Exponentially Stable Adaptive Control of MIMO Systems with Unknown Control Matrix
Abstract
The scope of this research is a problem of direct model reference adaptive control of linear time-invariant multi-input multi-output (MIMO) plants without any a priori knowledge about system matrices. To handle it, a new method is proposed, which includes three main stages. Firstly, using the well-known DREM procedure, the plant parametrization is made to obtain the linear regressions, in which the plant matrices and state initial conditions are the unknown parameters. Secondly, such regressions are substituted into the known equations for the controller parameters calculation. Thirdly, the controller parameters are identified using the novel adaptive law with the exponential rate of convergence. To the best of the authors’ knowledge, such a method is the first one to provide the following features simultaneously: 1) it is applicable for the unknown MIMO systems (e.g. without any information about state or control allocation matrices, the sign of the latter, etc.); 2) it guarantees the exponential convergence of both the parameter and tracking errors under the mild requirement of the regressor finite excitation; 3) it ensures element-wise monotonicity of the transient curves of the control law parameters matrices. The results of the conducted experiments with the model of a rubber and ailerons control of a small passenger aircraft corroborate all theoretical results.
keywords:
exponential stability, MIMO systems, unknown control matrix, regressor extension and mixing, finite excitation.© 2023 the authors. This work has been accepted to IFAC for publication under a Creative Commons Licence CC-BY-NC-ND
1 Introduction
The theory of Model Reference Adaptive Control (MRAC) was developed in the late 1950s as an approach for efficient and safe aircraft control under the condition of significant parameter uncertainty (Tao, 2003; Dydek et al., 2010; Annaswamy and Fradkov, 2021). Despite the difficulties, which were faced at the initial stage (Dydek et al., 2010), the basic MRAC principles were approved by the engineers over time and found real practical applications in aircraft engineering as well as in other branches of industry (Narendra and Monopoli, 2012). However, many of the conventional assumptions of the classical MRAC paradigm are still not fully relaxed to this day. This keeps the scientific community interested in the improvement of some aspects of this theory (Annaswamy and Fradkov, 2021; Tao, 2014).
In this research, we consider the requirement to know some a priori information about the control input (allocation) matrix for the implementation of the conventional adaptive laws of the form .
It is well known (Tao, 2003, 2014) that, in order to be implementable, such adaptive laws require to know either the control allocation matrix , its sign or for a matrix case. It is rather restrictive for a number of practical scenarios. Therefore, there have been some attempts (Narendra and Kudva, 1974; Reish and Chowdhary, 2014; Roy et al., 2017; Gerasimov et al., 2018; Glushchenko et al., 2021a, 2022) to minimize such a priori needed data about matrix for MRAC schemes.
In (Tao, 2003; Narendra and Kudva, 1974) conditions are stated, under which the substitution is allowed, where is the input matrix of the reference model. The method in (Narendra and Kudva, 1974) leads to a modified control law, which provides only local stability, and requires knowledge of the lower bound of the determinant of the feedforward controller parameter matrix due to the need for its inversion. The identification-based approach , which is proposed by (Reish and Chowdhary, 2014), does not require any a priori information about the matrix , but needs the plant state matrix to be known instead. This is an even more restrictive assumption for most applications. (Roy et al., 2017), inspired by (Reish and Chowdhary, 2014), have proposed a combined adaptive control scheme, in which the minimum singular value of the matrix is assumed to be known. The advantages of (Reish and Chowdhary, 2014; Roy et al., 2017) in comparison with the previous solutions (Tao, 2003; Narendra and Kudva, 1974) are the relaxation of the regressor persistent excitation (PE) requirement, which is used in (Tao, 2003; Narendra and Kudva, 1974), for the exponential stability of the control scheme and parameter convergence. The method in (Roy et al., 2017) includes a nonlinear operator, which prevents singularity when the controller parameters matrices are inverted. However, the finiteness of the number of switches in the course of the adaptation has not been rigorously proved for such an operator, and as a consequence, the chattering is possible.
