPs with a hidden size of 512 and LeakyReLU[36] as the activation function.
High-level plans.
To update the Ego tokens , multi-head attention(MHA) is used, with the Ego tokens directly incorporating distilled semantic information from the high-level actions embedding with CLIP encoder. The updates are defined as follows:
| (27) |
where is the token refined by the semantic embedding , and is the distilled semantic vector generated by the model as an approximation of . By directly incorporating into the update of the Ego tokens, we ensure that the Ego tokens remain aligned with the latest semantic context and driving intent as interpreted by the VLM, while reducing computational load in subsequent steps

A.4 Laplace-Based Uncertainty Estimation
We propose the probabilistic modeling of the reward based on the Laplace distribution for uncertainty estimation. The probability density function (PDF) of a univariate Laplace distribution is:
| (28) |
where is the random variable, is the location parameter, and is the scale parameter. This describes the distribution of a single variable.
Here, the target is the reward function at each time step. Assuming that the reward is a multivariate vector and the dimensions of are independent, each dimension follows a univariate Laplace distribution. The joint probability density for a single time step can be expressed as:
| (29) |
where is the dimension of the reward vector ; is the -th component of the reward vector at time ; is the -th component of the predicted reward at time , is the scale parameter, controlling the width of the distribution.
If , i.e., the reward is scalar, the formula simplifies to:
| (30) |
where is the -norm (absolute deviation) of the reward.
Extending this to the entire time sequence, we assume that the rewards at each time step are independent. The joint probability density over the sequence is:
| (31) |
where represents the model parameters that define the predicted rewards . Substituting the single-step probability density yields:
| (32) |
The Laplace distribution is chosen here because of its heavy-tailed nature and robustness to outliers. In dynamic driving scenarios, reward signals may be affected by noise or anomalies. Compared to the squared deviation (-norm) in Gaussian distributions, the absolute deviation (-norm) used in the Laplace distribution is more robust to outliers, avoiding excessive amplification of large deviations. Additionally, the Laplace distribution is parameterized by a single scale parameter , making it simpler to train and optimize. This makes the model suitable for handling dynamic and uncertain scenarios.
Appendix B More Details about Loss Function
Maximum Likelihood Estimation (MLE) Loss. In the context of language models, the MLE loss is typically used to optimize the likelihood of the target sequence given the input sequence. The MLE loss for a token sequence is defined as:
| (33) |
where is the conditional probability of the token given the previous tokens in the sequence. This loss is minimized during training to maximize the likelihood of generating the correct sequence, making it suitable for auto-regressive learning in tasks like trajectory prediction.
Appendix C More Details about Training Strategy.
Our training process is divided into three stages: (1) training the Fast Pathway for generating reasonable trajectories and a robust reward function, (2) fine-tuning Vision-Language Models (VLMs) to output structured vector representations, and (3) joint training of the Fast and Slow Pathways to align feedback and improve performance in complex scenarios.
C.1 Stage 1: Training the Fast Pathway
The first stage focuses on learning robust trajectory generation and designing a reward model that evaluates safety, efficiency, and comfort.
Objective:
-
•
Train the Fast Pathway to output accurate trajectories for real-time decision-making.
-
•
Optimize a reward model to score trajectories based on multiple factors.
The Fast Pathway processes raw sensory data and generates intermediate representations for trajectory prediction. The key components are described below:
-
•
Inputs:
-
–
Multi-view images (): The raw sensory input from front-view cameras at time , providing visual information for scene understanding and real-time decision-making.
-
–
-
•
Modeled Representations (Generated by the Fast Pathway):
-
–
BEV tokens (): Encoded spatial representations of the scene in a Bird’s Eye View format, capturing the positions and movements of surrounding entities. These are derived from BEV encoding layers.
-
–
Instance tokens (): High-level features derived from through modeling steps that involve self-attention and cross-attention mechanisms. These tokens include:
-
*
Ego Tokens (): Represent the ego vehicle’s state, such as position, velocity, and orientation.