Considering the adaptive output feedback control problem, the method, which is based on the dynamic regressor extension and mixing (DREM) procedure (Aranovskiy et al., 2016), is proposed in (Gerasimov et al., 2018). It guarantees no more than one switch of the nonlinear operator under the condition of a known lower bound of the high-frequency gain. Later this approach has been improved and applied to the problem of the state feedback control of the multi-input multi-output (MIMO) systems in (Glushchenko et al., 2021a), in which it is also guaranteed that no more than one switch is required. Such a method needs the lower bound value of the determinant of the control allocation matrix. In (Glushchenko et al., 2022), considering single-input single-output (SISO) systems, another direct adaptive law is proposed, which is based on the I-DREM procedure (Glushchenko et al., 2021b). It does not require any a priori information about and guarantees the exponential stability of the closed-loop system if the regressor is finitely exciting (FE).
The present paper is an attempt to extend the result of (Glushchenko et al., 2022) to the case of MIMO systems. The main scientific contribution of the research is threefold: 1) an adaptive control scheme for unknown MIMO plants without any a priori knowledge about system matrices is obtained; 2) the exponential stability of the closed-loop control system is guaranteed when the vector of signals (states and controls) measured from the plant is finitely exciting (FE); 3) the monotonicity of transients of all control law matrices elements is provided. To the best of the authors’ knowledge, properties 1-3 are provided simultaneously for the first time.
The paper is organized as follows. Section II presents a problem statement. Section III contains the main result. Section IV is to analyze the control system stability. The numerical experiments are presented in Section V.
Notation. is the absolute value, is the Euclidean norm of a vector, and are the matrix minimum and maximum eigenvalues, respectively, stands for the matrix vectorization. , and are identity, zero and ones matrices, respectively. We also use the fact that for all (possibly singular) matrices the following holds: . The following definition from (Tao, 2003) is also used.
Definition 1. The regressor is finitely exciting over if there exist and such that the following holds
| (1) |
where is the excitation level.
Let the corollary of Theorem 9.4 from (Tao, 2003) be introduced.
Corollary 1. For any matrix , a Hurwitz matrix , a matrix such that a pair is controllable there exists a matrix , a scalar and matrices of appropriate dimension such that:
| (2) |
2 Problem Statement
Let the problem of adaptive state feedback control of the linear time-invariant (LTI) MIMO systems be considered:
| (3) |
where is the measurable state vector, is the known (or possibly unknown) vector of initial conditions, is a control vector, is the state matrix, is the control (allocation) matrix of full column rank. The pair is controllable. The vector is considered to be measurable at each time instant , whereas is time-invariant and unknown.
The reference model, which is used to define the required control quality for (3), is described as:
| (4) |
where is the reference model state vector, is the initial conditions vector, is the reference, is the Hurwitz state matrix of the reference model, is the input matrix.
Assumption 1. There exist and such that the following holds:
| (5) |
Considering (5), the control law for (3) is chosen as:
| (6) |
where and are adjustable parameters and .
Having substituted (6) into (3) and subtracted (4) from the obtained equation, the following error equation is written:
| (7) |
Here . The following notation is introduced in (7):
| (8) |
where , is the vector of the control law adjustable parameters.
Considering (8) and the difference between the initial conditions for (3) and (4), the equation (7) is written as:
| (9) |
The objective is formulated on the basis of (9).
Goal. When , it is required to hold:
| (10) |
where is the augmented tracking error.
3 Main Result
The main result of this study is based on the direct self-tuning regulators concept. Having at hand, it is proposed to apply some mathematical transformations to and, using the obtained results, derive the measurable regression equation with the help of :
| (11) |
where are measurable signals.
Applying the results of (Glushchenko et al., 2022, 2021b), Corollary 1 and conditions of the exponential stability, it is proposed to derive the adaptive law for on the basis of , which guarantees that holds when .
The subsection of this section contains the description of steps to obtain the regression equation , under the condition that the plant matrices are unknown and is unmeasurable. The subsection presents the adaptive law, which ensures that is achieved and does not require a priori knowledge of the plant matrices.
3.1 Parameterization
Let the stable filters of the variables of be introduced:
| (12) |
where is the filter constant.
The regressor is calculated as a solution of the second equation of , whereas, according to (Glushchenko et al., 2021a), is calculated without the value of :
| (13) |
where are first elements of .
Considering and unmeasurable initial conditions in , the equation is rewritten as111If is known, then and do not contain and , respectively.:
| (14) |
where is a measurable function , is a measurable regressor, is an extended vector of the unknown parameters.
Assumption 2. The parameter is chosen so as the implication holds.
Let the minimum-phase operator be introduced . Then, the DREM technique (Aranovskiy et al., 2016) can be applied to :
| (15) |
where .
The following regressions are obtained from :
| (16) |
where , .
The main benefit of DREM application is that the regressions in (16) have scalar regressors, so, having multiplied (5) by , we can substitute (16) into (5) to obtain:
| (17) |
where .
It should be noted that the above-mentioned substitution is not possible without regression scalarization (15).
The equation is transposed and multiplied by to obtain exact to notation:
3.2 Adaptive Law
The adaptive law of the control law parameters (6) is introduced on the basis of the regression (11):
| (18) |
where is the adaptive gain.
However, only instantaneous data (see (Chowdhary et al., 2013)) are used in (18). So, based on proof from (Aranovskiy et al., 2016), the law (18) provides exponential convergence of to zero only when . This does not satisfy the objective (10). To this end, to achieve (10), the adaptive law is to be derived on the basis of one of the known approaches (Glushchenko et al., 2021b; Chowdhary et al., 2013; Ortega et al., 2021; Korotina et al., 2022), which relax to .
In this study, it is proposed to choose the one described in (Glushchenko et al., 2021b). According to it, let the exponential filter with forgetting be introduced and applied to the regression (11) to obtain:
| (19) |
where is the parameter of the operator .
The following holds for the new regressor .
Proposition 1. If over and or , then:
-
1.
-
2.
Proof of Proposition 1 is presented in (Glushchenko et al., 2022; Glushchenko and Lastochkin, 2022) (Section 2).
Using Proposition 1, the adaptive law to guarantee the exponential convergence of when , is:
| (20) |
4 Stability Analysis and Some Remarks
According to (Glushchenko et al., 2021b), the adaptive law (20) provides exponential convergence of the parameter error only. In the following theorem we formulate strict formal conditions, under which the law (20) guarantees that the objective (10) is met.
Theorem 1. Let , then, if value is chosen according to
| (21) |
then the adaptive law (20) ensures that:
-
1.
-
2.
-
3.
the error converges exponentially to zero at the rate, which minimum value is directly proportional to the parameters and .
Proof of Theorem is presented in Appendix.
Thus, in contrast to existing approaches (Tao, 2014; Narendra and Kudva, 1974; Reish and Chowdhary, 2014; Roy et al., 2017; Gerasimov et al., 2018; Glushchenko et al., 2021a, 2022), when is chosen according to (21), the adaptive law (20) does not require any a priori information about the matrices of the system (3) and guarantees that the objective (10) is fulfilled. Some additional technical details of the law (20) implementation can be found in (Glushchenko et al., 2022).
Remark 2. When , the switching of the nonlinear operator (21) may occur only once, since, according to Proposition 1, is a positive semidefinite function.
Remark 3. The condition is necessary but not sufficient to achieve (10). According to Assumption 2 and Remark 1, the necessary and sufficient conditions are and Assumption 2. This may become a dramatically critical requirement for some applications.
Remark 4. In contrast to the baseline direct laws of the form , the proposed one (20) provides stability of only when . Therefore, to implement (20) in practice, the a priori information is required that this condition holds. If for a particular plant (3) and a particular reference, then it is possible to hold artificially by addition of the dither noise to the control or the reference signal according to (Adetola and Guay, 2006; Cao et al., 2007). At the same time, we can not use conventional modular design (Krstic et al., 1995) to ensure stability of the control system when as neither the sign nor the values of elements of matrix B are known.The actual problem is to obtain conditions on , under which the requirement is met for the whole class of MIMO plants (3).
5 Numerical Simulations
Numerical simulation to test the proposed adaptive control system, which consists of the control law (6), processing procedure (12), (13), (15)-(17), (19), and the adaptive law (20), was conducted using the model of a lateral-directional motion of a conventional small passenger aircraft from (Lavretsky and Wise, 2013):
| (22) |
where is the bank angle, is the sideslip angle, is the roll rate, is the vehicle yaw rate, is the aileron position, is the rudder position. According to the problem statement, all plant (22) parameters and initial conditions were considered as unknown.