-
*
Agent Tokens (): Encode information about dynamic agents, including nearby vehicles and pedestrians.
-
*
Map Tokens (): Describe static environmental features such as lanes, traffic signals, and intersections.
-
*
-
–
Outputs:
-
•
Predicted waypoints : A sequence of waypoints representing the planned trajectory.
-
•
Reward scores : Evaluations of safety, efficiency, and comfort for the predicted trajectories.
Loss Function:
| (34) |
where:
-
•
: Trajectory prediction loss, computed as L2 distance between predicted and ground-truth waypoints.
-
•
: 3D detection loss.
-
•
: Map segmentation loss.
-
•
: Reward loss, defined as:
(35) where is the ground truth reward, calculated based on safety, efficiency, and comfort components, and is the predicted reward score.
Reward Model Training: The reward function evaluates trajectory quality:
| (36) |
where:
-
•
: Penalizes unsafe actions, such as collisions or near misses.
-
•
: Encourages smooth trajectories by minimizing abrupt accelerations or turns.
-
•
: Rewards timely and energy-efficient travel.
-
•
: Weights for each component.
Handling Uncertainty in Feedback: During training, feedback from the VLMs is only updated once per sample. If the predicted reward scores exhibit significant uncertainty or unreliability (e.g., hallucinations in the feedback causing poor trajectory alignment), the system discards the feedback and does not update the trajectory for that sample.
C.2 Stage 2: Fine-Tuning VLMs
The second stage focuses on fine-tuning Vision-Language Models (VLMs) to generate structured vector representations, enhancing the Slow Pathway’s ability to provide high-quality feedback for decision-making.
Objective: The goal of this stage is to train VLMs to interpret visual and BEV prompts, generating structured feedback vectors () and high-level plans ().
Inputs: The fine-tuning process utilizes the following inputs:
-
•
Visual prompts (): Front-view images containing trajectory information.
-
•
BEV prompts (): Bird’s Eye View representations for spatial context.
-
•
Question-answering tasks: Designed to simulate human-like reasoning and interaction with driving scenarios.
Outputs: The outputs of this stage include:
-
•
Planning states (): Representations of environmental context relevant to decision-making.
-
•
Meta-actions (): High-level actions derived from structured semantic understanding.
Loss Function: The fine-tuning process is guided by the following loss function:
| (37) |
where:
-
•
: Maximum Likelihood Estimation loss for token prediction, ensuring the model learns to generate accurate sequential representations.
-
•
: Reward-guided loss that aligns outputs with trajectory-based supervision, enhancing consistency and alignment with desired planning goals.
By fine-tuning the VLMs with these inputs, outputs, and loss functions, the model achieves a robust capability to interpret diverse driving scenarios and provide actionable, structured feedback to the Fast Pathway.
C.3 Stage 3: Joint Training of Fast and Slow Pathways
The final stage focuses on integrating the Slow Pathway’s reasoning-based feedback into the Fast Pathway’s real-time trajectory generation. This process ensures that the system combines the efficiency of the Fast Pathway with the contextual reasoning and adaptability of the Slow Pathway, aligning their outputs for improved overall performance.
Objective:
-
•
Refine the Fast Pathway’s real-time trajectory generation by incorporating structured feedback from the Slow Pathway.
-
•
Achieve alignment between the planning states , meta-actions , and waypoints generated by both pathways.
-
•
Minimize inconsistencies between Fast Pathway outputs and the Slow Pathway’s high-level plans, especially in complex or safety-critical scenarios.
Alignment Definition: Alignment in this context refers to ensuring that the outputs of the Fast Pathway (e.g., planning states and meta-actions ) are consistent with the reasoning-based decisions generated by the Slow Pathway ( and ). This alignment addresses the following:
-
•
Planning States Alignment ( vs. ): Ensures that the Fast Pathway accurately interprets and integrates the situational understanding provided by the Slow Pathway, such as obstacles, dynamic agent behavior, and environmental factors.