The parameters of the adaptive law (20), filters (12), operators , and the initial values of the parameters of the control law (6) were picked as follows:
| (23) |
As for practical implications of Assumptions 1 and 2, the plant and reference model had the same structure, all plant equations with parametric uncertainty contained sufficient number of controls, (12) ensured excitation propagation.
Figure 1 shows transient curves of the plant (22) states and ideal ones, which were obtained by setting into the reference model the following plant initial conditions: . Figure 2 is to compare the ideal control vector and the one obtained from the proposed adaptive system. Figure 3 demonstrates transients of the controller feedback parameters , whereas Figure 4 – of the feedforward ones . In the figures controller parameters estimates were ”frozen” till s as till that moment because condition (1) had not been satisfied yet ( s).
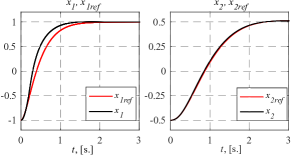
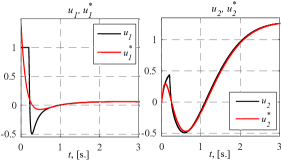
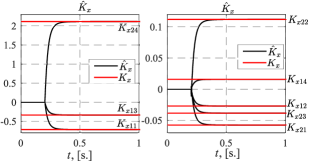
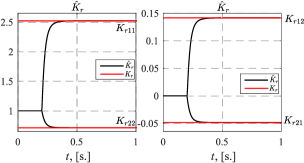
The results of the numerical experiments presented in Figures 1-4 validated the contribution of this work noted in the introduction in comparison with known solutions (Tao, 2014; Narendra and Kudva, 1974; Reish and Chowdhary, 2014; Roy et al., 2017; Gerasimov et al., 2018; Glushchenko et al., 2021a, 2022). They confirmed the theoretical conclusions of Theorem 1, and showed that (10) was achieved.
Important features of the developed system are the monotonicity of each controller parameter adjustment process, and the fact that the rate of the parameter convergence is directly adjustable by choice of scalar parameters and . These improve the transient behavior of states and control vector, and make the commissioning of the developed adaptive system significantly easier.
6 Conclusion
Considering the unknown MIMO plants, the adaptive state feedback control system has been proposed, which does not require any a priori information about the plant matrices. When the regressor vector , which is constituted of the plant states and control signals, is finitely exciting, the proposed system guarantees exponential stability of the tracking error, and the exponential convergence of the control law parameters identification error to zero. Considering numerical experiments, the effectiveness of the proposed approach to solve the adaptive control problem of the lateral-directional motion of the conventional small passenger aircraft was demonstrated.
Establishing the conditions, under which is FE for any generic MIMO system, is the scope of further research, as well as the plans to extend the obtained results to output-feedback control case.
Appendix
Proof of Theorem 1. As , the solution of (20) is:
| (A1) |
As , then it follows from (A1) that . This completes the proof of the first part of the theorem.
As is a Hurwitz matrix and is of full column rank, then according to the corollary of KYP lemma (2), there exist which satisfy (3). Then, the quadratic function to analyze the stability of (9) is chosen:
| (A2) |
Without the loss of generality, is chosen so as . Then we have:
| (A4) |
Two cases are considered: and . Firstly, let . Following (20) and (21), it holds that and . Then, (A4) is rewritten as:
| (A5) |
A maximum eigenvalue of over is introduced:
| (A6) |
Having solved (A7), it is obtained:
| (A8) |
As and , then we obtain from (A8) that the estimate of is bounded for :
| (A9) |
It holds for any that:
| (A11) |
The inequality (A12) is solved, and it is obtained for :
| (A13) |
References
- Adetola and Guay (2006) Adetola, V. and Guay, M. (2006). Excitation signal design for parameter convergence in adaptive control of linearizable systems. In Proc. of IEEE Conf. Decis. Control, 447–452. San Diego, CA.
- Annaswamy and Fradkov (2021) Annaswamy, A. and Fradkov, A. (2021). A historical perspective of adaptive control and learning. Annual Reviews in Control, 52, 18–41.
- Aranovskiy et al. (2016) Aranovskiy, S., Bobtsov, A., Ortega, R., and Pyrkin, A. (2016). Performance enhancement of parameter estimators via dynamic regressor extension and mixing. IEEE Trans. Autom. Control, 62(7), 3546–3550.
- Aranovskiy et al. (2022) Aranovskiy, S., Ushirobira, R., Korotina, M., and Vedyakov, A. (2022). On preserving-excitation properties of dynamic regressor extension scheme. IEEE Trans. Autom. Control. Ieeexplore.ieee.org/abstract/document/9767689.
- Cao et al. (2007) Cao, C., Hovakimyan, N., and Wang, J. (2007). Intelligent excitation for adaptive control with unknown parameters in reference input. IEEE Trans. Autom. Control, 52(8), 1525–1532.
- Chowdhary et al. (2013) Chowdhary, G., Yucelen, T., Muhlegg, M., and Johnson, E. (2013). Concurrent learning adaptive control of linear systems with exponentially convergent bounds. Int. J. of Adapt. Control Signal Process., 27(4), 280–301.
- Dydek et al. (2010) Dydek, Z., Annaswamy, A., and Lavretsky, E. (2010). Adaptive control and the nasa x-15-3 flight revisited. IEEE Control Syst. Mag., 30(3), 32–48.
- Gerasimov et al. (2018) Gerasimov, N., Ortega, R., and Nikiforov, V.O. (2018). Relaxing the high-frequency gain sign assumption in direct model reference adaptive control. Eur. J. Control, 43, 12–19.
- Glushchenko and Lastochkin (2022) Glushchenko, A. and Lastochkin, K. (2022). Exponentially convergent direct adaptive pole placement control of plants with unmatched uncertainty under fe condition. IEEE Control Systems Letters, 6, 2527–2532.
- Glushchenko et al. (2021a) Glushchenko, A., Petrov, V., and Lastochkin, K. (2021a). I-drem mrac with time-varying adaptation rate and no a priori knowledge of control input matrix sign to relax pe condition. In Proc. of Eur. Control Conf., 2175–2180. Rotterdam, Netherlands.
- Glushchenko et al. (2021b) Glushchenko, A., Petrov, V., and Lastochkin, K. (2021b). I-drem: Relaxing the square integrability condition. Autom. Remote Control, 82(7), 1233–1247.
- Glushchenko et al. (2022) Glushchenko, A., Petrov, V., and Lastochkin, K. (2022). Exponentially stable adaptive control. part i. time-invariant plants. Autom. Remote Control, 83, 548–578.
- Korotina et al. (2022) Korotina, M., Romero, J., Aranovskiy, S., Bobtsov, A., and Ortega, R. (2022). A new on-line exponential parameter estimator without persistent excitation. Sys. and Control Lett., 159, 105079.
- Krstic et al. (1995) Krstic, M., Kanellakopoulos, I., and Kokotovic, P. (1995). Nonlinear and Adaptive Control Design. Wiley, New York.
- Lavretsky and Wise (2013) Lavretsky, E. and Wise, K. (2013). Robust adaptive control. Springer, London.
- Narendra and Kudva (1974) Narendra, K. and Kudva, P. (1974). Stable adaptive schemes for system identification and control-part i. IEEE Trans. Syst., Man and Cyber., (6), 542–551.
- Narendra and Monopoli (2012) Narendra, K. and Monopoli, R. (2012). Adaptive Control Design and Analysis. Academic Press, New York.
- Ortega et al. (2021) Ortega, R., Bobtsov, A., and Nikolaev, N. (2021). Parameter identification with finite-convergence time alertness preservation. IEEE Control Syst. Lett., 6, 205–210.
- Reish and Chowdhary (2014) Reish, B. and Chowdhary, G. (2014). Concurrent learning adaptive control for systems with unknown sign of control effectiveness. In Proc. of IEEE Conf. Decis. Control, 4131–4136. Los Angeles, CA.
- Roy et al. (2017) Roy, S., Bhasin, S., and Kar, I. (2017). Combined mrac for unknown mimo lti systems with parameter convergence. IEEE Trans. Autom. Control, 63(1), 283–290.
- Tao (2003) Tao, G. (2003). Adaptive Control Design and Analysis. Wiley, New York.
- Tao (2014) Tao, G. (2014). Multivariable adaptive control: A survey. Automatica, 50(11), 2737–2764.