-
•
Meta-Actions Alignment ( vs. ): Guarantees that the high-level decisions (e.g., ”stop at intersection,” ”overtake”) recommended by the Slow Pathway are respected and reflected in the Fast Pathway’s trajectory outputs.
-
•
Trajectory Refinement: Enhances the trajectory generated by the Fast Pathway by incorporating corrections or modifications suggested by the Slow Pathway, such as reducing collision risks or ensuring regulatory compliance.
Inputs:
-
•
Waypoints from the Fast Pathway (): The initial trajectory predictions generated based on real-time inputs.
-
•
Feedback Vectors from the Slow Pathway: Includes refined planning states and high-level meta-actions , derived from VLM-based reasoning.
Outputs:
-
•
Updated Trajectories (): Trajectories that incorporate feedback to enhance safety, efficiency, and adaptability.
-
•
Refined Reward Scores (): Scores that reflect the quality of the updated trajectories based on multiple factors, including safety and compliance.
Loss Function: The joint training process optimizes a combined loss function:
| (38) |
where:
-
•
: Loss associated with the Fast Pathway, including trajectory prediction, detection, and segmentation errors.
-
•
: Loss associated with the Slow Pathway, including MLE-based and reward-guided loss components.
-
•
: Ensures alignment between the two pathways, defined as:
(39) This term penalizes discrepancies between the planning states and meta-actions of the two pathways.
Detailed Process:
Trajectory Alignment:
For each predicted trajectory from the Fast Pathway, feedback from the Slow Pathway adjusts the waypoints based on contextual reasoning. For example, if the Fast Pathway suggests an overly aggressive lane change, the Slow Pathway may recommend a more conservative maneuver to ensure safety. Iterative Feedback Refinement:
The Slow Pathway’s feedback is incorporated iteratively, with adjustments made to both the planning states and meta-actions of the Fast Pathway. This process ensures that the refined trajectories respect the broader contextual understanding provided by the Slow Pathway. Safety and Performance Optimization:
By integrating Slow Pathway insights, the system reduces risks associated with long-tail events (e.g., unexpected pedestrian crossings) and improves compliance with traffic regulations.
Example Scenario: Emergency Braking at Intersection.
Consider a scenario where the Fast Pathway predicts a trajectory to proceed through an intersection without noticing a stop sign partially obscured by a tree. The joint training ensures the following:
-
1.
Fast Pathway Prediction: Generates a trajectory that continues through the intersection without stopping.
-
2.
Slow Pathway Feedback:
-
•
Planning state : Indicates the presence of a stop sign and high traffic density at the intersection.
-
•
Meta-action : Recommends stopping at the intersection and waiting for clearance.
-
•
-
3.
Trajectory Refinement: The Fast Pathway adjusts its trajectory to include a stop action at the intersection, ensuring compliance and safety.
-
4.
Outcome: The refined trajectory avoids a potential collision or traffic violation, demonstrating the benefits of alignment.
Appendix D More Experimental Setting Details
Fast pathway implementation.
We adopted ResNet50[20] as the backbone network to extract image features. We take as input images with a resolution of 640 × 360 and use a 200 × 200 BEV representation to perceive the surrounding scene. For fair comparisons, we basically use the same hyperparameters as VAD-tiny[24]. We ffxed the number of BEV tokens, map tokens, and agent tokens to 100 × 100, 100, and 300, respectively. Each map token contains 20 point tokens to represent a map point in the BEV space. We set the hidden dimension of each BEV, point, agent, ego, and instance token to 256. We set the , in reward function.
For training, we set the loss balance factors to 1 and use the AdamW[35] optimizer with a cosine learning rate scheduler[34]. We set the initial learning rate to 2 × 10-4 and a weight decay of 0.01. By default, we trained our FASIONAD for 30 epochs with 8 NVIDIA Tesla A100 GPUs and adopted a total batch size of 8.